
Abstract
Cloud storage has rapidly become a cornerstone of many IT infrastructures, constituting a seamless solution for the backup, synchronization, and sharing of large amounts of data. Putting user data in the direct control of cloud service providers, however, raises security and privacy concerns related to the integrity of outsourced data, the accidental or intentional leakage of sensitive information, the profiling of user activities and so on. Furthermore, even if the cloud provider is trusted, users having access to outsourced files might be malicious and misbehave. These concerns are particularly serious in sensitive applications like personal health records and credit score systems.
To tackle this problem, we present
In the latter model, we prove a server-side computational lower bound of
In the former model, we present a cryptographic system that achieves secrecy, integrity, obliviousness, and anonymity. In the process of designing an efficient construction, we developed three new, generally applicable cryptographic schemes, namely, batched zero-knowledge proof of shuffle correctness, the hash-and-proof paradigm, which even improves upon the former, and an accountability technique based on chameleon signatures, which we consider of independent interest.
We implemented our constructions in Amazon Elastic Compute Cloud (EC2) and ran a performance evaluation demonstrating the scalability and efficiency of our construction.
Introduction
Cloud storage has rapidly gained a central role in the digital society, serving as a building block of consumer-oriented applications (e.g, Dropbox, Microsoft SkyDrive, and Google Drive) as well as particularly sensitive IT infrastructures, such as personal record management systems. For instance, credit score systems rely on credit bureaus (e.g., Experian, Equifax, and TransUnion in US) collecting and storing information about the financial status of users, which is then made available upon request. As a further example, personal health records (PHRs) are more and more managed and accessed through web services (e.g., private products like Microsoft HealthVault and PatientsLikeMe in US and national services like ELGA in Austria), since this makes PHRs readily accessible in case of emergency even without the physical presence of the e-health card and eases their synchronization across different hospitals.
Despite its convenience and popularity, cloud storage poses a number of security and privacy issues. The first problem is related to the secrecy of user data, which are often sensitive (e.g., PHRs give a complete picture of the health status of citizens) and, thus, should be concealed from the server. A crucial point to stress is that preventing the server from reading user data (e.g., through encryption) is necessary but not sufficient to protect the privacy of user data. Indeed, as shown in the literature [55,76], the capability to link consecutive accesses to the same file can be exploited by the server to learn sensitive information: for instance, it has been shown that the access patterns to a DNA sequence allow for determining the patient’s disease. Hence the obliviousness of data accesses is another fundamental property for sensitive IT infrastructures: the server should not be able to tell whether two consecutive accesses concern the same data or not, nor to determine the nature of such accesses (read or write). Furthermore, the server has in principle the possibility to modify client’s data, which can be harmful for several reasons: for instance, it could drop data to save storage space or modify data to influence the statistics about the dataset (e.g., in order to justify higher insurance fees or taxes). Therefore another property that should be guaranteed is the integrity of user data.
Finally, it is often necessary to share outsourced documents with other clients, yet in a controlled manner, i.e., selectively granting them read and write permissions: for instance, PHRs are selectively shared with the doctor before a medical treatment and a prescription is shared with the pharmacy in order to buy a medicine. Data sharing complicates the enforcement of secrecy and integrity properties, which have to be guaranteed not only against a malicious server but also against malicious clients. Notice that the simultaneous enforcement of these properties is particularly challenging, since some of them are in seeming contradiction. For instance, access control seems to be incompatible with the obliviousness property: if the server is not supposed to learn which file the client is accessing, how can he check that the client has the rights to do so?
Our contributions
In this work, we present
We formalize the problem statement by introducing the notion of Group Oblivious RAM (GORAM) in Section 2. GORAM extends the concept of Oblivious RAM [47] (ORAM)1
ORAM is a technique originally devised to protect the access pattern of software on the local memory and then used to hide the data and the user’s access pattern in storage outsourcing services.
In the obliviousness against malicious clients setting, we establish an insightful computational lower bound (Section 3): if clients have direct access to the database, the number of operations on the server side has to be linear in the database size. Intuitively, the reason is that if a client does not want to access all entries in a read operation, then it must know where the required entry is located in the database. Since malicious clients can share this information with the server, the server can determine for each read operation performed by an honest client, which among the entries the adversary has access to might be the subject of the read, and which certainly not.
We present
To bypass the aforementioned lower bound, we consider the recently proposed proxy-based Setting [13,66,79,87,93], which assumes the presence of a trusted party mediating the accesses between clients and server. We show, in particular, that a simple variant of TaoStore [79] guarantees obliviousness in the malicious setting as well as access control (Section 5).
We then move to the setting in which obliviousness holds only against a malicious server who does not collude with clients. We first introduce a cryptographic instantiation based on a novel combination of ORAM [90], predicate encryption [58], and zero-knowledge (ZK) proofs (of shuffle correctness) [10,51] (Section 6). This construction is secure, but building on off-the-shelf cryptographic primitives is not practical. In particular, clients prove to the server that the operations performed on the database are correct through ZK proofs of shuffle correctness, which are expensive when the entries to be shuffled are tuples of data, as opposed to single entries.
As a first step towards a practical instantiation, we maintain the general design, but we replace the expensive ZK proofs of shuffle correctness with a new proof technique called batched ZK proofs of shuffle correctness (Section 6.5.1). A batched ZK proof of shuffle significantly reduces the number of ZK proofs by “batching” several instances and verifying them together. Since this technique is generically applicable in any setting where one is interested to perform a zero-knowledge proof of shuffle correctness over a list of entries, each of them consisting of a tuple of encrypted blocks, we believe that it is of independent interest. This second realization greatly outperforms the first solution and is suitable for databases with relatively small entries, accessed by a few users, but it does not scale to large entries and many users.
In a second step we present a novel technique based on universal pair-wise hash functions [19] that speeds up batched shuffle proofs even further (Section 6.5.2). As opposed to batched shuffle proofs, which are secure when repeated λ many times where λ is the security parameter, this construction computes a constant number of proofs. It is generally applicable and we show that it outperforms batched shuffle proofs by one order of magnitude.
To obtain a scalable solution, we explore some trade-offs between security and efficiency. First, we present a new accountability technique based on chameleon signatures (Section 7). The idea is to let clients perform arbitrary operations on the database, letting them verify each other’s operation a-posteriori and giving them the possibility to blame misbehaving parties. Secondly, we replace the relatively expensive predicate encryption, which enables sophisticated role-based and attribute-based access control policies, with the more efficient broadcast encryption, which suffices to enforce per-user read/write permissions, as required in the personal record management systems we consider (Section 8). This approach leads to a very efficient solution that scales to large files and thousands of users, with a combined communication-computation overhead of only 7% (resp. 8%) with respect to state-of-the-art, single-client ORAM constructions for reading (resp. writing) on a 1 GB storage with 1 MB block size (for larger datasets or block sizes, the overhead is even lower).
We have implemented our constructions and conducted a performance evaluation demonstrating the scalability and efficiency of our constructions (Section 10). Although Group ORAM is generically applicable, the large spectrum of security and privacy properties, as well as the efficiency and scalability of the system, make it particularly suitable for the management of large amounts of sensitive data, such as personal records. We exemplify that in a case study presented in Appendix A.
We detail the problem statement by formalizing the concept of Group ORAM (Section 2.1), introducing the attacker model (Section 2.2), and presenting the security and privacy properties (Section 2.3).
Group ORAM
We consider a data owner
At registration time, each client
In the following we formally characterize the notion of Group ORAM. Intuitively, a Group ORAM is a collection of two algorithms and four interactive protocols, used to setup the database, add clients, add an entry to the database, change the access permissions to an entry, read an entry, and overwrite an entry. In the sequel, we let A Group ORAM scheme is a tuple of (interactive) on input a security parameter λ and an integer n indicating the maximum number of clients, this algorithm outputs on input the data owner’s capability on input the data owner’s capability on input the data owner’s capability on input a capability on input a capability (Group ORAM).
The attacker model
We consider an adversarial model in which the data owner
I.e., the server is regarded as a passive adversary, following the protocol but seeking to gather additional information.
Although we could limit ourselves to reason about all security and privacy properties in this attacker model, we find it interesting to state and prove some of them even in a stronger attacker model, where the server can arbitrarily misbehave and collude with malicious clients. This allows us to characterize which properties unconditionally hold true in our different systems, i.e., even if the server gets compromised (cf. the discussion in the end of this section).
We formalize the security and privacy requirements in the following as game-based definitions. Our framework models all of the properties in the presence of sequential accesses to the database. Security under concurrent executions and parallel accesses to the ORAM is an interesting avenue for future research.

