
Abstract
To solve the problem that individual visual features could not be accurately extracted from low-light and high-noise pig face images in intensive farming, the optimal fitting curve parameters of image brightness enhancement were defined, and the Zero-DCE model was improved and Denoise-Net was introduced to achieve brightness enhancement and high-noise suppression of a single low-light pig face image. The experimental results show that, compared with EnlightGAN, Zero-DCE, Retinex, and SSE, the algorithm in this paper (DCE-Denoise-Net) has good results on image quality metrics such as information entropy, Brisque, NIQE, and PIQE in the absence of reference images. The image quality is improved. On the basis of improving the low visibility of low-light images, denoising was achieved. It is more suitable for low-light pig face image enhancement in a real breeding environment.
Introduction
With the increasing proportion of pork in meat consumption, improving pork production and quality has become an urgent problem to be solved. In recent years, a series of food safety incidents and livestock and poultry epidemic infectious outbreaks of panic, such as “clenbuterol”, “mad cow disease”, “bird flu”, “African swine fever”, the world is more and more attention to food security, in the process of trying to reduce the production risk, online tracking back large animal products whole industrial chain. Individual identification is the key technology to achieve traceability of animal products [1].
With the visual and rapid popularization of the application of artificial intelligence technology in actual life, DNA, autoimmune antibody labels, nasal lines, retinas, and iris biometric identification technology are put forward and used for livestock and poultry individual identification, but a single biometric is restricted by various factors and has low recognition rate problems, making it difficult to meet the demand for individual accurate recognition applications [2]. In particular, most large-scale piggeries are closed indoor environments, and the light in the piggery is dim, so the visibility of captured visual images of individual pigs is low, which seriously affects the analysis of the visual characteristics of individual pigs. Therefore, it is of great significance to realize individual recognition to effectively capture features in visual images by means of intelligent image contrast and detail identification between different pixels to ensure the true color of visual images while avoiding excessive enhancement and noise amplification.
The existing traditional methods of low-light image enhancement mostly involve distribution in Retinex [4], multi-scale Retinex modeling [5], histogram equalization (HE) [3], and other categories, which ignore local detail features while improving the global brightness of the image. With the application of deep learning technology in visual technology, low-light image enhancement methods develop into both CNN (Convolutional Neural Network) and GAN (Generating Adversarial Network) [6]. The CNN method dataset relies on low/normal light contrast images in training. For example, Kin [7] proposes a cascading automatic encoder (LL-Net), using the contrast image denoising and weak light enhancement joint method. It is proved that the encoder can learn the signal characteristics of a low-light image after training and can enhance and denoise automatically. The Retinex-Net end-to-end framework proposed by Chen Wei et al. [8] constructs a dataset from paired low/normal light images obtained in the real scene, and integrates Retinex-Net theory and a deep network to achieve light state adjustment. GUO et al. proposed Zero-DCE [9] model, which takes an image specific curve estimation task to low-light image enhancement. The GAN-based system uses unsupervised training that doesn’t require paired images for input. However, it requires carefully choosing unpaired data. For example, in EnlightenGAN [10], the global-local discriminators are used to achieve the global and local low-light enhancement, and U-Net is used as the generator to preserve the original structure and texture of the image. Cameron Fabbri et al. [11] a technique based on GAN is proposed to improve the image quality of underwater scenes, a method of generating paired data is proposed using the CycleGAN to convert images from any arbitrary domain X to another arbitrary domain Y without image pairs. By using X and Y as a group of undeformed/formed underwater images to generate paired image data.
Both CNN and GAN image enhancement methods ignore noise processing while enhancing brightness. However, in intensive breeding mode, the light intensity of piggeries is low, resulting in high noise in the pig face image under low light. In addition, the pig individual under irregular movement cannot obtain a pair of low/normal light images [12]. Therefore, in this paper, Zero-DCE, a single low-light image enhancement of pig face, was used as the backbone network to improve the enhancement network model structure, separate image brightness and noise characteristics, and fuse the enhancement network again to achieve the purpose of pig face image enhancement under low-light and high-noise conditions.
The main contributions are as follows:
Aiming at the problem that pairs of low/normal light datasets cannot be obtained due to irregular movement of pigs, single low-light image enhancement technology is studied. Based on CNN, image enhancement of pig face under low light intensity is realized. In view of the problem of improving the noise points of the datasets in the harsh environment of the piggery, expand and enhance the network fitting ability, improve the Zero-DCE network model, integrate the enhancement and denoising modules, and suppress the image noise on the basis of preserving the inherent colors and details.
