
Abstract
In addition to a more extreme network experience and larger network capacity, 5G can also be used to rapidly transmit massive global text data at higher transmission speeds and higher reliability than previous communication technologies, allowing more communication devices around the world to operate at a faster rate. The transmission speed is safe and reliable to connect with each other. The rapid development of image recognition technology will be more effective in improving the operational efficiency of various industries. At present, scholars have used 5G technology and image recognition technology in the field of book management. This paper designs a book image recognition recommendation scheme based on 5G technology, in order to improve the problems of inaccurate book sales targets and low book classification efficiency of merchants from various perspectives. The image recognition book recommendation system combined with 5G technology is mainly divided into two steps: image recognition and book recommendation. The ultra-high speed provided by 5G technology can greatly improve the speed and accuracy of image recognition. Significantly reduces program running time. This paper first analyzes the related concepts of 5G, image recognition and recommendation algorithm, then sorts out the book image recognition method, and then designs the book recommendation purchase method. Combined with 5G technology, the image recognition and recommended purchase strategy are optimized. Finally, an online questionnaire is used to investigate the merchants using this method. The survey results show that the merchants who use this identification and purchase recommendation method have better performance in book classification, book personality recommendation, customer loyalty and book sales rate have greatly improved.
Introduction
5G technology
After nearly 40 years of rapid development, the mobile communication system is developing and entering the 5G era. The core of communication technology has also gradually shifted from 4G to 5G. So far, there has been a big breakthrough in the development of 5G, and many people have begun to use 5G mobile phones. Now when it comes to 5G, it mainly refers to the fifth generation of mobile communication technology. Compared with previous communication technologies, 5G has a variety of core advantages, which enable 5G technology to play an important role in various scenarios in the future [1, 2]. Compared with the past, its advantages mainly include fast transmission speed, rich spectrum and high overall efficiency. 5G technology has the characteristics of multiple base stations and large-scale MIMO communication. With the advent of the 5G era, China has proposed a moderate development for 5G construction and development, and vigorously develops 5G industry construction while satisfying the existing 4G network services [3]. According to a report by the Ministry of Industry and Information Technology, the number of netizens in China exceeds 1 billion, and 5G base stations have been opened about 1 million seats. The agency predicts the development trend of 5G technology as shown in Fig. 1.
The development trend of 5G technology.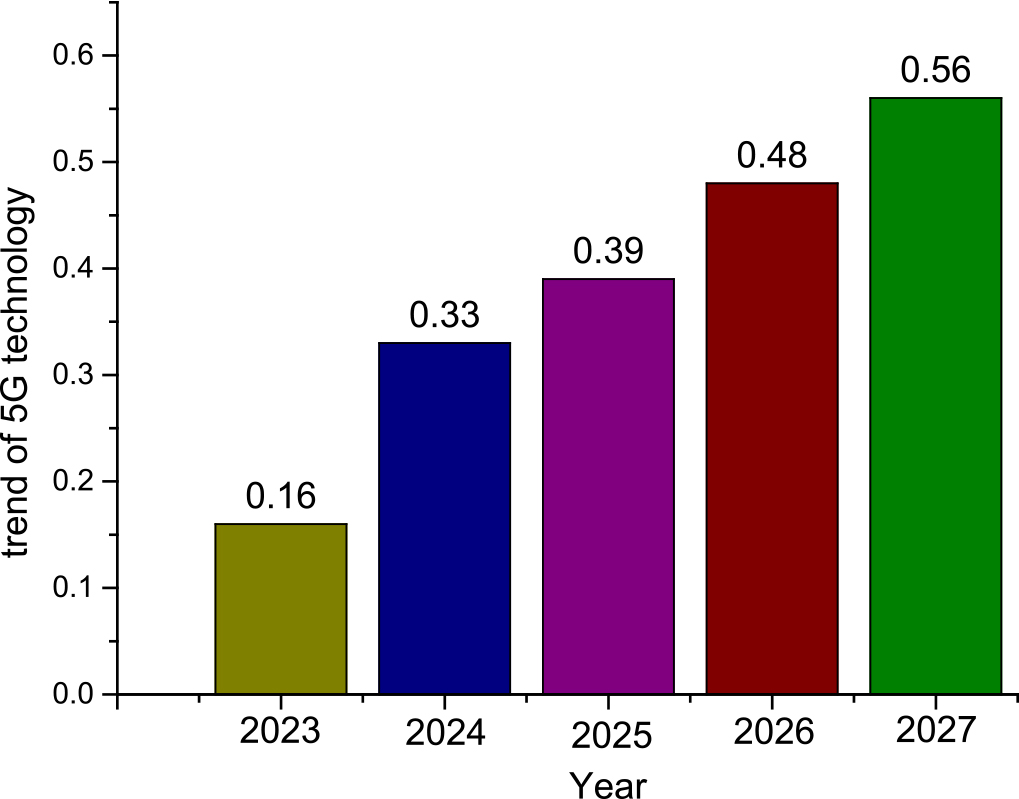
