
Abstract
Data provenance collects comprehensive information about the events and operations in a computer system at both application and kernel levels. It provides a detailed and accurate history of transactions that help delineate the data flow scenario across the whole system. Data provenance helps achieve system resilience by uncovering several malicious attack traces after a system compromise that are leveraged by the analyzer to understand the attack behavior and discover the level of damage. Existing literature demonstrates a number of research efforts on information capture, management, and analysis of data provenance. In recent years, provenance in IoT devices attracts several research efforts because of the proliferation of commodity IoT devices. In this survey paper, we present a comparative study of the state-of-the-art approaches to provenance by classifying them based on frameworks, deployed techniques, and subjects of interest. We also discuss the emergence and scope of data provenance in IoT network. Finally, we present the urgency in several directions that data provenance needs to pursue, including data management and analysis.
Keywords
Introduction
Data provenance contains the complete history of operations on data and processes starting from the system boot-up. It provides sufficient details of data ownership changes, data manipulation, and process activities [17,68,80]. Data provenance explains how data evolves from process to process. It clearly depicts the relationship between inputs and outputs of a process, which is important to infer the characteristics of that process (and application that holds it). In the case of a cyber attack, it produces adequate system traces to regenerate a successful (or unsuccessful) attack for the design of mitigation mechanisms. A trace is basically an imprint of past events or activities (malicious or benign) in the system [1]. Through the help of these attack traces, an analyzer can detect the origin of the attack as well as determine the critical events and activities. Even if the adversary intentionally deletes some attack traces, the analyzer can perform forward causal analysis to reconstruct those traces with the help of captured provenance records [33,45].
The captured attack traces contain information regarding the agents (e.g. users, groups) controlling the activities (e.g. processes) to interact with data objects (files, inodes, superblocks, socket buffers, IPC messages, IPC message queue, semaphores, and shared memory) during system execution [9,82]. If the provenance events, along with the agents and activities, are considered nodes, and the causal relationships among them are considered edges, the provenance traces can be depicted as a Directed Acyclic Graph (DAG) [11]. The analyzer can leverage this graph to infer the causality and dependency of different system events that contribute to the compromise.
Because of the continuous escalation of interest in system and data security, a lot of research efforts and advances have been made in provenance. These efforts can be roughly divided into three groups, namely provenance capture, management, and analysis. The provenance capture operations can be conducted at both kernel and user space levels. The capture mechanisms at the kernel space achieve their goals through either instrumenting the system calls [30,54] or monitoring operations upon the kernel objects [9,64]. The captured provenance records are at the granularity of process-level [9,10,59,64] or subprocess-level [45,47,48,62]. While the kernel level mechanisms can capture many details, special schemes must be used to map groups of provenance records back to semantics of system operations. Another group of capturing mechanisms focus on the user level information, and allow applications to intercept user operations and events to generate provenance records [10,47,69]. While these mechanisms usually provide more configuration power to users on granularity of captured information, integrity measures must be taken to make sure that the captured events are accurate and complete.
Once the provenance records are captured, management and analysis operations can be conducted on the data. Restricted by the size of captured data, the management approaches often use offline methods to reduce the number of stored provenance records and redundant information in the records [45,79]. In literature, a limited number of research efforts concentrate on online (on-the-fly) provenance reduction [72]. Similarly, data analysis and anomaly detection through provenance data can be conducted in either post-hoc methods [62] or runtime schemes [60]. The detection capability and accuracy continue to improve with the fast development and adoption of machine learning and AI mechanisms in provenance.
In this paper, we provide a review of the approaches in these three groups and comparatively discuss their advantages and limitations. We also comprehensively discuss the deployments of these approaches in IoT domain. The remaining of the article is organized as follows. In Section 2, we present the necessary background on data provenance and the design choice of a regular provenance system. In Section 3, we study the approaches in each group in detail, and in Section 4, we discuss data provenance extensively in the emerging IoT domain. We describe the security of provenance systems in Section 5 and the unique contributions this article brings to the community in Section 6. Later, in Section 7, we introduce several research directions that deserve more efforts from the provenance research community. Finally, we conclude the paper with Section 8.
Background
To reconstruct an attack scenario and determine the critical attack nodes, the provenance records are expected to be accurate and complete enough to facilitate the reconstruction of system traces to infer sufficient information about events. Though a sophisticated attacker is capable to alter a provenance capture mechanism, a good provenance system should ensure the tamperproofness of this mechanism [9,64]. In this section, we present the design choice of a good provenance system and conceptualize the components of provenance capture mechanism, provenance storage mechanism, and provenance analysis mechanism.
Design choice
The usability of provenance records depends on the design choice of the provenance system that ensures the trustworthiness and integrity of the captured records. In [9,50], the authors summarized the following four properties to ensure the usability of provenance records: (1) Reference Monitor Concept; (2) Traces Reproducibility; (3) Attested Disclosure; and (4) Network Authenticity. Below we will discuss the properties in detail.
Reference monitor concept
Reference monitor concept enforces the authorized access relationships between system subjects (e.g., users and processes that access the system resources) and objects (e.g. data, files, sockets, or subjects being accessed by the other subjects) based on an access control policy defined on reference validation mechanism. It is used to explicitly control each subject’s access to any system resource that is shared with other subjects. It ensures that no subject practices over-privilege (e.g. READ, WRITE, EXECUTE) on any system object or resource [7,41]. Since the provenance system itself can become the target of malicious attacks, it is imperative to make sure that the execution of provenance will not incur security violations.
A reference monitor concept maintains the following three properties:
A good provenance system should be built around this reference monitor concept. LPM [9] is an example of this. It is built on top of Linux Security Module (LSM) [77], where a number of provenance hooks are placed carefully to mediate each kernel object access. These hooks are customized codes in kernel which are deployed to capture provenance at runtime. Each provenance hook calls a kernel function when an object (e.g. inode) is about to be accessed. Moreover, LPM ensures the tamperproofness of the captured records through the deployment of SELinux MLS Policy [35]. The verification of LPM is automatically maintained due to the deployment of LSM. As each provenance hook of LPM follows each LSM authorization hook, the correctness of LSM hook placement automatically verifies the LPM hooks. There are many techniques to verify the correctness of LSM hook placement. One such technique is described by Edwards et al. [25], where they used both static and dynamic analysis to verify the correctness.
Traces reproducibility
To undermine the derivation of attack behavior by provenance analyzer, adversaries may intentionally delete some important attack traces after successful attacks. Since the analyzer leverages functional dependencies among system entities to determine the attack behavior, any missing trace can lead to the derivation of a faulty behavior. For example, if an adversary injects a fake thermostat event that causes a chain reaction (causing the occurrence of a sequence of events) in a trigger-action IoT environment that eventually unlocks the door of the smart home, the missing of one crucial trace (fake event injection) in the chain may output completely incorrect attack path to further harness any fruitful defense mechanism. Therefore, a good provenance system should ensure the reconstruction of missing attack traces to a certain extent so that these traces can be utilized in determining the attack behavior and understanding the level of damage. In [34], the authors describe the importance of traces reproducibility in detail in scientific experiments, Big Data processing, network configuration, and software testing.
