
Abstract
Text similarity is an important index to measure the similarity between two or more texts. It is widely used in many fields of natural language processing tasks. With the maturity of deep learning technology, a large number of neural network models have been used to calculate text similarity and have achieved good results in similarity calculation task of sentences or short texts. Among them, Bert model has become a research hotspot in this field due to its excellent performance. However, the application effect of existing similarity algorithms on long texts is not ideal, and they cannot truly extract richer semantic information hidden in the structure of long text documents. This paper takes Chinese long text as the research object, proposes a long text similarity calculation method using sentence sequence instead of word level sequence, constructs a long text semantic representation model with semantic progressive fusion, solves the practical problems faced by applications or natural language processing tasks related to long text semantics, in order to breaks through the bottleneck of long text similarity calculation.
Introduction
Text similarity computation is not only a basic research in the field of natural language processing, but also a hot research, which is widely used in intelligent search, text mining, automatic question answering, recommendation systems and other fields. The initial techniques were based on statistical information of text, which were simple in principle and easy to implement. However, these early methods were unable to accurately understand the semantic information of text. With the maturity of deep learning technology, a large number of neural network models have been used to calculate text similarity, and have achieved good results in sentence or short text similarity calculation tasks. Especially in 2018, the pre-trained language model Bert was proposed, which greatly improved the accuracy of NLP tasks through pre-trained and fine-tuning of the model. However, these methods have not been ideal in the application of Chinese long texts, mainly because the composition structure of long text is more complex than that of sentences or short texts, so the existing methods cannot extract richer semantic information hidden in the structure of long texts, resulting in unsatisfactory model performance. Therefore, the calculation of semantic similarity for long texts is more difficult and the application is more urgent.
This article takes Chinese long texts as the research object and adopts a three-level progressive structure from “word to sentence to text” to maximize the preservation of the true semantics of long texts based on the characteristics of their grammatical composition structure. It proposes a semantic progressive fusion method for long texts based on Bert model and a model algorithm suitable for calculating the similarity of long texts, so as to solve the applications related to long text semantics or the practical problems faced by natural language processing tasks, break the bottleneck of long text similarity calculation, and promote the development of NLP applications.
Related theories and technologies
Text similarity calculation
Text similarity calculation is a basic research in the field of natural language processing which can quantify the similarity between two or more texts based on different algorithms and models to achieve various text processing tasks. Common text similarity calculation methods include N-gram model, Edit distance, Jaccard similarity coefficient, etc. The principle of this kind of algorithm is relatively simple, but the deep semantic information of the text cannot be obtained directly through the literal distance. Therefore, it is necessary to introduce a model to digitize the text, representing it as a series of vectors capable of expressing text semantics, so that the model can capture the correlation between text semantics through such high-dimensional space, and thus measure the similarity between text semantics [1].
Previous similarity calculation model mostly processed text vectors through word vectors, and generally took average weighting method for word embedding. The biggest drawback of this method is that it ignores important information such as grammar and word order of the text, and cannot accurately represent the semantics of the text. Therefore, the calculation effect of the model is not ideal. In recent years, with the maturity of deep learning technology, more and more neural network models have been used for text semantic similarity calculation. Among them, the more active models include twin tower model DSSM, twin model Siamese LSTM, interactive model BIMPM, etc, which are basically improved on the original models such as CNN, RNN, LSTM, etc. Until 2018, the Bert pre-trained language model officially launched by Google, has presented the most advanced results in this field with its excellent performance, becoming a watershed in the field of text similarity calculation, and many subsequent studies mainly focus on optimization and improvement of Bert model.
Bert model
As a pre-trained language model, Bert (Bidirectional Encoder Representations from Transformers) [2] is considered to be one of the most advanced and popular models in the field of natural language processing. Compared to other pre-trained models, Bert uses a bidirectional Transformer encoder to more thoroughly capture the bidirectional relationships in statements, making the model perform well on various NLP tasks.
