
Abstract
As a result of alkali ASP flooding in oil and gas fields, strata and pipelines become seriously scaled, which poses a threat to the normal operation of crude oil production. We propose an intelligent knowledge reasoning model for dynamic scaling prediction in order to address the problems of high directivity, poor generalization ability, and poor application effect of existing scaling prediction methods. The model framework includes the knowledge acquisition layer which mainly relates to the manual acquisition of scaling prediction knowledge and the intelligent training of the knowledge base, and it includes the knowledge modeling layer that provides a set of standard domain common ontology and knowledge organization system using the ontology modeling technology, it also includes the knowledge inference layer which is the application layer of the model. The three layers collaborate and finally complete the scaling prediction through inference and expression. A total of 238 wells were selected for experimentation in the northern development area of the Xingshugang Oilfield. Experimental results indicate that the model has the highest accuracy of 91.87%. Additionally, the time series prediction trend for the six ions matches the trend of change in ion concentration in the scaling state, verifying the accuracy of the model’s predictions.
Keywords
Introduction
Various reservoir properties lead to different displacement methods. ASP (Alkali-Surfactant-Polymer) flooding technology has great potential. However, since alkali is introduced into ASP flooding, scaling in the reservoir environment and injection-production system becomes a serious concern, which limits the recovery efficiency of production wells. Currently, there are two main types of the scaling prediction methods: chemical mechanism-based scaling prediction methods and intelligent mining-based scaling prediction methods [1].
Among the chemical mechanism prediction methods, Vetter et al. [2] proposed Vescal II simulation program, which mainly calculated the generation trend of BaSO
In view of the excellent performance of machine learning theory in trend prediction problems in similar fields such as natural gas concentration [13], air quality, environmental pollution [14], researchers began to introduce machine learning theory to scaling prediction, and soon emerged a large number of intelligent scaling prediction methods represented by BP neural network, support vector machine [15, 16] and hybrid learning algorithm.
Fu Yarong and Yu Hao [17, 18] used BP neural network to predict scaling factors and scaling conditions in different water cut stages of oilfield. However, BP neural network has some problems, such as slow convergence speed and an easy tendency to fall into local minimum, which leads to a relatively large error in scaling prediction. Li Na et al. [19] used a wavelet neural network to combine the analysis characteristics with the pattern recognition characteristics of a neural network, and relatively improved the scaling prediction accuracy compared with the traditional neural network. Ma Liping [20] established an early warning model of oilfield water flooding development effects based on the principles of fuzzy comprehensive evaluation and artificial neural networks. The predicted results of the model are in good agreement with the actual test results. Cheng Jiecheng et al. established the quantitative prediction method of the scaling stage by using temperature, pressure, pH, ionic strength, and other factors, and the highest application accuracy rate in the test area was 92.8% [21]. Yuan Zhaoqi, Fu Yarong, Yu Hao, et al. predicted the scaling of the oil field gathering pipeline by using an artificial neural network. The experimental results have a small error and high reliability compared with the measured data. Ma Qing et al. established a scaling prediction classification model using a machine learning classification algorithm. By analyzing the ion assay data, the future scaling state is predicted, and good experimental results are obtaine. He Qiang predicted the scaling trend of produced fluid pipeline in Xinjiang Oilfield based on the FOA-SVM model, but the prediction error was lower than that of the neural network model [22].
The accuracy of scaling prediction depends on the validity of the knowledge of scaling prediction, which forms the core of the prediction method. While each prediction model has its own advantages and disadvantages, existing scaling prediction methods primarily focus on diagnosing specific geological conditions, oilfield water scaling states, scaling type, and scaling trend. However, in tertiary oil recovery systems, reservoir scaling is complex and the judgment criteria vary across different areas and blocks within the same area. Additionally, complex geological factors contribute to the scaling prediction characteristics, and the characteristic threshold is not universal. Furthermore, current intelligent scaling prediction methods primarily diagnose the phenomenon that has already occurred at the time of detection, lacking the ability to predict the time series trend of scaling phenomena. To address these issues, an intelligent knowledge reasoning model for dynamic scaling prediction has been developed through an analysis of the workflow and problems of real scaling prediction in the field. However, there is still a lack of intelligent customization methods for scaling cleaning and prevention schemes, which are the ultimate goal of scaling prediction.
Analysis of scaling prediction process
Analysis of the work flow of on-site scaling prediction
Scaling prediction is a complex task that involves multiple stages, from the injection system and underground reservoir to the production system. Each stage faces its own unique scaling challenges, making scaling diagnosis and prediction difficult. Oil production plants often use the ion content of oilfield water to predict scaling. Based on real-world scenarios, the traditional workflow for scaling prediction can be summarized into four stages: data acquisition, data integration, scaling prediction, and result application. This workflow is depicted in Fig. 1.
Data collection stage: According to the regional level of the prediction object, collect six ion, polymer, surfactant, silicon ion and other particle test data.
Data integration stage: Integrate and convert the reported original water quality data, screen and process abnormal data through manual experience, and sort the data into data that can be directly used for scaling prediction.
Scaling prediction stage: Combining the scaling state prediction mathematical model, scaling stage prediction knowledge and dosing scheme prediction knowledge given by field experts, analyze the ion assay data, predict the scaling state and scaling stage of single well, and predict the corresponding scaling prevention dosing adjustment scheme.
In that application stage of the prediction result, the actual scaling cleaning and anti-scaling dosing scheme is given in combination with the prediction scheme, and the dose is carried out for two dosing modes: single well and metering room, and the implementation result is observed.
