
Abstract
This paper uses a real-time anomaly attack detection based on improved variable length sequences and data mining. The method is mainly used for host-based intrusion detection systems on Linux or Unix platforms which use shell commands. The algorithm first generates a stream of command sequences with different lengths and subsumes them into a generic sequence library, de-duplicats and sortes shell command sequences. The shell command sequences are then stratified according to their weighted frequency of occurrence to define the state. Next, the behavioural patterns of normal users are mined to output the state stream and a Markov chain is constructed. Then, the state sequences are calculated based on a primary probability distribution and a transfer probability matrix. The System will check decision values of the short sequence stream. Finally, the decision values of the behavioural sequences are analysed to determine whether the current session user is behaving abnormally. The improved algorithm introduces the concept of multi-order frequencies and proposes a new separation mechanism. The extension module is integrated into the variable length model. By comparing the performance of the old and new separation mechanisms on the SEA dataset and the self-made dataset (SD), it is found that the improved model greatly improves the performance of the model and shortens the running time.
Introduction
Most current intrusion detection systems use anomaly detection techniques, which have the advantage of detecting unknown types of attacks and do not require much a prior knowledge. So anomaly detection has been widely studied as an important branch of network intrusion detection.
In practical anomaly attack detection, the training data for detection is often insufficient due to the variability of user behaviour, which requires that the detection model should have fault tolerance, generalisation ability and adaptability. In recent years, research has been conducted at home and abroad on the application of data mining, statistical theory, machine learning, deep learning and other techniques in anomaly attack detection. However the common problems of these anomaly attack detection methods are lack of adaptability to changes in user behaviour, stability and fault tolerance of detection performance, and need improve detection accuracy.
To overcome the above weaknesses, this paper uses a real-time anomaly attack detection method based on improved variable length sequences and data mining. The algorithm first generates a stream of command sequences and subsumes them into a generic sequence library, de-duplicats and sortes shell command sequences. The shell command sequences are then stratified according to their weighted frequency of occurrence to define the state. Next, the behavioural patterns of normal users are mined to output the state stream and a Markov chain is constructed. Then, the probabilities of short state are calculated based on the primary probability distribution A and the transfer probability matrix P. The System will check decision values of the short sequence stream. Finally, the decision values of the behavioural sequences are analysed to determine whether the current session user is behaving abnormally.
The improved algorithm introduces the concept of multi-order frequencies and proposes a new separation set mechanism. The extension module is integrated into the variable length model. By comparing the performance of the old and new separation mechanisms on the SEA dataset and the self-made dataset (SD), it is found that the improved model greatly improves the performance of the model and shortens the running time. The host real-time monitoring script is conjuncted in the detecting host, we achieve the real-time anomaly attack detection.
Current status of research
Machine learning approaches are mostly used for anomaly attack detection. Lane [3] investigated anomaly attack detection based on HMM. They used HMM to build a fame of the normal behaviour of legitimate users at user interface layer and trained the HMM using the Baum-Welch algorithm. The main advantage of this approach is the high detection accuracy and its disadvantage is poor detection efficiency. Kholidy [9] proposed DDSGA. To improve the performance, Qiu [10] combined the HMM with the the SA module. Xinguang Tian [12] mines user behaviour patterns by using variable length shell command sequences to and employs a similarity metric. Xi Xiao [13] greatly reduced the number of states, thereby reduced memory consumption. The model uses the weighted frequency of a variable-length sequence. He achieved the best results compared to previous models based on Markov chains.