The use of Bert model can be divided into two stages, namely the pre-training stage and the fine-tuning stage [3]. In the pre-training stage, Bert model utilizes a bidirectional Transformer structure to train on a large amount of unlabeled text data, obtaining universal word representations and contextual representations of sentences, which are referred to as the model’s pre-trained weights. In the fine-tuning stage, the model uses these pre-trained weights to initialize the new data and fine tune them on the upstream layer of specific task to better adapt to specific task requirements. Therefore, fine-tuning the pre fine-tuning layer can effectively achieve the task of text similarity calculation.
Transformer – bidirectional encoder
The structure that plays an important role in Bert model is the Transformer encoder. Compared to LSTM and GRU models that previously dominated the market, Transformer encoder improves model training speed utilizing attention mechanism, which has two significant advantages: firstly, improving model training efficiency using distributed GPU for parallel operations; secondly, capturing semantic associations with longer intervals more effectively when analyzing and predicting long texts [4]. It can be said that Transformer, which is the first model that completely relies on the Self Attention mechanism to calculate input and output, is superior to the previous RNN in precision and performance in terms of accuracy and performance combined with the complexity of the model itself [5].
From the article “Attention is all you need” published by Google, it can be seen that Transformer is an Encoder-Decoder model, with the encoder on the left and the decoder on the right [6]. Both the encoder and decoder are stacked from N identical layers. The encoder is used to extract features from the input and provide effective semantic information for the decoding process, and the decoder outputs the next result of the sequence based on the results of the encoder and the previous prediction.
In natural language processing, Transformer model has been proven to achieve excellent performance, and the Bert model only uses the encoder part of Transformer [7]. In Bert model, the input sequence is first transformed into a vector which is considered as the initial part of the encoder through the source text embedding layer, and then transformed into the representation of the output sequence through the multi-layer attention mechanism and feed-forward neural network.
Self attention mechanism
Self attention mechanism is an important attention mechanism in neural networks and also a core part of Transformer. It generates contextual feature representations by capturing the internal relationships of input sequences, which has good parallelism and scalability. Compared to traditional attention mechanisms, self attention mechanisms focus more on the associations between internal elements of input or output text, while attention mechanisms focus more on representing the connections between text and text [8]. For Chinese natural language processing tasks, the same word will fuse different semantic information in different contexts, thus showing different meanings. According to this principle, self attention connects the embedding of all words in the entire text, uses different semantics to distinguish polysemy, and weakens long-distance information, enabling the model to capture key information even in long texts.
In summary, Bert model adopts a Transformer structure, which performs better in processing long sequence data compared to traditional models such as CNN, RNN, and LSTM. In addition, Bert model based on self attention mechanism truly achieves bidirectional representation of text, allowing model to consider contextual information on left and right sides during the calculation process and making the representation of word vectors more comprehensive. Although Bert model has achieved significant success in NLP tasks, it mainly focuses on short text processing, and there are still obvious shortcomings in processing of long text. Firstly, due to the character length limit of 512 for Bert’s input, when the text character length exceeds this limit, the model will cut out the long text and only retain a portion of the text information, which can easily cause the loss of semantic information in the text. Secondly, the method that Bert model process the input long text as a whole and understands the meaning of the text through global contextual information, measures the semantics of the text only relying on word level information, and can easily lead to deviation in semantic extraction without considering complex information such as sentence structure in the long text.
Thus, this paper proposes a long text similarity calculation model based on Bert which replaces token level sequence with sentence sequence. On one hand, the length of input characters is no longer limited, on the other hand, the model takes into account the sentence level structural information of long texts, enhance the semantic expression of text vectors and ultimately improve the accuracy of long text similarity calculation.
Chinese long text similarity calculation model of semantic progressive fusion based on Bert
When the semantic information of a text is represented as a vector, the similarity calculation between two texts can be transformed into the similarity calculation of two vectors. Therefore, the Chinese long text similarity calculation model proposed in this article mainly consists of two parts. The first part is to obtain the semantic vector representation of long text, and the second part is to calculate the similarity of text. How to accurately obtain the semantic representation of long text is the focus of this research.
