
Abstract
With globalization and technological progress, the demand for language translation is increasing. Especially in the fields of education and research, accurate and efficient translation is considered essential. However, most existing translation models still have many limitations, such as inadequacies in dealing with cultural and contextual differences. This study aims to solve this problem by combining big data analysis, machine learning and translation theory, and proposes a comprehensive translation quality evaluation model. On the basis of screening and constructing a representative sample database, pre-processing and standardization, feature selection is carried out by combining multi-dimensional features such as grammatical complexity and cultural adaptability factors, and different machine learning algorithms are used for model construction and parameter optimization. Finally, by training and testing the model, the performance and effectiveness of the model are evaluated, and a comprehensive evaluation standard is constructed. The results show that this model can not only effectively improve the translation quality, but also has a high system application and universality.
Keywords
Introduction
With the acceleration of globalization and the deepening of international communication, the translation industry has become an important bridge connecting different cultures and languages. In the field of English literature, high-quality translation should not only ensure the accurate transmission of the original text, but also comprehensively consider the characteristics of culture, context and audience. Based on my personal experience and research, I deeply realize that the development of big data technology in recent years has provided a new perspective and tool for translation quality evaluation. Through the analysis of massive text data, we can gain insight into the inherent laws of translation, so as to provide a more objective and comprehensive standard for evaluating translation quality.
English literature plays an important role in global cultural exchanges. The global dissemination and translation quality of these works directly affect the understanding and evaluation of the original works by international readers. However, the traditional translation evaluation process is often subjective and complex, involving many factors, such as language characteristics, cultural differences and the background of the target audience. Traditional methods mostly rely on the personal experience and subjective judgment of experts, and it is difficult to form a unified and objective evaluation standard.
After entering the information age, big data technology provides the possibility for in-depth analysis of massive texts. In my research, I found that while trying to use big data techniques to objectively assess translation quality is a promising path, we still face a host of challenges in data quality, validity, model selection, and construction. In addition, the application of big data in the field of translation evaluation is still in its infancy and requires the cooperation of multiple disciplines such as translation studies, computer science and linguistics. Therefore, how to effectively integrate the knowledge of these disciplines and build a scientific and practical translation evaluation system has become an important task of our current research.
The study of translation quality evaluation has a long history in linguistics and computer science. However, in recent years, there have been significant breakthroughs in this field due to the development of big data and machine learning technologies. Chen explored the feasibility of applying data mining technology to design intelligent English translation and teaching models in higher education, which proved that data analysis can help improve the design and application of translation models, especially in teaching [1]. Similarly, Hu also points out that big data technology has significant feasibility and advantages in English translation, especially when dealing with large-scale data sets [2].
On the technical side, a variety of algorithms and frameworks are used to improve translation quality. For example, Zhang describes an Iot-based English translation and teaching system that uses particle swarm optimization and neural network algorithms to achieve more precise translation [3]. In addition, Bian et al. studied how to optimize English intelligent translation model through anomaly detection and machine learning, which provided new ideas for improving translation accuracy [4].
In terms of evaluation indicators, MAWEC and Brest conducted a comprehensive survey on the application of phrase-based statistical machine translation in Slavic languages and proposed a variety of possible evaluation criteria, such as grammatical complexity and cultural adaptability [5]. This is highly relevant to the goal of this study. Mahsuli et al. focused on how to improve the performance of neural machine translation through target length modeling in the case of low resources, which provided valuable experience for the study of high-quality translation in the case of limited resources [6]. The existing literature shows that combining big data and machine learning techniques has great potential in translation quality evaluation. These studies provide a solid theoretical foundation and technical support for this paper.
The core goal of this study is to build a scientific, objective and reusable English literary translation quality evaluation system through big data analysis. Specifically, the study first focuses on identifying and screening data sources and samples used to evaluate the translation quality of English literary works. Further research steps include identifying and analyzing key characteristics that affect translation quality, such as grammatical complexity and cultural adaptation factors. Based on these characteristics, this study will select or design appropriate machine learning models, and train and test them. Finally, the study aims to construct a comprehensive translation quality evaluation system based on the results of the model, which will include the weight setting and specific evaluation criteria for each evaluation dimension.
