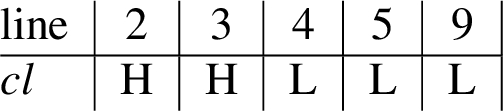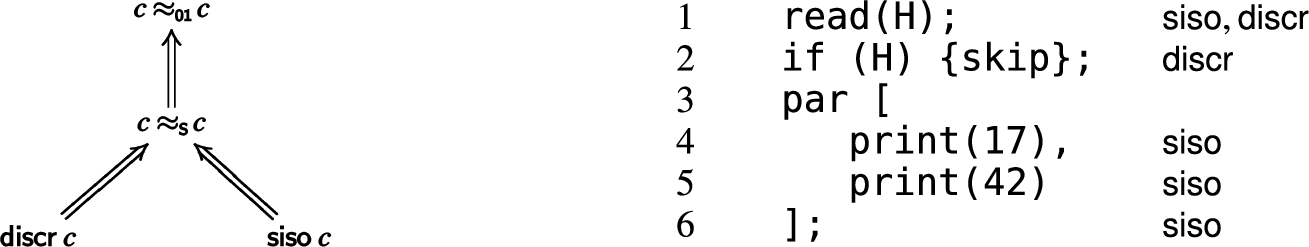We present a new algorithm, together with a full soundness proof, which guarantees probabilistic noninterference (PN) for concurrent programs. The algorithm follows the “low-deterministic security” (LSOD) approach, but for the first time allows general low-nondeterminism as long as PN is not violated.
The algorithm is based on the earlier observation by Giffhorn and Snelting that low-nondeterminism is secure as long as it is not influenced by high events [International Journal of Information Security14 (2015) 263–287]. It uses a new system of classification flow equations in multi-threaded programs, together with inter-thread/interprocedural dominators. Compared to LSOD, precision is boosted and false alarms are minimized. We explain details of the new algorithm and its soundness proof.
The algorithm is integrated into the JOANA software security tool, and can handle full Java with arbitrary threads. We apply JOANA to a multi-threaded e-voting system, and show how the algorithm eliminates false alarms. We thus demonstrate that low-deterministic security is a highly precise and practically mature software security analysis method.
Information flow control (IFC) analyses a program’s source or byte code for security leaks, namely violations of confidentiality and integrity. IFC algorithms usually check some form of noninterference [33]. Sound IFC algorithms guarantee to find all leaks, while precise algorithms generate no false alarms. Unfortunately, perfect precision and soundness cannot be achieved together: the famous Rice theorem states that such perfect program analysis is undecideable. Thus many algorithms and definitional variations for noninterference have been proposed, which vary in precision, scalability, language restrictions, necessary annotations, and other factors.
Concurrent or multi-threaded programs introduce new threats to security, as nondeterminism and interleaving can create subtle leaks which are much more difficult to find or prevent than in sequential programs. For multi-threaded programs, probabilistic noninterference (PN) as introduced in [34–36] is the established security criterion. One of the oldest and simplest criteria which enforces PN is low-security observational determinism (LSOD), as introduced by Roscoe [32], and improved by Zdancewic, Huisman, and others [17,41]. For LSOD, a relatively simple static check can be devised; furthermore LSOD is scheduler independent – which is a big advantage. However Huisman and other researchers found subtle soundness problems in earlier LSOD algorithms (which were mostly related to nonterminating programs), so Huisman concluded that scheduler-independent PN is not feasible [16]. Worse, LSOD strictly prohibits any, even secure low-nondeterminism – which makes LSOD unsuitable for practical purposes.
It is the aim of this article to demonstrate that improvements to LSOD can be devised, which invalidate these earlier objections. An important step was already provided by Giffhorn [7,8] who discovered that
an improved definition of low-equivalent traces can solve earlier soundness problems for infinite traces and nonterminating programs;
flow- and context-sensitive program analysis is the key to a precise and sound LSOD algorithm;
the latter can naturally be implemented through the use of program dependence graphs;
additional support by may-happen-in-parallel analysis, precise points-to analysis and exception analysis makes LSOD work and scale for full Java;
secure low-nondeterminism can be allowed by relaxing the strict LSOD criterion, while maintaining soundness.
Giffhorn’s algorithm was the first to allow low-nondeterminism, while basically maintaning the LSOD approach. The algorithm was described in detail in [8,14]; it is integrated into the JOANA IFC tool.2
see joana.ipd.kit.edu. JOANA can analyse full Java with arbitrary threads, and was applied in various projects [10,19,21,26]. Usage of JOANA is described in [11].
But Giffhorn’s discovery was just a first step. In this paper, we describe new improvements for LSOD, which boost precision and reduce false alarms compared to original LSOD and even Giffhorn’s algorithm. We first recapitulate technical properties of PN and LSOD. We then explain the new relaxed LSOD (RLSOD)3
Giffhorn’s original criterion was called RLSOD in [4,8,38], and the new criterion was called iRLSOD in [4]. In this article, the iRLSOD criterion and its improvements are called RLSOD, while Giffhorn’s original criterion is called “Giffhorn’s algorithm”.
criterion in detail. It is based on the notion of dominance in threaded control flow graphs, and on fixpoint iteration in program dependence graphs.
The main contribution of this article, as compared to the preceding conference version [4], is a full soundness proof, which in turn led to an even more general formulation of the RLSOD criterion. RLSOD was recently integrated into JOANA. We present a case study, namely a prototypical e-voting system with multiple threads, as well as performance and scalability measurements.4
Our work builds heavily on our earlier contributions [8,14], but the current article is aimed to be self-contained. We begin with an overview of the RLSOD framework and its attacker model.
The RLSOD framework and its assumptions
Language assumptions
The RLSOD approach is based on Program Dependence Graphs (PDGs, see Section 4.1 for details) and thus can be used with any imperative or object-oriented language for which a PDG can be constructed. PDGs are naturally flow- and context-sensitive, thus improving precision (see below). PDG construction must be sound and will then fulfill the assumptions of the slicing theorem (Section 4.1); sound PDGs have been constructed for C, full Java (see [14]), and many other languages. Thus there are no restrictions on language or control flow. In the current paper, we assume a simple imperative language with procedures and threads; a formal PDG construction for this language, together with a machine-checked soundness proof was provided in [40]. We would however like to point out some additional assumptions for multi-threaded programs.
We assume that statements resp. byte codes are deterministic, and that nondeterminism can only arise from scheduling choices. In particular, for a given statement, results and chosen branch (for conditionals) only depend on values read by the statement. The program can read input via input statements and produce output via output statements. At the beginning of execution, the statement is the only statement that can be scheduled.5
JOANA can also handle the Android Life cycle, see [26].
After executing a statement, its dynamic control flow successors can be scheduled (i.e. for conditionals, the first statement from the chosen branch; for forks the intra-thread successor and the first statement of the forked thread).
We therefore assume – like most other authors, e.g. [25,35] – interleaving semantics. Under the Java Memory Model, the compiler may, e.g. through reordering, in rare cases produce code which is not consistent with interleaving semantics. Allowing such behavior limits static analysis considerably, so most authors ignore this possibility.
We also assume that the program always terminates. Possibly nonterminating programs, e.g. truly interactive programs, lead to the problem of termination leaks [2]. Subtleties regarding nontermination are discussed in Section 4.2. Since we assume terminating programs, we can ignore those problems.
Scheduler assumptions
RLSOD requires that the scheduler is truly probabilistic. This means that for two statements and that can be scheduled, the relative probability to be scheduled next is independent of other possibly running threads, current program state, or the execution up to this point. It might however depend on the statements and themselves.6
Note that this is less restrictive than a uniform scheduler, where that relative probability is always 1. A truly probabilistic scheduler on the other hand can assign priorities to statements, e.g. increase the priorities for all statements of a specific (syntactic) thread.
The necessity of this assumption was stressed by various authors, e.g. [29,35]. To illustrate it, we assume a standard low/high classification for program variables (see Section 3 for details). A malicious scheduler can then easily read high values to construct an explicit flow by scheduling, as in
the scheduler can leak H by scheduling the L assignments after reading H, such that the first visible L assignment represents H.
Even if the scheduler is not malicious, but follows a deterministic strategy which is known to the attacker, leaks can result. As an example, consider Fig. 1. Assume deterministic round-robin scheduling which executes 3 basic statements per time slice. Then for H=1 statements are executed, while for H=0, statements are executed. Thus the attacker can observe the public event sequence 9→5 resp. 5→9, leaking H. However under the assumption of truly probabilistic scheduling, Fig. 1 is probabilistic noninterferent.
Deterministic round-robin scheduling may leak.
Thus allowing round robin schedulers severely restricts secure programs. This phenomenon has been observed by earlier authors (see Section 9 for details). RLSOD accepts the example in Fig. 1 as secure and therefore is not sound when used with round-robin. Probabilistic scheduling is the price to pay for RLSOD’s much better precision and freedom from program restrictions. We believe that in practice, scheduler restrictions are more acceptable than program restrictions or false alarms.
Attacker model
The traditional sequential attacker model assumes that the attacker can see the low part of both the initial state and the final state. Additionally, a static classification of all program variables is assumed. This means the attacker can see one part of the memory, but cannot see the other. For programming languages like C or Java, which include local variables and thus use an activation record stack, this implies that the memory addresses the attacker can observe change during execution. We therefore believe that this attacker model is unrealistic. Thus we assume that the attacker cannot see any internal memory of the program, and instead can only see low external input or low output events. The engineer has to provide information about the set of input and output statements and their classification. We further assume that the attacker might see multiple runs with the same input. For multi-threaded (nondeterministic) programs, where the probability of attacker-observable behaviors depends on the secret, the attacker might infer something about the secret by counting the different low-observable behaviors. This motivates the use of probabilistic noninterference.