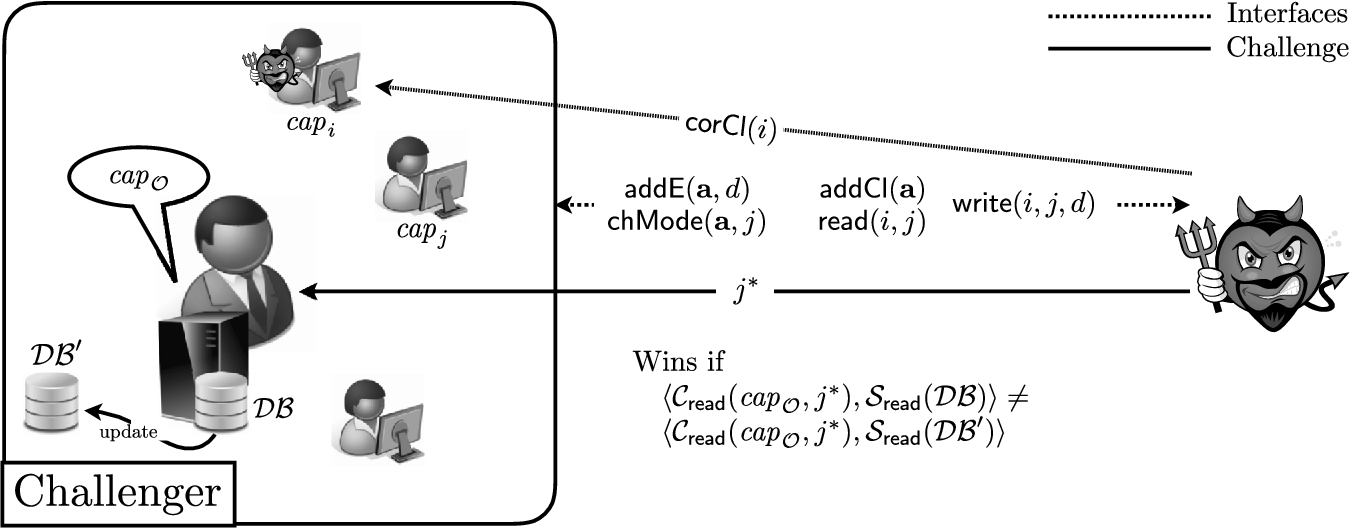
Game for secrecy.
Secrecy. Intuitively, a Group ORAM preserves the secrecy of outsourced data if no party is able to deduce any information about the content of any entry she does not have access to. We formalize this intuition through a cryptographic game in the following definition, which is illustrated in Fig. 1.
A Group ORAM
Setup. The challenger runs
Queries. The challenger provides On input On input On input On input On input On input
Challenge. Finally,
Output. In the output phase
Game for integrity.
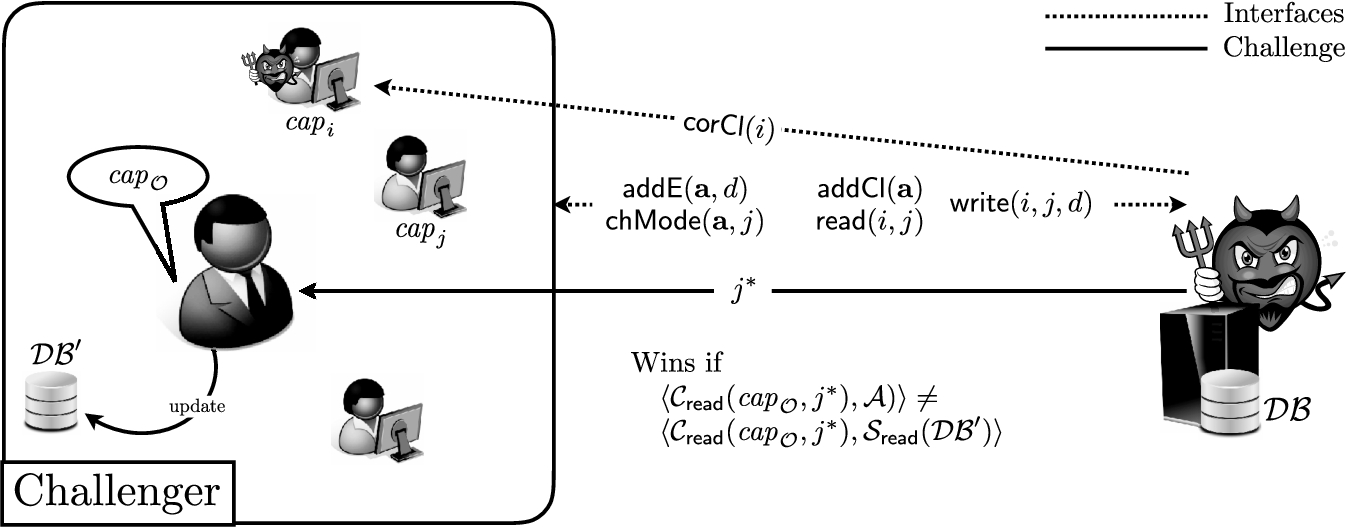
Integrity. A Group ORAM preserves the integrity of its entries if none of the clients can modify an entry to which she does not have write permissions. The respective cryptographic game is depicted in Fig. 2 and we formalize it below.
A Group ORAM
Setup. The challenger runs
Queries. The challenger provides
Challenge. Finally, the adversary outputs an index
Output. It outputs 1 if and only if
Game for tamper-resistance.
Tamper-resistance. Intuitively, a Group ORAM is tamper-resistant if the server, even colluding with a subset of malicious clients, is not able to convince an honest client about the integrity of some maliciously modified data. Notice that this property refers to a strong adversarial model, where the adversary may arbitrarily misbehave and collude with clients. Naturally, tamper-resistance holds true only for entries which none of the corrupted clients had ever access to. The respective cryptographic game is depicted in Fig. 3.
A Group ORAM
Setup. The challenger runs the Setup phase as in Definition 2. Furthermore, it forwards
Queries. The challenger provides
Challenge. Finally, the adversary outputs an index
Output. It outputs 1 if and only if

Game for obliviousness.
Obliviousness. Intuitively, a Group ORAM is oblivious if the server cannot distinguish between two arbitrary query sequences which contain
A Group ORAM
Setup. The challenger runs
Queries. The challenger provides On input
Output. Finally,

