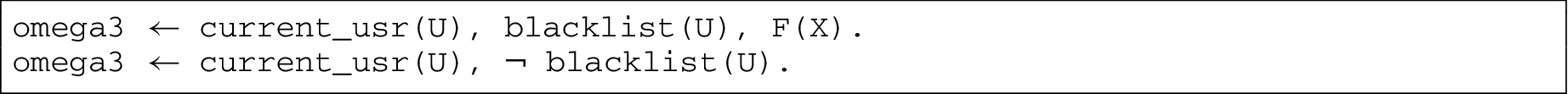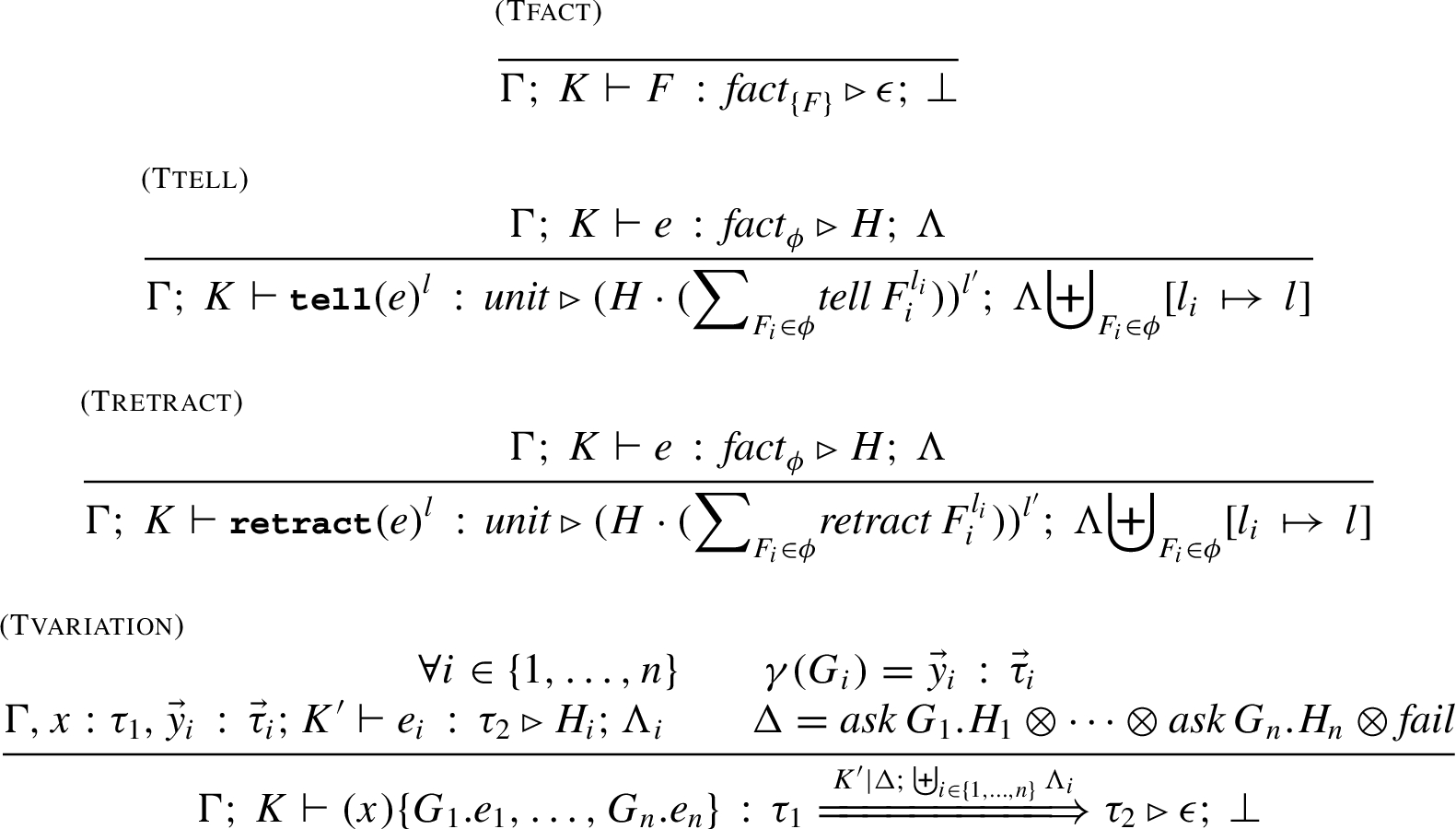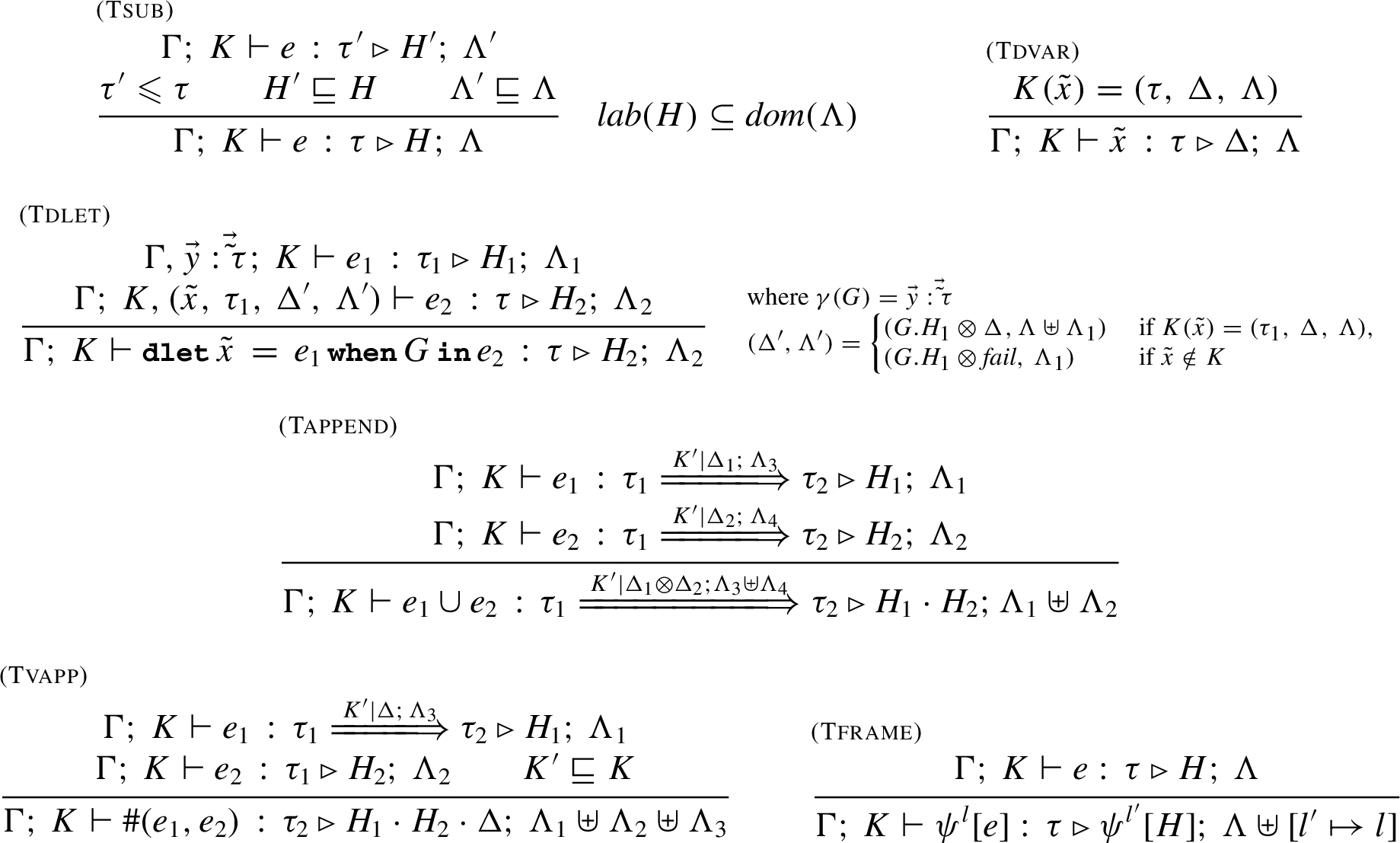Adaptive systems improve their efficiency by modifying their behaviour to respond to changes in their operational environment. Also, security must adapt to these changes and policy enforcement becomes dependent on the dynamic contexts. We study these issues within , (the core of) an adaptive declarative language proposed recently. A main characteristic of is to have two components: a logical one for handling the context and a functional one for computing. We extend this language with security policies that are expressed in logical terms. They are of two different kinds: context and application policies. The first, unknown a priori to an application, protect the context from unwanted changes. The others protect the applications from malicious actions of the context, can be nested and can be activated and deactivated according to their scope. An execution step can only occur if all the policies in force hold, under the control of an execution monitor. Beneficial to this is a type and effect system, which safely approximates the behaviour of an application, and a further static analysis, based on the computed effect. The last analysis can only be carried on at load time, when the execution context is known, and it enables us to efficiently enforce the security policies on the code execution, by instrumenting applications. The monitor is thus implemented within , and it is only activated on those policies that may be infringed, and switched off otherwise.
If you are in an airport for a little while and you want to have just a quick look at your mailbox, you would like to connect without bothering with all the details of the wireless connection, yet you would like to do that in a secure manner. A hosting environment and an application programmed in an adaptive fashion will transparently connect you to the available server. So, you never need to change your settings and capabilities, nor to worry about the new context and the resources it provides you. Instead you are likely to be worried about malicious activities that the hosting environment may carry on, and vice versa. Nevertheless, adaptivity amplifies the difficulties of security provisioning, because these two features are tightly interwoven. Their combination requires addressing two aspects. First, security may reduce adaptivity, because it adds further constraints on the possible actions of software. Second, new highly dynamic security mechanisms are needed to scale up to adaptive software.
These are the problems we address here from a linguistic point of view, in particular within a static analysis approach. To analyse such highly dynamic applications with a standard technique one has to take care of all the contexts that will be visited. This is computationally expensive and may even be unfeasible, because new contexts may appear later on, e.g. a new wireless network at the airport. We propose a technique that addresses these difficulties by splitting the analysis in two parts. The first collects at compile time information about the behaviour of the application regardless of the running context, while the second specialises this information at load time when the context is fully known.
Context and adaptivity. As intuitively anticipated above, today’s software systems are expected to operate every time and everywhere. They have to cope with changing environments, and never compromise their intended behaviour and their non-functional requirements, typically security or quality of service. Therefore, languages need effective mechanisms to sense the changes in the operational environment in which the application is plugged in, i.e. the context, and to properly adapt to changes, with little or no user involvement. At the same time, these mechanisms must maintain the functional and non-functional properties of applications after the adaptation steps.
The context is a key notion for adaptive software. Typically, a context includes different kinds of computationally accessible information coming from both outside (e.g. sensor values, available devices, code libraries offered by the environment), and from inside the application boundaries (e.g. its private resources, user profiles, etc.). There have been many different proposals to support dynamic adjustments and tuning of programs inside programming languages, e.g. [38,39,42,45,64,66,67]. However, they do not neatly separate the working environment from the application as done, e.g. in Context Oriented Programming (COP) [20]. The COP linguistic paradigm explicitly deals with contexts and provides programming adaptation mechanisms to support dynamic changes of behaviour, in reaction to changes in the context. In this paradigm software adaptation is programmed through behavioural variations, chunks of code that can be automatically selected depending on the current context hosting the application, so to dynamically modify its execution.
Security and contexts. Security is a major concern in context-aware systems, as witnessed by the interest risen in the business world [44], because an activity can be carried on safely in one operating environment and become weak in another. This implies that one has to determine which information in the environment is relevant for the security of the application. Also, it is important to constantly tune the security policies accordingly to the changes of the relevant part of the environment. New security techniques are therefore in order, that have to both scale up and maintain the ability of software to adapt as much as possible. These two interrelated aspects have already been studied in the literature [14,68] that presents two ways of addressing it: securing context-aware systems and context-aware security.
Securing context-aware systems aims at rethinking the standard notions of confidentiality, integrity and availability [58] and at developing techniques for guaranteeing them in adaptive applications [68]. The main challenge is to understand how to get secure and trusted context information. Contexts may indeed contain sensible data of the working environment (e.g. information about surrounding digital entities) that should be protected from unauthorised access and modification, in order to grant confidentiality and integrity. Also, one has to protect applications from portions of the context that may misbehave and forge deceptive data.
Context-aware security is dually concerned with the use of context information (identity, location, time and date, device type, reputation and so on) to dynamically improve and drive security decisions. Contextual information helps to overcome the “one-size-fits-all” security solutions. These now become more flexible because they can take into account the different situations in which a user is operating. For example, consider the usual no flash photography policy in museums. While a standard security policy never allows people to use flash, a context-aware security one does not allow flashing only inside particular rooms – in other words, the last policy has a scope. Similarly, a company might allow a user to access a database from the office, but deny access if the user attempts to from home, without an explicit authorisation. Accordingly, controlling and enforcing security need not to be placed everywhere, but only where needed, depending on the context that makes specific actions risky.