The role of flow- and context-sensitivity
PDGs have been chosen as the basis for JOANA and RLSOD because PDGs are automatically flow- and context-sensitive. That is, they respect statement order, and respect call sites of procedures. In contrast, most security type systems are flow-insensitive, and even the flow-sensitive type system in [18] is not context-sensitive. Thus statement order is ignored, and all call sites of a procedure are merged; this heavily reduces precision and increases false alarms (see [13,14] for a more detailed discussion; Section 9 presents additional examples). In the current paper, all definitions and proofs assume flow-sensitivity; this explains why some definitions differ from their “classical” version.
But note that there is a price to pay for flow- and context-sensitivity: RLSOD is not compositional. That is, RLSOD always needs the complete source or byte code. In practice however, stubs for missing functions can be used, which “simulates” compositionality (see case study in Section 7). Compositionality is discussed in more detail in Section 9.
Noninterference and LSOD
IFC guarantees that no violations of confidentiality or integrity may occur. For confidentiality, program variables are classified as “high” (H, secret) or “low” (L, public), and it is assumed that an attacker can see low values, but cannot see any high value.7
A more detailed discussion of IFC attacker models can be found in e.g. [8]. Note that JOANA allows arbitrary lattices of security classifications, not just the simple lattice. Note also that integrity is dual to confidentiality, but will not be discussed here. JOANA can handle both.
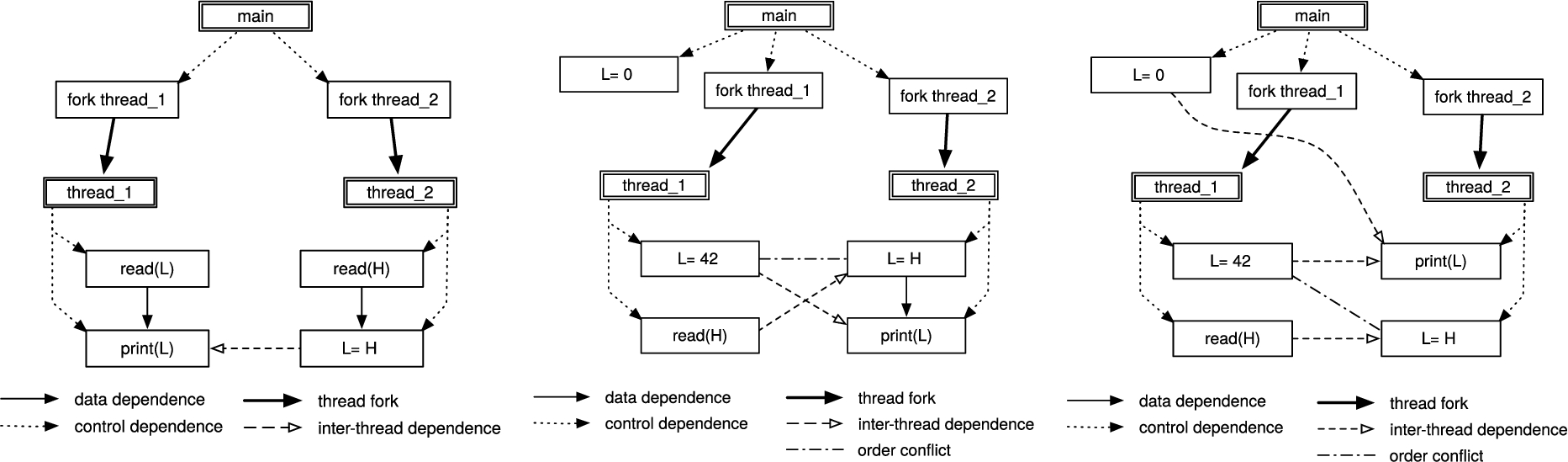
Figure 2 presents small but typical confidentiality leaks. As usual, variable H is “High” (secret), L is “Low” (public). Explicit leaks arise if (parts of) high values are copied (indirectly) to low output. Implicit leaks arise if a high value can change control flow, which can change low behaviour (see Fig. 2 left). Possibilistic leaks in concurrent programs arise if a certain interleaving produces an explicit or implicit leak; in Fig. 2 middle, interleaving order 5, 8, 9, 6 causes an explicit leak. Probabilistic leaks arise if the probability of low output is influenced by high values; in Fig. 2 right, H is never copied to L, but if the value of H is large, probability is higher that “JCS” is printed instead of “CSJ”. Thus when the program is run multiple times, by observing the distribution of results, the attacker can obtain information about the secret, namely estimations of the value of H.
Some leaks. Left: explicit and implicit, middle: possibilistic, right: probabilistic. For simplicity, we assume that read(L) reads low variable L from a low input channel; print(H) prints high variable H to a high output channel. Note that reads of high variables are classified high, and prints of low variables are classified low.
Sequential noninterference
Before we formalize RLSOD, let us repeat the classical definition of sequential noninterference. The classic definition assumes that a global and static classification of all program variables v as secret (H) or public (L) is given. It therefore assumes that the whole memory is divided into a part the attacker can observe and a part hidden from the attacker. Note that flow-sensitive IFC such as RLSOD does not use a static, global classification of variables; this will be explained in Section 4.1 (Definition 9).
(Sequential noninterference).
Letbe a program. Letbe initial program states, let,be the final states after executingin state s resp.. Noninterference holds iff
The relation means that two states are low-equivalent, that is, coincide on low variables: . Classically, program input is assumed to be part of the initial states , and program output is assumed to be part of the final states; the definition can be generalized to work with explicit input and output streams.
Probabilistic noninterference
In multi-threaded programs, fine-grained interleaving effects must be accounted for, thus traces are used instead of states. Through loops or recursion, a statement might be executed multiple times within a trace. To distinguish those, we use the concept of operations as in [7]. A trace is a sequence of events where the are operations (i.e. dynamically executed program statements ; we write ). Operations are unique within a trace. are the states before resp. after executing . We write ε for the empty trace. Since we assume programs to be terminating, all traces are finite.
For PN, the notion of low-equivalent traces is essential. Classically, traces are low-equivalent if for every , , it holds that and . This definition enforces a rather restrictive lock-step execution of both traces. Later definitions (e.g. [35]) use stutter equivalence instead of lock-step equivalence; thus allowing one execution to run faster than the other (“stuttering” means that one trace performs additional operations which do not affect public behaviour). To formalize PN, we begin with
N denotes the set of all program statements,the input statements (“sources”),the output statements (“sinks”),the classification of sources and sinks as provided by the user (“engineer”).
The following definition of low-equivalent traces assumes flow-sensitivity. It is slightly more complex than the “classical” definition, but increases precision as explained below.
For an operation o,are the program variables defined (i.e. assigned) resp. used in o. For state s and,is the projection of s onto d.
The low-observable part of an event is defined as
The low-observable subtrace of trace t is
Tracesare low-equivalent, written, if. Obviously,is an equivalence relation. Thus the low-class of t is
Note that the cannot be distinguished by an attacker, as all have the same low behaviour. Thus represents t’s low behaviour. Note also that the flow-sensitive projections , are usually much smaller than a flow-insensitive, statically defined low part of s. This results in more traces to be low-equivalent without compromising soundness. This subtle observation is another reason why flow-sensitive IFC is more precise (cmp. [8], Section 3).
PN is called “probabilistic”, because it essentially depends on the probabilities for certain traces under certain inputs. Thus we define
is the probability that a specific trace t is executed under input i.
is the probability that some trace(i.e.) is executed under i.
As is recursively enumerable, is a discrete probability distribution, hence .
The following PN definition uses explicit input streams instead of initial states. For all inputs the same initial state is assumed, but it is assumed that all inputs are classified low or high. Traditionally, input streams are low-equivalent () if they coincide on low values: . But this definition is not realistic: Suppose there is a race between a high and a low input statement. Then the classification of the input depends on the race and is no longer independent of a specific execution. This makes it difficult to properly define low-equivalence of inputs. Consequently, Giffhorn used a different definition of low-equivalent inputs: instead of one input stream with input values of varying classification, Giffhorn assumes several input streams with fixed classification each. This leads to
An input i of a program consists of one input stream per security level; we writefor the input stream of security level l. An input statementreads (and removes) the first value from.
Inputs are considered low-equivalent if their low input streams are equal:
is the set of all possible traces of a programunder input i.
(Probabilistic noninterference).
Letbe inputs; let. PN holds iff
That is, if we take any trace t which can be produced by i or , the probability that a is executed is the same under i resp. . In other words, probability for any public behaviour is independent from the choice of i or and thus cannot be influenced by secret input.
If , . Using the above sum property of , the PN condition is thus equivalent to
Applying this to Fig. 2 right, we first observe that all inputs are low-equivalent as there is only high input. For any trace t there are only two possibilities: …print("J")…print("CS")…, or …print("CS")…print("J")…. There are no other low events, hence there are only two equivalence classes
Now if i contains a small value, a large value, as discussed earlier as well as , hence PN is violated.
In practice, the are difficult or impossible to determine. So far, only simple Markov chains have been used to explicitly determine the for very small programs; where the Markow chain models the probabilistic state transitions of a program, perhaps together with a specific scheduler [28,35]. Fortunately, explicit probabilities are not needed for our soundness proofs. As a sanity check, we demonstrate that for sequential programs, PN implies sequential noninterference. Note that for sequential (deterministic) programs , and for the unique we have .
For sequential programs, probabilistic noninterference implies sequential noninterference.
Let . For sequential NI, input is part of the initial states, thus . Now let , hence . Due to PN, and . Due to sequentiality, and . Hence . That is, with probability 1 the trace executed under is low-equivalent to t. Thus in particular the final states in t resp. must be low-equivalent. Hence implies . □
Low-deterministic security
LSOD is the oldest and simplest criterion which enforces PN. LSOD demands that low-equivalent inputs produce low-equivalent traces. LSOD is scheduler-independent and implies PN (see below). It is intuitively secure: changes in high input can never change low behaviour, because low behaviour is enforced to be deterministic. This is however a very restrictive requirement and eventually led to popular scepticism against LSOD.