This research has many implications. First, it aims to reduce the subjectivity of translation evaluation through big data technology and provide a more scientific and objective evaluation framework, thus contributing to the standardization and specialization of the translation industry. Second, due to the high reusability and extensibility of the constructed evaluation system, the research results can be widely applied not only to English literary works, but also to translation quality evaluation of other types or languages. Third, the results of this study are practical and instructive, and can provide strong support for translation education and practice. Fourth, the research also promotes cross-cooperation and development of multiple disciplines such as translation studies, big data analysis and machine learning.
The main content of this study covers the whole process from data preparation to model construction, and then to the establishment of evaluation system. Specifically, data sources suitable for the quality evaluation of English literary works translation will be defined and selected first, with the aim of collecting representative and reliable data. Further, the study will explore the characteristic factors closely related to translation quality, such as grammatical complexity and cultural adaptability. Based on the selected features, the research will compare different machine learning algorithms and select the most suitable model for training and testing based on the algorithm comparison results. Then, according to the output results of the model, this study will build a translation quality evaluation system based on big data. The evaluation system will integrate the evaluation factors of different dimensions and give them appropriate weights, and finally form a comprehensive but easy to operate evaluation criteria. In addition, the research will also conduct multiple rounds of validation of the constructed evaluation system to ensure its accuracy and reliability.
In general, this study includes data collection, feature engineering, model selection and training, and evaluation system construction, aiming to provide a new solution for the translation quality evaluation of English literary works through a systematic and scientific method. This will not only enhance research understanding of the diversity and complexity of translation quality, but also provide strong technical support for translation education and practice.
Theoretical basis and research methods
Core factors of translation evaluation
Translation is a kind of communicative behavior, which is the communication and collision between one culture and another. With the development of translation, people have higher requirements for translation. Translation is not only about the exchange between codes, but also about the communication between cultural connotations. The level of translation has a profound impact on the communication between two different cultures [7, 8].
In this study, the core factors of translation evaluation are mainly considered in the following aspects.
The first is semantic accuracy, that is, whether the translated text accurately conveys the original meaning of the source text. This is often the number one criterion for evaluating the quality of a translation, as any deviation in semantics can lead to inaccuracies or misunderstandings in the delivery of information.
The second core factor is grammatical and structural compliance, including but not limited to sentence structure, tenses and parts of speech [9]. A high-quality translation should adhere to the rules of the target language while retaining the syntactic and rhetorical features of the source language as much as possible.
The third key factor is cultural and situational adaptation. Because translation is not only the conversion of language, but also the adaptation and conversion of cultural and social situations [10]. For example, certain idioms or cultural references may not have a direct counterpart in the target language and culture, and therefore need to be adapted appropriately through creative or interpretive means.
Finally, the fluency and readability of a translation are also important factors in evaluating its quality. This includes the choice of words, the fluency of sentences, and the logic and consistency of the overall text structure.
Based on the above factors, this study aims to quantify and synthesize these core factors through big data analysis and machine learning models to build a comprehensive and reliable translation quality evaluation system. Through this methodology, research can not only evaluate translation quality more scientifically and objectively, but also provide a more accurate diagnosis of possible problems in the translation process, thus promoting the continuous improvement of translation quality.
Big data analysis and processing
In this study, big data technology plays a crucial role, mainly applied to data acquisition, pre-processing, feature extraction and model training. Big data can not only process massive text data, but also ensure the representativeness and reliability of analysis results [11, 12]. In addition, considering the efficiency and scale of data processing, this study also combines cloud computing and distributed computing technologies to improve the speed and flexibility of data processing.
In the data collection stage, through the combination of big data platform and cloud storage, this research can collect comprehensive and in-depth data of multiple types of English literary works and their translations from multiple sources. The use of cloud computing makes large-scale data storage and access more flexible and scalable, providing strong data support for subsequent analysis.
Next, in the data preprocessing and cleaning phase, by combining distributed computing frameworks such as Apache Hadoop or Spark, big data tools can more efficiently process data in different formats and structures [13]. For example, distributed computing techniques can speed up the processing of tasks such as removing duplicates, correcting errors, standardizing text, and so on to quickly produce a clean, structured, and high-quality data set.
