
Abstract
Multimedia communication as well as other related innovations are gaining tremendous growth in the modern technological era. Even though digital content has traditionally proved to be a piece of legitimate evidence. But the latest technologies have lessened this trust, as a variety of video editing tools have been developed to modify the original video. Therefore, in order to resolve this problem, a new technique has been proposed for the detection of duplicate video sequences. The present paper utilizes gray values to extract Hu moment features in the current frame. These features are further used for classification of video as authentic or forged. Afterwards there was also need to validate the proposed technique using training and test dataset. But the scarcity of training and test datasets, however, is indeed one of the key problems to validate the effectiveness of video tampering detection techniques. In this perspective, the Video Forensics Library for Frame Duplication (VLFD) dataset has been introduced for frame duplication detection purposes. The proposed dataset is made of 210 native videos, in Ultra-HD and Full-HD resolution, captured with different cameras. Every video is 6 to 15 seconds in length and runs at 30 frames per second. All the recordings have been acquired in three different scenarios (indoor, outdoor, nature) and in landscape mode(s). VLFD includes both authentic and manipulated video files. This dataset has been created as an initial repository for manipulated video and enhanced with new features and new techniques in future.
Introduction
Digital multimedia technology has transformed the way of human beings, exist on this planet over the last two decades. Multimedia forensics has proved to be a significant and perhaps most likely prevalent field of research throughout this technological era. Digital Multimedia usually includes images and videos which are primarily used for communication and entertainment purposes. It has also performed a crucial role in the field of military, surveillance and judiciary. But somehow, it dominate a lot of our everyday lives and are also evolve tremendously. As the high tech and low-cost smartphone camera technology has been developed and it allows anyone to record multimedia content easily. Even with the advent of advanced yet readily available tools for video editing technologies (such as Adobe Photoshop, Apple Finalcut etc.), digital photos and videos are being modified more and more rapidly. Such alterations are made, knowingly or unknowingly by individuals to alter the truth for his amusement or to perform the illegal activity [53]. Alterations in videos happen in such a way that the forger may duplicate or shuffle the video sequence, erase object from a video sequence, impose object from another video sequence, and may form artifact by any of the available computer graphics software. Due to these issues, the authenticity of digital multimedia has been destroyed [47]. With the naked eye, visual detection of criminals is extremely difficult to find. Several other domains are affected by video forgery including video falsification for the videos of surveillance camera used in public places to defame the celebrities or disguise current trends. It is also very challenging in simulating the sources and content of digital visual information. Therefore, it further increases the need for the development of digital video forgery detection techniques.
Measures of video forensics
Video forgery detection mainly depends on two measures: active approaches and passive approaches [3,34]. Digital signatures [21,52] and watermarking [30,40] have made great strides as effective digital video forgery identification techniques. But pre-extracted or pre-embedded data is necessary for an active approach during the acquisition phase [13,43]. Many cameras, however, have no such feature, so the passive approaches are most commonly used in the latest research trend. Passive approaches do not require any historical information about the video. Interframe and intraframe video forgery are such techniques to manipulate videos. Interframe modification occurs at the sequence level where the pixels of the individual frame are retained, but the original frame sequence is altered [16]. Such manipulation generally involves removing frames from a video sequence, adding frames to a video sequence, duplicating the frames, and shuffling the video frame sequence [42]. Intra-frame alteration occurs at pixel level where the pixels of individual frames are manipulated. The prevalent intraframe forgery techniques are copy move, splicing and retouching [39]. The frame regions are copied and pasted somewhere else in the same frame in copy-move video forgery, to hide or add additional information in the original video, whereas two or more frame regions are used in splicing to create a forged frame [26]. Retouching is a soft destructive forgery technique in which an image/frame does not change fundamentally, but some of the original image features are enhanced [10,33].
The research paper presents a video forgery detection technique based on the Hu moments and also contains significant contributions as:
A technique for detecting frame duplication forgery in videos.
A new dataset for testing the tools and techniques proposed to detect the frame duplication forgery in videos.
