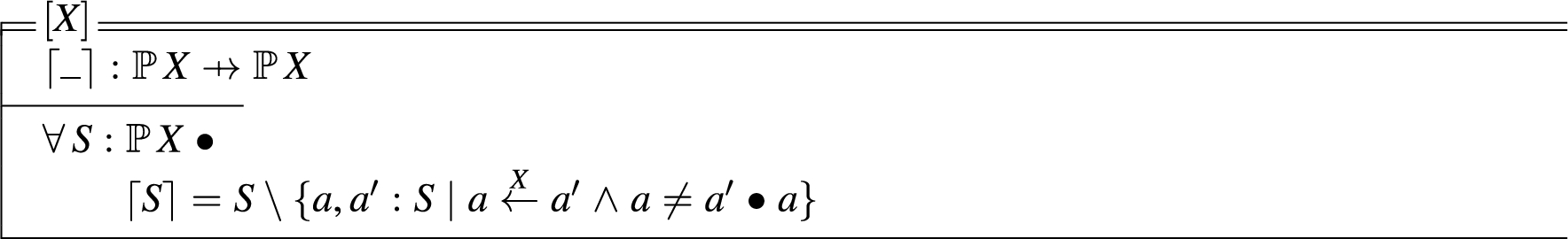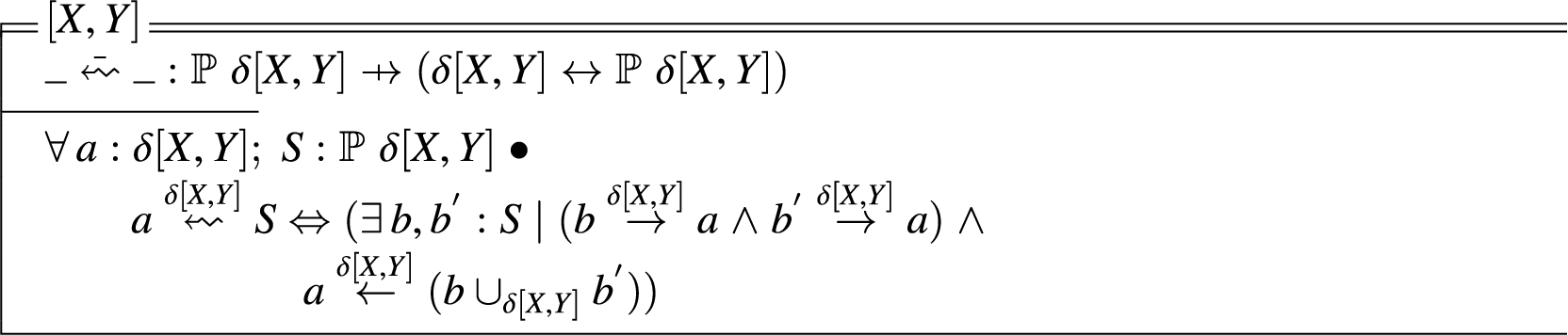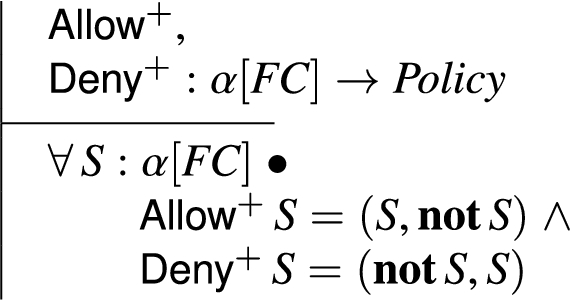Network and host-based access controls, for example, firewall systems, are important points of security-demarcation, operating as a front-line defence for networks and networked systems. A firewall policy is conventionally defined as a sequence of order-dependant rules, and when a network packet matches with two or more policy rules, the policy is anomalous. Policies for access-control mechanisms may consist of thousands of access-control rules, and correct management is complex and error-prone. We argue that a firewall policy should be anomaly-free by construction, and as such, there is a need for a firewall policy language that allows for constructing, comparing, and composing anomaly-free policies. In this paper, an algebra is proposed for constructing and reasoning about anomaly-free firewall policies. Based on the notion of refinement as safe replacement, the algebra provides operators for sequential composition, union and intersection of policies. The effectiveness of the algebra is demonstrated by its application to anomaly detection, and standards compliance. The effectiveness of the approach in practice is evaluated through a mapping to/from iptables. The algebra is used to specify and reason about iptables firewall policy configurations. A prototype policy management toolkit has been implemented.
Firewall policy management is complex and error-prone. A misconfigured policy may permit accesses that were intended to be denied and/or vice-versa. We regard the specification of a firewall policy as a process that evolves, as threats to, and access requirements for, resources behind a firewall do not usually remain static, and over time, a policy or distributed policy configuration may be updated on an ad-hoc basis, possibly by multiple specifiers/administrators. This can be problematic and may introduce anomalies; whereby the intended semantics of the specified access controls become ambiguous.
A firewall policy is conventionally defined as a sequence of order-dependent rules. A rule is composed of filter conditions and a target action. Filter conditions usually consist of fields/attributes from IP, TCP/UDP headers; with the most commonly used attributes being source/destination IP/port, and network protocol. Target actions are usually allow or deny. When a network packet matches with two or more policy rules, the policy is anomalous [2,10].
A firewall policy may be developed as a collection of independent or related specifications that an administrator will need to replace by a policy that adequately captures the requirements of the individual specifications. A configuration may need to be updated with additional policy specifications when a new threat is identified, or when a new permissible access is required. Therefore, having a consistent means of composing these specifications is desirable. The objective of this paper is to develop a theory about composing anomaly-free firewall policies. When a policy is anomaly-free, there is no ambiguity as to whether a given network packet is allowed or denied by the firewall. Our goal is to provide an algebra where policies are anomaly-free by construction.
When configuring the rules that define a firewall policy, the specifier must understand the relationship of each rule to every other rule in the policy. Consider, as a running example, a company that employs a team of administrators and a team of developers. There are two network security policy requirements, whereby network traffic destined to the IP range on ports is to be allowed from the administrators, and traffic destined to the IP range on ports is to be allowed from the developers. For ease of exposition, we give the IPs as natural numbers, and the IP and port ranges as intervals of . For simplicity, we do not consider the source IP ranges for the administrators and the developers.
Specifying the requirements. System Administrator manages the network access controls for the administration and development teams. He specifies the network security policy requirement for the administration team as: , whereby is the position of the rule in the policy, the first instance of is the required destination IP range, the second instance of is the required destination port range, and , means that network traffic matching this pattern is permitted traversal of the firewall. Similarly, for the development team, he specifies: . Bob needs to combine and into a single firewall policy, and security requirements may change. He requires a consistent means of composing firewall policies, whereby the result is anomaly-free and upholds the enforcements of each policy involved in the composition.
Sequential composition. To specify the firewall policy for the company, he tries sequentially composing and as follows: . This approach, however, does not does yield the desired result. That is, in the above specification (), the rule at position allows some of the IP/port pairs allowed by the rule at position and vice-versa. Therefore, the policy is anomalous. From this, we have that the naïve sequential composition of rules is not a consistent operation when specifying an anomaly-free policy.
A flattening approach. To specify the firewall policy, Bob considers the approach whereby for each IP/port pair allowed by the company’s network security policy requirements, there is a rule to allow each IP/port pair. He specifies: . This policy does provide the desired result, in that it is both anomaly-free and consistent with the two network security policy requirements involved in the composition. We observe however, that this approach is tedious, error-prone and not practical for large numbers of IPs/ports or large numbers of policy rules.
A different approach. Bob is required to specify the firewall policy whereby policy rules allow the IP/port-range pairs from either or . To specify the policy for the company, he decides to compose the two requirements into a single requirement as follows: . This approach, however, is inconsistent with the two network security policy requirements outlined by the company. That is, the result of composition is an overly-permissive firewall policy, whereby network traffic is permitted to IP on port , and to IP on port . Conversely, this approach would result in an overly-restrictive policy if the rules had a target action of .
A better approach. Bob is required to specify the firewall policy whereby the desired result is the smallest number of anomaly-free rules that allow all the IP/port pairs from either or . He specifies the policy: . In this case, the result is as desired, as it is the smallest number of anomaly-free rules that allow all the IP/port pairs from either or .
Mutual policy enforcements. Bob receives a request to configure the policy that allows the IP/port pairs from both and . He specifies: . In this case, the specification provides the desired result, and defines the smallest number of anomaly-free rules that allow all the IP/port pairs from both and . We observe that the resulting policy upholds the restrictions of both and .
Conflicting policy decisions. Suppose, for example, the policy rules specified were: . Then this policy is anomalous, as rule denies packets already allowed by rule . As such, then a semantically-equivalent interpretation of the policy, defining the smallest number of anomaly-free rules, may be specified by Bob as follows: .
For an administrator, it may be relatively straightforward to understand policy composition where only a small number of rules are involved, however, this does not scale. We argue that to reason confidently a policy or distributed policy configuration is anomaly-free and adequately mitigates the identified threats; a common framework is required, whereby knowledge related to detailed access control configurations and standards-based firewall policies can be represented and reasoned about.
In this paper, we present a firewall policy algebra for constructing and reasoning over anomaly-free policies. The algebra allows policies to be composed in such a way, that the result upholds the access requirements of each policy involved; and permits one to reason as to whether some policy is a safe (secure) replacement for another policy in the sense of [19,20,28]. In this paper, when one policy is considered a safe (secure) replacement for another, then this means that the former is no less restrictive than the latter. The proposed algebra is used to reason about iptables firewall policy configurations. We derive a filter condition specification for from a collection of attributes expressible in firewall rules from the iptables filter table. iptables is a command line utility used to define policies for the Linux kernel firewall Netfilter [37]. We focus on stateful and stateless firewall policies that are defined in terms of constraints on source and destination IP and port ranges, the TCP, UDP and ICMP protocols, and additional filter condition attributes. Note, the notion of state in iptables is an abstraction, where given literals signify user-land ‘states’ that packets within tracked connections can be related to.
The primary contribution of this paper is an algebra , that can be used to reason about firewall policies using refinement and composition operators. The effectiveness of the algebra is demonstrated by using it to characterise anomalies in firewall policies and to define standards compliance. The effectiveness of the approach in practice is evaluated through a mapping to/from iptables. The evaluation shows that the approach is practical for large policies. This paper is a revised and extended version of the work in [38]. In the sequel, we encode additional filtering specifications in , in particular, for OSI Layer 2 packet-types and MAC addresses, OSI Layer 7 Linux UIDs and GIDs, and Application layer protocols recognisable by iptables. We also develop a definition for time-based filtering rules. We include new definitions for anomaly detection through policy composition, and describe how to incorporate an additional target action of ‘log’ for firewall rules in the algebra. An extended definition for firewall rule (duplet datatype) ordering, as well as implementation definitions for duplet join and difference are given.
The paper is organised as follows. In Section 2, we specify the core filter condition specification for rules in the algebra. The specification is derived from filter condition attributes expressible in firewall rules for the iptables filter table. Section 3 introduces the notion of adjacency, which is at the heart of reasoning about/composing firewall rules that involve IP/port ranges. In Section 4 we define datatypes for firewall rule attributes, such as IP/port ranges. Section 5 defines the firewall policy algebra . In Section 6, we use to reason about firewall policies in practice. Section 7 describes a prototype policy management toolkit for iptables and presents some preliminary results. Related work is outlined in Section 8 and Section 9 concludes the paper. The Z notation [42] is used to provide a consistent syntax for structuring and presenting the definitions and examples in this paper. We use only those parts of Z that can be intuitively understood and the Appendix gives a brief overview of the notation used. Mathematical definitions have been syntax- and type-checked using the fuzz tool.
Attributes of a Linux-based firewall
In this section, the core filter condition attributes used to define firewall rules in the firewall algebra are formally specified. Attributes are derived from the Data Link, Network, Transport and Application Layers of the OSI model. Additional filter condition attributes are also defined. Attribute definitions are extended in Section 4 to specify range-based filter conditions used to define firewall rules in the policy algebra. The attributes defined in this paper are based on the expressiveness on the iptables firewall. The following example demonstrates the specification of a firewall rule using the iptables command-line syntax.
The following iptables access-control rule specifies that inbound (INPUT) TCP packets (-p tcp) originating from the IP address 0.0.0.1 (-s0.0.0.1) destined to the IP address 0.0.0.2 (-d0.0.0.2) will be permitted traversal of the firewall (-j ACCEPT).
Note, the filter table is the default table for iptables, therefore it is not necessary to include the (-t filter) option when specifying a firewall rule.