In terms of feature extraction, big data analysis combined with distributed algorithms can quickly extract multidimensional features related to translation quality evaluation from large-scale data sets [14]. For example, the use of distributed text mining and natural language processing technologies can more efficiently quantify the semantic accuracy, grammatical structure, and cultural adaptability of text.
Finally, in the model training and evaluation phase, combined with the cloud computing environment, it can provide more powerful parallel computing and efficient storage capabilities. This makes it possible to train complex machine learning algorithms in a relatively short time, while also enabling faster cross-validation and model optimization processes.
In general, by combining big data technology, cloud computing and distributed computing, this study not only accelerates the research process, but also greatly improves the accuracy and reliability of the research. This comprehensive application enables this study to evaluate the translation quality of English literary works more comprehensively and accurately, and provides powerful scientific support for translation practice and translation education.
Machine learning and text analysis
As an important branch of artificial intelligence, machine learning has shown great potential in the field of text analysis, especially in the evaluation of translation quality of English literary works. In doing so, machine learning algorithms are able to extract meaningful information and patterns from complex data sets, supporting scientific assessments of translation quality. Translation of English literary works involves not only direct language conversion, but also a deep understanding of culture, style and context [15, 16]. Therefore, in this study, the importance of machine learning in capturing these nuances is particularly emphasized.
In order to deal with the particularity of English literary translation more effectively, we have adopted a variety of machine learning algorithms, including decision trees, support vector machines and random forests. These algorithms not only analyze the grammatical accuracy and sentence structure complexity of the translated text, but also explore deeper features such as cultural adaptability and stylistic style [17, 18]. In addition, in order to ensure that the selection and application of machine learning models have a strict theoretical basis, fuzzy control algorithms are especially introduced in this study. This algorithm can deal with uncertainty and ambiguity, and is especially suitable for dealing with semantic and cultural differences in translation.
In the feature selection stage, this research makes extensive use of natural language processing (NLP) and text mining techniques, such as advanced techniques such as word embedding and topic modeling, to extract features closely related to the semantics and style of literary works. These techniques not only improve the accuracy of the model in predicting translation quality, but also help us gain a deeper understanding of the intrinsic meaning and translation effects of literary works.
In the stage of model training and testing, machine learning provides an automated and efficient means to automatically identify key factors affecting translation quality through learning training data sets and evaluate them accordingly [19]. At the same time, by applying optimization methods such as cross-validation and grid search, we are able to determine the best parameter Settings for the model and ensure the accuracy and reliability of the evaluation results.
In conclusion, machine learning not only enhances the data processing and analysis capabilities in this study, but also greatly improves the accuracy and reliability of the translation evaluation model through in-depth analysis of the linguistic and cultural dimensions unique to the translation of English literary works. With the help of advanced machine learning and text analysis techniques, this study aims to build a comprehensive, scientific and efficient English literary translation quality evaluation system to provide strong support for research and practice in related fields.
Data collection and sorting
Data source identification
In this study, the identification and evaluation of data sources is a key step to ensure the accuracy of model construction and evaluation. Taking into account the diversity and representativeness of data sources, the following main data sources were selected and the reliability and validity of each data source were analyzed in detail:
Open translation databases: These databases provide multiple translated versions of literary works, allowing detailed comparison and evaluation. The reliability of these data lies in the openness and diversity of their sources, making them suitable for evaluating hard indicators such as grammar and sentence structure. Literary journals and online platforms: The translated works on these platforms are professionally reviewed to ensure the high quality of the data. They are suitable for assessing overall quality and style, as these works have usually undergone a rigorous editing and proofreading process. Social media and review sites: User feedback and comments on these platforms provide a wide variety of data, reflecting the cultural adaptability and audience acceptance of the work. The effectiveness of data lies in the fact that they provide real feedback directly from readers. Expert review: The evaluation data from literature and translation experts are of high quality and professional, suitable for in-depth and detailed quality evaluation. The reliability of these data comes from the expertise and experience of the experts.
The main features and applicability of these data sources are listed in Table 1.
Data source information types
In the process of data collection, special attention was paid to the diversity and representation of the data in order to capture the various aspects that affect the quality of translation. At the same time, data availability and accessibility are also considered to ensure the wide applicability and practical value of the research.
