
Abstract
In order to improve the classification accuracy in the process of digital management of Library and information data, a method of information data management based on network analysis is proposed. First, based on the relevant theories of Library and information management, the target data set is obtained from the data source through data collection and extraction. Then the target data is preprocessed by cleaning, integration and transformation, so as to obtain the data set required for model construction. Finally, the network analysis method is used to establish the data evaluation model and management model, and to evaluate the availability of data. Simulation experiments show that the internal consistency of the data processed by the proposed model is maintained at more than 75%, the accuracy of data classification is high, and the fit between the evaluation index and the evaluation model is maintained at more than 0.83, which can meet the requirements of practical application.
Introduction
With the continuous application and development of modern information technology in the field of archives, the computerized digital management and data application of archives resources has become a key area of academic research and practice promotion. On one hand, users’ demand for comprehensive access to computer book resources has become a mainstream trend [1]. The political, academic and cultural needs of the government, society and individuals for historical archives are becoming more and more urgent, and new features such as digitization, networking, and knowledge are emerging [2]. On the other hand, the application of digital technology is reshaping the pattern of development and utilization of historical archives. Theoretical methods such as Digital Humanities, data mining and knowledge organization are widely used in the field of knowledge analysis [3]. However, in the face of voluminous, heterogeneous and diverse historical archives resources, the application effectiveness of deep aggregation, semantic interconnection, and knowledge mapping needs to be solved. Computer library information data is the digitized intelligence information. Information analysis is mainly through the cooperation of humans and machines to make up for the shortcomings of humans when using information, and to give full play to the role of computers in information analysis. Using computer technology for information analysis can effectively improve work efficiency, help visualize data analysis, limit the analysis process within a controllable range, and meet people’s needs for information use. Network analysis, that is, computer-aided network information analysis, is one of the important topics of future scientific and technological research [4, 5, 6]. From the analysis of the technical framework of computer-aided information analysis, in the future, information analysis will incorporate more social information, and will gradually reduce the limitations of time and space on computer-aided information analysis, and provide users with more accurate information analysis through the Internet. In order to further improve the management efficiency of library information data, this paper proposes the improvement of data management by using the method of network analysis.
Design of computer library information data management method
Information analysis is mainly through the cooperation of humans and machines to make up for the shortcomings of humans when using information, give full play to the role of computers in information analysis, and use computer technology to analyze information, which can effectively improve work efficiency [7]. For digital book information data, information classification, resource preference, data category, data scale and other aspects need to be reasonably analyzed and adjusted, so as to achieve accurate and efficient management. Therefore, with the help of information analysis, limit the analysis process to a controllable range, and meet people’s needs for information use.
Application of computer information data management related technology
Big data analysis realizes the requirements of data commercialization through data mining, crawling, and visual analysis. With the development of the era of big data, big data analysis has also undergone new changes [8]. Common tools are: front-end display, data warehouse, data mart, etc., these tools have the advantages of fast data processing speed and large storage capacity. Computer-aided information analysis mainly encounters several problems: there are still deficiencies in the algorithm, and ordinary algorithms cannot meet the requirements of big data analysis. Only by optimizing the algorithm can the multi-level data mining be better supported; in data collection, because the network, it is difficult to guarantee the authenticity and validity of the data.
Social network analysis studies the relationship structure and attributes between a group of actors, and can be widely used in public opinion monitoring, data visualization and data mining and other fields [9]. In recent years, social network analysis has been widely used in the field of bibliometrics, which has had a profound impact on its development. Social network analysis is widely used in various fields, such as the theoretical frontiers of physics, chemistry, biology, and data journalism [10]. Taking data news as an example, with the help of social network analysis and setting different observation objects, everyone in the social network can directly obtain news information.
Data mining refers to searching for hidden information content related to it from a large amount of data, which has a special relationship with the requested information. The main steps are to confirm the source of the data, check the data, remove the useless data, establish reasonable assumptions, verify through experiments, and apply [11]. Data mining technology is currently used in intelligent diagnosis of diseases, such as cervical cancer and uterine cancer in women. Assess the risk status of geological hazards, such as the causes of river pollution [12].
Computer library information data mining
At present, information analysis still mainly relies on big data, but the quality of data in the process of using big data will affect the effect of data information analysis. Therefore, it is necessary to mine useful information in advance through data mining technology.
