Tamarin is a popular tool dedicated to the formal analysis of security protocols. One major strength of the tool is that it offers an interactive mode, allowing to go beyond what push-button tools can typically handle. Tamarin is for example able to verify complex protocols such as TLS, 5G, or RFID protocols. However, one of its drawback is its lack of automation. For many simple protocols, the user often needs to help Tamarin by writing specific lemmas, called “sources lemmas”, which requires some knowledge of the internal behaviour of the tool.
In this paper, we propose a technique to automatically generate sources lemmas in Tamarin. Following the intuition of manually written sources lemmas, our lemmas try to keep track of the origin of a term by looking into emitted messages or facts. We prove formally that our lemmas indeed hold, for arbitrary protocols that make use of cryptographic primitives that can be modelled with a subterm convergent equational theory (modulo associativity and commutativity). We have implemented our approach within Tamarin. Our experiments show that, in most examples of the literature, we are now able to generate suitable sources lemmas automatically, in replacement of the hand-written lemmas. As a direct application, many simple protocols can now be analysed fully automatically, while they previously required user interaction.
Security protocols are notoriously subtle to design and analyse. Many different tools have been developed in order to detect flaws and prove security properties such as authentication, secrecy, or privacy. However, even a simple property like secrecy is undecidable in general [15]. Hence several tools focus on the analysis of a decidable fragment, e.g. by bounding the number of sessions (e.g. AVISPA [1], DeepSec [8]). But when considering wider classes of protocols, more general cryptographic primitives, and an unlimited number of sessions, one necessarily goes beyond the decidable fragment, possibly losing termination or even automation.
One popular tool in that direction is ProVerif [6], a push-button tool that has been able to analyse hundred of protocols including e.g. TLS 1.3 [5], the ARINC823 avionic protocol [7], or the Neuchâtel voting protocol [11]. However, ProVerif may fail to prove some protocols because of some internal approximations. In that case, the user must either simplify the model or just give up.
Another approach has been developed in the tool Tamarin [21]. One key feature of Tamarin is that it provides an interactive mode: if the tool fails to automatically prove a property by itself, the user may help the tool, for example by writing intermediate lemmas, or by manually guiding the proof search. Thanks to this approach, Tamarin supports many features that are typically out of reach of many tools (Diffie–Hellman, stateful protocols), and has been able to prove complex protocols such as 5G AKA [2] with exclusive or, group key agreement protocols [23], or Noise framework [18] with Diffie–Hellman keys.
However, the fact that Tamarin is not fully automatic makes it more difficult to use, at least in the learning phase. In particular, Tamarin fails to automatically prove some “simple” protocols of the literature such as the well-known Needham–Schroder protocol or the Denning–Sacco protocol. This is a barrier when teaching the tool for example at the university or in summer schools.
Automation in Tamarin fails in particular if it encounters “partial deconstructions”. To speed up the analysis, Tamarin computes in advance, for each protocol and intruder fact, all possible origins (called sources) of these facts, which are then repeatedly used in later steps of the analysis. However, this pre-computation can stop in an incomplete stage if Tamarin lacks sufficient information about the origins of some fact(s). In practice, as soon as Tamarin encounters such a “partial deconstruction”, it is unlikely that it will be able to prove any interesting property automatically. To solve the issue, the user needs to manually write a “sources lemma” to help Tamarin . Unfortunately, this manual step has to be done for many protocols, even simple ones.
Our contribution. In this paper, we automate the generation of sources lemmas. The main idea is to provide a systematic analysis of the origins of a term in a protocol. Intuitively, either a term has been forged by the attacker, or it comes from an earlier step in the protocol. To avoid the exploration of too many cases, we base our analysis on “deepest protected” subterms (when such a subterm exists). We prove that the sources lemmas that we generate are indeed true. Our result holds for any protocol provided that the cryptographic primitives can be expressed as a convergent subterm theory (modulo associativity and commutativity) with the finite variant property. This is the case of most standard cryptographic primitives such as symmetric and asymmetric encryptions, as well as signatures.
A preliminary version of these results have been presented in [10]. However, we noticed that sometimes, reasoning on the origin of a term by following the message flow is not enough. Indeed, a term may be first stored in a protocol fact and then released later on. This happens for example for protocols with private channels or counters, as those are often modeled through dedicated facts. Hence in this paper, we have also developed a way to generate sources lemmas that reason on protocol facts when following messages is not enough.
Interestingly, the correctness of Tamarin does not rely on the fact that we are able to prove that our sources lemmas hold. Tamarin will verify them anyway (as done with sources lemmas written by the user). This means that our technique can also be used even in cases where our theoretical justification does not apply. Our theoretical justification simply explains why Tamarin has a good chance to work. We have implemented our technique in Tamarin, as a new option —auto-sources. With this option, when partial deconstructions are detected, a sources lemma is generated automatically and added to the original model, so that the user can see it and possibly amend it, if needed. We have validated our approach with two kind of experiments.
First, we consider simple protocols of the literature, used as benchmarks for most tools. We modelled a handful of them and ran Tamarin. Our approach is able to solve all partial deconstructions. Actually, we found out that for these simple examples, this was the only reason they were not entirely automatic, hence thanks to our —auto-sources option, Tamarin can now analyse all these examples automatically.
We also wanted to evaluate how our technique behaves on more complex protocols and on protocols that have not been specified by ourselves. Hence we considered all the models provided within Tamarin ’s distribution, and that contained “partial deconstructions” and “sources lemmas”. For a majority of them, our technique successfully close all partial deconstructions and for about a half of these, Tamarin is now even able to analyse the whole protocol automatically.
Unsurprisingly, complex protocols still require the existing manually written intermediate lemmas or tailored heuristics. However, our technique considerably improves the degree of automation of Tamarin, yielding a better trade-off between what can be done automatically, and what needs to be done manually.
Related work. The Tamarin prover was first presented in 2012 [22]. Since then, work on the tool mostly focused on widening its scope and adding new features. In particular, support for various equational theories has been added (bilinear pairing [24], user-defined convergent equational theories [12], and exclusive-or [13,14]), as well as the possibility to perform equivalence proofs [3]. There also have been various extensions, e.g., for different input languages (e.g., [4,19]). Concerning improved automation, there is prior work aiming at automatically learning proof heuristics [27]. To the best of our knowledge, this work, initially presented at ESORICS 2020 [10], is the first to focus on the automatic generation of sources lemmas.
In the context of symbolic models, several other tools have been developed for analysing the security of protocols and most of them are fully automated like AVISPA [1], Maude-NPA [16,17], DeepSec [8], or SPEC [26], at the cost of bounding the number of sessions or limiting the expressivity of the tool w.r.t. covered primitives or properties. The main competitor of Tamarin prover is ProVerif [6], that is fully automated but cannot handle primitives like exclusive-or.
Overview
We illustrate our technique on a simple challenge-response protocol.