Yet, there is no unifying concept of security, because the two aspects above are often tackled separately. Indeed, mechanisms have been implemented at different levels of the infrastructure, in the middleware [60] or in the interaction protocols [29]. These mechanisms mostly address access control, often from a software engineering viewpoint [56]. Also, particular attention is being paid on the ways contextual policies are defined [48]. Ours is a first step towards developing a uniform and formal treatment of security and adaptation.
Our proposal. We study security within a linguistic approach to adaptivity, and we propose techniques for analysing and enforcing secure behaviour of adaptive applications since the early stages of software development. To investigate these issues, we chose the COP paradigm because it provides us with a neat framework, where contexts and applications are clearly defined and identified, even though strictly intertwined. Consequently, this separation reduces the complexity of the security analysis by first considering the application in isolation, and then by tailoring the obtained results to the running context.
Here we extend , a core of ML with COP features, recently proposed in [21–23]. It has two tightly integrated components: a declarative constituent for programming the context and a functional one for computing. The bipartite structure of reflects the separation of concerns between the specific abstractions for describing a context and those used for programming applications [61]. The context in is a knowledge base implemented as a (stratified, with negation) Datalog program [43,55]. Applications inspect the contents of a context by simply querying it, in spite of possibly complex deductions required. Programming adaptation is specified through behavioural variations, a sort of pattern matching with Datalog goals as selectors. The behavioural variation to be run is selected by the dispatching mechanism that inspects the actual context and makes the right choices. Note that the choice depends on both the application code and the “open” context, unknown at development time. If no alternative is viable, then a functional failure occurs as the application cannot adapt to the current context. We address context-aware security issues, in particular for defining and enforcing access control policies, by exploiting features. Our policies are expressed in Datalog, and are checked and enforced by just querying goals. In this regard, our version of Datalog is an asset because many logical languages for defining access control policies compile in it, e.g. [12,26,41]. In addition, it is powerful enough to express all relational algebras, it is fully decidable, and it guarantees polynomial response time [27]. There are two kinds of policies separately imposed by the context and by the applications. A single reference monitor enforces both at run time, aborting the execution when a security violation is about to occur.
More in detail, the designer of the context can define a context policy to protect some sensible entities hosted therein, e.g. specific devices or confidential data. The reference monitor prevents then an application running in that context from altering the values of the protected entities. Context policies are enforced along the execution of the application within the current context. Actually, the reference monitor is not required to stepwise supervise the execution of the controlled application, rather it only intervenes when an assertion concerning a protected entity changes in the context.
Instead, application policies are defined by the designer of the application, to protect its own resources and data. Following [9], we extend the original with the construct , called policy framing, where ψ is one of such policies and e is an expression within the application itself. The intuition is that the policy ψ has to be enforced stepwise during the execution of e, which is therefore its scope; when e is reduced to a value, the policy is no longer active. For example, suppose e is sending some confidential data. Then a policy can check whether all the recording devices in the context are off, so this sort of de-classification is not risky. When the transmission is completed, a recorder can be safely switched on, if the rest of the application does not care about. Of course, application policies can be nested, and are to be all obeyed by an expression occurring within the (nested) scope of their framing.
Observe that context and application policies have a different nature, mainly because they are defined by separate designers, in a completely independent manner. Actually, context policies are most likely unknown to the application developer at design and implementation time, and similarly for the application policies that are unknown to the context manager.
The execution model underlying our proposal assumes that the context is the interface between an application and the system running it. Applications interact with the system through a predefined set of APIs that provide handles to resources and operations on them. The system and the application do not trust each other, and may act maliciously. For instance, the first can alter some parts of the context inserting specific assertions so forcing the application to select a particular behavioural variation. The system can then falsify these assertions to drive the application in an unsafe state. The application developer can design and enforce a policy to protect sensible data against these malicious changes. In turn, the application can modify the context arbitrarily by driving the system in a vulnerable state, and context policies prevent these attacks. As a matter of fact, our policies specify the acceptable runs with respect to access control, so they are safety policies.
Here we do not address how code is protected against hostile modifications, and for that we assume our execution model to rely on known techniques, e.g. obfuscation [16]. A key point of our proposal is the instrumentation of the application code by inserting invocations to a reference monitor, and the resulting machinery is assumed to be suitably protected.
We aim at detecting policy violations (non-functional failures) as early as possible, so we conservatively extend the static approach of [22,23,28], briefly summarised below. It takes care of failures in adaptation to the current context (functional failures), dealing with the fact that applications operate in an “open” environment. Indeed, the actual value and even the presence of some elements in the current context are only known when the application is linked with it at run time. The first phase of our static analysis is based on a type and effect system that, at compile time, computes a safe over-approximation of the application behaviour, namely the effect. Then the effect is used at load time to verify that the resources required by the application are available in the actual context, and in its future modifications. To do that, the effect of the application is suitably combined with the effect of the APIs provided by the context that are computed by the same type and effect system. If an application passes this analysis, then no functional failure can arise at run time.
Our extensions are as follows. First, we record in the approximations the operations that modify the context, namely and , together with the scope of the policy framings in which they occur. The collected information is then used by our extended load time analysis. It requires building a graph, which safely approximates which contexts the application will pass through, while running. We also label the edges of the graph with (pointers to) the / operations in the code, exploiting the approximation. Before launching the execution, we detect the risky actions, i.e. those that might violate a reachable context or an active application policy. Now, we can call our reference monitor to guard the risky actions only, and leave it switched off for the remaining ones. Note that our two-phase analysis is similar to enforcing invariants over global data [52], which are however completely known at compile time. In our case instead the context is not available until run time, so an analysis at compile time would require predicting all the possible contexts an application will interact with – this is clearly overwhelming, or even unfeasible at all.
The detection of risky actions mentioned above drives code instrumentation, so to build applications that are prevented from violating security policies at run time. In a sense, the reference monitor is incorporated within the instrumented application, only using constructs of itself. Actually, the monitor is implemented by inserting in the source code of the application e a call to a suitable procedure (essentially a behavioural variation) for each occurrence of a / occurring in e. This form of instrumentation is not standard, as it does not operate on the object code, rather it is mechanically done at implementation time. Given a specific action and a set of policies, this procedure will obviously check whether the first obeys all the elements of its second argument. At load time, the information about which actions are risky and which policies can be violated by them is then used to link the actual and the formal parameters of the procedure. Indeed, the reference monitor is never called on those actions that the static analysis has safely predicted not to affect security.
Structure of the paper. The next section introduces and our proposal, with the help of an example, along with an intuitive presentation of the various components of our two-phase static analysis, and the way security is dynamically imposed and enforced. The syntax and the operational semantics of our extension of are in Section 3, and its type and effect system in Section 4. Section 5 presents the load time analysis, the results of which are used in Section 6 to describe our way of instrumenting applications. The conclusion summarises our results, discusses some future work, and briefly surveys related approaches. The proofs of the theorems establishing the correctness of our proposal are in the Appendices.
A preliminary version of some technical parts of this paper appeared in [11], that only considered context policies, and consequently had simpler definitions of the dynamic semantics, of the static analysis, and of the code instrumentation.
A guided tour of our proposal through an enterprise mobility scenario
We illustrate our proposal by considering a scenario of enterprise mobility, a typical example of ubiquitous and flexible computing: a mobile application used for accessing to some databases of a company through a tablet. For further details about the language and other applicative scenarios see [21,23].
We first intuitively introduce , focussing on its logical aspects, used to inquire and update the context, and on our extensions to ML, used to program adaptation in a functional way. In particular, we will emphasise on how an application installs itself in a context (Section 2.1) and how the main adaptation feature, namely behavioural variation, is resolved through the dispatching mechanism (Section 2.2). In Section 2.3 we will add to our example both a context and an application policy, and discuss why at run time two different techniques are required for enforcing each of them. Then in Section 2.4, we exemplify two different ways an application may fail, either because it cannot adapt to the hosting context (functional failure) or because it or the context attempt to violate a policy (non-functional failure). We also describe the two-phase static analysis we are proposing for detecting both kinds of failures and for efficiently controlling policies at run time. The first phase occurs at compile time and determines a sound abstraction of the behaviour of applications. The second phase analyses this abstraction at load time and provides us with the basis for instrumenting the code and for defining an adaptive reference monitor, that is only called on need. We conclude this intuitive presentation of our main contributions by briefly looking at some classical access control policies that show the expressivity of .
Context description and updates
As anticipated, the context in is a knowledge base implemented as a (stratified, with negation) Datalog program [43,55]. To retrieve the state of a resource, programs simply query the context, in spite of the possibly complex deductions required to solve the corresponding goal; the context is changed by using the standard tell/retract constructs.
In our example, the usage of the tablet depends on the current location and on the profile of who is using it. For simplicity, we suppose that the tablet is able to recognise three locations each providing access to the network: (i) office, (ii) home, and (iii) public spots. Information on the current location can be retrieved by querying the context, described by a set of Datalog clauses. In our case, the user’s location is described by the following clauses (for clarity, Datalog variables will be capital letters, while constants will be lower case identifiers):
Assuming a mechanism that connects the tablet to a specific network, the predicate wifi_connected identifies the current operating environment by the network name. In particular, the tablet results to be in the office (the predicate location(office) holds) when connected to the network in either the west or east wing of the building.
The company employees can perform different actions depending on their profiles. We assume to have three of them: (i) vendor, (ii) system administrator, (iii) admin staff. The profile of a user is represented in the context by the binary fact profile (e.g. profile(Jane,vendor)). As expected, the user profile enables different applications and features: for example, vendors can access a database of customers, but not the company balance of payments; while a member of the staff can access both.
Furthermore, the context represents the resources currently available and manages the access to them in a declarative manner. Below we discuss some examples of different kinds of resources.
In the code snippet below, the first case returns a handle for accessing the contents of a digital archive that is stored in the office server, the second for the archive in a public server:
Of course, also physical or hybrid resources can be represented using Datalog, as the following typical situation arising in the Internet of Things [57]. Suppose that employees can remotely control the thermostat of their office room R, through the handle S, e.g. for checking whether their own is on or off.
In there are two manners for dynamically updating a context. The first exploits the API provided by the system, e.g. a function disconnect for closing the connection with a specific network. The second one is more explicit: a programmer can use the Datalog primitive constructs tell and retract that add and remove facts. In our example, a system administrator can change the profile of an employee, e.g. moving Bob to the vending department, as follows:
Behavioural adaptation
The code in Fig. 1 implements a simple application which accesses a database and performs a query to retrieve data about customers. The labels of the expressions tell, retract, and psi are not part of the code, and will be mechanically added for supporting the static analysis; they will be discussed later on and are to be ignored for the time being. The behaviour of the application depends on the location and on the profile of the user: when inside the office, the user can directly connect to and query the database. Otherwise, the communication exploits a proxy which allows getting the database handle.
A simple application.
A first example of specific construct, namely context-dependent binding, is at line 2 where the name for the office archive is taken from the context and bound to the variable db_name. The idea is to implement a simple form of adaptivity of data because the actual value is extracted from the current context, only known at run time. As a matter of fact, the value of db_name depends on the location of the user as prescribed by the definition of office_archive. The retrieved value is then used by open_db to open a connection to the database.
The core of the snippet above is the behavioural variation (lines 3–18) bound to records that downloads the table of customers. Behavioural variations change the program flow in accordance to the current context. Syntactically, they are similar to pattern matching, where Datalog goals replace patterns and variables can additionally occur: a behavioural variation is a list where the expressions are guarded by Datalog goals . In the code above, there are two alternatives, starting at lines 4 and 9 respectively. The selection between them depends on the location and on the capabilities of the current employee. To be more precise, behavioural variations are a sort of functional abstractions and their application triggers a specific dispatching mechanism that inspects the context and selects the expression guarded by the first goal satisfied. If no guards are satisfied, the computation gets stuck, as the application behaviour is undefined in that specific context: the application cannot adapt to it and a functional failure occurs.
