
Abstract
In this paper, we consider restricted data sharing between a set of parties that wish to provide some set of online services requiring such data sharing. Each party is assumed to store its data in private relational databases, and is given a set of mutually agreed set of authorization rules that specify access to attributes over individual relations or joins over relations owned by one or more parties. The access restrictions introduce significant additional complexity in rule enforcement and query planning as compared with a traditional distributed database environment. We examine the problem of minimum cost rule enforcement which simultaneously checks for the enforceability of each rule and generation of minimum cost plan of its execution. However, the paper is not focused on specific cost functions, but instead of efficient methods for enforcing rules in the face of access restrictions and inter-party data transfer needs. We propose an efficient heuristic algorithm for this minimal enforcement since the exact problem is NP-hard. In some cases, it is not possible to enforce the rules with the regular parties only. In such cases, we need help of trusted third parties (TPs). If all parties trust a single TP, such a party can enforce all unenforced rules, but it is desirable to use the TP minimally. We also consider the extended case where multiple TPs are required since not every regular party can trust a single TP.
Introduction
Providing rich services to clients with minimal manual intervention or paper documents requires the enterprises involved in the service path to collaborate and share data in an orderly manner. For instance, to enable automated shipping of merchandise and status checking, the e-commerce vendor and shipping company should be able to exchange relevant information, perhaps by enabling queries to retrieve data from each other’s databases. Similarly, in order to provide integrated payment and payment status services to the client, the e-commerce vendor needs to share data with the credit card companies or other vendors that specialize in payment processing. There may even be a need for some data sharing between the payment processing and shipping companies so that the issue of payment for shipping can be smoothly handled.
Traditionally, such cross enterprise data access has been implemented in ad hoc ways. In particular, incoming queries may not be allowed to directly access the databases maintained by a company, and instead handled via some intermediate mechanism. More significantly, cross-enterprise data access is typically driven by bilateral agreements between the two parties that no other party knows anything about. While attractive from isolation perspective, such bilateral agreements introduce a high degree of cost, complexity, and inefficiency into the processes. In particular, bilateral agreements may require more data to be exposed to other parties so that it is possible to answer complex queries that require composition of data from multiple parties. Bilateral agreements also rule out possibilities of sharing computation results between parties. For instance, if the e-commerce company needs to get information involving join of data over three parties (e.g., the e-commerce company itself, a warehouse, and a shipping company), under bilateral agreements, we have to bring the relevant data from the other two parties to the e-commerce company first and then do joins. With multiparty interactions enabled, such data may already be available. The purpose of this work is to explore the general multi-party collaboration model and to develop algorithms for safely implementing the authorization rules so that only desired data can be accessed by authorized parties.
We expect the multi-party data sharing to be driven by twin consideration of business need and privacy; therefore, the rules should grant sufficient privileges for answering the agreed upon set of queries but no more. We assume that the collaborating parties generally trust one another and play by the rules. Typically, this would be enforced through legal and financial provisions in the agreements, but there may still be a need to take the “trust-but-verify” approach. The verification issue is beyond the scope of this paper and will be addressed in future work. The purpose of this paper is to focus on efficient mechanisms for executing queries in what amounts to a distributed database with access restrictions. To the best of our knowledge this is the first work of its kind, even though query planning in distributed databases has been considered extensively.
Although the enterprise data may appear in a variety of forms, this paper focuses on the relational model, with authorization rules specifying access to certain attributes over individual relations and some restricted joins over them. In our model, we only allow certain joins because we consider joins among data from different entities for collaboration, the joinable attributes among these data must be agreed among the data owners along with suitable mapping to make the value syntactically and semantically compatible. In particular, we acknowledge that data sharing across parties brings in the well-known and long-standing problems of differing syntax, semantics, and schemas. We do not presume to solve this very difficult problem, and instead take the view that since the parties are interested in collaboration, they have the incentive to provide suitable interfaces to allow for meaningful composition of data across parties.
For instance, a hospital may join its attribute “patient_id” with the attribute “insured_id” in the insurance company’s data. We assume that the two parties know that these attributes refer to the same entity (identity of a person) and they each provide a “stub”, if necessary, to convert the ID’s to a form where every individual will have the same representation. However, arbitrary joins on non-key attributes will mostly generate useless information for the collaborating entities. Thus, we always assume the join attribute should be at least key of one of the relations, and collaborating parties should pre-define allowed/expected joins and suitable interfaces for them. For simplicity and schema level treatment, we do not consider tuple selections as part of the rules in this paper. The problem then is to find ways of enforcing the rules and constructing efficient query plans.
Since each party is likely to frame rules from its own perspective, the rules taken together may suffer from inconsistency, unenforceability, and other issues. The consistency refers to the property that if a party is provided access to two relations, say R and S, then it must have access to its composition
The enforceability issue can be illustrated as follows: If a party P is given access to
Once the rules have been established to be enforceable, the next question is that of generating efficient plans for queries. A valid query can always be broken up into subqueries each of which is authorized by one of the rules. For each subquery, we ideally want an optimal plan, i.e., a plan with smallest overhead of data transmission among parties and joins at a party. We have examined this problem in [16] where we proposed a fast heuristic algorithm, since the problem of optimal query planning is not only NP-hard (as in traditional query planning literature) but also substantially more complicated because of the possibilities of exchange of partial results among parties.
