Data fragmentation has been proposed as a solution for protecting the confidentiality of sensitive associations when releasing data for publishing or external storage. To enrich the utility of data fragments, a recent approach has put forward the idea of complementing a pair of fragments with some (non-precise, hence loose) information on the association between them. Starting from the observation that in presence of multiple fragments the publication of several independent associations between pairs of fragments can cause improper leakage of sensitive information, in this paper we extend loose associations to operate over an arbitrary number of fragments.
We first illustrate how the publication of multiple loose associations between different pairs of fragments can potentially expose sensitive associations, and describe an approach for defining loose associations among an arbitrary set of fragments. We investigate how tuples in fragments can be grouped for producing loose associations so to increase the utility of queries executed over fragments. We then provide a heuristics for performing such a grouping and producing loose associations satisfying a given level of protection for sensitive associations, while achieving utility for queries over different fragments. We also illustrate the result of an extensive experimental effort over both synthetic and real datasets, which shows the efficiency and the enhanced utility provided by our proposal.
The amount of information being published, shared, and/or externally stored or processed in today’s society is growing at an incredible pace everyday. Together with the praise for the benefits and convenience of this scenario, comes however an ever increasing worry about the need to guarantee confidentiality of sensitive information. The problem of protecting confidentiality of sensitive information in these contexts has been receiving much attention by the research and development communities (as well as end users and individuals) and many approaches have been proposed (e.g., [18,25]). An important aspect to be taken into consideration in the development and application of protection techniques for ensuring confidentiality of sensitive information is the need to maintain utility in the data, avoiding their over-protection, where utility encompasses both the availability of certain information as well as the ability to perform queries over the data. While confidentiality can be provided by wrapping data with an encryption layer, query evaluation over encrypted data requires to adopt either indexing techniques (e.g., [5]), or specific encryption approaches such as homomorphic encryption (e.g., [17]), which however provide only limited capabilities for querying (as they support evaluation of only specific conditions). The need to maintain data in the clear to provide better support for queries has been, for example, one of the key observations in the design of solutions relying on fragmentation for protecting sensitive associations in data outsourcing (e.g. [1,8,13]). Fragmentation protects sensitive associations among data by splitting them in different fragments (vertical data views) that are not linkable one to the other. The advantage of fragmentation over data encryption is in fact the ability to query actual data (in contrast to indexes used when data are completely encrypted) and therefore to provide more convenience in terms of data accessibility and query performance. Fragmentation represents also a useful paradigm to enforce protection requirements and to produce different views over data that can be publicly released without the risk of disclosing sensitive information.
Along the same line of enhancing utility, loose associations have been recently proposed as a complement to fragmentation [12,14]. In fact, providing complete protection to sensitive associations can, in many cases, be considered an overdo and smaller protection guarantees (meaning uncertainty over the associations among data) are considered acceptable. Loose associations complement then data fragmentation by providing some information on the association among tuples in different fragments. Intuitively, being fragments unlinkable without loose associations, a tuple in a fragment could have, as its corresponding tuple, any tuple in another fragment. Loose associations provide information on the relationships between tuples of different fragments at the granularity of groups of tuples (in contrast to individual tuples) thus maintaining some degree of protection over the association. The original definition of loose associations operates assuming that a fragmentation includes two fragments only and a single loose association is defined between this pair of fragments. A fragmentation may however include an arbitrary number of fragments, and therefore multiple loose associations might need to be defined. The presence of multiple loose associations may unfortunately open the door to privacy breaches. In fact, while the associations released in loose form are protected, the publication of multiple loose associations could indirectly expose other sensitive associations (i.e., a recipient could be able to reconstruct them).
In this paper, we present a general approach to define loose associations that operate on an arbitrary number of fragments. With our approach, the data owner can specify multiple associations among different pairs of fragments with the assurance that their combination cannot introduce leakages. Also, it allows specifying loose associations involving more than two fragments. Our approach is based on the definition of a universal loose association, encompassing all the fragments and all the confidentiality constraints. Any projection of this universal loose association (including the complete association itself) provides a loose association involving a different subset of fragments and is guaranteed to maintain the aimed degree of protection to the sensitive associations. In [12] we presented an early version of our proposal that here is extended by introducing an approach that takes into account queries to be executed so to build loose associations that enhance utility for them. We then provide a heuristic algorithm for the computation of a loose association, and present the results of an extensive experimental analysis over synthetic and real datasets aimed at evaluating the efficiency, efficacy, and scalability of our algorithm, as well as the utility of the computed loose association.
The remainder of this paper is organized as follows. Section 2 introduces the basic concepts on which our approach builds. Section 3 illustrates the privacy risks caused by the release of multiple loose associations. Section 4 presents our definition of loose association, taking into account an arbitrary number of fragments. This section also introduces the properties that need to be guaranteed to ensure that a loose association satisfies a given privacy degree, and provides some observations on loose associations. Section 5 discusses the utility of loose associations in terms of providing better response to queries. Section 6 illustrates a heuristic algorithm for the computation of a loose association. Section 7 presents our experimental analysis, on synthetic as well as on real datasets, showing the efficiency of our approach and the utility provided in query execution. Section 8 discusses related work. Finally, Section 9 concludes the paper.
Basic concepts
We consider a scenario where a data owner wishes to release her data for publication or external storage. Data, represented for convenience as a single relation s over relational schema , are subject to confidentiality constraints stating that certain information (individual attributes or associations among them) is to be considered sensitive and should therefore not be disclosed. A confidentiality constraint is formally defined as follows [1,8].
(Confidentiality constraint).
Given a relation schema , a confidentiality constraint c over S is a subset of the attributes in S.
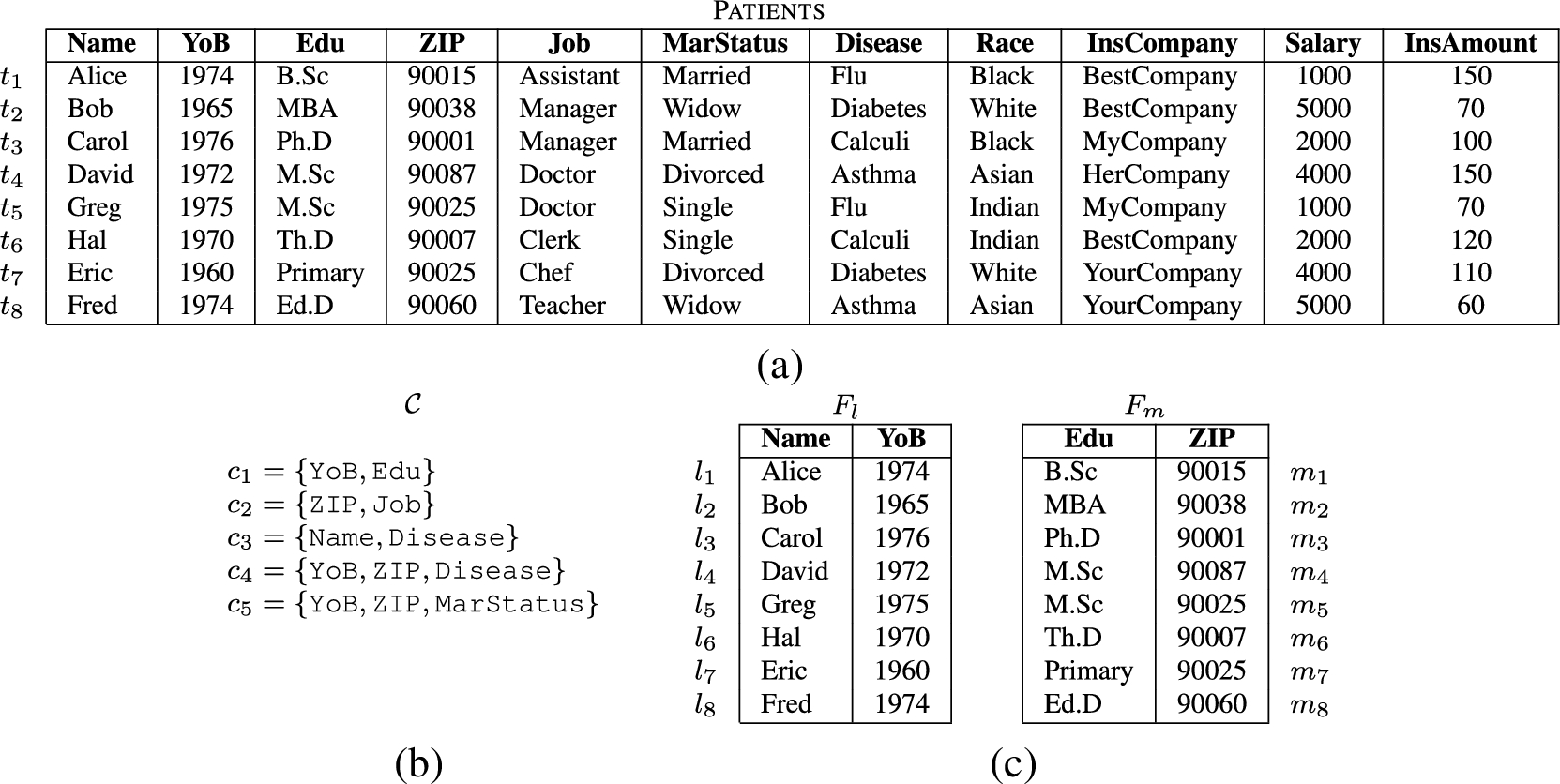
Confidentiality constraints are enforced before release by avoiding disclosure of sensitive attributes (singleton constraints), and fragmenting the relation into vertical views so to break sensitive attribute associations (non-singleton constraints). Note that non-singleton constraints can also be enforced by non-releasing a subset of the attributes in the constraint. At the schema level, fragmentation splits then S into a set of fragments. Each corresponds, at the instance level, to the vertical view obtained projecting s over . Given a fragmentation , sensitive information modeled by a set of confidentiality constraints is protected by ensuring that: (i) no individual fragment contains all the attributes involved in a confidentiality constraint (i.e., , ); and (ii) fragments are disjoint (i.e., , : ). We assume data to be fragmented no more than necessary to satisfy the constraints, and therefore fragmentations to be minimal, that is, merging any two fragments would violate at least one constraint. Figure 1 illustrates an example of relation to be released, of confidentiality constraints over it, and of a fragmentation satisfying the constraints. Note that fragments could cover either all the attributes that are not sensitive by themselves (i.e., not appearing in singleton confidentiality constraints) or only a subset of them, as in Fig. 1(c). In this paper, we do not impose any requirement on this, as our model is independent from such an assumption.
An example of relation (a), a set of confidentiality constraints over it (b), and a fragmentation that satisfies the confidentiality constraints in (c).
Fragmentation completely breaks the associations among attributes appearing in different fragments. In fact, since attributes are assumed to be independent,2
We maintain such an assumption of the original proposal to not complicate the treatment with aspects not related to loose associations. Dependencies among attributes can be taken into consideration simply by extending the requirement of unlinkability among fragments to include the consideration of such dependencies (for more details, see [13]).
any tuple appearing in a fragment could have, as its corresponding part, any other tuple appearing in another fragment. In some cases, such protection can be an overkill and a lower uncertainty on the association could instead be preferred, to mitigate information loss. A way to achieve this consists in publishing an association among tuples in fragments at the level of groups of tuples (in contrast to individual tuples), where the cardinality of the groups impacts the uncertainty over the association, which therefore remains loose. Hence, group associations are based on grouping of tuples in fragments, as follows.
