
Abstract
SQL injection attack has been a major security threat to web applications for over a decade. Now a days, attackers use automated tools to discover vulnerable websites from search engines and launch attacks on multiple websites simultaneously. Being extremely heterogeneous in nature, accurate run-time detection of SQL injection attacks, particularly those previously unseen, is still a challenge using regular-expression or parse-tree matching techniques suggested in the literature. In this paper, we present a novel approach for real-time detection of SQL injection attacks by applying document similarity measure on run-time queries after normalizing them into sentence-like form. The proposed approach acts as a database firewall and can protect multiple web applications using the database server. With additional inputs from human expert, the system can also become more robust over time. We implemented the approach in a tool named SQLiDDS and the experimental results are very encouraging. The approach can effectively detect all types of SQL injection attacks and previously unseen attacks with substantial accuracy yet negligible impact on overall performance of web applications. The tool was built with PHP and tested on web applications built with PHP and MySQL, but it can be adapted to other platforms with minimal changes.
Keywords
Introduction
Web applications are exposed to different types of security threats like Denial of Service (DoS), Structured Query Language (SQL) injection, Cross Site Scripting (XSS), etc. Among these, SQL Injection attack is predominantly used against web databases. The Open Web Application Security Project (OWASP) ranks it on top among the Top-10 security threats [38]. According to TrustWave [44] Global Security Report, SQL injection was the number one attack method for four consecutive years. Attacking a website using SQL injection has become much easier ever since attackers started using sophisticated tools and Botnets [33] which automatically discover URLs of vulnerable web pages from search engines like Google and launch mass SQL injection attacks on them simultaneously from distributed sources. About 97% of data breaches across the world occur due to SQL injection attacks alone [10]. As per a recent study [13] conducted by the Ponemon Institute1
Ponemon Institute conducts research on privacy and information security –
Research on SQL injection in the literature can be broadly categorized into three classes: defensive coding approaches, vulnerability testing approaches, and prevention based approaches. Defensive coding approaches proposed by Boyd and Keromytis [5], Johns et al. [22], Livshits and Erlingsson [32], Nguyen-Tuong et al. [37] etc., consist of techniques which are applied during application development so that SQL injections cannot happen. These require programmers to write their application code in a specific manner for securing against SQL injection attacks, but in practice, security aspects are often ignored during programming. On the other hand, vulnerability testing approaches developed by Benedikt et al. [3], Kals et al. [23], Wassermann et al. [50] etc., rely on extensively testing web applications to find out possible SQL injection vulnerabilities so that they can be fixed before releasing to production. The effectiveness of this approach is limited by the ability of tools to discover all possible security holes. Majority of research on SQL injection has been done under the prevention based approaches. In general, prevention based approaches by Bisht et al. [4], Buehrer et al. [6], Halfond and Orso [19], Lee et al. [29], Wang and Li [49] etc., consist of preparing a model of SQL queries and/or the application’s behavior during its normal-use in a secured environment and then utilize that model at run-time to detect anomalies for preventing SQL injection attempts. The major drawback in this approach is that, any modifications or enhancements to the application code afterwards (which is quite probable), requires rebuilding the normal-use model. Further, these are usually designed to protect only one web application from SQL injection attacks, and mostly suitable for a specific language and database platform.
The above discussion re-establishes the necessity for creating a system that (1) does not require writing code in a specific way, (2) does not need extensive vulnerability testing, (3) does not require building a normal-use model, (4) can protect multiple web applications interfacing with one database server (as in shared hosting environment), (5) is able to detect new forms of SQL injection attacks, and finally, (6) is adaptive and learns by itself (or with help of human expert) to become more robust over time. Accuracy of detection and minimal performance overheads are obvious requirements for any such system.
In this paper, we present a novel technique to detect SQL injection attacks by applying the concept of document similarity in an attempt to address the above requirements. Document similarity measures are typically used for web search, text categorization, information retrieval and in several other domains. We extend the query transformation scheme proposed by Kar and Panigrahi [24] to normalize SQL queries into a sentence-like form, which facilitates comparison between SQL queries by applying a document similarity measure. The technique was implemented in a tool named SQLiDDS (SQL injection Detection using Document Similarity) and validated experimentally on five sample web applications. The query normalization scheme and application of document similarity for identifying SQL injection attacks are the main contributions of our work. Based on interesting observations made during the course of research, we postulate that, it is sufficient to examine only the
This article is an extension of our previous work [25] in which we first introduced the idea of using document similarity measure for detecting SQL injection attacks at the database firewall layer. Besides elaborating the approach in a more comprehensible manner and providing fresh results of experiments, this version also incorporates the following additions and improvements to the earlier system:
The query normalization scheme has been modified based on a few weaknesses identified which could enable an attacker to bypass detection as discussed towards end of Section 4.1.
Various other similarity measures available in the literature have been looked into in Section 4.2 and the best measure suitable for our approach has been selected by performing experiments discussed in Section 4.3, thereby almost doubling the run-time performance.
A new clustering algorithm has been developed for clustering of normalized injection patterns, discussed in Section 4.5, that produces cohesive and spherical clusters improving accuracy.
The threshold similarity for clustering is now automatically determined through analysis and smoothing of histogram created from the similarity matrix, which is described in Section 4.6.
The architecture of the system has been enhanced by introducing a repository for storing genuine query structures (shown in Figs 4 and 5), so that known benign queries are instantly identified without going through the similarity matching process.
We compare our approach in Section 6.5 with some notable existing methods considering various criteria and type of SQL injection attacks detected.
The rest of the paper is organized as follows. Section 2 introduces the mechanism of SQL injection attack by taking a simple example. Section 3 states the SQL injection attack detection problem from the view point of a database firewall and lays down our motivation behind this study. Section 4 describes the overview of our approach in detail, covering query normalization, document similarity measures, detection strategy based on two interesting observations, and a new clustering algorithm for clustering of normalized queries. The system architecture is explained in Section 5. Experimental evaluation and results are discussed in Section 6 along with assessment of performance overhead. Quoting related works in Section 7, we conclude the paper in Section 8 with a note on future directions of research.