In this paper we seek a single combined enforcement and query planning algorithm instead of the two different ones studied in [14] and [16]. For this, we consider the rules as queries also – which they are. Basically, the algorithm checks for enforcement of each rule, but uses a cost metric to choose a minimum cost enforcement plan whenever the enforcement is possible. It is important to note here that our focus here is not on formulating the most appropriate cost metric, but rather on efficient enforcement given a suitable cost metric. The key advantage of a combined algorithm is that the plans of all rules can be precomputed and stored, and then simplified for specific queries (by removing retrieval of unnecessary attributes). The algorithm also has some key enhancements so that it is less likely to generate suboptimal query plans. The paper also provides more insights into the single TP case discussed in [15] and extend the analysis to multiple third parties.
The rest of the paper is organized as follows. Following the related work in Section 2, the problem is defined formally in Section 3. This section also illustrates why our problem is more complex than classical query planning and studies its complexity. Section 4 then describes a heuristic algorithm for combined enforcement and query planning and discusses its performance. Section 5 considers the issues in involving single and multiple third parties for rule enforcement and query planning. Section 6 then concludes the discussion.
Related work
The problem of collaborative data access has been considered in the past, and this has inspired our multi-party collaboration approach. In particular, De-Capitani et al. [8] consider such a model and discuss an algorithm to check if a query with a given query plan tree can be safely executed. However, this work does not address the problem of how the given rules are implemented and how the query plan trees are generated. The same authors have also proposed a possible architecture for the collaborative data access in [9] but this work does not address query planning. As we shall show shortly, regular query optimizers cannot be used here since they do not comprehend access restrictions and may fail to generate some possible query plans.
There are also existing works on distributed query processing under protection requirements [5,17] which consider a limited access pattern called binding pattern. It is assumed that the accessible data is based on some input data. For instance, if a party can provide names and ID’s of some individuals, it may be allowed to access their medical records. This is a completely different model from ours. There are also many classical works on query processing in centralized and distributed systems [3,6,12], but they do not deal with constraints from the data owners, which differs from our work.
Answering queries that takes advantage of materialized views is another well investigated research direction. Some of these works focus on query optimization [10] which use materialized views to further optimize existing query plans. In our case, we need to generate a query plan from scratch. Some works use views for maintaining physical data independence and for data integration [18]. They assume the scenario where data is organized in different formats and comes from different sources, and accessing data via views may not provide the complete information to answer the queries. Using authorization views for fine-grained access control is discussed in [19], and [21] analyzed the query containment problem under such access control model. Similarly, conjunctive queries are used to evaluate the query equivalence and information containment, and the work [11] presented several theoretical results. Compared to these works, our data model is homogeneous across the parties, and our authorization model not only puts constraints based on relational views but also the interactions among collaborating parties. Consequently, generating a query plan in our scenario is even more complicated. Some results from these works can be complementary to our work and can be used to further optimize the query plans generated by our approach. However, this is out of the scope of this paper.
In addition, there are services such as Sovereign joins [2] to provide third party join services; we can think this as one possible TP model in our scenario. There is also some research [1,7,20] about how to secure the data for out-sourced database services.
Authorization model
In this section we discuss our basic model for collaborative access control and query processing involving relational databases owned by a number of parties. The model is based on many of the issues discussed informally in Section 1. We will illustrate various concepts using a simple running example, and thus we start with the example first.
A running example
This example describes an e-commerce scenario with five parties: (a) E-commerce, denoted as E, is a company that sells products online, (b) Customer_Service, denoted C, provides customer service functions (potentially for more than one Company), (c) Shipping, denoted S, provides shipping services (again, potentially to multiple companies), (d) Warehouse, denoted W, is the party that provides storage services, and (e) Supplier, denoted as P, that supplies the product to the warehouse. To keep the example simple, we assume that each party owns but one table described as follows. In reality, each party may have several tables that are available for collaborative access, in addition to those that are entirely private and thus not relevant for collaborative query processing.
E-commerce (
Customer_Service (
Shipping (
Warehouse (
Supplier (
The relations are self-explanatory, with underlined attributes indicating the key attributes. In the following, we use
Authorization rules for the running example
Authorization rules for the running example
Beyond access to its owned table, each party may be given additional authorizations, henceforth called rules, that involve data from one or more parties. A rule
We consider a group of collaborating parties each with a sharable relational database (SDB) with collectively known schema. These SDBs are unlikely to be the internal databases maintained by the parties for their private operations; instead they represent “sanitized views” with following characteristics:
Only the columns (attributes) intended to be shared with other parties are included in the SDBs.1
It is also possible that a party wishes to share only those tuples that satisfy certain selection conditions on the shared attributes, but an explicit treatment of this aspect is beyond the scope of this paper.
Each SDB is in a standard form such as BCNF or 3NF.
The schema of SDBs along with syntax and semantics of each column and the functional dependencies (FD’s) are published in a central repository.
Sharing implies that the SDBs across parties will have certain attributes that are intended to represent same semantic entities (e.g., customer ids, part numbers, diagnosis, …). These corresponding attributes are assumed to be explicitly identified across all parties.
Although corresponding attributes could have different names in different SDBs (e.g., “patient_id” for a hospital vs. “insured_id” for insurance company), we can assume, without loss of generality, that they are mapped to identical names.