The initiator sends a nonce n encrypted with the public key of the responder, and then waits for the corresponding answer, i.e. the nonce n encrypted with his own public key. The symbols and are constants used to avoid confusion between the two types of messages: they indicate whether the ciphertext corresponds to a request or a reply. The full Tamarin input file modeling this protocol is given in Appendix. In particular, the responder role is as follows:
Intuitively, at the reception of a message of the form aenc{’req’, I, x}pk(ltkR), the agent R (with private key ltkR) sends the message aenc{’rep’, x}pkI on the network to the agent I (with public key pkI). Note that there are other rules modeling the Initiator role, as well as the key generation. The latter rule creates the !LtK and !Pk facts used here to retrieve the agents’ public and private keys.
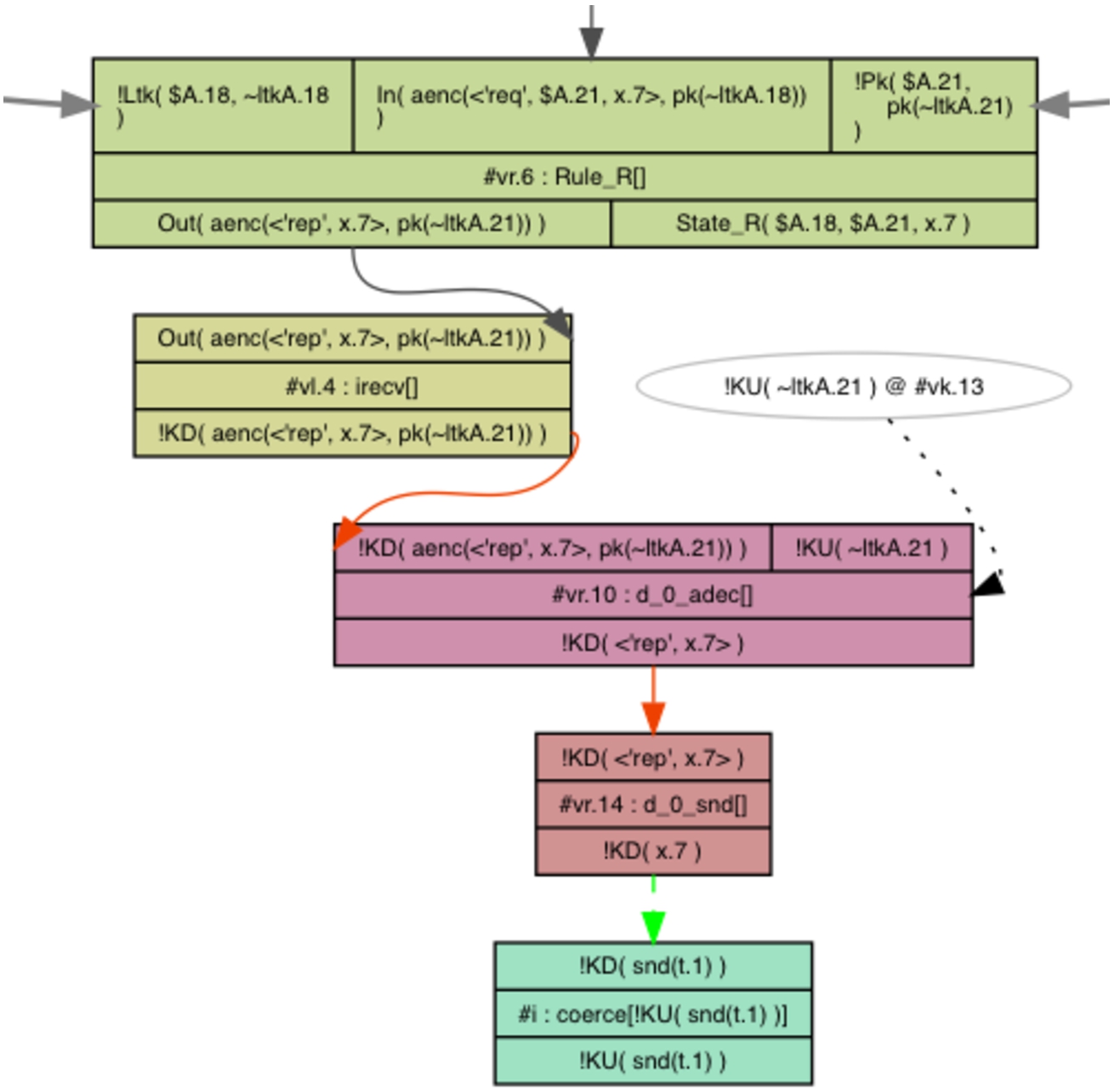
This protocol rule models the behavior of the responder role. It can be triggered arbitrary many times, possibly with different values for x. When loading this model in Tamarin, it turns out that the proof attempt of e.g. a simple secrecy property of nonce n does not terminate due to partial deconstructions. In Tamarin ’s interactive interface, they are identified by dashed green arrows as shown in Fig. 1. The green arrow symbolizes a deconstruction chain. Deconstruction chains are used in Tamarin’s intruder reasoning to extract values from messages output by the protocol. In this example, Tamarin tries to extract a fresh value from the message output by the rule Rule_R (at the top). Tamarin has computed that if it can decrypt the output of the rule (rule d_0_adec) and then extract the second term (rule d_0_snd), it obtains the value (a renaming of the variable given in the initial rule definition). However, here Tamarin is unable to continue its deconstruction, as can potentially be any value: directly the desired fresh value, or a pair of values, or an encryption, or something completely different. As this deconstruction is incomplete, it is called a partial deconstruction.
Example of a partial deconstruction.
In the above example, Tamarin does not know anything about the contents of the variable , hence, to ensure soundness, it is obliged to consider this case as a potential source for any value, which leads to an explosion of the number of cases, and often to non termination issues. This is the case here: the rule Rule_R producing the requires an input, which could itself be the result of (a different instantiation of) the same source, and so on.
To get rid of partial deconstructions, Tamarin uses sources lemmas. They are a special type of lemmas which are applied at the precomputation phase. More precisely, after computing the initial raw sources without any lemmas, Tamarin computes the refined sources using the sources lemmas to hopefully discard partial deconstructions. To ensure that the refined sources are correct, one further has to prove the sources lemmas correct, using only the raw sources. This can be done either automatically by Tamarin or manually in the interactive mode.
The idea behind a sources lemma is to provide more information regarding the origin of the message mentioned in the partial deconstruction, i.e., the one corresponding to the variable identified by the dashed green arrow. Going back to our example and assuming that:
R(aenc{’req’, I, x}pk(ltkR), x) is added as a label to the responder rule; and
I(aenc{’req’, I, n}pkR) is added as a label to the initiator rule,
a sources lemma could be as follows:
lemma typing [sources]: "All x m #i. R(m,x)@#i ==> ( (Ex #j. I(m)@#j & #j < #i) |(Ex #j. KU(x)@#j & #j < #i ))"
This lemma says that whenever the responder receives the value x inside a message m (at time point #i), either this message (actually a ciphertext) has been forged by the attacker who therefore knew x before, denoted KU(x), or it has been produced (for the first time) by another protocol rule, here the one denoted I(m). Indeed, a quick inspection of the protocol shows that here this is the only option to produce an output having the right format.