Data link layer filtering
Packet-type. iptables allows for the specification of firewall rules that filter the type of packet at the Data Link layer of the OSI model. Let be the set of Data Link-layer packet types, whereby:
Media access control (MAC) addresses. iptables allows for constructing firewall rules that filter the MAC address of a Ethernet device at the Data Link layer of the OSI model. Filtering is applied to source MAC addresses entering the FORWARD or INPUT chains of the filter table [37]. Let basic type be the set of all MAC addresses. We define:
For simplicity, we do not consider how the values of may be constructed, other than to assume that the usual human-readable notation can be used, such as 00:0F:EA:91:04:08 and .
Network layer filtering
IP addresses. iptables allows the specification of firewall rules that filter the source/destination IP address of a network packet. For simplicity, we consider only the IPv4 address range, as a firewall rule with an IPv6 address filter condition attribute must be specified using ip6tables; the equivalent IPv6 firewall [25]. In this paper, IP addresses as encoded using natural numbers, as there is a logical mapping from IPs to natural numbers, and a logical mapping from IP ranges and CIDR blocks to intervals of . This is done for ease of exposition, and to exploit the natural ordering of ⩽ over . We define the constant , whereby:
ICMP. iptables allows for filtering by ICMP Type and Code. Let be the set of all valid ICMP Type/Code pairs, as detailed in [40]. Most Type/Code pairs are given as , for example, is an ICMP Echo Request, however, some ICMP Types ; for example, Type (reserved for security), have no ICMP Code, and are given as . Note, for ease of exposition we use syntactic sugar in the definition of as a free-type.
Transport layer filtering
Network ports. A network port is a communication end-point used by the Transport layer protocols (for example, TCP/UDP) of the OSI model. iptables allows for constructing firewall rules that filter by source/destination ports. A port is a 16-bit unsigned integer. We define the constant , where:
UDP. iptables allows the specification of firewall rules that filter UDP traffic. Let define the set of packet values for the UDP protocol; whereby 1 signifies that a packet is using UDP or 0 signifies it is not. We define:
TCP. iptables allows for TCP firewall rules to be constructed using a pair of TCP flags specifications. The first, specifies the flags that are to be examined in a packet-header, and the second specifies the flags that are to be set in a packet-header, these are the mask and comp values for a TCP packet [25]. Let be the set of TCP flags filterable in an iptables rule (as a mask or a comp specification), whereby:
and let be the set of all (mask, comp) pairs, we define:
Application layer filtering
Layer 7 protocol filtering. iptables allows for constructing firewall rules that filter certain protocols at the Application Layer of the OSI model. Let be the set of all OSI Application-layer protocols recognised by iptables [33]. Note, for ease of exposition we use syntactic sugar in the definition of as a free-type. We define:
The Layer 7 protocol definitions specify how these protocol names correspond to regular expressions that are matched by Netfilter on the packet application layer data. For example, the following regular expression [32]:
^220[\x09-\x0d -~]*ftp
is used by the Netfilter firewall to match packets that are part of FTP traffic.
Packet-owner/creator filtering. For locally generated packets; iptables allows filtering by various characteristics of the packet creator through the owner module. Filtering is applied to the OUTPUT chain of the filter table [37]. We define the constant for 32-Bit Linux UIDs, where:
Similarly, the constant for 32-Bit Linux GIDs is defined as:
Additional filtering specifications
State. The iptables conntrack module defines the state extension [37]. The state extension allows access to the connection tracking state for a packet. Let be the set of connection tracking states for a packet/connection.
Time-based filtering. iptables allows for a filtering decision to be made if the packet arrival time/date is within a given range. The possible time range expressible in a rule is 1970-01-01T00:00:00 to 2038-01-19T04:17:07 [16], and is specified in ISO 8601 “T” notation. We define the constant , whereby is a function that converts a date specified in “T” notation to a Unix timestamp:
Network interfaces and direction-oriented filtering. iptables allows for a filtering decision to be made with respect to the interface the packet is arriving at/leaving through. Let basic type be the set of all interfaces on a machine, where for simplicity, we assume elements of resemble lo, eth0, wlan0, tun0, etc. We define:
Network traffic can be inbound or outbound on an interface. Direction-oriented filtering is defined as , whereby:
iptables chains. Let be the set of chains for the iptables filter table, we define:
A theory of adjacency
Range-based filter condition attributes (for example, IPs/ports) have logical mappings to intervals of . For example, the port range that includes all ports from SSH upto and including HTTP can be written as the interval .
Consider, as part of a running example, a system that is capable of enforcing firewall rules whereby the filter condition attribute for the rules is a destination port range only. A rule that allowed all ports from SSH to HTTP would be: , where i is the index of the rule in the policy, is the required port range, and means that network traffic matching this pattern is permitted. Suppose we had a second rule, that specifies allow everything from Quote Of The Day (QOTD) up to and including FTP Control, then specifies that for the rule at index j; the required port range is allowed. Intuitively we can see that the port ranges for the rules at index i and index j are adjacent, and we may want to join rule i and rule j into a single rule that looks like . This notion of adjacency becomes more complex when we consider comparing/composing firewall rules comprising two or more filter condition attributes.
The adjacency specification
In this section we define the filter condition attribute relationships of adjacency, disjointness and subsumption. These can be applied to any ordered set, not just number intervals. These relationships are at the heart of adjacency, and ultimately the algebra.
Let be the set of all intervals on the natural numbers, from up to and including . Intervals are defined by their corresponding sets.
For ease of exposition and when no ambiguity arises, we may write an interval as a pair , rather than by the set it defines. For example, .
Let define the set of all possible IPv4 address ranges, whereby:
Similarly, let define the set of all possible network port ranges, whereby:
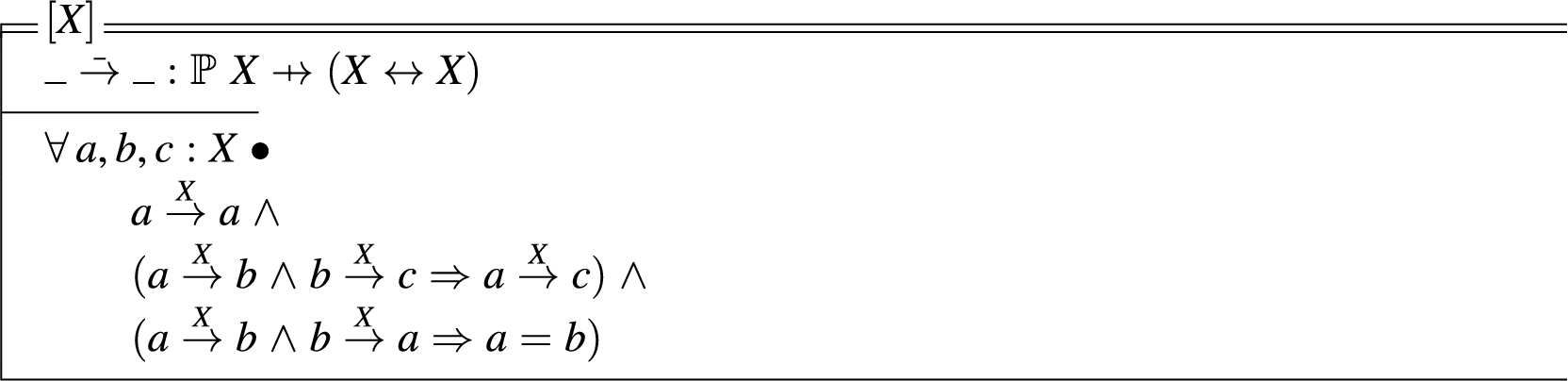
Adjacency. The relation defines adjacency over any ordered set. Adjacency is a general notion that is not limited to . We generalize adjacency to any attribute of generic type X, whereby for , if , then a and b are adjacent in the set X. The property of reflexivity is required as any should be adjacent to itself, that is; if for any a, that did not hold, then an inconsistency would exist. Symmetry follows from a similar requirement, where for , if a is adjacent to b in X, then b must also be adjacent to a in X. The following schema defines a generic adjacency relation that can be instantiated for adjacency over different datatypes.
Given a set , then the transitive closure of the adjacency relation for elements in S is defined as follows.
Interval adjacency. Two intervals on the set of natural numbers are adjacent if their union defines a single interval. For a given maximum value , we define:
Interval is adjacent to interval since , thus .
Number adjacency. Two numbers are adjacent if they are the same or if they are different by a value of one. We define:
Set adjacency. For a generic type X, and sets , then S and T are adjacent, as . We define:
Disjointness. The relation is used to define the notion of disjointness over any ordered set. Given , denotes a and b are disjoint in X. The property of irreflexivity is required, as a cannot be disjoint from itself, that is; if for any a, that did not hold, then an inconsistency would exist. Symmetry is also required for consistency, as if a and b are disjoint in X, then b and a must be disjoint in X also. The following schema defines a generic disjointness relation that can be instantiated for disjointness over different datatypes.
Interval disjointness. Two intervals are disjoint if they don’t intersect. For a given maximum value , we define:
The interval and interval are disjoint, since , thus .
Number disjointness. Two numbers are disjoint if they are different. We define:
Set disjointness. Two sets are disjoint if they don’t intersect. We define:
Subsumption. The relation is used to define subsumption over any ordered set. For , if , then b covers a in X. Reflexivity is required, as any a must cover itself. Transitivity follows from a similar requirement, where for , if a covers b and b covers c, then a must cover c. Antisymmetry follows from the assumption of irredundant elements, where if a covers b and b covers a then one of them is unnecessary [13]. The properties of reflexivity, transitivity and antisymmetry define as a non-strict partial order over X [5]. The following schema defines a generic subsumption relation that can be instantiated for subsumption over different datatypes.
Some subsumption orderings (for example, subset) may form a lattice with greatest lower bound (glb) and least upper bound (lub) operators for values in X.
Interval subsumption. An interval I subsumes (covers) an interval J, if . For a given maximum value , we define:
Interval covers interval , since , thus: .
Number subsumption. For then b covers a if a equals b. We define:
The equality relation is both symmetric and antisymmetric, and defines both an equivalence relation and a non-strict partial order. Thus, denotes that b subsumes/covers a.
Set subsumption. The definition for set subsumption is as expected, we define:
For a generic type X, and , then the flattening function gives the cover-set for the elements of S, whereby the cover-set of S has no subsumption. We define:
Given the set of all intervals on the natural numbers from , then we have:
We define a operator for , where gives the relative compliment of T in S. That is, everything that is of type X that is covered in S, but not in T. We define this as:
Given the cover-set for the set of all intervals on the natural numbers from , and the set , we have .
The adjacency datatype
For a generic type X, the Adjacency datatype , is the set of all closed subsets of X partitioned by adjacency.
We can use this to define all ways that an interval can be partitioned into sets of non-adjacent intervals.
Let define the set of all closed subsets for the intervals of the IPv4 address range, partitioned by adjacency, and similarly, let define the set of all closed subsets for the intervals of the network port range, partitioned by adjacency. We define:
Adjacency datatype ordering. An ordering can be defined over Adjacency-sets of a generic type X as follows:
The ordering relation ⩽ is a non-strict partial order over.