(Low-security observational determinism).
Let, Θ as above. LSOD holds iff
Under LSOD, all traces t for input i are low-equivalent: , thus . If there is more than one trace for i, then this must result from high-nondeterminism; low behaviour is strictly deterministic.
LSOD implies PN.
Let . WloG let . Due to LSOD, we have . As for , we have , and likewise , so . □
Zdancewic [41] proposed the first IFC analysis which checks LSOD. His conditions require that
there are no explicit or implicit leaks,
no low-observable operation is influenced by a data race,
no two low-observable operations can happen in parallel.
The last condition imposes the infamous LSOD restriction, because it explicitly disallows that a scheduler produces various interleavings which switch the order of two low statements which may happen in parallel, and thus would generate low-nondeterminism. Besides that, the conditions can be checked by a static program analysis; Zdancewic used a security type system.
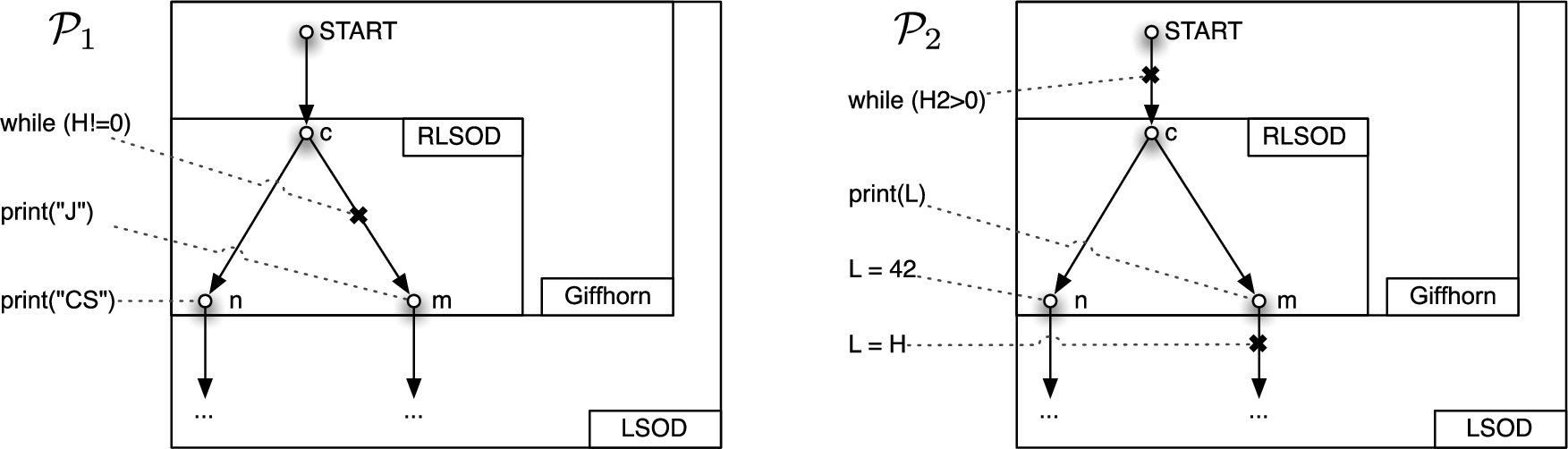
As an example, consider Fig. 3. In Fig. 3 middle, statements print(L) and L=42 – which are both classified low – can be executed in parallel, and the scheduler nondeterministically decides which executes first; resulting in either 42 or 0 to be printed. Thus there is visible low-nondeterminism, which is prohibited by classical LSOD. The program however is definitely secure according to PN, because the high read can only happen after the race outcome is already decided.
Giffhorn’s criterion
In this section, we recapitulate PDGs, their application for LSOD, and Giffhorn’s original criterion. This discussion is necessary in order to understand the new improvements for RLSOD.
PDGs for IFC
Snelting proposed to use Program Dependence Graphs (PDGs) as a device to check integrity of software as early as 1995 [37]. Later the approach was expanded into the JOANA IFC project. It was shown that PDGs guarantee sequential noninterference [39], and that they provide improved precision as they are naturally flow- and context-sensitive [14].
Left to right: PDGs for Figure 2 middle, and for Figure 3 left and middle.
In this paper, we just present three PDG examples and some explanations. PDG nodes represent program statements or expressions; edges represent data dependencies, control dependencies, inter-thread data dependencies, or summary dependencies. Figure 4 presents the PDGs for Fig. 2 middle, and for Fig. 3 left and middle. The construction of precise PDGs for full languages is absolutely nontrivial and requires additional information such as points-to analysis, exception analysis, and thread invocation analysis [14]. We will not discuss PDG details; it is sufficient to know the Slicing Theorem for sequential programs:
If there is no PDG path, it is guaranteed that statement a can never influence statement b. In particular, values computed in a cannot influence values computed in b.
Thus all statements which might influence a specific program point b are those on backward paths from this point, the so-called “backward slice” . In particular, information flow is only possible if . There are stronger versions of the theorem, which consider only paths which can indeed be dynamically executed (“realizable” paths); these make a big difference in precision e.g. for programs with procedures, objects, or threads [6,14,31].
As an example, consider Fig. 4. The left PDG has a data dependency edge from L=H; to print(L);, because L is defined in line 9 (Fig. 3 left), used in line 10, there is a path in the control flow graph (CFG) from 9 to 10, and L is not reassigned (“killed”) on the path. Thus there is a PDG path from read(H); to print(L);, representing an illegal flow from line 7 to line 10 (a simple explicit leak). In Fig. 4 right, there is no path from L=H; to print(L); due to flow-sensitivity: no scheduler will ever execute L=H; before print(L);. Hence no path from read(H) to print(L); exists, and it is guaranteed that the printed value of L is not influenced by the secret H.
In general, the multi-threaded PDG can be used to check whether there are any explicit or implicit leaks; technically it is required that no high source is in the backward slice of a low sink. This criterion is enough to guarantee sequential noninterference (see Theorem 2). For probabilistic noninterference, according to the Zdancewic LSOD criterion one must additionally show that public output is not influenced by execution order conflicts such as data races, and that there is no low-nondeterminism. This can again be checked using PDGs and an additional analysis called “May-happen-in-parallel” (MHP); the latter will uncover potential execution order conflicts or races. Several precise and sound MHP algorithms for full Java are available today (see e.g. [7,22,27]). Note that an imprecise MHP analysis will substantially degrade the precision of (R)LSOD, and cause many false alarms (see [7,8] for details).
In the following, we will need some definitions related to PDGs. For more details on PDGs, MHP, flow- context-, object- and time-sensitivity, see [14].
Letbe a PDG, where N consists of program statements and expressions, and → comprises data dependencies, control dependencies, summary dependencies, and inter-thread dependencies. The (context-sensitive) backward slice foris defined aswhereincludes only realizable (i.e. context-, object- and optionally time-sensitive) paths in the PDG.
For PDG-based analyses, the inputs (“sources”) and outputs (“sinks”) are nodes in the PDG, so . The soundness theorem for PDG-based sequential IFC can now be formalized:
Sequential noninterference holds if
Snelting’s original proof was in [39]; additional details are given in [14]. □
The user (“engineer”) classifications in the PDG can be propagated to yield a classification of all statements, which provides an alternate way of checking sequential noninterference. This definition will be expanded later to cover concurrent programs.
The classificationcan be computed fromvia the flow equationwith additional constraintsand.
For an operation o in a trace t, we haveand define.
Concerning it is important to note that PDGs are automatically flow- and context-sensitive, and may contain a program variable v several times as a PDG node; each occurence of v in N may have a different classification! Thus there is no global classification of variables, but only the local classification together with the global flow constraints . The latter can easily be computed by a fixpoint iteration on the PDG; which is initialized with the values for source nodes (see [14]). If fixpoint iteration eventually computes for a sink n, an explicit or implicit leak has been discovered [14]. JOANA offers additional support to analyse and localize leaks [9,11].
LSOD with PDGs
In his 2012 thesis, Giffhorn applied PDGs to PN. He showed that PDGs can naturally be used to check Zdancewic’s LSOD criteria, and provided a soundness proof as well as an implementation for JOANA [7]. Giffhorn also found the first optimization relaxing LSOD’s strict low-determinism.
Giffhorn’s motivation was to repair soundness leaks which had been uncovered in some previous LSOD algorithms. In particular, treatment of nontermination without being overly restrictive or allowing implicit leaks had proven to be tricky. Giffhorn provided a new definition for low-equivalent traces:
Letbe two finite or infinite traces.iff
ifare both finite, as usual the low events and low memory parts must coincide (see Definition
3
);
if wloG t is finite,is infinite, then this coincidence must hold up to the length of the shorter trace, and the missing operations in t must be missing due to an infinite loop (and nothing else);
for two infinite traces, this coincidence must hold for all low events, or if low events are missing in one trace, they must be missing due to an infinite loop.
The formal version of this definition can be found in [8]. It turned out that conditions 2. and 3. not only avoid previous soundness leaks, but can precisely be characterized by dynamic control dependencies in traces [8]. Furthermore, the latter can soundly and precisely be statically approximated through PDGs (which include all control dependencies). Moreover, the static conditions identified by Zdancewic which guarantee LSOD can naturally be checked by PDGs, and enjoy increased precision due to flow-, context- and object-sensitivity.
In this paper however, we ignore the issue of termination completely and concentrate on the formalization and improvement of Giffhorn’s LSOD check. We begin with some definitions.
We writeif MHP analysis concludes that n and m may be executed in parallel. Formally,holds if tracesexist where,.
