Data privacy is one of the main concerns for data outsourcing on the cloud. Although standard encryption can provide confidentiality, it prevents the client from searching/retrieving meaningful information on the outsourced data thereby, degrading the benefits of using cloud services. To address this data utilization versus privacy dilemma, Dynamic Searchable Symmetric Encryption (DSSE) has been proposed. DSSE enables encrypted search and update functionality over the encrypted data via a secure index. However, the state-of-the-art DSSE constructions leak information from the access pattern, making them vulnerable against various attacks. While generic Oblivious Random Access Machine (ORAM) can hide the access pattern, it incurs a heavy communication overhead, which was shown costly to be directly used in the DSSE setting. In this article, by exploiting the multi-cloud infrastructure, we develop a comprehensive Oblivious Distributed DSSE (ODSE) framework that allows oblivious search and updates on the encrypted index with high security and improved efficiency over the use of generic ORAM. Our framework contains a series of schemes each featuring different levels of performance and security required by various types of real-life applications. ODSE offers desirable security guarantees such as information-theoretic security and robustness in the presence of a malicious adversary. We fully implemented framework and evaluated its performance in a real cloud environment (Amazon EC2). Our experiments showed that ODSE schemes are - faster than using generic ORAMs on a DSSE encrypted index under real network settings.
The concept of storage-as-a-service provides a comprehensive storage architecture for companies or individuals to store data on the cloud, thereby reducing the data management and maintenance cost. Despite its usefulness, recent data breach incidents on such systems have shown the importance of preserving the confidentiality of sensitive data stored on the cloud. Although standard encryption (e.g., AES) can preserve data privacy, it also prevents the users from searching or retrieving meaningful information from outsourced data, which invalidates some benefits of using cloud storage services. To address this data utilization vs. privacy dilemma, the concept of searchable symmetric encryption (SSE) was introduced [35]. Since then, many SSE schemes have been developed in attempts to offer practical query functionality while, at the same time, preserving user privacy and data confidentiality. In the following sections, we first review the ongoing research on SSE and outline the security limitations of state-of-the-art approaches.
State-of-the-arts and limitation
SSE. Song et al. were the first to propose the concept of SSE [35]. Later, Curtmola et al. [12] defined indistinguishability under the adaptive chosen keyword attack (IND-CKA2) as a formal security notion for SSE, and presented an IND-CKA2-secure scheme supporting single keyword search. The security is achieved by constructing a secure index (I) representing the relationship between keywords and encrypted files (), both of which () are outsourced to the cloud. Several refinements based on this index model have been proposed to offer more functionality and query diversity such as ranked query [41] and/or multi-keyword search [8,39]. The main limitation of these constructions is that they are only static, meaning that they can only perform a search on the encrypted data with no update allowed after the setup. Kamara et al. were among the first to propose Dynamic Searchable Symmetric Encryption (DSSE) [25], which enables both search and update functionalities on encrypted files. After their studies, many DSSE schemes have been proposed, each offering distinct performance, functionality and security trade-offs [4,7,10,25,28,44,46].
Information leakages in SSE and limitations of other approaches. SSE without relying on the encrypted index has been shown to be vulnerable against many attacks [9,31]. On the other hand, although the encrypted index-based SSE is known to be more secure, it still leaks a lot of information that the adversary can exploit to conduct statistical attacks [23,27,45]. For instance, when the client performs a search on the encrypted index, the search token in DSSE might reveal the content files to be updated in the future as well as all of the historical updates on files matching with the token. These leakages are defined as forward-privacy and backward-privacy, respectively [37]. Zhang et al. showed that it is possible to learn which keywords have been searched in forward-insecure DSSE schemes through file-injection attacks [45]. Most efficient DSSE schemes [10,20,24,25] do not provide forward- and backward-privacy when searching on I. Although there are some forward- and backward-private DSSE schemes being proposed recently (e.g., [6,7]), they rely on costly public key operations [17]. More severely, since the search, update and retrieval queries in DSSE are deterministic, all standard DSSE schemes leak access patterns on both I and . In particular, the client leaks the file-access pattern when updating a file or when retrieving a set of files matching with the search query performed on the encrypted index. Similarly, the client leaks the index-access pattern when performing the search or update on the encrypted index. Liu et al. [27] demonstrated a practical attack that can determine which keywords being searched by observing the search pattern.
To seal most of the access pattern leakage in DSSE, one can use a generic1
By generic ORAM, we mean the technique that can hide whether the access is to read or to write as opposed to read-only Private Information Retrieval or Write-Only ORAM.
Oblivious Random Access Machine (ORAM) technique [38] to conduct oblivious access on I and . Garg et al. [15] proposed TWORAM, which optimizes the use of ORAM to hide file access patterns in DSSE.2
It differs from the objective of this paper, where we focus on hiding access patterns on the encrypted index in DSSE (see Section 8 for clarification).
Despite its merits, prior studies such as [10,29] stated that generic ORAM [38] is expensive to be used in DSSE setting due to its logarithmic client-bandwidth overhead. Although ORAM schemes with a constant bandwidth complexity have been introduced recently [14], they rely on costly cryptographic protocols (i.e., homomorphic encryption [30]), whose performance was shown worse than ORAMs with logarithmic bandwidth overhead [1]. Alternative solutions trying to avoid generic ORAM are either very costly or unable to seal access pattern leakage in DSSE [5,21].
Our contributions
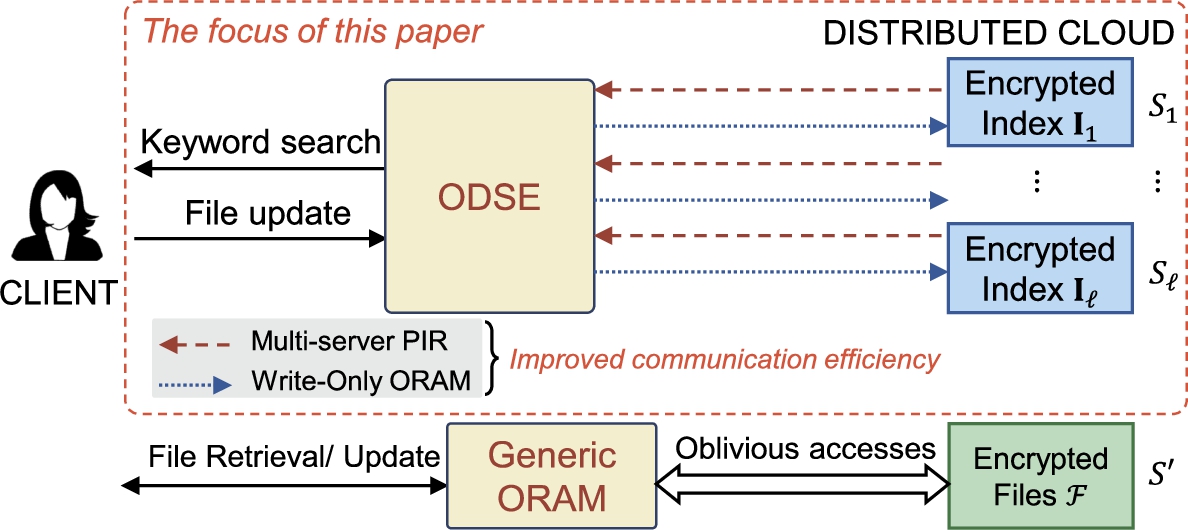
In DSSE, it is highly desirable to seal access pattern leakages when accessing the encrypted index (I) and encrypted files (). Since the size of individual files in can be arbitrarily large and each search/update query might involve with a different number of files, to the best of our knowledge, generic ORAM seems to be the only option for oblivious access on . In this paper, we focus more on oblivious access techniques on the index (I) that are more bandwidth-efficient than using generic ORAM (Fig. 1). Specifically, we propose , a comprehensive oblivious encrypted index framework in the multi-server setting with the application to DSSE. The framework contains three schemes including , and each offering various performance and security properties as follows.
Our research objective and high-level approach.
Full obliviousness with information-theoretic security: seals information leakages when accessing the encrypted index that might lead into statistical attacks. Our constructions hide the index-access pattern, and therefore provide forward- and backward-privacy and secrecy of the query types (search/update). and offers computational security for the encrypted index as well as access operations on it. On the other hand, provides information-theoretic statistical security (see Section 5).
Low end-to-end delay: All schemes offer low end-to-end-delay, which are - faster than using generic ORAM atop the DSSE encrypted index (with optimization [15]) under real network settings (see Section 8).