Library and information data mining
Data Mining (DM) is to extract the knowledge that people are interested in from the data of large database. The extracted knowledge can be expressed in the form of concepts, rules, disciplines, patterns, etc. These knowledges are implicit, unknown in advance, potential and useful information. It can also be considered that data mining is the process of extracting hidden, unknown, but potentially useful information and knowledge from a large amount of incomplete, fuzzy, and random data [13]. Simply put, data mining is the extraction or “mining” of knowledge from large amounts of data. Data mining is a new information processing technology. Data mining technology improves people’s application of data from low-level online query operations to more advanced applications such as decision support, analysis and prediction. Through the micro, meso and even macro statistics, analysis, synthesis and reasoning of the data, the correlation between computer library information knowledge is clarified. These knowledge information can be used to guide advanced activity.
The general process of data mining is as follows:
Data cleaning: This paper proposes a method to use rules to describe the cleaning logic, and use rule engine to execute the cleaning logic, so as to deal with various data quality problems. Consistent processing of data to remove noise or inconsistent data. Data integration: Use the open source ETL tool kettle to extract, transform and load information ETL model automatically generates the fact table of online behavior as the central table, and builds a data warehouse with multi-dimensional tables. Using kettle can quickly realize the integration of multi-source heterogeneous data, combine multiple data sources to integrate data. Data selection: Based on the principle of GSPAN algorithm, it introduces new pruning rules and modifies the form of DFS coding; Use the improved GSPAN to mine the DFS code of frequent graph structure, and then establish the index. Retrieve data related to the analysis task from the database, and filter the data. Data conversion: Connect the original time series and multidimensional space series, reconstruct the phase space of multi-source data, set a reasonable embedding dimension of phase space and chaotic time delay, extract the correlation dimension feature of chaotic time series in this phase space, predict the chaotic time series according to this feature, select the conversion frequency point of data conversion according to the prediction results, and finally realize the accurate conversion of data. Adjust the data format to convert the data into a form suitable for mining. Data mining: The attribute reduction function of rough set is used to reduce the data in the data warehouse, and the reduced data is provided to BP neural network as training data. Through rough set reduction, the clarity of training data expression is improved, and the scale of BP neural network is reduced. At the same time, BP neural network overcomes the influence of rough set on noise data sensitivity, so as to realize data mining. The process of extracting hidden patterns in data and extracting knowledge. Pattern evaluation: After mining and processing a large number of software engineering data Knowledge representation: It is mainly based on the knowledge representation based on semantic network, and uses the knowledge-based method to transform the knowledge representation of SNetL into the expression form of predicate logic, which is used for reasoning and analysis. Provide mining results to users.
Combined with the specific business problems of library information data, the basic process steps of data mining are: first, understand the computer library and information field to be applied by data mining and be familiar with the relevant knowledge. Next, a target dataset is established, and sub-target datasets are selected by sampling or decimation actions [14]. The target data is then preprocessed to eliminate erroneous and inconsistent data. The data is then simplified and transformed. Potential patterns are then discovered by corresponding data mining algorithms. Finally make it useful knowledge by explaining or evaluating patterns. And these processes can be cycled and repeated to complete the effective management of library and information data.
First of all, you need to understand the relevant knowledge of computer library and information. Through related research, it is found that MOOC, knowledge sharing, information literacy and education, and bibliometric research are the same themes of knowledge input and output in library and information science [15]. In addition, library and information science has input knowledge about the construction of information resources and knowledge management to the computer. Related technologies have been widely used to strengthen the security, convenience and effectiveness of library resource information management. Computer technology represented by resource exploration is applied to the analysis, retrieval and system guidance of information resource construction. The application of intelligent retrieval and input, demand classification and other related technologies has significantly improved the level of knowledge management. By absorbing and combining its own characteristics, computer science has improved the construction of educational information and promoted the process of library and information informatization. After clarifying the characteristics of information resources related to library information data, in order to ensure the quality of data mining, we need to design a data warehouse.
Data warehouse provides a way to integrate data. Data mining is the process and technology of discovering implicit and meaningful knowledge from data. Data warehouse and data mining can achieve effective connection, complement each other and work together [16]. The design of data warehouse is analysis-oriented, starting from the most basic theme, constantly developing new themes, improving existing themes, and finally establishing a theme-oriented analytical environment. In the construction process of the data warehouse, the most critical work is the design of the logical model, which determines the data frame of the data warehouse.
Estimate the amount of system data first. The logical model design of the data warehouse needs to first roughly estimate the data magnitude of the data warehouse in the future. Determine a relatively reasonable data granularity based on this rough estimate. A simple method for estimating the magnitude of data warehouse data:
Among them,
The meaning of Eq. (1) is the number of data warehouses
Then choose the data granularity. Extract target data according to different granularity strategies. Different data granularity strategies will be adopted for different data volumes. A single data granularity is adopted for environments with small data volumes, that is, direct storage of detailed data and periodic data synthesis based on the detailed data [17]. After the data is loaded, all detailed data will remain in the data warehouse, and will only be exported to the backup device after a storage period of several years. Figure 1 shows the strategy for a single data granularity.
