
Abstract
Temporal role-based access control (TRBAC) extends role-based access control to limit the times at which roles are enabled. This paper presents a new algorithm for mining high-quality TRBAC policies from timed ACLs (i.e., ACLs with time limits in the entries) and optionally user attribute information. Such algorithms have potential to significantly reduce the cost of migration from timed ACLs to TRBAC. The algorithm is parameterized by the policy quality metric. We consider multiple quality metrics, including number of roles, weighted structural complexity (a generalization of policy size), and (when user attribute information is available) interpretability, i.e., how well role membership can be characterized in terms of user attributes. Ours is the first TRBAC policy mining algorithm that produces hierarchical policies, and the first that optimizes weighted structural complexity or interpretability. In experiments with datasets based on real-world ACL policies, our algorithm is more effective than previous algorithms at optimizing policy quality.
Introduction
Role-based access control (RBAC) offers significant advantages over lower-level access control policy representations, such as access control lists (ACLs). RBAC policy mining algorithms have potential to significantly reduce the cost of migration to RBAC, by partially automating the development of an RBAC policy from an access control list (ACL) policy and possibly other information, such as user attributes [4]. The most widely studied versions of the RBAC policy mining problem involve finding a minimum-size RBAC policy consistent with (i.e., equivalent to) given ACLs. When user attribute information is available, it is also important to maximize interpretability (or “meaning”) of roles – in other words, to find roles whose membership can be characterized well in terms of user attributes. Interpretability is critical in practice. Researchers at HP Labs report “the biggest barrier we have encountered to getting the results of role mining to be used in practice” is that “customers are unwilling to deploy roles that they can’t understand” [2]. Algorithms for mining meaningful roles are described in, e.g., [10,16].
Temporal RBAC (TRBAC) extends RBAC to limit the times at which roles are enabled [1]. TRBAC supports an expressive notation, called periodic expressions, for expressing sets of time intervals during which a role is enabled. A role’s permissions are available to members only while the role is enabled. This allows tighter enforcement of the principle of least privilege. Access control in many existing systems supports some form of groups or roles and some form of periodic temporal constraints. This includes LDAP-based directory servers, such as Oracle Unified Directory and Red Hat Directory Server, XACML-based Identity and Access Management (IAM) products, such as Axiomatics Policy Server, some other IAM products, such as NetIQ Access Manager, some cloud computing services, such as Joyent’s Triton Compute Service, and many network routers and switches.
This paper presents an algorithm for mining hierarchical TRBAC policies. It is parameterized by a policy quality metric. We consider multiple policy quality metrics: number of roles, weighted structural complexity (WSC) [10], a generalization of syntactic policy size, interpretability (INT) [10,16], described briefly above, and a compound quality metric, denoted WSC-INT, that combines WSC and INT. Our algorithm does not require attribute data; attribute data, if available, is used only in the policy quality metric, if it considers interpretability. Our algorithm is the first TRBAC policy mining algorithm that produces hierarchical policies, and the first that optimizes WSC or interpretability.
Our algorithm is based on Xu and Stoller’s elimination algorithm for RBAC mining [16] and some aspects of Mitra et al.’s pioneering generalized temporal role mining algorithm, which we call GTRM algorithm, for mining flat TRBAC policies (i.e., policies without role hierarchy) with minimal number of roles [7,8], which inspired our work. Our algorithm has four phases: (1) produce a set of candidate roles that contains initial roles (generated directly from the entitlements in the input) and roles created by intersecting initial roles, (2) merge candidate roles where possible, (3) organize the candidate roles into a role hierarchy, and (4) remove low-quality candidate roles(this is a greedy heuristic). The generated policy is not guaranteed to have optimal quality. Fundamentally, this is because the problem of finding an optimal policy is NP-complete (this follows from NP-completeness of the untimed version of the problem ([10]).
To evaluate the algorithm, we created datasets based on real-world ACL policies from HP, described in [2] and used in several evaluations of role mining algorithms, e.g., [8,10,16]. We could simply extend the ACLs with temporal information to create a temporal user-permission assignment (TUPA), and then mine a TRBAC policy from the TUPA and attribute data. However, it would be hard to evaluate the algorithm’s effectiveness, because there is nothing with which to compare the quality of the mined policies. Therefore, we adopt a similar methodology as Mitra et al. [8]. For each ACL policy, we mine an RBAC policy from the ACLs and synthetic attribute data using Xu and Stoller’s elimination algorithm [16], pseudorandomly extend the RBAC policy with temporal information numerous times to obtain TRBAC policies, expand the TRBAC policies into equivalent TUPAs, mine a TRBAC policy from each TUPA and the attribute data, and compare the average quality of the resulting TRBAC policies with the quality of the original TRBAC policy, with the goal that the former is at least as good as the latter.