Flowchart of anomaly attack detection algorithm in the variable length model.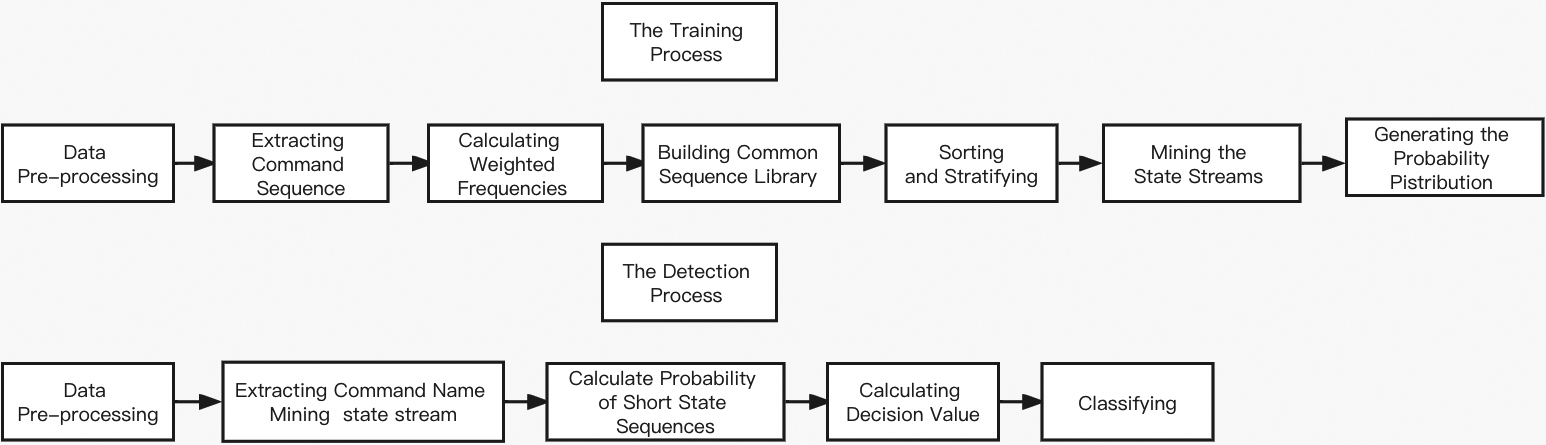
The system uses the SEA dataset to evaluate the improved variable-length Markov chain algorithm and the model trained on the RD dataset identifies host anomalous behaviour. The RD dataset is derived from the system shell command log and the shell commands entered by the user in real time. The training process of the variable-length model in the anomaly detection algorithm is: pre-processing the training data of the RD dataset, extracting only the command names, extracting command sequence streams of different lengths according to the parameters, calculating the weighted frequencies of the sequence streams and building a common sequence library, sorting in descending order according to the weighted occurrence frequency and stratifying, and finally mining the state streams of the training data through data mining, and finally generating the probability distribution. The detection process is: pre-processing the data, extracting only the command names, data mining and getting the state stream according to the initial state distribution A generated in the training phase and the state transfer probability matrix P, setting a sliding window to calculate the probability of short state sequences, and finally calculating the decision value and classifying it according to a pre-set threshold.
This paper proposes a new separation mechanism. The flowchart is shown in Fig. 2.
Flowchart of the new separate pooling mechanism.
Training module implementation in the variable length model
1) Data pre-processing
For the raw training data (OS) without any processing, only the command names are retained, filtering command parameters and events. Then we get finally training data (S). We let
2) Extraction of variable length sequences
[14] gives the definition formula of variable L and
Thus, in the extraction of variable-length sequences stage, a variable-length sequence library
Assume that the training data S is (‘cpp’, ‘sh’, ‘xrdb’, ‘mkpts’, ‘env’, ‘ksh’, ‘userenv’, ‘wait4wm’, ‘ksh’, ‘userenv’, ‘wait4wm’). Assuming L
A variable length sequence set T.
3) Calculation of weighted frequencies
[14] calculates the weighted frequency of occurrence of different sequences, the number of occurrences of the sequence
We introduce multiple orders and the real implementation of the algorithm is the “second-order” algorithm.
Where
So if
In the case of
Example
In the case of
Example table for
4) Building a generic sequence library
Repeated sequences
All different sequences are grouped together in a common sequence library (LGS).
According to the v-order weighted frequencies mentioned above, the v of generic sequence library will be generated.
Assuming L
LGS1 example.
LGS2 example.
5) Sort and merge in layers
Markov chains are actually models that portray transfer between states over time. Common Markov chain applications such as predicting the weather correspond to many states, e.g. sunny, rainy, snowy, etc. However, for shell sequences there is no state, so it is necessary to define states for shell sequences. If a shell sequence is used directly as a state, such as the sequence (cd, ls) corresponding to a state, then for thousands of training data, thousands of states will be defined. This will definitely leads to overfitting of the model and high computational overhead. So it is not suitable for real-time detection. Therefore, in order to define states, the features of the shell sequences need to be found in some way, and the sequences are grouped together and defined as one state based on the same features.
The method of extracting features in this paper uses the weighted frequency, which defines the state according to the magnitude of the frequency. The larger frequency of the sequence defines the state as 1, and the smaller sequence frequency defines the smaller state value. Therefore, it is necessary to sort each generic sequence library in descending order, and the generic sequence library is defined as G after sorting in descending order.
The descending sorted generic sequence library G is divided into N sets, denoted as
Giving N
Example diagram of separation G1.
Example diagram of separation G2.
6) Mining user behaviour to define states
After separating the set and defining the state, the next step is to mine the training data for patterns that reflect the user’s behaviour, which is divided into two main parts: defining the state and mining the user’s behaviour. The core idea of mining the user behaviour pattern function is to mine the training data behaviour through the generated Lamda1 and Lamda2. Assuming L
Example diagram for mining user behaviour.
