
Abstract
With the development of information technology, thousands of devices are connected to the Internet, various types of data are accessed and transmitted through the network, which pose huge security threats while bringing convenience to people. In order to deal with security issues, many effective solutions have been given based on traditional machine learning. However, due to the characteristics of big data in cyber security, there exists a bottleneck for methods of traditional machine learning in improving security. Owning to the advantages of processing big data and high-dimensional data, new solutions for cyber security are provided based on deep learning. In this paper, the applications of deep learning are classified, analyzed and summarized in the field of cyber security, and the applications are compared between deep learning and traditional machine learning in the security field. The challenges and problems faced by deep learning in cyber security are analyzed and presented. The findings illustrate that deep learning has a better effect on some aspects of cyber security and should be considered as the first option.
Introduction
The internet has become an inseparable component of our daily lives, and the number of network-connected devices has grown exponentially for many years. In 2015, more than 15 billion devices were connected. It is estimated that this number will exceed 50 billion by 2020, and more than 500 billion devices will be connected to the internet by 2030 [12].
The increasing popularity of inter-connectivity has led to many security issues [25], especially privacy issues that make users vulnerable to cyber attacks and identity theft. In addition, people are facing the threat of viruses, malicious code, and security attacks. In response to the security threats, people have used a variety of methods to develop applications to detect malware [11], prevent attacks [88], and prevent information leakage [65]. Methods based on traditional machine learning are also widely used in the area of cyber security [57].
In recent years, due to the breakthroughs of deep learning applications, more and more people use methods of deep learning to improve security. Deep learning is a special paradigm of machine learning with strong power and flexibility by learning the representation of the world as a nested hierarchy of concepts [33]. Because of more powerful computers, larger data sets, and technologies that can be used to train deeper networks, deep learning has been more popular and practical. In the next few years it will be full of challenges and opportunities to research deep learning and expose it to new areas.
Deep learning has many advantages over traditional machine learning. For example, it can automate feature engineering, eliminating many cumbersome feature engineering on construction processes. In this paper, we intend to summarize the application of deep learning from the perspective of cyber security. The differences from other related types of reviews are as follows:
Mohammad et al. [63] reviewed the deep learning models in conjunction with the Internet of Things (IoT) applications. They presented the fundamental characteristics of deep learning algorithms with typical applications to the IoT domain (such as Smart Homes, Smart City, Intelligent Transportation Systems, Healthcare, Wellbeing, and many more) from a system level overview. They summarized deep learning algorithms. However, cyber security based on deep learning has not been analyzed and summarized.
Al-Garadi et al. [2] summarized IoT security applications based on machine learning and deep learning. They offered a taxonomy of the threat and risk of IoT security. They attempted to convey a comprehensive survey at the system level in terms of the three layers—perception layer, network layer, and application layer. However, they did not analyze the cyber security of deep learning from the user’s point of view, nor did they analyze the limitations of traditional machine learning.
Liu et al. [55] lined up cyber insider threats together with three common types, namely traitor, masquerader, and unintentional perpetrator, which are categorized as host, network, or context data based on audit data source. But they did not analyze the outside threats and information leakage from devices and did not differentiate methods of traditional machine learning and deep learning.
In this paper, we review the cyber security aspects associated with deep learning. The contributions of this paper are as follows:
We divide the issues of cyber security into three areas, namely system internal security, system external security, and IoT device security. The corresponding security issues are mainly malware detection, intrusion detection, and privacy leakage of IoT devices. We review various malware detection methods based on deep learning and compare them with traditional machine learning methods. Deep learning methods have demonstrated better accuracy. We review methods of intrusion detection based on deep learning, and summarize characteristics and detection results of various deep learning methods. We review various privacy leak resolutions based on deep learning and analyze new risks and privacy leaks based on deep learning faced by various types of devices. We identify the challenges of deep learning in cyber security and propose future research directions.
Cyber security challenges of traditional machine learning approaches
In order to deal with the issues of cyber security, many solutions [9,42] have been given based on traditional machine learning algorithms (Linear Regression [103], Decision Tree [8], Logistic Regression (LR) [14], Support Vector Machine (SVM) [3], Naive Bayes [73], Random Forest [66], etc).
Different potentials of machine learning have been shown in enhancing cyber security [70] in the past, such as for detecting Distributed Denial of Service (DDoS) attacks, Kiruthika Devi et al. achieved accuracy of 98.99% by the method of hop count inspection algorithm coupled with SVM [23]. To identify android malware, different methods based on machine learning have been used in the past. The identification of android malware based on application permission achieved a maximum accuracy of 90.72% with a sample set of 200 and 160 extracted features through implementing k-means for training and J48 for classification [6]. Although existing methods based on machine learning techniques have achieved valued results [15], that is still not enough to completely overcome cyber security issues. People are looking for new ways to discover and detect various types of malware, attack methods, and phishing websites [13].
Some of the inherent features of traditional machine learning algorithms limit the application of these methods in the field of cyber security. The features of traditional machine learning algorithms are as follows:
The advantages of linear regression are simple and easy to interpret, and over-fitting can be avoided by regularization. In addition, linear models can easily update data by the random gradient descent method. But the poor effect on nonlinear data sets, makes it not ideal for identifying complex patterns.
Nonlinear relationships can be learned by Decision Trees (DT) which also have strong robustness to outliers. But single trees are easy to overfit, too many branches remember the training data, and the patterns are not recognized. Random forest can overcome some of its disadvantages.
The output of logistic regression has a good probability of interpretation, and in the algorithm, overfitting can be avoided by regularization. It is easy to apply the gradient descent method to update parameters. But it has poor performance in the face of multiple or nonlinear decision boundaries.
Support vector functions can model nonlinear decision boundaries, and there are many optional kernel functions. Support vector machines have strong robustness in the face of over-fitting, especially in high-dimensional spaces. However, support vector machines are memory-intensive algorithms. Choosing the right kernel function requires considerable skill and is not suitable for larger data sets. In current industry applications, random forests tend to outperform support vector machines.
The essence of Naive Bayes (NB) is a probability table, which is updated by training data. Even though the assumption of conditional independence is difficult to establish, the Naive Bayesian algorithm in practice can perform very well. The algorithm is easy to implement and can be updated with data sets. However, the Naive Bayesian algorithm is too simple for complex tasks, it is easily replaced by the above classification algorithm.
Random forests can process high-dimensional data without feature selection, and have strong adaptability to data sets. When the number of decision trees in a random forest is large, the space and time required for training will be large. On some noisy samples, models of random forests are prone to overfitting.
Overall, one of the problems with traditional machine learning methods [1] is that they often generate many false alarms. In addition, there are very low detection rates for some attacks, like Remote to Local (R2L) and User to Root (U2R).
In intrusion detection, it is often necessary to extract many features from packets [86], which may cause some methods of machine learning to suffer from overfitting, especially when the data has many features and relatively small examples [36].
Often, more complex tasks tend to correspond to more complex models [31,71], especially in the case of large amounts of complex data and multiple features [29]. When the dimensionality of the data is high, many machine learning problems become quite difficult. This phenomenon is called a dimensional disaster [33]. When using methods of traditional machine learning to solve cyber security issues, it also faces a dimensional disaster. For methods of traditional machine learning, at the beginning, performance (recognition rate) will increase with the increase of data, but after a period of time, its performance will enter the platform period. It is difficult to handle massive amounts of data through these models.