Robustness against malicious adversary: In the present work, we provide secure methods not only in the honest-but-curious setting but also in the malicious environment. Our schemes offer various levels of robustness in the distributed setting. In the semi-honest setting, and are robust against corrupted servers that do not respond due to system/network failure. All schemes can be extended to be secure against malicious adversary. Specifically, the extended scheme can detect if there exists any malicious server in the system (but without knowing which server it is). The extended and schemes can not only detect which server(s) is malicious, but also be robust against incorrect replies by malicious servers.
Full-fledged implementation and open-sourced framework: We fully implemented all the proposed schemes, and evaluated their performance on real-cloud infrastructure. To the best of our knowledge, we are among the first to open-source an oblivious access framework for the encrypted index in DSSE (see Section 8). The code is available at https://github.com/thanghoang/ODSE.
Improvement over the IFIP DBSec’18 Conference Version [
22
]. This article is the extended version of [22], which includes the following improvements. First, we introduce a new scheme called , which is a hybrid scheme between and originally presented in [22]. inherits the best of both worlds, in which it features low search/update delay and robustness in the distributed setting simultaneously. Second, we extended all the proposed schemes into the malicious-setting, which was only discussed briefly in [22]. Third, we conducted more experiments to evaluate the performance of the new scheme as well as all the extended schemes in the malicious setting with different number of corrupted servers.
Preliminaries and building blocks
Notation
We denote a finite field as where p is a prime. Operators and ⊕ denote the concatenation and XOR, respectively. denotes the binary representation. denotes . denotes the dot product of two vectors u and v. denotes that x is randomly and uniformly selected from . Given I as a row/column of a matrix, denotes accessing the i-th component of I. Given a matrix I, denotes accessing columns j to of I. and denotes accessing the entire row i and column j of I, respectively. Let be an IND-CPA symmetric encryption [26]: generating key with security parameter λ; encrypting plaintext M with key κ and counter c; decrypting ciphertext C with key κ and counter c.
We present -threshold Shamir Secret Sharing (SSS) scheme [33] in Fig. 2. Given a secret to be shared, the dealer generates a random t-degree polynomial f and evaluates for each party , at point which is a non-zero element of . is used to identify party ( algorithm). We denote the share for as for . The secret can be reconstructed by combining at least correct shares via Lagrange interpolation ( algorithm).
is a t-private secret sharing scheme in the sense that any combinations of t shares leak no information about the secret. offers homomorphic properties including addition, scalar multiplication, and partial multiplication. We extend the notion of SSS-share of value to indicate the share of a vector. That is, given a vector , indicates the share of v for party , in which each components in is the -share of the corresponding components in v.
Private information retrieval
Private Information Retrieval (PIR) technique enables private retrieval of a data item from a (unencrypted) public database server. PIR in the distributed setting is defined as follows.
Let be a database consisting of n items being stored in ℓ servers. A multi-server PIR protocol consists of three algorithms as follows. Given an item in b to be retrieved, the client creates queries and distributes to server for each . Each server responds with an answer . Upon receiving answers, the client computes the value of item b by invoking the reconstruction algorithm .
A multi-server PIR is correct if the client can obtain the correct value of b from ℓ answers via algorithm with the probability 1. A multi-server PIR is t-private if , s.t. , the probability distributions of and are identical.
We recall two efficient multi-server PIR protocols as follows.
XOR-based PIR [
11
]. It relies on XOR trick to perform the private retrieval, in which the database b contains n items , each being interpreted as a m-bit string (Fig. 3).
-based PIR [
2
,
16
]. It relies on to improve the robustness of multi-server PIR, in which the database b contains n items , each being interpreted as an element of (Fig. 4).
Write-Only ORAM. ORAM allows the user to hide access patterns when accessing their encrypted data on the cloud. In contrast to generic ORAM where both read and write operations are hidden, Blass et al. [3] proposed a Write-Only ORAM scheme, which only hides the write pattern in the context of hidden volume encryption. Intuitively, memory slots are used to store n blocks, each assigned to a distinct slot and a position map is maintained to keep track of block’s location. Given a block to be rewritten, the client reads slots chosen uniformly at random and writes the block to a dummy slot among slots. Data in all slots are encrypted to hide which slot is updated. By selecting λ sufficiently large, one can achieve a negligible failure probability, which might occur when all λ slots are non-dummy. It is also possible to select a small λ. In this case, the client maintains a stash component S of size to temporarily store blocks that cannot be rewritten when all read slots are full.
System and security models
In this section, we present the system and security models of our framework.
System model
Our system model comprises a client and ℓ servers , each storing a version of the encrypted index. The encrypted files are stored on a separate server different from (as in [21]), which can be obliviously accessed via a generic ORAM scheme [32,38]. In this paper, we focus only on oblivious access on distributed encrypted index on . We present the definition of as follows.
An Oblivious Distributed Dynamic Searchable Symmetric Encryption () scheme is a tuple of one algorithm and two protocols , where the input and the output for the client and the servers are separated with semicolon such that:
: Given a set of files as input, the algorithm outputs a distributed encrypted index and a client state σ.
: The client inputs a keyword w to be searched and the state σ; the servers input the distributed encrypted index . The protocol outputs to the client a set containing file identifiers, in which w appears.
: The client inputs the updated file and a state σ; the servers input the distributed encrypted index . The protocol outputs a new state and the updated index to the client and servers, respectively.
Security model
In our system, the client is trusted and the set of servers are untrusted. We first consider the servers to be semi-honest, meaning that they follow the protocol faithfully, but can record the protocol transcripts to learn information regarding the client’s access pattern. Later, we show that our framework can be extended to be secure against malicious servers that can tamper with the input data to compromise the correctness and the security of the system (Section 6). We allow up to (privacy parameter) servers among to be colluding, meaning that they can share their own recorded protocol transcripts with each other. Formally, the security of in the semi-honest setting can be defined as follows.
( security w. r. t. semi-honest adversary).
Let be an operation sequence, where , w is a keyword to be searched and is a file with identifier whose relationship with unique keywords in the distributed encrypted index need to be updated, and σ denotes a client state information. Let represent the client’s sequence of interactions with server , given an operation sequence .
Correctness: An is correct if for any operation sequence , returns data consistent with , except with negligible probability.
t-security: An is t-secure if such that , for any two operation sequences and where , the views and observed by a coalition of up to t servers are computationally indistinguishable.
operation obliviousness. By Definition 2, keyword search and file update are the two main operations in searchable encryption. Given that these operations might incur different procedures, we can trigger both search and update protocols for any actual action to achieve the operation obliviousness according to Definition 3. In this case, the server can guess (at best) with a probability of what operation the client is performing “in real” i.e. either search or update.
The proposed (semi-honest) schemes
Intuition. In DSSE, keyword search and file update on I are read-only and write-only operations, respectively. This property permits us to leverage specific bandwidth-efficient oblivious access techniques for each operation such as multi-server PIR (for search) and Write-Only ORAM (for update) rather than using a generic ORAM. The second requirement is to identify a suitable data structure for I so that these bandwidth-efficient techniques can be adapted. In DSSE, forward index and inverted index are the ideal choices for the file update and keyword search operations, respectively as proposed in [20]. However, performing search and update on two isolated indexes will lead to inconsistency. The server might perform a synchronization to make two indices consistent; however, this will leak significant information regarding the client query and file content. Therefore, to avoid this problem, it is mandatory to seek a data structure, where both search index and update index can be integrated together. Fortunately, this can be achieved by harnessing a two-dimensional index (i.e., matrix), which allows keyword search and file update to be performed in two separate dimensions without creating any inconsistency at their intersections. This strategy permits us to perform computation-efficient (multi-server) PIR on one dimension, and communication-efficient (Write-Only) ORAM on the other dimension to achieve oblivious search and update, respectively.
In the following, we first describe the data structures used in framework, and then present semi-honest schemes in details. We analyze the security of schemes and present their extension into malicious setting in Section 5 and Section 6, respectively.
data structures
symbols and notation
Symbol
Description
Maximum number of files and keywords in DB.
I
Incidence Matrix Index
Number of -bit blocks (i.e., ).
Static hash tables for files and keywords.