The development of object recognition research based on image technology so far mainly refers to the objective perception and recognition of the three-dimensional world we live in and its recognition, it is an advanced computer vision technology. It is based on digital image recognition and processing technologies and combines the research direction of deep learning, AI, cloud computing, statistics and other technologies. In the 1950s, the pioneer researchers of this technology began to study basic text recognition, initially to recognize English letters, Arabic numerals and common punctuation marks, from printed words such as newspapers to recognizing handwritten words in human daily life [4, 5]. Recognition is not only widely used but also has a high degree of refinement. At the same time, researchers have also developed many special equipment for character recognition. The research on more complex digital image processing and recognition began in the mid-1960s. Compared with outdated and backward Analog images, digital images can be stored safely and quickly, and file transmission is fast and convenient [6, 7]. The huge advantages such as easy image damage and distortion, easy processing and no threshold, the above-mentioned significant advantages not only provide a steady stream of impetus for the development of image recognition technology, but also allow subsequent researchers to see part of the future development direction of this technology [8, 9].
Recommendation algorithms
Content-based recommendation simply means mining personal preferences from users’ historical behaviors and recommending new items of the same type that they are interested in. The algorithm based on popularity is very easy to understand. It is like daily headlines, Weibo hot list, news, etc. in daily life. It calculates the ranking based on data such as daily click rate or sharing rate and recommends the top items to users. The algorithm is relatively easy to implement and helps solve the cold start problem for new users. However, its disadvantage is that it needs to standardize products, and it will not recommend new projects to users, resulting in missing things that users may be interested in. Following the trend, only popular projects can be accepted, and unpopular projects rarely have the opportunity to be observed. Although there are various recommendation algorithms, each recommendation algorithm has its own advantages and disadvantages. In order to promote strengths and avoid weaknesses, the idea of hybrid recommendation is generally adopted in the recommendation system [10, 11]. Just like ensemble learning in machine learning, there are many talents and talents. By combining two or more recommendation algorithms, the combination of multiple recommendation algorithms can avoid or make up for the limitations of their respective algorithms and improve the shortcomings of a single algorithm. Improve the accuracy and improve the effect of the recommendation. The recommendation effect obtained by the hybrid recommendation is better than that of any single algorithm, but it also increases the difficulty of implementation [12, 13].
The research adopts a combination of questionnaire research and data simulation, which can not only grasp the real needs of bookstore customers, but also better judge the potential needs of customers with the help of contemporary information technology, so as to provide computer science and engineering calculation in the field of book purchase recommendation. The application provides a very useful reference.
