
Abstract
We study users behavior in online social networks (OSN) as a means to preserve privacy. People widely use OSN for a variety of objectives and fields. Each OSN has different characteristics, requirements, and vulnerabilities of the private data shared. Sharing-habits refers to users’ patterns of sharing information. Sharing-habits are implied by the communication between users and their peers. While social networks allow users to have some control over the dissemination of their information, most users are not aware that the private information they share might leak to users with whom they do not wish to share it. In this paper we address the growing need of social network users to share information with close fiends while hiding it from others. We apply several different well-known strategies from graph-flow theory to an OSN graph with sharing-habits insights, to control the information flow among OSN users. The goal of the method we present is to allow maximum information sharing while enforcing a user’s pre-defined privacy criteria. Our method is evaluated using real data from well known social networks and the results are analyzed in terms of accuracy and run-time.
Introduction
Online Social networks (OSN) are websites enabling users to build connections and relationships among each other. The OSN structure represents social relationships between its users. Social networks are widely used by their members for information sharing with the purpose of reaching as many friends as possible. Users should have control over the dissemination of their information, however they are not fully aware of the possible consequences of their preferences when specifying access rules to their shared data. Most access rules are defined in terms of the degree of relationship required to access ones data and are not refined enough to allow dynamic denial of content from certain peers of the community. It is the responsibility of OSN administrators to effectively enforce these rules to reduce the risk of information leakage. For example, consider a chocolatier that owns a small Chocolate boutique shop. The chocolatier has established a customers club as a closed-group in his Facebook account. The chocolatier introduces new tastes, sales opportunities, and coupons to his Facebook closed-group. He invents a new taste for the incoming Valentine’s day, and makes a special offer to his customers club in advance. The chocolatier would like this information to be shared with as many people as possible, but to remain hidden from his competitors (adversaries). Currently the Chocolatier has limited control over the information shared on his Facebook group, each member of the group, can re-post the shared information, that might reach one of his competitors.
We propose a model for access control that works with minimal user intervention. The model is based on users’ patterns of sharing information denoted as Sharing-habits. To minimize the risk of information leakage, the social network is analyzed based on these habits, to determine the probability of information flow through network connections. In a graph representation of the network, where nodes are users and edges indicate relationship between users, the challenge is to select the set of edges that should be blocked to prevent leakage of the shared information to unwanted recipients. We review some methods for handling and preserving privacy in social networks, and present our new privacy preserving approach, based on sharing-habits data. Our model combines algorithms that use graph flow methods such as max-flow-min-cut, and contract. Experimental results show the effectiveness of these algorithms in controlling the flow of information to allow sharing with friends while hiding from others. To the best of our knowledge, this paper is the first to provide dynamic access control model which is based on users dynamic interactions and not on user profiles.
The rest of the paper is structured as follows: in the next section we review related work, in Section 3 we define the privacy assurance in OSN problem, and in Section 4 we present our method for dealing with this problem. We explain our evaluation method and primary results in Section 5 and conclude by summarizing our contribution and discussing directions for future work in Section 6.
Related work
There are various types of Online Social Networks, each with different properties. Privacy preservation can be viewed and handled from various aspects. In [12], Papacharissi et al. present several aspects regarding social networks: social network’s structure, evolution, and properties, including identities, communities, and the culture on social network sites. They present self-presentation and social connection in the digital age, behavioral norms, patterns and routines on social networks. The authors conclude that there are emerging patterns of networked sociability that combine newer social habits with old habits, including social routines of the past, and reflect social tendencies and tensions that take shape on networked planes of social activity. Social media platforms introduced a space where boundaries between private and public space have become fuzzy, which opens up new possibilities for identity formation.
Barabasi [1] examines the structure and evolution of social networks. Most networks have the “scale-free” property, which means that they do not depend on a specific node (user), and randomly removing nodes, will not destroy the social network. Every network has a few hubs that hold the whole network together, combining communities that are relatively isolated groups of nodes that work independently. Networks are hierarchical, they are built of communities that are grouped together into bigger communities.
LaRose et al. [14] discuss the social networking addiction, and media habits. Some people develop an obsession with some social network sites, known as “Facebook addiction”. For many Internet users, social networking has become a media habit, as a form of automatism. People develop an automatic habit of media consumption, for some it turned into a “bad” habit, that might be termed compulsive, problematic, pathological, or addictive, and for others it turned into a “good” habit. A new category of mental illness, called “Internet usage disorder” has been proposed, including a subcategory of email/text messaging. Models of media behavior can be extended from an understanding of
Kim et al. [8], investigated the cultural difference in motivations for using social network sites, between American and Korean college students. American and Korean showed a similar pattern of daily use of the social networks. A notable difference between American and Korean was found in the number of connections included in their “friends” list. The number of connections defines the
Carmagnola et al. [18] present a research about the factors that help user’s identification, and information leakage in social networks, based on entity resolution. They conducted a study on the possible factors that make users vulnerable to identification, and of personal information leakage, and the perception of users about privacy related to the spreading of their public data. To find the risk factors, they studied the relations between the user behavior (habits) on OSNs and the probability of users’ identification.
Kleinberg and Ligett [10] describe the social network as a graph where nodes represent users, and an edge between two nodes indicates that these two users are enemies that do not wish to share information. The problem of information sharing is described as the graph coloring problem, Kleinberg and Ligett [10] analyze the stability of solutions for this problem, and the incentive of users to change the set of partners with whom they are willing to share information.
Tassa and Cohen [2], handle the information release problem, and present algorithms to compute an anonymization of the released data to a level of k-anonymity; the algorithm can be used in sequential and distributed environments, while maintaining high utility of the anonymized data.
Vatsalan et al. [19] survey the ‘privacy-preserving record linkage’ (PPRL) techniques, and overview techniques that allow the linking of databases between organizations while preserving the privacy of these databases. In this paper Vatsalan et al. [19] present a taxonomy of PPRL which characterizes the known PPRL techniques along 15 dimensions. They highlight the shortcomings of current techniques avenues for future research.
Jaehong and Ravi [13] present the ORIGIN CONTROL access control model where every piece of information is associated with its creator forever. As we show later, such a model can be used to control content dependent information flow within the social network.
Ranjbar and Maheswaran [11], describe the social network as a graph where nodes represent users, and an edge between two nodes indicates that these two users are friends that wish to share information. They present algorithms for defining communities of users, where the information is shared among users within the community. They also propose algorithms for defining the set of users that should be blocked in order to prevent the shared information from reaching adversaries, and leaking outside the community. In OSN, communities are subsets of users connected to each other which can be described by a connected graph, where each user is a node in the graph, and an edge connecting two nodes indicates a relationship between two users. A community is defined by Ranjbar and Maheswaran [11] from the view point of an individual user. myCommunity is defined as the largest sub-graph of users who are likely to receive and hold the information without leaking. In other words, myCommunity is the subset of an individual user’s friends with whom it has intense and frequent interactions. It describes a grouping abstraction of the set of users that surrounds an individual based on the communication patterns used for information sharing. Our study is based on the ideas described in their paper however, while [11] only share information within the defined community, and block all users that might leak information to adversaries, and as a result may block friendly users from all information, we relax the limitation defined in their study, and block only edges on the path to the adversaries while minimizing the impact on the user defined community.
The privacy assurance in OSN problem
In this section we define the general problem of privacy assurance in OSN and our proposed method that uses information from users sharing-habits.
Let
We define the distance between two vertices in a graph,
The δ-community of a user, represented by the ego vertex

