
Abstract
Sensors as the sensing end of intelligent control can be used to collect various data instead of human beings. In the context of technological development, the variety of sensors leads to multiple and structurally unequal data sources, and fusion of these data becomes a problem for consideration. The study constructs an intuitionistic fuzzy transformation method to handle data with various attributes with the help of fuzzy mathematical concepts, which characterizes the data based on the hesitancy and ideal solutions under Gaussian distribution. Simulations of classical classification data show that the intuitionistic fuzzy transformation method can effectively differentiate the affiliation of data points in the dataset, and the results of 800 simulations show that the qualitative accuracy of the algorithm can reach 89%, while the causes of abnormal data are explored and it is found that the attributes of the dataset based on Gaussian distribution are too close to each other as the cause of misclassification; the algorithm is also optimized from multi-dimensional considerations, and a An optimization operator based on the distance method of superior and inferior solutions was constructed and simulated for several optimization paths. The results show that the study uses an optimization scheme that is significantly better than the existing fuzzy operator, and 800 times can improve the accuracy rate up to 95.23%, which is 14.01% higher than that of a single attribute. This indicates that the intuitionistic fuzzy algorithm of this study has some rationality and is able to fuse the data of multiple attributes of the sensor for determination and provide the necessary basis for decision making.
Introduction
Multi-source heterogeneous data fusion models are widely available in various fields, and the application of such fusion models has spread to military, medical and environmental monitoring industries with the development of intelligent control and sensors, and decision-level fusion according to the fusion level is a higher level model, which is highly fault-tolerant and not too dependent on sensors [1]. However, the own characteristics of multi-source heterogeneous data determine that accurate quantitative processing of data can be computationally expensive, because unequal data structures and distributions and nonlinear relationships create great difficulties for computation, so the use of fuzzy quantitative ideas based on fuzzy mathematics can effectively improve this problem and also reduce some pressure on the data fusion center for sensors [2]. The basic idea of using fuzzy sets for data fusion is to fuzzify the original data qualitatively and transform it while preserving the attribute features to obtain the affiliation of that data [3]. In most of the fusion centers or decision centers are able to make determinations or decisions regarding the attributes, the model needs to be guaranteed to have simplicity from the acquisition to the final process [4]. The study will construct an intuitive fuzzy transformation method based on fuzzy sets for data obeying Gaussian distribution, while optimizing the operators in the algorithm to correct the dependence on attributes. Finally, the model is tested by a classical classification dataset to evaluate its performance.
Related work
Fuzzy mathematics meets the practical needs of fuzzy phenomena and its good performance of quantified fuzzy objects ensures the wide application of the tool. Mao and Zhang [5] used fuzzy mathematics in the education industry, they created a model based on fuzzy mathematics as an evaluation tool for entrepreneurship education, and an example analysis of several universities showed the practical relevance of the model. Alexandru and Ciobanu [6] used fuzzy sets in a finite support mathematical framework to describe infinite universe fuzzy sets by introducing finite support, in the process they also found algebraic properties of fuzzy sets when applied and also they introduced specific arithmetic and expansion principles. Wang [7] used fuzzy mathematics to build a multi-level qualitative and quantitative evaluation system to solve the problem that it was difficult to advance the geological study of the gas reservoir, and successfully predicted three favorable regions of coalbed methane system and multi-layer mixed production with this system. Their research breakthrough lies in applying the fuzzy mathematical model to the field that was difficult to solve. And based on the purpose and practicality of the fuzzy concept of the characteristics of effective play. Liu [8] proposed a fuzzy mathematics-based control method for water quality pollution volume to solve environmental problems, which first sets the target of total discharge volume, and then evaluates the pollution in key areas with the control method. Introducing fuzzy mathematics into sewage discharge is a creative attempt, because the calculated cost of precise control of urban pollution cannot bring better benefits, and this point form has better operability. Peng [9] proposes a new analysis method on the management model of aviation industry in the context of big data, which is based on fuzzy mathematics and error correction model processing tool, the processing results will be used for the estimation of BP model, using the constructed database situation they believe that the method has some positive significance for the intelligent management of the aviation industry, in addition they make some suggestions on the prediction results.
