
Abstract
Information Flow Control (IFC) is a form of dependence analysis that tracks and prohibits dependence of public outputs on secret inputs. Such a dependence analysis is often carried out using a type system. IFC type systems can track dependence (via confidentiality labels) at varying levels of granularity. On one extreme, there are fine-grained type systems that track dependence at the level of individual values. They label individual values. On the other extreme, there are coarse-grained type systems that track dependence at the level of entire computations. These type systems do not label individual values but instead label entire sub-computations.
An important foundational question is one of the relative expressiveness of these two classes of IFC type systems. In this paper we show that, despite the glaring differences in how they track dependence, the two classes of type systems are actually equally expressive. We do this by showing translations from FG, a fine-grained IFC type system derived from SLAM (In Proceedings of the ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages (POPL) (1998)), to
As a separate, more foundational contribution we show how to extend logical relation models of information flow to languages with higher-order state. Specifically, we build world-indexed (Kripke) logical relations for FG,
Keywords
Introduction
Information Flow Control (IFC) is a technique for tracking flows of information between different elements of a computer system. This is often used to prevent illicit flows with respect to a relevant security policy. In a language-based setting, IFC can be performed dynamically using runtime monitoring [5,6] or statically using type systems [1,8–10,15,19,20,22,27] for instance. In this paper, we focus only on the latter, i.e., on type-based approaches for IFC.
IFC type systems use security labels (elements of a security lattice) for tracking and prohibiting undesired flows of information. There are two significant aspects of security labels that govern the expressiveness of a sound type system, i.e., how many secure programs the type system can accept.1
Since checking correctness of IFC is undecidable by Rice’s theorem, no IFC type system can be both sound and complete, i.e., accept exactly all secure programs.
The second aspect, which is the focus of this paper, is the granularity of labeling (which is different from the granularity of the label itself). It pertains to the extent to which labeling is used on a program. Under this classification, a fine-grained type system is one which labels every program value individually by including a label in every type. For instance, FlowCaml [22] is a fine-grained IFC type system for ML. Every type constructor in FlowCaml is annotated with a security label. For example,
Coarse-grained type systems [1,8,10,19], on the other hand, are very different. They do not assign a label to every individual value. Instead, a label is associated with an entire sub-computation. Values in the scope of the sub-computation implicitly inherit the label of the sub-computation.2
This idea traces lineage to IFC for operating systems [12,17,28], where the notion of sub-computation is a process, and a single label is associated with a process, but flows within a process are not tracked. However, this historic connection is not important for understanding the results of this paper.
We use a different font face to represent the type constructor. This is done to differentiate the type constructor from the name of the type system.
Looking at these vastly contrasting type systems for enforcing information flow control, a natural question that arises is that of their relative expressiveness [23]. By this we mean whether all programs that can be expressed in a fine-grained type system can also be expressed in a coarse-grained type system (and vice versa)? Upfront, it seems that a fine-grained type system should be able to express every program that a coarse-grained type system can, as the former abstracts less flows than the later. But the reverse (expressing a fine-grained type system in a coarse-grained one) is not immediately obvious. However, then one wonders if by structuring programs as extremely small sub-computations in a coarse-grained type system one may recover the expressiveness of a fine-grained type system after all.
In this paper, we show that both these intuitions are actually correct. We do this constructively, by showing an embedding of a fine-grained type system in a coarse-grained type system and vice versa. We do this in the setting of a higher-order language with state, to which we assign a fine-grained and a coarse-grained type system. For the fine-grained type system, we choose a system which is very close to SLAM [15] and the exception-free fragment of FlowCaml [22]. We call this type system FG here. For the coarse-grained type system, we work with
While this is sufficient to prove the equi-expressiveness of fine-grained and coarse-grained IFC type systems, we note that the translation from FG to
We believe that this resolves the question of the relative expressiveness of fine-grained and coarse-grained IFC type systems. A practical consequence of our theoretical results is that, since a coarse-grained type system involves less labeling annotations than a fine-grained one, a programmer can always choose to work with a coarse-grained type system without worrying about its expressiveness. In places where the precision of the fine-grained type system is really required, it can be simulated in the coarse-grained type system itself, following our (constructive) embedding of the fine-grained type system in the coarse-grained one.
As a second contribution of independent interest, we describe how to set up logical-relation based semantic models for the three type systems (FG,
We also use our logical relations to show that our translations are meaningful. Specifically, we set up cross-language logical relations to prove that our translations preserve program semantics, and from this, we derive a crucial result for each translation: Using the noninterference theorem of the target language as a lemma, we are able to re-prove the noninterference theorem for the source language directly. This implies that our translations preserve labels meaningfully [7]. Like all logical relations models, we expect that our models can be used for other purposes as well.
To summarize we make the following contributions through this work:
We show the equi-expressiveness of fine-grained and coarse-grained IFC type systems using type- and semantics-preserving cross translations.
We develop a new coarse-grained type IFC type system, CG, that breaks the input-output relation between the label indices of
We develop logical relations models for fine-grained and both of the coarse-grained type systems for a language with higher-order state.
We give alternate proofs of soundness for FG and
Accompanying appendix. Many technical details omitted from the paper to keep its length manageable are presented in an online appendix available from the authors’ homepages.
Differences from the conference version. This paper is an extended version of a paper that appeared in CSF 2018 [24]. The conference version showed only the translations from FG to CG (and vice versa), omitting the translations from FG to
In this section, we describe the fine-grained type system and one of the two coarse-grained type systems we work with. Both these type systems are set up for higher-order stateful languages, but differ considerably in how they enforce IFC. The fine-grained type system, FG, works on a language with pervasive side-effects like ML, and associates a security label with every expression in the language. The coarse-grained type system,
Both FG and
The fine-grained type system, FG