Figure 1 describes an ego-community graph for the ego node
As shown by the figure the δ-community of friends is usually much larger than the β-community of close friends.
We use the following definitions as defined by Ranjbar and Maheswaran [11]: Outflow is the number of sharing interactions from Inflow is the number of sharing interactions from
The likelihood of
For example, if in Fig. 6, the number of sharing interactions from user 4 to his friends is 23 (13 to user 3 and 10 to user 5), and the number of sharing interactions from 4’s friends to 4 is 30 (9 from user 7 and 21 from user
The Probability of Information Flow (PIF), is the maximum probability of information flow throughout the entire paths between
Our aim is to enable a user Minimum Friends Information Flow: the minimum information flow from Let Close Friends Distance: Close friends are defined by their distance from Let B be the set of blocked edges, then
Maximum Adversaries Information Flow: the maximum information flow from
For example the threshold parameters can be:
Cuts in a graph
A cut in a graph is a set of edges between two subsets of a graph, one containing
A naive algorithm for solving the problem would be an algorithm that finds any cut between the adversaries’ set and
The naive algorithm is not suitable for our problem, since it doesn’t address (1) Minimum Friends Information Flow and (2) Close Friends Distancecriteria of our problem. However it serves as a basic framework to our proposed solution.

Naive algorithm for blocked users
In the Appendix we analyze the complexity of Sharing-habits based Privacy Assurance in OSN (SHPA) problem. We show that a “Minimum-Distance with Maximum-Flow and Minimum Leakage” problem, which is a simple subset of the “Sharing-habits based Privacy Assurance problem” (defined next) is NP-Complete, and so does the general Sharing-habits based Privacy Assurance in OSN problem.
In Section 4 we present a practical approximating solution for the general problem.
Maximum-flow minimum-leakage problem definition
Let
Given a set
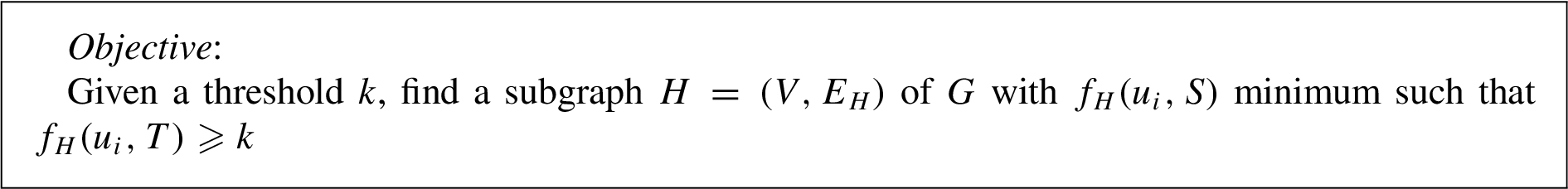
A particular case of Maximum-Flow Minimum-Leakage Problem is the Minimum-Distance Maximum-Flow Minimum-Leakage Problem, which is a simple subset of our general problem, were the adversaries are in the boundaries of
In the Appendix we show the proof for the claim that the Minimum-Distance Maximum-Flow Minimum-Leakage problem is NP-complete and so does the simple problem, and furthermore does the general problem.
In the next chapter we present several approximations algorithms to the general problem.
The sharing-habits based privacy assurance in OSN solution
As we show in the Appendix the problem presented here is NP-Complete, next we propose a model for finding the set of edges that should be blocked to allow maximum information sharing with the community of the information source and minimum information leakage. In Section 5.2.2 we analyze the complexity of the proposed model, and show that it is
Our model consists of two major steps: the first is the initialization step in which we create a multi-graph with a super-vertex
Algorithm 2 is a skeleton outlines these steps: It starts with the initialization step (lines 1–8), next it calls the procedure that finds candidates-sets of edges to be blocked (line 12), by using min-cut algorithm, contract algorithm, or both, and then it calls the procedure that examines the proposed set against the required privacy criteria (line 13). Figure 2 describes the main building blocks of the algorithm for defining the edges to be removed from

Construct blocked edges

Construct Blocked Edges main building blocks.
Next we describe in detail each one of these building blocks.
The δ-community of a member
Figure 3(a) describes a δ-community graph for
Construct blocked edges candidates
A candidate-set of blocked edges is a cut between two sets of vertices, one set containing
The candidate-set is evaluated against the privacy criteria we have defined in Section 3 and is described later in Section 4.3. We use the following two methods for finding the initial candidate-set of edges to block:
Block edges by min-cut
Algorithm 3 implements the Sharing-habits privacy assurance based on the max-flow min-cut method [4], and then tests for privacy criteria compliance:
Find a minimum cut between super-vertex
Check if the cut complies with the required privacy criteria as defined in Section 3.1, and select the final candidates-set. This process is described in Section 4.3.