Deep learning has lots of advantages over traditional machine learning. For example, it can automate feature engineering, it is easy to adapt to different fields and applications.
Deep learning methods are data-driven and need a lot of data to train the model, while the methods of traditional machine learning only need a relatively small amount of data. Deep learning methods can be regarded as a feature learner, while the methods of traditional machine learning can be used for daily tasks that don’t need additional features. However, for complex cyber security issues, we often need feature engineering [58]. From a user’s point of view, cyber security issues are mainly divided into the following three aspects: (1) system internal security, (2) system external security, and (3) device security, as shown in Fig. 1. System internal security mainly considers malware. We often install or download malware without knowing. The malware may steal our account number, password, bank card number, and other important information. System external security is mainly caused by various external attacks or abnormal information, such as denial of service attacks [35], port scanning, vulnerability intrusion, flag insertion, and more. Device security mainly considers privacy leaks, including phishing websites, illegal access, and information reasoning etc.
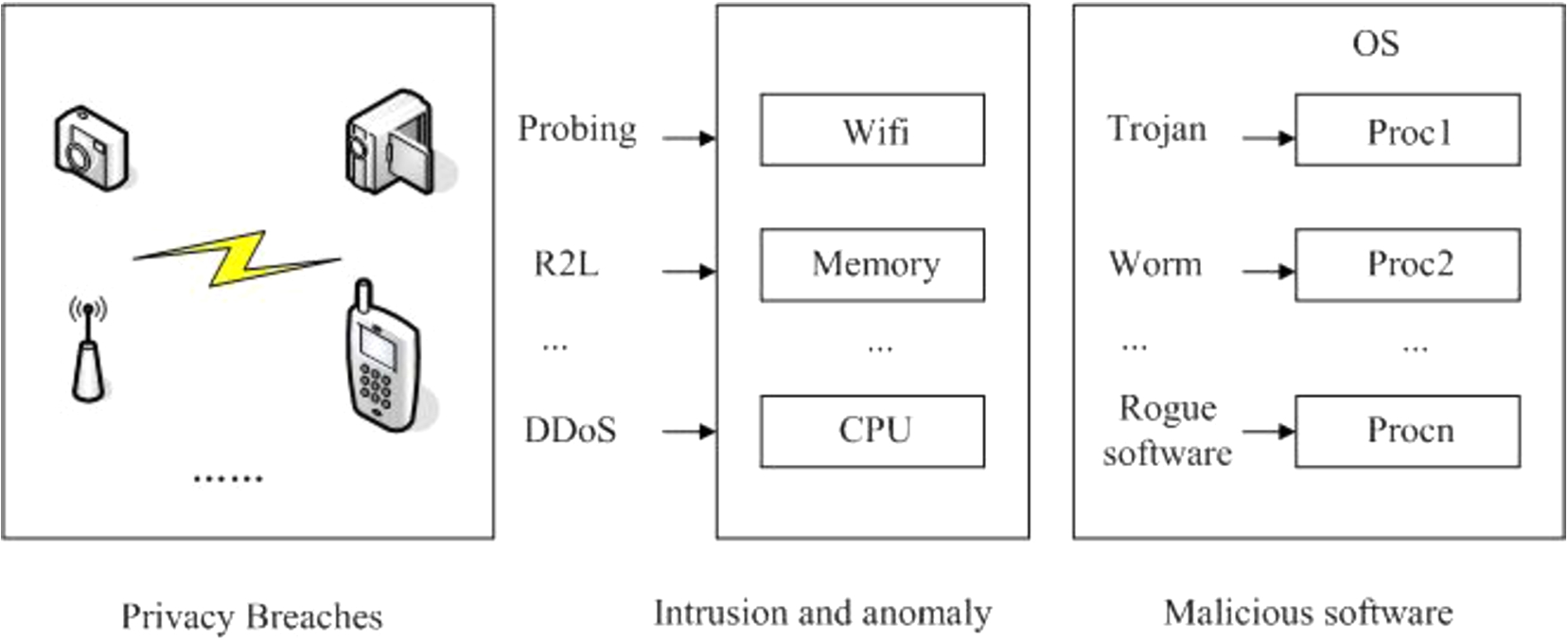
Cyber security diagram.
In order to deal with these security issues, traditional machine learning methods are applied to malware detection [8], network intrusion detection [48], phishing website detection [44], malicious domain name detection [7,81], etc. However, since these methods face the establishment of feature engineering, more features mean more dimensions, the methods of traditional machine learning face the dimension disaster, that is, when the dimension of the feature increases, it can not be solved well by the methods of traditional machine learning. The deep learning methods do not have such problems, and can automate feature engineering, so more and more solutions of deep learning are applied to the field of cyber security.
Considering difficulties in achieving effective security [89], researchers have looked for alternative methods and identified deep learning as one of the latest technologies to deal with the issues related to cyber security [72]. Deep learning is a branch of machine learning and Artificial Intelligence (AI). Deep learning is also known as the artificial brain that can identify objects in a similar way to the human brain in real-time. Although most of the applications of deep learning are in pattern recognition, it is widely accepted in dealing with cyber security related issues [38].
Deep learning is a form of machine learning algorithm, inspired by our brain’s capability to classify objects. As our brain, we can receive input through our sensory and process it to learn the high-level features of the object itself, deep learning can learn to identify the objects on the basis of training provided by inputting images through deep neural networks. In comparison to other machine learning algorithms, deep learning has narrowed its focus to learning high-level features to attain higher accuracy and faster processing. Deep learning has proven its success in driver-less cars and AlphaGo (a computer program which is the first to beat a professional human Go player) that has achieved a 99.8% winning rate against other Go programs [82].
Deep learning is different from neural networks as they provide a better detection rate in both supervised and unsupervised learning. To detect the defects of security in early stages, for traditional methods, it requires a lot of labelled data which is expensive and practically not possible as new attacks are evolving on a daily basis. Deep learning can learn from unlabelled data and achieve better performance than hand-engineered features. For example, as compared to signature-based and heuristic techniques of malware detection, deep learning is helpful to do predictive analysis and detect defects in real time to avoid cyber-attack [76]. Its self-learning capacity produces faster processing speed and more accurate results than traditional methods. There are different deep learning methods, which can be categorized into supervised, hybrid, unsupervised, and semi-supervised, as shown in Fig. 2.