Language syntax and type system of FG (selected rules).
FG is based on the SLam calculus [15], but uses a presentation similar to Flow Caml, an IFC type system for ML [22]. It works on a call-by-value, eager language, which is a simplification of ML. The syntax of the language is shown at the top of Fig. 1. The language has the usual constructs for functions, pairs, sums, and mutable references (heap locations). Along with that the language also includes constructs for label quantification (
Every type τ in FG, including a type nested inside another, carries a security label. The security label represents the confidentiality level of the values the type ascribes. It is also convenient to define unlabeled types, denoted
FG’s typing rules are shown in Fig. 1. We describe some of the important rules. In the rule for case analysis (FG-case), if the case analyzed expression e has label ℓ, then both the case branches are typed in a
The rule for function application (FG-app) states if the function expression
In the rule for assignment (FG-assign), if the expression

FG subtyping.
All introduction rules such as those for λs, pairs and sums produce expressions labeled ⊥. This label can be weakened (increased) freely with the subtyping rule FGsub-label. The other subtyping rules (described in Fig. 2) are the expected ones, e.g., subtyping for unlabeled function types
The main meta-theorem of interest to us is soundness. This theorem says that every well-typed expression is noninterferent, i.e., the result of running an expression of a type labeled low is independent of substitutions used for its high-labeled free variables. This theorem is formalized below. Note that we work here with what is called termination-insensitive noninterference; we briefly discuss the termination-sensitive variant in Section 6.
Suppose (1)
By definition, noninterference, as stated above is a relational (binary) property, i.e., it relates two runs of a program. Next, we show how to build a semantic model of FG’s types that allows proving this property.
