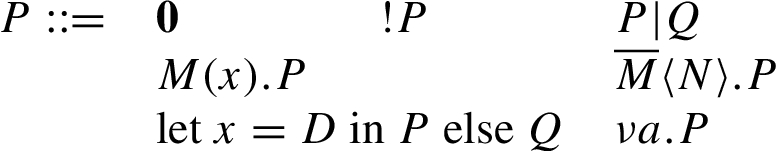We introduce a variant of the Universal Composability framework (UC; Canetti, FOCS 2001) that uses symbolic cryptography. Two salient properties of the UC framework are secure composition and the possibility of easily defining security by giving an ideal functionality as specification. These advantages are now also available in a symbolic modeling of cryptography, allowing for a modular analysis of complex protocols.
We furthermore introduce a new technique for modular design of protocols that uses UC but avoids the need for powerful cryptographic primitives that often comes with UC protocols; this “virtual primitives” approach is unique to the symbolic setting and has no counterpart in the original computational UC framework.
In the analysis of cryptographic protocols, symbolic analysis techniques (going back to Dolev and Yao [21]) have shown to be very fruitful. Symbolic techniques allow for much better automation than techniques working in the computational model (wherein messages are bitstrings and adversaries are runtime-limited computations). In a symbolic model of cryptography, messages are typically modeled as terms in a certain algebra, and the capacities of the adversary are described by, e.g., certain deduction rules over these terms.
In this work, we show how to apply the idea of Universal Composability (UC) [9] to the setting of symbolic cryptography. (The independently developed Reactive Simulatability [3] has the same idea. For simplicity, we only refer to UC in the following.) The Universal Composability framework is a framework for specifying security properties of cryptographic protocols that has the following two salient properties:
Specifying security properties via functionalities. In the UC framework, the security goals of a protocol are specified by describing a so-called ideal functionality which is a hypothetical entity which, by construction, achieves all the desired security goals. For example, if we wish to ask whether a protocol is a secure communication protocol, we simply specify the secure channel functionality. This very simple functionality just takes a message from Alice, informs the adversary that Alice sent a message, and gives that message to Bob. From the description of the functionality, it is then obvious what properties we achieve: The adversary learns nothing except that a message is delivered (secrecy). The message Bob receives is the same as the one that Alice sent (integrity).
Given the description of an ideal functionality, we then call a protocol secure if it “UC-emulates” that functionality. UC-emulation essentially means that the protocol is as secure as the functionality, i.e., that any security property satisfied by the functionality (secrecy and integrity in our example) is also satisfied by the protocol.
Using ideal functionalities to describe what security a protocol achieves is often simpler than explicitly describing all required properties one by one. For example, the security of the Direct Anonymous Attestation protocol [8] is only specified by an ideal functionality.
Another view on this definition is one of security preserving refinement. The functionality is an abstract specification, and the protocol is a refinement that preserves security.1
Many other refinement notions do not preserve, e.g., anonymity. For example, imagine a protocol where user Alice sends A or B over the network (chosen non-deterministically). And Bob sends A or B. Then the adversary cannot distinguish Alice and Bob. A refinement might be that Alice sends A and Bob sends B. Obviously, the anonymity of Alice and Bob is now violated.
Note that the fact that UC-emulation preserves security can be formalized: For a certain class of security properties we have that if the functionality has this property, so has any protocol that UC-emulates that functionality. (See Section 6.)
Composition and modular design and analysis. Security in the UC framework implies secure composition. That is, assume a secure protocol ρ that uses an ideal functionality as a building block (e.g., ρ uses a secure channel ). Then, if another protocol π UC emulates (i.e., π is a message transmission protocol), we can replace by π in ρ and again get a secure protocol.
This composition operation enables the modular design and analysis of a protocol. For example, in Section 8, we show that a variant of the Needham–Schroeder–Lowe protocol [25] UC-emulates the key exchange functionality which gives a secure key to two parties. Another protocol UC-emulates the secure channel functionality . And finally, assume we had some complex protocol implementing some complex functionality (think, e.g., of some large e-commerce application), and that uses secure channels. Then we can plug , , and together, and get a protocol that still UC-emulates . (And due to the composition theorem, we do not need to verify the composed protocol anew.) In contrast, without the composition theorem, we would have had to analyze in one go; that analysis being much more complex because the implementation of the secure channel would be intermixed with the complex protocol .
The composition theorem also has the implication that a protocol will keep its security when run in other, as yet unknown, contexts. This is a very important property, because on the Internet, a protocol will hardly run alone. (Cryptographers often call security definitions that do not have this property “stand-alone models”.)
The UC framework has been defined in the context of computational cryptography. However, its two salient properties, security specification via functionalities and secure composition, are as useful in a context where cryptography is modeled symbolically. In particular, even though computer verification in the symbolic setting scales much better than the usually manual verification in the computational setting, most analysis techniques still cannot deal with arbitrarily complex protocols.2
Verification by type checking (e.g., [5]) being a notable exception; this approach usually scales very well. But annotating a protocol with types suitable for verification can be daunting.
So being able to design and verify a protocol modularly will allow us to analyze more complex protocols.
Our contribution. In this work, we show that the ideas of the UC framework carry over to the symbolic setting. We show that the composition theorem and the fact that security properties carry over still hold in the symbolic UC framework. (Concurrent composition turns out to be non-trivial because we need to encode a special variant of process replication in the applied pi calculus that provides session ids to replicated processes.) We present an example analysis of a key exchange using the Needham–Schroeder–Lowe protocol, and how to use it in a secure channel protocol via composition.
We show that impossibilities from the computational UC framework unfortunately still apply in the symbolic setting; in particular, implementing a commitment functionality without any trusted setup is impossible. On the positive side, we show that this impossibility can be circumvented to a large part by a trick that we call “virtual primitives”; here we perform the proof of security under the assumption that the cryptographic primitives have some exotic features, but in the end conclude security for the original cryptographic primitives without these exotic features. This “virtual primitives” – approach is unique to the symbolic setting, to the best of our knowledge no corresponding technique exists in the computational world.
We also show how to use Proverif as a helping tool for performing the observational equivalence proofs when showing security in our framework. For this we develop a set of lemmas that help in rewriting processes and allows us to use Proverif as a tool even for observational equivalence proofs that do not involve so-called biprocesses and are thus out of the scope of Proverif. (Mostly in the full proofs of Section 8.) We believe that this set of lemmas is useful also in other settings than that of our work.
Prior work. The problem of transporting the ideas of the UC framework into the symbolic setting has already been tackled by Delaune, Kremer and Pereira [20]. They do, however, differ from the original UC framework (and from our work) in one crucial point: In the original framework, the existence of a so-called simulator is required that makes two different protocol executions – the “real and ideal execution” – indistinguishable (this will become clearer later). Instead of indistinguishability, [20] use an observational preorder. That is, everything that can happen in the real world can non-deterministically be matched by the ideal world, but not necessarily vice-versa. This was due to certain problems in constructing simulators when using observational equivalence instead. However, we show that using an observational preorder limits the strength of the security definition considerably. For example, if a functionality guarantees anonymity (e.g., an anonymous broadcast), a protocol that emulates that functionality will not necessarily satisfy anonymity. On the other hand, we show that using observational equivalence instead of an observational preorder gives a stronger definition that does, e.g., preserve anonymity properties. Furthermore, we show that, when designing the functionality according to a simple guideline, the problems with observational equivalence that [20] observed vanish. (However, there are challenges when dealing with concurrent composition that apply only in our setting, and not when using the weaker definition based on observational preorders.) We explain the issues related to [20] in more detail in Section 7.
On the computational side, relevant prior work is of course the UC framework [9] itself. Other models based on the same ideas are Reactive Simulatability (RSIM) [3], SPPC [19], IITM [23], Task-PIOA [10,11], and GNUC [22]. Some of our results are adaptations of existing computational soundness results: the impossibility of commitments [13] in Section 9.3 and the joint state technique [15] in Section 8. Finally, the symbolic setting is not the first example of the fact that the UC framework can easily adapted to other settings to get different or stronger security guarantees, e.g., GUC (UC with shared functionalities) [12], quantum-UC [28,29], UC with local adversaries [16], UC/c (incoercibility) [30], UC with everlasting security [26]. Furthermore, links between UC and symbolic models occurred where UC-like models were used to establish computational soundness results [2,14]. Furthermore, [4,27] present UC protocol constructions where impossibilities are circumvented by giving the simulator additional power (namely superpolynomial-time computation); this shows some parallels to our “virtual primitives” – approach, see the discussion on p. 26.
Outlook. Further research might tackle the following points:
Using our framework for analyzing the security of existing protocols. A particular interesting candidate is the Direct Anonymous Attestation protocol [8] because its security is already formulated in a UC model.
Although we partially used Proverif for some of the proof steps, the analysis of our example protocols still used a lot of manual work. Can the verification of symbolic UC security be automated?
