
Abstract
Since the outbreak of COVID-19, wearing masks outside has become a daily habit. In view of the current problems of low accuracy and lack of non-standard detection of mask wearing, a detection method for mask wearing based on key points is proposed. First, the YOLOv7_tiny algorithm is used to detect whether the face is wearing a mask, and the resulting ROI (Region of Interest) is scaled to a fixed size. Then, the key point detection algorithm was adopted to extract 68 key points of the face from the ROI region, and the image segmentation of the mask area is performed simultaneously. Finally, the correspondence between face landmarks and the mask area is used to assess whether the mask is worn correctly. The experimental results show that the average detection speed of this method in the natural environment is about 14FPS, the mAP (mean Average Precision) of whether to wear a mask is 66.34%, and the detection accuracy of whether to wear a mask is 96%, which can effectively meet the actual application requirements.
Introduction
Since the outbreak of the COVID-19, human life and health have been threatened at all times, while work and life have also faced great challenges. In order to curb the spread of the epidemic, wearing masks in public has become one of the effective means to prevent the spread of the epidemic [1, 2]. This is not only a civilized habit, but also a legal obligation of citizens. However, there are often behaviors in life that do not wear or do not wear masks in a standardized manner, so measures need to be taken to remind of non-standard behaviors. Relying on manual reminders to standardize the wearing of masks in crowded occasions is not only inefficient, but also takes up a lot of human resources. Therefore, using visual detection equipment instead of manual detection is of great significance for epidemic prevention and control.
Relevant research has been carried out at home and abroad on the detection issue of whether to wear a mask. Currently, relevant detection methods are generally divided into two categories: one is to use mature face detection networks to locate faces, and then perform subsequent processing on the positioning area. For example, Xue et al. used the MTCNN (Multi-task convolutional neural network) face recognition algorithm to locate faces, and used the MobileNet to classify whether faces were wearing masks or not [3]. The other type uses target detection algorithms to directly identify whether a face is wearing a mask. For example, Li et al. used the Fast R-CNN (Region-based Convolutional Neural Networks) target detection network to detect the presence or absence of a mask in AIZOO and FMDD data sets with an accuracy rate of 90% [4]. Guo et al. proposed the YOLOv5 algorithm to detect the presence or absence of a mask in dim conditions, with an accuracy rate of 92% [6]. Yu et al. improved the IoU (Intersection over Union) evaluation index of SSD (Single Shot MultiBox Detector) algorithm and applied it to mask detection tasks, which can meet practical needs [6, 7].
For the above methods, the first type is easily disturbed by obstructions and face localization fails. In the second type of methods, SSD [8] and YOLO [9, 10] belong to a first-stage algorithm, and the target detection task is implemented as a recursive method, with a slightly faster speed. Fast R-CNN [11] belongs to a two-stage target detection algorithm. The first stage is to generate a large number of candidate anchors from the picture, and the second stage is to classify and regress them. Therefore, the real-time performance of the algorithm is poor. During the research process, both types of schemes focused on whether to wear masks, but there is a lack of attention to the standardization of mask wearing [12].
Aiming at the existing problems, this paper proposes a detection method for wearing standardized masks based on key point detection. Firstly, k-means algorithm is used to cluster the existing dataset with a priori box to obtain an appropriate priori box, and YOLOv7-tiny target detection algorithm is trained. YOLOv7_tiny algorithm has excellent performance in accuracy and efficiency, usually dividing target detection into one-stage and two-stage algorithms. The first stage algorithm is represented by the SDD and YOLO series algorithms, and the second stage algorithm is represented by the R-CNN series algorithms. The second stage algorithm usually takes a long time and has high accuracy; The first stage algorithm takes a short time and has slightly lower accuracy, but the YOLO series has surpassed other algorithms in terms of time and accuracy of iteration in this years. In the process, the YOLOv7-tiny algorithm is first used to locate the face and intercept the ROI of the face, and then shrink the ROI to 196
Algorithm flow chart.