Semantic model of FG
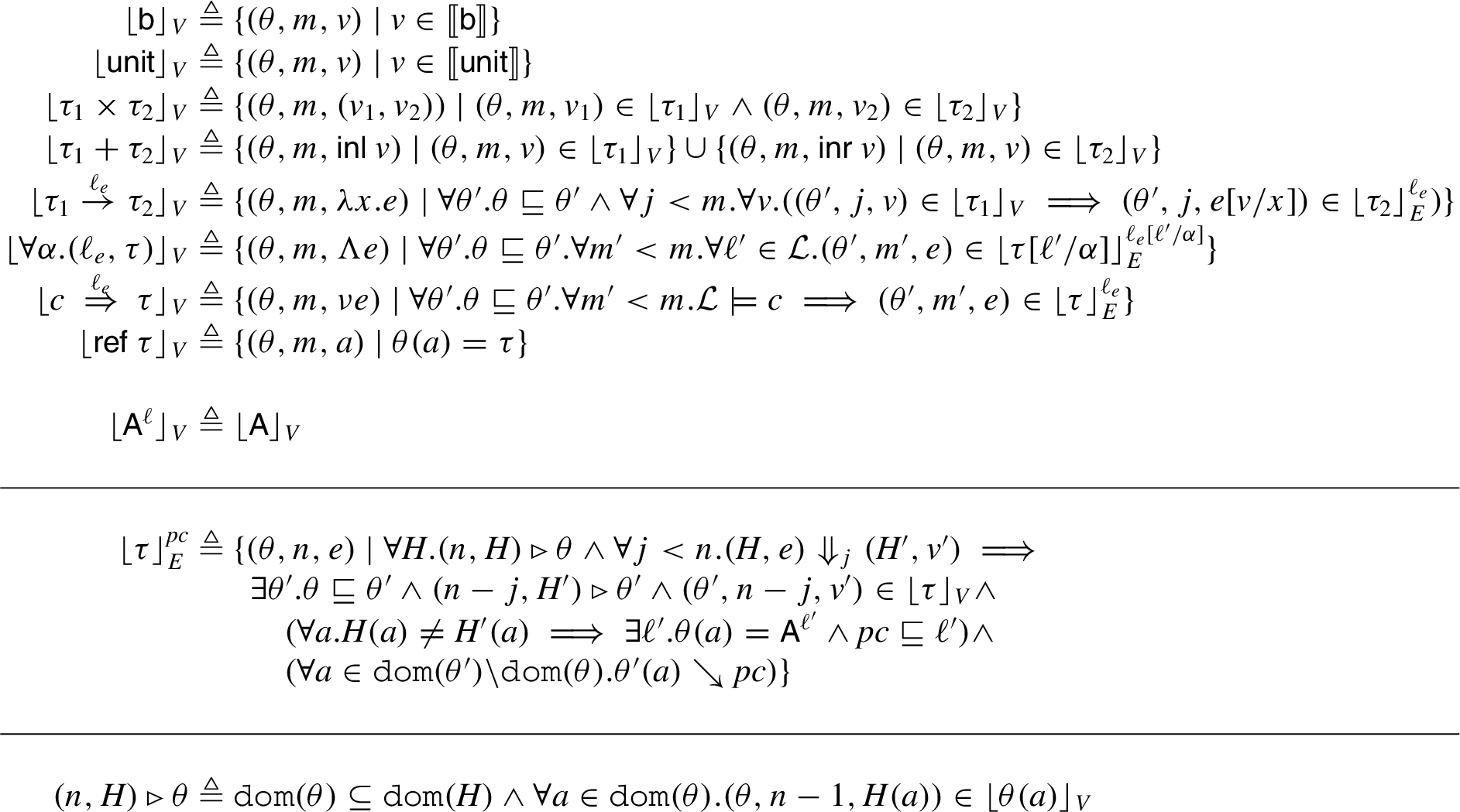
Unary value, expression, and heap conformance relations for FG.
We now describe our new semantic model of FG’s types. We use this model to show that the type system is sound (Theorem 2.1) and later to prove the soundness of our translations. Our semantic model uses the technique of step-indexed Kripke logical relations [2] and is more directly based on a model of types in a different domain, namely, incremental computational complexity [11]. In particular, our model captures all the invariants necessary to prove noninterference.
The central idea behind our model is to interpret each type in two different ways – as a set of values (unary interpretation), and as a set of pairs of values (binary interpretation). The binary interpretation is used to relate low-labeled types in the two runs mentioned in the noninterference theorem, while the unary interpretation is used to interpret high-labeled types independently in the two runs (since high-labeled values may be unrelated across the two runs). What is high and what is low is determined by the level of the observer (adversary), which is a parameter to our binary interpretation. Readers familiar with earlier models of IFC type systems [1,15,25] may wonder why we need a unary relation, when prior work did not. The reason is that we handle an effect (mutable state) in our model, which prior work did not. In the absence of effects, the unary model is unnecessary. In the presence of effects, the unary relation captures what is often called the “confinement lemma” in proofs of noninterference – we need to know that while the two runs are executing high branches independently, neither will modify low-labeled locations.
The interpretation itself consists of three mutually inductive relations – a value relation for types (labeled and unlabeled), written
The value relation
The expression relation