Ideas of the model framework
The accuracy and expressive power of text vectors directly affect the performance and effectiveness of the downstream tasks, so high-quality text vectors are particularly important. Considering the characteristics of Chinese long text in terms of grammatical composition structure, a three-layer structure from “word to sentence to text” is adopted to progressively generate the semantic representation of long text and different level generates corresponding information representation as the input for the next level. That is, the sentence semantic representation is generated from word vectors first, and then the text semantic representation is generated from sentence semantic representations. Finally, based on the spatial mapping of long text semantic vectors, the similarity between two long texts is calculated using the cosine of the included angle. The algorithm flow of long text similarity calculation model is shown in Fig. 1.
Algorithm flow of long text similarity calculation model.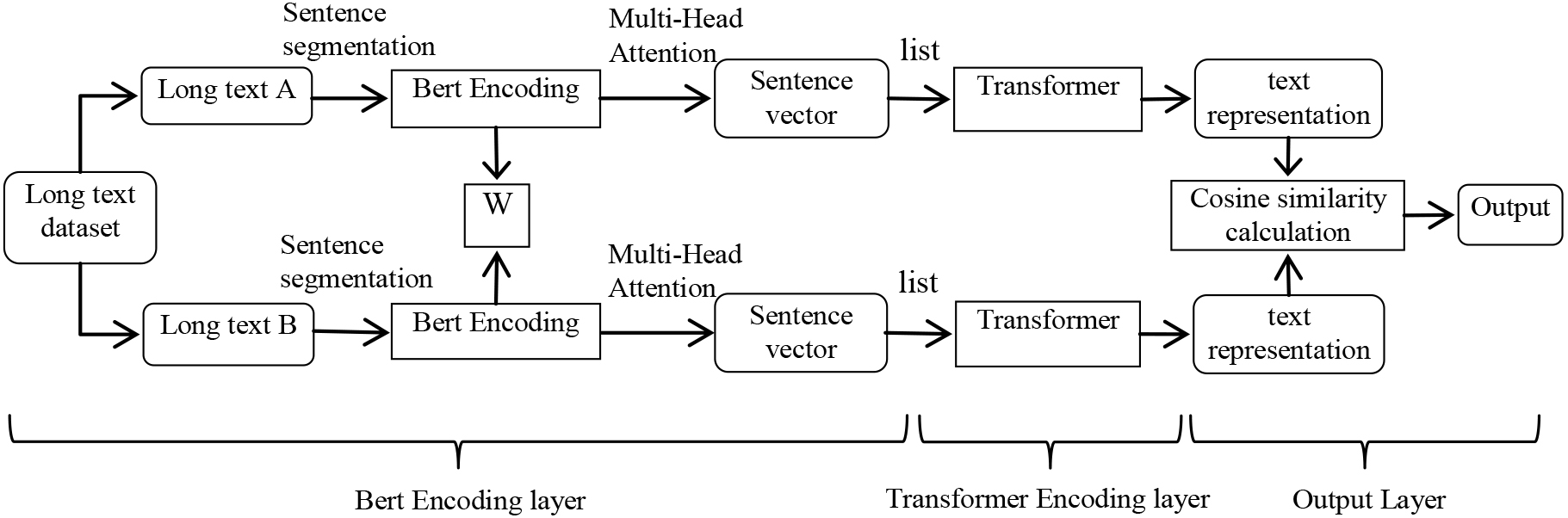
Start: enter two long texts and divide each text into sentences, which are sequentially stored in two lists.
Repeat: loop calling Bert model to obtain the semantic representation of each sentence in each list.
