
Abstract
Design and implementation of the system for retrieving information about mathematical formulas – MFIRS. The structure of the system is mainly divided into the modules: input normalization, mathematical formula unification, mathematical formula encoding, text information feature extraction, mathematical formula feature extraction, mathematical formula indexing, retrieval and ranking. A method for extracting mathematical formulas and keywords based on FastText word embedding technology is proposed. This method can be used not only to get the structural features of the formula, but also to facilitate the calculation of the similarity of the formula by the vector result. At the same time, the model introduces the semantic features of context-rich mathematical formulas to improve the domain correlation of search results. The MathRetEval dataset was created based on about 7.9
Keywords
Introduction
Background
If you search the digital library, you can find much of what you need. The common search technology is mainly focused on the search for simple texts. Text documents in the form of word bags, do not support the processing of mathematical formulas.
The scientific literature is full of indices and complex mathematical formulas, even in the basic metadata, titles, and abstracts of papers. Research experience with Google Scholar has shown that failure to include mathematical formulas in references can lead to serious search problems.
The current situation and significance of the country
The standard for mathematical exchange between related software tools is MathML of the W3C. Few people want to write MathML directly. Most prefer some sort of compact symbol in the style of TeX, such as LaTeX or AMSLaTeX. As a result, the mathematical query system allows users to use their preferred symbols, such as the TEX package or similar (AMS) LATEX, for querying. To meet the varied retrieval preferences of users, the data should be converted into a uniform format. Presented MathML or Content MathML is only used for the output of software systems.
In the search for scientific and technical literature, the unsolved problem of mathematical search becomes very clear and arouses great interest, as the system that does not support the search for mathematical formulas is not perfect. Therefore, we evaluated the currently popular mathematical retrieval systems, including MathDex [1], MathFind [2], EgoMath [3], Egothor [4], LatexSearch [5], LeActiveMath [6], MathWebSearch [7], MSE [8], FSE [9], ICST [10], IFISB [11], KWARC [12], MCAT [13], MIRMU [14], RIT (Rochester Institute of Technology) [15], TUW [16], et al. Table 1 compares the aforementioned mathematical retrieval systems.
Comparison of mathematical retrieval systems
Comparison of mathematical retrieval systems
The developed system splits the index content into a mathematical formula index and an ordinary text index when indexing XHTML, HTML, and other documents. The indexing methods for the two types of content are different; ordinary text indexes are indexed in the conventional way.
The Fig. 1 below shows the overall architecture of the system.
The overall architecture of the system.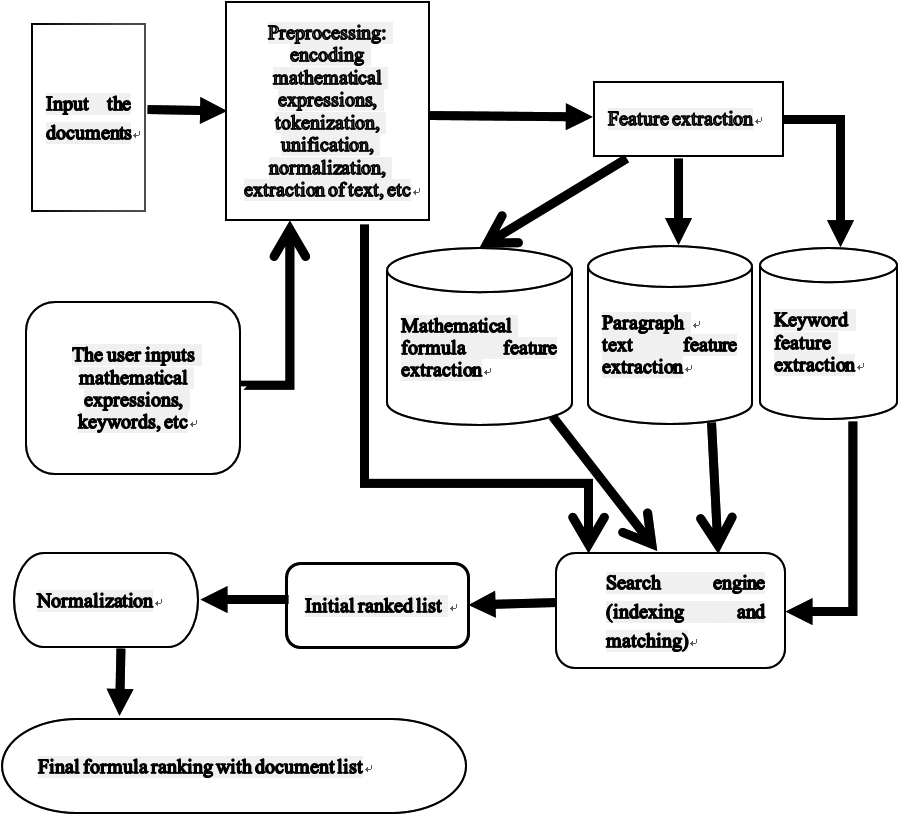
The index module of the realized system is mainly used for normalizing the input and preprocessing the mathematical formula.
The MathML document is normalized using the UMCL toolset to avoid the problem of mathematical formulas with the same semantics being represented by different MathML symbols. MathML documentation is normalized using the UMCL toolset to prevent issues with mathematical formulas that have the same semantics but are represented by different MathML symbols. To effectively align the MathML index form and query and improve the fairness of document similarity evaluation, standardizing MathML is used in the index and query phases.