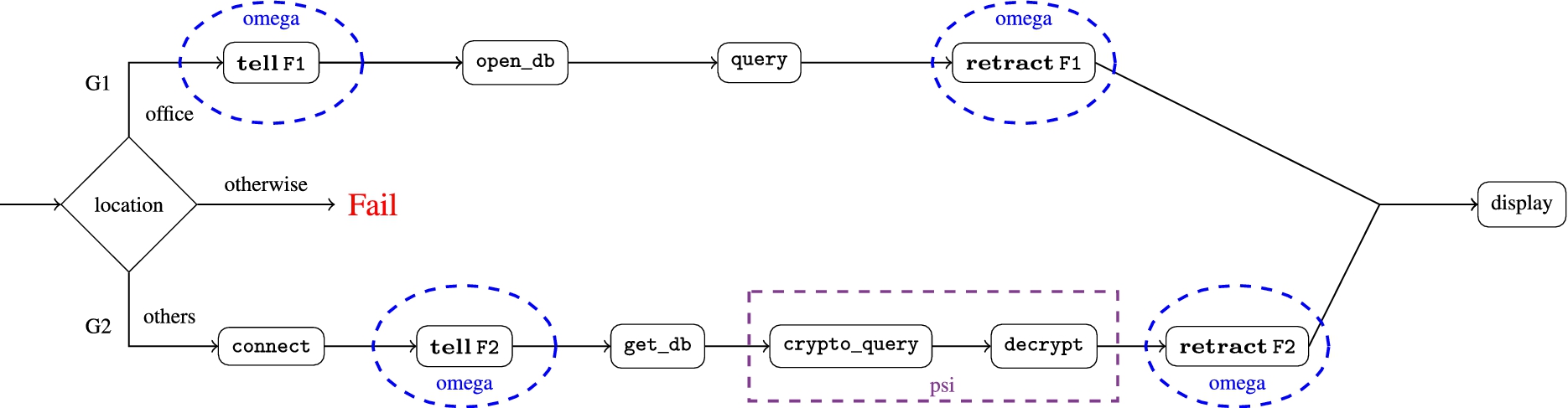
In our example, the application behaves differently depending on the current location of the vendor, as intuitively shown in Fig. 2. If the vendor is inside the office, he can directly access customers data connecting to db1; when outside, he has to first connect to the company proxy, then he can access db2 through a secure channel; otherwise the application raises an error because running in an unexpected context. Note that every resource available to the application, is only accessible through a handle provided by the context and only manipulated through system functions provided by the API.
If the second case is selected, the IP address of an available proxy is retrieved by the predicate proxy that binds the corresponding handle to the variable ip. Then the application calls the API function connect to establish a communication through chan. By exploiting this channel the application gets a handle to the database (through the API function get_db at line 13) in order to obtain the required data. Accessing and releasing the relevant database is notified by updating the context through the tell and retract actions at lines 5, 12 and 8, 18, respectively. Note that the third argument of crypto_query at line 15 is a lambda expression (in a sugared syntax) that invokes another API function select-from (as common, we assume that the cryptographic primitives are supplied by the system). Other resources and APIs occur in the snippet above: the database connection channel c at line 6, the cryptographic key k at line 10, and open_db at line 6, query at line 7, decrypt at line 16.
The code lines 15 and 16 are within the scope of the application policy psi, discussed in the next section. It guards the execution of the calls to crypto_query and decrypt: intuitively the policy psi guarantees the compatibility of the cryptographic key k and of the channel c.
A flow chart intuitively describing the function main.
Security policies
We now discuss how the context protects itself against misuses by applications and symmetrically how applications constrain the usage of their data and resources. For that, provides two kinds of security policies: context and application policies. As a matter of fact, policies predicate on the context, so they are easily expressed in Datalog and enforced by the deductive machinery of . As anticipated, the enforcement of a context policy ω is done by a reference monitor that checks the validity of ω right before every context change, i.e. before executing each tell/retract. Checking whether an application policy ψ is obeyed by a context has to be done continuously by the reference monitor, actually before and after each reduction step. Below we describe some examples of both kinds of policies.
Since the boundaries between personal and business space and time are blurred, the company adopts security policies to limit certain functionalities such as access to data from outside the office. In this scenario, the employees have different access rights: the vendors, among which Jane and Bob, can access the databases from both inside and outside the office, and the following facts specify which databases Bob and Jane can access, whereas the predicate allows an administrator to grant permissions:
A context policy that controls how vendors access the database db2 from outside the office follows
Pictorially, the dotted circles in Fig. 2 (blue in the pdf) represent that every modification of the context requires checking the policy omega.
As an example, if Jane is outside the office, no violation occurs. Instead, if Bob attempts to access the database from outside and has no delegation from the administrator, the policy omega is infringed at line 12. Of course policies can take into account any other kind of contextual information. One may e.g. constrain less the accesses of a vendor if he is using a corporate tablet whose running operating system is trusted. Also, a policy can prohibit vendors from accessing any databases during the week-ends.
As intuitively introduced above, the application policy psi regulates the usage of cryptographic keys and communication channels. We assume that the application has its own private key k, stored in the application context. The communication infrastructure offers channels supporting different cryptographic protocols. The application is designed in such a way that the key used is compatible with the protocol sec_protocol associated with the channel c returned by the call get_db(chan). Context information is therefore used for choosing the suitable cryptographic protocol for the communication [40]. For simplicity, here compatibility means that the protocol can use keys of a certain length, following the context-agile encryption technique of [59]. Formally
Note that an application policy cannot be rendered by a behavioural variation, because its guards are only checked when it is applied. Instead, the goal corresponding to the check of an application policy is queried by the reference monitor at each execution step. Assume in our simple example above that the protocol used to communicate and the channel c are compatible, but that the API crypto_query selects another protocol which is not compatible. Consequently, psi holds when entering the policy framing and a behavioural variation replacing line 14 will succeed at that execution point. However, a security violation occurs thereafter, because the case of the behavioural variation has been already selected. Instead our mechanism for application policy detects the violation: psi is indeed enforced step-wise along the execution of the API functions crypto_query (and decrypt) as intuitively shown by the dotted rectangle in Fig. 2 (purple in the pdf).
Failures, static analysis and instrumentation
An application fails to adapt to a context (functional failure), when it has not been designed for the actual hosting context, e.g. because a missing facility was assumed to be present. In our example, this happens when a vendor attempts to access the database from home. A functional failure is reflected by a failure of the dispatching mechanism that causes the computation to get stuck. As a matter of fact, adaptive applications are prone to a new class of run time errors that are hard to catch, since the running contexts are unpredictable.
Another kind of failure happens when an application does not manipulate resources as expected (non-functional failure) and causes a violation of a policy. As said above, in our example Bob infringes the context policy omega when attempting to access the database db2 if not delegated to. Another example is the violation of the application psi occurring when the key k is too short for the protocol associated with the channel c in lines 14–17.
To avoid functional failures and to optimise policy enforcement, we extend the two-phase static analysis of [22,23]. This analysis consists of (i) a type and effect system, and (ii) a control-flow analysis. It checks whether an application will be able to adapt to its execution contexts, and detects which contexts possibly violate the required policies.
In more detail, at compile time, we associate a type and an effect with an expression e. The type is (almost) standard, and the effect is an over-approximation of the actual run time behaviour of e, called history expression. The effect abstractly represents the changes and the queries performed on the context during its evaluation. The second phase occurs at load time and exploits the history expression to build a graph describing how the context may evolve during the execution.
For example, the history expression associated by the type system with the behavioural variation records is the following:
In the symbol · abstracts sequential composition; ψ represents the application policy psi; is the abstract counterpart of the behavioural variation records, where ⊗ sequentially composes the pair of effects associated with a guard and its expression; goals and represent the goals at lines 4 and 9, respectively; facts and are accessing(db1) and accessing(db2).
History expressions are labelled (for the sake of readability, we just show the relevant ones in ). These labels enable us to link the abstract actions in histories to the corresponding actions of the code, that we assume labelled by the compiler. For instance, the in corresponds to the tell at line 5 in records, which is labelled by 1; the is similarly linked to the policy framing with label 4. All the correspondences are (the abstract labels that do not annotate tell/retract actions or policies have no counterpart; also, the correspondence needs not to be injective as it happens in this example).
At load time, the virtual machine of performs two steps: linking and verification. The first step resolves the system names, and constructs the initial context C, by combining the one of the application with the system context that includes information on the current state, e.g. available resources and their usage constraints. The linking step also checks the logical consistency of the context C. The verification first checks whether no functional failure occurs, i.e. whether the application adapts to all evolutions of C that may occur at run time. If this is the case, the application will not be run. Then, the analysis looks for the points in the code where non-functional failures can occur, i.e. when the application may act against the policies established by the system that loads the program, and vice versa. This information is used to drive the activation of a run time monitor by need.
To perform our analysis conveniently and efficiently, we build a graph describing the possible evolutions of the initial context C, through a control flow analysis of the history expression H. The nodes of over-approximate the contexts arising at run time and its edges carry (the labels of) the actions which change the context. A distinguished aspect of our analysis is that it depends on the initial context C, right because our application may behave correctly in one context and fail in another, so this analysis can only be done at load time.
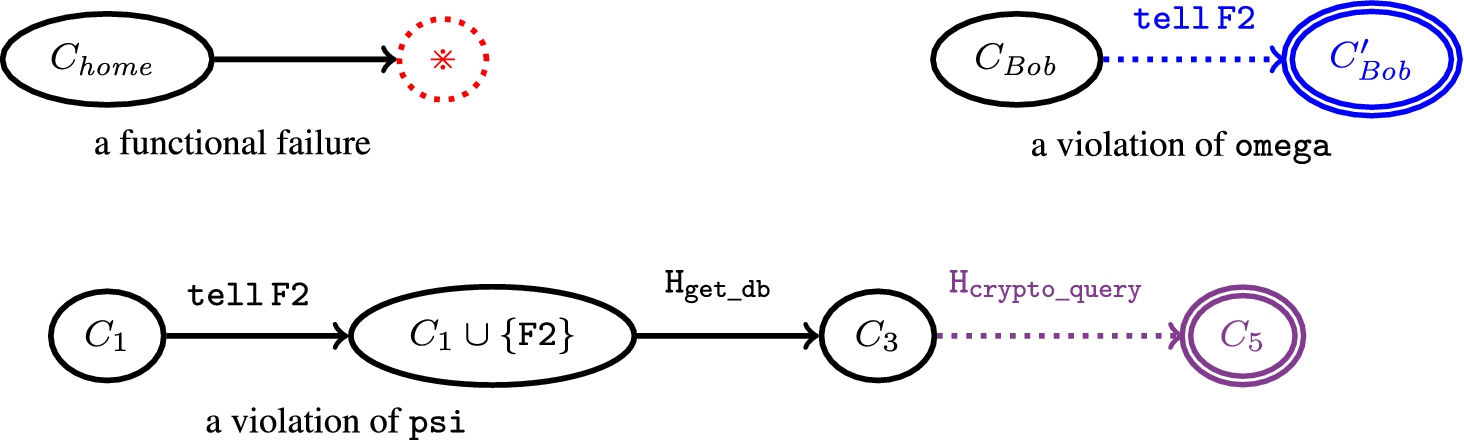
Back to our example, we consider three cases depending on different initial contexts, depicted in Fig. 3, where for the sake of brevity we collapsed parts of the graph as a single edge labelled by the relevant history expression. The first initial context records that the vendor is at home (predicate wifi_connected(myplace) holds). Since no case of the behavioural variation records can be selected because the application is not designed to work in that context. No guards are satisfied, and the dispatching mechanism fails. A pictorial representation of this functional failure is in Fig. 3: the failure node ⋇ (red in the pdf) is reachable from the initial one. Suppose now that in the context the predicate current_usr(Bob) holds. The is risky because it may violate the context policy omega (actually it does), therefore the corresponding action, labelled by 3 in the code, must be blocked. For achieving this, it suffices switching on the run time monitor, right before executing this operation. Another potential non-functional failure arises when the cryptographic key and the protocol are not compatible (the application policy psi is violated). This is shown in Fig. 3 assuming as done above that the crypto_query may cause the violation. Again the correspondence between the label in the history expression and the label 4 in the code indicates that the run time monitor has to be switched on when entering the scope of the policy psi and switched off when leaving it. Of course, if in context one proves that the cryptographic key and the protocol agree, there is no potential non-functional failure and the application runs without any monitoring.
Three evolution graphs showing a functional failure (assuming that wifi_connected(myplace) holds in ) and two policy violations. The context policy omega is not obeyed because the user in is Bob; the application policy psi is violated because the key is not compatible with the protocol. The dotted edges will be cut off by the run time monitor.
Other examples of security policies
We conclude the intuitive presentation of our proposal with a few examples showing how Datalog expresses other policies and how we manage them. In particular, we consider below delegation, dynamic activation and deactivation of policies, and a way of controlling which data in a context a user is allowed to access.
Imagine that the company allows a vendor to delegate another vendor to access the data of a particular customer without resorting to the system administrator as done above. Such a delegation is represented in the context as the fact grant_permission(user1, user2) meaning that the employee user2 can operate in place of the employee user1. So a tell of this fact suffices to activate the delegation. Of course, the delegation is better constrained by the following policy that forbids a member of the staff to delegate a vendor and vice versa:
In order to dynamically activate or deactivate context policies, we require that their definition includes a fact, that acts as an activation flag. If this fact holds in the current context, then the corresponding policy is active, otherwise it is not. So the context manager can activate/deactivate a policy by simply changing the value of the corresponding flag. For example, take the policy omega above regulating the accesses to the database db2 from the outside. Its dynamic version is the following where policy_flag is the activation flag:
We can also express policies that control which parts of the context an application is allowed to modify, by suitably guarding the facts to be protected by a context policy. For example, the following one bans the users blacklisted from retracting a specific fact F. The first case of omega3 requires that the fact F always holds in a context where the current user is blacklisted. Any attempt to remove F leads to a violation of the policy, while this is not the case if the user is allowed to retract F.
Suppose that the cryptographic algorithm used by crypto_query and decrypt are energy consuming. The following policy protects our application to run short of battery, when it wraps lines 15 and 16:
Below, we survey the syntax and the semantics of , along with some small examples to illustrate its peculiar constructs; for more details see [23].