YOLO series of algorithms belong to the first-stage target detection algorithms, and their running speed is significantly superior to other algorithms. YOLOv7 is o one of the best performing algorithms in the known object detection algorithm [13]. Its simplified version, YOLOv7-tiny has a faster running speed and can ensure detection accuracy. Therefore, this algorithm is selected to locate the face position.
YOLOv7-tiny network
YOLOv7-tiny network structure.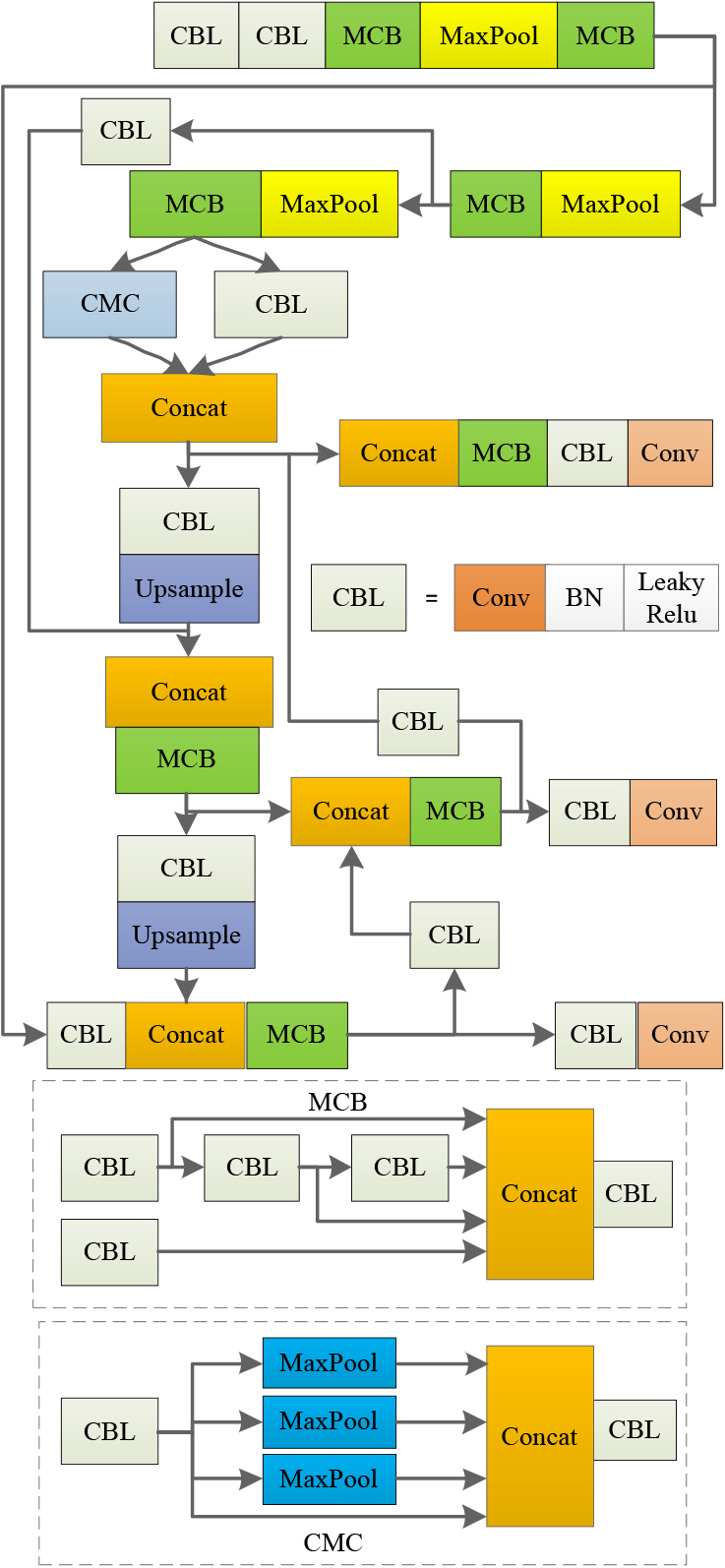
In the YOLOv7-tiny algorithm, various stacking modules (MCBs) are used, that is, multiple convolutional integration branches are stacked into one, so that the network has a denser residual structure. The residual network is easy to optimize and can improve the detection accuracy by increasing the network depth. The use of jump connections in the residual blocks within its network can effectively alleviate the problem of gradient vanishing caused by deep nerves increasing accuracy by increasing depth. The network structure diagram is shown in Fig. 2.
