Many breakthroughs on security and privacy-preserving techniques have emerged to mitigate the trust loss of cloud hosting environment caused by various types of attacks. To enhance memory-level security of multi-keyword fuzzy search, a widely occurred query request, we take the initiative to apply Trusted Execution Environment (a.k.a TEE) technology to our protocol design which provides hardware-based tamper-proof enclaves. Then we propose the Edit Distance-based Obfuscation Mechanism to further protect the query process executed outside TEE against access pattern leakage. With concerns of practicality and performance, we also propose the two-layer fuzzy index structure and Trend-aware Cache. The former addresses the space limitation of TEE memory for searching large datasets, while the latter optimizes the cache utility of TEE with trend-aware coordinator to effectively reduce the communication overhead.
With the prosperity of cloud computing, the studies of privacy preserving data access protocols in cloud hosting environment become increasingly significant and attractive. The concerns of data security and privacy have been widely involved in the communication among data owners, authorized data users, and the cloud platforms. Under this communication model, the core security issues generally consist of data confidentiality in cloud storage, the establishment of trusted computing and the secure query request processing. In either of these aspects, the cloud platforms tend to be an untrusted or at least a semi-honest party. Overlooking from previous researches, the key-based data encryption is imposed to guarantee data confidentiality and maintain the utility of data owners/users as preliminary solutions. To further enrich and upgrade the cloud service, novel cryptographic schemes, such as fully homeomorphic encryption [19] and zero-knowledge proof [5,21,56], are proposed for trust computing. In the scenario of query processing, searchable encryption schemes [10,14], Private Information Retrieval (PIR) technologies [11], query obfuscation schemes [22] and oblivious data retrieval protocols [20,47] are adopted to cope with multiple types of security and privacy threats which naturally exist in cloud environment. For different types of data, special privacy-preserving schemes are provided, such as [25,26] that designed for location-base data. However, these security schemes usually generate large overhead in both computational and bandwidth costs which dramatically reduce the efficiency of query processing. Unfortunately, currently no general solution is claimed to be capable of balancing the tradeoff between security yields and efficiency loss for all types of queries due to the differences in the characteristics of data, the accuracy requirements of query results, and the demanded levels of security. Fortunately, it is still desirable and feasible to find an optimal design for a particular type of query.
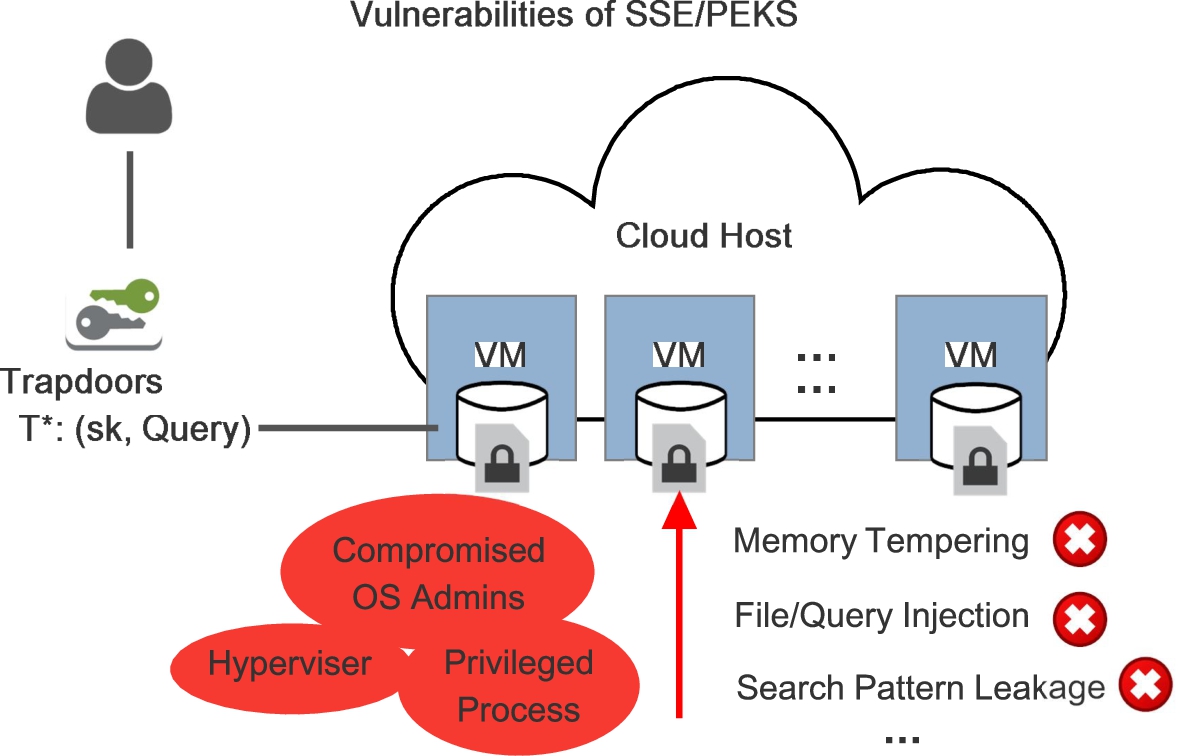
Unsolved vulnerabilities of SSE/PEKS.
In this paper, we propose the OTKI-F protocol, a fast oblivious trend-aware keyword index with fuzzy search capability over the encrypted document data. To clarify the design goals of our protocol, we decompose the research problem into three issues and introduce them as below.
Trustworthy multi-keyword fuzzy searching over encrypted data on cloud. The fuzzy keyword searching offers convenience to data users in many aspects, such as disposal of typos, uncertainty allowance in queries, and inspiring extra searching results. In many scenarios, such search services are privately delivered to authorized data users, e.g., company staff, organization members, and consortiums, through untrusted cloud platforms. Though massive efforts, represented by Searchable Symmetric Encryption (SSE) and Public-Key Encryption with Keyword Search (PEKS), have been developed to improve the security of query processes, the cloud platforms encounter new security challenges from time to time, as illustrated in Fig. 1. To the best of our knowledge, the existing privacy-preserving fuzzy keyword search protocols merely take the compromised cloud infrastructures into account. The searching process for candidate fuzzy keyword trapdoors, which is the core step in fuzzy keyword search schemes, is vulnerable to such security threats. As different from the trapdoor entries which can be protected by encryption approaches and hash functions, if this searching process is intervened, the attackers can successfully tamper with the query result withouts being detected. Fortunately, recent researches of hardware-base security technologies [1,28,33] offer near-ideal solutions for these hidden dangers, although they are still imperfect in terms of practicality. As a flagship product, the trust executive environment (TEE) of Intel SGX eliminates the threats of these newborn attack methods conducting memory tampering or monitoring via privileged processes, compromised OS administrators, and VM hypervisors (as further introduced in Section 2.2). Moreover, inside TEE, the search can be efficiently processed over a plaintext keyword index, which can be further sorted for fast searching, only at the cost of an additional user-to-cloud attestation procedure. With the aid of IntelSGX, we are able to implement a fuzzy keyword index addressing such security threats from essence. The most challenging problem in our design is the limitation of enclave memory. We solve the problem by introducing a separate-type index structure to load the fuzzy trapdoors (i.e. entries of keyword index) on demand, while only maintain a group of secondary indexes in the enclave to search such candidate trapdoors (as seen in Section 3.3).
Memory access pattern hiding in untrusted memory. With the concern of large-scale datasets and the large number of demanded keywords, the enclave space cannot cache all the entries of keyword index. The coordination between the enclave and untrusted main memory is necessary. Consequently, the access patterns are left on main memory which can be monitored by semi-honest adversaries on cloud platform for valuable information. Such leakage, includes the access frequency to the same block, the occurrence of the same batch of keyword indexes, and other patterns which can help the attackers to explore sensitive information about user behavior, ‘hotness’ of the words, etc. Moreover, such analytical attacks are far more convenient to conduct than CPA-formed Keyword Guessing Attack (KGA) [9]. To overcome this, we propose an edit distance-based obfuscation mechanism (as seen in Section 3.4) to prevent the adversaries from deriving useful information from observing the access pattern of untrusted memory.