(k-grouping).
Given a fragment , its instance , and a set of group identifiers, a k-grouping function over is a surjective function such that .
A group association is the association among groups, induced by the grouping enforced in fragments. Looseness is defined with respect to a degree k of protection corresponding to the uncertainty of the association among tuples in groups within the fragments (or, more correctly, among values of attributes involved in confidentiality constraints whose attributes appear in the fragments). Group associations have been introduced in [14] and defined over a pair of fragments. Given two fragment instances, and , and a ()-grouping over them (meaning a -grouping over and a -grouping over ) group association contains a pair , for each tuple .
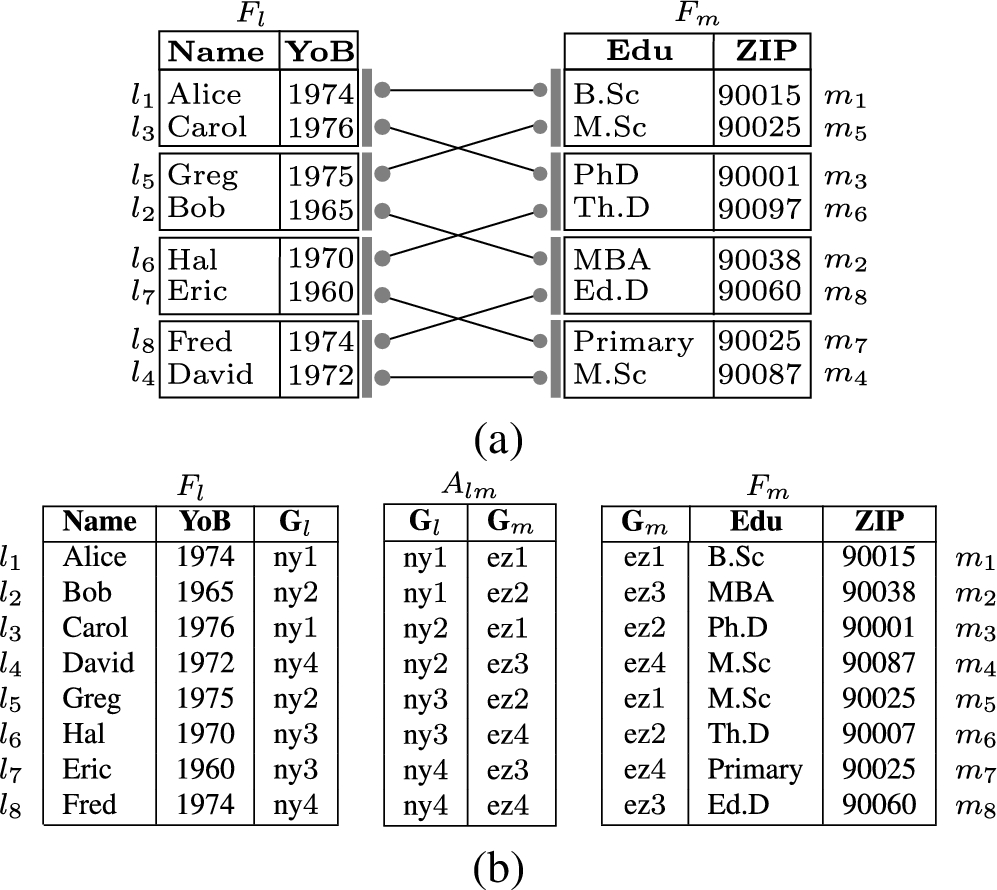
Figure 2(a) illustrates a -grouping over fragments and in Fig. 1(c), and the induced group association over them. The group association, graphically represented by the edges among the rectangles corresponding to groups of tuples in Fig. 2(a), is released as a table containing the pairs of group identifiers in and by complementing fragments with a column reporting the identifier of the group to which each tuple belongs (Fig. 2(b)). In the following, for simplicity, given a tuple t in the original relation, we denote with l (m, respectively) tuple (, respectively) in fragment (, respectively).
Graphical representation (a) and corresponding relations (b) of a 4-loose association between fragments and in Fig. 1(c).
The degree of looseness guaranteed by a group association depends on the uncertainty given not only by the cardinality of the groups, but also by the association among attribute values for those attributes appearing together in a confidentiality constraint c that is covered by the fragments (i.e., ). For instance, a looseness of for the association in Fig. 2 ensures that for each value of there are at least different values for , for each confidentiality constraint c covered by and . If the ()-grouping satisfies the heterogeneity properties given in [14], the association among the fragments is ensured to be k-loose with . These heterogeneity properties demand diversity in the definition of the group association (i.e., no two groups can be associated more than once), as well as in the values of attributes that appear in a confidentiality constraint for those tuples that belong to the same group (in either or ), or to groups in (, respectively) that are associated with the same group in (, respectively).
Note that the release of a group association between and may only put at risk constraints whose attributes are all contained in the fragments (i.e., all confidentiality constraints c such that ). For instance, the association in Fig. 2 may put at risk only the sensitive association modeled by confidentiality constraint , and satisfies k-looseness for (and therefore also for any lower k). In fact, any value of is associated with at least (exactly, in this case) four different values of and vice versa.
Problem statement
The proposal in [14] supports group associations between pairs of fragments. Given a generic fragmentation composed of an arbitrary number of fragments, different group associations can be published on different fragments pairs. A simple example shows how such a publication, while guaranteeing protection of the specific associations released in loose form, can however expose other sensitive associations.
Graphical representation (a) and corresponding relations (b) of a 4-loose association between and , and a 4-loose association between and , with , and three fragments of relation Patients in Fig. 1(a).
Consider the example in Fig. 3, where relation Patients in Fig. 1(a) has been split into three fragments , and . The -grouping over and , and the -grouping over and induce two 4-loose group associations: between and , and between and , respectively. The looseness of guarantees protection with respect to constraint , covered by and , ensuring that for each value of YoB in the group association provides at least four possible values of Edu in (and vice versa). The looseness of guarantees protection with respect to constraint , covered by and , ensuring that for each value of ZIP in the group association provides at least four possible values of Job in (and vice versa). This independent definition of the two associations does not take into consideration constraints expressing sensitive associations among attributes that are not covered by the pairs of fragments on which a group association is specified (, and in our example), which can then be exposed. Consider, for example, constraint . Alice (tuple in ) is mapped to group ny1 which is associated by with groups ez11 and ez12, that is, tuples , , and in . These tuples are also grouped as ez22 and ez21, associated by with groups jmd1 and jmd2, that is, tuples , , and in . Hence, by combining the information of the two associations, we know that in is associated with one of these four tuples in . While an uncertainty of four is guaranteed with respect to the association among tuples, such an uncertainty is not guaranteed at the level of values, which could then expose sensitive associations. In particular, since the disease in both and is Flu and the disease in both and is Calculi, there are only two possible diseases associated with Alice, each of which has 50% probability of being the real one.
This simple example shows how group associations between pairs of fragments, while guaranteeing protection of the associations between the attributes in each pair of fragments, could indirectly expose other associations, which are not being released in loose form. To counteract this problem, group associations should be specified in a concerted form. In the next section, we extend and redefine group associations and the related properties to guarantee a given looseness degree to be enforced over an arbitrary number of associations and fragments.
Loose associations
Our approach to ensure that the publication of different associations does not cause improper leakage is based on the definition of a single loose association encompassing all the fragments on which the data owner wishes to specify associations so to take into account all the confidentiality constraints. Any projection over this “universal” group association will then produce different group associations, over any arbitrary number of fragments, which are not exposed to linking attacks such as the one illustrated in the previous section.
k-Looseness
We start by identifying the constraints that are potentially exposed by the release of group associations involving a set of fragments, as follows.
(Relevant constraints).
Given a set of fragments and a set of confidentiality constraints, the set of relevant constraints for is defined as .
Intuitively, the constraints relevant for a set of fragments are all those constraints covered by the fragments (i.e., all confidentiality constraints that are a subset of the union of the fragments). For instance, the only constraint among those reported in Fig. 1(b) that is relevant for the set of fragments in Fig. 1(c) is ; all constraints are instead relevant for the set of fragments in Fig. 3.
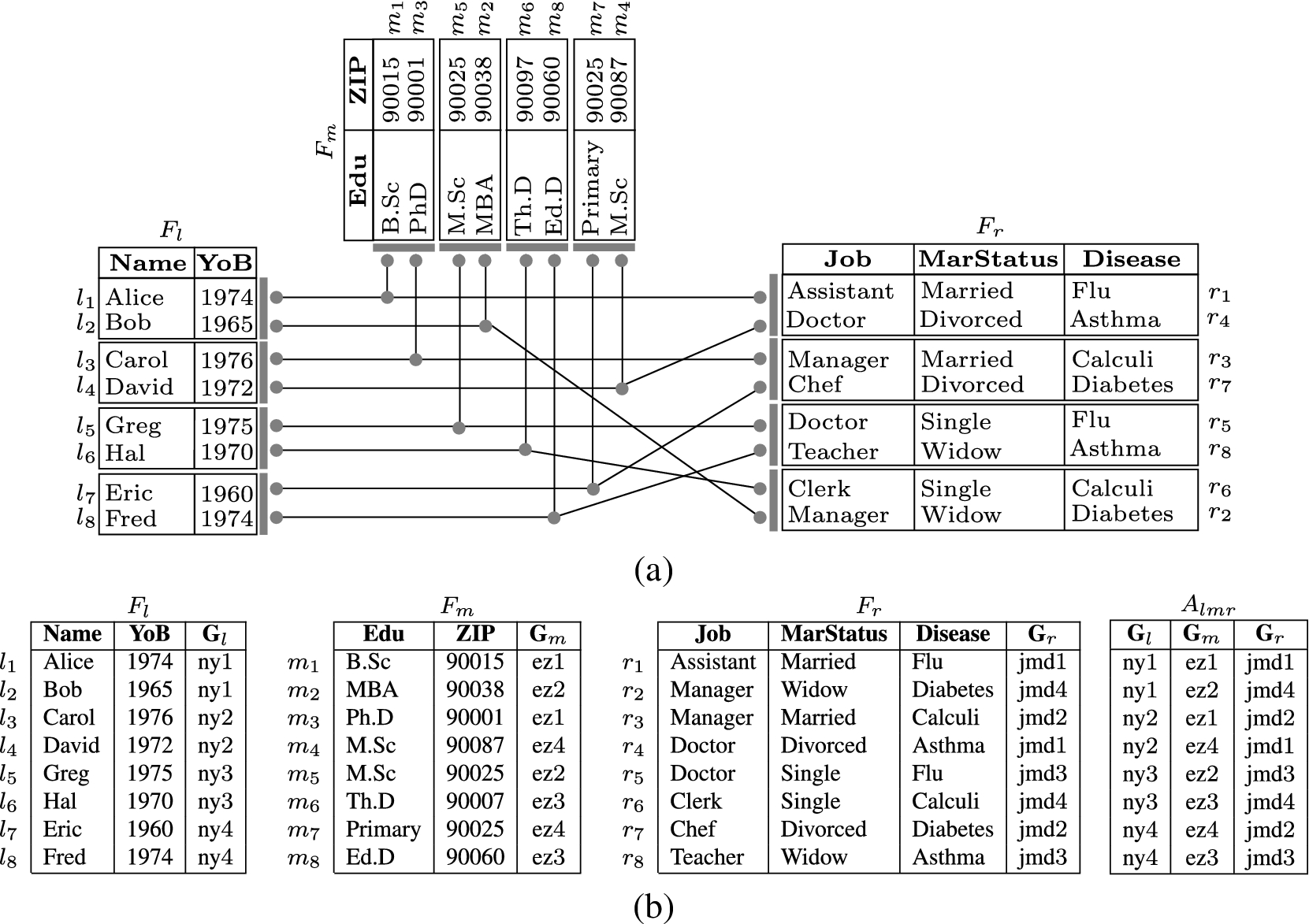
Graphical representation (a) and corresponding relations (b) of a 4-loose association among three fragments , and of relation Patients in Fig. 1(a).