Data acquisition
In July 2021, pig face samples were collected from four piggeries in the Zhejiang Huateng Pig Breeding Base. An industrial camera with HD1080 resolution (1920
Quantity and pictures of video collection
Quantity and pictures of video collection
First for low light pig face video preprocessing, remove fuzzy, no pig face video, video at 30 frames per second to extract the image, get rid of the fuzzy, no pig face appeared redundant image, according to the light intensity will be pig face samples are divided into nearly normal light, and low light image, extremely low light image, pig face according to the front and side pig face statistical image number such as Table 1, There were 5560 near normal light, 6341 low light and 6096 extremely low light, altogether 17997 pig face images is shown in Fig. 1, from left to right, near normal light, low light, extremely low light. Near normal light images were those with relatively clear pig face position and contour but with a relatively dark background; low light images were those with only partial pig face and dark background. Extremely low light images were those with an extremely dark brightness, and pig face and background could not be clearly seen.
Images of pig faces under different light intensities.
As live pigs are living animals, irregular movement leads to a failure to collect a data set of paired light information, so it is necessary to enhance a single low-light image. In order to realize the enhancement and denoising of a single porcine face image, the improved enhanced denoising network in this paper randomly selected porcine face images from multiple angles with low image similarity and similar number of near normal light, low light and extremely low light, and finally constituted 1320 low-light pig face samples.
Zero-DCE
In order to effectively identify the brightness enhancement of a single low-light pig face image, CNN, which meets the capacity and flexibility of image feature collection [13, 14], is selected as the basic network model. In combination with the regularization characteristics of CNN, the RELU activation function [15], residual learning [17], and batch normalization (BN) [16] are adopted to accelerate the model training process. Improve the result of denoising.
Zero-DCE network model carries out image enhancement based on CNN. By setting non-reference loss functions, the network can carry out end-to-end training without reference images, and the whole method obtains SOTA on multiple datasets, but the network does not consider the problem of noise. The enhancement result of the image with noise in the real environment is not ideal, so this paper intends to improve and optimize it on the basis of its network structure.
Zero-DCE regards the image enhancement as an adjustment of the task for the curve of the image pixels, a lightweight enhancement network through training, inputting a low-light pig face image by mapping a nonlinear curve, the output of a high-order curve, through the study of the dynamic range of the curve adjustment, and designing a loss function to achieve low-light image enhancement. And there is no need to pair pig face image datasets during training. Where curve estimation is configured as follows:
Where
As
Where
Inspired by literature [18], this paper introduces a denoising module into the Zero-DCE network structure, and the denoising process is regarded as clean images being extracted from a noisy image. A value with noisy
The network we named DCE-Denoise-Net consists of two modules. the Zero-DCE low-light enhancement module and the Denoise module. The Zero-DCE low-light enhancement module contains 7 convolution layers, and each convolution layer is symmetrically connected. In the first 6 convolution layers, each convolution layer contains of size 3
The first layer of the Denoise module contains of 3
Improved algorithm network structure.
Since Zero-DCE network doesn’t require paired or unpaired dataset in the training process, the key lies in propose a series of non-reference loss functions to determine the enhancement effect, so that model can assessment the image quality after enhancement. In order to enhance the denoising effect of the model, DCE-Denoise-Net uses the mean square error (MSE) of the input image with noise and the final output image as the loss function of the denoising module.
Where
Where
Where
Where
Trainable argument
The total loss function is:
Experimental platform and parameter setting
GeForce GTX 2080Ti GPU is used for training, and the training network is built based on the Windows operating system and Pytorch framework. The input of training stage is 1920
Experimental analysis
To verify the enhanced performance of adding the denoising module, the Zero-DCE results without adding the denoising module were compared with the improved Zero-DCE model (DCE-Denoise-Net). The training datasets consisted of 1320 pig face data sets, and the Zero-DCE was trained with open parameters. All experiments were carried out on the same experimental environment and equipment. Figures 3 and 4 show the enhancement results of two groups of pig faces with different light intensity. It can be found that the DCE-Denoise-Net model retains the semantic information of the image on the basis of Zero-DCE, and reduces the noise, which is more consistent with human visual perception.
Comparison of experimental results of different algorithms in pig face dataset.
Comparison of experimental results of different algorithms in pig face dataset.
Comparison of experimental results of different algorithms in SICE dataset.
In order to further verify the generalization ability of the model, this paper conducted training on the public dataset SICE [19], and the comparison of the results is shown in Figs 5 and 6. The problem of color degradation in the enhancement results of the Zero-DCE algorithm model is serious. The enhancement results in this paper are more natural with fewer noise points, which also indicates that the added denoising module is effective.
Comparison of experimental results of different algorithms in SICE dataset.
Training results of Pig face dataset.
The authors trained on the public dataset SICE, the pig face dataset, and tested using the SCIE public dataset, respectively, and the comparison results obtained are shown in Figs 7 and 8. The results of Zero-DCE and DCE-Denoise-Net on the pig face dataset can improve the brightness, but the softness and realism of the images are lower than those on the SICE dataset. DCE-Denoise-Net outperforms Zero-DCE in image brightness, image softness, and noise removal on both the SCIE and pig face datasets.