For , then means that T covers S, that is, every is covered by some . The ordering relation ⩽, is defined as a subsumption ordering/an antisymmetric preorder, where the properties of reflexivity, transitivity and antisymmetry hold for ⩽ over as is a non-strict partial order for elements of type X. We have:
The elements define the least and greatest bounds, respectively, on , where ⊥ is the unique minimal element that is covered by all elements, and ⊤ is the unique maximal element that covers all other elements. We have:
□
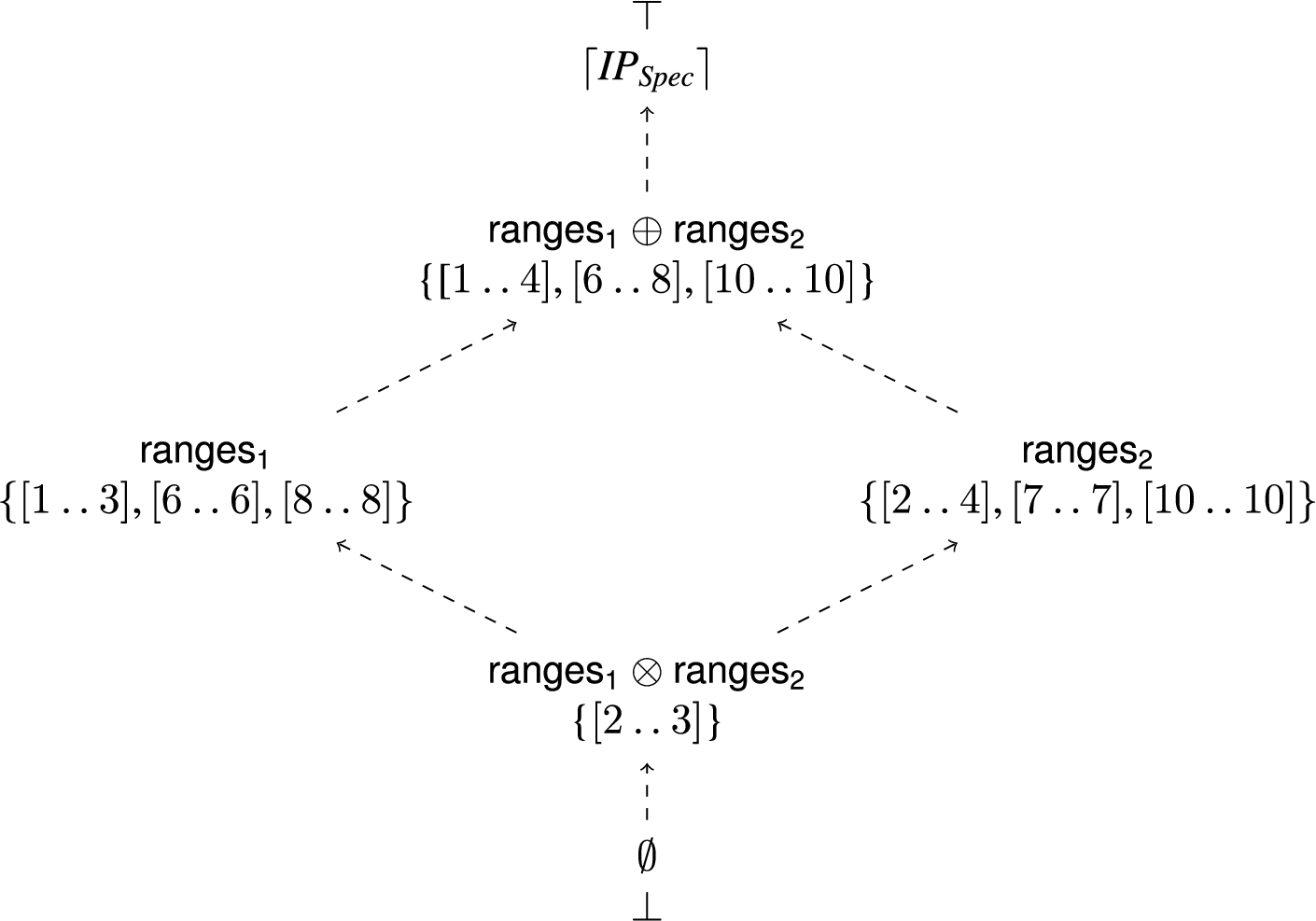
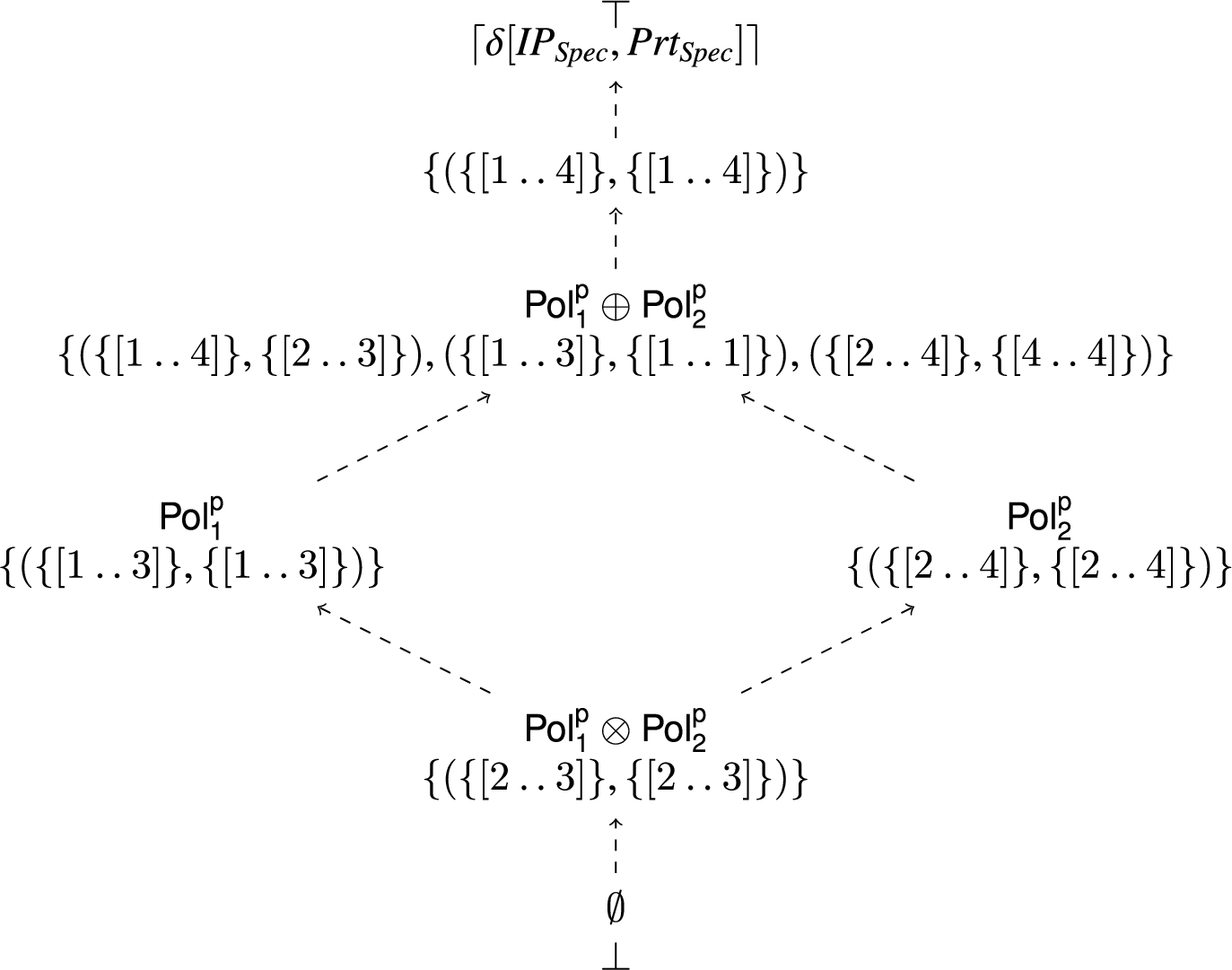
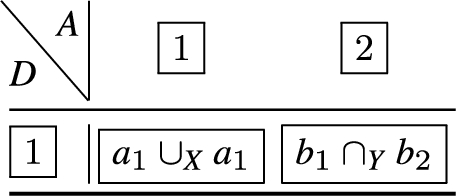
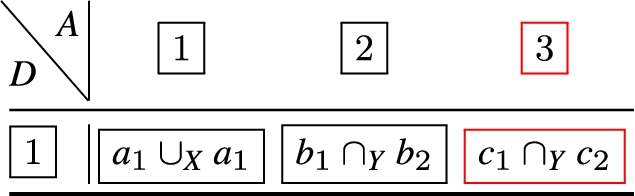
Given , where:
then Fig. 1 depicts a partial Hasse diagram, for the composition of and under the relative ordering of ⩽ over .
Adjacency datatype union. The join of is defined using subsumption, as the generalized intersection of all Adjacency-sets, where each element of covers an element in either S or T. Intuitively, this means that the values of the join are exactly a union of the elements from both S and T.
ordering fragment.
The operator ⊕ is a least upper bound operator on.
The generalized intersection in the join operation for some defines the smallest collection of that cover all of the elements from both S and T by subsumption. If we take some , such that and , then .
Thus, Adjacency join provides a lowest upper bound operator. Since ⊕ provides a lub operator we have and . □
Adjacency datatype intersection. Under this ordering, the meet, or intersection of is defined using subsumption, as the cover-set for the generalized union of all Adjacency-sets, where each element of is covered by an element in both S and T. Intuitively, this means that the values of the meet are all non-empty intersections of each value in S with each value in T.
The operator ⊗ is a greatest lower bound operator on.
It follows from Lemma 3.2 by an analogous argument that Corollary 3.3 holds. □
Since ⊗ provides the glb operator, then for we have is covered by both S and T, that is and .
Adjacency datatype negation. Given , then defines a complement operator in , where is the cover-set for all elements of type X that are not covered by some member of S. We have:
The posetforms a lattice with lowest-upper, and greatest lower bound operators, ⊕ and ⊗ respectively, and complement operator.
This follows from the definition of ⩽ as a subsumption ordering/an antisymmetric preorder, the properties of , the definition of the meet as the cover-set for the generalized union of all Adjacency-sets, where for , each element of is covered by an element in both S and T, and the definition of the join as the generalized intersection of all Adjacency-sets, where each element of covers an element in either S or T. □
The duplet datatype
The notion of adjacency becomes more complex when we consider comparing/composing firewall rules comprising two or more filter condition attributes. When joining adjacent firewall rules, in some cases the rules may coalesce and in other cases they may partition into a number of disjoint rules.
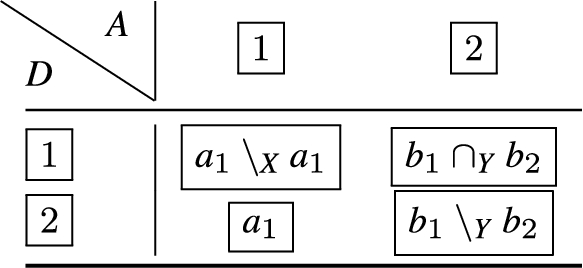
Recall from Example 3 in this section, the firewall system that supports only destination port range filter conditions. Suppose we want to extend the expressiveness of the policy rules for this system to include a definition for destination IP range. Consider, two policy requirements; whereby network traffic is to be allowed to the IP range on ports , and to the IP range on ports . Then modelling this using adjacency-free IP/port range pairs, we have , whereby:
If we consider the attributes separately, we observe that the IP range in is adjacent to the IP range in , and the port ranges in and are also adjacent. However, in composing and under a lowest-upper-bound style operation one cannot simply take a union of the sets of intervals to be the IP/port range pair: , as this results in an overly permissive policy, given that network traffic is permitted to IP on port , and to IP on port as a result of composition. Conversely, this would result in an overly restrictive policy if we were composing deny rules.