Game for obliviousness against malicious clients.
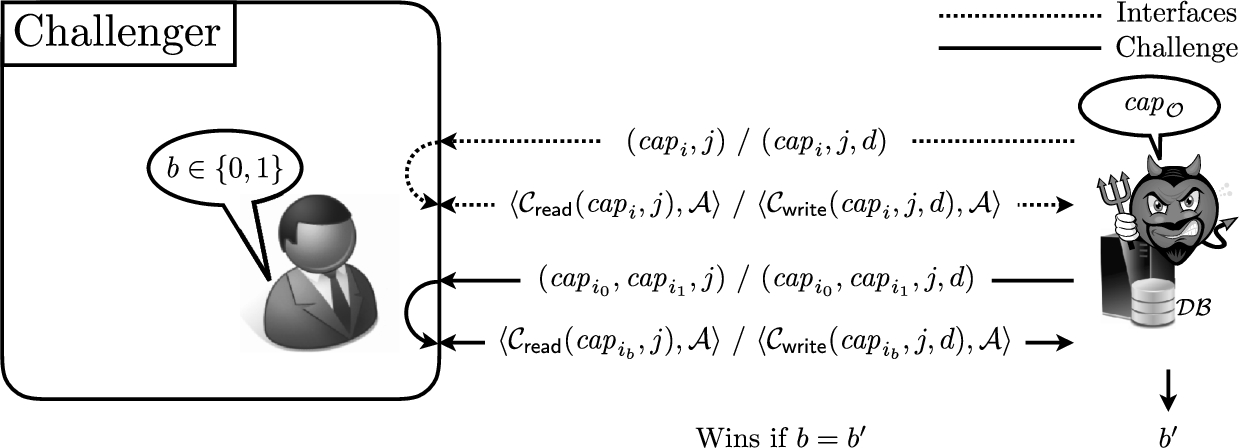
Obliviousness against malicious clients. Intuitively, a Group ORAM is oblivious against malicious clients if the server and an arbitrary subset of clients cannot get any information about the access patterns of honest clients, other than what is trivially leaked by the entries that the corrupted clients have read access to. The following definition, graphically supported by Fig. 5, is an extension of the previous one which allows the adversary to corrupt arbitrary clients. However, in order to avoid trivial attacks, we restrict the queries of the adversary to the
A Group ORAM
Setup. The challenger runs
Queries. The challenger provides On input
Output. Finally,
Game for anonymity.
Anonymity. A Group ORAM preserves anonymity if the data owner cannot efficiently link a given operation to a client, among the set of clients having access to the queried index. We formalize anonymity as a cryptographic game in the following definition, depicted in Fig. 6.
A Group ORAM
Setup. The challenger runs
Queries. The challenger provides On input On input
Challenge.
Output. Finally,
Accountable integrity. Intuitively, a Group ORAM preserves accountable integrity, if every client who modifies an entry without holding write permissions on that entry will be detected by an honest client. Clients detected of misbehavior are blamed and there is evidence in form of audit logs that can be used to hold them accountable. The blaming of clients must be correct in a natural way: (1) honest parties are never blamed and (2) in case of misbehavior by some party, at least one dishonest party is blamed. The literature defines this notion of accountability as fairness (cf. 1) and completeness (cf. 2) [61]. We define the accountable integrity property through a cryptographic game, illustrated in Fig. 7.
(Accountable integrity).
A Group ORAM
Game for accountable integrity.
Setup. The challenger runs the Setup phase as in Definition 3.
Queries. The challenger runs the Query phase as in Definition 3.
Challenge. Finally, the adversary outputs an index
Output. It outputs 1 if and only if
Security and privacy properties together with their minimal assumptions
Discussion. Table 1 summarizes the security and privacy properties presented in this section, along with the corresponding assumptions. The HbC assumption is in fact only needed for integrity, since the correctness of client operations is checked by the server, thus avoiding costly operations on the client side. We will see in Section 7 that the HbC assumption is still needed for the accountable integrity property, since the server maintains a log of accesses, which allows for blaming misbehaving parties. Secrecy, tamper-resistance, and anonymity hold true even if the server is malicious and colludes with clients. Furthermore, we treat two variants of obliviousness, which differ in the non-collusion assumption: in the first variant, it holds only against a malicious server that does not collude with clients while the second variant allows for collusion. The rest of the paper is organized with respect to these two variants: we first investigate on the collusion-enabled variant in Section 3, Section 4, and Section 5. Then we focus on the non-collusion variant in Section 6, Section 7, and Section 8. The reason for this organization is motivated by the improvement in efficiency that we gain with each further construction.
In this section, we study how much computational effort is necessary to realize a Group ORAM where obliviousness should hold against a server colluding with malicious clients. Our result shows that any construction, regardless of the underlying computational assumptions, must access the entire memory (up to a constant factor) in every operation. Our lower bound can be seen as a generalization of the result on history independence of Roche et al. [78], in the sense that they consider a “catastrophic attack” where the complete state of the client is leaked to the adversary, whereas we allow only the corruption of a certain subset of clients. Note that, while the bound in [78] concerns the communication complexity, our result only bounds the computation complexity on the server side.
Formal result
In the following we state a formal lower bound on the computational complexity of any ORAM secure against malicious clients. The proof is postponed to Appendix D. We denote by physical addresses of a database the memory addresses associated with each storage cell of the memory. Intuitively, the lower bound says that the server has to access each entry of the dataset for any read and write operation. Let n be the number of entries in the database and
Given the lower bound established in the previous section, we know that any Group ORAM scheme that is oblivious against malicious clients must read and write a fixed constant fraction of the database on every access. However, the bound does not impose any restriction on the required communication bandwidth. In fact, it does not exclude constructions with sublinear communication complexity, where the server performs a significant amount of computation. In particular, the aforementioned lower bound calls for the deployment of private information retrieval (PIR) [24] technologies, which allow a client to read an entry from a database without the server learning which entry has been read.
The problem of private database modification is harder. A naïve approach would be to let the client change each entry in the database
The following sections describe our approach to bypass these two lower bounds. First we show how to integrate non-algebraic techniques, specifically out-of-band communication among clients, so as to achieve sublinear amortized communication complexity (Section 4). Second, we show how to leverage a trusted proxy performing the access to the server on behalf of clients in order to reach a logarithmic overhead in communication and server-side computation, with constant client-slide computation (Section 5).
PIR-GORAM
In this section, we present
More precisely, when operating on index j, the client performs a PIR read on
After explaining how to achieve obliviousness, we also need to discuss how to realize access control and how to protect the clients against the server. Data secrecy (i.e., read access control) is obtained via public-key encryption. Tamper-resistance (i.e., a-posteriori detection of illegal changes) is achieved by letting each client sign the modified entry so that others can check that this entry was produced by a client with write access. Data integrity (i.e., write access control) is achieved by further letting each client prove to the server that it is eligible to write the entry. As previously mentioned, data integrity is stronger than tamper-resistance, but assumes an honest-but-curious server: a malicious server may collude with malicious clients and thus store arbitrary information without checking integrity proofs.
Cryptographic preliminaries
Notation for cryptographic primitives
Notation for cryptographic primitives
Data structures.
Gossiping is necessary since we do not trust the server for consistency.
Database layout. We represent the logical database
Client capabilities. We assume that every client
The entry structure of an entry in the main database. If an entry resides on the stack, it contains only the part
Entry structure. An entry in the database
This notation simplifies the presentation, but in the implementation we use of course hybrid encryption (cf. Section 10).
Note that one cannot store the signing key
Update. Entries residing on a client’s stack consist only of
Multiple data owners in one ORAM. The entry structure and database layout of
Obliviously broadcasting new indices. We propagate the updates of the entries to the clients with read access via broadcast. That is, if
Clients having read access update their position map as follows. Upon receiving such a message c, the client
Since malicious clients could potentially send wrong gossip messages about entries, e.g., claiming that an entry is residing in a different place than it actually is, we require that clients upload their broadcast messages also onto an append-only log, e.g., residing on the cloud, which is accessible by everyone. If a client does not find an entry using the latest index information, due to the malicious behavior of another client, then it just looks up the previous index and tries it there, and so on. Such append-only logs can be realized securely both in centralized [52] and decentralized [28] fashion. Utilizing such logs also enables accountability since the client who announced a wrong index is identifiable and, hence, blamable.
Setup. The input to the setup algorithm is a list of data