We created two datasets, using different temporal information when extending RBAC policies to obtain TRBAC policies. For the first dataset, we use simple periodic expressions, each of which is a range of hours that implicitly repeats every day.We use the same time intervals as [8]. They are designed to cover various relationships between intervals, such as overlapping, consecutive, disjoint, and nested. For the second dataset, we use more complex periodic expressions based on a hospital staffing schedule.For both datasets, we use the same attribute data, namely, the high-fit synthetic attribute data for these ACL policies described in [16].
In experiments using number of roles as the policy quality metric, Mitra et al.’s GTRM algorithm, designed to minimize number of roles, produces 34% more roles than our algorithm, on average. In experiments using WSC-INT as the policy quality metric, our algorithm succeeds in finding the implicit structure in the TUPA, producing policies with comparable (for the first dataset) or moderately higher (for the second dataset) WSC and better interpretability, on average, compared with the original TRBAC policy.
Mitra et al. developed another temporal role mining algorithm, called the CO-TRAPMP-MVCL algorithm [9]. It minimizes a restricted variant of WSC based on the sizes of two components of the policy. In experiments using that variant as a policy quality metric, and using datasets created by Mitra et al., our algorithm produces policies that are 41% smaller, on average, than the policies produced by the CO-TRAPMP-MVCL algorithm.
We explored the effect of different inheritance types on the quality of the mined policy and found that weakly restricted inheritance leads to policies with significantly better WSC and slightly better interpretability, on average. We experimentally evaluated the benefits of some design decisions and quantified the cost-quality trade-off provided by a parameter to our algorithm that limits the set of initial roles used in intersections in phase 1.
This paper is a revised and extended version of [12]. The main improvements are substitution of FastMiner for CompleteMiner when computing role intersections and an empirical justification for this, an improved metric for selecting a subset of initial roles for use in role intersections, more explanation and details of the algorithm, and more experiments, including an experimental comparison with Mitra et al.’s CO-TRAPMP-MVCL algorithm [9].
Section 2 provides background on TRBAC. Section 3 defines the policy mining problem. Section 4 presents our algorithm. Section 5 describes the datasets used in the experimental evaluation. Section 6 presents the results of the experimental evaluation. Section 7 discusses related work. Directions for future work include: mining TRBAC policies from operation logs, by extending work on mining RBAC policies from logs [11]; optimization of TRBAC policies, i.e., improving the quality of a TRBAC policy while minizing changes to it, by extending work on optimizing RBAC policies [14]; and mining temporal ABAC policies, by extending work on ABAC policy mining [6,17].
Background on TRBAC
An RBAC policy is a tuple
A periodic expression (PE) is a symbolic representation for an infinite set of time intervals. The formal definition of periodic expressions in [1,8] is standard and somewhat complicated; instead of repeating it, we give a brief intuitive version. A calendar is an infinite set of consecutive time intervals of the same duration; informally, it corresponds to a time unit, e.g., a day or an hour. A sequence of calendars
For example, consider the sequence of calendars Quadweeks, Weeks, Days, hours, where a Quadweek is four consecutive weeks – similar to a month, but with a uniform duration. The periodic expression
A bounded periodic expression (BPE) is a tuple
A BPE set (BPES) is a set of BPEs. It represents the union of the sets of time intervals represented by its members
A temporal RBAC (TRBAC) policy is a tuple
We consider two types of inheritance [5]. In both cases, a senior role r inherits permissions from each of its junior roles
A temporal user-permission assignment (TUPA) is a set of triples of the form
The meaning of a role r in a TRBAC policy π, denoted
The relaxed TRBAC policy mining problem
A policy quality metric is a function from TRBAC policies to a totally-ordered set, such as the natural numbers. The ordering is chosen so that small values indicate high quality; this might seem counter-intuitive at first glance, but it is natural for metrics such as policy size. We define three basic policy quality metrics and then consider combinations of them.
Number of roles is a simplistic but traditional policy quality metric.
Weighted Structural Complexity (WSC) is a generalization of policy size [10]. For a TRBAC policy π of the above form with a role-time assignment
Interpretability is a policy quality metric that measures how well role membership can be characterized in terms of user attributes. User-attribute data is a tuple
Compound policy quality metrics take multiple aspects of policy quality into account. We combine metrics by Cartesian product, with lexicographic order on the tuples. Lexicographic order means
A TRBAC policy π is consistent with a TUPA T if they grant the same permissions to the same users for the same sets of time intervals. When the given TUPA contains noise, it is desirable to weaken this requirement. A TRBAC policy π is ϵ-consistent with a TUPA T, where ϵ is a natural number, if they grant the same permissions to the same users for the same sets of time intervals, except that, for at most ϵ entitlement triples
The relaxed TRBAC policy mining problem is: given a TUPA T, policy quality metric
We refer to this as the relaxed TRBAC policy mining problem, because of the relaxed consistency requirement; Mitra et al. refer to it as the generalized TRBAC policy mining problem.