Block edges by Min-Cut
The minimum cut between the beta community of user
Algorithm 4 implements the Sharing-habits privacy assurance based on the contract method by Karger and Stein [6,17].
In each iteration, the contract algorithm finds a different cut between the super-vertex containing
Note:
The contract algorithm may be called many times until the resulting cut complies with the required privacy criteria, as defined in Section 3. When repeated enough times the contract will find the min-cut.
Algorithm 4 is composed of the following main steps:

Block edges by Contract

ContractFindCut
Algorithm 5 is called by Algorithm 4 to find a cut between two vertices by randomly selecting an edge and contracting the two vertices connected by the selected edge into one super-vertex.
Figures 4–5 describe a simple community graph and some steps of one run of the contract algorithm.

Contract: (a) Edge

Contract: (a) Edge
After selecting the initial candidates-set of edges to block, each method uses Algorithm 6 for selecting the final candidates-set of edges that should be removed from
The contract algorithm may provide at each run different cuts with different sets of edges to be blocked, the optimal set of edges to be blocked may vary in terms of the number of blocked edges, the amount of information flow to acquaintances and the amount of information leakage to adversaries. The order of selecting the edges to be blocked may provide different acceptable solutions to our problem. We propose three methods for selecting and removing an edge from the initial candidates-set, and insert the selected edge back to δ-community graph:
Randomize: select an edge randomly. Maximum PIF: select the edge with the maximum probability of information flow. Minimum PIF: select the edge with the minimum probability of information flow.
The motivation for the second choice is to reduce maximum flow to adversaries. The motivation for the third choice is to increase flow to friends. It is hard to find a balanced set since the general problem is NP-complete.
Algorithm 6 implements the three methods and Algorithm 7 tests the criteria.

Compute final candidates-set

Compute the required criteria
In this section we describe the evaluation method we use for the proposed algorithm, and the results we obtained using real data [9]. We first demonstrate our methods and the difference between them using a toy community.
Demonstration using a synthetic community
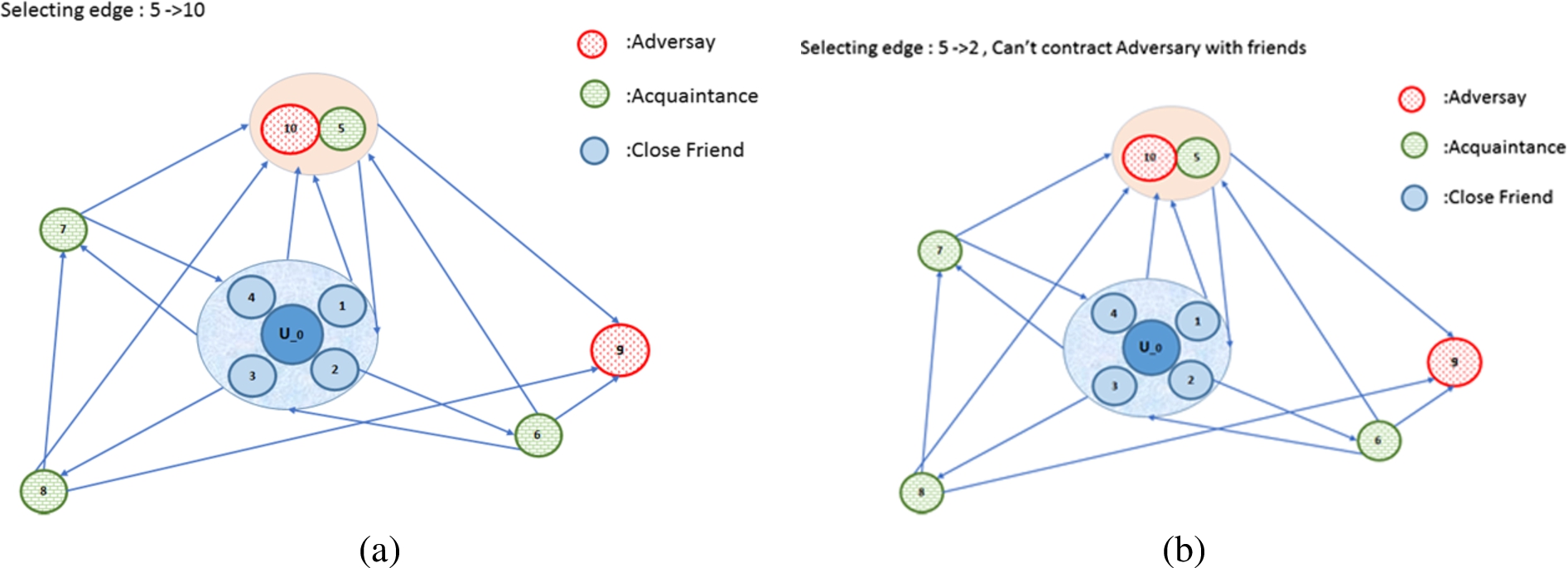
We demonstrate our algorithms on a small graph representing a community based on the example given in [15], containing 11 vertices and 23 edges with the following community parameters: distance
Figure 6 describes the synthetic community graph with high probability of information flow on the edges to adversaries. This situation simulates a collision, for which it is hard to find a cut other that trivially cut the edges to adversaries. In these cases a cut will be found only for privacy criteria that allows very low levels of information flow to
In Fig. 6