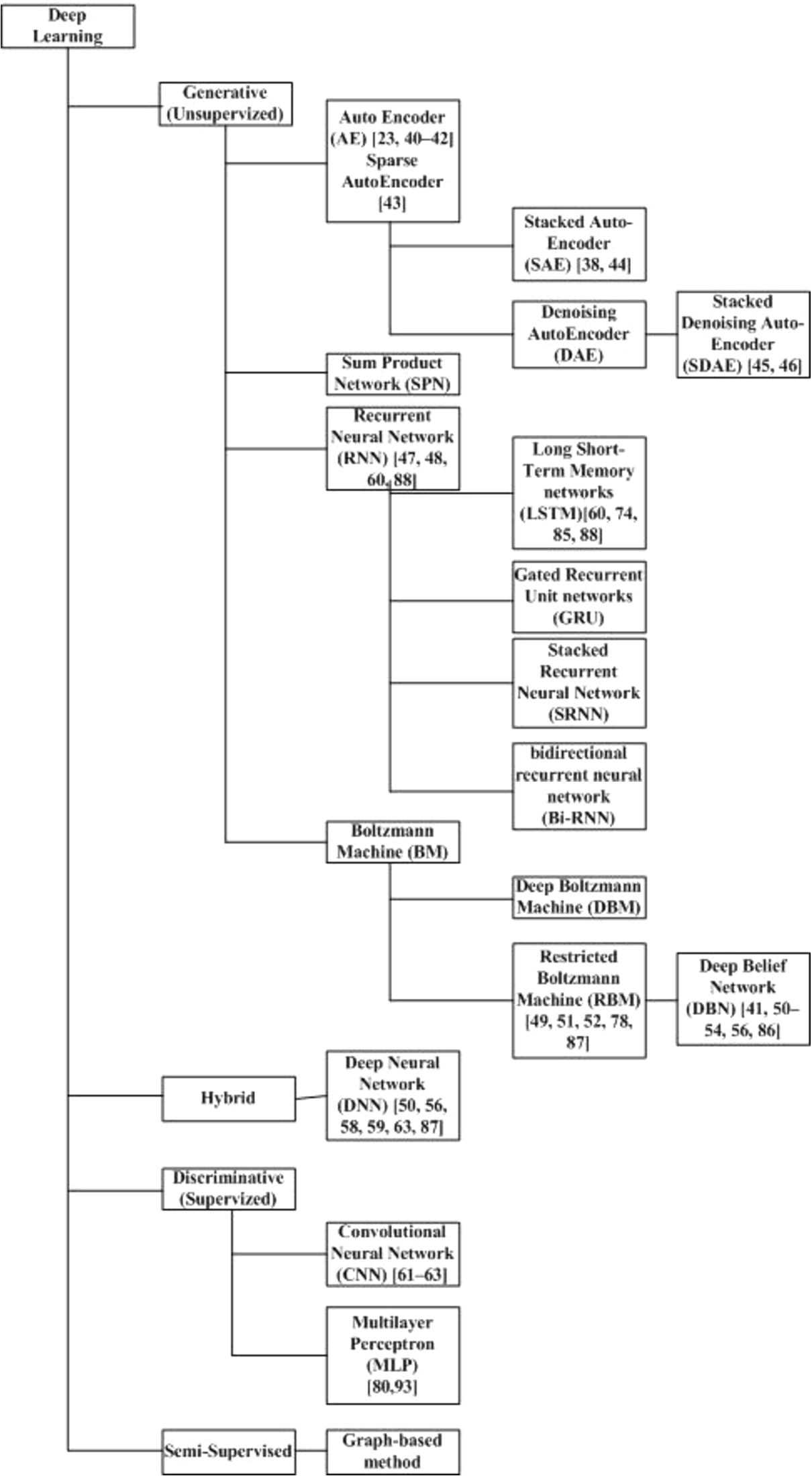
Classification of deep learning methods according to model and some applications in the field of cyber security.
Auto Encoder (AE): An autoencoder is a network trained to copy its input to its output by having a few neurons in the hidden layer. Data is provided as input and the output tries to reconstruct the input using unsupervised learning. It is performed using back propagation and useful for dimensionality reduction [56].
An autoencoder usually consists of an encoder and a decoder. The encoder is to transform high-dimension data into low-dimension data and the decoder reconstructs the data from the code [40]. Different AE structures can be stacked up to build deep networks. The middle layer of each structure is cascaded. This new structure is called Stacked Autoencoder (SAE) [41].
A denoising autoencoder (DAE) is used to reconstruct a clean “repaired” input from a corrupted version of it. To avoid overfitting, and to encourage learning structure instead of noise, denoising autoencoders are used [93].
Restricted Boltzmann Machine (RBM): Boltzmann Machine (BM) is a network of stochastic binary units that are symmetrically coupled [74]. The learning algorithm of BM is very slow in network with many layers of feature detectors. Whereas RBM is a shallow neural network which has only two layers, one visible and one hidden layer, used to find patterns in data by reconstructing the input. It is called restricted because neurons in the same layer are not connected. It is useful for handling unlabelled data. It extracts the key features from the input and combines them to form patterns. It is a type of autoencoder that constitutes the building block of a deep belief network.
Deep Belief Network (DBN): DBN are considered as an alternative to the back propagation [62]. A DBN can be regarded as a stack of RBMs where a hidden layer of one RBM is the visible layer of another RBM above it. Each layer of RBM is trained to carry the entire input. It can be used for feature extraction, non-linear dimensionality reduction when the number of units in the highest layer is small [39].
Hybrid deep learning
Deep Neural Network (DNN): A neural network with more than three layers is considered to be a DNN. These deep architectures have the capability to learn more complex models than traditional machine learning, but they need a large amount of complex computation during the training phase. The training phase includes forward pass of input to obtain output and a backward pass of errors to adjust weights, which is computationally exhaustive. To achieve better accuracy, it requires a huge amount of data as an input [22,24].
Supervised deep learning
Convolutional Neural Network (CNN): CNN is a specialized kind of feed-forward neural network for processing data that has a known, grid-like topology. CNN includes an input layer, a hidden layer, and an output layer, wherein the hidden layer further includes a convolution layer, a pooling layer, and a fully connected layer. The convolutional layer performs feature extraction on the input data, which may contain multiple convolution kernels. The pooling layer selects the pooling area. The fully connected layer is located at the last part of the hidden layer of CNN. Its function is to non-linearly combine the extracted features to obtain an output [32,33].
Recurrent Neural Network (RNN): RNN is an artificial neural network in which nodes are connected in a loop. Its internal state can exhibit dynamic timing behavior. RNN can use its internal memory to process input sequences of arbitrary timing, which makes it easier to handle handwriting recognition, speech recognition, etc. RNN is divided into Long Short-Term Memory networks (LSTM), Gated Recurrent Unit networks (GRU), Stacked Recurrent Neural Network (SRNN), bidirectional recurrent neural network (Bi-RNN), and the like [33,52].
Semi-supervised deep learning
Semi-supervised learning refers to learning a representation by using both unlabeled data and labeled data so that data from the same class have similar representations. The most active area of research in semi-supervised learning is graph-based methods which start by constructing a graph from the training samples [80].
Deep learning and cyber security
Due to the characteristics of deep learning, it is gradually applied to the field of cyber security, such as malware detection, intrusion detection, privacy breaches, and so on. Google added deep learning to its robust spam filters in Gmail and claims it already blocks more than 99.9 percent of spam, phishing and malware emails.1
According to the news report on
Malicious code, also known as malware, is an aggregate term that refers to programs which enter a system without user’s permission and do any kind of unsolicited activities on a computer system. It is a significant risk nowadays as it continuously rises in volume and advances in complexity. With the current evolution in high-speed internet, malware spreads quickly [79]. Hence, it is crucial to detect and remove malware in an intelligent way. Based on the actions, malware can be categorised as Spyware, Adware, Ransomware, Virus, Trojan, Worm, Rootkit, Backdoors, and Botnet.