Multi-source heterogeneous data fusion models can process data with various attributes from sensors, and the model construction concept of this processing model has a great relationship with the usefulness of the data, and various industries in the context of big data are very interested in the development prospects of fusion models. Li et al. [10] noticed that most of the existing multi-source heterogeneous fusion models pay attention to the network structure information modeling and ignore the multivariate information of different nodes, so they proposed. Zhou et al. [11] considered that the traditional deep learning methods were lacking in feature extraction of multi-source heterogeneous data, and in order to improve the accuracy of fault diagnosis they proposed an alternating optimization network model, and the alternating training. The results showed that the method can tap the deep common features of multi-source heterogeneous data and provide some ideas for fault detection of rolling bearings. For this reason, Chai et al. [12] constructed a multi-source heterogeneous analysis method, and simulation experiments on specific futures data showed the practicality of their proposed framework. Liu et al. [13] considered that mining information from urban multi-source heterogeneous data is a challenging task, and for this reason, they constructed a knowledge mining network to solve urban flow related problems, they experimented with Chengdu drop order and POI datasets as simulated objects, and the results showed that the model is effective. Zhu et al. [14] constructed a systematic data fusion method for recommendation of heterogeneous features, which can mix user interaction activities with tensor factors to achieve accurate course recommendation, and they performed multiple data generated by several participants simulations and the results show that the method outperforms existing neural networks and matrix models, but the data sources they studied are relatively stable and the ability to fuse data of different dimensions is yet to be improved.
The idea of the way to construct multi-source heterogeneous fusion models is very broad and the breadth of application is expanding, and scholars are actively promoting their research. The objects handled by the fusion model are unequal types of data from various sensors, which leads to the difficulty of fusion models to satisfy both accuracy and efficiency, and the need of constructing the model fits better with the performance of fuzzy mathematical quantification data, and it will be a meaningful attempt to introduce fuzzy theory into the fusion model of multi-source heterogeneous data.
Fuzzy mathematics-based multi-source heterogeneous data fusion model building
Intuitionistic fuzzy integration algorithm construction based on multi-attribute data
The fuzzy set concept is a localization theory used for classification, which enables the determination of attributes of the data transmitted by the sensor, with a specific mechanism that uses the defined affiliation function to extend the variation of the individual-sample set affiliation, thus determining a non-exact description of the problem, and the distribution of the sensor’s with the data is shown in Fig. 1.
Cluster sensing structure.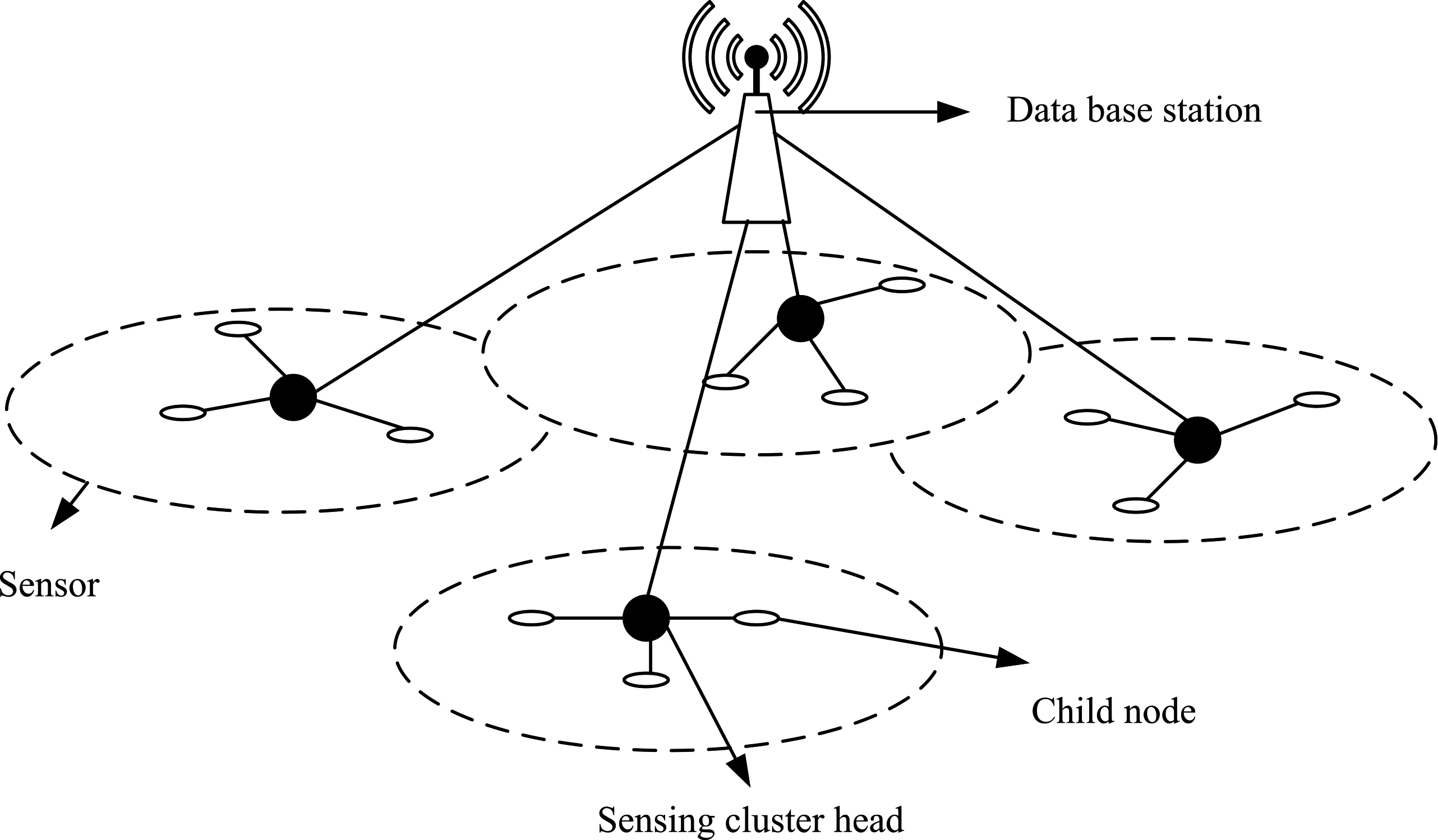
The complete decision fusion process in wireless sensor domain should be from node acquisition to decision proposal, but since the result of local decision can directly affect the final fusion, an accurate decision algorithm needs to be constructed to achieve a simplified local decision process. The intuitive fuzzy set construction algorithm is by far the more commonly used method, which first fuzzifies the attribute values of the raw information collected by the sensors and transforms the domain of affiliation values to between
The above Eq. (1) of
In the above Eq. (2)