For any pair of corresponding attributes, say
Two important subcases where the last assumption is required are (a) join across corresponding attributes (since equijoin requires a value comparison), and (b) selections that compare values. For the purposes of this paper, only (a) is relevant. In our running example, this means, for example, that “order_id” in tables E, C, S refer to the same entities and can be treated as having identical representation.
Although the issue of how the representation of and operations on SDBs relate to the operations on internal DBs of parties is an important issue, we do not address it here.
With the above assumptions (including #6), we can allow access rules involving joins on corresponding attributes. Joins on other attributes are likely meaningless and not of much value. We further require that (a) at least one of the two corresponding attribute sets in a join is a key attribute set in its SDB,2
Since a relational key could, in general, include multiple attributes, we need to speak of set of attributes forming the key, or key attribute set for short. For the same reason, we need to speak of join attribute set rather than a single join attribute.
Henceforth we only consider meaningful joins and refer to them as simply joins. We assume that the (meaningful) join schema is known across all parties. The join schemas can be flat or hierarchical, but we do not allow cyclic schemas. Of course, depending on the access rules, only some of the joins may be possible for a given party. We assume that the set of accessible attributes of a relation (single or one obtained via a meaningful join over other relations) always includes its key since access to a relation without access to key is generally not very useful. We also assume all keys to be primary keys; even though our model can handle foreign keys properly, it is unlikely that the collaborating parties will impose foreign key restrictions on one another, and thus we do not explicitly consider foreign keys. Now we can formally define the notion of join path as follows:
A join path
According to this definition,
As stated earlier, the rules in our model specify accessible attributes over a join path. We specifically disallow tuple selection conditions in rule definitions in this paper; we are currently working on extending our results to include Selections, which will be reported in future work. Our queries will also be limited to simple select–project–join (SPJ) queries, with selections further replaced by access to the attributes mentioned in the selection conditions.
Given the rules that involve join to relations from multiple SDBs, the parties would need to store the relations obtained from such joins. While the intermediate results during the rule enforcement may be stored only temporarily, the one required to enforce the rules may be stored for longer periods instead of recalculating them every time. Such extra relations could be considered as part of the SDB of the party that obtains them. Therefore to distinguish the entire SDB from the original part put up by a party, we called the latter as original SDB.
The relational data model allows several other operations beyond SPJ (select–project–join). A few common operations are union, difference, and intersection of two relational schemas. Since we assume that the schemas are shared, it is trivial to determine what accesses a party has; however, such operations are unlikely to be very useful in a multiparty environment. The same applies to tuple level operations. For example, if we allow a party access to the union of tuples from relations R and S, it is no different than allowing access to R and S individually. If the access is to the intersection, we would first need that R and S have identical schema in the sense of assumptions (1)–(6) in Section 3.2. This is unlikely to be the case in general, although one could easily consider intersection operation for defining consistency and enforceability.
Based on the discussion above, we collect together the key assumptions here to make them more explicit.
Only “meaningful joins” are addressed in this paper; parties could, of course, do other types of joins, but we make no claim about their usefulness in retrieving information, or the additional information leakage produced by them. The schema concerning meaningful joins is known to all collaborating parties. The set of accessible attributes to a party always includes the key attributes. All parties involved are considered cooperative and non-malicious in this paper; therefore, issues of cheating or holding back information are not considered here.
A query can originate from any collaborating party, but will be allowed only if the originating party has adequate accesses to authorize the query. A query q in our model can be represented by a pair
Now let us consider the query authorization. Since we represent all rules explicitly (including the derived rules), the query must have the same join path as some rule, and request no more attributes than the rule allows. We formalize this notion with equivalent join path:
We say that two join paths
Now we can define an authorized query as follows:
A query q is authorized (⪰) if there exists a rule
To be clear, we are not considering query rewriting here. The queries are still evaluated on the original set of relations. Answering an authorized query requires a sequence of operations (i.e., projection, join, and data transfer), each of which must be consistent with the given rules. The specific consistent operation requirements are as follows:4
The notion of an operation being consistent with rules should not be confused with the earlier notion of consistency of the rule set itself. The latter refers to the rules being closed under all meaningful joins.
For a projection (π) to be consistent with the rule set
Join (⋈) is a binary operation where two input relations
Data transmission (→) involves an input relation
If
A query plan for an authorized query
A query plan is naturally organized as an hierarchy starting with the original SDBs of each party and moving up in join path length order. We can consider the plan at intermediate steps as a sub-plan. While such a recursive procedure applies to classical query planning as well, the unique issues in our case include: (a) data transfers among parties to retrieve “missing” attributes, and (b) ensuring that each operation is consistent with the rules. These issues makes our query planning different and more complex than classical distributed query planning as discussed later in Section 3.4. Therefore, our focus is on issues like least expensive ways of retrieving the required attributes rather than the classical issues of indexing, disk accesses, join orders, etc. It is certainly possible to integrate the traditional data access details with our query plans to solve real world problems, but we do not discuss that aspect in this paper.
Since a query is ultimately authorized by a rule, there is a close relationship between queries and rules in our model. In particular, rules can be viewed as model queries themselves, and thus generating efficient plans for enforcing rules is one way of handling queries and is the approach taken in the paper. It allows the plans to be generated ahead of time, and then suitably modified by skipping the retrieval of the attributes that the query does not need.