The definition of a group association over different fragments is a natural extension of the case with two fragments, where the association is induced by groupings enforced within the different fragments. The consideration of the universal group association implies that only one grouping is applied within each fragment. Hence, given a fragmentation , a -grouping is a set of grouping functions defined over fragments (i.e., a set of -groupings over , ). Figure 4 illustrates a -grouping over fragments , and of relation Patients in Fig. 1(a), and the induced group association .
Like for the case of two fragments, a group association permits to establish relationships among the tuples in the different fragments, while maintaining the uncertainty on which tuple in each fragment is actually associated with each tuple in another fragment. Such an uncertainty is given by the cardinality of the groups. The reconstruction made available by a group association, and obtained as the joins of the fragments in and A, generates in fact all possible combinations among the tuples of associated groups. Let us denote with such a join. Guaranteeing k-looseness for the sensitive associations represented by relevant constraints requires ensuring that the reconstruction of tuples, made possible by the association among groups, is such that: for each constraint c relevant for and for each fragment F, there are at least k tuples in such that, if , then . The k-looseness requirement must then take into consideration not only the number of tuples in other fragments with which a tuple can be associated but also the diversity of their values for the attributes involved in confidentiality constraints. In fact, different tuples that have the same values for these attributes do not provide the diversity needed to ensure k-looseness. We then start by identifying these tuples as follows.
(Alike).
Given a fragmentation with its instance , and the set of confidentiality constraints relevant for , tuples , , are said to be alike with respect to a constraint , denoted , iff and . Two tuples are said to be alike with respect to a set of relevant constraints, denoted , if they are alike with respect to at least one constraint .
According to this definition, given a fragmentation , two tuples in a fragment instance of fragment are alike if they have the same values for the attributes in at least one constraint relevant for . For instance, with reference to the fragments in Fig. 4, as . Since we are interested in evaluating the alike relationship with respect to the set of relevant constraints, in the following we omit the subscript of the alike relationship whenever clear from the context (i.e., we write instead of ).
Based on the definition of relevant constraints and alike relationship, we can now define k-looseness of a group association. Intuitively, a group association A is k-loose if, for each relevant constraint , each tuple in A represents at least k associations among sub-tuples in fragments including attributes in c, and these associations correspond to at least k different combinations of values of the attributes in c. In other words, represents k tuples that may belong to the original relation and that are not alike with respect to c. Formally, k-looseness is defined as follows.
(k-looseness).
Given a fragmentation with its instance , the set of confidentiality constraints relevant for , and a group association A over , A is said to be k-loose with respect to iff , let , and let with and , , , .
As an example, consider the group association in Fig. 4 and confidentiality constraint in Fig. 1. The first tuple in represents 8 possible associations among sub-tuples in , and (i.e., any possible combination of tuples from sets , and ). These associations correspond to the following 8 possible combinations of values of attributes YoB, ZIP and MarStatus that may belong to the original relation: ⟨1974, 90015, Married⟩, ⟨1974, 90015, Divorced⟩, ⟨1974, 90001, Married⟩, ⟨1974, 90001, Divorced⟩, ⟨1965, 90015, Married⟩, ⟨1965, 90015, Divorced⟩, ⟨1965, 90001, Married⟩, ⟨1965, 90001, Divorced⟩.
k-looseness guarantees that none of the sensitive associations represented by relevant constraints can be reconstructed with confidence higher than . Figure 4 illustrates a fragmentation of the relation in Fig. 1(a) and a group association that guarantees 4-looseness for the sensitive associations expressed by the confidentiality constraints in Fig. 1(b).
Clearly, there is a correspondence between the size of the groupings and the k-looseness of the association induced by them. Trivially, a -grouping cannot provide k-looseness for a . Consider a constraint c, which includes attributes in and only. The -grouping can provide uncertainty over the associations existing among the attributes in c for a . Indeed, any tuple in is associated with at least tuples in , which have different values for the attributes in c if groups are properly defined. With reference to the group association in Fig. 4, the sensitive association represented by constraint enjoys a k-looseness of four: each value of can be indistinguishably associated with at least four possible values of and vice versa. A constraint c involving more than two fragments may enjoy higher protection from the same -grouping. Considering the example in Fig. 4, the sensitive association expressed by constraint enjoys a k-looseness of eight: for each value of there are at least eight possible different pairs of (); for each value of there are at least eight possible different pairs of (); and for each value of there are at least eight possible different pairs of (). For instance, value 1965 for attribute YoB can be associated with ⟨90015, Married⟩, ⟨90015, Divorced⟩, ⟨90001, Divorced⟩, ⟨90001, Married⟩, ⟨90038, Widow⟩, ⟨90038, Single⟩, ⟨90025, Widow⟩, ⟨90025, Single⟩. Since we consider minimal fragmentations, for each pair of fragments , in there exists at least a confidentiality constraint c relevant for and only (i.e., , , s.t. , Theorem A.2 in [14]), which enjoys a k-looseness of . Hence, a -grouping can ensure k-looseness with for the constraints in . Whether the -grouping provides k-looseness for lower values of k depends on how the groups are defined. In the following, we introduce three heterogeneity properties of grouping (revising and extending those provided in [14]) whose satisfaction ensures k-looseness for .
Heterogeneity properties
The heterogeneity properties ensure diversity of the induced associations, which are defined as sensitive by confidentiality constraints. They operate at three different levels: groupings, group associations, and value associations.
The first property we introduce is group heterogeneity, which ensures diversity within each group by imposing that groups in a fragment do not include tuples with the same values for the attributes in relevant constraints. In this way, the minimum size of the groups in fragment , , reflects the minimum number of different values in the group for each subset of attributes that appear together in a relevant constraint.
(Group heterogeneity).
Given a fragmentation with its instance , and the set of confidentiality constraints relevant for , grouping functions over , , satisfy group heterogeneity iff with .
This property is a straightforward extension of the one operating on two fragments, as its enforcement is local to each individual fragment to take into account all constraints relevant for (not only those relevant for a pair). For instance, in Fig. 4 the grouping functions of the three fragments satisfy group heterogeneity for while the grouping function of fragment in Fig. 5(a) violates it with respect to confidentiality constraint . In fact, fragment instance includes a group with tuples assuming the same value for attribute (i.e., Diabetes).
Examples of violations of heterogeneity properties with respect to constraint .
The second property we introduce is association heterogeneity, which imposes diversity in the group association. For a group association A between two fragments, this property requires that A does not include duplicate tuples, that is, at most one association can exist between each pair of groups of the two fragments. By considering the more general case of a group association among an arbitrary number of fragments, this property requires that, for each constraint c in , each group in a fragment such that appears in at least k tuples in A that differ at least in the group of one of the fragments storing attributes in c (i.e., ). In other words, the association heterogeneity property implies that A cannot have two tuples with the same group identifier for all attributes , corresponding to fragments storing attributes that appear in a constraint. Since we consider minimal fragmentations, there exists at least one relevant constraint for each pair of fragments in . Therefore, a group association A satisfies the association heterogeneity property if it does not have two tuples with the same group identifier for any pair of group attributes , , , and .
(Association heterogeneity).
A group association A satisfies association heterogeneity iff , such that , and .
Figure 4 illustrates a group association that satisfies the association heterogeneity property, while the group association in Fig. 5(b) violates it since a group of fragment is associated twice with a group in fragment .
The third property we introduce is deep heterogeneity, which captures the need of guaranteeing diversity in the associations of values behind the groups. Considering a pair of fragments and , deep heterogeneity requires that a group in be associated with groups in that do not include duplicated values for the attributes in a constraint (i.e., tuples are not alike with respect to c). In fact, if the groups in with which a group in is associated contain alike tuples with respect to c, the corresponding tuples do not contain different values for the attributes in c, meaning that the group association offers less protection than expected. For instance, groups jmd1 and jmd3 in Fig. 4 have the same values for attribute (i.e., Flu and Asthma). Therefore, a group in cannot be associated with both jmd1 and jmd3 because of constraint (otherwise, the association between and would be 2-loose instead of 4-loose). Considering the more general case of a group association among an arbitrary number of fragments, and a constraint c composed of attributes stored in fragments , deep heterogeneity requires a group () be associated with groups in that do not permit to reconstruct (via the loose join ) possible semi-tuples that have the same values for all the attributes in c. Note that deep heterogeneity does not require diversity over all the fragments storing the attributes composing a constraint, since this condition would be more restrictive than necessary to guarantee k-looseness. In fact, it is sufficient, for each tuple in a fragment , to break the association with one of the fragments (, ) storing the attributes in c. For instance, with reference to the example in Fig. 4, it is sufficient that each group in be associated with groups of non-alike tuples in either or to guarantee a 4-looseness for the sensitive association modeled by . The deep heterogeneity property is formally defined as follows.
(Deep heterogeneity).
Given a fragmentation with its instance , and the set of constraints relevant for , a group association A over satisfies deep heterogeneity iff ; , ; , the following condition is satisfied: , .
Given a constraint c whose attributes appear in fragments , deep heterogeneity is satisfied with respect to c if no two tuples t, in A that have the same group in are associated with groups that include alike tuples with respect to c for all the fragments , and . This property must be true for all the groups in each fragment. This guarantees that, for each constraint, no sensitive association can be reconstructed with confidence higher than . An example of group association that satisfies deep heterogeneity is illustrated in Fig. 4. Note that deep heterogeneity is satisfied even though the two tuples in group ny2 for are associated with groups jmd1 and jmd2 in , which include tuples and . In fact, constraint is not covered by and but by the three fragments all together, and heterogeneity of the associations in which and ( and , respectively) are involved is provided by the tuples in . Figure 5(c) illustrates an example of violation of the deep heterogeneity property with respect to confidentiality constraint . In fact, the groups in the instances and with which a group in is associated include tuples that are alike with respect to confidentiality constraint (i.e., two tuples in have the same value for attribute ZIP and two tuples in have the same value for attribute Disease), clearly reducing the protection offered by the association. In fact, the tuples that can be reconstructed by joining these two groups in and include occurrences of the same values for the attributes in (i.e., and ). Hence, the association , and holds with probability higher than .
If the three properties above are satisfied by a -grouping and its induced group association, then the group association is k-loose for any , as stated by the following theorem.
