We study the problem of privately performing database queries (i.e., keyword searches and conjunctions over them), where a server provides its own database for a client’s query-based access. We propose a cryptographic model for the study of such protocols, by expanding previous well-studied models of keyword search and private information retrieval to incorporate a more practical data model: a time-varying, multi-attribute and multiple-occurrence database table.
Our first result is a 2-party private database retrieval protocol. This is the first protocol that preserves query and data privacy on such a practical data model. Like all previous work in private information retrieval and keyword search, this protocol still satisfies server time complexity linear in the database size.
Our main result is a private database retrieval protocol in a 3-party model where encrypted data is outsourced to a third party (i.e., a cloud server), satisfying highly desirable privacy and efficiency properties; most notably: (1) no unintended information is leaked to clients or servers, and only minimal ‘access pattern’ information is leaked to the third party; (2) for each query, all parties run in time only logarithmic in the number of database records; (3) the protocol’s runtime is practical for real-life applications, as shown in our implementation where we achieve response time that is only a small constant slower than commercial non-private protocols like MySQL. This is the first protocol that achieves privacy of database and query content with practical performance.
Finally, we show a second private database retrieval protocol in the 3-party model for which we can show that no unintended information is leaked to an adversary corrupting both clients and third parties, at an only constant additional performance overhead cost.
Current technology evolutions in information computing and storage systems are driven, among other things, by an impressive growth in the amount of generated and collected data (i.e., ‘big data’). This growth is naturally accompanied by critical needs of efficient and scalable procedures for the storage, access and management of massive amounts of data. According to other current and important technology trends (i.e., ‘cloud-based data storage and retrieval’), such data is outsourced to a logical single server (physically implemented as a distributed collection of Internet servers) which has significant storage and computing resources and thus can more reliably and efficiently carry out these procedures. Storage and retrieval of huge amounts of data both with and without outsourcing the data to a cloud server pose significant new functionality and performance challenges to conventional database and storage management systems, which are thus evolving to accommodate these new trends.
Similarly as seen with the enhanced communication methods that became implicit with the use of Internet, the multiple data sharing methods available to today’s computer users pose significant threats to privacy of such data, and ultimately to the individuals themselves. There are many examples of scenarios where user data is currently subject to potential privacy compromise. For instance, in the private sector, most businesses collect users’ information in everyday transactions and services, and store them for a long time. In the public sector, government agencies have been often suspected or even discovered to be very interested in users’ communications as well as transaction data. Moreover, the two scenarios often mix into each other (e.g.: a government agency could be interested in whether the list of individuals boarding a certain airplane contains a specific name from a maintained watchlist).
To partially address privacy needs, database-management systems can use privacy-preserving database retrieval protocols, as investigated in current security and cryptography research. In these protocols, a server holds a database, and a client submits a query and receives matching records in a way so that at the end of the protocol: (a) clients do not learn anything new about the database records, other than the content of the matching records; and (b) database servers do not learn which queries are submitted. The research literature has succeeded in proposing solutions that satisfy these privacy requirements, although in limited database models and with limited efficiency properties. In this paper we address these two limitations, by using a practical database model, and proposing a participant and privacy model in which data is outsourced to a third party (in encrypted form) and privacy-preserving database retrieval protocols with practically efficient performance are possible even in the presence of a very large dataset. Specifically, the first problem we consider is the design of client–server protocols with a practical database model, as follows:
Is it possible to design a provably privacy-preserving client–server protocol for retrieval of information from a database table?
A version of this problem with very simplified data models has received significant research attention in the areas of private information retrieval (PIR), started with [4,19], and keyword search (KS), started with [2,3,11,19,24]. Instead, Problem 1 targets the design of such protocols when the data is stored into a general yet practical model: a (time-varying, multi-attribute, and multiple-occurrence) database table.
In all known privacy–preserving client–server protocols, the server has to necessarily access all database records before generating an answer. Therefore, these protocols only scale well to databases of a certain limited size, and are not practically efficient for many large databases encountered in practice. A natural question then becomes to design protocols in a different model, which are scalable to large databases, and therefore have practically efficient performance. Specifically, we consider the following problem.
Is it possible to design a provably privacy-preserving protocol in a model where client and server are helped by a third party (i.e., a cloud-based server), for the retrieval of information from a database table that has practically efficient performance?
When compared with Problem 1, Problem 2 can be seen as a way to achieve very desirable performance properties by updating the participant model. A simplified version of this problem has received some research attention in the areas of commodity-based cryptography (starting with [1]) and commodity-based PIR (starting with [9]). In these and follow-up work, provable privacy properties were achieved in a simplified data model and, most importantly, with limited efficiency properties. Instead, Problem 2 targets the same general yet practical data model as for Problem 1, with the additional important challenge of achieving practically efficient performance.
Our contribution. Continuing the well-studied areas of PIR and KS, we propose privacy-preserving client–server protocols for database retrieval in a more practical database model, capturing record payloads, multiple attributes, possibly equal attribute values across different database records, and multiple answers to a given query and insertion/deletion of database records. In this model, we define suitable correctness, privacy and efficiency requirements, by showing previously not discussed technical reasons as to why we cannot use the exact same requirements from the PIR and KS areas.
We then design a first database retrieval protocol that solves Problem 1 and, in particular, satisfies the desired privacy properties (i.e., the server learns no information about the query value other than the number of matching records, and the client learns no information about the database other than matching database records) in our novel and practical database model (i.e., a time-varying, multi-attribute and multiple-occurrence database table). This protocol is based on oblivious pseudo-random function evaluation protocols and PIR protocols and still has server time complexity linear in the database size (a fact keeping previous PIR and KS protocols efficient only for limited-size databases). This drawback seems inherent with client–server protocols and is dealt with in our next result, by critically using a different participant model.
After expanding the participant model with a third party (i.e., a cloud server, as in the database-as-a-service model [15]), we provide a first solution to Problem 2 by designing a second protocol, only based on pseudo-random functions (implemented very efficiently as block ciphers), where both server and third party run queries in time at most logarithmic in the number of database records and the following privacy properties hold: the server learns nothing about the query value, the client learns nothing about the database other than the payloads associated with the matching records, and the third party learns nothing about the query value or the database content, other than any repeated occurrences of client queries and any repeated access to the encrypted data structures received by the server at initialization. Thus, we solve the long-standing problem of achieving efficient server runtime at the (arguably small) cost of a ‘third-party’-server and some ‘access-pattern’ type leakage to this third party. We stress that this protocol has efficient running time not only in an asymptotic sense, but in a sense that makes it ready for real-life applications (where such form of leakage to the third party is tolerable), answering another long-standing question in the PIR area. In our implementation, we reached our main design goal of achieving response time to be only a small constant slower than commercial non-private protocols like MySQL, as documented by performance results. Solving a number of technical challenges posed by the new data model (including a reduction step via a novel multiplicity database) using simple and practical techniques was critical to achieve this goal. The privacy loss traded for such a practicality property can be rather minimal in many scenarios, as neither the client nor the server learn anything new, and the third party does not learn anything about the plain database content or the plain queries made, but only some leakage data that can be provably characterized as an ‘unlabeled histogram’ describing the relative occurrences of (encrypted) matching records and (encrypted) query values within the protocol. In Section 7 we also provide a more detailed discussion of this leakage, its potential impact and more or less efficient techniques available to eliminate it.
We also provide a second solution to Problem 2 by designing a third protocol, with a somewhat different privacy/performance properties tradeoff with respect to the first solution. Specifically, on one hand, we can show that no unintended information is leaked to an adversary corrupting both clients and third parties, but on the other hand this protocol does leak some additional information (i.e., the number of matching records) to the server, and additionally requires clients and servers to run an oblivious pseudo-random function evaluation protocol, which overall only incurs a constant additional performance overhead cost.
In all our protocols, we only consider privacy against a semi-honest adversary. Compiling protocols with such privacy level into protocols that preserve privacy against malicious adversaries is possible, using known techniques, based on the general paradigm of [13], although these techniques come with varying performance costs.
Related work. Our work revisits and extends work in the PIR and KS areas, which have received a large amount of attention in the cryptography literature. (See, e.g., [21].) Both areas consider rather theoretical data models, as we now discuss. In PIR, a database is modeled as a string of n bits, and the query value is an index . In KS, the data models differ depending on the specific paper we consider; the closest data model to ours is the one from [11], where a database is a set of records with per-record payloads, but has a single attribute, admits a single matching record per query and no record insertions/deletions. The inefficiency of the server runtime in PIR and KS protocols has been well documented (see, e.g., [26]). Some results attempted to use a third party and make the PIR query subprotocol more efficient but require a practically inefficient preprocessing phase [9].
In both PIR and KS, the database owner is the server that hosts the plain data. In some related research areas, such as oblivious RAM (starting with [14]), and searchable symmetric encryption (starting with [24]), the database owner is the client that uses the server to host a carefully prepared and encrypted version of the data. In public-key encryption with keyword search (starting with [2]) the data is provided in encrypted form by multiple independent servers to a third party that helps satisfying a client’s query. Because of these critical differences, results in the cited areas do not solve the problem addressed by PIR and KS and use substantially different techniques, which are not directly comparable to ours.