Synthetic community graph with collision.
Adversary 9 has three incoming edges
Adversary 10 has also three incoming edges
The maximum probability of information flow from
PIF from
Next, using this example we show why the contract approach has better chance of finding a good set of edges that can be blocked while satisfying the privacy criteria.
Candidates found by Min-Cut
Candidates found by Contract
Candidates found by Contract
The Minimum cut found by Min-Cut method is depicted in Table 2.
If we remove the initial candidates-set edges from
Block edges by contract method
Two Cuts found by iterations of contract method are depicted in Tables 3 and 4. If we remove the initial candidates-set edges depicted in Table 3, the probability of information flow to 5, 6, and 8 will be 0, meaning no flow at all and this does not comply with the required privacy criteria. Therefore following Algorithm 6 we unblock each edge from the initial candidates-set, until we meet the required privacy criteria; the final candidates-set is empty, since each edge we unblock not only improves the information flow to
It is obvious that when the edges to the adversaries have high probabilities, the max-flow-min-cut methods might not select those edges, and might not find a solution that comply with the required privacy criteria, while the contract method might find the trivial cut that contains only the edges to the adversaries, as depicted in Table 4, and thus comply with the required privacy criteria.
Test on SNAP database
We evaluated our algorithms using real data from Facebook, Twitter and Gplus networks data, available from Stanford Large Network Data-set Collection (SNAP) [9]. The SNAP library is being actively developed since 2004 and is organically growing as a result of Stanford research pursuits in analysis of large social and information networks. The website was launched in July 2009.
The first social network graph describes social circles from Facebook (anonymized) and consists of 4,039 nodes (users), and 88,234 edges. The social network graph of Twitter, is a directed graph describing social circles from Twitter which consists of 81,306 nodes (users), and 1,768,149 edges. The social network graph of Gplus, is a directed graph describing social circles from Google+ which consists of 107,614 nodes (users), and 13,673,453 edges.
In real world, the user’s willingness to share information with friends and acquaintances may be set periodically as described in Section 3, or by using learning techniques on user’s sharing habits. Since interactions between members are not reported in the SNAP datasets, we use the structure and relationship from this database, and assign random probabilities to the edges in the network graph as described next.
We define four types of users, to express a user’s willingness to share information: very high, medium, low, and very low. For each user in the graph we randomly assign a type. For each edge from a user node we randomly assign a probability that conforms to the user’s type according to the following ranges: high (0.75–1), medium (0.5–0.75), low (0.25–0.5), very low (0–0.25). The four types are generated uniformly among all network users. In real life these probabilities can be learned from the traffic patterns and users sharing habits.
In each run a random node is selected as the ego-node, the α, γ and δ parameters are set randomly and the β parameter is set to 1. A random number of adversaries (between 1% and 5% of community vertices) are selected from the δ-community of the ego-node. We used three methods for selecting the final candidate-set of edges to block: edges with max PIF (Probability of Information Flow), edges with Min PIF, and random edges. All three methods yield similar results, thus we only present the results from using the max PIF method.
Evaluation results
Figures 7–14 present several sub-communities derived from Facebook database by randomly selecting a sharing user with
Figure 7 describes two communities derived from Facebook database. The two communities have the same order of vertices, however we can see a clear division to clusters of vertices in community (a) which has a larger number of edges (connections), and consequently higher density.

Facebook: (a)

Initial Contract edges, sparse.
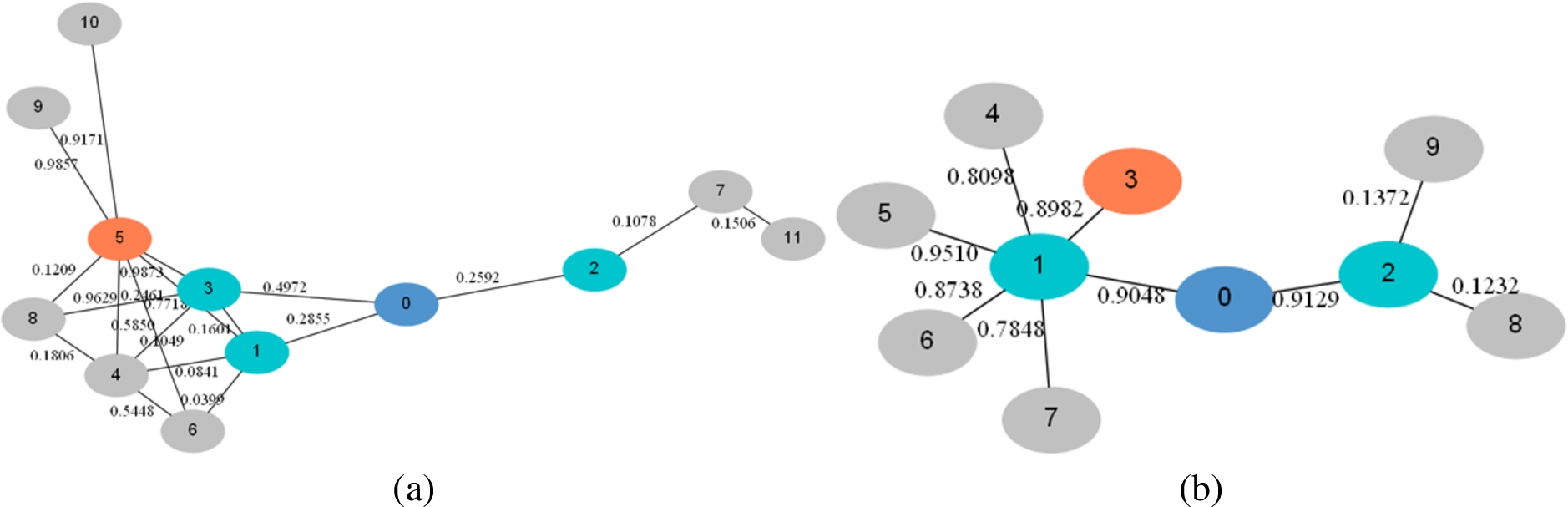
Figure 8 is a zoom into the sub-community depicted in Fig. 7(b), with two adversaries, 182, colored with green, and 209, colored with magenta. The ego-user is marked with red circle, and the red lines depict the initial candidates-set of edges to be blocked, found by the contract algorithm.