Responses to the change of searching trend to accelerate real-time keyword queries. From the observation of keyword searching, the query service shared in a relatively stable cluster of data users tends to show continuous iteration of a set of hot keywords along with the timeline. To speed up the query processing associated with the current popular keywords, we make full use of the enclave memory to selectively cache the keyword indexes. The changes in the prevalence of keywords are recorded by the proposed Trend-aware Cache which periodically notifies the enclave to load in the popular fuzzy indexes and evict the aged ones. The detailed mechanism is introduced in Section 3.5.
To summarize, our main contributions of this paper are as follows.
Leveraging TEE technology, we design a secure protocol for fuzzy multi-keyword queries to resist the threats in cloud environment.
In concern of access pattern leakage, we propose a specialized ED-based Obfuscation Scheme (EDOS) upon fuzzy query processors to alleviate the threats of relevant analytic attacks.
We optimize the protocol with novel mechanisms, i.e. Two-layer Fuzzy Index(TFI) and Trend-aware Cache (TAC), to enhance system practicality as well as efficiency.
We conduct intensive experiments on the real-world datasets to demonstrate our security improvement and functional yields compared with the baseline solution.
The rest of the paper is organized as follows. Some preliminaries of fuzzy keyword queries over encrypted data and TEE technology are introduced in Section 2. We illustrate our system design and the proposed feature mechanisms in Section 3, followed by the analytic discussions on security model in Section 4. Our experimental results are demonstrated in Section 5 and comparative studies with related works are made in Section 6. In Section 7 we conclude this paper.
Preliminaries
In this section, we introduce the fundamental technologies and baseline solutions to which we reference in our research. Some notations related to this work are summarized in Table 1.
Notations and symbols
Symbol
Definition
Fuzzy Multi-keyword Search over Encrypted Data
W
The set of exact keywords of given dataset
Inverted Index of given W to
Edit distance from fuzzy keyword to exact keyword
Trapdoor function of keyword
in OTKI-F
Distance scaler
The distance scaler of query
keyword index, secondary index
Encrypted form of
fuzzy index group with edit distance d to
Searching results of k-th querying keyword
r
Recession rate of each non-matched time interval
Fuzzy keyword search over encrypted document data
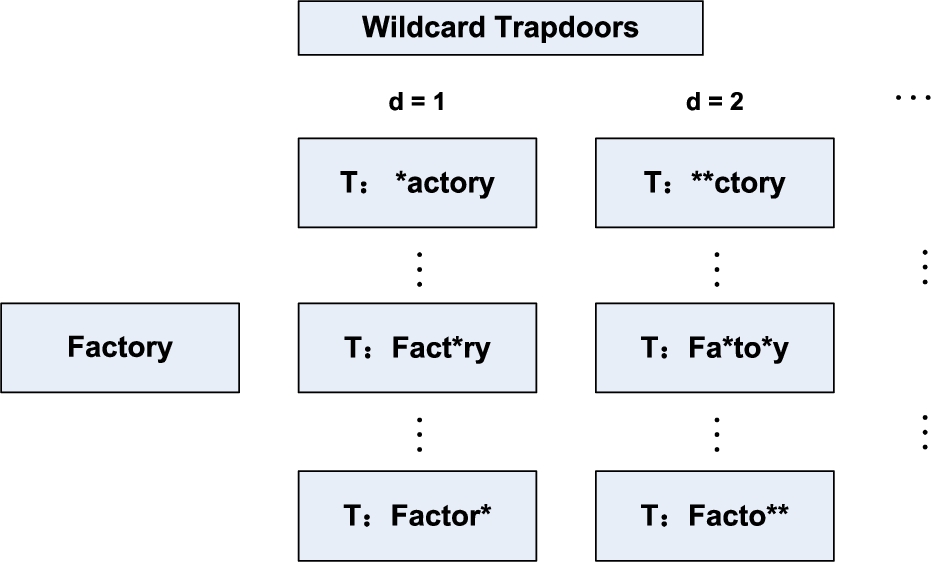
The keyword search over encrypted data allows authorized data users to issue queries to data storage via trapdoor functions while avoiding revealing the keyword-to-results mappings to potential adversaries. On the other hand, the fuzzy searching brings extra advantages in practice over the exact or Boolean keyword search [24] by providing resilience to the typos in keyword inputs. To support fuzzy searching, a straightforward solution is to expand each original keywords into augmented groups that include all similar keywords of them. In previous studies [37,46], the degree of similarity is defined as the edit distance (ED), whose value indicates the number of letter-wise differences to the original keyword. It is noteworthy that, the numbers of trapdoors required to support such fuzzy search increase exponentially with the pre-configured ED, i.e., the coefficient of growth on the number of trapdoors for alphabet text is , where d is the edit distance and l is the length of original keyword. To reduce this number, Li et al. propose the wildcard fuzzy set [37]. As illustrated in Fig. 2, they index the fuzzy keywords with the same edit distance d and the positions of letter-wise differences as a trapdoor. Though the wildcard fuzzy set and its variants have narrowed down the size of fuzzy indexes, it cannot scale well to large document databases where each index entry can contain overwhelmingly large number of encrypted document IDs with fuzzy keywords sharing the same d and positions.
Wildcard fuzzy index.
IntelSGX – trusted execution environment
A trusted execution environment (TEE) is an isolated environment not accessible by the operating system where an application can run its code and lock its sensitive data [13]. A TEE in Intel SGX technology is called an ‘Enclave’, which is executed in processor reserved memory (PRM). The sealed application code segments and accessory data in the Enclave are encrypted and signed by a key locked inside the Hardware Security Module (HSM). To serve the authorized users of TEE applications, IntelSGX provides remote attestation [32] to assert that the launched program code is not unexpectedly modified [2]. The remote entity requests Intel Attestation Service (IAS) to verify the enclave quote which is signed by the platform’s Enhanced Privacy ID (EPID) before communicating with the applications. Though regarded as state-of-the-art TEE technology, IntelSGX shows limitations in some aspects. First, the current SGX version (1.0) has rigorous limitations on computing resources in Enclave. Notably, the maximum heap size for an SGX Enclave is only about 90 MB [42] in some mainstream OS platforms and cannot be inter-relocated with untrusted memory. Furthermore, due to the independence of OS, the enclave forbids disk I/O and most of the syscalls. Therefore, the data retrieved from disk need extra security measures [13].
OTKI-F protocol
In this section, we present our OTKI-F protocol for index-based multi-keyword fuzzy search using TEE. We first introduce the system model and overall algorithm, then provide detailed discussion of the three featured enhancements on privacy preservation and query performance.
System and security model
As shown in Fig. 3, the system model consists of three parties, i.e. data owner, data users, and cloud server. Data owner outsources her document database to the cloud server, which provides keyword search service 1
In this paper, we assume the keyword search only returns the topmost matched documents.
to data users. In this model, the data owner does not trust the cloud server and thus encrypts the database before outsourcing. An adversary can be either ‘hostile’ attackers or ‘honest-but-curious’ observers. A ‘hostile’ attacker can tamper with the query protocol to recover the encrypted data. On the other hand, an ‘honest-but-curious’ observer learns sensitive information from the memory access pattern of query execution.
More specifically, a cloud server consists of a variety of components including the IntelSGX enclave. We trust the IntelSGX enclave and its validated communication channel with outside parties. All other components, such as the OS, hypervisor, other active processes as well as all levels of memory storage are not untrusted. Note that IntelSGX is known to be vulnerable to several side-channel attacks [8,27,35], but since most of them require strong assumption on the attacker and workload, we do not take them into consideration in this paper. To summarize, our memory-secure keyword fuzzy search can be defined as follows.
(Memory-secure keyword fuzzy search).
A fuzzy query is processed under an untrusted environment E, leaving a series of access pattern and returning a result set R containing the keyword trapdoors. An adversary A has full access to all levels of memory in E. A fuzzy query processing protocol is memory-secure in E, if it simultaneously satisfies the following 3 conditions: (i) The result set R is always a correct answer of the trapdoor searching. (ii) During the search, A can only obtain the query statement of and the result set R in an encrypted form. (iii) Let denote a batch of such queries. For either two queries , if they are semantically same, i.e. , the probability that they show the same series of access pattern to A always suffices . where . is a trivial probability.
We will give the security proof of OTKI-F protocol against this definition in Section 4.