Attested disclosure
Provenance recorder collects application-level semantic information from provenance-aware applications and incorporate it with kernel-level provenance records captured in kernel space. Hence, the low integrity of user space applications is a matter of concern. Therefore, a good provenance system should ensure the integrity of the applications prior to the disclosure of user-level provenance records. The applications should never be able to modify themselves when they are already loaded into memory. In this circumstance, Integrity Measurement Architecture (IMA) [66] guarantees the integrity check of the applications in Linux kernel [9].
Network authenticity
In a distributed environment, where provenance records are transmitted over the network, the provenance system must authenticate each outbound packet. One possible way to achieve this goal is to utilize a DSA signature to sign each outbound network packet prior to transmission, which should be verified immediately after receiving the packets at receiving end [9].
A conceptual system overview
As shown in Fig. 1, a conceptual provenance system consists of the following three components: (1) Provenance collection component; (2) Provenance storage component; and (3) Provenance analysis component. The figure visually explains how data flows from the point of capture to the storage and integrity assessment, and eventually to the analysis. Although provenance collection conveys a larger meaning than just provenance capture, in this paper, we use the terms collection and capture interchangeably to denote the same thing for the readers’ convenience throughout the rest of the paper.
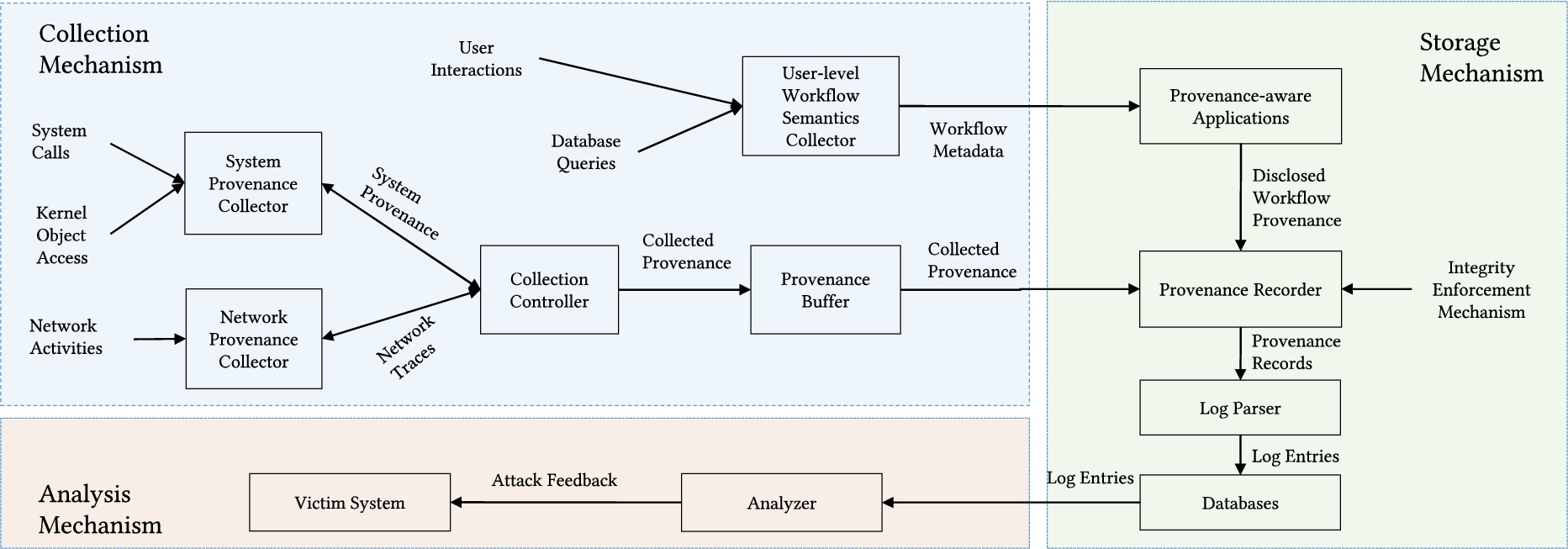
A conceptual view of a provenance system architecture.
Provenance collection mechanism deals with the capture of provenance records both in kernel space and user space. Kernel space provenance records are cached temporarily in a small buffer and later, transferred into user space for further processing. On the other hand, user space provenance records are directly fed into provenance recorder for the storage and subsequent analysis purposes. Our observation is that the whole collection mechanism consists of the following five components:
i. System provenance collector. System provenance records are mainly collected in kernel space through different techniques, including system call instrumentation [30,54], provenance hooks deployment [9,64], and Tracepoints [24] deployment [48]. Different types of hooks and Tracepoints are basically deployed to monitor the kernel objects and wait for any operations upon them to record the provenance data, while system calls are instrumented to directly attribute the processes, users, or connections.
ii. Network provenance collector. In the existing literature, Netfilter [57] hooks, along with provenance hooks and Tracepoints, are deployed in kernel space to keep track of all processes and network activities (e.g. socket activities), including non-IP packets [48,59,64]. In Linux platform, these network provenance collectors are expected to be minimally invasive to the rest of the Linux network stack [9].
iii. User-level workflow semantics collector. Since the visibility of OS is only limited to kernel space, in order to achieve whole-system provenance, a provenance system should support a layered structure where workflow semantics with high task structure is collected in user space. In the existing literature, workflow metadata is collected by intercepting user interactions with application data [69] or extracting web queries and further inspecting the list of objects associated with those queries [10]. We also see the use of semantic program annotation and instrumentation method to capture workflow metadata with application-specific task structure in the literature [47]. When these user-level workflow metadata are collected, they are disclosed by provenance-aware applications to the provenance recorder for further processing.
iv. Collection controller. Collection controller is an entity that registers system and network provenance collectors (e.g. provenance hooks, Tracepoints, Netfilter hooks) and regulates their operations. It performs file versioning to avoid cycles in provenance graphs, generates access control policy for the distributed system, and assigns random identifier for each outbound packet [9].
v. Provenance buffer. A provenance buffer is a fixed-length storage space utilized for the exportation of captured system and network provenance records from kernel space to user space. Whenever provenance collectors capture a system or network provenance record, the collection controller immediately passes it to the provenance buffer. Then, the buffer exports it to the provenance recorder in user space for further operations. One such buffer is relayfs [37], which is used by LPM [9] and CamFlow [59].
Provenance storage component
When provenance records are exported to the user space, the provenance storage mechanism converts them into suitable log entries prior to storage operations. It performs integrity assessment of the provenance-aware applications when they intend to disclose workflow semantics. The whole mechanism consists of the following three components:
i. Provenance recorder. Provenance recorder facilitates the storage of provenance records to either local storage space or external server through the help of log parser. It receives captured provenance records from the provenance buffer and disclosed workflow semantics from provenance-aware applications. In the case of disclosed provenance, it first ensures the integrity of the provenance-aware applications with the help of integrity enforcement mechanism [66]. The main purpose of this mechanism is to generate a cryptographic hash of each binary that is computed prior to each execution. This hash is used by the recorder to make a decision about the integrity of a provenance-aware application prior to accepting the disclosed provenance.
ii. Provenance-aware applications. When workflow semantics collector dispatches user-level workflow metadata to provenance-aware applications, provenance-aware applications report those metadata to the provenance recorder. This reporting is referred to as disclosed provenance in the literature [9,54,59]. When workflow metadata are disclosed to the provenance recorder, the recorder first performs the integrity check of the applications, and then, forwards them to the log parser for further processing.
iii. Log parser. Provenance recorder forwards the provenance traces to the log parser to convert them into log entries so that the analyzer can easily perform queries over those entries. The log entries are further stored in databases in different formats, including Gzip, PostGreSQL, Neo4j, and SNAP [9].