Final Contract edges, sparse.
In Fig. 9 the red lines represent the final candidates-set of edges to be blocked, found after computing the required privacy criteria and unblocking edges from the initial candidates-set of edges depicted in Fig. 8. We can see that the edges to be blocked, are edges on the path to adversary 209 (colored with magenta) only; there is no need to block edges in the paths to adversary 182 (colored with green) since it is connected to the sub-community with one edge from friend 2 to adversary 182 and the probability of sharing information along that edge is very small, 0.0732.

Twitter: (a)
Figures 10 and 11 describe communities derived from Twitter database, the ego-user is colored with steel blue, first degree friends are colored with turquoise, the adversaries are colored with coral, and community members are colored with gray. We can see that Twitter database is built from clusters of star-communities, generally connected by a small amount of edges.
Twitter: (a)
Twitter: (a) Initial Contract edges (b) Final Contract edges.
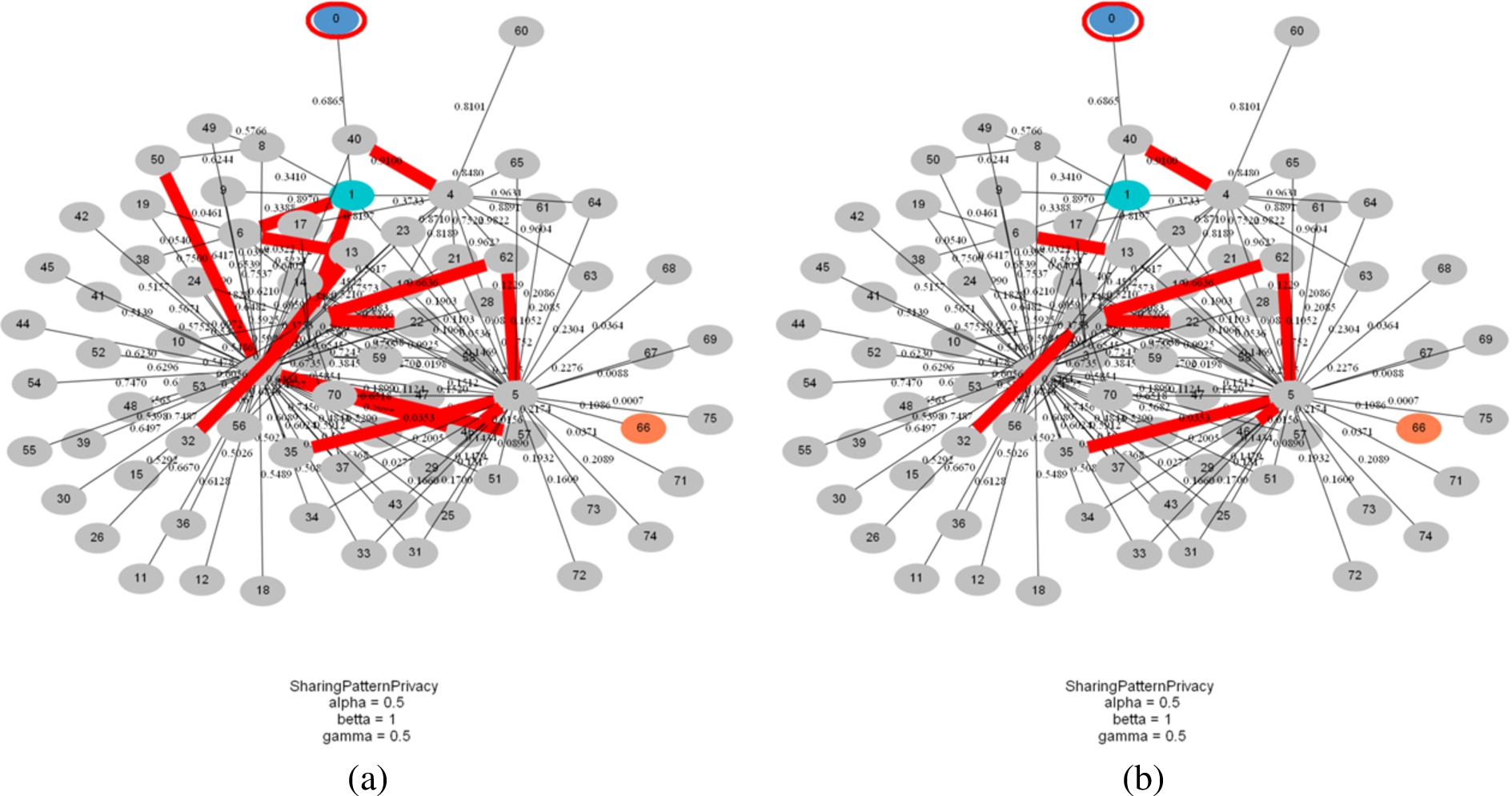
Figure 12 is the same sub-community as Fig. 10(a), with one adversary colored coral (66). The ego-user is marked with red circle, and the red lines depict the initial and final candidates-set of edges to be blocked, found by the contract algorithm.
Figure 13 describes two sub-communities derived from Google Plus database, we can see that Google Plus database resembles Facebook database and is built from clusters sub-communities, generally connected by a small amount of edges.
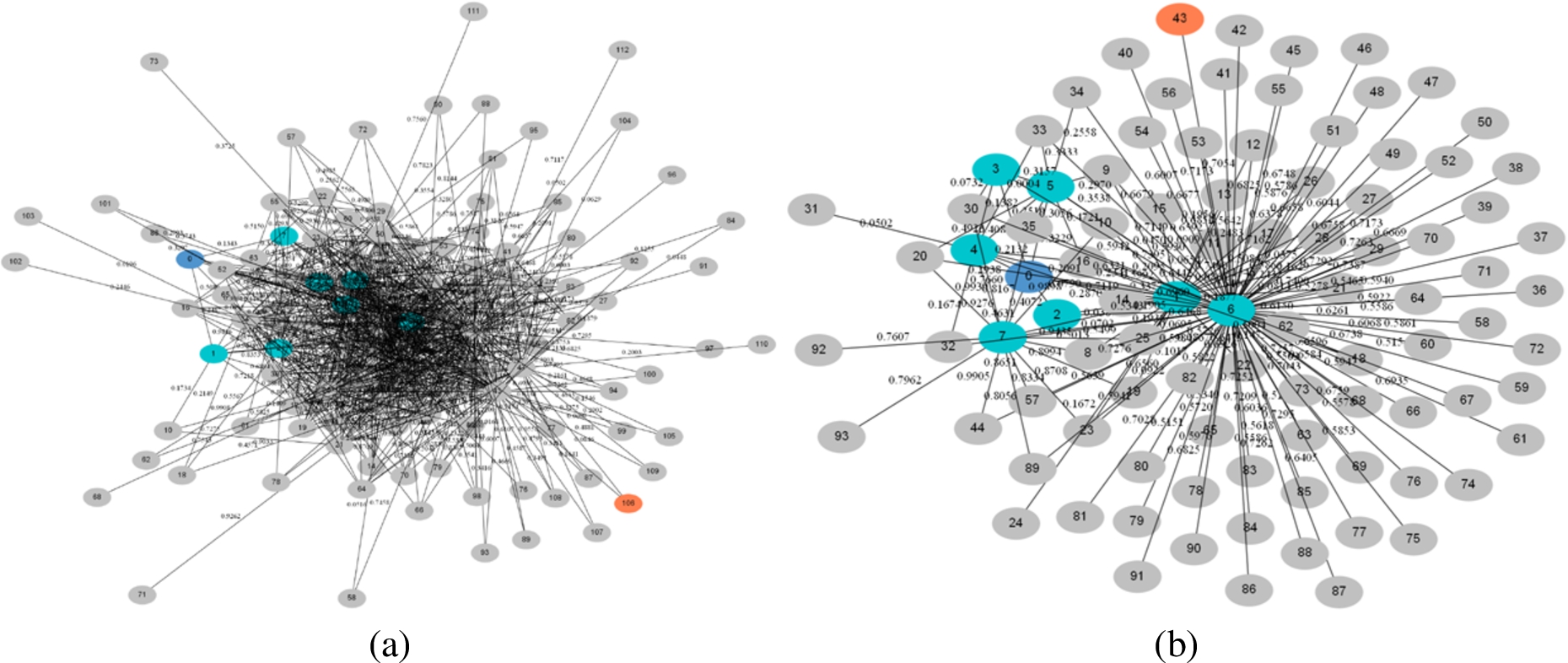
GPlus: (a)