OTKI-F overview
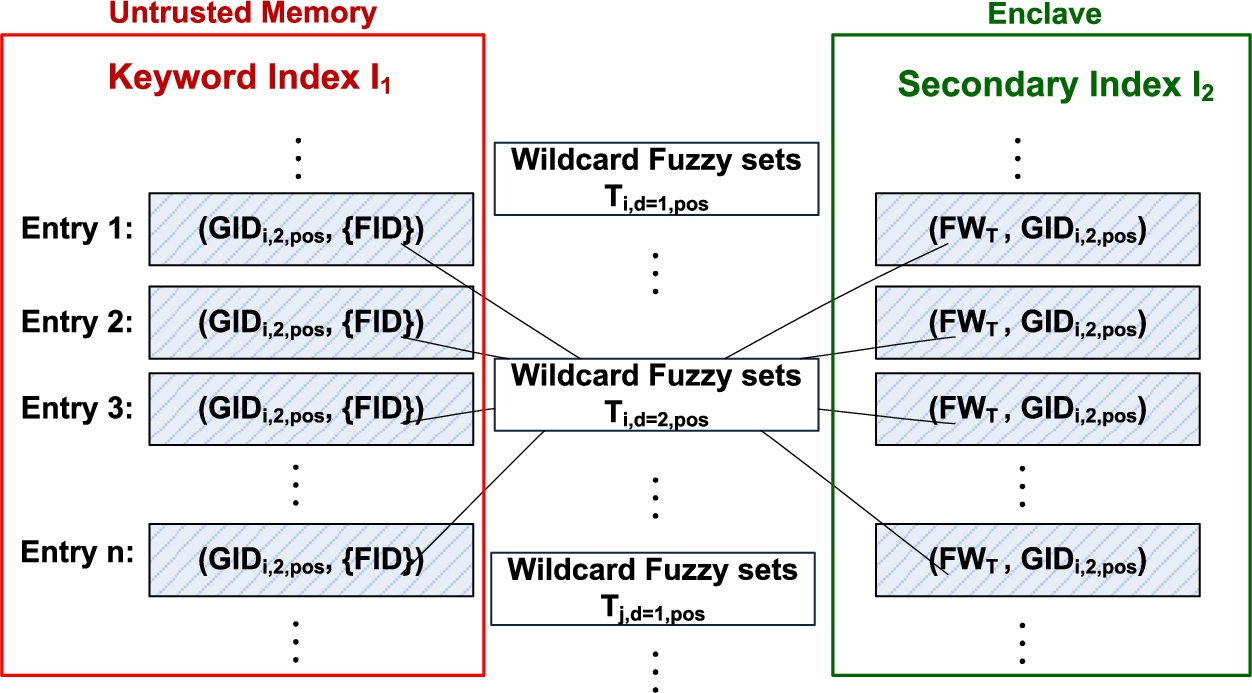
Our proposed OTKI-F protocol consists of two phases, namely the index deploying phase and fuzzy keyword querying phase, as introduced later in this subsection. There are three main building blocks associated with protocol: keyword index, secondary index, and trend-aware cache (TAC). The keyword index and secondary index form a two-layer hierarchical OTKI-F index to accelerate query processing. The keyword index is stored in an encrypted form in the untrusted memory, while the secondary index is stored in the enclave (i.e. the TEE of IntelSGX technology) as plaintext. The trend-aware cache is a data structure inside the enclave that offers the trend-awareness feature to further improve the efficiency of query processing under real query workloads.
Processing fuzzy keyword queries.
A. Index Building Phase The data owner first pre-generates HMAC secret key K. Based on the inverted index of the document database, he first converts it to Wildcard fuzzy sets then further builds them into a two-layer fuzzy index as the structure shown in Fig. 4. The detailed procedure of building the index will be presented later in Algorithm 2. Then, he invokes the SGX instruction “EENTER” to create an enclave instance and initializes the secondary index which is encrypted with the enclave secret key . After that, he hashes the keyword index with K and deploys it in the untrusted memory of cloud server.
Two-layer fuzzy index.
B. Fuzzy Querying Phase The data user provisions with the enclave through a remote attestation and derives the user session key . In more detail, remote user first derives the enclave’s EPID GID (extended group ID of EPID) and requests Intel Attestation Server (IAS) to retrieve the enclave’s signature revocation information (SigRL) for verifying the enclave. Then it further checks the QUOTE Report (sgx_quote) with IAS to attest the enclave is at correct cryptographic status. Finally, the remote user and enclave provision secret through the shared key produced by a DHKE session. After the remote attestation, data user’s query request Q is encrypted with and sent to be decrypted inside enclave. When request Q is received by cloud server, it is processed by retrieving the two-layer index under the protection of ED-based Obfuscation Mechanism (i.e., Algorithm 3). Briefly, the secondary index handles the query first and returns candidate fuzzy keyword groups whose original keywords are similar to the input query words. Afterward, the candidate keywords are searched in the trend-aware cache (TAC). If they are found, the final query results will contain those documents that have a particular keyword. Otherwise, the fuzzy keyword groups are retrieved from the keyword index. After combining the partial results from each input, the trend-aware cache is updated according to Algorithm 4.
Overall OTKI-F protocol
The entire protocol workflow combining the two phases are depicted with the arrow diagram in Fig. 3. In Algorithm 1, we demonstrate its logic sketch.
Two-layer fuzzy index
The two-layer fuzzy index is composed of an encrypted keyword index outsourced to the untrusted cloud server and a secondary index encrypted by the provisioned secret key and pre-loaded into IntelSGX enclave.
Algorithm 2 shows the construction process of this index. The data owner first traverses inverted index converting each of its entries to Wildcard fuzzy sets. A Wildcard fuzzy set is denoted as , where is the identifier of wildcard-based fuzzy set containing the information of differences to original keyword and indicates the associated documents which contain the identifier. Then, each τ is assigned to a fuzzy index group through a one-to-one mapping based on the edit distance d to the original keyword and the position list of character differences. Note that the index groups of a given original keyword may intersect with other index groups. For example, a fuzzy set of original keyword “MERS” with edit distance can overlap with the index group of the exact original keyword () “SARS” on . Meanwhile, a user-defined threshold is introduced to discard those fuzzy keywords whose edit distances exceed this threshold. As such, each encoded group id serves as the key of keyword index and becomes its corresponding index value. Then the algorithm hashes of each index entry in with key K (e.g., HMAC-SHA256) into before deploying the latter to the cloud database. To build the secondary index , the algorithm uses the plaintext as the index key and as its corresponding index value. Before sealing it into the enclave, the algorithm encrypts with the secret key into .
Build OTKI-F index
ED-based obfuscation mechanism
In processing user queries with the two-layer fuzzy index, access pattern leakage will occur when TEE retrieves the keyword index from the untrusted memory. Specifically, to limit the number of search results, many fuzzy search protocols have a threshold on edit distance between word input and its feasible keyword. As such, the same access patterns on keyword index may be inferred as the same queries, which jeopardizes the privacy of users and compromises the security of keyword space. To guard against this, we propose ED-based Obfuscation Mechanism to make individual keyword queries indistinguishable by adversaries with polynomial time. As shown in Algorithm 3), it resolves this issue by retrieving probabilistic supersets of requested keyword indexes from untrusted memory. An obfuscation parameter ϵ is used to determine the scale of such supersets and balance the trade-off between communication overhead and obfuscation degree. The security analysis of this mechanism will be presented in Section 4.2 and the discussion on the impact of ϵ on the performance will be shown in Section 5.3.
The ED-based Obfuscation Mechanism works as follows. An encrypted fuzzy search request T contains n querying inputs and an edit distance parameter , denoted as . Once the server receives the request, it scans the key of plaintext (sorted) secondary index , namely , with each querying word for their matched entries. Except for the string match to identifier , the sequential search also references to the edit distance d between original keyword and . If , it merges the entry value directly to the intermediate set , whereas the rest entries whose d suffices are selected with probability before being merged into . The enclave retrieves first in the trend-aware cache and then in keyword index for the candidate document IDs. The matched entries of keyword index are aggregated in , which is a superset of the real query. A followup pruning by removes redundant elements whose original keywords deviate from input word in a distance larger than . As such the document IDs in are merged into a partial result set associating with single querying word accordingly. Finally, the enclave obtains the multi-keyword searching results by intersecting all .