, which denotes thatare low-nondeterministic;
, which denotes there is a data race betweenwhich can influence the value read at.
is a path in the CFG. We will also useto denote the set of all nodeson CFG paths from n to.
Then the PDG-based LSOD criterion – a formalization of Zdancewic’s criterion using PDGs – requires:
Condition 1 is just sequential noninterference (no explicit/implicit leaks, see Theorem 2), condition 2 guarantees that no race is in the backward slice of a low sink, and condition 3 prohibits any low-nondeterminism. Note that the race definition8
from Definition 11 is asymmetric: Giffhorn discovered that only two of the three classical race situations (“write-write, write-read, read-write“) are relevant. The case can never cause a leak because the value written at n is independent of the outcome of that race! Thus the example from the top of Fig. 5 is considered secure, whereas a symmetric race definition would have caused a false alarm. Also note that conditions 2 and 3 are not completely disjoint, in particular if both conditions are violated.
Races with one node in the backward slice of a low sink. Top: , , , . Bottom: , , , .
Applying Giffhorn’s criterion to Fig. 2 right, it discovers a leak according to condition 3, namely low-nondeterminism between lines 6 and 11; which is correct. For the example in Fig. 5 bottom, condition 3 is not violated, but condition 2 is violated. In Fig. 3 left, a leak is discovered according to condition 1, which is also correct (cmp. PDG example above). In Fig. 3 middle and right, the explicit leak has disappeared (thanks to flow-sensitivity), but another leak is discovered by condition 2: we have and , which causes a false alarm.
The example motivates Giffhorn’s optimized criterion: low-nondeterminism may be allowed, if it cannot be reached from high events. That is, there must not be a path in the control flow graph from some , where , to n or , where . If there is no path from a high event to the low-nondeterminism, no high statement can ever be executed before the nondeterministic low statements. Thus the latter can never produce visible behaviour which is influenced by high values. This argument leads to Giffhorn’s optimized criterion, which replaces condition 3 from Definition 12 by
This condition can be rewritten by contraposition to the more practical form
In fact Giffhorn’s optimization works for data races as well: no data race may be in the backward slice of a low sink, unless it is unreachable by high events. That is, condition 2 can be improved the same way as condition 3, leading to
.
By contraposition, we obtain the more practical form
Remember that condition is not symmetrical in , due to Giffhorn’s simplified race definition. Figure 2 right violates Giffhorn’s criterion, because one of the low-nondeterministic statements, namely line 11, can be reached from the high statement in line 8; thus criterion is violated. Indeed the example contains a probabilistic leak. Figure 3 middle is secure according to Giffhorn, because the data race between line 6 resp. 9 can not be reached from any high statement – condition 2 is violated (note that in this example, ), but holds. Indeed the program is PN. Figure 3 right is however not covered by Giffhorn’s criterion, because the initial read(H2) will reach any other statement. But the program is PN, because H2 does not influence the data race determining the low behavior!
The example shows that Giffhorn’s optimization does indeed reduce false alarms, but it removes only false alarms on low paths beginning at program start. Anything after the first high statement will usually be reachable from that statement, and does not profit from rule resp. . Still Giffhorn’s algorithm was a big step, as it allowed – for the first time – low-nondeterminism, while basically maintaining the LSOD approach.
RLSOD
In the following, we will generalize conditions and to obtain the much more precise RLSOD criterion.
To motivate the improvement, consider again Fig. 2 right (program ) and Fig. 3 right (program ). Both contain race conditions influencing low behavior, through low-nondeterminism and through a data race. When comparing and , a crucial difference comes to mind. In the troublesome high statement can reach both statements forming the race condition, whereas in , the high statement can reach only one of them. In both programs some loop running time depends on a high value, but in , the subsequent statements are influenced by this “timing leak” in exactly the same way, while in they are not.
In terms of the PN definition, remember that has only two low-classes and . Likewise, has two low-classes and , depending on the outcome of the data race. The crucial difference is that for , the probability for the two classes under i resp. is not the same (see above), but for , holds!
Technically, contains a point c which dominates both racing statements and , and all relevant high events always happen before c. Domination means that any control flow from to n or m must pass through c. In , c is the point immediately before the first fork. In contrast, has only a trivial common dominator for the low-nondeterminism, namely the node, and on the path from to there is no high event, while on the path to there is.
Intuitively, the high inputs can cause strong nondeterministic high behaviour, including stuttering. But if LSOD conditions 1 + 2 are always satisfied, and if there are no high events in any trace between c and n resp. m, the effect of the high behaviour is always the same for n and m and thus “factored out”. It cannot cause a probabilistic leak – the dominator “shields” the low-nondeterminism from high influence. Note that contains an additional high statement but that is behind n (no control flow is possible from to n) and thus cannot influence the nondeterminism.
Improving conditions and
The above example has demonstrated that low-nondeterminism may be reachable by high events without harm, as long as these high events always happen before the common dominator of the nondeterministic low statements. This observation will be even more important if dynamically created threads are allowed (as in JOANA, cmp. Section 7). We will now provide precise definitions for this idea.
(Common dynamic ancestor).
Letbe statements.
c is a dominator for n, written, if c occurs on every CFG path fromto n.
c is a common dominator for, written, if.
c is a common dynamic ancestor for, written, if
.
Ifand, then c is called an immediate common dynamic ancestor.
Efficient algorithms for computing dominators can be found in many compiler textbooks. They can be extended to calculate common dynamic ancestors. The stricter definition of common dynamic ancestors compared to common dominators is needed to deal with the possibility that the same thread can be spawned several times, as e.g. in our case study (chapter 7). Note that itself is a (trivial) common dynamic ancestor for every . RLSOD works with any common dynamic ancestor. We thus assume a function which for every statement pair returns a common dynamic ancestor, and write . Note that the implementation of may depend on the precision requirements, but once a specific is fixed, c depends solely on n and m. Straightforward implementation of the RLSOD idea leads to the following rules, replacing rules and from Giffhorn’s optimized criterion:
These conditions are most precise (generate the least false alarms) if returns the immediate common dynamic ancestor, because in this case it demands that for the smallest set of nodes “behind” the common ancestor.9
Note that in programs with procedures and threads, immediate dynamic ancestors may not be unique due to context-sensitivity [5].
Fig. 6 illustrates the RLSOD definition (condition ). Note that Giffhorn’s optimized criterion trivially fulfils conditions and , where always returns . In [4], we provided a soundness proof for the case of just one low-nondeterminism. However, as the next section will show, in the case of multiple low-nondeterministic statements those rules are not sound.
Visualization of LSOD vs. Giffhorn’s criterion vs. RLSOD (condition ). CFGs for Figure 2 right resp. Figure 3 right are sketched. n/m produces low-nondeterminism, c is the common dominator. LSOD prohibits any low-nondeterminism; Giffhorn allows low-nondeterminism which is not reachable by any high events; RLSOD allows low-nondeterminism which may be reached by high events if they are before the common dominator. The marked regions are those affected by low-nondeterminism; inside these regions no high events are allowed. Thus RLSOD is much more precise.
Classification revisited
A leak which goes undiscovered if classification of statements is incomplete.
Consider the program in Fig. 7 middle/right. This example contains a probabilistic leak as follows. H influences the running time of the first while loop, hence H influences whether line 10 or line 18 is performed first. The value of tmp2 influences the running time of the second loop, hence it also influences whether L1 or L2 is printed first. Thus H indirectly influences the execution order of the final print statements. Indeed the program does not fulfill Giffhorn’s criterion, as the print statements can be reached from the high statement in line 3 (middle). Applying , the common dynamic ancestor for the two print statements is line 10. But the only input statement is line 3, which is before the cda.
The classification of line 10 is thus crucial. If we had , then this classification propagates in the PDG (due to the flow equation ) and lines 12/13 are classified high. RLSOD is violated, and the probabilistic leak discovered.
Hence we use the flow equation to calculate the classification propagation from line 3 to line 10, and then 12/13. Only line 3 is explicitly high and only lines 4, 7, 8 are PDG-reachable from 3. Thus . Hence RLSOD would be satisfied because 3, 4, 7, 8 are before the common dominator. The leak would go undiscovered! The problem is that rules and are not applied recursively. To capture the effect of recursive influence through nondeterminism, the flow equations must be extended.
In general, the rule is as follows. The standard flow equation expresses the fact that if a high value can reach a PDG node m upon which n is dependent, then the high value can also reach n. Likewise, if there is low-nondeterminism with , and , and the path violates RLSOD – that is, it contains high statements – then the high value can reach n. Thus must be enforced. This rule must be applied recursively until a fixpoint is reached.
(Classification in PDGs).
A PDGis classified correctly, if
,
.
and.
In condition (a), ⩾ must be used because (b) can push higher than . Condition (b) can be rewritten as ; making it formally similar to (a).10
This formulation is used by JOANA; it also has the advantage that RLSOD can be used for an arbitrary security lattice. Note that our current soundness proof works only with the lattice.
Note the asymmetry in condition (c): Treating a public input value as secret is sound, thus one might want to use in that condition. However, we assume that the attacker can observe when low input statements are executed. Thus, whether they are executed must not depend on H values, so must be enforced as well.
For a sequential program, is always false, so only rules (a) and (c) remain. Note that (a)+(c) is equivalent to Definition 9, the calculation of sequential noninterference. In Fig. 7 middle/right, Definition 14 enforces line 10 to be classified high, as we have , and on the path from 6 to 10, lines 7 and 8 are high.
Now, classification rules (a), (b) and (c) could be combined with , and to yield a sound RLSOD criterion. But surprisingly it turns out that this is not necessary – Section 6 will demonstrate that classifiability according to Definition 14 already implies PN! In fact, , and are necessary conditions for classifiability:
If the program can be classified according to Definition
14
, then the RLSOD conditions,,hold.