The ultimate goal of present paper is to recognize the challenges of past research in this field. More precisely, it focuses on the ongoing problem of integrity and authenticity of the video content. The paper is organized in six sections and is as follows: Section 1 presents a concise description of digital image and digital video forensics, also describes the techniques used for detecting forgery in images or videos, as well as the necessity of dataset for assessment. Section 2 delivers a review of existing relevant papers on video forgery from 2005 to 2020, as well as a brief analysis of their identification techniques. The paper specifically discusses the significance and unresolved issues in the existing work of the various frame duplication video forgery detection techniques. Section 3 demonstrates the nature of the dilemma in the proposed technique and reveals the significance for the same. It begins with the basic principle of the algorithm key topics. Comprehensive description for each step in the proposed algorithm is also provided in this section. Then the experimental findings obtained using the proposed technique are presented in Section 4. Ground truth about the dataset contributions is discussed in Section 5. Ultimately, Section 6 summarizes the overall work and provides recommendations for further studies in the area of video forgery detection.
Related works
Inter-frame forgery detection
The detection of interframe forgeries covers four types of manipulation [42,46]: Frame Insertion, Frame Deletion, Frame Duplication, Frame Shuffling. In order to expose digital video forgery, [46] used motion-compensated edge artifacts (MCEA). It requires a hard threshold factor and degradation of performance in slow motion videos. The limitations severely limit its realistic adaptability. Authors [11,24,32,45] introduced the techniques for the identification of frame deletion forgery but not all of them work properly if the frames deleted becomes an integral multiple of Group of Pictures (GOP). In addition, a proposed scheme of [23] also a coarse-to-fine technique that consists of candidate clip selection, estimation of spatial similarity, and identification of frame replication. The histogram difference of two adjacent frames in the RGB color space has been used as a function to classify duplicate candidates for the temporal domain and to measure the spatial correlation using a block-based algorithm. This strategy did not work well if copied frames shuffled before they pasted into another region. The given technique also requires more computational time and unacceptable for the videos with post processing operations. To detect frame duplication forgery in videos an author [22] introduce a passive-blind scheme, but the approach failed to perform localization. In [54] the authors introduced a method based on the consistency of the velocity field designed to detect the interframe falsification in digital video. The proposed technique only work on videos obtained through static surveillance. Another technique in [41] has adopted sub blocks based features to recognize the frame replication forgery. Compression often degrades the system performance as the strategy works with correlation. The author in [56] presented a technique for frame duplication detection which divides the video into subsequent overlapping frames, and then applied singular value decomposition (SVD) for every frame of the video. This approach limit the identification of duplicated frames when there present only fewer duplicated frames than the size of the window considered. Zernike moment correlation has been used in [25] to calculate Zernike opponent chromaticity moments (ZOCM) from the chromaticity space. The technique was adequate for static or slow-motion camera mode but did not work in dynamic background videos. For the residue dataset contribution during the decoding process, spatial energy (SE), temporal energy (TE) and SNR are determined. Interframe forgeries, e.g. replication, insertion and removal forgery associated with [12] also dependent on these kinds of procedures. It moreover failed to capture both irregularities and identification if any frame removed from a static scene. In [6], the author suggested a two-stage forensic technique for the detection of video interframe forgery. Initially, outlier frames become identified by using the Haralick coded frame correlation and then analyses carried out to eradicate false positives, thus increasing the effectiveness of forgery detection. But this technique failed to identify frame reshuffling and replacement tampering.
Intraframe forgery detection
A technique has been designed to detect tampering in interlaced and de-interlaced videos in [49]. Spatial and temporal correlation introduced by deinterlacing algorithm demolished due to the manipulation in videos. This disrupted the motion of surrounding frames. The authors also suggested a technique for detecting region duplication in [50] using correlation that failed when replication has performed instantaneously with time. Block-level correlation values of noise residuals become retrieved in [14] and their distribution modelled as a Gaussian mixture model (GMM) in the forged and normal video. The expectation maximization (EM) algorithm was then used to estimate the parameters of GMM model. Based on the estimated parameters, Bayesian classifier employed to find the optimal threshold value. This method was not good enough for moving camera or dynamic background