There are extensions of the UC framework. For example [30] provides an extension that captures incoercibility. That model could be translated to the symbolic setting and used for the analysis of voting protocols.
In combination with computational soundness results (these are results that show that symbolic security in certain cases implies computational security), the virtual primitives approach could be a viable new technique for showing computational security: Design the protocol symbolically modularly using virtual primitives, and then carry the security over to the computational setting.
Organization. In Section 2 we review the applied pi calculus as used here (with some additional concepts introduced in Section 2.1). Section 4 introduces our security definition. Section 5 shows the composition theorem, Section 6 that we have property preservation. In Section 8 we give an example of our framework based on the Needham–Schroeder–Lowe protocol, we illustrate composition and joint state techniques (the latter is a technique for dealing with functionalities shared by several protocol instances). Finally, in Section 9 we present the virtual primitives technique. The Supplemental material (Appendices B–J) contains some delayed details; mostly proofs.
Review of the applied pi calculus
In this section we very briefly review the syntax and semantics of the applied pi calculus from [7] which is used throughout this paper. A more detailed review can be found in the Supplemental material (Appendix B).
Syntax of processes in the applied pi calculus.
In our calculus terms take up the role of data (messages), while processes (following the grammar in Fig. 1) model functional behavior. is a process that does nothing, (pronounced “bang P”) is an unbounded number of copies of P, is P and Q in parallel, waits for a message on channel M and assigns it to x, outputs N on channel M, evaluates the destructors in D, assigns the result to x and continues with P (or Q if a destructor fails). A signature Σ consists of function symbols which we split in constructors and destructors. A term is either a name, a variable or the application of a constructor to terms. We define the semantic of terms in two ways: One is the equational theory which induces equivalence classes on the set of terms and is defined by set of equations E. The other is a set of rewrite rules R defining the mechanics of destructors. Each rule defines the result of a specific application of a destructor. We call the entity of a signature, a set of equations and a set of rewrite rules a symbolic model. Except for Section 9, it will be clear from the context which symbolic model we use. In Section 9 we focus on the relation between different symbolic models. Only then we will introduce a notation that explicitly states the symbolic model underlying a property, e.g., observational equivalence of two processes.
With , , , we denote the free names, bound names, free variables and bound variables of a process, respectively. Analogously , for terms T. We introduce the usual relations on processes: structural equivalence (≡), internal reduction () means that is the immediate successor process of P in an execution and observational equivalence (≈) which intuitively means that no context can distinguish the two processes. means that the destructor term D evaluates to the term M.
Additional concepts used in this work
In this section, we describe several nonstandard concepts related to the applied pi calculus that we use in this work.
Miscellaneous. A context always contains a single occurrence of the hole. Sometimes we need a context which may or may not contain a hole: A 0–1-context is defined like a context, except that there may be zero or one occurrences of the hole.
We refer to occurrences of terms that identify channels in a process as channel identifiers. E.g., in M is a channel identifier and T is not – even if M and T were the same term (because M and T are different occurrences).
We allow destructors with conditional rewrite rules following [18], see Appendix B in the Supplemental material. None of our results actually require these conditional destructors, though. The reader may safely assume the usual, unconditional definition of destructors.
Natural symbolic models. A number of lemmas in this paper only hold when the symbolic model we use satisfies certain natural conditions. Instead of stating these explicitly each time, we collect all these conditions in the following definition.
(Natural symbolic model).
We say a symbolic model is natural if it satisfies the following conditions:
there is a constructor ,
a constructor for pairings, denoted , is part of the signature Σ,
there is a destructor with rewrite rule and no further rewrite rules that contain ,
there are destructors with rewrite rules and ,
for all terms T, with there exists a term with and furthermore for all such and vice versa,
for arbitrary terms , , , we require that entails and ,
for any destructor term D and any name we require that for a term T entails the existence of a term with , and ,
there are terms T, with .
In the following, we will always assume that the symbolic model is natural in the sense of Definition 2.1.
Equivalence of processes modulo rewriting. Structural equivalence ≡ does not allow us to replace a term M by another term . In some places, we will therefore need to apply to processes, and we will also use an extension of ≡ that allows us to replace terms.
We extend to destructor terms and processes as follows:
Given two destructor terms D, , we have iff D can be rewritten into by replacing subterms by -equivalent subterms. (But replacing destructors is not allowed.) E.g., if d is a destructor and f, g are constructors, and is in the equational theory, we have but not . Formally, is the smallest equivalence relation on destructor terms such that for destructor terms D and terms .
Given two processes P, , we have iff P can be rewritten into by α-conversion and by replacing terms and destructor terms by -equivalent ones. Formally, is the smallest equivalence relation closed under α-renaming such that for processes P and terms .
Given two processes P, , we have iff P can be rewritten into by and ≡. Formally, .
Full observational equivalence. A substitution σ is a closing substitution for P if is closed. We call two (not necessarily closed) processes P and Q fully observationally equivalent (denoted ) iff for all closing substitutions σ (where we implicitly assume that the bound names in P, Q are renamed so that they are distinct from the free names of σ). Since ≈ is closed under ≡ it follows in a straightforward way that ≋ is closed under ≡.
The motivation behind the definition of ≋ is the following lemma which allows us to replace fully observationally equivalent subprocesses by each other.
Let P and Q be processes and. Thenfor every context.
Product processes. In order to argue about concurrent composition, as a technical tool, we will need an extension of the applied pi calculus that supports infinite parallel compositions of processes which are tagged with distinct terms.
Intuitively, the indexed replication stands for when . (Like stands for .) We call processes from this extended calculus product processes. Note that our main definitions and results are still stated with respect to the original calculus from [7]; we only use product processes in some specific situations.
(Product processes).
Product processes are defined by the grammar in Fig. 1 with the additional construct where x is a variable, S a (possibly infinite) set of terms, and P a product process. (We call an indexed replication.)
(Note that we consider to be a binder. I.e., in , we consider x a bound variable.)
Structural equivalence (≡) on product processes is defined as on processes.
The reduction relation → on product processes is defined using the same rules as on processes, with the following additional rule (IREPL): If , then with . (Essentially S is treated as a set of session ids which contains each sid at most once modulo .)
Observational equivalence (≈) on product processes is defined like observational equivalence on processes.
Notice that processes are also product processes, and that on processes, the new definitions of ≡, →, and ≈ coincide with the original definitions. (See the Supplemental material (Appendix B) for precise definitions.)
Useful properties of the pi calculus
In this section, we introduce a number of useful lemmas for the applied pi calculus. These lemmas are useful to derive observational equivalences of processes via step by step rewriting (and for using Proverif as a tool in deriving equivalences that Proverif cannot handle). We believe that they may be useful in other similar situations, too. All proofs can be found in the Supplemental material (Appendix D). Although those lemmas turn out to be quite useful in particular when showing that a concrete protocol emulates another protocol (see, e.g., the proofs of the results in Section 8 and in Section 9), their usefulness may not be obvious at first reading. Thus, the reader may skip this section at first reading. We recommend to simply keep in mind that these lemmas are available and to refer to this section when performing a concrete proof of observational equivalence between two processes.
For natural symbolic models, the following hold:
If, then.
for names.
for all terms M,and names.
Let P,be processes. Let D,be destructor terms. Let M,be terms.
If, then.
If, then.
Assume P is closed and that P does not contain unprotected3
We call an occurrence of an input/output within a process unprotected if it is only below parallel compositions () and restrictions (ν), i.e., it can be executed “right away”.
inputs or outputs. Assume, and that for allwithwe have. Then.
If M,are terms with, then.
If for all substitutions σ that close D, M we have, and for allwithwe have, then.
If D is closed and there is no M with, then.
If for all substitution σ that close D,there exist M,with,andthen.
We have.
for.
Let C be a 0–1-context whose hole is not under a bang and such that n does not occur in C, Q or t. Assume that C does not bind any oforover its hole. Then.
Let C, D be contexts, Q a process, n, m names, t,terms, and x a variable. Assume that C, D have no bang over their holes. Assume that. Assume that C, D do not bind n, m,. Assume that.
Then.
Let A, B, C be closed processes. If, then there is a closed processsuch that.
Relating events and observational equivalence
For stating Lemma 3.7 below, we will need processes containing events. The variant of the applied pi calculus presented in Section 2 (which is used by Proverif for observational equivalence proofs) does not support events. When using Proverif for showing trace properties defined in terms of events, a different variant of the applied pi calculus is used [6]. We will call processes in that calculus event processes. Syntactically, event processes differ from processes as in Section 2 only by an additional construct which means that the event f is raised, with arguments (these are normal terms), and then the event process P is executed.
The semantics of event processes are formulated in [6] in a different way from the semantics used here. Fortunately, we will be able to encapsulate everything that we need to know about that semantics in Lemma 3.6 below, so we do not need to repeat those semantics here.
Instead, we extend the definition of the internal reduction relation → to event processes. → is defined as usual, except that we add the following rule:
The semantics defined by → will be related to those from [6] by Lemma 3.6 below. Event contexts are contexts that additionally contain events, and evaluation event contexts are evaluation contexts that additionally contain events, but not over their hole.