Problems with workflow
From the perspective of data- and knowledge-driven scaling diagnosis and prediction, the traditional scaling prediction workflow has the following shortcomings:
Scaling prediction workflow.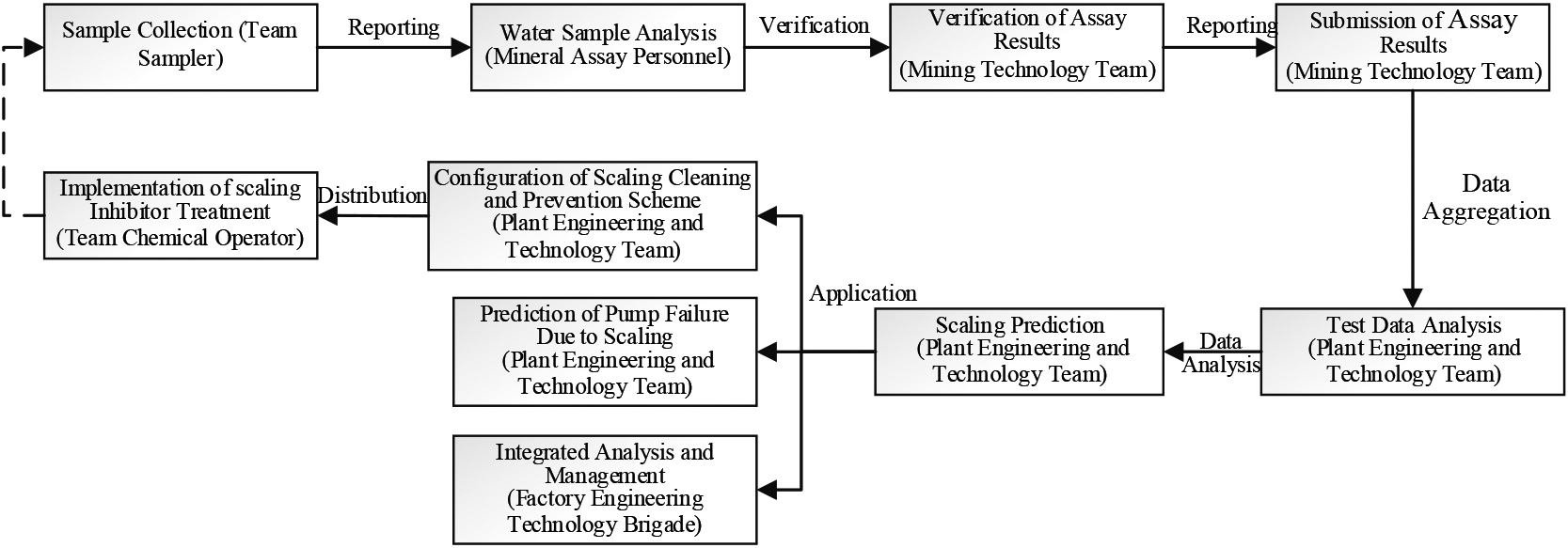
(1) Lack of effective knowledge organization and integration
The knowledge of scaling prediction is based on historical experience and exhibits characteristics such as large dispersion, various types, and an unfixed judgment threshold. Additionally, there is a lack of effective and unified semantic description methods for this knowledge. The knowledge required for scaling prediction is distributed across literature, mathematical models, electronic prediction records, and the experiences of field staff. As a result, acquiring and integrating this knowledge can be challenging, which ultimately limits its practical application.
(2) The dynamic variability of the scaling prediction method is weak
Scaling diagnosis and prediction requires high levels of timeliness, accuracy, and reliability. Qualitative knowledge and experience cannot accurately predict scaling with the continuous application of ASP flooding. While the scaling prediction can be accomplished intuitively, quickly, and accurately through manual experience, the processing speed is slow, and the staff is required to maintain a high level of professionalism.
(3) Low level of knowledge sharing
Several scaling prediction methods, based on chemical mechanisms, expert systems, and machine learning, have been developed based on the results of the field investigation and literature review. Unfortunately, the lack of a unified knowledge sharing platform for scaling prediction results in the slow updating of scaling knowledge based solely on the experiences of experts and field personnel.
As a result of the above problems, a data mining-based scaling prediction model has been developed to achieve accurate scaling prediction, rationalization and maximization of resources and the use of data mining technology to improve the accuracy and utilization of the scaling prediction model.
Design of intelligent prediction process for scaling
Scaling prediction is primarily intellectualized through the intellectualization of application and solution processes. Therefore, an intelligent scaling prediction process is designed, as shown in Fig. 2. Below is a description of the process.