Single data granularity strategy.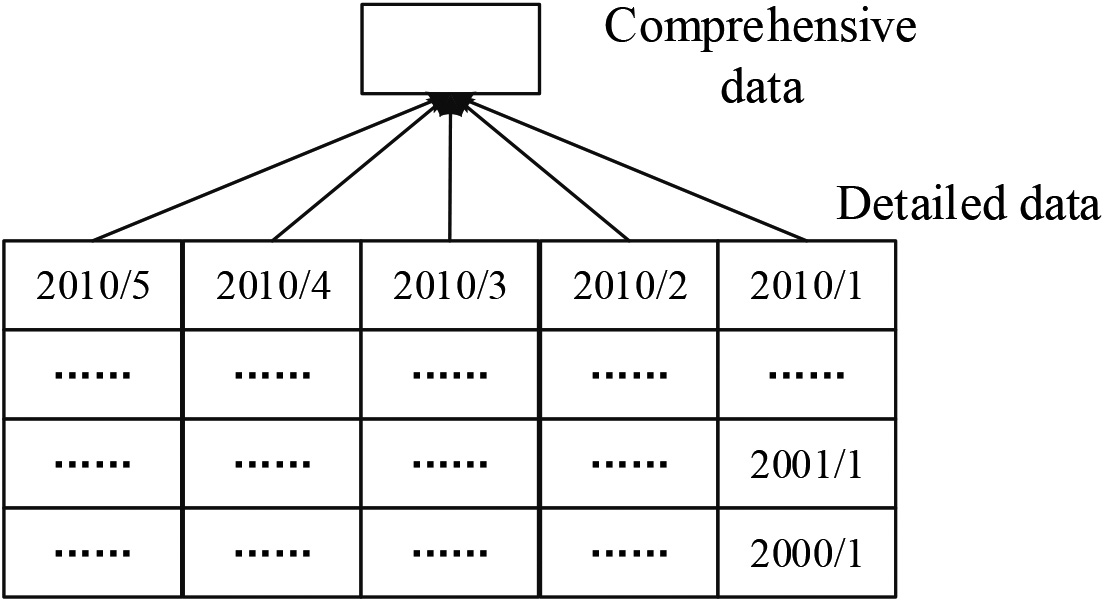
Large amounts of data require dual granularity, with detailed data only keeping recent data in the data warehouse. When the retention period arrives, data that is farther away is exported to other storage devices to make room for new data. In-cycle data warehouses retain detailed data, and out-of-cycle data only retain comprehensive data. Figure 2 shows a strategy for dual data granularity.
Dual data granularity strategy.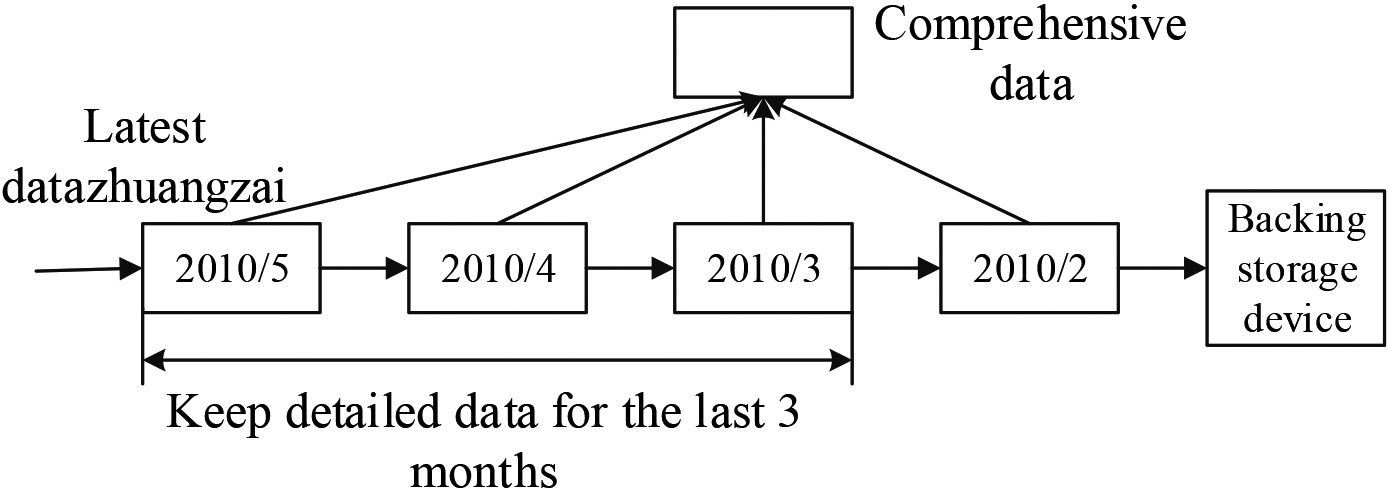
In-cycle data refers to the data within the relevant collection cycle, which can reflect the latest changes of things, while out-of-cycle refers to the historical data obtained outside the collection cycle, which can reflect the historical changes of things.