Provenance analysis component
The provenance analysis mechanism takes log entries as input, performs suitable queries over the entries, and outputs necessary attack information. It explains how closely different system events (both benign and malicious events) are interrelated [62], and what is the underlying behaviour of an attack.
The main component of this mechanism is the provenance analyzer, which is generally invoked by the users when they experience unusual activities in the system. Its primary task is to provide attack feedback to the target system after determining the attack behavior of the adversary. It accesses stored log entries from the database and performs suitable queries over those entries. That’s why its performance is bounded to the number of database entries and their formats.
Provenance representation
World Wide Web Consortium (W3C) proposes a conceptual data model named PROV-DM [11] to facilitate the representation of provenance records that describe the system entities, agents, and corresponding activities. PROV-DM allows the generation of a provenance graph to delineate the data flow scenario throughout the whole system and illustrate the dependencies among system entities. Hence, the provenance graph is a directed acyclic graph where the entities, agents, and activities are the graph nodes and the relationships among them are the graph edges. In an attack scenario, this graph helps the analyzer discover the compromised system nodes and determine the attack path. To explain how the graph representation of provenance records helps analyze an attack, let us consider the following smart home scenario:
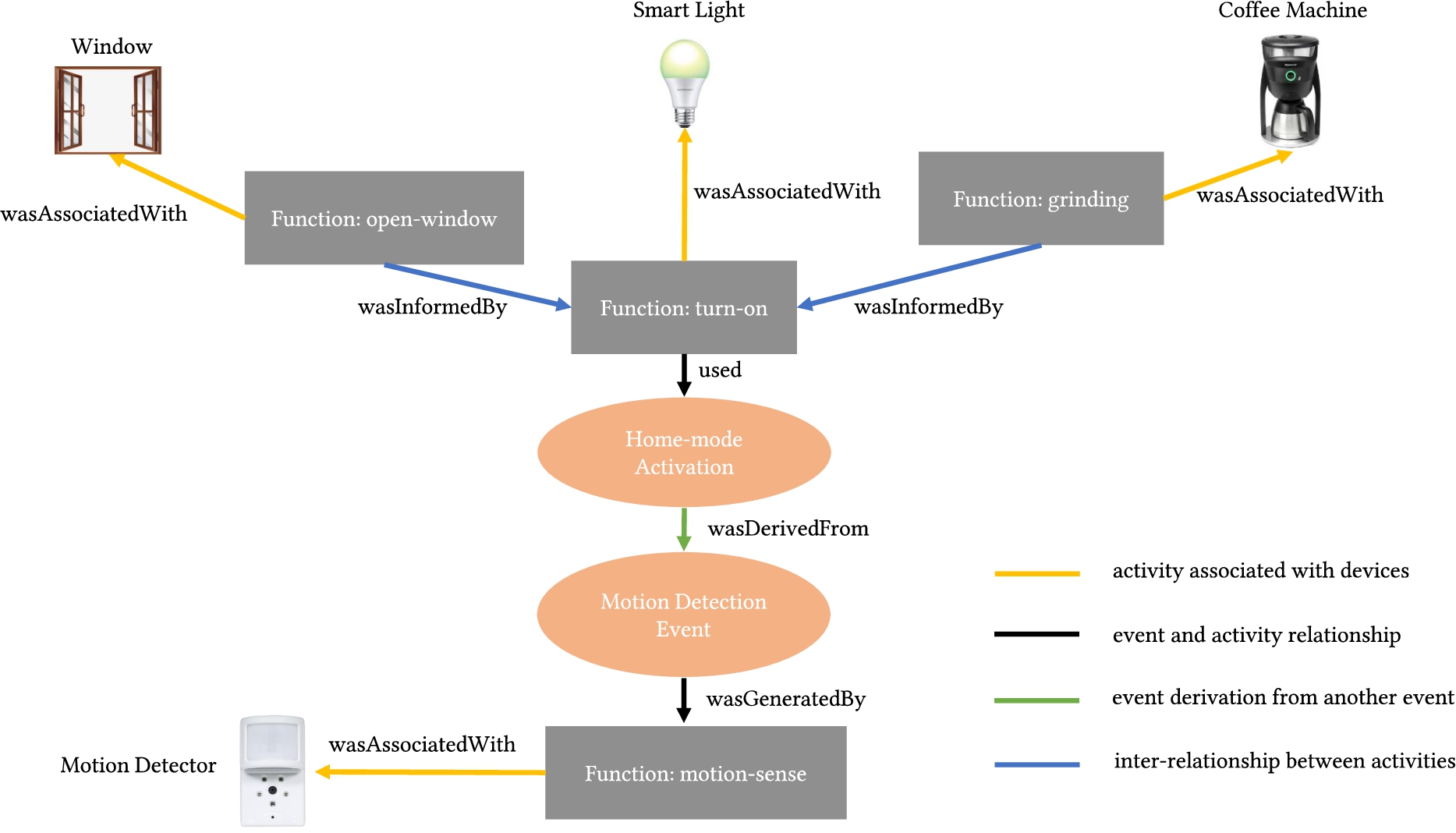
Provenance graph explaining Bob’s trigger-action attack.
Alice owns a smart home equipped with a smart lock, a motion detector, a smart light, a smart window, and a smart coffee machine. Alice controls these devices with mobile applications that function based on different trigger-action rules. Bob, on the contrary, is an attacker who is interested in adversely manipulating the actions of the devices. Alice always uses the smart lock mobile application to open the front door when she returns home from outside. When the door is unlocked, and she walks through the living room, the motion detector senses her motion and activates the home-mode. This home-mode activation event triggers the turn-on event associated with the smart light. When the light is turned on, the window automatically opens, and the coffee machine starts grinding coffee immediately. Now, Bob knows the exact locations of the devices and intentionally sets up his own devices just outside the home, which have greater sensing capability and computational power compared to Alice’s devices. His ultimate goal is to open the window and start the coffee machine maliciously. Let us assume that, his devices somehow generate a fake motion detection event that activates the home-mode and subsequently triggers the turn-on event of smart light. If he becomes successful in triggering this turn-on event, he can easily open the window and start the coffee machine to grind coffee.
Figure 2 depicts how data flows into different entities in the aforementioned scenario given that Bob becomes successful in manipulating the actions of the smart window and the coffee machine. Please note that the ovals represent the events that have occurred, and the rectangles represent the activities that are triggered during Bob’s attack. The edges of the graph tell us how different events were produced or derived as well as how activities were generated and utilized. For example, through fooling the motion sensor (1), the attacker activates the “home-mode” (2), and turn on the light (3).
In addition to PROV-DM, W3C also proposes several provenance representation schemes, including PROV-XML [53], PROV-JSON [38], and PROV-O [12].