Book image recognition strategies
In the content of image processing, contour extraction is the most important part of image processing, and its application is more and more extensive, and it has become one of the main research directions of people. The role of computer vision technology in the field of intelligent monitoring is mainly to analyze and process the image information captured by the camera, and identify the behavior of objects in the image [14]. The contour extraction technology can accurately locate the position of the object in the image and realize object tracking and human behavior. At the same time, it can also realize the classification of objects, which can be used by book merchants to improve the efficiency of merchants sorting books. From the point of view of the recognition principle, the computer itself needs certain processes and steps to recognize the image by the CNN algorithm. First, the computer is given an internal storage pattern that is consistent with the target pattern, and then the CNN recognition algorithm is performed on the image to be recognized to recognize the target [15, 16]. The pattern is compared with pre-stored by the computer itself. If the comparison result is consistent, the computer will make a judgment that the unknown pattern is indeed the standard identification pattern stored by the computer. In addition, CNN can not only compare the target pattern with the standard pattern, but also calculate it through a local contrast method, which is the convolution operation explained by CNN [17]. However, the disadvantage of CNN is that for computers, when comparing two pictures, the main comparison is the pixel value of the picture, and the computer’s “vision” is more rigid than the more flexible human vision, so it is not enough to face some problems. “Standard” recognition targets, it is difficult for the computer to compare and recognize, and errors are prone to occur.
During the identification process, there may be image noise in the book, which needs to be filtered. The principle is that in the process of reading and transportation, the digital image will inevitably be disturbed by various noises [18]. Although the mean filtering algorithm is simple, it cannot completely remove the salt and pepper noise, and the image of the book may still not be clear enough. The median filtering method can avoid various problems. In addition, there are different angles of identification, and the specific situation is shown in Table 1.
The angle parameters of book image recognition
The angle parameters of book image recognition
The traditional book image contour extraction is to identify edge information from the high-frequency signal of the image. Generally speaking, the main method of contour identification and extraction is differential operation, but these methods are easily affected by noise, so the extracted contour Ineffective. After the development and improvement of science and technology, people have researched many kinds of contour extraction methods, which are mainly divided into four steps: filtering, enhancement, detection and positioning. In order to simulate and verify the design of real book image recognition [19], this experiment takes opencv as the core, and an auxiliary function library is needed in this development environment to complete this experiment. Use the opencv module and the numpy module to extract the contour, package the file, and then install the mirroring system on the Raspberry Pi through the 48 g memory card. After the preparation of the above experimental environment, it was found that the books could be effectively recognized under the lens after the experiment of Python’s opencv library, and then the classification algorithm and robotic arm could be added to automatically classify the books.
When faced with massive network information resources, it is often difficult for users to quickly search for what they want and are really useful. Often valuable information is difficult for users to find, resulting in the phenomenon of “information overload”. “Information overload” can be seen everywhere, and it exists in the fields of information service provision such as movies, music, shopping, and books on the Internet. It is also an important problem that researchers need to solve urgently. In the field of online reading and online book sales, due to the variety of Internet information, there is also an “information overload” phenomenon for end users, that is, it is difficult to easily and quickly search for books of interest through the Internet. In terms of business, the need to accurately recommend books of interest to customers, increase sales, reduce advertising costs, and efficiently promote products is becoming more and more urgent.
This paper addresses the limitations in the original recommender system by introducing popularity-based recommendation techniques. The specific process as follows: first, a hybrid model of collaborative filtering and content-based recommendation is established; in the established model, the collaborative filtering algorithm is first introduced, the Euclidean distance algorithm is used to calculate the similarity between the target reader and other readers, and then the according to the degree of similarity, find out the K neighbors most similar to the target reader among the existing readers, and then calculate the recommendation degree of each book according to the distance between the neighbor and the target reader among the books rated by these neighbors; secondly, according to the books that readers have read and rated, the initial rough results are obtained; finally, the recommendation algorithm based on popularity is added to the recommendation results generated by the above model, and the final accurate results are obtained according to the ranking of the book Douban scores. The simulation process is divided into data preparation, experimental parameter and environment preparation, and experiment. The experimental data in this paper uses the information of the books in Douban reading collected by the Octopus crawling website and the score data of users on the books. The collection fields include the book name, Douban score, and book feature attributes (the number of feature collections is 5), Reader ID, Reader Score (The number of readers collected is 5 per book, corresponding to 5 scores). Douban score is the reference standard for the ranking of a book among all books, and serves as the basis for the recommendation algorithm based on popularity; the feature field is a feature extracted from the book feature attribute group that can represent the category of the book. The basis of the content recommendation algorithm; the reader field should try to use the reader behavior information of the books that two users have at least one rating in common, as the basis for the collaborative filtering recommendation algorithm. The collected data has 342 records, which are stored in .csv files. Through the cleaning process, delete the records of logged-out users and ungraded users, filter duplicate items, and filter out the book data that two users have at least one common score to get 50 records. The purpose of this experiment is to use the improved hybrid recommendation algorithm to recommend 5 books to the target readers.
