
Abstract
This paper presents a formal framework for run-time enforcement mechanisms, or monitors, based on probabilistic input/output automata [Task-structured probabilistic I/O automata, Technical Report MIT-CSAIL-TR-2006-060, 2006; Proceedings of the 8th International Workshop on Discrete Event Systems, 2006, pp. 207–214], which allows for the modeling of complex and interactive systems. We associate with each trace of a monitored system (i.e., a monitor interposed between a system and an environment) a probability and a real number that represents the cost that the actions appearing on the trace incur on the monitored system. This allows us to calculate the probabilistic (expected) cost of the monitor and the monitored system, which we use to classify monitors, not only in the typical sense, as sound and transparent [ACM Transactions on Information and System Security
Introduction
A common approach to enforcing security policies on untrusted software is run-time monitoring. Run-time monitors, e.g., firewalls and intrusion detection systems, observe the execution of untrusted applications or systems, e.g., web browsers and operating systems, and ensure that their behavior adheres to a security policy.
Given the ubiquity of run-time monitors and the negative impact they have on the overall security of the system if they fail to operate correctly, it is important to have a good understanding of their behavior and strong guarantees about their correctness and efficiency. Such guarantees can be achieved through the use of formal reasoning.
Schneider introduced security automata [36], an automata-based framework to formally model and reason about run-time enforcement of security policies. Several extensions have been proposed to investigate different definitions of and requirements for enforcement, such as soundness, transparency, and effectiveness (e.g., [25]). A common observation is that once requirements for enforcement are set, more than one implementation of a monitor might be able to fulfill them.
Two examples of common run-time enforcement mechanisms are transport layer proxies and TCP scrubbers [27]. Both of these convert ambiguous TCP flows to unambiguous ones, thereby preventing attacks that seek to avoid detection by network intrusion detection systems (NIDS). Transport layer proxies interpose between a client and a server and create two connections: one between the client and the proxy, and one between the proxy and the server. TCP scrubbers leave the bulk of the TCP processing to the end points: they maintain the current state of the connection and a copy of packets sent by the external host but not acknowledged by the internal receiver. Figure 1 (adapted from [27]) depicts the differences between the two mechanisms in a specific scenario. Although both mechanisms can correctly enforce the same high-level “no ambiguity” policy, the proxy requires twice the amount of buffering as the scrubber, which suggests that the proxy is more costly (in terms of computational resources).
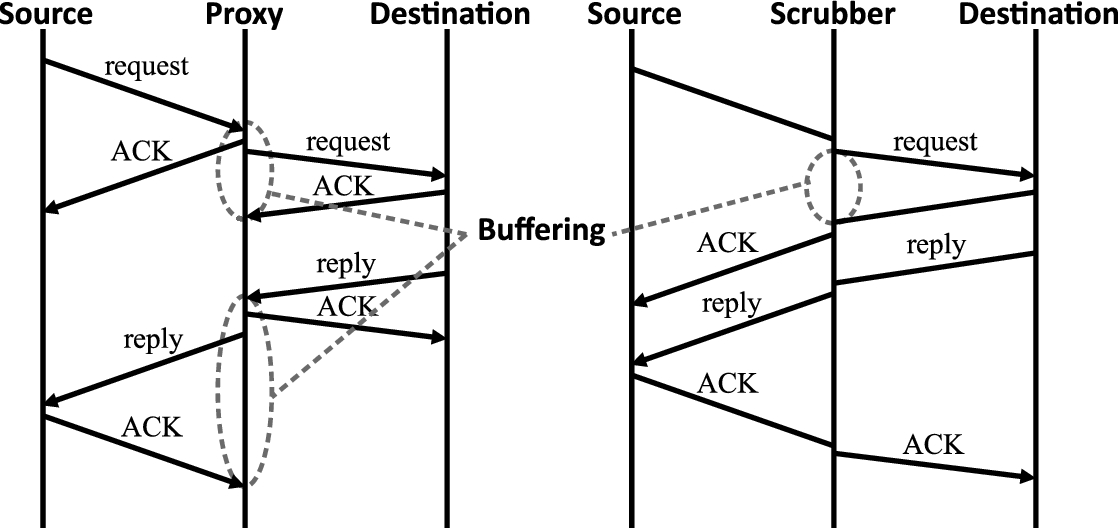
TCP transport layer proxies and scrubbers. The circled portions represent the amount of time that data is buffered.
Recent work has started looking at cost as a metric to classify and compare such monitors. Drábik et al. introduced a framework that calculated the overall cost of enforcement based on costs assigned to the enforcement actions performed by the monitor [16]; this framework can be used to calculate and compare the cost of different monitors’ implementations. This framework provides means to reason about cost-aware enforcement, but its enforcement model does not capture interactions between the target and its environment, including the monitor; recent work has shown that capturing such interactions can be valuable [29]. In addition, in practice the cost of running an application may depend on the ordering of its actions, which may in turn depend on the scheduling strategy.
In practice, when administrators evaluate the cost of enforcing a security policy, they typical take into account, besides costs, the likelihood of attacks or other specific desirable or undesirable events, i.e., a probabilistic model of the system’s behavior. For example, a security policy that describes how to protect a system against different attacks might depend on the probability that these attacks, e.g., a DDOS attack or insider attack, will occur against that particular system. With these probabilities and an estimation of the cost of the impact of the attacks, administrators can calculate the expected costs of the attacks, and then estimate the optimal cost of a monitor to defend against the attacks. For instance, they might decide to invest more resources on a mechanism to defend against DDOS attacks, and fewer resources to defend against insider attacks, because for their systems the former has a higher expected cost.