Set of dummy (empty) columns
S
Stash to (temporarily) store column data
c
Column counter vector
Our index to be stored at the server(s) is an incidence matrix (I), where each cell () represents the relationship between the keyword indexed at row i and the file indexed at column j. So, each row of I represents the search result of a keyword and each column represents the content (i.e., keywords) of a file. Since we use Write-Only ORAM for file update, the number of columns in I are doubled to the maximum number of files that can be stored in the outsourced database. In other words, given N distinct files and M unique keywords in the database, our index is of size . At the client side, we leverage two position maps , to keep track of location of keywords and files in I, respectively. They are of structure , where is a keyword or file ID and is the (row/column) index of in I. Due to Write-Only ORAM, the client maintains a stash component S to temporarily store columns that might not be written back during the update due to the overflow. Table 1 summarizes notation and symbols used to describe our schemes.
: Fast ODSE
We introduce , an scheme that offers a low search delay by using XOR trick. We present the setup algorithm in as well as its oblivious search and update protocols as follows.
setup algorithm.
search protocol.
Setup. Fig. 5 presents setup algorithm to construct the encrypted index in . Specifically, it first initializes an unencrypted incidence matrix () of size (line 1), and generates a master key to be used for generating row keys to encrypt each row of (line 3). It extracts unique keywords from input files (line 4), assigns each keyword and file into a row and column of selected randomly (lines 6, 9), and then sets the value for each cell of corresponding to the relationship between keywords and files (line 10). Finally, the algorithm generates a distinct key for each row of by the master key (line 12), and encrypts each cell of by a distinct pair of row key and column counter resulting in an encrypted index I (line 14). We encrypt the index bit-by-bit and the resulting ciphertext of each input bit is also one bit long. This can be implemented by, for example, AES with CTR mode, where we generate a 128-bit pseudorandom stream key by the master row key () and the column counter (), but only XOR the plaintext bit with the most significant bit of the stream key. To this end, the client sends a replica of I to ℓ servers and keeps some information (i.e., ) private.
Search. harnesses XOR-based PIR on the row dimension of I to conduct the oblivious keyword search as shown in Fig. 6. The client first looks up the keyword position map to get the row index of the searched keyword (line 1). The client then creates XOR-PIR queries (line 2) and sends them to corresponding servers, each answering the client with the output of the PIR retrieval algorithm (line 4). Notice that the data is IND-CPA encrypted rather than being public as in the standard PIR model. Therefore, after recovering the row from the PIR retrieval (line 6), the client generates the row key (line 7) and then decrypts the row to obtain the search result (line 9).
Update. Recall that the content (i.e., keywords) of a file is represented by a column in I. Given a file to be updated, applies Write-Only ORAM mechanism on the column dimension of I to update keyword-file pairs in as shown in Fig. 7. The client creates a new column representing the relationship between the updated file and keywords in the database (lines 2–3), and stores it in the stash (line 4). The client then randomly selects λ column indexes and requests an arbitrary server to transmit the corresponding columns of I (lines 5–6). The client generates row keys and decrypts λ columns (lines 7–10). The client overwrites dummy columns among λ columns with columns stored in the stash (lines 11–12). Finally, the client re-encrypts λ columns and sends them to ℓ servers (lines 18–20).
update protocol.
: Robust
The described scheme requires all ℓ servers in the system to answer the client. If one server does not reply due to system/network failure, the correctness of will not hold anymore. We propose , an scheme that can achieve the robustness against unresponsive servers. harnesses the t-out-of-ℓ property of , which allows to maintain the correctness given that some servers (i.e., up to ) do not answer. We define the setup algorithm along with the oblivious search and update protocols in scheme as follows.
Setup. works over the index encrypted with IND-CPA encryption. Therefore, the setup algorithm of is identical to that of scheme as shown in Fig. 8.
setup algorithm.
search protocol.
update protocol.
Search. harnesses -based PIR protocol on the row dimension of I to conduct keyword search as shown in Fig. 9. Specifically, the client first retrieves the row index of the searched keyword from the keyword position map (line 1). The client then creates -based PIR queries (line 2) and sends to corresponding servers, each replying with the output of the -based PIR retrieval algorithm. Notice that the -based PIR retrieval algorithm performs the dot product between the client query and the database input via scalar multiplication and additive homomorphic properties of SSS. This requires the database input to be elements in . Since each row in I is a uniformly random binary string of length due to IND-CPA encryption, the servers split each row of I into chunks () with the equal size such that (line 6). The dot product is performed iteratively between the search query and divided chunks from all rows of I (lines 7–8). After receiving answers from ℓ servers, the client recovers all chunks of the searched row (lines 10–12) and finally, decrypts the row to obtain the search result (lines 13–17).
Update. harnesses Write-Only ORAM mechanism on the column dimension of I to perform file update. Since the index I in is identical to , the update protocol of is also identical to that of (Fig. 10).
: Robust and information-theoretically secure
scheme relies on IND-CPA encryption for the encrypted index so that it only offers (at most) computational security. In this section, we introduce , an scheme that can achieve the highest level of security (i.e., information-theoretic) for the index as well as any operations (search and update) on it. The main idea is to share the index with , and harness -based PIR to conduct private search. We describe the algorithms of as follows.
Setup. Fig. 11 presents the setup algorithm to construct the distributed index in . Specifically, it first constructs an (unencrypted) index () representing keyword-file relationships as in other schemes. Instead of encrypting with an IND-CPA encryption scheme, it creates the shares of with and distributes them to corresponding servers. As discussed above, operates over elements in . Therefore, it is required to split each row of into -bit chunks (line 4), and compute share for each chunk (line 5). Therefore, the “encrypted” index in contains ℓ-shares of for ℓ servers, each being a matrix of size , where and . To this end, the client sends to server and keep position maps (i.e., ) private.
setup algorithm.
search protocol.
Search. Similar to , harnesses the -based PIR protocol on the row dimension of I to conduct the keyword search as presented in Fig. 12. Generally speaking, the client gets the row index to be searched from the keyword position map, creates SSS-based PIR queries and send them to the corresponding servers, each replying with the outputs of the -based PIR retrieval algorithm (lines 1–6). Notice that since the index stored on is a share matrix, each dot product computation in the -based PIR retrieval algorithm will result in a share represented by a -degree polynomial. Therefore, the client needs to call the -based recover algorithm with the privacy parameter of (vs. t as in ) to obtain the correct search result (line 8).
update protocol.
Update. Similar to other schemes, harnesses Write-Only ORAM mechanism on the column dimension of the index for the oblivious file update as outlined in Fig. 13. Specifically, the client creates a column representing the relationship between the updated file and keywords in the database, and temporarily stores it in the stash (lines 1–4). In , each column of the share index on actually contains the share of columns of the unencrypted index . Therefore, it suffices to read random columns of from arbitrary servers to reconstruct λ columns of (lines 5–10). The update is similar to other schemes, in which the client aggressively over-writes dummy columns of with columns stored in the stash (lines 11–12). Finally, the client creates new shares for the retrieved columns (lines 13–16) and writes them back to ℓ servers (lines 18–20).
Security analysis
One might observe that search and update operations in schemes are performed on the row dimension and the column dimension of the encrypted index, respectively. This access structure might enable the adversary to learn whether the operation is search or update, even though each operation is secure. Therefore, to achieve security as in Definition 3, where the query type should also be hidden, we can trigger both search and update protocols (one of them is the dummy operation) regardless of whether the intended action is search or update.
We argue the security of our proposed schemes as follows.
scheme is computationally-secure by Definition
3
.
(Sketch) (i) Oblivious Search: leverages XOR-based PIR and therefore, achieves ()-privacy for keyword search as proven in [11]. (ii) Oblivious Update: employs Write-Only ORAM which achieves negligible write failure probability and therefore, it offers the statistical security without counting the encryption. The index in is IND-CPA encrypted, which offers computational security. Therefore in general, the update access pattern of scheme is computationally indistinguishable. performs Write-Only ORAM with an identical procedure on ℓ servers (e.g., the indexes of accessed columns are the same in ℓ servers), and therefore, the server coalition does not affect the update privacy of . (iii) ODSE Security: By Remark 1, performs both search and update regardless of the actual operation. As analyzed, search is -private and update pattern is computationally secure. Therefore, achieves computational -security by Definition 3. □
scheme is computationally t-secure by Definition
3
.
(Sketch) (i) Oblivious Search: leverages a SSS-based PIR protocol and therefore, achieves t-privacy for keyword search due to the t-privacy property of as proven in [2,16]. (ii) Oblivious Update: Similar to , leverages Write-Only ORAM over IND-CPA encrypted database, which offers computational security as shown in [3]. (iii) ODSE Security: By Remark 1, for each actual operation, the client triggers both search and update protocols. Given that search is t-private and update pattern is computationally oblivious, the access pattern in is a computationally indistinguishable in the presence of t colluding servers. □
scheme is information-theoretically (statistically) t-secure by Definition
3
.