Syntax. consists of two components: Datalog with negation to describe the context, and a core ML extended with COP features. The Datalog part is standard: a program is a set of facts and clauses.
Let (ranged over by ), (ranged over by ) and (ranged over by ) be a set of variables, of basic constants and of predicate symbols, respectively. The syntax is
As usual in Datalog, a term is a variable x or a constant c; an atom A is a predicate symbol P applied to a list of terms; a literal is a positive or a negative atom; a clause is composed by a head, i.e. an atom, and a body, i.e. a possibly empty sequence of literals; a fact is a clause with an empty body and a goal is a clause with empty head. We let goals be ranged over by G, with the intuition that it occurs in a behavioural variation. Context and application policies are ranged over by ω and ψ, respectively. As expected, a policy is obeyed if and only if the corresponding goal holds. For simplicity, we assume that there is a unique context policy Ω (referred in the code as Omega), resulting from the conjunction of all the relevant policies.
In the following, we assume that each Datalog program is safe and stratified [18] (our world is closed, so we can deal with negation). As anticipated in the Introduction, our version of Datalog can express all relational algebras, is fully decidable, and guarantees polynomial response time [27]. Also, many logical languages for defining access control policies follow this stratified-negation-model, e.g. [12,26,41].
The functional part inherits most of the ML constructs. In addition to the usual ones, our values include Datalog facts F and behavioural variations. Moreover, we introduce the set of parameters, i.e. variables that assume values depending on the properties of the running context, while are identifiers for standard variables and functions, with the proviso that . The syntax of is below.
To facilitate our static analysis (see Section 5) we associate each / and each policy ψ with a different label ; labels do not affect the dynamic semantics, which is defined below.
Standard expressions are evaluated in the usual way. Very briefly, a variable x evaluates to the value it is bound. Both expressions in an application are to be evaluated to values and , and if , the evaluation goes on by substituting for all the (free) occurrences of f in e and for those of x. The evaluation of a is that of where all the (free) occurrences of x have been replaced by the value of . Conditionals evaluate as expected.
The COP-oriented constructs of include behavioural variations , each consisting of a variation, i.e. a list of expressions guarded by Datalog goals (x free in ). At run time, the first goal satisfied by the context selects the expression to run (dispatching). For instance, in Section 2, we declared the behavioural variation records, that returns information on customers, by accessing to different databases depending on the vendor’s location.
Context-dependent binding is the mechanism to declare variables whose values depend on the context. The construct implements the context-dependent binding of a parameter to a variation . Note that context-dependent binding is designed for expressing adaptability of data, while behavioural variations express adaptability of control flow.
The and constructs assert and retract facts in the context, provided that no violation of security occurs.
The append operator concatenates behavioural variations, so allowing dynamic composition.
A behavioural variation applies to its argument . To do so, the dispatching mechanism is triggered to query the context and to select from the expression to run, if any.
Furthermore, we use the construct , called policy framing, to guarantee that the context obeys the policy expressed by ψ while running e. With this construct programmers can protect their application from a possible misuse of the running context C. We require ψ to be true in C until e completes its execution, and then the scope of the policy framing is left and the policy de-activated. Also, policy framings can be nested, with the intuition that an expression enclosed in many of them is executed only if the running context obeys them all. The (context) policies ω are instead imposed by the context, to protect its sensible data and devices from a misuse of an application, during its entire evaluation. We will formalise later on how both kinds of policies will be enforced. We presented some examples in the previous section: omega is the (part of) context policy that only allows vendors with explicit authorisation to access the database db2; omega3 controls which parts of the context an application is allowed to modify.
Semantics. The Datalog component has the standard top-down semantics [18]. Given a context and a goal G, we let mean that the goal G, under a ground substitution θ, is satisfied in the context C.
The SOS semantics of is defined for expressions with no free variables, but possibly with free parameters, thus allowing for openness. To this aim, we have an environment ρ, i.e. a function mapping parameters to variations . A transition represents a single evaluation step. It says that under the environment ρ the expression e is evaluated in the context C and reduces to changing C to . The initial configuration is , where contains the bindings for all system parameters, and C results from joining the predicates and facts of the system and of the application .
The reduction rules for the ML-like constructs of .
The reduction rules for the constructs of concerning adaptation and policies.
Figures 4 and 5 show the inductive definitions of the reduction rules for : we briefly comment below on those for our new constructs.
The rules (Dlet1) and (Dlet2) for the construct , and the rule (Par) for parameters implement our context-dependent binding. For brevity, we assume here that contains no parameters. The rule (Dlet1) extends the environment ρ by appending in front of the existent binding for . Then, is evaluated under the updated environment. Note that the does not evaluate , but only records it in the environment in a sort of call-by-name style. The rule (Dlet2) is standard: the whole reduces to the value to which reduces.
The (Par) rule looks for the variation bound to in ρ. Then, the dispatching mechanism selects the expression to which reduces. The dispatching mechanism is implemented by the partial function , defined as follows
It inspects a variation from left to right looking for the first goal G satisfied by C, under a substitution θ. If this search succeeds, the dispatching mechanism returns the corresponding expression e and θ. Then, reduces to , i.e. to e, whose variables are bound by θ. Instead, if the dispatching fails because no goal holds, the computation gets stuck, because the program cannot adapt to the current context.
As an example of context-dependent binding, consider the simple conditional expression , in an environment ρ that binds the parameter to and in a context C that satisfies the goal , but not :
where we first retrieve the binding for (recall it is ), with , for a suitable substitution θ. Since facts are values, we can bind them to parameters and test their equivalence by a conditional expression.
The application of the behavioural variation evaluates the subexpressions until reduces to and to a value v. Then, the rule (VaApp3) invokes the dispatching mechanism to select the relevant expression e from which the computation proceeds after v is substituted for x. Also in this case the computation gets stuck, if the dispatching mechanism fails. As an a example, consider the behavioural variation and apply it to the constant in a context C that satisfies the goal , but not the goal . Since for some substitution θ, we get:
The rules (Tell1, Tell2) update the context by asserting a fact, that is a value of ; similarly (Retract1, Retract2) retract a fact (note that labels are immaterial here, and will only be used in the static analysis). The new context , obtained from C by adding/removing F, is checked against the security policy Ω (recall that we assume to join all the context policies in the single one Ω). In this way we prevent the application from damaging the context, as exemplified below. We can easily reuse our dispatching machinery above: we implement the check as a call to the function where the first argument is and the second one is , the trivial variation with goal Ω. If this call produces a result, then the evaluation yields the unit value and the new context .
The following example shows the reduction of a in a context , under a context policy Ω requiring that the fact always holds. Let and evaluate . If evaluates to (without changing the context), the context eventually produced violates the policy in hand, fails, and therefore the evaluation gets stuck:
where ↛ means that no transition goes out from . If, instead, reduces to , there is no policy violation and the evaluation reduces to :
The rules for sequentially evaluate and until they reduce to behavioural variations (rules (Append1, 2)). Then, they are concatenated together by renaming bound variables to avoid name captures (rule (Append3)). The policy ψ of the application e is also enforced along its evaluation when asserting or retracting a fact by rule (Frame1). Before performing one of these actions, the ψ has to be shown true in the context C, and the changes made on the context must preserve ψ true, i.e. . This check is implemented at run time through a call to the dispatching mechanism, as suggested in the comment to the rules for /. The rule (Frame2) simply discards the framing, so it de-activates the policy ψ as soon as a value is produced.
Back to the example of Section 2, assume that Jane wants to access the database from outside the office, then we have the following computation ( indicates a non empty computation):
where e is the code at lines 15 and 16. From the first to the second configuration the dispatching mechanism queries the context C and selects the second case of records. From the third to the fourth configuration the connection to the database is established and the data are retrieved. The framing construct checks the policy psi at each step of this computation.
Note that imposing a context policy ω to an application e could be intuitively implemented by wrapping its whole code within the framing , at load time. However, monitoring context and application policies is done differently, and separation of concerns and efficiency reasons strongly suggest us keeping them apart.
Type and effect system
We now associate an expression with a type, an abstraction called history expression, and a function called the labelling environment. During the verification phase, the virtual machine uses the history expression to ensure that the dispatching mechanism will always succeed at run time. The labelling environment helps in selecting which portions of the code may lead to violations of the security policies, and in instrumenting the code with suitable calls to a run time monitor. First, we briefly present History Expressions and labelling environments, and then the rules of our type and effect system.
History expressions
A history expression is a term of a simple process algebra that soundly abstracts program behaviour [10,63]. Here, they over-approximate the sequence of actions that an application may perform over the context at run time, i.e. asserting/retracting facts and asking if a goal holds. History expressions also record the application policies that are to be enforced. We assume that a history expression is uniquely labelled on a given set of . Labels will be used to link static actions in histories to the corresponding dynamic actions inside the code; we feel free to omit them when immaterial. The syntax of History Expressions is as follows:
The empty history expression abstracts programs that do not interact with the context. For technical reasons, we syntactically distinguish when the empty history expression comes from the syntax (), and when it is instead obtained by reduction in the semantics (∍ that is unlabelled). With we represent possibly recursive functions, where h is the recursion variable; the “atomic” history expressions and are for the analogous constructs of ; the non-deterministic sum abstracts --; the concatenation is for sequences of actions that arise, e.g. while evaluating applications; the history expression is the abstract version of the security framing; Δ mimics our dispatching mechanism, where Δ is an abstract variation, defined as a list of history expressions, each element of which is guarded by an . For instance, the history expression intuitively introduced in Section 2 abstracts the behavioural variation records in Fig. 1.
Semantics of History Expressions.
Given a context C, the behaviour of a history expression H is formalised by the transition system inductively defined in Fig. 6. A transition means that H reduces to in the context C and yields the context . Most rules are similar to the ones of [10]: below we only comment on those dealing with the context and with the policy framings. The rules for Δ scan the abstract variation and look for the first goal G satisfied in the current context; if this search succeeds, the whole history expression reduces to the history expression H guarded by G; otherwise the search continues on the rest of Δ. If no goal is satisfiable, the stuck configuration is reached, meaning that the dispatching mechanism fails.
An action reduces to ∍ and yields a context , where the fact F has just been added; similarly for the action . Differently from what we do in the semantic rules, here we do not consider the possibility of a violation of a context policy ω: a history expression approximates how the application would behave in the absence of any kind of check imposed by the context.
The rules for policy framings are much alike those of the dynamic semantics: a non-empty history expression H can transform into , provided that in both the starting context C and in the next one the policy ψ holds; when ∍ is reached, the policy framing is left.
Labelling environment. We assume as given the function that recovers a construct in a given history expression from a label . Using μ, we can link the occurrences of , and ψ in a history expression to the corresponding operations in an expression e (labelled on , see Section 3), while type-checking e. This correspondence is recorded in the auxiliary labelling environment introduced below. It will later on help in instrumenting the code.
(Labelling environment).
A labelling environment is a (partial) function , defined only if .
We shall write ⊥ for the function undefined everywhere.
As anticipated in Section 2, the labelling environment puts in correspondence the labels of the history expression with those in the code snippet in Fig. 1. Note that labelling environments need not to be injective.
Typing rules
We assume that each Datalog predicate has a fixed arity and a type (see e.g. [51]). From here onwards, we also assume that there exists a Datalog typing function γ that, given a goal G, returns a list of pairs (x, type-of-x), for all variables .
The rules of our type and effect system have:
the usual environment , binding the variables of an expression; ∅ denotes the empty environment, and denotes an environment having a binding for the variable x (x not in the domain of Γ). A standard assumption is to have an initial environment containing the signatures of the APIs;
a further environment , that maps a parameter to a triple consisting of a (i) type, (ii) an abstract variation Δ, used to solve the binding for at run time, and (iii) a labelling environment Λ that links the , and ψ occurring in Δ to the corresponding operations in an expression e; denotes an environment with a binding for the parameter ( not in the domain of K).
Our typing judgements have the form
and express that in the environments Γ and K the expression e has type τ, effect H and yields a labelling environment Λ.
Our types are either basic for constants and variables, or functional types for functions and behavioural variations, or types for facts:
Some types are annotated for analysis reasons. In , the set ϕ contains the facts that an expression can be reduced to at run time (see the semantics rules (Tell2) and (Retract2)).
In the type associated with a function f, the environment K stores the types and the abstract variations of the parameters occurring inside the body of f, and represents a precondition needed to apply it. The history expression H is the latent effect of f, i.e. the sequence of actions that may be performed over the context during the function evaluation. The labelling environment Λ links (some of) the labels of H to those occurring in the body of f.
Similarly, the behavioural variation has type , where K is a precondition for applying ; Δ is an abstract variation, that represents the information used at run time by the dispatching mechanism to apply ; and Λ is as above.