Intelligent prediction process of scaling and corresponding problems to be solved.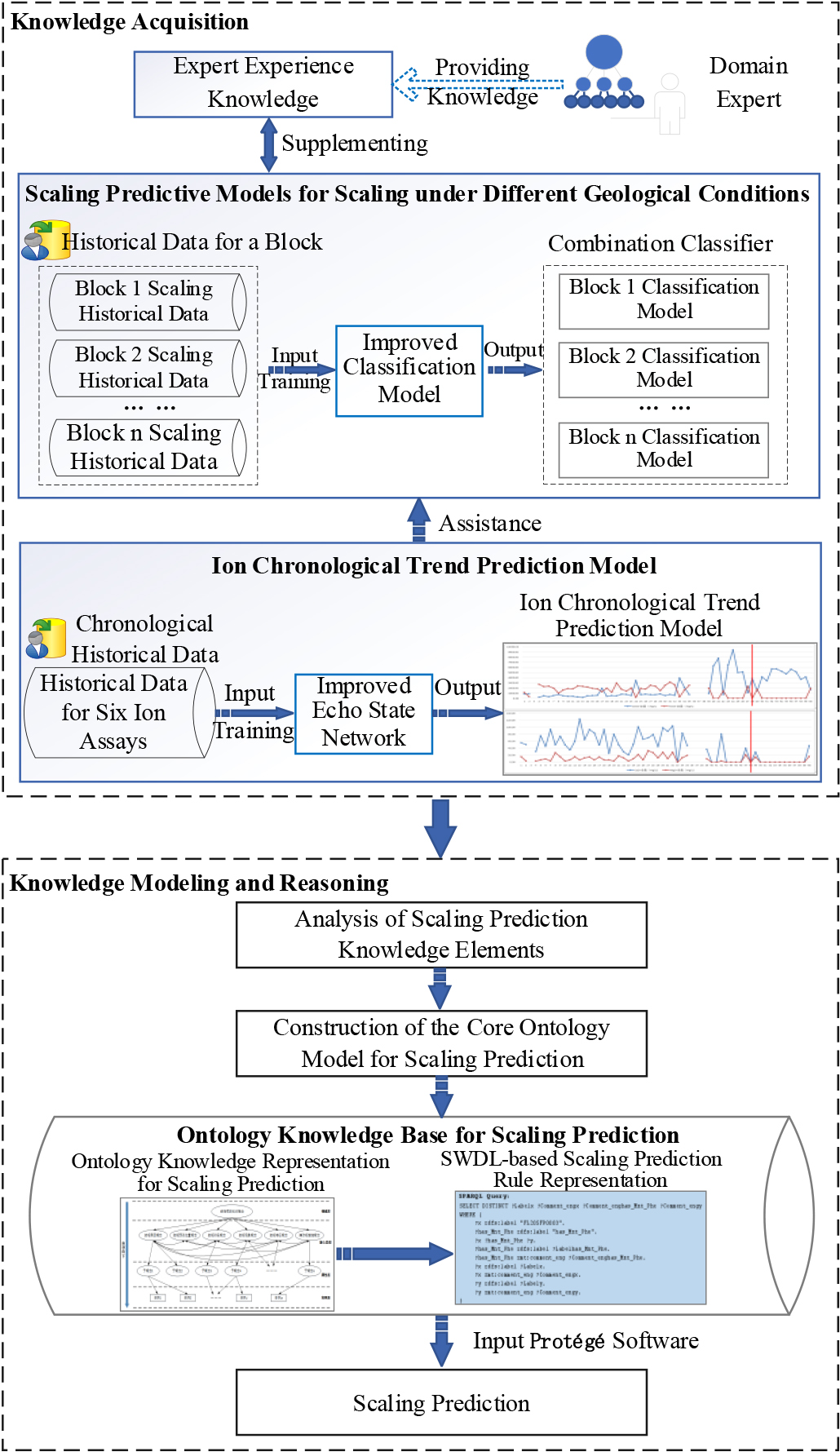
Step 1: Obtain scaling prediction knowledge. In this stage, expert experience knowledge, scaling prediction knowledge based on the similarities and differences of geological conditions, and ion time series trend prediction knowledge are obtained.
Expert experience knowledge is mainly converted into law by the domain expert through induction of the knowledge into his own brain or through the experience of others. By using data mining methods, the scaling prediction model under different geological conditions is mined to compensate for the leakage of expert experience knowledge. However, empirical knowledge and scaling prediction models can only be used to diagnose the scaling condition in oilfield water at the time of inspection. In conclusion, based on the time series data of ion assay in historical data, the time series prediction model is studied to assist pattern mining, and the scaling early warning and prediction are truly realized.
Step 2: Scaling prediction knowledge element analysis. By analyzing the components of the acquired scaling prediction knowledge, the logical relationship between the elements and the hierarchical structure, the reuse of knowledge is realized, and the basic elements and logical support are provided for the construction of the scaling prediction knowledge model.
Step 3: Construction of the core ontology model for structure prediction. Because the structural prediction knowledge has the characteristics of dynamic, multi-source and heterogeneous, the ontology technology is adopted to establish the core class, object attribute, axiom and relationship of the scaling prediction ontology according to the reusable scaling prediction elements and their relations, and the structural prediction ontology knowledge model is constructed to solve the problem of scaling prediction knowledge modeling in real scenes.
Step 4: Build that ontology knowledge base of scaling prediction. The scaling prediction knowledge model was used to construct the scaling prediction ontology knowledge base and rule base. The integration of knowledge base is improved, and the flexible application and sharing of scaling prediction knowledge are realized.
Step 5: Dynamic scaling prediction. Based on the ontology knowledge base, the scaling prediction is realized by using Protégé software, OWL axiom, SWDL rules and other reasoning methods.
SASP intelligent prediction model for reservoir scaling based on data mining, also known as the SASP-DMSP model, is designed to achieve intelligent acquisition of scaling prediction knowledge, the construction of scaling prediction standard knowledge models, and the application of scaling early warning reasoning. The model framework is shown in Fig. 3.
In order to achieve dynamic updating of the knowledge base, the training module is added at the time of knowledge acquisition, and the knowledge modeling module is added at the time of model standardization and sharing. As a result, the model framework of SASP-DMSP is composed of the knowledge acquisition module (KAM), the knowledge modeling module (KMD), and the knowledge-based reasoning module (KBR). Below is a detailed description of the components of the model.
(1) Knowledge acquisition layer
The KAM layer is the basic layer of the model, which is used to induce and acquire knowledge of scaling prediction. Knowledge is acquired in the KAM layer primarily through artificial induction and intelligent mining, and knowledge types acquired include experience knowledge and training knowledge. The working mechanism of the KAM layer is shown in Fig. 4. Manual induction is used to obtain empirical knowledge. For the purpose of filling the loss of empirical knowledge, intelligent mining technology is used to train historical data in order to acquire prediction knowledge. To integrate scaling prediction history data and ion assay data, the KAM layer utilizes an integration system for scaling prediction data. Accordingly, the three modules of the knowledge acquisition layer are described in detail in terms of the types of knowledge acquired in the field of scaling prediction.
1) Scaling prediction experience knowledge acquisition
This module mainly uses the artificial way to realize the experience knowledge refinement. Domain experts first obtain scaling experience, including their own experience, scaling prediction business mechanism, scaling mechanism and existing scaling prediction models. The acquired experience is collated, summarized and extracted by manual means.