There are various methods implemented to detect malicious behaviour [64]. The two main techniques to detect malware are signature based methods and anomaly based methods. With the two technologies, we can efficiently detect known malware, but unknown malware or mutant malware in the network cannot be detected.
There are three main types of malware detection methods based on deep learning, namely static detection, dynamic detection, and image-based malware detection, as shown in Table 1.
Main results comparison of deep learning-based malware detection
Main results comparison of deep learning-based malware detection
Static malware detection
In this kind of method, the software to be detected has been extracted some features according to certain rules in advance.
There are many malware detection methods based on traditional machine learning, such as Naive Bayes, SVM, Decision Tree, K-nearest neighbor, etc. However, these methods have some problems, including inappropriate feature extraction, low detection rate and low accuracy, and too complicated algorithms. In order to change this situation, Li et al. proposed a hybrid malware detection model based on deep learning [53]. The model uses a method that combines AE and DBN. AE is used to perform the task of dimensionality reduction and extract feature information, and DBN is used for malware classification. The KDDCUP’99 dataset was used for the experiment. The dataset consists of 494,021 training data and 311,029 testing data and each data comprises 41 features. The experiment used 2000 samples extracted from the 10% sample proportion. Experimental results show that the average accuracy of this method for detecting malware reaches 92.1%. It is better than the detection accuracy of the DBN method alone. But the authors did not conduct experiments compared with the performance of traditional machine learning methods.
Deep learning methods are superior to that of traditional machine learning in malware detection, which is verified in [95]. To detect malicious JavaScript code, Wang et al. have suggested a deep learning approach that uses stacked denoising autoencoder (SDAE) for feature extraction and uses logistic regression (LR) as a classifier [95,97]. The dataset includes 12320 benign samples collected from ‘Alexa Top’ website and 14783 malicious JavaScript samples collected from ‘VX Heaven’ and ‘Malicious Website Labs’. They used Google Safe Browsing service to verify both benign and malicious samples. For training, 7,392 benign and 2,464 malicious samples are used, and for testing, 8,868 benign and 2,959 malicious samples are selected. The preprocessing method converts each letter of JavaScript code into eight-bit binary code to generate a binary feature vector as the input of DL model. The preprocessing will generate 20,000 features (dimensions) which are further reduced through method of Sparse random projection and 250 features are extracted. The network configuration selected to achieve a better result has 3 hidden layers, 250 neurons in each layer, 1,000 pretraining epochs, 6,000 fine-tuning epochs, 0.3 corruption level with a learning rate of 0.01 [95]. In comparison to other classifiers such as RBF SVM, ADTree, RIPPER and NB, Sda-LR (Stacked Denoising AE with Logistic Regression) classifier generated the best results with precision rate of 94.9%, recall rate of 94.8% and F-measure 0.948. NB took the least training time of 13.26 sec than all others and Sda-LR consumed only 0.34 sec for testing. The drawback is that the classifier misclassifies some good JavaScript codes as malware. Another drawback is that JavaScript code is open source and it is not easy to identify benign code and malicious code when collecting samples for dataset. In that case, it is possible to misclassify some of the good codes. A robust verification method is required to identify both malicious and benign samples.
Dynamic malware detection
In this method, the features of software to be detected do not need to be extracted beforehand. In the detection process, the features are extracted, and we can detect malware through deep learning.
Hardy et al. applied Stacked Auto Encoders (SAE) for malware detection. On the same data set, the deep learning method has better performance than traditional machine learning methods such as ANN, SVM, NB, and DT [38]. The model works on windows Application Programming Interfaces (API) that are extracted from Portable Executable (PE) files using PE parser. The dataset for training and testing of the system consists of 50,000 samples collected from Comodo Cloud Security center [38]. 22,500 malware and 22,500 benign samples are used for training of the model and the remaining 5,000 unknown samples are used for testing. A total of 9649 APIs are extracted from such 50,000 collected samples. Different network configurations have been tested in terms of true positive rate (TPR) and false positive rate (FPR) to test the usefulness of deep learning based malware detection system. It is concluded that the DL model with 3 hidden layers and 100 neurons at each layer outperforms the other network configurations with 2,3,4 and 5 hidden layers and 50 and 100 neurons on each layer. It has achieved TP of 2,396 and FP of 114 with 95.64% of accuracy in testing dataset. The system has experimented with shallow learning methods such as ANN, SVM, NB, and DT where NB has achieved the lowest accuracy of 65.82% in testing data. The system shows a detection efficiency of 0.1 second for each unknown sample that shows its practical impact on real industry.
Deep learning is once again proven to perform well in android malware detection by DBN-based method in [102]. Authors have used static analysis to collect 120 permissions, dynamic analysis of apk file to generate 13 dynamic behavior. The DBN framework has 2 hidden layers with 150 neurons each. For training and testing of the framework, randomly selected 880 benign and 880 malicious apps are used and equal sets of 880 mixed samples are defined for both training and testing. They achieved an accuracy of 96.67%. The system has outperformed methods of C4.5, SVM, NB, and LR where LR has attained the lowest accuracy of 71.19% in testing data.
Similarly, Yuan et al. suggested a learning framework based on DBN [101]. The framework works on the permissions of android application, sensitive APIs and dynamic behavior. They used both static analysis and dynamic analysis. The static analysis is used to collect 120 permissions, 64 sensitive APIs, the dynamic analysis of apk file is used to generate 18 dynamic behaviors. For the same set of training (300 samples) and testing (200 samples) dataset, the framework has achieved the accuracy of 96.5%. Other methods, such as SVM, C4.5, NB, LR, and Multilayer Perceptron (MLP), have achieved the accuracy of 80%, 77.5%, 79%, 78% and 79.5%, respectively [101]. As the dataset contains public application set, it is shown from the significant difference of detection accuracy that the deep learning framework has better accuracy for malware detection.
Saxe et al. in [76] defined a DNN-based malware detection system using binary features of program. The framework is defined with three components. One is feature extraction, the second is deep learning-based classifier, and the third is score calibration model to distinguish a malware and benign file. The four features extracted in component one are Contextual Byte Features, PE import features, String 2d histogram Features, and PE metadata features. The deep learning model has one input layer with 1,024 input features, two hidden layers (each with 1,024 parametric rectified linear unit (PReLU), activation units), and one Sigmoid unit output layer.
Component three works on the threat score to identify whether the file is malware or not. According to [76], the Bayesian Rule is used to define the threat score as follows:
Kernel Density Estimator (KDE) is used to further derive the density probability function of threat score. The dataset contains 431,926 binaries which are labelled into malware and benign binaries. On evaluation, it achieved the accuracy of 95% at 0.1% FPR. The system is computationally efficient as it took about 40 minutes to train the full dataset of 431,926 binaries. The drawback of the system is that the size of binaries dataset was relatively small as compared to large enterprise networks, that limited the feature space sampling.