videos. In [18], the magnitude and orientation of the motion vectors were computed from adjacent frames and used to differentiate the authentic region and the forged region. The distribution of MVs often uniform for normal movement compared to the tampered region. So, the variance of the angle of the MVs in the tampered regions bigger than those in the normal moving regions. In [20], an approach detect tampering by using inpainting methods, such as temporal copy-and-paste (TCP) and exemplar-based texture synthesis (ETS). These inpainting methods fill the holes left by removed objects. Frame motion information calculated from the grayscale convert video for frame grouping and an alignment to handle the camera motion so that it has been neglected in the subsequent analysis and detection steps. Spatio-temporal coherence analysis performed over each frame group independently. This produced a group coherence abnormality pattern (GCAP) which now used to identify regions having unnaturally high or abnormally low coherence. Each spatio-temporal slice has been compared to its GCAP to determine if it is tampered with or not. A method to detect region tampered frames (add/remove objects) using features extraction from motion residuals of each frame has been proposed by [7]. In order to create the system robust to variable GOP structure videos, collusion operators have been used for generating motion residues. A sequence of frames centered at k taken, to compute the motion residue of the kth frame. A method to detect copy-move forgery using Zernike moments and 3D patch match has also been discussed by [9]. The authors extended the 2D patch match for images used in [8] to account the temporal information. Though the method achieved very low accuracy, it is rotation and scale invariant. The authors [5] developed a hybrid mechanism in which authors compared the triangles and then determine the interesting points in the figures to detect copy-move forgery. The block matching approaches worked efficiently for pure translation but incredibly slow in geometric transformation, so they did not work well. In order to identify upscale crop and splicing tampering, [37] introduced a technique called resampling in digital videos. For pixel-covariance correlation analysis the modified Gallagher Detector (MG) and the fractional modified Gallagher Detector (F-MG) has been used. The technique also used in the regions of interest (ROIs) of video frames for the identification of splicing (region-level) tampering. This method presented the major challenge in estimating parameters used for analytical considerations like scaling factors and interpolation filter for identification. To explore the area of splicing(region level) detection [38] used sensor pattern noise (SPN), Hausdorff distance-based clustering and color filter array (CFA) for copy-paste forgery detection and localization. The authors explored the technique to detect and locate copy-paste falsifications when the specific area of a video frame modified. The methods for copy-paste forgery detection and localization includes sensor pattern noise (SPN), Hausdorff distance-based clustering and color filter array (CFA). Considering the frame-to-frame and region-based matching involved in this procedure face great difficulty in the computation. By using the block correlation matrix, [4] presented a brilliantly simple strategy for detecting copy-move attacks, but the strategy has false positive and false negative results which create detection errors.
In this paper, greater emphasis is placed on the strategies for inter-frame falsification. The systematic review of interframe forgery detection techniques of all the papers discussed above shown in Table 1 focusing on the state-of-the-art matrices of their research gaps, test dataset and resolution of test dataset. In brief, however, certain techniques detect video inter-frame forgery efficiently, but their methods require a high time to compute and less suited for real-life applications [23,25,41,54,56]. Furthermore, the techniques have been evaluated by using a low-resolution video dataset [6,12]. In the same way, the entire research aims to develop a quick method for detecting and locating duplicate frames in videos. A video-interframe forgery detection technique based on Hu invariant moments and the coarseness evaluation has been presented to significantly increase the detection effectiveness and accuracy. In addition, high-resolution VLFD dataset library has also been designed to enable future researchers in evaluating their findings. It contains 420 original and forged videos in FullHD and UltraHD mode. The technique efficiently detect forgery in static scene and also it performed well in case of reshuffling. Experimentation work is performed with high resolution test videos. In the best of my knowledge, till now there is no such dataset repository available with ultra-high resolution. Section 4.2 carried out a comparative overview with the available dataset libraries.
Systematic review of interframe forgery detection techniques
Systematic review of interframe forgery detection techniques
The proposed technique is designed to detect frame duplication forgery in videos by using seven invariant Hu moments. Hu moments are used to effectively extract features from an image or frame and is robust against preprocessing. The paper presents a frame duplication video forgery detection technique. Figure 1 demonstrates the various phases of the proposed technique.