Training results of SICE dataset
The pig face dataset in this paper is compared and tested in the unsupervised low light enhancement methods of EnlightenGAN, Retinex [7] and SSE [20]. Since Retinex and SSE require paired datasets for training, the LOL dataset [7, 18] is used for training. This dataset contains 485 low-light and normal-light image pairs, and the final comparison results are shown in Fig. 9.
Comparison of experimental results of different algorithms.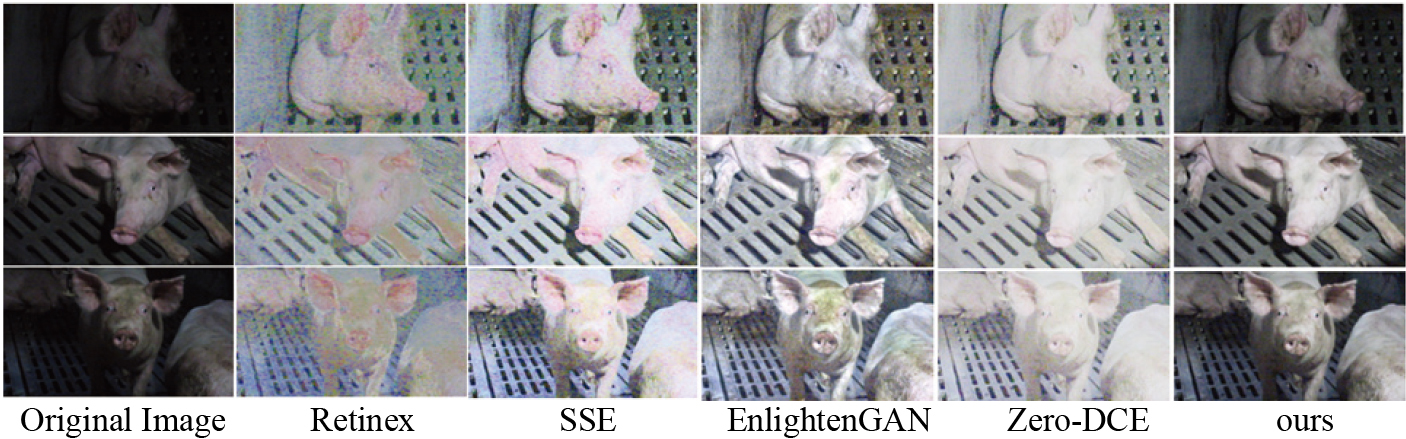
Experimental results show that the traditional Retinex and its improvements can effectively enhance the image, such as Retinex and SSE, but for the image enhancement results outside the training set scene, there are some problems such as color distortion, overexposure, and blurred details. The EnlightenGAN and Zero-DCE based on unsupervised low light enhancement can directly deal with low light images, but cannot achieve a good suppression effect for noise. Although the enhancement result of the method in this paper is weak for the background enhancement of the extremely low illumination image, the original information of the pig face image in low illumination is better retained, the color information is more accurate, and the noise can be effectively suppressed. Through experimental comparison and analysis, the performance of the algorithm in this paper is superior.
The pig face dataset proposed in this paper is shot in low light scene in real breeding environment without reference to normal light images. The image sharpness evaluation index GM (information entropy) is used to measure the richness of image information. There are no reference image evaluation quality indexes brisque [21], NIQE [22], PIQE [23, 24] conducts quantitative analysis on the experimental results of the method. In this paper, five algorithms in Table 2 are trained in the same training set, the LOL dataset (Retinex, SSE is 485 pairs of low light/normal images, EnlightGAN, Zero-DCE, and DCE-Denoise, where 485 pairs of images are trained together without matching images), is tested with a pig face image, where the larger the GM indicator is represented as an upward arrow in Table 2, and the smaller the brisque, NIQE, and PIQE indicator are represented as a downward arrow. Table 2 shows that the sharpness, noise processing, and quality evaluation of the image have been improved after the addition of the denoising module in this paper.
Comparison results of different algorithms
Comparison results of different algorithms
For intensive cultivation mode for pig face images in low light, high noise can accurately extract the individual features in question, and because pig individuals have no regulation motion, it is not possible to obtain data sets pairing low/normal illumination, a convolution neural network based network with a high order curve, dynamically adjusting the image pixel mapping, and a fused denoising network. Experimental results show that compared with EnlightGAN, Zero-DCE, Retinex and SSE without reference image quality index, DCE-Denoise improved 19.2% over Zero-DCE, 0.9% over EnlightGAN, 6.9% over SSE, and 22% over Retinex in GM image evaluation quality metrics. Brisque improves by 18.7%, 19.5%, 8.8%, and 3.9% over the other algorithms; NIQE improves by 9.3%, 19.4%, 43.6%, and 9.6%; and PIQE improves by
Footnotes
Acknowledgments
This work was partially supported by the Research and Development Program of Natural Science Foundation of Beijing (Grant:4202029) and Outstanding Scientist Training Program of Beijing Academy of Agriculture and Forestry Sciences (Grant:JKZX202214).