Running example. As another example (which we will use as a running example in this paper), consider the scenario illustrated in Fig. 2(a). A file server S is hosting a password file with high integrity requirements. Clients (
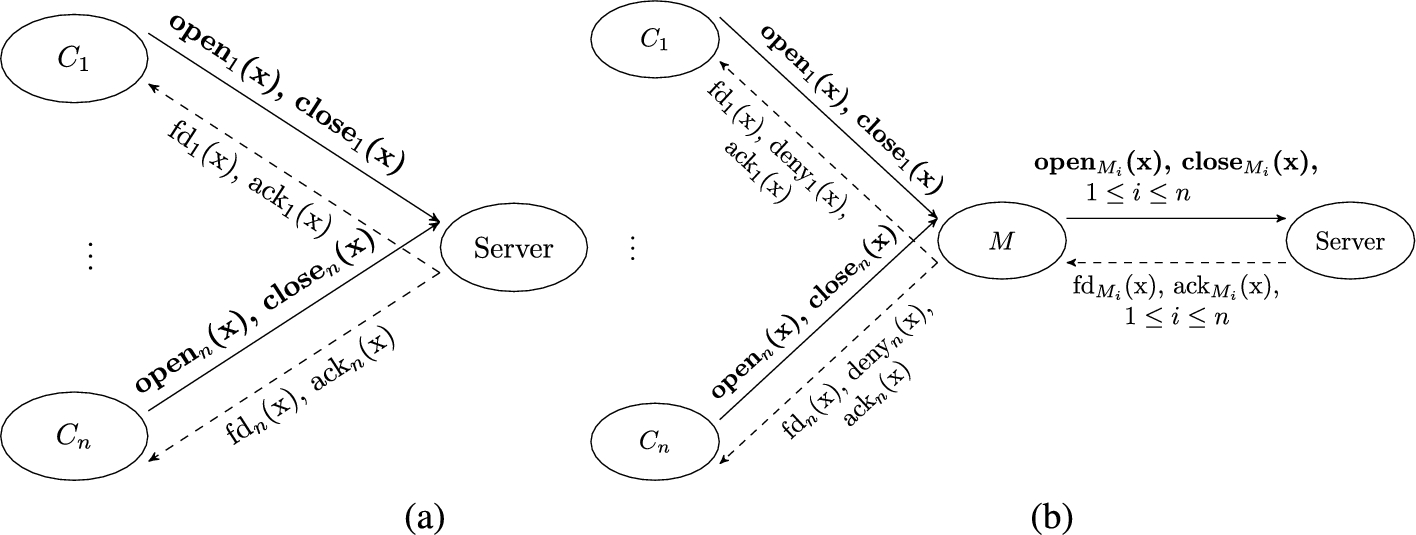
Diagrams of interposing a monitor between clients and server. (a) Clients and server. (b) Clients and monitored server.
Although not depicted in the figure, let us also assume that the users can update their passwords to S. The concurrent access to the file by multiple clients may compromise the integrity of the file. This compromise can incur a high cost to the server (e.g., penalty costs by the SLA, since the clients will not be able to access the file, costs for recovering the file, etc.). In such cases (where multiple concurrent accesses to a file could compromise its integrity), it is typical to require that access to the file is “locked” to at most one client (and user) at a time. This requirement can be seen as a security policy P stating that at most one client at a time can access a particular file. One way to enforce P is to interpose a monitor between the clients and the server, as shown in Fig. 2(b). The monitor has the ability to deny access to a file requested by a client if the file is already in use. Since only one client can access the file at a time, and may use it for an arbitrary amount of time, the most cost-efficient solution for the server is to give priority to clients that make many requests and use the file for the least amount of time. This way, there are fewer denied accesses, and the server has to pay a smaller amount of money.
A monitor can use past usage data to identify clients that make fewer requests and use the file for a shorter amount of time (e.g., because they have fewer users, or fewer services). Through this data the monitor has a probabilistic estimate of the likelihood that a client will request to access the file. Given these estimates, the monitor can optimize its strategy to minimize the expected cost for the server by, for example, giving priority to clients that are more likely to make multiple requests withing a given time frame. Thus, by combining probabilistic knowledge with cost metrics, we are able to reason about, and compare, monitor designs in a way that is closer to how monitors are selected in practice.
Contributions. The main contribution of this paper is a formal framework that enables us to (1) model monitors that interact with probabilistic targets and environments (i.e., targets and environments whose behavior we can characterize probabilistically), (2) check whether such monitors enforce a given security policy, and (3) calculate and compare their cost of enforcement. More precisely:
Our framework is based on probabilistic I/O automata [9,10]. This allows us to reason about partially ordered events in distributed and concurrent systems, and the probabilities of events and sequences of events. We extend probabilistic I/O automata with abstract schedulers to allow fair comparison of systems where a policy is enforced on a target by different monitors. We define cost security policies and cost enforcement, richer notions of (Boolean) security policies and enforcement [36]. Cost security policies assign a cost to each trace, allowing richer classification of traces than just as bad or good. We also show how to encode Boolean security policies as cost security policies. Finally, we show how to use our framework to compare monitors’ implementations and we identify the sufficient conditions for constructing cost-optimal monitors.
In this section we briefly discuss the outline of this paper, the problems that we focus on, how we use our framework to solve them, and, finally, some practical considerations.
In Section 3 we briefly review probabilistic I/O automata (PIOA) [9,10], which we build on in this paper. PIOA allow us to model monitors (as automata) and probabilistic knowledge we have about their environment (as probabilities over transitions). In Section 3.4 we show how to use PIOA to model our running example of the clients, server, and monitor, and how to calculate probabilities of their executions. Typically these calculations rely on probabilistic knowledge about the environment of a monitor.