Finally, [6] defines the concept of a trace property. We will only need trace properties of a specific form, namely
Intuitively, an event process P satisfies a trace property if in any execution , we have that if one of the transitions raises the event , then or in the same trace, the event is also raised (for any adversarial R not containing events).
Formally, satisfying a trace property is defined with respect to the semantics from [6].4
Strictly speaking, the semantics described in [6] does not allow expressions of the form in trace properties. Such expressions are, however, supported by Proverif. Also, [6, footnote 3 in the full version] explains how to encode such equality tests in the trace properties supported by [6]. In their notation, our trace property becomes the somewhat less readable trace property: .
Also, the semantics described [6] do not support equations (i.e., iff in their semantics). However, Proverif supports these, so we assume the intended semantics of Proverif is that of [6] with the natural extension of equality tests to equality modulo .
Instead of giving those semantics here, we present the following lemma which summarizes seven facts about that definition. We will not use any other facts. The facts can be verified by inspecting the semantics and definitions from [6].
Letbe terms. Let ℘ stand for the trace property. Let P be an event process.
Ifand P satisfies ℘, thensatisfies ℘.
Assumeand P satisfies ℘ and the reductiondoes not use the EVENT rule. Thensatisfies ℘.
Let t be a closed term. Assumewhere C is an event context not bindingover its hole. Assume that P satisfies ℘. Thensatisfies.
Assumewhere C is an event context. Assume that P satisfies ℘. Thensatisfies ℘.
Assume P satisfies ℘ and E is an evaluation context (not containing events) and E does not bindover its hole. Thensatisfies ℘.
Assume E is an evaluation event context that does not bind any names over its hole. Assume. Assume that P satisfies ℘. Thenfor some i.
Ifsatisfies ℘, then P satisfies ℘.
We explain the intuitive reason for each fact:
Structurally equivalent processes behave identically and thus raise the same events.
If without raising an event, then for any event trace that may produce, P may produce the same by first reducing to .
has the same event traces as P, except that some -events are removed. If does not satisfy , then there must be an event with that is not preceded by a -event. But then also in a trace of P, there would be an -event not preceded by (since the traces only differ in their -events and ).
has the same event traces as P, except that various -events are removed. (Since t is not necessarily closed, may be instantiated to different -events.) If a trace of does not satisfy ℘, this means there was an -event not preceded by a event. Then also in P the corresponding -event is not preceded by a -event, as P has the same -events, and more -events.
The semantics of satisfying trace properties are defined with respect to P running in parallel with an adversary R not containing events. Thus the case of an evaluation context running with P is already covered. (It is important that E does not bind because otherwise the terms occurring in the process would be considered different from those in ℘.)
There is a trace of P that consists only of an -event. That trace does not satisfy . Thus it satisfies ℘ only if ℘ contains as one of its clauses.
has the same traces as P, except that occurrences of a in the P-traces are replaced by a fresh restricted name . Thus, if P does not satisfy ℘, then there is a trace containing an -event without preceding -event such that . In the corresponding -trace, we have an -event without preceding -event. Since and a is fresh, also . Hence the -trace does not satisfy ℘, either.
Let s be a name. Let P be a process containing the subterm s only in constructs of the formand(for arbitrary and possibly different t,,).
Letdenote the process resulting from P by replacing all occurrencesandby.
Letdenote the process resulting from P by replacing all occurrencesbyandby.
Assume thatsatisfies the trace property.
Then.
(Unpredictability of nonces).
Let C be a context not binding the variable x and let P, Q be processes. Then.
Symbolic UC
Intuition. We start by presenting the intuition that underlies the original UC framework [9] and thus also our work. The basic idea is to define security of a protocol π by comparing it to a so-called ideal functionality . The ideal functionality is a machine that by definition does what the protocol should achieve. For example, if the task of the protocol is to transmit a message m securely from Alice to Bob, then the functionality is a trusted machine that expects a message m from Alice over a secure channel, sends to the adversary that such a message was received (but does not send the message itself), and then after the adversary allows delivery, forwards the message to Bob. (In the applied pi calculus, this functionality would be where the -channels belong to the adversary; see Definition 6.2 below.) In a sense, the functionality is an abstract specification of the protocol behavior, and the protocol is supposed to be a concrete instantiation of that specification using crypto, in a way that preserves the security properties of the specification.
So how to model that a protocol π is as secure as a functionality ? The basic idea is to ensure that any attack on π is also possible on . Since by assumption does not allow any attacks, this implies that π does not allow any attacks either, so π is secure. To model that any attack on π is possible on , we require that for any adversary attacking π, there is a corresponding adversary (the “simulator”) attacking that performs an equivalent attack. And what do we mean by equivalent? Any “environment” that can observe the overall protocol outcome (inputs and outputs), and that can talk to the adversary (i.e., it learns what secret information the adversary might have obtained), cannot distinguish between the two attacks. In other words, for any adversary A, there is a simulator S such that for all environments Z, we have that (the protocol running with A and Z) and are indistinguishable from Z’s point of view. Notice that we do not wish to allow Z to observe the internal protocol communication – doing so would require that π and work the same way internally, but we only want that the two have the same “observable effects”, we do not care about their inner workings. Due to this, in a formal definition, we need to distinguish between the protocol-internal communication channels (net-channels), and the protocol’s interface (io-channels). Only the latter is accessible to the environment.
Formal definition. To formalize the above intuition in the applied pi calculus, we first formalize the distinction between channels that make up the protocol’s input/output interface, and those that make up the protocol’s internal channels. We partition the set of all names into two sets and (both infinite). We will then require adversaries and simulators to only communicate on channels. (We do not forbid the environment to access channels. But we will give the adversary/simulator the ability to rename and hide channels, and thus effectively protect the protocol’s channels from the environment.)
In order to keep the distinction between NET-channels and IO-channels, we also want to avoid that NET-channels are transmitted to the environment (we use this in a few places in our proofs).
We call a process P-stable if every name in P occurs only in channel identifiers (i.e., in particular, P does not send n to the environment).
Note that there is no restrictions on the bound names. Thus a -stable adversary is free to share arbitrary fresh names with the environment and to use them as channels.
We now define the concept of an adversary. Essentially, an adversary is just a process A that is intended to interact with the protocol (or functionality). Since the adversary connects to the protocol over some -names, the specification of the adversary additionally includes a list of NET-names of the protocol that will be accessed by A (and are thus private between A and the protocol). Finally, an adversary/simulator sometimes needs to rename NET-channels of the protocol/functionality to avoid name clashes. Since NET-channels are protocol internal and not part of the externally visible interface, it should not matter whether the same name is used in protocol and functionality or not. This is achieved by letting the adversary rename NET-names, we model this by specifying a renaming φ as part of the adversary.
An adversary is a triple where A is a closed -stable process with , a bijection and a list of names .
We can now state our security definition. Both protocol and functionality are modeled by processes P and Q, respectively. An adversary connecting to P is modeled as , as we would expect from the meaning of φ and explained above. To model that P emulates Q, we would require that and are indistinguishable for any environment for a suitable simulator . We do not need to specify the environment explicitly because we have the notion of observational equivalence: means that no context can distinguish the left- and right-hand side. The following definition captures this, except that we make one simplification: Instead of quantifying over all adversaries , we fix , the identity, and the empty list, so that . (Such an adversary, that essentially just leaves all NET-channels accessible to the environment, is usually called a dummy adversary.) This definition is often technically much simpler to handle, and Lemma 4.4 below guarantees that it is equivalent to the more natural definition that quantifies over all adversaries.
Let P and Q be processes. We say P emulates Q (written ) iff there exists an adversary such that . will often be called simulator.
We use ≋ instead of ≈ to get a more general definition, allowing non-closed P, Q. For the applications presented in this paper, the special case using ≈ (which is equivalent to our definition restricted to closed processes) is sufficient. (Note however that we would still use ≋ to state various technical lemmas more conveniently.)
Note that there is no formal distinction between protocols and functionalities. Indeed, it can sometimes be convenient to compare two protocols P, Q. Furthermore, note that ⩽ is weaker than ≋: entails (and ) with the simulator .
As observed in [24] there are several approaches to define simulation based security. The following Lemma shows that our definition (resembling strong simulatability ) is equivalent to the two alternatives: black-box simulatability and universally-composable simulatability (the latter being the definition that corresponds directly to the intuition given at the beginning of this section).
For processes P, Q we have that the following are equivalent:
strong simulatability:,
black-box simulatability:,
universally-composable simulatability:,
where all triples are adversaries according to Definition4.2.
(Reflexivity, transitivity).
Let P, Q, R be processes. Then. And ifand, then.