In contrast to PROV ontology, Cyber-investigation Analysis Standard Expression (CASE) [18] offers more flexibility to represent links and associations between objects using Relationship objects. It also provides necessary functionalities to specify inputs, outputs, and the instruments used in Action. In CASE, the result of an Action can also be another Action, which is not possible to cover in PROV ontology.
In this section, we comparatively study existing approaches to provenance collection, management, and analysis. The complete categorization of the state-of-the-art approaches is depicted in Fig. 3.
Provenance collection schemes
Existing literature includes a number of research efforts on provenance collection schemes. They mostly deal with event capturing with an emphasis on the optimization of reducing granularity of captured data. The detailed comparison among these mechanisms is illustrated in Table 1.
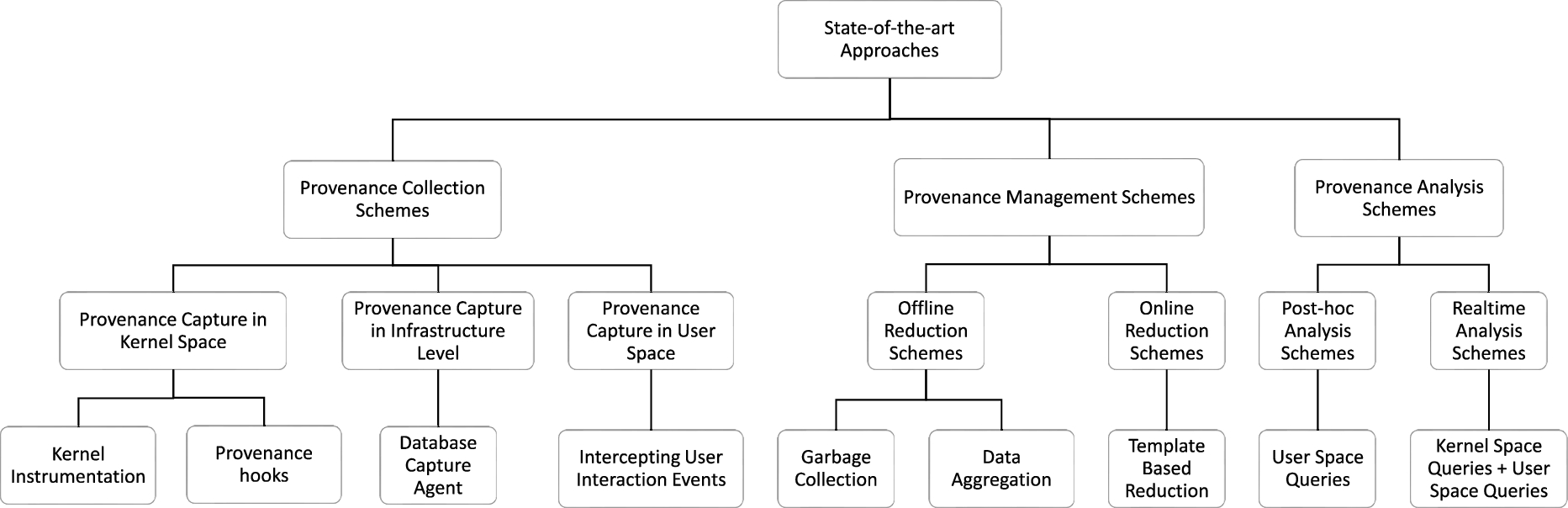
Categorization of the state-of-the-art approaches.
Comparison among the provenance collection schemes
The state-of-the-art provenance collection schemes mostly capture either kernel-level provenance records in kernel space or semantic-aware provenance with application-level task structures in user space or at the infrastructure level [16,61].
The earliest research efforts in the literature, including Forensix [30], PASSv1 [55], PASSv2 [54], and SPADE [28], directly instrument or intercept system calls to capture provenance records in kernel space. Since they only deal with the system calls, they are unable to capture all the non-persistent objects required to ensure whole-system provenance. Hence, the missed non-persistent objects include IPC messages, socket buffers, shared memory, and the other objects that deal with the controlled data types defined by Zhang et al. [82].
To address this issue, Pohly et al. [64] introduce Hi-Fi that captures high fidelity whole-system provenance starting from early kernel initialization through system shutdown. Hi-Fi leverages Linux Security Modules (LSM) [77] to mediate the access to system objects. It is built around reference monitor concept, and it satisfies the design goals we presented in Section 2.
In contrast to Hi-Fi, LPM [9] creates a Trusted Computing Base (TCB) to collect whole-system provenance. It places 170 provenance hooks, one for each of the LSM authorization hook, to observe the system events and capture the provenance records. In addition, it uses several Netfilter hooks [57] to facilitate secure network transmission by implementing a cryptographic message commitment protocol.
Similar to LPM, CamFlow [59] also leverages LSM and Netfilter hooks to capture observed provenance records. It is proposed to support the integration of provenance across distributed systems and to minimize the overhead compared to Hi-Fi and LPM. It allows users to define the scope of provenance capture according to their own requirements. Users can decide whether CamFlow will capture whole-system provenance or selective provenance. If users choose selective-provenance, they can specify individual or combinations of the following criteria: (1) filters on nodes and edges; (2) specific programs and directories; (3) specific processes; and (4) specific network activities.
In addition to the techniques described above, there are several other capturing mechanisms, such as the deployment of Tracepoints [24] and reverse engineering to capture kernel level provenance data [46]. Protracer [48] places Tracepoints in both kernel and user code to provide hooks to call kernel functions. It performs event logging when an operation has permanent effect on the system entities (e.g. when a file is written, or a packet is sent through a socket). Otherwise, it performs unit-level taint propagation for intra-process information flow. Protracer alternates between event logging and taint-propagation to reduce the volume of captured records and to achieve fine granularity. BEEP [46], on the other hand, reverse engineers the program loops from the application binaries. It reverse engineers the instructions that cause workflows between process units.
Since kernel-level provenance data is difficult to interpret because of the semantic gap between kernel space and user space, there is always a demand of infrastructure-level or user space provenance capture mechanism in the application domain. Story Book [69] facilitates the provenance capture in user space by intercepting the events of user interactions with application data and by sending these events to application specific extensions to interpret and generate provenance records of task level structures. As Story Book generates provenance data based on the user interactions with applications, it stores the generated provenance records separately from the application data.
DAP [10] is an add-on of LPM which is deployed at the infrastructure-level to capture semantically rich workflow provenance. The capture agent is a multi-threaded TCP proxy server that listens on the database engine’s assigned ports. It extracts the database queries issued by the web applications and passes them through a Bison parser [29]. Then, it inspects the list of database objects that are accessed and creates a provenance event for each object.
Data granularity
The granularity of provenance data captured by instrumenting or intercepting system calls is, at best, instruction-level [28,30] or file-level [54,55]. On the contrary, the granularity of provenance data captured by the schemes based on provenance hooks is at process-level. Hi-Fi [64], LPM [9], DAP [10], and CamFlow [59] are a few examples. However, these schemes frequently suffer from dependence explosion problem that basically arises when a large volume of inputs and outputs are associated with a long running process, and each output of the process is causally dependent on all previous inputs. It emerges when a process has a non-trivial lifetime and inputs/outputs are repeatedly processed [46].