Suggested role assignments for new users. If attribute data is available, the system can compute and store a best-fit attribute expression
TRBAC policy mining algorithm
Inputs to the algorithm are the TUPA T, the type of inheritance
In traditional RBAC and TRBAC notation, roles are identifiers (not objects), and separate relations such as
Our pseudocode uses the following notation for sets and dictionaries. “new Set()” and “new Dictionary()” create an empty set and empty dictionary, respectively. The methods of a set s include
Phase 1: Generate roles. Phase 1 generates initial roles and then creates additional candidate roles by intersecting sets of initial roles.
Phase 1.1: Generate initial roles. Pseudocode for generating initial roles appears in Fig. 1. It uses a semantic containment relation ⊑ on PEs, BPEs, and BPESs:

Phase 1.1: Generate initial roles. “s.t.” abbreviates “such that”.
Phase 1.2: Intersect roles. Phase 1.2 starts to construct a set

Phase 1.2: Intersect roles.
This phase is expensive for large datasets. To reduce the cost, we allow role intersections to be limited to a subset of the initial roles containing the roles mostly likely to produce useful intersections. To support a flexible trade-off between cost (running time) and policy quality, we introduce a parameter that controls the size of the subset.
The subset is characterized using a new role quality metric, called the usefulness-for-intersection metric (
We used a Support Vector Machine (SVM) to find the weights that maximize the
To control the cost-quality trade-off, we introduce a parameter
Phase 2: Merge roles. Phase 2 merges candidate roles to produce a revised set of candidate roles. It uses the following types of merges. (1) If candidate roles r and

Phase 2: Merge roles.
Phase 3: Construct role hierarchy. Phase 3 organizes the candidate roles into a role hierarchy with full inheritance. A TRBAC policy has full inheritance if every two roles that can be related by the inheritance relation are related by it, i.e.,
Phase 3.1: Compute inheritance. Phase 3.1 determines inheritance relationships between candidate roles, based on the requirement of full inheritance. Function

Phase 3.1: Determine inheritance relationships.
Phase 3.2: Compute assigned users and permissions. Phase 3.2 computes the directly assigned users

Phase 3.2: Compute directly assigned users and directly assigned permissions.
Phase 4: Remove roles. Phase 4 removes roles from the candidate role hierarchy if the removal preserves ϵ-consistency with the given ACL policy and improves policy quality. When a role r is removed, the role hierarchy is adjusted to preserve inheritance relations between parents and children of r, and the sets of directly assigned users and permissions of other roles are expanded to contain users and permissions that they previously inherited from r.
The order in which roles are considered for removal affects the final result. We control this ordering with a role quality metric
The redundancy of a role r measures how many other roles also cover the entitlement triples covered by r. We say that a role r covers an entitlement triple t if
The clustered size of a role r measures how many entitlements are covered by r and how well they are clustered. A first attempt at formulating this metric (ignoring clustering) might be as the fraction of entitlement triples in T that are covered by r. As discussed in [16], it is better for the covered entitlement triples to be “clustered” on (i.e., associated with) fewer users rather than being spread across many users. The clustered size of r is defined to equal the fraction of the entitlements of r’s members that are covered by r. In the temporal case, each entitlement triple
Our role quality metric is
Our algorithm may remove a role even if the removal worsens policy quality slightly. Specifically, we introduce a quality change tolerance δ, with
Pseudocode for removing roles appears in Fig. 6. It repeatedly tries to remove all removable roles, until none of the attempted removals succeeds in improving the policy quality. The policy π is an implicit argument to auxiliary functions such as removeRole and addRole. Function
When testing whether ϵ-consistency is violated, it is sufficient to check the size of
The following auxiliary functions are used in removeRole.