Given a fragmentationwith its instance, the setof constraints relevant for, and a-grouping that satisfies Properties4.4–4.6, the group association A induced by the-grouping is k-loose with respect to(Definition4.3) for each.
(Sketch). To assess the protection offered by the release of a -grouping that satisfies Properties 4.4–4.6, we first analyze the protection provided to the sensitive association represented by an arbitrary confidentiality constraint c in .
By Definition 2.2, each group contains at least tuples, . Each group appears in at least tuples in A, each associating to a different group in , for each fragment in by Property 4.5. Hence, each is associated with at least different groups in , , . Each tuple in A having has at least (with , ) occurrences in the join . Let us denote with the tuples in of the occurrences of a tuple in A. Tuples in are not alike with respect to c. In fact, by Properties 4.4, each group in is composed of at least tuples that are not alike with respect to c, such that . By Property 4.6, for each pair of tuples , in A with , the tuples in are not alike with respect to c. Hence, has at least tuples, all with , that are note alike with respect to c.
Then, a -grouping satisfying Properties 4.4–4.6 induces a group association that is k-loose with respect to c for each k, such that .
Since we consider minimal fragmentations only, for each pair of fragments , in there exists at least a confidentiality constraint c that is relevant for and only. Hence, the -grouping satisfying Properties 4.4–4.6 induces a group association that is k-loose with between and (i.e., it guarantees a protection degree to the constraints relevant for and ).
We can then conclude that the -grouping satisfying Properties 4.4–4.6 induces a group association that is k-loose with respect to for each . □
We note that the protection degree offered by a -grouping that satisfies Properties 4.4–4.6 may be different (but not less than k) for each confidentiality constraint c in . Indeed, the protection degree for a constraint c is .
Some observations on k-looseness
The consideration of all the constraints relevant for the fragments involved in a group association guarantees that no sensitive association can be reconstructed with a probability greater than . For instance, confidentiality constraint is properly protected, for a looseness of 4, by the group association in Fig. 4 while, as already illustrated in Section 3, the two group associations in Fig. 3 grant only a 2-looseness protection to it.
Given a k-loose association A among a set of fragments, the release of this loose association is equivalent to the release of , with , k-loose associations (one for each subset of fragments in ). Indeed, the projection over a subset of attributes in A represents a k-loose association for the fragments corresponding to the projected group of attributes. This is formally captured by the following observation.
Given a fragmentation , a subset of , and a k-loose association over , group association is a k-loose association over .
For instance, with respect to the 4-loose association in Fig. 4, the projection of A over attributes and is a 4-loose association between and .
Since a k-loose association defined over a set of fragments guarantees that sensitive associations represented by constraints in be properly protected, the release of multiple loose associations among arbitrary (and possibly overlapping) subsets of fragments in provides the data owner with the same protection guarantee. The data owner can therefore decide to release either one loose association A encompassing all the associations among the fragments in , or a subset of loose associations defined among arbitrary subsets of fragments in by projecting the corresponding attributes from A. This is formally captured by the following observation.
Given a fragmentation and a k-loose association over it, the release of an arbitrary set of k-loose associations , with , provides at least the same protection guarantees as the release of A.
For instance, the data owner can decide to release the group associations obtained projecting and from the group association in Fig. 4. This solution does not suffer from the privacy breach illustrated in Section 3, while providing associations between groups of the same size (i.e., the same utility for data recipients).
According to the two observations above, the data owner can release more than one group association among arbitrary subsets of fragments in without causing privacy breaches. Note however that if the group associations of interest operate on disjoint subsets of fragments (i.e., no fragment is involved in more than one group association), they can be defined independently from each other without risks of unintended disclosure of sensitive associations. This is formally captured by the following observation.
Given a fragmentation , and a set of subsets of fragments in , the release of n loose associations , does not expose any sensitive association if , , .
Queries and data utility with loose associations
The reason for publishing group associations among fragments, representing vertical views over the original data, is to provide some (not precise) information on the associations among the tuples in the fragments while ensuring not to expose the sensitive associations defined among their attributes (for which the degree of uncertainty k should be maintained). Group associations then increase the utility of the data released for queries involving different fragments. However, given a set of fragments, different group associations might be defined satisfying a given degree k of looseness to be provided. There are two different issues that have to be properly addressed in the construction of group associations: one is how to select the size of the grouping of each fragment such that the product of any two is equal to or greater than k; and one is how to group tuples within the fragments so to maximize utility.
With respect to the first issue of sizing the groups, there are different possible values of the different that can satisfy the degree k of protection. For instance, for a group association between two fragments, we can use , , and . In the case of multiple fragments, the best utility can be achieved by distributing as much evenly as possible the sizing of the groups, hence imposing on each group a size close to . An uneven distribution would in fact result in an over-protection of the group associations over some of the fragments (a value of looseness much higher than the required k for constraints covered by a subset of the fragments in ). Experiments show that this would lead to a significant reduction in the precision of the queries (see Section 7). For instance, a looseness of 12 over three fragments could be achieved with a -grouping; a solution creating a -grouping would indeed provide the required protection overall but would probably provide little utility for the association between the second and third fragments (whose association would in fact be 144-loose for the constraints that are relevant for the second and third fragment only).
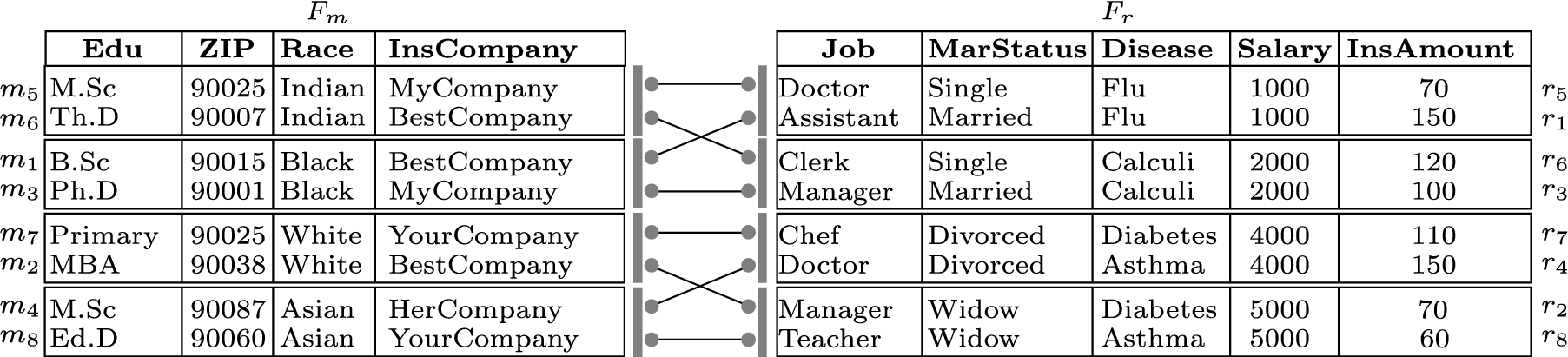
An example of group association between two fragments and of relation Patients in Fig. 1(a) where tuples are grouped taking into account the similarity of the values of attributes Race and Salary.
With respect to the issue of grouping within a fragment, we first note that queries that involve a single fragment (i.e., all the attributes in the query belong to the same fragment) are not affected by fragmentation as they can be answered exactly by querying the fragment. For instance, with respect to the fragments in Fig. 6, query q = “select avg(Salary) from Patients group byJob” involves attributes that belong to fragment only. Hence, the execution of the query over fragment returns exactly the same result as its execution over the original relation Patients in Fig. 1(a). On the following, we focus our discussion on queries that involve two or more fragments, on which a group association is to be defined, with the goal of determining how to group the tuples in fragments so that the induced group associations maximize query utility. In particular, we consider aggregate queries of the form “selectAtt, fromSgroup byAtt”, where are aggregation functions (e.g., count, avg, min, max functions), and as well as set Att (this latter optional in the select clause) are attributes that appear in fragments. For instance, with reference to Fig. 6, query q = “select avg(Salary) from Patients group byRace” aims at computing the average salary grouped by the race of patients. We measure utility of a group association as the average improvement over the accuracy of the results (i.e., with less error) with respect to the results obtained in absence of the group association. Intuitively, utility is obtained as 1 minus the ratio of the average difference with respect to the real values in presence of group associations, and the average difference with respect to the real values in absence of group associations.
The execution of queries over group associations brings in, together with the real tuples on which the query should be executed, all the tuples together with them in their groups and the uncertainty – by definition – of which sub-tuples in a fragment are associated with which sub-tuples in other fragments. Our observation is therefore that groups within fragments should be formed so to contain as much as possible tuples that are similar for the attributes involved in the queries (have close values for continuous attributes). The intuition behind this is that, although the query is evaluated on a possibly larger number of tuples included in the returned groups, such tuples – assuming similar values – maintain the query result within a reasonable error, thus providing utility of the response. The more the attributes involved in the query on which such an observation has been taken into account in the grouping, the better the utility provided by the group association for the query. In fact, similarity of values within groups (even when ensuring diversity of the values) might provide limited uncertainty of values within a group. We therefore expect that not all the attributes involved in confidentiality constraints should be taken into account in this process.
Let us see now an example of queries over our fragmentation involving attributes such that none, some, or all of them have been subject to the observation above in the grouping (i.e., groups include similar values for none of, some of, or all the attributes in the query). Consider the fragments and group association in Fig. 6, computed over relation Patients in Fig. 1(a), where the group association has been produced grouping tuples with similar Race values for fragment and similar Salary values for fragment . We can then see the following three different cases.