In the project supporting this paper, other performing teams like ours concurrently and independently came up with different and interesting solutions to similar problems (see, e.g., [17,22]). As the most reasonable comparison term, we considered a 3-party protocol for database retrieval via keyword and conjunction queries in the semi-honest adversary model, in our paper and in the cited papers. On one hand, we note that all 3 solutions achieve efficiency remarkably close to commercial, non-private, database systems. On the other hand, all 3 solutions can be seen as three uncomparable points in a 3-dimensional metric space with functionality, privacy and efficiency as dimensions. Among the many differences, the cited papers use ingredients like random oracles and public-key cryptography operations [17], or general-purpose cryptographic primitives [22] like Yao’s garbled circuits [27], which are less desirable for the following reasons. Random oracles are an abstraction which is known to be not instantiated by cryptographic primitives. General-purpose cryptographic primitives, even after substantial optimization efforts, are known to pay a notable inefficiency price to guarantee their generality. Public-key cryptography operations are known to be orders of magnitude less efficient than symmetric-key ones. Instead, our solution does not use random oracles or general-purpose cryptographic primitives or public-key cryptography operations, and only uses symmetric-key cryptography operations.
Finally, a preliminary version of our first two protocols was sketched in the conference version of this work [6], and our 3-party database retrieval protocols well combine with database policy compliance protocols from [7] that allow a server to authorize (or not) queries by a client according to a specific policy, while maintaining privacy of queries and policy.
Models and requirements
Data and query models. We model a database as an n-row, m-column table or matrix , where each column is associated with an attribute, denoted as , for . The first columns are keyword attributes, and the last column , is a payload attribute. A database entry is denoted as keyword or, in the case , as payload . The database schema is the collection of parameters n, m and of the description of each domain associated with each of the m attributes, and to which database entries belong. The database schema is assumed to be publicly known to all parties. A database row is also called record, and is assumed to have the same length (if data is not already in this form, techniques from [10] are used to efficiently achieve this property), where is constant with respect to n. We consider a database update as an addition, deletion, or change of a single record, and refer to the current database (resp., current database schema), as the database (resp., database schema) obtained after any previously occurred updates. We will use the term SDE data model to denote the restriction of the described data model, where: (1) no database records are added or deleted; (2) for each the database entries relative to the jth attribute are all distinct. The unrestricted data model, where database records can be added or deleted, and attribute entries may not be distinct, will also be called the general data model. We will design protocols in two steps: first, in the SDE data model, and then transform them so that they work in the unrestricted data model.
A query q is modeled to refer to one or more database attributes and to contain one or more query values from the relative attribute domains. We will mainly consider KS queries, such as: “,” where v is the query value. A valid response to such a query consists of all payloads , for , such that , if , for some . We say that the records in a valid response match the query. We will also discuss extensions of our techniques to other query types, such as conjunctions (via logical AND gates) of KS queries. The number of records containing the same query value v at attribute is also called the j-multiplicity of v in the database, and is briefly denoted as . KS queries are always made to a specific attribute , for some , and therefore in their discussion the index j is omitted to simplify notation and discussion.
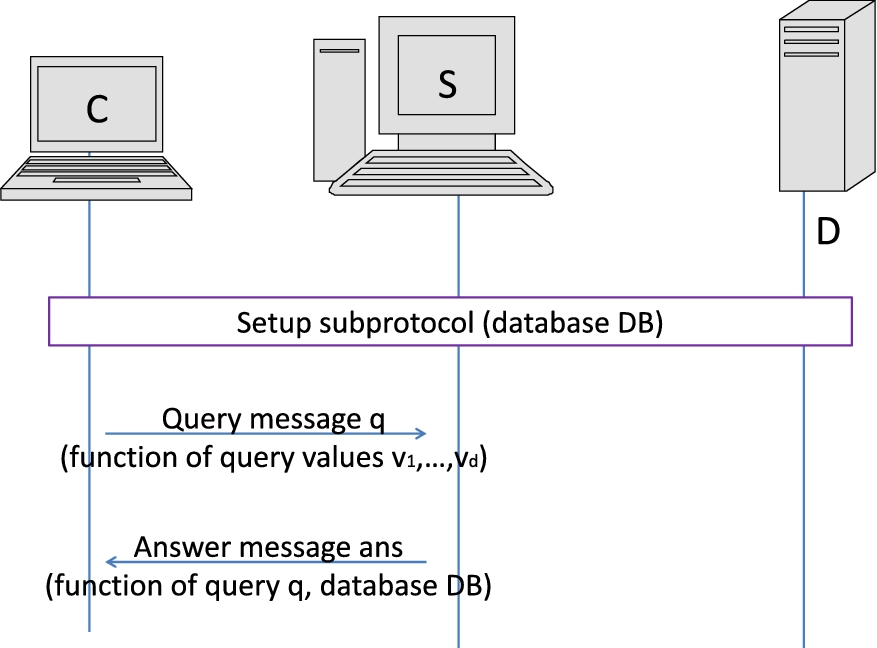
Participant models. We consider the following efficient (i.e., running in probabilistic polynomial-time in a common security parameter ) participants. The client is the party, denoted as C, that is interested in retrieving data from the database. The server is the party, denoted as S, holding the database (in the clear), and is interested in allowing clients to retrieve data. The third party, denoted as , helps the client to carry out the database retrieval functionality and the server to satisfy efficiency requirements during the associated protocol. By 2-party model we denote the participant model that includes C, S and no third party. By 3-party model we denote the participant model that includes C, S, and . (See Figs 1, 2 for a comparison of the two participant models.)
Structure of our 2-party DR protocol.
Structure of our 3-party DR protocols.
Database retrieval protocols. In the above data, query, and participant models, we consider a database retrieval (briefly, DR) protocol as an evolution of the KS protocol, as defined in [11] (in turn, an evolution of the PIR protocol, as defined in [19]), with the following three main model and functionality extensions, which are consistent with the functioning of typically deployed databases: (1) databases contain multiple attributes (or columns with keywords); (2) each database attribute can have multiple occurrences of the same keyword; and (3) database entries may change as a result of record addition and deletion. Specifically, we define a DR protocol as a triple of subprotocols, as follows. The initialization subprotocol is used to set up data structures and cryptographic keys before C’s queries are executed. The query subprotocol allows C to make a single query to retrieve (possibly multiple) matching database records. The record update subprotocol allows S to periodically update the data structures and cryptographic keys set during the subprotocol, as a result of a record addition or deletion. As a first attempt, we target DR protocols that satisfy the following (informal) list of requirements:
Correctness: the DR protocol allows a client to obtain all payloads from the current database associated with records that match its issued query;
Privacy: the DR protocol preserves privacy of database content and query values, ideally only revealing what is leaked by system parameters known to all parties and by the intended functionality output (i.e., all payloads in matching records to C);
Efficiency: the protocol should have low time, communication and round complexity; ideally, a constant number of messages per query, and time and communication sublinear in the number n of database records.
It turns out that these requirement cannot be exactly satisfied as written, and the missing properties are different depending on whether we consider the 2-party or the 3-party model. Thus, we continue with formal definitions common to both models, and then defer different formal definitions of privacy and efficiency to later sections.
Preliminary requirement notations: Let σ be a security parameter. A function is negligible if for all sufficiently large natural numbers , it is , for any polynomial p. Two distribution ensembles and are computationally indistinguishable if for any efficient algorithm A, the quantity is negligible in σ (i.e., no efficient algorithm can distinguish if a random sample came from one distribution or the other). A participant’s view in one or many protocols is the distribution of the sequence of messages, inputs and internal random coins seen by the participant while running the protocol(s). A DR protocol execution is a sequence of executions of subprotocols , where , for , for some q polynomial in σ, and all subprotocols are run on inputs provided by the involved parties (i.e., a database from S, query values from C, and database updates from S). We only consider stateless subprotocols, in that they can depend on the outputs of and subprotocols but not on the output of previous subprotocols.
Correctness: for any DR protocol execution, and any inputs provided by the participants, in any execution of a subprotocol, the probability that C obtains all records in the current database that match C’s query value input to this subprotocol, is 1.
Background primitives. A random function R is a function that is chosen with distribution uniform across all possible functions with some pre-defined input and output domains. A keyed function is a pseudo-random function (PRF, first defined in [12]) if, after key k is randomly chosen, for any efficient algorithm allowed to ask query to (and receive answers from) an oracle function O, the distribution of all queries and answers when O is is computationally indistinguishable from the distribution of all queries and answers when O is a random function R (over the same input and output domain). A keyed function is a pseudo-random permutation if it is a pseudo-random function where, for any key k, the function is a permutation (i.e., a one-to-one and onto function). We will use the fact, first shown in [20], that it is possible to construct a pseudo-random permutation starting from any pseudo-random function.
An oblivious pseudo-random function evaluation protocol (oPRFeval, first defined in [11]) is a protocol between two parties A, having as input a string x, and B, having as input a key k for a PRF F. The protocol’s outcome is a private function evaluation of the value , returned to A (thus, without revealing any information about x to B, or any information about k to A, in addition to the intended value ). oPRFeval protocols were constructed in [11,18] using number-theoretic hardness assumptions.