GPlus: (a) Initial Contract edges (b) Final Contract edges.
Figure 14 is the same sub-community presented in Fig. 13(a), with one adversary, 106, colored with coral. The ego-user is marked with red circle, and the red lines depict the initial and final candidates-set of edges to be blocked, found by the contract algorithm.
Tables 5–6 summarize the results of several different evaluation runs, for different communities.
Table 5 presents several runs with the different sub-communities derived from the SNAP database. The community size is derived from the sharing user (ego node) and friends column refers to the amount of first degree friends of this user.
The size of the tested communities,
Table 6 present the results obtained by nineteen runs, with close friends distance, β set to 1.
Columns 2–3 present the threshold parameters used for each run. For each community graph we performed the algorithms with medium thresholds (
When the adversary is in the middle of the community’s boundaries, and there is a path with maximum information flow to a community member that passes through an adversary vertex (e.g., runs 8, 9, 10 and 14), it is highly likely that the maximum information flow will be reduced considerably and therefore no good solution can be obtained for high levels of α. When the ego-user rarely shares data with community member, there is no need to block edges, or the solution is the trivial solution (e.g. runs 7, 9, 13, and 19).
While both algorithms are complete, in the non trivial cases, min-cut finds the the best solution in terms of flow ratio between the initial and final flow to community members (e.g runs 16 and 18). Contract, on the other hand, may find a good solution that blocks adversaries to the extent required by the blocking criteria and even allows more sharing with friends (e.g., runs 5 and 8).
Evaluation Runs Results
(Continued)
Executing the contract algorithm multiple times ensures that each time a different set of initial candidate-edges is selected and may result in different final cuts. This way we avoid cases such as 3 where contract result in no solution.
We evaluated our algorithms on various databases with random ego-nodes, community distance, and information sharing probabilities. When the density of δ-community graph for the selected ego-node is high we got better results using the contract method in terms of number of blocked edges. When the min-cut method finds a solution it blocks a larger amount of edges (users) than the contract method (e.g., runs
Figure 15 presents the CPU time results obtained by our algorithms for the first phase that builds the initial candidate set on sub-communities with different densities as described in Section 4.2. The sub-communities were derived from Facebook database by randomly selecting a sharing user with
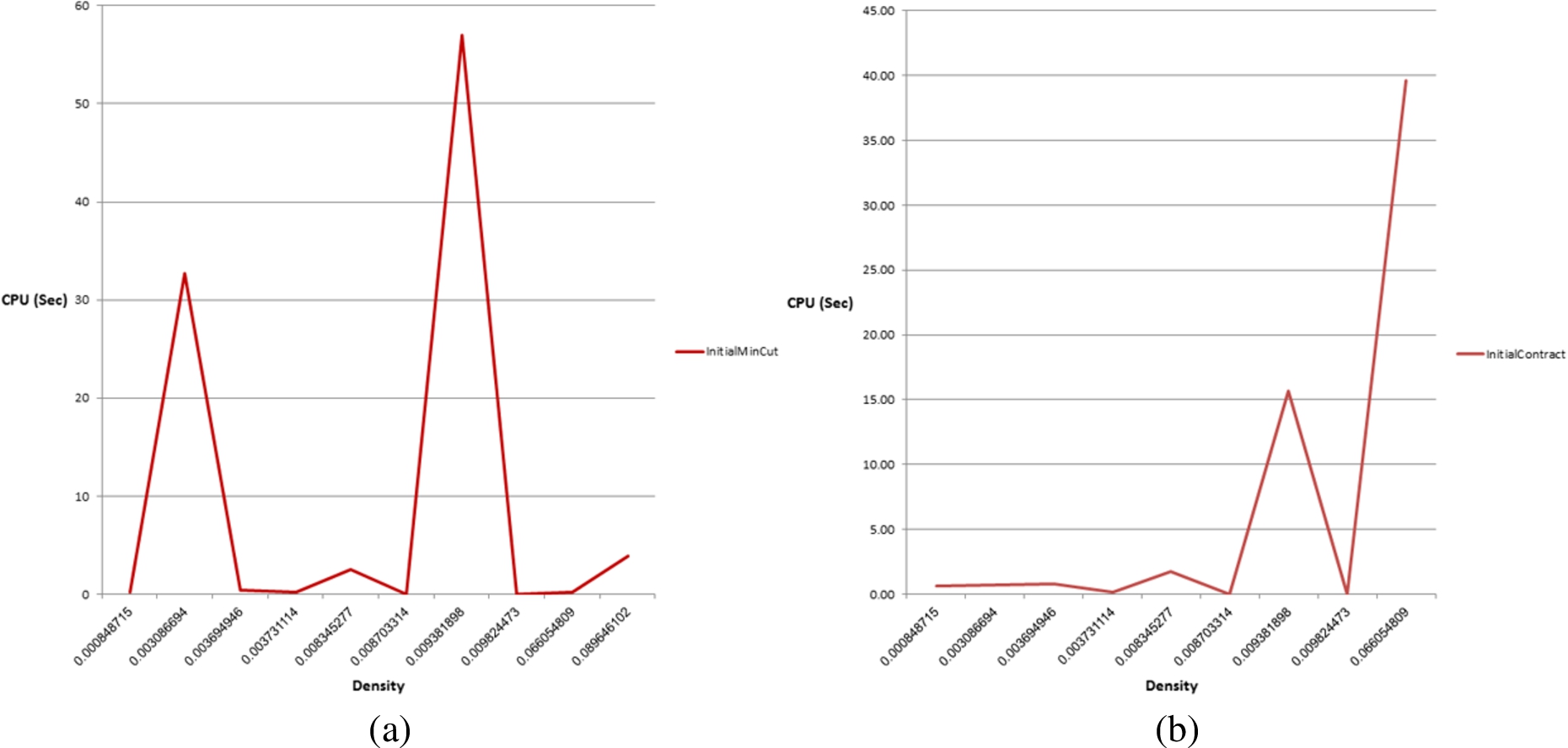
Facebook sub-community: (a) Initial Min-Cut CPU (b) Initial Contract CPU.