A part of the hesitancy degree is divided to the affiliation degree and another part is assigned to the non-affiliation degree according to the proportional case of the above Eq. (3), which is usually designed based on the original proportion of the affiliation degree. In order to obtain the conversion relation from fuzzy sets to intuitionistic fuzzy sets, the following Eq. (4) is designed for the construction method of fuzzy sets.
According to the construction method of the above Eq. (4) to reach the intuitionistic fuzzy affiliation can be derived from the following Eq. (5).
According to the above Eq. (5), if the hesitation degree of the fuzzy set is determined, the values of the affiliation and non-affiliation degrees can be calculated, so the selection of the hesitation degree is the most central step in the whole fuzzy set construction link, the existing hesitation degree calculation methods are based on intuitionistic fuzzy entropy and proximity point information, but this method cannot be used in the network environment of wireless sensing, so the study will determine a wireless sensing network based of adaptive hesitation calculation method, which still considers the Gaussian distribution of the received data of sensing nodes [16]. And in the Gaussian distribution, the variance is positively related to the data dispersion, so if the variance of the data set is smaller, the distribution of the data is more concentrated, and then the affiliation of the data with the set can be easily determined, and vice versa, so the variance size has a direct relationship to the selection of the hesitation degree of the intuitionistic fuzzy set. Based on this relationship, it is assumed that the maximum hesitation of different values for each category under the attribute
In the above Eq. (6),
After establishing the calculation equation, the algorithm will be constructed by first inputting each sample
The intuitive fuzzy integration algorithm constructed from the attribute values of individual data detected by wireless sensors can only be used as a basis for judgments in a single dimension, while multiple sources of heterogeneous data often possess different dimensions, which leads to the fact that a single integration algorithm does not serve as the final framework for decision-level fusion models, and therefore multidimensional result fusion is required to ensure the accuracy of decisions [17]. The general wireless sensor data points present inter-category similarity and the fusion direction of the study will be constructed considering this principle to derive a method for determining the weight of each attribute. Finally, the multi-attribute classification problem is solved according to the superiority-disadvantage solution distance method, and finally the data fusion of sensor network nodes is completed.
Intuitionistic Fuzzy Weighted Averaging (IFWA) and Intuitionistic Fuzzy Weighted Geometric (IFWG) are common fuzzy integration operators that can obtain more accurate multi-attribute results. Weighted Geometric, IFWG), although the results of these two operators are also intuitionistic fuzzy and also have general functional properties, they are weighted with a single attribute weight, which leads to results that are too attribute dependent and ignore the importance of the intuitionistic fuzzy number [18]. Various improved operators have been derived from the above two basic operators, among which the Intuitionistic Fuzzy Hybrid Averaging (IFHA) operator with weighting coefficients
The study uses the Technique for Order Preference by Similarity to an Ideal Solution (TOPSIS) for the decision problem of multidimensional attributes, the principle of this algorithm is to use the distance between the evaluated object and the ideal solution as the basis of superiority and inferiority, which is divided into optimal and inferior objectives [19]. The decision matrix for a given problem
The ideal distance between each sample in the matrix and Eq. (8) is calculated and the result is output according to Eq. (9).