Combining RNN and CNN, Tobiyama et al. proposed a method of malware detection in which RNN was implemented for feature extraction and CNN for classification. They first record the process behavior as an API call sequence and construct the feature extractor based on language model with Long Short-Term Memory (LSTM). Then, RNN is trained to extract features as feature vectors which are converted to feature images. Such feature images that contain various local parameters representing process activities, are used to train CNN and classified as malware and benign processes. A total of 81 malware process log files and 69 benign process log files are used for training and validation phase [87]. Each log file consists of logged information of API call sequence consisting with PID, Time, Process, Event, Process, Name, Path, Result, Details parameters. Cuckoo sandbox is used to identify generated and infected process behavior. From April 2014 to October 2014, 26 malware files were collected from NTT Secure Platform Laboratory to obtain the malware process log files dataset which were further categorized into 11 malware families by Symantec [87]. In malware log files, 46 samples are processes of determined malware, 33 samples are produced by such determined malware files and 2 samples are malware injected. A total of 44 malware log processes and 39 benign logs are used for RNN training and 150 feature images are generated as an output. The training and evaluation of CNN is performed using 150 feature images. The framework obtained an overall accuracy of 96%.
A malware detection framework is described based on convolutional neural network (CNN) [59]. Authors used raw opcode sequence from each method of disassembled apk. The CNN-based framework is used to distinguish patterns that are indicative of malware in the disassembled byte-code of android applications. The application has been validated on four different datasets of android malware. Each dataset has android applications of benign and malware labeled. Small dataset from Android malware Gnome project contains 863 benign applications and 1260 malware from 49 malware families. The large Dataset from McAfee Labs contains 2475 malware samples and 3627 benign applications. No malware families are labeled in it and may have similarities with the small dataset. V.Large dataset from McAfee Labs consists of 9,268 benign files and 9,902 malware files. Each dataset is trained and tested separately by splitting each into 90% for training and validation and 10% for testing. Malware classification results for these datasets are measured and compared against other deep learning based malware detection methods from literature.
The fourth dataset is the Realistic testing dataset that contains 96,412 benign apps, 24,103 malware apps collected during July-August 2016 from Google play store. The V.Large dataset is used for training the model. It receives an accuracy of 0.69 with a recall of 0.74 and 0.71 F-score [59]. It is required to use a larger training dataset to obtain more accurate classification. The accuracy for Small dataset is 0.98 whereas for Large dataset and V.Large, it is 0.80 and 0.87 because the testing dataset used for Small dataset is larger than the one used for training in comparison to the other two datasets. Hence, using a much larger dataset of testing than the dataset of training shows that the model can generalize realistic data based on the limited learned features. The advantage of this method is that the network can be applied to perform another type of malware analysis as well by making a minor change to its architecture. Its implementation can be moved from desktop GPU to mobile device GPU to detect android app malware beforehand.
Image-based malware detection
In this method, software is directly converted into images and convolutional neural network is used to detect malware from the images.
In the previous methods, the first step is feature extraction. This limits real-time malware detection. And, some new malware may modify these features pertinently, which makes the system unable to detect it. In order to avoid feature extraction, and to improve the real-time performance of malware detection, in [91,96] Vinayakumar et al. proposed a method of malware detection that was based on image processing technology. Using digital signal and image processing technology, the binary data of malware is converted into gray image, and then the malware can be detected and classified by convolutional neural network and LSTM. The main advantage of the method is that it can handle packed malware and detect all kinds of malware, regardless of the operating system. In the process, CNN consists of convolution one-dimensional layer, pool one-dimensional layer and fully connected layer. CNN can have more than one convolution one-dimensional layers, pool one-dimensional layers and fully connected layer. This method is insensitive to packing and operating systems. In addition, it takes less time than static and dynamic analysis due to that it does not require disassembly or execution in a virtual environment. The experimental results show that for data set 1 (containing 9,339 malware samples from 25 malware families), the accuracy reaches 96.3%, and for data set 2 (crawled from VirusSign and VirusShare), the detection and classification accuracy reaches 98.8%, which is higher than other malware detection methods.
In order to protect cyber devices from denial of service attacks by botnets, a lightweight method is proposed in [84] to detect the malware of denial of service attacks. Firstly, the binary data of software is converted into a scalable gray image, and then the gray image data is input into the convolutional neural network for detection. In this way, the resource-limited devices of the Internet of Things can run the recommended detection system. The experimental results show that for normal software and denial of service attack software, the accuracy of the recommended system can achieve 94%. The system can be deployed in real IoT devices.
Malicious PDF documents have embed binary or JavaScript code that triggers specific vulnerabilities and performs malicious actions. In [46] Jeya et al. proposed a new convolutional neural network that is designed to take an unexecutable sequence of bytes as input and to predict whether a given sequence has malicious behavior. Experimental results show that the proposed network is superior to several representative machine learning models and other convolutional neural networks with different settings in PDF file detection.
As can be seen from Table 1, numerous deep learning methods are applied to malware detection. Such as DBN, AE, SAE, SDAE, DNN, RNN, CNN, LSTM, etc, in terms of the detected content, there are Windows malware, Android malicious apps and other malware. From the comparison of the detection results, deep learning methods are superior to traditional machine learning methods.
For traditional machine learning, the major issues of malware detection are feature extraction, feature learning, and feature representation that need extensive domain knowledge. Moreover, once the attacker knows the key features, the malware can evade being detected easily [91]. By using deep learning, we can avoid the phase of feature engineering. During the training process, deep learning can catch higher level representation of features by deep hidden layers with the ability to learn from mistakes. When facing increasing data, new patterns can be captured by deep learning and associations can be established with the already captured pattern to enhance the performance of tasks.
Many of the early works on deep learning for cyber security are focused on Intrusion Detection Systems (IDS). Signature-based and anomaly-based IDSs are popular but attackers can bypass such a system if intrusion signature is new or the activity of intrusion lies within the normal usage pattern, that defines normal system activities. The basic problem of intrusion detection system for machine learning is the lack of labeled traffic dataset. Deep learning methods are used to overcome such problems as they are resilient to change and can correctly handle unlabeled data.
The testing dataset based on network traffic is an important factor in judging the quality of the detection method. To this end, ACM provides the most influential datasets of intrusion detection, which are KDDCUP’99 and NSL-KDD. Although many years have passed, the datasets are still the benchmark data for intrusion detection. In recent years, the two datasets are still used on deep learning based intrusion detection as main test data. Various testing methods and their characteristics are shown in Table 2:
Deep learning-based intrusion detection on KDDCUP’99
KDDCUP’99 dataset contains one normal type of labeled data and 22 types of attack data. In addition, 14 types of attack data only appear in the test dataset.
Gao et al. suggested a DBN based intrusion detection model, a combination of supervised (based on Back Propagation (BP)) and unsupervised learning network (based on RBM) [30]. The network has been experimented on KDD’99 dataset. The features of dataset are mapped to 121 numerical attributes based on method of encoding mapping, which are further normalized by min-max normalization. The DBN framework is pre-trained through RBM and fine-tuned through BP. The dataset has 494,021 records for training and 11,850 records for testing. To verify the model performance, RBM with different number of layers has been experimented and compared against the SVM and Neural Network (NN) model. For the same training and testing dataset, SVM and NN achieved classification accuracy of 86.82% and 82.30% whereas DBN with three RBM hidden layers achieved 90.07% and DBN with four hidden RBM layers achieved 93.49%. The use of pre-training and fine-tuning significantly improves the performance of IDS over traditional methods such as SVM and NN.