When generating the refined sources from the raw sources, Tamarin applies the sources lemmas. In this case, the sources lemma above will allow it to learn that is either a nonce (generated by the initiator role) or a message already known by the attacker. This solves the partial deconstruction as the previous sources will be refined into two refined sources. The first one is the case where the intruder learns the nonce generated by the initiator, by passing the initiator’s message to the responder, and then extracting the nonce like the variable above. However, Tamarin now knows that is not any value, but the initiator’s nonce. The second case will be discarded by Tamarin since, if the intruder already knew before, it is useless to extract it again.
Tamarin syntax and semantics
We explain here the syntax and semantics of Tamarin, as presented in [13,22], as necessary background for the remainder of the paper.
Term algebra
Cryptographic messages are represented by a (sorted) term algebra. In Tamarin, terms are all of sort and there are two incomparable subsorts and used to represent respectively fresh names (e.g. nonces or keys) and public names (e.g. agent names). We assume an infinite set of names of each sort and an infinite set of variables of each sort as well. A variable x of sort s is denoted . The sort is often omitted, that is, the variable x typically denotes a variable of sort . Each cryptographic primitive is represented by a function symbol that takes n arguments of sort resp. and returns a term of sort s. We assume given a signature Σ, i.e. a set of function symbols with their arities. Then the set of terms is built from the application of symbols of Σ to names and variables and is denoted . The set of variables occurring in a term t is denoted . A term is ground if it contains no variable. A substitution θ is grounding for t if is ground.
The standard primitives are often expressed by the signature
where all functions are of sort .
They model respectively symmetric encryption and decryption, asymmetric encryption and decryption, and concatenation and (left and right) projections.
The properties of the primitives are reflected through an equational theory E. In Tamarin, user defined equational theories are given as a convergent rewrite system. Tamarin additionally supports built-in theories such exclusive or [13] and a set of equations for Diffie–Hellman (DH) exponentiation [22]. The equality modulo associativity and commutativity () is denoted and the normal form of a term t, modulo , is denoted (we consider any representative of the normal form of t). Two terms and are unifiable (modulo ) if there exists a substitution θ such that . Positions of a term t are defined as usual considering operators as binary symbols. A subterm of t is a term such that for some position p.
Tamarin assumes equational theories that have the finite variant property [9], that is where all the instances of a given term follow a finite number of different patterns. Formally, a convergent equational theory E has the finite variant property if for any term t, there exists a finite number of substitutions such that, for any substitution θ, there is , there exists a substitution such that . A particular class of rewriting systems is the class of subterm rewriting system. A rewriting system is said subterm if it is defined by a set of equations of the form such that r is a subterm of l or a (public) constant. Many cryptographic primitives can be modeled by (convergent) subterm rewriting systems, such as signatures, symmetric and asymmetric encryption, pair, hash, etc. Our theoretical development only consider equational theories that can be defined by a subterm rewriting system, convergent modulo , that have the finite variant property. Tamarin is not limited to subterm equational theories, and actually our approach can be applied in this general setting too, relying on Tamarin to establish the correctness of the generated lemmas.
Orienting from left to right the equations below yields a subterm convergent rewrite system that is usually used to model concatenation and asymmetric encryption. Here, there is no symbol.
In what follows, we will consider sets and multisets. Given a multiset S, denotes the set of its elements. The symbol ⊆ denotes the set inclusion. We will write even if S and are multisets, which is then interpreted as . In contrast, denotes the multiset inclusion. Similarly, denotes the multiset union and the multiset difference.
Transition system
In Tamarin, a protocol execution is modeled as a transition system where a state contains a multiset of facts, representing the current knowledge of the attacker and the current steps of the protocol, for each agent and each session. Formally, we assume a set of fact symbols partitioned into linear and persistent fact symbols. A fact is an expression where and . Given a multiset of facts F, denotes the multiset of its linear facts while denotes the multiset of its persistent facts.
Linear facts represent resources that are consumed. Tamarin includes three pre-defined linear fact symbols: models the generation of a fresh name n, represents a message m sent over the network by a participant, and denotes that the adversary has sent message m, that can then be received by an agent of the protocol. Persistent facts represent facts that remain forever and are not consumed by rules. Tamarin includes the persistent fact symbol that models the knowledge of the attacker, as well as and that allow to distinguish between the terms built by the attacker and those obtained from listening to the network or by decomposing learned messages. Then the protocol may use other user defined facts, that can be either linear or persistent. The latter are denoted using the ! operator in front of the fact.
The protocol execution is specified through labelled multiset rewriting rules where are multisets of facts. The multiset l denotes the premises of the rule that need to be present in the state in order for the rule to be executed; a denotes the actions of the rule (later used to specify properties), while r contains the conclusions, added to the state. There are three kinds of rules.
Fresh name generation ()
This is the only rule that can produce facts of the form . Moreover, to ensure freshness, a distinct name n is used for each application.
Message deduction rules ()
They are pre-defined in Tamarin and represent the attacker’s actions.
model the fact that the attacker can learn any message sent by the protocol and conversely, may send any message of her knowledge. Note that this is the only rule where the predicate appears as an action of a rule. The rules
express respectively that the attacker can learn any public name and can create fresh name on his own. Finally, the attacker can extend his knowledge by applying function symbols. The intuitive rule is:
Actually, this rule is split into two cases in Tamarin, depending on whether the attacker is building a term, or decomposing it. Formally, for any substitution θ (in normal form), we consider the rule
when is in normal form. When the term reduces to a subterm of for some (remember that we only consider subterm theories), then we consider
where for all and . Intuitively, the deduction rule is annotated with when the attacker applies a “constructor” term such as an encryption and a pair. It can also be annotated with when the attacker applies a deconstructor (for example, a decryption), if the term cannot be further reduced (for example, the decryption fails). Conversely, the deduction rule is annotated with when the attacker decomposes a term. Finally, it is possible to switch from to thanks to the “coerce” rule:
for any message m in normal form that is not a pair.
Protocol rules
Then the protocol as well as additional attacker capabilities are specified through protocol rules, that are multiset rewriting rules that satisfy some conditions.
A protocol rule is a multiset rewriting rule such that
it does not contain fresh names and does not occur in r
, , , and do not occur in l
, , , do not occur in r
.
The first condition guarantees in particular that fresh names are only produced thanks to the fresh name generation rule. The last three rules are easily met by any rule modeling a protocol step.
Going back to our running example, the rule given in Section 2 is a protocol rule where and are user-defined persistent facts used to model generation of long-term keys. Actually, our model contains the following rule:
where is variable of sort , and is a variable of sort . This protocol rule represents the possibility to generate key pairs for any identity . The public part of the key is revealed to the attacker.
Execution traces
A set of protocol rules P induces a transition relation between states. We have if there exists a rule of the form and a grounding substitution θ such that
, the linear facts of should be present in S, with enough occurrences,
,
and . The linear facts of are removed and all the conclusion facts are added to the state.