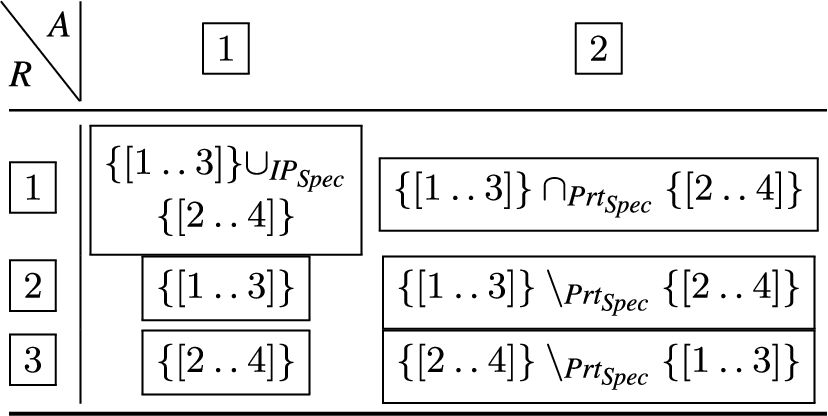
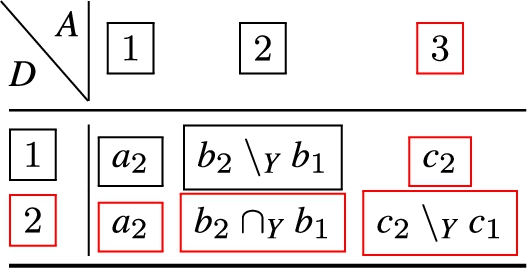
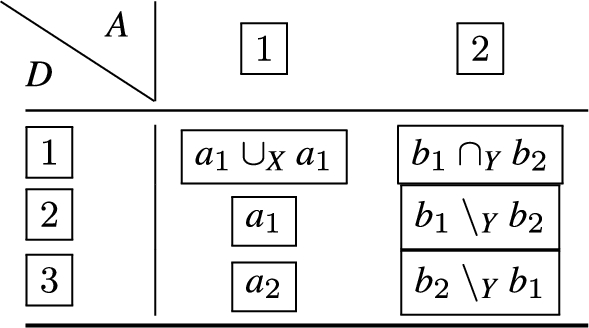
When we consider how the join of and may be defined, whereby the desired result is the smallest number of non-adjacent rules that cover both and , then we can apply an adjacency-precedence to the IP ranges in and , and observe that the port ranges in and are not disjoint. We refer to this as the 1st attribute major ordering, and the cover for and is given as:
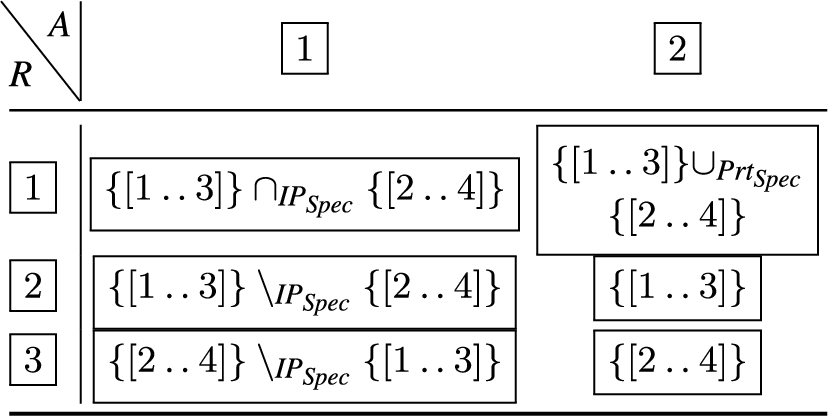
In this case, the result is a set of disjoint rules that exactly cover the IP/port-range pair constraints from and . We note, however, that instead, the adjacency-precedence may be applied to the second attribute, where in this case we observe that the port ranges in and are adjacent, and the IP ranges in and are not disjoint. We refer to this as a 2nd attribute major ordering, and would therefore expect the set of disjoint rules that exactly cover the IP/port-range pair constraints from and to be:
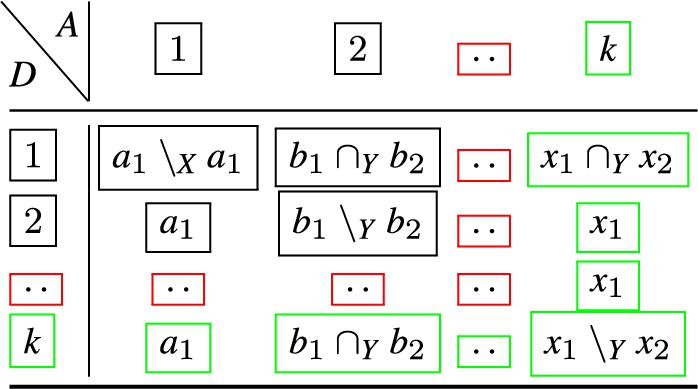
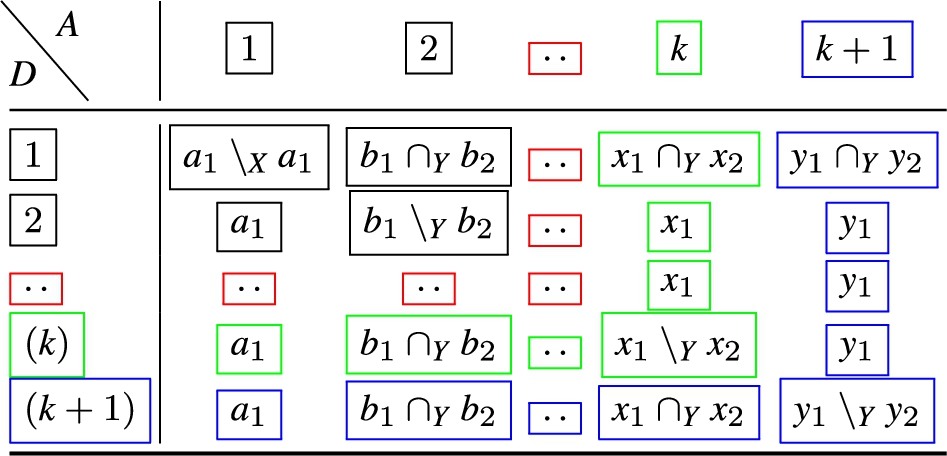
The resulting operations for the attribute major ordering are illustrated in Table 1, whereby the label R signifies the new rule, and the label A means filter condition attribute. In Table 2, the operations for the 2nd attribute major ordering the are encoded.
A two-attribute rule join, attribute major ordering
A two-attribute rule join, attribute major ordering
For the remainder of this paper, we consider firewall rule join in terms of the attribute major ordering. However, we also consider the join of rules where there is an adjacency in other than the first attribute, we refer to this type of adjacency as forward adjacency.
Duplets. A duplet is an ordered pair, where the set of all duplets for generic types , is defined as , whereby:
For and , we have:
and gives the set of all duplets for adjacency-free IP/port-range pairs.
If the ordering over X is a lattice and the ordering over Y is a lattice, then the ordering overis also a lattice.
Given the definition of as the Cartesian product of X and Y, then if the ordering over X is a lattice and the ordering over Y is a lattice; it follows that forms a lattice under the product order of X and Y. □
Forward adjacency. A pair of duplets are forward adjacent to each other if the attributes in the first coordinate are equal and the attributes in the second coordinate are adjacent. For , we define forward adjacency, whereby:
Given duplets , then these duplets are forward adjacent, as: .
Duplet adjacency. A pair of duplets are adjacent, if the attributes in the first coordinate are adjacent, and the attributes in the second coordinate are not disjoint, or a and b are forward adjacent. For , we define:
We have that , since the IP ranges are adjacent and the port ranges are not disjoint and we have .
Duplet disjointness. A pair of duplets are disjoint if the attributes in the first coordinate are disjoint, and/or the attributes in the second coordinate are disjoint. For , we define:
We have , since
Duplet intersection. The definition for duplet intersection is defined as the intersection of the attributes in each coordinate under their respective orderings. For , we define:
For and , we have .
Duplet merge. The definition for duplet merge is defined as the union of the attributes in each coordinate under their respective orderings. For , we define:
Given and , we have .
Duplet subsumption. A duplet covers a duplet in , if covers in X, and covers in Y. Thus, we define duplet subsumption as:
For and , we have and .
Precedence subsumption. A precedence subsumption is defined for duplets, whereby we explicitly define subsumption orderings separately in each coordinate. The relation defines a general format for precedence subsumption over any ordered set. For , if , then a covers b by precedence in X. The properties of reflexivity, transitivity and antisymmetry define as a non-strict partial order over X [5]. The following schema defines a generic precedence subsumption relation that can be instantiated for precedence subsumption over different datatypes.
A duplet covers a duplet by precedence in , if covers in X, and covers in Y. Thus, we define precedence subsumption as:
For , and duplets , then we have:
Precedence cover. For a duplet and a set of duplets , then S covers a if the duplet merge of all elements in S that each cover a by precedence subsumption, cover a by duplet subsumption. We define:
For , and duplets , we have: as holds.
Intersecting elements. For and , then is the set of all non-empty intersections of a with each value . We define:
For , and duplets , then:
Duplet adjacency ordering
In this section, an ordering is defined for Adjacency-sets of duplets.
Duplet adjacency difference. Given , then is the cover-set for the set of all duplets covered in S by a duplet, or by a collection of duplets, and not covered in T. Thus, we define the difference of Adjacency-sets of duplets as:
Given , where:
then:
The implementation definition for duplet difference is given in Section 7.2.
Duplet adjacency ordering. An ordering can be defined over Adjacency-sets of duplets as follows:
The ordering relation ⩽ is a non-strict partial order over.
For , then means that T covers S, that is, every is covered under duplet subsumption, either by a duplet, or by a collection of duplets in T. The ordering relation ⩽, is defined as an antisymmetric preorder, where the properties of reflexivity, transitivity and antisymmetry hold for ⩽ over .
Reflexivity. For , we have for , then a covers itself under duplet subsumption. Since S is adjacency-free, then every duplet in S covers only itself under a duplet subsumption in S. Since duplet subsumption is reflexive, then ⩽ is reflexive; that is:
Transitivity. For , then if all are covered in T under duplet subsumption. Then if we take some , such that , then all are covered in U under duplet subsumption. Therefore, all are covered in U under duplet subsumption as duplet subsumption is transitive. Then ⩽ is transitive; that is:
Antisymmetry. For , then if all are covered in T under duplet subsumption, and if then all are covered in S under duplet subsumption. Therefore, from the definition of duplet subsumption, if and then . Then ⩽ is antisymmetric; that is:
The elements define the least and greatest bounds, respectively, on , where ⊥ is the unique minimal element that is covered by all elements, and ⊤ is the unique maximal element that covers all other elements. We have:
Then we have:
Thus, ⩽ is a non-strict partial order over . □
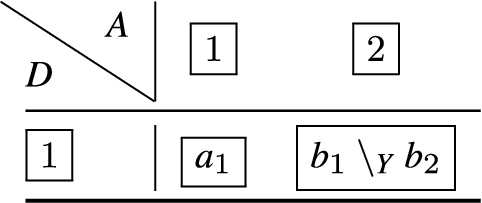
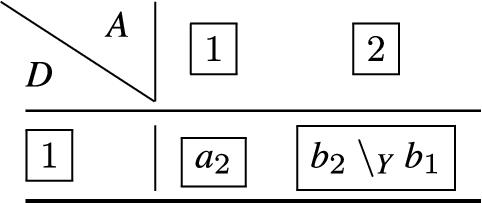
Figure 2 depicts a partial Hasse diagram, for the composition of and from Example 23 under the relative ordering of ⩽ over .
Adjacency duplet union. The join of is defined using subsumption, as the cover-set for the duplet merge of the transitive closure of adjacent duplets, from the generalized intersection of all sets of sets of duplets, whereby each element of the generalized intersection covers an element in either S or T by duplet precedence subsumption. The generalized intersection defines the smallest collection of duplets that cover all of the duplets from both S and T by precedence subsumption. Given that all duplets in this set are now disjoint, the cover-set for the duplet merge of the transitive closure of adjacent duplets merges any forward-adjacent duplets from S and T. If we take some , such that and , then . Thus, Adjacency join provides a lowest upper bound operator, we have:
The implementation definition for duplet adjacency-set join is given in Section 7.2.
Duplet ordering fragment.
Adjacency duplet intersection. Under this ordering, the meet of is defined using subsumption, as the cover-set for the generalized union of all Adjacency-sets, where each element of is covered by a duplet, or by a collection of duplets in both S and T. The meet is defined as the largest set of adjacency-free duplets that is covered by both S and T. Thus, ⊗ provides the glb operator, then for we have is covered by both S and T, that is and .
Adjacency duplet negation. Given , then defines a complement operator in , where is the cover-set for all elements of type X that are not covered by some member of S. We have:
The posetforms a lattice with complement operator.
This follows from the definition of ⩽ as an antisymmetric preorder, the properties of , and the definitions of ⊕ and ⊗.
Commutative laws. We observe that changing the order of the operands/Adjacency-sets does not change the composition result.
Associative laws. We observe that the order in which the operations are performed does not change the outcome of the operation.
Absorption laws. The following identities link ⊕ and ⊗.
Idempotent laws. We observe that for all , S is idempotent with respect to ⊕ and ⊗.
Identity laws. We observe that is a bounded lattice/algebraic structure, such that is a lattice, ⊥ is the identity element for the join operation ⊕, and ⊤ is the identity element for the meet operation ⊗.
Distributivity laws. The join operation distributes over the meet operation and vice-versa.
Thus, is a lattice. □
filter conditions
In this section, the filter condition attribute datatypes for the policy model are defined.
OSI layer 2. Let define the set of all additional filter condition attributes at the Data-Link Layer, given as the set of all duplets over the set of all sets of packet-types and the set of all sets of MAC addresses .
From Lemma 3.5, we have that is a lattice.
The following iptables rule specifies that inbound (INPUT) TCP broadcast packets (-p tcp --pkt-typebroadcast) destined for the IP address 0.0.0.1 (-d0.0.0.1) be denied (-j DROP).
The following iptables rule specifies that TCP packets being routed beyond the firewall (FORWARD -p tcp) destined for the IP address 0.0.0.1 (-d0.0.0.1) with source MAC address 00:0F:EA:91:04:08 (-m mac --mac-source00:0F:EA:91:04:08) be denied (-j DROP).
OSI layer 7. Let define the set of all additional filter condition attributes at the OSI Application Layer, given as the set of all duplets over the set of all sets of Layer 7 protocols (), the set of all closed subsets for the ranges of all Linux UIDs partitioned by adjacency (), and the set of all closed subsets for the ranges of all Linux GIDs () partitioned by adjacency.
From Lemma 3.5, we have that is a lattice.
The following iptables rule specifies that outbound (OUTPUT) SSH packets (-m layer7 --l7protossh), originating from the Linux application UID 1001 (-m owner --uid-owner1001), destined for the IP address 0.0.0.2 (-d0.0.0.2) be allowed (-j ACCEPT).
The stateful/protocol datatype. Let define the set of all stateful protocols, given as the set of all duplets over the TCP protocol (), the UDP protocol (), the ICMP protocol (), and the set of all sets of connection tracking states for a packet/connection ().