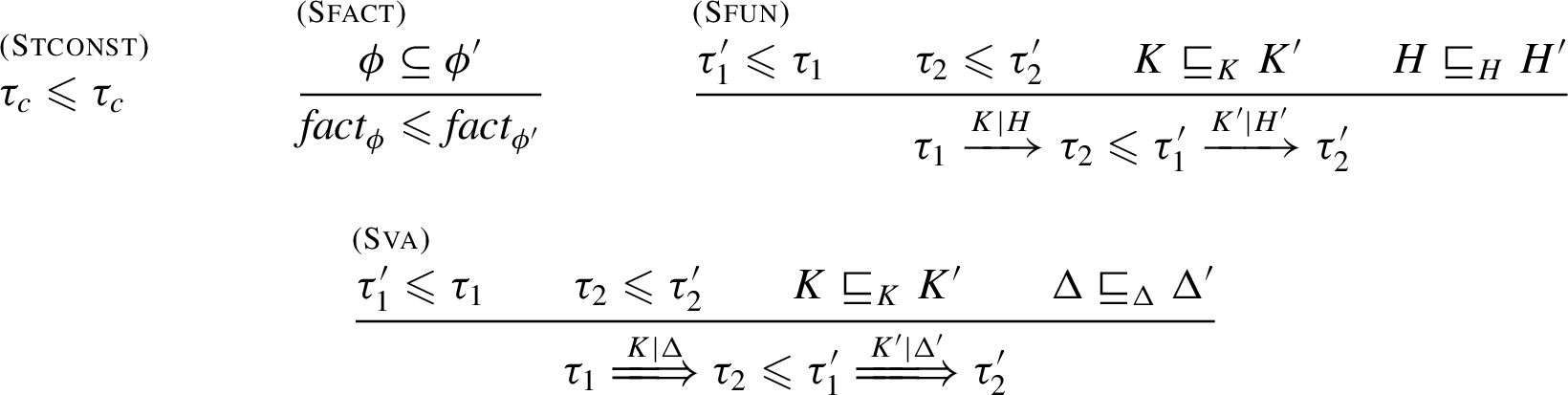
We now introduce four partial orderings, , , on H, Δ, K and Λ, respectively, and we often omit the indexes when no ambiguity may arise. Below the symbol ⊎ stands for disjoint union, the type ordering ⩽ is defined in Fig. 7, and we assume that , so will have a single trailing .
The subtyping relation.
The rules of our type and effect system inherited from ML are displayed in Fig. 8, while the others are introduced in Figs 9 and 10.
Typing rules for ML-like constructs of .
Typing rules for context updates.
ML-inherited rules. We briefly comment on the most relevant rules in Fig. 8. In the rules (Tconst), (Tvar) and (Tabs) the labelling environment is empty. The rule (Tif) is standard, apart from the resulting labelling environment that is the (disjoint) union of those of the components . Same for (Tlet) and for (Tapp) where the labelling environment of the latent effect is also considered. Note that in the conclusion of (Tapp), the precondition of the latent effect of e must be included in the environment K to guarantee that all parameters will be duly bounded. The rule (Tabs) is standard, except for the way the environments K and Λ are handled. As usual, the actual effect guessed in the premise becomes latent in the conclusion of the rule, while the effect and the labelling environment become empty; note that in the premise the guessed parameter environment is the one used for typing e, while the guessed effect H and the guessed labelling environment Λ are those of e.
Context rules. The rules for the constructs that handle the context are in Fig. 9. A few comments follow. The rule (Tfact) gives a fact F type annotated with and the empty effect. The rule (Ttell) asserts that the expression has type , provided that the type of e is . The overall effect is obtained by combining the effect of e with the non-deterministic summation of , where F is any of the facts in the type of e. The current labelling environment is extended with links from the elements of ϕ to the label of . Similarly for (Tretract). In rule (Tvariation) we determine the type for each subexpression under , and the environment Γ, extended by the type of x and of the variables occurring in the goal (recall that the Datalog typing function γ returns a list of pairs (z, type-of-z) for all variables z of ). Note that all subexpressions have the same type , but of course they have different effects and labelling environments. We also require that the abstract variation Δ results from concatenating with the effect computed for . The arrow in the type of the behavioural variation is annotated by and by the union of all the labelling environments . Consider e.g. the behavioural variation . Assume that the two cases of this behavioural variation have type τ and effects and , respectively, under the environment (goals have no variables) and the guessed environment . Hence, the type of will be with , while the effect will be empty.
Typing rules for adaptation and security.
Rules for adaptation and security. In Fig. 10 we list the rules dealing with adaptation and security. The rule (Tsub) allows us to freely enlarge types and effects by applying the subtyping and subeffecting rules (and the orderings on them). Also the labelling environment can be enlarged, and it is required to be defined on all the labels of the (larger) history expression H (). The rule (Tdvar) associates with the triple stored in the environment K. The rule (Tdlet) requires that has type in the environment Γ extended with the types for the variables of the goal G. Also, has to type-check in an environment K, extended with the information for parameter . The type and the effect for the overall expression are the same as , while the labelling environment is the union of those of , and of the one coming from . The rule (Tappend) asserts that two expressions , with the same type τ, except for the abstract variations , in their annotations, and effects and , are combined into with type τ, and concatenated annotations and effects. The rule (Tvapp) type-checks behavioural variation applications and reveals the role of preconditions. As expected, is a behavioural variation with parameter of type and with type . We get a type if the environment , which acts as a precondition, is included in K according to ⊑. The type of the behavioural variation application is that of the result of , and the effect is obtained by concatenating the ones of and with the history expression Δ, occurring in the annotation of the type of . The overall labelling environment results from joining those of the subexpressions and of the latent effect.
Finally, in the single rule for the security framing (Tframe), the effect computed for e is wrapped with the policy ψ, and the labelling environment is the union of that of e with a link from the occurrence of ψ in the history expression to the corresponding one in the code.
Soundness
Our type and effect system is sound with respect to the operational semantics of . To prove this result, we first introduce a notion for typing a dynamic environment ρ in a way consistent with the type environments Γ and K.
(Typing dynamic environment).
Given the type environments Γ and K, we say that the dynamic environment ρ has type K under Γ (in symbols ) if and only if
; and
. , ; . it is with ; and and .
Now, the soundness of our type and effect system easily derives from the following standard results.
(Preservation).
Let e be a closed expression; and let ρ be a dynamic environment such thatincludes the set of parameters of e and.
Ifand, then,for someand.
The next corollary ensures that the effect computed for e soundly approximates the actions that may be performed over the context during the evaluation of e. Also, the type of the expression obtained after some evaluation steps is the same of e, because of Theorem 4.1, and of course the obtained label environment is included in .
(Over-approximation).
Let e be a closed expression; and let ρ be a dynamic environment such thatincludes the set of parameters of e and.
Ifand, thenand there exists a sequence of transitions, for someand.
The Progress theorem stated below assumes that the effect H never evaluates to fail, namely it is viable. We will see that this implies that while executing the expression e that has effect H, the dispatching mechanism will always succeed. The control flow analysis of Section 5 will check viability of history expressions. To establish our result, we also require that no policy is violated along evaluation. We shall guarantee that this is the case through the analysis presented in Section 5, possibly resorting to a reference monitor; see also Property 6.1.
From now onwards, we shall use the following abbreviations. Given an environment ρ, a context C and a closed expression e, we write
if and only if there exists no such that ;
e violates no policies if and only if the rule (Frame1) successfully applies to all its derivatives .
(Progress).
Let e be a closed expression such that; and let ρ be a dynamic environment such thatincludes the set of parameters of e, and.
If; e violates no policies; and H is viable for C (i.e.), then e is a value.
We are now ready to state the theorem that ensures the semantic correctness of our approach.
(Correctness).
Letbe a closed expression such that; let ρ be a dynamic environment such thatincludes the set of parameters of, and that; finally let C be a context such that. Then either the computation ofterminates yielding a value () or it diverges, but it never gets stuck.
Load time analysis
Our execution model for extends the one in [23]: the compiler1
Our prototype [15] does not fully integrate the F# type system with ours; presently we only have an early implementation of our analyses.
produces a quadruple given by (i) the application context C; (ii) the object code e; (iii) the history expression H over-approximating the behaviour of e; and (iv) the labelling environment Λ associating labels of H with those in the code. Given this quadruple, the virtual machine performs the following two steps at load time:
linking: to resolve system variables and constructs the initial context (combining C and the system context); and
verification: to build, from H, a graph that describes the possible evolutions of . This graph will be used to support a further analysis, and code instrumentation. Instrumenting the code will allow us to call on need a reference monitor that prevents actions violating the security policies in force.
Technically, we compute through a static analysis, specified in terms of Flow Logic [54]. To ease the formal development, we assume below that all the bound variables occurring in a history expression are distinct. So it is straightforward to define, by structural induction, a function mapping a variable to the history expression that introduces it.
The static approximation is represented by a quadruple , called estimate for H, with
where ⋇ is the distinguished “failure” context representing a dispatching failure. For each label l we define the following four sets:
the pre-ctx and the post-ctx, containing the contexts possibly arising before and after evaluating , respectively;
the pre-pol and the post-pol, containing the application policies possibly active before and after evaluating , respectively.
The analysis is specified by a set of clauses upon judgements of the following form
with the intended meaning that the four functions , , and form an acceptable analysis estimate for the history expression . This is the first step for proving an estimate to soundly approximate the behaviour of H as it will be formalised below through the notion of validity.
The notion of acceptability has been used in [22,23] to check whether the history expression H, hence the expression e it is an abstraction of, will never fail in a given initial context C (made of the system and the application contexts) because the dispatching mechanism does not succeed. Here, we also detect which actions, if any, may violate the security policies in force.
In the following we introduce into two parts (shown in Figs 11 and 12, respectively) the set of inference rules that validate the correctness of a given estimate . As expected, the checks in the clauses mimic the semantic evolution of the history expression in a given context, by modelling the semantic preconditions and the consequences of the possible reductions.
Specification of the analysis for History Expressions associated with standard ML expressions.
Specification of the analysis for History Expressions for adaptation and security.
Rules for the standard construct. The rules for the history expressions that abstract standard ML expressions are in Fig. 11. The rule (Aeps) says that the estimate is acceptable for the “syntactic” if the pre-sets are included in the corresponding post-sets.
The rules (Aseq1) and (Aseq2) handle the sequential composition of history expressions. The first rule states that is acceptable for if it is valid for both and . Moreover, the pre-ctx of must include the pre-ctx of H and the pre-ctx of includes the post-ctx of ; finally the post-ctx of H includes that of . Just the same condition is required for the pre- and post-pol. The second rule states that is acceptable for if it is acceptable for and the pre-ctx (pre-pol, respectively) of includes that of H, while the post-ctx (post-pol, resp.) of H includes that of .
By the rule (Asum), is acceptable for if it is valid for each and ; the pre-ctx of H is included in the pre-sets of and ; the post-ctx of H includes those of and ; and the same inclusions hold between the pre- and the post-pol.
By the rule (Arec), is acceptable for if it is valid for , the pre-ctx (pre-pol, resp.) of includes that of H; and the post-ctx (post-pol, resp.) of H includes that of .
Finally, the rule (Avar) says that is an acceptable estimate for a variable if the pre-ctx (pre-pol, resp.) of the history expression introducing h, namely , is included in that of , and the post-ctx (post-pol, resp.) of includes that of .
Rules for adaptation and security. We now introduce and discuss the rules for adaptation and security, displayed in Fig. 12.
The rule (Anil) says that every pair of functions is an acceptable estimate for the “semantic” empty history expression ∍ (the empty history expression reached after a successful execution).
In the rule (Atell), we check whether the context C is in the pre-ctx, and is in the post-set, while the pre-pol have to be included in the post-pol; similarly for (Aretract), where should be in the post-set.
The rules (Aask1) and (Aask2) handle the abstract dispatching mechanism. The first states that is acceptable for , provided that, for all C in the pre-ctx of H, if the goal G succeeds in C then the pre-ctx of includes that of H and the post-ctx of H includes that of . Otherwise, the pre-ctx of must include the pre-ctx of H and the post-ctx of is included in that of H. The rule (Aask2) requires ⋇ to be in the post-ctx of . Note that this implies that the dispatching mechanism may fail at run time. Needless to say, in both rules the same inclusions must hold between the pre- and the post-pol.
Finally, through the rule (Aframe) we say that is acceptable for if it is such for ; if the pre-ctx (pre-pol, resp.) of is included in the pre-ctx (pre-pol, resp.) of ; if the post-ctx of includes that of ; if additionally the policy ψ belongs to the pre-pol of and the post-pol of without ψ (recall that the framing is left) is included in the post-pol of . In other words, all the policies that have to be enforced before entering the policy framing for ψ are still active when the framing is left, and furthermore ψ is in force entering the framing and is de-activated when leaving it.
Semantic properties. We now formalise the notion of valid estimate for a history expression, plugged in a context; we prove that there always exists a minimal valid analysis estimate; and that a valid estimate is correct with respect to the operational semantics of history expressions. Valid estimates then soundly approximate the behaviour of history expressions.
(Valid analysis estimate).
Given and an initial context C, we say that the quadruple is a valid analysis estimate for H and C iff and .
It is easy to partially order the set of analysis estimates by set inclusion, component-wise, and to prove that they are a Moore family. Since such families contain a least element (as well as a greatest one), there always exists a least choice of that is acceptable. The existence of a least estimate is stated below.
(Existence of estimates).