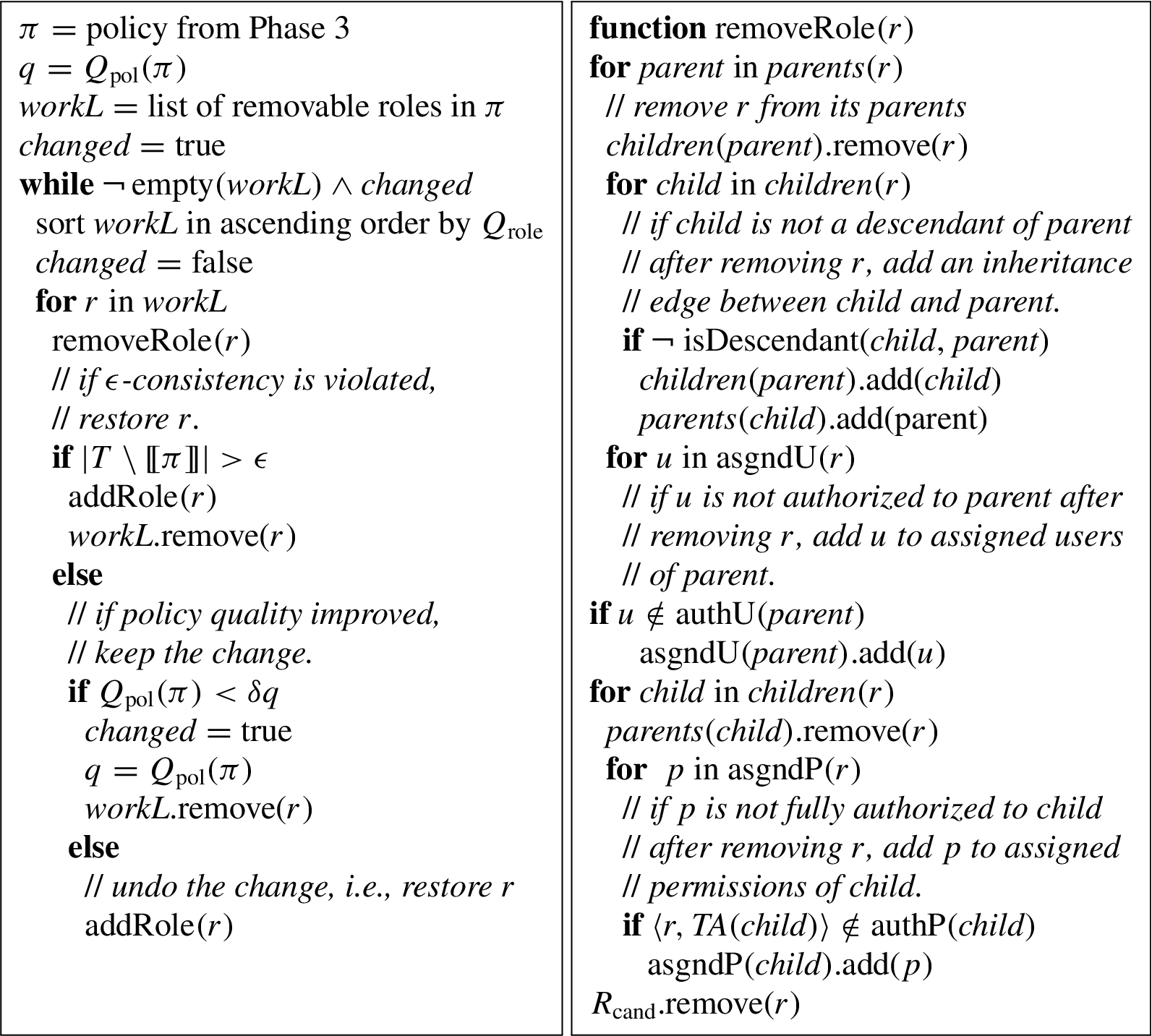
Phase 4: Remove roles.
We generated two datasets based on real-world ACL policies from HP, described in [2], and the high-fit synthetic attribute data for these ACL policies described in [16]; see those references for more information about the ACL policies and attribute data. Briefly, the ACL policies are named americas_small, apj, domino, emea, firewall1, firewall2, and healthcare. The synthetic attribute data is generated pseudorandomly, using statistical distributions based on statistical summaries of some real-world attribute data, to make the synthetic data more realistic. The number of attributes ranges from 20 to 50, depending on the policy size. The type of attribute values is unimportant (the only operation used by our algorithm on attribute values is equality), so we simply use natural numbers for the values of all attributes.
As outlined in Section 1, for each ACL policy, we mine an RBAC policy from the ACLs and the attribute data using Xu and Stoller’s elimination algorithm [16], and pseudorandomly extend the RBAC policy with temporal information several times to obtain TRBAC policies. For each ACL policy except americas_small, we create 30 TRBAC policies. For americas_small, which is larger, we create only 10 TRBAC policies, to reduce the running time of the experiments. We extend the RBAC policies in two ways, using different temporal information.