Overall, by synthesizing multiple data sources, the study was able to construct a comprehensive and multidimensional dataset, which provided a solid foundation for subsequent model construction and evaluation. This is also in line with the original intention of this study to use big data and machine learning methods for translation quality evaluation.
After determining the data source, the next key step is sample selection and construction. As the focus of this study is to evaluate the translation quality of English literary works based on big data, it is crucial to ensure the representativeness and randomness of the sample. The following steps were used in this study to ensure the diversity and representation of the sample:
Stylistic diversity: Ensure that the sample includes a variety of literary genres, such as fiction, poetry, and drama, to reflect the broad range of literary work. Diversity of translations: Samples of at least two or more translations of each literary work are selected for comparison and evaluation. Cultural and regional differences: Literary works reflecting different cultural and regional characteristics are selected to examine the adaptability of translation under different cultural backgrounds. Time span: Translation works of different publication years are included, and the change of translation quality over time is observed.
In order to ensure the randomness of the sample and avoid bias, this study adopted a random sampling method to select literary works from each classification. This method can guarantee the wide coverage and unbias of samples.
Table 2 shows an example of a sample build.
Sample construction examples
In order to ensure the quality and reliability of the data, the study also set a series of screening criteria, such as: excluding translated versions published by non-professional platforms or individuals; Exclude translations with a low number of reviews or reviews; Only translations with full text are considered.
Through such screening and construction process, this study has formed a sample library with both breadth and depth. This can not only meet the needs of big data analysis, but also ensure the accuracy and effectiveness of model construction and evaluation.
Data preprocessing is a key step in data mining and analysis, especially in complex projects involving big data and text data. At this stage, the collected sample data is cleaned, formatted, standardized and variable constructed. Specifically, the process mainly consists of the following steps:
Remove duplicate and invalid data: Remove duplicate or invalid translation versions in the sample set. Text cleaning: Delete redundant punctuation, Spaces, unified case and so on. Text segmentation: The text is divided into words or phrases for further analysis. Text standardization: Stem extraction or morphological reduction to unify words of different forms. Feature construction: Extracting features related to translation quality, such as word frequency and lexical diversity.
As shown in Table 3, sample data after data preprocessing are presented.
Data preprocessing of samples
In this way, the pre-processed data is easier for further analysis and model construction. Through the rigorous and meticulous work in this stage, the data quality is not only improved, but also prepared for the subsequent model construction and the establishment of translation quality evaluation system. This step is an indispensable part of the whole research process, which is related to the accuracy and reliability of the subsequent analysis.
Research on relevant features of translation evaluation
Syntax complexity
Grammatical complexity is one of the important indicators to evaluate the quality of translation, especially for the evaluation of English literary works. In practical applications, the research focuses not only on theoretical grammatical complexity, but also on how to directly correlate this index with translation quality. Therefore, consider the following more practical quantitative indicators:
(1) Average Sentence Length (ASL): The average sentence length per paragraph or text. The following Eq. (1) is shown:
(2) Clause frequency (SCF): The frequency of the occurrence of a clause in the text. The following Eq. (2) is shown:
(3) Lexical Diversity (VD): An indicator used to assess lexical richness. The following Eq. (3) is shown:
Figure 1 shows how these features are represented in different translations.