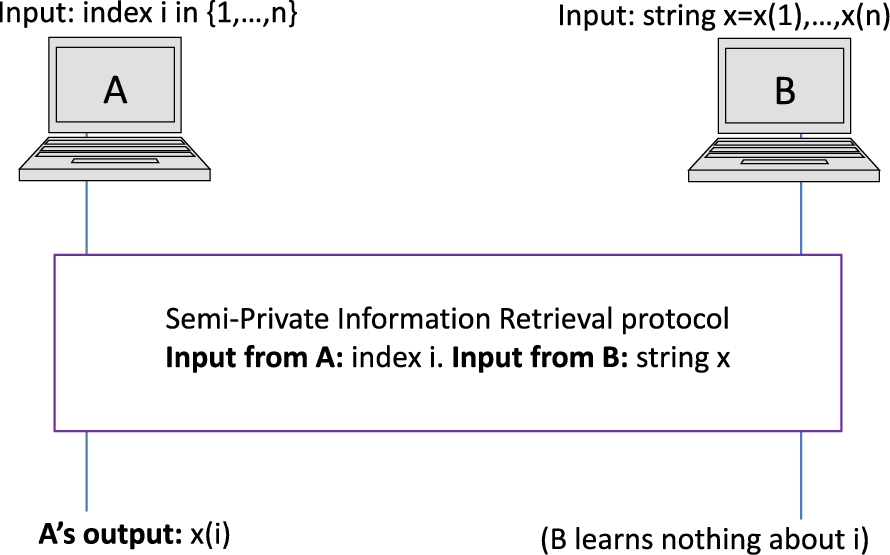
A single-database private information retrieval protocol (PIR, first defined in [19]) is a protocol between two parties A, having as input a value , and B, having as input a database represented as a sequence of equal-length values . The protocol’s outcome is a private retrieval of the value , returned to A (thus, without revealing any information about i to B or about to A). A semi-private PIR protocol is a protocol where privacy only consists of preventing the revealing any information about i to B. Several PIR and semi-private PIR protocols have been presented in the cryptographic literature, starting with [19], using number-theoretic hardness assumptions.
A pictorial description of the structure of oPRFeval protocols and semi-private PIR protocols can be found in Figs 3 and 4.
Structure of oPRFeval protocols.
Structure of semi-private PIR protocols.
Two-party database retrieval
We define privacy and efficiency requirements in the 2-party model in Section 3.1 and describe our first DR protocol (for KS queries in the 2-party model) in Section 3.2.
Privacy and efficiency in the 2-party model
Informally, our privacy and efficiency requirements are modified with respect to our first attempt in Section 2, so that a 2-party DR protocol can leak the number of matching records to S, has communication complexity sublinear in n if the number of matching records is also sublinear in n, and allows S to run in time linear in the number n of database records. A formal treatment follows.
Privacy: We require that the subprotocols in a DR protocol execution to not leak information beyond the following intended leakage:
: system parameters (including, e.g., security, length, algorithm parameters) and the database schema will be known to all participants;
, based on query value v, attribute index j, and the current database: the pair will be known by S and all payloads such that will be obtained by C, as a consequence of the correctness requirement;
: on input a record addition or deletion to the current database, the current database (after the update) will be known by S, as a consequence of the correctness requirement, and the current database schema (after the update), as part of overall system parameters, will be known by all participants.
Given this characterization of the intended leakage, the formal privacy definition is obtained using known definition techniques from simulation-based security and composable security frameworks often used in the cryptography literature. Specifically, for any efficient adversary corrupting one of the parties, there exists an efficient simulator algorithm S that, on input the above intended leakage, returns an output such that and the adversary’s view during a DR protocol execution are computationally indistinguishable.
Consistently with the literature on secure function evaluation, PIR and KS protocols, it might have seemed reasonable just to require that no new information about the query value is revealed to S, as we hoped to achieve in our first attempt in Section 2. It turns out that this level of privacy cannot be obtained, as we now explain. Let us consider a specific execution of subprotocol within a DR protocol execution. Since more than one record may match C’s query value v, by the correctness property, at the end of this execution of subprotocol , C must be able to compute all payloads corresponding to records matching v, where denotes the multiplicity of v in the jth database attribute . Moreover, since the executions of the and protocols only leak the database schema to C, and since subprotocol is stateless, all previous subprotocol executions within the DR protocol execution do not help in computing all matching records to this specific execution of subprotocol . In other words, C must be able to compute all matching records from the communication received during this specific execution of subprotocol . By a standard application of Shannon’s source coding theorem (see, e.g., [5]), this implies that the communication exchanged in this execution is an upper bound to the entropy H of payloads (over the probability distribution of the source that generates the database payloads). Thus, we obtain the following
For any v, letdenote the number of bits exchanged in an execution of subprotocolon input query value v and attribute index j. It holds that.
In Proposition 1, the entropy term is maximized when database payloads are randomly and independently distributed, in which case the communication exchanged in each execution of subprotocol leaks an upper bound on the value , i.e., the number of matching records, to both C and S. Accordingly, we target the design of protocols that may leak also to S during each execution of subprotocol on input query value v and attribute index j (as formulated in the above privacy requirement).
Efficiency: A DR protocol’s round complexity (resp., communication complexity) is the max number of messages (resp., the max length of all messages), as a function of the system parameters n, m, σ, required by any of the , and subprotocols, for any inputs to them. A DR protocol’s S-time complexity for subprotocol π is the max running time (as a function of the system parameters n, m, σ) required by S in subprotocol , over all possible inputs to it. Asymptotic requirements consistent with the literature on PIR and KS protocols include the following: (1) the communication complexity of each execution of protocol is sublinear in n; (2) the S-time complexity in each execution of protocol is sublinear in n. Requirement (1) is achieved by PIR and KS protocols in the literature when up to a single record is sent as a reply to each query. However, in our DR protocols, a query could be matched by a possibly linear number of records; accordingly, we only require the communication complexity to be sublinear whenever the number of matching records is sublinear. Requirement (2), when coupled with the privacy requirement that an execution of the protocol only leaks minimal information to C, is known to be unachievable in the 2-party model (or otherwise privacy of the query value v would not hold against the server), as discussed in many papers including [11,19].
Our protocol in the 2-party model
Our DR protocol for KS queries follows the general structure outlined in Fig. 1 for the 2-party model and satisfies the following
Under the existence of oPRFeval protocols [
11
]and (single-database) PIR protocols [
19
], there exists (constructively) a DR protocolfor KS queries in the 2-party model, satisfying:
correctness;
privacy against C (i.e., it only leaks the matching records to C);
privacy against S (i.e., it only leaks the queried attribute and the number of matching records to S);
the communication complexity ofisif so is the number of matching records;
the round complexity ofis;
the S-time complexity in(resp.) (resp.,) is(resp., is) (resp., is).
The protocol claimed in Theorem 1 is presented in two steps: first, we describe a DR protocol in the SDE data model (where all keywords in each database attribute are distinct, and no record additions or deletions happen), and then we describe the DR protocol that builds on to remove these restrictions.
The DR protocol. Informally speaking, this protocol is a combination of a KS protocol, denoted as Protocol 2 in [11] (in turn building on a semi-private KS protocol from [3]), and an oPRFeval protocol for interactively computing a pseudo-random permutation f, as follows.
. On input database , S returns a pseudo-random version of the database, denoted as , where all entries are replaced by pseudo-random versions of them; specifically, based on k and pseudo-random permutation f, S computes an associated pseudo-random database , as follows:
for all and ;
, where is a random string and , for .
S also sends the schema for database D to C.
. On input query value v and attribute index j from C, and key k and database from S, the following steps are run:
C and S run an oPRFeval protocol to return to C;
C sends j to S;
C and S run the semi-private KS protocol from [3], where C uses as query value and S provides as a 2-column database;
Let be C’s output at the end of this subprotocol (i.e., is equal to if there exists such that or to ⊥ otherwise);
If then
C and S run an oPRFeval protocol to return to C;
C computes the (plain) payload as , where .
Here, the semi-private KS protocol from [3] consists of using a PIR protocol, such as the one from [19], to probe a conventional search data structure built by S on top of the pseudo-database keywords in a way that is oblivious to S.
Protocol can be shown to be a DR protocol in the SDE data model. Intuitively, the privacy of C’s query value v follows from the fact that v is only used as part of the input to oPRF and KS subprotocols and from privacy properties guaranteed by such subprotocols. Privacy of S’ database D follows by using the observation that only a pseudo-random version of D is used as input to the semi-private KS subprotocol, and thus only pseudo-random values are possibly leaked to C, with the only exception of the value , for i such that , which C is intended to obtain, because of the correctness requirement.
We remove the two SDE data model restrictions by combining the following ideas: S can transform the original database into one where each column has distinct keywords (or payload), by computing a padded database, where keywords are padded with a multiplicity counter; S can compute a preliminary multiplicity database to let C obtain the multiplicity of its query value from S using protocol ; given the multiplicity of the query value, C can request the matching records by making one query for each matching record to the padded database, using again protocol ; updating the padded and multiplicity databases and associated data structures can be done efficiently by careful choices of padding and data structures. We stress that revealing the multiplicity value to C does not provide any more information than sending the matching records (which C is entitled to receive).