(Sketch) (i) Oblivious Search: leverages an SSS-based PIR protocol and therefore, achieves t-privacy for keyword search due to the t-privacy property of [16]. (ii) Oblivious Update: The index in is -shared, which is information-theoretically secure in the presence of t colluding servers. also employs Write-Only ORAM, which offers statistical security due to negligible write failure probability. Therefore in general, the update access pattern of scheme is information-theoretically (statistically) indistinguishable in the coalition of up to t servers. (iii) ODSE Security: By Remark 1, performs both search and update protocols regardless of the actual operation. As analyzed above, search is t-private and update pattern is statistically t-indistinguishable. Therefore, is information-theoretically (statistically) t-secure by Definition 3. □
in the malicious setting
In previous sections, we have shown that schemes offer a certain level of collusion-resiliency and robustness in the semi-honest setting where the servers follow the protocol faithfully. In some privacy-critical applications, it is necessary to achieve data integrity and robustness in the malicious environment, where the adversary can tamper with the query and data to compromise the correctness and privacy of the protocol. In this section, we show that our proposed semi-honest schemes can be extended to be secure and robust against malicious adversaries.
To achieve integrity of the index and the server-computation, our main idea is to harness computational and information-theoretic message authentication code (MAC) techniques. We first provide the definition of computational and information-theoretic MAC as follows.
Computational MAC [
26
]: Let be a secure keyed MAC scheme [26]: generating a MAC key with security parameter λ; generating a tag for message with key θ; verifying if the tag (μ) associated with the message (m) is either valid (1) or invalid (0).
∙ Information-theoretic MAC [
13
]: Let be a global MAC key, which is known only by the client. The MAC tag (μ) for each data block (b) is computed as (over ). Given that the client maintains a consistent relationship between μ, b and θ while keeping them hidden from the adversary, the adversary cannot change b without changing μ and/or α. Therefore, μ is secret-shared among servers along with the shares of b. The verification can be done by reconstructing the block (b) as well as its tag (μ) from the shares, and comparing if holds at the end.
In and schemes, we leverage the computational MAC scheme to achieve the integrity of the index encrypted by IND-CPA encryption. On the other hand, the offers information-theoretic security since its index is secret-shared, instead of IND-CPA encrypted. Therefore, we apply information-theoretic MAC to this scheme to preserve its security level. We now present the extensions of ODSE schemes into the malicious setting in details as follows.
: Maliciously-detectable
We present , the extended version of from Section 4.2, which offers security against malicious adversary using the computational MAC. The verification allows the client to abort the protocol if he/she detects any malicious behaviors attempting to tamper with the encrypted index and/or the search/update query. Our protocols are defined as follows.
Setup. Fig. 14 presents the setup of MD- scheme with the MAC tag generation for the encrypted index. Generally speaking, it first generates the encrypted index I similar to semi-honest (line 1), and then generates a MAC key (line 2), followed by computing a matrix T containing the MAC tag for each -bit blocks of each row of I (lines 3–5). In this context, each server in the system stores two matrices including the encrypted index I and the MAC matrix T.
Search. Fig. 15 presents the search protocol of , which is extended from the search protocol of semi-honest to be secure against malicious adversary. Specifically, the client generates XOR-PIR queries for ℓ servers similar to the semi-honest scheme (line 1). Each server performs the XOR-PIR retrieval on both the encrypted index (line 3) and the MAC components (line 4) using the same query received, and sends the result to the client. The client recovers the row of the encrypted index (line 6) as well as its corresponding tag (line 7). The client verifies each -bit block with its corresponding tag (lines 8–10). If all the tags are valid, the client continues to decrypt the row to obtain the search result as in the semi-honest scheme (line 11). Otherwise, the client aborts and notifies that at least one of the servers is malicious (line 10).
setup algorithm. Extensions from its semi-honest version are highlighted.
search protocol. Extensions from its semi-honest version are highlighted.
update protocol. Extensions from its semi-honest version are highlighted.
Update. Fig. 16 presents the update protocol of extended from the semi-honest for malicious security. Instead of downloading λ random 1-bit columns as in the semi-honest , the client downloads λ random columns of -bits as well as their corresponding MAC tag. Before decryption, the client verifies the integrity of the retrieved data by the MAC (lines 5–8). If there exists one invalid tag, the client aborts and notifies that at least one server is malicious (line 8). Otherwise, the client performs the update following the same line with the semi-honest (line 9). Finally, the client creates new MAC tags for re-encrypted columns and send all of them to ℓ servers to be updated (lines 10–14).
: Maliciously-robust
Since relies on for oblivious search, we can extend it in various ways to not only detect but also be robust against malicious adversary. One straightforward extension is to consider as a particular instance of Reed Solomon Code, and then implement Reed Solomon Decoding techniques [19,42] to handle incorrect server replies. However, this approach can only handle a small number of the malicious servers in the system (e.g., if using [42]), which might increase the deployment cost. Another approach is to harness the t-out-of-ℓ threshold property of along with the MAC technique presented in the previous section. The main idea is to select answers among ℓ answers from the servers to recover the encrypted search result and its MAC tags. If there exists one invalid MAC, we repeat the recover process by selecting a different set of answers until we find that all the tags are valid. This strategy offers the detection capability and robustness against malicious behaviors given that the majority of the servers is honest (i.e., ). Therefore, we opt-to this approach to design , the maliciously-robust version of as follows.
Setup. The index structure of is identical to that of . Thus, its setup algorithm is identical to that of , where the MAC tag is created for each -bit blocks in each row of the encrypted index (Fig. 17).
Search. Fig. 18 outlines the search protocol of extended from that of for malicious security. For each time of oblivious keyword search, the client creates SSS-based PIR query as in the semi-honest (line 1), and the servers perform the -based PIR retrieval on both the encrypted index (line 3) and MAC components (line 4). Once receiving answers from ℓ servers, the client picks out of ℓ replies (lines 6–7), and performs the recover via the Lagrange interpolation to obtain the encrypted search row (line 8) as well its MAC tag (lines 9–14). The client verifies the integrity of the encrypted row and decrypts it if all MAC tags are valid. If there exists one invalid tag, the client selects another set of replies, and repeats the verification process. If the client tries all possible sets, which incurs (in total) verification tests, but none produces all valid tags, the client aborts the protocol and notifies that a majority of servers () is corrupted (line 13).
Update. The update protocol in is similar to that of (Fig. 19). To improve the robustness against malicious adversary, the client can request ℓ servers to transfer λ-bit columns, and selects one of ℓ replies to verify the integrity and performs the update.
setup algorithm.
: Maliciously-robust and IT-secure
In this section, we present , the extended version of that inherits all properties of (e.g., information-theoretic security) along with the robustness against malicious adversary. To preserve the information-theoretic security, we use the information-theoretic MAC as defined above for each block. The details are as follows.
search protocol. Extensions from its semi-honest version are highlighted.
update protocol.
Setup. follows the principles in the semi-honest scheme to create the share index (Fig. 20, line 1). It then creates a global MAC key by selecting a random element in (line 2). It multiplies the representative element in of each index block with the global MAC key over yielding the MAC tag, and then creates the shares for each tag (line 3). The shares of MAC tags are distributed along with the share index across ℓ servers.
Search. Fig. 21 presents the search protocol of extended from that of for malicious security. The extension follows the line of the scheme. Specifically, the servers perform SSS-based PIR retrieval on both index and the MAC components (lines 3–4). The client picks out of ℓ replies to recover and verify the integrity of the search result (lines 6–7). If after trials with different subsets but none producing the valid tags, the client aborts the protocol and notifies that more than servers are malicious (line 7). Otherwise, the client continues to process the recovered data as in the semi-honest scheme to obtain the final search result (line 15).
setup algorithm. Extensions from its semi-honest version are highlighted.
search protocol. Extensions from its semi-honest version are highlighted.
update protocol. Extensions from its semi-honest version are highlighted.
Update. Fig. 22 presents the update protocol of . Basically, the client downloads λ columns of the share index and their corresponding MAC from ℓ servers. The client selects replies to recover and verify the integrity of downloaded data before performing update. If all tags are valid, the client performs the write-only ORAM procedure as in scheme, re-calculates the MAC tag for each block, and then creates new shares for each tag. Otherwise, the client aborts the protocol and notifies that a majority of servers is malicious.