Alrawashdeh et al. provided a better method based on DBN and RBM [5]. If the number of training samples increases, it can achieve promising results in the analysis of network traffic. Multicore CPUs can make the training process faster than serial training process. But the GPUs can not achieve the expected performance due to the type of data used in dataset. A multiclass regression classifier based on DBN is designed to detect the new attacks with anomaly intrusion detection system. The result shows that the method can achieve accuracy of 89.25% for classifying R2L [5]. The system is experimented on DARPA KDDCUP’99 dataset and has achieved overall accuracy of 97.904% in anomaly detection with a low false negative rate of 2.47%.
Deep learning-based intrusion detection on NSL-KDD
Using techniques of sparse autoencoders (SAE) and soft-max regression(SMR), Javaid et al. proposed an approach for network intrusion detection system (NIDS) that works on self- taught learning (STL) [45]. NSL-KDD dataset is used to experiment the framework. The individual record in dataset contains 41 features including basic features obtained from a TCP/IP connection, traffic features collected in a windows interval, and content features extracted from the application layer data of connections [45]. The features are labeled as classes of normal, DoS attack, U2R attack, R2L attack, and probe attack. The feature learning is completed through sparse autoencoders which are completely unsupervised and novel. The performance of STL is evaluated through 2-class data(one normal and one attack class) and 5-class data(one normal and 4 attack classes). For 2-class data, STL achieved the accuracy of 88.39% whereas for 5-class data the accuracy rate is 79.10%. In comparison, SMR achieved better precision rate for both 2-class and 5-class data but STL attained a significantly higher recall rate and f-measure for the datasets.
DNN has been used to enhance the intrusion detection system’s capability to detect different types of attacks in network traffic [69]. The main idea of this method is to evaluate DNN training with multi-core CPU’s as well as GPU’s. To evaluate the effectiveness of the detection system based on DNN, NSL-KDD dataset is used. 125,973 records are used for training and 22,543 records for testing. Both tasks, feature learning and classification, are performed with DNN. Authors also evaluated the performance of DNN through data of 2-class, 3-class, 4-class, and 5-class as [45]. The detection accuracy for 2-class data is 97.5% which is much higher than [45]. For DoS attack, it attains accuracy of 96.5% for both 3-class data and 4-class data whereas for 5-class data it is 97.7%. For U2R and R2L, the accuracy is only 39.6% and 18%, which has failed the system as these are the popular attacks on network traffic [67]. For probe attack, the detection accuracy is 85.5% and 89.8% for 4-class data and 5-class data.
A hybrid network intrusion detection system has been discussed based on DBN and Support Vector Machine (SVM) [75]. In the system, NSL-KDD dataset has been used for training and testing. The dataset consists of 41 features for normal and attack classes. In the dataset, 22 different types of attacks are used for training and 39 different types of attacks are used for testing. Deep belief network consists of two RBM, lower and higher, which is used for feature reduction. The size of the dataset is reduced to 13% through reducing 41 features into 5 features. Using Lower RBM 41 features are first scaled to 13 features, then as an input 13 features are passed to higher RBM, through which 13 features are reduced to 5 features only. SVM is trained based on reduced features and tested through different portions of dataset. They calculated time spent and classification accuracy. When 20% of training dataset is used, it took 2.54 sec to train the hybrid IDS and the accuracy is 90.06%. As the size of training dataset increases, the accuracy increases and the performance is improved in terms of time complexity. For 30% of training dataset, detection accuracy is 91.50% with 2.54 sec spent whereas for 40% of training dataset, unit time spent is reduced and it took 3.07 sec to train the system, but achieved a better detection accuracy of 92.84%. The same dataset is also used to experiment with DBN and SVM separately. The time performance of DBN is much better than that of SVM and hybrid method (DBN-SVM). It attained a maximum 0.31 sec for 20% of training set and minimum 0.24 sec for 40% of training set whereas for SVM, the time performance lies between 10.4 sec to 16.67 sec. Overall, DBN-SVM scored the maximum classification accuracy with 92.84% whereas for DBN and SVM, it was 89.63% and 88.33%.
Another hybrid intrusion detection model has been discussed in [10]. The experiment is conducted on combination of two density estimation methods i.e. Centroid and Kernel Density Estimation (KDE) with autoencoder (AE). Data samples are collected from Wisconsin Breast Cancer Database (WBC), Wisconsin Diagnostic Breast Cancer (WDBC), Cleveland heart disease (C-heart), Australian Credit Approval (ACA), and NSL-KDD [10]. The dataset is first used to train on AE and then compressed and used to build a density model and set threshold for density model. In the testing phase, the compressed data is categorized on value of density threshold as normal and anomalous. The framework training has performed on normal data only whereas testing dataset contains both normal and anomalous data. The classifier building is based on normal dataset only. The experiment is divided into two parts: 1) Hybrid of AE and KDE density estimation model (OCKDE) 2) Hybrid of AE and Centroid density estimation model (OCCEN). The learning rate is set to 0.01 and a fixed 5,000 epochs are used to train AE. The results are divided into DoS, R2L, U2R and Probe attack class for both combinations of AE with a reconstruction error (RE) of 0.459. For OCKDE, it attains accuracy of 0.974 for DoS, 0.891 for R2L, 0.945 for U2R, 0.987 for Probe whereas for OCCEN it is 0.956, 0.839, 0.888, 0.986 respectively. Overall, OCKDE shows better classification accuracy in comparison to OCCEN. Another classier based on AE itself (OCAE) has also experimented for cross verification of the proposed method. It attains accuracy of 0.960, 0.909, 0.928, 0.971 in DoS, R2L, U2R and Probe attack classes respectively. It is clear from the outcomes that OCKDE outperforms both classifier OCCEN and OCAE except for R2L attack class where OCAE generates better results. The model can be easily adjusted according to the variation of normal and anomalous data presented in the dataset.
Deep learning-based anomaly detection on other data sets
The facts gathered in real time are characteristics of the ISCX dataset [4]. On this dataset, authors evaluate the suitability of a RBM as a deep learning model for anomaly network intrusion detection. The best accuracy that can be achieved is 79.8 ± 1.2% and this happens at 3500 iterations.
A semi-supervised anomaly detection method has been discussed for network traffic based on restricted Boltzmann machine [28]. The method is trained on normal dataset only and anything that does look normal is considered anomalous. They have performed two experiments. The first experiment was trained and tested on real-world data and the second experiment was trained on KDD’99 dataset and tested on real-world data.
For experiment 1, two real-world workstations have been selected, one of which was infected with bot and another host flowed normal traffic. They collected 12,056 connections in clean dataset and 12,317 connections in second dataset with 4182 infected connections. For experiment 2, the RBM was trained on 10% of the training data i.e. 49,4021 connections, of the KDD’99 dataset. A total of 28 features were selected to use.
Both experiments took 186.4h over 15 epochs with a learning rate of 0.1. The accuracy attained by experiment 1 is in-between 93%–94% whereas for experiment 2, it is in-between 84%–85%. The results from recorded dataset for training and testing can vary when implemented on real-world system. As in real-world scenarios, the network parameters, considered for training, may vary according to an organization, region or culture. The policies implemented on network traffic by organizations also put an impact on the results.