Assume that (a), (b), (c) hold, but one of the rules , , is violated. We therefore have 3 cases:
is violated: Since an H source n is in the backward slice of an L sink , with classification rule (c) we have , and . But then repeated application of rule (a) demands , which is a contradiction.
is violated: For the two statements n and we have by rule (c). But then we have a statement with on the control flow path from to n or to . Without loss of generality we assume that lies on the path from c to n. But then rule (b) demands , contradicting .
is violated: We have by rule (c), and by rule (a) we have since . Since we also have , n must write the same variable that reads or writes, and thus we have and as well. Then we can apply the same argument to n and as in the previous case. □
Henceforth, we will subsume Definition 14 under the notion of RLSOD. To actually use it as a PN checker, it uses a fixpoint iteration similar to the sequential one (Definition 9, see also [9,14]).
The general soundness proof
In the conference paper preceding this article [4], a soundness proof was provided for the special case that there is just one occurrence of low-nondeterminism (i.e. ). The full proof posed more difficulties than expected, but eventually led to a simpler formulation of the RLSOD criterion, namely in form of Definition 14. We thus omit the proof of the special case (see [4], Section 4.3), but will in this section describe the full soundness proof, based on Definition 14. As in [4], the proof relies on the notion of conditional probability for traces.
Letbe the set of traces beginning with prefix, so thatis the probability that execution under input i begins with. For a set T of traces let. We denote withthe conditional probability that after, execution continues with; we haveThis notion extends to sets of traces:
In the following it will always hold that , hence .
The following soundness theorem and its derivation will of course be based on Definition 3 (low-equivalent traces), but in the proofs we will also need a variant of this definition as an auxiliary construction: We define , and exactly as , and (see Definition 3), except that in the definition is replaced by . We omit a repetition of the definition details, as , and are only used in the proofs and do not appear in the soundness theorem itself.
We have from Definition 3 for all since is a composition of and . With the definition of , this implies .
, using equation (1) and the fact that all traces begin with , so .
□
For the following theorems, let denote the operation of an event c, i.e. for , we have . For convenience, we first prove the following lemmas:
Letbe a terminating program. Assume that classification rules (a) and (c) according to Definition
14
hold. Letandwith,,and.
Then.
Let . If o reads input, we have , and by rule (c), and it therefore reads from the low input stream. From rule (c) we also have that all other operations that have read from this stream before are classified as low, and thus show up in -low-observable subtraces. This means the same reads must have happened before c and , and so c and read the same values from input.
If o reads values from memory, o is data dependent on the operations that wrote those values, so those must be classified as L by classification rule (a). But then those show up in a -low-observable subtrace, and since , the same of those operations must have happened for and , and they wrote the same values in the same order. Therefore, c and read the same values. Since statements themselves are deterministic, the values written by c and are equal as well. Thus we have . □
Letbe a program that always terminates and let classification rule (a) according to Definition
14
hold. Letbe a possible trace forand. Letwithalso be a possible trace.
Thenmust occur on.
Since operations are unique in a trace, cannot contain , and neither can since . Thus, it suffices to show that is executed on . This is trivially fulfilled for the starting operation. Else, let p be the operation that directly controls whether is executed. We have or is control dependent on . With classification rule (a), we have . Since , p was executed on as well and has read the same values as on . Therefore, it chooses the same branch, so must occur on as well. □
We now show that if a program’s PDG can be classified correctly, then for a -low-class, the probability of observing it does not differ between low-equivalent inputs:
Letbe a program that always terminates anda user annotation for. Letbe a correct classification of its PDG according to Definition
14
.
Now letbe two inputs with, let t be a trace. Then
We will prove the equation by contradiction. So, let us assume . Let be the decomposition of t into single events. With the calculation rules from Lemma 3, applying rule 2 and then repeatedly applying rule 3, we get
and the same for . Since the left sides for i and are not equal, the same must hold for at least one factor. Furthermore, we have
by the following argument: If not both sides are 1, there is a low event that is possible after a trace in . From Lemma 5 we then have that this event occurs on every trace , making both probabilities 0.
Thus, there is a j that the factor
is different for i and . Let and . Then we have
In the following, we will focus on these two conditional probabilities, so we can assume that the trace that has happened until that point is -low-equivalent to .
Without loss of generality we assume
(switch i and if necessary). gets executed for i since the former probability is greater than zero, and we have because else both probabilities would be equal to 1. With Lemma 5 we have that will be executed in every trace in .
Since the remaining trace must execute given an execution in has happened, its -low-observable part cannot be empty. The conditional probabilities for the different -low-observable parts of low events given must add up to 1 for i and , but we have
Thus, there is a with such that
Analogously to above, must happen after each trace in .
If , with Lemma 4 we get , contradicting . Thus . Let and . o and must be executed after a trace in has been executed. In fact, o can be executed directly after it (at least for input i) and since , must then happen after o. Analogously, o can happen after . This makes and an pair. Let . Then by classification rule (b) with all nodes in are classified as L. o can be scheduled for input i, so the CFG predecessors of s that were already executed allow o to be executed next. Those are in since otherwise we would have , which is impossible because with we have , a contradiction to Definition 13. Thus, they are -low-observable and therefore have happened for any trace as well. Thus, o can be scheduled for every such trace , regardless of i or . The same argument shows that can be scheduled after every such . From Lemma 4 we also have that the only possible -low-observable part of the event for o is , so
and
(we use here as a shorthand for ). The same holds for and . If we go from i to , the probability of scheduling o gets smaller but the probability of scheduling gets greater. Therefore, the relative scheduling probabilities do not stay the same, even though for both inputs, both operations can be scheduled. This contradicts the assumption of a truly probabilistic scheduler. □
We now can prove that the conditions of the previous theorem guarantee PN.
Letbe a terminating program anda user annotation for. Letbe a correct classification of its PDG according to Definition
14
.
Classification rule (c) ensures that all sources and sinks n with also fulfill . Thus, for all traces we have . Therefore, we can write as disjoint union of all . With the probability formula for disjoint unions we have
and the same for . By applying Theorem 5, we get for all . Thus,
□
Case study: E-voting
We will now apply RLSOD to an experimental e-voting system developed in collaboration with R. Küsters et al. This system aims at a provably secure e-voting software that uses cryptography to ensure computational indistinguishability. To prove computational indistinguishability, the cryptographic functions are replaced with an “ideal variant”: The encryption creates a random number as encrypted message and remembers the connection of this message and the key to the plaintext. The decryption can then get the plaintext back by providing the key and the encrypted text.11
Note that due to this construction, at the encryption site there is no flow from the plaintext or key to the encrypted message.
It is then checked by IFC that no flow exists between plain text, secret key and encrypted message; that is, probabilistic noninterference holds for the e-voting system with ideal crypto implementation. By a theorem of Küsters, noninterference of the ideal variant implies computational indistinguishability for the system with real encryption [19,21].
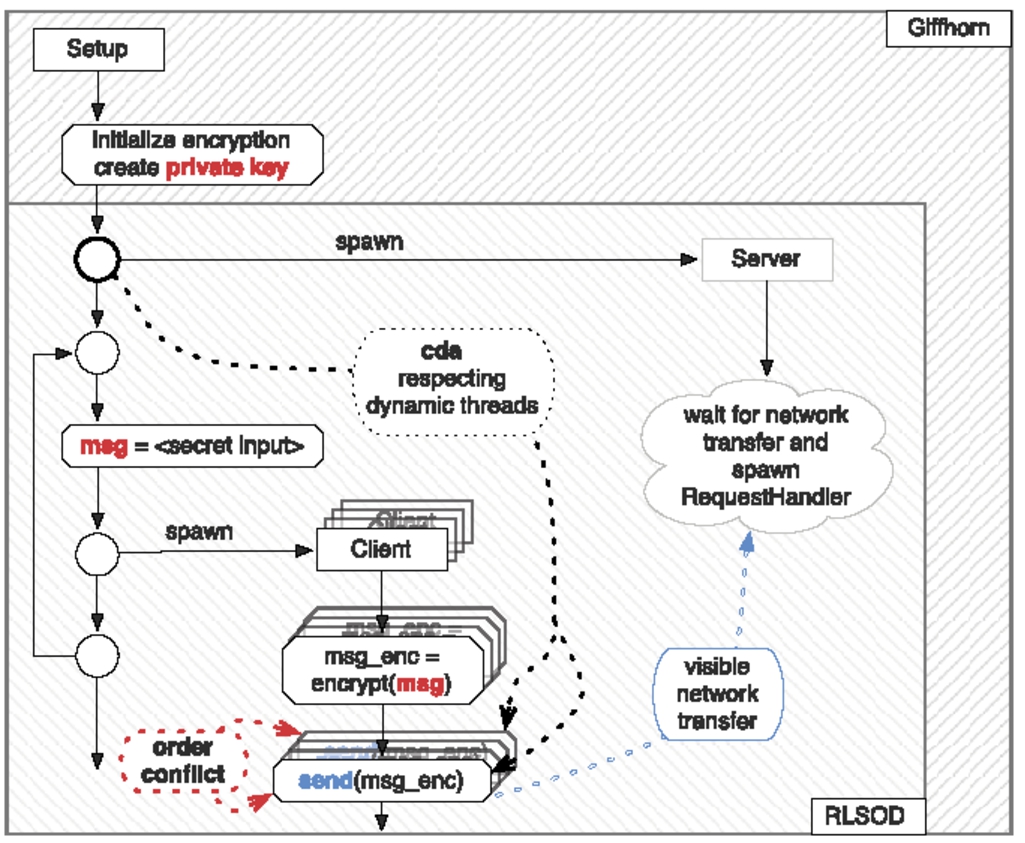
The example uses a multi-threaded client-server architecture to send encrypted messages over the network. It consists of 550 LoC with 16 classes. The interprocedural control flow is sketched in Fig. 8; Fig. 9 contains relevant parts of the code. The main thread starts in class Setup in line 2ff: First it initializes encryption by generating a private and public key, then it spawns a single Server thread before entering of the main loop. Inside the main loop it reads a secret message from the input and spawns a Client that takes care of the secure message transfer: The client encrypts the given message and subsequently sends it via the network to the server. Note that there are multiple instances of the client thread as a new one is started in each iteration.