Feature representation in different translated versions.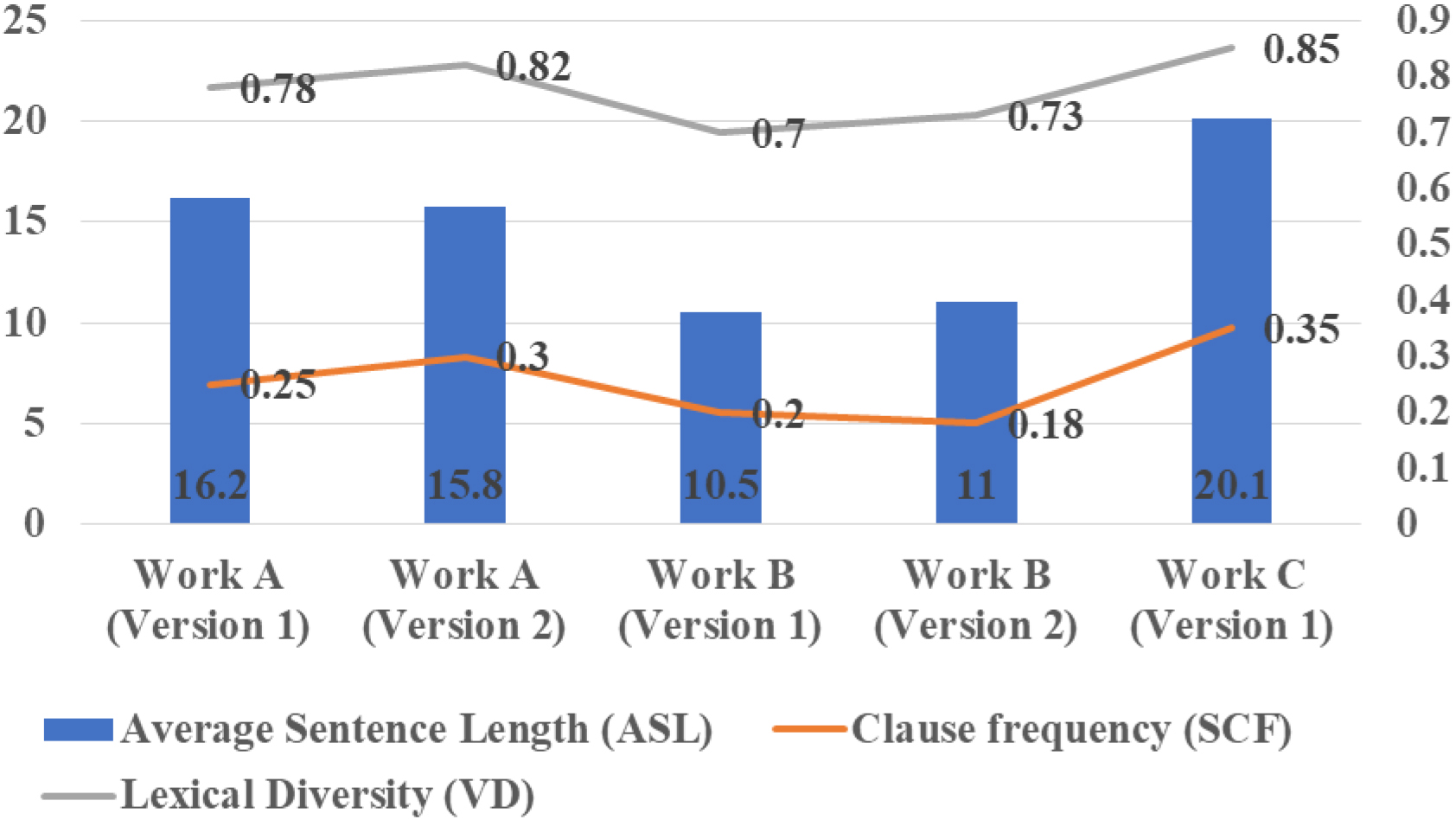
By quantifying these features, the study can not only more accurately evaluate the grammatical complexity of each translated version, but also provide useful input features for subsequent machine learning model construction. These features will play a key role in model training and evaluation system establishment.
In addition to grammatical complexity, cultural adaptability is another important dimension to measure translation quality. In the actual evaluation, special attention is paid to the practicability of the following quantitative indicators:
To quantify cultural adaptation, the following main indicators need to be considered:
(1) Word cultural Fitness (VCA): Measures how many words or phrases in a translated text successfully match the target cultural context. The following Eq. (4) is shown:
(2) Idiom fitness (IA): A measure of how many idioms or fixed collocations are translated or replaced properly. The following Eq. (5) is shown:
(3) Cultural Reference Fitness (CRA): Measures whether cultural references (such as place names, personal names, historical events, etc.) have been accurately and appropriately translated. The following Eq. (6) is shown:
Figure 2 shows the performance of these cultural adaptation factors in different translations.
Cultural adaptability in different translations.
These indicators not only help research to more fully understand the cultural adaptability of different translations, but also serve as input features for subsequent machine learning models. Through these quantitative indicators, the translation quality can be evaluated more effectively, and the translation results can be analyzed and understood more deeply. Note that these cultural adaptation factors will be used together with the previous factors such as grammatical complexity to construct a more comprehensive and accurate evaluation system of translation quality.