In this process, firstly, dynamic word vectors which can accurately fuse contextual semantic information are obtained through the feature extraction of Bert. At the same time, the previous approach of generating sentence representations through simple linear combinations is abandoned, and a self-attention mechanism is adopted to better capture bidirectional semantic dependencies. On this basis, the final sentence vector representation is obtained through pooling strategy.
Then: convert long text into sentence level sequences to obtain the semantic representation of long text.
By analogy with the structural relationship between a long text and a sentence, the model can train the word sequence of a sentence, so it is natural to train the sentence sequence of a text. Therefore, each sentence is regarded as a word level token, so a long text is transformed into a sentence at another level, then the transformer model is used again to train the sentence sequence of a long text. Finally, a long text representation with semantic progressive fusion is obtained.
Finally: after obtaining the semantic representation of two long texts, use the cosine of the included angle in vector space to calculate the similarity between the two texts.
Directly using the output vector of [CLS] in Bert as sentence representation is not very effective. This project uses Bert for modeling to obtain dynamic word vectors rich in contextual information, and then uses a more suitable network model to obtain sentence vectors containing richer information. In addition, Bert needs to perform a mask operation on the corpus when pre-training the language model, so that the model can predict the masked words when the token is not visible. In the official BERT-base (Chinese) released by Google, Chinese segmentation is based on word granularity, without considering the characteristics of Chinese segmentation. Joint Laboratory of HIT and iFLYTEK Research (abbreviated as HFL) has applied full word mask method to Chinese text, performing [MASK] on all Chinese characters that make up the same word [9]. Compared with the original BERT-Chinese model and the Baidu open-source Chinese pre-training model ERNIE, this model has achieved better performance in multiple Chinese tasks. Full word mask requires first segmenting the Chinese corpus, and then performing a mask operation on each token belonging to the same word. The effect of the mask is shown in Table 1.
Example of Generating a Full Word Mask in Chinese
Example of Generating a Full Word Mask in Chinese
aIn order to preserve the segmentation structure and masking features of Chinese text, only the original text has been translated into English here.
Therefore, using full word mask method of HFL, the given long text is first subjected to Chinese word segmentation processing, and then thrown into Bert model to obtain a dynamic word vector for each word through training.
The acquisition of sentence vectors based on Bert involves two stages: input stage and Transformer encoding stage. Firstly, in the input stage, three important vectors are extracted to represent the information of the input sentence: word vector, segmentation vector, and position vector. The word vector represents the vector corresponding to each token in a sentence, which is pre-trained by Bert model and contains the semantic information and contextual information of each word in the input sequence and can be adaptively adjusted according to subsequent encoding and training. The segmentation vector assigns a unique identifier to each sentence to distinguish between two different sentences in the input text. The position vector supplements the lack of position information in the Transformer model, artificially adding vectors representing positions to enable the model to understand the positional relationship of each word in the text, thereby identifying the semantic correlation between words. These three vectors overlap with each other, ultimately forming the initial input vector of Bert. The input layer settings of the Bert model are shown in Fig. 2.
Input layer settings for Bert.
After the input stage, Bert model uses a multi-layer Transformer encoder to process the input vectors, capturing various semantic relationships in the text and generating corresponding output vectors. In addition, this article changes the self attention mechanism of encoder to a multi head attention mechanism to better capture the multiple relationships and subtle differences between each word, thereby obtaining a semantic representation of sentences with more implicit information.
Although dynamic word vectors are generated based on Bert, its fatal limitation is that the word sequence length can be up to 512 (including [CLS] and [SEP]), which is obviously not sufficient for long texts. Therefore, by analogy with the structural relationship between long text and sentence, this article considers using sentence sequences instead of word sequences to train again to obtain the semantic representation of a long text.
Therefore, this article takes the sentence vector obtained earlier as the input vector of Transformer encoder, and simulates the method of generating token level vectors to train the sentence vector to obtain complex information between sentences in long texts. Figure 3 shows the semantic generation process of a long text. A long text is divided into N sentences according to the sentence ending symbol, then after training with Bert model, the N sentence vectors obtained are stored in a list, and then the position encoder of Transformer model is used to process these vectors, so as to better capture the structural relationships and semantic information of each sentence in the entire sequence, and improve the expression effect of the output vector on text semantic information.