To address this issue and achieve finer granularity, BEEP [46] and Protracer [48] partition the execution of a process into multiple individual execution units depending on kernel-level programming paradigms named event handling loops. It results in event graphs with a lot of redundancy which are storage ineffective. Moreover, these schemes require prior training to detect memory dependencies across partitions, which is hard to achieve. MPI [47] is, therefore, introduced to address these issues. It allows a semantic program annotation and instrumentation technique to partition executions based on the application specific task structures. It first prompts an annotation miner that helps user annotate the program source code. Then, LLVM [73] pass takes the user annotations and analyzes the program to determine the data structures to instrument. Hence, the annotation miner is a data structure profiler and the LLVM pass is the analysis component.
Layered provenance service
In the existing literature, PASSv2 [54], LPM [9], and CamFlow [59] support layered provenance structure in order to attain whole-system provenance. However, there are some fundamental challenges related to the layering of provenance services, which are listed by Muniswamy-Reddy et al. [54].
Efficient communication among the provenance-aware components
Object identification and dependence extraction
Maintenance of consistency semantics between data and provenance
Cycle detection and removal
Query support over provenance
Security enforcement
PASSv2 introduces Disclosed Provenance API (DPAPI) to allow the secure transfer of provenance between the components of the system and between layers. Whenever an object is accessed repeatedly, PASSv2 creates a new version of that object to avoid cycle. LPM also supports this type of file versioning for cycle avoidance. CamFlow, on the other hand, provides an API that allows the association of application provenance with system objects to ensure the avoidance of cycle as long as there is an available file descriptor to the application. In the case of integrity check of provenance-aware applications prior to the disclosure, LPM and CamFlow both use Linux IMA [66].
Provenance management schemes
Provenance management schemes help reduce the size of collected provenance to save storage space and optimize query performance. In the literature, there are two types of management schemes – offline data reduction schemes and online data reduction schemes. Most of the introduced reduction schemes are offline schemes that work on log entries on storage media. The online schemes, on the contrary, deal with on-the-fly data. For the reader’s convenience, we will use the terms online and on-the-fly interchangeably throughout the rest of the paper. The detailed comparison among the offline and online schemes are shown in Table 2.
Offline reduction schemes
LogGC [45] and Causality Preserved Reduction (CPR) [79] are the two most common offline reduction approaches. LogGC is basically a garbage collection algorithm that discards log entries based on lifespan and influence over the dependency analysis. The main idea behind this algorithm is that many event entries are bound to specific operations which are destroyed after the termination of those operations without further influencing any process or object. LogGC collects these entries as garbage since they are unreachable and not needed for future causal analysis. It leverages BEEP [46] to partition the execution of a process into multiple execution units to achieve fine granularity. LogGC is an application specific adaptation, and it requires human-in-the-loop to understand and change approach for the specific applications.
Causality Preserved Reduction (CPR) [79], on the other hand, leverages the dependencies between system events to reduce the number of log entries. The key idea is that some events have identical contributions to the dependency analysis and can be aggregated [70] without damaging inter-dependencies. It usually aggregates repeated kernel level events (e.g. read events) between two OS objects. Unlike LogGC, CPR is an enterprise adaptation, where there are hundreds of hosts containing thousands of diverse applications.
Comparison among the provenance reduction schemes
Comparison among the provenance reduction schemes
In terms of reduction rate, LogGC reduces 92.89% of the original audit logs for client systems and 97.35% for server systems. On the other hand, CPR achieves a maximum of 77% data reduction. CPR achieves less reduction compared to LogGC because CPR deals with a number of diverse applications that incur a diverse set of system events with unequal contributions to the dependency analysis. Since CPR is an enterprise adaptation, the reduction rate heavily depends on the type of applications exist in the enterprise. For instance, some applications (e.g. system daemons) produce bursts of irreducible events although they all seem semantically similar. These irreducible events contribute unequally to the dependency analysis, and we can not just aggregate them without hampering inter-dependencies. However, LogGC and CPR are orthogonal – LogGC primarily focuses on the life span of the events while CPR mainly concentrates on event causality equivalence.
NodeMerge [72] is a template-based online data reduction scheme that achieves an additional 11.2% reduction on the host level and 32.6% reduction on the application level on top of Causality Preserved Reduction (CPR) [79]. The key insight here is that some constant and intensive actions (e.g. loading libraries, accessing read-only resources, and retrieving configurations) are performed at every process initialization, and they can easily be grouped together without breaking the original data dependencies since they are read-only, and they do not contain any useful system dependency information. NodeMerge generates templates based on the frequent access pattern of files and merges the incoming file events with the template files if there is a match.
Protracer [48], however, frequently switches between event logging and tainting based on the effect of operations. If the effect is permanent, it only logs. Otherwise, it performs unit-level taint propagation. For example, Protracer logs the events if there is a write operation to a disk or a packet is sent through socket for either IPC or real network communication. In other cases, it performs taint propagation for any kind of intra-process operations.
In terms of reduction rate, Protracer reduces even more than LogGC and CPR, since it avoids logging the redundant events, along with the dead-end events; while LogGC only removes the dead events and CPR aggregates the events based on the dependency.
Provenance analysis schemes
Provenance analysis schemes leverage data relationship to determine the root cause and impact of system compromise. In the existing literature, there are two types of provenance analysis schemes: post-hoc analysis schemes and runtime analysis schemes.
Post-hoc analysis scheme
Post-hoc analysis schemes utilize stored provenance records to discover the relationships between system events and entities, and to determine the attack behavior. It is usually invoked after a system compromise, and it requires human-in-the-loop to perform the analysis. The recent advances in research lead to the automated implementation of the tasks. One such example is Hercule [62], which is an automated log-based intrusion analysis system that models the multi-stage intrusion analysis as a community discovery problem. The ultimate goal of this approach is to discover the “attack communities”. The key insight is that the attack logs are always heavily and densely connected with each other compared to the benign logs. Hercule performs causality analysis in modeling the relationship among multiple logs, and generates multi-dimensional weighted graphs. Then, it employs community detection algorithm to extract the attack communities. The whole process described here takes place in user space after system compromise.
Runtime analysis scheme
Runtime analysis schemes, on the other hand, facilitate the timely response to a malicious incident in a system, which is crucial for a realtime security application. To thwart an ongoing attack, security measures are required to enforce in kernel space. Security enforcement in kernel-space ensures the tamperproofness of the collection method as well as the accuracy of the provenance records to perform analysis with. Runtime analysis schemes, such as CamQuery [60], allow this type of enforcement by generating kernel level provenance graphs in kernel space, and by performing query analysis over the generated graphs. CamQuery specifically extends CamFlow [59] to enable thread-level provenance capture. When provenance graphs are generated using the captured events, they are immediately fed into Loadable Kernel Module (LKM) to perform query analysis within the kernel space. After performing inline analysis, these graph elements are further transferred to the user space for post-hoc analysis or remote transmission.