The similarity ranking of feasible solutions is performed according to the calculation result of Eq. (10) above, and the result of the ranking will be used as the superiority or inferiority of the evaluation object in order to provide a basis for decision making. The key of this method is the selection of positive and negative ideals, while the standard TOPSIS method can only reflect the internal situation of the sample set, if the object is a single value, the solution determined according to this method is not representative; secondly, it lies in the determination of attribute weights, most of the traditional sources of weights are given by experts, while wireless sensors need to be trained on historical information to obtain specific weights. Therefore, the study will improve the method adaptively by converting the data monitored by the sensor node
The
Equation (12) of
The similarity matrix of the attributes is obtained according to the similarity equation based on the category distance matrix of Eq. (13), and then the results are normalized to obtain the weight vector of the attributes, which is calculated according to Eq. (14).
The above Eq. (14) of
The above Eq. (15) in
Weighted TOPSIS intuitionistic fuzzy heterogeneous data fusion algorithm.
The training sample set in Fig. 2 above has the category of
The first step of multi-source heterogeneous data fusion is to intuitively fuzzify the data from real scenes and fuzzify the original “heterogeneous” data from sensors. The study will use 40 sets of data as training data and 10 sets as reference data to evaluate the performance of the model.
The performance analysis of the fuzzy conversion mechanism was first conducted to evaluate the accuracy of the classification by the case of the degree of affiliation and non-affiliation, and the study randomly selected data as a test set to observe the conversion of the intuitionistic fuzzy construction method, and the specific performance is shown in Fig. 3.
The intuitionistic fuzzy situation of class I data.