Binary value, expression and heap conformance relations for FG.
The heap conformance relation
As before, the interpretation itself consists of three mutually inductive relations – a value relation for types (labeled and unlabeled), written
The value relation
Finally, and most importantly, at a labeled type
The expression relation
The heap conformance relation
To write these theorems, we define unary and binary interpretations of contexts,
If
(Binary fundamental theorem).
If
The proofs of these theorems proceed by induction on the given derivations of
FG’s noninterference theorem (Theorem 2.1) is a simple corollary of these two theorems.
The coarse-grained type system,
In this section, we describe our first coarse-grained type system,
The choice of call-by-value evaluation is made to match the evaluation approach used for FG. The original SLIO [10] is defined for a language with call-by-name evaluation.
Unlike FG,
We use the term forcing to mean execution of the computation of the monadic type.

Syntax and type system of
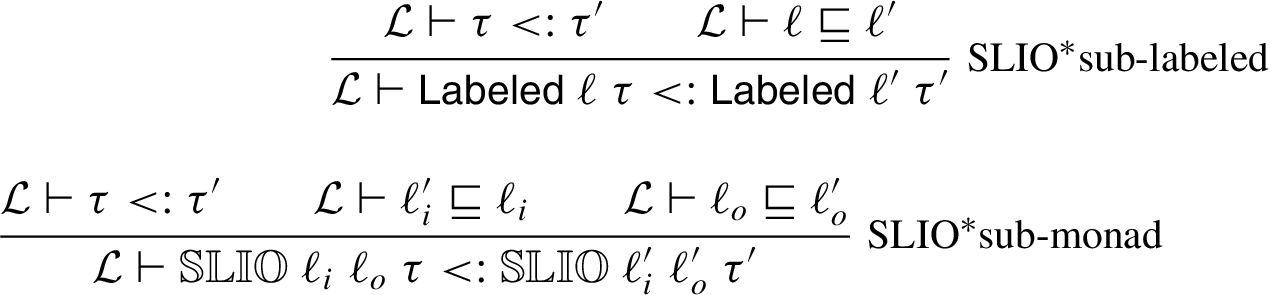
Having explained the various types of the
Note that the
All the rules related to references perform heap-related effects and thus all of them have monadic types.
Selected subtyping rules for
We prove soundness for
Suppose (1)
Semantic model of
We build a new semantic model of
Translations between FG and
In this section, we describe our translations from FG to

Unary logical relation for

Binary logical relation for
Translating FG to
We begin by looking at the translation of the typing judgment for FG, which is essentially the type preservation theorem that we would eventually like to prove. Here,
Suppose
Theorem 3.1 basically states that every well-typed FG expression e can be translated into some
The constraint
We describe the full type translation function in Fig. 9. The type translation function is indexed with a label ℓ. The interesting case is the translation of the function type. The constraints in the translation of this type are similar to the ones we have in the theorem above. Additionally, we have two more constraints –