The MathML specification form generated with the UMCL transformation not only improves the fairness of the similarity evaluation, but also helps in adapting queries to the indexed form of MathML.
Mathematical formula unification
There are three different types of unified algorithms used by the system. In order to obtain multiple common representations of all formulas, the algorithm performs a tokenization process.
The system returns matches similar to user queries, preserving formula structures and alpha-equations.
The three types of unified algorithms are shown below.
Sort Unify: Sort Unify by the number of operations that can be substituted. Unify Variable: Replace all variables with a unified symbol (ID) and retain the mandatory variables. Unify constant: Replace all numeric constants with a unified symbol (constant).
Common formulas include MathML, LaTeX, MTEF, OpenMath, binary trees, multi-member trees, and infix formats.
To preserve the hierarchical information of mathematical formulas and the connections between mathematical symbols, MFIRS uses the N-ary tree encoding method for mathematical formulas based on the representative MathML format. After mapping the two-dimensional structure of the formula using an N-tree, the formula must be converted into a linear sequence. Then, the “word structure” of this new language must be defined, using a single symbol node as the substructure of the word that resolves the formula. And here, a pair-based structure is used to define the word.
Since there are currently several formats for describing mathematical formulas, it is necessary to convert these formulas into a uniform format for memory processing in order to meet the requirements of retrieval. In future versions of MFIRS, the key implementation of the mathematical formulas will be converted into a unified format and stored in a big data system for retrieval.
Extract text information features
The text information is extracted at the following level: keyword level, paragraph level and document level, which mainly contains titles, summaries and keywords, as well as the description of the mathematical formula.
The keyword extracts the most relevant set of words from the text, which induces the text content, and can reduce the impact of irrelevant content in the context on the information acquisition process. In this work, the Rapid Automatic Keyword Extraction (RAKE) algorithm is used to process the context of mathematical formulas. Considering the co-occurrence relationship between word frequency and words, each word in the candidate phrase can be assigned a score. For the word w, it is scored as follows Eq. (1):
Where
The final process of extracting the text keywords around the formula is as follows:
Segmenting text into words, for the 10 sentences surrounding a given formula, based on punctuation marks and stop words as criteria for segmentation. Build a co-occurrence matrix of text. Extract the three characteristics of word frequency, word degree, and the ratio between word degree and word frequency. Score words based on the formula: Score Sort documents by vocabulary score in descending order.
The degree of a word refers to the number of times the word appears in other phrases, and the degree value divided by the frequency of the word is the score of the word. It then iterates through all the candidate phrases, sums the total scores of all the words that make up the phrase, and sorts the candidate phrases in order of their scores. The top 38.2% of the total score in the sorted results is used as the final keyword that rakes extracts.
This article uses the FastText model to train word embeddings on English text words around formulas. For text features containing mathematical content, the training process is improved, enabling it to capture the characteristics of professional vocabulary.
(1) Choice of stopwords
In the general text corpus, some common functional words belong to qualifiers, such as “the”, “a”, “an”, “that”, “those”, and so on. These words are referred to as stop words and are removed from the corpus. Some stop words that may affect mathematical semantics, such as “by”, “allow”, “near”, “everywhere”, etc., are calculated according to Eq. (2) to calculate the probability of deletion.
Where
(2) Apply negative sampling technology
In the traditional CBOW (continuous bag of words) model, the negative sampling technique is applied to predict the word w through its context, so for all given contexts Context (w), the word w is a positive sample, and other words are negative samples. Generally, 10 negative sample words will be selected for each context, and the selected words follow the unigram model, meaning that the probability of the selected word is equivalent to the frequency of the word in the corpus. The calculation formula is shown in Eq. (3):
For both the built positive samples and the selected number of negative samples, the goal of the model is to maximize the following functions Eq. (4):
Where
By using the negative sampling technique, the efficiency of the model weight update is improved, and the time complexity of calculating the negative sample is effectively reduced.
Mathematical formulas express logical semantics through the combination of mathematical symbols and varied spatial relationships. This system uses an N-ary arithmetic tree to represent the structure and hierarchy information of the formula and traverses the mathematical formula in depth using the N-ary arithmetic tree to convert it into a linear sequence. An analytical method based on the operational structure is designed to generate a substructure sequence of mathematical formulas. In the process of parsing formulas, we normalize and reconstruct arithmetic trees to reduce the occurrence of synonyms. Then we use the word embedding technique, FastText model, to learn the feature representation vector of mathematical formula substructures.
Considering the influence of the hierarchy and frequency of the substructure on the feature representation of the mathematical formula, we use the Smooth Inverse Frequency (SIF) method to assign weights to the substructure of the mathematical formula and calculate the feature vector based on these weights. The mathematical formula feature extraction method proposed in this section not only retains the formula hierarchy and structural features but also avoids the problem of high complexity in tree structure matching.
Input: formula sequence
Output: Formula embedding vector
1: for tuple t in
2:
3:
4: end for
5: for formula sequence f in F do
6:
7: for tuple t in f do
8:
9: The total number of tuples in the layer where the
10:
11: end for
12:
13: end for
14: Construct matrix X with column values
15: Set
16: for formula sequence f in F do
17:
18: end for
Index math formula
This system indexes documents, paragraphs, and mathematical formulas, and the index data is placed in Tables 2 and 3. The index model data structure uses an abstract tree inverted index; that is, a tree structure combined with an inverted table. Use the form of an abstract tree to index the formula; that is, describe it by the level of the tree. The closer to the root node, the more abstract it is, and vice versa. An inverted index of an abstract tree requires the mathematical formulas to be described abstractly. This abstract tree index model can perform both abstract and structural queries on mathematical formulas.