Dataset with simple PEs. A simple PE is a range of hours (e.g., 9am–5pm) that implicitly repeats every day.We define the WSC of a simple PE to be 1. This dataset uses the same simple PEs as in [8], namely,
Dataset with complex PEs. For this dataset, we use periodic expressions based on a hospital staffing schedule, based on discussions with the Director of Timekeeping at Stony Brook University Hospital. The periodic expressions are not taken directly from the hospital’s staffing schedule, but they reflect its general nature. The schedule does not repeat every week, but rather every few weeks, because weekend duty rotates. Clinicians may work 3 days/week for 12 hours/day starting at 7am or 7pm, or 5 days/week for 8.5 hours/day starting at 7am, 3pm, or 11pm.The probabilities of these work schedules are 0.144, 0.094, 0.284, 0.284, and 0.194, respectively. We create two instances of each of these five types of work schedules, by pseudorandomly choosing the appropriate number of days of the week in each of the four weeks of a Quadweek, using a uniform distribution. Each BPES is based on exactly one of the resulting 10 work schedules. Multiple PEs are needed to represent work schedules that wrap around calendar units; for example, a 7pm–7am shift is represented using two PEs, with time intervals 7pm–midnight and midnight–7am. The PEs are based on the following sequence of calendars:
Evaluation
The experimental methodology is outlined in Section 1. All experiments use quality change tolerance
Our Java code and datasets are available at
Experiments using dataset with simple PEs
All experiments on this simple PEs dataset use role intersection cutoff
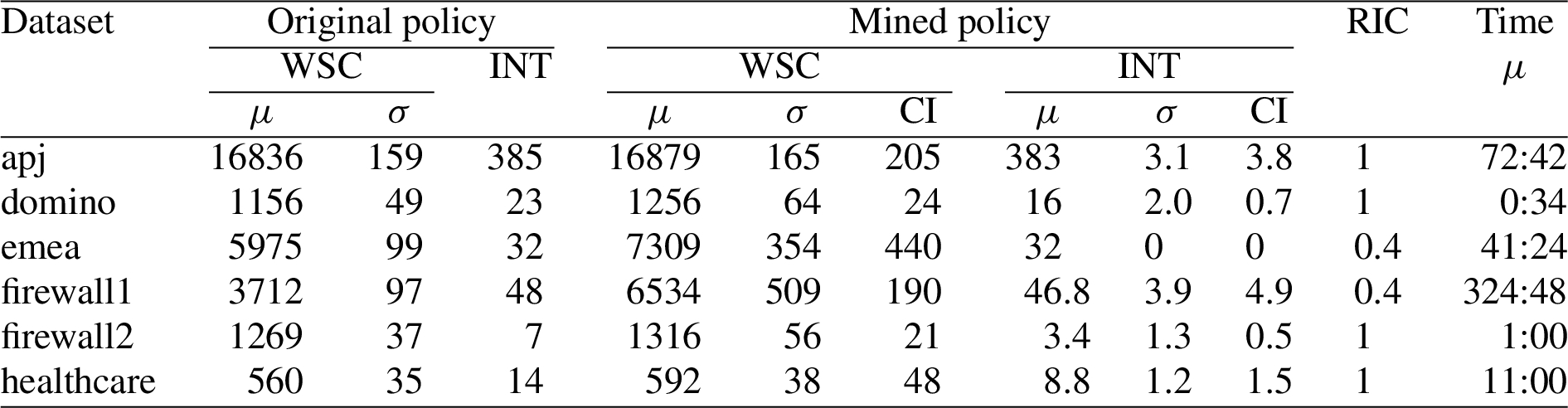
Comparison of original and mined policies. Figure 7 shows detailed results from experiments on this dataset. In the column headings, μ is mean, σ is standard deviation, CI is half-width of 95% confidence interval using Student’s t-distribution, and time is the average running time in minutes:seconds. There is no standard deviation column for INT, because interpretability is unaffected by the role-time assignment and hence is the same for all TRBAC policies generated by extending the same RBAC policy. Ignore the last 2 columns for now. The averages and standard deviations are computed over the TRBAC policies created by extending each RBAC policy. The WSC of the mined TRBAC policy ranges from about 2% lower (for healthcare) to about 5% higher (for firewall1) than the WSC of the original TRBAC policy. The interpretability of the mined policy ranges from about 40% lower (for firewall-2) to about 1% lower (for apj) than the interpretability of the original TRBAC policy. On average over the seven policies, the WSC is about 0.5% higher, and the interpretability is about 19% lower. Thus, our algorithm succeeds in finding the implicit structure in the TUPA and producing a policy with comparable WSC and better interpretability, on average, than the original TRBAC policy.

Results of experiments with simple PEs.
Comparison of FastMiner and CompleteMiner. In Phase 1.2 (Intersect roles), instead of the FastMiner approach of computing intersections only for pairs of initial roles, we could instead adopt the CompleteMiner approach of computing intersections for all subsets of initial roles [15]. We ran our algorithm, modified to use CompleterMiner, on our simple PE dataset, omitting emea and americas_small because of their longer running times. Figure 8 shows the results using FastMiner and CompleteMiner. Surprisingly, CompleteMiner did not improve policy quality: it increased the average WSC by 4% on average, ranging from 0.2% (for firewall2) to 11% (for domino), and it increased (worsened) the average INT by 10% on average, ranging from 1% (for apj) to 19% (for firewall1). Although one might expect that generating additional candidate roles would only improve the quality of the final policy, the role selection phase uses imperfect heuristics, so additional candidate roles sometimes lead to decreases in policy quality. Not surprisingly, CompleteMiner is slower: it increased the average running time by 160% on average, ranging from 15% for firewall2 to 201% for apj.