For detecting video forgery and single-image splicing, two applications of deep learning have been explained [18,21]. In [21], AE is used for feature extraction and learning, and RNN is used for anomaly/forgery detection in video. Whereas in [18], AE is used for identifying in an image where splicing is done.
By combining methods of network-based intrusion detection system (NIDS) and host-based intrusion detection system (HIDS), Vinayakumar et al. proposed a method of DNN to detect cyberattacks proactively [90]. They evaluate the efficacy of various classical machine learning algorithms and DNN on various NIDS datasets (KDDCup’99, NSL-KDD, UNSW-NB15, Kyoto, WSN-DS, CICIDS2017) and HIDS datasets (Linux (ADFA-LD)/ADFA, Windows (ADFAWD)) to identify whether network traffic behavior is either normal or abnormal when facing an attack that we can classify into corresponding attack categories.
Hybrid intrusion detection algorithm combining deep learning, machine learning, and Intelligent agents defending
Both deep learning and machine learning algorithms have their own advantages. How to combine the advantages of different algorithms to further improve the accuracy of intrusion detection? Some scholars have explored it.
A hybrid algorithm of deep learning and machine learning is proposed by Ployphan [83] for multiple cyber intrusion detection, which include C4.5, k-NN, MLP, SVM, and LDA. UNB-CICT or network traffic dataset, Phishing website dataset, UNSW-NB15 data set, NSL-KDD dataset, and KDD Cup’99 dataset are used for evaluating the performance. The results show that higher efficiency can be produced by the proposed method.
Since random forest has excellent performance on structured data while convolutional neural network is suitable to process unstructured data, in [60] authors combined the advantages of both for intrusion detection. Extensive experiments show that their method has superior performance.
IoT intelligent agent defense is a possibility for future development. Rory Coulter et al. [17] gave a review of intelligent agents defending for an IoT perspective. They propose that we should widen our perspective on security, artificial intelligence and the IoT to achieve autonomous defense. But there are still many problems that need to be solved.
As can be seen from the above, in deep learning-based intrusion detection, the methods used are DBN, RBM, AE, RNN, DNN, MLP, CNN, and DRBM. In addition, in intrusion detection, the KDDCUP’99 and NSL-KDD data sets are mainly used. This is because the acquisition of a large number of data samples for intrusion detection is difficult, both economically and in terms of time. In Table 2, the literature does not give a performance comparison between different deep learning methods, nor does it give a comparison between deep learning methods and traditional machine learning methods, because even if the same data set is used, if the training and test subsets are different, the results are meaningless.
Comparison of deep learning-based intrusion detection
Comparison of deep learning-based intrusion detection
Although some machine learning methods can achieve high detection accuracy, these methods may only be used to detect a certain type of data, such as DDoS attacks [43,61]. The deep learning method has obvious advantages in the general detection methods for various types of data. This is mainly due to the high-dimensional data processing capability of the deep learning method. Of course, if the advantages of several methods are combined [51], the overall detection accuracy can be improved.
Deep learning-based phishing detection
Phishing is a very widespread method of attacks that leads to privacy leaks, identity theft, and property damage. The spread of phishing is no longer limited to traditional methods such as email, text messaging, malicious URL, and pop-ups. Many embarrassing phishing attacks are hosted on websites with HTTPS and SSL certificates, as many users believe that HTTPS sites may be legitimate [98].
Based on Deep Belief Network (DBN), Yi et al. focused on the deep learning framework to detect phishing websites [100]. Tests on ISP (Internet Service Provider) real IP traffic show that the DBN-based detection model can achieve a true positive rate (TPR) of 90% and a false positive rate (FPR) of 0.6%.
For rapid detection of phishing websites, Yang et al. proposed a method including CNN-LSTM and multi-dimensional features [98]. First, character sequence features of given URL are extracted and used for rapid classification through deep learning. Then, they combined the URL statistics features, the webpage code features, the webpage text features, and the fast classification result of deep learning into multidimensional features. The method can be used to shorten the detection time of the threshold setting. Testing on a data set that contains millions of phishing URLs and normal URLs, the TPR is 98.99%, and the FPR is only 0.59%.
The method of detecting and classifying malicious URLs proposed in [77] uses stacked RBM for feature selection and DNN for binary classification. They tested 27,700 url samples, and the results show that DBN-DNN can learn a better generation model and can better complete the identification task of malicious urls, and the detection is reliable.
Vinayakumar et al. evaluated various deep learning architectures such as LSTM, RNN, CNN, etc [92]. By modeling the character-level language of the benign and malicious URL, through various experiments on different parameters and network structures, the optimal parameters of the deep learning architecture are found. All experiments lasted up to 1000 iterations and the learning speed was in the range of 0.01–0.5. In the experiment, the deep learning mechanism is superior to the handcrafted feature mechanism [85]. Specifically, the mixed network of LSTM and CNN and the network of LSTM has reached the highest accuracy. The accuracy is 0.9995 and 0.999 respectively. This may be due to that the deep learning mechanism has the ability to learn hierarchical features and long-range dependencies in various sequences.
In order to discover effective detection technology to prevent the threat of phishing emails, Fang et al. first analyzed the structure of e-mail. Then, based on the improved RCNN model, they proposed a new model named THEMIS for phishing email detection [26]. They use THEMIS to model emails at the email headers, email body, character levels, and word levels simultaneously. To evaluate the validity, they use an unbalanced dataset with real-rate phishing and legal emails. The overall accuracy of the system reaches 99.848%. The FPR is 0.043%. High precision and low FPR ensure that the filter recognizes high probability phishing emails and filters legitimate emails as little as possible. The result is better than the existing detection methods and verifies the effectiveness of THEMIS in phishing email detection.
Deep learning-based privacy leak detection on android app
Users download applications from the app marketplace, such as Apple’s AppStore and GooglePlay Store, and grant permissions on their phones to install them. Some of the permissions granted (such as accessing photo gallery and contact list) are related to user privacy. They allow applications to access sensitive information, leading to potential information leakage and privacy leaks.
For evaluating the consistency of mobile app descriptions and permissions, Feng et al. proposed a neural network framework AC-NET that uses technology of natural language processing (NLP) and deep learning [27]. AC-NET takes the descriptions of applications as input and outputs consistency of descriptions and permissions. In order to better understand the semantic representation of the application descriptions, they proposed a new learning model TextGRU. In the implementation process, they do not directly adopt the deep learning model, but combine the multi-layer features. Through learning, the model predicts the permissions corresponding to the description sentences.
About 69,713 Android apps were collected from Google Play, a snapshot of a popular app that claims to have at least one permission. They chose some APP permissions for research. The 16 permissions involved in their work, these permissions can be divided into three official protection levels by Google, dangerous permissions, normal permissions, and signature permissions. They evaluate their AC-NET real-world application descriptions, covering 16 typical permissions. Evaluating the consistency between descriptions and permissions of mobile applications, they do not output simple answers but focus on the degree of consistency. The experimental results show that AC-NET has better performance, the average accuracy of ROC-AUC is 97.4%, and the average PR-AUC is 66.9%.