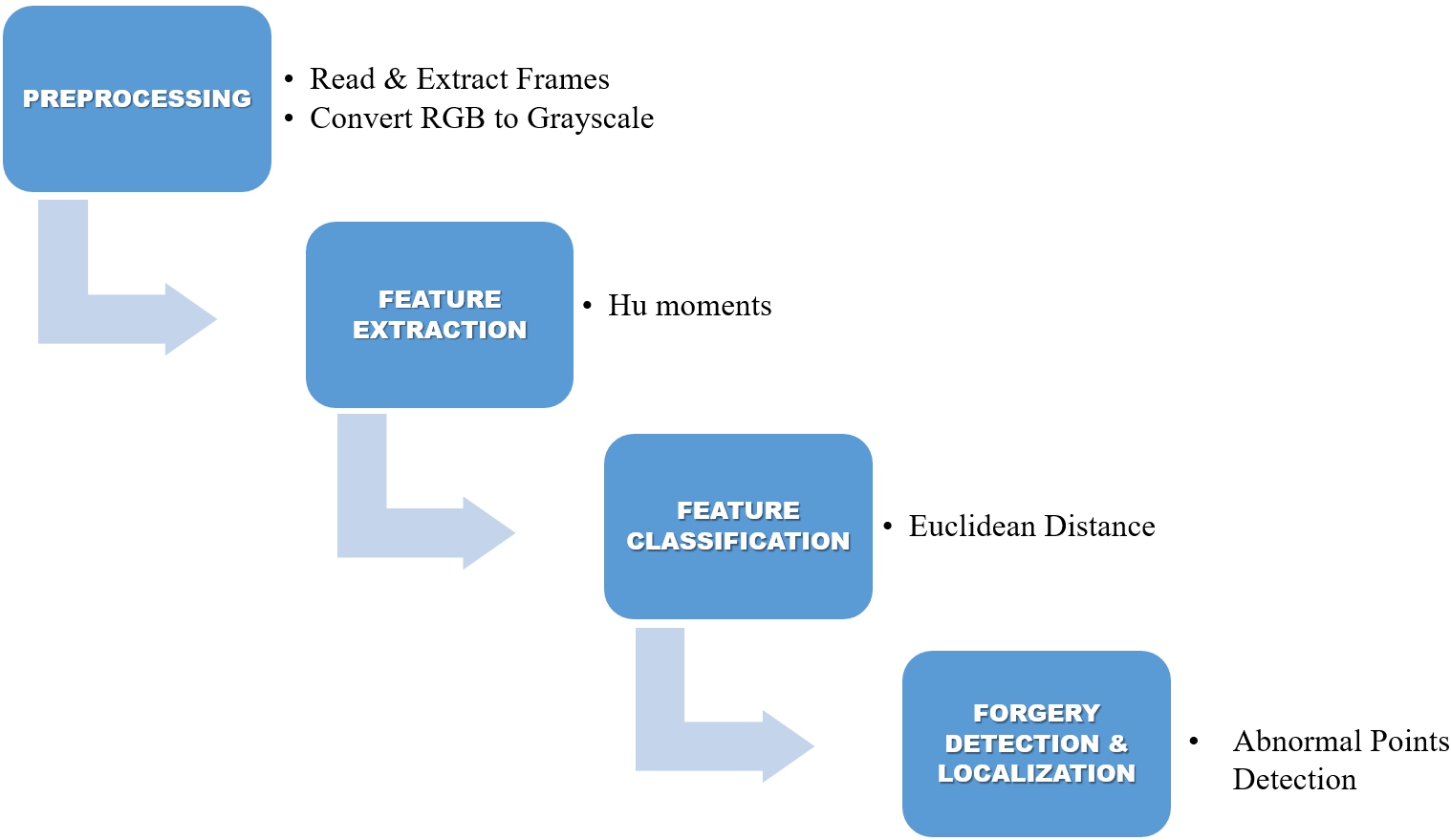
Workflow of proposed technique.
The first step is to convert a video into the frame sequence. Every multipixel frame is made up of three colors red, green and blue(RGB). The required storage space of an RGB color image is three times larger than that of a gray image. Consequently, in order to minimize calculations, gray images are used, which represent the real color image. The primary motivation for each frame’s preprocessing operations is to improve efficiency by eliminating redundancies. The operations involved in the preprocessing phase are image re-sizing, filtering etc. The gray scale image is represented by ‘I’ and the size of each frame is ‘
Feature extraction
The areas under which hu moments are often used seems to be image processing, video processing and computer vision [27]. Such moments and their invariant functions are primarily applied for extracting features including pattern recognition and for other digital watermarking techniques.
Hu moments
In present technique the feature extraction with hu moments searches for feature vectors and frame invariants. The Hu invariant moments seems to be statistical key measures originally developed to remain unchanged after object rotation, scaling, translation and certain other transitions. Hu moments present a generic view of objects and extraction is convenient [28]. The two dimensional frame is represented as
The transformations such as the translation, rotation or scaling of frame f(x, y) varies but the moments in Eq. (2) cannot be invariant. The invariant features can indeed be fulfilled by using central moment
Centroid of the frame
The author [15] used the normalized central moments and then introduced seven invariants of the moment. Such moments are applied on each frame for feature extraction and also illustrated as the nonlinear combination of
Classification
The feature vectors have been fetched to SVM classifier for the classification and labelling of authentic or tampered video frames. Support Vector Machine(SVM) [17] is the classificator used for classification of genuine or tampered video frames labelling. The kernal function in SVM converts the input feature vectors into higher dimensional feature space. The optimul hyperplane is then drawn and it acts as a decision boundary between the similar classes and rest of the classes. The classes having similar feature vectors is classified as tampered, while the classes having dissimilar feature vectors are classified as genuine.