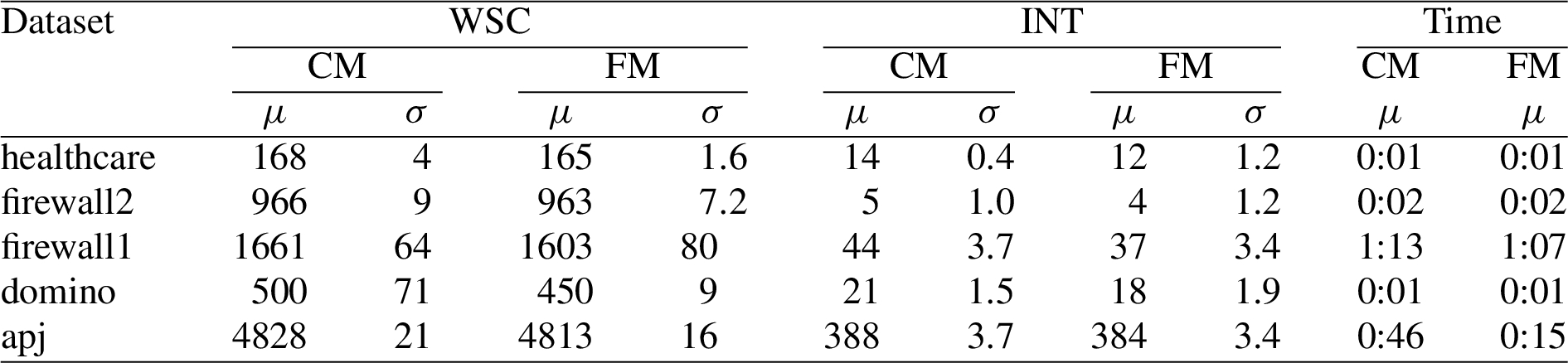
Results of experiments with Complete Miner (CM) and Fast Miner (FM).
Comparison of inheritance types. We ran our algorithm again on the same dataset with all policies except americas_small, specifying strongly restricted inheritance for the mined policies. This caused a significant increase in the WSC of the mined policies. The percentage increase averages 51% and ranges from 6% (for apj) to 105% (for firewall1 and healthcare). Intuitively, the reason for the increase is that, with strongly restricted inheritance, the temporal information associated with directly assigned and inherited permissions may be different, and this may prevent removing inherited permissions from a role’s directly assigned permissions. Inheritance type has less effect on the average INT, increasing (worsening) it by about 3% on average.
Evaluation of choice of initial roles. Recall from Section 4 that the definition of permBPES in Fig. 1 uses the condition
The policy quality benefit of permBPES over permBPES− can also be demonstrated with a simple example. Consider the input TUPA
We also evaluated the effect of using both permBPES and permBPES−, i.e., of replacing the call
We considered reducing the cost of Phase 1.1 by removing the first call to addRole. Note that Mitra et al.’s algorithm does not include an analogue of this call. This change increased the average WSC by 9% on average over the policies used in this experiment (all except americas_small), ranging from 7% (for emea and firewall2) to 10% (for domino). It increased (worsened) the average INT by 8% on average over those policies, ranging from 2% (for firewall2) to 12% (for firewall1).
Comparison with Mitra et al.’s GTRM algorithm. We ran Mitra et al.’s GTRM algorithm [8], and our algorithm with number of roles as policy quality metric (because GTRM algorithm optimizes this metric), on our dataset with simple PEs. Their code supports only simple PEs, so we used only the simple PE dataset in the comparison. Their code, implemented in C, gave an error (“malloc: …: pointer being freed was not allocated”) on some TRBAC policies generated for emea and firewall1; we ignored those results. Their code did not run correctly on americas_small, so we omitted it from this comparison.
The last two columns of Fig. 7 show the numbers of roles generated by the two algorithms. Standard deviations are omitted to save space but are small: on average, 3% of the mean, for both algorithms. The GTRM algorithm produces 34% more roles than ours, on average. Our algorithm produces hierarchical policies, and their algorithm produces flat policies, but this does not affect the number of roles. There are many other differences between the algorithms, discussed in Section 7, which contribute to the difference in results. The above paragraph on evaluation of choice of initial roles describes two experiments that explore differences between our algorithm and the GTRM algorithm and quantify the benefit of those differences. The effects of some other differences between the two algorithms, such as the use of elimination vs. selection in Phase 4, were investigated in the untimed case in [16] and likely have a similar impact here.
Results of experiments with complex PEs.
Comparison of original and mined policies. Figure 9 shows detailed results from experiments on this dataset. The original TRBAC policies here have higher WSC than the ones in Section 6.1, because complex PEs have higher WSC than simple PEs. We averaged over 30 TRBAC policies each for domino and firewall2, and (to reduce the running time of the experiments) 5 TRBAC policies each for the others. For emea and firewall1, we use
The higher running times, compared to the dataset with simple PEs, are due primarily to the larger number of candidate roles created by role intersection (there are more overlaps between BPESs in this dataset), and secondarily to the larger overhead of manipulating more complex PEs.