Givenand an initial context C, the setof the acceptable estimates of the analysis forand C is a Moore family; hence, there exists a minimal valid estimate.
The next theorem guarantees that the analysis estimates are preserved under execution steps.
(Subject reduction).
Letbe a closed history expression and let. If for allwe have thatthen;;;; and.
Viability of history expressions. We now define when a history expression H is viable for an initial context C, i.e. when it passes the verification phase at load time, following [22,23]. Actually, a viable H never evaluates to fail, and the expression the behaviour of which it abstracts will never get stuck, because the dispatching mechanism fails.
(Viability).
Let H be a history expression; let be the set of labels of the sub-terms in H; and let C be an initial context. We say that H is viable for C if the minimal valid analysis estimate is such that for no .
Note that if the minimal valid estimate satisfies the requirement above, then no other valid estimate will violate it, because of the Moore family property.
Let H be a history expression associated with an application e. If H be viable for a context C, then it is never the case that .
To illustrate how viability is checked, consider the following history expression and the initial context , only consisting of facts:
The left part of Fig. 13 shows the values of and for , while those for and for are omitted being the emptyset everywhere. Note that the pre-ctx of includes , and the post-ctx also includes a set containing . Also, the pre-ctx of includes , while the post-ctx includes . The column for contains ⋇ nowhere, so is viable for C.
The analysis estimate ( and are always ∅ and are omitted) and the evolution graph for the history expression and for the initial context .
Instead, an example of a history expression that fails to pass the verification phase when put in the same initial context is
where there are two trivial policies: respected if and only if holds, and if and only if . A functional failure occurs because the fact holds in no reachable context. This is reflected by the occurrences of ⋇ in and , and in , as shown in the upper part of Fig. 14. The functional failure may occur because the goal does not hold in C, and indeed is not viable. This phase also detects that a policy violation may occur, and if the program had passed the verification phase, at run time the reference monitor would have forbidden the action corresponding to to occur, because it violates .
The analysis estimate and the evolution graph for the initial context , and for the history expression .
We now exploit the valid estimates computed by the above analysis to build up the evolution graph for a history expression H in an initial context C. It describes how C may be updated at run time, paving the way to security enforcement. In the following definition we use the function μ introduced right before in Definition 4.1 that recovers a construct in H from a label l.
(Evolution graph).
Let C be a context and be a history expression; let and be the sets of facts and of labels occurring in H, respectively; and let be a valid analysis estimate for H and C.
The evolution graph of C under H is , with nodes in N labelled by and edges in E labelled by , where
Intuitively, the nodes of are sets of contexts reachable from C by running H, and we label them with the policies of the application that are to be enforced. An edge between two nodes and says that is obtained from , through an action or , a reference to which is recorded in the edge label. Note in passing that the graph is a compact and easy way to manipulate representation of the information computed by the analysis, and that it paves the ways for more involved verification mechanisms. For example, one could check CTL formulas on it, where the atomic propositions are Datalog goals. Consider again the history expressions and and their evolution graphs and in Figs 13 and 14. In , from the initial context C there is an edge labelled to , because of , and there is an edge labelled to the , because of . Of course, all the nodes are labelled by ∅, since no policy occurs in . A simple reachability algorithm suffices in showing viable for C (even less, as ⋇ does no occur in ). Instead, ⋇ is a reachable node of showing not viable. In addition, in there are two application policies, and so the nodes of the graph are labelled with those that must be checked there, in particular is labelled by . It is now equally simple showing that the action has to be blocked, since .
Note that the labels on the edges of a graph indicate a super-set of actions or that may lead to a context violating the required policies, while those on the nodes are a super-set of the application policies in force. As a consequence, their correspondence with the labels in the code can be exploited at load time to compute which security checks are necessary. In the next section, we will present a run time reference monitor, defined within, that is only switched on need.
Code instrumentation
We use the information stored in the labels of the evolution graph for a history expression H of an application e and a context C, to anticipate at load time (a super-set of) the security checks needed when e will run in C. We suggest instrumenting the original code before deploying it with checks that will only be activated if the policy actually needs to be enforced, be it a context or an application policy. At load time, we use the labels of the arcs of to locate the abstract or actions in H that may lead to a context violating a given context policy ω. Similarly, we check every application of a policy ψ in the label of a node n against each context included in n to single out those that may violate ψ. As we are statically analysing the behaviour of the approximation H, we need to recover in the code e the actual actions that may lead to these violations, and for that we will resort to the component Λ of the provided valid estimate for H and C.
Assume then that are the context policies and that are the application policies occurring within e, the application in hand. Also, let H be the history expression and Λ be labelling environment resulting from having type checked e. As seen in the previous section, a node n of a graph represents a set of contexts reachable while executing e.
We first statically verify whether each context in n satisfies ω. If this is not the case, we consider as risky all the edges with target n and the set of their labels – clearly over-approximating bad behaviours. We then consider the application policies active in n, i.e. , and we check whether they are obeyed by the contexts represented by n. The set of the application policies violated is called . Now, the labelling environment Λ determines those actions in the code that require monitoring during the execution. Formally, given the graph for H and C, we let
The property below directly follows from Property 5.3 and provides us with the conditions for an application to never fail because of unresolved behavioural variations and to never violate the required policies.
Given an expression e with associated history expression H, let be the evolution graph of H and C.
If H is viable and for all nodes n the set , then the evaluation of e never gets stuck.
Consider again the history expressions of Example 5.1 and assume that there is a context policy ω that holds if and only if . For all , we have that , signalling that the reference monitor for ω can safely be switched off, while running the actual code of which both history expressions are an abstraction.
Now consider . We have , while for all other nodes the value is ∅. Also here we see that the application policy will always be obeyed, so the reference monitor for it can be kept off. Instead, the execution of the action identified through requires checking the policy that is actually violated.
We now explain our lightweight form of code instrumentation, which is not standard, because it does not operate on the object code. As said in Section 2, the compiler labels the source code e and generates specific calls to monitoring procedures, so implementing the reference monitor. We remark that requires no further mechanism to do that, as it will be clear shortly.
We define a procedure, called check_violation(e,l), for verifying if a policy is satisfied. It takes an expression tell/retract and its label l as parameters (and returns the type , and empty effect and labelling environment). At load time, we assign two global masks and to each label l of a tell/retract action occurring in the source code. The values of these masks contain the set of the context and the application policies, respectively, that are worth checking. Their definition is as follows:
Note that represents the set of the labels corresponding to all the risky actions, i.e. the tell or retract actions that may lead to a policy violation. Conversely, if a policy does not appear in this set, there is no point in checking it, because it will always be obeyed at run time.
The procedure code follows that switches on the reference monitor on need (for clarity, we use a sugared version of ):
If there is a application policy associated with the label l we trigger the dispatching mechanism through the call ask psi.(). If the call fails then a policy violation is about to occur. In this case the computation is aborted or a recovery mechanism is invoked, if any. Otherwise the tell or retract is performed and every active policy, be it a context or an application one, is checked on the resulting context.
Our compilation schema needs to replace every tell(e)l in the source code with the following:
As expected, the same has to be done for every retract(e)l. This is indeed what happens in the example above with the action corresponding to the retract F that violates the policy (say that ). After the instrumentation, that occurrence in the code will be check_violation(. tell(e), l), and the execution will go stuck – unless there is a recovery mechanism, which we do not discuss here.
Note that, if the set of the risky actions is empty, then there is no need for checking, when calling either tell or retract.
Conclusions
Contributions. We have addressed security issues in an adaptive framework, by extending and instrumenting , a functional language introduced in [21,23] for adaptive programming. We also extended its two-step static analysis to deal with security. To the best of our knowledge, this is the first contribution to security within a linguistic approach to adaptivity, although its importance in this field is growing hot [56]. In summary, we have
expressed and enforced context-dependent security policies using Datalog, originally employed by to deal with contexts. Policies are of two kinds: (i) context policies, a priori unknown to the applications, that protect the context from unwanted changes or accesses, and (ii) application policies, a priori unknown to the context manager, that protect the running code, and that can be nested and have a scope;
extended the type and effect system of [22,23] for computing a type and a labelled abstract representation of the overall behaviour of an application, including the security policies it imposes and those it has to obey. Actually, an effect over-approximates the sequences of the possible dynamic actions over the context. The security-critical operations of the abstraction are labelled, so to link them with those in the code of the application, keeping track of the scope of the application policies;
considerably enhanced the static analysis of [22,23] that guarantees an application to adapt to all the possible contexts arising at run time; now, our analysis also identifies the operations that may violate the context and the application policies in force. Recall that this step can only be done at load time, because the execution context is only known when the application is about to run, and thus our static analysis cannot be completed at compile time;
defined a way to instrument at implementation time the code of an application, so as to incorporate in it an adaptive reference monitor, ready to stop executions when about to violate a policy to be enforced. When an application enters a new context, the results of the static analysis mentioned above are used to suitably drive the invocation of the monitor that is switched on and off if needed.
It is worth noting that itself required little extensions to be equipped with security policies and with mechanisms for checking and enforcing them. Indeed, policies are just Datalog clauses enforced by asking goals, and code is instrumented by using available constructs, namely behavioural variations and functions. Even though our proposal of a two-step static analysis is still a proof-of-concept, the underlying idea of complementing type-checking with the load time analysis, and the consequent instrumentation procedure appear to be well applicable to other adaptive programming paradigms.
Future work. We are currently experimenting on our language, in particular on the usage of the static analysis on more realistic examples. We are using a prototypical implementation of that extends F# [15] and that is available together with some case studies.2
https://github.com/vslab/fscoda.
To do that, we exploit the well-established metaprogramming mechanisms of F#, so to both minimise the learning cost for users and to avoid the need of any modification to the compiler and to the underlying .NET runtime. We also have a two-step type inference algorithm, and a naive construction of the evolution graph and of the reachability algorithm.
Besides a full implementation of , and of an efficient tool for the static analysis and for the instrumentation, we plan to investigate recovery mechanisms appropriate for behavioural variations, to allow the user to undo some actions considered risky or sensible, and force the dispatching mechanism to make different, alternative choices. Recovery mechanisms are obviously needed also to adapt applications that raise security failures. If the violated policy comes from the context, the easiest solution is abandoning that context, and possibly undoing the computation done so far. Nevertheless, this is not completely satisfying and makes it quite challenging to look for suitable and smarter recovery mechanisms. A long-term goal is extending these policies with quantitative information, e.g. statistical information about the usage of contexts, reliability of resources therein, so to rank contexts and to possibly suggest the user the ones guaranteeing more performance.
Related work. Starting from the initial proposal of the COP paradigm by Costanza [20], several authors [1,6,30,37] mainly addressed the design and the implementation of concrete programming languages (see [5,62] for an overview). All these approaches describe the context as a stack of layers, which are elementary properties of the context. Layers can be activated/deactivated at run time, and those holding in the running context are determined by only considering the code of the application. Since behavioural variations are bound to layers, activating/deactivating a layer corresponds to activating/deactivating the corresponding behavioural variation. Some papers [3,4,19,31,34,35] just to cite a few, are also concerned with foundational aspects of various COP languages, often based on Java. They propose static (and dynamic) techniques for guaranteeing applications to perform well, e.g. that methods within behavioural variations are correctly invoked.
The usage of Datalog and of its rich predicates for representing the context is perhaps the main difference with the approaches mentioned above. Also, in behavioural variations are a first class, higher-order construct, that can then be referred to by identifiers, and used as parameters in functions. This fosters dynamic, compositional adaptation patterns, as well as reusable, modular code. Another difference with other COP languages is that the dispatching mechanism inspects the actual context that depends on both the application code and the “open” context unknown at development time.
As already remarked, we approached context-aware security from a formal linguistic viewpoint. To the best of our knowledge, in the literature there are few papers aiming at providing a uniform treatment of security and adaptivity. In the pure, foundational formalism of the Ambient Calculus [17] some papers, among which [13,24,53], studied properties concerning the way processes move within different environments, representing the topology of a network. However, in these proposals the context is a sub-set of ours, because it essentially consists of the locations where processes can be hosted.
The proposal in [56] is still along this line, but from a perspective more oriented towards software engineering. This paper can be seen as the starting point for the development of Ariadne [65], a tool for security in adaptive cyber-physical systems. Also in this case, the context is only focused on the topology of a cyber-physical scenario. Ariadne allows defining and maintaining a model of the running system, based on Bigraphical Reactive System [47]. When the system topology changes, an analysis at run time detects possible security risks, so to plan countermeasures.
A conceptual model of security contexts has been recently proposed in [36], that also takes into account social aspects. It is specifically designed for the specification, management and analysis of security issues in ubiquitous social systems.
Other approaches implement security mechanisms at different levels of the infrastructure, in the middleware [60] or in the interaction protocols [29]. Most of them address access control for resources, e.g. [32,68,69], and for smart things, e.g. [2,25]. In this strain, there are many papers on the ways of expressing context-aware access control. As an example, Role-Description Language (RDL) is a programming language for defining context-aware role-based access control policy [46]. The key idea is to activate or deactivate a role and the permissions granted by it depending on the context information. A RDL program receives as input context changes and outputs the members of each role. The proposal of [48] is similar to ours in that the rules are expressed in a logical fashion. The context information is represented through facts and logical rules, but the context itself is distributed among different principals, so that granting access to a resource requires a distributed deduction. Each principal is equipped with policies declaring which participants of the distributed system are considered trusted when resolving a particular query. An alternative approach to rule-based policies for context-aware access control is in [49], that proposes the notion of contextual graph to control the access to resources in a distributed environment. Along this line, Aspect-Oriented Programming and contexts are discussed in [50], as a pragmatic way to decoupling security concerns and business logic in Web Services.