The define state function passes an index to the function of mining user behaviour. The index points to the first shell command. Assuming L
After (cpp, sh, xrdb) is mined, the index will increase the length of the mined sequence, which points to mkpts. Since Lamda is formed from training data, it must be able to mine the behavioural sequence for training data. But for unknown detection data, it is likely that the sequence has never been in Lamda. When the comparison finds that the weighted frequency frequency corresponding to (cpp, sh) and the weighted frequency corresponding to (cpp, sh, xddb) are both 0, null is returned and the index is added by 1.
After a number of mining behaviours, the index points to userenv, at which point the sequence marked in red is found to be of length 2. Noting that 2
Next we will describe the definition of the state function. This function calls the behaviour sequence obtained from the function of mining user behaviour: [first-order behaviour sequence, second-order behaviour sequence]. Then we define a state for the behaviour sequence based on the Lamda after separating the sets. For the same sequence, the second-order method returns two sequences of behaviours. Then the indexes of the first-order behaviour sequence in Lamda1 and the second-order behaviour sequence in Lamda2 are found and assigned to state1 and state2 respectively. In data mining, a sequence can only be defined as one state, hence we do the normalisation process.
For the case
The algorithm defines the state of the Markov chain through a variable-length sequence of shell commands. This enhances the model’s ability to mine normal behavioural features and its adaptability to variable user behaviour. In addition, the frequency-first based approach finds behavioural patterns in the set in Lamda’s order. This speeds up the matching time of the sequences.
By mining the user behaviour to define the states, the training data is processed to eventually form the state stream STATES, which lays the foundation for A and P.
7) Establishing probability distributions
The Markov chain consists of A and P. The state flow is obtained by defining the states and A and P are found based on statistical ideas.
For the second order method in the case
The core of the idea in the old mechanism for separating sets is to equate as much as possible the generic library of sequences sorted in descending order G. Assuming N
In order to furtherly mine the weighted frequency feature, This paper proposes a new separation set mechanism. For a sorted generic sequence library G of length K, the weighted frequencies of adjacent sequences are computed sequentially to obtain the set of differences
Finally, the final Lamda is obtained by dividing the set of N sets according to the set of sequences Index. If a sequence of length 5 is {(cpp, sh), (spp, sh, xrdb), (ksh, userenv), (cpp), (vim, sqlmap)}, and the sequence corresponds to a weighted frequency of (2, 1.5, 1.4, 1.3, 0.9).
Example of comparison of separation mechanisms.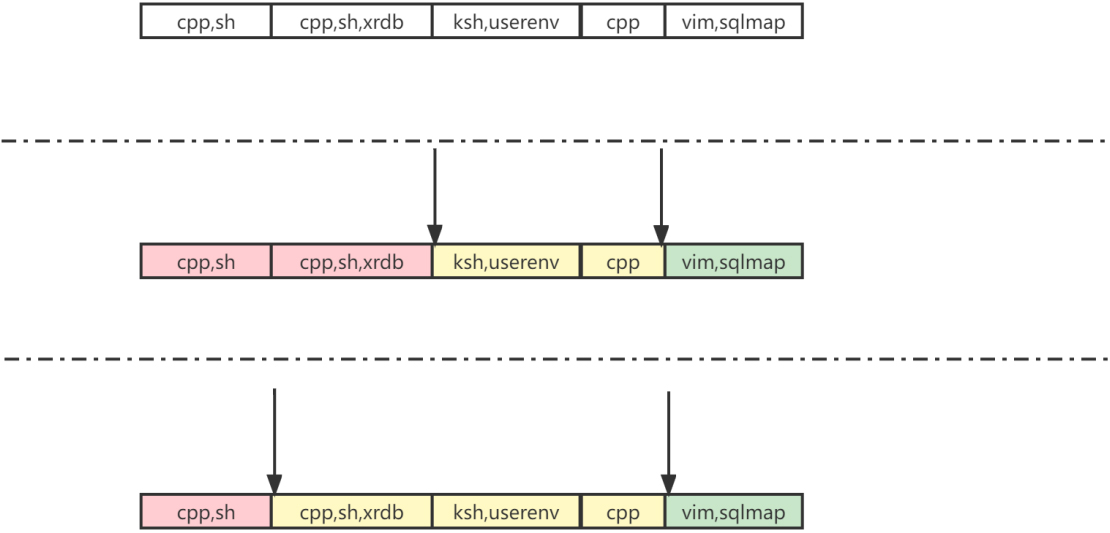
The sequence weighted frequencies are (2, 1.5, 1.4, 1.3, 0.9). The old separation mechanism does not consider the specific real-value distribution of the weighted frequencies, and divides the set into two sets of length 2 and one set of length 1 based on the idea of equal division. The new separation mechanism, on the other hand, calculates the D-value set D
1) Calculating the probability of a short state sequence
After Data pre-processing and Mining data behaviour to define states like the training data. In a real-time host-based intrusion detection scenario, the task is to find the probability of a sequence of states occurring simultaneously to obtain the final decision value, rather than to know the current state and predict the next state. Therefore the probability of the states occurring simultaneously needs to be required,which is the joint distribution.