SQL injection attacks occur due to a commonly found vulnerability of constructing dynamic SQL queries using raw input data received through web forms or URL query string parameters without proper validation. An attacker exploits this vulnerability by inserting carefully crafted SQL keywords, values and symbols through the parameters or form fields, which effectively alters the structure and semantics of the dynamic queries, causing them to behave differently. The injected query returns results intended by the attacker instead of the results expected by the programmer. To understand the basic mechanism of SQL injection, consider a product detail page of an E-commerce website accessed by the URL:
The script
When a genuine request with a normal integer value is received through the parameter
Upon execution, the query returns one row containing all attribute values for the product ID 24 from the products table (assuming that the product exists in the database), which is what the programmer intended. It may be observed that in the PHP code, the value of
Each ‘
When executed, this query will fetch all records from the products table because the query evaluates to true for all rows, the record pointer will be positioned at the first record which could be any other product, and the web page will show its details instead of product ID 24. By appending “
Given that SQL injection vulnerability stems from use of unvalidated inputs from external sources to construct dynamic SQL queries, prepared statements are highly recommended as they offer a good degree of protection against such attacks. As a defensive coding method, prepared statements can prevent most of SQL injection attack attempts, especially when the bound parameters in the prepared queries are of numeric data types. However, improper use of prepared statements can still expose SQL injection vulnerabilities. For example, consider a web page showing products from a category ordered by a key field in ascending or descending order, accessed by the following URL:
Suppose the programmer writes the PHP code using prepared statements in the following manner:
In the code, the programmer correctly binds the three parameters with type specification “
Over 74 million websites built with Wordpress exist on the Internet.
Many organizations deploy commercially available Network Intrusion Detection Systems (NIDS) or Web Application Firewalls (WAF) to protect their web infrastructure against various attacks including SQL injection attacks. While these can be an effective component of a layered defense strategy, they are still penetrable. Most WAFs require a tremendous amount of expert configuration and tuning before they can provide adequate protection. These WAF systems mostly rely on regular expression based rule-sets and filters created from previously known attack signatures. However, signature-based detection is not foolproof and can be circumvented using different techniques [11,35,39], such as alternate character encoding, mixing of upper and lowercase alphabets, whitespace spreading, and comment embedding. An attacker usually starts with running simple tests to determine if any NIDS or WAF has been deployed. After identifying the characteristics of the perimeter security, the subsequent attacks are devised for bypassing detection resulting in successful SQL injection. For example, consider the following attacks, showing only the injection code added by an attacker:
All of these expressions evaluate to true, hence they are tautological attacks. Variations only in the RHS of the expressions have been shown here, but can be used in the LHS or both, making it possible to bypass detection by the WAF. Similar bypassing techniques can also be used in other types of SQL injection attacks. In fact, SQL injection attack expressions can be formed in a number of ways to the extent that constructing regular expression based filters becomes almost impossible. Signature based systems can be eluded by the attacker with creative changes to the expressions with a little effort.
SQL injection vulnerability was originally published by Jeff Forristal [26] under the alias RFP (rain.forest.puppy) in Phrack Magazine [40] in a section titled “ODBC and MS SQL Server 6.5.” Numerous websites have been attacked in the past using SQL injection causing leakage of sensitive data and huge loss to organizations. According to the Web Hacking Incidents Database3
An SQL injection attack attempt is successful only when an injected SQL query gets executed on the database. Therefore, it must be detected before the query is sent to database server for execution. This involves examining an incoming SQL query at the database firewall level to determine if it contains any injected malicious code. The problem of SQL injection detection can therefore be stated as:
“Given an SQL query, determine if it is injected.”
Let
We intend to take a step away from the traditional path of string, regular expression or parse-tree matching because these approaches generally fail to detect previously unseen attacks. Our main motivation in this research is to apply the notion of similarity instead. This is driven by the fact that new forms of SQL injection attacks often do not qualify as entirely new, but minor and creative variations of previously seen attack vectors. We postulate that a run-time query can be identified as injected with sufficient accuracy, if it is highly similar to one or more previously known injected queries. Our focus is on practical implementation and ease of deployment in a shared hosting scenario.
A part of the problem is “how to compute similarity between SQL queries?” as there may be special characters, operators, brackets, etc. The solution to this is to normalize SQL queries completely into text form that is suitable for applying document similarity measure without losing their syntactic structure. This is much simpler and straightforward than generating parse trees of queries and determine similarity between them by matching sub-trees. We propose a query normalization scheme which converts an SQL query into a sentence-like form so that similarities can be appropriately computed using available document similarity measures.
Overview of proposed approach
As stated already, our approach is centered around two key ideas: the query normalization scheme and application of document similarity measure. In brief, the proposed system begins with a preloaded set of known SQL injection attacks normalized into text form, which are grouped into clusters using a document similarity measure. The attack vectors in each cluster are merged into a document. At run-time, SQL injection attacks are detected by comparing the similarity of an incoming query with the documents containing the clustered attack vectors. The rest of this section elaborates various components of the proposed approach.
The query normalization scheme
Query transformation was proposed by Kar and Panigrahi [24] to convert SQL queries into structural form, with an important argument that the identifiers in a query, such as table names, column names, etc., are irrelevant with regards to its overall structure. In this work, we extend the transformation scheme to normalize a query purely into text form, i.e. a series of words separated by spaces, facilitating application of document similarity measures. In information retrieval, punctuations and symbols appearing in text are ignored while computing similarity because they do not contribute towards the textual content of the documents. However, in an SQL query, various symbols, operators, brackets, etc., are important structural and syntactic elements. It would be inappropriate to compute similarity between two SQL queries without considering these.
The normalization scheme uses only capital alphabets A–Z for all tokens and space character as token separator. Symbols, special characters, operators, etc., are also converted into words. Digits are also converted into tokens except where they are a part of an SQL keyword or function, such as
The query normalization scheme
The query normalization scheme
Normalization of special characters and symbols (Step-8 of Table 1)
Each step of query normalization is a find-and-replace operation, done by appropriately using the
It may be noticed that the substitutions (e.g., ’
To visualize working of the normalization process, consider the following SQL queries, intentionally written in mixed-case to demonstrate the effect of normalization:
By applying the normalization scheme, these are converted into the following forms respectively:
It may be observed that the normalized queries are like readable sentences (in a way), still preserving the semantics of the original queries. Consider an injected query generated due to a cleverly crafted injection attack to bypass detection (taken from the examples given in Section 2):
This query contains a number of symbols, operators and SQL function calls. The normalization scheme converts it into the following form:
Any SQL query, irrespective of its length and complexity, is thus normalized into a series of words separated by spaces, just like a sentence in English. The syntactic structure of the query is correctly maintained. Due to the way various symbols, operators, values, etc. are normalized; many different queries get converted into the same form, which helps reduce the size of query repositories.
The normalization scheme is also designed to take care of common techniques used by attackers to bypass detection in the following ways:
Newline, carriage-return and tab characters in the query are replaced with normal space character (see Step-1 in Table 1) which neutralizes bypassing attempt by whitespace spreading.
MySQL allows identifiers such as database, table, and column names to be delimited by the backquote (`) character wherever necessary to differentiate from reserved keywords. An attacker can unnecessarily delimit every identifier in the injection attack to bypass detection. As backquotes do not contribute towards the structural form of a query, they are removed from the query before substituting other symbols (see Table 2).