UDP operators are . From Lemma 3.5, we have that is a lattice.
Stateful/protocol disjointness. A pair of stateful protocols are disjoint if the TCP, UDP and ICMP attributes are disjoint, and/or their state is disjoint. For , , and , we define:
Additional filtering specifications. Let define the set of all additional filter condition attributes of interest, given as the set of all duplets over the set of all closed subsets for the ranges of all Unix timestamps, from 0 up to and including (), the set of all sets of all network interfaces on a machine (), the set of all sets of directions for direction-oriented filtering () and the set of all sets of iptables chains ().
From Lemma 3.5, we have that is a lattice.
The following iptables rule specifies that for all inbound (INPUT) packets arriving on interface eth0 (-ieth0) from the IP address 0.0.0.1 (-s0.0.0.1), attempting to traverse the firewall between 8 a.m. January 1st 2017 and 6 p.m. January 3rd 2017 (-m time --datestart2017-01-01T08:00:00--datestop2017-01-03T18:00:00), are to be denied.
Filter conditions. A filter condition is a eight-tuple (s, , d, , p, , , a), representing network traffic originating from source IP ranges s, with source port ranges , destined for destination IP ranges d, with destination port ranges , using stateful-protocols p, with additional Layer 2 attributes , additional Layer 7 attributes and additional filtering specifications a. Let define the set of all filter conditions, whereby:
From Lemma 3.5, we have that is a lattice.
Forward adjacency. Recall, for , we define forward adjacency, whereby: . A pair of filter conditions are forward adjacent if the attributes in the first coordinate are equal, and there is one adjacent attribute in the second coordinate, while all other attributes in the second coordinate are equal.
The firewall algebra
In this section we define an algebra , for constructing and reasoning about anomaly-free firewall policies. We focus on stateless and stateful firewall policies that are defined in terms of constraints on source/destination IP/port ranges, the TCP, UDP and ICMP protocols, and additional filter condition attributes. A firewall policy defines the filter conditions that may be allowed or denied by a firewall. Let define the set of all firewall policies, whereby:
A firewall policy defines a policy as a pair of adjacency-free sets of filter conditions under the duplet adjacency ordering, whereby a filter condition should be allowed by the firewall, while a filter condition should be denied. Given then A and D are disjoint: this avoids any contradiction in deciding whether a filter condition should be allowed or denied. The policy destructor functions and are analogous to functions and for ordered pairs:
Thus, we have for all then .
defines the set of anomaly-free policies.
Given a policy , as A and D are adjacency-free sets, then A has no redundancy and D has no redundancy, as Adjacency-sets have no subsumption. Therefore, all packets matched in filter conditions allowed by the policy are distinct, as are all packets matched in filter conditions that are denied by the policy. Given a policy , as and are disjoint, then P has no shadowing.
As P has no subsumption and P has no shadowing, then P has no generalised filter conditions and P has no correlated filter conditions. Therefore, as P has no redundancy/shadowing/generalisation/correlation, then defines the set of anomaly-free policies. □
Note that need not partition : the allow and deny sets define the filter conditions to which the policy explicitly applies, and an implicit default decision is applied for those filter conditions in . For the purposes of modelling iptables firewalls it is sufficient to assume default deny, though we observe that can also be used to reason about default allow firewall policies.
Policy refinement. An ordering can be defined over firewall policies, whereby given then means that P is no less restrictive than Q, that is, any filter condition that is denied by Q is denied by P. Intuitively, policy P is considered to be a safe replacement for policy Q, in the sense of [19,20,28] and any firewall that enforces policy Q can be reconfigured to enforce policy P without any loss of security. The set forms a lattice under the safe replacement ordering and is defined as follows.
Formally, iff every filter condition allowed by P is allowed by Q and that any filter conditions explicitly denied by Q are also explicitly denied by P. Note that in this definition we distinguish between filter conditions explicitly denied in the policy versus those implicitly denied by default. This means that, everything else being equal, a policy that explicitly denies a filter condition is considered more restrictive than a policy that relies on the implicit default-deny for the same network traffic pattern. Safe replacement is defined as the Cartesian product of Adjacency orderings over allow and deny sets and it therefore follows that is a poset. ⊥ and ⊤ define the most restrictive and least restrictive policies, that is, for any we have . Thus, for example, any firewall enforcing a policy P can be safely reconfigured to enforce the (not very useful) firewall policy ⊥.
The set of all policiesforms a lattice under safe replacement, with greatest lower bound (⊓) and lowest upper bound (⊔) operators in.
The ordering of adjacency-free filter condition/duplets is a lattice under subsumption, the Cartesian product is a lattice under the definitions of glb and lub, therefore, is a lattice. □
Policy intersection. Under this ordering, the meet , of two firewall policies P and Q is defined as the policy that denies any filter condition that is explicitly denied by either P or Q, but allows filter conditions that are allowed by both P and Q. Intuitively, this means that if a firewall is required to enforce both policies P and Q, it can be configured to enforce the policy since is a safe replacement for both P and Q, that is; and . Given the definition of safe replacement as a product of two Adjacency lattices, it follows that the policy meet provides the glb operator. Thus, provides the ‘best’/least restrictive safe replacement (under ⊑) for both P and Q.
Policy union. The join of two firewall policies P and Q is defined as the policy that allows any filter condition allowed by either P or Q, but denies filter conditions that are explicitly denied by both P and Q. Intuitively, this means that a firewall that is required to enforce either policy P or Q can be safely configured to enforce the policy . Since ⊔ provides a lub operator we have and .
Constructing firewall policies
The lattice of policies provides us with an algebra for constructing and interpreting firewall polices. The following constructor functions are used to build primitive policies. Given a set of adjacency-free filter conditions A, then is a policy that allows filter conditions in A, and is a policy that explicitly denies filter conditions in D.
This provides what we refer to as a weak interpretation of allow and deny. Network traffic patterns that are not explicitly mentioned in parameter S are default-deny and therefore are not specified in the deny set of the policy. The following provides us with a strong interpretation for these constructors:
In this case allows filter conditions specified in A, while explicitly denying all other filter conditions, and denies filter conditions specified in D while allowing all other filter conditions.
A firewall policy can be decomposed into its corresponding allow and deny sets, and re-constructed using the algebra; for any , since A and D are disjoint then:
Given, then:
Follows since . □
Given, then it follows that
Reasoning about policies in practice
Sequential composition. A firewall policy is conventionally constructed as a sequence of rules, whereby for a given network packet, the decision to allow or deny the packet is checked against each policy rule, starting from the first, in sequence, and the first rule that matches gives the result that is returned. The algebra can be extended to include a similar form of sequential composition of policies. The policy constructions in Section 5.1 can be regarded as representing the individual rules of a conventional firewall policy.
Let denote a sequential composition of an allow rule with policy Q with the interpretation that a given network packet matched in A is allowed; if it does not match in A then policy Q is enforced. The resulting policy either: allows filter conditions in A (and denies all other filter conditions), or allows/denies filter conditions in accordance with policy Q. We define:
which is as expected. A similar definition can be provided for the sequential composition , whereby a given network packet that is matched in D is denied; if it does not match in D then policy Q is enforced. We define:
While in practice its usual to write a firewall policy in terms of many constructions of allow and deny rules, in principle, any firewall policy can be defined in terms of one allow policy and one deny policy and since the allow and deny sets of P are disjoint we have . We define this as:
Let define the set of all firewall rules, whereby:
We define a rule interpretation function as:
A firewall policy is defined as a sequence of rules , for , and is encoded in the policy algebra as . In practice, firewall policies are often anomalous [43], where a policy’s deny rules are not disjoint from it’s allow rules, and a “first match” principle is applied to filtered packets. Mapping a sequence of potentially anomalous firewall rules into the algebra gives a semantically-equivalent anomaly-free .
Policy negation. The policy negation of allows filter conditions explicitly denied by P and explicitly denies filter conditions allowed by P. We define:
From this definition it follows that is simply and thus and . Note however, that in general policy negation does not define a complement operator in the algebra , that is, it not necessarily the case that and . However, the sub-lattice of policies with allow and deny sets that exactly partition the same set has policy negation as complement ( for all P in the sub-lattice).
A target action of log in. In this paper, the focus is on firewall rules with a target action of either or . However, from a compliance perspective, it is considered best practice to log traffic for auditing purposes [41]. Future work should extend the algebra to include a target action of for firewall rules. An approach may be taken, whereby we extend to , where and a filter condition should be logged by the firewall. We give the destructor function for firewall policies; whereby . For policy composition, then for , we have signifies the operation for logged filter conditions. Similarly, for we have the logged filter conditions . From this, we have that the ordering for logged filter conditions is defined similarly to the ordering for denied filter conditions. In practice, a logged filter condition may be shadowed by a filter condition with a target action of or . However, it is not the case that a filter condition with a target action of can shadow a filter condition with a target action of or . Therefore, for sequential composition, then we have defines the logged filter conditions for the resulting policy as: . Encoding a definition for Network Address Translation in is also a topic for future research.
Detecting anomalies in firewall policies
A firewall policy is conventionally constructed as a sequence of order-dependent rules, and when a network packet matches with two or more policy rules, the policy is anomalous [2,3,10]. By definition, the adjacency-free allow and deny sets of some are disjoint, therefore P is anomaly-free by construction. We can however define anomalies using the algebra; by considering how a policy changes when composed with other policies.
Redundancy. A policy P is redundant given policy Q if their composition results in no difference between the resulting policy and Q, in particular, if:
Further definitions may be given for redundancy. For example, there are redundant packets with a target action of allow in filter conditions between policy P and policy Q, if:
as:
A similar interpretation follows for redundant packets with a target action of deny between filter conditions in a policy P and filter conditions in a policy Q. In particular, we have redundant denies if:
as:
Shadowing. Some part of policy Q is shadowed by the entire policy P in the composition if the by filter condition constraints that are specified by P contradict the constraints that are specified by Q, in particular, if:
This is a very general definition for shadowing. Perhaps a more familiar interpretation of this definition is one where the policy P is a specific allow/deny rule that shadows a part or all of the policy with which it is composed. Recall that and, for example, in all or part of policy Q is shadowed by the rule/primitive policy if Q denies the filter conditions specified in A, that is, . Similarly, in part or all of policy Q is shadowed by the rule/primitive policy if .
Further definitions may also be given for shadowing. For example, we have that some of the packets denied by filter conditions in a policy P shadow some of the packets allowed by filter conditions in a policy Q if:
as:
Similarly, some of the packets allowed by filter conditions in a policy P shadow some of the packets denied by filter conditions in a policy Q if:
as:
Generalisation. A generalisation anomaly exists between P and Q if some of the packets allowed by filter conditions in P shadow some of the packets denied by filter conditions in Q, in particular, if:
and, those packets shadowed by filter conditions in Q are subsumed by Q’s denies:
whereby:
Similarly, a generalisation anomaly exists between P and Q if some of the packets denied by filter conditions in P shadow some of the packets allowed by filter conditions in Q, in particular, if:
and, those packets shadowed by filter conditions in Q are subsumed by Q’s allows:
as:
Inter-policy anomalies. We can also use the algebra to reason about anomalies between the different policies of distributed firewall configurations. In the following, assume that P is a policy on an upstream firewall and Q is a policy on a downstream firewall.
Redundancy. An inter-redundancy anomaly exists between policies P and Q if some part of Q is redundant to some part of P, whereby the target action of the redundant filter conditions is deny. Given some set of filter conditions A denied by P, and some set of filter conditions B denied by Q, then there exists an inter-redundancy between P and Q, if:
Further definitions may be given for inter-redundancy. For example, there are redundant packets with a target action of deny in filter conditions between upstream policy P and downstream policy Q, if:
Shadowing. An inter-shadowing anomaly exists between policies P and Q if some part of Q’s allows are shadowed by some part of P’s denies. Given some set of filter conditions A denied by P, and some set of filter conditions B allowed by Q, then there is an inter-shadowing anomaly between P and Q, if:
Further definitions may also be given for inter-shadowing. For example, we have that some of the packets denied by filter conditions in a policy P shadow some of the packets allowed by filter conditions in a policy Q if:
Spuriousness. An inter-spuriousness anomaly exists between policies P and Q if some part of Q’s denies are shadowed by some part of P’s allows. Given some set of filter conditions A allowed by P, and some set of filter conditions B denied by Q, then there exists an inter-spuriousness anomaly between P and Q, if:
Spuriousness may also be defined as follows, whereby some of the packets allowed by filter conditions in a policy P shadow some of the packets denied by filter conditions in a policy Q. We have an inter-spuriousness anomaly from an upstream policy P to a downstream policy Q, if:
To apply the definitions presented in this section to the detection of anomalies in firewall policies in practice, an approach may be taken, whereby an algorithm is constructed, that incorporates the anomaly definitions into the sequential composition of policies/rules when mapping a potentially anomalous, already deployed firewall policy into . That is, given a sequence of firewall rules , then before each sequential composition, an anomaly check can be made using the definitions in this section, the result of which can be used to alert an administrator to the presence of anomalies in the policies/rules under question.