Corruption. So far, we have not yet modeled the ability of the adversary to corrupt parties. There are two main variants of corruption: static and adaptive corruption. In the case of static corruption, it is determined in the beginning of the protocol who is corrupted. For adaptive corruption, corruption may occur during the protocol and depend on protocol messages. Modeling static corruption is quite easy in our model: When a party X is corrupted, we simply remove the subprocess corresponding to that party from the protocol P, make all NET-names occurring in public, and – in the case of a functionality – additionally rename all IO-names of into NET-names. For example, if where occurs in and and only in , and has IO-names , then corrupting A leads to . And a functionality with IO-names , becomes .
So, if we want to verify that a P emulates for any corruption, we need to check:
Uncorrupted: .
Alice corrupted: .
Bob corrupted: .
An example is given in Section 9.1 in the case of UC secure commitments.
Modeling adaptive corruptions is more complex. For this one would need to introduce special parties that react to a special signal from the environment and then switch into a corrupted mode. We do not follow that approach here.
Comparison with computational UC. We quickly highlight a few differences between our symbolic UC model and the computational UC model from [9]. The most obvious difference is, of course, that in our model messages are terms, while in the computational UC model messages are bitstrings. And the adversary’s capabilities in our model are specified by the equational theory and the destructors, while in the computational UC model, the adversary can perform any probabilistic polynomial-time computation. Also, nonces are modeled via fresh names in our model (and thus in principle unguessable), while nonces would be realized by hard to guess (but not impossible to guess) random bitstrings in the computational UC model. Our model does not allow to model probabilism (i.e., if we would design a protocol where an attack is possible with very small probability, our model would consider that protocol totally insecure).
Besides that, there are a number of smaller differences: Scheduling decisions (e.g., when two messages are sent at the same time) are non-deterministic in our model while in computational UC, the scheduling is determined by the adversary. The computational UC model does not know the concept of a blocking output (i.e., when sending a message, the recipient cannot influence the sender by not accepting the message), while in our model we have both blocking () and non-blocking () outputs.5
However, we find that security proofs get harder when actually making use of the blocking outputs in our protocols and functionalities. See our guideline on p. 21.
The computational UC model has a built-in framework for distinguishing parallel-composed processes using session-ids while in our model we need to work hard to mimic those session-ids (see the next section). We believe, however, that none of these differences are crucial for building a symbolic UC variant. They simply result from using the applied π-calculus as our underlying calculus. We could as well have chosen to model our symbolic UC model to mimic the computational UC model in every respect except for the fact that the messages are symbolic.6
That is, we could go through the definition of the computational UC framework and essentially replace the machine model from Turing machines to machines that operate on terms and not change much else.
(Note that the converse does not hold: we do not see how to add non-determinism to a computational UC model because non-determinism and probabilism do not easily interact.)
Composition
One of the salient properties of the UC framework is composition. Assume a protocol π UC-emulates a functionality . And ρ is a protocol using . Then (which is ρ with replaced by π) UC-emulates ρ. And hence, by transitivity, if ρ emulates some functionality , UC-emulates .
In our context, ideally we would like a composition theorem such as for arbitrary contexts C. Unfortunately, the situation is not as simple. A simple observation is that if C may contain NET-names, then composition will not work: For example, assume , and P is a protocol using some NET-channel to implement an ideal functionality Q (which does not use ). And receives on a NET-channel and outputs the received messages on an IO-channel . Then will output protocol-internal messages on (observable to the environment), while will not (since the functionality Q will not use the channel ). Hence . We give a formal analysis of the various cases in which the composition theorem does not hold in Appendix A.
Thus a first condition on C is that it may not use the same NET-names. In fact, we show below (Theorem 5.10) that if C is an evaluation context binding only IO-names and not using any of the NET-names of P, Q, then holds.
This already allows for a large range of composition operations. (In particular, we can connect different protocols through their interfaces securely by composing them in parallel, and restricting the IO-channels through which they are connected.) But one important operation is missing, namely concurrent composition. Concurrent composition means that if , then where consists of many instances of P and analogously. Such a result is important in many cases, e.g., if P is a single session key-exchange, but an embedding protocol needs a large number of keys. The most obvious way to model this in our setting would be a theorem stating .
Unfortunately, such a theorem cannot hold, either. The intuitive reason is as follows: When trying to construct a simulator for , then this simulator will not be able to distinguish messages from different instances of Q. The simulator will then be unable to even decide whether he talks to a single instance or several. For example:
Here we have because a simulator receiving on or just has to replace it by some fresh name m. However, we do not have . Depending on the messages the environment sends on , will output either the same name m on , , or different names m, . However, a simulator interacting with in both cases gets , on , . The simulator then does not know whether he should change this into m, m or m, for fresh m, . Thus the simulator fails. (The formal argument is in Appendix A.)
So we cannot have a theorem stating . Does this mean concurrent composition is not possible? No, just that ! is not the right operator to model it. In the computational UC framework, composition also does not involve a number of indistinguishable instances. Instead, each instance of P and Q is given a unique session id, and all communication is tagged with that session id so that it can be routed to the right instance. In our setting, one possibility to achieve this is to define an operator [17] such that behaves like an unlimited number of instances of P, where each instance is tagged with a unique session id . I.e., each channel C in P is replaced by .7
One might instead consider tagging the messages sent over the channel with . This, however, does not work as well: One would need a specific multiplexer process that given a message discovers the corresponding instance of P and delivers to it. This might be possible, but is probably considerably more complicated than the approach we take further.
The question is how to define . The applied pi calculus does not have any construct that conveniently allows to perform infinite branching with different ids. Thus, we have to work around this restriction by introducing a more elaborate construction. As a first step, we define the tagged version of the process P in the following definition.
Let P be a process, and let M be a term. We write for P with every occurrence of replaced by and every occurrence of replaced by . (If M contains bound variables or bound names from P, we assume that these bound variables/names are first renamed in P.)
Now we have to somehow define as where range over some infinite set of session ids. Using product processes (see Section 2.1) this is easy: does the job. However, product processes are a nonstandard extension of the applied pi calculus, but we wish to stay compatible with existing variants (in particular, to be able to use Proverif for verification). Thus, instead of using , we define a suitable context such that behaves like . Then we can define . Of course, depending on the particular set we choose, a different context will be needed. Instead of fixing a particular one, we thus give a general definition what contexts are suitable for a given set , and from then on, just assume an arbitrary such context.
(Indexing context).
Given a set S of terms, a variable x (will be used for tagging), and names , we call a closed context with and (not containing indexed replications) an S-indexing context iff for all processes P with 8
P may have but we forbid to avoid technicalities in the definition of due to the shadowed x.
and we have
In the following, we fix a set of terms containing no names or variables. The set will represent the set of all session IDs. We assume that entails for (different IDs are never equivalent by the equational theory).
Note that not for every set a -indexing context exists. For example, if is not semi-decidable (but the equational theory is), then there is no -indexing context. One might be concerned that our definition of -indexing contexts cannot be fulfilled. The following definition shows that this is not the case, at least if we use suitably encoded bitstrings as SIDs.
Assume that a nullary constructor and unary constructors and are part of our symbolic model. Let be the set of all terms built from , and . Assume furthermore that for in our symbolic model entails . Let
Intuitively, is a factory with parameters xand afor tagged instances of P that realizes the abstract construction of . The following lemma formalizes this fact.
is an-indexing context.
We stress that is just one example of an indexing context. From now on is an arbitrary but fixed set of indexes and an arbitrary but fixed -indexing context according to Definition 5.2. All our results then hold independently of the particular choice of .
We can now finally define in the following definition.
(Indexed replication).
Let P be a process. We define for some arbitrary with . We write for with .
Notice that our definition is a bit more general, we can even write , in this case P will have access to the sid via the variable x. We need this added flexibility in Section 8.3 for the protocol .
Note that since by definition, we can actually think of as being defined as . Our definition, however, has the advantage that is actually a process in the original calculus, the concept of product processes was only used as a tool for defining .
On real-life implementations of. When implementing a process in real life (i.e., in software for actual deployed protocols), a process such as is probably best implemented by a process that listens on c for messages of the form . Whenever such a message is received, a new instance of with session id is spawned, and all further messages with that are routed to that instance of . On the other hand, a process such as cannot be implemented, because such a process would non-deterministically send for all possible . A process , where A and B correspond to processes run on different computers, does not immediately make sense, because if, e.g., A receives a message that spawns a new instance, B would have to spawn a new instance, too, without communication between A and B. Fortunately, we show in Lemma 5.9 below that ; then A and B can spawn instances independently. (Note: when we write several occurrences of , the implicit set is the same for all of them.)
Properties of. The following four lemmas state several important properties of . We will need these to prove the composition theorem below. Lemmas 5.6, 5.7 and 5.9 also hold for ! instead of . But Lemma 5.8 is specific to , and is crucial for enabling the composition theorem.
Let P be a process andbe a permutation on names. Thenfor all variables.
Let P, Q be processes. Thenfor all variables.
Let P be a process and n be a name that occurs only in channel identifiers in P. Thenfor all variables.
Let P and Q be processes. Thenfor all variables.