Searching indexes with ED-based obfuscation
Trend-aware cache
It is a common observation that keyword search exhibits a changing trend of prevalent words over time [23,58], for example, in a material e-library of editorial studio, and email search in an institutional email archive. To this end, caching the documents (more precisely the document IDs) which contain frequently searched keywords in an enclave heap can reduce the number of OCALLs to the untrusted memory to retrieve keyword index . Ideally, the keywords of all search requests can be cached. However, in practice, since the enclave has limited size and popular words change over time, such cache cannot always hit. To capture the change of “hot” keywords precisely and improve the utility of limited enclave cache space, we propose a mechanism called Trend-aware Cache (TAC).
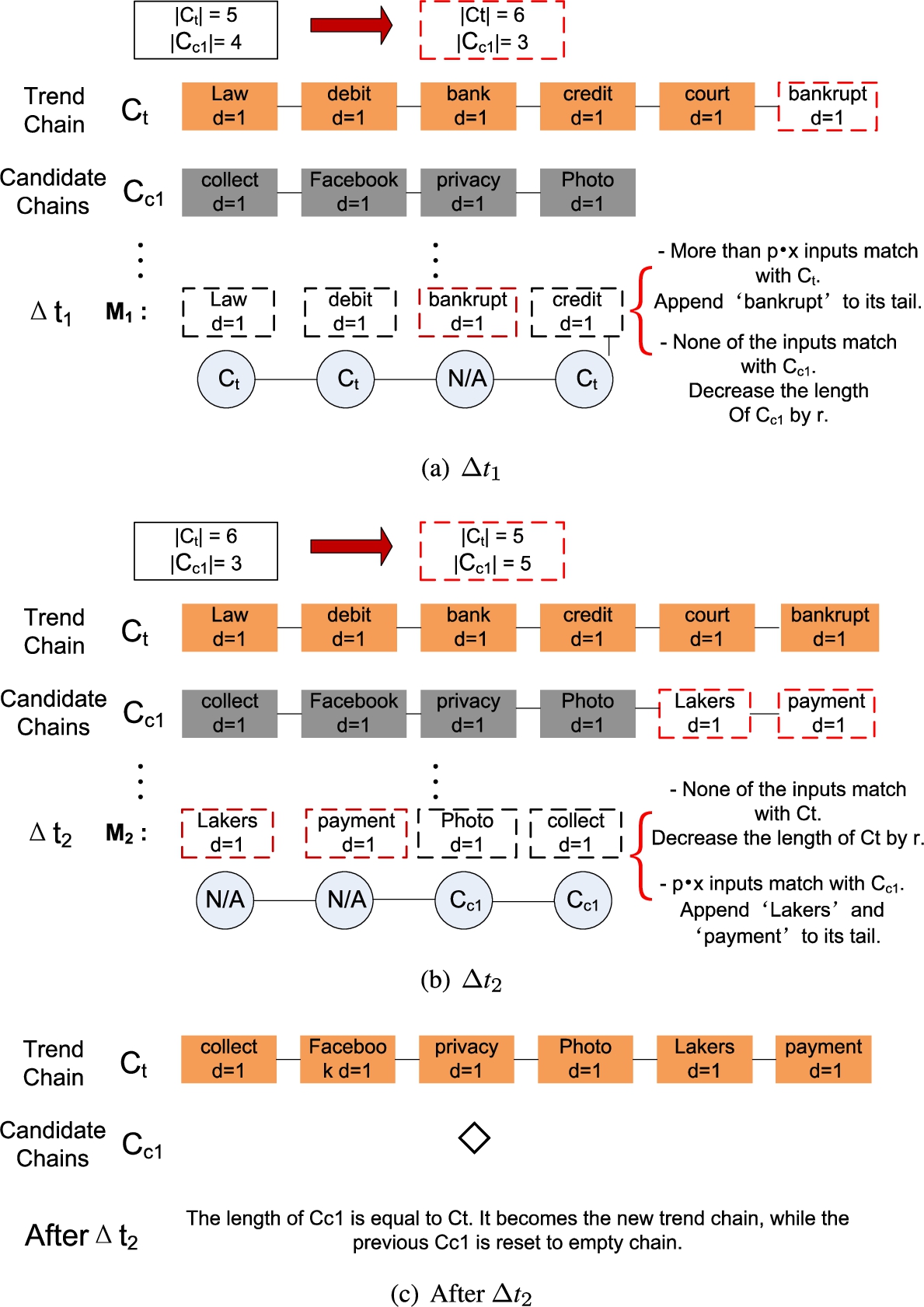
Example of trend chain updating.
Trend-aware Cache (TAC) is composed of one trend chain2
We do not restrict the number of trend chains. There can be more than 1 prevalent themes coexist in the enclave cache. For simplicity, however, we use this setting throughout the paper as default.
and s candidate chains initialized as an empty chain ◇. Each of these chains contains keywords that frequently co-occur in the keyword index retrieval. Hence each chain indicates a possible active theme among the conversations of users. In a nutshell, TAC always cumulates the lengths of the chains which may contain appearing prevalent themes, while reduces the lengths of rests. As such, the longest chain represents the most popular theme in keyword search services. As demonstrated in Algorithm 4, after each time interval , the aforementioned chains are updated based on the most recent index group retrieval records and compete for the prevalent theme. The meta-data of records is the x most frequently accessed index groups, denoted as . Then, it scans each chain with the indexes in and counts the number of matches and for and respectively. The trend chain is examined in prior. If it is empty or is no less than a thresholding percentage p of x, the unmatched index group IDs are appended to the tail of the trend chain. In other cases, it continues to examine the candidate chains. Likewise, if either chain whose is equal or greater than or is an empty chain, the unmatched index group IDs in are appended to its tail. For all the chains, once appended with new IDs, its length or increases with or respectively. Otherwise, the chains which are not appended undergo a deduction on their lengths for loss on the hotness. The number of deduction is determined by preset receding rate r. After scanning all the chains, the longest chain is copied to substitute the trend chain, while itself is restored to ◇. We give an example of the changes in chains in Fig. 5.
Trend-aware cache
Limitations
First, the proposed OTKI-F protocol does not cover the access to the actual document files. A secure and oblivious protocol for secure document file retrieval from untrusted sources is hence needed. Second, we assume the keyword index can be loaded entirely into the untrusted memory for execution. However, if this assumption does not hold, such protocol will be vulnerable to those attacks leveraging the auxiliary knowledge already derived from disk storage. For example, the is split into separated DB files on disk with explicit identifiers, such as file names, and is loaded partially on demand. That said, adversaries can imply the scope of keywords that are likely to be searched currently. On the other hand, for the extremely large database or keyword space, the enclave may fail to load even the secondary index in one pass. We plan to resolve this with some oblivious swapping mechanisms in the future.
Security analytics
In this section, we analyze the security and privacy functionalities of protocol components and finally prove that the OTKI-F protocol satisfies all three conditions in our definition of memory-secure keyword fuzzy search (as seen in Definition 1).
Condition i and security
We now give the proof that query process of OTKI-F Protocol satisfies the Conditions i and based on the security standards claimed in the literature.
(Condition sufficiency).
A keyword fuzzy search protocol satisfies Condition i andsecurity, if each of its building blocks associated with keyword index (trapdoors) searching is inaccessible to the adversaries and the entries of keyword index are protected by acknowledged cryptographic schemes.
Since the adversary cannot access the building blocks which are directly related to the search process of candidate trapdoors in the enclave, the search always returns the correct results. Therefore Condition i holds. The utilization of encryption and hash function ensures the accessible memory space is always operated in encrypted form including query statement and results. Therefore Condition holds.
Recall that, there are three main components in the proposed protocol, i.e. keyword index (trapdoors), secondary index, trend-aware cache. Among them, keyword index (trapdoors) is located in untrusted memory. As a community consensus, the applied HMAC-SHA256 hash function is resistant to collision attack and remains robust against length extension attack. The secondary index and trend-aware cache are sealed into IntelSGX enclave and the outgoing channels are protected by secure function calls [13] and the usage does not surpass the guaranteed security boundary of SGX as explained in Intel’s manuals and reference books [31,34]. Hence, Theorem 1 holds for OTKI-F protocol. □
Though the existence of attacks based on L1 terminal fault flaw, e.g. Foreshadow [49], has challenged the trust model of IntelSGX, it is still trustworthy in the cloud environment with the conditions that Intel microcode patches have been updated or the hyperthreading is turned off.