Standards compliance
RFC 5735 [9], details fifteen IPv4 address blocks that have been assigned by IANA for specialized/global purposes. Some of these address spaces may appear on the Internet, and may be used legitimately outside a single administrative domain, however, while the assigned values of the address blocks do not directly raise security issues; unexpected use may indicate an attack [9]. For example, packets with a source IP address from the private address space 172.16.0.0/12, arriving on the Wide Area Network interface of a network router, may be considered spoofed, and may be part of a Denial of Service (DoS), or Distributed DoS attack.
RFC 5735 compliance. Best practice recommendations are implemented for each of the fifteen specialized IP address block ranges in [9], resulting in one hundred and twenty iptables rules. In [18], we defined this ruleset for a firewall management tool. We define IP spoof-mitigation policies for each iptables chain separately. For the INPUT chain, a compliance policy is defined, whereby for each of the IP address block ranges, the following iptables rules are enforced.
Similarly, for the OUTPUT chain, an IP spoof-mitigation compliance policy is defined, whereby for each of the specialized IP address block ranges we have:
For the FORWARD chain, then enforces the following iptables rules for each of the IP address block ranges.
Each policy, , terminates with a final iptables rule that specifies all other traffic be permitted on the given iptables chain.
A redefined firewall policy. We model these iptables rules in the algebra by redefining some policy-model attributes, and provide more formal definitions of , and . Let be the set of all duplets for additional filter condition attributes of interest, where:
A revised definition for the set of all filter conditions is given as:
A revised definition for the set of all policies is given as:
The compliance policies , define the minimum requirements for what it means for some perimeter network firewall policy to mitigate the threat of IP spoofing for all traffic, in accordance with RFC 5735. Thus, we have for all if:
then P complies with the best practice recommendations outlined in [9] for IP address spoof-mitigation.
Encoding and evaluating iptables policies
A prototype policy management toolkit has been implemented in Python for iptables. The prototype allows for parsing the system’s currently enforced iptables ruleset by chain, using the Python-iptables package [36], and then normalizing each rule to a primitive/singleton policy. The overall policy for the chain being evaluated as . Once the sequential composition of the system’s currently enforced iptables policy is computed, the prototype generates a semantically-equivalent adjacency-free set of iptables rules and re-writes this new ruleset to the system.
We reason over policies using the ⨾, ⊔, and ⊑ policy operators. The test-bed for the experiments was a 64-Bit Ubuntu 14.04 LTS OS, running on a Dell Latitude E6430, with a quad-core Intel i5-3320M processor and 4 GB of RAM. Every experiment was conducted three times; the median result chosen for inclusion in this paper. Overall, the results are promising. In this section, the firewall datatypes for the prototype are described.
Firewall rules. An iptables rule is modelled as a list of generic filter conditions. The current implementation defines firewall rules with filter condition attributes for source/destination IP/port ranges, the ICMP, UDP and TCP protocols, and additional filter condition attributes. The relationships of adjacency, disjointness and subsumption have been encoded, as have composition operators for rule intersection and rule join/combination.
Range-based attributes. Filter condition attributes defined as ranges in the framework, for example, source/destination IP/port ranges, are implemented as interval sets, using the Pyinter Python package [39]. The package was modified to include definitions for relative compliment operators and adjacency over intervals and interval sets.
ICMP and UDP. The ICMP protocol is modelled as the set of all valid ICMP Type/Code pairs, given in Section 4. UDP has been defined as a binary attribute. Boolean operators apply for the UDP filter condition attributes.
TCP. The TCP protocol is encoded as a bit array, whereby the position of each bit is mapped to an index value in a table. This table is the implementation of the object defined in Section 4, and is encoded as the list of TCP (mask, comp) pairs, as pairs of six-bit arrays. A value of at a given position in the bit array indicates that this particular arrangement of TCP flags are matched in the packets specified by the firewall rule. Table 3 gives an overview of the lookup.
Partial TCP lookup table
Index
Mask
Comp
1
‘000000’
‘000000’
2
‘000000’
‘000001’
8
‘000000’
‘000111’
4096
‘111111’
‘111111’
Additional attributes. Attributes for direction-oriented filtering, network interface and iptables chains have been encoded as sets for firewall rules.
Firewall policies. A policy is implemented as a disjoint pair of adjacency-free sets of firewall rules. The adjacency-free sets of rules have been modelled following the approach taken to model the interval-sets in the Pyinter package [39].
Transitive closure of adjacent rules. The transitive closure for the adjacency relation over rules in firewall policies has been implemented recursively, following the approach used in the Pyinter package to implement the transitive closure over adjacent intervals [39]. A set of firewall rules is adjacency-free by construction. When a new rule is added to the ruleset, a check is made firstly to determine if there are any rules in the set that are adjacent to the new rule. If there are none, the new rule is added. Otherwise, the adjacent rules are removed from the ruleset, and rules resulting from the combination of the new rule with the adjacent rules are added to the ruleset, starting again with a check to determine if there are any rules in the set that are adjacent to the new rule.
Evaluating policy operators
Evaluating sequential policy composition. The implementation parses the system’s currently enforced iptables ruleset by chain, and then normalizes each rule to a primitive/singleton policy . The overall policy for the chain is evaluated as . Two datasets were generated for experimentation. Each dataset consists of iptables policies of size . One dataset contains policies where no rule is adjacent to any other rule (other than itself), and the other dataset consists of policies where every new rule is adjacent to the previous rule; to ensure the maximum number of possible rules are generated as a result of composition. The rules all have a target action of allow. Table 4 details the results for the non-adjacent dataset, while the results for the adjacent dataset are illustrated in Table 5.
Sequential composition with no adjacent rules (in seconds)
Num rules
Time
Ratio
0.07
–
0.13
1.85
0.29
2.23
0.67
2.31
1.73
2.58
4.98
2.87
16.09
3.23
57.81
3.59
Sequential composition with adjacent rules (in seconds)
Num rules
Time
Ratio
0.80
–
2.02
2.53
5.13
2.98
15.32
3.34
51.18
3.58
183.42
3.85
707.15
3.85
2792.81
3.94
We observe that as the number of rules increase, the cost of computing the sequential composition of non-adjacent rules is relatively cheap, and we see that for the largest ruleset, , the evaluation time is approximately one minute. For the adjacent dataset, the cost of computing the sequential composition of adjacent rules is expensive, but is also proportional to the number of rules used in the experiment. However, the cost is by orders of magnitude more expensive than the cost for evaluating the sequential composition of non-adjacent policies of the same size. For rules, the time taken for the evaluation of sequential composition is around three minutes, and the time taken for rules is approximately forty six minutes.
Evaluating policy union. Experiments were conducted to test policy lub, whereby each policy in the adjacent dataset used in the sequential composition experiments was split into two policies, whereby the first policy contains the odd (index) rules from the original policy, and the second policy contains the even (index) rules from the original policy. The odd (index) policies are adjacency-free, as are the even (index) policies. Constructing the dataset from the odd-index and even-index policies allows us to evaluate the cost, in terms of time, of composing policies of different sizes, whereby for the policy union experiments, the maximum number of rules are generated as a result of composition. For each in this split dataset, the time taken for the operation is given by Table 6.
Time taken to compute (in seconds)
A benefit of conducting the policy join experiments in this way, is that in practice, we may want to update a policy P, comprising a large number of rules, with a smaller policy Q that permits some new accesses. The time taken for composition of policies of equal size is approximately the same as (slightly less than) the time necessary to sequentially compose the rules from both policies. That is; for example, the time taken for the sequential composition of rules is around three minutes, as is the join of the two policies of size . This is highlighted through the diagonal in the matrix, and is as expected; given that we used all allow rules, and the sequential composition of the rules used in these experiments results in the eventual join of the rules.
Evaluating policy compliance. A dataset consisting of iptables policies of size is generated to test policy compliance. Each policy in this dataset is RFC 5735 compliant by construction, for TCP traffic arriving on the iptables INPUT chain to/from each of the fifteen special-use IPv4 addresses [9]. Recall, the compliance policy defined in Section 6.2 for policies. Rules from the previously defined non-adjacent dataset have been re-written with a target action of , and are used to construct the remaining rules for each policy in the compliance dataset. For each in the compliance dataset, the time taken in seconds for the evaluation of is given in Table 7. We observe that the compliance test has a cheap cost in terms time, and all evaluation times for are negligible.
Time taken to compute (in seconds)
Num rules
Time
Ratio
0.07
–
0.09
1.28
0.15
1.66
0.32
2.13
0.50
1.56
0.87
1.74
1.64
1.88
Implementing duplet join and difference
In this section, the Python prototype implementations of duplet/rule join and duplet/rule difference are defined. We demonstrate how Algorithm 1 (duplet join) and Algorithm 2 (duplet difference) relate to firewall rule composition in . For ease of exposition, we use colours in tables when illustrating rule/duplet composition. The colours used are of no particular significance. The Python implementation is expected to shortly be uploaded to an open-source repository.
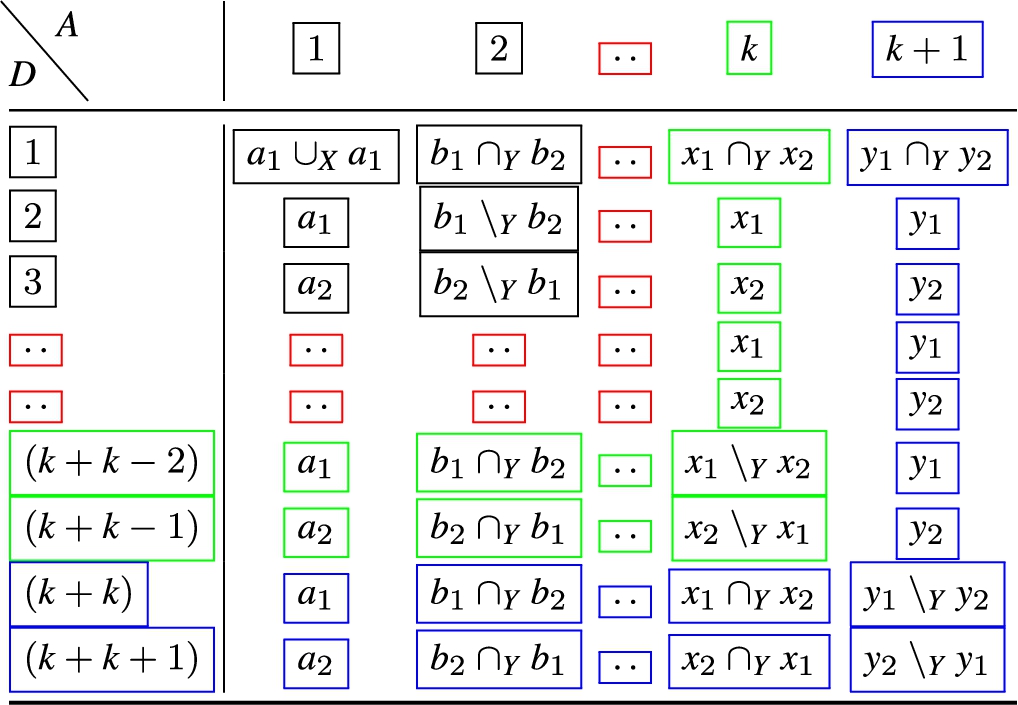
Duplet combination. For , then the combination operation defines a set of adjacency-free duplets that exactly cover f and g.
The operation is described using three recursive functions; center, left and right, and is defined as the set union of the duplets resulting from , and . For ease of exposition, a duplet is given as a sequence of filter condition attributes. We assume f and g always have the same number of attributes. The functions are defined as follows.