CFG structure of the multi-threaded server-client based message transfer.
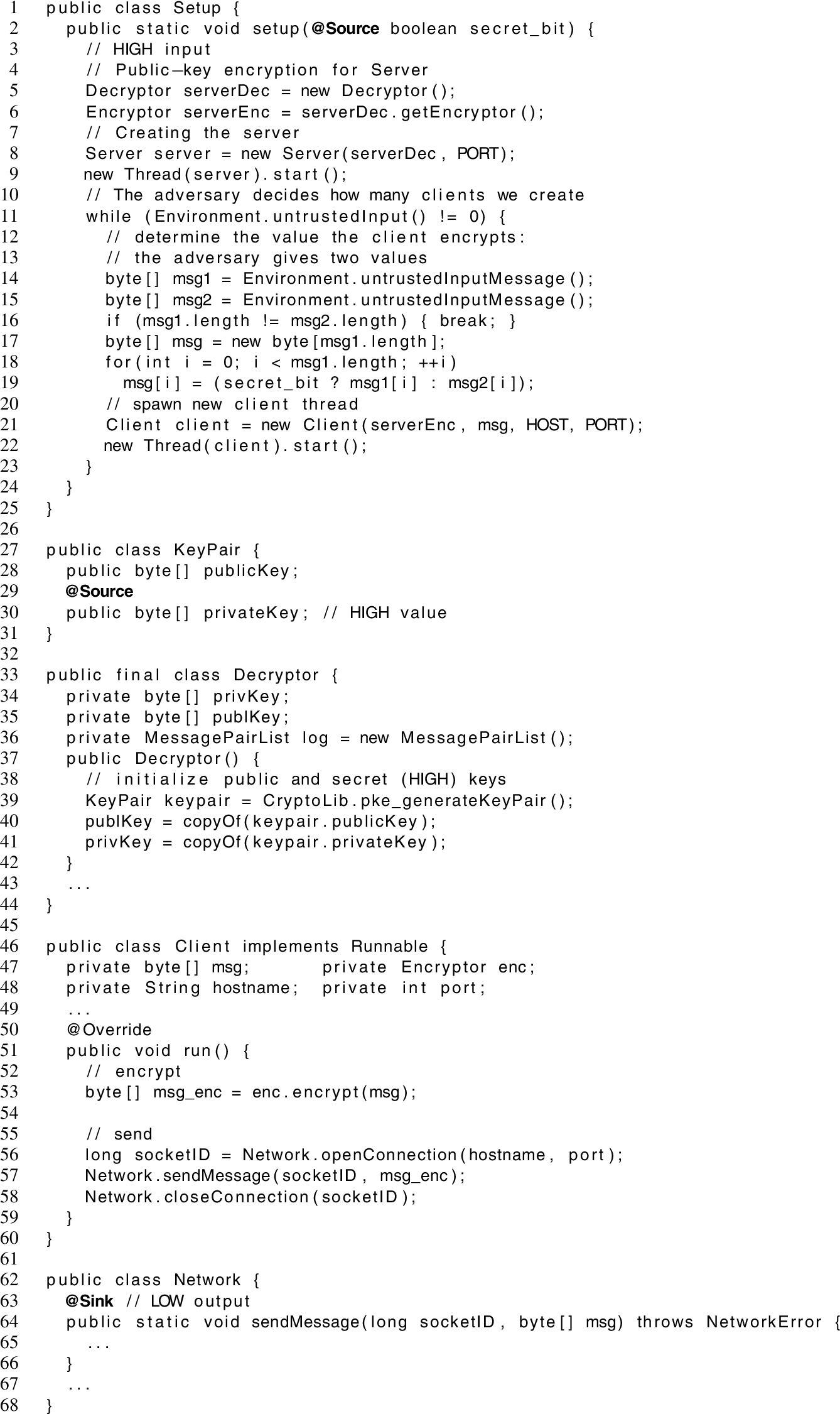
Relevant parts of the multi-threaded encrypted message passing system with security annotations for JOANA.
JOANA analysing the e-voting source code.
There are two sources of secret (high) information: (1) the value of the parameter secret_bit (line 2) that decides about the content of the message; and (2) the private key of the encryption (line 30). Both are marked for JOANA with a @Source annotation, signalling an input statement (with a default security level of H). By Definition 14, (2) propagates to lines 39, 41, 5, and 9 which are also classified High. Likewise, (1) propagates to lines 19 and 22, which are thus High as well.
As information sent over network is visible to the attacker, calls to the method sendMessage (line 57f) are marked as a low@Sink, signalling an output statement (with a default security level of L). JOANA was started in “Giffhorn” mode, and – analysing the “ideal variant” – immediately guarantees that there are no explicit or implicit leaks. However the example contains two potential probabilistic leaks, which are both discovered by JOANA using Giffhorn’s criterion; one is later uncovered by RLSOD to be a false alarm.
To understand the first leak in detail, remember that this e-voting code spawns new threads in a loop. This will cause low-nondeterminism because the running times for the individual threads may vary and thus their relative execution order depends on scheduling. This low-nondeterminism is (context-sensitively) reachable from the high private-key initialization in line 39, hence criterion will cause an alarm. Technically, we have ; that is, line 57 is low-nondeterministic with itself (because the same thread is spawned several times). Furthermore, . Thus criterion 3′ is violated: Giffhorn’s criterion (as well as classical LSOD) thinks there is a probabilistic leak.
Now let us apply RLSOD to this leak. The common dynamic ancestor for all the low-nondeterministic message sends in line 57 is located just before the loop header: .12
Note that we indeed need instead of here, such that the static lies before all dynamically possible spawns. JOANA handles such situations correctly, as well as handling interprocedural, context-sensitive dynamic ancestors.
Now it turns out that the initialisation of private keys lies before this common dynamic ancestor: lines 30, 39, 41, 5, 8, and 9 context-sensitively dominate line 11, and cannot happen parallel to it. Thus by RLSOD criterion , this potential leak is uncovered to be a false alarm: the private key initialisation is in fact secure!
The second potential probabilistic leak comes from the potential high influence by secret_bit in line 19 to the low-nondeterministic message sends in line 63. Technically, we have the PDG High-chain , but is manually classified Low. However this second leak candidate is not eliminated by RLSOD, and indeed is a probabilistic leak: since the encrypt run time may depend on the message, the scheduler will statistically generate a specific “average” order of message send executions (remember the scheduler must be probabilistic). An attacker can thus watch this execution order, and deduce information about the secret messages. Technically, this subtle leak is discovered by RLSOD because the high operation which accesses the secret bit lies behind the common dynamic ancestor, but before the low-nondeterminism: .
JOANA must and will report this probabilistic leak. The engineer might however decide that the leak is not dangerous. If the engineer can guarantee that the encrypt run time does not depend on msg, the leak may be ignored.
JOANA detects both potential probabilistic leaks in about 5 seconds on a standard PC (including PDG construction). A JOANA screenshot showing the analysis of the e-voting source code is given in Fig. 10; more details on the JOANA GUI can be found in [11]. After JOANA is set to RLSOD, one of the leaks disappears as described above. We consider the e-voting program a rather spectacular example how RLSOD improves precision. Note however that a systematic evaluation of RLSOD precision has not yet been tackled, as it is difficult to find realistic example programs with probabilistic leaks.
Evaluation
PDG construction times (in milliseconds) for benchmark programs
#BC Instr.
PDG time
PDG time O-S
wallet
116
504
924
clientserver
601
204
298
battleship
937
408
1,078
corporatecard
1,186
427
821
safeappplet
1,295
376
1,332
hybrid
1,479
454
729
cloudstorage
1,972
563
1,030
j2mesafe
5,519
3,937
–
purse
10,807
6,004
13,165
barcode
11,406
1,307
–
onetimepass
13,034
48,729
–
bexplore
14,041
21,538
–
keepass
16,427
9,495
–
freecs
49,396
1,301,072
–
hsqldb
126,860
4,129,274
–
Table 1 presents PDG construction times for various programs. These times are taken from a recent JOANA scalability study provided by J. Graf in [9]. All measurements took place on a machine with a Core i7 processor, 32 GB RAM, with Java 8 64-Bit. For the 15 benchmark programs, program size in byte code instructions is given (without library functions), as well as PDG construction time in milliseconds. “PDG time O-S” is PDG construction time with object-sensitive points-to analysis; this variant is more expensive but much more precise. The largest program is “hsqldb” with 126860 byte code instructions, which corresponds to about 65kLOC source code.
[9] provides additional data on PDG size, summary edges, impact of points-to analysis details, and more. RLSOD time is not included in the PDG construction times. One observes that runtimes are strongly nonlinear, but moderate (1–2 hours/50kLOC). Memory is the limiting factor (7 of the programs cannot be analysed using object-sensitive points-to with 32 GB). Note that JOANA offers many analysis options, in particular choices for MHP and points-to precision [11].
Table 2 shows the runtimes of LSOD, Giffhorn’s criterion and RLSOD for a subset of the programs in Table 1, “BarrierBench” from the Java Grande Benchmark and the e-voting program from Section 7; on the same machine configuration as above. PDG construction time is not included. PDGs were built with object graphs and instance-based points-to precision (cmp. [9]). For each we selected n sources and n sinks randomly from the PDG nodes. For each program, criterion and n we performed 10 measurements. The table shows the average runtime in milliseconds. For the top four programs, we used a more precise and more expensive MHP analysis. Since it does not scale for the last two programs, we used a simple MHP analysis there. Note that this choice only affects precision, not soundness. For the small programs, all (R)LSOD times are less than 100 msec; for the largest program (R)LSOD times are below 2 min. Interestingly, for the largest program and , “Giffhorn” is a little faster than LSOD, and RLSOD is 4 times faster. The reason is that both the LSOD and Giffhorn implementations use multiple backward slices according to Definition 12 resp. conditions , while RLSOD is based on Definition 14 and needs no backward slices. This also explains why RLSOD does not really depend on n.