Moreover, if the applied rule is the rule then and n must be a new name not used earlier. The execution of a protocol is simply modeled by a sequence of transitions. A trace of a protocol is the sequence of actions that appear in the execution. Formally, we have that:
Continuing Example 3, the protocol rule modeling key generation can be used twice (or even more) to generate two key pairs for two different identities leading to the following trace:
where , . Here and are names of sort whereas are public names of sort . This corresponds to the application of the Fresh rule followed by the protocol rule to obtain key material for the first agent A and then for a second agent B. The last rule corresponds to an application of an rule adding the public key of A to the knowledge of the attacker.
Properties
Security properties are expressed as properties on the traces of a protocol. Tamarin offers a first order logic to specify properties. Formulas make use of variables of a novel sort to reason about when a fact occurs and to be able to express that some event occurs before another one. The full syntax and semantics of the logic is provided in [22]. We provide here only informally the semantics of atomic formulas:
, where i is of sort , refers to the fact F that occurs in the ith element of the trace;
expresses that the timepoints i and j are equal;
expresses that timepoint i occurs before j;
says that and are equal (modulo the equational theory).
The first order logic is built from atomic formulas and closed by the boolean connectors ∨, ∧, and ¬, as well as the quantifications ∃ and ∀.
A set of protocol rules P satisfies a formula ϕ, denoted if, for any trace , then tr satisfies ϕ.
Continuing the running example, a typical lemma expressing nonce secrecy of the challenge is as follows: lemma nonce_secrecy: "not(Ex A B s #i #j. (SecretI(A, B, s)@#i & K(s)@#j))"
This requires us to annotate the rule of the Initiator role with the action fact SecretI. Then intuitively this lemma expresses that there does not exit any trace such that SecretI(A, B, s) occurs at stage i (for some A, B, and s) and the attacker knows s at stage j. If we consider only the three protocol rules mentioned so far (initiator’s rule, responder’s rule, and key generation), then this security property is satisfied. However, as expected, the same lemma is not satisfied as soon as we model corruption, for example with the following rule. rule Reveal_ltk: [!Ltk(xid, xsk)] --[RevLtk(xid)]-> [Out(xsk)]
Tamarin also allows to express diff-equivalence, a refined notion of equivalence. This can be used for example to state that a protocol preserves unlinkability, anonymity, or other privacy properties such as ballot privacy. For example, the fact that Alice remains anonymous is often expressed as the property that . This intuitively says that an adversary should not see the difference when Alice is playing protocol P or Bob is playing protocol P. The formal definition of diff-equivalence can be found in [22]. We do not need to provide it here as our automatically generated lemmas are simple trace properties and do not use diff-equivalence. Note however that our approach applies to protocols with diff-equivalence as well since our generated lemmas also helps Tamarin to terminate in the case of diff-equivalence properties.
Automatically generated sources lemmas
Whenever Tamarin fails to complete a deconstruction, we aim at providing the tool with a sources lemma that resolves the partial deconstruction. We formalise here our approach and prove it to be correct.
Definitions
We introduce the notion of protected term, which is any term that is headed by a function symbol that is not a pair (because we know the adversary can always open such terms) nor an symbol (simply because our heuristic does not apply to case of failures due to an theory).
A protected term t is a term whose head symbol is not nor an AC symbol. Given a term t and a variable x occurring in t, we say that is a deepest protected subterm w.r.t. x if is a protected term, subterm of t that contains x and such that one of the paths from the root of to x contains only pair symbols (except for head symbol at top level).
Intuitively, if is a deepest protected subterm w.r.t. x, then the only way to obtain is either by extracting it directly from some output, or by building it, in which case x is already known to the attacker.
Let . There are two deepest protected subterms w.r.t. x, namely t itself and .
We denote by the set of subterms of u that can be obtained from u simply by projecting. Formally, is formally defined as
Normalised traces. In order to keep track of the origin of a protected subterm, we need to assume that the shape of a term is not modified by the application of the equational theory. Fortunately, since we assume an equational theory with the finite variant property, it is possible to compute in advance the shapes of all the terms obtained after normalisation. Given a set of protocol rules P, Tamarin computes the variants of P such that, for any rule , for any substitution θ, there is and a substitution such that and is normalised, that is, for any fact occurring in , we have that . Moreover, for some σ. Tamarin considers only traces that are normalised, i.e. executions of the form and such that:
the execution involves only rules and substitutions θ such that is normalised;
pairs are always decomposed before being used, that is, if appears in then for any .2
This comes from the fact that, whenever the attacker learns a pair , she cannot directly convert it in since the coerce rule does not apply to terms headed with a pair. Hence it is necessary to decompose it first (with rules) and then reconstruct it (with rules).
We write if for any normalised trace tr of P, tr satisfies ϕ. Then, given a formula ϕ that does not contain the fact nor , we have if, and only if, , which is what is actually checked by Tamarin. This follows from the soundness of Tamarin [22].
In some cases, computing the variants of a protocol rule may introduce new variables on the right of the rule, and thus lead to rules that are not protocol rules (according to Definition 1).
The rule is a protocol rule. However, one of its variant is which is not a protocol rule according to Definition 1.
However, such cases correspond to badly defined protocols and Tamarin typically raises a warning in this case. Hence, in what follows, we consider well-formed protocol rules P, that is such that is still a set of protocol rules. In practice, protocol rules representing a protocol are indeed well-formed.
Algorithm
Given a set P of protocol rules, Tamarin first computes its variants . It then precomputes sources as already explained. Whenever Tamarin fails to complete a deconstruction, it returns the partial deconstruction. For the moment, assume that we can extract a rule of and a variable x for which the deconstruction has failed. In practice there might be multiple composed rules, as explained in Section 7.1, but the approach is similar. It must be the case that x appears in some fact of l.
For each deepest protected subterm t occurring in a rule of P, we assume new fact symbols and that will be used to further annotate the rules of . These facts will appear only in the sources lemmas we generate.
The sources lemma associated to a partial deconstruction on variable x and rule for protocol P is defined by Algorithm 1. Intuitively, we first look for any occurrence of x in the premisses of , under a (deepest) protected term and we annotate the rule with . Then we look for all facts in the conclusions of a rule that may have produced , that is that contain a term that can be unified with and we annotate those rules with . Finally, we generate the formula that says that if we have at some step i, then either x is already known to the attacker, that is holds at an earlier step, or y has been obtained from the protocol, that is holds at some earlier step.
Going back to our running example developped in Section 2, our algorithm will be applied on the rule Rule_R and the variable x.
The only deepest protected subterm w.r.t. x is aenc{’req’, I, x}pk(ltkR) and it plays the role of . Therefore, we annotate this rule with , and then we identify which fact may provide . Actually the only candidate is the encrypted term coming from the Rule_I given below: rule Rule_I: [ Fr(~n), !Pk(R, pkR),!Ltk($I, ltkI)] --[SecretI($I,R,~n)]-> [ Out(aenc{’req’,I, ~n}pkR)]
Therefore, an annotation is added to this rule. The resulting formula ϕ is exactly the one given by the algorithm, i.e.:
In the implementation, since it is not possible to use terms as indices of a fact, we use the position of the term inside the rule Rule_R as part of the fact name. The formula above alone allows us to get rid of the 6 partial deconstructions produced on this simple example, and the secrecy lemma, as well as the sources lemma itself, are proved automatically by Tamarin.