Single-granularity or dual-granularity There are multiple levels of integration in the data warehouse. The difference is how long the detail data is stored in the high-speed storage device. Behavioral analytics data warehouses employ multiple granularities.
In terms of table management, the commonly used segmentation strategy is to segment data tables with a large amount of data according to time after the granularity is determined. Add time field: Add a suitable time field to the new table after division according to the data granularity/segmentation strategy. Table division: Due to the frequent updating of some fields in the data in the table, some fields are frequently accessed. In order not to affect the access efficiency, the tables can be divided according to the stability of the data, or the tables can be divided according to business rules, information analysis such as “Average” or “Total” in the comprehensive table to facilitate the subsequent use of the generated export data.
The logical model of the data warehouse describes the logical realization of the subject of the data warehouse, which is to map the information of different subjects and dimensions to the specific tables in the data warehouse, that is, the definition of the relational schema of the relational table corresponding to each subject. Therefore, the logical model used in the design of the data warehouse is the relational model. In the design of the logical model of the data warehouse, the star schema and the snowflake schema are often used. Figure 3 shows the data model structure.
Data model structure diagram.
Starting from the two basic design principles of ease of use and high performance in data warehouse applications, the logic modeling of behavior analysis data warehouse adopts star schema. As the needs of behavioral analysis continue to evolve, the star schema of the data warehouse continues to expand. star schema. A star schema is a multidimensional structure that generally includes two different types of tables: fact tables and dimension tables. An n-dimensional multidimensional table often has a fact table and n-dimension tables. In the star schema, the main body is the fact table, and the relevant details are described in the dimension table. This star structure is especially suitable for data analysis and statistics. Under two data granularity strategies and data relationship models, the library information data are preliminarily screened. In the data warehouse, the optimization method of the data storage strategy is adopted, the data content of the table is first queried, and the table is stored in the physical storage module in order according to the query access sequence. Then, according to the year, the division table is summarized into the corresponding year in turn.
The essential difference of library information data is based on different user behaviors. Suppose that the sequences in dataset
Among them,
Suppose the action sequence is
Among them,
The representation of the mixed model is:
The probability that the mixture model produces this sequence for any sequence
For the set number of clusters
After estimating the model parameters
After the computer book data is preprocessed, the data is simplified and transformed.
In order to transform the test data results into a computer library and information evaluation data set that can be analyzed uniformly. In this study, the system data reduction technology in big data mining will be used to analyze and process the target data preprocessed above [19]. It is assumed that there are a total of
Among them,
After using this formula, the dimensionless part of the library information data can be processed, so as to realize the unified analysis of the data. After determining the distance between intelligence data samples,
Set
At this time, the data sample spatial distance between each evaluation index category is
Use Eqs (11) and (12) to repeatedly process the data in the database to obtain the simplified result of the special intelligence data system. Based on this result, the number of categories and the amount of data in each category are determined. The content of the processed database is used as the basis for the construction process of the intelligence data evaluation index system.
Intelligence data quality evaluation model
According to the library information data group processed by data mining, the intelligence data evaluation index system is constructed. In order to improve the use effect of this evaluation index system. Use an expert evaluation system to judge among the selected evaluations. Invite
Among them,
In the formula,
Using this formula, the selected metric is sorted and the metric level is divided. After the establishment of the intelligence data evaluation index system, due to the difference in the importance and dimensions of the indicators, determining the importance of each index will help to achieve an objective evaluation of intelligence data. In this study, the AHP method in network analysis is used to determine the weight of the evaluation index. The idea of using the AHP to solve the problem is as follows: First, decompose the problem into different constituent factors, and combine them according to the mutual influence and affiliation of the factors to form an orderly hierarchical structure model. Then, according to people’s judgment of objective reality, the relative importance of each level factor in the model is quantitatively expressed, and then the weight of the relative importance order of each level and each factor is determined by mathematical methods. Finally, comprehensively calculate the relative importance weights of the factors of each layer, and obtain the combined weight of the relative importance order of the lowest layer (scheme layer) relative to the highest layer (overall goal), which is used as the basis for evaluating and selecting options.