Out of these four lemmas, Lemma 5.7 was surprisingly hard to prove. We very roughly sketch the proof idea here: The main thing to show is that for arbitrary fixed M. To show this, we define an operation that maps to P, i.e., removes the tag M from all channels. Then we wish to prove that the following relation is a bisimulation: . Once we have that, we see that and hence . Unfortunately, is not really a bisimulation. A bisimulation must be closed under evaluation contexts, even under contexts in which not all channels are tagged with M. To solve this problem, we tweak in such a way that non-tagged channels C are mapped to specially marked channels (using a special name ) which can then be mapped back to C when tagging again. And we need to tweak the notion of a bisimulation slightly, so that only needs to be closed under evaluation contexts on which our operation works properly. These tweaks lead to an unexpectedly complex proof of Lemma 5.7.
Alternative definitions of. Of course, our definition of is not the only possible definition of a replication with session ids. For example, one might try to define in such a way that an instance of P is spawned for arbitrary terms as sessions id, not only terms in some fixed set . In particular, a fresh name could then be used as session id which is not possible with our modeling.9
One needs to be careful with the following situation, though: If is a process with a secret name k, then where stands for without the session id k. That is, a new process has been spawned that “magically” knows the secret name k of Q. One needs to ensure that the name k can never leaks to the outside of , e.g., by ensuring that only communicates with processes that already know k.
Any definition of that satisfies Lemmas 5.6–5.9 would lead to the same composition theorem. (If that definition is applicable only to a certain set P of processes, we additionally need that P is closed under parallel composition, restrictions, renaming, and , and that the definition of ⩽ (Definition 4.3) is with respect to simulators in P.)
The composition theorem. We can now state and prove the composition theorem. It says that if , we can restrict the IO-names, compose in parallel with processes that have disjoint NET-names, rename names (as long as NET- and IO-names are not interchanged), and perform concurrent composition.
(Composition theorem).
Let P, Q be processes with. Then
For any list of nameswe have.
For any process R withwe have.
For any permutationwe haveand.
For any permutationwe have.
If Q is a-stable process,for all variables.
In the following, let be as in Definition 4.3. (They exist because .)
since ≋ is closed under the application of evaluation contexts;
since neither S nor φ contain names from .
W.l.o.g. we can assume and that φ is the identity on . These assumptions guarantee (∗) in the upcoming equations. .
. Therefore, with as simulator, we have . With we have .
since S, φ and do not contain names and thus are not affected by .
Note that is -stable since Q is -stable. Then entails
Thus is a proper simulator for . □
Property preservation
Besides secure composition, the second salient property of the UC framework is the fact that security properties of the ideal functionality automatically carry over to any protocol emulating . For example, a secure channel functionality that takes a message m from Alice and gives it directly to Bob will obviously have the property that m stays secret. Then, if π UC-emulates , any message given to π will also stay secret. A similar property preservation law holds in our case, the following theorem formalizes it.
(Property preservation).
Let P, Q be NET-stable processes with. Letandbe contexts whose holes are protected only by parallel compositions (|), restrictions (ν), and indexed replications (). Assume that,do not contain NET-names (neither bound nor free). Assume that the number of(possibly with different x) over the hole is the same inand.
If, then.
Thus, any security property that can be expressed by an indistinguishability game of the form “” with , as in the theorem will carry over from the ideal functionality Q to the protocol P, given . Note that even many trace based properties can be expressed in such a way. E.g., if we want to say that does not raise an event (modeled by emitting on a special channel), we just define to be like , but without the event. Then implies that does not raise the event.
(Strong secrecy).
We illustrate the use of this theorem with an example. Consider the secure channel functionality in the following definition.
(Secure channel).
We want to show the following lemma.
If, then P has strong secrecy in the following sense: We havewhere.
Let . We use Proverif to show that . The Proverif code is given in Fig. 2. By Theorem 6.1 (and using that ≈ and ≋ coincide for closed processes), we have . □
Proverif code for showing in Lemma 6.3 (prop-pres.pv, see Proverif input files in the Online supplement).
Anonymity properties are modeled very similarly, except that instead of different payloads , , different user ids are provided to the two processes.
(Unlinkability).
The next example is strong unlinkability [1]. This property requires that the adversary cannot distinguish whether every user runs only one session of a protocol, or whether every user runs many sessions. Formally: if we assume that P contains free names , for the user id and the session id. At a first glance, such a property seems to be excluded by the restriction of Theorem 6.1 that , may not have a ! over their hole. This is, however, not the case if protocol P (and the functionality Q) are modeled suitably, namely if P is already a multi-session protocol. For example, if P expects a pair of user id and session id on an IO-channel for each session to be run, then strong unlinkability can be expressed in the following definition.
A protocol P has strong unlinkability iff
Then Theorem 6.1 guarantees that if Q has strong unlinkability and , then P has strong unlinkability.
Notice that if we model a different session id mechanism, we also need a different definition. For example, if P and Q are constructed using the operator, session ids will be part of the channel name (we would have channels such as ). The variant described above seems most realistic for unlinkability, though, because includes session ids in the clear in all network-messages, so constructing unlinkable protocols by concurrent composition of individual sessions using does not seem to work well.
In Appendix A we show that the various restrictions in Theorem 6.1 are necessary. In particular, property preservation for contexts , having a ! over their hole (instead of a ) does not hold. The reasons are similar to those that forbid ! in the composition theorem (cf. Section 5). This is another indication that an operator like is more natural in this context.
Relation to Delaune–Kremer–Pereira
DKP-security. As mentioned in the Introduction, Delaune, Kremer and Pereira [20] have already presented a variant of the UC model in the applied pi calculus. In this section, we describe the differences between their and our model, and why these differences are necessary to achieve stronger security results.
Let ⪯ (observational preorder) be the largest simulation (not bisimulation).
Let P, Q be processes. Then iff there exists a simulator S (a context) such that .
Here a simulator S is an evaluation context subject to certain conditions, see [20], notably that it only binds NET-names.
Notice that in this definition, the main difference to our definition is that P and do not have to be observationally equivalent, but only observationally preordered. (Also, the notion of the simulator S is somewhat different from ours, but not in essence.) The effect of this is that the simulator may introduce additional non-determinism. For example, in our model, if the protocol P can take one out of two actions, the simulator needs to simulate the appropriate action, he thus needs to figure out which of the two actions is taken. With respect to DKP-security, the simulator can just non-deterministically choose which action to take; the observational preorder takes care that the right action is taken in the right situation. This makes simulators for DKP-security much easier to construct and DKP-security into a considerably weaker notion.
DKP-security satisfies similar laws as our notion. In particular, is reflexive and transitive and it satisfies a composition theorem (which differs from ours mainly in that holds, no need to introduce ). They do not state a property preservation theorem. We believe, though, that their DKP-security supports property preservation for certain kinds of trace properties.10
Probably a law of the following kind holds: Assume . Let , and E be a context satisfying certain properties. Then . Compare with Theorem 6.1 which can deal with indistinguishability properties.
The problem with observational preorder. We explain why we believe that a definition based on observational preorder instead of equivalence does not give sufficient security guarantees. We illustrate this by the following example. Consider a simple functionality that is supposed to model an insecure but anonymous channel:
Obviously, this functionality preserves anonymity about whether Alice or Bob sends a message (i.e., whether an input on or occurs). Formally: . (In fact, we even have ≡.) Now consider a naive protocol in which Alice and Bob send their message over distinct channels , . Formally:
Obviously, P does not provide anonymity, it is easy to see that . Consequently (Theorem 6.1), we have as we would expect since P gives less security than .
On the other hand, with respect to DKP-security, P is considered as secure as , i.e., . We use the following simulator: . Then because S relays messages sent on onto or , and the definition of ⪯ makes sure that the message is non-deterministically delivered on the right channel or . Hence .
(With non-rigorous proof).
.
Thus, the security of a protocol in the sense of [20] does not imply that the protocol has the same anonymity properties as the ideal functionality. The same probably holds for other equivalence properties such as strong secrecy etc. We consider this a strong restriction of the notion and thus believe that a symbolic analogue to UC security should use observational equivalence or a similar notion of equivalence.
Why observational preorder? The reader may wonder why [20] use observational preorder instead of observational equivalence, in particular since observational equivalence is the more direct analogue to the indistinguishability in the computational UC framework [9]. We explain the reasons as we understand them (this is based both on explanations in [20] and on our own insights while working on the current result), and due to what definitional decisions we managed to get around those reasons:
It is not possible to model “relays”. That is, if we have a process P that outputs on a channel c, then as a technical tool we might wish to construct a process R (a relay) that forwards all message on c to another channel , i.e., we want . Unfortunately, such a relay does not seem to exist in the applied pi calculus. does not work. Consider, e.g., . Then but . With respect to ⪯, however, we can have relays ().