Soundness of our algorithm
We can show that under our assumptions the generated sources lemmas always hold, which explains why Tamarin is usually able to prove them.
Given a set of well-formed protocol rules P, a rule, a variable x occurring in, andbe the conjunction of formulas returned by, then for any, we have thatis satisfied by, that is.
Let P be a set of protocol rules, , and x a variable occurring in . Let be the formula returned by , and let . The rule is of the form and is of the form:
for some deepest protected term w.r.t. x. By definition of a deepest protected subterm, for some position and there are only pairs along the path (except at position ϵ).
Let tr be a normalised trace of . Let us show that tr satisfies .
Let i be such that for some terms . Then the ith applied rule must be a rule in such that is a subterm of some with for some and there are only pairs along the path (except at position ϵ):
Moreover, there exists a substitution in normal form (the one used to instantiate ) such that and . Since the trace is normalised, and . Let . Again, we have . Since is a subterm of and is not headed by an symbol, we have that m is a subterm of u (modulo ). Moreover by definition of the application of a rule.
Let be the first occurence of j such that m (modulo ) is a subterm of a fact in and consider the jth rule that has been applied.
Either this rule is a rule in of the form
and there exists in normal form (the substitution used to instantiate ) such that m (modulo ) is a subterm of . Since the trace is normalised, . Let be the position at which m occurs in , i.e. such that .
Either is a path of that does not end on a variable. Then with a protected subterm of .
We have that thus and are unifiable (modulo ) thus we have annotated , that is, , which concludes this case.
Or is a path of that ends on a variable or is not a path at all. Then there must exist a variable y in such that m (modulo ) is a subterm of . Then y also appears in some premise fact , thanks to the definition of a protocol rule and the fact that the variant rules are still protocol rules. Therefore m (modulo ) is a subterm of a fact in (since ), which contradicts the minimality of j.
Or the rule is a rule. Since m is a protected term, the rule cannot be nor since these two rules only generate names. By minimality of j, it cannot be the rule , nor , nor the rule either. So it must be a deduction rule, either in the version or in the version.
Either it is the rule
with in normal form. We have . Then, by minimality of j, and since m is not headed with an symbol, we must have , otherwise we would have that m is subterm of some hence subterm of or m is a constant, which cannot be the case since m is a protected subterm. Remember that is a subterm at position (for some ) of
such that there are only pairs along , that is, . Since the trace is normalised (i.e. pairs are decomposed before being used), we get that , that is . Now, by inspection of the rules, we notice that the only way to obtain in a state is through a rule annotated by , hence we can conclude that appears in one of the actions of an earlier rule.
Or the rule
has been applied, with that can be reduced at top level. Since the equational theory is a subterm theory, it must be the case that is a subterm of one of the , hence a subterm of a fact of , which contradicts the minimality of j.
This concludes the proof. □
Even if all the sources lemmas generated using our algorithm are correct, we will see in Section 7 that we make the choice to implement a slightly different version of our algorithm for practical reasons, in particular to avoid non-termination issues.
Improvement over the first algorithm
Unfortunately, the algorithm presented in Section 4 does not allow one to discard all partial deconstructions. In particular, it is useless to solve partial deconstructions that do not come from an encrypted term.
Motivation
We illustrate the weakness of this first algorithm through a simple example.
The first rule allows a user to send his password on a private channel (modelled using the fact Ch), and the second one can be used to model the fact that when a first authority receives such a password, she may send it to another authority for performing additional checks. The third rule allows one to model corruption: at some point a password may be leaked and revealed to the attacker.
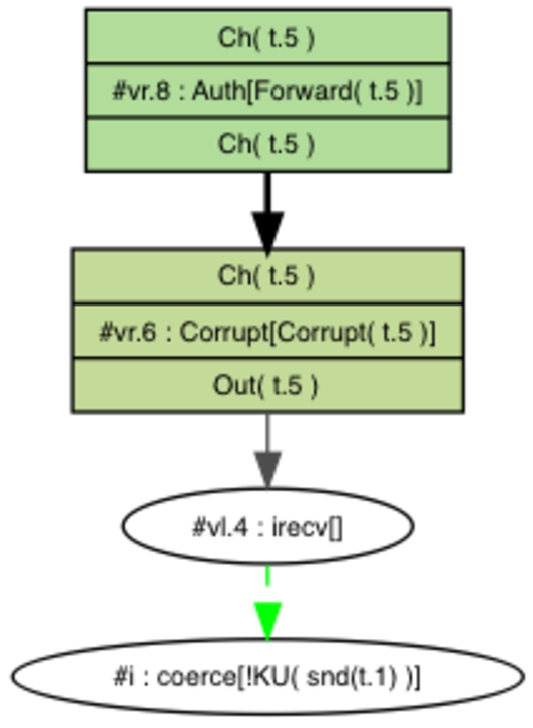
Example of a partial deconstruction.
On the above example, Tamarin will generate 3 partial deconstructions, one of them is reproduced in Fig. 2. Tamarin does not know anything about the contents of the variable , it is thus obliged to consider this case as a potential source for any value, and this will actually lead to non termination when trying to prove for instance a simple secrecy lemma as the one stated below:
lemma password_secrecy: " not( Ex #i x. Pwd(x)@i & (Ex #j. K(x) @ j) & not(Ex #r. Corrupt(x)@r) )"
It is easy to see that our algorithm will be of no help since there is no encrypted term involved in this protocol.
Algorithm
The sources lemma associated to a partial deconstruction on a variable x and a rule for protocol P are defined by Algorithm 2. Intuitively, we now consider any unprotected occurrence of x in the premisses of that occurs in a fact that is not an input, and we annotate the rule with . Then, we look for all facts in the conclusions of a rule that may have produced , that is, facts that can be unified with , and we annotate the rule with . We then generate the lemma as expected, that says that if we have at some step i, then holds at an earlier step. The reason why we do not need to consider the case where x is already known by the attacker is that we reason here on protocol facts, which cannot be accessed or modified by the attacker.
Going back to our running example developped in Section 6.1, we will apply our algorithm on rule Auth w.r.t. x. An annotation will be added on rule Auth, and the annotation will be added twice: one on SendPwd with as a parameter, and the other one on Auth with x as a parameter. Indeed, these two rules are the only ones producing a fact of the form .
The resulting sources lemma is as follows (with ):
This sources lemma is correct (as formally stated and proved in the theorem above). However, it does not allow Tamarin to generate the refined sources due to a loop on rule Auth. We will come back to this issue in Section 7.
We can show that under the same assumptions than Theorem 1, the sources lemmas generated by Algorithm 2 always hold, which explains why Tamarin is usually able to prove them. The proof follows the same lines as the one done for Theorem 1. Actually, its proof is easier since the fact (where F is a fact symbol) cannot be produced by the attacker.
Given a set of (well-formed) protocol rules P, a rule, a variable x occurring in, andbe the conjunction of formulas returned by, then for any, we have thatis satisfied by, that is.
Let P be a set of protocol rules, and a variable x occurring in , let be the formula returned by , and let . The rule is of the form and is of the form:
for some such that x is an unprotected subterm of some .