Each reader corresponds to one number, and a piece of data records the reader’s score for a certain book. Correspondingly, each book corresponds to one number. In order to reduce the complexity of data, each book and each reader select the corresponding numbering operation to form a book feature table (books.csv) and reader rating table (ratings.csv). The book feature table contains bookID, title and genres (book features) fields, and the reader rating table contains raeaderID, bookID and rating fields, and 53 readers are screened out, with a total of 250 records. The specific parameter settings are shown in Tables 2–4.
Book and reader numbers
Book and reader numbers
Book recommendation parameters
Book features
Build collaborative filtering and content-based recommendation models. The environment is the TensorFlow framework suitable for various machine learning algorithms. Import the books.csv and ratings.csv files and create a book rating matrix rating and rating record matrix record, where m represents the number of books, n represents the number of readers, calculate the average score of each book, and the final recommendation score
If only the content-based recommendation algorithm is used, the recommendation system will take the words “reasoning and suspenseful” that appear in the book content that the reader has read, and use the TF-IDF weighted statistical method to calculate the effect of the word on the text set of the book feature content. Collaborative filtering recommendation, there is data sparsity. When only one reader of a book has read it, such a reader cannot be recommended by the collaborative filtering algorithm, because there is no nearest neighbor, and the similarity cannot be calculated. In this example, the collected field is that each book corresponds to 5 readers, so there is no record of only one reader for a book. At the same time, there is also a scalability problem. From the first book “Golden Dreamland” collected, the similarity between the target reader “Ayigu Xiong” and other readers is calculated, and it can be found that the nearest neighbor with the highest similarity is the reader “Zhao Doudou”. It will recommend to target readers based on the books that the nearest neighbors have read. Recommendations based on popularity, recommend the books with the highest ratings to readers, readers can only accept books that have been read by most people and have high ratings, and potentially high-quality, unpopular books that have not been discovered by many readers. It will hardly be recommended, which will cause readers to miss the books they are interested in. Using the improved hybrid recommendation algorithm, the readers recommended “The Story of a New Name”, “Walking in the White Night”, “The Golden Age”, “The Devotion of Suspect X”, and “Little Doudou by the Window”, compared with the original results. The recommended book content features more attributes, including “female”, “reasoning”, “suspense”, “novel”, “literature”, “education” and other types, in order to avoid the content received by the target readers being too simplistic; and correspondingly reduce the categories of “reasoning” and “suspense”, so that readers can not only read books similar to their own preferences, but also avoid the same type of recommended books, eliminating readers’ lack of psychology; Popular high-quality books bring novelty to readers and can keep pace with the times to receive books that are currently popular with the public.
The traditional hybrid recommendation mechanism still has the problem of user cold start and the problem of only recommending books with similar content and lack of novelty. In this problem, the popularity-based recommendation technology just solves this limitation. It can synthesize similar neighbors. The result obtained from the collection of the books read and the books that the readers have read and the characteristic attributes of the books, and then adding the current popular elements to give the readers a perfect recommendation, so that the readers can not only receive books recommended by similar neighbors, and can receive books with similar content characteristics and attributes in combination with the books they have read, and will not miss the popular books that are currently popular among the public. It will also bring novel “surprises” to readers, which solves the problem of similar book content and readers psychological problems of scarcity.