Formula index table
Formula index table
Formula document corresponds to the table
Suppose we extract the formulas M1 and M2 from the document and their normalized standard form is M (assuming that the index entry already exists), then we can directly insert them into the equivalent formula set with index content M on the index table, as shown in Table 2. In this way, when the user queries, if they search for formula M3, it is normalized to obtain its standard form M, abstracted and matched in the abstract tree, the match M is found, and then the equivalent formula set corresponding to M is found in the index table. Then, it finds the document where these formulas are located according to the formula document corresponding table (as shown in Table 3) and returns the result to the user.
MFIRS mainly utilizes keyword extraction and keyword feature learning algorithms to obtain key information in the text surrounding the formula, reduce the interference of irrelevant content in the text on the similarity calculation, and further improve the accuracy of the model retrieval. The specific retrieval process of MFIRS is as follows.
Select 16 pieces of data as the query statement for 16 types of scientific and technological documents. Extract keyword phrases using the RAKE algorithm. The keywords vector and formula vector are obtained by the keyword feature extraction algorithm and the formula feature extraction algorithm, respectively. Compute the vector of query keywords and formulas, then compute the cosine similarity between the keyword vectors and formula vectors of all data sets in the test set, respectively. The calculation formula is shown below in Eqs (5) and (6), and then the query results should be sorted from largest to smallest to obtain the top 10,000 results. Finally, Eq. (7) should be used to rank the documents containing the query results.
Where the
Where Use Eq. (7) to compute the similarity between the query input and Document A in the dataset and their corresponding keywords, then compute the similarity of all documents in the dataset and sort all the resulting documents.
The default value of
In this paper, a large-scale evaluation is achieved with the aid of a mathematical text repository.
Dataset
To evaluate our system, we built a library of mathematical texts called MathRetEval. We downloaded the document from arXiv.org, where the TeX document was converted into an XML document. For representing mathematical formulas, the W3C standard MathML is used. The documents used come from various scientific fields. For example, mathematics and physics, computer science, statistics, quantitative finance, and quantitative biology.
In this experiment, we used the corpus dataset from this real mathematical paper to evaluate the performance of this system. First, the arXiv document is converted into content-based XHTML format and presentation-based MathML format. The resulting corpus is decompressed to a size of 260 GB and compressed to a size of 16 GB.