Deep learning-based attacks detection or privacy reasoning on embedded sensing devices
Sensory data from smart devices is an important resource for nourishing mobile services, and they are considered to be harmless information that can be obtained without user consent. In [54], they showed that these seemingly innocuous messages can lead to serious privacy issues. First, they demonstrated that the location of a user’s sensory data based on the location of the smart device can be identified by some deep learning techniques. Second, they can collect clickstream profiles for each application to accurately infer the user’s application habits.
In experiments, they collected sensory data and usage information of mobile apps from 102 volunteers. The results show that with the framework of CNN, the accuracy of inference for TAP location can reach more than 90%. Furthermore, based on the inferred information of TAP location, the user’s application habits and passwords can be accurately inferred. In the security, we should consider how to avoid privacy leakage in this case.
Real-time positioning systems have also become the target of attackers [34]. In order to detect these attacks, authors used a variety of methods for testing and verification. As a result, the MultiLayer Perceptron classifier obtained the highest test score and the lowest verification error.
The new automotive systems, integrated with Electronics control unit (ECU), have hundreds of millions of lines of source code. ECU works as the heart of automotive system and if any problem/attack occurs on it, it will lead to all sorts of problems possible with the system. ECUs are very sensitive to remote attacks and can cause bigger problems. To enhance in-vehicle security and detect the attack packets effectively, a DNN based intrusion detection system is proposed in [49]. The framework uses Deep Belief Network (DBN) for feature extraction, unsupervised pre-training and uses DNN for classification of normal and compromised CAN (Controller Area Network) packets. 70% of the dataset is used for training and 30% for the testing of experiments. The system obtained an accuracy of 97.8% with 1.6% false positive errors and 2.8% of false negative errors.
Attacks that manipulate phasor data may lead the control centers to take wrong actions which may cause bad consequences for reliable power supply. Wang et al. proposed a deep autoencoder to solve the problem in [94].
Comparison of deep learning and traditional machine learning
Comparison of deep learning and traditional machine learning
From the above analysis, it can be seen that deep learning methods have a wider application in the privacy leakage and attack detection of devices. The methods used are CNN, DBN, LSTM, RNN, RCNN, DNN, MLP, etc. The devices involved are also very extensive, including mobile phones, mobile robots, automotive systems, and power sensing devices. Due to the complexity of these application environments, there are better application scenarios and application effects for deep learning. At the same time, there are still many application scenarios to develop, such as USB side-channel attack on Tor [99].
Finally, we compare methods of traditional machine learning with that of deep learning, as shown in Table 3. It can be seen that traditional machine learning is simple and easy to use, and the required data labeled is small, but in the case of multi-featured, high-dimensional data, the detection accuracy is general. Deep learning is complicated, and it requires a large amount of labeled data, but it can process high-dimensional data with multiple features, and the detection accuracy is high.
In terms of handling cyber security, the deep learning approach embodies greater advantages, but still faces many challenges, mainly in the following aspects:
Lightweight development, which makes it easy to deploy to IoT devices [63], and could resolve problems that some malware steals data directly from IoT devices [70]. With the development of 5G technology, intrusion detection of IoT devices based on cloud deployment is also possible. For some micro-intrusion attacks, the huge security system is difficult to detect and respond in a short period of time. At this point, some relatively lightweight security mechanisms are required to achieve a fast response to intrusions and avoid loss expansion [84]. At the same time, the lightweight protection technology can better be compatible with the protocol conflicts of different IoT product manufacturers [20].
Universality, detection does not depend on specific software features, even if malware modifies features, it can not escape from detection. Authors in [50] provided a method to quantify the resilience of various different machine learning classifiers, for attackers may manipulate malware’s features to avoid detection, but now there has not been such quantification for various deep learning classifiers. In [47] the features of attack dataset’s are reduced. Then with the reduced feature set, their approach achieves good classification rate for R2L and U2R attacks.
Screening of suitable software models and parameters, there are many deep learning models to choose from, such as DNN, CNN, RNN, DBN, etc. For each model, there are many parameters to choose from, such as the learning rate of deep learning, the number of hidden layers, the number of hidden cells per layer, the connection type of each layer, the activation function and other parameters [91], the selection of models and parameters requires a large number of experiments for analysis and comparison [90].
Generative adversarial networks, we can use deep learning methods to improve detection of security issues such as malware, cyber attacks, and privacy breaches. But the emergence of adversarial networks has led to two changes in deep learning [68,78]. If malware or cyber attackers use deep learning to train malware or attack methods, it will make malware or cyber attacks more and more difficult to detect. We can see from [19] that cyberattacks started themselves to employ artificial intelligence to automate labour-intensive tasks like social media and other public information analysis to prioritize targets, to evade current techniques [37], to generate domains or to perform human-like operations.
Lack of labeled data, to achieve good results, deep learning methods require a large amount of labeled data for training or learning. More data is also needed to achieve more accuracy and prevent the overfitting of the models [63]. However, it is not easy to find and mark these data, which is another challenge to solve in cyber security [61].
We can see the challenges similar to this paper in other survey papers, such as the surveys published on IEEE network communications tutorials and surveys. Including the following: The need to acquire large amounts of data to train and classify models, lightweight development and deployment.
The difference with this paper is: other survey papers also believe that due to the complexity of computing, real-time applications of deep learning face challenges. High performance hardware is needed to handle large computing problems [61]. The problem of slow learning speed affects the application of multi-agent learning. Other challenges include storage and management of big volume, high velocity and variety data, knowledge extraction and management of intelligent decision making [16,55].
In view of the above analysis, we think that further research work should be carried out, such as model selection analysis based on deep learning, research of generative adversarial networks based on cyber security, and hybrid security detection of deep learning and traditional machine learning. In order to solve these problems better, we can start from both theoretical and experimental aspects. For deep learning-based model selection, when faced with a security issue, we can choose a variety of deep learning models, such as CNN, DBN, DNN, etc, but which model is better, how many layers can be selected to achieve better results, how the relationship is between the number of layer nodes and the accuracy that requires theoretical and experimental exploration.
Deep learning has many advantages in cyber security, but it is not in all respects better than other methods such as traditional machine learning. In terms of big data or high-dimensional data analysis in the field of cyber security, deep learning has obvious advantages. However, there are some threats with little data and low-dimensional features in the field of cyber security. For these problems, traditional machine learning methods are more convenient, accurate and fast [63].
Conclusions
Deep learning has better results and more possible solutions when it is used to deal with cyber security issues. This is done by absorbing knowledge about the human brain, statistics, and applied mathematics. In the previous analysis, we reviewed the comparison between methods of deep learning and that of traditional machine learning in malware detection. The results show that the methods of deep learning have better accuracy. Deep learning also has different solutions for intrusion detection and privacy leakage. At the same time, in cyber security there are also facing new problems, such as marking a large amount of sample data for deep learning, how to balance the training time and recognition accuracy of deep learning, model selection and parameter selection. In this regard, many more research results would be expected in the future.
Compliance with ethical standards
This study was funded by the China Scholarship Council No. 201808420377.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Conflict of interest
Guangjun Li has received research grants from the China Scholarship Council. Preetpal Sharma declares that she has no conflict of interest. Lei Pan declares that he has no conflict of interest. Sutharshan Rajasegara declares that he has no conflict of interest. Chandan Karmakar declares that he has no conflict of interest. Nicholas Patterson declares that he has no conflict of interest.