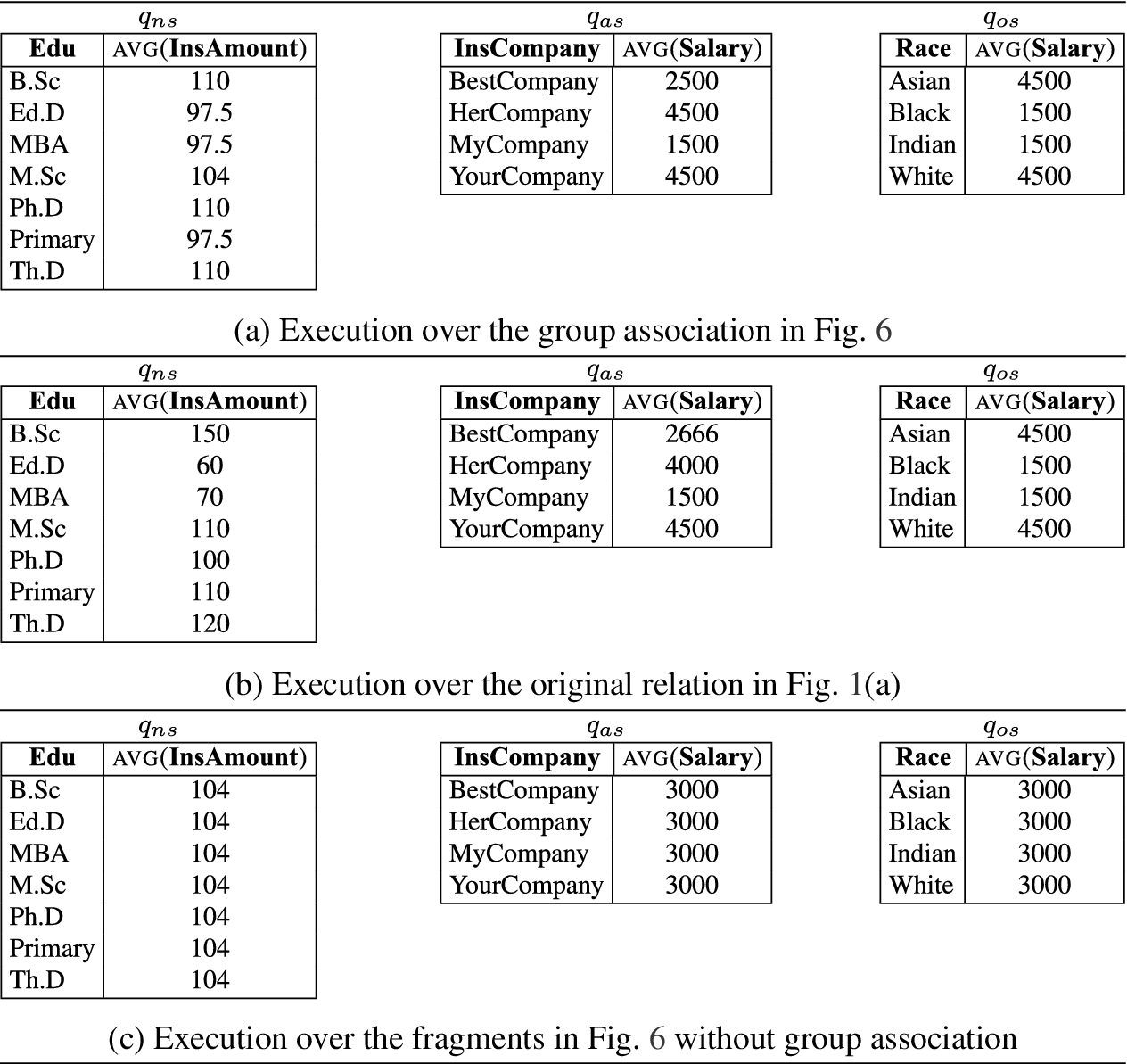
A queryinvolves none of the attributes whose similarity has been considered in the grouping. An example of such a query on the group association in Fig. 6 is = “selectEdu, avg(InsAmount) from Patients group byEdu”, requiring the average insurance amount for the different education levels recorded. In this case, the utility of the association typically remains limited. We note however that the utility for this kind of queries has always been positive in our experimental analysis, reaching values close to 40% for some queries.
A queryinvolves also (but not only) attributes whose similarity has been considered in the grouping. An example of such a query on the group association in Fig. 6 is = “selectInsCompany, avg(Salary) from Patients group byInsCompany,” requiring, for each insurance company, the average salary of insurance holders. Enjoying the fact that the additional tuples involved in the computation will typically have salary close to the values of real tuples, this query provides quite appreciable utility with respect to the real result. As we will discuss in Section 7, utility for queries of this type has typically shown values close to 80% in our experimental evaluation.
A queryinvolves only attributes whose similarity has been considered in the grouping. An example of such a query on the group association in Fig. 6 is = “selectRace, avg(Salary) from Patients group byRace” requiring the average salary of patients grouped by race. This query can benefit from the fact that similarity has been considered for both the attributes involved, which ensures that the additional tuples, brought-in in the evaluation because of the looseness of the association, have values for the involved attributes close to the ones on which the computation would have been executed if the query was performed on the original relation. As we will discuss in Section 7, the utility for this kind of queries is very high, and has typically shown values near 100% in our experimental evaluation.
Figure 7 shows the results of the queries above when executed over the group association in Fig. 6 or over the original relation in Fig. 1(a).
Results of sample queries on a group association (a), on the original relation (b), and on fragments without group association (c) for queries involving none (), some (), or all () of the attributes that have been considered for similarity in the grouping.
Computing a k-loose association
Heuristic algorithm that computes a k-loose association.
Figure 8 illustrates our heuristic algorithm that computes a k-loose association aiming at providing greater utility in query evaluation. The algorithm takes as input a relation s defined over relation schema , a fragmentation and its instance , a set of confidentiality constraints relevant for , privacy parameters , and a set of attributes often involved in the expected queries. The algorithm returns a k-loose association (with ), and the corresponding grouping functions . Intuitively, the algorithm first identifies an optimal group for each tuple – without considering heterogeneity properties – in such a way that each group in a fragment contains tuples with similar values for attributes in . Our solution to identify such an optimal grouping is based on the observation that similarity can be conveniently translated into an ordering of values within the attribute domains. Maximum similarity can in fact be guaranteed by keeping in the same groups elements that are contiguous in the ordered sequence of attribute values. The algorithm first orders tuples in the fragment instances based on their values for attributes in , and then partitions the tuples in groups of size k. In this way, each optimal group will contain k tuples that, thanks to the ordering, have similar values for attributes in . Clearly, different ordering criteria can be applied to different attributes, to properly model the similarity requirement. As an example, for numerical values, we adopt the traditional ⩾ order relationship. The groupings obtained by ordering the tuples according to are optimal with respect to similarity (and hence utility of query responses), but they do not provide any guarantee with respect to the confidentiality of sensitive associations. Optimal groupings are then used by the algorithm to drive the real allocation of tuples to groups: for each fragment, the algorithm tries to assign the tuples to the group closest to the optimal group so that also the heterogeneity properties are satisfied. In the assignment of tuples to groups, the algorithm follows two main criteria: (i) it favors groups close to the optimal group of each tuple; and (ii) it prefers groups of size over larger groups. Our heuristic algorithm implementing this approach is presented in details in the remainder of this section.
The algorithm starts by initializing variable , representing the set of tuples that still need to be allocated to groups, to the tuples in s, and by creating an empty group association A (lines 1–2). The algorithm then operates in four steps as follows.
Step 1: Ordered grouping. For each fragment , the algorithm identifies the optimal grouping, allocating tuples with similar values for the attributes in to the same group(s). To this purpose, the algorithm orders the tuples in s according to the attributes in (line 5). It then partitions the ordered tuples in sets of contiguous tuples each, and assigns to each partition a different group identifier (lines 6–13). In this way, contiguous tuples in the ordered relation are ideally assigned to the same group (or to contiguous groups). The result of this step is a matrix with one row for each tuple t in s, one column for each fragment F in , and where each cell contains the identifier of the optimal group for tuple t in fragment .
Step 2: Under-quota grouping. The algorithm tries to assign each tuple to the group closest to the optimal one that satisfies all the heterogeneity properties, but without generating over-quota groups (i.e., groups in with more than tuples) to maximize utility. In fact, large groups limit the utility that can be obtained in query evaluation. For each tuple t in , the algorithm calls function Find_Assignment in Fig. 9 (lines 15–16), which allocates tuples to groups according to the heterogeneity properties.
Pseudocode of functions Find_Assignment, Try_Assignment and Re_Assign.
Function Find_Assignment receives as input a tuple t, the candidate tuple that represents t in the group association A (which is null when t has not been assigned to any group), a fragment identifier i, a Boolean variable (which is true only if over-quota groups are permitted), and the array computed in Step 1. This function then tries to assign t to a group in close to the optimal one. Function Find_Assignment first checks whether t can be inserted into , that is, it checks whether the heterogeneity properties are satisfied. If the heterogeneity properties are not satisfied, the function checks the groups of fragment , denoted , in increasing order of distance from (lines 3–13). In fact, similar values are ideally assigned by Step 1 to groups close to the optimal one. The satisfaction of the heterogeneity properties is verified by calling function Try_Assignment in Fig. 9 (line 9 and line 13). Function Try_Assignment takes as input tuple t, the candidate tuple that represents t in the group association A, the fragment identifier i, and a group identifier g, and returns true if can be assigned to g; false, otherwise. When a correct assignment of t to a group in is found, if is the last fragment in , function Find_Assignment returns tuple representing the computed assignment of t to groups (lines 14–15). Otherwise, function Find_Assignment recursively calls itself to assign t to a group in fragment (line 16). If the recursive call succeeds (i.e., it returns a group association for t), function Find_Assignment returns ; it tries to allocate t to a group at higher distance from , otherwise (lines 18–19). If t cannot be assigned to any group in , the function returns null (line 20).
If function Find_Assignment returns a tuple , the algorithm inserts into the group association A and removes t from (lines 17–19).
Step 3: Over-quota grouping. If Step 2 could not allocate all the tuples in s, the algorithm tries to allocate the remaining tuples in to the existing groups, thus possibly creating over-quota groups. To this purpose, for each tuple t in , the algorithm calls function Find_Assignment with variable set to true. The algorithm updates A and according to the result returned by function Find_Assignment (lines 20–25).
Step 4: Re-assignment. Once tuples in s (or a subset thereof) have been allocated to groups, the algorithm determines the set of groups generated by Steps 2–3 that are under-quota, that is, the groups that do not include the minimum number of tuples necessary to provide privacy guarantees (line 27). The algorithm then calls function Re_Assign in Fig. 9 (line 28).
Function Re_Assign receives as input the set of non-empty but under-quota groups, and tries to reallocate their tuples to other groups (lines 30–38). Tuples in under-quota groups that cannot be reallocated will be removed from the fragmentation and are inserted into (lines 39–40). When a tuple t is inserted into , the corresponding tuple in A is removed from the group association and, for each fragment , is set to null (lines 44–45). Due to the removal of t, the group to which t belong in loses a tuple and it might become under-quota with the consequence that it should be removed. If this is the case, is inserted into (line 43). Function Re_Assign returns the set of tuples to be removed from the fragmentation (line 46).
The algorithm then deletes from each fragment both the tuples that have never been assigned to groups and the tuples returned by function Re_Assign (lines 29–30).
The utility of the k-loose association computed by this heuristic algorithm as well as its efficiency are evaluated in Section 7.
Coverage, performance and utility
We implemented a prototype, written in Python, of the algorithm described in the previous section, and ran several sets of experiments to the aim of evaluating the ability of our approach to compute a k-loose association, while limiting the number of suppressed tuples (i.e., tuples that cannot be included in any group), and of assessing its performance (Section 7.2). We then analyzed the utility provided in query evaluation (Section 7.3). We now present the experimental setting (Section 7.1) and then discuss the experimental results.
Experimental setting
We considered both synthetic and real-world datasets. Synthetic data allow us to fully control all the parameters used for data generation, such as the variability in the distribution of attributes values, leading to a robust analysis of the behavior of our technique. Real data allow us to assess the applicability of our technique in a concrete setting. Synthetic datasets were generated starting from a relation schema composed of 7 attributes Patients(Name, YoB, Education, ZIP, MarStatus, Disease, Salary), split over two fragments ( and ), to satisfy confidentiality constraints and . The datasets were randomly generated adopting distinct characterizing parameters for each attribute. A statistical correlation was introduced between Salary and Education; all the other attributes were set using independent distributions. This allowed us to have knowledge of information in the protected data that we were interested in retrieving through the query computing the average Salary of patients with the same Education level.