Abnormal point detection
After classification of authentic and tampered video frames the exact location of duplicate frames will be extracted. The technique has firstly computed the mean
VLFD dataset contributions
In video forensics, several scholars have proposed variety of methodologies for the identification of image and video forgery and significantly reducing multimedia felony. RAISE, VISION, UCID, CASIA and other dataset libraries are available to test and validate proposed techniques in image forensics. In the same way, reliable dataset for the evaluation of proposed video forgery detection techniques developed by numerous researchers and are limited.

Video interframe forgery.
Video Forensics Library for Frame Duplication (VLFD) is mainly designed for the validation of techniques proposed for video frame duplication forgery detection. Video frame duplication is a kind of interframe video forgery where a sequence of frames are copied and placed somewhere else in the same video to create a forgery attack. This attack is performed to hide an object present in the video frame sequence for entertainment or sometimes it is performed to hide the criminal activity. In Fig. 2 video inter-frame forgery attacks are illustrated. As discussed in literature, a series of techniques have been introduced by various researchers to detect these forgeries but to validate these techniques dataset libraries are scarce. Therefore, a new dataset library is introduced where 210 native videos are acquired with modern smartphone cameras belonging to different brands: ASUS and VIVO. These devices are able to generate standardized and great quality videos.
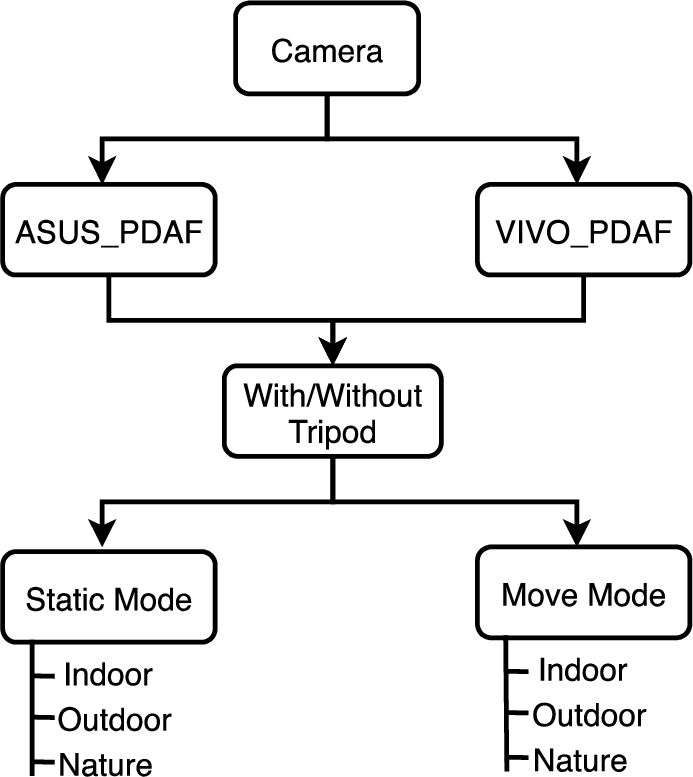
Layout for building the library by utilizing data from different devices.
Figure 3 demonstrates a framework for building the library by utilizing data from different devices. All videos from both devices have been specifically acquired in landscape mode. There are also different scenarios for video acquisition i.e. flat, indoor, outdoor and nature. Video adhering to the flat scenario includes sky, walls etc. Videos taken inside the building are included in the indoor scenario while videos taken outside, in open crowded areas like gardens are considered as outdoor videos. Nature corresponds to the various aspects of the environment. An example of different scenarios is illustrated in Figs 4, 5, 6. Figure 4(a) and 4(b) depicts the original and forged video frames of butterflies and shot indoor. As showing in this example, the video sequences in the first row are manipulated in the form of frame duplication forgery, while the second row depicts the original video frames. The original and forged video frames from proposed video dataset has been shown in Fig. 5(a) and 5(b). As demonstrated in the context, an outdoor video sequence depicts a car on the road and a tree. The video sequences in the first row contain the original video frames while the second row depicts the manipulated video frame sequence with the form of frame replication forgery where some previous frames are duplicated. Eventually, the images illustrate a simple video sequence of nature in Fig. 6(a) and 6(b). After this, the two different acquisition modes (i.e. still mode and move mode) have been used for each scenario. Acquiring the video of static areas is named as still mode while in move mode there is some movement happening; for example, a user strolls while attempting to capture the video. All the captured videos have the static or moving object with or without a tripod.