Type translation from FG to

Expression translation for FG to
Given this translation of types, we next define a type derivation-directed translation of expressions. This translation is formalized by the judgment
Selected rules for the expression translation from FG (source) to
To do this, we bind
Importantly, the function
Our translation satisfies type preservation (Theorem 3.1). Type preservation is a necessary but insufficient condition for the goal we are after – showing equi-expressiveness of FG and
The cross-language relation (described in Fig. 11) relates a term of FG with a term of
The expression relation embodies semantics preservation by stating that a FG’s expression (
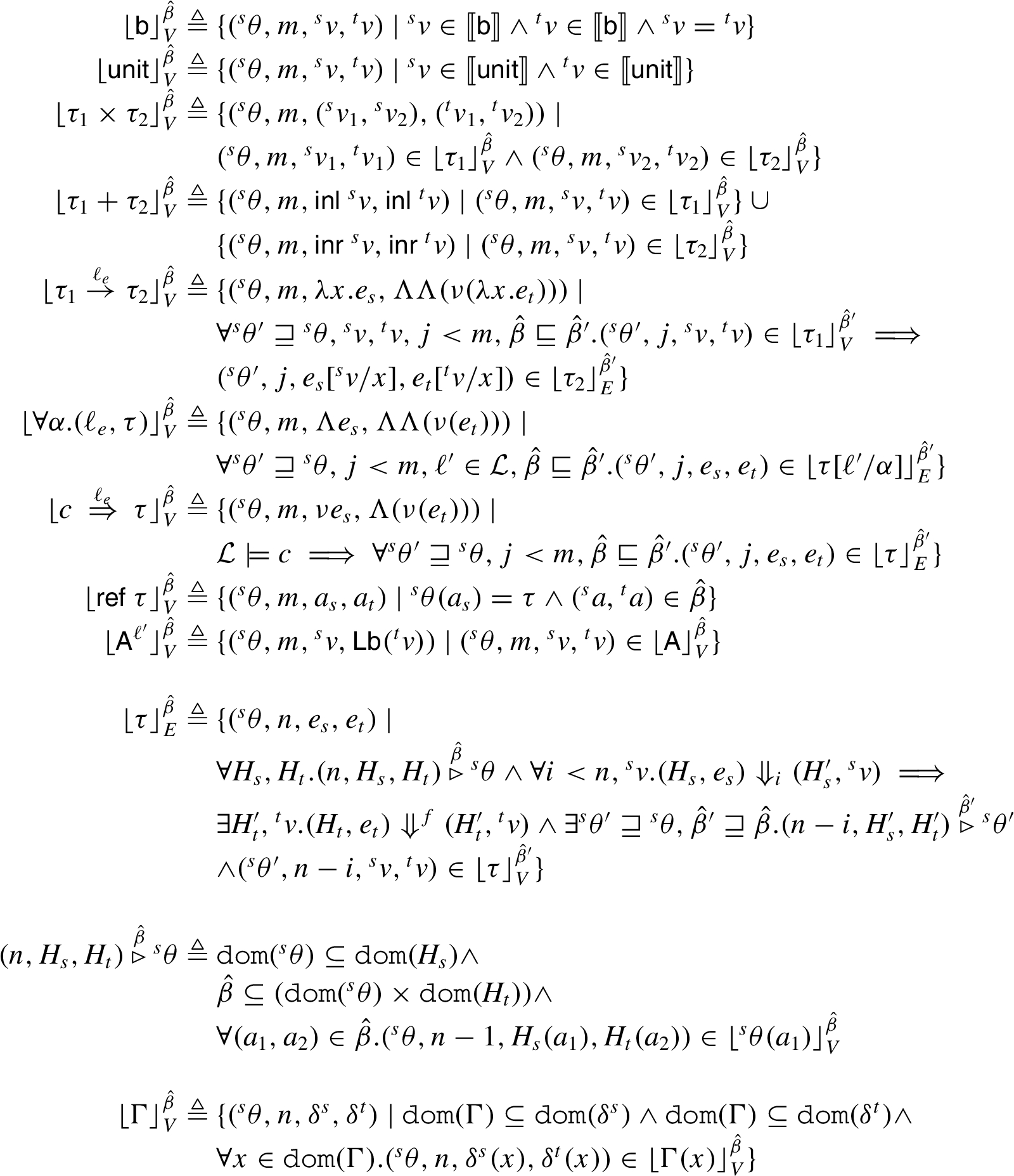
Cross language value and expression relation for FG to
The logical relation can be extended to substitutions in a standard way. This enables us to state and prove the fundamental theorem.
This theorem immediately implies that the FG to
Translating
to FG