In our experiments we considered, as a base configuration, a dataset including 10,000 tuples. We analyzed the behavior of the system varying several parameters. First, we considered the impact of variations of k, with values ranging between 4 and (k was equal to 12 for experiments that did not change this parameter). Then, we considered changes on a parameter γ that drives the generation of the synthetic dataset, guiding the distribution of the attribute values. Low values of γ produce compact ranges of values for all the attributes and a high probability of similarity among tuples; high values of γ produce values for the attributes covering a wider range, with small similarity among tuples. The interval we considered in the experiments is between 4 and 12 (value 8 was used in experiments that did not consider variations of this parameter). Finally, we considered the impact of the variations of parameters and and, always choosing pairs of values such that , we considered several possible pairs (in experiments that did not consider variations of these parameters, we chose the pair and that had and minimum distance between and ; e.g., when , and ). As a real world dataset, we considered the IPUMS dataset [22], which has been widely used in the literature to test anonymization approaches. Among the attributes in the dataset, we considered the projection over attributes {Region, Statefip, Age, Sex, MarSt, Ind, IncWage, IncTot, Educ, Occ, HrsWork, Health}, representing for each citizen: the region where she lives, the state where she lives, age, sex, marital status, the type of industry for which she works, salary, annual total income, education level, occupation, the number of hours she works per week, and health status rated on a five point scale. The relation includes 95,000 tuples with a not null value for IncWage attribute. When considering the real dataset, we ran experiments over two fragmentations: the first one is composed of two fragments and satisfying constraints and ; the second fragmentation has three fragments , and satisfying constraints , and . Experiments have been run on a server with two Intel(R) Xeon(R) E5504 2.00 GHz, 12 GB RAM, one 240 GB SSD disk, and Ubuntu 12.04 LTS 64 bit operating system. The reported results have been computed as the average of a minimum of 5 (for the largest configurations) and a maximum of 120 (for more manageable configurations) runs of the same experiment.
Coverage and performance
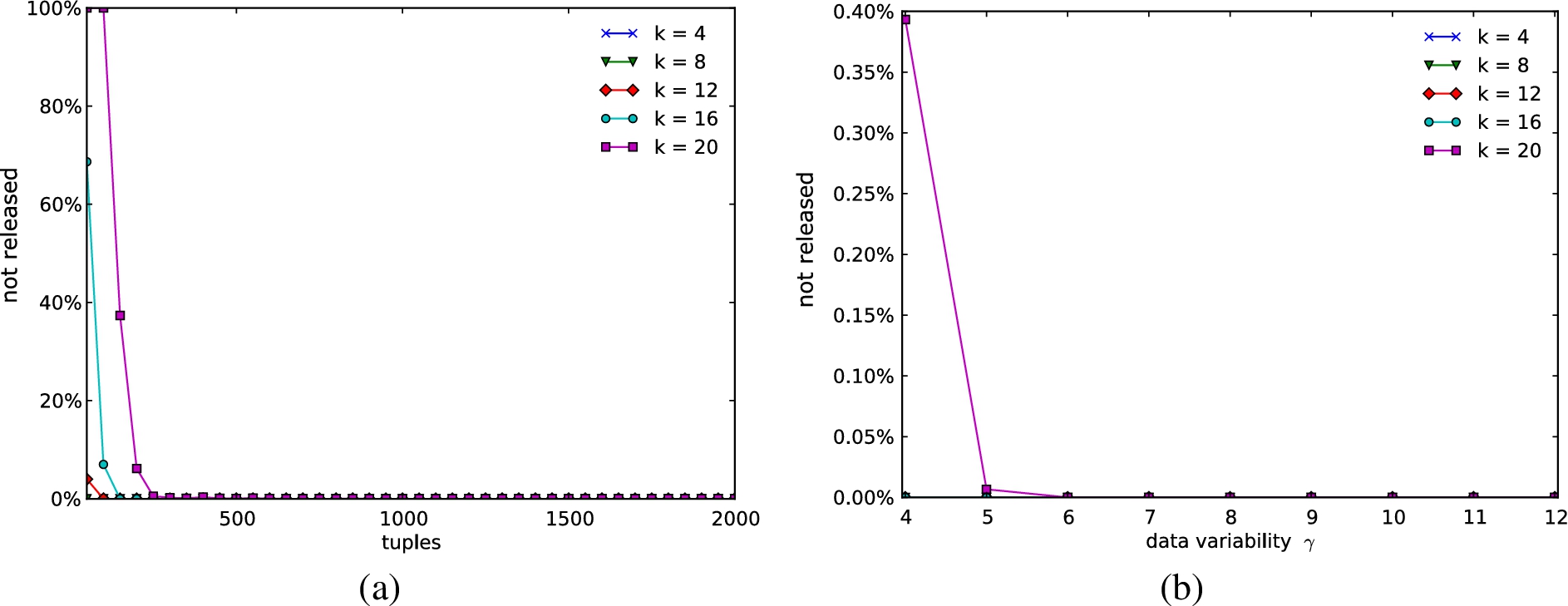
We ran a first set of experiments on synthetic data aimed at assessing the coverage of the solution computed by our algorithm, that is, the number of tuples of the original relation that could not be published as they could not be allocated to any group without violating k-looseness. The experiments focused on evaluating how the number of tuples in the relation (Fig. 10(a)) and the variability in the distribution of attribute values (Fig. 10(b)) have an impact on the number of tuples that cannot be released, for different values of k.
Percentage of tuples in the original relation that are not released, varying the number of tuples in the relation (a) and the variability in the distribution of attribute values (b). (Colors are visible in the online version of the article; https://dx-doi-org.web.bisu.edu.cn/10.3233/JCS-140513.)
Figure 10(a) shows that the algorithm is more likely to suppress tuples when operating over small datasets, as the number of candidate groups in each fragment is small. It is then harder to find an assignment for each tuple that satisfies all the heterogeneity properties. As it can be expected, the percentage of suppressed tuples grows with k, since it is harder to define larger groups of tuples (especially for small datasets).
Figure 10(b) illustrates the impact of the variability in the distribution of attribute values on the number of suppressed tuples. As visible from the figure, datasets characterized by low variability cause higher suppression. This is due to the fact that it is hard to assign tuples to groups when there is a higher probability that some of them have the same values for attributes in relevant confidentiality constraints. Indeed, two tuples with the same values for attributes in constraints cannot be assigned to the same group. In the experiments performed on the IPUMS dataset, no tuple has been suppressed.
Computational time necessary to determine a k-loose association, varying the number of tuples in the relation (a) and the variability in the distribution of attribute values (b). (Colors are visible in the online version of the article; https://dx-doi-org.web.bisu.edu.cn/10.3233/JCS-140513.)
A second set of experiments on synthetic data evaluated the impact of the size of the original relation and of the variability in the distribution of attribute values on the performance of our algorithm.
To prove the scalability of our approach, we ran our algorithm with large instances of the original relation, with a number of tuples varying between 2,000 and 100,000. Figure 11(a) illustrates the time necessary to compute a k-loose association and confirms the scalability of the proposed approach. In fact, our prototype is able to find a k-loose association for relations with 100,000 tuples in less than one minute for (and we speculate that, according to publicly available Python/C performance ratios [28], an optimized C implementation would take less than one second).
Figure 11(b) illustrates the impact of the variability in the distribution of attribute values on the time necessary to compute a k-loose association, considering configurations with 10,000 tuples. The figure confirms that, as already noted, the lower the variability, the harder the task to find a k-loose association. Both Fig. 11(a) and (b) also show that the computational time grows with the protection degree offered by the k-loose association: higher values of k require a higher computational cost.
In the experiments on the IPUMS dataset, our algorithm always computed a solution in less than 90 s.
Utility
We ran a set of experiments specifically focused on assessing the gain provided by loose associations, in terms of the utility of query results. We used as a reference the query that identifies the relationship between the Education level of patients and their Salary (i.e., select avg(Salary) from Patients group byEducation). We then defined a k-loose association that aims at keeping in the same group patients with the same Education level in fragment and with similar Salary in fragment .
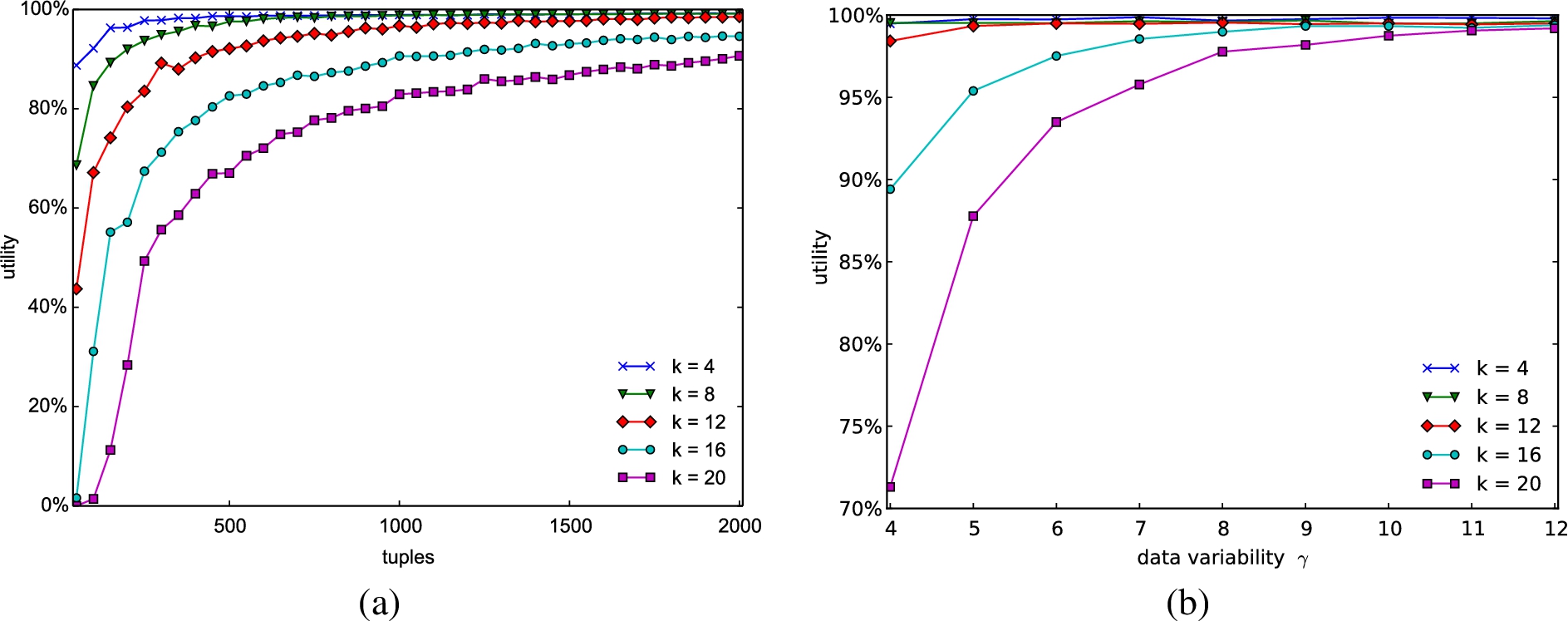
Utility provided by a k-loose association, varying the number of tuples in the relation (a) and the variability in the distribution of attribute values (b). (Colors are visible in the online version of the article; https://dx-doi-org.web.bisu.edu.cn/10.3233/JCS-140513.)