Performance of LSOD, Giffhorn’s criterion and RLSOD with different numbers of sources/sinks (in milliseconds)
Program
#BC Instr.
LSOD
Giffhorn
RLSOD
1
5
10
1
5
10
1
5
10
barrierbench
416
38
31
32
38
31
34
93
63
55
battleship
937
11
17
24
13
17
21
25
17
14
evoting
1,106
13
9
11
13
10
12
37
23
21
barcode
11,406
20
21
25
25
23
28
58
37
36
freecs
49,396
23,945
34,502
50,427
23,622
32,072
45,160
54,280
53,042
56,111
hsqldb
126,860
16,427
70,740
133,777
17,288
62,581
119,767
31,885
30,333
30,333
Related work
Zdancewic’s work [41] was the starting point for us, once Giffhorn discovered that the Zdancewic LSOD criteria can naturally be checked using PDGs. Zdancewic uses an interesting definition of low-equivalent traces: low-equivalence is not demanded for traces, but only for every subtrace for every low variable (“location traces”). This renders more traces low-equivalent and thus increases precision. But location traces act contrary to flow-sensitivity (relative order of variable accesses is lost), and according to our experience flow-sensitivity is essential.
While strict LSOD guarantees probabilistic noninterference for any scheduler, it is too strict for multi-threaded programs. RLSOD considerably improves the precision of LSOD, while giving up on full scheduler-independence (by restricting RLSOD to truly probabilistic schedulers). This same tradeoff has been proposed by earlier authors. Smith [35] improves on PN based on probabilistic bisimulation, where the latter forbids the execution time of any thread to depend on secret input. Just as in our work, a probabilistic scheduler is assumed; the probability of any execution step is given by a markov chain. A secure program requires that the probability to go from one low-equivalence class of states A to another (after possibly remaining, or stuttering in A for some time) is independent of the specific state . This approach is called weak probabilistic bisimulation, and allows the execution time of threads to depend on secret input, as long as it is not made observable by writing to public variables. The authors present a static check in form of a type system, and discuss an extension for thread creation. If the execution time up to the current point depends on secret input, their criterion allows to spawn new threads only if they do not alter public variables. In comparison, our based check does allow two public operations to happen in parallel in newly spawned threads, even if the execution time up to c (i.e.: a point at which at most one of the two threads involved existed) depends on secret input.
Approaches for PN based on type systems benefit from compositionality, a good study of which is given in [29]. Again, a probabilistic scheduler is assumed. Scheduler-independent approaches can be found in, e.g., [25,30]. The authors each identify a natural class of “robust” resp. “noninterfering” schedulers, which include uniform and round-robin schedulers. They show that programs which satisfy specific possibilistic notions of bisimilarity (“FSI-security” resp. “possibilistically noninterferent”) remain probabilistically secure when run under such schedulers. Since programs like Fig. 7 left are not probabilistically secure under a round-robin scheduler, their possibilistic notion of bisimilarity require “lock-step” execution at least for threads with low-observable behaviour. Compared to RLSOD this is more restrictive for programs, but less restrictive on scheduling.
A completely different approach to noninterference and PN is the use of program logics and verification. For example the KeY system [1] has been used to verify noninterference and other nonfunctional security properties; KeY was also applied to Küster’s e-voting system (cmp. chapter 7) [20]. Recently, relational program logics have been proposed which allow to express probabilistic properties of programs, including PN [3]. Such verification systems are very powerful and allow to verify properties beyond PN, but are never automatic such as RLSOD and JOANA. We are thus exploring the combination KeY + JOANA: JOANA can, due to a programming interface, export relevant analysis results, such as points-to relations, PDG reachability, PN guarantees, or leak localizations. KeY can use JOANA as a black box to considerably simplify security verification [12].
Detailed comparison with type-system-based analysis for FSI
FSI-Variants of Fig. 2, left, and of Fig. 7, left.
In Fig. 11, the type system for FSI-Security from [25] for a concurrent language is repeated verbatim. FSI-Security implies -Security for all robust schedulers . Both these notions require an explicit global classification of all variables, implying a classification for all expressions. The attacker is assumed to observe the initial and final values of low variables. Intuitively, a judgment means that is secure, with a running time influenced only by input of level or lower, and observable effects (specifically: writes to variables) only of level or higher.
The observational model in our work differs slightly: we assume the attacker to observe not the final value of low variables, but instead the values of variables at observable nodes, i.e.: nodes n with . The two FSI programs corresponding to Fig. 2, left, and to Fig. 7, left are shown in Fig. 12, assuming .
Comparing RLSOD with FSI, consider the example in Fig. 12, left; which contains simple explicit and implicit leaks. RLSOD requires via the PDG path and requirement (a) in Definition 14, violating , (via requirement (c)); and the leak is exposed. Likewise, FSI requires
where is the statement at line i, and are the security levels in judgements appearing in candidate derivation trees for the hypothesis . , are the security levels in judgements for sequentially composed statements . Thus FSI discovers the same leak.
But FSI does not use the “dominator trick”. To see the effect, consider Fig. 12, right, which is secure w.r.t. a probabilistic scheduler, but FSI-insecure as follows: Aside from , we have , and also . But attempting to derive a type for via rule requires . The latter is a contradiction, thus FSI is violated.
RLSOD, however, correctly classifies the corresponding program from Fig. 7 left secure w.r.t. a probabilistic scheduler, as witnessed by the classification
Specifically, this classification does not violate requirement (b) of Definition 14, since , but for all nodes on paths we have . The dominator avoids a false alarm.
Comparison with syntactic criteria for resumption based noninterference
In [29], the authors assume a uniform scheduler, and describe a lattice of security properties (Fig. 13) ordered by implication, the weakest of which being 01-bisimilarity (). 01-bisimilarity is not compositional w.r.t. every syntactic construct of the source language considered. Nevertheless, the authors derive syntactic criteria that, whenever a given construct is not compositional w.r.t. the security property, defer to a stronger property which is compositional w.r.t. this construct.
Instead of or , their language assumes a parallel composition statement . For a direct comparison, the program corresponding to Fig. 7 left is shown in Fig. 13. Each line is annotated with its strongest security properties holding. For example, read(H) is self-isomorphic (): if started in low-indistinguishable states (and: given low-indistinguishable inputs), executions take the same branches with the same probabilities. It also is discreet (): during the computation, the states stay low-indistinguishable from the initial state, and no low output is made. Using the syntactic criteria, we can conclude that read(H); if (H) {skip} is (but not: ). Unfortunately, the syntactic criteria of [29] do not allow us to conclude that sequential composition of a and a command (like the -Statement) are , and hence produce a false alarm.
Resumption Based Security: Security Properties [29], and the Program corresponding to Figure 7, left.
Compositionality
Typical problems of compositional analyses.
Compositionality is a useful property, but can be achieved only at the price of either losing precision, or losing automatic analysis. Let us explain this in more detail.
Typically, type systems are compositional because they use static classification. For example, in Fig. 14 left, the first two lines alone are secure, as well as the last two. A compositional IFC with static classification will discover the simple leak in this code piece once both fragments are composed, because there are conflicting (static) classifications for T. Unfortunately, static classification is very unprecise. In particular, it is not flow-sensitive and will produce a false alarm for the program in Fig. 14 middle: since the high value is overwritten in line 4, the program always outputs 0 and is secure. Note that there might be many more statements between the two writes to T (cmp. [14]).
For concurrent programs, compositionality is even more problematic. Consider the program in Fig. 14 right: it is sequential and always prints 0, and therefore fulfills PN for every scheduler. If this program is composed in parallel with the secure program print(1);, it however contains a probabilistic leak similar to Fig. 2 right. Therefore, a typical compositional analysis (e.g. [25,35]) will reject the isolated code piece in Fig. 14 right, because it conservatively assumes that it can be composed with arbitrary (unknown) threads. RLSOD in contrast is a whole-program analysis, and uses MHP information to exactly infer possible concurrency (cmp. Section 4.1). Thus it considers the isolated code piece secure – which it is. It should be noted that compromises between the two extreme positions “fully compositional” vs. “whole-program” have been attempted, e.g. [23,24].
Program logics as discussed above are also compositional, typically because they use Hoare triples. In contrast to type systems and RLSOD, program logics for PN can be made arbitrarily precise. But the price is high: program logics and verification are never fully automatic, and in practice require high manual effort for specification and verification. We thus believe that in practice, RLSOD is a good compromise: it is fully automatic yet very precise, and compositionality can be simulated by stubs.
Conclusion
We described a new algorithm for probabilistic noninterference, named RLSOD, which allows secure low-nondeterminism, while basically maintaining the low-deterministic security (LSOD) approach. RLSOD benefits from flow- and context-sensitive program analysis methods such as PDGs, points-to analysis, and dominators in multi-threaded programs. It turns out that RLSOD heavily reduces false alarms compared to LSOD, while a full soundness proof could be achieved. An Isabelle formalization of the soundness proof has already begun.
RLSOD is integrated into the JOANA IFC tool. JOANA can handle full Java with arbitrary threads, while being sound and scaling to 200k LOC. The decision to base PN in JOANA on low-deterministic security was made at a time when mainstream IFC research considered LSOD too restrictive. In the current paper we have shown that flow- and context-sensitive analysis, together with new techniques for allowing secure low-nondeterminism, has rehabilitated the LSOD idea.