Parentheses are used to enclose function parameters and subqueries in SQL, but it is syntactically correct to use additional parenthesis-pairs even if not required. For example,
MySQL allows version-specific commands to be embedded inside a query within inline comments. For example, in the query “
Document similarity measures are typically used in information retrieval domain and is an extensively researched area. Several document similarity measures exist in the literature which have been defined for different applications. We look into some commonly used similarity measures of symmetric nature bounded in
Vector space model
The Vector Space Model (VSM) is quite popular in information retrieval [34, Chap. 6]. In this model, documents are represented as feature vectors in a high-dimensional space. Similarity between two documents
A popular method in VSM, known as the bag-of-words model, represents documents as term vectors using term-frequency (TF) and inverse-document-frequency (IDF) weighting. The TF weight of a term
Two documents
Equation (1) can therefore be expanded to:
Although TF-IDF weighting is popular in information retrieval domain and has been used for intrusion detection [7,17,30,42], our experiments using this measure on normalized queries did not produce results within acceptable limits. A major shortcoming of the TF-IDF based measure is that it ignores the order of occurrence of terms in the document. Two sentences: “John is older than Mary” and “Mary is older than John”, are determined as identical documents (i.e. similarity = 1.0) by this measure. Our initial reasoning was that, because SQL syntax follows a strict grammar, the order of terms should be automatically accounted for. For example, a query “
The shortcomings of term-based similarity can be overcome by considering phrases instead of individual terms. By phrase, we mean a contiguous sequence of terms, not the syntactical or structural clauses of SQL. A phrase in this context is same as an N-gram where each gram corresponds to a term; we prefer to use the term phrase for simplicity. Considering that a document d is a sequence of terms
Following Eq. (5), cosine similarity based on phrase frequencies can be written as:
It can be seen that the similarity computed by Eq. (6) is indirectly dependent on the phrase-length w. Taking
Set based models
Set based models, also known as Binary Similarity Coefficients, are based on presence or absence of elements between two sets without considering their frequency of occurrence. These similarity coefficients are widely used in systematic biology, entomology, anthropology etc., to compare similarity between two sets of samples for taxonomy and classification. Binary similarity coefficients also find applications in text categorization, clustering and information retrieval. We look into some popular binary similarity coefficients which produce similarity values in the range
Considering phrases as basic elements of a document, every document can be represented as a set of phrases. Similarity between two documents can be determined by presence or absence of phrases in them. Recall that, if the phrases extracted from two documents
In other words, a represents number of phrases common to
Jaccard coefficient (JC). Also known as the Jaccard Index, it was developed by Paul Jaccard (1912) to compare regional flora. It basically computes the ratio of intersection to union of two sets. Similarity between
Second Kulczynski coefficient (2KS). Proposed in 1927, the second Kulczynski similarity coefficient averages the proportion of common elements from the two sets, given by:
Sørensen–Dice coefficient (DC). Developed independently by Raymond Dice (1945) and Thorvald Sørensen (1948), the coefficient gives higher weight to items common between two sets. The similarity coefficient is given by:
Ochiai/Otsuka coefficient (OC). The Ochiai or Otsuka similarity coefficient developed in 1957 is same as cosine similarity in VSM where each component of the vectors is either 0 (absent) or 1 (present). The coefficient is given by:
Sokal and Sneath coefficient (SSC). Unlike the Sørensen–Dice coefficient, the Sokal and Sneath coefficient (1963) considers penalty for mismatching items. The coefficient is given by:
Tripartite similarity index (TSI). Tulloss [45] critically examined the properties of various similarity coefficients under different situations and suggested three cost functions U, S and R, taking ideas from the manufacturing industry. The Tripartite Similarity Index is defined using these cost functions as:
Positive matching index (PMI). Dos Santos and Deutsch [14] examined the properties of TSI and proposed a new similarity index named Positive Matching Index (PMI) with optimal characteristics, given by:
Selection of similarity measure
All the similarity measures discussed in Section 4.2 fulfill the basic requirement of being symmetric, i.e.,
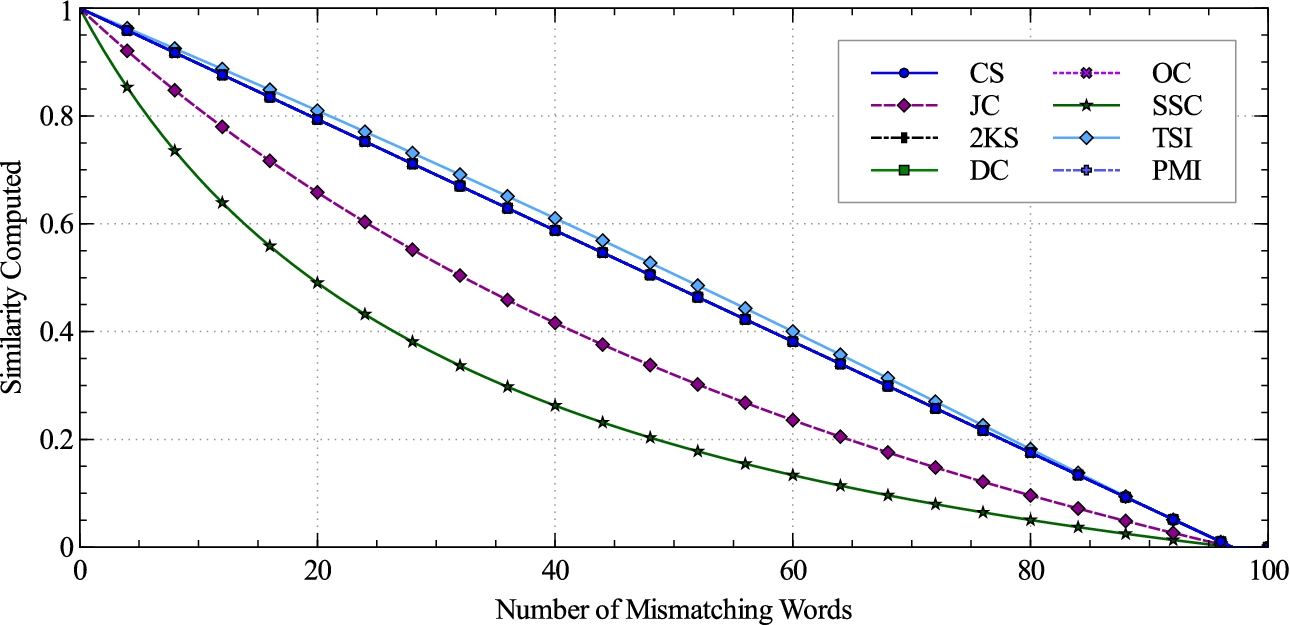
Behavior of the similarity measures was tested by taking two identical strings of 100 words (taken randomly from the vocabulary of 686 words mentioned in Section 4.1) and then changing one word at a time until the strings are completely different. For each word changed, the similarity was computed by each of the binary similarity measures, and the values were plotted against number of mismatching words as shown in Fig. 1.