Condition security
In this subsection, we prove that the query process of OTKI-F Protocol suffices the Condition based on the quantitative evaluation. Prior to the proof, we formally define the selective access pattern attack that may take place in OTKI-F protocol as below.
( Access pattern attack).
The adversary holds the oracle that the queries toward certain specified original keywords will burst in the coming time period. He then begins to monitor the index entries of retrieved to be loaded to the enclave. From his perspective, the same access pattern for a retrieval means the same fuzzy search request. Based on this, the sensitive information he can further infer includes the original keywords of encrypted keyword indexes, the frequency of a particular query, etc.
(Condition sufficiency).
In OTKI-F Protocol, if the access pattern attack succeeds only with a trivial probability, the protocol satisfies Conditionsecurity.
According to Definition 2, during the bursting period, the adversary actually regards the arriving queries as the same input to seek a match in corresponding access pattern on . Therefore, if the probability of the occurrence of the same series of access patterns is trivial with such oracle, the Condition in Definition 1 must also hold. □
In what follows, we model the success rate of the access pattern attack to show it is indeed negligible in practice, and therefore Theorem 2 holds. During the runtime, is accessed for searching requested index group IDs based on the instructions issued from the enclave. The set of requested index group IDs forms the superset of feasible original keywords of querying word inputs as mentioned in Section 3.4. In the retrieval of secondary index , we do not attempt to predict the actual original keyword of a fuzzy input (namely, target keyword) which means the additional index groups contained in the superset consists of not only the entries whose edit distance fall in the span but also the associate index groups of other original keywords whose edit distances to the particular input are less than . In the nature of ED-based Obfuscation Mechanism, the more such probabilistic additional index groups retrieved from , the memory access patterns become more oblivious to the adversaries.
We now evaluate the obfuscation imposed to adversary produced by protocol mechanism based on the probability . that two queries with same x querying words generate exactly the same access pattern on . The core factor of the probability is the number of additional index groups involved in the superset. We formulate . as:
where is the total number of additional index groups of the i-th input word.
For each input word i, given the maximal edit distance of , the query distance allowance , the set of index groups with distance equal to or under is denoted as . The superset of containing all possible keyword index groups is denoted as , and the differential set of and is denoted as . We expand as = , where indicates the k-th possible target keyword associated the input keyword. We use to denote the expectation number of additional index groups associate with the k-th possible target keyword after the probabilistic selection. Then is calculated as:
Next, we substitute the value of with:
where denotes the length of k-th possible target keyword. For each target keyword, d denotes the edit distance to the corresponding original keyword of the specific index group.
Finally, we perform a stepwise substitution to with the above expressions and derive the quantitative evaluation model of obfuscation functionality as the equation below:
In practice, we set , , , , and fix to 5 as close to the average length of English word (4.7) [40]. It shows that the success rate . of access pattern attack drops to which is trivial in practical settings, when ϵ is set to a reasonable value, 0.3, to control the communication overhead. Hence, Theorem 2 holds for OTKI-F protocol.
Experimental results
In this section, we evaluate the performance of OTKI-F as a memory-secure multi-keyword fuzzy search protocol. We first demonstrate the size of OTKI-F two-layer index to show its practicality and compatibility with Intel SGX. Then we thoroughly evaluate the efficiency of OTKI-F fuzzy search algorithm under a variety of parameter settings. Third, we evaluate the effectiveness of ED-based obfuscation mechanism which enhances the privacy of keywords. At last, we test the performance yield of trend-aware cache with simulated queries of dynamic trending keywords.
Efficiency of building index
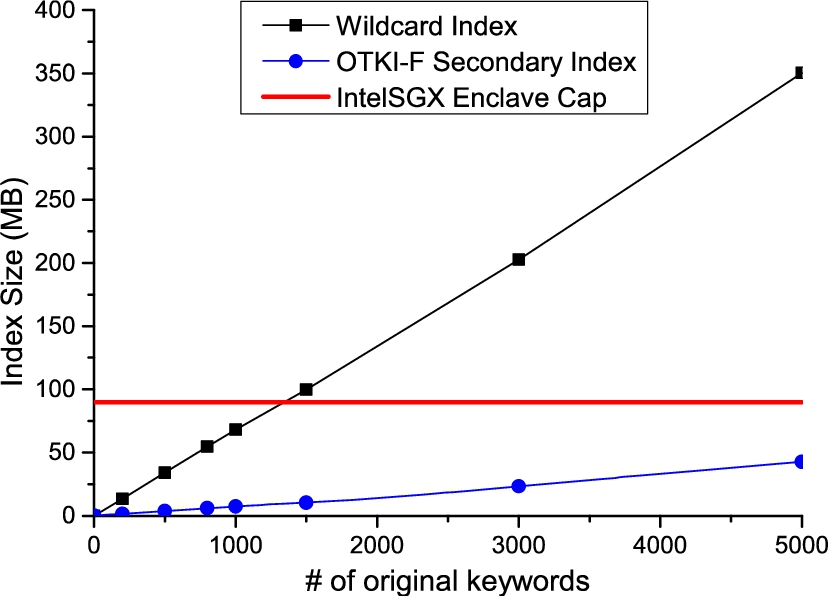
In this subsection, we measure the overall size of OTKI-F index and compare it with the naive Wildcard protocol [37]. We use a truncated ‘ENRONMAIL’ dataset containing 10,000 files to extract the keywords for indexing. With the same maximal fuzzy scale , both OTKI-F and Wildcard indexes assemble the possible fuzzy words into their entries, respectively. In the experiment, the keys of Wildcard index entries are hashed with HMAC-SHA256, while the OTKI-F secondary indexes are measured in plaintext.
Index size: wildcard fuzzy index vs. OTKI-F secondary index.
As shown in Fig. 6, the secondary index of OTKI-F is about smaller than the naive Wildcard index throughout the process. Further, according to this figure, we can project that an approximately 90 MB enclave can accommodate a secondary index with around keywords, which is sufficient in practice as the latest Longman Dictionary of Contemporary English only identifies 9,000 English words as common ones.
Performance of fuzzy keyword search
In this subsection, we perform three sets of experiments to evaluate the impact of dataset and queries on the performance of two-layer index. The experiments are conducted on a desktop computer with Intel i7 6700HQ CPU, 16 GB RAM running Windows 10. An Intel SGX enclave instance is created in hardware mode and pre-configured with ‘MAX_STACK_SIZE = 2 MB’ and ‘MAX_HEAP_SIZE = 30 MB’. We use 5000 annotated email files in the ‘ENRONMAIL’ dataset to build an inverted index and then convert it to an OTKI-F two-layer index. Then we decrypt and sort the secondary index in the enclave as plaintext meta-data. For the three experiments, we fix the maximum edit distance for the first two experiments and fuzzy scale allowance for all three. The trend-aware caching is disabled to avoid its impact on the performance measurements in the second and third experiments.
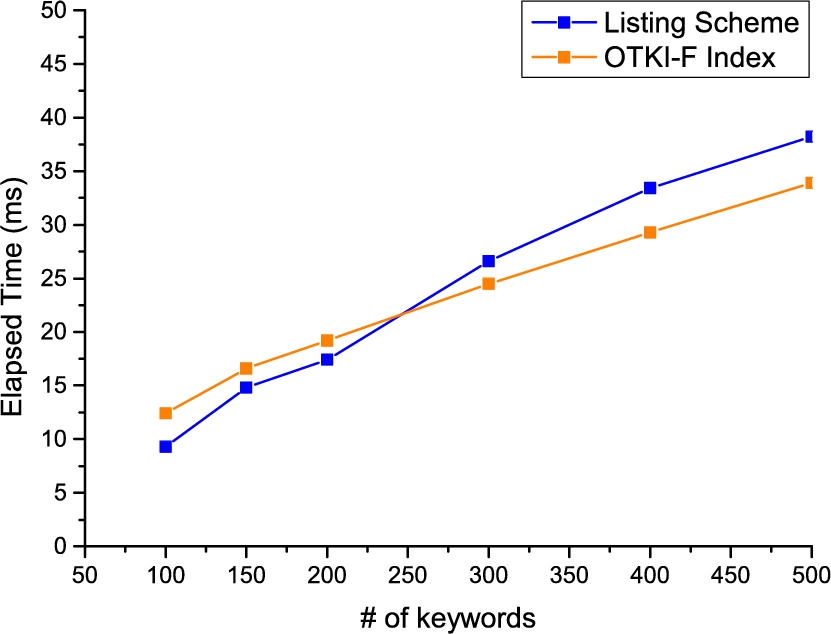
In the first experiment, we measure a single request search processing time by varying the size of keyword universe. Since a large proportion of keywords of inverted index are sparse in mapping to documents (i.e., owns less than 5 mapped email files). We randomly remove them from the keyword universe before converting to an OTKI-F index and the remaining number of keywords ranges from 100 to 500. Each query is composed of 3 wrongly spelled keywords, each with edit distance to its target keyword.