As an example, consider enforcement of rule
In the context of enforceability, we call a rule as Target Rule
On the same party, we call a join path as a sub-join path of
Generating a consistent plan that answers an authorized query in our scenario is much more complex than the well-studied problem of query planning for distributed databases (without any access restrictions). We illustrate this by an example. Suppose that there are two collaborating parties
In classical query planning, we will generate a query plan tree and try to assign the appropriate operations to different parties. There is no constraint of data access in classical case. Therefore, either party
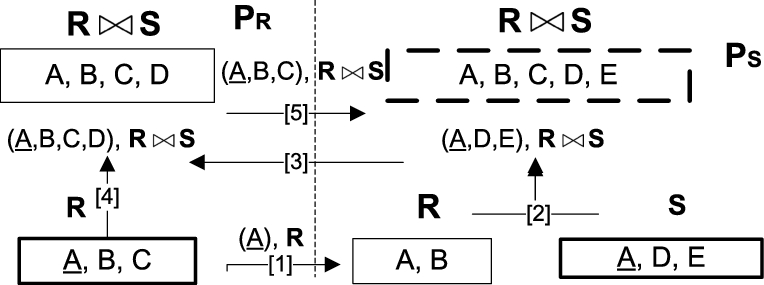
Illustration of query planning.
To generate the consistent plan for answering the query, it is required that we do the semi-join first, and party
It is well known that the optimal query planning in the context of single party database access is NP-hard. The most significant aspect of this classical problem is the order in which the joins should be performed, since the number of tuples in a joined relation depends on the selectivity among the constituent relations. Join Selectivity is a number between 0 and 1.0 that provides an estimate for the size of the joined relation [12] as a fraction of the size of their Cartesian product. While this aspect remains unchanged in our model whenever there are multiple join order possibilities, our main focus is how to provide an optimal enforcement (with respect to joins, data transfers, and attribute retrievals) in the presence of rather complex accessibility constraints. However, as the proof of the next theorem shows, even if we simplify the problem to an extent that is straightforward in a classical query planning scenario, it is still NP-hard with the constrained access in our model.
With any fixed per operation cost metric
Consider two basic relations R and S which can join together, a set of attributes Party Each of the other parties
We note that the above proof maps the set covering problem to a very simple version of our problem – one without complex costs or access restrictions. While these additional complexities would not change the theoretical complexity, they make it more complex to enumerate all feasible solutions. We discuss these and other challenges in the following.
To generate a consistent plan for a query, we first need a plan that enforces the query join path. This can be further joined with other plans to get all the requested attributes. Obviously, in order to consider a join path of length n, one needs to consider all top level join subpaths of lengths k and
An added difficulty is that we cannot just pick the subpaths based on the join or data transfer cost – we also need to pay attention to the attributes that can be accessed by doing the join. For instance, if the goal is to answer
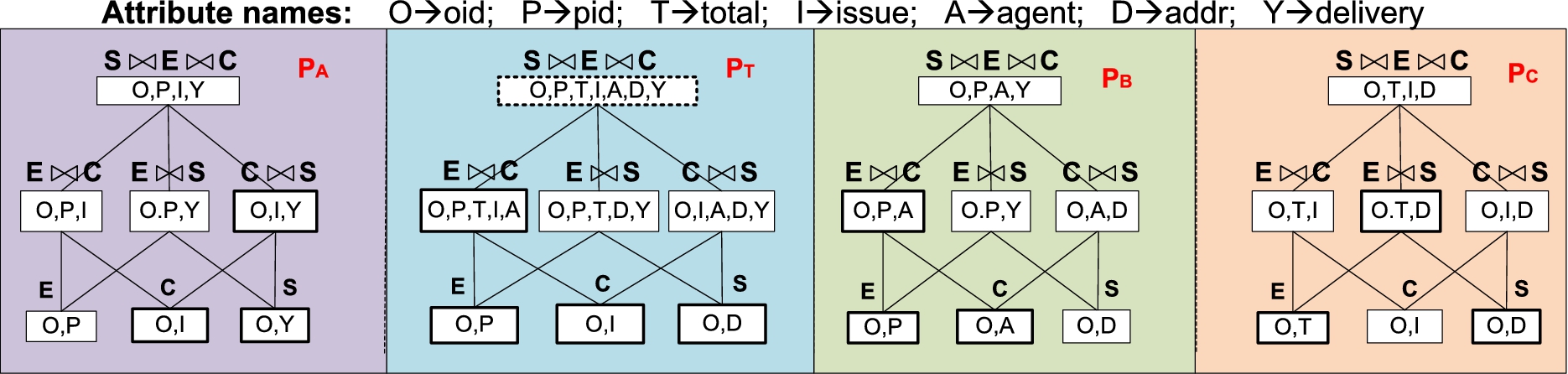
Illustration of enforcement complexity.