Obtaining accurate information about the probability of future events is often very difficult. Thus, in practice, these probabilities must be estimated. Sometimes this is accomplished by logging a system’s past interactions with the environment (or obtaining such logs for similar systems) and using this data to infer the probabilities for future events [37]. New, or small, companies might not have access to such data; in this case probabilities can be assigned based on qualitative criteria (e.g., the security manager assigns probabilities based on her experience and knowledge, or uses techniques such as threat categorization [37], or probability ranges rather than point estimates [8]). In this paper we assume that such probabilistic knowledge is available.
In Section 4 we show how to extend PIOA by adding costs to the model. We model costs using the same mathematical representations as probabilities (i.e., measure theory and cones of traces). The addition of costs to PIOA allows us to calculate the expected costs of monitors. These calculations are very similar to the calculations of probabilities described in Section 3.4. We also discuss how one can calculate costs of monitors based on costs of individual events (or actions). This is relevant in practice, since we typically have information about the cost of individual events, from which we can infer or calculate long term costs. For example, we can calculate (or approximate) the running time of a program from knowing how many CPU cycles each individual instruction requires. Similarly to probabilities, calculating the costs of individual events (or executions) depends highly on the specifics of the scenarios we are modeling. For example, the exact cost incurred by a corrupted password file might depend on the existence of a backup, the cost of recovery, the cost of downtime because users cannot access resources, etc. Obtaining and deriving costs of operations bears similar difficulties to the ones we described above for obtaining accurate information on probabilities of future events. Since the goal of this paper is not to examine how such costs can be derived accurately, but rather how they can be used in the context of comparing monitoring designs, we will assume that such costs have already been derived.
As we discussed in Section 1, one of the goals of this paper is to allow us to choose which of two monitors – both of which may correctly enforce a security policy – minimizes or maximizes some cost of interest. For instance, in our running example, if we have two monitors that correctly enforce the given security policy, we may want to know which one minimizes the average number of clients who are denied access to the file (because some other client has already gained access). Before discussing how to compare two monitors, we need to define what it means for a monitor to enforce a security policy. This is the goal of Section 5. Previous work has focused on policies that classify executions of a system as either valid or invalid [36]. Since one of our goals in this paper is to compare monitors, we extend the definition of a security policy to a more granular one that classifies monitors (and their executions) according to their expected costs.
Finally, in Section 6 we show how monitors that have been modeled in our framework can be compared in terms of expected costs. To compare monitors we introduce some technical machinery, such as abstract schedulers (a contribution of this paper). These tools are necessary to overcome difficulties that often arise in frameworks that deal with interaction, probabilities, and costs. We show using our framework that under certain constraints, a monitor can be the optimal one for enforcing a particular security policy. We also discuss sufficient conditions for the construction of such optimal monitors. Our goal is to emphasize both the existence of optimal monitors, and that, in the general setting, there might be no automated way or algorithm to construct optimal monitors (unless the scenarios under consideration are sufficiently constrained). In practice, this means that we cannot have a generic algorithm that will take as input a security policy, probabilistic knowledge about the environment, and cost estimates of attacks and defenses, and will output a monitor that minimizes (or maximizes) the expected cost for enforcing the given policy. However, the constraints we identify using our framework apply to many practical applications, which means that there are many real-world scenarios in which we can construct (verifiably) optimal monitors.
Background
We introduce our notation in Section 3.1 and then in Section 3.2 briefly review probabilistic I/O automata (PIOA) [9,10], which we build on in this paper: more details can be found in standard PIOA references, e.g., [9,10]. In Section 3.3 we extend PIOA by introducing the notion of abstract schedulers, which we use in the cost comparison of monitors in Section 6. Finally, in Section 3.4 we show how to use PIOA to model practical scenarios through a running example that we will use in the rest of the paper to illustrate the main ideas of our framework.
Preliminaries
We write
A σ-field over a set X is a set
A probability measure on
A support of a probability measure μ is a measurable set C such that
A signed measure on
Given two discrete measures
If
A function
Probabilistic I/O automata
An action signature S is a triple of three disjoint sets of actions: input, output, and internal actions (denoted as
Given a signature S we write
A probabilistic I/O automaton (PIOA) P is a tuple
Given a PIOA P, we write
If a PIOA P has a transition
A non-probabilistic execution e of P is either a finite sequence,
We write
The trace of an execution e, written
The symbol λ denotes the empty sequence. We write
An automaton that models a complex system can be constructed by composing automata that model the system’s components. When composing automata
a is enabled in some
for all
Schedulers. Non-deterministic choices in P are resolved using a scheduler. A scheduler for P is a function
A scheduler σ together with a finite execution e generates a measure
0, if
1, if
Standard measure theoretic arguments ensure that
For full details the reader is referred to [9]. The measure of a cone of an execution e corresponds, intuitively, to the probability for e to happen.
We note that the
In this section we introduce abstract schedulers, a novel extension of PIOA and one of the contributions of this paper. Abstract schedulers are used in the cost comparison of monitors (Section 6). Schedulers, as defined above, assign probabilities to specific PIOA and their transitions. Thus, one scheduler cannot be defined for two different monitors. As we discuss in Section 6, there are certain difficulties when trying to fix a scheduler for two different monitors even if they are defined over the same signature. We overcome these difficulties, by introducing abstract schedulers that are defined for all possible traces over a given signature. These abstract schedulers can then be refined to schedulers for particular PIOA.