Semantic generation process of long text.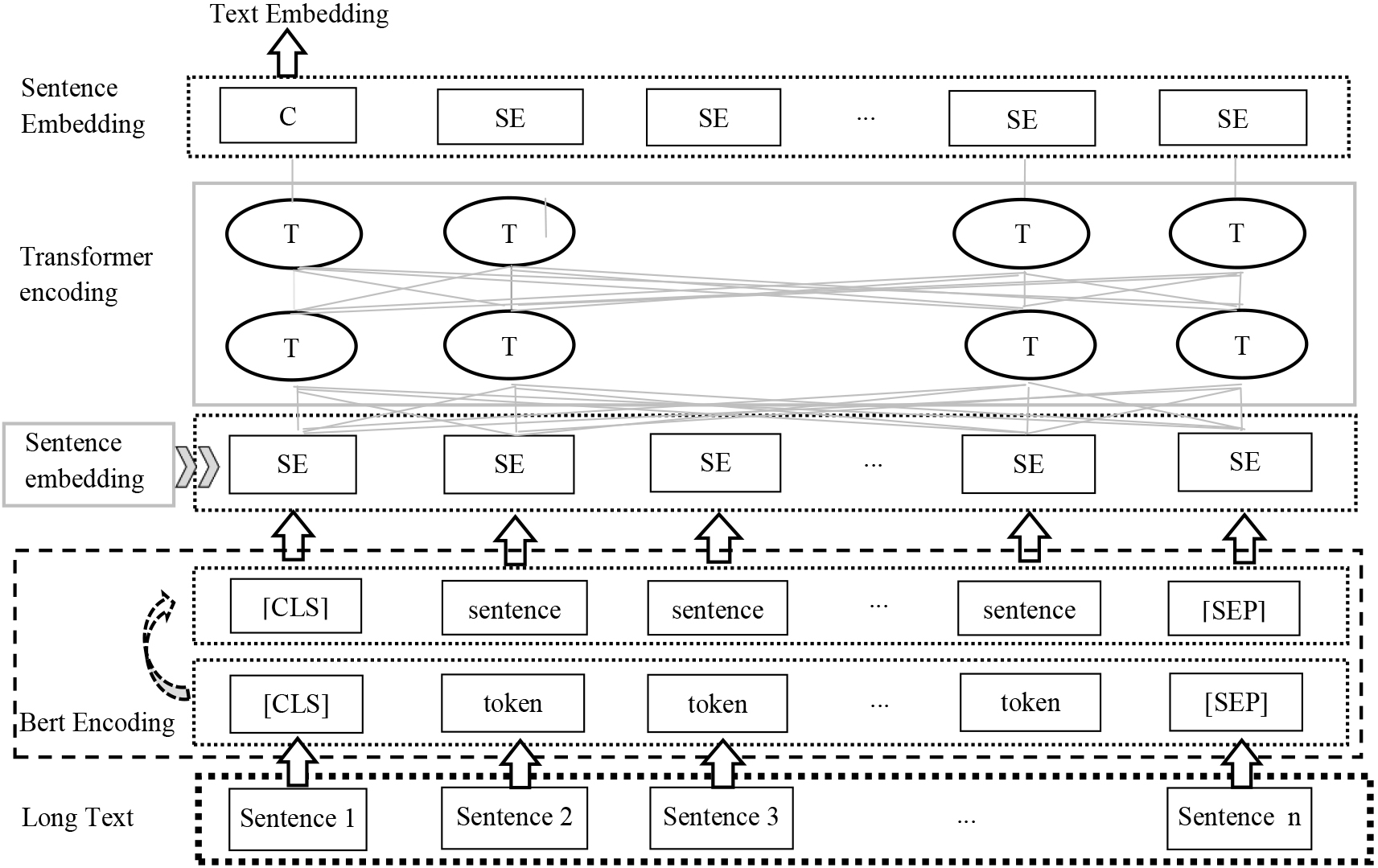
Setting the maximum length of words in a sentence to 512, the resulting shape for a sentence is (512, 768). A text sample is set with 80 sentences, if there are more than 80 sentences, the first 80 will be taken. If there are less than 80 sentences, the sentence vectors that need to be supplemented will be filled with all zero. Thus the resulting form is: (N, 80, 768), where “N” represents the number of text samples, “80” represents the maximum length of sentences, and “768” represents the vector dimension. Finally, a vector representation that integrates the semantic information of the long text will be obtained through Transformer model.