Reading and writing. To read or write to the database, clients have to perform two steps: extracting the data (Algorithm 1) and appending an entry to the personal stack (Algorithm 2 for writing and Algorithm 3 for reading).
To extract the payload, the client performs two PIR queries: one on
The next step (i.e., adding an entry to the stack), however, requires more care in order to retain obliviousness. In particular, when writing, the client appends an entry to its personal stack that replaces the actual entry in
Flushing the stack (Algorithm
4
). The flush algorithm pushes the elements in the stack that are up-to-date to
Some elements may be outdated, since a different user may have the most recent version in its stack.

If the currently downloaded entry is outdated, the client takes the locally stored data from
In case there is no entry in the stack that is more recent, it rerandomizes the current entry in
Adding new clients. To grant a new client
Adding new entries. To add a new entry to the database,
Changing access permissions. To change access permissions of a certain entry,
We elaborate on the communication complexity of our solution. We assume that
Our flushing algorithm assumes that
To conclude, the construction achieves a worst-case complexity of
Variations
We discuss some variations of our constructions that achieve different assumptions and properties.
Malicious server. The construction, as we presented it, achieves integrity against an honest-but-curious server. If the server is malicious though, we cannot rely on it to verify the integrity proofs: a way to overcome this problem could be to force the server into honest behavior by letting him prove the correctness of his actions (e.g., using SMPC [20,46,63,95]). This is, unfortunately, prohibitively expensive. Furthermore, since the whole database is solely stored on the server, it is clearly impossible to guarantee that the read operation is always perfomed correctly (e.g., the server could just go offline and therefore effectively erasing all the entries in the database) and thus to achieve any meaningful notion of integrity. However, we can still allow clients to detect a-posteriori illegal data changes, a security property that we address as tamper resistance. For achieving this property, integrity proofs are useless and can be dropped.
Relaxed
Discussion
The construction presented in this section leverages PIR for reading entries and an accumulated PIR writing technique to replace old entries with newer ones. Due to the nature of PIR, one advantage of the construction is its possibility to allow multiple clients to concurrently read from the database and to append single entries to their stacks. This is no longer possible when a client flushes her personal stack since the database is entirely updated, which might lead to inconsistent results when reading from the database. To overcome this drawback, we present a fully concurrent, maliciously secure Group ORAM in Section 5. Another drawback of the flush algorithm is the cost of the integrity (zero-knowledge) proofs. Since we have to use public-key encryption as the top-layer encryption scheme for every entry to allow for proving properties about the underlying plaintexts, the number of proofs to be computed, naïvely implemented, is proportional to the block size. Varying block sizes require us to split an entry into chunks and encrypt every chunk separately since the message space of public-key encryption is a constant amount of bits. The zero-knowledge proof has then to be computed on every of these encrypted chunks. Our later construction for obliviousness only against the server, called
TAO-GORAM
Driven by the goal of building an efficient and scaleable Group ORAM that achieves obliviousness against malicious users, we explore the usage of a trusted proxy mediating accesses between clients and the server, an approach advocated in recent parallel ORAM constructions [13,79,87]. In contrast to previous works, we are not only interested in parallel accesses, but also in handling access control and providing obliviousness against multiple, possibly malicious, clients.
TaoStore [ 79 ]. In a nutshell, trusted proxy-based ORAM constructions implement a single-client ORAM which is run by the trusted entity on behalf of clients, which connect to it with read and write requests in a parallel fashion. We leverage the state of the art, TaoStore [79], which implements a variant of a Path-ORAM [90] client on the proxy and allows for retrieving multiple paths from the server concurrently. More specifically, the proxy consists of the processor and the sequencer. The processor performs read and write requests to the untrusted server: this is the most complex part of TaoStore and we leave it untouched. The sequencer is triggered by client requests and forwards them to the processor which executes them in a concurrent fashion.
Our modifications. Since the proxy is trusted, it can enforce access control. In particular, we can change the sequencer so as to let it know the access control matrix and check for every client’s read and write requests whether they are eligible or not. As already envisioned by Sahin et al. [79], the underlying ORAM construction can be further refined in order to make it secure against a malicious server, either by following the approach based on Merkle-trees proposed by Stefanov et al. [90] or by using authenticated encryption as suggested by Sahin et al. [79]. In the rest of the paper, we call the system
GORAM
In this section, we first show how to realize a Group ORAM using a novel combination of ORAM, predicate encryption, and zero-knowledge proofs (Section 6.2 and Section 6.3). Since even the usage of the most efficient zero-knowledge proof system still yields an inefficient construction, we introduce a new proof technique called batched ZK proofs of shuffle (Section 6.5.1) and instantiate our general framework with this primitive.
Cryptographic preliminaries
Our construction relies on predicate encryption, public-key encryption, and NIZKs. We summarize the missing notation for predicate encryption in Table 3. Notice that
Additional notation for cryptographic primitives
Additional notation for cryptographic primitives
Data structures and database layout. The layout of the database
We assume that each client has a local storage of
Client capabilities. Every client
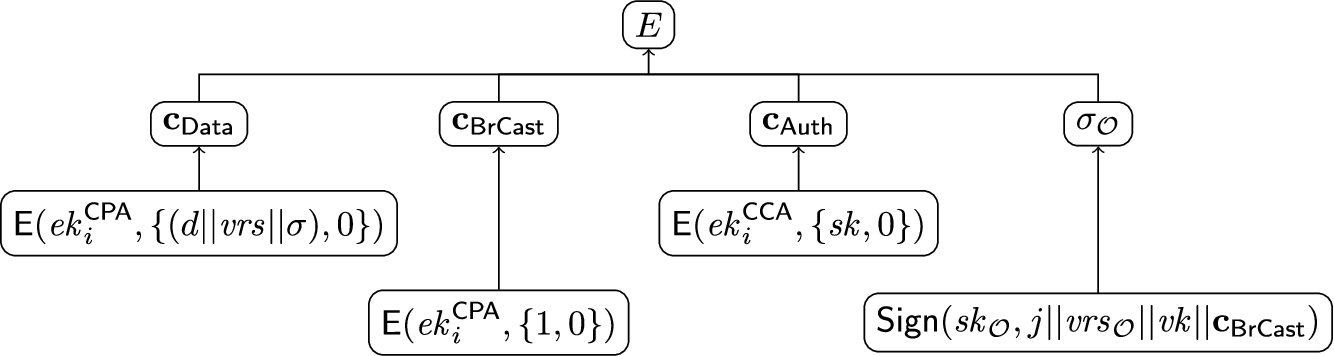
Structure of an entry and access control modes. Abstractly, database entries are tuples of the form
Since encrypting a long payload using predicate encryption is expensive, the concrete instantiation that we evaluate in Section 10 uses hybrid encryption instead.
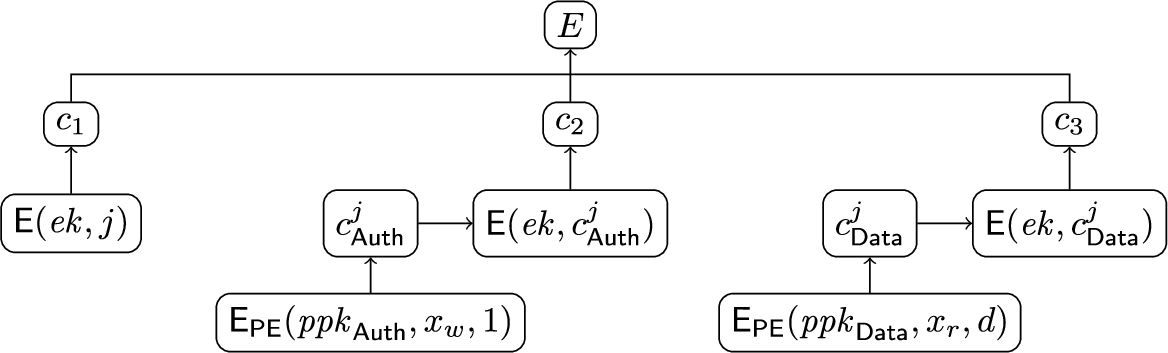
The entry structure of an entry in the database.
Intuitively, using a client
Implementation of
For simplifying the notation, we assume for each encryption scheme that the public key is part of the secret key.