The problem of context-aware security has often been faced in many specific domains of application. Below, we just mention a few papers, because they address issues that are orthogonal to our proposal. The work of [8,33] study authorisation in context-aware systems and propose mechanisms for granting authorisation transparently to a user operating in a smart environment. Access control for Android smartphones is addressed in [7], using a descriptive logic. There are some papers, among which the already cited [40,59], that study how protocols can be adapted to different operating environments in order to guarantee different levels of security.
Footnotes
Acknowledgments
Work is supported in part by the MIUR-PRIN project Security Horizons and by Università di Pisa PRA_2016_64 Project Through the fog.
Below, we present the proofs of the theorems establishing the correctness of our proposal, where we feel free to omit the labels whenever immaterial.
Properties of the type and effect system
Below we prove Theorems 4.1 and 4.2 and Corollary 1. We start giving some lemmas and definitions useful for the formal development.
In the following we denote with .
The proof of the following three properties follows immediately by definition ⊑ and by the semantics of history expressions.
Let H be a history expression then .
Let , , be history expressions, then it holds .
If then and .
(Preservation).
Let e be a closed expression; and let ρ be a dynamic environment such thatincludes the set of parameters of e and.
Ifand, then,for someand.
By induction on the depth of the typing derivation and then by cases on the last rule applied.
In the proof we implicitly use the fact that for each H (except for the case (Tsub)).
rule (Tvariation) or (Tconst) or (Tfact) or (Tabs) or (Tvar)
In this case we know that is a value (or a variable in the case (Tvar)), then for no it holds , so the theorem holds vacuously.
rule (Ttell)
We know that for some and also by the (Ttell) premise that holds and . We have only two rules by which can be derived.
rule (tell1)
We know that is an expression and and and there is in our derivation a subderivation with conclusion . By the induction hypothesis , for some and . By using the rule (Ttell) we can conclude that , and . Lemma B.14 now suffices for establishing that and by Property B.17. Since the thesis follows.
rule (tell2)
We now that , and . We have to prove that , but from the rule (Tconst) we know that this holds with and . It remains to show that . From Lemma B.12 we know . Then, .
rule (Tretract)
Similar to (Ttell) rule ( substitutes ).
rule (Tappend)
We know and and and , and also by the premise of (Tappend) that and hold. There are three rules only by which can be derived.
rule (append1)
We know that and are not values and . By applying the induction hypothesis with for some and . By applying the (Tappend) rule we can conclude that . The thesis follows by applying Lemma B.14 and Property B.17.
rule (append2)
We know that . By applying the induction hypothesis with for some and . By the rule (Tvariation) we know that and by applying the rule (Tappend) we can claim that . Then and by Property B.15. By Lemma B.12 we know , then , proving the thesis since .
rule (append3)
We know that is
and that is
By the premise of the rule (Tvariation), we also know that we have (recall that ) and we have (recall that ). By Lemma B.10 it holds that and . So by applying the rule (Tvariation) for all judgements indexed by i and j we can conclude that . By applying twice Lemma B.12 we have for . Then, the thesis follows because .
rule (Tvapp)
We know that , and hold by (Tvapp) premises. There are three rules only by which can be derived.
rule (vapp1)
We know that . By the induction hypothesis with for some . By (Tvapp) rule we have . By Lemma B.14 we can conclude and the thesis follows by Property B.17 and because .
rule (vapp2)
We know that . By using Lemma B.11 we have and by the induction hypothesis with for some and . By (Tvapp) and Property B.15 holds. By Lemma B.12 we have , then . By Lemma B.14 we have and Property B.17 and prove the thesis.
rule (vapp3)
We know that where , for and . From our hypothesis and from Lemma B.8(2) we have that for all it holds . By Lemma B.11 we also know that . So by Lemma B.9 we have that for . By Lemma B.12 we have for , then . The thesis follows by using Lemma B.14.
rule (Tdlet)
If the last rule in the derivation is (Tdlet) we know that there is a subderivation with conclusions and and with when or and when . There are two rules by which can be derived.
rule (dlet1)
We know that and with . By Lemma B.1 with and by Lemma B.2 we know that . So by induction hypothesis with for some . The judgement follows by applying the rule (Tdlet) and since .
rule (dlet2)
We know that and . By hypothesis we know that and by the Lemma B.13 we have and the thesis follows by choosing vacuously.
rule (Tdvar)
By the premise of rule (Tdvar), where , where each abstracts the corresponding expression stored in . We have to prove that , if , that implies that there exists a such that . Since we have that for all it holds where and by Lemma B.9 we conclude that it is . The thesis holds from Lemma B.14 and .
rule (Tapp)
By the premise of rule (Tapp) we know that , and hold. Three rules only may drive .
rule (app1)
We know that . By using the induction hypothesis we have that with for some and . By the (Tapp) rule we have and by Lemma B.14 and Property B.17 we can establish the thesis.
rule (app2)
We know that . By using Lemma B.11 we have and by the induction hypothesis with for some and . By (Tapp) holds. By Property B.15 holds, and we also have that by Lemma B.12. So and the thesis follows by Property B.17 and because .
rule (app3)
We know that and . We prove that . By Lemma B.11 we know that and . By hypothesis and Lemma B.8 we conclude that . By Lemma B.9 we have that . The thesis follows because it holds for by Lemma B.12 and because .
rule (Tlet)
By the premise of rule (Tlet) we know that and hold. There are only two rules by which can be derived.
rule (let1)
We know that . By the induction hypothesis we have that and for some , and . The thesis follows by Lemma B.14 and Property B.17.
rule (let2)
We know that , , and . By Lemma B.11 and by Lemma B.9. By Lemma B.12 we have , so proving the thesis.
rule (Tif)
By the premise of rule (Tif) we know that , and hold. There are three rules only by which can be derived.
rule (If1)
We know that . By using the induction hypothesis we have that with for some and . So by rule (Tif) we conclude that and the thesis follows by Lemma B.14 and Property B.17.
rule (If2)
We know that , and . By Lemma B.12 we know , so the thesis is immediate because .
rule (If3)
Similar to rule (If2).
rule (Tsub)
By the premise of rule (Tsub) we know , and and . Then by the induction hypothesis , and for some and . By applying the (Tsub) rule with and we have for some . The thesis follows because and because .
rule (Tframe)
By the premise of the rule Tframe we know that holds. There are two rules only by which can be derived:
rule (frame1)
We know that , . By the induction hypothesis we have that and for some and . By applying the rule (Tframe) we have and (by Property B.17) and .
rule (frame2)
We know that and . By hypothesis we know that and by Lemma B.11 we have so the thesis follows immediately. □
(Over-approximation).
Let e be a closed expression; and let ρ be a dynamic environment such thatincludes the set of parameters of e and.
Ifand, thenand there exists a sequence of transitions, for someand.
An easy inductive reasoning on the length of the computation suffices to prove the statement by using Theorem 4.1. □
(Progress).
Let e be a closed expression such that; and let ρ be a dynamic environment such thatincludes the set of parameters of e, and.
If; e violates no policies; and H is viable for C (i.e.), then e is a value.
Let below be the set of the free dynamic variables occurring in e. By induction on the depth of the typing derivations and then by cases on the last rule applied. The cases (Tconst), (Tfact), (Tabs), (Tvariation) are immediate since is a value. The case (Tvar) cannot occur because is closed with respect to identifiers. So we assume that is not a value and it is stuck in C.
rule (Tif)
If is stuck, then it is only the case that is stuck. By induction hypothesis this can occur only when is a value. Since by our hypothesis and or by Lemma B.7(1), either rule (if2) or (if3) applies, contradiction.
rule (Tlet)
If is stuck, then it is only the case that is stuck. By induction hypothesis this can occur only when is a value, hence (let2) rule applies, contradiction.
rule (Ttell)
If is stuck, then it is only the case that e is stuck. By induction hypothesis this can occur only when e is a value v and by Lemma B.7(4) , so the rule (tell2) applies, contradiction.
rule (Tretract)
Similar to the (Ttell) case.
rule (Tappend)
If is stuck then there are only two cases: (1) is stuck; (2) is a value and is stuck. If is stuck by induction hypothesis is a value and by Lemma B.7(3) . If reduces, rule (vappend2) applies, contradiction. If is stuck we are in case (2). By induction hypothesis is a value and Lemma B.7(3) , hence, rule (vappend3) applies, contradiction.
rule (Tsub)
Straightforward by induction hypothesis.
rule (Tapp)
If is stuck then there are only two cases: (1) is stuck; (2) is a value and is stuck. If is stuck by induction hypothesis is a value and by Lemma B.7(2) . If reduces, rule (app2) applies, contradiction. If is stuck we are in case (2). By induction hypothesis is a value, hence, rule (app3) applies, contradiction.
rule (Tdvar)
If is stuck we can have two cases only. The first case is that . But this is not possible because by our hypothesis. The second case is that and is not defined. But this is not possible because by our hypothesis, so the is defined and (dvar) rule applies, contradiction.
rule (Tvapp)
If is stuck then there are only two cases: (1) is stuck; (2) is a value and is stuck. If is stuck by induction hypothesis is a value and by Lemma B.7(3) . If reduces, rule (VaApp2) applies, contradiction. If is stuck we are in case (2). By induction hypothesis is a value, hence, rule (VaApp3) applies, contradiction.
rule (Tdlet)
If is stuck, then it is only the case that is stuck. By the premise of (Tdlet) rule and by Lemma 4.2 with and . Since we can apply the induction hypothesis so is a value. In this case the (dlet2) rule applies, contradiction.
rule (Tframe)
If is stuck, then it is only the case that e is stuck because we assumed that violates no policies. But the induction hypothesis says that e is a value, thus the rule (Frame2) can be applied (contradiction). □
(Correctness).
Letbe a closed expression such that; let ρ be a dynamic environment such thatincludes the set of parameters of, and that; finally let C be a context such that. Then either the computation ofterminates yielding a value () or it diverges, but it never gets stuck.
Assume that for some i it is where is a non-value stuck expression. By Proposition 1 we have and , and since we have also . Then, Theorem 4.2 suffices to show that is a value (contradiction). □
Properties of the load time analysis
In this subsection we prove some properties about the load time analysis in Section 5, in particular we prove Theorems 5.1, 5.2. Firstly, we define the complete lattice of the analysis estimate by ordering and by inclusion and by exploiting the standard construction of Cartesian product and functional space. More in detail, we write , whenever their components are ordered by pointwise set inclusion. Furthermore, their meet , where ⊓ is pointwise set intersection.
By exploiting standard lattice theory it is straightforward to prove that analysis estimates are a complete lattice. In the following we denote the top of this lattice with .
By exploiting the above two lemmata we can prove:
To prove the subject reduction we need the following definition and two lemmata.
References
1.
F.Achermann, M.Lumpe, J.Schneider and O.Nierstrasz, PICCOLA – A small composition language, in: Formal Methods for Distributed Processing, Cambridge University Press, 2001.
2.
F.Al-Neyadi and J.Abawajy, Context-based e-health system access control mechanism, in: Advances in Information Security and Its Application, 2009, pp. 68–77.
3.
T.Aotani, T.Kamina and H.Masuhara, Featherweight eventCJ: A core calculus for a context-oriented language with event-based per-instance layer transition, in: Proceedings of the 3rd International Workshop on Context-Oriented Programming (COP’11), ACM, New York, NY, USA, 2011, Article No. 1, pp. 1–7.
4.
T.Aotani, T.Kamina and H.Masuhara, Unifying multiple layer activation mechanisms using one event sequence, in: Proceedings of the 6th International Workshop on Context-Oriented Programming, COP’14, ACM, New York, NY, USA, 2014, Article No. 2, pp. 1–6, ISBN 978-1-4503-2861-6.
5.
M.Appeltauer, R.Hirschfeld, M.Haupt, J.Lincke and M.Perscheid, A comparison of context-oriented programming languages, in: International Workshop on Context-Oriented Programming (COP’09), ACM, New York, NY, USA, 2009, Article No. 6, pp. 1–6.
6.
M.Appeltauer, R.Hirschfeld, M.Haupt and H.Masuhara, ContextJ: Context-oriented programming with Java, Computer Software28(1) (2011), 272–292.
7.
G.Bai, L.Gu, T.Feng, Y.Guo and X.Chen, Context-aware usage control for Android, in: Security and Privacy in Communication Networks – Proceedings of the 6th International ICST Conference, SecureComm 2010, Singapore, 7–9 September 2010, LNICST, Vol. 50, Springer, 2010, pp. 326–343.
8.