Figure 3 shows the intuitive fuzzy construction of data set I, among which Fig. 3a is about the membership results of the three data sets. The three bar graphs of each group of data from 1 to 10 indicate the membership of the data only to the sample set where the data is located. Except for the second group of data, the results show that the membership of the data to the attribute is relatively high, and the membership of several groups exceeds 0.8. It shows that the membership division of this method is reasonable; Fig. 3b is about the non-membership of the three data sets. The results show that the non-membership degree of the data pair is mostly below 0.1, and the non-membership degree of each data pair is not higher than the membership degree of other data sets, with an average gap of more than 0.5. Therefore, this intuitionistic fuzzy method has good classification performance and can effectively screen data from various sources based on attributes. In order to quantify the accuracy of this classification, fuzzy score value is introduced, and the size of the score is proportional to the accuracy. The specific score is shown in Fig. 4.
Membership scores of Class I sample data to sets II and III.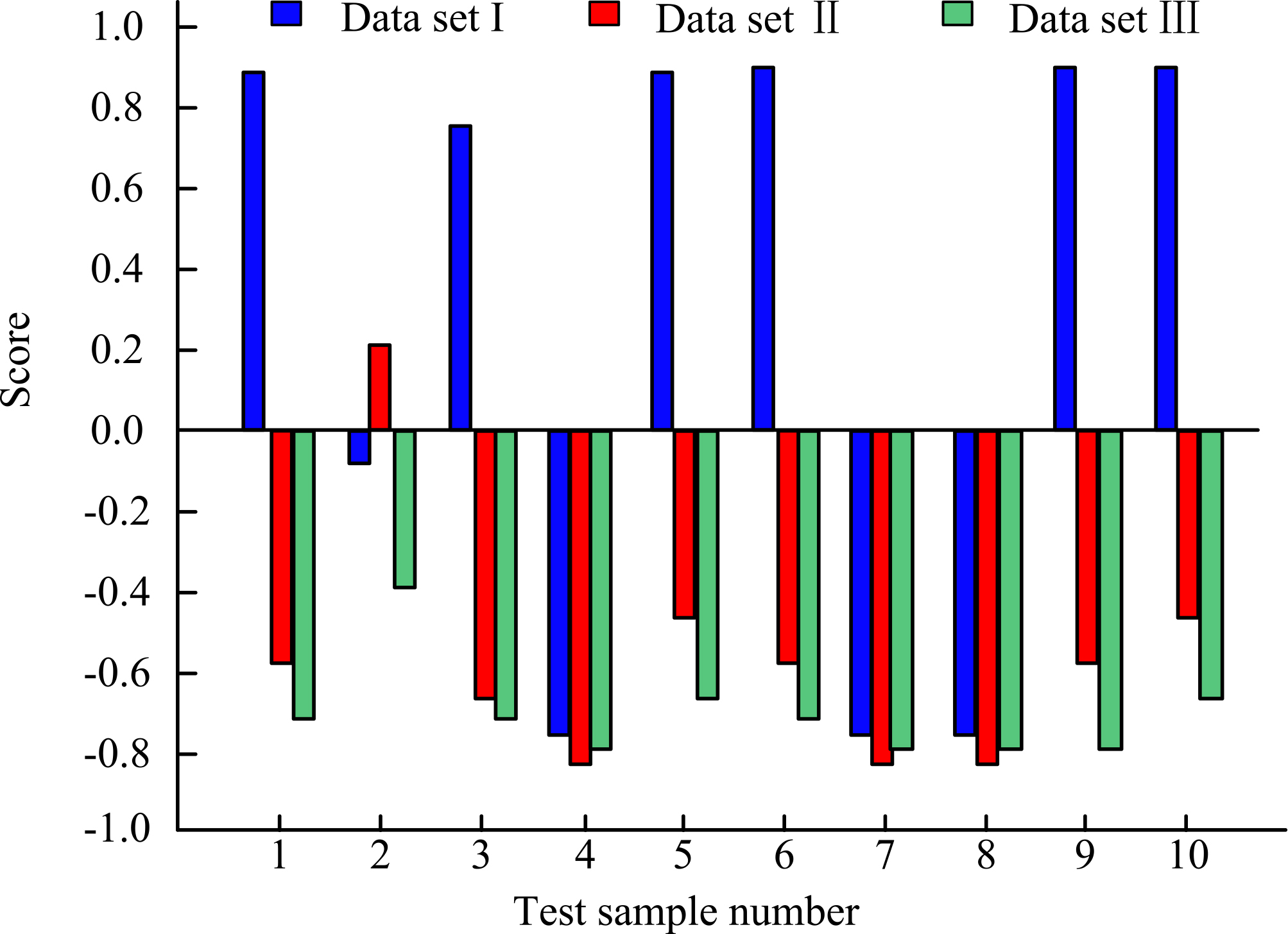
According to the scores in Fig. 4 above, it can be seen that the affiliation score of each data point to the set in which it is located is significantly higher than the other sets except for the second set of data, and the experiment as a whole further validates the classification accuracy of the method. Since the second set of data mentioned above showed deviations, in order to test the percentage of such deviations, the study conducted 800 experiments using the method, and the results showed an accuracy of 89%, which indicates that the accuracy of the conversion method can meet the requirements of the data fusion model with a certain degree of reliability. The analysis of the anomalies involved in the experiments yielded the affiliation functions for Class I and Class II as shown in Fig. 5.
Membership function analysis of outliers.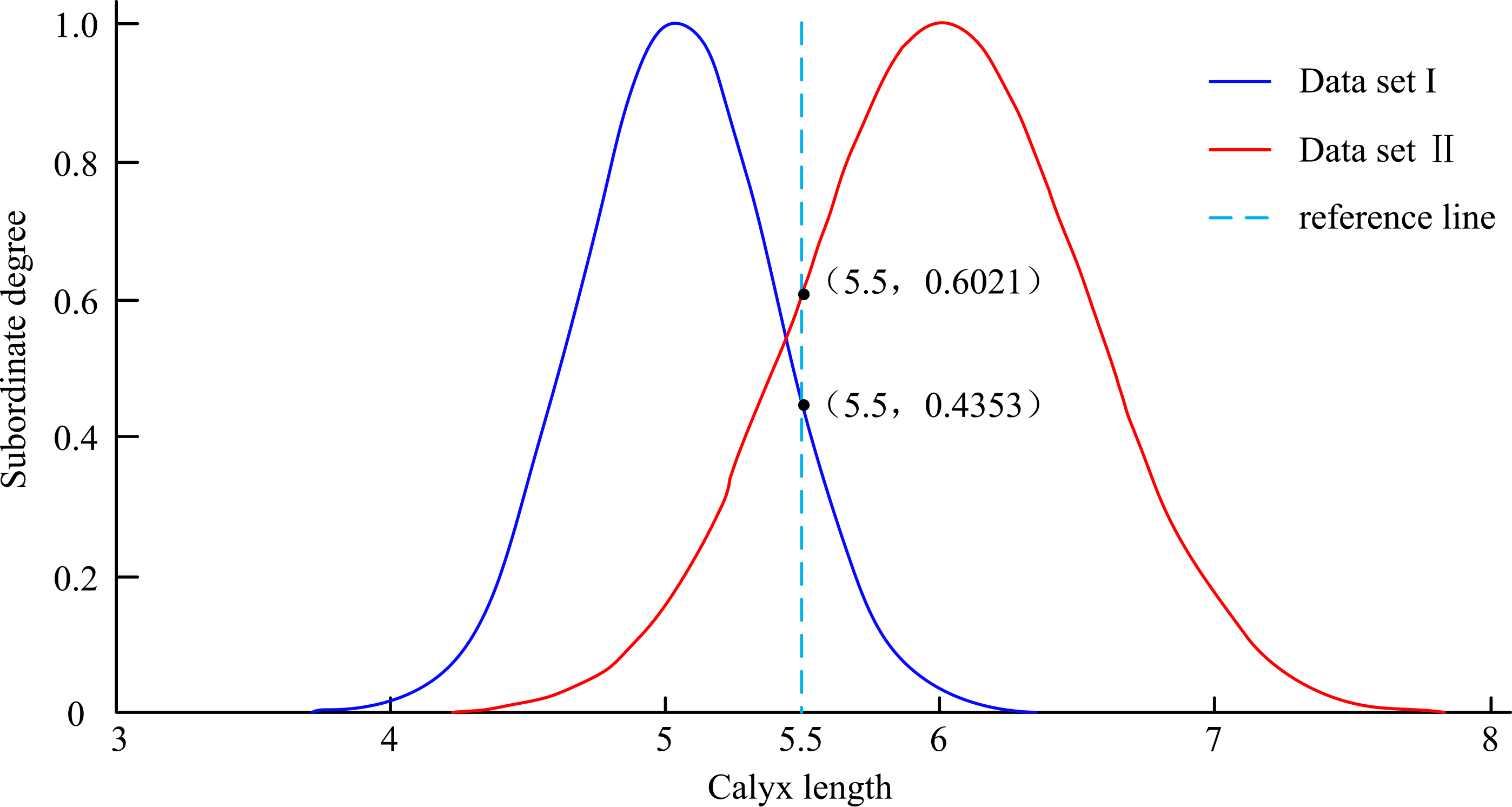