A high-level view of protocol (only initialization and query subprotocols) can be found in Fig. 5. A more formal description follows.
High-level view of protocol .
The DR protocol. Based on the above DR protocol , we define protocol as follows.
. On input database , S builds an associated padded database , as follows. The payload is equal to . Then, for each , and each , the keyword is defined as where is the multiplicity counter from such that is the th occurrence of value within array . Then S builds an associated multiplicity database , as follows. For each , and each , the keyword is defined exactly as . The payload is denoted as , where is defined as when and a null string ⊥ of the same length otherwise. Finally, S runs to compute pseudo-random versions and of databases and , respectively, and to send the schema for databases and to C.
. On input query value v and attribute index j for C, and key k and databases , for S, the following steps are run:
C and S run subprotocol on input database from S, and query value and attribute index j from C. Let be the payload obtained by C at the end of this protocol, for some . If then the protocol stops. Otherwise C sets the value .
For , C and S run subprotocol on input database from S, and query value and attribute index j from C.
. In subprotocol , we consider record addition and record deletion operations, and on each of them, we need to efficiently update any values changing as a result of these operations; specifically:
the data structures required in ;
the multiplicity value used in ;
the multiplicity counters in the padding structures used in and ;
the database schema for both and ; and
the pseudo-random databases and .
First, with respect to (1), we observe that the data structures used in are those from [3] and are conventional data structures with the only requirement of performing search in logarithmic time. Our added requirement of having efficient insertion and deletion does not require a modification of the data structures, since many of the data structures used in [3] (e.g., binary search trees) can be used to perform logarithmic-time search, insertion and deletion. Then, the values in (2), (4) and (5) can be updated in time constant with respect to n, as follows. As for (2), updating the multiplicity value only requires changing one payload entry in the multiplicity database , regardless of the multiplicity of v, and can be done in . As for (4), S can just update the database schema for both and and send those to C. As for (5), S can again use key k to recompute new and values, where .
With respect to values in (3), we now describe how to update the multiplicity counters after a record update. In the addition case, a record would also be added in the databases and , and the multiplicity counter in the added record is set to . In the deletion case, a record would also be deleted in the databases and , and we cannot stop there as this would likely create a discontinuity in the sequence of multiplicity counters (e.g., when , deleting the record with multiplicity counter 2 would leave only records with counters 1 and 3). Instead, S resets the multiplicity counter of ith record such that as equal to the multiplicity counter of the just deleted record, thus keeping no discontinuity in the sequence of multiplicity counters.
Properties of
We now show that satisfies the correctness, privacy and efficiency properties defined in the 2-party model. In doing that, we often use the following fact: in , the subprotocol can be seen obtained as the sequential composition of one execution of subprotocol on the pseudo-random variant of the multiplicity database , followed by parallel executions of one execution of subprotocol on the pseudo-random variant of the padded database .
Correctness. First we show that satisfies the correctness property in the restricted data model. By the correctness property of the oPRFeval subprotocol used, C obtains the value at the end of step 1 of and can thus run step 3. Moreover, by the correctness property of the KS subprotocol used, C obtains the record such that (if any) at the end of step 3 of . These two latter facts continue to hold across multiple operations.
Now we use the correctness property of in the restricted data model to show that satisfies correctness in the general data model. First, we analyze a single execution of and then we discuss how the analysis is extended to a sequence of operations.
At the end of the first execution of , by the correctness of , if C’s query value v satisfies for some , C can compute the ith payload in the multiplicity database and thus the multiplicity value . Given this value, C can directly obtain multiplicity counters to be used as part of the input to the executions of on database . Then, at the end of these executions of , again by the correctness of , if C’s query value v satisfies for some , C can compute the th payload in database , for , which includes the payloads from the original database D, by construction of the padded database .
By protocol inspection, we observe that the updates to the data structures used (i.e., the data structures required in , the multiplicity values in , the multiplicity counters in , and the database schema for and ) preserves the data structure properties used when analyzing a single execution of (i.e., the success of value search on the data structures in , and the continuity of the multiplicity counters). Therefore, the above analysis continues to hold across any sequence of and operations.
Privacy. We show that satisfies our privacy requirement when the adversary corrupts any one among S or C.
When the adversary corrupts S, privacy (i.e., corrupting S does not provide the adversary any new information about C’s query v) directly follows by the privacy of the oPRF subprotocol and the semi-private KS subprotocol used. A simulator is obtained by directly combining the simulators associated with the two subprotocols.
When the adversary corrupts C, privacy (i.e., corrupting C does not provide the adversary with any information about S’s database D other than what intended by the correctness requirement) follows by the following fact: databases and are pseudo-random versions of databases and , respectively, where the key used k is unknown to C. Thus, they are computationally indistinguishable from random databases (of the same length parameters) to C, only conditioned by the protocol answer that C obtains at the end of the protocol; that is, either the record if there exists such that or a failure symbol ⊥ if such i does not exist. Accordingly, C’s view during can be simulated by running the protocol on input C’s private input, and databases , which are filled with random strings, subject to the above correctness condition.
Efficiency. The communication complexity of is about times the communication complexity of on an n-record database. The latter is sublinear in n since uses the semi-private protocol in [3], which, in turns, uses a PIR protocol with communication complexity sublinear in n. Thus, if is sublinear in n, then so is the communication complexity of .
The round complexity of is since it is dominated by the round complexity in , and thus of the semi-private protocol in [3].
The server’s time complexity in is as it is dominated by the time to construct the data structures in the semi-private protocol in [3]. The server’s time complexity in is as it is dominated by the time to update the same data structures on a single record addition or deletion. The server’s time complexity of is about times the server’s time complexity in , which is linear in n already for small values of . This inefficiency is one major drawback of all 2-party model solutions for protocols like PIR, KS, and therefore, of protocol as well. Indeed, this motivated our study of the 3-party model in Section 4.
Three-party database retrieval
We define privacy and efficiency requirements in the 3-party model in Section 4.1 and describe two DR protocols (for KS queries in the 3-party model) in Sections 4.2 and 4.4.
Privacy and efficiency in the 3-party model
Informally, our privacy and efficiency requirements are modified with respect to our first attempt in Section 2, so that a 3-party DR protocol can leak the number of matching records as well as ‘access-pattern’ leakage to , and has communication complexity sublinear in n if the number of matching records is also sublinear in n. (In particular, we keep the requirement that S and have to run in time sublinear in the number n of database records.) A formal treatment follows.
Privacy: The privacy leakage we allow in the 3-party model has two differences with respect to the 2-party model: the number of matching records is now leaked to and/or S instead of just S; moreover, the following additional leakage to is allowed: repeated (or not) occurrences of the same query made by C, and repeated (or not) accesses to the same initialization information sent by S to at the end of the initialization protocol. More precisely, we require the subprotocols in a DR protocol execution in the 3-party model to not leak any information beyond the following intended leakage:
: the database schema, as part of overall system parameters, will be known to all participants and an additional string (for encrypted data structures) will be known to ; here, is encrypted under one or more keys unknown to and its length is known from quantities in the database schema;
, based on query value v, attribute index j, and the current database: all payloads such that will be obtained by C, as a consequence of the correctness requirement; the queried attribute j, all bits in read by according to the instructions in the protocol, and which previous executions of used the same query value v, will be known to ; the multiplicity value will be known to or/and S;
: on input a record addition or deletion to the current database, the current database (after the update) will be known to S, as a consequence of the correctness requirement, and the current database schema (after the update), as part of overall system parameters, will be known by all participants; all bits in read and/or modified by according to the instructions in the protocol will be known to , who will also determine up to one record previously or currently present in the database containing the same query value as the one in the added/deleted record.
Given this characterization of the intended leakage, the formal privacy definition is obtained using known definition techniques from simulation-based security and composable security frameworks often used in the cryptography literature. Specifically, for any efficient adversary corrupting one of the parties, there exists an efficient simulator algorithm S that, on input the above intended leakage, returns an output such that and the adversary’s view during a DR protocol execution are computationally indistinguishable. We will also consider the same definition in the case where an adversary can corrupt 2 parties (e.g., C and ).
Using a direct extension of Proposition 1 to the 3-party model, we can prove an analogue result with respect to leaking to the coalition of S and . Thus, different 3-party DR protocols could leak only to S, or only to , or somehow split this leakage between S and . Having to choose between one of these options, we made the practical consideration that privacy against S (i.e., the data owner) is typically of greater interest than privacy against (i.e., the cloud server helping C retrieve data from S) in many applications, and therefore we focused in this paper on seeking protocols that leak to and nothing at all to S. The other definitional choice of leaking repetition patterns (even though not actual data) to is not due to a theoretical limitation, but seems a rather small privacy price to pay towards achieving the very efficient S and time-complexity requirements discussed below.