Framework of intelligent scaling prediction model.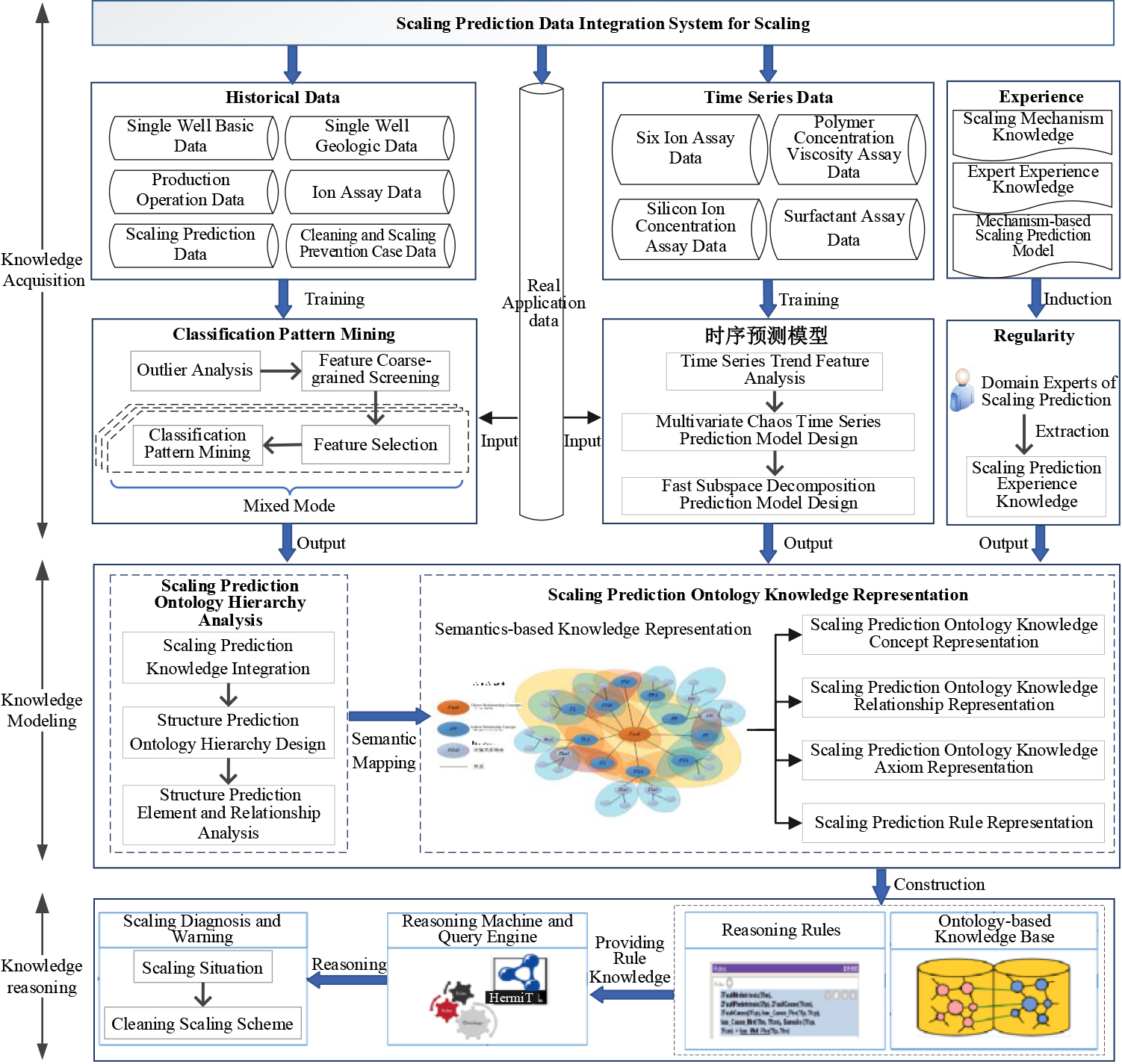
2) Knowledge acquisition of scaling prediction classification
In order to address the problem of the leakage of scaling prediction experience knowledge, a module for acquiring scaling prediction classification knowledge has been designed. By using the data mining method, the scaling prediction classification mode is mined, and the dynamic updating of scaling prediction knowledge is realized. Moreover, the corresponding scaling prediction model is provided for different geological conditions, improving the accuracy of scaling prediction.
In this paper, prediction models of scaling formation in different geological conditions are mined by taking block size as granularity, and a mixed prediction model is formed. The pattern mining process has the same stages and methods of processing; the difference lies in the input historical training data and the output classification patterns.
A classification pattern mining process consists of four stages: outlier analysis, coarse-grained screening of features, feature selection, and pattern mining. In the outlier analysis phase, the main objective is to analyze and define outliers, in order to provide a reference for the subsequent data mining technology on how to deal with outliers. During the coarse-grained feature selection stage, irrelevant factors in historical data are removed to avoid dimension disaster and to improve the speed of the subsequent feature selection process. In the feature selection stage, a neighborhood rough model and an improved heuristic algorithm are used to select the optimal feature subset, which affects scaling. During that stage of pattern mining, the decision tree method is employed in order to achieve the scaling prediction classification pattern mining process.
KAM layer working mechanism.
3) Time series prediction knowledge acquisition
With the help of echo state network technology, a time series prediction module is designed for mining the trend of scaling prediction data, and an early warning system for scaling is implemented. The time series prediction process consists of two stages: an analysis of the time series trend characteristic of the scaling prediction field, and the design of the time series prediction model. This phase aims to extract the characteristic characteristics of the training data and provide a reference range for the subsequent selection of appropriate time series prediction techniques. In the design phase of the time series prediction model, the corresponding techniques that can be adapted to the training data are selected according to the characteristics of the training data.
(2) Knowledge modeling layer
The knowledge of scaling prediction is the core content to determine the accuracy of scaling prediction. The high efficiency of knowledge application and the consistency of semantics are the keys to ensuring the accuracy of scaling prediction. Therefore, the KMD layer is designed as the middle layer of the model, and the scaling prediction knowledge obtained from the KAM layer is standardized and normalized to provide a standard specification for the KBR layer. The KMD layer consists of two stages: the analysis of scaling prediction ontology hierarchy and ontology knowledge representation.