Implementation
We fully implemented all schemes in C++. We used Google Sparsehash library [36] to implement position maps and . We utilized Intel AES-NI library [18] to implement AES-CTR encryption/decryption in and schemes. We leveraged Shoup NTL library [34] for pseudo-random number generator and arithmetic operations over finite field. We used ZeroMQ library [43] for client-server communication. We used multi-threading technique to accelerate PIR computation at the server. The code is available at https://github.com/thanghoang/ODSE.
Performance evaluation
Configurations
Hardware and network settings. We used Amazon EC2 with r4.4xlarge instance for server(s), each equipped with 16 vCPUs Intel Xeon @ 2.3 GHz and 122 GB RAM. We used a laptop with Intel Core i5 @ 2.90 GHz and 16 GB RAM as the client. All machines ran Ubuntu 16.04. The client established a network connection with the server via WiFi connection. We used a real network setting, in which the download/upload throughput is 27/5 Mbps, respectively.
Dataset. We used the subsets of the Enron dataset to build I containing from millions to billions of keyword-file pairs. The largest dataset contain around 300,000 files with 320,000 unique keywords. Our tokenization is identical to [29] so that our keyword distribution and query pattern are similar to [29].
Instantiation of compared techniques. We compared with a standard DSSE scheme [10], and the use of generic ORAM atop the DSSE encrypted index. The performance of all schemes was measured under the same setting and configuration We configured schemes and their counterparts as follows.
ODSE: For the semi-honest setting, we deployed two servers for and schemes, and three servers for scheme. We selected for and , and with where p is a 16-bit prime for schemes . We note that selecting larger p (e.g., bits) can reduce the PIR computation time with the cost of the bandwidth overhead due to the increase of query size. We chose a 16-bit prime field to achieve a balanced computation and communication overhead. For the malicious setting, we first fixed the number of servers for and schemes to be two, three and four, respectively to handle one adversary. We then increased the number of servers to allow more malicious servers (see Section 8.6 for details).
Standard DSSE: We selected one of the most efficient DSSE schemes by Cash et al. in [10] (i.e., variant) to demonstrate the performance gap between and the standard DSSE. We estimated the performance of using the same software/hardware environments and optimizations as (e.g., parallelization, AES-NI acceleration). Note that we did not use the Java implementation of this scheme available in Clusion library [40] for comparison due to its lack of hardware acceleration support (i.e., no AES-NI) and the difference between running environments (Java VM vs. C). Our estimation is conservative in which, we used numbers that would be better than the Clusion library.
Using generic ORAM atop DSSE encrypted index: We selected non-recursive Path-ORAM [38] and Ring-ORAM [32], as counterparts since they are the most efficient generic ORAM schemes for data outsourcing to date. Since we focus on encrypted index rather than encrypted files in DSSE, we did not explicitly compare our schemes with TWORAM [15] but instead used one of their techniques to optimize the performance of using generic ORAM on DSSE encrypted index. Specifically, we applied the selected ORAMs on the dictionary index as in [29] along with the round-trip optimization as in [15]. Note that these estimates are also conservative, where memory access delays were excluded, and cryptographic operations were optimized and parallelized for an objective comparison.
Latency of semi-honest schemes and their counterparts.
Overall end-to-end delay in the semi-honest setting
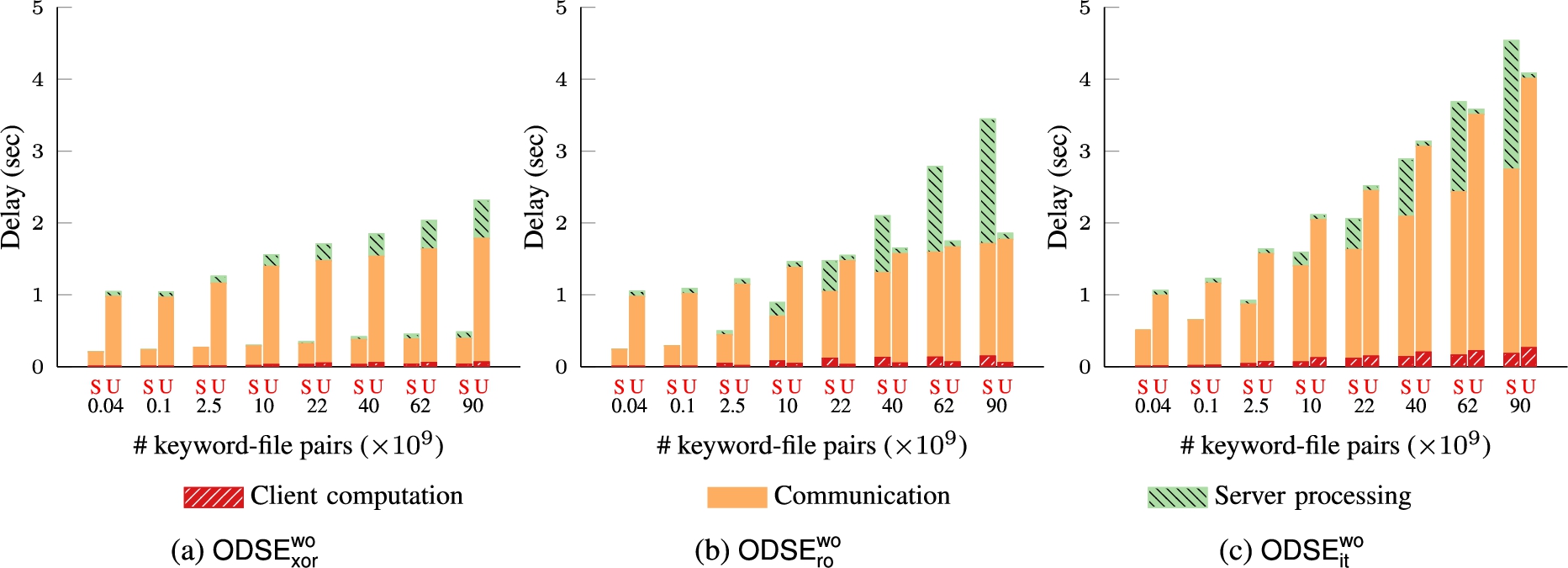
Figure 23 presents the end-to-end delays of schemes and their counterparts, where we performed both search and update protocols in schemes to hide the actual type of operation (see Remark 1). offers a higher security than standard DSSE at the cost of a longer delay. Nevertheless, schemes are – faster than the use of generic ORAMs atop DSSE encrypted index to hide the access patterns. Specifically, with an encrypted index consisting of ten billions of keyword-file pairs, cost 36 milliseconds and 600 milliseconds to finish a search and update operation, respectively. and , respectively, took 2.8 seconds and 8.6 seconds to accomplish both keyword search and file update operations, compared with 160 seconds by using Path-ORAM with the round-trip optimization [15].
We present the separate delay for the search and update operations in schemes in Table 2. is the most efficient in terms of search, whose delay was less than 1 second. This is due to the fact that only triggers XOR operations and the size of the search query is minimal (i.e., a binary string). and are more robust (e.g., malicious tolerant) and one of which is more secure (e.g., information-theoretic security) than at the cost of higher search delay (i.e., 4 seconds) due to its larger search query and arithmetic computations. is the slowest among the three schemes since it requires three servers and, therefore, the client needs to transmit more data.
Comparison of and its counterparts for oblivious access on I
This delay is for semi-honest setting with encrypted index containing 300,000 files and 320,000 keywords under the network and configuration presented in Section 8.1.
ℓ is # servers in the system. We define the robustness in distributed setting as the ability to tolerate unresponsive server(s) in the semi-honest setting or incorrect replies in the malicious setting. In , encrypted index and search query are SSS with the same privacy level. Generic ORAM solutions have a stronger adversarial model than ours because they are not vulnerable to collusion that arises in the distributed setting.
All schemes perform search and update protocols to hide the actual query type. In , search is IT-secure due to SSS-based PIR and update is computationally secure due to IND-CPA encryption. Hence, its overall security is computational.
The encrypted index in is information-theoretically secure because it is . Other schemes employ IND-CPA encryption so that their index is computationally secure (see Section 5).
For the oblivious file update, and achieved a similar delay since they have the same number of servers and incurred the same amount of data to be transmitted. is slightly slower than and because the client transmitted data to three servers, instead of two. We can see that in many cases, where it is not necessary to hide the operation types (search/update), using to conduct individual oblivious operations, especially the keyword search, is much more efficient than generic ORAMs. We further provide a comparison of ODSE schemes with their counterparts in Table 2. In the following section, we dissect the end-to-end delay of schemes to understand which factors contributing the most to their performance.