During the operation of the book image recognition strategy in the first two chapters, it is necessary to search the Internet image library or the image library that has been trained. There is a network comparison process in this process, and the fiber-to-the-home technology of the current fourth-generation mobile communication is used to ensure the speed. There may be a high image recognition delay, and the delay performance itself affects the speed of book sorting for merchants and the experience of subsequent customer recommendation. If you want to maintain a high speed, you need to use the 5G network. The fifth-generation communication technology greatly improves the data transmission speed compared with 4G by arranging a large number of small base stations in a short distance. Speed to the book image recognition process, thereby reducing the time consuming of its recognition process.
During the operation of the book purchase recommendation algorithm, it is necessary to first process the customer’s shopping habit data and demand data, and then compare the book’s inventory data to make recommendations. The operation process of this strategy not only requires high speed, but also may be delayed due to the operation of the algorithm itself. Compared with 4G, special technologies such as massive MIMO provided in 5G technology have stronger anti-noise interference function, which not only improves the speed of the book recommendation algorithm, but also reduces the possibility of errors during the operation of the algorithm.
The specified content of MIMO technology is to separate the user’s data association and generate it into many parallel data streams. After that, it is now such a time that such transmissions are now accurate, which can nullify the overall transmit power. We can play the raw data stream to access the spatial characteristics of the parametric data stream of the antenna array.
Another major MIMO technique is the use of multiple antenna arrays for transmit/receive terminals, where space vectors and different spatial characteristics can be derived from spatial radio channels, so that the number of independent channels is added. Use this new channel as space diversity gain. That system uses exclusively rich radio channels for transmission and reception. The experimental environment settings for the recommended purchase of book image recognition combined with 5G technology are shown in Table 5.
Experimental environment combined with 5G technology
Experimental environment combined with 5G technology
Book classification before and after combining 5G and image recognition.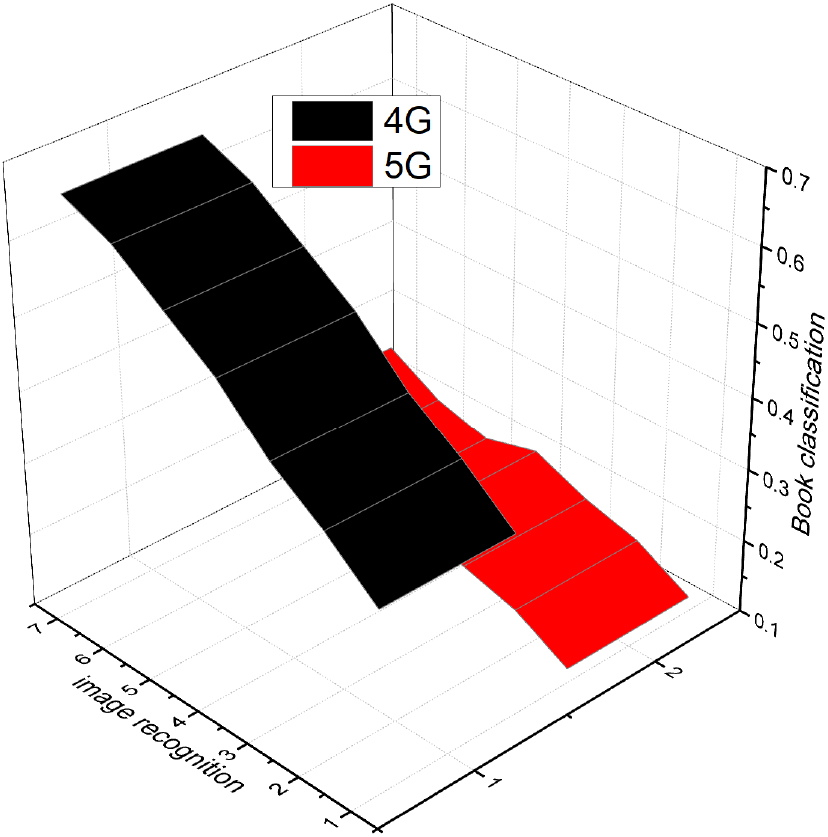
Personalized book recommendation before and after combining 5G and image recognition.