Linearity testing of binary similarity coefficients.
It is observed that SSC exhibits a very nonlinear (concave upwards) behavior. The similarity drops at a higher rate with few words changed and then at a lower rate as the documents tend towards complete dissimilarity. JC also exhibits similar behavior though less than SSC. The TSI is close to linearity but exhibits slightly concave downward nature. The rest of the five similarity measures are uniform in their behavior and perfectly linear from 1 to 0. Therefore, JC, SSC and TSI are excluded as candidate measures from our approach.
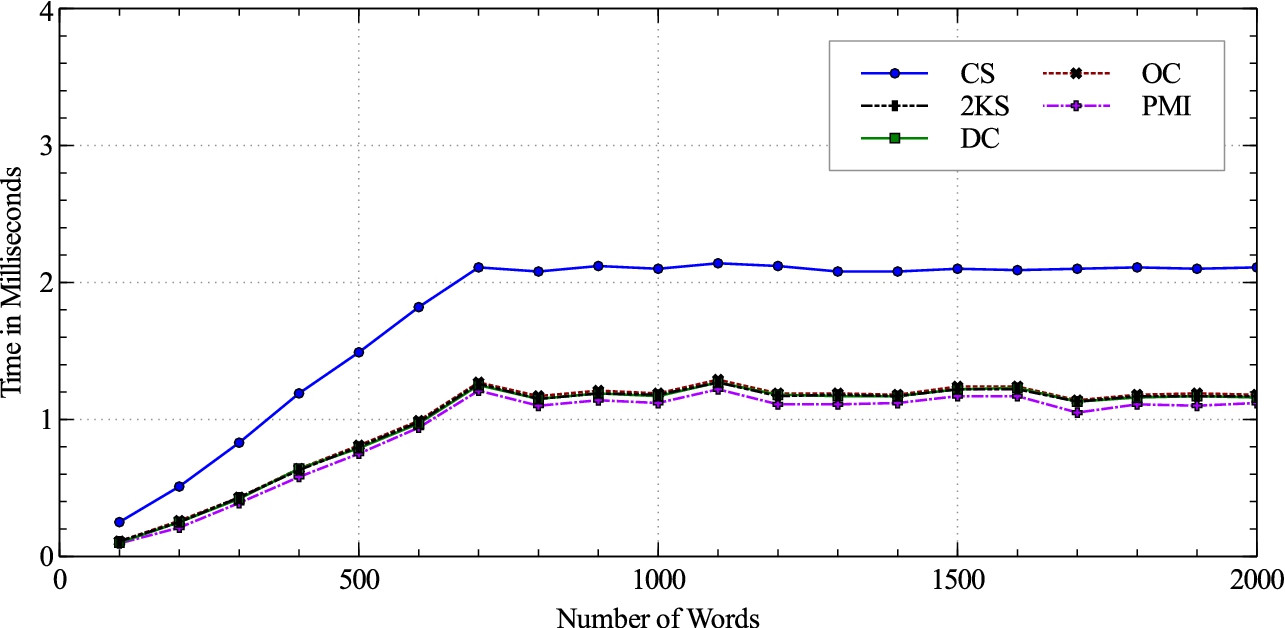
The remaining five similarity measures were tested for execution time by applying each between two strings of 100 to 2000 words selected randomly from the same vocabulary. The average execution time of 1000 runs on our experimental setup (described in Section 6) is shown in Fig. 2. As the vocabulary of words used in the normalization scheme consists of 686 words, after the length of strings cross about 700 words, the number of distinct phrases does not increase due to which the execution time of all similarity measures becomes almost constant.
Execution time of similarity measures.
It is found that, computing cosine similarity by vector space model takes nearly twice the time than the set based measures. The five set theoretic measures exhibit almost the same time of execution while PMI takes slightly less time than 2KS, DC and OC. Considering that several queries may need similarity matching at run-time per web page, even a marginal saving in execution time can improve performance. Therefore, PMI is selected as the most appropriate similarity measure for our system.
The proposed approach for SQL injection detection is strategically guided by two interesting observations which we were unable to find mentioned anywhere in the literature. The first observation surfaced while looking for an answer to “where do SQL injections most commonly occur in an injected query?” Looking at the general programming practices for developing web applications, we find that, dynamic SQL queries are usually constructed in two parts: (1) a static part that is directly hard coded by the programmer, and (2) a dynamic part produced by concatenation of SQL elements, delimiters and received input values. Since the objective of constructing a dynamic query is to fetch different set of records depending on the input, the parameter values must be used to specify the selection criteria, i.e., in the
Here, the dropdown box ‘
In this case, both the parameters ‘
This observation resolves that SQL injections happen after the
The second interesting observation stems from the basic intention behind an SQL injection attack – stealing sensitive information from the back-end database such as credit card numbers. By carefully formulating the injection code, the attacker tries to get the intended data displayed on the web page itself. Consider a product detail page that displays information of the selected product on the web page, such as product name, price, description, etc., which is determined by the parameter passed in the query string (e.g.,
These two observations lead to the strategic conclusion that, it is sufficient to examine the tail end of an SQL query for presence of any injection attack. This strategy significantly narrows down the scope of processing. Another plausible strategy may be to intercept only
A cognizant question may be raised here concerning a special kind of SQL injection, known as Second Order SQL Injection, which is initiated through
Apart from greatly reducing the processing overhead, limiting the investigation only to the tail end of queries also enhances the detection capability using document similarity. Since the portion before the
Continuing the discussion from Section 4.2.1 on choosing a suitable value for phrase-length, we now give more justification on why
If the web page displays error messages or does not display normally, the attacker concludes that the parameter
The tail end of these queries get normalized to “
Clustering of normalized injected queries
Normalization of the tail-end of previously collected SQL injected queries produces a set of injection attack patterns in text form which are considered as small documents. These are clustered into groups based on their document similarity and the patterns in each cluster are merged. The purpose of clustering is to create a set of larger documents, each containing a number of highly similar SQL injection patterns. This enables similarity matching against a small set of documents at run-time.