Detailed Search (S) and Update (U) costs of semi-honest schemes.
Detailed cost analysis
Figure 24 presents the detailed delays of separate keyword search and file update operations in schemes. There are three main factors impacting the end-to-end delay of schemes as follows.
Client processing: As shown in Fig. 24, the client computation contributes the least amount to the overall search delay (less than ) in all schemes. It comprises the following operations: (i) Generate search queries with PRF in or SSS in and schemes; (ii) recovery (in and ) and/or IND-CPA decryption (in and ); (iii) Filter dummy columns and collect columns in the stash. Note that the client delay of schemes can be further reduced (by at least 50%–60%) via pre-computation of some values such as row keys and PIR queries (only contain shares of 0 or 1). For the file update, the client performs either decryption followed by re-encryption on λ columns (in and ), or SSS over blocks (in ). Since we used crypto acceleration (i.e., Intel AES-NI) and highly optimized number theory libraries (i.e., NTL), all these computations only contributed to a small fraction of the total delay.
Client-server communication: Data transmission is the most dominating factor in the delay of schemes. The communication cost of is the smallest among all ODSE schemes since the size of search query and the data transmitted from servers are only binary strings. In and schemes, the size of components in the search query vector is 16 bits. Their communication overhead can be reduced by using a smaller finite field at the cost of increased PIR computation on the server side.
Server processing: The cost of PIR operations in is negligible as it uses XOR tricks. The PIR computation overhead in and is reasonable because it operates on a considerably large amount of 16-bit values. For the file update operations, the server-side cost is mainly due to memory accesses to overwrite some columns of the encrypted index. and schemes are highly memory access-efficient since we store their matrix-based index column-wise in the memory. This memory layout organization allows the inner product in PIR to access contiguous memory blocks thereby, minimizing the memory access delay not only in the update but also in the search. In , we stored the matrix row-wise for row-friendly access to permit efficient XOR operations during search. However, this requires file update to access non-contiguous memory blocks. Hence, the file update in incurred a higher memory access delay than that of and as shown in Fig. 24.
Storage overhead
The main limitation of schemes is the size of encrypted index, whose asymptotic cost is , where N and M are the number of files and unique keywords, respectively. Given the largest database being experimented, the size of our encrypted index is 23 GB. The client storage includes two position maps of size and , the stash of size , a counter vector of size and a master key (in scheme). Empirically, with the same database size discussed above, the client requires approximately 22 MB in all schemes.
Delay of semi-honest schemes and their counterparts with different fraction of keywords/files involved in a search/update.
Experiment with various query sizes
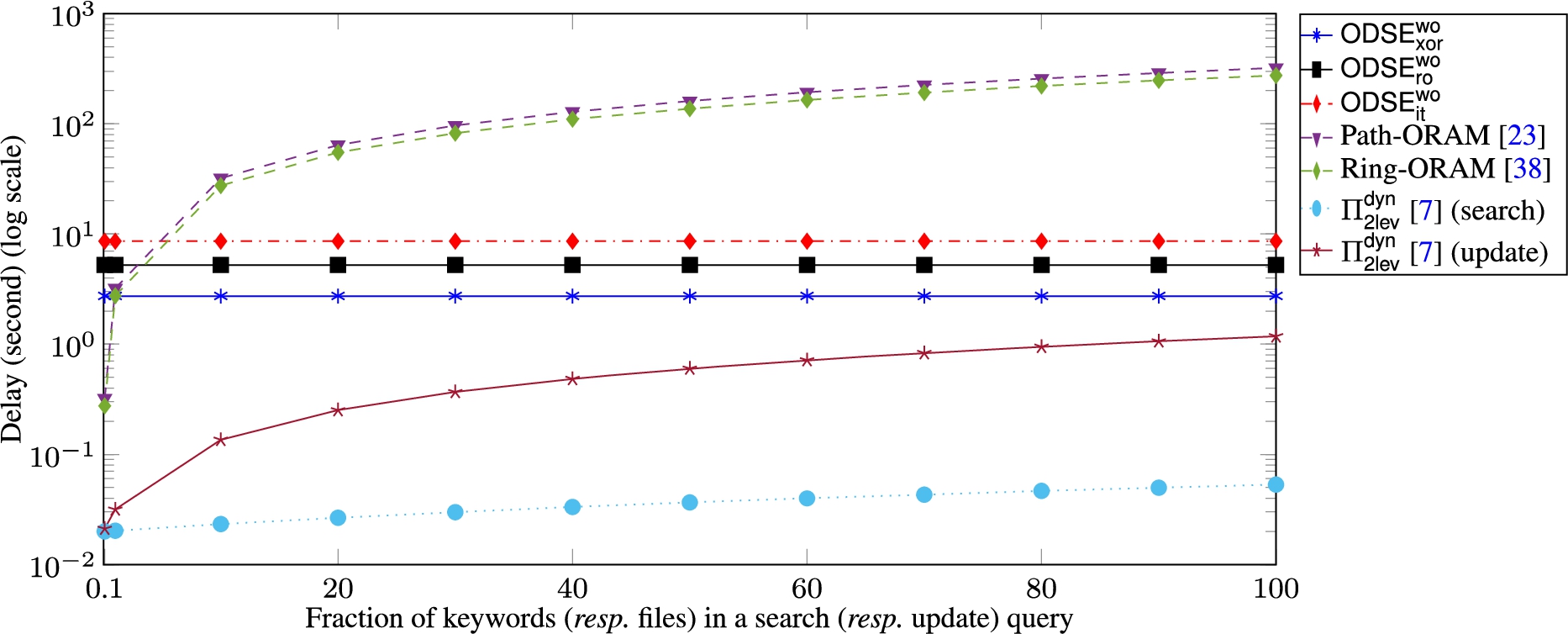
We studied the performance of our schemes and their counterparts in the context of various keyword and file numbers involved in search and update operations that we refer to as “query size”. As shown in Fig. 25, schemes are more efficient than using generic ORAMs when more than 5% of keywords/files in the database are involved in the search/update operations. Since the complexity of schemes is linear to the number of keywords and files (i.e., ), their delay is constant and independent from the query size. The complexity of ORAM approaches is , where r is the query size. Although the bandwidth cost of schemes is asymptotically linear, their actual delay is much lower than using generic ORAM, whose cost is poly-logarithmic to the total number of keywords/files but linear to the query size. This confirms the results of Naveed et al. in [29] on the performance limitations of generic ORAM and DSSE composition, wherein we used the same dataset for our experiments.
End-to-end delay of maliciously-secure schemes in the presence of one malicious adversary.