The purpose of the ontology hierarchy analysis phase is to build a reusable conceptual model, provide standard specifications for knowledge, reduce errors in the conceptual model phase, and improve modeling efficiency. First, in this stage, the knowledge acquired from the KAM layer is integrated. Second, according to the business characteristics, the predicated logic method is used to analyze the scaling prediction factors, and the hierarchical structure of the scaling prediction ontology is constructed. Finally, the prediction elements and their attributes and relationships are defined to guide the construction of ontology knowledge.
In the ontology knowledge representation stage of scaling prediction, OWL DL is used to describe the knowledge of scaling prediction, and the concept, relation, axiom and prediction rule of scaling prediction knowledge are represented under the guidance of hierarchy structure and element definition.
(3) Knowledge reasoning layer
The KBR layer is the application layer of the model, which stores the ontology knowledge and rule knowledge of scaling prediction, and completes the scaling prediction and treatment scheme customization through reasoning and expression. The KBR layer mainly includes three stages: the construction of the ontology knowledge base, the selection of reasoning engine and the application of reasoning.
In that KBR lay, Protégé is used as the ontology model tool, and in the ontology knowledge base construction stage, the knowledge base and rule base of scaling prediction are constructed under the guidance of the ontology knowledge conceptual model of the KMD lay. In the reasoning engine selection stage, the HermiT reasoning engine based on the Hyper tableleaux algorithm is selected through comparative analysis to realize efficient semantic reasoning. In that reasoning application stage, the scaling diagnosis and early warning are accomplished by the reasoning engine and query engine, and the knowledge application is realized.
The SASP-DMSP model shows the architecture of knowledge-based scaling prediction. The SASP-DMSP model can effectively collect scaling prediction knowledge distributed in the human brain, documents, and data and can provide corresponding scaling prediction knowledge for different geological conditions from the perspective of the regional dimension. The above analysis shows that the structurally intelligent prediction model has the following advantages.
It can predict the scaling stage before the fault occurs and provide accurate prevention measures. Using intelligent means to customize the anti-scaling scheme, reducing the maintenance cost, and achieving careful calculation. Through time series prediction, it can predict the fault caused by scaling, prevent it in advance, reduce the possibility of fault occurrence, and reduce the cost consumption of the fault diagnosis process. The consumption of mechanical equipment in the production system can be effectively reduced by predicting scaling.
At the same time, the model has the characteristics of extensibility, intelligence, universality, and sharing, which are described as follows.
(1) Extensibility
The extensibility of the SASP-DMSP model is embodied in the extension of knowledge type, ontology knowledge model, and knowledge base. In the SASP-DMSP model, knowledge is transferred through interfaces, and KAM layer has low coupling in practical application, so that the type and mode of acquiring knowledge can be changed to meet practical application requirements. Ontology knowledge model is mainly based on predicate logic knowledge element analysis method to realize the construction of the ontology conceptual model. When the knowledge type and elements change, the ontology knowledge model and knowledge base will be updated and improved dynamically.
(2) Intelligence
The model adopts intelligent analysis techniques such as data mining and machine learning methods to mine the key knowledge hidden in the data through historical data and improve the quality of scaling prediction knowledge. At the same time, the knowledge model of scaling prediction is established by using ontology technology, which improves the ability of scaling state diagnosis and decision-making, and truly realizes the early warning and prediction.
(3) Generality
Factors affecting scaling are different under different geological conditions. In this paper, the geological regions are divided by block, and the corresponding scaling prediction classification knowledge is mined according to different geological conditions to form a hybrid prediction model, which can be transplanted and applied to different geological regions to ensure the universality of the model.
(4) Shared
The model collects scaling prediction knowledge from the point of view of data and knowledge, which is helpful to establish a comprehensive and rich knowledge base. At the same time, this paper uses ontology technology to build the scaling prediction knowledge model, which can effectively represent and rent the scaling prediction knowledge, and has clear semantics to ensure the sharing of scaling prediction knowledge.
Overall system structure design
According to the real business requirements, the scaling prediction system of compound flooding (hereinafter referred to as the intelligent system) is designed and developed, including the Ontology-based knowledge management system for scaling prediction (SP-OBKMS), scaling prediction data integration system (SP-DIS) and scaling prediction and scaling control system (SP-SCS). The system operation mode is shown in Fig. 5.