Figure 12(a) compares the utility provided by the release of a k-loose association with different values for k, varying the number of tuples in the input dataset. The figure clearly shows that the release of a k-loose association permits to obtain high utility in query evaluation. In most of the considered configurations, utility is nearly 100%, meaning that the result computed over fragmented data complemented with loose associations is nearly the same obtained on the original relation. This figure also confirms that the quality of the loose association computed by our algorithm improves with the number of tuples in the dataset, as it becomes easier to have tuples with similar values for Education and Salary in the same group.
Figure 12(b) illustrates the impact of the variability in the distribution of attribute values on the obtained utility. Greater values of γ increase the variability and lead to a reduction in the probability for an attribute to present the same values in different tuples. Conflicts arise in a group when tuples present the same values on the attributes involved in a constraint. Then, the probability of conflicts decreases as γ increases. The utility provided by the release of a k-loose association is always high, and increases as the variability in the attribute values increases. Our experiments also clearly show that, in line with the observation that utility and privacy are two contrasting requirements, utility decreases as k increases. It is then expected that improvements in confidentiality guarantees of the solution correspond to worsening in the utility of the released data. It is however worth noticing that, also for the worst case in which , if the size of the input dataset is not too limited (i.e., in the order of hundreds of tuples) the measured utility was higher than 80%, implying a high utility in query evaluation also when adopting privacy parameters higher than the values we expect to be used in real-world scenarios.
Utility provided by a k-loose association with ordering on Education and Salary. (Colors are visible in the online version of the article; https://dx-doi-org.web.bisu.edu.cn/10.3233/JCS-140513.)
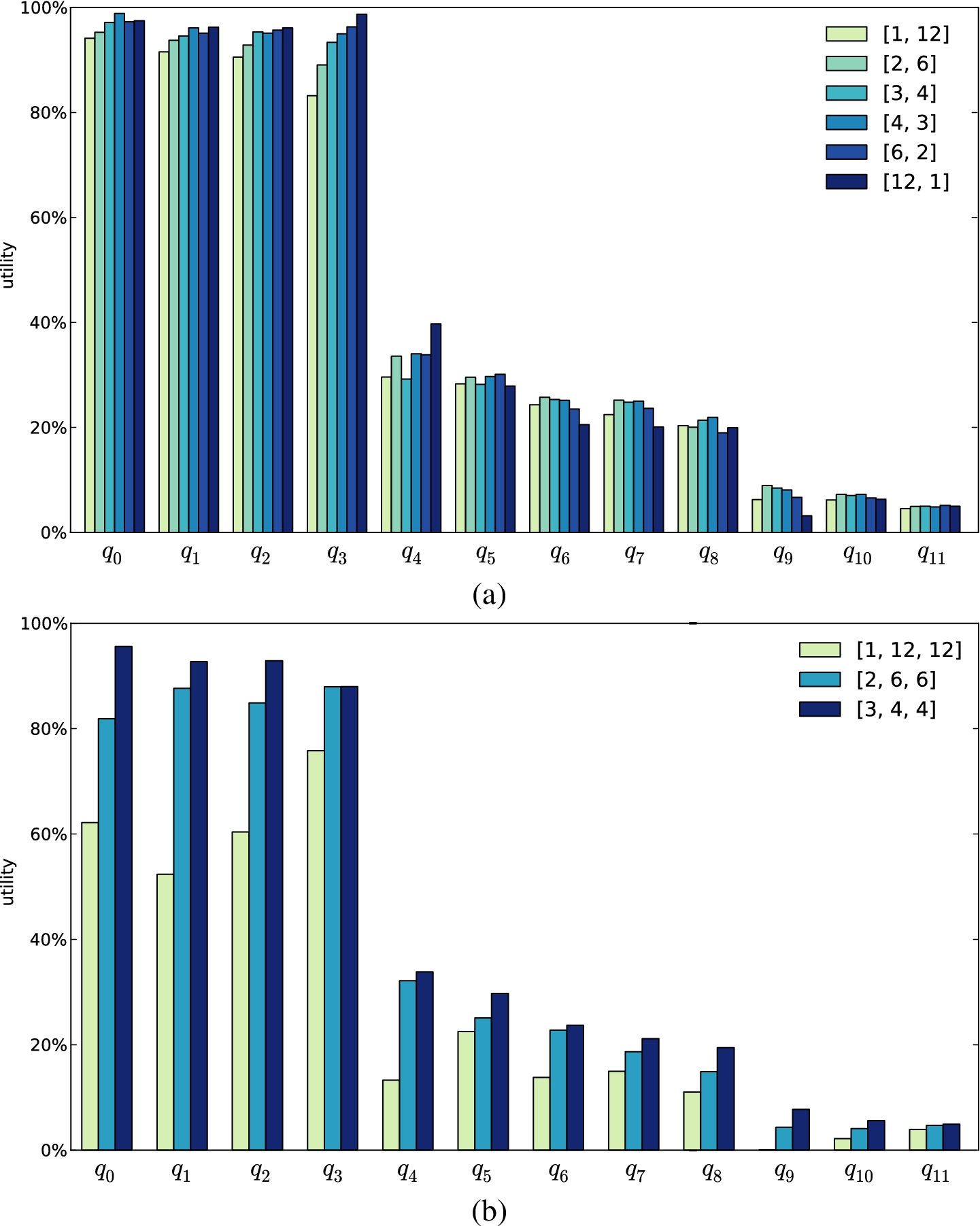
We ran a second set of experiments for evaluating the impact of keeping in the same group similar values for an attribute (or a set thereof) of interest for query evaluation (see Section 5). To this aim, we compared the utility of queries (operating on both Education and Salary), (operating only on Education or only on Salary), and (operating on neither Education nor Salary). Figure 13 compares the utility obtained with 7 different queries (query as representative for , queries , , for , and queries , , for ) with , varying and . Each query is represented by a group of bars, where each bar presents the utility obtained with one of the configurations for parameters and . The results clearly show that the query with highest utility (almost 100%) is , which benefits from the ordering over both Education and Salary (i.e., query ). Queries , and take advantage only of the ordering over one attribute, which however permits to obtain utility higher than 80% in all the considered configurations. Our experimental evaluation shows that the release of a loose association provides limited, but not null, utility also for queries . We can then conclude that keeping in the same group tuples with similar values permits to achieve better results in the utility of query evaluation.
Utility provided by a k-loose association over two (a) and three (b) fragments. (Colors are visible in the online version of the article; https://dx-doi-org.web.bisu.edu.cn/10.3233/JCS-140513.)
In the experiments performed on the IPUMS dataset, we first defined a k-loose association between fragments and , and identified two representative sets of queries. The first set of queries operates on the attributes on which fragments of the loose association have been ordered (i.e., , represented by query and , represented by queries , , ). The second set of queries instead operates only on attributes different from those on which the ordering was performed (i.e., , represented by queries ). Figure 14(a) illustrates the utility obtained in executing these two sets of queries over a k-loose association with and varying the values of and . Each query is represented by a group of bars in the figure. Queries involving at least one of the attributes on which the ordering has been performed (i.e., queries ) showed excellent utility in the result, close to 100% for all queries. As expected, the utility in executing queries operating on unordered attributes only (i.e., queries ) is lower. It is however worth noticing that the results are still appreciable, with most of the queries showing utility between 20% and 35%. Compared to the experiments on the synthetic dataset, the queries of type exhibit better utility. In particular, Fig. 14(a) shows that queries involving both ordered and unordered attributes exhibit utility values similar to query that involves ordered attributes only. Our explanation for the higher utility obtained on IPUMS dataset is that real data are more structured and present greater regularity and correlations among attribute values than the randomly generated data in our synthetic dataset, which is characterized by one correlation only (the one between attributes Education and Salary).
Figures 13 and 14(a) describe configurations that, keeping k constant, progressively increase the value of parameter (and reduce accordingly). The utility remains relatively stable across all these configurations, even if we can see that, for some queries, the utility decreases as increases, while for a few queries the utility grows with . Overall, we consider as preferable the intermediate solutions, with and near to , because they are not associated with the lowest levels of utility and because this criterion offers strong benefit when applied to fragmentations with more than two fragments, as observed in the following.
To further evaluate our technique, we performed the same experimental analysis on the fragmentation of IPUMS dataset composed of three (rather than two) fragments. Figure 14(b) reports the utility of queries provided by the release of a k-loose association with , comparing the results obtained with a -, - and -grouping. The crucial difference among these configurations is that queries that combine the second and third fragment will operate on a k-loose association between the two fragments with k equal to 144, 36 and 16 (for the constraints that are relevant for the second and third fragment). As we already noticed, an increase in k leads to a reduction in utility. The graph in Fig. 14(b) clearly shows the increase in utility that occurs going from - to -grouping for queries . This result proves that, for fragmentations with more than two fragments, there is a significant utility benefit in building loose associations with similar values for parameter on all the fragments.
Query results computed ordering on Educ and IncWage on a k-loose association among two (a) and three (b) fragments. (Colors are visible in the online version of the article; https://dx-doi-org.web.bisu.edu.cn/10.3233/JCS-140513.)
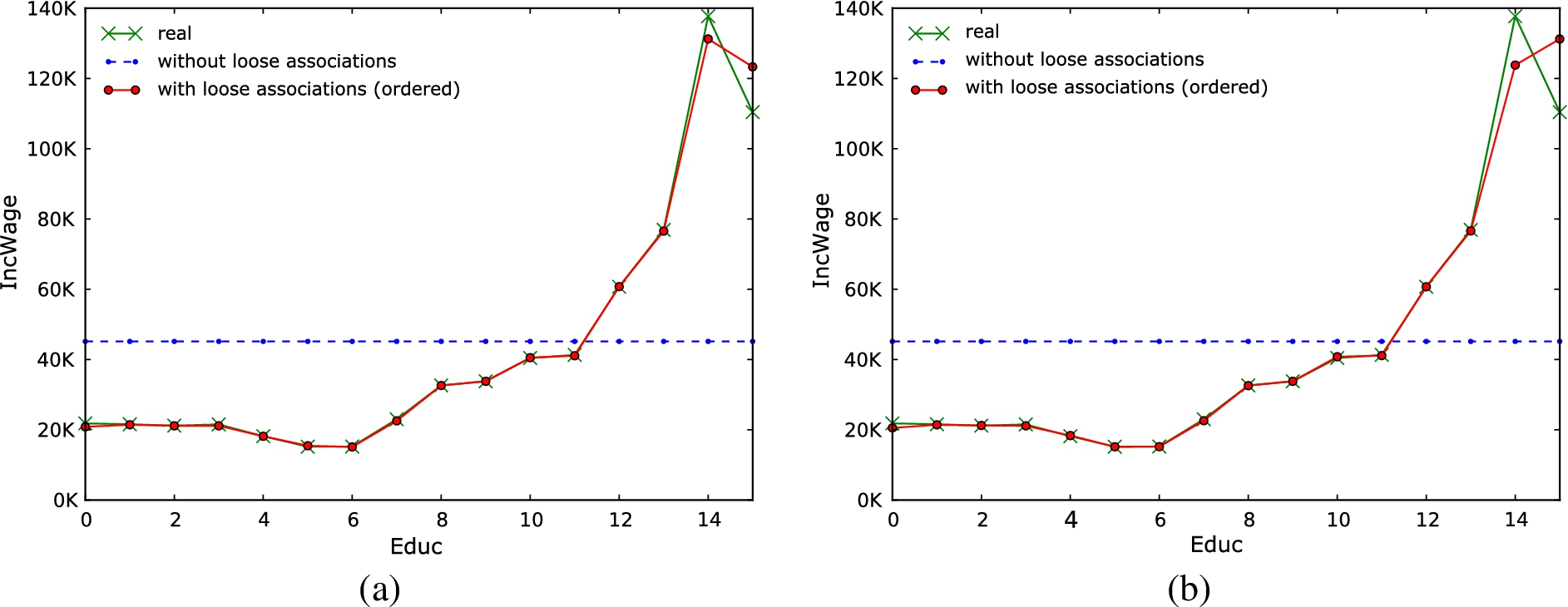
Figure 15 demonstrates in a different way the utility that can be obtained by the use of loose associations, analyzing query of the previous experiments. The graph has on the x-axis the different values of attribute Educ, which represents the number of years of education reported in the census, and on the y-axis the average salary (attribute IncWage) for the cohort of people with that level of education. In essence, the graphs plot the result of query = “select avg(IncWage) from ipums_census group byEduc”. The continuous green line (i.e., the line labeled “real”) reports the results obtained on the real data. The dashed blue horizontal line (i.e., the line labeled “without loose associations”) in the middle is the result that we can obtain without loose associations, because IncWage and Educ belong to different fragments and the global average salary will be returned for every education level. The continuous red line (i.e., the line labeled “with loose associations (ordered)”) describes the result obtained with a k-loose association with . Figure 15(a) shows the results obtained in the configuration with two fragments and assuming a -grouping, while Fig. 15(b) illustrates the results obtained in the configuration with three fragments and assuming a -grouping. In both graphs, the green and red lines are overlapping over most of the range, clearly showing the utility that can be obtained by loose associations.