The target detection algorithm relies on a loss function to evaluate the prediction results, which is divided into three parts: coordinates, target confidence, and classification. The target confidence and classification adopt a binary cross entropy function, and the coordinate loss is based on ROI overlap. The YOLOv7-tiny algorithm uses CIOU to evaluate the degree of overlap [14], which adds factors such as center distance and scale to the IOU. The formula is expressed as follows:
Where:
Where:
According to the YOLO series of object detection algorithms, the image to be detected is divided into three scales, with each scale corresponding to three different sizes of prior anchors (boxes). Generally speaking, the more prior anchors (boxes), the higher the accuracy, but the detection time will also increase. Therefore, this inherits the previous version of YOLO and selects 9 prior anchors (boxes) to balance the detection accuracy and speed requirements. At the same time, the prediction grid is expanded adjacent to each other to increase the number of prediction anchors. Assuming that the center point of the real box falls in the fourth quadrant of the grid, a grid is expanded to the right and down respectively, and all three grids are responsible for predicting the current real box. The adjacent expansion diagram is shown in Fig. 3.
Grid for neighborhood expansion.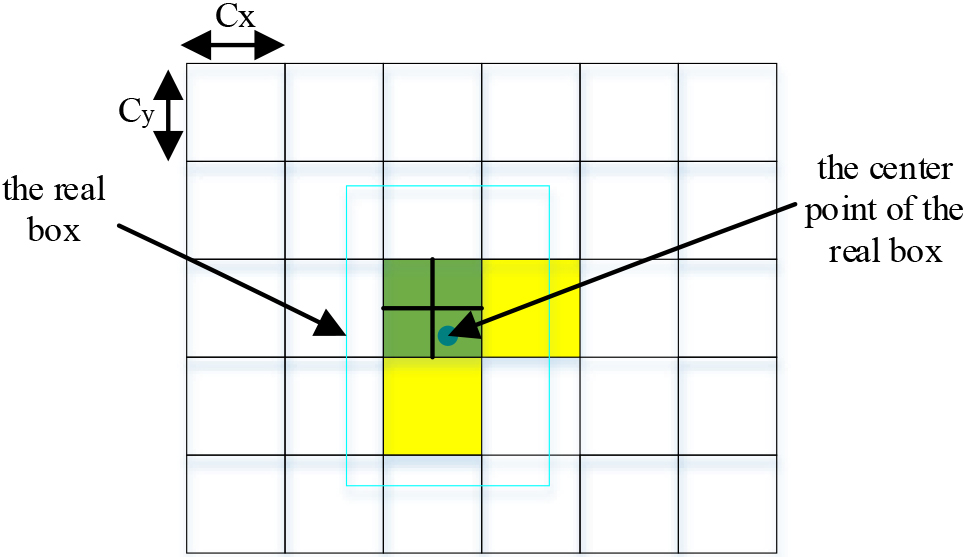
Each effective grid in the above process will produce the same number of prediction anchors (boxes), and then accurately filter the prediction anchors through SimOTA adaptive matching algorithm to obtain a positive sample.
In order to accurately detect whether to wear a mask properly, it is necessary to detect the feature points of the face and segment the image of the face region to obtain the pixels of the mask region. The face ROI intercepted by object detection is scaled to 196
Face key point detection
The facial keypoint localization algorithm in the Dlib library is composed of a cascaded regression tree (ERT) proposed by Vahid Kazemi et al. [15]. Compared with traditional algorithms, ERT algorithm has the advantages of easy construction, fast speed, and the ability to process missing data.