Test results
The following tests the developed system’s ability to index and retrieve relatively large real scientific literature repositories. The goal is to observe how system parameters affect the index file size, retrieval time, and ranking of retrieved documents. Check the scalability of the system. Under different configurations, the evaluation system has both text and textile retrieval performances.
The entire document set contains 1.5
Computing resources and experimental parameters: 512 GB of RAM, 48-core Intel Xeon CPU, Ubuntu v22.04 operating system.
The results of the scalability test of input documents and indexed formulas.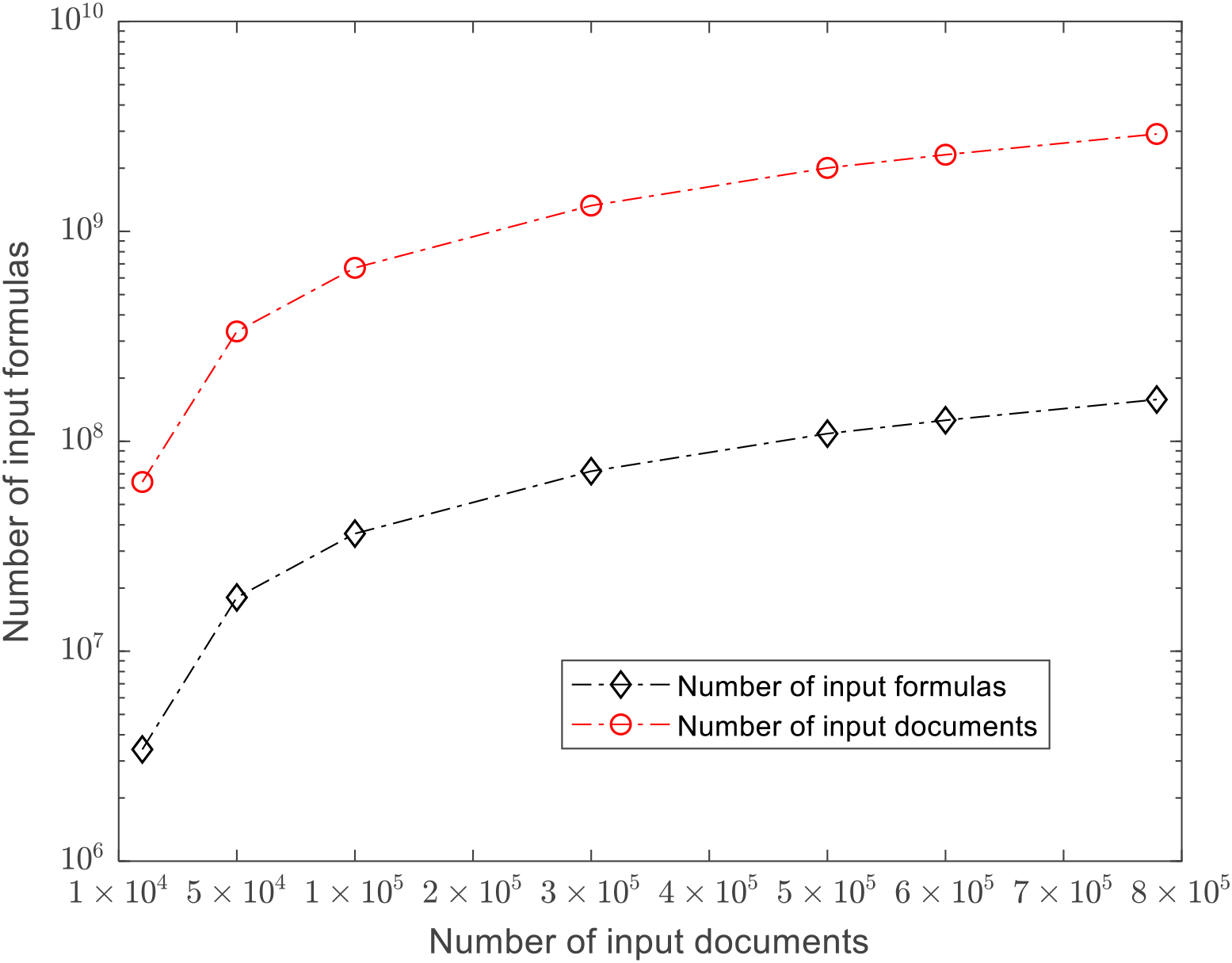
As shown in Fig. 2, the system’s scalability is approximately linear with the number of documents. This provides a viable response time even for billions of index sub-formulas, and even small formulas can score matches in most documents. We use different complex queries, such as hybrid, non-hybrid, high/low complexity single/multi-formula, and so on, to create an index. Then measure the average query time of the system on the MathRetEval dataset, resulting in an average query time of 512 milliseconds.
Comparison of index consumption times of various systems.
Comparison of index sizes of various systems.
As the number of input documents increases, Fig. 3 shows that the index consumption time of each system has an increasing trend. When the number of input documents is fixed, the index consumption time of the LatexSearch system is the longest, and the index consumption time of the MFIRS system is the shortest. When the number of input documents reaches 1.46 million, the indexing time curves of the LeActiveMath, MathWebSearch, and TUW systems appear to overlap. The indexing time of MFIRS shows an approximately linear increase.
As the number of input documents increases, Fig. 4 shows that the index file size of each system tends to increase. Among them, LeActiveMath has the largest index file, followed by MathWebSearch and LatexSearch; TUW is in third place, and MFIRS has the smallest index file. When the number of input documents reaches approximately 12.9 billion, the index file size of LatexSearch, LeActiveMath, and TUW is almost the same.
Comparison of the average search times of various systems.
As can be seen from Fig. 5, the average search time per system shows an increasing trend with an increase in the number of documents. Among them, the average search time of LeActiveMath and MathWebSearch tends to coincide and is the longest, followed by LatexSearch and TUW. At 2.5 million of the number of documents entered, the average search time for MFIR was around 91 milliseconds, and the average search time for LeActiveMath, MathWebSearch, TUW, and MathWebSearch was all longer than the average search time for MFIR.