End-to-end searching time with changing keyword universe size and fixed .
We compare the end-to-end searching time of OTKI-F index with SSE-based listing approach mentioned in [37]. The listing approach indexes the encrypted document files with trapdoors of fuzzy sets of keywords on different edit distances. As the number of original keywords increases, OTKI-F index gradually outperforms the listing approach when the number of original keywords grows as shown in Fig. 7. We attribute this observation to two reasons: (a) The advantage of plaintext index search in enclave applied in our protocol compared to the SSE-based search used in listing approach becomes obvious. (b) The trend-aware cache reduces the frequency of retrievals for .
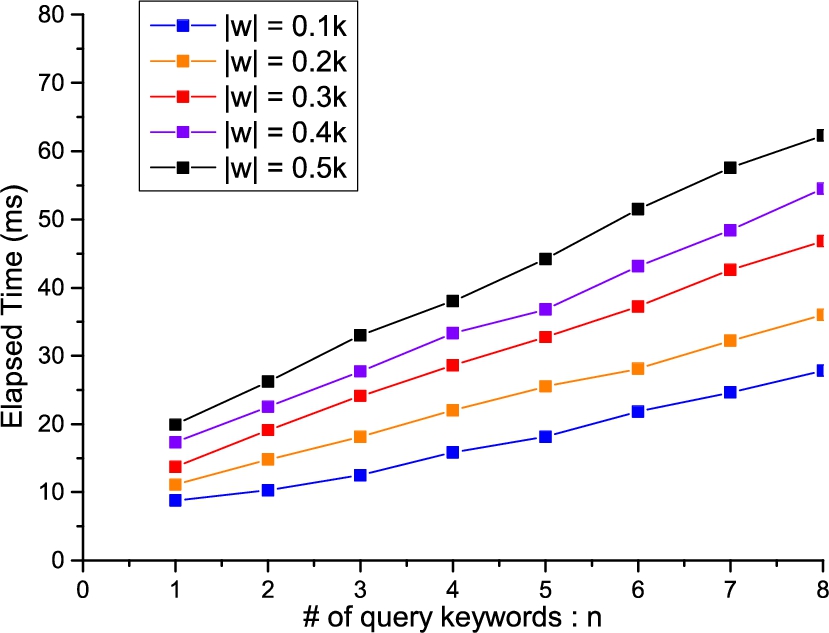
In the second experiment, we increase the number of input words n from 1 to 8 in 5 series of trial runs. Each series illustrates a different number of original keyword universe ranging from 100 to 500. As shown in Fig. 8, the elapsed time shows a linear increase with the growth of n. Further, the gaps between the series also increase due to the logarithmic growth of elapsed time with the increase on .
End-to-end searching time of multiple keywords queries.
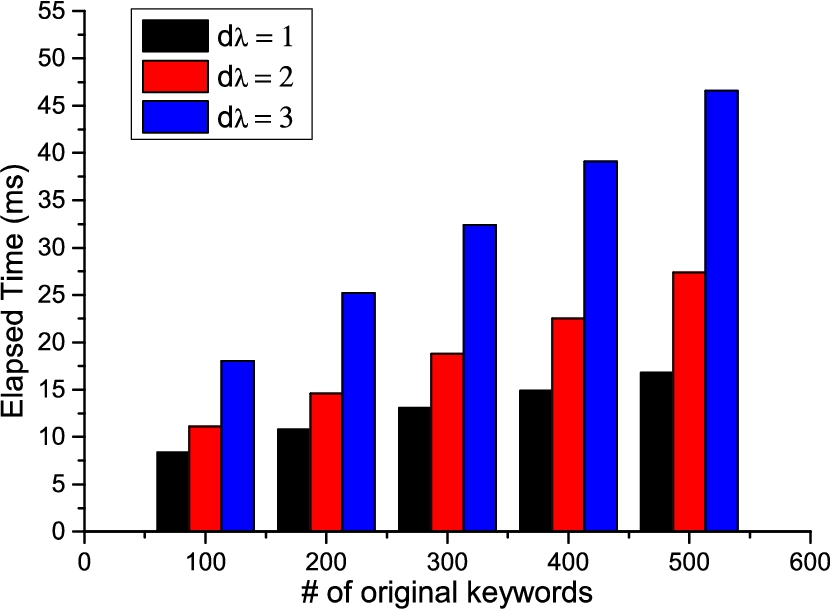
In the third experiment, we fix the number of input words and measure the elapsed time under various maximal fuzzy scales and 3. Figure 9 plots the 3 sets of results against the change of on X-axis. We find the increasing rate on query processing time with growing tends to be linear when , while remains sub-linear when . We attribute this phenomenon to the exponentially increase on fuzzy index entries caused by the maximal fuzzy scale .
End-to-end searching time on changing .
Effectiveness of ED-based obfuscation mechanism
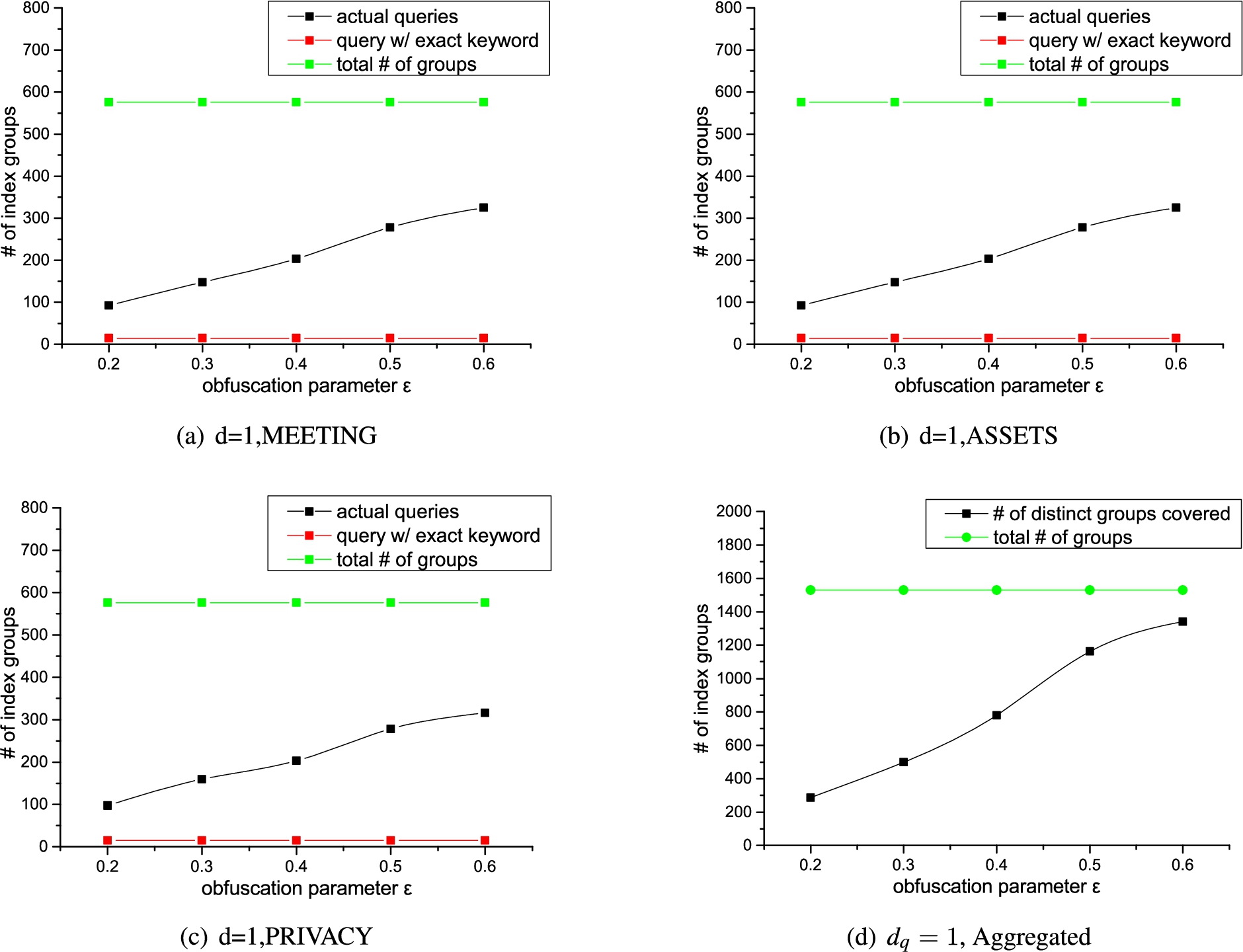
In this subsection, we analyze the degree of confusion incurred to adversary by the proposed ED-based Obfuscation Mechanism. Recall the analytic model in Section 4.2, the effect of access pattern hiding on keyword index is correlated with the number of additional index groups accessed on . The actual value of is directly impacted by the obfuscation parameter ϵ. To this end, we collect the average numbers of accessed entries (i.e. index groups) with changing ϵ ranging in . We use a fixed query string containing three input words to perform a fuzzy search against the simulated dataset (100 original keywords) with maximal fuzzy scale . Each of the three inputs is a fuzzy keyword with to its target keyword and does not overlap with others on index groups. We collect the actual numbers of additional index groups retrieved from of each keyword. 5 trial runs are conducted for each ϵ. Figure 10 plots the actual value of for each input word as well as the aggregated number of distinct index groups being accessed.