Customer loyalty before and after combining 5G and image recognition.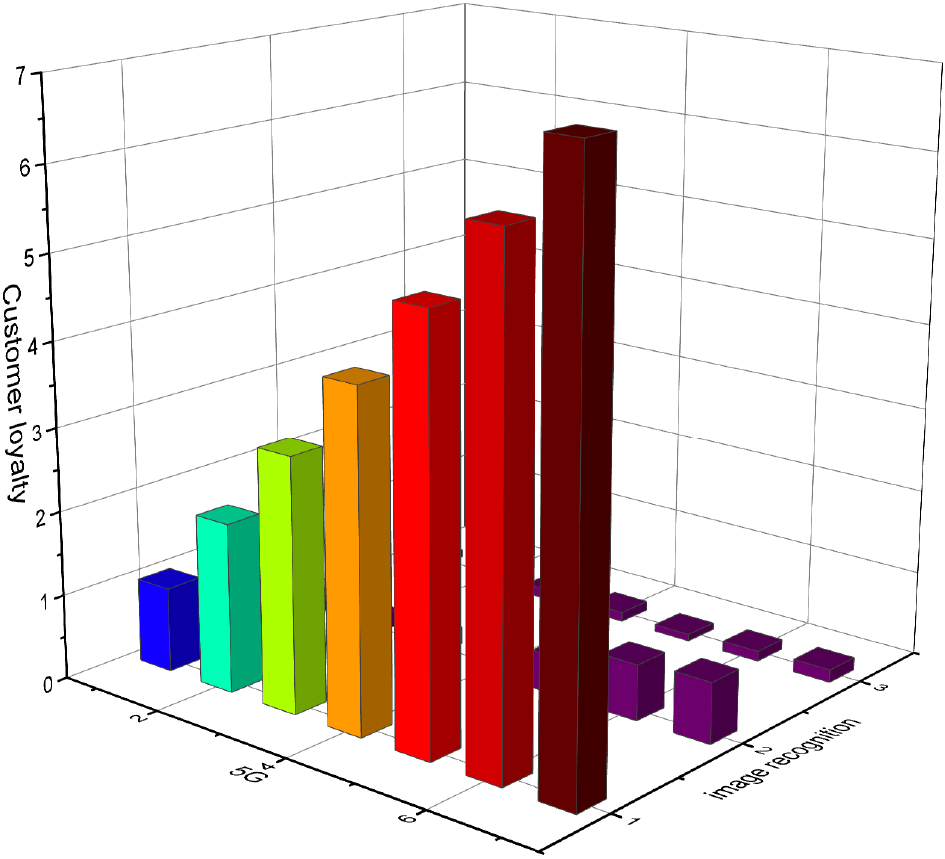
Book sales rate before and after combining 5G and image recognition.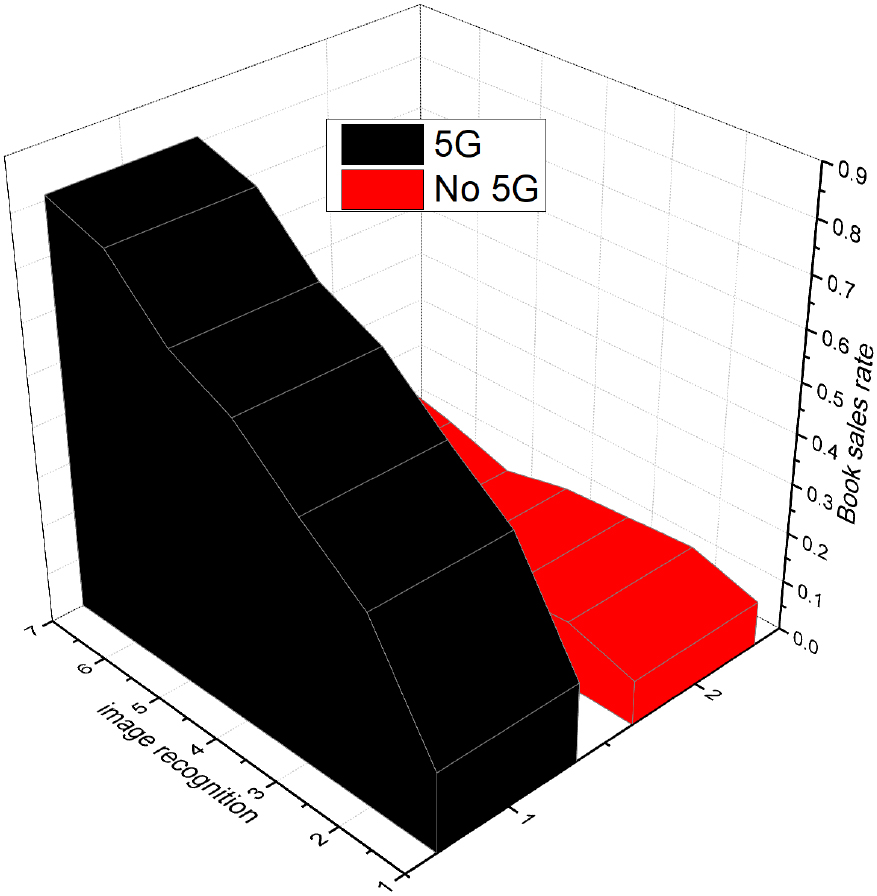
In order to investigate the situation of merchants who have adopted image recognition, collaborative filtering algorithm and 5G technology to recommend book purchases, the author distributed 400 questionnaires through the Questionnaire Star platform, and surveyed the merchants who adopted this algorithm in various e-commerce platforms and micro-businesses. The main survey contents are book classification, book personality recommendation, customer loyalty and book sales rate before and after adopting the strategy. 398 questionnaires were effectively recovered, and the recovery rate was close to 100%.
Among them, book classification is the first step to facilitate the follow-up recommendation query of books. When the classification efficiency is high, the operating efficiency of the merchants will also improve. The data display of book classification in this questionnaire is shown in Fig. 2.
Personalized book recommendation is highly related to the reading interest of customers. Accurate recommendation can quickly retain customers and improve the possibility of selling products. The data on personalized book recommendation in this questionnaire is shown in Fig. 3.
Customer loyalty is closely related to the durability of merchants’ store operations and the promotion of merchants’ products. The data on customer loyalty in this questionnaire survey is shown in Fig. 4.
The book sales rate determines the final revenue and profit of the merchants. The data display of the book sales rate in this questionnaire is shown in Fig. 5.