In order to show the high complexity of optimal enforcement, Fig. 2 shows a situation crafted based on but not limited to our running example. It considers 3 relations, namely, S, E, and C that can join over the same attribute
In this section we discuss a combined enforcement/query planning algorithm for all rules based on suitable cost assignments. In this process, if we find that some rules cannot be enforced, our algorithm will simply mark them as unenforceable. We assume that the enforcement plans for all rules are derived in advance and stored in a repository. Then at run-time when a query q is received, a simple match over the join path can identify the rule
Enforcement cost considerations
There are two major cost factors in our collaborative data sharing model: (a) cost of data transfer from one party to another, denoted as
As an illustration of our simple cost model, suppose that parties
It is certainly possible to consider a more sophisticated cost model that depends on data size. We describe such a model here but use it only in Section 5.1 in the context of minimum information transfer to third party. For this, we assume that the number of tuples in the relations are known. Assuming that we have the historical statistical information of the tables, so we can estimate the join selectivity and hence the number of tuples. The join cost also depends on a number of other factors including how the matching tuples are found, the size of the index, and whether it involves IO, etc. The data transfer costs include the cost of sending input relations (with suitable attribute projections) to the third party and retrieving the join result. The data transfer costs depend on the number of attributes sent, attribute sizes, and number of tuples, and can often be reduced by using compression techniques. While it is possible to consider all these aspects in our cost model, this will perhaps obscure the insights that are possible with a very simple cost model. Besides, these aspects have been studied amply in the literature.
It is worth noting that even a good estimate of actual transfer/compute sizes may be inadequate if the third party is allowed to do some caching of data. It is reasonable to assume that the TP will retain data for the duration of a query, but may be allowed additional capabilities as well.
Consistent query planning
Due to the difficulties in enumerating all possible ways of answering a query, we develop a greedy algorithm that simultaneously checks for enforcement and generates an efficient query plan for the rules.
The basic approach is to start with rules involving individual parties, i.e., rules of join path length (JPL) of 1, and then systematically go to longer join path lengths. Enforcement of rules with
As the algorithm iterates, it also builds a graph structure capturing the enforceable information and the relationships among the rules. Each node in the graph is an enforceable rule with its maximal enforceable attribute set. All non-enforceable rules and attributes are discarded. Two nodes on the same party are connected if one is relevant to the other. Among different parties, nodes can be connected if they have equivalent join paths. Figure 3 shows part of the built graph for our running example. In particular, party
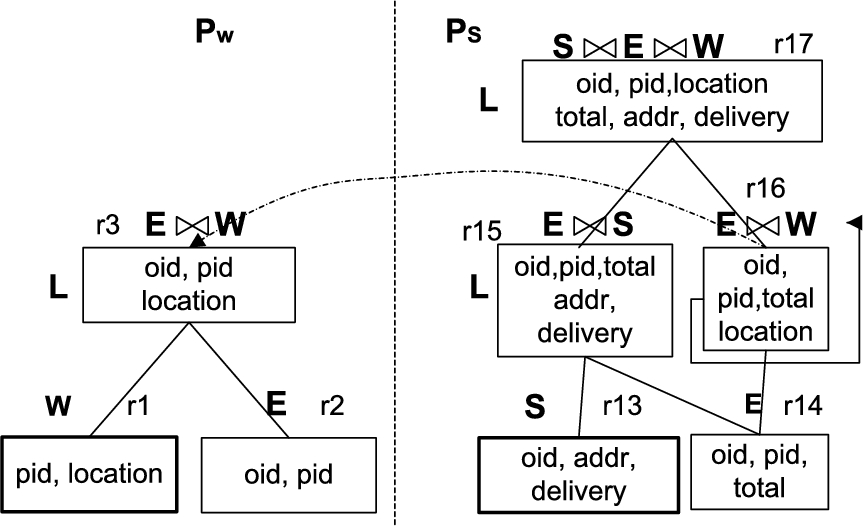
Relevance graph for local enforcement.
The local enforcement attempt of rule

Minimum cost rule enforcement
Algorithm 1 sketches the overall process. The first for loop initializes the cost and marks the rules with JPL (join path length) of 1 as totally enforced. The next “for” loop then steps through each JPL in increasing order. Each target rule
The next for loop, starting at line 17, then tries to obtain missing attributes from other parties for each rule
The last for loop (starting at line 34) is executed after we have gone through all entries in the Queue and thus done with the current JPL value. At this point we do a scan through all the totally enforced rules for current JPL, and check if any rule can be enforced with a lower cost. Note that we no longer consider rules that do not provide all the desired attributes.
The key quantity in the running time of the algorithm is
A query plan generated by Algorithm 1 is consistent with the set of access rules R
Based on our defined notion of consistent operations, the basic operations to enforce join paths are consistent. Each join operation step in the plan is added according to a legitimate local join over the relevant rules, and each data transmission operation happens only between
In order to avoid exhaustive search and hence the exponential complexity of the exact solution, the algorithm takes two short cuts that could potentially lead to suboptimal results in large examples. First, when looking for local enforcement of a rule at level n, the algorithm only considers relevant rules at levels
Now let us turn to the experimental evaluation of the algorithm to compare its performance against the optimal solution. Ideally, this would involve implementing a brute-force algorithm that examines all (exponential number of) possibilities and thereby determines the optimal solution. Unfortunately, as already illustrated above, the brute force solution gets out of hand very quickly. Therefore, we took the following approach for the evaluation. We generated 10 different variants of our running example by changing some rules (i.e., increasing or decreasing the attributes allowed by the rule), or deleting/adding some rules. Then we considered the algorithm generated minimal cost enforcement and optimal cost enforcement for each of the 24 or so rules in each of the 10 variants. In the following we list some of these rules and the costs. To allow for easy interpretation of costs, we assumed that
The rule changes listed in the following are as follows:
Rule enforcement and planning results
Rule enforcement and planning results
Table 2 shows query plans for 10 different cases. Note that in several cases, we are showing the enforcement of the same rule but in the presence of changes to some other (usually lower level) rules as listed. For example, the first 3 rows of the table consider enforcement of Rule
It is clear from the results that the algorithm provides the optimal results in all cases, which means that: (a) the algorithm was able to find total enforcement of rules in all cases, and (b) the enforcement cost was optimal. This is true not only for the 10 cases shown in Table 1, but for all 190 rule enforcements across these variants. In all cases, the algorithm runs in less than 0.1 seconds.