Center. For , then defines the join of the adjacent and common attributes in f and g. For duplets comprising two attributes, we define:
Table 8 specifies the operations and duplet resulting from for two-attribute duplets. The label D signifies duplet, while A means the attribute. For f and g of length greater than two, we define for each additional attribute:
Table 9 specifies the operations and duplet resulting from for duplets with three attributes.
function for two-attribute duplets
function for three-attribute duplets
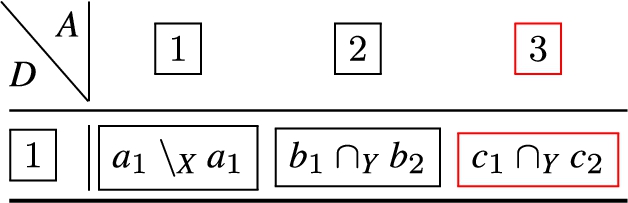
Left. For , then defines the remaining attribute constraints covered in f, that are not covered in . For duplets comprising two attributes, we define:
Table 10 specifies the operations and duplet resulting from for two-attribute duplets. For f and g of length greater than two, we define for each additional attribute:
Table 11 specifies the operations and duplets resulting from for duplets comprising three attributes.
function for two-attribute duplets
function for three-attribute duplets
function for two-attribute duplets
function for three-attribute duplets
Right. For , then defines the remaining attribute constraints covered in g, that are not covered in . For duplets comprising two attributes, we define:
Table 12 specifies the operations and duplet resulting from for two-attribute duplets. For f and g of length greater than two, we define for each additional attribute:
Table 13 specifies the operations and duplets resulting from for duplets comprising three attributes.
Thus, we define the combination operation for f and g as:
The duplet combination operation defines the adjacency-free combination for all, where.
We will show that for , then defines the adjacency-free combination for all , where , using induction on n.
Base case. For , then for , the resulting operations and duplets for f and g as two-attribute duplets are given in Table 14. From these results, we have that Theorem 7.1 holds when .
A two-attribute duplet join
A k-attribute duplet join
A -attribute duplet join
Inductive hypothesis. Suppose Theorem 7.1 holds for , where , and . Then for , the resulting operations and duplets for f and g as k-attribute duplets are given in Table 15.
Inductive step. Let . Then by the recursive definitions of , and , the resulting operations and duplets for f and g as -attribute duplets in are given in Table 16. Therefore, from these results, we have that Theorem 7.1 holds for . By the principal of mathematical induction, the theorem holds for all , where . □
Algorithm 1 summarises the duplet combination operation, whereby the input is a pair of duplets , the number of attributes (), and an empty list () to hold the result. The output is the list (), whereby .
Duplet combination operation
A bottom-up approach to duplet join. Recall, the definition for the join operation of given in Section 3.3 is constructed following a top-down approach with respect to the ordering relation ⩽, whereby:
For all , we define the implementation definition for sets of adjacency-free duplets as:
Adjacency duplet union implementation. The implementation definition for the join of is defined as the cover-set for the duplet merge of the transitive closure of adjacent duplets, from the coverset for the generalized union of sets from the duplet combination operation (), for all transitively adjacent duplets in S and T. The coverset for the generalized union defines the smallest collection of duplets that cover all of the duplets from both S and T by precedence subsumption. Given that all duplets in this set are now disjoint, the cover-set for the duplet merge of the transitive closure of adjacent duplets merges any forward-adjacent duplets from S and T. If we take some , such that and , then . Thus, the implementation definition for duplet Adjacency-set join provides a lowest upper bound operator.
The two given definitions for joining sets of adjacency-free duplets are equivalent.
Given that both definitions define the cover-set for the duplet merge of the transitive closure of forward adjacent duplets from the smallest collection of disjoint adjacency-free duplets that cover all of the duplets from both S and T by precedence subsumption, then Theorem 7.2 holds. □
Duplet difference. For , the operation defines a set of adjacency-free duplets that are covered by f but not by g. The operation is described using two recursive functions; center, and the left function given previously. The function is defined as the set union of the duplets resulting from and .
difference function for two-attribute duplets
difference function for three-attribute duplets
A two-attribute duplet difference
A k-attribute duplet difference
Center. For , then for duplets comprising two attributes; is defined as follows:
The operations and duplet resulting from for two-attribute duplets are given in Table 17. For f and g of length greater than two, we define for each additional attribute:
The operations and duplet resulting from for duplets with three attributes are given in Table 18. Thus, we define the difference operation for f and g as:
The duplet difference operation defines the adjacency-free duplet-difference for all, where.
We will show that for , then defines the adjacency-free duplet difference for all , where , using induction on n.
Base case. For , then for , the resulting operations and duplets for f and g as two-attribute duplets are given in Table 19. From these results, we have that Theorem 7.3 holds when .
Inductive hypothesis. Suppose Theorem 7.3 holds for , where , and . Then for , the resulting operations and duplets for f and g as k-attribute duplets are given in Table 20.
A -attribute duplet difference
Duplet difference operation
Inductive step. Let . Then by the recursive definitions of and , the resulting operations and duplets for f and g as -attribute duplets in are given in Table 21. Therefore, from the results we observe that Theorem 7.3 holds for . By the principal of mathematical induction, the theorem holds for all , where . □
Algorithm 2 summarises the duplet difference operation, whereby the input is a pair of duplets , the number of attributes (), and an empty list () to hold the result. The output is the list (), whereby .
Related work
There is a rich literature of work on managing firewall policy configurations. For example, The goal of [2,3,8,10,23,44] is to provide an administrator with the means to detect/resolve anomalies, and work such as [15,17,34,35] allows for querying a policy configuration with regard to the filtering of specific network traffic. High-level specification languages such as [1,4,12,26,31] allow an administrator to abstractly specify what would otherwise be low-level rules. However, in general, the literature for policy management is focused on the conventional five-tuple firewall rule with a binary target action of or , and few have considered stateful firewall configurations.
Hari et al. [27] report some of the earliest research on conflict detection and resolution in policies for packet-filters, and model rule relations within a policy in a directed graph. Al-Shaer et al. [2,3] provide definitions for firewall policy anomalies. The authors use a form of Binary Decision Diagram (BDD) to represent a firewall policy, and define relationships between pairwise rules. The Firewall Policy Advisor [2] tool implements algorithms used to identify firewall rule anomalies using set theory. In this paper, we use a subset of the classifications from [2,3] when reasoning about firewall policy anomalies. Cuppens et al. [10] and García-Alfaro et al. [24], present MIRAGE (MIsconfiguRAtion manaGEr), and provide definitions alternative to[2,3] for intra- and inter-firewall policy anomalies. Given a firewall configuration, MIRAGE will automatically detect and remove intra-redundant [10,24] and intra-shadowed [10,24] rules, and generate a semantically-equivalent order-independent set of disjoint rules that are anomaly-free. In contrast to [27], the approach incorporates the automatic re-writing of anomalous rules. Yuan et al. [44] present the FIREMAN (FIREwall Modelling ANalysis) tool. Policy configurations are analysed for inconsistencies that consider intra-shadowing, intra-generalisation, intra-correlation and inter-shadowing anomalies [2,3]. Firewall inefficiency in packet classification and memory consumption is also considered as a result of intra-redundant rules, and ‘verbosities’, whereby a set of rules may be summarized into a smaller number of rules without changing the filtering semantics of the policy. Chomsiri and Pornavalai [8] propose a method of firewall policy analysis using relational algebra. The definitions provided for intra-redundant and intra-shadowed rules are analogous to [10], and upon detection, such rules are removed in order to reduce the size of the policy. The definitions given for intra-generalization and intra-correlation are analogous to [2]. Similar to the notion of verbosities in [44], Chomsiri and Pornavalai propose combining rules that may be ‘summarized’ without changing the filtering semantics of the policy. Buttyán et al. [7] propose a tool based on FIREMAN [44] for managing anomalies in stateful firewall policies. The authors argue that verifying a stateful firewall for inconsistencies can be reduced to the problem of verifying a stateless firewall for inconsistencies. A limitation of the approach is that their model does not distinguish rules with different state information, that is, for example, there is no differentiation between the establishment and termination phase of a given stateful protocol, and as a consequence, they do not consider more complex anomalies that may occur specifically in the stateful case. Cuppens et al. [11] and García-Alfaro et al. [23] propose an algorithmic approach to detect and resolve anomalies in a stateful firewall policy. A connection-oriented protocol is modelled using general automata, whereby the permitted protocol states and transitions are encoded. Intra-redundant and intra-shadowed rules [10] are considered for the stateful firewall policy. Further definitions are proposed, whereby an intra-state anomaly occurs in a stateful firewall policy if there are policy rules that partially match (complete) the paths of the protocol automata. In the case of missing rules, then covering-rules are suggested to the administrator as a means of completing the path of the protocol automata. Their work also considers invalid protocol states, and inter-state anomalies that may occur in a firewall policy that filters packets against both stateful and stateless rules. The work in [11,23] also extends the MIRAGE [24] tool. To consider the types of stateful anomalies from [23] in the proposed model , then it would be necessary to apply additional constraints when constructing and composing anomaly-free firewall policies. For example, a policy that specifies a firewall rule that enables the establishment of a TCP connection from host X to host Y, should also include rules that allow for the various other permissible transitions of the TCP protocol.
Firewall query analysis allows an administrator to pose questions of a policy configuration, such as, for example, “does the policy permit SSH traffic from system X to system Y?”. Mayer et al. [35], present Fang (Firewall ANalysis enGine). Based on graph algorithms and a rule-base simulator, Fang parses vendor-specific firewall policy and configuration files, and constructs a model of the network topology and a global firewall policy for the network. Fang interacts with the administrator through a query-and-answer session, and queries are constructed as triples, consisting of source IPs, destination IPs and endpoint services/ports. Eronen and Zitting [15] propose an expert system for query analysis, implemented in constraint programming logic. A query is constructed as a six-tuple, consisting of source and destination IP and port, network protocol, and flags. The flags attribute is for TCP connections, however, only the SYN and ACK flags are considered. Eronen and Zitting argue that in comparison to Fang [35], the expert system is a more natural solution for query analysis. Liu et al. [34] present the Structured Firewall Query Language (SFQL), an SQL-like query language. Liu et al. state that constructing an expert system such as [15] “just for analysing a firewall is overwrought and impractical” [34], however, they do not give their reasoning for this assertion. SFQL queries can be constructed over and rules for an arbitrary number of filter fields. While query analysis provides an administrator with a means of asking questions of a firewall policy, what can actually be queried is restricted by the collection of filter condition attributes and target actions expressible in the query language. Effective query analysis may be further hampered by the complexity of the query language, or through an administrators inability to construct useful queries. A consequence of the algebra proposed in this paper, is that it enables an administrator to perform effective query analysis of a firewall policy configuration. While we do not construct individual high-level queries, we do however demonstrate how policies in the algebra may be tested/queried for compliance with best practice standards and recommendations.
High-level specification languages provide an administrator with the means to reduce the complexity of constructing a firewall policy configuration. Guttman [26] reported some of the earliest research in this area. Bartal et al. [4] present the Firmato toolkit. The proposed specification language allows an administrator to specify the network security policy and the topology for the network in terms of an entity-relationship (ER) model. Subsequently, a policy configuration is synthesised from the ER model. A limitation of the work is that it only applies to packet-filter policy configurations. The High Level Firewall Language (HLFL) [31] translates high-level firewall rules into usable rulesets for iptables, Cisco ACLs, IPFW and others. However, the generated rulesets are order-dependant and may contain anomalies, and the approach does not provide support for incorporating knowledge about a network topology when specifying the high-level rules. Fitzgerald and Foley [17] propose using ontologies to represent knowledge about firewall policy configurations. Policies are specified using Description Logic and SWRL. Semantic Threat Graphs [21] are used to encode catalogues of best practice firewall rules, and an automated synthesis of standards-compliant rules for a policy configuration is considered. However, the administrator must manually construct the rulesets for the catalogues then populate the Semantic Threat Graphs, and this process is error-prone. The proposed model in [17] can also be used for firewall policy query analysis. Adão et al. [1] propose a declarative policy specification language, and present Mignis, a tool that translates high-level access control specifications into low-level policy configurations for Netfilter. An abstract model of the Netfilter firewall is proposed, and definitions for Network Address Translation and stateful filtering are encoded. The synthesised policies consist of order-independent iptables firewall rules. However, the proposed approach is tightly coupled with Netfilter. Brucker et al. [6] present a formal model of both stateless and stateful firewalls, including Network Address Translation. The authors follow a theorem-proving approach to reason about firewall policies, and provide formal and machine-verifiable proof of correctness using the Isabelle theorem prover. Diekmann et al. [14] present a fully verified firewall ruleset analysis framework for iptables, that similar to Brucker et al. [6], also provides proof of correctness using Isabelle. In this paper, we use the Z notation to provide a consistent syntax for systematically presenting the proposed model . Mathematical definitions have been syntax- and type-checked, however the proofs in this paper are of the conventional pen-and-paper variety.