Comparison of the number of index formulas between each system.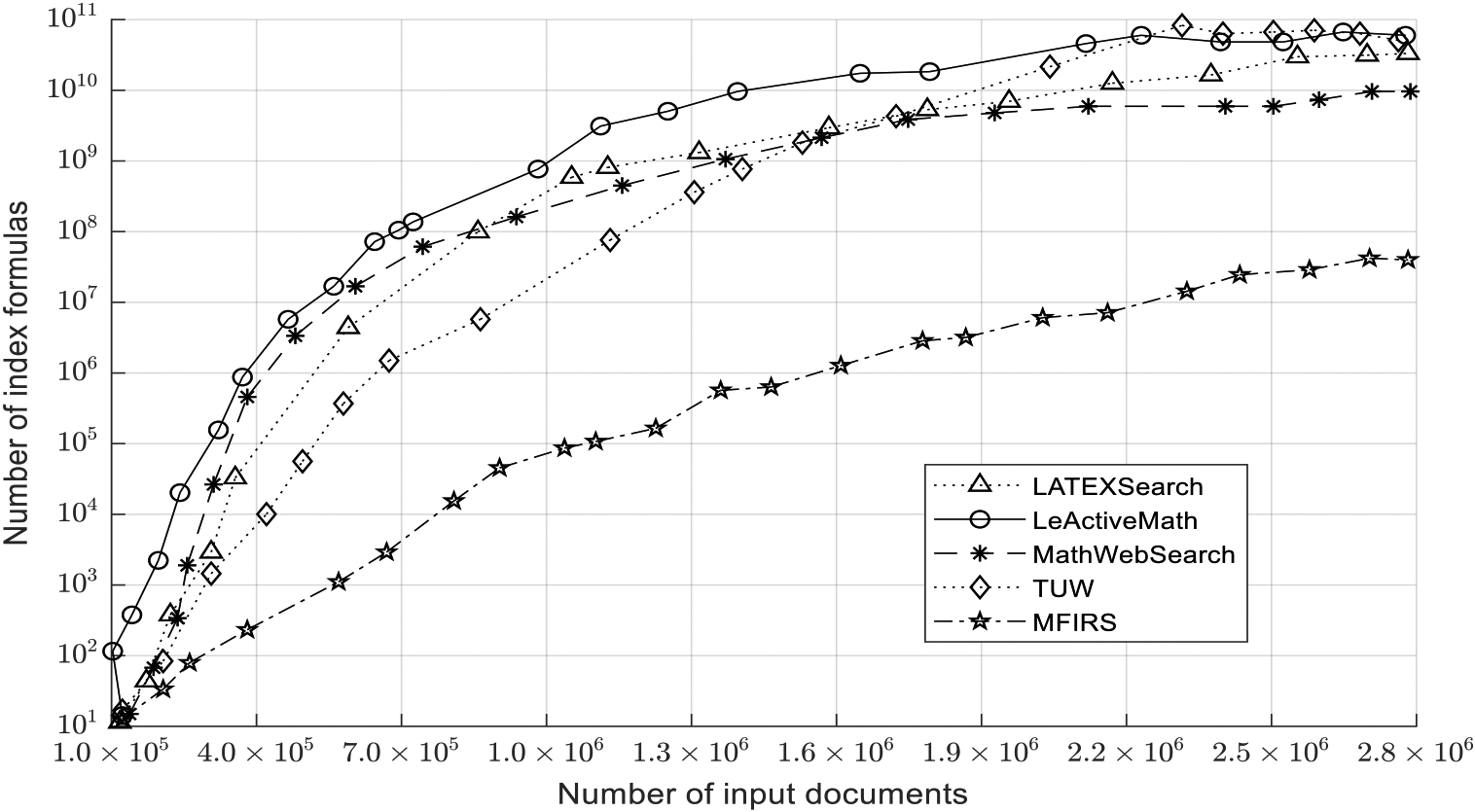
As can be seen from Fig. 6, as the number of input documents increases, the number of index formulas in each system tends to increase. When the number of input documents is fixed, the LeActiveMath system has the most index formulas, while the MFIRS system has the fewest. The index formula curves of LatexSearch, TUW, and WebSearch overlap in many places, indicating that the number of index formulas of the three systems is essentially the same.
The proposed formula retrieval approach has been tested using multiple configurations on various standard datasets. In this section, we describe the three major sets of experiments used for evaluating and improving our model.
On the designed dataset, the proposed algorithm system is compared to the current popular mathematical formula retrieval system. The experimental metrics used include precision@k, recall@k, nDCG@k, F1@k, and nDCG@k.
Define the following points: TP (True Positive): Indicates that the true category of the sample is positive and the final predicted result is also positive. FP (False Positive): A false positive indicates that the true category of the sample is negative, but the final predicted result is positive. TN (True Negative): A true negative indicates that the true category of the sample is negative and the final predicted result is also negative. FN (False Negative): A false negative indicates that the true category of the sample is positive, but the final predicted result is negative.
Precision@k is the proportion of correctly predicted relevant results out of the returned k results, which quantifies how many items in the top k results are relevant. Mathematically,
where
The Precision@k values of each system are shown in Figs 7–10.
Comparison of various systems on the P@5 metrics.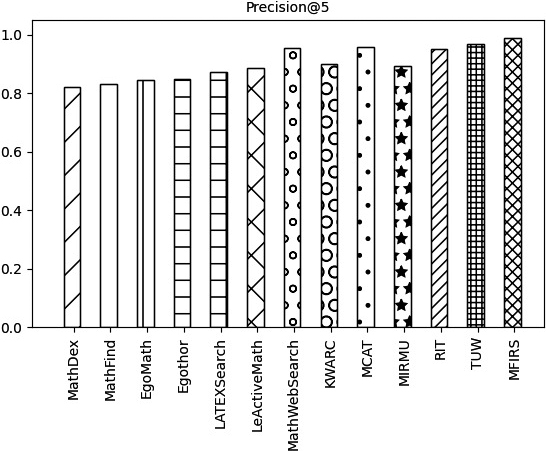
A comparison of various systems based on the Precision@10 metric.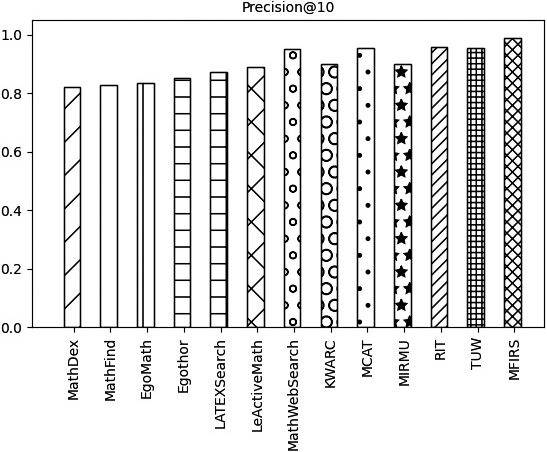
Comparison of Systems on Precision@15 metrics.
Comparison of systems on Precision@20 metrics.
As can be seen from Figs 7–10, the systems with higher and comparable accuracy include MathWebSearch, MCAT, TUW, RIT, and MFIRS. Relatively less accurate and comparable systems include KWARC, MIRMU, LeActiveMath, LatexSearch, Egothor, EgoMath, MathFind, and MathDex. The MFIRS system has the highest accuracy and the MathDex system has the lowest accuracy. The accuracy of all systems is greater than 0.8. A limitation of Precision@k is that it does not take into account the location of correlation results.
Recall@k is the proportion of correctly predicted correlation results to all relevant results, and the calculation Eq. (9) is shown below.
where
Comparison of systems on Recall@5 metrics.
Comparison of systems on Recall@10 metrics.
Comparison of systems on Recall@15 metrics.