Efficiency: The definition of a 3-party DR protocol’s round complexity, communication complexity and S-time-complexity are naturally extended from those of 2-party DR protocols. We also define the -time-complexity by naturally adapting the server time-complexity definition. As for 2-party protocols, we require that 3-party DR protocols have communication complexity to be sublinear whenever the number of matching records is sublinear. Contrarily to 2-party protocols, we do require that the S-time complexity and the -time complexity in each execution of protocol is sublinear in n, whenever is the number of matching records is sublinear in n (and achieving this property is one of the major goals in the constructions in this paper). We also target a practical response time efficiency requirement: the response time within a execution is only a small constant c worse than the response time within the same subprotocol for a non-private protocol such as MySQL.
Our first protocol in the 3-party model
Our first 3-party DR protocol for KS queries follows the general structure outlined in Fig. 2 and satisfies the following
Under the existence of a PRF, there exists (constructively) a DR protocolfor KS queries in the 3-party model, satisfying:
correctness;
privacy against S (i.e., it does not leak anything to S);
privacy against C (i.e., it only leaks the matching records to C);
privacy against(i.e., it only leaks number of matching records, the repetition of query values and the repeated access to initialization encrypted data structures);
the communication complexity of(resp.) (resp.,) isif so is the number of matching records (resp., is) (resp., is);
the S-time complexity in(resp.) (resp.,) is(resp., is) (resp., is);
the-time complexity in(resp.) (resp.,) isif the number of matching records is(resp., is) (resp., is);
the round complexity ofis.
Informally, our protocol is obtained by performing several improvements in the 3-party model to protocol (which was designed in the 2-party model). In particular, we avoid using the oPRFeval protocol by encrypting the database entries and the query values using a key shared by C and S, and unknown to . Moreover, we avoid using the semi-private PIR protocol by using search data structures that can be used by to search for the encrypted query values among encrypted database entries. As done for , we first construct a DR protocol in a restricted data model, and then a DR protocol that combines with the ideas of multiplicity database and padded database to obtain a DR protocol in our more general data model.
The DR protocol. Informally speaking, this protocol can be viewed as a simplified construction of , taking advantage of the 3-party model.
. On input database , where contain keywords and contains a payload, S first computes a shuffled version of database D; that is, , where for and , where ρ is a random permutation over . Then, similarly as in , S computes a pseudo-random version of the database , denoted as , and computed by replacing both keyword and payload entries with pseudo-random entries for all and , where k is a random key and f is a pseudo-random permutation (here, using a permutation instead of a function will later facilitate C’s decryption of any received payloads). Moreover, S generates a search data structure (i.e., a binary search tree ) over the keywords in , for . Then, S sends , to and the key k to C, in addition to sending D’s schema to both C and .
. In this protocol, C takes as input key k, a query value v and attribute index j, S takes as input key k and database D, and takes as input , . On these inputs, the protocol goes as follows:
C computes and sends to .
searches for in the search data structure .
If finds i such that , then
sends the associated (encrypted) payload to C;
C computes the (plain) payload as ;
otherwise sends a failure symbol ⊥ to C and the protocol halts.
We note that significantly simplifies in that C can directly compute , without need to run an oPRFeval protocol, and can directly search for in the data structure , without need to run a semi-private PIR protocol.
Protocol can be shown to be a DR protocol in the 3-party model and in the following restricted data model: (1) the database entries do not change; (2) for each the database entries relative to the jth attribute are all distinct. We remove these two restrictions exactly as done in Section 3: we generate from using a padded database, a multiplicity database, and composing times protocol .
A high-level view of protocol (only initialization and query subprotocols) can be found in Fig. 6. A more formal description follows.
High-level view of protocol .
The DR protocol. Based on , we define protocol as follows.
. On input database , S builds an associated padded database , and an associated multiplicity database , exactly as done in . Finally, S runs twice, the first (resp., second) time using (resp., ) as the input database. In these executions S computes and sends to the following: pseudo-random and shuffled versions and of databases and , search data structures (i.e., binary search trees) for and for , and the schema for databases and . S also sends the schema for databases and to C.
. On input query value v and attribute index j for C, and key k and databases , for S, the following steps are run:
C and run subprotocol on input database from , and query value and attribute index j from C. Let be the payload obtained by C at the end of this subprotocol, for some . If then the protocol stops. Otherwise C sets the value .
For , C and run subprotocol on input database from , and query value and attribute index j from C, who thus obtains payloads , , from .
For , C computes the tth original payload from D as , where k is the key obtained during the execution of .
. We consider record addition and record deletion operations, and on each of them, we need to efficiently update any changed values; specifically:
the data structures required in , including ;
the multiplicity value used in ;
the multiplicity counters in the padding structures used in and ;
the database schema for and ;
the pseudo-random and shuffled databases and .
The updates for values in (1)–(4) are done as in ; in particular, the updates to the data structure are conventional data structure updates in the presence of one insertion or one deletion. As for (5), S can again use key k to recompute new and values; moreover, several approaches would work to update each permutation ρ used for the shuffled versions of and ; here is an example: upon a record insertion, the newly inserted record is considered the th record in D and is defined as = ; upon a deletion of the ith record, the value is defined as = i.
Properties of
We now show that satisfies the correctness, privacy and efficiency properties defined in the 3-party model. In doing that, we use the following facts: (a) can be seen as a simplification and an adaptation of to the 3-party model; (b) in , the subprotocol can be seen as the sequential composition of one execution of subprotocol on the pseudo-random variant of the multiplicity database , followed by parallel executions of one execution of subprotocol on the pseudo-random variant of the padded database .
Correctness. First we show that satisfies the correctness property in the restricted data model. Since S sends k to C, the latter can compute value and thus run step 1 of , so that at the end of step 3, C can compute the desired payload if there is an i such that . This fact also holds across multiple operations. Finally, showing that satisfies correctness in the general data model can be done analogously as done for , using the following properties: (a) the correctness property of in the restricted data model; and (b) updates to the data structures used preserve the data structure properties when analyzing a single execution of .
Privacy. We show that satisfies our privacy requirement when the adversary corrupts any one among S, C or .
In the case where the adversary corrupts S, we note that S does not take part into and only sends messages to C and during , without receiving any message from them. Thus, it is immediate to observe that no information is leaked to an adversary corrupting S other than system parameters and legitimate inputs to S.
Now, consider the case where the adversary corrupts C. We first observe that in protocol , C receives a random key k and database schemas from S during and only a single answer message from during . Moreover, the latter message is computed by analogously as done in by S. This implies that a simplification of the simulation approach done for will also generate a distribution which is computationally indistinguishable from C’s view during a DR protocol execution associated with . Thus, an adversary corrupting C does not learn any additional information other than system parameters and the matching records that are intended by the correctness requirement.
Now, consider the case where the adversary corrupts . We can show that if a single execution of is run after , does not learn anything other than system parameters and the number of records matching C’s query. This follows from the following fact: in a single execution of and , ’s view is efficiently simulatable as it contains an encryption of C’s query value, a randomly permuted and encrypted versions , of , , and the matching records in distinct positions randomly distributed over . However, in a DR protocol execution with multiple and executions, the permutation and encryptions used to compute , or are not refreshed (for efficiency reasons), and thus the following distributions will be correlated across the various subprotocols in the DR protocol execution: (1) the (encrypted) matching, added and deleted records; and (2) the (encrypted) queried values. This will leak some ‘access pattern’ information to . In what follows, we point out what this information is and show that it suffices as input to a simulator to efficiently generate a distribution that is computationally indistinguishable from ’s view during the DR protocol execution. Specifically, the simulator will use the following input items:
system parameters in , including D’s schema;
an encrypted data string of the same length as , and encrypting the real content of , in correspondence with the records obtained by C during executions of protocol ;
all locations in accessed or modified via read or write during the DR protocol execution of ;
the index j corresponding to the queried attribute and the number of matching records during any execution of , where v denotes the query value;
information denoting whether a query value v on an execution of is equal to any of the query values in previous executions of ;
updates to the above input quantities due to any execution of .
Given these inputs, the simulator can efficiently generate the following output items:
database schema for D, , ;
encrypted strings , ;
data structures , ;
encrypted query values and for any received by in executions of ;
encrypted records sent to C as responses from in executions of .
More specifically, the simulator works as follows. Output items 1 and 2 are generated by directly copying the appropriate information from input items 1 and 2, respectively. Output item 3 is generated from input items 1 and 2, using the same algorithm used by S in when generating such data structures over encrypted data. Output item 4 is generated from input items 1, 4 and 5, by almost the same computation, only replacing the pseudo-random function with a random function, built using ‘lazy’ generation of its outputs (i.e., outputs are only generated when needed). Output item 5 is generated by selecting and copying the appropriate information from input items 1, 2 and 3. Input item 6 triggers modifications to all previous output items, also generated by direct information copying.
The described simulator satisfies two properties: (1) its input satisfies the privacy definition from Section 2; and (2) its output is computationally indistinguishable from a DR protocol execution of to an adversary corrupting , assuming the existence of pseudo-random permutations. Property 1 is proved by direct inspection of the input list. Property 2 is proved by showing that the simulator’s output is almost identical to ’s view during the DR protocol execution of , the only difference being in the use of a random function instead of a pseudo-random function (which, by a standard ‘hybrid argument’ proof technique, is computationally indistinguishable to an adversary corrupting , since the latter does not have the function’s key).
Efficiency. The round complexity of is since it consists of just 2 query messages sent by C to and 2 answer messages sent by to C.