Given a signature S, an abstract scheduler τ for S is a function
Note that the term “trace” is overloaded: it refers to either the result of applying the function
An abstract scheduler τ together with a finite trace t generate a measure
0, if
1, if
Standard measure theoretic arguments ensure that
Refining abstract schedulers. Abstract schedulers give us (sub-)probabilities for all possible traces over a given signature. However, a given PIOA P might exhibit only a subset of all those possible traces. Thus, we would like to have a way to refine an abstract scheduler τ to a scheduler σ that corresponds to the particular PIOA P and is “similar” to τ w.r.t. assigning probabilities. This similarity can be made more precise as follows. First, if an abstract scheduler τ assigns a zero probability to a trace t, then this means that t cannot happen (e.g., the system stops due to overheating). Thus, even if t is a trace that P can exhibit, we would like σ to assign it a zero probability. Second, assume we have a trace t that can be extended with actions a, b, or c, and an abstract scheduler τ that assigns a non-zero probability to all traces
Given an abstract scheduler τ over a signature S, and a PIOA P with
Let if if otherwise,
where
Given an abstract scheduler τ and a PIOA P, standard measure theoretic arguments ensure that if τ together with a finite trace t generate a probability measure
We now formalize the relationship between schedulers and abstract schedulers. Given an abstract scheduler τ over a signature S, and a PIOA P with
To illustrate how our framework can be used to model enforcement scenarios we will show how to model the running example introduced in Section 1 (illustrated in Fig. 2(b)), using PIOA.
Each client

Client i PIOA definition.
The pseudocode3
We use the precondition pseudocode style that is typical in I/O automata papers (e.g., [9]).

Server PIOA definition.
To further illustrate some of the capabilities of our framework we introduce two example types of monitor:
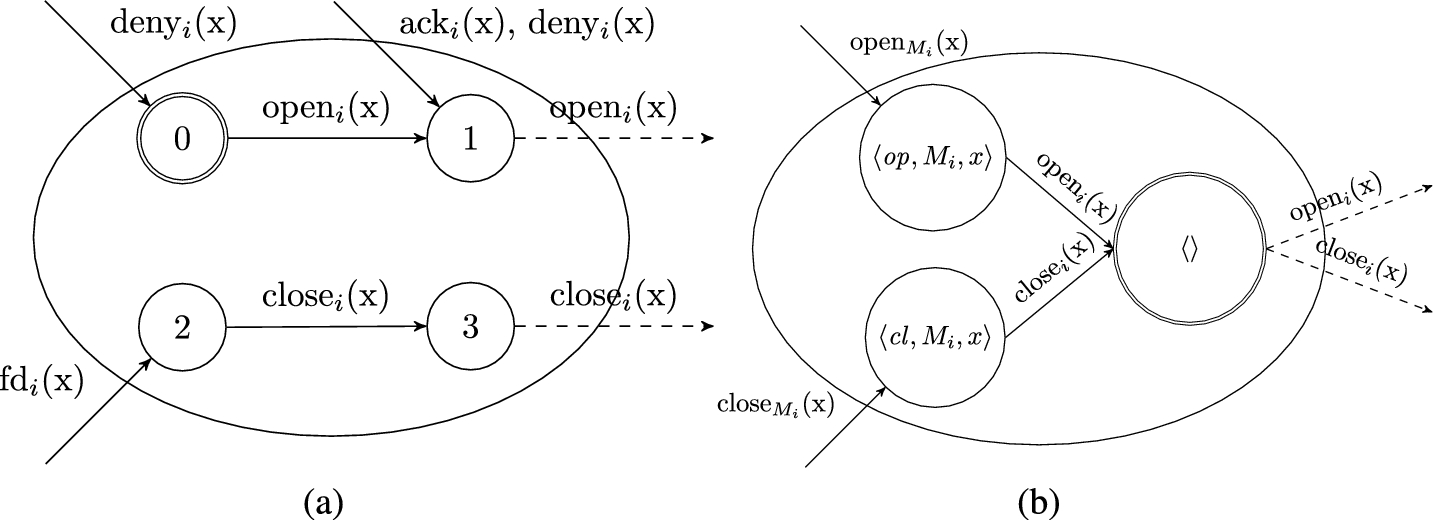
PIOA state transition diagrams. (a) Client PIOA state transition diagram. (b) Server PIOA state transition diagram.

The pseudocode for

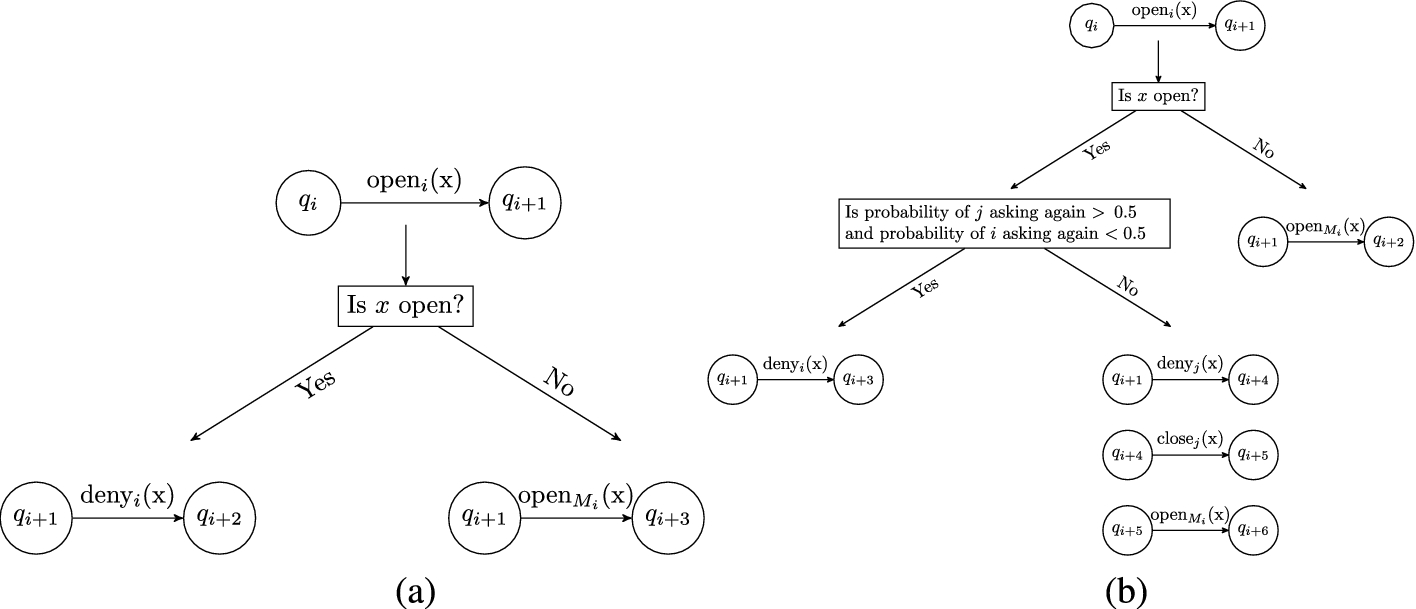
Decision diagrams. (a) Monitor
Let us now consider the composed system
The corresponding traces are:
In
Let us consider the scheduler σ that schedules transitions based on the following high-level pattern:
Let us assume that σ chooses each client to take a turn with probability
If we were to consider the execution
In this section we develop the framework to reason about the cost of an automaton P.