Benefit of general PEs. PEs can be translated into sets of simple PEs. For example, the set of PEs
Cost-benefit trade-off from role intersection cutoff. We investigated the cost-benefit trade-off when varying the role intersection cutoff
Benefit of new

Relative running time and relative WSC as functions of
Mitra et al.’s CO-TRAPMP-MVCL algorithm, called the CTR algorithm for brevity, minimizes a variant of WSC, called cumulative overhead of temporal roles and permissions (CO-TRAP), defined by
Dataset. Our experimental comparison with the CTR algorithm uses the datasets generated by Mitra et al. for their experiments with CTR algorithm described in [9]. It is based on the same real-world ACL policies from HP as our datasets described in Section 5. It contains TRBAC policies generated by mining non-temporal RBAC policies using Ene et al.’s algorithm [2], and then extending them with synthetic temporal information containing simple PEs. First, they create 10 sets of contained time intervals (the intervals in each set are totally ordered by the subset relation) and 10 sets of overlapping time intervals (every pair of intervals in each set has a non-empty intersection). They create a role-time assignment by pseudorandomly associating some of these time intervals with each role, selecting from the sets of contained time intervals and overlapping time intervals with probability d and
Results. Figure 11 shows the average μ and standard deviation σ of CO-TRAP for policies generated by our algorithm, and average CO-TRAP for policies generated by CTR algorithm as reported in [8, Table 6]. The average CO-TRAP for policies generated by our algorithm ranges from 68% lower (for healthcare c100) to 19% lower (for emea o100) than the corresponding results for the CTR algorithm. On average over all five datasets for all eight ACL policies, results for policies generated by our algorithm are 41% lower than results for policies generated by the CTR algorithm. Thus, our algorithm is significantly more effective than the CTR algorithm at minimizing CO-TRAP.
It took less than 2 minutes to run our algorithm for all 30 TRBAC policies generated from each of the ACL policies healthcare, domino, firewall2, and emea. It took less than 2 minutes to run our algorithm for each TRBAC policy generated from apj, firewall1, and americas_large (an ACL policy from HP not used in the datasets described in Section 5). It took approximately 24 minutes to run experiments for each TRBAC policy generated from americas_small. Mitra et al. report that “each individual run took no more than 24 minutes” [9]. Although these measurements are from experiments on different hardware and software platforms (our algorithm is implemented in Java, and CTR algorithm is implemented in C), they suggest that running times of our algorithm and CTR algorithm are comparable.
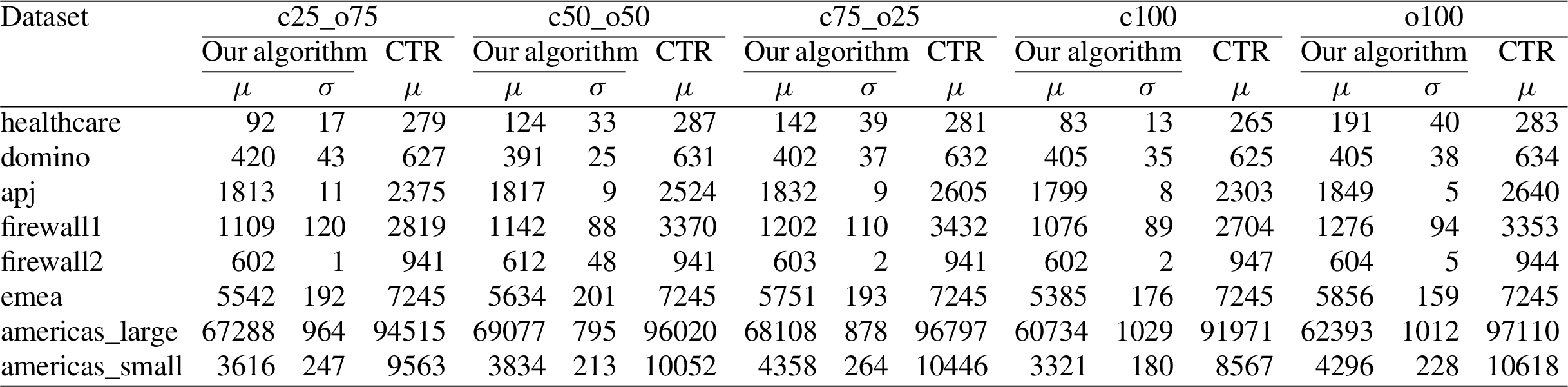
Comparison of our algorithm and the CO-TRAPMP-MVCL (a.k.a. CTR) algorithm using the CO-TRAP metric.
We discuss related work on TRBAC policy mining and then related work on RBAC mining. Role mining (for RBAC or TRBAC) is also reminiscent of some other data mining problems, but algorithms for those other problems are not well suited to role mining. For example, association rule mining algorithms are designed to find rules that are probabilistic in natureand are supported by statistically strong evidence. They are not designed to produce a set of rules strictly consistent with the input that completely covers the input and is minimum-sized among such sets of rules.