Defining u as the length of the short state sequence, the short state sequence is defined as
The decision value
Supposing that the state sequence obtained after the short state sequence processing is [03, 30]. If
The decision value is calculated and the given decision threshold
Comparison of experimental results
The SEA dataset was used to demonstrate the improvement of the model with the new separation mechanism, while the SD dataset was used for practical testing.
Assessment methods
This experiment evaluates model performance with multiple metrics, using ROC curves for the SEA dataset and the area AUC of the ROC. In the experiment, the AUC average performance is evaluated for multiple users.
For
In the SD dataset, the model was evaluated using the PR curve as well as the area AP of the PR curve.
In order to demonstrate the advantages of the new separation mechanism, six algorithms were compared in this experiment: equal-length Markov chains (Markov), first-order Markov chains (MarkovF1), second-order Markov chains (MarkovF2), equal-length Markov chains with the new separation mechanism (Markov-N), first-order Markov chains with the new separation mechanism (MarkovF1-N1), second-order Markov chains with a new separation mechanism (MarkovF2-N2).
In order to fully evaluate the new separation mechanism, data statistics, two experimental evaluations and one additional experiment were carried out on the SEA dataset. At the same time, an algorithm comparison was also performed for the SD dataset, which is described in turn below.
SEA dataset
1) SEA dataset statistics
Although the SEA dataset collected the behaviour of 50 users and were randomly inserted by blocks of anomalous data, not all users had anomalous data. Figure 10 shows the anomalous data blocks for all users.
Statistical chart of abnormal user data blocks.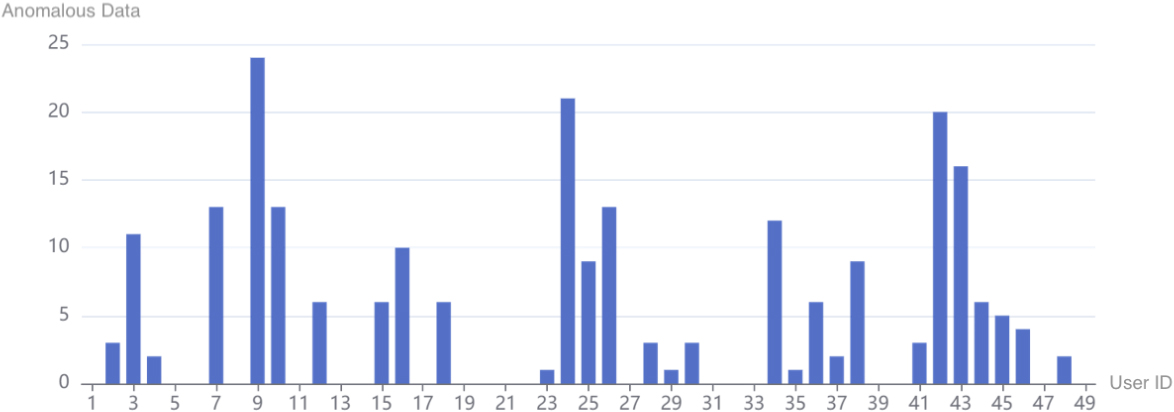
Parameter space for the isometric method (Markov)
First-order method (MarkovF1) parameter space
Second order method (MarkovF2) parameter space
Comparison of the three algorithms for AUC.