# of accessed entries with changing ϵ.
As shown in Fig. 10, the rise of average along with the increasing ϵ reflects a positive correlation between the degree of obfuscation and obfuscation parameter ϵ. It is also worth noticing that the number of distinct additional index groups accumulates fast to a relatively large coverage of theoretical , which coincides with the analytical model in Section 4.2).
Performance of trend-aware cache
In this subsection, we evaluate the performance of Trend-aware Cache (TAC) by measuring its cache hit rates from search results. We sort the truncated ‘ENRONMAIL’ dataset used in Section 5.1 by date. For each date, we select top-6 frequent included keywords from the annotated emails of that day as the seeds of search trend. We set the time interval as 1 day and search with random fuzzy words of selected hot keywords.3
In this experiment, the search stops after deriving the results of secondary index search.
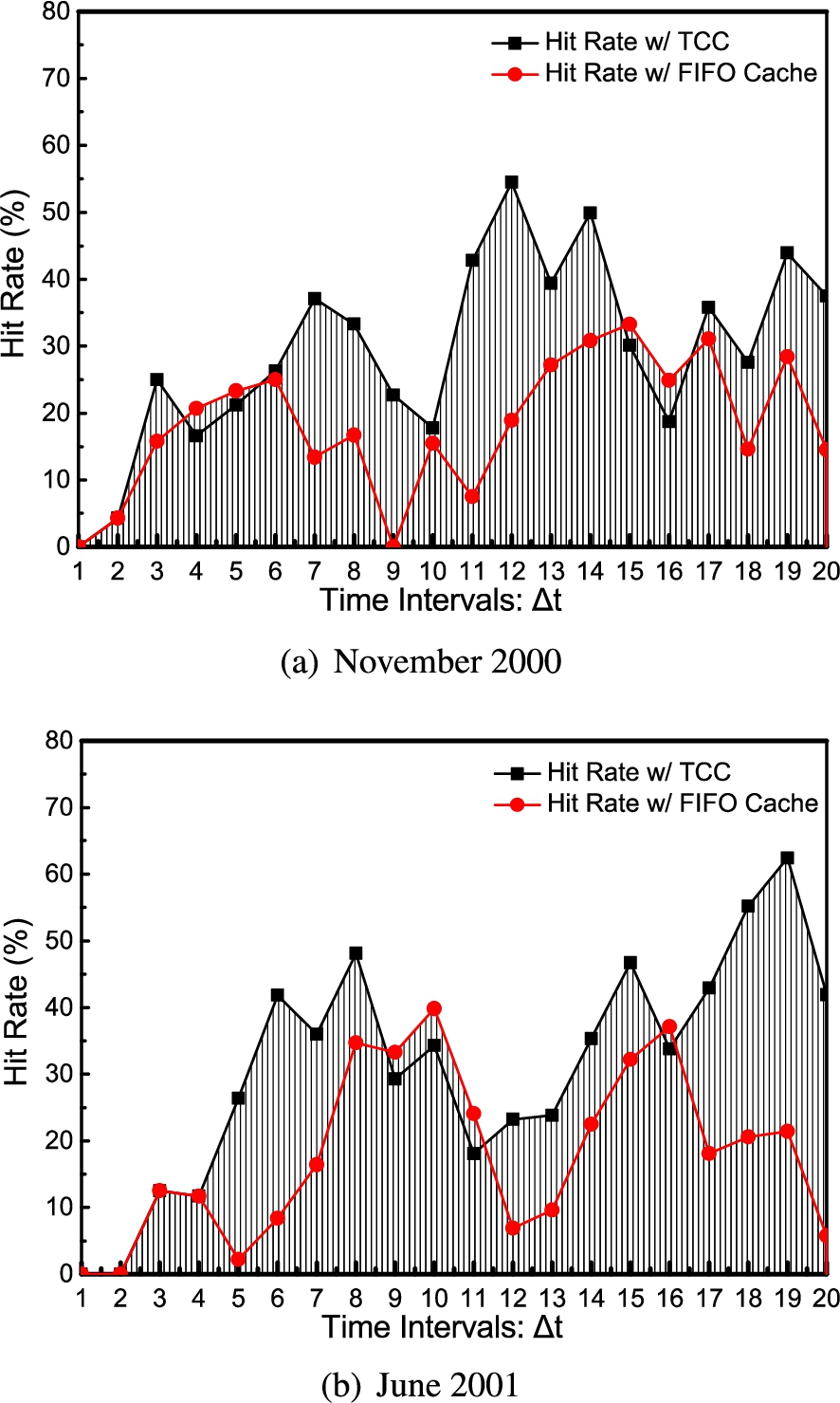
We collect the numbers of requested index groups after scanning and the numbers of index groups in the fixed 4 MB cache to calculate the hit rate. As for the TAC parameters aforementioned in Section 3.5, we set the number of candidate chains as , the threshold percentage in identifying the potential trend, and the receding rate to control the eviction speed. We randomly select two date spans from the database, each with 20 constant days, and repeat 10 trials for each to obtain average values.
As shown in Fig. 11(a) and (b), the cache hit rates maintain above after several intervals in both date spans and show a peak at and respectively. Compared with first-in-first-out (FIFO), a common cache eviction strategy, hit rates of enclave cache are improved by and on average.