The S-time, -time, and communication complexities in are , where denotes the length of a database record, as they are dominated by the construction (by S) and transmission (from S to ) of the permuted and encrypted databases , and relative data structures . The S-time, -time, and communication complexities in are dominated by the time to update the data structures (by S) and the transmission of updates to the data structures and possibly the added record (from S to ), which are . The S-time complexity in is minimal as S does not take part into this subprotocol. The communication complexity of is about , where denotes the length of a database record, as it is dominated by the transmission of encrypted matching records by to C. Thus, if is sublinear in n, so is the communication complexity of . The -time complexity in is about , as is dominated by the time to search and retrieve the encrypted matching records plus the time to transmit them. Thus, if is sublinear in , then the -time complexity is sublinear in n.
Our second protocol in the 3-party model
We now describe a second 3-party DR protocol for KS queries. This protocol follows the general structure outlined in Fig. 2 and is built by extending the 3-party protocol so that it satisfies privacy in the presence of an adversary corrupting both C and . This protocol satisfies the following
Under the existence of a PRF and of oPRFeval protocols [
11
], there exists (constructively) a DR protocolfor KS queries in the 3-party model, satisfying:
correctness;
privacy against S (i.e., it only leaks the number of matching records to S);
privacy against C (i.e., it only leaks the matching records to C);
privacy against(i.e., it only leaks the number of matching records, the repetition of query values and the repeated access to initialization encrypted data to);
privacy against a coalition of C and(i.e., it only leaks the matching records, the repeated occurrences of query values, and the repeated access to initialization encrypted data structures to an adversary corrupting both C and);
the communication complexity of(resp.) (resp.,) isif so is the number of matching records (resp., is) (resp., is);
the S-time complexity in(resp.) (resp.,) isif so is the number of matching records (resp., is) (resp., is);
the-time complexity in(resp.) (resp.,) isif the number of matching records is(resp., is) (resp., is);
the round complexity ofis.
Informally, our protocol is obtained as a suitable extension of protocol so as to preserve privacy against an adversary corrupting both C and . Specifically, note that in any such adversary is allowed access to both the encrypted database and the encrypting key, and thus can directly obtain the entire plain database. Accordingly, in we use a different approach to encrypt the database content: S will use a key not shared with C or to encrypt both the database payloads and the database keywords. Moreover, C asks S for help, via an oPRFeval subprotocol, both to be able to generate an encrypted query and to be able to decrypt the matching records. As done for , we first construct a DR protocol in a restricted data model of distinct and static database entries, and then a DR protocol that combines with the ideas of multiplicity database and padded database to obtain a DR protocol in our more general data model.
The DR protocol. This protocol uses both a PRP for encryption and an oPRFeval protocol.
. On input database , where contain keywords and contains payloads, S first computes a shuffled version of database D; that is, , where for and , where ρ is a random permutation over . Then S randomly chooses a key k, not to be shared with any other party. Based on k and pseudo-random permutation f, S computes an associated encrypted database , as follows:
for all and ;
, where is a random string and , for .
Similarly as before, using a permutation instead of a function will later facilitate C’s decryption of any received payloads. Moreover, S generates a search data structure (i.e., a binary search tree ) over the keywords in , for . Then, S sends , to , in addition to sending D’s schema to both C and .
. In this protocol, C takes as input a query value v and an attribute index j, S takes as input key k and database D, and takes as input and . On these inputs, the protocol goes as follows:
C and S run an oPRFeval protocol to return to C.
C sends and j to .
searches for in the search data structure .
If finds i such that , then
sends the value to C,
otherwise sends a failure symbol ⊥ to C and the protocol halts.
C and S run an oPRFeval protocol to return to C.
C computes the (plain) payload as , where .
Protocol can be shown to be a DR protocol in the 3-party model and in the following restricted data model: (1) the database entries do not change; (2) for each the database entries relative to the jth attribute are all distinct. We remove these two restrictions exactly as done in Section 3: we generate from using a padded database, a multiplicity database, and composing times protocol .
A high-level view of protocol (only initialization and query subprotocols) can be found in Fig. 7. A more formal description follows.
High-level view of protocol .
The DR protocol. Based on , we define protocol as follows.
. On input database , S first of all builds a padded database and a multiplicity database , exactly as done in . Then, for each of and , S builds an encrypted database, exactly as done in , as follows.
On input database , S first computes a shuffled version of database ; that is, , where for and , where is a random permutation over . Then, based on key k and pseudo-random permutation f, S computes an encrypted database, exactly as done by , as follows:
for all and ;
, where is a random string and , for .
Analogously, on input database , S first computes a shuffled version of database ; that is, , where for and , where is a random permutation over . Then, based on key k and pseudo-random permutation f, S computes an encrypted database , as follows:
for all and ;
, where is a random string and , for .
Similarly as before, using a permutation instead of a function will later facilitate C’s decryption of any received payloads. Moreover, S generates a search data structure (i.e., a binary search tree ) over the keywords in , for , and a search data structure (i.e., a binary search tree ) over the keywords in , for . Then, S sends data structures and , and databases , to , in addition to sending the database schema for and to both C and .
. On input query value v and attribute index j for C, and key k and databases , for S, the following steps are run:
C and run subprotocol on input database from , and query value and attribute index j from C. Let be the output obtained by C at the end of this subprotocol execution, for some . If then the protocol stops. Otherwise C sets the value .
For , C and run subprotocol on input database from , and query value and attribute index j from C; let , for some , be the outputs obtained by C at the end of this subprotocol execution; if then the protocol stops.
C returns payloads: .
. We consider record addition and record deletion operations, and on each of them, we need to efficiently update any changed values; specifically:
the database schema for and ;
the data structures required in ;
the multiplicity value used in ;
the multiplicity counters in the padding structures used in and ;
the encrypted and shuffled databases and .
The updates for values in (1)–(4) are done as in ; in particular, the updates to the data structures , are conventional data structure updates in the presence of one insertion or one deletion. As for (5), in the case of a record addition, S can randomly choose a new nonce value and use key k to compute new and values. Several approaches would work to update the permutations , , the example provided for being applicable here as well.
Properties of
We now show that satisfies the correctness, privacy and efficiency properties defined in the 3-party model. In doing that, we use the following facts: (a) can be seen as a variant of , so to further satisfy privacy against an adversary corrupting both C and ; (b) the subprotocol can be seen obtained as the sequential composition of one execution of subprotocol on the variant of the multiplicity database , followed by parallel executions of one execution of subprotocol on the variant of the padded database .
Correctness. First we show that satisfies the correctness property in the restricted data model. Consider an execution of following an execution of . By the correctness of the oPRFeval protocol used, C obtains value and can thus run step 2 of , so that at the end of step 3, C can compute the nonce value if there is an i such that . Then C can use as input to the oPRFeval subprotocol in step 5 and use this subprotocol’s output to successfully recover the desired payload in step 6. This reasoning also holds across multiple operations.
Finally, showing that satisfies correctness in the general data model can be done analogously as done for and , using the correctness property of in the restricted data model and the fact that any data structure updates preserve the data structure properties used when analyzing a single execution of .
Privacy. We show that satisfies our privacy requirement, under suitable assumptions, in the following two cases: (1) when the adversary corrupts any one among S, C or ; (2) when the adversary corrupts both C and .
First, assume the adversary corrupts S. We note that in a DR protocol execution associated with , S only receives messages in each execution of , and specifically while S runs executions of the oPRFeval subprotocol. By the privacy property of such subprotocol, S does not learn any information about C’s input. However, S does learn the number of such executions, and thus the value , in addition to system parameters and legitimate inputs to S. A simulator of S’s view can then be constructed by taking as additional input the value , and repeatedly running the simulator for the oPRFeval protocol.
Now, consider the case where the adversary corrupts C. We observe that in a DR protocol execution associated with , C receives the following information: database schema’s from S during , outputs of the oPRFeval subprotocol executions from S, and an answer message from during each execution of . To show that all such information can be efficiently simulated, we note that database schema’s are part of system parameters, the messages in the oPRFeval executions can be simulated using the simulator associated with the oPRFeval protocol, and the answer from only contains random nonces and encrypted data or payloads. The latter data and payload consist of either the multiplicity or the matching record payloads that C is intended to learn by the correctness requirement. Thus, this latter message is simulated similarly as done for and .
Now, consider the case where the adversary corrupts . The proof for this case goes almost identically as for , with no conceptual modification. Even in this case, in a DR protocol execution associated with and containing more operations than just one and one executions, the following distributions will be correlated across the various subprotocols in the DR protocol execution: (1) the (encrypted) matching, added and deleted records; and (2) the (encrypted) queried values. As before, this will leak some ‘access pattern’ information to . However, the same simulation approach shown for will continue to work here, with the same simulator inputs.