We note that our current (new) algorithm is more thorough than the algorithm in [16]. That algorithm only considers rules at level

New vs. old algorithm for local enforcement.

New vs. old algorithm for remote enforcement.
It was discussed earlier that some rules may be unenforceable. As discussed in Section 3.2 there are 3 situations with respect to a rule: (a) the rule is totally enforceable by the regular parties, (b) the rule is only partially enforceable, meaning that it is possible to generate the desired join path but some attributes on this join path remain unavailable, and (c) the rule is unenforceable in that even the desired join path cannot be generated. In [14] we devised a scheme to minimally enhance the rules with additional attributes so as to make partially enforceable rules totally enforceable. We assume here that such a procedure is already used so that there are no partially enforceable rules. Although in theory one could add additional rules to handle unenforceability as well, this is highly undesirable as it may violate the privacy policies of the regular parties. Instead, we examine the use of trusted third parties to provide the additional accesses necessary for enforcing the unenforceable rules.
It is possible to have many models for TPs, largely depending on the trust issues. The simplest model is a single TP that is trusted by all parties and thus acts as a conduit for doing the joins that cannot be done otherwise. Such a service is intended to be free from any side effects – it simply takes the input relations, returns the join, and then erases everything. If the TP is considered “honest but curious”, it is possible encrypt the fields – perhaps using an order preserving encryption mechanism – but this does not materially affect the mechanisms explored here.
A more complex model is that of multiple TPs such that each of them is trusted by some (but not all) regular parties. In either case, the TPs may be either used only for enforcing unenforceable rules (the original intent), or given an expanded role where some otherwise enforceable rules may be enforced through TP because the latter can do so more cheaply. We will examine both of these scenarios. TPs can be involved even more deeply such as being instructed or allowed to cache data to reduce data transfer overhead, although we do not address such scenarios in this paper.
Minimum cost enforcement through join service
Consider a target rule
In order to enforce
Suppose that the join path of the target rule
Let
In selecting the rule attributes to send to the TP, we need to avoid duplications since rules will generally have several common attributes. However, when to avoid duplicates is a bit complicated. Consider two relations R and S available at parties
Thus, in general, the per tuple cost

Selecting minimal relevant data for TP
Let us now consider the complexity of the problem. Note that our goal is to choose rules so as to cover all required attributes at minimal cost. This is similar to the well-known weighted set covering problem where each rule can cover certain subset of the required attributes and has a certain cost. Such a problem is known to be NP hard, and the best known greedy algorithm finds the most effective subset by calculating the number of missing attributes it contributes divided by the cost of the subset. That is the heuristic algorithm selects the subset
In our problem, with one more rule selected, the TP needs to perform one more join operation, and possibly one more join attribute needs to be transferred to the TP. Therefore, when selecting a candidate rule, we examine the number of attributes this rule can provide and the costs of retrieving these attributes. Note that each time we select a new rule, we need to retrieve the key attribute set to do the join (in addition to the required attributes). Since this increases cost, the algorithm prefers rules providing more attributes and results in fewer selected rules which is consistent with our goal. We present our Greedy Algorithm in Algorithm 2.
We now show some results obtained via simulations. Figure 6 show the relationship between the total number of rules and the number of top level relevant rules that any algorithm would need to consider for enforcement. In the figure, legend “len7, node12” means the target join path length is 7 and there are 12 cooperative parties in total. The most important result is that the number of relevant rules remains rather limited even if the total number of rules grows substantially. The significance of this result is that the complexity of the enforcement is primarily governed by the number of relevant rules, and thus remains constrained. Significantly, this result holds whether or not third parties are used for enforcement. Nevertheless, since the BruteForce algorithm is exponential, the Greedy algorithm presented here is still required. Figure 7 shows this result. While the complexity of greedy algorithm does not change much, the BruteForce algorithm takes off beyond about 15 top level relevant rules.

Number of candidate rules.