According to the relevant principles of the AHP method, and then determine the index judgment matrix, there are:
In the formula,
According to the judgment matrix, then calculate the product
After normalizing the
In the formula,
The calculation weight of the indicators covered by the first-level indicator layer
According to the calculation result of the weight of each indicator, the indicator is assigned a value. And use it as the basis for the construction of a special physical fitness model.
Apply the evaluation index system constructed above and the results of weight assignment to construct a management model of intelligence data. Before the model is constructed, it is necessary to verify the reliability of the index assignment results through the consistency analysis method. The largest eigenvector of the above indicators is set as:
Among them,
Among them,
Multiply this matrix by the preset indicator weight set
Using Eq. (23), the evaluation result of intelligence data can be obtained, and the availability of intelligence data can be determined according to the evaluation result. The content of the text is integrated, so far, the design of the computer library information data management method based on network analysis is completed.
Experiment environment
The experimental environment required in this paper mainly depends on the selection of appropriate target data sources. For this, Chinese academic literature is selected as the analysis object. In consideration of the professionalism and representativeness of the literature and the accuracy and professionalism required for analysis, the journal data in CSSCI (China Social Science Citation Index) database is selected as the target data in the study. The database is rich in content and has a high utilization rate. The relevant information data should be retrieved from China National Knowledge Infrastructure (CNKI) to ensure the representativeness and authority of the data. Based on the above factors, this paper finally selects the top 15 CSSCI journals of CNKI as the data source of this study.
Intelligence data classification
For the library information data evaluation model, the application of different data processing techniques will have a corresponding impact on the use of the evaluation model. In the data source, extract 5 data sets of different sizes: CN-01 (200 data), CN-02 (185 data), CS-03 (230 data), CS-04 (80 data), CS-05 (194 pieces of data). The genetic algorithm and decision tree algorithm are selected as the comparison methods, and the internal consistency of the data after the classification of the data processed by different methods is compared. The value of this indicator is determined by the proportion of abnormal data in the data set. The result of data processing is shown in Fig. 4.
Intelligence data classification.
Through the analysis of intelligence, it can be seen that when the internal consistency value of the data group is greater than 70%, the data segmentation result is applicable. From the study of the data in the above image, for five data sets of different sizes, the internal consistency of the segmentation results of the genetic algorithm is less than 70%, so it does not meet the requirements of data segmentation. Both the decision tree algorithm and the method proposed in this paper have an internal consistency of more than 70%, which can meet the application requirements. However, by comparing the internal consistency values of the two algorithms, it can be seen that for data sets of different sizes, the internal consistency value of the method in this paper remains above 75%, which is better than the decision tree algorithm. This also proves that the evaluation model of big data mining of this method has high data processing ability.
After analyzing a large number of literatures, the fit between the evaluation index and the algorithm is selected as the experimental comparison index. The specific calculation process is as follows:
Among them,
The calculation process is completed according to this standard, and the obtained experimental result image is shown in Fig. 5.
Evaluation indicators and evaluation model fit.
It can be seen from Fig. 5 that the fitting degree of multiple indicators of this method is maintained above 0.83, meeting the requirements of practical application. In the calculation results of the index fitting degree of the decision tree algorithm and the genetic algorithm, 3 indicators do add export fields coordination (Z10) index in this method is slightly lower than 0.85. At present, scholars generally believe that a single indicator does not meet the standard and will not cause adverse effects on the use of the model. Therefore, from an overall point of view, the big data mining model fits better.
In order to improve the classification accuracy of Library and information data, this paper proposes to use network analysis to manage library information data. Design the model of data warehouse according to the demand of intelligent data. Understand the computer library and information field of data mining application, and be familiar with relevant knowledge. And selects sub target data sets through sampling or extraction operations. The target data is then preprocessed to eliminate errors and inconsistent data. And then simplify and transform the data. Then the potential patterns are found by corresponding network analysis methods. Finally, by interpreting or evaluating the model as useful knowledge, these processes can be repeated to complete the effective management of the library and information data. The simulation experiment shows that the internal consistency value of the method is kept above 75% after data processing, the data classification accuracy is high, and the fitting degree between the evaluation index and the evaluation model is kept above 0.83, which meets the requirements of practical application. It shows that this method has better management performance and higher classification accuracy for computer intelligent data. In the next stage of work, we can consider further improving the algorithm and model and building an analysis system to make the intelligent work more efficient and systematic.