A cost function assigns a real number to every finite and infinite trace over a signature S, i.e., every possible sequence of external actions of S. More formally:
A cost function
Given a signature S one can construct such an automaton
Remember that a cone
Note that in this paper we use the word cost to refer to both expenses and profits. For instance, one can use positive values of costs to possibly represent something you pay (i.e., an expense) and negative values of costs to represent something you gain (i.e., profit). The use of the word when describing practical examples will be clear from the context.
We calculate the expected cost of a trace, called probabilistic cost, by multiplying the probability of the trace with its cost. More formally:
Given a scheduler σ and a cost function
Probabilistic costs of traces can be used to assign expected costs to automata: the probabilistic (i.e., expected) cost of an automaton is the set of probabilistic costs of its traces. However, it is often useful for the cost to be a single number, rather than a set. For example, we might want to build a monitor that does not allow a system to overheat, i.e., it never goes above a threshold temperature. In this case the cost of an automaton (e.g., the composition of the monitor automaton with the system automaton) could be the maximal cost of all traces. Similarly, we might want to build a monitor that “cools down” a system, i.e., lowers a system’s temperature below a threshold, infinitely often. Here we could assign the cost of an automaton to be the minimal cost that appears infinitely often in its (infinite) set of traces, and check whether that cost is smaller than the threshold. It is clear that it can be beneficial to abstract the function that maps sets of probabilistic costs of traces to single numbers. We formalize this as follows.
Given a scheduler σ and a cost function
Note that the definition is parametric in the function
As an example, consider the infinite set
For the rest of the paper we will assume that
Note that if we were to assign costs to actions
Next, we show how one can define the cost of a system given cost functions for its components.
Assume that we have cost functions for the clients, the monitor, and the server (resp.
More formally:5
We use addition as the function between costs of actions in the trace. One can define appropriate cost functions by using other functions
Remember, λ denotes the empty trace.
The probabilistic cost of a trace and the probabilistic cost of an automaton are now defined, as above, using the cost function
One can alternately define the cost of a system based on costs assigned to smaller components. For example, we can define cost functions over individual actions (or transitions) and use them to define the cost of a trace, and the cost of an automaton. In this case, the cost of traces would be independent of the interleaving of transitions (unless we define costs over transitions and use some coding trick, e.g., allow states to encode the trace history). This approach is similar to the definition of
In this section we define security policies and what it means for a monitor to enforce a security policy on a system.
Cost security policies. A monitor M is a PIOA. A monitor mediates the communication between system components
By assumption, M and S are compatible. In scenarios where this is not the case, one can use renaming to make the automata compatible [9,10,29].
The cost function defined in Section 4 describes the impact of a monitor on a system. A cost function is not necessarily bound to a specific security policy, which allows for the analysis of the same monitor against different policies. In practice, a monitor’s purpose is to ensure that some policy is respected by the monitored system. In the running example, the monitor’s role is to ensure that a file is not simultaneously opened by two clients. Furthermore, since each
Given a (monitored) system
Remember
When we talk about the signature, actions, etc. of
Given a cost security policy
Cost security policy enforcement. In Section 4 we showed how to calculate the expected cost of a trace of an automaton, and the expected cost of an automaton. In the previous paragraph we defined the notion of a (probabilistic) cost security policy. We will now define what does it mean for a monitor to enforce a cost security policy on a system.
Given a scheduler σ, a cost function
We say that a monitor M
The definition of enforcement says that a monitor M enforces a policy
Enforcement is defined with respect to a global function
In the previous instantiation of our running example, there might exist some trace t where
A question a security designer might have to face is whether it is possible, given a Boolean security policy that describes what should not happen and a cost policy that describes the maximal/minimal allowed cost, to build a monitor that satisfies both. This problem can help illuminate a common cost/security tradeoff: the more secure a mechanism is, the more costly it usually is.
There is a close relationship between Boolean security policies (e.g., [36]) and cost security policies: given a Boolean security policy there exists a cost security policy such that if the cost security policy is n-enforceable then the Boolean security policy is enforceable as well (and vice versa). Specifically, given a Boolean security policy P, we write
In the other direction, since cost security policies are more expressive than Boolean security policies, we need to pick a bound that will serve as a threshold to classify traces as acceptable or not. Given a probabilistic cost security policy
Expressing cost security policies as Boolean security policies allows one to embed in our framework a notion of sound enforcement [25]: a monitor is a sound enforcer for a system S and security policy P if the behavior of the monitored system obeys P. As described above, one encodes P in our framework as
Transparent cost enforcement. Assume that we are given a scheduler σ, a cost function
Previous work on run-time enforcement has identified (similar) situations where trivial monitors enforce (Boolean) policies by consuming all inputs and denying all actions the target system wants to execute [18,22,24]. Transparency is one notion that aids in ruling out such uninteresting cases: if the target system wants to perform an action that obeys the policy, then the monitor must allow it. Most definitions of transparency that have been introduced so far are within frameworks where policies reason only about the target’s behavior [25,36]: a policy is a predicate over traces of the target (i.e., a subset of the traces that the target might exhibit) and not over traces that the monitored target can exhibit through the interaction of the monitor with the target.