Comparison of old and new separation mechanisms.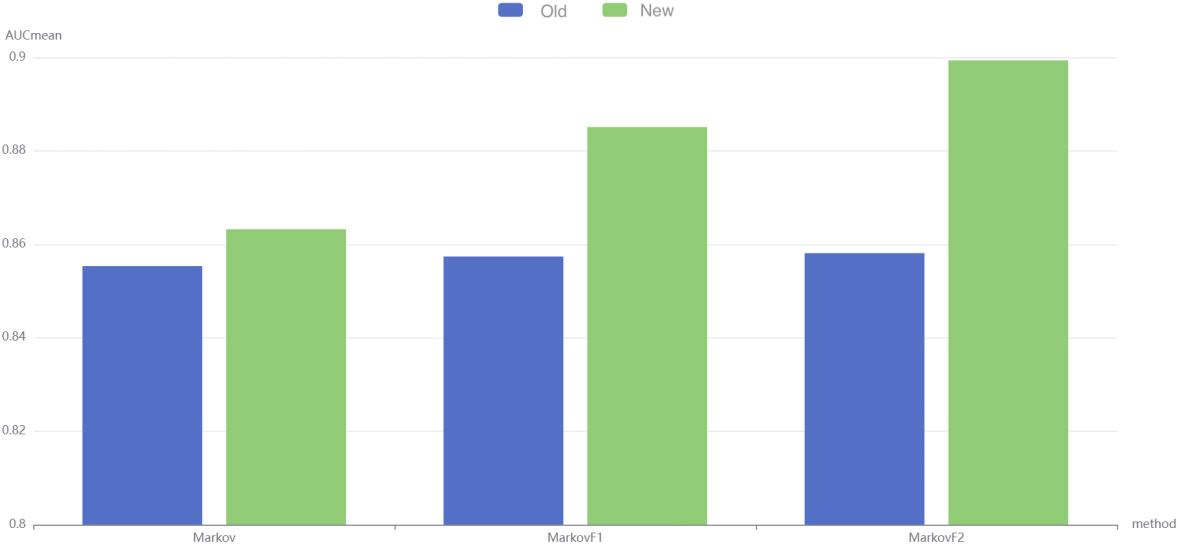
MarkovF2-N2 performance as a function of w, N.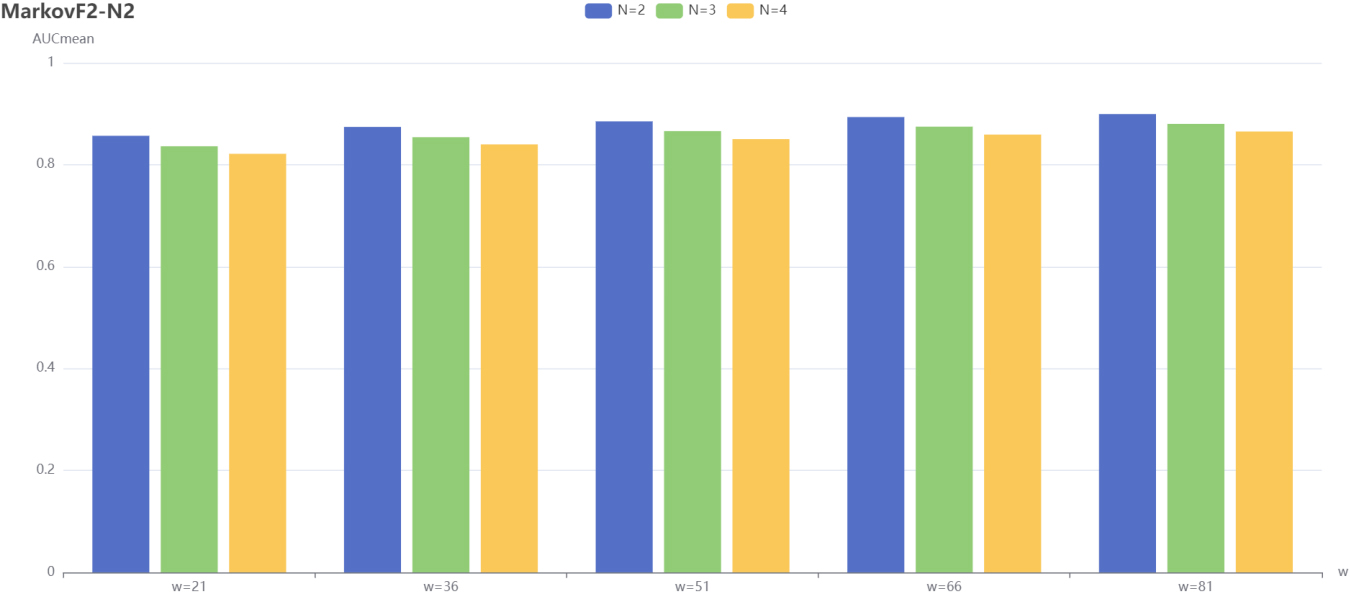
MarkovF1-N1 performance versus w and N.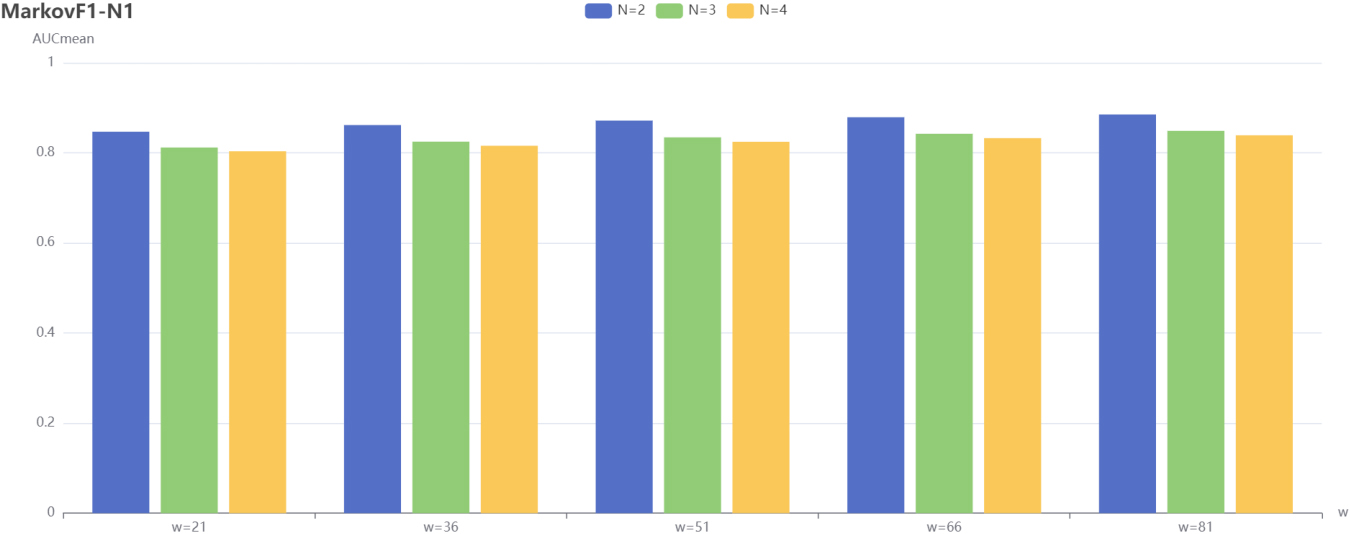
Markov-N performance as a function of w, N.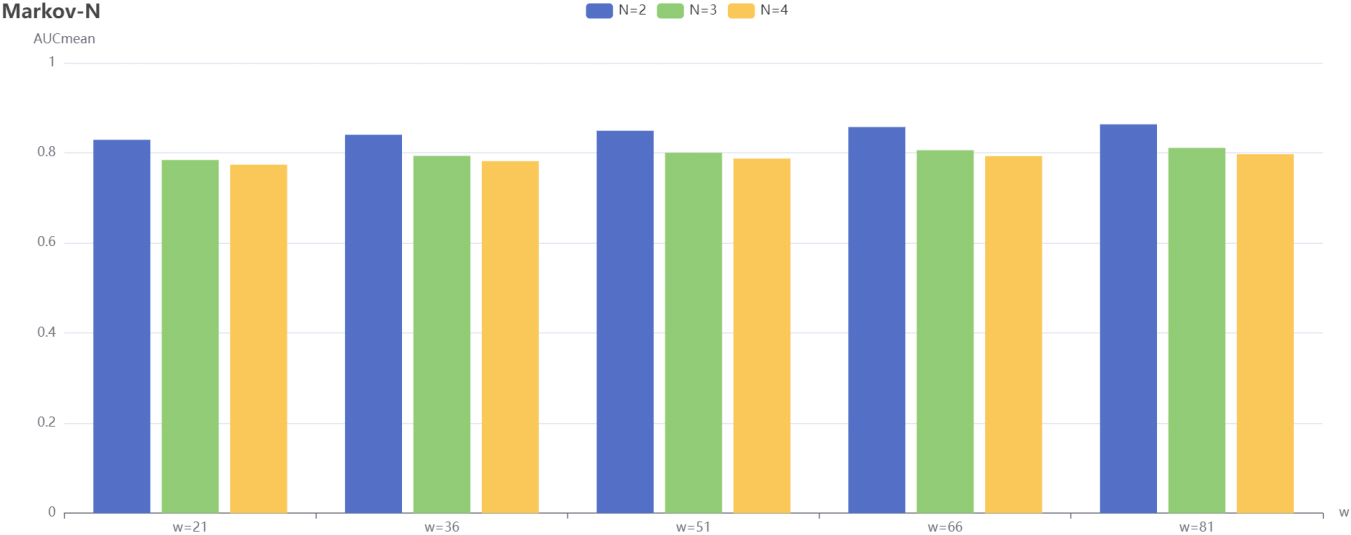
It can be seen that only 29 users dataset were inserted by random blocks of abnormal data and some users had only 1 or 2 blocks of abnormal data. Considering that the sliding window has a requirement for the number of users’ abnormal data, the top 20 users’ blocks of abnormal data are userd in the fellowing experiments.