Indoor video frames: (a) original frames (b) forged frames.

Outdoor video frames sequence: (a) original frames (b) forged frames.

Nature video frames sequence: (a) original frames (b) forged frames.
In the dataset library, there are 50 still and 60 move mode videos using ASUS smartphone camera having 3840 × 2160 resolution. Phase detection autofocus (PDAF) camera technology is used in this model with an aperture scale of f2.2. The frame rate of each video is 30 frames per second(fps). Furthermore, the dataset collected using Vivo smartphone camera includes 50 still and 50 move mode videos with 1920 × 1080 resolution. The camera technology used in this model is Phase detection autofocus(PDAF) and the aperture is f2.2. Each video uses 30 frames per second(fps). The length of all the acquired videos using both cameras is less than 15 seconds. The key features of the whole dataset are listed in Table 2. It describes Brand, Model, Camera, Resolution, Frame rate, Aperture, Length and the number of videos captured on both devices. Moreover, it also explains the type of forgery implemented and the quantity of indoor, outdoor and nature videos.
Generalized framework of video forgery process
Frame duplication is the most common forgery in VLFD video tampering dataset.The measures of tampering procedure are:
Original videos are acquired using smartphone camera with file type (.mp4);
Import video to Video Editor;
Frame duplication is performed in Video Editor;
Export Tampered Video.
A basic flow chart of the video frame duplication tampering process is illustrated in Fig. 7. In the present work Openshot software has been used, which is most successful in video manipulation, to conduct frame duplication falsification. The tampering process begins with the import of videos into the software and drags them one by one into the timeline. By utilizing appropriate tools, copy the range of frames from the surrounding region and paste at some random location onto the same video for frame duplication manipulation. Eventually, the tampered video has been exported to the storage device.
The key features of VLFD dataset
The key features of VLFD dataset

Generalized framework of video forgery process.
This segment summarizes the existing scenario in video forgery dataset. One of the most admired datasets generated in 2012 by [31] is SULFA. SULFA dataset is accessible via the URL of the University of Surrey website [31]. This dataset has been applied for the validation of techniques commonly proposed for copy-paste forgery detection. The forgery is implemented with the help of CS3 and CS5 Adobe Photoshop over the original video. The resolution of the video captured is 320 × 240 and that is very low. Even, the REWIND dataset contribution expanded the Surrey University Library for Forensic Analysis (SULFA) dataset. It has 10 original and 10 forged videos and has 320 × 240 pixel resolution, and the frame rate is 30 fps. A dataset library has been proposed to create manipulated clips with the help of Mokey 4.1.4 [44]. Afterwards, a dataset collection was introduced by [1] also known as Video Tampering Dataset (VTD) that includes the video forensic library located on YouTube URL [2] and publicly accessible. The primary aim is to evaluate the methodologies used for the identification of splicing, swapping frames and copy-move forgery. Another, huge dataset SYSU-OBJFORG is developed by [7] for object-based video forgery, but not available free of cost to the public. A dataset introduced by [36] is accessible in the [35] web address, and has been granted free access to the research community. It is not effective for all forgery detection techniques. Table 3 illustrates a range of alternative repositories for video manipulation, along with their key characteristics. The table also elaborates and compare various features of proposed VLFD dataset with the existing state of the art techniques. The proposed dataset is efficient and reliable when compared with the existing datasets. PDAF camera is used to acquire the FullHD and UltraHD resolution videos. VLFD dataset also provided ground-truth which contains significant information about the video dataset repository.
Comparative summary of notable video forgery dataset contributions
Comparative summary of notable video forgery dataset contributions
The primary objective of developing the ground truth of this dataset is to provide comprehensive details and information on the type of video manipulation encountered in the approach to the study. VLFD dataset allows the investigators to rapidly test and analyze their methods using a reliable repository. The latest repository with the maximum number of videos and lengthiest 12 sec encompassed numerous forms of video manipulation technology. Indeed the contributions also include a number of falsified videos ascertained by manipulating the original video. In addition, the VLFD dataset includes 200 original and 200 forged videos. All the original videos are manipulated by applying frame duplication forgery, a category of video inter-frame forgery technique. The information on the key fact of the dataset is shown in Table 4. It incorporates about the video, the context in which the video is captured, the actual duration of the video, the total frames in the video, the quantity of frames manipulated in the video and, finally, the proportion of area manipulated in the video. The dataset contribution is very valuable for researchers and capable of allowing a clearer understanding of the methodologies used in their study.