Text clustering has been extensively researched and many clustering algorithms have been proposed in the literature [1]. Clustering algorithms used in information retrieval have also been described by Manning et al. [34, Chaps 16–17]. Flat clustering algorithms like k-means are not suitable for our purpose primarily because of two reasons. Firstly, injection vectors are extremely heterogeneous, due to which an expert guess of k is likely to be inappropriate. Secondly, SQLiDDS is intended to be adaptive and the number of clusters would vary over time when re-clustering is done after addition of new injection patterns to the repository. Hierarchical agglomerative clustering (HAC) algorithm does not require the number of clusters to be prespecified. Though it has at least

Clustering of normalized injection patterns
We developed a variation of the priority-queue based efficient HAC [see 34, p. 386] for clustering of the normalized injection patterns as shown in Algorithm 1. The process begins with computation of a 
The algorithm takes the similarity matrix
Like the simple bottom-up HAC [34, Section 17.1], the algorithm forms clusters by successively merging pairs of clusters. However, it does not continue up to merging all clusters into a single cluster containing all documents; rather it terminates when the set of preference queues
In each iteration, whether two clusters get a chance to merge or not, the first preference of the potential merge pairs are removed from the queues, allowing the clusters to try merging with some other cluster in the next iteration. This way each preference queue gradually reduces and finally becomes empty. Empty preference queues are eliminated from subsequent iterations. The algorithm terminates when there are no more preference queues left. The time complexity of the algorithm still turns out to be
A question may be raised on a situation when none of the first preferences mutually match – this could result in a deadlock causing the algorithm run into an infinite loop. However, it can be easily proved that such a deadlock situation will never arise. Let the first preference of
The threshold similarity
In image processing domain, threshold selection by histogram analysis is quite popular [18]. The main advantage of threshold selection by histogram analysis is to make it data dependent, i.e. with changed data, the threshold can automatically change. The similarity range
The histogram is iteratively smoothed using moving average method by taking the frequency at any bin as the average of previous, current and next bin, i.e.,
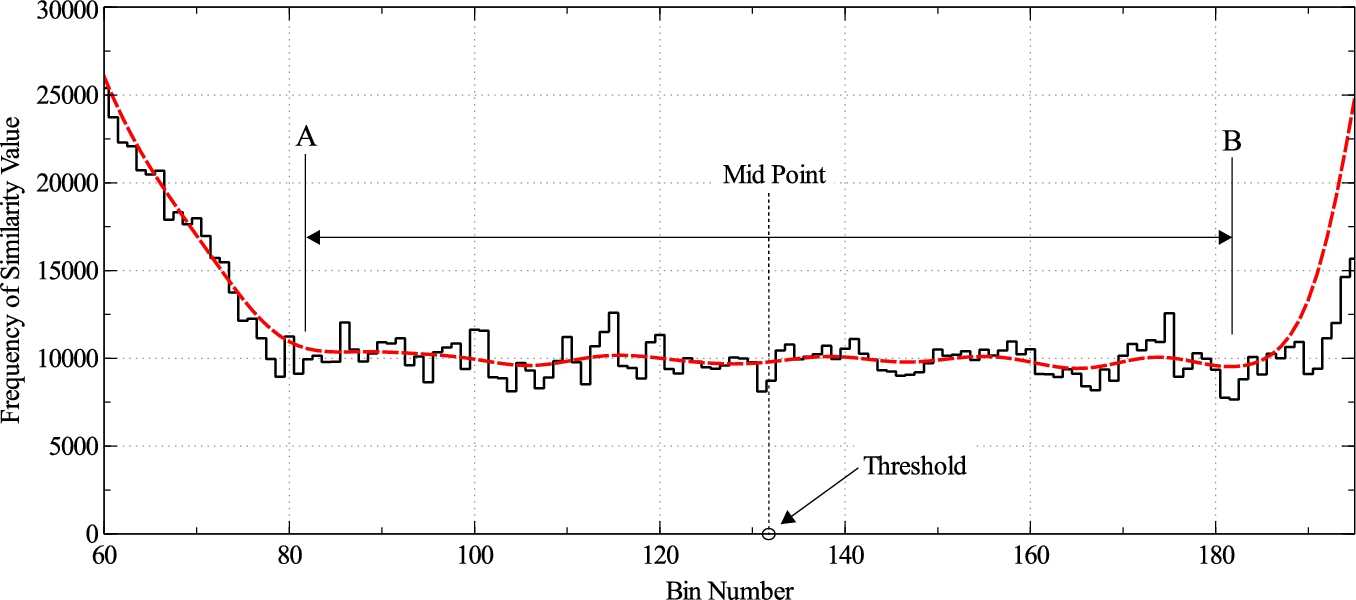
Histogram smoothing for determination of threshold similarity.
SQLiDDS operates in two distinct phases: (1) offline phase, and (2) run-time phase. The offline phase can be considered as the training phase and is required only once. At run-time, the system performs hash-table lookup to detect known SQL injection attacks while previously unseen injection attacks are detected by similarity matching. The system thus re-trains itself from its detection history and also with inputs from the DBA. The rest of this section explains the two phases of our approach in detail.
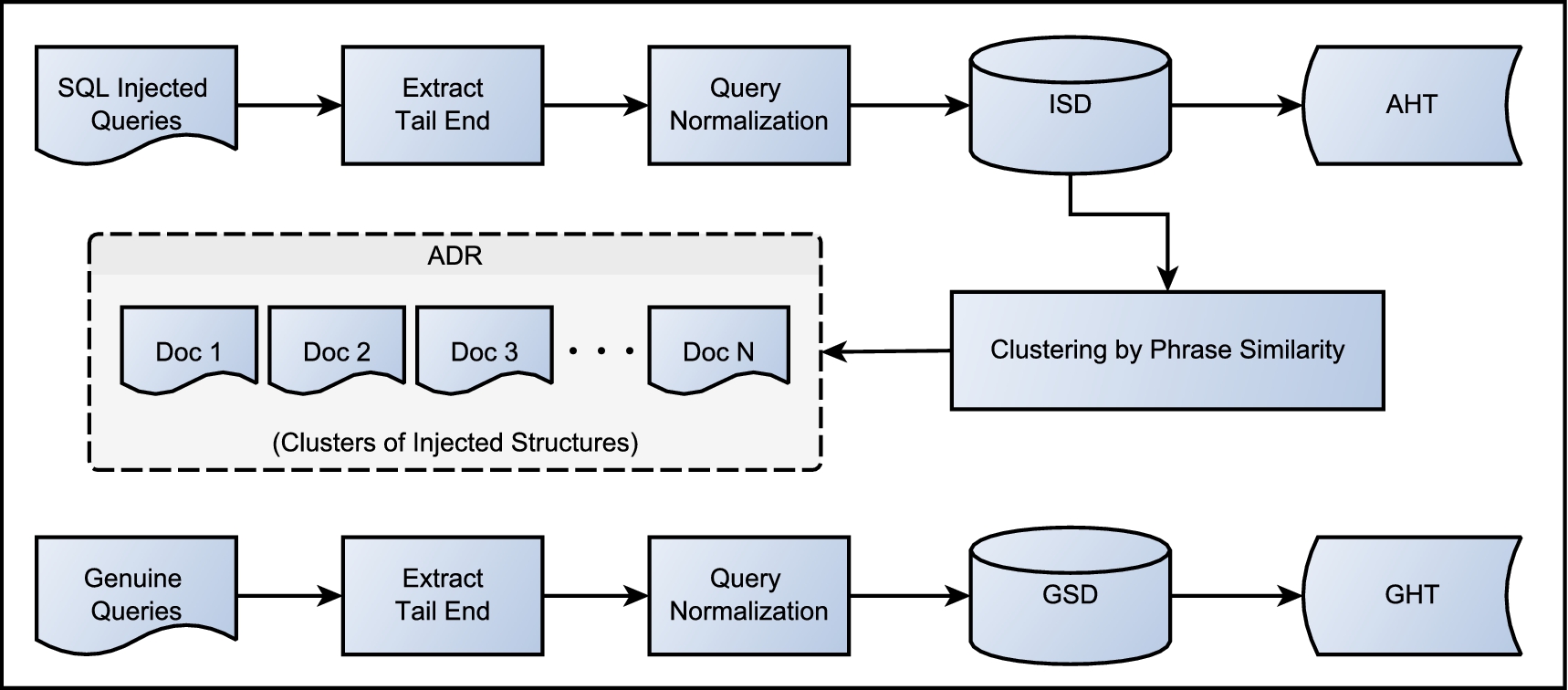
The offline phase of SQLiDDS.