Let tr be a normalised trace of . Let us show that tr satisfies .
Let i be such that for some terms . Then the ith applied rule must be an instance of a rule in such that:
Moreover, there exists a substitution in normal form (the one used to instantiate ) such that for any . Since the trace is normalised, for any . We have that by definition of the application of a rule.
Let be the first occurrence of j such that is a fact in and consider the rule that has been applied. This rule is necessarily an instance of a rule of the form:
and there exists in normal form (the substitution used to instantiate ) such that for any . Since the trace is normalised, for any . We have that for any , thus and are unifiable (modulo ) thus we have annotated , that is , which concludes this case. □
Implementation and experimental evaluation
We have implemented our approach in Tamarin version 1.6.1 [20]. The automatic generation of sources lemmas is activated using the command line option —auto-sources. When Tamarin is called, it will first load the theory and run the pre-computations normally (in particular it computes rule variants and sources). If Tamarin is called using —auto-sources, and if the theory does not contain a sources lemma but has partial deconstructions, our new algorithm(s) are executed on the computed rule variants to generate a new sources lemma, which is then added to the theory, as well as the required rule annotations. In the interactive mode, the user can inspect the generated lemmas and annotations, and prove lemmas as usual. He can also download the modified theory if he wants to export the lemma, or modify it. In the automatic mode, Tamarin directly tries to prove the generated sources lemma. When showing the results, Tamarin displays the sources lemma among the other lemmas, and whether it managed to prove it.
Implementation
Dealing with composed rules. Actually, during the precomputations, Tamarin might compute the composition of several rules. For example, when a rule depends on a rule in the sense that can only be executed if has been executed previously, Tamarin will return the composition of both, not only . This yields bigger steps and it allows Tamarin to prove lemmas more quickly.
Thus, the sources computed by Tamarin are actually composed variants of initial protocol rules. Formally, given two rules and , we define the composition of and w.r.t. θ, denoted as the rule defined as follows:
We denote the rule obtained by iterating compositions: . Since the rules do not share any variable, θ is just the union of substitutions where the domain of is the set of variables of . It is easy to check that compositions of protocol rules yield protocol rules. Not all compositions are computed by Tamarin, but we do not need to characterize which compositions are considered exactly. We simply show that any sources lemma generated from a composed rule is also sound.
Algorithm 3 describes how to generate a sources lemma from a composed rule. The idea is simply to identify, given a variable x, for which the partial deconstruction is incomplete, at which positions x appears in the some rule used for composition. We then generate the sources lemmas based on this rule. Note that Algorithm 3 is well defined only if (resp. ) is called only in case is a variable. However, this follows from the fact that is a variable (with the notations of Algorithm 3).
Note that there are two subtleties here: First, in the first part of the algorithm concerning the protected subterms (), we examine the premises of all rules inside the composed rule for occurrences of the variable x. For the second part, concerning the facts (), we only examine the premises of the composed rule, meaning that if the variable occurs in the premise of an initial rule which was already solved during the composition, this occurrence is ignored. This turns out to be sufficient to resolve the partial deconstructions, and simplifies the generated lemmas. Second, we only use the second algorithm if the first one did not produce a lemma for a given variable x. Again, this is sufficient and generates simpler lemmas which are easier to prove for Tamarin.
Given a set of well-formed protocol rules P, a composed rulewith, a variable x occurring in, andbe the conjunction of formulas returned by, then for any, we have thatis satisfied by, that is.
The correctness of Algorithm 3 is a direct consequence of Theorems 1 and 2. Indeed, let be the formula returned by , and . Then is actually an element of the conjunction of the formula returned by or for some and some variable of . Applying Theorem 1 (or Theorem 2, respectively), we have that , hence the conclusion. □
Heuristic and Optimizations. Our first experiments using Algorithm 3 showed that, for some examples, the generated lemmas, while true, caused Tamarin to loop in the precomputations. This happened when the algorithm considered the case where a fact in the premises of a rule might have been produced by a fact in the conclusion of the same rule, as in Example 9. Hence, we have implemented an additional check that ignores this case, should it arise. For instance, in Example 9, the rule Auth is not annotated with , although the conclusion fact unifies with its premise fact. Note that in this example the generated lemma is still true, as the premise and conclusion are actually equal, and Tamarin successfully proves the lemma.
In general, this additional condition means that the generated lemmas could potentially be false, however we did not observe this in practice. On the contrary, the examples that looped can now be proven correct, as described for Example 9. Also note that this does not contradict our theorems, as our lemmas are not minimal – we consider potentially too many cases, so removing some (unnecessary) ones can still result in a correct lemma.
Finally, we implemented a small optimization: in the case where our algorithm is unable to find any matching conclusions (i.e., no annotation is placed), we simplify the generated formula by replacing the by ⊥. For example, instead of
we obtain
This is obviously correct if there are no annotations.
Evaluation
SPORE examples. “Partial dec.” indicates the number of partial deconstructions, “resolved” indicates whether our auto-generated lemmas resolve them, and can be proven correct by Tamarin. “Automatic” means that our auto-generated lemmas are then sufficient to directly prove or disprove the desired security properties
Protocol Name
Partial Dec.
Resolved
Automatic
Time
Andrew Secure RPC
14
45.5 s
Modified Andrew Secure RPC
21
135.3 s
BAN Concrete Andrew Secure RPC
0
–
10.3 s
Lowe modified BAN Andrew Secure RPC
0
–
31.8 s
CCITT 1
0
–
0.9 s
CCITT 1c
0
–
1.2 s
CCITT 3
0
–
181.4 s
CCITT 3 BAN
0
–
4.0 s
Denning Sacco Secret Key
5
0.8 s
Denning Sacco Secret Key – Lowe
6
2.8 s
Needham Schroeder Secret Key
14
3.4 s
Amended Needham Schroeder Secret Key
21
7.1 s
Otway Rees
10
8.5 s
SpliceAS
10
5.6 s
SpliceAS 2
10
6.7 s
SpliceAS 3
10
7.1 s
Wide Mouthed Frog
5
0.6 s
Wide Mouthed Frog Lowe
14
3.3 s
WooLam Pi f
5
0.7 s
Yahalom
15
3.4 s
Yahalom – BAN
5
0.9 s
Yahalom – Lowe
21
2.4 s
To evaluate the effectiveness of our approach, we selected several classical examples from the SPORE library of cryptographic protocols [25] and checked for standard properties such as secrecy of the exchanged key and mutual (injective and non-injective) authentication. Because of partial deconstructions, many of them were not entirely automatically verifiable in Tamarin previously (except for extremely simple examples such as CCITT with only one message). The results are presented in Table 1, the Tamarin models are available in the directory examples/features/auto-sources/spore of the Tamarin repository [20]. Our approach succeeded in all cases.
Examples from Tamarin repository. “New” and “previous” verification times indicate the total verification time of all lemmas, either with the auto-generated lemma, or the manual sources lemma (if provided).
The generated lemma removes all partial deconstructions and is automatically proven correct by Tamarin.