References
1.
W.Ahrendt, B.Beckert, R.Bubel, R.Hähnle, P.H.Schmitt and M.Ulbrich (eds), Deductive Software Verification – the Key Book – from Theory to Practice, Lecture Notes in Computer Science, Vol. 10001, Springer, 2016.
2.
A.Askarov, S.Hunt, A.Sabelfeld and D.Sands, Termination-insensitive noninterference leaks more than just a bit, in: Proc. ESORICS, LNCS, Vol. 5283, 2008, pp. 333–348.
3.
G.Barthe, C.Fournet, B.Grégoire, P.Strub, N.Swamy and S.Z.Béguelin, Probabilistic relational verification for cryptographic implementations, in: The 41st Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL ’14, San Diego, Ca, Usa, January 20–21, 2014, 2014, pp. 193–206.
4.
J.Breitner, J.Graf, M.Hecker, M.Mohr and G.Snelting, On improvements of low-deterministic security, in: Proc. Principles of Security and Trust (POST 2016), Lecture Notes in Computer Science, Vol. 9635, Springer Berlin Heidelberg, 2016, pp. 68–88. doi:10.1007/978-3-662-49635-0_4.
5.
B.De Sutter, L.Van Put and K.De Bosschere, A practical interprocedural dominance algorithm, Acm Trans. Program. Lang. Syst.29(4) (2007).
6.
D.Giffhorn, Advanced chopping of sequential and concurrent programs, Software Quality Journal19(2) (2011), 239–294. doi:10.1007/s11219-010-9114-7.
7.
D.Giffhorn, Slicing of Concurrent Programs and its Application to Information Flow Control, PhD thesis, Karlsruher Institut für Technologie, Fakultät für Informatik, 2012.
8.
D.Giffhorn and G.Snelting, A new algorithm for low-deterministic security, International Journal of Information Security14(3) (2015), 263–287. doi:10.1007/s10207-014-0257-6.
9.
J.Graf, Information Flow Control with System Dependence Graphs — Improving Modularity, Scalability and Precision for Object Oriented Languages, PhD thesis, Karlsruher Institut für Technologie, Fakultät für Informatik, 2016.
10.
J.Graf, M.Hecker, M.Mohr and G.Snelting, Checking applications using security APIs with JOANA, 2015, 8th International Workshop on Analysis of Security APIs.
11.
J.Graf, M.Hecker, M.Mohr and G.Snelting, Tool demonstration: JOANA, in: Proc. Principles of Security and Trust (POST 2016), Lecture Notes in Computer Science, Vol. 9635, Springer Berlin Heidelberg, 2016, pp. 89–93. doi:10.1007/978-3-662-49635-0_5.
12.
S.Greiner, M.Mohr and B.Beckert, Modular verification of information flow security in component-based systems, in: Software Engineering and Formal Methods – 15th International Conference, SEFM 2017, Proceedings, Trento, Italy, September 4–8, 2017, 2017, pp. 300–315.
13.
C.Hammer, Experiences with PDG-based IFC, in: Proc. ESSoS’10, F.Massacci, D.Wallach and N.Zannone, eds, LNCS, Vol. 5965, Springer-Verlag, 2010, pp. 44–60.
14.
C.Hammer and G.Snelting, Flow-sensitive, context-sensitive, and object-sensitive information flow control based on program dependence graphs, International Journal of Information Security8(6) (2009), 399–422. doi:10.1007/s10207-009-0086-1.
15.
S.Horwitz, J.Prins and T.Reps, On the adequacy of program dependence graphs for representing programs, in: Proc. POPL ’88, ACM, New York, NY, USA, 1988, pp. 146–157. doi:10.1145/73560.73573.
16.
M.Huisman and T.M.Ngo, Scheduler-specific confidentiality for multi-threaded programs and its logic-based verification, in: Proc. Formal Verification of Object-Oriented Systems, 2011.
17.
M.Huisman, P.Worah and K.Sunesen, A temporal logic characterisation of observational determinism, in: Proc. 19th CSFW, IEEE, 2006, p. 3.
18.
S.Hunt and D.Sands, On flow-sensitive security types, in: POPL ’06, ACM, 2006, pp. 79–90. doi:10.1145/1111037.1111045.
19.
R.Küsters, E.Scapin, T.Truderung and J.Graf, Extending and applying a framework for the cryptographic verification of Java programs, in: Proc. POST 2014, LNCS 8424, Springer, 2014, pp. 220–239.
20.
R.Küsters, T.Truderung, B.Beckert, D.Bruns, M.Kirsten and M.Mohr, A hybrid approach for proving noninterference of Java programs, in: IEEE 28th Computer Security Foundations Symposium, CSF 2015, Verona, Italy, 13–17 July, 2015, 2015, pp. 305–319.
21.
R.Küsters, T.Truderung and J.Graf, A framework for the cryptographic verification of Java-like programs, in: Computer Security Foundations Symposium (CSF), 2012 IEEE 25th, IEEE Computer Society, 2012.
22.
L.Li and C.Verbrugge, A practical MHP information analysis for concurrent Java programs, in: Proc. LCPC’04, LNCS, Vol. 3602, Springer, 2004, pp. 194–208. doi:10.1007/11532378_15.
23.
H.Mantel, M.Müller-Olm, M.Perner and A.Wenner, Using dynamic pushdown networks to automate a modular information-flow analysis, in: Pre-Proceedings of the 25th International Symposium on Logic Based Program Synthesis and Transformation (LOPSTR), 2015.
24.
H.Mantel, D.Sands and H.Sudbrock, Assumptions and guarantees for compositional noninterference, in: Proceedings of the 24th IEEE Computer Security Foundations Symposium (CSF), IEEE Computer Society, Cernay-la-Ville, France, 2011, pp. 218–232.
25.
H.Mantel and H.Sudbrock, Flexible scheduler-independent security, in: Computer Security – ESORICS 2010, D.Gritzalis, B.Preneel and M.Theoharidou, eds, Lecture Notes in Computer Science, Vol. 6345, Springer Berlin Heidelberg, 2010, pp. 116–133. ISBN 978-3-642-15496-6. doi:10.1007/978-3-642-15497-3_8.
26.
M.Mohr, J.Graf and M.Hecker, JoDroid: Adding Android support to a static information flow control tool, in: Gemeinsamer Tagungsband der Workshops der Tagung Software Engineering 2015, Dresden, Germany, 17.–18. März 2015, CEUR Workshop Proceedings, Vol. 1337, CEUR-WS.org, 2015, pp. 140–145.
27.
G.Naumovich and G.S.Avrunin, A conservative data flow algorithm for detecting all pairs of statements that may happen in parallel, in: Proceedings of the 6th ACM SIGSOFT International Symposium on Foundations of Software Engineering, ACM, New York, NY, USA, 1998, pp. 24–34.
28.
T.M.Ngo, Qualitative and quantitative information flow analysis for multi-threaded programs, PhD thesis, University of Enschede, 2014.
29.
A.Popescu, J.Hölzl and T.Nipkow, Formalizing probabilistic noninterference, in: Certified Programs and Proofs – Third International Conference, CPP 2013, Proceedings, Melbourne, VIC, Australia, December 11–13, 2013, 2013, pp. 259–275.
30.
A.Popescu, J.Hölzl and T.Nipkow, Noninterfering schedulers, in: Algebra and Coalgebra in Computer Science, R.Heckel and S.Milius, eds, Lecture Notes in Computer Science, Vol. 8089, Springer Berlin Heidelberg, 2013, pp. 236–252. doi:10.1007/978-3-642-40206-7_18.
31.
T.Reps, S.Horwitz, M.Sagiv and G.Rosay, Speeding up slicing, in: Proc. FSE ’94, ACM, New York, NY, USA, 1994, pp. 11–20.
32.
A.W.Roscoe, J.Woodcock and L.Wulf, Non-interference through determinism, in: ESORICS, LNCS, Vol. 875, 1994, pp. 33–53.
33.
A.Sabelfeld and A.Myers, Language-based information-flow security, IEEE Journal on Selected Areas in Communications21(1) (2003), 5–19. doi:10.1109/JSAC.2002.806121.
34.
A.Sabelfeld and D.Sands, Probabilistic noninterference for multi-threaded programs, in: Proceedings of the 13th IEEE Computer Security Foundations Workshop, CSFW ’00Cambridge, England, UK, July 3–5, 2000, 2000, pp. 200–214.
35.
G.Smith, Improved typings for probabilistic noninterference in a multi-threaded language, J. Comput. Secur.14(6) (2006), 591–623. doi:10.3233/JCS-2006-14605.
36.
G.Smith and D.Volpano, Secure information flow in a multi-threaded imperative language, in: Proc. POPL ’98, ACM, 1998, pp. 355–364. doi:10.1145/268946.268975.
37.
G.Snelting, Combining slicing and constraint solving for validation of measurement software, in: SAS ’96: Proceedings of the Third International Symposium on Static Analysis, Springer-Verlag, London, UK, 1996, pp. 332–348.
38.
G.Snelting, D.Giffhorn, J.Graf, C.Hammer, M.Hecker, M.Mohr and D.Wasserrab, Checking probabilistic noninterference using JOANA, It – Information Technology56 (2014), 280–287. doi:10.1515/itit-2014-1051.
39.
G.Snelting, T.Robschink and J.Krinke, Efficient path conditions in dependence graphs for software safety analysis, ACM Trans. Softw. Eng. Methodol.15(4) (2006), 410–457. doi:10.1145/1178625.1178628.
40.
D.Wasserrab, D.Lohner and G.Snelting, On PDG-based noninterference and its modular proof, in: Proc. PLAS ’09, ACM, 2009.
41.
S.Zdancewic and A.C.Myers, Observational determinism for concurrent program security, in: Proc. CSFW, IEEE, 2003, pp. 29–43.