Ground truth of video forgery dataset
Ground truth of video forgery dataset
Experimental environment
The proposed technique is implemented on a machine using Intel(R) Core(TM) i3–7020U processor and 4 GB of RAM and Microsoft Windows 10 with a 64 bit operating system with MATLAB. Parallel processing has been used to reduce the implementation of serial order processing and enables the faster execution of a project.
Experimental procedure
The proposed frame duplication detection algorithm has been evaluated for effect of generated 420 original and forged videos. Based on the proposed discussed VLFD dataset the simulation of the proposed technique has been allowed to conduct using MATLAB environment. To validate the current scenario, a frame sequence has been obtained from a video and then each RGB frame is converted into grayscale in preprocessing stage. Afterwards, by using the Hu invariant moment keypoints are extracted from each frame. As one frame is reproduced using frame duplication, so original and destination frame contain identical features in the forged video. A comparison has been performed to find variance of values in the forged video frames. It has been represented using the graph in Fig. 8(a). Ultimately abnormal points are generated to localize the actual location of duplicated frames present in the video. The frames containing with abnormal points are labelled as tampered, while the rest of the frames are considered to be the original frames. Figure 8(b) describes the results of a forged video.
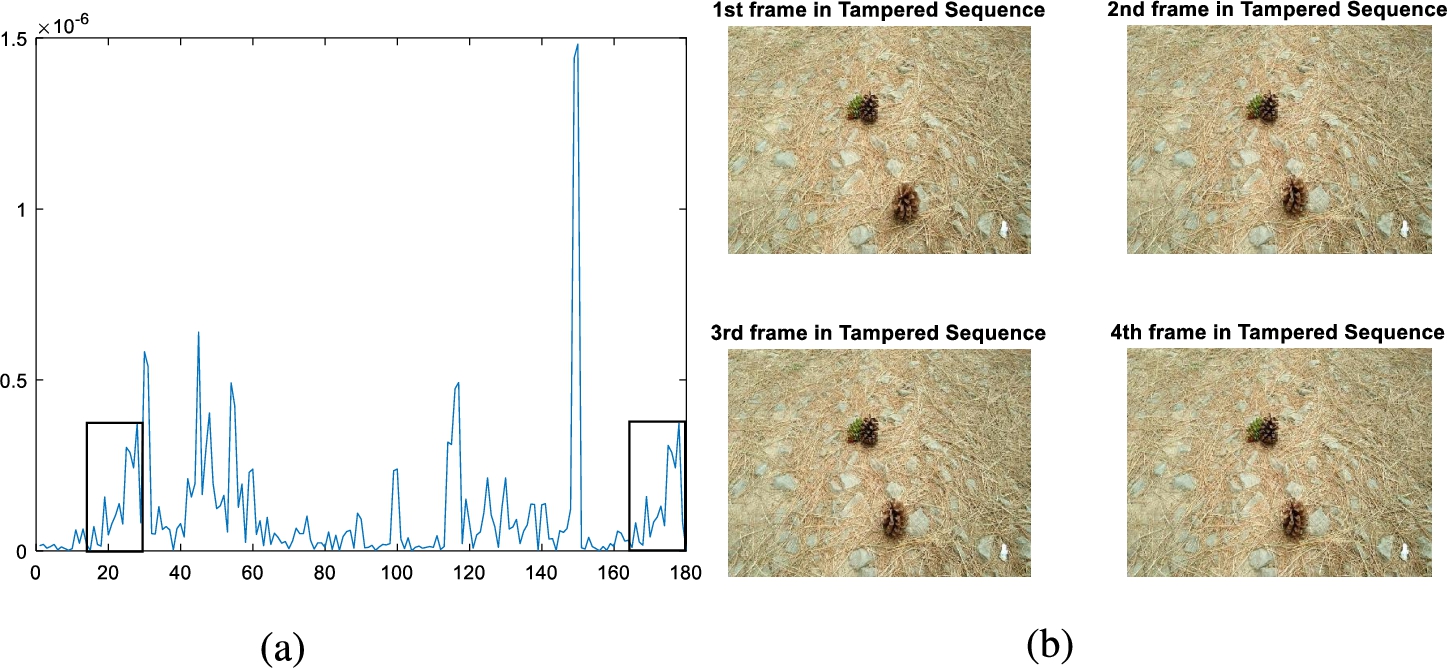
Visualization of tampered video frame sequence.