The algorithm gradually approximates the actual position of key points from the rough estimated initial position by establishing a cascaded residual regression tree. Assuming that there is training data
Where:
The Dlib library contains a trained face key point detection model with excellent real-time performance. This paper uses this model to detect 68 key points on faces. The distribution of facial key points is shown in Fig. 4, which divides facial features into 68 points. Among them, points 30–36 belong to nose feature points, points 50–68 belong to lip feature points, points 18–27 belong to eyebrow feature points, and points 37–48 belong to eye feature points.
Face key point distribution map.
In order to accurately obtain the positional relationship between the facial feature points and the mask, a deep learning model PSPNet is used to recognize and segment the mask region. First, feature extraction is extracted from the features, and then the extracted features are pooled at different scales to effectively improve the receptive field of each pixel. During the feature extraction process, replacing the original ResNet50 network with the faster MobileNetV2 to improve its real-time detection performance [17]. The core of the PSPNet network is the PSP module [18], which adopts a pyramid pooling structure to enhance feature extraction. The PSP module divides the input feature layers into 6
Schematic diagram of PSPnet semantic segmentation network.
The dataset is provided by the ROI intercepted by the target detection algorithm. During the training process, the initial learning rate is set to 0.01, and the minimum learning rate is 0.0001. The learning rate decreases by cosine annealing attenuation. The optimizer adopts SGD. After 300 iterations of training, the final loss value stays at around 0.012 and does not decrease. At this point, the training is completed.
In this paper, algorithms such as YOLOv7-tiny, PSPNet, and facial feature point detection are integrated to identify and detect whether a mask is worn properly, and algorithm comparison experiments are conducted.
Experimental environment: computer (i5-9300H processor, 12G memory, NVIDIA GTX1650 graphics card); The operating system is Windows 10; Deep learning framework Python 1.8; The dataset is a self-made dataset with a total of 1600 images.
Target detection results
According to the 9 prior anchors (boxes) of the YOLOv7 tiny algorithm, 1600 datasets were clustered to make them more in line with facial proportions. The k-means algorithm is used for clustering. According to the results of the cluster center, the small sizes are [6, 12], [8, 17], [11, 23]; The middle size are [17, 34,], [25, 51], [38, 76]; The large sizes are [67, 66], [67, 128], [143, 150]. The clustering result graph is shown in Fig. 6.
Schematic diagram of k-means clustering results.
mAP and the iteration count curve.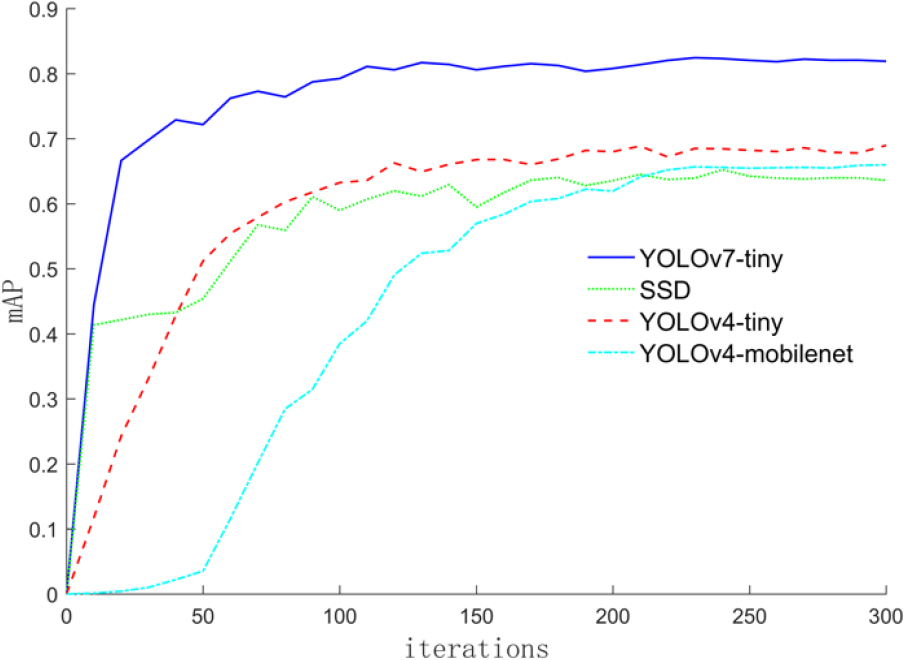
The 1600 image datasets were manually annotated using the LabelImg tool. The dataset is divided into three categories: The noMask who do not wear mask, The mask who wear mask, and The shelter who wear mask with large areas of occlusion. Among them, those who do not wear masks and those with large areas of occlusion do not enter the normative detection process, with 10% for test sets and 90% for training sets.