Implementation of

Implementation of

Eviction. In all ORAM constructions, the client has to rearrange the entries in the database in order to make subsequent accesses unlinkable to each other. In the tree construction we use [90], this is achieved by first assigning a new, randomly picked, leaf index to the read or written entry. After that, the entry might no longer reside on the path from the root to its designated leaf index and, thus, has to be moved. This procedure is called eviction (Algorithm 8).
This algorithm assigns the entry to be evicted to a new leaf index (line 8.1). It then locally shuffles and rerandomizes the given path according to a permutation π (lines 8.2–8.4). After replacing the old path with a new one, the evicted entry is supposed to be stored in a node along the path from the root to the assigned leaf, which always exists since the root is part of the permuted nodes. A peculiarity of our setting is that clients are not trusted and, in particular, they might store a sequence of ciphertexts in the database that is not a permutation of the original path (e.g., they could store a path of dummy entries, thereby cancelling the original data).
Integrity proofs. To tackle this problem, a first technical novelty in our construction is, in the

Implementation of

Implementation of
Obliviousness in presence of integrity proofs.

Implementation of
In
The integrity proofs
Permanent entries. Some application scenarios of
The computational and communication complexity of our construction, for both the server and the client, is
Integrity proofs revisited
A zero-knowledge proof of shuffle correctness of a set of ciphertexts proves in zero-knowledge that a new set of ciphertexts contains the same plaintexts in permuted order. In our system the encryption of an entry, for reasonable block sizes, yields in practice hundreds of ciphertexts, which means that we have to perform hundreds of shuffle proofs. These are computable in polynomial-time but, even using the most efficient known solutions (e.g., [10,56]), not fast enough for practical purposes. This problem has been addressed in the literature but the known solutions typically reveal part of the permutation (e.g., [57]), which would break obliviousness and, thus, are not applicable in our setting.
General problem description. Let
We propose two solutions to this problem that we discuss in the sequel. The underlying idea of both solutions is to compress the data on which the shuffle proof is computed so as to lower the amount of proofs that have to be computed.
Batched zero-knowledge proofs of shuffle correctness
The first solution is a new proof technique that we call batched zero-knowledge proofs of shuffle correctness, based on the idea of “batching” several instances and verifying them together. Our interactive protocol takes advantage of the homomorphic property of the public-key encryption scheme in order to batch the instances.
Intuitively, the batching algorithm randomly selects a subset of columns (i.e., block indices) and computes the row-wise homomorphic sum of the corresponding blocks for each row. It then computes the proof of shuffle correctness on the resulting single-block ciphertexts. The property we would like to achieve is that modifying even a single block in a row should lead to a different sum and, thus, be detected. Notice that naïvely multiplying all blocks together does not achieve the intended property, as illustrated by the following counterexample:

Batched zero-knowledge proofs of shuffle correctness
The detailed construction is depicted in Algorithm 12. In line 12.1,
Formal guarantees. We establish the following result for our new protocol and prove it in Appendix E.
Let
The hash-and-proof paradigm
The second solution improves the integrity proofs even further. The high-level idea is to design a compression technique that is collision-resistant with overwhelming probability, which is in contrast to the previous compression technique, which can lead to collisions with probability 1/2. In a nutshell, a technique based on pairwise independent hash functions [19] applied on each row of the ciphertext matrix allows for reducing the number of computed proofs of shuffle correctness to one.
The detailed construction is reported in Algorithm 13, where we leverage the fact that the message space

Shuffle proofs based on the hash-and-proof paradigm
Formal guarantees. We establish the following result for our new protocol and prove it in Appendix E.
Let
Discussion
The improvements presented in this section cannot only be applied to
GORAM with accountable integrity (A-GORAM)
In this section we relax the integrity property by introducing the concept of accountability. In particular, instead of letting the server check the correctness of client operations, we develop a technique that allows clients to detect a posteriori non-authorized changes on the database and blame the misbehaving party. Intuitively, each entry is accompanied by a tag (technically, a chameleon hash along with the randomness corresponding to that entry), which can only be produced by clients having write access. All clients can verify the validity of such tags and, eventually, determine which client inserted an entry with an invalid tag. This makes the construction more efficient and scalable, significantly reducing the computational complexity both on the client and on the server side, since zero-knowledge proofs are no longer necessary and, consequently, the outermost encryption can be implemented using symmetric, as opposed to asymmetric, cryptography. Such a mechanism is supposed to be paired with a data versioning protocol in order to avoid data losses: as soon as one of the clients detects an invalid entry, the misbehaving party is punished and the database is reverted to the last safe state (i.e., a state where all entries are associated with a valid tag).
Cryptographic preliminaries
Our construction relies on predicate encryption, private-key encryption, digital signatures, and chameleon hashes. We summarize the missing notation for private-key encryption and chameleon hashes in Table 4. A chameleon hash allows for computing an explicit collision for the hash value if one knows a secret trapdoor. Further details are postponed to Appendix B.
Notation for cryptographic primitives
Notation for cryptographic primitives
Data structures and database layout. We assume the same layout and data structures as for
Client capabilities. As in

The entry structure of an entry in the database.
Structure of an entry and access control modes. The structure of an entry in the database is depicted in Fig. 10. An entry E is protected by a top-level private-key encryption scheme with a key
j is the index of the entry;
r is some randomness used in the computation of t;
t is a concatenation of hash tags: a chameleon hash tag produced by hashing
σ is a signature on the tag t, signed by the data owner
Intuitively, only clients with write access are able to decrypt
Basic algorithms. The basic algorithms follow the ones defined in Section 6.3, except for natural adaptions to the new entry structure. Furthermore, the zero-knowledge proofs are no longer computed and the rerandomization steps are substituted by re-encryptions. Finally, clients upload on the server signed paths, which are stored in the
Entry verification. We introduce an auxiliary verification function that clients run in order to verify the integrity of an entry. During the execution of any protocol we maintain the invariant that, whenever a client i (or the data owner himself) parses an entry j that he downloaded from the server, he executes Algorithm 14. If the result is ⊥, then the client runs