Although we did not optimize our algorithms with respect to CPU time and memory usage, both algorithms run very fast and can be used in real world networks. For example, using a graph with density 0.0635 (987 vertices and 61831 edges), the initial contract run time is 34.86 seconds, and min-cut run time is 35.85 seconds. The run time of the final step, the compute criteria, varies according to the size of the initial cut: 0.045 seconds for a cut with 35 edges, and 19.79 seconds for a cut with 286 edges. The CPU time for both algorithms on sub-community graphs with low density is very low and almost the same. When running our algorithms on sub-communities with higher density, the Min-cut algorithm CPU time grows faster than the contract algorithm CPU time. The contract CPU time depends not only on the density of the graph but also on the probability of flow on the edges of the graph, thus each run may provide different CPU time that is bounded to
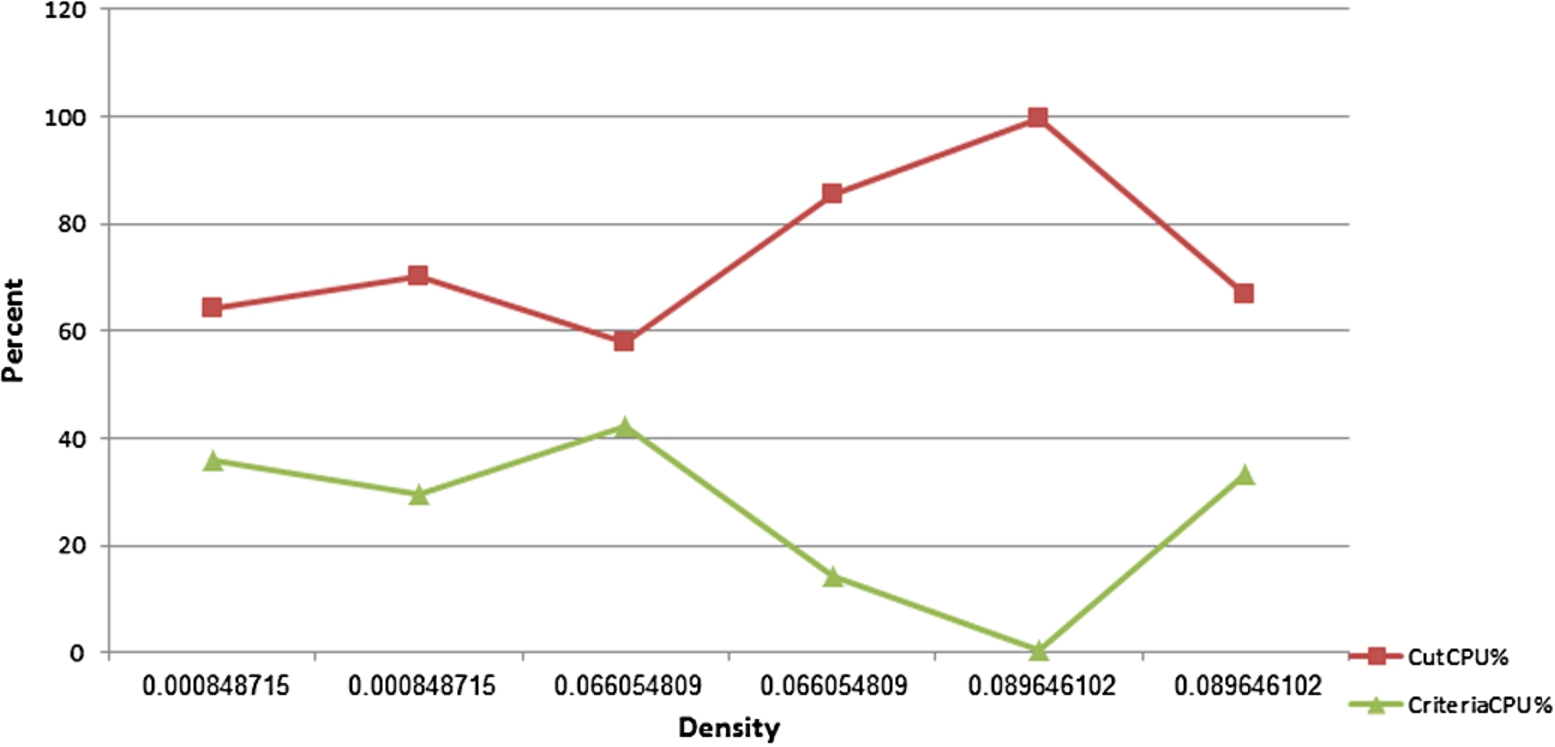
%CPU of the two main part of the algorithm.
CPU % Per Phases
Figure 16 and Table 7 demonstrate the relative CPU time of each of the two main parts of the algorithm: find initial candidate set and compute criteria. The runs presented were configured with
The algorithm we propose is composed of three major steps: the first is the initialization step that creates a multi-graph with a super-vertex
In the initialization step, the BFS (Breadth-First Search) traversal algorithm is used starting at the ego-node. The time complexity is
For the second step we use two methods derived from flow problems, to find the initial candidates-set of edges to be blocked. The candidate set is actually a cut between super-vertex
We implemented the Edmonds-Karp [7] algorithm for finding the initial candidates set by Min-Cut, implying time complexity of
The contract algorithm is a randomized algorithm that repeatedly contract vertices to super-vertices, until it gets two super-vertices connected by a set of edges that defines a cut between the two sets of vertices contained in each super-vertex. The algorithm randomly selects an edge
When using permutations to define the order for selecting edges for contraction, one iteration takes
If the algorithm is repeated
The final step of our algorithm attempts to remove edges from the candidates-set of edges to be blocked, as long as the remaining δ-community graph for user
As we show in the Appendix the problem presented is NP-Complete, the overall complexity of our proposed model is
Table 8 summarizes the overall complexity of our algorithms.
Algorithm’s complexity
Algorithm’s complexity
The problem of uncontrolled information flow in social network is a true concern to ones privacy. In this paper we address the need to follow the social trend of information sharing while enabling the owner to prevent their information from flowing to undesired recipients. The goal of the suggested method is to find the minimal set of edges that should be excluded from ones community graph to allow sharing of information while blocking adversaries. To reduce side effect of limiting legitimate information flow, we minimize this impact according to the flow probability.