The offline phase, as shown in Fig. 4, begins with an adequate collection of SQL injected queries. The process of collecting injected queries has been discussed later in Section 6.1. The tail-end of the injected queries are extracted and converted into text form using the query normalization scheme. A major advantage of the normalization scheme is that several queries get converted into the same form. For example, two attacks “
A collection of genuine SQL queries is also prepared in the same manner. The process of collecting genuine SQL queries is much simpler. The sample web applications are run in a secured environment and the queries generated by the web pages are recorded. The tail-end of these queries are extracted and normalized. For example, the query “
The offline phase completes with creation of the injected and genuine structure databases, the hash tables and the documents of clustered injected structures, making SQLiDDS ready for deployment as a database firewall between a web server and database server and start intercepting incoming SQL queries. Two thresholds, (1) Rejection Threshold (
Run-time phase
In the run-time phase (shown in Fig. 5), SQLiDDS intercepts queries issued by web applications to the database server. The tail-end of each intercepted query is extracted and normalized using the query normalization scheme. This produces the pattern which needs to be checked for any SQL injection attack. The MD5 hash of the pattern is computed and first the GHT is looked up for a match. If a match is found, the query is confirmed as a genuine query and forwarded to database server for execution. In case a match in GHT is not found, the AHT is looked up next. If a match is found in the AHT, then it is confirmed as a known SQL injection attack and the query is rejected without any further check. When a match is not found in the AHT, its phrase similarity with the documents in the ADR is computed. If the highest similarity with any document is above the predefined rejection threshold

The run-time phase of SQLiDDS.
If the highest similarity is
Our experimental setup consisted of a standard desktop computer with Intel® Core-i3™ 2100 CPU @ 3.10 GHz and 2GB RAM, running CentOS 5.3 Server OS, Apache 2.2.3 web server with PHP 5.3.28 set up as Apache module, and MySQL 5.5.29 database server. Five client PCs of same hardware configuration were connected through a passive switch to the server creating a 100 mbps LAN environment.
In the literature, some researchers have used the AMNESIA testbed4
SQLiDDS requires an adequate collection of known injected queries to begin the offline phase, which was generated using a honeypot based technique. First, we switched on the General Query Log5
In addition to these tools, several SQL injection tips & tricks were collected from tutorials, cheat-sheets, security forums, black hat sites, etc., and applied manually on the websites. As the websites were made entirely vulnerable, all the automated and manual injection attacks were successful. In the process, every SQL query generated by the web applications was logged by MySQL server in the general query log as planned. Over 4.52 million lines were written by MySQL into the log files, from which 3.35 million SQL queries were extracted. After removing duplicates,
Each query was manually examined and the injected queries were carefully separated out. Out of the 49,273 injected queries identified, total 16,702 unique queries were obtained. The collection contained a good mix of all types of injection attacks, though the percentage of UNION-based, blind injection attacks, and time-based blind attacks was observed to be higher than others. In fact, these three SQL injection techniques are most commonly used by attackers. The tail-end (i.e., the portion after the first
For preparing the ADR, the normalized injection patterns were clustered using Algorithm 1. The threshold was determined as 0.645 from the similarity matrix by histogram smoothing as described in Section 4.6. Total 108 clusters were obtained including 17 singleton clusters. The patterns in each cluster were merged into a document and the documents were stored in the ADR. The phrases of each document were pre-extracted for efficiency and stored in comma separated format.
For run-time evaluation, all the five sample web applications were used without any changes to their input handling. As we collected injected queries from three web applications during the offline (training) phase, this may be regarded as using approximately 60% of the data for training and 40% for testing. The rejection and suspicious thresholds were determined empirically by testing phrase similarity between injected and genuine patterns selected randomly from the structure databases, and set as 0.885 and 0.682 respectively. With SQLiDDS activated to intercept incoming queries, the web applications were attacked by using the automated tools and manual techniques from the client PCs as mentioned in Section 6.1. In addition, to quickly simulate genuine browsing of the web applications, we used Xenu Link Sleuth7
Results of SQL injection detection by SQLiDDS
The experimental results show that SQLiDDS exhibits good accuracy of detection. For all test applications, the true positive rate (TPR) is above 96.5% and the true negative rate is above 98.8%. The false positive rate (FPR) is below 1% except for the Forum application. The false negative rate (FNR) is below 1.5% except for the Forum and NewsPortal applications. The class averaged precision varies from 93.17% for NewsPortal to 97.09% for Classifieds. The class averaged recall is close to 98% for NewsPortal, and is above that for the other applications. The F1 score for all applications is above 95.5%. Out of the false positives and negatives, total 96 queries (42.5%) were tagged as suspicious queries for the DBA to examine. Considering all applications together, the overall precision, recall, and F1-score of the system comes out as 95.70%, 98.78%, and 97.22% respectively.