Confusion matrix, precision, recall and accuracy are the metrics used to assess the efficiency of the proposed technique. A table that defines the performance of a classifier using the test dataset for which the true values are specified, and is called the confusion matrix. It enables the quality of an algorithm to be visualized and illustrated in Table 5.
Confusion matrix for evaluation process
Confusion matrix for evaluation process
True Positive (TP) represents duplicated frames are available in video and are also classified after evaluation as forged. True Negative (TN) represents original frames are classified after evaluation as original. False Negative (FN) represents duplicated frames are available in video and are classified after evaluation as original. False Positive (FP) represents original frames are classified after evaluation as forged. Accuracy is defined by the overall degree to which the classification process is accurate. Accuracy is given by the equation (11)
Precision is defined by the accuracy of the model and by the amount of actual positive expectations. Sometimes it is also termed as the positive predictive value (PPV). Precision is given by the equation (12):
Recall is defined as the appropriate identification of the model by all possible positive labels. Sometimes it is also termed as the true positive rate (TPR). Recall is given by the equation (13)
Experiments are performed on original and forged videos of the proposed dataset in this segment, to demonstrate the proposed technique efficacy. The features have been obtained first using hu moments. Then these feature vectors have been compared with each other for each frame, to identify duplicate frames. Such features improve the proposed technique efficiency, reliability and achieve more accuracy on higher resolution videos when compared with other state of art techniques. Performance thus calculated shows a prominent result. The performance of proposed technique in frame duplication forgery detection has been evaluated in terms of Accuracy, Precision and Recall. Proposed dataset videos are used to analyze the methodology’s performance. Figure 9 illustrates the accuracy, precision and recall of the Hu moment based technique for different video categories. Implementing the proposed technique on ASUS database Fig. 9(a) demonstrates the precision, accuracy and recall, while Fig. 9(b) reveals accuracy, precision and recall by implementing on the proposed VIVO database. Forgery detection in outdoor videos using the Asus PDAF camera may have the highest Precision up to 94.84% whereas indoor videos also have the highest precision and recall. It can be observed that even though TPR is highest for outdoor videos and is slightly better than scenic videos but FPR for indoor videos is much better than natural videos. Recall for people videos is also better than other categories. The proposed technique has been applied to all original and tampered videos to detect whether a video has tampered with or not, and results are shown in Fig. 9.

Dataset evaluation.
The proposed technique is compared with the equivalent existing state of art techniques in terms of detection efficiency and implementation period, in order to determine its effectiveness. While certain techniques have reasonable accuracy, the technique suggested has been computationally effective. Table 6 shows a comparison between the proposed technique and existing techniques, [6,12,19,22,23,25,41,51,54,56,57] in terms of average execution time, accuracy, localization and resolution of test videos. The proposed technique takes less computation time especially in comparison with [6,12,19,22,23,25,41,51,54,56,57]. Due to optical flow estimates the method in [51] takes the maximum computation time. Although [22,23] has not identified the location of the forgery but the proposed method has resolved the issue and returns exact location of forged videos. Furthermore, the resolution of videos used for testing proposed technique is even higher than the datasets used by existing state of the art techniques.
Comparision with existing state of art techniques
Comparision with existing state of art techniques
Due to increased Video editing software and dependency on multimedia content, video forgery detection is the necessity of time. This research paper has proposed a technique for the detection of frame duplication forgery in videos to accomplish the objective. The features of each video frame are extracted by Hu moments on the basis of gray values, which are then evaluated to identify and locate tampering in the video. Further, the paper proposes a new VLFD dataset containing 210 native videos. It is introduced as a valuable resource for evaluating forgery detection techniques. The phase detection autofocus (PDAF) camera technology has been used to acquire the dataset videos. These videos have been acquired with or without a tripod. The detailed quantitative analysis of the proposed dataset in comparison to the existing dataset(s) has also been discussed. Finally, the evaluation of the proposed dataset has been presented using the proposed technique. The proposed technique has validated the dataset and significantly outperforms in comparison to the existing state of the art techniques. The technique has achieved higher accuracy and less computation time. This paper may help future researchers to propose and evaluate the new techniques in video forensics. The dataset has been created as an initial repository for manipulated videos and can be enhanced with more types of forgeries in the future. Anti-forensic counterparts for the proposed technique can also be explored in the future.