2) Experiment 1: Top 20 user evaluation
Experiment 1 beganed with a model comparison of Markov, MarkovF1 and MarkovF2. Due to time constraints, this experiment was conducted by greedy search to find the optimal parameters in a given parameter range for the ROC curve area AUC comparison. For each algorithm, the sum of the AUCs of 20 users was obtained for each round of training, and then divided by 20 to obtain AUC
The ratio of training set: test set is 5000*20: 10000*20.
After a local search for the best parameters with the greedy algorithm, it was found that the second order method was slightly higher than the first order method and the first order was slightly higher than the equal length method. Figure 11 shows the comparison results.
Then, the new separation mechanism was introduced in the experiment, corresponding to the three algorithms Markov-N, MarkovF1-N1 and MarkovF2-N2, which were compared with the three algorithms Markov, MarkovF1 and MarkovF2 of the original separation mechanism, respectively. Figure 12 shows experimental results.
The experimental results show that the variable-length model based on second-order weighted frequencies outperforms the first-order variable-length model and the equal-length model. All of the models with the new separation mechanism achieve very significant improvement in AUC. The second-order method achieves the most significant improvement.
3) Additional experiments: Sliding window and number of separating sets
From Experiment 1, we can learn that for TOP20 users, the models that adopt the new separation mechanism are all improved from the original ones. Next, for the Markov-N, MarkovF1-N1 and MarkovF2-N2 algorithms, the effects of the sliding window w and the number of separation sets N on the models are explored.
Comparison table between the old and new separation mechanisms
Comparison of the effects of the old and new separation mechanisms for ROC curve area.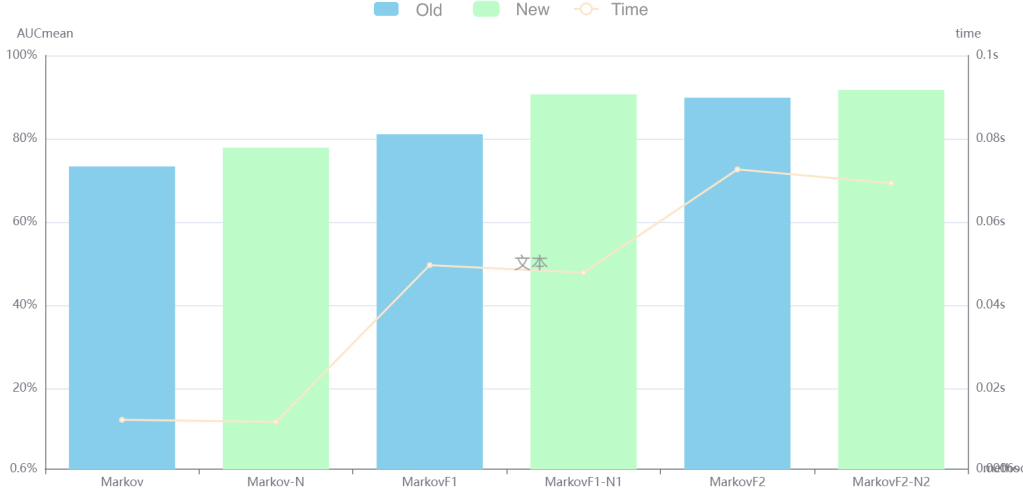
Comparison of the effects of the old and new separation mechanisms for PR curve area.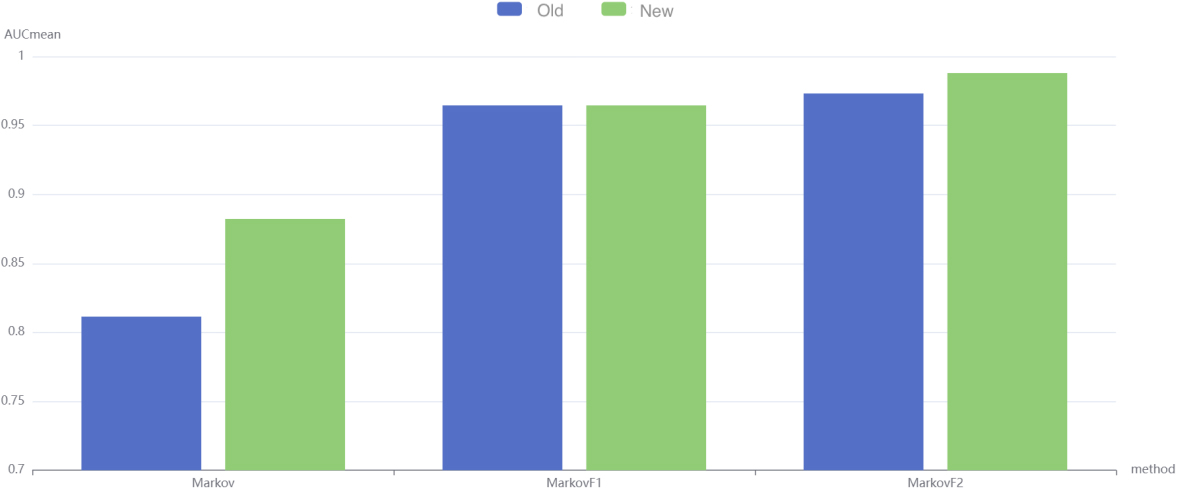
PR graphs for the four algorithms.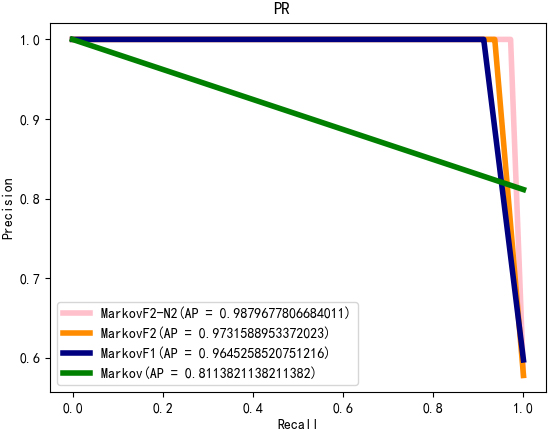
For all other hyperparameters the best parameters of the corresponding model are used. The sliding window w is set in the range [21, 36, 51, 66, 81] and the number of separation sets N is set in the range [2, 3, 4].
Figures 13–15 correspond to the relationships of the MarkovF2-N2, Markov-N and MarkovF1-N1 algorithms respectively.
The performance of all three algorithms, MarkovF2-N2, Markov-N and MarkovF1-N1, is shown. which increases with the sliding window w and decreases with the number of separation sets N.
4) Experiment 2: Four User (NU4) Assessment
Six models MarkovF2-N2, MarkovF1-N1, Markov-N, MarkovF2, MarkovF1, and Markov were compared for ROC area (AUC) by finding the optimal parameters within a given parameter range by grid search. The training detection times of the old and the new separation mechanisms were compared. Each algorithm runs one hundred times. The final training detection time is the running time of each algorithm divided by 100. So Training set: test set