Why are relays important? One reason is whether a dummy adversary exists. Such a dummy adversary is an adversary that forwards all messages on NET-channels from the protocol to the environment and vice versa. (So, essentially, a relay.) The existence of the dummy adversary is used implicitly or explicitly in most structural theorems (reflexivity, transitivity, concurrent composition). In fact, it seems that when using observational equivalence in [20], one would not even have reflexivity.
We get around this problem by using a slightly different definition of adversaries/simulators (Definition 4.2). In our setting, a dummy can be trivially constructed as where φ just renames the protocol’s NET-channels to the NET-channels that the environment expects the messages on. This simple trick obviates the need for using relays in the construction of the dummy adversary.
The second problem is that one does not get a composition theorem that guarantees when using observational equivalence. However, we believe that this is a natural limitation because we can show that property preservation does not even hold for equivalence-based security properties that replicate the protocol. Thus we cannot expect to get such a composition theorem and simultaneously have property preservation for equivalence properties. We get around this problem by defining a different notion of concurrent composition, using the operator (see Section 5).
Finally, the non-existence of relays is a problem when proving the security of concrete protocols : A typical thing a simulator has to do is to take a message m on a NET-channel and somehow rewrite it (e.g., to ) before sending it on to the environment. This, of course, is a generalization of the concept of a relay. Thus, if relays are impossible, we can hardly expect to construct sensible simulators. This, however, is not true if we pay some attention in the definition of the functionality and obey the following guideline:
Guideline: When designing a functionality, use different names for all NET-channels and, whenever sending something on a NET-channel C, use instead of .
In these cases, will usually work as a relay (e.g., for ).
Example: Secure channels
In this section we apply symbolic UC hands on. We illustrate how our results from Section 5 can be usefully applied in practice to construct a secure channel from the widely known NSL protocol and a PKI. Furthermore, when extending the secure channel to multiple sessions, we present an example for a joint state, i.e., multiple instances of one protocol that jointly use one instance of another functionality. While the original UC model of Canetti [9] requires an additional theorem to handle joint states [15], we can directly use in our case. We used Proverif11
Version 1.88pl1.
for our proofs as much as possible to show how it helps with the verification of various properties in the context of symbolic UC.
In this section, we only consider an example where we assume all parties to be honest (as the goal of secure channels is to protect from an outside adversary). For an example with corruption, see Section 9.
We first define the symbolic model used in this section. The constructors are: , , , , , , and , representing public-key encryption, public and secret keys, symmetric encryption, pairs, hashing, and empty messages, respectively. Encryption has a third argument modeling randomness used for encrypting. More specifically, models a public key encryption using key , plaintext m, and randomness r, and a symmetric encryption using key k, plaintext m, and randomness r. We believe that without the additional randomness argument r would also work in our setting. However, we introduce this additional nonce to help Proverif, which can then better distinguish ciphertexts (e.g., one of the Proverif scripts in the proof of Lemma 8.6 (Fig. 8 in the Online supplement) fails without r due to Proverif’s overapproximation technique). We have no equations in our theory.
Furthermore we have the destructors , , , and , modeling public-key decryption, symmetric decryption, extraction of a public key from a secret key, and extraction of a public key from a ciphertext. (The latter two are not needed in our protocols, but we provide them to make the adversary more realistic.) The behavior of the destructors is specified by the following rewrite rules:
The Proverif code for this symbolic model is given in Fig. 3.
Key-exchange example: Proverif code for the symbolic model (secchan-model.pv, see Proverif input files in the Online supplement).
Key exchange using NSL
With the symbolic model set up we next show how to tailor a UC-secure key exchange from using a PKI functionality . Towards this goal we model the ideal key exchange functionality , the PKI and the protocol based on as follows:
(Key exchange functionality).
(Public key infrastructure functionality).
(Needham–Schroeder–Lowe).
The differences to the original NSL protocol [25] are: The original protocol does not specify what to do with the nonces , , while we use them to derive a key . Also, [25] also presents an extended version of the protocol that explicitly communicates with a server S for getting the keys for Alice and Bob. We could get this extended protocol by proving that this retrieval protocol implements , and then composing our NSL protocol with the retrieval protocol.
We can now state the first result of this section, namely that the is a UC-secure realization of .
.
The proof of this lemma is given in the Supplemental material (Section I.1). We only show the simulator here: , φ the identity, where is without the initial , analogously, and .
Secure channel from key exchange
Next, we realize a secure channel. Since we already have a realization of a secure key exchange at hand, we realize the secure channel from the idealized key exchange . Later we replace by .
The proof of this lemma is given in the Supplemental material (Section I.2). We only show the simulator here:
and .
With (Lemma 8.4) and (Lemma 8.6) at hand we can now use the compositional capabilities of UC: We define an evaluation context where and are the processes from Definition 8.5. Since meets the requirements of Theorem 5.10 implies . Since and we have, by transitivity of ⩽ (Lemma 4.5), .
We did construct a secure channel from a PKI using the NSL protocol. More interesting than this result is the way we achieved it: We did not have to analyze the complete system in one piece but could replace the protocol with an idealized functionality. This illustrates two striking advantages of the UC approach:
The fact that realizes an ideal key exchange can be re-used for security proofs of further systems.
We cannot only plug into but any protocol that realizes a secure key exchange (e.g., if no PKI is available and thus is not an option).
Instead of one monolithic security proof for we end up with smaller proofs and results which can be used flexibly. Furthermore, to split the security analysis of a complex system into smaller parts might be the only feasible option to tackle it at all.
Generating many keys from one
While the example until now illustrates composition and the power of UC, only realizes a single-use secure channel. To transfer multiple messages, we could just use concurrent composition to have . However, the resulting protocol uses one instance of per message, and – since contains , another PKI for each message that is sent. This is clearly unrealistic. To get rid of this overhead we want to have all the instances of to jointly use just one key exchange , i.e., we want to use the previously mentioned joined state technique here. Towards this goal we model a wrapper protocol which uses one key exchange to emulate multiple key exchanges (from a key k it derives session keys where is the session id). Formally, we define as follows and then show .
where .
.
The proof of this lemma is given in the Supplemental material (Section I.3). We only show the simulator here: , and . This proof is the only one in this paper in which we could not outsource all proofs that actually involve the details of the cryptographic primitives to Proverif. This is because Proverif cannot understand , and the lemma relies on the fact that ensures that no two processes with the same session id are created.
Analogously to the single session case we define a suitable context by replacing in with □ and have
Finally, we have a protocol which realizes multiple secure channels while invoking the protocol and using only one PKI.
Virtual primitives
In this section, we present a technique for deriving security of protocols in the symbolic UC model that is specific to the symbolic model. No analogue in the computational world seems to exist. The idea is the following: When constructing UC secure protocols, it is often necessary to include specific “trapdoors” that allow the simulator to extract or modify certain information. For example, when constructing a simulator for a commitment scheme, we need to include in the protocol some way for the simulator to extract the value of the commitment when given a commitment by the environment (extractability), or to change the content of a commitment when producing a commitment for the environment (equivocality), see [13]. These additional trapdoors often make the protocols more complex, and they often also need more complex cryptographic primitives. A simple commitment protocol in which the committer just sends for message m and randomness r is not UC secure because the simulator cannot extract or equivoke. Instead, one would need to assume a special hash function that takes an additional parameter (the common reference string) in such a way that given a suitably chosen “fake” , one can find collisions in or extract m from . With such a hash function, one can construct a UC secure commitment relatively easily (see Definition 9.3 below). However, now our protocol uses a considerably more complex primitive than a simple hash function. And certainly common hash functions such as SHA-3 do not have these properties.
This leads to a strange situation: We have a protocol that we can only prove secure using a hash function that has additional weaknesses (namely that given a “bad” crs, one can cheat). One might be tempted to state that if the protocol is secure for such weak hash functions, it should in particular be secure for good hash functions. Unfortunately, such reasoning does not work in the computational setting: We cannot just remove the existence of trapdoors from the hash function – if we do so, we have a completely different hash function and our security proof makes no claims about that function.
In the symbolic world, things are different. Here it turns out that we can indeed first analyze a protocol using a hash function with trapdoors, and then remove these trapdoors in a later step, still preserving security. We call this approach the “virtual primitives” approach, because we use primitives (in this example a hash function with trapdoors) that do not need to actually exist, and that are removed in the final protocol.
In a nutshell, the virtual primitives approach when trying to realize a functionality (e.g., a commitment) works as follows:
First, identify a symbolic model containing cryptographic primitives (e.g. a hash function) that should be used in the final protocol.
Extend by additional constructors, destructors, or equality rules, call the resulting model . The extension should be “safe” in the sense that in an adversary will have at least as much power as in (this will be made formal in Section 9.2).
Design a protocol P. Show that P emulates with respect to .
Compose P with other protocols, leading to a complex protocol (with respect to ) where is some desired final goal, e.g., some crypto-heavy voting protocol.
Property preservation guarantees that any property ℘ that holds for also holds for (with respect to ). Since only makes adversaries stronger, ℘ also holds for with respect to .