When training the target detection algorithm, set the initial learning rate to 0.01, used the SGD optimizer, set the momentum parameter to 0.937, and set the attenuation weight to 0.0005, and enabled Mosaic data enhancement to enrich the diversity of the training set. During the training process, The mean average precision (mAP) and Loss values were recorded. The correlation curves between mAP, loss, and iteration times are shown in Figs 7 and 8. The performance comparison of target detection algorithms is shown in Table 1.
Comparison of the results of different algorithms
Loss and the iteration count curve.
YOLOv7_tiny test result heat map.
Mask standardized wear testing diagram.
From Figs 7 and 8, it can be seen that using Method YOLOv7_tiny for target detection has better recognition accuracy in distinguishing whether a mask is worn or not, and the convergence speed of Loss during training is better than other algorithms. After 300 iterations of this algorithm, the final mAP reaches 0.82, and the Loss value decreased to 0.04. It can be seen from Table 1 that using the YOLOv7_ Tiny algorithm mAP is significantly higher than other algorithms, and FPS is slightly lower than YOLOv4_ Tiny algorithm.
In the field of deep learning, thermal maps helped to understand which parts of pixels in a picture participate in neural network decision-making. Three images of unwearing masks, standardized masks and non-standard masks were taken from the test set for testing. The thermal diagram results are shown in Fig. 9.
As can be seen from the thermodynamic diagram in Fig. 9, in YOLOv7_ tiny target detection algorithm, the pixels that play a decision-making role are mainly concentrated in the nose position, so this is also one of the problems that the target detection algorithm cannot robustly distinguish between standard wearing and non-standard wearing masks.
Aiming at the problem that target detection algorithms are difficult to distinguish between standard and non-standard wearing, this paper adopted a method cooperation between face key point detection algorithm and image segmentation algorithm. Based on the position of facial feature points shown in Fig. 4, determine the coverage relationship between feature points 30–36, 50–68, 18–27, 37–48 and the mask area to complete the standardized detection of mask wearing. Among them, feature points 30–36 belong to the nose feature points, 50–68 belong to the lips feature points, 18–27 belong to the eyebrows feature points, and 37–48 belong to the eyes feature points. The detection results are shown in Fig. 10. The top figure a) represents the detection of facial mask wearing without background debris. The middle figure b) represents the detection of facial mask wearing in a living environment. The middle figure c) represents the detection of facial mask wearing in the background of buildings. In the figures, the numbers represent the confidence level obtained during target detection. ‘nomask 0.88’ representing the category of nomask is 88% and the higher the confidence level, the better. Color represents categories, blue represents Nomask categories, and red represents Non Standard and Mask categories.
The experimental results show that the key point of the mask wearing specification detection method is 66.34% in terms of mAP for distinguishing whether a mask is worn or not, and the detection accuracy of whether a mask standardized worn is 96%. Under existing hardware conditions, using a ordinary camera with a frame rate of 30 frames, the detection speed of this algorithm is approximately 14 FPS, with object detection and image segmentation accounting for 80% of the algorithm’s time. This algorithm can meet the standardized detection of masks in crowded situations.
Conclusion
The key point based standardized mask wearing detection method proposed in this paper uses multiple algorithms to cooperate with each other, effectively solving the problem of low attention paid to standardized detection in current mask wearing detection schemes. The experimental results show that the detection accuracy and real-time performance of this detection method can meet actual detection needs, promote epidemic prevention and control and public safety, and provide some references for the detection of whether to standardize mask wearing.
Footnotes
Acknowledgments
This work was supported in part by the “Teacher Professional Development Project” for Domestic Visiting Scholars in Colleges and Universities in 2022 of China under Grant FX2022123.