System operation mode.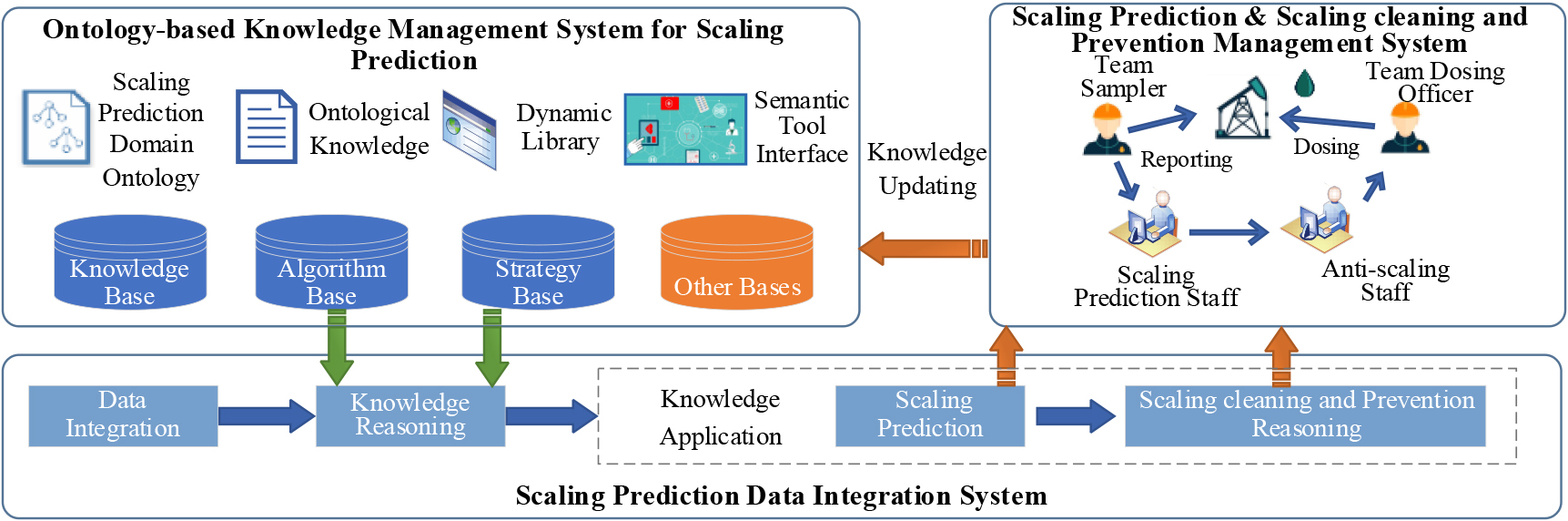
Among them, SP-OBKMS mainly realizes knowledge collection, modeling, and management. SP-DIS is mainly used to integrate data related to scaling prediction, diagnose and reason scaling state and stage, predict scaling time sequence, customize and analyze scaling cleaning and prevention scheme. SP-SCS mainly realizes informatization and intelligent scaling prediction, provides work scenarios and prediction knowledge for business staff, and realizes auxiliary decisions. Knowledge updating occurs through real feedback from business staff.
With the SASP-DMSP model as the theoretical guidance, the overall system architecture is constructed, as shown in Fig. 6. SP-DIS is the data layer and reasoning layer of the architecture, SP-OBKMS is the learning layer and ontology layer of the architecture, and SP-SCS is the application layer of the architecture.
The data layer provides training data for knowledge learning and updating, and knowledge reasoning results for scaling prediction application. Firstly, in the data layer, the original data is extracted and integrated according to the business requirements and business data model, and transformed into training data that can be used by the learning layer and basic data that can be used by the service layer. Secondly, the data layer makes use of the domain knowledge obtained by the interaction of the learning layer and the ontology knowledge layer to conduct knowledge reasoning according to the business requirements, and obtain the business-related diagnosis and prediction results. Finally, the data is provided to the service layer for knowledge application.
Overall system architecture design.
The application layer mainly implements scaling prediction, customization of scaling cleaning and prevention schemes, analysis of experimental well effect and operation status of production wells, and provides demand input, feedback result correction, and feedback result application service for scaling prediction reasoning.
The scaling prediction module in the system is based on the ion assay data and time series prediction data, and uses the scaling stage diagnosis knowledge and scaling state diagnosis knowledge to realize single-point scaling prediction (i.e., the scaling situation at the current detection time point), as shown in Fig. 7. The Fig. shows the scaling state and stage prediction results at the time point of mine-team detection and draws the scaling state of the reservoir under the regional dimension in the form of a scatter diagram with pH value as the horizontal axis and carbonate ion as the vertical axis. Meanwhile, it describes the work diagram of the production well, the detailed production operation data at the sampling time point, and the predicted scaling, cleaning, and prevention type and dosing concentration.
SP-SCS scaling prediction at sampling time points.
According to the predicted scaling stage and scaling type, the knowledge base is adjusted by using the scaling cleaning and prevention scheme, the scaling cleaning and prevention implementation prediction scheme is deduced, and the final scaling inhibitor theoretical implementation scheme is determined, as shown in Fig. 8.
Adjustment of SP-SCS dosing concentration and scaling inhibitor type.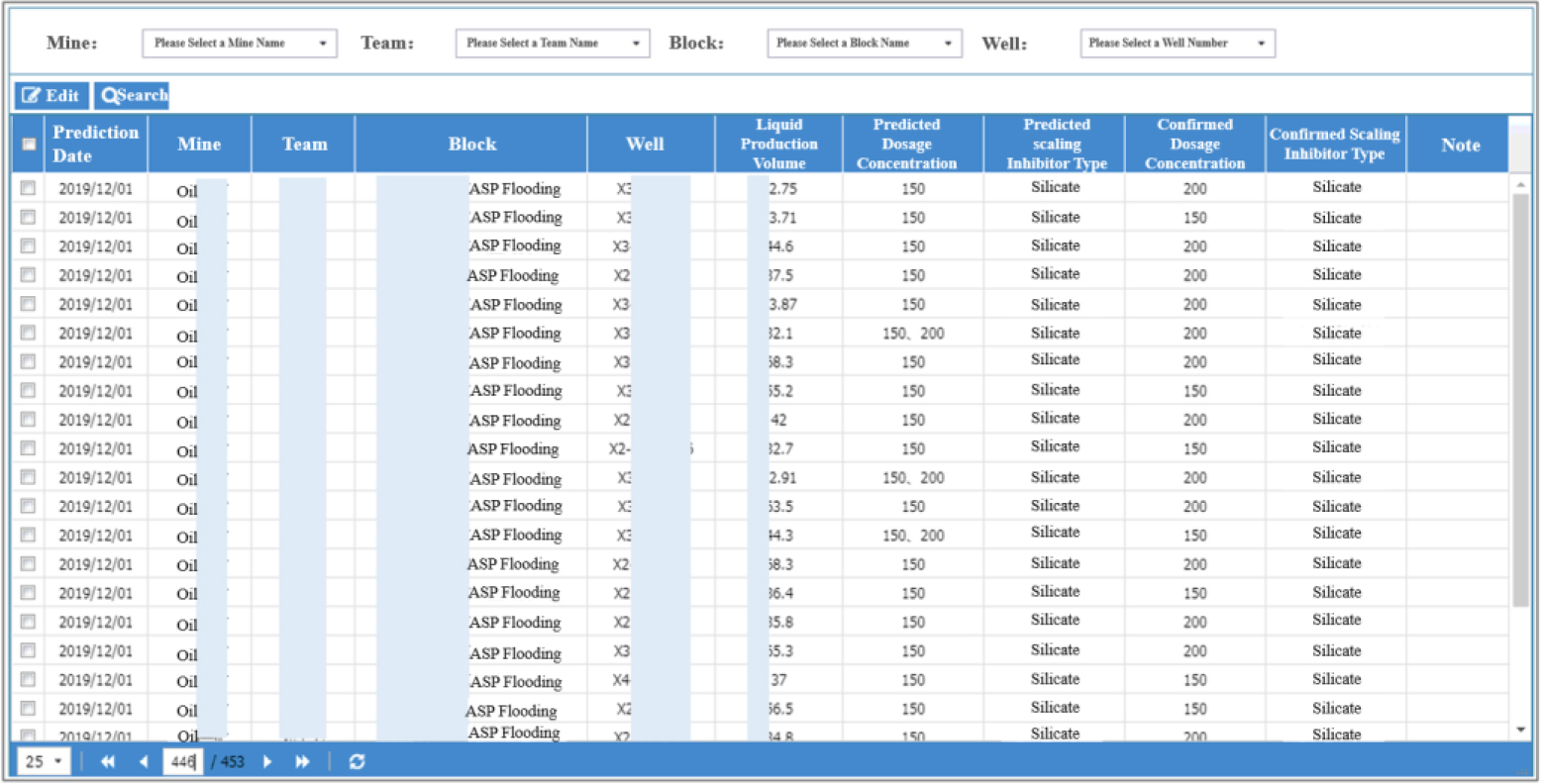
By referring to the theoretical implementation scheme of the historical scaling inhibitor and combining the data of the previous single dosage and the daily dosage on site, the system judges whether to adjust the daily dosage on site and the type of the agent, as shown in Fig. 9.
Adjustment of wellhead dosing scheme for SP-SCS.
The design of the intelligent system has essentially changed the working mode and task of the field staff. The working mode has changed from relying on artificial experience to relying on intelligent training and learning. Workers ’ tasks have changed from original analysis and customization to assistance and correction. The real fouling prediction workflow after the application of the intelligent system is shown in Fig. 10.