Summarizing, we have constructed a protocol in a modular way such that uses the symbolic model (without any trapdoors) and has all the security properties of the functionality .
The virtual primitive approach is not limited to commitments. But in the following sections, we illustrate it in the case of a commitment protocol. Note however, that the main theorem that allows us to conclude that -security implies -security is formulated for general safe extensions.
A few words are in order why the virtual primitives approach works in the symbolic setting. What is the specific property of the symbolic model – in contrast to the computational one – that makes it possible? In our interpretation, this is due to the fact that a primitive (like hashes) in the symbolic world is a concrete object (i.e., a particular constructor with certain reduction rules and equalities) while in the computational world it is a class of objects (hash functions) that are described by some negative properties (“functions such that the adversary cannot…”). Therefore in the symbolic world, it is possible to formally compare executions using different kinds of a primitive (e.g., hashes with and without trapdoors); executions in one setting can be mapped into executions in the other setting by rewriting the terms sent around. In contrast, in the computational setting, this is not possible: a security result for hash functions with trapdoors has no implications for hash functions without trapdoors – these two are completely different mathematical functions on bitstrings, and it is not possible to rewrite an execution that uses one hash function into an execution using another (in particular if the adversary makes his actions depend on individual bits of the hashes). This difference between the symbolic and the computational setting seems to be the reason why virtual primitives work in the symbolic setting.
Related approaches in the computational model. Although virtual primitives as described above are restricted to the symbolic setting, somewhat related techniques do exist in the computational model. [4,27] show how to circumvent UC impossibility results (such as the impossibility of oblivious transfer, commitment, or general multi-party computation without trusted setup) by giving the simulator additional power. Namely the simulator is allowed to run in (slightly) superpolynomial time. This is in some sense similar to giving the simulator access to additional constructors/destructors for extraction/equivocation as we do. Yet, there are three crucial differences to our setting: First, they can only use primitives that can actually exist computationally. For example, even a superpolynomial-time simulator cannot invert a fixed-length hash function, as part of the input is information-theoretically lost. In contrast, we can add arbitrary properties to, e.g., hash functions by introducing new equations in the symbolic model. Second, their final protocols have to use whatever primitives have been introduced for proof purposes; it is not possible to remove additional properties in the end as done in our approach. Third, their protocols involve advanced cryptographic techniques which makes the protocols considerably more involved and, consequently, inefficient. On the other hand, of course, protocols designed with our techniques are only proven secure in the symbolic model but lack a proof in the computational model – we believe therefore that our and their approaches are incomparable with respect to their advantages and disadvantages.
Realizing commitments
For simplicity, we formulate a commitment functionality where the adversary is not informed that a commitment takes place (when both Alice and Bob are honest). Of course, such a functionality can only be realized if we assume perfectly secure channels between Alice and Bob that do not even allow the adversary to notice or block messages. If our protocols were to use secure channels where the adversary can notice and block communication, we would instead realize a somewhat weaker functionality which notifies the adversary12
Namely, .
(the resulting changes in the proof are orthogonal to the issues of this chapter).
(Commitment).
.
Symbolic model. The symbolic model has constructors , , and (pairs) – means f has arity n –, has destructors , , has no equalities, and has the rewrite rules for , , prescribed by Definition 2.1. This model is quite standard and does not use any cryptography except hash functions ( is binary for convenience only).
As explained above, to construct UC-secure commitments, we need additional “trapdoors” in our equational theory. Let be the symbolic model with the following additions: Constructors , , , , destructor , equation , and rewrite rule .
The Proverif code for this symbolic model is given in Fig. 4.
Virtual primitives example: Proverif code for the symbolic model (virtprim-model.pv, see Proverif input files in the Online supplement).
Notice that if we have a CRS and know n, we can open to arbitrary values. Similarly, if the CRS is and we know n, we can extract m from . These two facts allow us to construct a simulator that does equivocation and extraction.
Note that we introduced two different CRS-constructors for faking, and . It would be tempting to use only one of them, i.e., use the equation and the reduction rule . But then we would have for any terms k, m, r that , so by computing the adversary can derive any term m, thus the adversary will know all secrets. This is clearly not a sensible symbolic model.
The commitment protocol. The protocol we construct uses a crs, so we first need to define the crs functionality that gives a random non-secret value k to Alice, Bob, and the adversary.
(Common reference string).
.
Our protocol is then as expected. To commit to a message , Alice fetches the crs , picks a random r, and sends to Bob. To unveil, Alice sends , so that Bob can check whether h indeed contained these values. We call Alice’s part of the protocol and Bob’s part .
(Commitment protocol).
To show that is a secure commitment protocol, we need to show the following lemma (cf. also the discussion on how to model corruptions in Section 4).
With respect to, we have
Uncorrupted case:.
Alice corrupted:.
Bob corrupted:.
The proof of this lemma is given in the Supplemental material (Section J.1), we only show the simulators for the three cases here:
Uncorrupted case: . φ the identity. .
Alice corrupted:
φ the identity. .
Bob corrupted:
φ the identity. .
We show the corresponding observational equivalences by a sequence of rewriting steps on the protocol, interspersed with automated Proverif proofs for the steps that actually involve the symbolic model (i.e., we do not have to manually deal with the complex symbolic model ).
A note on adaptive corruption
We have only modeled static corruption in our examples, i.e., it is fixed in the beginning of the execution which parties are corrupted. If we were to model adaptive corruption where parties may be corrupted during the protocol execution, we would face an additional challenge (besides the fact that the descriptions of the processes would be much more complex): Since the simulator may have to provide the CRS before he knows whether Alice or Bob will be corrupted, he will not know whether he should use or as CRS. And on p. 27 we explained why we cannot just replace both and by a single constructor because then the adversary would be able to deduce any term. However, this problem can be solved using the conditional destructors supported by Proverif 1.87: we can make sure that the rewrite rule only triggers if for all M, . The resulting symbolic model is shown in Fig. 5. We can show Lemma 9.4 also using this symbolic model by replacing all occurrences of and in the simulators by . Proverif still shows all the necessary equivalences. Although this does not show adaptive security, it shows that the simulator does not need to choose the CRS depending on who is corrupted, giving hope for the adaptive case. We leave that case for future work.
Removing the virtual primitives
In this section, we will consider different symbolic models. Since the relation symbols →, ⇓, ≈, , etc. do not explicitly specify the symbolic model, we use the following convention: When referring to a symbolic model , we write , , , , etc. We say a term (or destructor term) is an -term (or -destructor term) if it contains only constructors (and destructors) from . We call a process an -process if it contains only -terms and -destructor terms.
We have now shown that is a secure commitment protocol with respect to . However, we would like to deduce security of protocols using with respect to . For this, we first need to formalize what it means that is a safe extension of in the following definition.
(Safe extension).
We call a symbolic model a safe extension of a symbolic model iff the following holds:
.
If D is an -destructor term, and M is an -term, and , then there exists an -term with .
For all -destructor terms D and -terms M, we have .
For all -terms M, we have .
The following lemma is relatively easy to show.
is a safe extension of.
The following theorem justifies the above definition of safe extensions.
Assume thatis a safe extension of. Then-terms M, we have P,, we have for all-processes P,we have.
Virtual primitives example: Proverif code for the symbolic model when using constructor (virtprim-model-x.pv, see Proverif input files in the Online supplement). Note that we use the typed Proverif syntax here because Proverif 1.87 does not support conditional destructors in the untyped syntax.
Now we can finally state the following result that derives security of with respect to in any context (we state it generally, though).
Let P,be-processes (representing a protocol and an ideal functionality, e.g.,and). Letbe a safe extension of. Assume that.
Let C be an-context whose hole is protected only byfor IO-names, by parallel compositions, and by !, and that does not contain any NET-names in. Assume thatfor some-process.
Let,be-contexts satisfying the conditions of Theorem6.1(property preservation).
Ifthen.
By the composition theorem (Theorem 5.10), implies . With transitivity and , this implies . Then by the property preservation theorem (Theorem 6.1), implies . Since is a safe extension of , this implies by Theorem 9.7. □
On removing the CRS
Using virtual primitives, we have managed to get rid of the need for trapdoors in our commitment protocol. However, we still use a common reference string. This leads to the question whether the CRS can also be removed from the protocol. We do not answer that question here, but we give some indications as to how it might be possible to remove the CRS, also.
First, the question is whether we can construct a UC secure commitment protocol without using a CRS in the first place (i.e., instead of the protocol from Section 9.1). We know that this is impossible in the computational UC setting (no matter what primitives we use) [13]. Unfortunately, their impossibility result carries over to the symbolic setting in the following lemma.
There are no closed processes A, B and NET-nameswith the following three properties:
.(Uncorrupted case.)
.(Bob corrupted.)
.(Alice corrupted.)
Thus, a UC secure commitment protocol has to be of the form for some functionality , e.g., .
Assume that there are such processes A, B and NET-names .
Then there are simulators , , and such that
for suitable names , , , . The equalities use the fact that does not contain any NET-names.