Expression translation
This section describes the translation in the other direction – from
The key idea of the translation is to map a source (
The type translation,
The most interesting case of the translation is that for
The expression translation is directed by source typing derivations and is defined by the judgment
If
Again, a corollary of this theorem is that well-typed source programs translate to non-interfering target programs.
We further prove that the translation preserves the semantics of programs. Our approach is the same as that for the FG to
CG: A new coarse-grained type system
We explained in Section 2.2 that
CG is defined for the same language as

CG’s type system (selected rules).
CG’s typing judgment is written
The monadic construct
Next, we describe rules pertaining to the type
Rule CG-deref says that dereferencing (reading) a location of type
The last typing rule we highlight pertains to the construct
We prove soundness for CG by showing that every well-typed expression satisfies noninterference (Theorem 4.1). The proof is done by developing logical relations of the kind we saw earlier for FG and
Suppose (1)
Translations between FG and CG
In this section, we describe our translations from FG to CG and vice-versa. The purpose of describing these translations is two fold: 1) To show that these two type systems are equally expressive and, more importantly, to show that the translation from a fine-grained to a coarse-grained IFC type system does not have to be as complex as we saw in Section 3.1. We show the latter by describing a much simpler translation from FG to CG. 2) To show that CG and
Translating FG to CG
Our goal in translating FG to CG is to show how a fine-grained IFC type system can be simulated in a coarse-grained one in a very simple manner. This translation is directed by the type derivations in FG and preserves typing, semantics and security annotations. As before, we use the subscript or superscript s to indicate source (FG) elements, and t to indicate target (CG) elements.
The key idea of our translation is to map a source expression
The function
The translation should be self-explanatory. The only nontrivial case is the translation of the function type
The expression translation uses ideas similar to that of the translation from FG to

Expression translation FG to CG (selected rules only).
If
An immediate corollary of this theorem is that well-typed source programs translate to non-interfering target programs (since target typing implies noninterference in the target).
Next, just like our previous translations we also show that this translation is semantics preserving by developing a cross-language relation between FG and CG terms. The cross-language relation is similar to (but not the same as) the cross-language relation we saw for the FG to
Discussion
Another relevant question in whether our equivalence result can be extended to type systems that support declassification and, more foundationally, whether our logical relations can handle declassification. This is a nuanced question, since it is unclear hitherto how declassification can be given a compositional semantic model. We are working on this problem currently.
Related work
We focus on related work directly connected to our contributions – logical relations for IFC type systems and language translations that care about IFC.
Our models are based on the now-standard step-indexed Kripke logical relations [2], which have been used extensively for showing the soundness of program verification logics. Our model for FG is directly inspired by Cicek et al.’s model for a pure calculus of incremental programs [11]. That calculus does not include state, but the model is structurally very similar to our model of FG in that it also uses a unary and a binary relation that interact at labeled types. Extending that model with state was a significant amount of work, since we had to introduce Kripke worlds. Our models for
Conclusion
This paper has examined the question of whether information flow type systems that label at fine granularity and those that label at coarse granularity are equally expressive. We answer this question in the affirmative, assuming that the coarse-grained type system has a construct to limit the scope of the taint label. We show this via cross-translations between a fine-grained type system, FG, and a coarse-grained type systems
Footnotes
Acknowledgments
This work was partly supported by the German Science Foundation (DFG) through the Collaborative Research Center “Methods and Tools for Understanding and Controlling Privacy” (SFB 1223).