Finally, consider the case where the adversary corrupts both C and . Because the key k used to encrypt the database and query values is only known to S, an adversary corrupting does not gain any new information in further corrupting C. Thus, this proof is very similar to the previous case of the adversary only corrupting , but we still provide some more details for completeness. We can show that if a single execution of is run after , the adversary does not learn anything other than system parameters and the number of records matching C’s query. This follows by considering that in a single execution of and , the adversary’s view only contains the following information (which is efficiently simulatable): an encryption of C’s query value and of a random nonce , randomly permuted and encrypted versions , of , , and the matching records in distinct positions randomly distributed over . However, in a DR protocol execution with multiple or executions, the permutation and encryptions used to compute , , or , are not refreshed (for efficiency reasons), and thus the following distributions will be correlated across the various subprotocols in the DR protocol execution: (1) the (encrypted) matching, added and deleted records; and (2) the (encrypted) queried values. This will leak some ‘access pattern’ information to the adversary. Specifically, the adversary is leaked the same information as in case where the adversary only corrupts , which was previously characterized in the proof for .
Efficiency. The round complexity of is since it consists of just 2 query messages sent by C to , 2 answer messages sent by to C, and 2 executions of an oPRFeval subprotocol between C and S, each of these subprotocols requiring messages.
The S-time, -time, and communication complexities in are , where denotes the length of a database record, as they are dominated by the construction (by S) and transmission (from S to ) of the permuted and encrypted databases , and relative data structures , . The S-time, -time, and communication complexities in are dominated by the time to update the , data structures (by S) and the transmission of updates to the , data structures and possibly the added record (from S to ), which are . The S-time complexity in is as it consists of running oPRFeval subprotocols. The communication complexity of is about , where denotes the length of a database record, as it is dominated by the transmission of encrypted matching records by to C, as well as of messages associated with the executions of an oPRFeval subprotocol. Thus, if is sublinear in n, so is S-time complexity and the communication complexity in . The -time complexity in is about , as is dominated by the time to search and retrieve the encrypted matching records plus the time to transmit them. Thus, if is sublinear in , then the -time complexity is sublinear in n.
Extension: Conjunction formulae
We extend the KS protocols from Sections 3 and 4 to the conjunction formulae over KS queries; that is, the AND of c KS queries, for some .
A first approach would be to process, in parallel, an individual KS query for each term in the conjunction, and then having compute the intersection across the matching sets. This approach is clearly undesirable both for privacy and efficiency reasons. With respect to privacy, such a protocol would reveal to C the multiplicity of the query value in each conjunct, which is not necessarily computable from the number of records matching all conjuncts. With respect to efficiency, it is not hard to find examples of conjunctive queries for which at least one conjunct is matched by a linear number of records, but the number of records matching all conjuncts is sublinear in n. On such queries, the communication complexity would be linear even though the information to which C is entitled by the DR protocol functionality is sublinear.
To avoid both problems, we designed the following ‘combined-index’ approach. In the initialization subprotocol, a specific combined index on the tuple of attribute values can be created by concatenating the attribute names and query values, thus allowing the conjunction to be treated as a single keyword query. For example, a conjunctive query of and becomes a single KS query . The combined index for is treated exactly as indices for single attributes. The initialization, insertion and deletion subprotocols are the same as those for KS queries, working on the Cartesian product of the domain. C runs the KS query algorithm using the combined attribute values. Good properties of the method include: support of conjunctive queries with an arbitrary number of conjuncts; it is only necessary to create a single combined index for each set of attribute values as opposed to each permutation of the attribute values (i.e. only an index for is necessary, not one for and one for ); and querying on the single index is faster than querying on multiple indices and determining the intersection of the results. The unattractive property is that it requires one index for each supported conjunctions, resulting in an exponential (in c) number of indices if all possible conjunctions have to be supported. Still, many practical formulae can be addressed, as the scenario where the number of attributes is constant with respect to n is the most typical, and storage is an inexpensive resource nowadays.
Performance evaluation
In this section we present performance results for KS queries and boolean formulae over KS queries for a small number of queries executed using our first protocol in the 3-party model, implemented with an additional SSL/TLS layer to satisfy communication security properties. MySQL was used for obtaining baseline results in a non-private setting using the same schema and records as for . The performance of our second protocol in the 3-party model is also briefly discussed, as it is very much related to the performance of protocol .
Setup. We used 5 different database sizes: 10K, 100K, 1M, 10M, and 100M records. All records were stored in a single database table having the schema shown in Table 1.
Schema of database table used in performance evaluation
The S and processes and an instance of MySQL server version 5.5.28 were running on a Dell PowerEdge R710 server with two Intel Xeon X5650 2.66 GHz processors, 48 GB of memory, 64-bit Ubuntu 12.04.1 operating system, and connected to a Dell PowerVault MD1200 disk array with 12 2 TB 7.2K RPM SAS drives in RAID6 configuration. Database clients were running on a Dell PowerEdge R810 server with two Intel Xeon E7-4870 2.40 GHz processors, 64 GB of memory, 64-bit Red Hat Enterprise Linux Server release 6.3 operating system, and connected to the Dell PowerEdge R710 server via switched Gigabit Ethernet. Regular TCP/IP connections were used for MySQL. We built MySQL indices on FirstName, LastName, Gender, and Number. We built keyword indices for our protocol on FirstName, LastName, Number, and a combined index on FirstName, Gender. The following query templates were used for executing database queries. Each query was executed five times using different values, and the average query response was used.
Q1: SELECT ∗ FROM main WHERE Number = value,
Q2: SELECT ∗ FROM main WHERE FirstName = value AND Gender = value,
Q3: SELECT ∗ FROM main WHERE FirstName = value AND LastName = value,
Q4: SELECT ∗ FROM main WHERE FirstName = value OR LastName = value.
We implemented a B+-tree as the search data structure (used as attribute index) due to its sub-linear search performance for disk-resident data. We note that for query Q3, we did not build a combined index, but, for sake of performance comparisons, we implemented an alternative conjunction protocol (a work in progress, omitted here) with yet unclear privacy properties. Also, for Q4, we implemented a disjunction protocol where the parties simply run the query protocol for both queries at the disjuncts (also a work in progress, since disjunction protocols with improved privacy may be desirable).
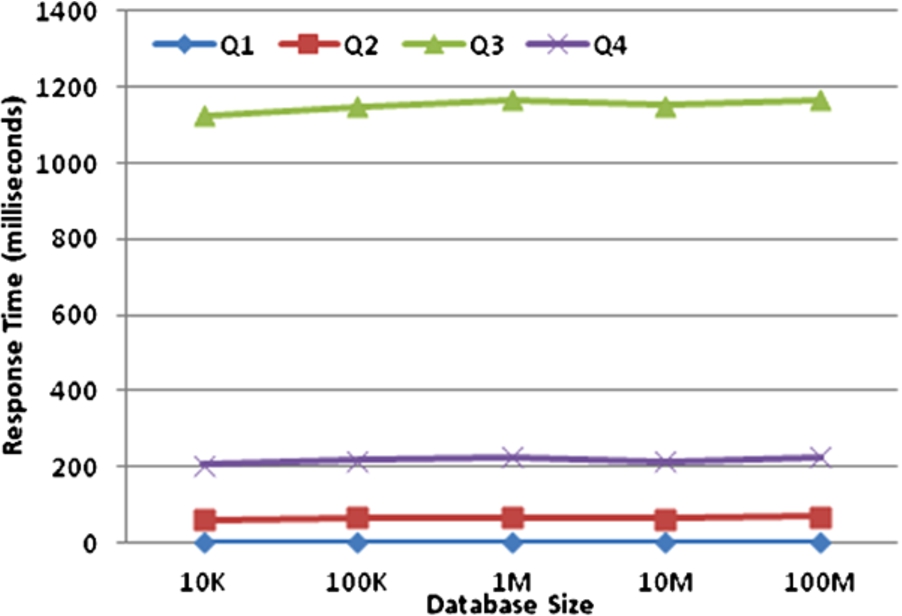
Our 3-party query performance.
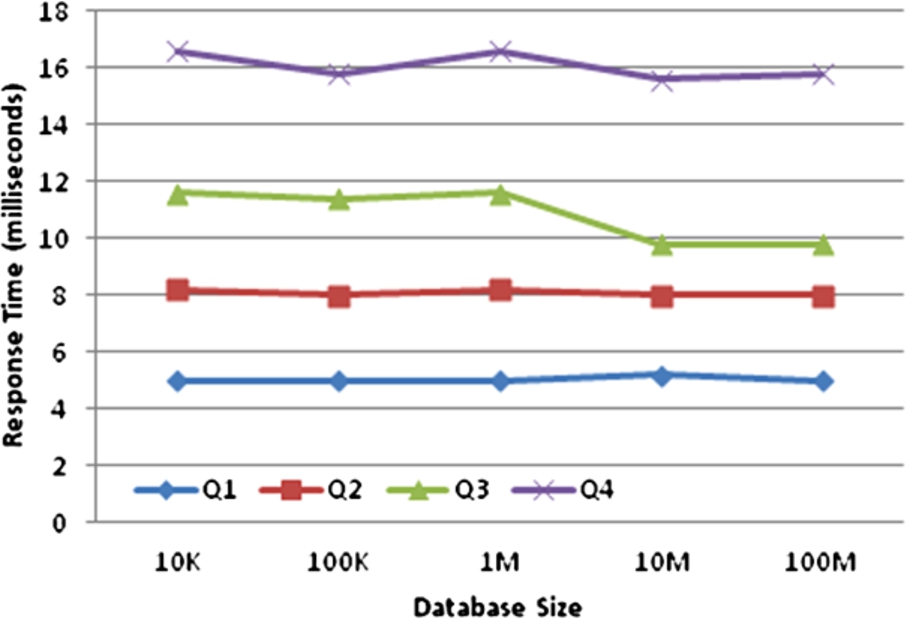
MySQL query performance.