Let
where c is a fresh name. Intuitively, this context commits to a fresh nonce r, waits until the commit succeeds, then opens the commitment and checks whether the unveiled value is indeed r. For a “good” commitment scheme, this should always be the case. Indeed: By definition of (and using that does not contain IO-names), we have that . By (1) we have and thus .
We now use (2) and (3) to transform into a process that does not use the commitment protocol any more, but instead uses two instances of :
We can show that the RHS of (4) never emits c. Intuitively, this is because E only emits c if it gets r back from the second (via ). However, r is only sent to the first (via ) and only revealed by the first (due to a signal on ) after the second has gotten its value (which E can enforce by receiving on ). Thus the value received from the second cannot be r. To prove this formally, a lengthy calculation is required, we defer it to the Supplemental material (Section J.4). Since the RHS of (4) does not emit c but the LHS of (4) emits c, this contradicts the observational equivalence (4). Thus our assumption was wrong that processes A, B and NET-names as in the statement of the lemma exist. □
However, Lemma 9.9 does not exclude that an approach similar to the virtual primitives approach might work: We first construct a UC secure commitment protocol (again, commitments are just one example), build a complex protocol from it using the composition theorem, and then show that security of the complex protocol implies (non-UC) security of a modification that does not use the CRS. It is likely that this works as the CRS returned by the CRS functionality is just a fresh public name, so instead of the CRS we should be able to just use some fresh (non-restricted) name a.
There is one subtlety, though: When composing the commitment protocol P, we end up with a complex protocol that may use multiple instances of . In particular, if contains , then will contain an unbounded number of -instances. So we cannot replace just by a single name, we will need a way to generate an arbitrary number of fresh values. The obvious way for this is to use something like instead of the CRS that we get from the -instance with session-id (here a is a fresh name).
A lemma roughly like the following conjecture should therefore lead to a method for removing the CRS from a protocol that was produced by UC composition.
Letbe a free constructor (i.e., not occurring in any equations or rewrite rules in the symbolic models). Let P be a process. Let,be contexts. Assume thatdoes not occur in,, P. Let.
Letresult from P by replacing all subterms “” by “”. Thenimplies.
Letresult from P by replacing all subterms “” by “letin Q”. Thenimplies.
Proving (i) is probably considerably simpler than proving (ii). An alternative to proving (ii) could be to make sure that does not contain under a . This could be achieved if we design a commitment protocol P that does not implement , but (compare with Section 8.3). Then a single copy of P would be sufficient in .
We leave further exploration of approaches to get rid of the CRS to future research.
Footnotes
Acknowledgments
We thank Stephanie Delaune for intensive discussions. Florian Böhl was supported by MWK grant “MoSeS”. Dominique Unruh was supported by the European Union through the European Regional Development Fund through the sub-measure “Supporting the development of R&D of info and communication technology”, by the European Social Fund’s Doctoral Studies and Internationalisation Programme DoRa, and by the Estonian Centre of Excellence in Computer Science, EXCS.
Limits for composition and property preservation
In this section, we show that the restrictions of the composition theorem are necessary. More precisely, we show that if , then not necessarily or or or or (for R that has NET-names in common with P, Q). We show that this is not just a limitation of the composition theorem, we show that similar limitations also apply to property preservation. More precisely, property preservation , does not necessarily hold if , contain a bang (!) over their hole, or an input/output over their hole, or an if/let over their hole, or a different number of ’s over their respective holes, or restrict NET-names over their holes, or use NET-names.
The proofs of Lemmas A.5 and A.6 are identical to those of Lemmas A.3 and A.4, except that and are exchanged.
Remember that is syntactic sugar for . So this example is a counterexample for let-statements.
References
1.
M.Arapinis, T.Chothia, E.Ritter and M.Ryan, Analysing unlinkability and anonymity using the applied pi calculus, in: CSF 2010, 23rd IEEE Computer Security Foundations Symposium, IEEE, 2010, pp. 107–121.
2.
M.Backes, B.Pfitzmann and M.Waidner, A composable cryptographic library with nested operations, in: Proceedings of the 10th ACM CCS, 2003, pp. 220–230.
3.
M.Backes, B.Pfitzmann and M.Waidner, The reactive simulatability (RSIM) framework for asynchronous systems, Information and Computation205(12) (2007), 1685–1720.
4.
B.Barak and A.Sahai, How to play almost any mental game over the net – Concurrent composition via super-polynomial simulation, in: Proceedings of the 46th IEEE Symposium on Foundations of Computer Science (FOCS), 2005, pp. 543–552.
5.
J.Bengtson, K.Bhargavan, C.Fournet, A.D.Gordon and S.Maffeis, Refinement types for secure implementations, ACM Transactions on Programming Languages and Systems (TOPLAS)33 (2011), 8.
6.
B.Blanchet, Automatic verification of correspondences for security protocols, Journal of Computer Security17(4) (2009), 363–434.
7.
B.Blanchet, M.Abadi and C.Fournet, Automated verification of selected equivalences for security protocols, Journal of Logic and Algebraic Programming75 (2008), 3–51.
8.
E.F.Brickell, J.Camenisch and L.Chen, Direct anonymous attestation, in: Proceedings of the 11th ACM Conference on Computer and Communications Security, ACM Press, 2004, pp. 132–145.
9.
R.Canetti, Universally composable security: A new paradigm for cryptographic protocols, in: Proceedings of the 42nd IEEE Symposium on Foundations of Computer Science (FOCS), 2001, pp. 136–145.
10.
R.Canetti, L.Cheung, D.Kaynar, M.Liskov, N.Lynch, O.Pereira and R.Segala, Task-structured probabilistic I/O automata, Technical Report MIT-CSAIL-TR-2006-060, MIT CSAIL, 2006, available at: http://dspace.mit.edu/handle/1721.1/33964.
11.
R.Canetti, L.Cheung, D.Kirli Kaynar, M.Liskov, N.A.Lynch, O.Pereira and R.Segala, Time-bounded task-PIOAs: A framework for analyzing security protocols, in: DISC, 2006, pp. 238–253.
12.
R.Canetti, Y.Dodis, R.Pass and S.Walfish, Universally composable security with global setup, in: Proceedings of the 4th Theory of Cryptography Conference (TCC), 2007, pp. 61–85.
13.
R.Canetti and M.Fischlin, Universally composable commitments, in: Advances in Cryptology, Proceedings of CRYPTO 2001, J.Kilian, ed., LNCS, Vol. 2139, Springer, 2001, pp. 19–40, Full version available at: http://eprint.iacr.org/2001/055.ps.
14.
R.Canetti and J.Herzog, Universally composable symbolic security analysis, Journal of Cryptology24(1) (2011), 83–147.
15.
R.Canetti and T.Rabin, Universal composition with joint state, in: Proceedings of CRYPTO 2003, LNCS, Vol. 2729, Springer, 2003, pp. 265–281.
16.
R.Canetti and M.Vald, Universally composable security with local adversaries, in: SCN 2012, I.Visconti and R.De Prisco, eds, LNCS, Vol. 7485, Springer, 2012, pp. 281–301.
V.Cheval and B.Blanchet, Proving more observational equivalences with ProVerif, in: POST 2013, D.Basin and J.Mitchell, eds, LNCS, Vol. 7796, Springer, 2013, pp. 226–246.
19.
A.Datta, R.Küsters, J.C.Mitchell and A.Ramanathan, On the relationships between notions of simulation-based security, in: Theory of Cryptography, Proceedings of TCC 2005, J.Kilian, ed., LNCS, Springer, 2005, pp. 476–494.
20.
S.Delaune, S.Kremer and O.Pereira, Simulation based security in the applied pi calculus, in: FSTTCS, R.Kannan and K.Narayan Kumar, eds, LIPIcs, Vol. 4, Schloss Dagstuhl – Leibniz-Zentrum für Informatik, 2009, pp. 169–180.
21.
D.Dolev and A.C.-C.Yao, On the security of public key protocols (extended abstract), in: FOCS, IEEE, 1981, pp. 350–357.
R.Küsters, Simulation-based security with inexhaustible interactive Turing machines, in: CSFW 2006, Computer Security Foundations Workshop, IEEE Computer Society, 2006, pp. 309–320, Long version available at: Cryptology ePrint Archive: Report 2006/151.
24.
R.Küsters, A.Datta, J.C.Mitchell and A.Ramanathan, On the relationships between notions of simulation-based security, Journal of Cryptology21(4) (2008), 492–546.
25.
G.Lowe, An attack on the Needham–Schroeder public-key authentication protocol, Information Processing Letters56 (1995), 131–133.
26.
J.Müller-Quade and D.Unruh, Long-term security and universal composability, Journal of Cryptology23(4) (2010), 594–671.
27.
M.Prabhakaran and A.Sahai, New notions of security: Achieving universal composability without trusted setup, in: Proceedings of the 36th Annual ACM Symposium on Theory of Computing (STOC), 2004, pp. 242–251.