Algorithm comparison and selection
In the model building phase, choosing the right machine learning algorithm is a crucial step. To this end, this study selected several commonly used machine learning algorithms for comparison, including support vector machines (SVM), decision trees, random forests, and logistic regression.
Figure 3 shows a comparison of the performance of these algorithms on a verification set.
Comparison of verification set algorithms.
Based on this data, it can be found that Random Forest performs best in accuracy, accuracy, recall and F1 scores. Therefore, random forest is chosen as the main algorithm to evaluate translation quality in this study.
This choice is based on several reasons:
On the validation set, Random Forest showed the highest performance indicator, indicating that it was able to classify translation quality more accurately. Generalization ability: Random forests are widely used because of their strong generalization ability. The model can effectively deal with different types of features, including grammatical complexity and cultural adaptability, which are the concerns of this study. Robustness: Compared with other algorithms, random forest shows better robustness in the face of noise and outliers in the data.
Despite the many advantages of random forests, there are some limitations, such as relatively slow model training and prediction, and less explanatory of model results than some simple models. Nevertheless, given the requirements and data characteristics of this study, random forest is still the most appropriate choice.
Based on the above analysis, this study will further optimize the parameters of the random forest model and use it to construct the translation quality evaluation system of this study.
After random forest is selected as the model of this study, parameter adjustment and optimization become the key. The performance of a model largely depends on the choice of its parameters. The main parameters of random forest include the number of decision trees, the maximum depth of each decision tree, and the minimum number of partition samples.
The study used Grid Search combined with cross-validation to determine the best combination of parameters. Table 4 is a summary of the results of the study on the adjustment of the main parameters of the random forest.
Adjustment of main parameters of random forest
Adjustment of main parameters of random forest
In this process, it was found that the model performs best on the validation set when the number of decision trees is 150, the maximum depth is 20, and the minimum partition sample number is 5.
In order to more vividly describe the performance of the model under different parameter combinations, a model performance index
Where
Under the above optimal parameter combination, the model performance index
After parameter optimization, the model enters the stage of training and testing. In order to quantify the model performance, the following indicators were selected in this study: Accuracy, Precision, Recall, and F1 Score.
The data set was divided into a training set (70%) and a test set (30%). There are a total of 1000 samples, of which the training set consists of 700 samples and the test set consists of 300 samples.
In the training phase, the random forest model is fitted with the training data. In this study, a grid search method is used to determine the optimal model parameters, such as the number of trees, maximum depth and minimum sample segmentation. Through cross-validation, we evaluated the performance of different parameter combinations and ultimately selected the best-performing parameter configuration.
In the testing phase, the model is applied to an independent test set to evaluate its performance on unseen data. In order to quantify the model’s performance on the test set, the study defines a mathematical representation of the model’s performance, as shown in Eq. (7).
Figure 4 shows the index values of the model on the test set.
Test set indicators.
After training and testing, the performance of the model on the test set is close to that of the training set, indicating that the model has no overfitting and has good generalization ability. Through this model, the translation quality of English literary works can be evaluated more accurately, and the translation quality evaluation system can be improved and developed.
Model performance and validity
Based on the model training and testing, the performance and effectiveness of the model are evaluated in detail. Using cross-validation (e.g., 5-fold cross-validation) methods, studies can obtain statistical measures of model performance from multiple different training and validation datasets to more accurately assess model stability and reliability.
(1) Model performance measurement
The overall performance measurement of the research-defined model is shown in the following Eq. (8):
Where,
In the 5-fold cross-validation, the accuracy rates are 0.85, 0.86, 0.87, 0.88 and 0.89, respectively. The average accuracy of cross-validation is 0.87.
Using the above formula, we can obtain:
(2) Model validity
In addition to the above numerical evaluation, the effect of the model was verified by actual translation samples. A random selection of 10 literary translations, including content of different styles and themes, was compared with the model output through expert review.
Methods: The trained model was used to evaluate the translation of each literary work. Independent evaluation by professional translators; Pearson correlation between computational model evaluation and professional translator evaluation
As shown in Fig. 5, the translation effect is compared by randomly selecting 10 literary works.