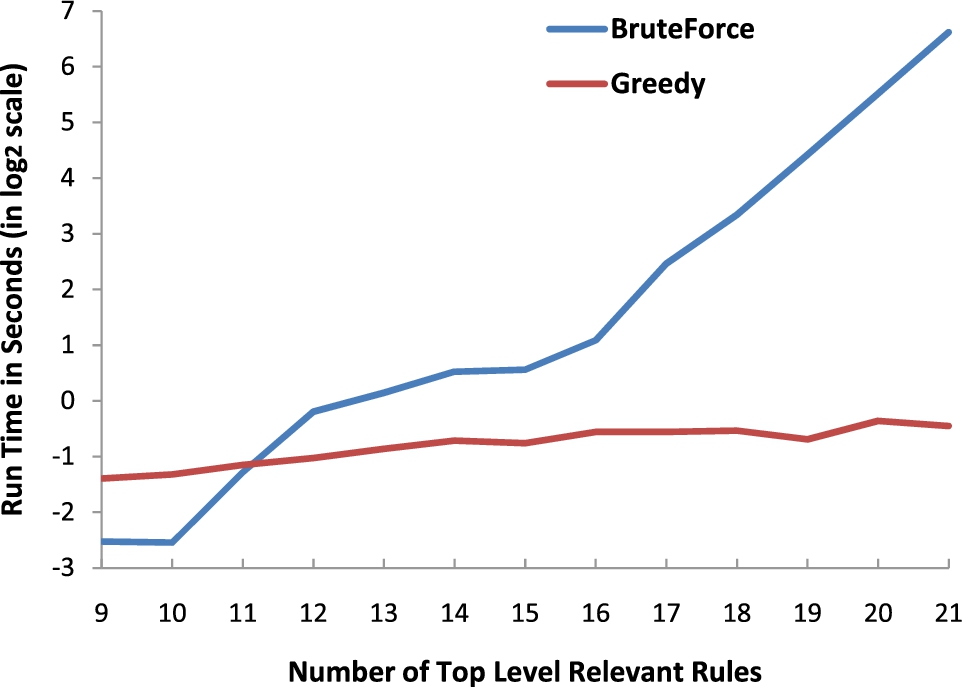
Time comparison between two algorithms.
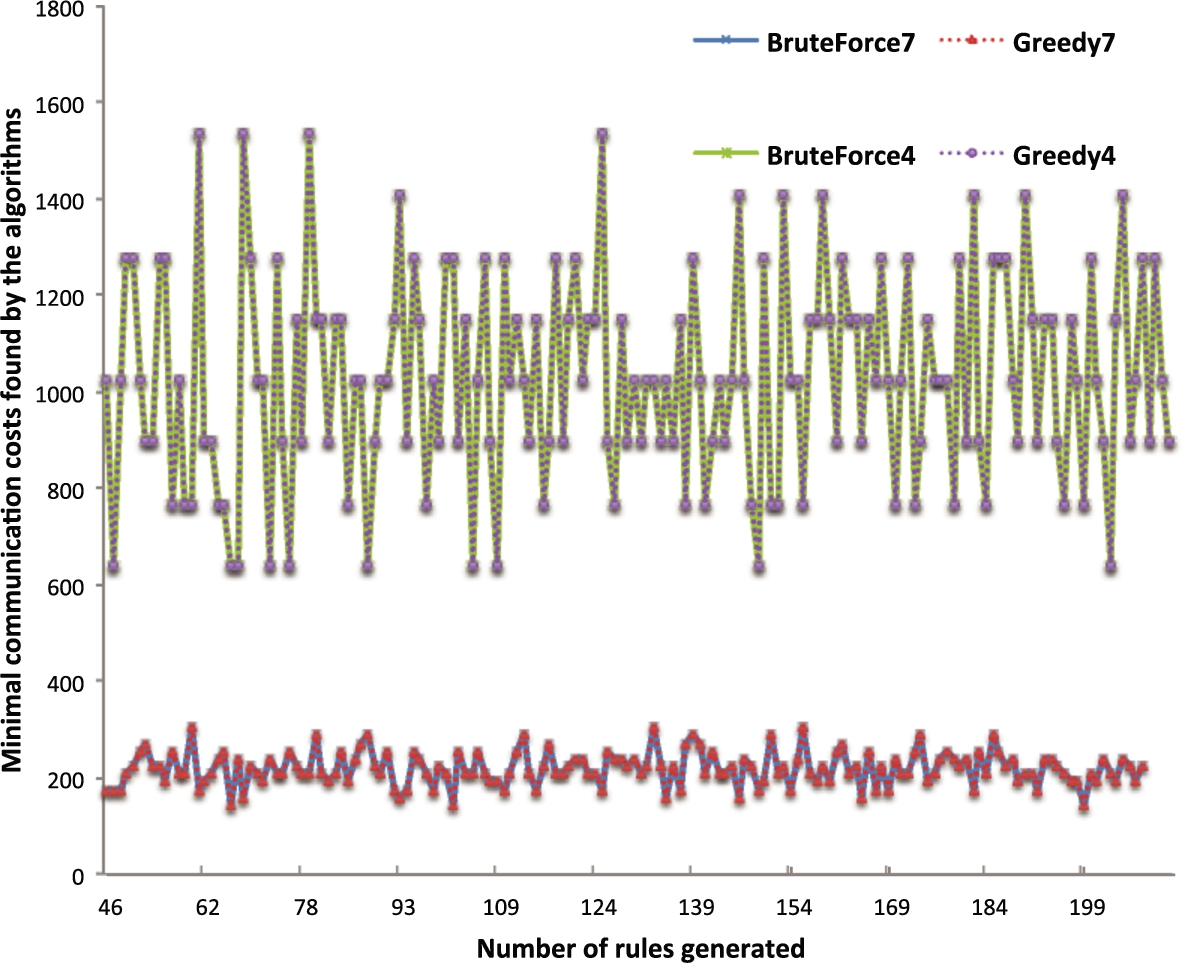
Minimal communication costs found by two algorithms.