Provenance in IoT environment
The rapid emergence of IoT devices in both public and private spaces poses a real concern regarding the access and use of sensitive user data [19,27]. Commodity and health IoT devices capture a wide range of user data on a daily basis including personal information, energy usage, locations frequently visited, personal habits, and physical conditions. These sensitive data can be harnessed without user’s permission to generate severe impacts on user’s health insurance policy, credit card usage, employment eligibility, and utility services [26,40]. Therefore, FTC staff report [40] suggests to follow Fair Information Practice Principles (FIPPs) in handling captured user data. This report focuses on four FIPPs in particular: (1) security; (2) data minimization; (3) notice; and (4) choice. Data provenance mechanisms can be deployed to verify that these four FIPPs are followed when user data is dealt with. Since in this paper we focus on provenance approaches, we discuss the security and privacy issues of IoT from the following perspectives: origin of data, information flow across the IoT network, and integrity of provenance records. The topics such as security and privacy of outsourced data, protocols used in IoT, and authentication methods will not be extensively studied because of space limitation.
In this section, we primarily discuss how data provenance can be employed to detect policy violations in an IoT environment that the adversary seeks to achieve in order to compromise IoT devices and subsequently, access user data. We also discuss how data provenance can be used to detect underlying attack chains in trigger-action IoT platforms, and how we can enforce data provenance to ensure the data integrity in an IoT environment.
Ensuring policy compliance
In an IoT network, devices continuously capture user data and share with clouds and end users. If the network is considered insecure, it is possible for an adversary to get those captured data through different side channel attacks. The adversary can eavesdrop on communication channels when devices communicate with each other or send data to the cloud servers. It can also conduct a man-in-the-middle attack between a valid cloud server and an IoT device. On the other hand, an adversary can also tamper user data during the data uploading or sharing procedures without creating any suspicion [6]. Since cloud providers are assumed to be honest-but-curious entities, we cannot guarantee that user data stored in cloud servers are protected. Therefore, Pasquier et al. [61] suggests that the handling of sensitive user data should require the participation of end users in the process. A user-in-the-loop method can ensure that no IoT device attains over-privilege, or captures and shares sensitive data to external entities without user’s permission. For example, a user-in-the-loop method can perform access control in terms of approve or reject operations at runtime when a certain device wants to access user location, capture user’s photo, record user’s voice, or sense heart beat.
The deployment of data provenance can guarantee the contextual integrity of information flow across a network by identifying the appropriate contexts of sensitive actions. ContexIoT [44] is a context-based permission system that identifies fine-grained contexts for sensitive actions and provides sufficient context information to users at runtime so that users can enforce effective access control. To achieve fine granularity, ContexIoT defines context as execution paths at IPC and data flow levels and performs taint analysis to label the data source at runtime. It provides an application patching mechanism that collects context information before executing an action by isolating the execution flow and subsequently, modifies the ContextIoT-incompatible smart application into a ContexIoT-compatible application based on user decisions.
To ensure that an IoT environment is secure and operating correctly, Soteria [21] employs a model checker on the state model extracted from the instrumented smart apps to validate the IoT security properties. First, Soteria instruments the source code of smart apps using staic analysis, and then extracts a state model from the instrumented apps with device attributes as states and events changing the attributes as transitions. Security properties independent of an app’s semantics (e.g. race conditions, attributes of conflicting values) are validated during the extraction time, while rest of the security properties are validated by the model checker. As a foundation of model checking, Soteria performs dependence analysis to identify the sources of numerical-valued attributes and prunes the infeasible paths based on path- and context-sensitivity. Later, it generates a union state model to represent the interactions of apps with each other.
IoTGuard [20] extends the idea of validating IoT security properties into a dynamic policy-based enforcement system that blocks unsafe and insecure state transitions in an IoT environment. It completes the source code instrumentation process in a similar fashion as Soteria: identifies hook points in smart app’s source code, instruments extra logic to capture provenance data at runtime, and guards device actions. When instrumented apps are deployed at runtime, data collector captures provenance data to extract the runtime behavior of interacting apps. From these captured provenance records, a dynamic unified model is constructed based on which IotGuard identifies whether an undesired transition happens between two states in the IoT environment. Similar to Soteria, device attributes are considered as states and events changing the attributes are considered as transitions. Once IotGuard finds an unsafe and insecure state transition, it performs two policy actions: block the transition automatically, and ask the user either to allow or deny the transition. IoTSan [58] follows a quite similar approach to identify an unsafe state transition in an IoT environment. It uses a model generator that translates smart apps written in Groovy into Promela, the programming language of SPIN [36]. This generator outputs a SPIN model checker that covers the app’s configurations, user defined security properties, and the dependency graph in source code of the apps. This output model checker then verifies whether there is any unsafe state transition in IoT environments.
IoTDots [8] addresses the policy violation in a slightly different way. It checks whether a user inside a smart environment performs any activity that potentially violates the security policies. It leverages the relationship between device states to identify unwanted or malicious activities performed by an adversary or a valid user. IoTDots Modifier (ITM), one of the two key components of IoTDots, performs static analysis to determine the possible hook points (e.g. a socket activity, a function call) and add some hooks to collect provenance data at runtime. The collected provenance data are stored in IoTDots Logs Database (ITLD), which is subsequently accessed by IoTDots Analyzer (ITA), the second key component of IoTDots, to detect user behavior or determine any policy violation.
For the purpose of centralized auditing, Wang et al. [76] proposed ProvThings to determine the root cause of a sequence of malicious activities and enforce necessary policies to a chain of activities. Similar to Soteria, IoTGuard, IoTSan, and IotDots, it performs static analysis to the source code of smart apps to determine the hook points to add extra logic to capture provenance records at runtime. But it deploys a selective instrumentation algorithm to instrument the source code by identifying security-sensitive sources and sinks to make sure that the instrumentation is achieved in a minimally invasive manner. Hence, a source is a security sensitive data object, while a security sensitive method is considered as a sink. After collecting provenance records at runtime, ProvThings converts all the collected metadata into a provenance graph which is finally leveraged by the policy monitor to determine a suitable policy for a chain of activities.
Apart from the aforementioned provenance systems, we see some other research efforts in the literature that either address the unsafe state transitions of a state machine or the verification of a sequence of events. Peeves [14] and HoMonit [81] are two such research efforts. Peeves verifies with the help of an array of sensors whether or not a sequence of physical events actually happened. It leverages the observation that the physical events which actually happen at certain times have different impact signatures from those of the injected fake events. It uses supervised learning with distributed sensor data to extract the signatures. On the other hand, HoMonit uses Deterministic Finite Automaton (DFA) matching algorithm to extract DFAs from the source of the applications. Later, these DFAs are compared with the event signatures extracted from wireless network traffics at runtime using side channels to detect any misbehavior of an IoT device. The authors observe that a certain DFA model correctly represents the behavior of a smart home app, and it is comparable to the fingerprints derived from the traffic. Hence, a DFA model is basically a set of states and transitions, where each state represents the status of an app and its corresponding device while each transition represents the interaction between the app and the device it controls. The detailed comparison among all the provenance systems used for ensuring policy compliance in IoT is presented in Table 3.