Comparison of translation effects.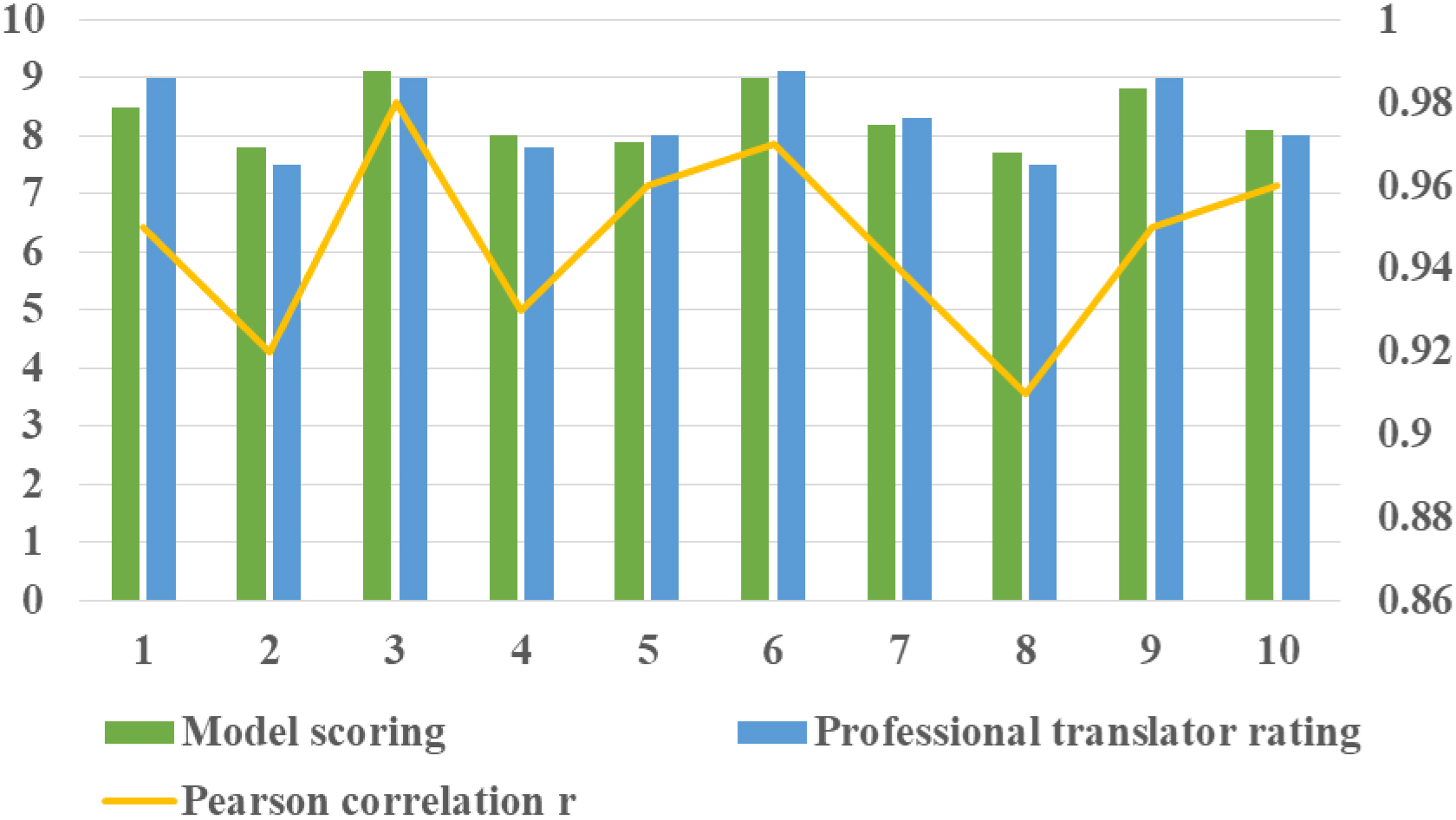
The results show that the Pearson correlation
In summary, the cross-validation and practical validation methods demonstrate the excellent performance and wide application prospects of the model in the evaluation of translation quality of English literary works.