performance in the presence of malicious adversary
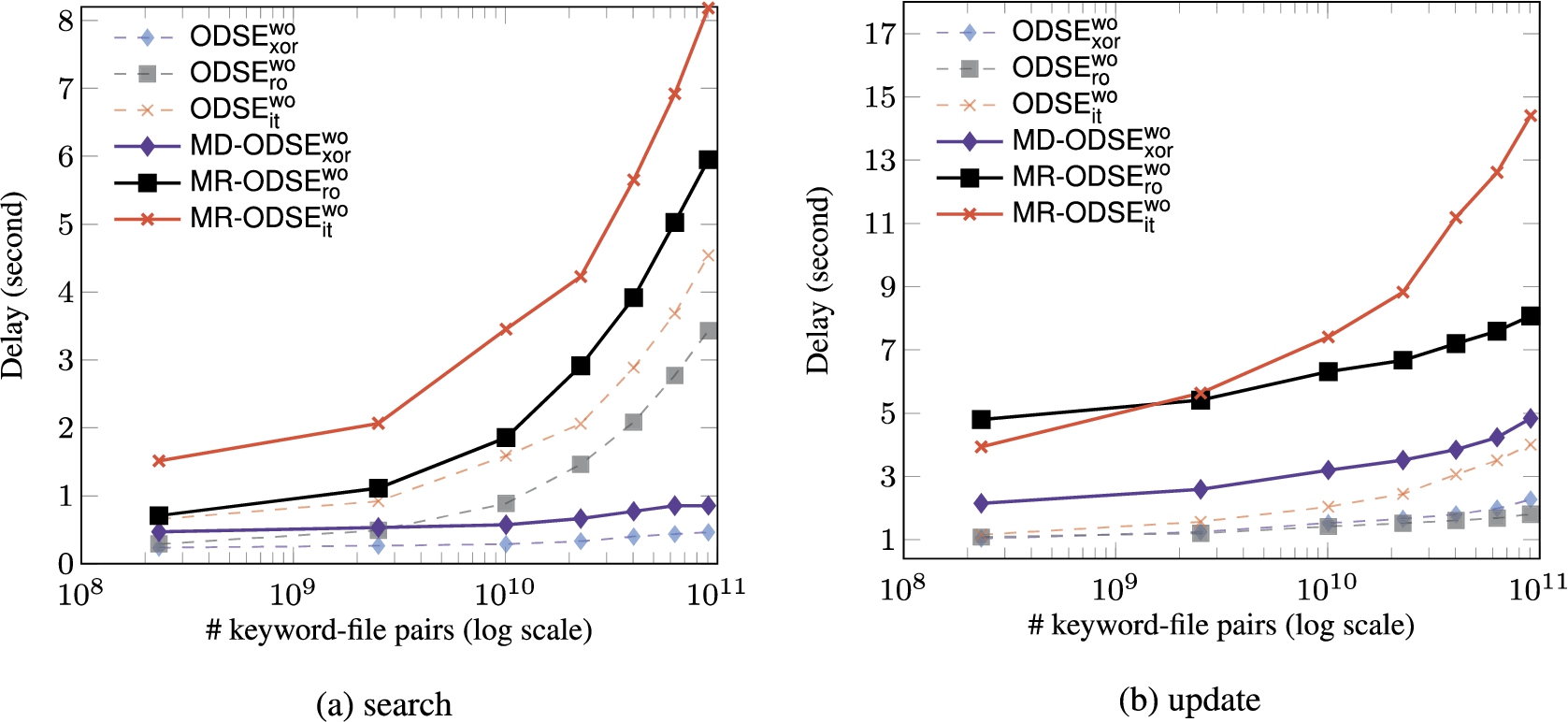
In this section, we present the performance of maliciously-secure schemes described in Section 6. Figure 26 presents the search and update delay of , and schemes in the presence of one malicious adversary, compared with their corresponding semi-honest version. Recall that in this setting, we set the number of servers in the system for , and schemes to be two, three and four, respectively. We can see that the search delays of maliciously-secure schemes are around two times slower than their semi-honest version. It is mainly due to the additional processing and network transmission overhead for the MAC components stored at the server-side, which has the same size with the encrypted index. The update of and schemes are around three times slower than that of their semi-honest version. The main reason is that and requires an extra server in the system to detect one malicious adversary, which leads to the increase of the client bandwidth overhead.
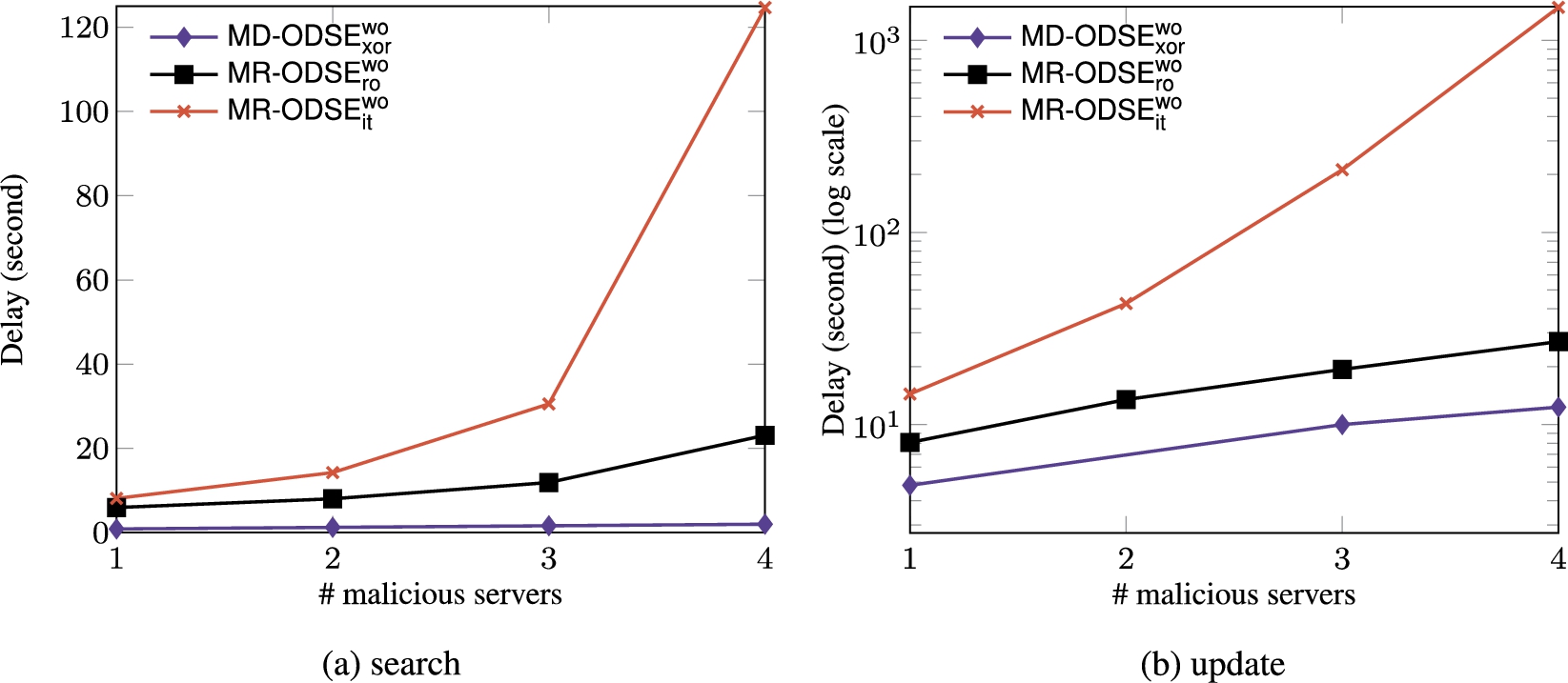
Delay of maliciously-secure schemes with varied number of malicious servers.
We also explored the performance of maliciously-secure schemes when the number of malicious servers increases. Allowing more servers to be malicious requires to deploy more servers in the system. Specifically, and schemes need and servers in total to be robust against t number of malicious servers, respectively. Figure 27 presents the performance of maliciously-secure schemes with the varied number of corrupted servers. We can see that it is expensive to offer the robustness for a number of malicious servers in the system. This is because it incurs not only the client bandwidth overhead to communicate with more servers, but also the client computation overhead. In the worst case, and requires the client to perform and times of MAC verification, respectively, to find an authentic -bit data block in the presence of (less than) t malicious servers. Since can only detect the malicious behavior (without knowing which server it is), its overhead only increases slightly when allowing more servers to be malicious. This is because it only requires to deploy more servers in the system, and the client aborts the protocol immediately when he/she finds an invalid MAC tag (without trying aggressively to find an alternative authentic block as in and schemes).
Conclusion
In this article, we present a novel Oblivious Distributed DSSE framework called , which offers access pattern obliviousness, hidden size pattern, and low end-to-end for index access. These properties are achieved by exploiting unique characteristics of the index data structure and searchable encryption, which allows to deploy computation- and bandwidth-efficient techniques (i.e., multi-server PIR and Write-Only ORAM) to conduct oblivious search and update separately. Our framework contains a series of schemes each featuring different levels of performance and security in terms of data confidentiality and access pattern obliviousness. Specifically, offers the lowest end-to-end delay, smallest bandwidth overhead and the highest resiliency against colluding servers. offers the robustness and information-theoretic security for access patterns and the encrypted index. inherits the best of both and schemes: low end-to-end delay and robustness in the distributed setting. All these schemes can also be extended to be secure/robust against malicious adversary.
References
1.
I.Abraham, C.W.Fletcher, K.Nayak, B.Pinkas and L.Ren, Asymptotically tight bounds for composing ORAM with PIR, in: IACR Public Key Cryptography, Springer, 2017, pp. 91–120.
2.
A.Beimel and Y.Stahl, Robust information-theoretic private information retrieval, in: International Conference on Security in Communication Networks, Springer, 2002, pp. 326–341.
3.
E.-O.Blass, T.Mayberry, G.Noubir and K.Onarlioglu, Toward robust hidden volumes using write-only oblivious RAM, in: Proceedings of the 2014 ACM CCS, ACM, 2014, pp. 203–214.