The pseudo-code for the verification of an entry in the database which is already decrypted
Blame. In order to execute the function
As explained above, the accountability mechanism allows for the identification of misbehaving clients with a minimal computational overhead in the regular clients’ operation. However, it requires the server to store a log that is linear in the number of modifications to the database and logarithmic in the number of entries. This is required to revert the database to a safe state in case of misbehaviour. Consequently, the
Scalable solution (S-GORAM)
Even though the personal record management systems we consider rely on simple client-based read and write permissions, the predicate encryption scheme used in
The subset of clients that can decrypt
Security and privacy results
In this section, we show that the Group ORAM instantiations presented in Section 4, in Section 5, in Section 6, in Section 7, and in Section 8 achieve the security and privacy properties stated in Section 2.3. The proofs are reported in Appendix F. A brief overview of the properties guaranteed by each construction is shown in Table 5. As previously discussed, relaxing the obliviousness property so as to consider only security against the server or assuming a trusted component in the system is required to enable constructions that are more efficient from a communication point of view. Hence,
Security and privacy properties achieved by each construction
Security and privacy properties achieved by each construction
The following theorems characterize the security and privacy properties achieved by each cryptographic instantiation presented in this paper. Interestingly enough, the properties of
Let
Let
Let
Let
(
).
Assume that TaoStore is a secure realization of a parallel ORAM. Then
(
).
Let
Let
Let
Let
Let
(
).
Let
Let
Let
(
).
Let
Let
Let
Implementation and experiments
In this section, we present the concrete instantiations of the cryptographic primitives that we previously described (Section 10.1), we study their asymptotic complexity (Section 6.4), describe our implementation (Section 10.2), and discuss the experimental evaluation (Section 10.3).
Cryptographic instantiations
Encryption schemes. We use AES [29] as private-key encryption scheme with an appropriate message padding in order to achieve the elusive-range property [64].8
This property is formally necessary when proving the hybrid version of our constructions tamper-resistant. We refer to [69, Proof of Lemma 3] for the full proof in the hybrid version.
Let
In order to encrypt a message
In order to decrypt a ciphertext
In order to rerandomize a ciphertext
For
Private information retrieval. We use XPIR [1], the state of the art in computational PIR.
Zero-knowledge proofs. We deploy several non-interactive zero-knowledge proofs. For
A careful analysis of the computation shows that the technique from batched shuffle proofs mapped to standard PEPs as we deploy them in
In
Groth–Sahai proofs are generally not zero-knowledge. However, in our case the witnesses fulfill a special equation for which they are zero-knowledge.
Chameleon signatures. We use a chameleon hash function by Nyberg and Rueppel [5], which has the key-exposure freeness property. We complete the chameleon hash tags with SHA-256 for the ordinary hash function and combine both with RSA signatures [77].
Implementing permanent entries in
We implemented the six different versions of
Cryptographic setup. We use MNT curves [72] based on prime-order groups for primes of length 224 bits. This results in 112 bits of security according to different organizations [14]. We deploy AES with 128 bit keys and we instantiate the El Gamal and Cramer–Shoup encryption scheme, the RSA signature scheme, and the chameleon hash function with a security parameter of 2048 bits. According to NIST [14], this setup is secure until 2030.
Experiments
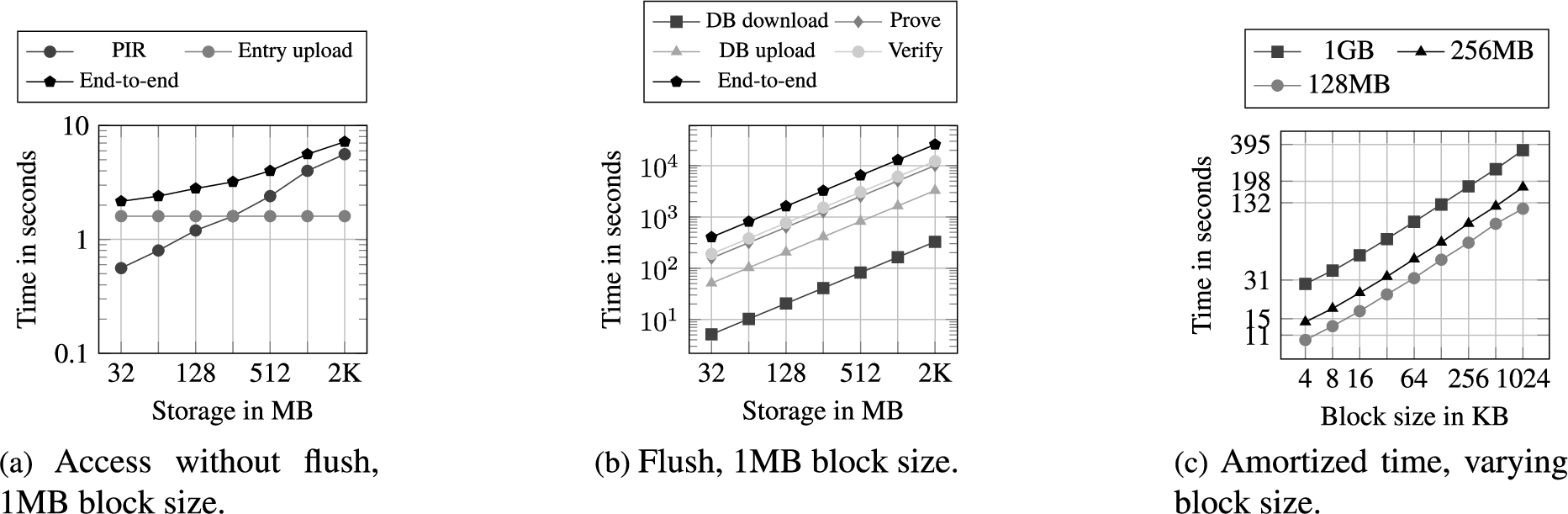
We evaluated the six different implementations. As a first experiment, we measured the computation times on client and server for the
The second experiment focuses on the solution with accountability. Here we measure also the overhead introduced by our realization with respect to a state-of-the-art ORAM construction, i.e., the price we pay to achieve a wide range of security and privacy properties in a multi-client setting. Another difference from the first experiment is the hardware setup. We run the server side of the protocol in Amazon EC2 and the client side on a MacBook Pro with an Intel i7 and 2.90 GHz. We vary the parameters as in the previous experiment, except for the number of clients which we vary from 1 to 100 for
The end-to-end running time of an operation in
Figure 11 and Fig. 16 report the results for
Figure 16 shows the improvement as we compare the combined proof computation and proof verification time in the flush algorithm of
Our solution
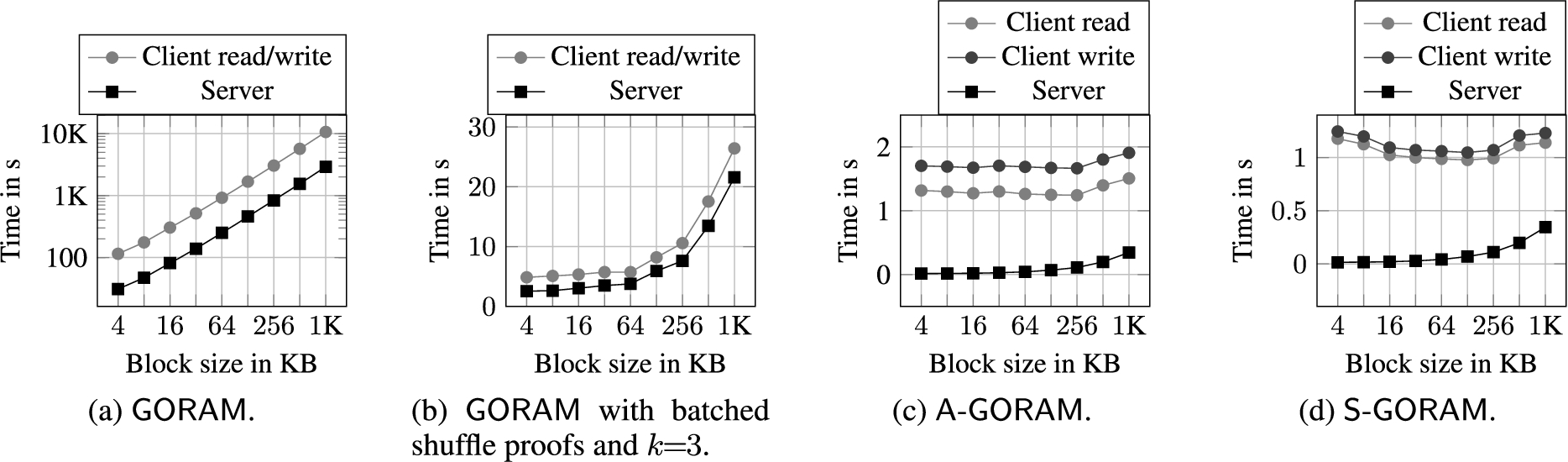
The average execution time for the