We model a firewall policy as an ordered pair of disjoint adjacency-free sets, where the set of policies forms a lattice under ⊑, and each is anomaly-free by construction. In [2,3,10,27,44] an algorithmic approach is taken to detect/resolve anomalies. In contrast, we follow an algebraic approach towards modelling anomalies in a single policy, and across a distributed policy configuration through policy composition. In [45], a firewall policy algebra is proposed. However, the authors note that an anomaly-free composition is not guaranteed as a result of using their algebraic operators. Our work differs, in that policy composition under the ⊓, ⊔ and ⨾ operators defined in this paper all result in anomaly-free policies. In earlier work [22], we developed the algebra , and used it to reason over host-based and network access controls in OpenStack. In the algebra, we focused on stateless firewall policies that are defined in terms of constraints on individual IPs, ports and protocols. In this paper, the algebra is defined over stateful firewall policies constructed in terms of constraints on source/destination IP/port ranges, the TCP, UDP and ICMP protocols, and additional filter condition attributes. We argue that gives a more expressive means for reasoning over OpenStack security group and perimeter firewall configurations. In [30], cloud calculus is used to capture the topology of cloud computing systems and the global firewall policy for a given configuration. This paper could extend the work in [30], given that may be used in conjunction with cloud calculus to guarantee anomaly-free dynamic firewall policy reconfiguration, whereby the ordering relation ⊑ may give a viable alternative for the given equivalence relation defined over ‘cloud’ terms for the formal verification of firewall policy preservation after a live migration. The proposed algebra is used to reason about and compose anomaly-free policies and therefore we do not have to worry about dealing with conflicts that may arise. Anomaly conflicts are dealt with in composition by computing anomaly-free policies, rather than using techniques such as [29] to resolve conflicts in policy decisions.
Conclusion
A policy algebra is defined in which firewall policies can be specified and reasoned about. At the heart of this algebra is the notion of safe replacement, that is, whether it is secure to replace one firewall policy by another. The set of policies form a lattice under safe replacement and this enables consistent operators for safe composition to be defined. Policies in this lattice are anomaly-free by construction, and thus, composition under glb and lub operators preserves anomaly-freedom. A policy sequential composition operator is also proposed that can be used to interpret firewall policies defined more conventionally as sequences of rules. The algebra can be used to characterize anomalies, such as shadowing and redundancy, that arise from sequential composition. Best practice policy compliance may be defined using ⊑. The algebra provides a formal interpretation of the network access controls for a partial mapping to the iptables filter table.
is a generic algebra and can also be used to model other firewall systems. The results in this paper are described in terms of the algebra , for stateful firewall policies that are defined in terms of constraints on source/destination IP/port ranges, the TCP, UDP and ICMP protocols, and additional filter condition attributes.
Footnotes
Acknowledgments
The authors would like to thank the anonymous reviewers for their valuable feedback. This work was supported, in part, by Science Foundation Ireland under grant SFI 10/CE/I1853 and Irish Research Council/Chist-ERA.
The Z notation
A set may be defined in Z using set specification in comprehension. This is of the form , where D represents declarations, P is a predicate and E an expression. The components of are the values taken by expression E when the variables introduced by D take all possible values that make the predicate P true. For example, the set of squares of all even natural numbers is defined as . When there is only one variable in the declaration and the expression consists of just that variable, then the expression may be dropped if desired. For example, the set of all even numbers may be written as . Sets may also be defined in display form such as .
In Z, relations and functions are represented as sets of pairs. A (binary) relation R, declared as having type , is a component of , where is the powerset of X. For and , then the pair is written as , and means that a is related to b under relation R. Functions are treated as special forms of relations. The schema notation is used to structure specifications. A schema such as defines a collection of variables (limited to the scope of the schema) and specifies how they are related. The variables can be introduced via schema inclusion, as done, for example, in the definition of sequential composition.
References
1.
P.Adão, C.Bozzato, G.Dei Rossi, R.Focardi and F.L.Luccio, Mignis: A semantic based tool for firewall configuration, in: Computer Security Foundations Symposium (CSF), 2014 IEEE 27th, IEEE, 2014, pp. 351–365. doi:10.1109/CSF.2014.32.
2.
E.Al-Shaer and H.Hamed, Firewall policy advisor for anomaly discovery and rule editing, in: 8th IFIP/IEEE International Symposium on Integrated Network Management, Colorado Springs, USA, March, 2003.
3.
E.Al-Shaer, H.Hamed, R.Boutaba and M.Hasan, Conflict classification and analysis of distributed firewall policies, IEEE Journal on Selected Areas in Communications23(10) (2005), 2069–2084.
4.
Y.Bartal, A.Mayer, K.Nissim and A.Wool, Firmato: A novel firewall management toolkit, in: 20th IEEE Symposium on Security and Privacy, Oakland, CA, USA, May, 1999.
5.
G.Birkhoff, Lattice Theory, 3rd edn, American Mathematical Society Colloquium Publications, Vol. XXV, American Mathematical Society, 1967.
6.
A.D.Brucker, L.Brügger and B.Wolff, Formal firewall conformance testing: An application of test and proof techniques, Softw. Test. Verif. Reliab.25(1) (2015), 34–71. doi:10.1002/stvr.1544.
7.
L.Buttyán, G.Pék and T.V.Thong, Consistency verification of stateful firewalls is not harder than the stateless case, Infocommunications Journal64(1) (2009), 2–8.
8.
T.Chomsiri and C.Pornavalai, Firewall rules analysis, in: International Conference on Security and Management (SAM), Las Vegas, Nevada, USA, June, 2006.
9.
M.Cotton and L.Vegoda, Special use IPv4 addresses, RFC 5735, January 2010.
10.
F.Cuppens, N.Cuppens-Boulahia and J.García-Alfaro, Detection and removal of firewall misconfiguration, in: IASTED International Conference on Communication, Network and Information Security (CNIS), November, 2005.
11.
F.Cuppens, N.Cuppens-Boulahia, J.García-Alfaro, T.Moataz and X.Rimasson, Handling stateful firewall anomalies, in: Information Security and Privacy Research – 27th IFIP TC 11 Information Security and Privacy Conference, SEC 2012, Heraklion, Crete, Greece, June 4–6, Proceedings, 2012, pp. 174–186.
12.
F.Cuppens, N.Cuppens-Boulahia, T.Sans and A.Miège, A formal approach to specify and deploy a network security policy, in: 2nd Workshop on Formal Aspects in Security and Trust (FAST), August, 2004.
13.
D.E.Denning, A lattice model of secure information flow, Commun. ACM19(5) (1976), 236–243. doi:10.1145/360051.360056.
14.
C.Diekmann, J.Michaelis, M.P.L.Haslbeck and G.Carle, Verified iptables firewall analysis, in: 2016 IFIP Networking Conference, Networking 2016 and Workshops, Vienna, Austria, May 17–19, IEEE, 2016, pp. 252–260. doi:10.1109/IFIPNetworking.2016.7497196.
15.
P.Eronen and J.Zitting, An expert system for analyzing firewall rules, in: 6th Nordic Workshop on Secure IT Systems (NordSec), Copenhagen, Denmark, November, 2001, pp. 100–107.
16.
M.Fabrice, iptables extensions – time module, http://ipset.netfilter.org/iptables-extensions.man.html (accessed February 2017).
17.
W.M.Fitzgerald and S.N.Foley, Management of heterogeneous security access control configuration using an ontology engineering approach, in: 3rd ACM Workshop on Assurable and Usable Security Configuration, SafeConfig 2010, Chicago, IL, USA, October 4, 2010, pp. 27–36.
18.
W.M.Fitzgerald, U.Neville and S.N.Foley, MASON: Mobile autonomic security for network access controls, Journal of Information Security and Applications (JISA)18(1) (2013), 14–29. doi:10.1016/j.jisa.2013.08.001.
19.
S.N.Foley, Reasoning about confidentiality requirements, in: Seventh IEEE Computer Security Foundations Workshop – CSFW ’94, Franconia, New Hampshire, USA, June 14–16, Proceedings, 1994, pp. 150–160. doi:10.1109/CSFW.1994.315939.
20.
S.N.Foley, The specification and implementation of commercial security requirements including dynamic segregation of duties, in: ACM Conference on Computer and Communications Security, 1997, pp. 125–134.
21.
S.N.Foley and W.M.Fitzgerald, An approach to security policy configuration using semantic threat graphs, in: 23rd Annual IFIP WG 11.3 Working Conference on Data and Applications Security (DBSec), LNCS, Springer, 2009, pp. 33–48.
22.
S.N.Foley and U.Neville, A firewall algebra for openstack, in: 2015 IEEE Conference on Communications and Network Security, CNS 2015, Florence, Italy, September 28–30, 2015, pp. 541–549. doi:10.1109/CNS.2015.7346867.
23.
J.García-Alfaro, F.Cuppens, N.Cuppens-Boulahia, S.Martínez Perez and J.Cabot, Management of stateful firewall misconfiguration, Computers & Security39 (2013), 64–85. doi:10.1016/j.cose.2013.01.004.
24.
J.García-Alfaro, F.Cuppens, N.Cuppens-Boulahia and S.Preda, MIRAGE: A management tool for the analysis and deployment of network security policies, in: Data Privacy Management and Autonomous Spontaneous Security – 5th International Workshop, DPM 2010 and 3rd International Workshop, SETOP 2010, Athens, Greece, September 23, Revised Selected Papers, 2010, pp. 203–215.
25.
L.Gheorghe, Designing and Implementing Linux Firewalls with QoS Using Netfilter, iproute2, NAT and l7-Filter, PACKT Publishing, 2006.
26.
J.D.Guttman, Filtering postures: Local enforcement for global policies, in: IEEE Symposium on Security and Privacy, May, 1997, pp. 120–129.
27.
A.Hari, S.Suri and G.Parulkar, Detecting and resolving packet filter conflicts, in: 19th Annual Joint Conference of the IEEE Computer and Communications Societies, INFOCOM, Vol. 3, 2000, pp. 1203–1212.
28.
J.L.Jacob, The varieties of refinement, in: Proceedings of the 4th Refinement Workshop, J.M.Morris and R.C.Shaw, eds, Springer, Heidelberg, 1991, pp. 441–455. doi:10.1007/978-1-4471-3756-6_19.
29.
S.Jajodia, P.Samarati, M.L.Sapino and V.S.Subrahmanian, Flexible support for multiple access control policies, ACM Trans. Database Syst.26(2) (2001), 214–260. doi:10.1145/383891.383894.
30.
Y.Jarraya, A.Eghtesadi, M.Debbabi, Y.Zhang and M.Pourzandi, Cloud calculus: Security verification in elastic cloud computing platform, in: International Conference on Collaboration Technologies and Systems (CTS), IEEE, 2012, pp. 447–454. doi:10.1109/CTS.2012.6261089.
31.
A.Launay, High level firewall language, 2003, https://www.cusae.com/hlfl/ (accessed August 2016).
A.Liu, M.Gouda, H.Ma and A.Hgu, Firewall queries, in: 8th International Conference on Principles of Distributed Systems (OPODIS), Grenoble, France, December, 2004, pp. 197–212.
35.
A.Mayer, A.Wool and E.Ziskind, Fang: A firewall analysis engine, in: 21st IEEE Symposium on Security and Privacy, Oakland, CA, USA, May, 2000.
36.
V.Nebehaj, Python-iptables – Python bindings for iptables, https://pypi.python.org/pypi/python-iptables (accessed August 2016).
37.
Netfilter Core Team, Linux iptables – CLI for configuring the Linux kernel firewall, Netfilter, http://www.netfilter.org/projects/iptables/index.html (accessed February 2017).
38.
U.Neville and S.N.Foley, Reasoning about firewall policies through refinement and composition, in: Data and Applications Security and Privacy XXX – 30th Annual IFIP WG 11.3 Conference, DBSec 2016, Trento, Italy, July 18–20, Proceedings, 2016, pp. 268–284.
39.
I.Ocean, Pyinter – a small and simple library written in Python for performing interval and discontinous range arithmetic, 2015, https://pypi.python.org/pypi/pyinter/ (accessed August 2016).
40.
J.Postel, D.Johnson, T.Markson, B.Simpson and Z.Su, Internet control message protocol (ICMP) parameters, 2013, https://www.iana.org/assignments/icmp-parameters/icmp-parameters.xhtml (accessed February 2017).
41.
K.Scarfone and P.Hoffman, Guidelines on firewalls and firewall policy: Recommendations of the National Institute of Standards and Technology, NIST Special Publication 800-41, Revision 1, September 2009.
42.
J.M.Spivey, The Z Notation: A Reference Manual, 2nd edn, Series in Computer Science, Prentice Hall International, 1992.
43.
A.Wool, Trends in firewall configuration errors: Measuring the holes in Swiss cheese, IEEE Internet Computing14(4) (2010), 58–65. doi:10.1109/MIC.2010.29.
44.
L.Yuan, H.Chen, J.Mai, C.Chuah, Z.Su and P.Mohapatra, Fireman: A toolkit for firewall modeling and analysis, in: 2006 IEEE Symposium on Security and Privacy, IEEE, 2006, 15 pp. doi:10.1109/SP.2006.16.
45.
H.Zhao and S.M.Bellovin, Policy algebras for hybrid firewalls, Number CUCS-017-07, March 2007.