Abnormal number of attributes.
The reference value of the Class I data in the data set is 5.5. The membership function result in Fig. 5 shows that the membership degree of the class II data at 5.5 is 0.06021, which is 0.1668 higher than that of the class I (0.4353). This is because the determination method of the hesitancy proposed in the research is based on variance, so the hesitancy degree of this type of data is larger. But different from the traditional fuzzy construction relationship, the greater the degree of membership of the data. Therefore, the intuitionistic fuzzy structure proposed in this study changes the membership results of the outliers, and this result is more in line with the reality.
The data of each dataset is classified, and the attribute categories are divided into four attributes of calyx length and width and petal length and width, which are represented by A1, A2 and B1, B2, respectively, and the traditional method fuzzy construction method and the intuitionistic fuzzy algorithm proposed by the study are used to classify the dataset, and the evaluation results will directly affect the accuracy judging, based on this detection method for all test samples for outlier statistics, the results are shown in Fig. 6.
As shown in Fig. 6, the attribute construction of all test samples shows that the number of anomalies of A1 and A2 attributes is above 4, while the abnormal value of B1 and B2 attributes is below 2. This indicates that the cause of abnormal data or inaccurate classification may be the misjudgment of attributes. In order to explore the interference of the similarity of four attributes on the degree of membership, the distribution of four attributes based on normal distribution was studied, and the results are shown in Fig. 7.
Distribution of three data sets under four attributes.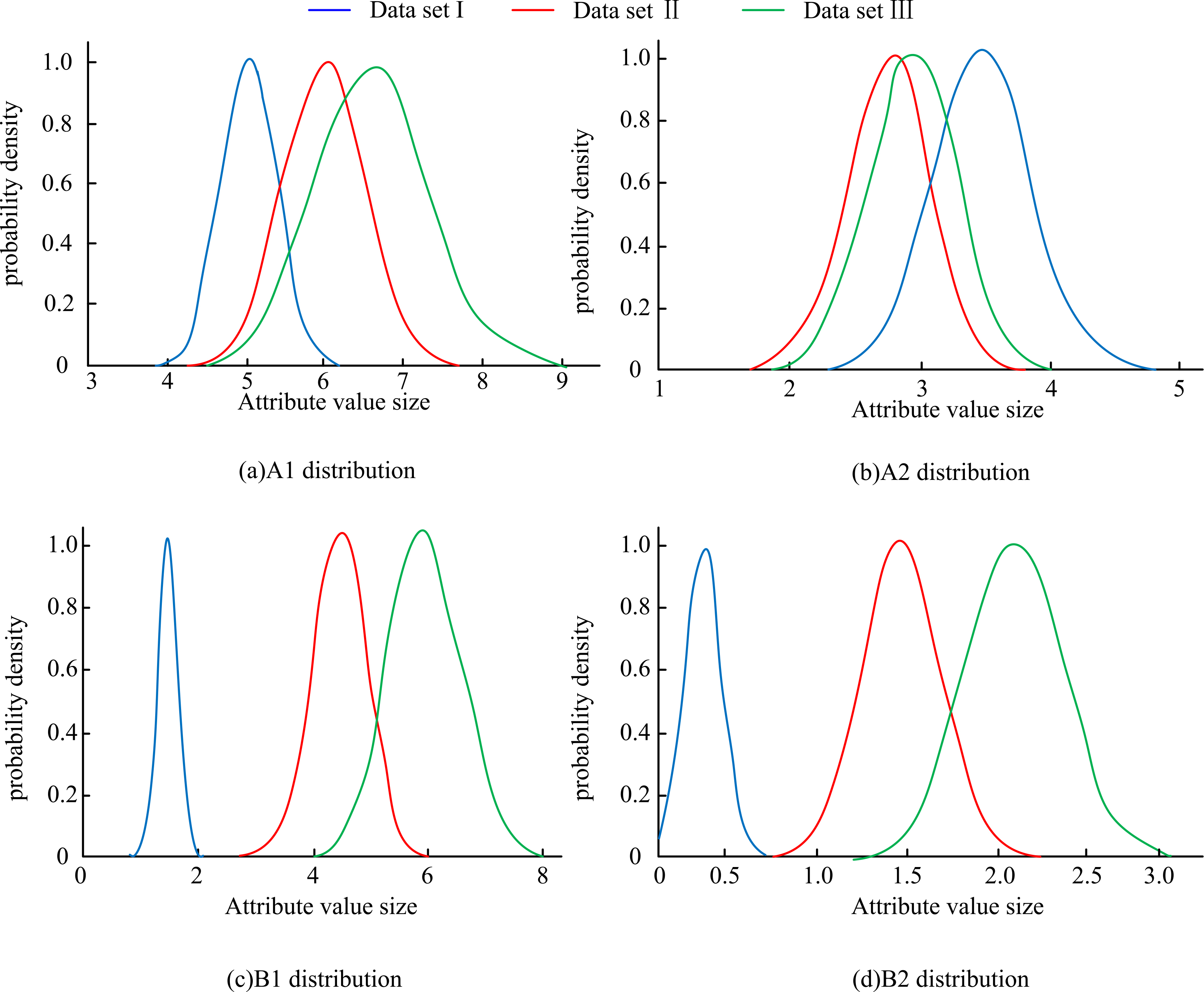
The distribution of Fig. 7 above shows that as far as attributes A1 and A2 are concerned, the three groups of data are more closely distributed, especially the distribution of Classes II and III is more closely distributed, and there is a possibility of affecting the accuracy of the classification, but the two attributes B1 and B2 show more dispersion, which indicates that the method is still valid.