After obtaining the text vector, the cosine similarity calculation method is used to calculate the similarity of the text vector, and the cosine similarity calculation is shown in the following formula.
Cosine similarity uses the cosine value of the angle between two vectors in the vector space as a measure of the difference between two individuals and its value range is [0,1]. The closer the cosine value is to one, the closer the angle is to zero degrees, which means that the two vectors are more similar [10].
Model experiment and result analysis
Sentence vector generation and optimization based on Bert
The test data for this experiment come from some datasets collected online, and experts provide similarity judgment labels for these test data. During the experiment, the similarity calculation of sentence vectors generated by Bert clearly deviated from expert judgment, so the Bert model was optimized and improved.
Sentence vectors obtained from Bert model
In the experiment of generating sentence vectors through Bert, the hidden layer output of the last layer is used as the vector representation of the sentence. Then, the similarity between the two texts calculated through the cosine formula will be compared with the binary classification labels provided by experts (1 indicates that the two texts are similar, 0 indicates that they are not). The data in column “Expert Label” and “Similarity(Bert)” in Table 2 shows the results of partial experimental data.
Comparison of three experimental data for sentence similarity calculation
Comparison of three experimental data for sentence similarity calculation
From the experimental results, it can be seen that the effect of sentence similarity calculation using the vectors of Bert’s hidden layer is not ideal. When there are many high-frequency words or similar words in two sentences, the model cannot accurately express the semantic information of the sentence, and it is easy to judge them as similar, such as the test data from the 3rd, 5th, and 6th group in the experiment, where the expert’s judgment of similarity is 0, and the similarity score of the two sentences calculated by Bert is higher, indicating that the model believes that these two sentences are relatively similar, which goes against the semantic information of the text and the prediction results are not very accurate.
There are two reasons for the above situation: (1) The vector space generated by Bert is anisotropic and the word embedding presents a conical distribution [11], where high frequency words gather at the head of the cone and are closer to the origin, while low frequency words are scattered at the tail and are relatively sparse, so high frequency words will dominate the vector representation of some sentences. (2) The premise of cosine similarity calculation is that the vector base is orthogonal basis, but the high-dimensional vector output from the Bert hidden layer cannot guarantee the orthogonal basis, so the calculation result is not accurate.
This article improved the structure of Bert to obtain sentence vectors that can fully express sentence semantics. Sentence pairs were input into two identical Bert models through Siamese networks [12] to obtain corresponding embedding vectors, and then perform comparative loss calculations on the embedding vectors. By minimizing the distance between similar texts and maximizing the distance between different texts, the semantic relationship and similarity between sentences are better represented.
The data in column “Similarity(Siamese Bert)” in Table 2 shows the results of sentence vector similarity calculation for the improved Bert added with Siamese network. From the table, it can be seen that the fine-tuned Siamese Bert performs better than the original Bert on sentence vectors. Taking the 3th set of problematic test data in the above experiment as an example, the similarity results calculated by the model match well with the actual label. From the experimental results, the performance of these indicators are good, indicating that the model performs well in sentence similarity tasks, which can effectively distinguish semantic relationships between sentences.