Compared with the traditional offline book sales model, the online book sales system has quite a few advantages, mainly as follows: first, it reduces the sales cost of merchants; second, the transaction relies on the Internet, which makes the merchants transaction activities with users are no longer restricted by various factors such as region and time; in the current situation of fierce competition in various industries, people’s continuous in-depth understanding of information technology has gradually increased the number of people who learn to use the Internet. The sales of books are gradually increasing, and at the same time, they are playing an increasingly important role in the market economy. Therefore, if businesses want to occupy a place in it, they must improve work efficiency and work quality.
This paper first analyzes the related concepts of 5G, image recognition and recommendation algorithms, then sorts out the book image recognition method, and then designs the book recommendation purchase method. Combined with 5G technology, the image recognition and recommended purchase strategy are optimized. Finally, an online questionnaire is used to investigate the merchants using this method. The survey results show that the merchants who use this identification and purchase recommendation method have better performance in book classification, book personality recommendation, customer loyalty and book sales rate. Greatly improved.
In the context of the rapid development of 5G technology, big data analysis can better realize scientific judgment on the actual and potential needs of the people, so as to conduct more targeted production and sales of products. In the field of book recommendation, data analysis also shows great value. Research confirms that the merchants who use this identification and purchase recommendation method have better performance in book classification, book personality recommendation, customer loyalty and book sales rate have greatly improved.