4.
C.Bösch, P.Hartel, W.Jonker and A.Peter, A survey of provably secure searchable encryption, ACM Computing Surveys (CSUR)47(2) (2015), 18.
5.
C.Bosch, A.Peter, B.Leenders, H.W.Lim, Q.Tang, H.Wang, P.Hartel and W.Jonker, Distributed searchable symmetric encryption, in: Privacy, Security and Trust (PST), 12th International Conference on, IEEE, 2014, pp. 330–337.
6.
R.Bost, Sophos – forward secure searchable encryption, in: Proceedings of the 2016 ACM Conference on Computer and Communications Security, ACM, 2016.
7.
R.Bost, B.Minaud and O.Ohrimenko, Forward and backward private searchable encryption from constrained cryptographic primitives, Technical Report, IACR Cryptology ePrint Archive 2017, 2017.
8.
N.Cao, C.Wang, M.Li, K.Ren and W.Lou, Privacy-preserving multi-keyword ranked search over encrypted cloud data, IEEE Transactions on Parallel and Distributed Systems25(1) (2014), 222–233. doi:10.1109/TPDS.2013.45.
9.
D.Cash, P.Grubbs, J.Perry and T.Ristenpart, Leakage-abuse attacks against searchable encryption, in: Proceedings of the 22nd ACM CCS, 2015, pp. 668–679.
10.
D.Cash, J.Jaeger, S.Jarecki, C.S.Jutla, H.Krawczyk, M.-C.Rosu and M.Steiner, Dynamic searchable encryption in very-large databases: Data structures and implementation, IACR Cryptology ePrint Archive 2014 (2014), 853.
11.
B.Chor, E.Kushilevitz, O.Goldreich and M.Sudan, Private information retrieval, Journal of the ACM (JACM) (1998).
12.
R.Curtmola, J.Garay, S.Kamara and R.Ostrovsky, Searchable symmetric encryption: Improved definitions and efficient constructions, in: Proceedings of the 13th ACM CCS, ACM, 2006, pp. 79–88.
13.
I.Damgård, V.Pastro, N.Smart and S.Zakarias, Multiparty computation from somewhat homomorphic encryption, in: Annual Cryptology Conference, Springer, 2012, pp. 643–662.
14.
S.Devadas, M.van Dijk, C.W.Fletcher, L.Ren, E.Shi and D.Wichs, Onion oram: A constant bandwidth blowup oblivious ram, in: Theory of Cryptography Conference, Springer, 2016, pp. 145–174. doi:10.1007/978-3-662-49099-0_6.
15.
S.Garg, P.Mohassel and C.Papamanthou, TWORAM: Round-optimal oblivious RAM with applications to searchable encryption, IACR Cryptology ePrint Archive 2015 (2015), 1010.
16.
I.Goldberg, Improving the robustness of private information retrieval, in: IEEE Symposium on Security and Privacy, IEEE, 2007, pp. 131–148.
17.
M.D.Green and I.Miers, Forward secure asynchronous messaging from puncturable encryption, in: Security and Privacy (SP), 2015 IEEE Symposium on, IEEE, 2015, pp. 305–320. doi:10.1109/SP.2015.26.
18.
S.Gueron, White paper: Intel Advanced Encryption Standard (AES) new instructions set, Document Revision 3.01, September 2012.
19.
V.Guruswami and M.Sudan, Improved decoding of Reed–Solomon and algebraic-geometric codes, in: Foundations of Computer Science, 1998. Proceedings. 39th Annual Symposium on, IEEE, 1998, pp. 28–37.
20.
F.Hahn and F.Kerschbaum, Searchable encryption with secure and efficient updates, in: Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, ACM, 2014, pp. 310–320.
21.
T.Hoang, A.Yavuz and J.Guajardo, Practical and secure dynamic searchable encryption via oblivious access on distributed data structure, in: Proceedings of the 32nd Annual Computer Security Applications Conference (ACSAC), ACM, 2016.
22.
T.Hoang, A.A.Yavuz, F.B.Durak and J.Guajardo, Oblivious dynamic searchable encryption on distributed cloud systems, in: IFIP Annual Conference on Data and Applications Security and Privacy, Springer, 2018, pp. 113–130.
23.
M.S.Islam, M.Kuzu and M.Kantarcioglu, Access pattern disclosure on searchable encryption: Ramification, attack and mitigation, in: NDSS, 2012.
24.
S.Kamara and C.Papamanthou, Parallel and dynamic searchable symmetric encryption, in: Financial Cryptography and Data Security, Springer, 2013, pp. 258–274. doi:10.1007/978-3-642-39884-1_22.
25.
S.Kamara, C.Papamanthou and T.Roeder, Dynamic searchable symmetric encryption, in: Proceedings of the 2012 ACM Conference on Computer and Communications Security, ACM, 2012, pp. 965–976.
26.
J.Katz and Y.Lindell, Introduction to Modern Cryptography, CRC Press, 2014.
27.
C.Liu, L.Zhu, M.Wang and Y.-a.Tan, Search pattern leakage in searchable encryption: Attacks and new construction, Information Sciences (2014).
28.
T.Moataz, I.Ray, I.Ray, A.Shikfa, F.Cuppens and N.Cuppens, Substring search over encrypted data, Journal of Computer Security (2018), 1–30.
29.
M.Naveed, The fallacy of composition of oblivious RAM and searchable encryption, in: Cryptology ePrint Archive, Report 2015/668, 2015.
30.
P.Paillier, Public-key cryptosystems based on composite degree residuosity classes, in: International Conference on the Theory and Applications of Cryptographic Techniques, Springer, 1999, pp. 223–238.
31.
D.Pouliot and C.V.Wright, The shadow nemesis: Inference attacks on efficiently deployable, efficiently searchable encryption, in: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, ACM, 2016, pp. 1341–1352.
32.
L.Ren, C.W.Fletcher, A.Kwon, E.Stefanov, E.Shi, M.van Dijk, S.Devadas and O.R.A.M.Ring, Closing the gap between small and large client storage oblivious RAM, IACR Cryptology ePrint Archive (2014).
33.
A.Shamir, How to share a secret, Communications of the ACM (1979).
34.
V.Shoup, NTL: A library for doing number theory, 2016.
35.
D.X.Song, D.Wagner and A.Perrig, Practical techniques for searches on encrypted data, in: Proceedings of the 2000 IEEE Symposium on Security and Privacy, IEEE Computer Society, 2000, pp. 44–55.
36.
sparsehash: An extemely memory efficient hash_map implementation, February 2012.
37.
E.Stefanov, C.Papamanthou and E.Shi, in: Practical Dynamic Searchable Encryption with Small Leakage, NDSS, San Diego, California, USA, 2014.
38.
E.Stefanov, M.Van Dijk, E.Shi, C.Fletcher, L.Ren, X.Yu and S.Devadas, Path ORAM: An extremely simple oblivious RAM protocol, in: Proceedings of the 2013 ACM CCS, ACM, 2013, pp. 299–310.
39.
W.Sun, B.Wang, N.Cao, M.Li, W.Lou, Y.T.Hou and H.Li, Privacy-preserving multi-keyword text search in the cloud supporting similarity-based ranking, in: ACM SIGSAC AsiaCCS, ACM, 2013, pp. 71–82.
40.
The Clusion Library.
41.
C.Wang, N.Cao, J.Li, K.Ren and W.Lou, Secure ranked keyword search over encrypted cloud data, in: IEEE 30th International Conference on Distributed Computing Systems, IEEE, 2010, pp. 253–262.
42.
L.R.Welch and E.R.Berlekamp, Error correction for algebraic block codes, Google Patents, 1986, US Patent 4,633,470.
43.
ZeroMQ library, 2016.
44.
R.Zhang, R.Xue, T.Yu and L.Liu, Dynamic and efficient private keyword search over inverted index-based encrypted data, ACM Transactions on Internet Technology (TOIT)16(3) (2016), 21. doi:10.1145/2940328.
45.
Y.Zhang, J.Katz and C.Papamanthou, All your queries are belong to us: The power of file-injection attacks on searchable encryption, in: 25th USENIX Security Symposium (USENIX Security, Vol. 16, 2016, pp. 707–720.
46.
F.Zhou, Y.Li, A.X.Liu, M.Lin and Z.Xu, Integrity preserving multi-keyword searchable encryption for cloud computing, in: International Conference on Provable Security, Springer, 2016, pp. 153–172.