In this paper we take a (more general) view, that has been recently introduced, which allows policies to describe how monitors are allowed to react to target’s requests [26,29] (in addition to considering policies which reason about cost). Thus, enforcement is now implicit in the definition of a policy (i.e., in the traces that the policy allows). This means that we can define transparency as a specific type of interaction between the target and the monitor.
Since our definition of policies is more expressive than previous ones with respect to the interaction between the target and the monitor, to talk about transparent enforcement we first need to encode previous definitions of policies (i.e., sets of traces by a target) in our framework [28]. The main idea is as follows: given a policy that describes which target’s traces are allowed, we build a policy (over the monitored target) in which every valid trace of the target is “forwarded” by the monitor to the environment (and vice versa). The way that the “forwarding” can be achieved by the monitor depends on the notion of fairness that we assume in the model: if the monitor is not allowed to finish forwarding the valid trace of the target then it will not achieve transparent enforcement, even though the same monitor under different circumstances would be transparent. Thus, we need to choose a notion of transparency depending on whether we assume fairness in our model or not [28]. In the framework of this paper (weak) fairness can be encoded by schedulers that do not assign zero probabilities to steps of an automaton from a given state (if such steps are defined in the transition relation of the automaton). Once we have encoded (Boolean) policies of targets and a notion of transparent enforcement as a (Boolean) policy over monitored targets, we can use the translation described previously to derive a cost policy and talk about cost transparent enforcement. This process has some technical nuances but it is straightforward to implement and we will not pursue it more in this paper.
Given a system S, a function
To meaningfully compare monitors, we need to fix the variables on which the cost of a monitor depends, i.e., functions
To overcome this difficulty we rely on the abstract schedulers introduced in Section 3.3. Namely, to compare two monitored systems we use a single abstract scheduler which we then refine into schedulers for each monitored system.9
An abstract scheduler τ also provides a meaningful way to compare monitors with different signatures: calculate the union S of the signatures of the two monitors and (1) use a τ with signature S, and (2) extend each monitor’s signature to S. This is useful when comparing monitors of different capabilities, e.g., a truncation and an insertion monitor [24], where the insertion monitor might exhibit additional actions, e.g., logging.
Abstract schedulers allow us to “fairly” compare two monitors, but additional constraints are needed to eliminate impractical corner cases. To this end we introduce fair abstract schedulers.
An abstract scheduler τ over the signature of a class of monitored targets
Constraint (1) ensures that a fair abstract scheduler will not starve the monitor, i.e., the monitor will always eventually be given a chance to enforce the policy. We do not impose the stronger requirement that the monitor intervenes at each step that the target takes. This is because, in the context of comparing two monitoring strategies that enforce a security policy over a given target, the requirement for the monitor to intervene at each step would exclude some potentially cost-efficient, but still sound, strategies. For example, assume that checking a target’s security relevant action incurs a fixed cost. If a given target can misbehave only on every other security relevant action, then a monitor that checks every target’s action is going to incur a higher cost than a monitor that only checks every other action. For that particular target, the second monitor can still enforce the security policy.
Constraint (2) ensures that the abstract scheduler is not biased towards a specific monitoring strategy. For example, an unfair scheduler could assign zero probability to arbitrary monitoring actions (e.g., the scheduler “stops” insertion monitors [24]) and non-zero probability to monitors that output “valid” target actions verbatim (i.e., the scheduler allows suppression monitors [24]). Such a scheduler would be unlikely to be helpful in performing a realistic comparison of the costs of enforcement of an insertion and a suppression monitor. Note, that an abstract scheduler could still assign zero probabilities to all possible monitors. This allows us to model highly adversarial scenarios, such as the case where the attacker has control over the operating system and can stop the execution of a monitor at will.
There might be scenarios where such schedulers are appropriate,10
This is a similar situation with having various definitions for fairness [23].
Note that, in our model, there are two ways for adversarial behavior to appear. First, the attacker is one of the clients, i.e., the attacker provides inputs to the monitor. In principle, the attacker could attempt to drive the higher-cost behavior of a program through carefully crafted inputs. But, in this paper we do not consider an explicit, active attacker. Instead, we consider the cost of a monitor that interacts with many clients, each of which has the potential to perform some actions that would violate the security policy if there was no monitor to prevent that. By modeling the clients (i.e., the environment of the monitor) probabilistically, we represent a mixed population of clients, consisting of: honest clients that never try to perform any non-secure action; honest clients which might attempt to perform a non-secure action by mistake; active attackers, which might try to perform only non-secure actions; and clients which might act differently in different contexts. Of course, an active attacker might cause a huge cost on its own, forcing the monitor to keep performing costly security actions, but, in practice, such a client is balanced by a secure client, whose actions have no cost for the monitor. Hence, in this paper, we present a framework that allows to model the overall expected cost of enforcement, rather than on the worst case scenario, which would assume that each client is an active attacker. Note that modeling the worst case is still expressible in our framework (by modeling each client as an attacker).
Second, the attacker could affect the scheduler (or equivalently, the scheduler could be adversarial). In this case we have made two assumptions. First, the monitor designer “knows” the attacker’s strategy. This is equivalent to stating that the monitor designer designs the monitor for defending against specific attacks. This is typical in the context of security, where a defense is proven secure against a specific attacker or threat model. Second, we assume that the attacker cannot arbitrarily stop the monitor from intervening (Definition 7). If that was the case, then the monitor would be unable to enforce a policy, even though in principle it could.