It may be observed that the performance is better for the Bookstore, Classifieds and JobPortal. This is no surprise because these three applications were used as honeypots for collection of injected queries. However, the F1 score for the Forum and JobPortal applications are still above 95.5%, which is interesting as well as encouraging, and confirms efficacy of the approach. The main reason behind this is that web applications are generally written using similar programming practices, databases are created using standard relational database design principles, and parameter values are used in the same manner to construct dynamic queries. While normal SQL queries issued by different web applications may be quite different depending on their database schema and intended function, when the
The knowledge-base of SQLiDDS consisting of injection attack vectors (stored in the AHT and ADR) was built by launching injection attacks on three honeypot web applications using over 23 different automated tools along with large number of manually constructed attacks. The run-time evaluation was conducted upon all five web applications to simulate real-world attacks in a shared hosting environment. During the study, we observed that, many of the attack tools randomly determine the vulnerable parameters (or form fields) and accordingly formulate the injection vectors. If a web page has multiple vulnerabilities, the same tool may attack it differently in successive runs. In addition, many tools also randomize the attack vectors to avoid detection by an IDS. Therefore, although the same set of attack tools are used for run-time evaluation, the attack vectors are not guaranteed to remain same; otherwise the system would yield 100% accuracy for the three honeypot applications simply by hash-matching with the AHT. The objective of the study was to establish that the attacks on any web application in a shared hosting environment are most likely to be similar to previously seen attacks which can be identified by comparing document similarity of normalized tail-ends of run-time queries with the knowledge-base. Considering the breadth of attack tools used to train the system, we believe that this objective is well realized.
Nevertheless, a question may be raised concerning the tests being incestuous, because the same set of tools are used for training as well as evaluation, though we include the non-honeypot applications in the evaluation. Since the injection vectors during training and testing are generated from the same set of attack tools, it may be possible that the system is learning the attack patterns of the specific tools instead of structural characteristics of SQL injection. A popular way to adjust for this, as suggested by Dietterich [12], is to conduct a repeated two-fold validation by partitioning the injection vectors according to the attack tools used. In other words, training and testing may be conducted on mutually exclusive set of attack tools to ensure that the injection vectors during testing are not generated from the same set of tools used for training, thus avoiding the incestuous relationship. However, it requires extreme bookkeeping for tracking the provenance of a particular injected query. To collect the injected queries for training (see Section 6.1), we attacked the honeypot web applications simultaneously from the five client computers, so all queries were recorded in the same MySQL log file. Though the web application that issued the query is recorded in the log, the attack tool that produced the injected query is not known. To conduct a two-fold validation encompassing all attack tools, the attacks must be launched serially on the web applications, each run starting with an empty log file. Each log file, containing several thousands of queries (genuine and injected), must then be scrutinized to extract the injected queries generated by that particular tool. Since many of the attacks (particularly blind and time-based blind injection attacks) take in order of days to complete, it would be extremely time consuming as well as cumbersome.
Therefore, we conducted a small scale two-fold validation using four attack tools on one web application. The Bookstore application was chosen as it was the largest among the five sample applications. The four attack tools selected were: (1) The Mole, (2) sqlmap, (3) darkMySQLi, and (4) sqlsus. These tools were selected because they are almost equally capable of generating various types of injection attacks, focus mainly on MySQL databases, and exhibit randomness in the attack vectors. Dietterich [12] recommends five iterations in total; by taking injection attacks generated from two tools for training and the rest for testing, six iterations were conducted.
The Bookstore application was serially attacked by these four tools, each attack session starting with a fresh installation of its database and an empty query log file. After completion of each attack tool, the log file was carefully examined and injected queries were separated out. The tail-ends were normalized and duplicates arising due to normalization were removed. This way, four sets of samples were prepared, each containing injection patterns generated from one source. In each iteration, two sets of samples were taken together and clustered to generate the documents of the ADR. The injection patterns in the other two sets were verified against these documents. The same similarity measure, rejection and suspicious thresholds as during run-time evaluation were used. Table 4 shows the results of the two-fold validation, where SPR refers to the percentage of samples determined as suspicious. Since the validation is between injected queries only, true negatives (TN) or false positives (FP) are not applicable.
Results of two-fold validation using four attack tools on the Bookstore application
Results of two-fold validation using four attack tools on the Bookstore application
On the first look, the results may appear to be on lower side, but they are actually quite encouraging. We find that, when only four attack tools are used to generate the disjoint training and testing samples, on average 74.61% of injected queries are correctly identified. The suspicious rate indicates that, average 17.99% of the samples exhibit good similarity, though not up to the rejection threshold. On the other hand, the average false negative rate shows that, only 7.39% of injection vectors across disjoint sets are dissimilar and fall below the required similarity score. If the thresholds are recalculated considering only the samples in hand, then the results would improve because several instances which are determined as suspicious or failed, would move towards being correctly identified or suspicious respectively. For example, if 10 instances move from being suspicious to true positive, and 5 instances move from false negative to suspicious, the true positive rate improves by 2%. Also, because the number of training samples is much less, the clustering process generates more singleton clusters. As a result, several documents in ADR contain only one injection pattern, which adversely affect the similarity scores during testing. Intelligibly, if all attack tools are included in the two-fold validation, the training and testing sets would be about four times larger, and the figures would converge to the run-time evaluation results.
Like any other SQL injection detection system, SQLiDDS also adds some processing overhead to the run-time performance of web applications, which consists of four components: (1) extracting the tail-end of a query, (2) normalization of the tail-end into text form, (3) lookup of the reference hash tables, and (4) similarity matching with clustered documents. Out of these, (1) and (3) consume negligible amount of time and can be ignored for calculating the net performance impact of the system.
The time consumed for query normalization was measured by applying it on 1000 queries selected randomly from the 245,356 queries collected. Average time of 1000 such runs was found to be 0.625 ms. Time consumed for similarity matching was measured by computing phrase-based similarity using Positive Matching Index between an injection pattern (out of the 3896) and a document of clustered structures (out of the 108), both selected randomly. The average time of 1000 runs was found to be 1.917 ms. To further improve run-time performance, instead of storing the clustered structures as simple text documents, the phrases were pre-extracted and stored in comma-separated format. With this optimization in the storage structure of the ADR, the average time reduced to 0.228 ms. Considering that similarity with half of the documents needs to be computed on average, total processing overhead comes to ≃ 12.7 ms per incoming query. Assuming that a standard web page issues 10 queries on average for execution and all queries require up to the similarity matching step, theoretically the total delay introduced by SQLiDDS is ≃ 127 ms for each page load. Considering that the page load times are generally in the order of several seconds over the Internet, a delay of 127 ms would not affect the end-user experience.