Firstly, the SP-DIS system realizes the analysis of laboratory data. The data analyst only needs to check and correct the output data and push it to the SP-SCS system. Secondly, the scaling predictor uses the SP-OBKMS system to realize the entry of scaling prediction experience knowledge, and push the relevant data to the SP-SCS system. Finally, to the SP-SCS system to achieve scaling prediction, cleaning and anti-scaling scheme configuration and other comprehensive analysis, scaling forecasters and pharmacists only need to test and correct the generated results, through the operation of SP-OBKMS, SP-DIS, SP-SCS three subsystems, to achieve the final scaling prediction and related work. This reduces the workload of scaling prediction staff.
Application effect analysis
In order to verify the effectiveness of the proposed model and system, the operation data of the northern development area of the Xingshugang Oilfield are selected as experimental materials. According to the requirements of the training model, the experimental samples are divided into training samples and test samples. The three subsystems, SP-OBKMS, SP-DIS, and SP-SCS, obtain the results of feature selection, classifier construction, and time series prediction mining through the training samples and verify the effectiveness of the system through the test samples.
(1) Experimental samples and experimental environment
Select the production operation data, ion assay data, and dosing program data as experimental data.
The database server is a SUN 7300 workstation; the maximum
The experimental environment is Windows Server 2008R2, CPU 3.5GHz, memory 8GB, 64-bit operating system. The training experiment was carried out using Matlab2018b.
(2) Selection of experimental sample data
238 production wells in a small team in the northern development zone of Xingshugang Oilfield are selected as the research objects. It has been more than 50 years since Xingshugang northern development zone was established in 1966. The main reason for selecting this site as the test area is that the ASP flooding technology has been applied for a long time in Xingbei, and a large number of reliable original data have been retained in the application process. At the same time, the geological characteristics, scaling mechanism and scaling prediction data model of the test area are representative in the field of tertiary oil recovery, and the well condition is in good condition, which is convenient for experimental comparison and evaluation.
According to the time domain range of the samples, the experimental data in the process of constructing the time series prediction model contains 20099 data objects, of which 14070 objects are used as training data and 6017 objects are used as test data. The data of six months from December 2022 were selected as the validation data.
1. UTF8gbsn添加特征筛选和数据处理的过程
In the process of feature screening, firstly, the intuitive useless and associated useless attributes are eliminated, such as the intuitive useless attributes such as well number, oilfield name, block unit, blank attributes and associated attributes such as flow pressure and casing pressure. The experimental data contain 138 conditional attributes and 5 decision attributes. Through the secondary screening of on-site experts, the descriptive attributes such as date format attributes, types, marks, horizons, and layers were eliminated, and 14 attributes that could be used for experiments were finally obtained.
The main characteristics of the classification model include the top depth of reservoir (YCDBS1), Mg
Some training data are shown in Table 1.
Part of training data table
Part of training data table
(3) Application effect analysis
The scaling prediction system of compound flooding is used to select the scaling state features of the training samples and construct the classification model. Finally, the classification model suitable for the training samples is obtained as follows.
The question mark (?) in the model indicates that the ion data is empty. When the feature data is empty, it shows that other features need to be considered.