Related work on TRBAC policy mining
Mitra et al. define a version of the TRBAC policy mining problem, called the generalized temporal role mining (GTRM) problem, based on minimizing the number of roles. They present an algorithm, which we call the GTRM algorithm, for approximately solving this problem [8]. It is an improved version of their earlier work [7].
Mitra et al. also define another version of the TRBAC policy mining problem, called cumulative overhead of temporal roles and permissions minimization problem (CO-TRAPMP), based on minimizing the CO-TRAP metric described in Section 6.1. They present another algorithm, called CO-TRAPMP-MVCL, for heuristically solving this problem [9].
Our algorithm is more flexible than the GTRM and CO-TRAPMP-MVCL algorithms, because our algorithm can optimize a variety of metrics, including WSC and interpretability. The importance of interpretability is discussed in Section 1. WSC is a more general measure of policy size than number of roles or CO-TRAP and can more accurately reflect expected administrative cost. For example, the average number of role assignments per user is a measure of expected administrative effort for adding a new user [13], and this can be reflected in WSC by giving appropriate weight to the size of the user-role assignment. Neither number of roles nor CO-TRAP take the size of the user-role assignment into account.
Our algorithm produces hierarchical TRBAC policies. The GTRM and CO-TRAPMP-MVCL algorithms produce flat TRBAC policies. Role hierarchy is a well-known feature of RBAC that can significantly reduce policy size and administrative effort by avoiding redundancy in the policy.
Our algorithm and the GTRM algorithm have a similar high-level structure: they both (1) create a large set of candidate roles based on the input TUPA, (2) merge some candidate roles, and then (3) select a subset of the candidate roles to include in the final policy. The algorithms also have many differences. Some differences are related to policy quality metric and role hierarchy, as discussed above. Some other differences are: (1) Our algorithm determines which candidate roles to include in the final policy by elimination of low-quality roles, instead of selection of high-quality roles. We showed that elimination gives better results in the untimed case [16]. (2) Our algorithm creates more initial roles than the GTRM algorithm. The benefit of creating these additional initial roles is shown in Section 6.1. The GTRM algorithm creates unit roles, which are similar to our initial roles but have only one permission. In particular, an initial role created by the second call to addRole in our algorithm is a unit role only when P is a singleton set and
The CO-TRAPMP-MVCL algorithm has a different high-level structure than our algorithm: roughly speaking, it (1) repeatedly generates a small set of candidate roles based on the current set of uncovered triples and adds the best one among them to the policy, and then (2) merges some roles. In the experiments in Section 6.3, our algorithm produces higher-quality policies than CO-TRAPMP-MVCL algorithm, as measured using the CO-TRAP metric which the CO-TRAPMP-MVCL algorithm is designed to optimize.
Our implementation supports periodic expressions for specifying temporal information, while Mitra et al.’s implementations of the GTRM and CO-TRAPMP-MVCL algorithms support only ranges of hours that implicitly repeat every day. Design and implementation of operations on sets of PEs is non-trivial.This includes operations such as testing whether one set of PEs covers all of the time instants covered by another set of PEs, and handling numerous corner cases, such as time intervals that wrap around calendar units (e.g., a 7pm–7am work shift).
Related work on RBAC mining
A survey of work on RBAC mining appears in [4]. The most closely related work is Xu and Stoller’s elimination algorithm [16]. We chose it as the starting point for design of our algorithm, because in the experiments in [16], it optimizes WSC more effectively than Hierarchical Miner [10]and the Graph Optimisation role mining algorithm [18], while simultaneously achieving good interpretability, and it optimizes WSCA, an interpretability metric defined in [10], more effectively than Attribute Miner [10].
Our algorithm retains the overall structure of the elimination algorithm but differs in several ways, due to the complexities created by considering time. Our algorithm introduces more kinds of candidate roles than the elimination algorithm, because it needs to consider grouping permissions that are enabled for the same time or a subset of the time of other permissions. Our algorithm attempts to merge candidate roles; the elimination algorithm does not. Construction of the role hierarchy is significantly more complicated than in the elimination algorithm; for example, with strongly restricted inheritance, a permission p can be inherited by a role r from multiple junior roles with different BPESs, which may together cover all or only part of the time that p is available in r. This also complicates adjustment of the role hierarchy when removing candidate roles. The role quality metric used to select roles for removal is more complicated, to give preference to roles that cover permissions for more times.
Footnotes
Acknowledgments
This material is based on work supported in part by NSF under Grants CNS-1421893, CCF-1248184, and CCF-1414078, ONR under Grant N00014-15-1-2208, and AFOSR under Grant FA9550-14-1-0261. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of these agencies. We thank the authors of [8,![]() ] – Barsha Mitra, Shamik Sural, Vijayalakshmi Atluri, and Jaideep Vaidya – for sharing their code and datasets with us and helping us understand their work.
] – Barsha Mitra, Shamik Sural, Vijayalakshmi Atluri, and Jaideep Vaidya – for sharing their code and datasets with us and helping us understand their work.