J.Bardram, R.E.Kjær and M.Ø.Pedersen, Context-aware user authentication – Supporting proximity-based login in pervasive computing, in: Proceedings of the UbiComp 2003, Seattle, USA, LNCS, Vol. 2864, Springer, 2003, pp. 107–123.
9.
M.Bartoletti, P.Degano and G.L.Ferrari, Planning and verifying service composition, Journal of Computer Security17(5) (2009), 799–837. Abridged version in: Proceedings of the CSFW, IEEE Press, 2005, pp. 211–223.
10.
M.Bartoletti, P.Degano, G.L.Ferrari and R.Zunino, Local policies for resource usage analysis, ACM Trans. Program. Lang. Syst.31(6) (2009), Article No. 23.
11.
C.Bodei, P.Degano, L.Galletta and F.Salvatori, Linguistic mechanisms for context-aware security, in: Proceedings of the 11th International Colloquium on Theoretical Aspects of Computing, LNCS, Vol. 8687, Springer, 2014, pp. 61–79.
12.
P.Bonatti, S.De Capitani Di Vimercati and P.Samarati, An algebra for composing access control policies, ACM Transactions on Information and System Security5(1) (2002), 1–35.
13.
D.Bucur and M.Nielsen, Secure data flow in a calculus for context awareness, in: Concurrency, Graphs and Models, LNCS, Vol. 5065, Springer, 2008, pp. 439–456.
14.
R.Campbell, J.Al-Muhtadi, P.Naldurg, G.Sampemane and M.D.Mickunas, Towards security and privacy for pervasive computing, in: Proceedings of the 2002 Mext-NSF-JSPS International Conference on Software Security: (ISSS’02), LNCS, Vol. 2609, Springer, 2003, pp. 1–15.
15.
A.Canciani, P.Degano, G.-L.Ferrari and L.Galletta, A context-oriented extension of F#, in: FOCLASA 2015, EPTCS, Vol. 201, 2015, pp. 18–32.
16.
J.Cappaert, Code Obfuscation Techniques for Software Protection, PhD thesis, Katholieke Universität Loewen, 2012, https://www.cosic.esat.kuleuven.be/publications/thesis-199.pdf.
17.
L.Cardelli and A.D.Gordon, Mobile ambients, Theor. Comput. Sci.240(1) (2000), 177–213.
18.
S.Ceri, G.Gottlob and L.Tanca, What you always wanted to know about Datalog (and never dared to ask), IEEE Trans. on Knowl. and Data Eng.1(1) (1989), 146–166.
19.
D.Clarke and I.Sergey, A semantics for context-oriented programming with layers, in: International Workshop on Context-Oriented Programming (COP’09), ACM, New York, NY, USA, 2009, Article No. 10, pp. 1–6.
20.
P.Costanza, Language constructs for context-oriented programming, in: Proceedings of the Dynamic Languages Symposium, ACM Press, 2005, pp. 1–10.
21.
P.Degano, G.-L.Ferrari and L.Galletta, A two-component language for COP, in: Proceedings of the 6th International Workshop on Context-Oriented Programming, ACM Digital Library, 2014. doi:10.1145/2637066.2637072.
22.
P.Degano, G.-L.Ferrari and L.Galletta, A two-phase static analysis for reliable adaptation, in: Proceedings of the 12th International Conference on Software Engineering and Formal Methods, LNCS, Vol. 8702, Springer, 2014, pp. 347–362.
23.
P.Degano, G.-L.Ferrari and L.Galletta, A two-component language for adaptation: Design, semantics and program analysis, IEEE Transactions on Software Engineering (2016). doi:10.1109/TSE.2015.2496941.
24.
P.Degano, F.Levi and C.Bodei, Safe ambients: Control flow analysis and security, in: Proceedings of the 6th Asian Computing Science Conference, Malaysia, LNCS, Vol. 1961, Springer, 2000, pp. 199–214.
25.
M.Deng, D.D.Cock and B.Preneel, Towards a cross-context identity management framework in e-health, Online Information Review33(3) (2009), 422–442.
26.
J.DeTreville, Binder, a logic-based security language, in: Proceedings of the 2002 IEEE Symposium on Security and Privacy, SP’02, IEEE Computer Society, 2002, pp. 105–113.
27.
T.Eiter, G.Gottlob and H.Mannila, Disjunctive Datalog, ACM Transactions on Database Systems5(1) (1997), 1–35.
28.
L.Galletta, Adaptivity: Linguistic mechanisms and static analysis techniques, PhD thesis, University of Pisa, 2014, http://www.di.unipi.it/~galletta/phdThesis.pdf.
29.
T.Heer, O.Garcia-Morchon, R.Hummen, S.Keoh, S.Kumar and K.Wehrle, Security challenges in the IP-based Internet of things, Wireless Personal Communications61(3) (2011), 527–542.
30.
R.Hirschfeld, P.Costanza and O.Nierstrasz, Context-oriented programming, Journal of Object Technology7(3) (2008), 125–151.
31.
R.Hirschfeld, A.Igarashi and H.Masuhara, ContextFJ: A minimal core calculus for context-oriented programming, in: Proceedings of the 10th International Workshop on Foundations of Aspect-Oriented Languages, ACM, 2011, pp. 19–23.
32.
R.Hulsebosch, A.Salden, M.Bargh, P.Ebben and J.Reitsma, Context sensitive access control, in: Proceedings of the ACM Symposium on Access Control Models and Technologies, 2005, pp. 111–119.
33.
R.J.Hulsebosch, M.S.Bargh, G.Lenzini, P.W.G.Ebben and S.M.Iacob, Context sensitive adaptive authentication, in: Proceedings of the EuroSSC 2007, Kendal, England, LNCS, Vol. 4793, Springer, 2007, pp. 93–109.
34.
A.Igarashi, R.Hirschfeld and H.Masuhara, A type system for dynamic layer composition, in: FOOL 2012, 2012, p. 13.
35.
H.Inoue, A.Igarashi, M.Appeltauer and R.Hirschfeld, Towards type-safe JCop: A type system for layer inheritance and first-class layers, in: COP’14, ACM, New York, NY, USA, 2014, Article No. 7, pp. 1–6, ISBN 978-1-4503-2861-6.
36.
V.Jovanovikj, D.Gabrijelcic and T.Klobucar, A conceptual model of security context, Int. J. Inf. Sec.13(6) (2014), 571–581.
37.
T.Kamina, T.Aotani and H.Masuhara, EventCJ: A context-oriented programming language with declarative event-based context transition, in: Proceedings of the 10th International Conference on Aspect-Oriented Software Development (AOSD’11), ACM, 2011, pp. 253–264.
38.
J.O.Kephart and D.M.Chess, The vision of autonomic computing, IEEE Computer36(1) (2003), 41–50. doi:10.1109/MC.2003.1160055.
39.
G.Kiczales, E.Hilsdale, J.Hugunin, M.Kersten, J.Palm and W.Griswold, An overview of AspectJ, in: ECOOP 2001 – Object-Oriented Programming, J.Knudsen, ed., LNCS, Vol. 2072, Springer, Berlin, Heidelberg, 2001, pp. 327–354, ISBN 978-3-540-42206-8.
40.
B.Ksiezopolski and Z.Kotulski, Adaptable security mechanism for dynamic environments, Computers & Security26(3) (2007), 246–255.
41.
N.Li and J.C.Mitchell, DATALOG with constraints: A foundation for trust management languages, in: Proceedings of the 5th International Symposium on Practical Aspects of Declarative Languages (PADL’03), LNCS, Vol. 2562, Springer, 2003, pp. 58–73.
42.
J.Ligatti, D.Walker and S.Zdancewic, A type-theoretic interpretation of pointcuts and advice, Science of Computer Programming63(3) (2006), 240–266. doi:10.1016/j.scico.2006.01.004.
43.
S.W.Loke, Representing and reasoning with situations for context-aware pervasive computing: A logic programming perspective, Knowl. Eng. Rev.19(3) (2004), 213–233.
44.
N.MacDonal, The future of information security is context aware and adaptive, Technical report, Gartner RAS, 2010.
45.
J.Magee and J.Kramer, Dynamic structure in software architectures, SIGSOFT Softw. Eng. Notes21(6) (1996), 3–14, ISSN 0163-5948.
46.
C.Masone and A.D.Kotz, Role Definition Language (RDL): A language to describe context-aware roles, Technical report, 2002.
47.
R.Milner, Bigraphical reactive systems, in: Proceedings of the CONCUR 2001, Aalborg, Denmark, LNCS, Vol. 2154, Springer, 2001, pp. 16–35.
48.
K.Minami and D.Kotz, Secure context-sensitive authorization, Pervasive and Mobile Computing1(1) (2005), 123–156.
49.
G.K.Mostéfaoui and P.Brézillon, Context-based constraints in security: Motivations and first approach, Electr. Notes Theor. Comput. Sci.146(1) (2006), 85–100.
50.
G.K.Mostéfaoui, Z.Maamar and N.C.Narendra, SC-WS: A context-based, aspect-oriented approach for handling security concerns in web services, IJOCI4(2) (2014), 31–44.
51.
A.Mycroft and R.A.O’Keefe, A polymorphic type system for prolog, Artificial Intelligence23(3) (1984), 295–307.
52.
A.Nanevski, A.Banerjee and D.Garg, Dependent type theory for verification of information flow and access control policies, ACM Trans. Program. Lang. Syst.35(2) (2013), Article No. 6.
53.
F.Nielson, H.Riis Nielson, R.R.Hansen and J.G.Jensen, Validating firewalls in mobile ambients, in: Proceedings of the CONCUR’99, Eindhoven, The Netherlands, LNCS, Vol. 1664, Springer, 1999, pp. 463–477.
54.
H.R.Nielson and F.Nielson, Flow logic: A multi-paradigmatic approach to static analysis, in: The Essence of Computation, T.A.Mogensen, D.A.Schmidt and I.H.Sudborough, eds, LNCS, Vol. 2566, Springer, 2002, pp. 223–244.
55.
G.Orsi and L.Tanca, Context modelling and context-aware querying, in: Datalog Reloaded, O.Moor, G.Gottlob, T.Furche and A.Sellers, eds, LNCS, Vol. 6702, Springer, 2011, pp. 225–244.
56.
L.Pasquale, C.Ghezzi, C.Menghi, C.Tsigkanos and B.Nuseibeh, Topology aware adaptive security, in: Proceedings of the 9th International Symposium on Software Engineering for Adaptive and Self-Managing Systems, SEAMS 2014, ACM, New York, NY, USA, 2014, pp. 43–48, ISBN 978-1-4503-2864-7.
57.
C.Perera, A.B.Zaslavsky, P.Christen and D.Georgakopoulos, Context aware computing for the Internet of things: A survey, IEEE Communications Surveys and Tutorials16(1) (2014), 414–454.
58.
C.Pfleeger and S.Pfleeger, Security in Computing, Prentice-Hall, 2003.
59.
L.G.Pierson, E.L.Witzke, M.O.Bean and G.J.Trombley, Context-agile encryption for high speed communication networks, Computer Communication Review29(1) (1999), 35–49.
60.
M.Román, C.Hess, R.Cerqueira, A.Ranganathan, R.Campbell and K.Nahrstedt, Gaia: A middleware platform for active spaces, ACM SIGMOBILE Mobile Computing and Communications Review6(4) (2002), 65–67.
61.
M.Salehie and L.Tahvildari, Self-adaptive software: Landscape and research challenges, ACM Trans. Auton. Adapt. Syst.4(2) (2009), Article No. 14, pp. 1–42, ISSN 1556-4665.
62.
G.Salvaneschi, C.Ghezzi and M.Pradella, Context-oriented programming: A software engineering perspective, Journal of Systems and Software85(8) (2012), 1801–1817.
63.
C.Skalka, S.Smith and D.V.Horn, Types and trace effects of higher order programs, Journal of Functional Programming18(2) (2008), 179–249.
64.
O.Spinczyk, A.Gal and W.Schröder-Preikschat, AspectC++: An aspect-oriented extension to the C++ programming language, in: CRPIT’02, Australian Computer Society, Inc., Darlinghurst, Australia, 2002, pp. 53–60, ISBN 0-909925-88-7.
65.
C.Tsigkanos, L.Pasquale, C.Ghezzi and B.Nuseibeh, Ariadne: Topology aware adaptive security for cyber-physical systems, in: 37th IEEE/ACM International Conference on Software Engineering, Florence, Italy, Vol. 2, IEEE, 2015, pp. 729–732.
66.
D.Walker, S.Zdancewic and J.Ligatti, A theory of aspects, SIGPLAN Not.38(9) (2003), 127–139, ISSN 0362-1340.
67.
M.Wand, G.Kiczales and C.Dutchyn, A semantics for advice and dynamic join points in aspect-oriented programming, ACM Trans. Program. Lang. Syst.26(5) (2004), 890–910, ISSN 0164-0925.
68.
K.Wrona and L.Gomez, Context-aware security and secure context-awareness in ubiquitous computing environments, in: XXI Autumn Meeting of Polish Information Processing Society, 2005.
69.
G.Zhang and M.Parashar, Dynamic context-aware access control for grid applications, in: Proceedings of the Fourth International Workshop on Grid Computing, IEEE, 2003, pp. 101–108.