Given a system S, a function
Running example. Typically, when a monitor modifies the behavior of the system some cost is incurred (e.g., the usability of the system decreases, computational resources are consumed). For instance, building on the running example (Section 3.4), one way monitors can modify the behavior of the system is by denying an access to a client.
Let us assume that each deny action incurs a cost of 1. Then we can define a function
We observe that if we assume that
Also, observe that the last result is sound only under the assumption that schedulers
In this section we discuss the existence of cost optimal monitors and the sufficient conditions for constructing cost-optimal monitors.
A monitor M is cost optimal for a system S and a well order ⊴ if and only if for all monitors
The next proposition states that for any system S a cost optimal monitor exists.
Given a system S there is a cost optimal monitor M
Proofs can be found in the Appendix.
Note that although for every system S we can find a cost optimal monitor M, M is cost optimal for a specific well-order ⊴ which might not be the standard well-order ⩽. For example, if the expected costs of monitored systems take values from the natural numbers then there exists an optimal monitor under ⩽. On the other hand, if the expected costs of monitored systems range over the integers, or real numbers, then there might not exist a cost optimal monitor under ⩽ (although a cost optimal monitor might exist for a different well order ⊴11
For instance, since there are countably many monitors, one can use a bijection that maps monitors to natural numbers and the standard well-ordering of the natural numbers.
Proposition 6.1 guarantees that a cost-optimal monitor exists (for given system S, function
Given two sets X, Y of pairs of traces and real numbers, i.e.,
We say that a function
The next theorem formalizes the intuition that when dealing with monotone functions we can exploit knowledge about the scheduler and the cost function to build cost optimal monitors.
Given
a finite-state system S
a cost assignment
a cost function
a weakly fair
12
As described in Section 5, weakly fair schedulers are the schedulers that do not assign zero probabilities to steps of an automaton from a given state (if such steps are defined in the transition relation of the automaton).
a function
Theorem 6.1 provides a generic description of the conditions sufficient for constructing a cost-optimal monitor. In the constructive proof of Theorem 6.1 we try to find a monitor M such that the (finite-state) monitored system
For example, let us assume that targets are infinite-state systems (i.e., typical programs) that output their own descriptions (i.e., source code). Also, assume that monitors receive the descriptions of targets and output the descriptions of other programs (i.e., they transform programs from one form to another). Finally, assume that our cost policy is that the monitor outputs the smallest program with the same behavior as the target. In this case, an algorithm to construct a cost optimal monitor would amount to a “fully optimizing compiler”, which is known to be undecidable [1].
Running example. We extend the running example from the previous subsection and Section 3.4. We assume that each deny action incurs a cost of 1. We define the function
Now assume we have three clients
Let us assume that
It is worth noting that, with such a system, we still have
One important point is that
N-step optimality. In practice, the risk (cost-benefit) analysis is a dynamic process: probabilities for attacks to happen (arrival of inputs) are re-evaluated based on the current state of the system (e.g., sudden publicity, or increase in the value of the company), costs might have changed (e.g., the state of the art cryptographic protocols might require more computational resources), and such changes affect the optimality of an enforcement system. Theorem 6.1 gives us a generic description of what conditions are sufficient for constructing a cost-optimal monitor.
However, the assumption of having schedulers and cost functions that have valid information about the future might be too ambitious. Next, we present a special case of the theorem where we only have information about n-steps ahead in the future, where
Given a scheduler σ intuitively we construct a n-step scheduler
Given a scheduler σ, an n-step scheduler
Note that a n-step scheduler
The definition of an n-step abstract scheduler follows that of a n-step scheduler:
Given an abstract scheduler τ over a signature S, an n-step abstract scheduler
Given a cost function
Given a cost function
We calculate the n-step probabilistic cost of a trace as described in Section 4, i.e., by multiplying the probability of the trace with its cost. Note that when a trace has length larger than n then its n-step probabilistic cost will be zero. Although we could have defined the (expected) cost of such a trace to be undefined (e.g., ⊥) rather than a concrete value, we set up our definitions in such a way that this value does not cause any conflicts when the expected costs of traces with length less than n is also zero. In the alternative case we would have to adjust many definitions and calculations, e.g., those of measures, with significant notational overhead.
Given a function
Given a system S, a function
A monitor M is n-step cost optimal for a system S and a well order ⊴ if and only if for all monitors
Now we are ready to state the equivalent of Theorem 6.1 for the case where our information and knowledge is limited for just n-steps:
Given a number
a finite-state system S
a n-step cost function
a n-step abstract scheduler
a function
we can construct a n-step cost optimal monitor for the standard ordering ⩽ of real numbers
Note that a lot of the constraints of Theorem 6.1 have been relaxed. The lack of knowledge arbitrarily far in the future can actually help us to constraint and enumerate the variables that affect cost optimality and thus build an optimal monitor.
Although n-step cost-optimal monitors are practically relevant, they are limited in their capability to optimize the cost of the monitored system on a longer interval than they are supposed to. For example one cannot iterate an n-step cost-optimal monitor and expect to have the same results as using a (infinite-horizon) cost-optimal monitor.
The first model of run-time monitors, security automata, was based on Büchi automata [36]. Security automata observe individual executions of an untrusted application and halt the application if the execution is about to become invalid. Schneider observed that security automata enforce only safety properties, providing the first classification of policies enforceable by run-time monitors. Since then, several similar models have extended or refined the class of enforceable policies based on the enforcement and computational powers of monitors (e.g., [4,19,20,22]).
Recent work has revised these models or adopted alternate ones to more conveniently reason about applications, the interaction between applications and monitors, and enforcement in distributed systems. This includes Martinelli and Matteucci’s model of run-time monitors based on CCS [30], Gay’s et al. service automata based on CSP for enforcing security requirements in distributed systems [21], Basin’s et al. language, based on CSP and Object-Z (OZ), for specifying security automata [5], and Mallios’ et al. I/O automata-based model for reasoning about incomplete mediation and knowledge the monitor might have about the target [29].