To assess impact on performance in production usage scenario, load testing on the web applications was conducted using Pylot8
Open source website performance testing tool:
An HTTP load testing and benchmarking utility:
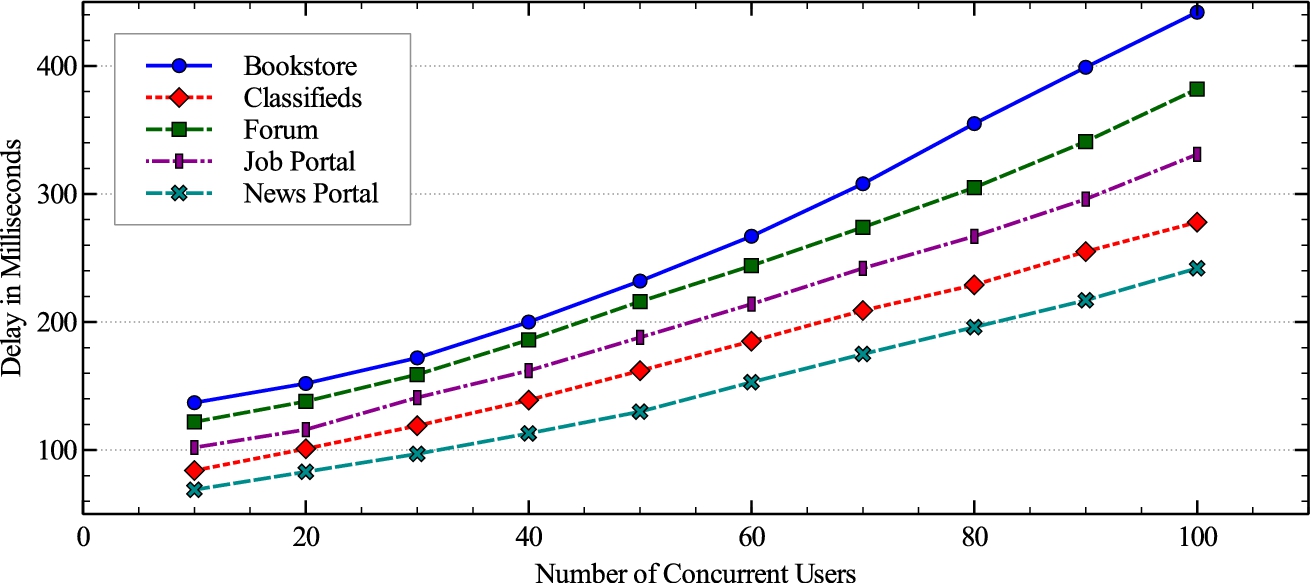
Performance overhead of SQLiDDS.
Being a serious threat to web applications for nearly 15 years, excellent research on SQL injection prevention and detection exists in the literature. Researchers have attempted to provide a solution at various locations of web applications’ tiered architecture such as: (1) inspecting HTTP request packets before reaching the web server, (2) using specific coding methods while developing the web application, (3) retrofitting the code of existing web application, (4) examining queries issued by the web application before sending to the database server, (5) during query compilation or optimization phase at the database server, (6) after the query is executed by analyzing the query result size, and (7) identifying attacks by mining the web server access log or database query log. Our approach fits at the location 4 by sitting in between the web server and database server. Technically this location allows us to focus only on the SQL query issued by the web applications. Another advantage is that, the system is independent of the programming language used in the web applications, as well as which database server is used in the back-end. It is also possible to tune to system towards vendor specific SQL dialects.
Though many approaches have been acknowledged as detection or prevention techniques, only some of them have been implemented from prospective of practicality. Due to non-availability of any standard data set of SQL injection attacks, most of the approaches have been validated using synthetic ones or sample applications mimicking near real-world scenarios. Since each approach has its benefits as well as shortcomings under specific situations and systems, it is difficult to do a rational comparison based on experimental figures. Therefore, we provide an analytical comparison of our approach with some notable approaches we studied, shown in Table 5, which is based on the following considerations:
Specific coding method: Whether the approach is based on a specific coding methodology or use of a proposed framework to prevent SQL injection attacks.
Source code access: Whether the approach requires access to the source code or modifies it for static analysis, retrofitting, or identifying weakness in input validation.
Platform specific: Whether the approach is applicable or suitable only for a specific programming language and/or database platform.
Normal-use modeling: Whether the approach requires building a model of the SQL queries generated by the web application with benign inputs run in a secured environment.
Multiple websites: If the approach applies to only one web application or can protect multiple web sites hosted on a shared server.
Adaptive/self-learning: Whether the approach is adaptive and self-learning to be able to detect previously unseen attacks.
Time complexity: Whether the general time complexity of the system is high or low.
Practical usability: How well the system is practically usable in a real production environment.
Analytical comparison of SQLiDDS with existing techniques
Analytical comparison of SQLiDDS with existing techniques
We also compare our approach with these approaches based on the ability to prevent or detect various types of SQL injection attacks as shown in Table 6.
Types of SQL injection attacks detected (∙ : yes, ∘ : partially,
Although SQLiDDS detected almost all of the tautological attack vectors in our tests, we still show it as partial because theoretically tautological expressions can be formed in infinite number of ways.
Apart from document search, text categorization, or information retrieval, similarity measures have been long used by researchers for spam email detection [2], phishing website identification [51], unknown malicious executable detection [41], etc. However, to the best of our knowledge, document similarity measures have not been proposed specifically for detection of injection attacks at the SQL query level in the literature so far. A few studies have used similarity measures on HTTP requests or payloads for classification of different types of web attacks including SQL injection, which may be considered as related to our work to some extent.
Walenstein et al. [48] used similarity measures on N-grams of disassembled code to identify variants of known malwares. Small et al. [42] also used similarity measure along with string alignment techniques for detecting malicious HTTP payloads. At the same time, Gallagher and Eliassi-Rad [16] applied term frequency based similarity measure for classification of HTTP requests to identify and classify web attacks. Ulmer and Gokhale [46] used document similarity on HTTP data for a configurable hardware classifier for web attacks. Later they proposed massive parallel acceleration for the document-similarity classifier on multi-core processor architecture, focusing mainly on hardware implementation of similarity computation [47]. N-gram splitting and classification using Support Vector Machine (SVM) to detect SQL injection and XSS attacks was proposed by Choi et al. [8]. However, their approach extracts N-grams from the queries ignoring the symbols and operators, which are important syntactic elements in a query. Application of document similarity measures on normalized queries for detecting SQL injection attacks is proposed for the first time in this study to the best of our belief.
Conclusions and future work
This paper presented a novel approach to detect known as well as previously unseen SQL injection attacks in real-time using query normalization and applying document similarity measure. The approach was implemented in a tool named SQLiDDS designed to work as a database firewall. We adopted the strategy to examine only the
In future, we will examine feasibility of improving the normalization scheme by converting a group of symbols (such as arithmetic operators) into one token, keeping in mind that over-normalization may lead to loss of accuracy. Next we plan to devise a weighting scheme for frequently occurring phrases which could help to reduce false negative and positives. We also plan to implement incremental clustering so that the attack document repository can be regenerated as soon as a new attack is detected. Multiple installations of SQLiDDS, communicating with each other to keep their attack vector repositories up to date could also be another interesting option to work on in the future.