Comparison of systems on Recall@20 metrics.
The recall rate of each system is shown in Figs 11–14.
It can be seen that the recall rate of each system is above 0.81; the MFIRS system has the highest recall rate, and the MathDex system has the lowest. Similar systems with higher recall include MathWebSearch, MCAT, TUW, and RIT. The relatively low recall includes KWARC, MIRMU, LeActiveMath, LatexSearch, Egothor, EgoMath, and MathFind.
F1@K is the harmonic mean of Precision@k and Recall@k, and the Eq. (10) is shown below.
The range of values for F1@k is [0,1], with a higher value being preferable.
The results of the comparison of the F1@K values of each system are shown in Figs 15–18.
Comparison of systems on 
Comparison of systems on 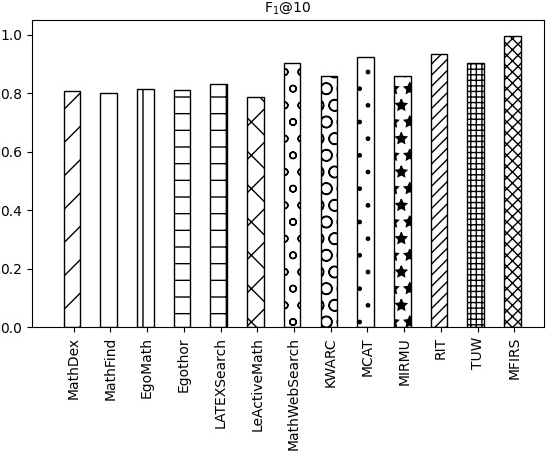
Comparison of systems on 
Comparison of systems on 
The F1 value of each system exceeds 0.8, as can be seen in Figs 15–18. The F1 values of MathWebSearch, MCAT, TUW, RIT, and MFIRS systems are higher and similar, and the F1 value of the MFIRS system is the highest. The KWARC, MIRMU, LeActiveMath, LatexSearch, Egothor, EgoMath, MathFind, and MathDex systems had relatively low F1 scores, and the MathDex system had the lowest F1 score.
There is also a variant of F1, as shown in Eq. (11):
The PR curve is often used in the field of information extraction, and it can be used to replace the ROC when the class distribution in the dataset is not balanced. The horizontal and vertical axes of the PR curve represent precision and recall, respectively. Accuracy is the ratio of the actual number of positive samples to the predicted number of positive samples.
Comparison of the average accuracy of each system.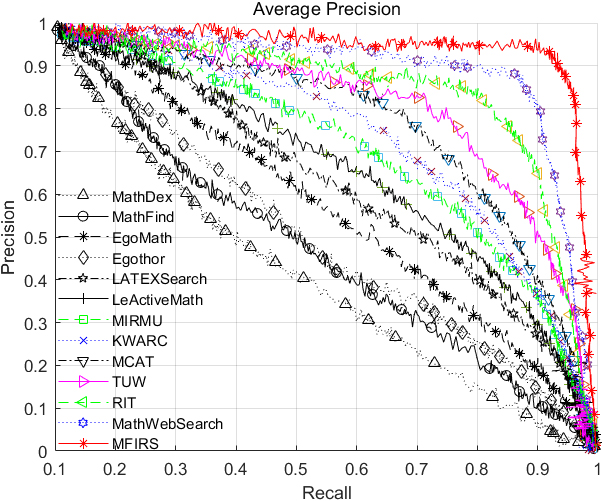
The ROC curve is similar to the PR curve. When comparing multiple models, the model with better performance will be closer to the upper right corner of the corresponding ROC or PR curve.
ROC graph of each system.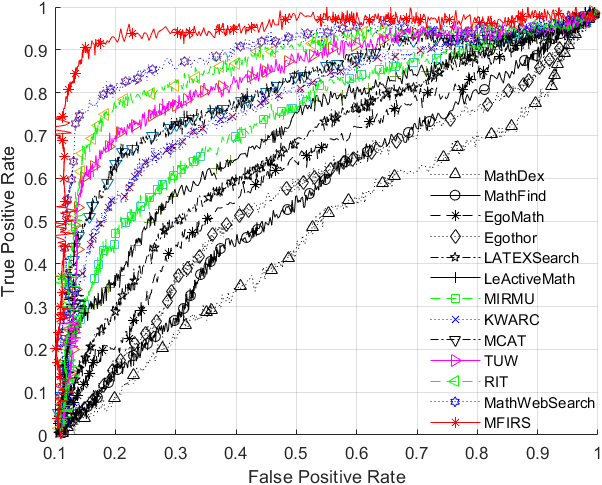
The average accuracy of each system is shown in Fig. 19. It can be concluded from Fig. 20 that the average precision of the MathWebSearch, RIT, TUW, MCAT, KWARC, MIRMU, LeActiveMath, LatexSearch, and EgoMath systems decreases sequentially. The MathDex system has the lowest average precision. MathFind has almost the same average precision as the Egothor system. The average precision of the MFIRS system is the highest, and the corresponding area under the PR curve (Precision & Recall@k) is the largest.