In order to compare the performance of Greedy and BruteForce algorithms, we considered a join schema with 8 parties. The number of tuples in a rule is defined as a function of the join path length, basically
There are several reasons why considering multiple TPs may be sensible. First, some regular parties may have established working relationship with certain TPs and thus prefer to involve them. (Obviously, each regular party introducing its own TPs is not helpful; instead, we want much fewer TP’s than regular parties, with the latter trusting 2 or more TPs.) The second reason for multiple TPs is risk reduction – allowing a single TP to access data from many regular parties makes the TP a good target for hacking. The third reason may be related to proximity and cost considerations. Transferring large amounts of data across geographic regions may be slow and undesirable, and different TPs may have different cost structures.
We assume that we have K TP’s, denoted
In Section 5.1, we focused on the problem of choosing the highest level rules to send so that the data transfer to TP is minimized. With multiple TPs, there are two additions issues to consider: (a) choosing among TPs if more than one TP can enforce a rule, and (b) handling situation where a single rule enforcement requires multiple TPs. One way to address Problem (a) is to check for each TP if it can enforce the rule, and then use the cost minimization from the previous section. Problem (b) really does not arise as stated, since it is generally undesirable to allow a direct TP to TP communication. Instead, if a TP should simply return the enforced rule result to the regular party (or parties) that are given access to it. Thus, if these results are needed by another TP to enforce a higher level rule, that TP will still get the rule from a regular party. In other words, if the rules are enforced in the join path length order (as they are), there is no question of going through more than one TP.
If each TP is trusted by only a few regular parties, case (a) is also unlikely. In fact, if several TPs can enforce a rule, that probably implies that we are being indiscriminate about the use of TPs. Thus, instead of extending the TP handling approach of Section 5.1 to multiple TPs, we use a different approach. First, we only consider a simple operation count based cost metric as discussed in Section 4.1. Second, instead of first enforcing all rules that can be enforced without TPs, we consider minimal cost enforcement with TPs also included among the existing parties. Although the TPs are algorithmically treated similar to regular parties in this case, they do not own any data and their costs could be quite different from those for regular parties.
Authorization rules for running example
Authorization rules for running example
Our algorithm for query planning with multiple TPs starts out by including all TPs and regular parties. The rules given to
Table 3 shows sample results for our running example with 4 parties only (i.e., Party P removed) and with all 5 parties. The unit cost of regular party join/data transfer is 1, but the unit cost for the TP is chosen as 0.5, 1.0 and 2.0. The unit cost of 0.5 would give preference to TP and cost of 2.0 would avoid TPs. The total cost reported is the minimum cost for enforcing the highest level rule. The number of third parties is assumed to be 0, 1, or 2. The rules are chosen such that it is possible to enforce them without any third party, but the third party may help as shown in the results. In this example, more than one TP does not help in the 4 party or 5 party case. In general, how much multiple TP’s help depends on how many parties trust them. One would expect that more TP’s would help up to a point, and any additional TPs will only increase the cost. This is because with many TPs, we are likely to have more fragmented trust relationships, and hence it takes more steps to enforce the rules. The higher cost may still be desirable since in these situations we are accommodating the interests of regular parties in terms of using the parties that they can trust. Also, in Table 3, a TP cost of 2.0 does not help at all. The total cost in last 3 rows remains 20.0 since the optimal enforcement does not use any TP’s at all.
In the multiple TP model, we have implicitly assumed that if a two regular parties
In this paper we considered the problem of efficiently enforcing rules and planning queries in a collaborative database environment both without and with the help of third parties. Because of the complexity of the problem, practical algorithms must necessarily be heuristic. We presented such algorithms and showed that they can solve the problem efficiently and effectively.
In this paper we considered rule enforcement with and without third parties. It is possible to explore further variations on this in terms of what sort of operations are outsourced to third parties and which ones are done collaboratively among the original parties. Another issue is that of materializing certain popular joins and allowing the queries to be rewritten using those. In addition to deciding which joins to materialize and how to best exploit them, we also need to consider issues of updating them and accessing them efficiently.
As stated earlier, this paper specifically leaves out the consideration of selection operations in the access rules. This is reasonable in most cases, particularly since a party could decide to share tuples only in certain ranges. However, in general, it may be desirable to share tuples over joins of two or more relations only under certain conditions. For example, consider a party providing customer service in some province (or state) X. Then it may be useful to limit this party to the orders coming from customer belonging to state X as well. It turns out that with suitable restrictions, it is possible to extend the analysis to such cases, provided that the enforceability of the rules can still be determined at schema level.
Another issue glossed over in this paper is the relationship between internal DBs of a party and what it chooses to expose to other parties. This aspect needs a more careful study with respect privacy of individual party’s data vs. collective benefit of sharing. In particular, if parties were free to arbitrarily withhold tuples from sharing, this may cause inconsistencies and seriously limit the value of sharing. As a trivial example, if two parties share tuples in disjoint ranges of some corresponding attribute, a join on this attribute is useless. We plan to address this issue carefully in the future. A closely related issue is to examine ways of detecting compliance of a party to its declared sharing policies.
Finally, we plan to study the cooperative relationships among enterprises in various real world scenarios, and test our mechanisms under these cases.
Footnotes
Acknowledgment
This research was supported by NSF award CNS-1527346.