In terms of the algorithm itself, the degree of affiliation is directly related to the hesitation degree
As can be seen from Fig. 8 above, the total number of anomalies remains stable at
The fusion algorithm is optimized with weighted TOPSIS compared with the traditional model, and the intuitionistic fuzzy averaging operator is upgraded to be applicable to the processing of various data. To test the improvement effect will be tested using the above data set as well as the relevant experimental conditions for various improvement paths, and the number of tests remains 800, and the results are shown in Table 1.
Performance comparison of several algorithms
Distribution of three data sets under four attributes.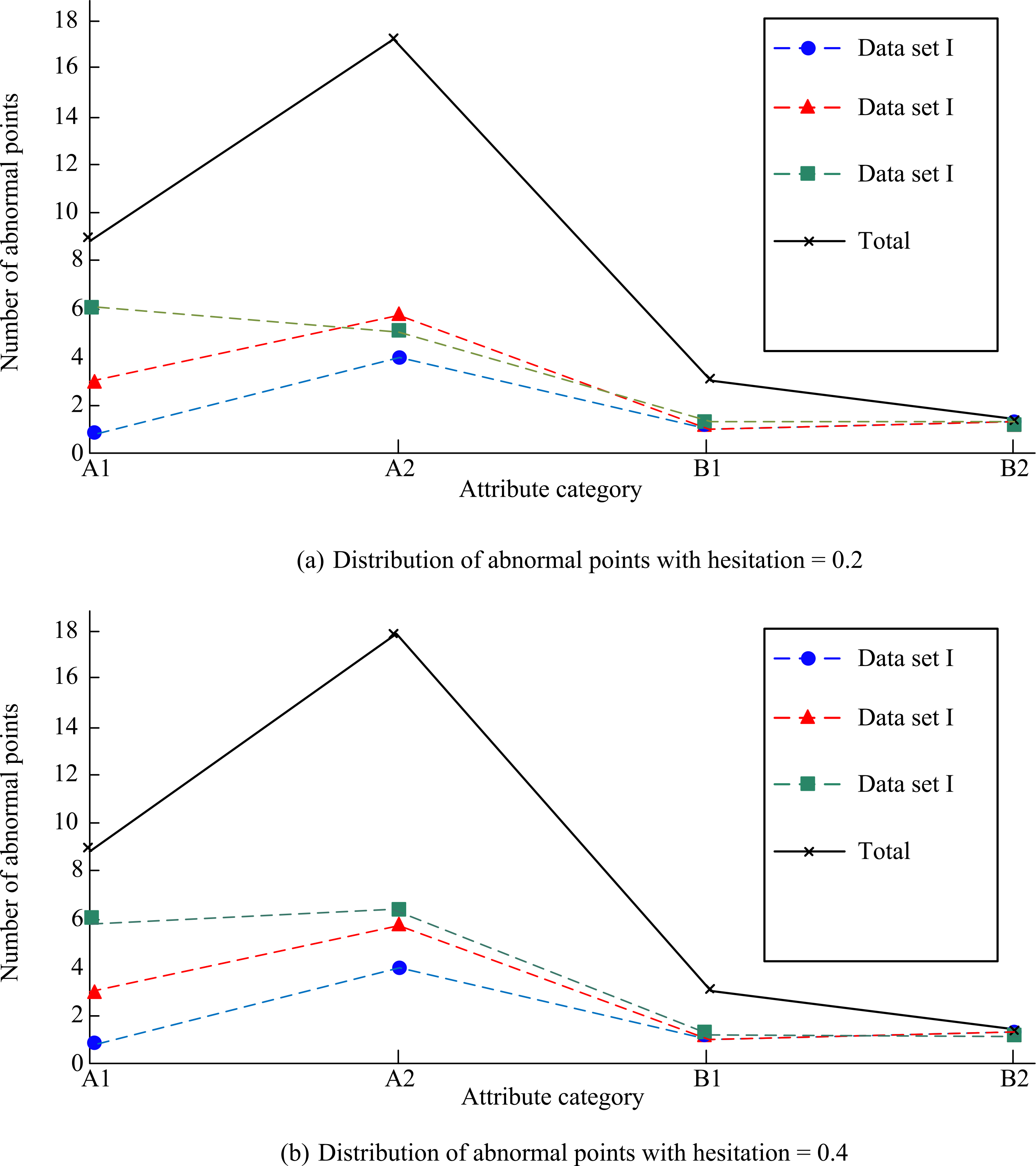
Through the above experimental results, it can be seen that the improved algorithm proposed in the study has a more significant effect on the optimization and improvement of the traditional fusion algorithm, and the accuracy rate is improved by 14.01%, and the optimized path of IFWA has a lower accuracy rate for the original algorithm, which is caused by the fact that the weight assignment of this operator will take into account the importance of the attributes; while IFWG has a certain improvement on the accuracy rate, and overall the optimized algorithm of this study The algorithm of path construction has the best performance, and the improvement of TOPSIS has some positive significance on the decision result of fused data. The above control experiments were evaluated for prediction performance according to different hesitation thresholds, and the results are shown in Fig. 9.
Comparison of accuracy of algorithms under different thresholds.