Results using protocol. Figures 8, 9 show the performance results for our protocol and MySQL, respectively. For all database sizes, Q1–Q4 matched 1, 500, 1000 and 2000 records, respectively. We observe that the database size has minimal impact on query response time. This was expected since the same number of records were matched by each query.
Our protocol ’s performance (∼2 ms) is better than MySQL (∼5 ms) for Q1 despite the additional overhead of SSL/TLS communications, because of the minimalistic approach used by our implementation, in terms of simpler query execution and data structures, compared to traditional database management systems. When the number of matched records increases, MySQL outperforms our protocol by a factor of around 8.6, 119.1, and 14.4 for Q2, Q3, and Q4, respectively. Unlike MySQL, where once the first match is found in the B+-tree data structure used for the queried column then a simple forward scan of the tree leaf pages is needed for locating all matches, our protocol performs a separate scan of the search data structure (a B+-tree) for each matched value. Because these scans are for ciphertext values, it is highly unlikely that any two scans will traverse the same path from the root of the B+-tree down to the same leaf page. Thus, the number of I/O operations required for fetching B+-tree leaf pages into the in-memory cache for locating matched records is proportional to the number of matched records. Our protocol’s response times in Q3 are more than 17 times slower than response times in Q2 despite the fact that they have the same structure and, in addition, Q3 matched twice as many records as Q2. Furthermore, Q3 is 5 times slower than Q4 although Q4 resulted in twice as many matched records. The main reasons for this are the inefficiency of the protocol used for Q3 as well as the fact that Q2 was answered using a combined index, while Q3 and Q4 required scanning of two B+-tree indices.
On the performance of protocol. From a performance viewpoint, the main difference between protocol and protocol is that the former includes an additional executions of an oPRFeval protocol. Accordingly, the overall latency of is estimated to be only worse than that of by a multiplicative factor that is constant (i.e., independent on the number n of records or the number of matching records). A good estimate of this multiplicative factor is the ratio of the running time of the oPRFeval protocol to the running time to decrypt a database record (using a symmetric encryption scheme). This ratio is maximized for databases with short (as opposed to long) records, in which case it can be as high as 2 orders of magnitude.
Conclusions
Current technology trends (e.g., ‘big data’, ‘cloud-based data retrieval’, ‘data privacy’) imply that in today’s computer system there is critical need to perform efficient and scalable computations over large amounts of encrypted data. In this paper, we studied the problems of designing practically efficient and privacy-preserving protocols for the processing of keyword queries, and conjunctions over them, on encrypted databases. We presented solutions both in the client–server participant model, and in the 3-party model where an encrypted copy of the database can be outsourced to a third party (i.e., a cloud server). Our main result in the 3-party model satisfies practical efficiency and scalability properties, and provable privacy of the query and the data content against a semi-honest adversary. We consider three research directions for improvement of this result as being of interest for future work.
First, it would be of interest to reduce the leakage to the third party, which is provably characterized as ‘access pattern’ information, and includes the histogram of accesses to encrypted database and query content. Some techniques to mitigate this leakage were proposed in [16]. We note that such leakage might be eliminated using dedicated solutions based on general cryptographic primitives (i.e., secure 2-party function evaluation protocols [27]) and/or oblivious RAM protocols [14]. Using the latter types of protocols is indeed a promising direction as, while years ago Oblivious RAM was considered inefficient, recent advances (see, e.g., [25]) have made it significantly less inefficient.
Second, it would be useful to expand the set of queries for which one can design analogue solutions with at least comparable efficiency and privacy properties (as, for instance, range queries [8]).
Finally, it would be of interest to extend results to adversary models beyond the semi-honest model, possibly to the malicious model, while preserving the achieved privacy and efficiency properties.
Footnotes
Acknowledgments
This work was supported by the Intelligence Advanced Research Projects Activity (IARPA) via Department of Interior National Business Center (DoI/NBC) contract number D13PC00003. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright annotation hereon. Disclaimer: The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of IARPA, DoI/NBC, or the U.S. Government.
References
1.
D.Beaver, Commodity-based cryptography (extended abstract), in: Proc. of ACM STOC, 1997, pp. 446–455.
2.
D.Boneh, G.Di Crescenzo, R.Ostrovsky and G.Persiano, Public key encryption with keyword search, in: Proc. of EUROCRYPT, Springer, 2004, pp. 506–522.
3.
B.Chor, N.Gilboa and M.Naor, Private information retrieval by keywords, IACR Cryptology ePrint Archive (1998).
4.
B.Chor, E.Kushilevitz, O.Goldreich and M.Sudan, Private information retrieval, J. ACM45(6) (1998), 965–981.
5.
T.M.Cover and J.A.Thomas, Elements of Information Theory, 2nd edn, Wiley, 2006.
6.
G.Di Crescenzo, D.Cook, A.McIntosh and E.Panagos, Practical private information retrieval from a time-varying, multi-attribute, and multiple-occurrence database, in: Proc. of IFIP DBSec, Springer, 2014.
7.
G.Di Crescenzo, J.Feigenbaum, D.Gupta, E.Panagos, J.Perry and R.N.Wright, Practical and privacy-preserving policy compliance for outsourced data, in: Proc. of WAHC, Springer, 2014.
8.
G.Di Crescenzo and A.Ghosh, Privacy-preserving range queries from keyword queries, in: Proc. of ACM DBSec, 2015.
9.
G.Di Crescenzo, Y.Ishai and R.Ostrovsky, Universal service-providers for private information retrieval, J. Cryptology14(1) (2001), 37–74.
10.
G.Di Crescenzo and D.Shallcross, On minimizing the size of encrypted databases, in: Proc. of IFIP DBSec, Springer, 2014.
11.
M.J.Freedman, Y.Ishai, B.Pinkas and O.Reingold, Keyword search and oblivious pseudorandom functions, in: Proc. of TCC, Springer, 2005, pp. 303–324.
12.
O.Goldreich, S.Goldwasser and S.Micali, How to construct random functions, J. ACM33(4) (1986), 792–807.
13.
O.Goldreich, S.Micali and A.Wigderson, How to play any mental game or a completeness theorem for protocols with honest majority, in: Proc. of ACM STOC, 1987, pp. 218–229.
14.
O.Goldreich and R.Ostrovsky, Software protection and simulation on oblivious RAMs, J. ACM43(3) (1996), 431–473.
15.
H.Hacigümüs, B.R.Iyer, C.Li and S.Mehrotra, Executing SQL over encrypted data in the database-service-provider model, in: Proc. of ACM SIGMOD, 2002, pp. 216–227.
16.
M.S.Islam, M.Kuzu and M.Kantarcioglu, Access pattern disclosure on searchable encryption: Ramification, attack and mitigation, in: Proc. of NDSS, 2012.
17.
S.Jarecki, C.S.Jutla, H.Krawczyk, M.-C.Rosu and M.Steiner, Outsourced symmetric private information retrieval, in: Proc. of ACM CCS, 2013, pp. 875–888.
18.
S.Jarecki and X.Liu, Efficient oblivious pseudorandom function with applications to adaptive OT and secure computation of set intersection, in: Proc. of TCC, Springer, 2009, pp. 577–594.
19.
E.Kushilevitz and R.Ostrovsky, Replication is not needed: Single database, computationally-private information retrieval, in: Proc. of IEEE FOCS, 1997, pp. 364–373.
20.
M.Luby and C.Rackoff, How to construct pseudorandom permutations from pseudorandom functions, SIAM J. Comput.17(2) (1988), 373–386.
21.
R.Ostrovsky and W.Skeith, A survey of single-database private information retrieval: Techniques and applications, in: Proc. of PKC, Springer, 2007, pp. 393–411.
22.
V.Pappas, F.Krell, B.Vo, V.Kolesnikov, T.Malkin, S.G.Choi, W.George, A.D.Keromytis and S.Bellovin, Blind seer: A scalable private DBMS, in: Proc. of 2014 IEEE SOSP, 2014, pp. 359–374.
23.
Project Gutenberg, http://www.gutenberg.org.
24.
D.X.Song, D.Wagner and A.Perrig, Practical techniques for searches on encrypted data, in: Proc. of IEEE SOSP, 2000, pp. 44–55.
25.
E.Stefanov, M.van Dijk, E.Shi, C.W.Fletcher, L.Ren, X.Yu and S.Devadas, Path ORAM: an extremely simple oblivious RAM protocol, in: Proc. of 2013 ACM CCS, 2013, pp. 299–310.
26.
S.Wang, X.Ding, R.H.Deng and F.Bao, Private information retrieval using trusted hardware, in: Proc. of ESORICS, Springer, 2006, pp. 49–64.
27.
A.C.-C.Yao, How to generate and exchange secrets (extended abstract), in: Proc. of IEEE FOCS, 1986, pp. 162–167.