During the scaling period, according to the law of ion variation, the concentration of calcium and magnesium ions increased first, then decreased, and the concentration of silicon ions increased to over 30 mg/L in the initial stage of scaling. Carbonate scaling made up approximately 55% of scaling, while silicon scaling made up approximately 20%. In that peak period of scaling formation, the concentration of silicon ion is above 100 mg/L, and the concentration of calcium and magnesium ions is below 5 mg/L. The content of carbonate scaling in the scaling is reduce to about 17%, and the content of silicon scaling is increased to more than 65%. In that decay period of scaling formation, when the concentration of silicon ion reach 500 mg/L or more, the concentration of HCO
Statistical table of validation effect of classification model
197 oil wells with real scaling results verified by scaling prediction experts in the first ten days of December 2019 are selected as verification data to verify the accuracy of the classification model. See Table 2 for verification results. Among them, 181 samples were positive, the positive rate was 91.87%. For the 5 wells with leakage, the water cut is between 89.6 and 91.3, so the scaling state cannot be determined. Six wells in 11 wells are misjudged as having data meeting the condition of YCDBS1
pH, Si
The data of 5 wells in the test area are selected as verification data. Taking one single well as an example, the change trend of 6 ions is predicted, as shown in Fig. 10.
Prediction trend of ion variation time series.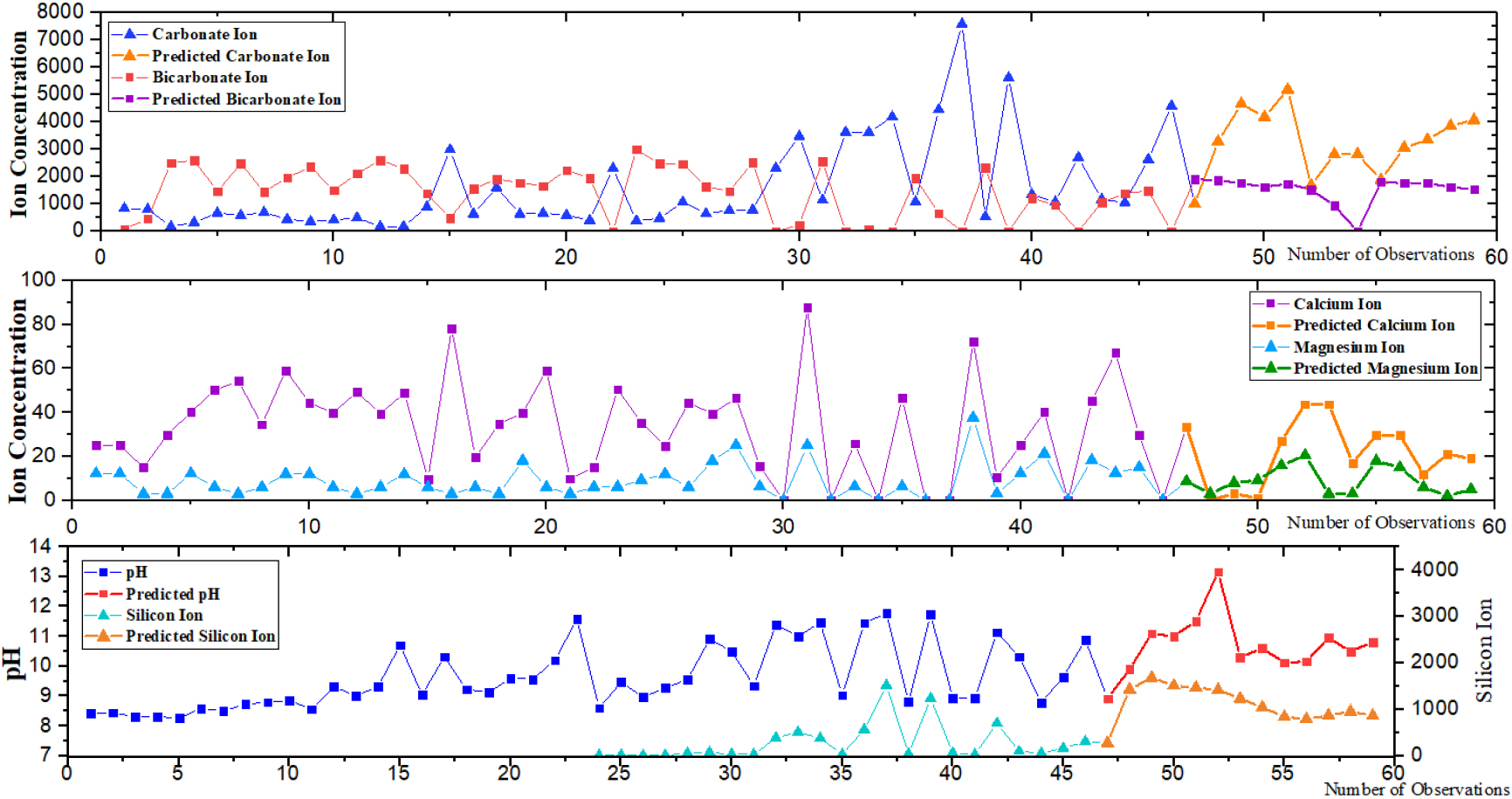
As can be seen from the Figure, the variation trend of the predicted 12 consecutive data is characterized by the rising trend of pH value and Si4
The intelligent scaling prediction model based on data mining is constructed, which can mine important characteristics according to actual geological information and construct a classification model to predict scaling. It has good portability and dynamic updating ability, and provides an intelligent and transferable solution for oilfield production prediction and similar industrial production and development prediction. A prediction system is designed to meet the dynamic demand of scaling, which provides scaling prediction characteristics and scaling prediction classification models suitable for different geological conditions, and realizes intelligent and accurate prediction of scaling state, scaling stage and adopted scaling cleaning and prevention measures. Through field application and expert analysis, the accuracy of scaling prediction reaches 91.87%, which meets the application requirements of real work scenarios.
Footnotes
Funding
This work was supported by the Fundamental Research Funds for the Northeast Petroleum University under Grants 2022QGP-01, by the Fundamental Research Funds for the Daqing Science and Technology Bureau under Grants zd-2021-44, and by the Fundamental Research Funds for the Qinhuangdao Science and Technology Bureau under Grants 202101A226.