As can be seen from Fig. 9 above, compared with a single dimension, both IFWG and IFWA operators can effectively improve the accuracy, but the most significant improvement is the optimization of the TOPSIS operator. The prediction accuracy of the hesitation degree in the interval (0.15, 0.5) can be as 0.8 is the dividing line to distinguish between a single dimension and the accuracy of the optimization operator, which further shows that the optimization path of the operator is reliable and has a fault-tolerant space, which can significantly improve the classification accuracy.
Multi-source heterogeneous data needs fusion data as the basis for intelligent control decision-making in various fields. Transforming it according to the function of fuzzy mathematics takes advantage of the consistency of results and methods. Specifically, the decision-level fusion model constructed requires the help of Fuzzy mathematics to achieve data classification. The research constructs an intuitionistic fuzzy transformation algorithm based on fuzzy sets to transform the original data. The simulation results of the algorithm performance show that the overall classification performance of the algorithm is good. Although there will be errors in evaluating the algorithm from attributes, it will cause this situation. The reason is that the data set itself is close to the Gaussian distribution; the multiple simulation results of the iris data set show that the accuracy of the model is operable; in order to solve the problem of insufficient classification performance in a single dimension, the study introduces fuzzy ensemble. The TOPSIS algorithm used in the case of the operator improves the accuracy of the original model. Although the IFWG and IFWA operators can improve the accuracy to more than 80% when the hesitation degree is in the interval (0.15, 0.5), the operator introduced in the study showed higher performance. This shows that this construction idea and optimization path are reliable and can meet the decision-making needs of the fusion center in the wireless sensor network environment. However, this research only improves the classification accuracy from the local decision-making. In the future, the multi-type sensor data fusion model will be carried out. explore.