Although these models are richer and orthogonal revisions to security automata and related computational and operational extensions, they maintain the same view of (enforceable) security policies: binary predicates over sets of executions. In this paper we take a richer view assigning costs and probabilities to traces and define cost-security policies and cost-enforcement, which as shown in Section 5 is a strict extension of binary-based security policies and enforcement.
Another difference is that some of these models (e.g., security and edit automata [25,36]) assume that the monitor has no information about the future behavior of targets. Other work has introduced models where monitors do have such information about the future behavior, e.g., through access to the source code of the target application (e.g., [22,29]). Our model introduces another source of information that the monitor could have about the future behavior of the target, i.e., expectation about its future behavior. For example, a security manger of a web-server that streams movies, can use data that has collected over a number of days, to build a probabilistic model of future behavior of streaming clients. For instance, it could infer that during, or after, dinner time the requests for movies are really high. Then, if the cost of a DDOS monitor is prohibitive to run continuously, the security manager can make a decision to run the monitor only during rush-hours, and thus minimize its expected costs.
Note that by modeling the system in a probabilistic way, we consider averaging a mixed population of clients consisting of honest clients that behave correctly, honest clients that do not behave correctly by accident, and attackers that always try to violate the policy. In practice, the attacker will try to cause a huge cost by its own, but this cost will be balanced by well-behaved users. Hence, in this paper we try to focus on the expected cost of enforcement, rather than the worst case scenario, which assumes that all clients are actively attacking the system. In practical applications, focusing on the overall cost is often necessary: investing too much into expensive defenses for an unlikely attack can be as detrimental as a successful attack. (That said, our system still allows reasoning about the worst case, by selecting the scheduler and cost function accordingly.)
Drábik et al. introduce the notion of calculating the cost of an enforcement mechanism based on a relatively simple enforcement model, which does not include input/output actions or a detailed calculation of the execution probabilities [16]. To some extent, the notion of cost security policy defines a threshold characterising the maximal/minimal cost reachable, while taking the probability of reaching this threshold into account. Such a notion of threshold is also used by Cheng et al., where accesses are associated with a level of risk, and decisions are made according to some predefined risk thresholds, without detailing how such policies can be enforced at runtime [13]. In the context of runtime enforcement, Bielova and Massacci propose to apply a distance metrics to capture the similarity between traces, and we could consider the cost required to obtain one trace from another as a distance metrics [7].
An important aspect of this work is to consider that a property might not be locally respected, i.e., for a particular execution, as long as the property holds globally. This possibility is also considered, which quantifies the tradeoff correctness/transparency for non-safety Boolean properties [15]. Caravagna et al. introduce the notion of lazy controllers, which use a probabilistic modelling of the system in order to minimize the number of times when a system must be controlled, without considering input/output interactions between the target and the environment as we do [11]. These lines of work are in the scope of going towards a notion of quantitative enforcement [31], where enforcement mechanisms are quantitatively evaluated and decisions made using quantitative analysis, rather than the binary adherence to a policy, in the context of process algebra.
Finally, the idea of optimal monitor is considered by Easwaran et al. in the context of software monitoring [17]. There, correcting actions are associated with rewards and penalties within a Directed Acyclic Graph, and the authors use dynamic programming to find the optimal solution. Similarly, Markov Decision Process (MDP) can be used to model access control systems [32], and the optimal policy can be derived by solving the corresponding optimisation problem. In our context, PIOA provide a more expressive framework to model enforcement scenarios, particularly due to the classification of actions to input, internal, and output. First, PIOA’s state transitions do not have to satisfy the Markov property (i.e., the scheduler can discriminate based on the entire trace and not just the current state of the automaton) and thus they can model strictly more scenarios than MDPs. Second, the classification of actions to those that are under the automaton’s control or those that are not, help us to better model the interaction between a target and a monitor, and the fact that there are target’s decisions that are outside the monitor’s control. Third, PIOA are equipped with a native notion of composition that helps with specifying the interactions between programs that we deal with in this paper. A potential lead for future work would therefore be to focus on Probabilistic I/O Automata that satisfy the Markov property and combine them with MDPs, in order to reuse the computation of optimal policy of the latter within the expressive framework of the former.
Another direction for future work and constructing optimal monitors is to automate the synthesis of monitors by restricting the set of security policies to those that are expressible under a suitable logic. Previous work on run-time monitor synthesis has focused on variations of LTL [3,34,35] and shown how to construct a minimal monitor [6]. However, these approaches do not take into account probabilities, or generalized notions of cost (other than minimizing the monitor’s size [6]). Previous work on synthesis, not for security purposes, that focuses on systems’ synthesis from probabilistic components (e.g., [33]) or synthesis from specifications expressed in Probabilistic Computation Tree Logic (e.g., [2]) might be helpful.
Conclusion
We have introduced a formal framework based on probabilistic I/O automata to model and reason about interactive run-time monitors. In our framework we can formally reason about probabilistic knowledge monitors have about their environment and combine it with cost information to minimize the overall cost of the monitored system. We have used this framework to (1) calculate expected costs of monitors (Section 4), (2) define cost security policies and cost enforcement, richer notions of traditional definitions of security policies and enforcement [36] (Section 5), and (3) order monitors according to their expected cost and show how to build an optimal one (Section 6).
Footnotes
Acknowledgments
This work was supported in part by NSF Grant CNS-0917047, by EU FP7 project NESSoS, by MIUR PRIN Security Horizons, and by the Army Research Laboratory under Cooperative Agreement Number W911NF-13-2-0045 (ARL Cyber Security CRA). The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Army Research Laboratory or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation here on.