Due to time constraints, the number of sets N was set uniformly to 2, the sliding window w to 21 and eta to 0.1.
The experimental results are shown in Fig. 16, where the dashes indicate the running time of the corresponding algorithms and the bars indicate the AUC of the corresponding algorithms. Table 6 indicates the specific parameters.
For the SD dataset, six models MarkovF2-N2, MarkovF1-N1, Markov-N, MarkovF2, MarkovF1, and Markov were compared. Because the proportion of positive and negative samples was very even, the PR curves and the PR curve area AP were compared by finding the optimal parameters in a given range of parameters with grid search.
The SD data set has 4000 normal data and 1000 abnormal data. The first 3000 normal data were training data, 500 normal data, the first 500 abnormal data were used as validation set, and the last 500 normal data and the last 500 abnormal data were used as test set. The data were divided in a ratio of 6:2:2. The parameters of the six algorithms took the same range of values as mentioned above. Figure 17 represents the comparison of the PR curve area AP for the six algorithms.
To make the graph more intuitive, Fig. 18 represents the PR curves for the four algorithms MarkovF2-N2, MarkovF2, MarkovF1 and Markov.
The performance of the model with the new separation mechanism is improved for the RD dataset, and the PR curve of MarkovF2-N2 has the largest area. In addition, the PR curve of MarkovF2-N2 wraps around the remaining three curves, and this experiment shows that the MarkovF2-N2 model has the optimal effect.
Summary
In this paper, the attack detection problem is implemented based on a variable length model. This paper has accomplished the following:
A variable-length anomaly attack detection model is implemented. Based on the variable-length model, the concept of multi-order frequency is introduced and a new separation mechanism is proposed to improve the model. Through experimental comparison, it is found that the new separation mechanism proposed by this paper outperforms the original model in terms of TPR, FPR, ROC curve, PR curve and running time. The SD was self-made data and deployed to a real environment for testing in combination with a real-time monitoring command script.
At the same time, there are shortcomings in this paper, as shown below:
The variable length-based model only extracts one feature, the command name, and the feature extraction is relatively single. No higher order models are implemented for The project is only deployed for a single host, in a real enterprise environment there are often dozens or even hundreds of hosts.
Footnotes
Acknowledgments
This work was support by National Natural Fund “The research of the trusted and security environment for high energy physics scientific computing system.”