The average execution time for the
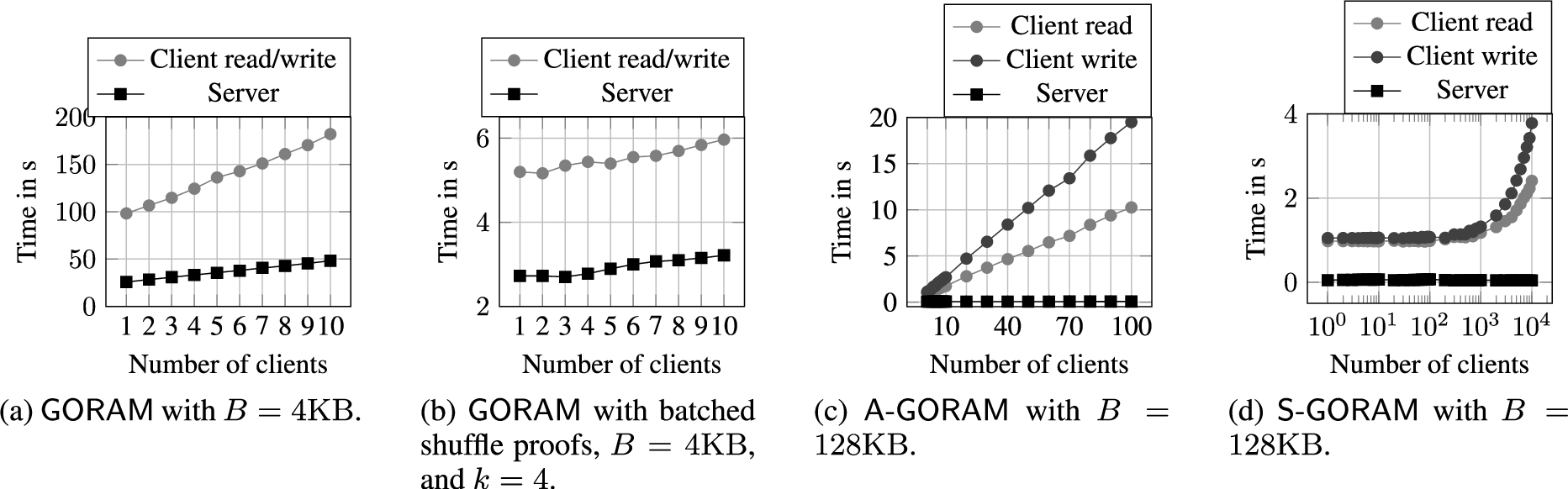
The average execution time for the
The results of the experiments for
The average execution time for the
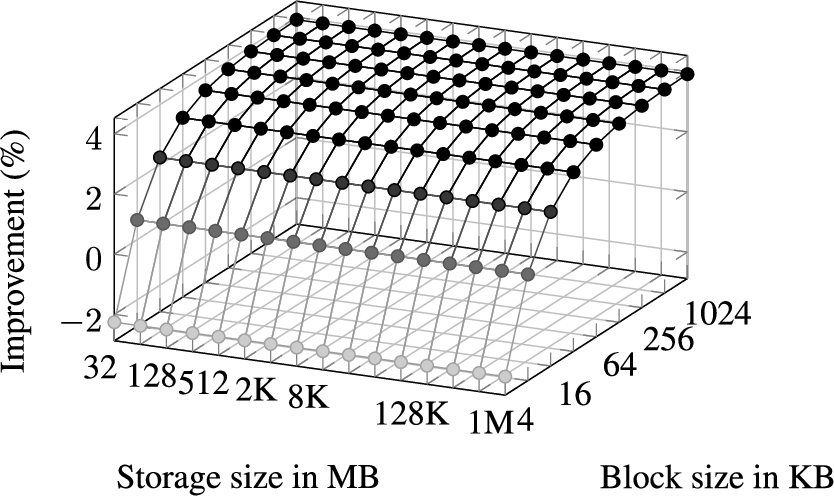
The improvement in percent when comparing the combined proof computation time on the client and proof verification time on the server for varying storage and block sizes, once without and once with the universal homomorphic hash.

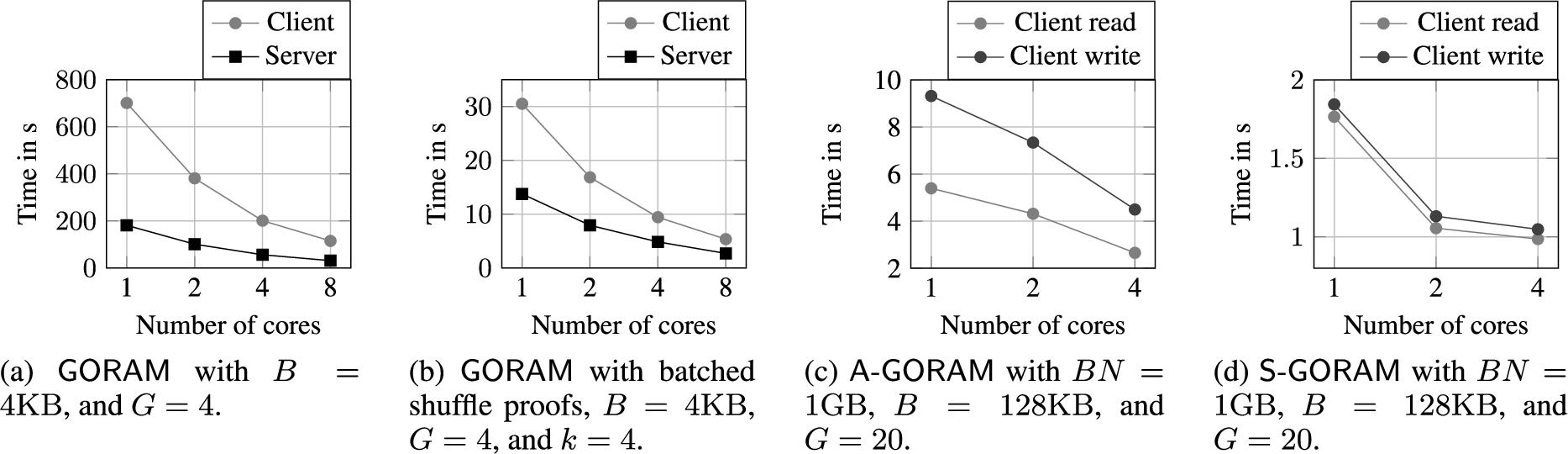
Average execution time for the
The results obtained by varying the storage size (Fig. 13) and the number of clients (Fig. 14) prove what the computational complexity suggests. Nevertheless, it is interesting to see the tremendous improvement in computation time between
If we compare