Comparison among the provenance systems used for ensuring policy compliance in IoT
Comparison among the provenance systems used for ensuring policy compliance in IoT
Due to the advent of trigger-action platforms (e.g. IFTTT [39]), IoT devices create a chain of interactions maintaining functional dependencies between entities and actions [20]. Because of the nature of trigger-action platforms, action of a certain device can be easily triggered by the occurrence of another event(s) at another device. For instance, a window may open automatically when a thermostat gives a measurement of 110°F. Such inter-dependencies generate a chain of interactions that may enable exploits under certain cases. An adversary can take advantage of this scenario to perform an attack upon a smart home or smart city.
Ronen et al. [65] show how Zigbee protocol can be manipulated to perform an attack in a smart city. Their observation is that it is possible to initiate a factory reset procedure on a standard Zigbee transmitter that disintegrates all the street lamps up to 400 meters from the controllers. According to the authors, the factory reset is possible since a major bug exists in Atmel stack in its proximity test. By replacing a valid lamp with a malicious lamp into the proximity of other lamps and subsequently performing over-the-air firmware updates, they claim that it is possible to infect all the street lamps of a city with worms even if the total number of lamps is greater than 15000.
In a smart home environment, it is possible for an adversary to inject a malicious event somewhere in the chain using a ghost device and activate a critical action (e.g. door opening) due to autonomous trigger-action scenario. The IoT environment can also be manipulated to transition into an unsafe and insecure state. Therefore, any unsafe or insecure state transition should be blocked by the user. IotGuard [20], IoTSan [58], and IoTDots [8] eliminate the vulnerability of transitioning into unsafe and insecure states. Peeves [14] and HoMonit [81], on the other hand, prevent the malicious injection of an event into the chain from happening by verifying the occurrence of that event using impact signatures. Because of the limitations in computing and communication capabilities of IoT devices, these solutions usually depend on the joint efforts between IoT devices and the cloud environment.
Enforcing data integrity in IoT environment
When IoT devices upload data to cloud servers, adversaries may perform malicious attacks to get access to or tamper with those data. Besides, IoT devices are highly vulnerable to impersonation attacks. Therefore, data provenance and data integrity are tied together in securing an IoT environment. We can achieve this goal by deploying provenance modules to keep traces of IoT events and integrity enforcement mechanisms to ensure that data is not tampered by adversaries.
The existing literature benefited from the use of SELinux MLS Policy [35] in kernel space to ensure the integrity of kernel-level provenance [9]. We also see the deployment of Integrity Measurement Architecture (IMA) [66] to guarantee the integrity check of user applications by provenance recorder [9]. In this subsection, we will not discuss how the integrity of provenance records is maintained both in kernel and user spaces. On the contrary, our discussion will focus on the approaches used in enforcing integrity over IoT data shared with cloud servers.
In [42], the authors presented BlockPro network model to address the question of maintaining integrity of IoT data. They integrated Physical Unclonable Functions (PUF) with the blockchain network with smart contracts to enforce data integrity along with data provenance. Hence, the PUF is assumed to be a system-on-chip (SoC) that provides unique hardware fingerprint for a device. It is characterized by a challenge response pair (CRP) that basically represents a one-to-one mapping between a challenge and a response. The PUF of different devices will generate different responses to the same challenge, thus can be used as the fingerprint.
In BlockPro network model, each IoT device first registers itself with a smart contract by sharing its unique ID and PUF CRP, which subsequently connects the device to the blockchain network. After a device completes its registration, the smart contract puts it into a trusted list. Later when that device requests to upload some data to cloud servers, the smart contract looks for the ID stored in the trusted list and sends a challenge to the device if the ID is located. Otherwise, the request is terminated by the contract. Thus, it preserves the data provenance of the devices in the network. If the device returns the expected response to the smart contract, the data is added into the blockchain which is then mediated by another smart contract. Since each block in a blockhain contains the hash of a timestamp and its previous block, it is not possible for an adversary to tamper with the data through manipulating individual blocks. Moreover, the decentralized nature of blockhain ensures that no single entity in the network can manipulate the data records.
A similar blockchain-based integrity enforcement approach is discussed in [3]. In this approach, the authors present a scenario in which IoT devices communicate with the blockchain network through a gateway node that performs the device registration and key management operations. Each IoT device registers itself with the gateway node using a DNS name, and then, the gateway node maps the DNS name to a unique ID (e.g. Public/Private Key). The gateway node keeps a registry manager to store these mappings. To ensure the provenance of the device identities, stored data, and traffic profile in cloud servers, the authors propose four smart contracts to mediate with the blockchain: (1) device registration contract, (2) device provenance contract, (3) data provenance contract, and (4) traffic profile provenance contract. Similar to BlockPro network model [42], this approach also ensures data provenance and data integrity in an IoT environment through the integrated use of blockhain, smart contracts, and gateway nodes.
The existing literature also showed the combination PUF and other non-hardware fingerprints to verify the origin of data in IoT networks. One such example is [6], where wireless fingerprints such as RSSI (received signal strength indicator) is used with PUF to verify the provenance of data. Since the wireless channel characteristics between two network entities is intrinsically symmetric, it is possible to retrieve wireless fingerprints based on the way two entities communicate with each other. These fingerprints preserve the integrity of on-the-fly provenance, while PUF asserts the origin of data. The same concept of wireless fingerprinting is also deployed in [32] to enable autonomous device pairing between heterogeneous IoT devices.
Security of provenance systems
Just as many other security measures, the provenance system itself can become the target of cyber attacks. Therefore, it is essential to investigate schemes for the establishment of root-of-trust. There have been several protocols such as LPM [9] and CamFlow [59] that depend on Trusted Computing Base (TCB) to provide resistance to attacks upon provenance modules. We believe that the security of provenance systems in IoT could benefit from those experiences.
Before we present any technical details, we would like to first present researchers’ understanding about IoT security kernels [23]. The authors suggest two possible approaches. First, through the adoption of a Memory Protection Unit (MPU), we can achieve effective memory isolation so that attackers cannot tamper with the program or data of the provenance systems. The second approach refers to formal proofs of security features enforced by the operations (such as before and after a kernel system call). If the safety of a provenance system is built upon the second approach, it is essential to verify that the assumptions for the proofs will hold in the specific systems.
Based on this understanding, we will discuss two groups of approaches that could be used to guarantee the safety of provenance systems in IoT environments. Since IoT devices usually have very limited resources, the approaches that we recommend here depend on some special hardware features for efficiency and safety reasons.
The first group of approaches that we recommend build the root-of-trust in special sections of the processor. For example, with the design and deployment of Intel Software Guard Extensions (SGX) [13] and the ARM TrustZone [63], we will be able to establish trusted execution environments (TEEs) in a device. We will be able to store some essential information and provide some secure APIs through the TEE so that any manipulations to the provenance evidences can be effectively detected. If we generalize the dependency on hardware, we can also build the safety of provenance systems upon tamper resistant memory units [74] or secure cryptographic unit (SCU) [49]. These units comprise a hardware cryptographic engine and a built-in access control functionality, which are usually enforced by a software gate or a hardware gate. More recently, to support existing low end MCU structures for IoT devices in which resource hunger operations cannot conduct, the authors of GAROTA (Generalized Active Root-Of-Trust Architecture) [4] propose a scheme to monitor the operations of a TCB (trusted computing base) and issue a reset if some trigger conditions are satisfied. It is implemented as a hardware component that monitors the CPU signals to detect violations to security properties.