As can be seen from Fig. 20, the ROC curve of MFIRS almost contains the ROC curves corresponding to other systems. Therefore, MFIRS has the best performance, and the other ROCs are ranked from highest to lowest according to their advantages, followed by MathWebSearch, RIT, TUW, MCAT, KWARC, MIRMU, LeActiveMath, and LatexSearch. EgoMath and MathFind converge at FPR
As an international general mechanism for evaluating search algorithms, MRR averages the reciprocal rankings of multiple search matches; that is, the first match has a score of 1, the second match has a score of 0.5, and the nth match has a score of 1/n. If there is no matching sentence, the score is 0, and the final score is the sum of all scores. Therefore, the MRR assessment is based on the only relevant outcome. The formula for calculating the MRR Eq. (12) is shown below.
Where
The Binary Preference (Bpref) measure ignores unrated matches and quantifies the ability of the ranking method to rank judged-relevant matches higher than irrelevant ones. For a given query with multiple related documents R and irrelevant documents N, we define NonRelevant (r) as the number of irrelevant elements in the rank of the relevant match r. Then the definition of Bpref is shown in the following Eq. (13).
Both precision and recall can only measure one aspect of retrieval performance, and the ideal situation is for both precision and recall to be relatively high. When we want to improve the recall rate, it will affect the accuracy rate, so the accuracy rate can be regarded as a function of the recall rate, namely:
where rel(k) indicates If the k-th document is relevant, rel(k) is 1; otherwise, it is 0.
In the result list, the rth-related document position from front to back is denoted by “position (r)”. The total number of related documents is denoted as R.
The meaning of AveP is to add a P at each R position while gradually increasing the recall rate from 0 to 1, thus ensuring a relatively high accuracy rate and making the final AveP relatively large.
Usually, multiple query statements are used to measure the performance of the retrieval system, so the mean of average precision scores should be calculated for the Average Precision (AveP) of multiple query statements; that is, the Mean Average Precision (MAP) calculation Eq. (16) is shown below.
The average accuracy for a topic is obtained by averaging the accuracies of individual documents related to the topic.
Comparison of systems on mean reciprocal rank metrics(MRR).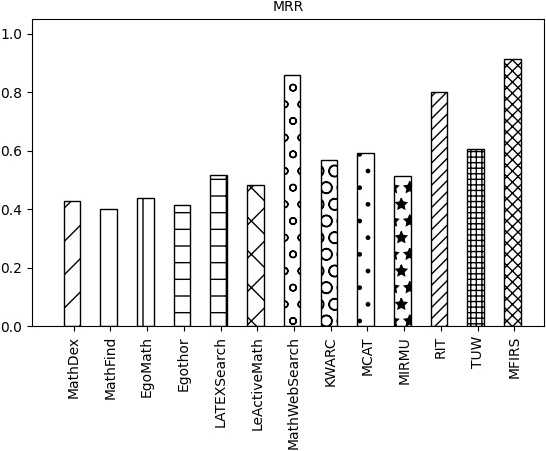
Comparison of systems on Bpref metrics.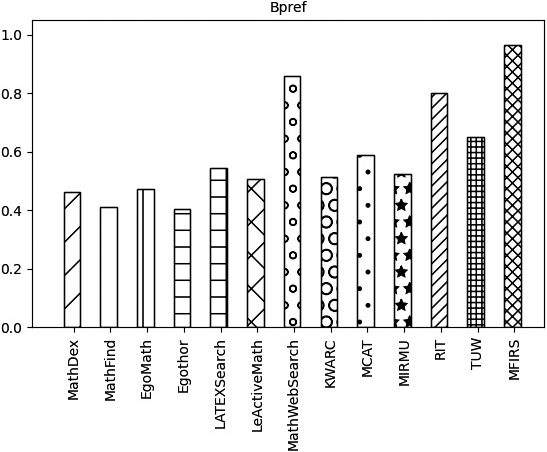
Comparison of systems on MAP metrics.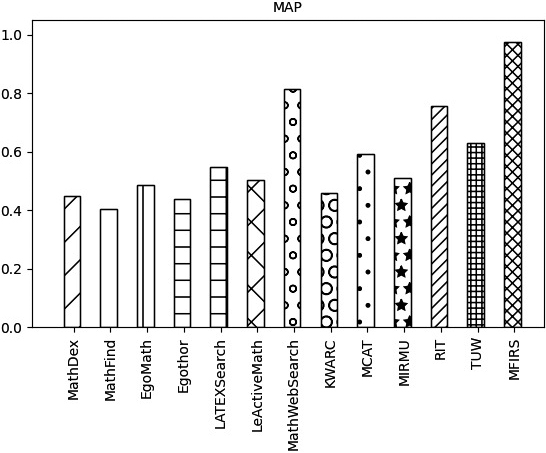
The mean accuracy of the individual subjects is the mean accuracy of the master set (MAP). The system’s retrieval performance for all relevant documents is measured by the single-value index MAP. During the retrieval process of the system, if no relevant documents are returned, the precision is zero. If the returned document is ranked higher, the MAP value will be greater.
The measurement standard for MAP is relatively simple. The relationship between query (q) and retrieved document (d) is either 0 or 1. The core is to use the position of the relevant data corresponding to Q to perform an accurate evaluation of the sorting algorithm. It should be noted that when using the evaluation of MAP, one needs to know: how many words are related to each query; the positions of these words in the sorting result.
The index values of MRR, Bpref, and MAP for each system are shown in Figs 21–23, respectively.
As can be seen in Figs 21–23. MFRS has reached the highest value in MRR, Bpref, and MAP indicators. MathWebSearch, TUW, RIT, and MCAT are ranked second, third, fourth, and fifth respectively in these three indicators. KWARC, MiRMu, LeActiveMath, and LatexSearch ranked ahead of Egothor, EgoMath MathFind, and MathDex systems.