The generated lemma removes all partial deconstructions, however Tamarin does not terminate while trying to prove its correctness automatically.
The generated lemma fails to remove all partial deconstructions.
Automatic:
All other lemmas are automatically proven or disproven by Tamarin, without further annotations or special proof heuristics.
Tamarin fails to prove (some of) the other lemmas without additional annotations or special proof heuristics.
The sources lemma needs to be annotated with reuse for
3
the following lemmas to be proven automatically.
The file contains further intermediate lemmas annotated with reuse.
The file requires the use of a special proof heuristic.
The original file did not contain a sources lemma, although partial deconstructions are present.
Tamarin does not terminate while trying to prove the other lemmas using the generated lemma.
Tamarin does not terminate while trying to compute the refined sources using the generated lemma.
To see whether our approach works on more complicated examples, we selected all files from the Tamarin github repository [20] that contained lemmas annotated with sources, and that were not marked as “experimental”, “work in progress”, or “manual”. It turned out that in some cases these examples did not actually contain any partial deconstructions, and that these “sources” lemmas were actually used to prove other protocol invariants. As our approach is only meant to handle partial deconstructions, we removed these examples from the set. Table 2 summarizes our results on the remaining examples, the files can be found in the directory examples/features/auto-sources/tamarin-repo of the Tamarin repository [20].
It turns out that our algorithm still succeeds in generating successful sources lemmas in the majority of cases, in the sense that the sources lemma resolve all the partial deconstructions and can be proved correct by Tamarin. Our examples include protocols with equivalence properties and SAPIC-generated3
SAPIC translates from applied pi models to Tamarin theories.
theories. However, as the examples are more complex, even with a correct sources lemma, Tamarin does not always succeed in proving all other lemmas fully automatically.
Note also that although most examples are handled by Algorithm 1, Algorithm 2 applies for some more complex examples (OpenID Connect, Alethea, 5G AKA, PKCS11 AEAD/SIV). Again, the algorithm is successful in resolving the partial deconstructions in most cases, even though many of the files do not become fully automatic. However, for example in the case of Alethea, all following lemmas can be proven using the same heuristics as used in the initial files. Note also that two Alethea models initially did not contain a sources lemma although partial deconstructions are present, and by using our auto-generated lemmas we were able to improve the verification times slightly. In the first version of our work [10], our approach failed on these examples as we only used Algorithm 1.
We also encountered a few examples (most 5G AKA models and TPM Envelope) where the generated lemmas are sufficient to resolve the partial deconstructions, but Tamarin does not succeed in (automatically) proving those lemmas correct. This is probably due to the complexity of the models – the initial files contained stronger invariants as sources lemmas and/or used special heuristics to prove them. In the case of PKCS11 AEAD/SIV, the generated lemma causes a loop in the precomputations similarly to the case of a rule where its conclusion matches its premise, but this time involving multiple intermediate rules. This causes our safeguard of avoiding unifications within the rule itself to fail in avoiding the problem. We tried to manually break the loop by removing the problematic annotation, but then the lemma becomes incorrect. Again, this model seems to require a stronger lemma.
We also analysed the examples where our algorithm failed to generate a correct sources lemma. The reasons turned out to be either a too complex equational theory (e.g., FOO and Okamoto, using blind signatures, or NSLPK3XOR and Chaum using XOR), or a particular modeling used in SAPIC that causes rules to have unbound variables (PKCS11-templates). Both cases are out of scope for our approach, as the files violate our initial assumptions on the equational theories or the well-formedness of the rules. It is thus expected that our generated lemmas do not solve the partial deconstructions, and even that they may be wrong. In the NSLPK3XOR example, the generated sources lemma helps a bit by discarding some partial deconstructions (the number of partial deconstructions went down from 24 to 12). However, in all other examples, this is not the case, and the number of partial deconstruction even increases. This can happen if the lemma causes the existing partial deconstructions to occur repeatedly instead of removing them.
When our approach succeeds, the verification times are close to timings measured using the manual sources lemmas. All timings have been measured on a standard laptop (Core i7, 16 GB RAM, Ubuntu 20.04).
Conclusion
We have provided a technique that allows to automatically generate sources lemmas in Tamarin, which otherwise had to be written by the user. In return, most simple protocols can now be analyzed automatically with Tamarin.
As future work, it should be possible to further improve the level of automation. First, in several cases where our sources lemmas solve the partial deconstructions but are not yet sufficient to prove the security properties specified by the user, we are actually close to full automation. What is missing is to indicate to Tamarin that it should reuse one of the properties (e.g. secrecy of some long-term key) to prove another property (e.g. authentication). One interesting direction is to investigate how to automate these “re-use” annotations, without increasing the complexity of the tool.
Our result holds for subterm convergent theories (modulo AC) that have the finite variant property. However, our algorithm does not generate lemmas for terms headed with an AC symbol (for example exclusive or) as the resulting lemmas would be false in most cases. Hence, manual sources lemmas are still necessary. A future research direction is to explore how to extend our result to tackle this case, which may require to write more complex sources lemmas, e.g. to account for all possible decompositions induced by the exclusive or operator.
Thanks to our sources lemma, the automation of Tamarin has improved, in particular on simple protocols. It would be interesting to compare extensively the tools ProVerif and Tamarin, in order to identify on which cases they are both automatic, and on which kind of protocols, one of the two tools is more likely to conclude automatically. This should also provide directions to improve the automation of both tools.
Footnotes
Acknowledgments
This work has been partially supported by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program (grant agreement No 714955-POPSTAR and grant agreement No 645865-SPOOC), as well as from the French National Research Agency (ANR) under the projects TECAP and SEVERITAS.
Tamarin source of our running examples
These files are also available on our fork of the Tamarin github repository [20].
theory runningAlgo2begin/*We formalize the following password-based protocol 1. U -> A1: pw 2. A1 -> A2: pwThe two first exchanges are done on a private channel.This corresponds to the fact the password is sent on aprivate channel to an authority A1, and then forwardedto another authority A2.We also add a rule to model corruption.*/rule SendPwd: [ Fr(~pw) ] --[ Pwd(~pw) ]-> [ Ch(~pw) ]rule Auth: [ Ch(x) ] --[ Forward(x) ]-> [ Ch(x) ]rule Corrupt: [ Ch(x) ] --[ Corrupt(x) ]-> [ Out(x) ]lemma password_secrecy: "not( Ex #i x. Pwd(x)@i & (Ex #j. K(x) @ j) & not(Ex #r. Corrupt(x)@r) )"end
References
1.
A.Armando, D.Basin, Y.Boichut, Y.Chevalier, L.Compagna, J.Cuellar, P.Hankes Drielsma, P.-C.Héam, O.Kouchnarenko, J.Mantovani, S.Mödersheim, D.von Oheimb, M.Rusinowitch, J.Santiago, M.Turuani, L.Viganò and L.Vigneron, The AVISPA tool for the automated validation of Internet security protocols and applications, in: 17th International Conference on Computer Aided Verification, CAV’2005, K.Etessami and S.Rajamani, eds, Lecture Notes in Computer Science, Vol. 3576, Springer, Edinburgh, Scotland, 2005, pp. 281–285.