The second group of approaches that we recommend will build the safety upon the combination of physical unclonable function (PUF) with distributed digital ledger such as blockchain. The PUF [22,52] are embedded functions that are determined by the variances during the manufacturing procedure. For two different microchips, even if they are from the same manufacturing line, the PUF functions will still be different. Therefore, the responses to PUF functions can be viewed as a hardware signature. In [2], the authors use the PUF features of SRAM for key derivation and ECC encryption so that data integrity can be properly protected. The PUF function can also be combined with the non-interactive zero-knowledge proof to achieve both data provenance and privacy preservation for trustworthy and dependable IoT systems [31].
The blockchain technique depends on the uniformity of common knowledge/information to defend against fake data or attacks. Therefore, it fits the IoT environment very well when we consider the large number of devices and their restricted processing power. In [78], the authors use the FPGA to build an efficient TEE for industrial IoT devices. Through the adoption of blockchain, it removes the single root-of-trust and allows many parties to jointly accomplish the management of the devices. Similarly, the PUF functions of multiple components in a single IoT device can be used to achieve cross-monitoring with the help of blockchain [56]. The high density of IoT devices in a relatively small area also allows the node to conduct mutual attestation through the adoption of PUF and blockchain [43].
Unique contributions
With more research efforts attracted to the domain of system provenance, investigators conducted comparative study of the approaches and identified potential extensions. For example, Simmhan et al. [67] presented one such survey, in which the authors comparatively discussed the existing approaches by classifying them based on five criteria – 1) usage of provenance, 2) subject of provenance, 3) provenance representation, 4) provenance storage, and 5) provenance dissemination. The goal of the paper was to identify the unique characteristics of the provenance systems used in e-science as well as present interesting open research questions on provenance and existing challenges that researchers need to address in order to make provenance more ubiquitous. Prior to this survey, the literature also saw surveys on workflow management systems [5], lineage retrieval systems [15], and early provenance systems used for scientific data processing [51]. Unfortunately, none of these surveys cover the provenance systems used for security enforcement because data provenance, at that time, was limited to the management of data lineage and the verification of event sources.
Later, when data provenance was introduced in cybersecurity, the literature shifted its focus to various provenance collection, management, and analysis mechanisms. Herschel et al. [34] surveyed the existing provenance systems based on the applications of provenance, type of provenance being captured, and the impact of the resources and system requirements on the choice of deploying a certain provenance system. The authors also surveyed provenance systems used for distributed Big Data processing. In another survey paper [75], the authors studied the provenance systems employed for the processing of distributed Big Data. But the most compelling recent survey of the provenance systems used for security enforcement was presented by Tan et al. [71]. Here the authors provide a comprehensive survey of the provenance approaches with an emphasis on 1) data source optimization and 2) data relationship analysis. The approaches that concentrate on data source optimization either guarantee the integrity of provenance systems or optimize the granularity of the captured data. Contrarily, the approaches that focus on data relationship analysis study the relationship between system entities. However, this survey does not include some recent provenance systems that facilitate on-the-fly provenance reduction or runtime provenance analysis. Moreover, this survey, including all the previous ones mentioned in this section, do not explain provenance and its development in the IoT environment.
The unique contributions that this survey brings to the community are as follows:
This survey includes a comprehensive overview of the very recent provenance systems that facilitate on-the-fly provenance reduction and runtime provenance analysis This survey comparatively discusses the state-of-the-art provenance systems used in Internet of Things (IoT) This survey discusses the security of provenance systems themselves This survey introduces several future research directions that should be pursued to enable the changes to the landscape of the provenance research
Future directions
Based on our discussion in the previous sections, it is quite evident that there is a demand for research efforts on online data reduction, runtime analysis, and several other aspects. In this section, we briefly introduce several future research directions that may emerge as intriguing in the future.
Noise reduction in kernel level graphs
In a system where execution partitioning schemes, such as BEEP [46] and Protracer [48], are deployed, the kernel level provenance graphs generated in the kernel space contain a number of redundant nodes. This redundancy introduces noise in causal graphs that adversely impacts the performance of inline and runtime graph analysis [47]. Therefore, noise reduction in kernel level graphs deserves more research efforts.
Online data reduction
In the case of APT (advanced persistent threat) attacks upon an organization, the causality analysis becomes prohibitively expensive and slow unless an on-the-fly reduction scheme removes a large portion of log entries prior to the storage operation. Typically, in a 3-4 month APT attack period upon a medium-sized enterprise, Peta Bytes of logs are generated [72]. If all these logs are stored in backend, the storage cost becomes undesirably high. Moreover, the generated causality graphs include a number of redundant dependencies that slow down the analysis procedure. In the existing literature, a limited number of research efforts have been conducted to reduce the captured volume on-the-fly, and therefore, there is ample room to delve into this domain.
Leveraging machine learning into provenance analysis techniques
Machine learning algorithms can significantly impact the post-hoc analysis schemes. They can be deployed to determine the behavioral patterns of malicious activities. Similar to the deployment of community discovery algorithm in Hercule [62], other sophisticated machine learning algorithms can be used to discern the attack behavior efficiently. In runtime analysis schemes, machine learning models can be used to predict kernel level dependencies in order to quickly analyze the kernel space graphs.
Leveraging data provenance to audit compliance with the privacy policy in Internet of Things
Since commodity IoT devices capture sensitive user data, such as health information, user movement, user gesture, and user photo, the devices should always comply with the privacy policies for any kind of transactions. Users should know where and how their personal data are being used. They should always be notified about any changes in the usage policy. The data flows from device to device, or device to server should be transparent to the user.
Pasquier et al. in [61] recommend the deployment of data provenance to audit compliance with the privacy policy in IoT. Data provenance may capture the inter-dependencies between IoT devices and applications. It may provide the holistic view of the system activities [76] that can be facilitated to audit compliance with the privacy policy. Some approaches are needed to deal with the accurate extraction of inter-dependencies, while others should concentrate on the deployment of these inter-dependencies into policy-level.
Conclusion
Data provenance provides us with the comprehensive history of data and processes. We can leverage data provenance to reconstruct attack traces to learn how malicious activities propagate through a system. Traditionally, provenance is captured in the kernel space by instrumenting system calls or installing system hooks. It is arguably true that a well-crafted capture mechanism built around the reference monitor concept can capture whole system provenance, including both bootstrap provenance and shutdown provenance. However, semantic program annotation and instrumentation techniques can be leveraged to achieve more enriched provenance with application specific task structures. The captured provenance records should necessarily pass through an online data reduction scheme to enable low-cost and efficient post-hoc analysis. Though an efficient post-hoc analysis is required to derive the attack behavior of an adversary, it is evident that we need inline and runtime provenance analysis techniques for the realtime security applications to counter ongoing attacks. In this article, we discuss different research approaches on provenance capture, management, and analysis. We also discuss the deployment of provenance systems in IoT environment to ensure policy compliance, detect attack chains in trigger-action platforms, and maintain data integrity. We believe that more research efforts on on-the-fly data reduction and runtime analysis will be pursued in future, and provenance techniques will be hugely used in the emerging IoT domain. In conclusion, we recommend some probable research topics that may enrich the existing literature.