According to the relevance of documents, the nDCG index can be used for multi-level scoring. The MAP metric that relates to the scoring of both relevant and irrelevant documents can be used.
The calculation Eq. (17) is as follows:
The relevance level of the document is denoted by
Due to the lack of sensitivity to positional information in the calculation of
The Eq. (19) for calculating DCG (Discounted Cumulative Gain) is as follows:
Another commonly used DCG calculation Eq. (20) is used to increase the proportion of the correlation’s influence as follows:
IDCG (Ideal DCG) is the ideal DCG for a query statement and p; the maximum value of the DCG is calculated using Eq. (21):
Where REL indicates that the documents are sorted in the most relevant way, and the first p documents are taken to form a set.
Comparison of systems on nDCG@5 metrics.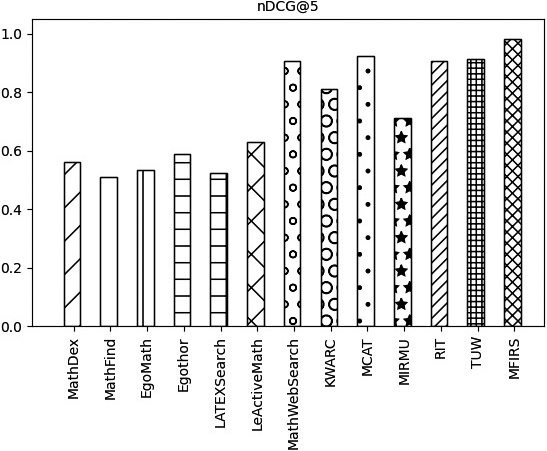
Comparison of systems on nDCG@10 metrics.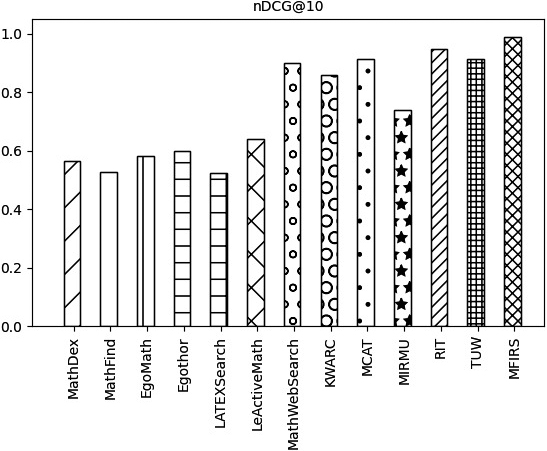
Comparison of systems on nDCG@15 metrics.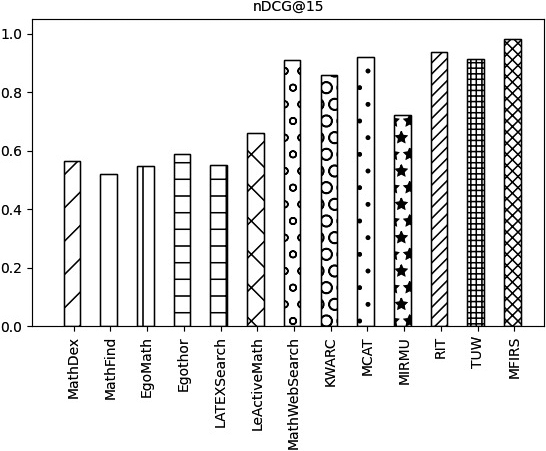
Comparison of systems on nDCG@20 metrics.
The length of the result document set retrieved by each query statement varies in nDCG (Normalized DCG). The reason for normalizing the DCG for different query statements is that it cannot be averaged, and the calculation of the DCG is significantly impacted by differences in
The calculation Eq. (22) uses IDCG to normalize nDCG, indicating the distance between IDCG and DCG.
In this way, the
NDCG@k is the Normalized Discounted Cumulative Gain (NDCG), which is an evaluation index that takes into account the order of the returns. The range of values is [0,1], the higher the value, the better the effect. For example, NDCG@10 and NDCG@20 represent nDCG when p is between 10 and 20, respectively.
The nDCG@k indicator values of each system are shown in Figs 24–27.
The nDCG@k values of the KWARC MIRMU, LeActiveMath, LatexSearch, Egothor, EgoMath, MathFind, and MathDex are all lower than those of the nDCG@k values of the MathWebSearch, MCAT, TUW, RIT and MFIRS systems, as can be seen in Figs 24–27.
As shown in Figs 24–27, the MFIRS system has the highest nDCG@k value, and the MathDex system has the lowest.
A method of mathematical retrieval, indexing, and sorting is proposed and integrated into the implemented system of mathematical formula information retrieval. The feasibility of this method has been verified on the MathRetEval dataset. Verification testing of system scalability is based on this.
Plans for the future are underway to use this technology in digital library projects around the world. The system’s web front end is fully functional and can convert mathematics into presentation MathML for full-text retrieval. The system is well-expanded and has the capability to be used in large digital libraries.
In the future, the system will not only be able to retrieve mathematical formulas of representational MathML but also retrieve mathematical formulas of content-based MathML.
Footnotes
Acknowledgments
The authors acknowledge the Anhui Province Excellent Talent Training Project (Research and Application of Multi-instance Learning Algorithm (gxyq2018107); Key Project of Anhui Provincial Department of Education (KJ2020A0744); Bengbu University High-level Talent Startup Project (BBXY2018KYQD07).