2.
D.Basin, J.Dreier, L.Hirschi, S.Radomirovic, R.Sasse and V.Stettler, A Formal Analysis of 5G Authentication, in: 25th ACM Conference on Computer and Communications Security (CCS’18), 2018.
3.
D.Basin, J.Dreier and R.Sasse, Automated symbolic proofs of observational equivalence, in: 22nd ACM SIGSAC Conference on Computer and Communications Security (ACM CCS 2015), ACM, Denver, United States, 2015, pp. 1144–1155.
4.
D.A.Basin, M.Keller, S.Radomirovic and R.Sasse, Alice and Bob meet equational theories, in: Logic, Rewriting, and Concurrency – Essays Dedicated to José Meseguer on the Occasion of His 65th Birthday, N.Martí-Oliet, P.C.Ölveczky and C.L.Talcott, eds, Lecture Notes in Computer Science, Vol. 9200, Springer, 2015, pp. 160–180. doi:10.1007/978-3-319-23165-5_7.
5.
K.Bhargavan, B.Blanchet and N.Kobeissi, Verified models and reference implementations for the TLS 1.3 standard candidate, in: IEEE Symposium on Security and Privacy (S&P’17), San Jose, CA, 2017, pp. 483–503.
6.
B.Blanchet, An efficient cryptographic protocol verifier based on prolog rules, in: 14th IEEE Computer Security Foundations Workshop (CSFW-14), IEEE Computer Society, Cape Breton, Nova, Scotia, Canada, 2001, pp. 82–96.
7.
B.Blanchet, Symbolic and computational mechanized verification of the ARINC823 avionic protocols, in: 30th IEEE Computer Security Foundations Symposium (CSF’17), Santa Barbara, CA, USA, 2017, pp. 68–82.
8.
V.Cheval, S.Kremer and I.Rakotonirina, DEEPSEC: Deciding equivalence properties in security protocols – theory and practice, in: Proceedings of the 39th IEEE Symposium on Security and Privacy (S&P’18), IEEE Computer Society Press, 2018, pp. 525–542.
9.
H.Comon-Lundh and S.Delaune, The finite variant property: How to get rid of some algebraic properties, in: Proc. 16th International Conference on Rewriting Techniques and Applications (RTA’05), LNCS, Vol. 3467, Springer, Nara, Japan, 2005, pp. 294–307.
10.
V.Cortier, S.Delaune and J.Dreier, Automatic generation of sources lemmas in Tamarin: Towards automatic proofs of security protocols, in: 25th European Symposium on Research in Computer Security, ESORICS 2020, Guildford, UK, September 14–18, 2020, Proceedings, Part II, Vol. 12309, Guilford, United Kingdom, 2020, pp. 3–22.
11.
V.Cortier, D.Galindo and M.Turuani, A formal analysis of the Neuchâtel e-voting protocol, in: 3rd IEEE European Symposium on Security and Privacy (EuroSP’18), London, UK, 2018, pp. 430–442.
12.
J.Dreier, C.Duménil, S.Kremer and R.Sasse, Beyond subterm-convergent equational theories in automated verification of stateful protocols, in: POST 2017 – 6th International Conference on Principles of Security and Trust, Proceedings of the 6th International Conference on Principles of Security and Trust, Vol. 10204, Springer, Uppsala, Sweden, 2017, pp. 117–140.
13.
J.Dreier, L.Hirschi, S.Radomirovic and R.Sasse, Automated unbounded verification of stateful cryptographic protocols with exclusive OR, in: CSF 2018, 2018, pp. 359–373.
14.
J.Dreier, L.Hirschi, S.Radomirović and R.Sasse, Verification of stateful cryptographic protocols with exclusive OR, Journal of Computer Security28(1) (2020), 1–34. doi:10.3233/JCS-191358.
15.
N.Durgin, P.Lincoln, J.Mitchell and A.Scedrov, Undecidability of bounded security protocols, in: Workshop on Formal Methods and Security Protocols, Trento, Italia, 1999.
16.
S.Escobar, C.Meadows and J.Meseguer, A rewriting-based inference system for the NRL protocol analyzer: Grammar generation, in: ACM Workshop on Formal Methods in Security Engineering (FMSE’05), 2005, pp. 1–12.
17.
S.Escobar, C.Meadows and J.Meseguer, A rewriting-based inference system for the NRL protocol analyzer and its meta-logical properties, Theoretical Computer Science367(1–2) (2006), 162–202. doi:10.1016/j.tcs.2006.08.035.
18.
G.Girol, L.Hirschi, R.Sasse, D.Jackson, C.Cremers and D.Basin, A Spectral Analysis of Noise: A Comprehensive, Automated, Formal Analysis of Diffie–Hellman Protocols, in: Usenix Security, 2020.
19.
S.Kremer and R.Künnemann, Automated analysis of security protocols with global state, J. Comput. Secur.24(5) (2016), 583–616. doi:10.3233/JCS-160556.
20.
Main source code repository of the Tamarin prover for security protocol verification, Accessed on 12/03/2021.
21.
S.Meier, B.Schmidt, C.Cremers and D.Basin, The TAMARIN prover for the symbolic analysis of security protocols, in: Computer Aided Verification, 25th International Conference, CAV 2013, Proc., LNCS, Vol. 8044, Springer, Princeton, USA, 2013, pp. 696–701.
22.
B.Schmidt, S.Meier, C.J.F.Cremers and D.A.Basin, Automated analysis of Diffie–Hellman protocols and advanced security properties, in: CSF 2012, 2012, pp. 78–94.
23.
B.Schmidt, R.Sasse, C.Cremers and D.Basin, Automated verification of group key agreement protocols, in: IEEE Symposium on Security and Privacy (S&P’14), 2014.
24.
B.Schmidt, R.Sasse, C.Cremers and D.Basin, Automated verification of group key agreement protocols, in: 2014 IEEE Symposium on Security and Privacy, 2014, pp. 179–194. doi:10.1109/SP.2014.19.
25.
Security Protocols Open Repository, Accessed on 04/24/2020.
26.
A.Tiu and J.E.Dawson, Automating open bisimulation checking for the spi calculus, in: Proc. 23rd IEEE Computer Security Foundations Symposium (CSF’10), 2010, pp. 307–321.
27.
Y.Xiong, C.Su, W.Huang, F.Miao, W.Wang and H.Ouyang, SmartVerif: Push the limit of automation capability of verifying security protocols by dynamic strategies, in: 29th USENIX Security Symposium (USENIX Security 20), USENIX Association, 2020, pp. 253–270, https://www.usenix.org/conference/usenixsecurity20/presentation/xiong. ISBN 978-1-939133-17-5.




 The generated lemma removes all partial deconstructions and is automatically proven correct by
The generated lemma removes all partial deconstructions and is automatically proven correct by  The generated lemma removes all partial deconstructions, however
The generated lemma removes all partial deconstructions, however  The generated lemma fails to remove all partial deconstructions.
The generated lemma fails to remove all partial deconstructions. All other lemmas are automatically proven or disproven by
All other lemmas are automatically proven or disproven by 