Related work
Several research efforts have addressed the problem of protecting privacy in data publishing, proposing approaches based on either sanitizing (e.g., [10,15,16,19–21,23,30]) or fragmenting data (e.g., [1,2,7–9,11,29]) before their release. Our approach bears some similarity with k-anonymity [24] for the notion of grouping and more similarity with ℓ-diversity [21] for the consideration of the different values that are involved in the sensitive associations. Apart from this, our problem and solution are different from k-anomymity-like approaches, which are typically based on generalization of quasi-identifying attributes. By contrast, in our approach fragments contain the attribute values that appear in the original relation, while it is the association among fragments that is obfuscated. Most fragmentation works, although showing similarities with our proposal, address an orthogonal problem with respect to the one considered in this paper, as they aim at breaking sensitive associations while maximizing the ability of recipients of evaluating queries on fragments. Recent proposals have also considered the problem of improper information leakage due to data dependencies, which can be exploited to link different fragments [3,13]. Our loose associations can nicely complement these proposals, thus increasing the utility of fragmented data and ensuring proper protection of confidentiality constraints also in presence of data dependencies.
The works closest to our complement published (fragmented) data with information on their association, without disclosing sensitive information [11,14,31]. Our proposal is however more general than these solutions, since they operate on two fragments (or views/tables) only, while we consider an arbitrary number of fragments when defining loose associations. The work in [11] does not take into consideration the possible existence of duplicate values for non-key attributes. Sensitive associations on non-key attributes are therefore exposed to frequency-based attacks. Our heterogeneity properties overcome this issue by preventing the presence of duplicates in the same group of tuples. Anatomy [31] considers the specific problem of protecting the association between respondents’ quasi-identifiers and a sensitive attribute while our solution permits to protect any association among attributes. Anatomy also partitions the original relation in groups of ℓ tuples before splitting attributes in two disjoint fragments. Our approach provides more flexibility in defining groups of tuples because for each fragment we can consider a different privacy parameter (and a different grouping function) instead of a single ℓ value. By comparing Anatomy with a loose association on two fragments, we can see that the two techniques provide the same protection guarantees and the same utility [14]. Anatomy can then be considered as a specific instance of our approach, where the original relation is partitioned in two fragments: , storing the quasi-identifier, , storing the sensitive attribute, and and (or vice versa).
Our work may also bring some resemblance with the proposals in [6,26,27]. The work in [27] adopts horizontal and vertical fragmentation to protect privacy of sparse multidimensional data (e.g., transactional data). The approach in [6] focuses instead on protecting recommendation data expressed by customers (i.e., Netflix movie ratings). Besides operating on different data models, both these proposals differ from our work since they are specifically targeted at protecting respondents’ identities and their association with sensitive attributes. Also, they both adopt a dual approach with respect to loose associations, requiring homogeneity of values in fragments. The work in [26] addresses the problem of destroying the correlation between two disjoint subsets of attributes, preserving as much as possible the other correlations. Our approach does not aim at destroying correlations among attributes, as our goal is to preserve them as much as possible, while satisfying privacy constraints. Also, the solution in [26] adopts masking techniques, while our approach maintains data truthfulness.
Alternative approaches to protect privacy in data release are based on differential privacy (e.g., [15,16]). Although addressing a similar problem, approaches based on differential privacy are not directly applied since they introduce noise in the dataset that depends on the expected users queries. Our approach instead aims at releasing truthful data.
A different line of work is represented by Controlled Query Evaluation (CQE) (e.g., [2,4]). These solutions provide the data owner storing a data collection with a technique for controlling whether users’ queries should be permitted or denied depending on both confidentiality constraints and the history of past interactions. These approaches are not applicable to our scenario, since we publicly release a dataset.
Conclusions
We addressed the problem of extending loose associations to operate on multiple fragments. We first described how the publication of multiple loose associations between pairs of fragments can expose sensitive associations, and then presented an approach supporting the definition of a loose association among an arbitrary number of fragments. We also described a heuristic algorithm for the computation of a loose association, and showed the results of an extensive experimental evaluation aimed at analyzing both the efficiency and the effectiveness of the proposed heuristics as well as the utility provided by loose associations in query execution. Our work leaves space for further investigations, including the consideration of external knowledge that data recipients can exploit to reconstruct sensitive associations among attributes in different fragments, and of dynamic datasets, where data in the original relation change over time.
Footnotes
Acknowledgments
The authors would like to thank Enrico Bacis for support in the implementation of the system and in the experimental evaluation. This work was supported in part by: the EC within the 7FP under grant agreement 312797 (ABC4EU) and the H2020 under grant agreement 644579 (ESCUDO); the Italian Ministry of Research within PRIN project “GenData 2020” (2010RTFWBH); and the NSF under grant IIP-1266147.
References
1.
G.Aggarwalet al., Two can keep a secret: a distributed architecture for secure database services, in: Proc. CIDR 2005, Asilomar, CA, USA, 2005.
2.
J.Biskup, Dynamic policy adaptation for inference control of queries to a propositional information system, JCS20(5) (2012), 509–546.
3.
J.Biskup and M.Preuß, Database fragmentation with encryption: under which semantic constraints and a priori knowledge can two keep a secret?, in: Proc. DBSec 2013, Newark, NJ, USA, 2013.
4.
J.Biskup, M.Preuß and L.Wiese, On the inference-proofness of database fragmentation satisfying confidentiality constraints, in: Proc. ISC 2011, Xi’an, China, 2011.
5.
A.Ceselli, E.Damiani, S.De Capitani di Vimercati, S.Jajodia, S.Paraboschi and P.Samarati, Modeling and assessing inference exposure in encrypted databases, ACM TISSEC8(1) (2005), 119–152.
6.
C.-C.Chang, B.Thompson, H.W.Wang and D.Yao, Towards publishing recommendation data with predictive anonymization, in: Proc. ASIACCS 2010, Beijing, China, April2010.
7.
V.Ciriani, S.De Capitani di Vimercati, S.Foresti, S.Jajodia, S.Paraboschi and P.Samarati, Fragmentation and encryption to enforce privacy in data storage, in: Proc. ESORICS 2007, Dresden, Germany, September2007.
8.
V.Ciriani, S.De Capitani di Vimercati, S.Foresti, S.Jajodia, S.Paraboschi and P.Samarati, Combining fragmentation and encryption to protect privacy in data storage, ACM TISSEC22 (2010), 1.
9.
V.Ciriani, S.De Capitani di Vimercati, S.Foresti, S.Jajodia, S.Paraboschi and P.Samarati, Selective data outsourcing for enforcing privacy, JCS19(3) (2011), 531–566.
10.
V.Ciriani, S.De Capitani di Vimercati, S.Foresti and P.Samarati, k-anonymous data mining: a survey, in: Privacy-Preserving Data Mining: Models and Algorithms, C.C.Aggarwal and P.S.Yu, eds, Springer-Verlag, 2008.
11.
G.Cormode, D.Srivastava, T.Yu and Q.Zhang, Anonymizing bipartite graph data using safe groupings, The VLDB Journal19(1) (2010), 115–139.
12.
S.De Capitani di Vimercati, S.Foresti, S.Jajodia, G.Livraga, S.Paraboschi and P.Samarati, Extending loose associations to multiple fragments, in: Proc. DBSec 2013, Newark, NJ, USA, July2013.
13.
S.De Capitani di Vimercati, S.Foresti, S.Jajodia, G.Livraga, S.Paraboschi and P.Samarati, Fragmentation in presence of data dependencies, in: IEEE TDSC, 2014, Preprint.
14.
S.De Capitani di Vimercati, S.Foresti, S.Jajodia, S.Paraboschi and P.Samarati, Fragments and loose associations: respecting privacy in data publishing, PVLDB3(1) (2010), 1370–1381.
15.
S.De Capitani di Vimercati, S.Foresti, G.Livraga and P.Samarati, Protecting privacy in data release, in: Foundations of Security Analysis and Design VI, A.Aldini and R.Gorrieri, eds, Springer, 2011.
16.
C.Dwork, Differential privacy, in: Proc. ICALP 2006, Venice, Italy, July2006.
17.
C.Gentry and S.Halevi, Implementing Gentry’s fully-homomorphic encryption scheme, in: Proc. EUROCRYPT 2011, Tallinn, Estonia, May2011.
18.
R.Jhawar, V.Piuri and P.Samarati, Supporting security requirements for resource management in cloud computing, in: Proc. CSE 2012, Paphos, Cyprus, December2012.
19.
D.Kifer and J.Gehrke, Injecting utility into anonymized datasets, in: Proc. SIGMOD 2006, Chicago, IL, USA, June2006.
20.
N.Li, T.Li and S.Venkatasubramanian, t-closeness: privacy beyond k-anonymity and ℓ-diversity, in: Proc. ICDE 2007, Istanbul, Turkey, April2007.
J.Vaidya, A survey of privacy-preserving methods across vertically partitioned data, in: Privacy-Preserving Data Mining: Models and Algorithms, C.C.Aggarwal and P.S.Yu, eds, Springer-Verlag, 2008.
30.
K.Wang and B.C.M.Fung, Anonymizing sequential releases, in: Proc. KDD 2006, Philadelphia, PA, USA, August2006.
31.
X.Xiao and Y.Tao, Anatomy: simple and effective privacy preservation, in: Proc. VLDB 2006, Seoul, Korea, September2006.