One of the main purposes of our evaluation was to compare the solutions obtained by the different algorithms. Based on our experiments we can conclude that except for cases where adversaries are connected with very few edges, the solutions acquired by Mincut are inferior to those obtained with the Contract algorithm. Furthermore contract is usually more efficient even if run for several iterations.
Our algorithms can be used within the ORIGIN CONTROL access control model [13]. In this model every piece of information is associated with its creator forever. The set of cut edges found by our algorithms, is stored for each user when the data is released and can be checked when the origin controlled information is accessed. This way the administrator can check whenever this information is accessed by a certain user, if the edge between them was cut for the originator user, and thus prevent the information to pass through that edge to that certain user.
Optimizations. In the last part of our algorithm we check if by removing all initial-candidates-set of edges from
Other extensions. In this work we used two approaches to identify the set of edges to be blocked, the max-flow-min-cut method, and the contract method that finds any cut between two sets in a graph.
In future work these algorithms can be extended in several ways. One approach is to use k-shortest-paths as the source for edges to be blocked. In this method one can start by finding the k-shortest path from the ego-node (source) to the adversary (sink), and set the edges on the first shortest-path as candidates for blocking. If the required privacy criteria is not achievable, the second shortest path is set as the initial candidates set, etc. Another approach is to set the combination of all k-shortest paths from the ego-node to the adversaries as the initial candidates set of edges for blocking. Node centrality can be use to select edges from central nodes to adversaries as the initial candidates set
Another challenge is to automatically identify
Finally, this model of controlling flow needs to be integrated not only within the ORIGIN CONTROL access control model [13], but with other models of privacy in social networks such as the models described in [20].
Footnotes
The Sharing-habits based Privacy Assurance in OSN problem – proof
Here we present the proof for the claim that the Sharing-habits based Privacy Assurance in OSN problem is NP-complete. We start by showing that the Maximum-Flow Minimum-Leakage Problem is a Hitting-Set-hard.
A
Given a subset A of nodes of a graph J, let
Garey and Johnson showed in [5] that the Hitting-Set problem is NP-hard by showing that the hitting-set problem is equivalent to the vertex-cover problem.
In the hitting-set problem, the objective is to cover the left-vertices using a minimum subset of the right vertices; by interchanging the two sets of vertices we convert the bipartite graph problem into the hitting-set problem.
Let
Given an instance of Hitting-Set with
Let