Based on the analysis of the model’s performance and validity, a comprehensive evaluation standard system is proposed to comprehensively evaluate the translation quality of English literary works. This system takes into account several evaluation dimensions, such as grammatical complexity, cultural adaptability, and other important quality indicators.
(1) Dimension weight setting
The weight setting formula of the comprehensive evaluation standard system is shown in Eq. (9) below:
Where,
Weights of different evaluation dimensions
(2) Translation quality evaluation criteria
On the basis of the above weights, the specific calculation of comprehensive evaluation criteria can be given, as shown in the following Eq. (10):
Where,
For example, let a translation of a literary work score in these dimensions as:
Using the above formula, we can obtain:
Examples of translation quality evaluation
Through the application of practical translation cases, this comprehensive evaluation standard can not only comprehensively evaluate the translation quality, but also provide improvement directions for different dimensions of translation, so as to ensure the practicality and practical application value of the evaluation system.
After establishing the comprehensive evaluation system and verifying its effectiveness, this study further investigates the systematic application and universality of the evaluation system. The focus is to explore whether the evaluation system can be widely applied to the translation of English literary works of different types and styles.
The model was tested by applying it to three different types of literary works, such as novels, poems and plays. Specific application performance is shown in the following Eq. (11):
Where,
As shown in Fig. 6.
Model application test.
The main differences and advantages between this evaluation system and traditional evaluation methods are as follows:
Data-driven and objective: Traditional evaluation methods usually rely on the subjective judgment of experts, while the evaluation system of this study is based on data driven and uses quantitative indicators and machine learning models to provide a more objective and scientific evaluation. Comprehensiveness and accuracy: Traditional methods may not be able to fully capture all aspects of translation, but the evaluation system in this study improves the comprehensiveness and accuracy of the evaluation by integrating multi-dimensional features such as grammatical complexity and cultural adaptability. Automation and efficiency: Compared with manual evaluation, the evaluation system in this study improves the evaluation efficiency through automated processes, especially when processing large amounts of data.
In order to further explore the universality of the evaluation system, literary works in different languages (such as French and Japanese) were selected for the same evaluation process. The universality evaluation function is defined, as shown in the following Eq. (12):
Where
Let the French works have a score of 0.85 and a weight of 0.5, and the Japanese works have a score of 0.88 and a weight of 0.5. Using the above formula, we can obtain:
In summary, the comprehensive evaluation system in this study shows high reliability and effectiveness in terms of system application and universality, and provides a powerful tool and reference for future translation quality evaluation.
The aim of this study is to build a quality evaluation system for English literary translation based on big data. Through in-depth analysis of multi-dimensional characteristics such as grammatical complexity and cultural adaptability, this study reveals the importance of these factors in the evaluation of translation quality. Combining big data analysis and machine learning techniques, we successfully designed and trained a model to automatically evaluate translation quality.
The model has been verified on various types of English literature works, and its high consistency with expert evaluation results proves its accuracy and reliability. In addition, the universality of the evaluation system has also been verified, indicating that its applicability is not limited to English literary works, but can also be extended to literary works translation evaluation in other languages.
The main contribution of this study lies in the automation and standardization of translation quality evaluation, which not only provides a new perspective for the field of translation studies, but also has practical application value, especially in the field of translation education and practice.
In the course of the research, this research has faced several challenges. First, the limitations of data sources are a major concern. Current datasets focus primarily on modern literature, which limits the adaptability and accuracy of models for classical works. Second, although the model shows high accuracy, the performance of the model still needs to be further optimized when facing some texts with specific cultural background and complex context.
Future studies can further improve the accuracy and universality of translation quality evaluation from multiple perspectives. For example, more languages and styles of literature are introduced, and more dimensions of characteristic factors and algorithms are explored to improve the applicability and generalization ability of the model. In addition, addressing the diversity and coverage of data sources in more detail is also a key direction for future research.
In conclusion, this study provides a novel and effective framework for the evaluation of translation quality of English literary works, and shows a wide range of research and application prospects.
Footnotes
Funding
Key Research Project of Higher Education Institutions in Henan Province in 2022: Innovative Path Research on Strengthening Science Education and Promoting Science Popularization in Higher Education Institutions under the Background of New Media Era (No.22A880027).