The up-/download amount of data compared between Path-ORAM [90] and
Figure 15 shows the results obtained by varying the number of cores. In
Finally, Fig. 19(b) compares

Comparison of the two integrity proof improvements and the overhead with respect to state-of-the-art ORAM.
Oblivious RAM. Oblivious RAM (ORAM) [47] is a technique originally devised to protect the access pattern of software on the local memory and thus to prevent the reverse engineering of that software. The observation is that encryption by itself prevents an attacker from learning the content of any memory cell but monitoring how memory is accessed and modified may still leak a great amount of sensitive information. While the first constructions were highly inefficient [47], recent groundbreaking research paved the way for a tremendous efficiency boost, exploiting ingenious tree based constructions [2,4,17,31,32,49,68,76,85,86,88], server side computations [53,71], and trusted hardware [13,54,66,79,87].
While a few ORAM constructions guarantee the integrity of user data [88,92], none of them is suitable to share data with potentially distrustful clients. Goodrich et al. [50] studied the problem of multi-client ORAM, but their attacker model does not include malicious, and potentially colluding, clients. Furthermore, their construction does not provide fine-grained access control mechanisms, i.e., either all members of a group have access to a certain data, or none has. Finally, this scheme does not allow the clients to verify the data integrity.
The fundamental problem in existing ORAM constructions is that all clients must have access to the ORAM key, which allows them to read and potentially disrupt the entire database. Hence, dedicated solutions tailored to the multi-client setting are required.
Multi-client ORAM. A few recent constructions gave positive answers to this question, devising ORAM constructions in the multi-client setting, which specifically allow the data owner to share data with other clients while imposing fine-grained access control policies. Although, at a first glance, these constructions share the same high-level goal, they actually differ in a number of important aspects. Therefore we find it interesting to draw a systematic comparison among these approaches (cf. Table 6). First of all, obliviousness is normally defined against the server, but in a multi-client setting it is important to consider it against the clients too (
Franz et al. pioneered the line of work on multi-client ORAM, introducing the concept of delegated ORAM [42]. The idea of this construction, based on simple symmetric cryptography, is to let clients commit their changes to the server and to let the data owner periodically validate them according to the access control policy, finally transferring the valid entries into the actual database. Assuming periodic accesses from the data owner, however, constrains the applicability of this technique. Furthermore, this construction does not support multiple data owners. Finally, it guarantees the obliviousness of access patterns with respect to the server as well as malicious clients, excluding however the accesses on data readable by the adversary. While excluding write operations is necessary (an adversary can clearly notice that the data has changed), excluding read operations is in principle not necessary and limits the applicability of the obliviousness definition: for instance, we would like to hide the fact that an oncologist accessed the PHR of a certain patient even from parties with read access to the PHR (e.g., the pharmacy, which can read the prescription but not the diagnosis).
Comparison of the related work supporting multiple clients to our constructions. The abbreviations mean: MC : Oblivious against malicious clients, MD : Supports multiple data owners sharing their data in one ORAM, PI : Requires the periodic interaction with the data owner, CS : Requires synchronization among clients, AC : Access control, Pr : Trusted proxy, P : Parallel accesses, S comp. : Server computation complexity, C comp. : Client communication complexity, Comm. : Communication complexity
Comparison of the related work supporting multiple clients to our constructions. The abbreviations mean:
Another line of work, summarized in the lower part of Table 6, focuses on the parallelization of client accesses, which is crucial to scale to a large number of clients, while retaining obliviousness guarantees. Most of them [13,66,79,87] assume a trusted proxy performing accesses on behalf of users, with TaoStore [79] being the most efficient and secure among them. These constructions do not formally consider obliviousness against malicious clients nor access control, although a contribution of this work is to prove that a simple variant of TaoStore [79] guarantees both. Finally, instead of a trusted proxy, BCP-OPRAM [15] and CLT-OPRAM [22] rely on a gossiping protocol while PrivateFS [93] assumes a client-maintained log on the server-side, but they do not achieve obliviousness against malicious clients nor access control. Moreover, PrivateFS guarantees concurrent client accesses only if the underlying ORAM already does so.
Other multi-client approaches. Huang and Goldberg have recently presented a protocol for outsourced private information retrieval [53], which is obtained by layering a private information retrieval (PIR) scheme on top of an ORAM data layout. This solution is efficient and conceals client accesses from the data owner, but it does not give clients the possibility to update data. Moreover, it assumes ℓ non-colluding servers, which is due to the usage of information theoretic multi-server PIR.
De Capitani di Vimercati et al. [33] proposed a storage service that uses a shuffle index structure to conceal access patterns over outsourced databases. The focus of their work is to study how indexing data in the storage can leak information to clients that are not allowed to access these data, although they are allowed to know the indices. In a followup work [34], the authors integrate access control in the shuffling index approach using selective encryption. However, this line of work achieves a weaker notion of obliviousness and does not consider verifiability.
Verifiable outsourced storage. Verifying the integrity of data outsourced to an untrusted server is a research problem that has recently received increasing attention in the literature. Schröder and Schröder introduced the concept of verifiable data streaming (VDS) and an efficient cryptographic realization thereof [81,82]. In a verifiable data streaming protocol, a computationally limited client streams a long string to the server, who stores the string in its database in a publicly verifiable manner. The client has also the ability to retrieve and update any element in the database. Papamathou et al. [75] proposed a technique, called streaming authenticated data structures, that allows the client to delegate certain computations over streamed data to an untrusted server and to verify their correctness. Other related approaches are proofs-of-retrievability [84]–[89], which allow the server to prove to the client that it is actually storing all of the client’s data, verifiable databases [12], which differ from the previous ones in that the size of the database is fixed during the setup phase, and dynamic provable data possession [40]. All the above do not consider the privacy of outsourced data. While some of the latest work has focused on guaranteeing the confidentiality of the data [91], to the best of our knowledge no existing paper in this line of research takes into account obliviousness.
Personal health records. Security and privacy concerns seem to be one of the major obstacles towards the adoption of cloud-based PHRs [18,30,94]. Different cloud architectures have been proposed [65], as well as database constructions [60,62], in order to overcome such concerns. However, none of these works takes into account the threat of a curious storage provider and, in particular, none of them enforces the obliviousness of data accesses.
This paper introduces the concept of Group ORAM, which captures an unprecedented range of security and privacy properties in the cloud storage setting. Based on our definitional framework
This work opens up a number of interesting research directions. Among those, it would be interesting to prove a lower bound on the communication complexity. Furthermore, we would like to relax the obliviousness property in order to bypass the lower bound established in this paper, coming up with more efficient constructions and quantifying the associated privacy loss. Finally, a further research goal is the design of cryptographic solutions allowing clients to learn only limited information (e.g., statistics) about the dataset.
Footnotes
Acknowledgments
This research is based upon work supported by the state of Bavaria at the Nuremberg Campus of Technology (NCT). NCT is a research cooperation between the Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU) and the Technische Hochschule Nürnberg Georg Simon Ohm (THN). Dominique Schröder is supported by the German Federal Ministry of Education and Research (BMBF) through funding for the project PROMISE and by an Intel Early Career Faculty Honor Program Award. Furthermore, this work has been partially supported by the European Research Council (ERC) under the European Unions Horizon 2020 research (grant agreement No 771527-BROWSEC), by Netidee through the project EtherTrust (grant agreement 2158), by the Austrian Research Promotion Agency through the Bridge-1 project PR4DLT (grant agreement 13808694) and COMET K1 SBA.