Experimental comparison of long text similarity calculation
Experimental data
This experiment selected a partial dataset of Tan Songbo’s text classification corpus from Fudan University and tested on the model proposed by this article and the original Bert model, and compared the results. The dataset contains three column information: Text A, Text B, and a binary classification label given by experts.
The experimental parameters are as follows: the maximum length of a single sentence is 512, the maximum number of sentences is 80, and the learning rate of the model is 2e-5. The pre-training model involved in the experiment was Chinese-Bert-WWM released by HFL.
Experimental setting
The long text similarity calculation model in this article replaces token level sequences with sentence sequences. The long text is segmented first, and then sentence vectors with rich semantics are output through the twin network pre-training model. These vectors are saved in the list according to the order of appearance and finally converted into vector matrix, which are position coded and semantic trained through Transformer model, so as to obtain a long text vector with semantic progressive fusion. Finally, the similarity of the output text vectors are calculated. Following is the experimental code for obtaining long text vectors for this model:
x1
arr_reshaped1
end1
pe
pe_result1
x1
mask1
layer
en
en_result1
Figure 4 shows the Chinese long text data used for this experiment, a row is a set of two long texts for comparison. Table 3 lists the similarity results calculated by the proposed model in this article and the original Bert model on the blue marked text. The output of the original Bert is a two-class probability, and the probability value of one classification is taken to represent the semantic similarity calculated by the original Bert. In the table, column “Similarity” is the cosine similarity value calculated by the model proposed in this article, column “Probability” is the semantic similarity value of the original Bert.
Chinese long text data used in the experiment.
Vector representation and similarity of group 5.
Long text similarity comparison between two models
Taking group five as an example, the long text vectors obtained by the model proposed in the article and the final similarity calculation result are shown in Fig. 5.
This experiment is used to verify the application effect of the long text similarity calculation model this article proposed. Using the classification label of the original Bert model as the reference group, the semantic similarity results generated by the two models are compared with the label so as to evaluate their ability to handle text similarity.
From Table 3, it can be seen that the long text similarity calculation model proposed in this article has achieved good classification performance in the processing of long text datasets, which can fully represent the semantic information of long texts and effectively improve the accuracy of semantic similarity of long texts. Taking the data from the second, third, and fourth group in the experiment as an example, the experimental results match the actual labels, and the similarity of the model in this paper is more suitable for the text content and discriminate. Compared with the original Bert model, this model can more accurately obtain semantic information of long texts. Taking the first and fifth groups in the experiment as examples, when the two texts have some slight semantic relationships but are not enough to be classified as similar, this model can better describe the semantic relationships between texts. For example, the similarity score calculated by Bert model in the first group is 0.0014, the similarity score calculated by the model in this article is 0.6756, and the similarity score calculated by Bert model in the fifth group is 0.0017, the similarity score calculated by the model in this article is 0.5224. Both sets of data accurately represent the similarities between two long texts in some aspects, but there are also certain differences. In summary, the long text similarity calculation model proposed in this article has obvious advantages in the task of long text semantic similarity, with higher accuracy, stronger representation ability, and better adaptability.
Conclusion
Taking full account of the structural features of Chinese long texts, this paper proposes a Chinese long text similarity calculation model of semantic progressive fusion based on Bert. The model first converts the long text into a sentence sequence, which replaces the original word sequence for training. At the same time, it adds the feature training of Transformer and multi head attention mechanism at the level of bidirectional semantics and internal relevance to obtain the text semantic representation that combines context information and hidden text internal features, and ultimately improves the accuracy of text similarity calculation. From the experimental results, it can be seen that the model proposed in this article effectively solves the input character limitation and information loss of sentence level structure in the original Bert model, and has a significant improvement in the accuracy of similarity calculation.
Footnotes
Acknowledgments
This work was support by 2022 Henan Province Key R&D and Promotion Special Project (Science and Technology Research): 222102210259, and was support by Innovation Team of the Ministry of Education in Oracle Bone Inscription Information Processing: 2017PT35.