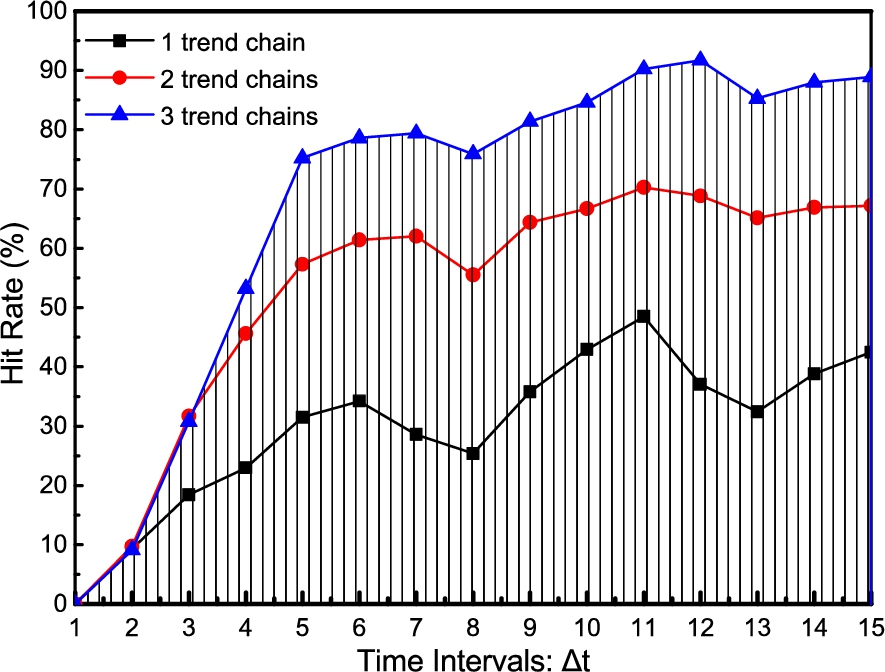
Furthermore, Trend-aware Cache receives higher performance yield when more trend chains are allowed to co-exist, especially for the datasets whose search trends concentrate on more than one theme, such as “WEIBO Hotwords” provided by [55]. As plotted in Fig. 12, we sort 15 consecutive hourly hot word sets (Date: June 29th, 2020) and select top-20 keywords for each hour to evaluate TAC performance of different numbers of trend chains. We set the threshold percentage and keep the rest settings unchanged as in the previous experiment. The resulting hit rates show a positive correlation with the number of trend chains on average values.
Cache hit rates change with constant queries.
Cache hit rates change with the # of trend chains.
Related work
A. Secure Keyword Search over Encrypted Data
The literature of advanced secure keyword search over encrypted data which extended from the fundamental studies on single keyword exact/fuzzy search [6,14,37,43,50] can be generally divided into two tracks. One seeks performance enhancements upon cryptographic primitives for different demands of queries. For multi-keyword conjunctive fuzzy search, we remark [7,12,51,52] for their notable progress on query performance leveraging diverse technology dependencies. Among them, [12] optimized Bed-tree [57] with privacy-aware feature and [51] used the locality-sensitive hashing (LSH) [30] and Bloom Filter [4] to build index. For rank-ordered fuzzy search, Wang et al. initially gave a baseline solution in [53]. Fu et al. addressed its limitation on ‘one-letter-mistake’ later in [18]. More recent work [15] further improved the processing speed with the aid of term frequency–inverse document frequency (TF-IDF). Among the studies of preferred keyword query, [44] introduced keyword weight in relevance scoring and reached acceptable efficiency. A follow-up solution [17] applied a history-oriented user interest model to achieve efficiency and personalization yields. Nevertheless, the exposure of runtime memory makes their solutions vulnerable to privileged attack methods [9,59] in cloud platforms. The other track focuses on exploring security improvements with various tools. By optimizing the architecture of service, [29] traded communication overhead between two cloud servers for the security improvements. By adopting user authorization and access control, the representative works, [38] and [45] reduced the data owner’s privacy leakage resulting from search results by delegating search capabilities to data users using Hierarchical Predicate Encryption (HPE). However, they are incapable of large datasets or multi-keyword queries due to the slow processing and remain compromised with ‘semi-honest’ adversaries who possess extra knowledge about searching manners of users. In contrast, our work simultaneously achieves both query performance and highly complete memory security.
B. Processing Queries with Trusted Execution Environment
Trusted Execution Environment (TEE) technology is widely adopted in applications to provide tamper-proof query processing. In respect of SQL queries, TrustedDB [3], CryptSQLite [54] and ObliDB [16] migrated relational query engines into TEE while [36] and pRide [39] encapsulated location-based (spatial) query processing with IntelSGX enclave. In parallel with our work, we highlight [48] and [41] which also implemented the prototype keyword search protocol using IntelSGX. However, they are different from OTKI-F protocol in support of fuzzy search, oblivious primitives used for access pattern hiding, and practical concerns of enclave memory space.
Conclusion
In this paper, we propose OTKI-F, a memory secure multi-keyword fuzzy search protocol built on a separate type keyword index. Leveraging IntelSGX technology, we ensure the exclusive access of authorized stakeholders to the second layer of index. The first layer is protected by cryptographic tool and a novel obfuscation mechanism from memory tampering and access pattern sniffing respectively. We perform rigorous analysis on the claimed security and privacy functionality with the security definition. On the other hand, we employ a trend-aware cache coordinator to achieve moderate query performance or even higher for trend-sensitive queries. We evaluate system performance and internal parameters of OTKI-F with various simulation experiments and real dataset tests. The novel mechanisms proposed in this work can be solely applied to other applications offering significant enhancements. As for the extension of this study, we plan to keep updating with the progress of TEE technology and provide security solutions to different types of queries.
Footnotes
Acknowledgments
This work was supported by National Natural Science Foundation of China (Grant No: 62072390, 62102334), and the Research Grants Council, Hong Kong SAR, China (Grant No: 15222118, 15218919, 15203120, 15226221, 15225921, and C2004-21GF).
References
1.
ARM.com, ARM TrustZone. https://www.arm.com/products/security-on-arm/trustzone.
2.
J.Aumasson and L.Merino, SGX Secure Enclaves in Practice–Security and Crypto Review, Black Hat, 2016.
3.
S.Bajaj and R.Sion, Trusteddb: A trusted hardware-based database with privacy and data confidentiality, IEEE Transactions on Knowledge and Data Engineering26(3) (2014), 752–765. doi:10.1109/TKDE.2013.38.
4.
B.H.Bloom, Space/time trade-offs in hash coding with allowable errors, Communications of the ACM13(7) (1970), 422–426. doi:10.1145/362686.362692.
5.
M.Blum, P.Feldman and S.Micali, Non-interactive zero-knowledge and its applications, in: Providing Sound Foundations for Cryptography: On the Work of Shafi Goldwasser and Silvio Micali, 2019, pp. 329–349.
6.
D.Boneh, G.Di Crescenzo, R.Ostrovsky and G.Persiano, Public key encryption with keyword search, in: International Conference on the Theory and Applications of Cryptographic Techniques, Springer, 2004, pp. 506–522.
7.
C.Bösch, R.Brinkman, P.Hartel and W.Jonker, Conjunctive wildcard search over encrypted data, in: Workshop on Secure Data Management, Springer, 2011, pp. 114–127. doi:10.1007/978-3-642-23556-6_8.
8.
F.Brasser, U.Müller, A.Dmitrienko, K.Kostiainen, S.Capkun and A.-R.Sadeghi, Software grand exposure: {SGX} cache attacks are practical, in: 11th USENIX Workshop on Offensive Technologies (WOOT 17), 2017.
9.
J.W.Byun, H.S.Rhee, H.-A.Park and D.H.Lee, Off-line keyword guessing attacks on recent keyword search schemes over encrypted data, in: Workshop on Secure Data Management, Springer, 2006, pp. 75–83. doi:10.1007/11844662_6.
10.
D.Cash, S.Jarecki, C.Jutla, H.Krawczyk, M.-C.Roşu and M.Steiner, Highly-scalable searchable symmetric encryption with support for Boolean queries, in: Annual Cryptology Conference, Springer, 2013, pp. 353–373.
11.
B.Chor, O.Goldreich, E.Kushilevitz and M.Sudan, Private information retrieval, in: Foundations of Computer Science, 1995. Proceedings., 36th Annual Symposium on, IEEE, 1995, pp. 41–50.
12.
M.Chuah and W.Hu, Privacy-aware bedtree based solution for fuzzy multi-keyword search over encrypted data, in: 2011 31st International Conference on Distributed Computing Systems Workshops, IEEE, 2011, pp. 273–281. doi:10.1109/ICDCSW.2011.11.
R.Curtmola, J.Garay, S.Kamara and R.Ostrovsky, Searchable symmetric encryption: Improved definitions and efficient constructions, Journal of Computer Security19(5) (2011), 895–934. doi:10.3233/JCS-2011-0426.
15.
S.Ding, Y.Li, J.Zhang, L.Chen, Z.Wang and Q.Xu, An efficient and privacy-preserving ranked fuzzy keywords search over encrypted cloud data, in: 2016 International Conference on Behavioral, Economic and Socio-Cultural Computing (BESC), IEEE, 2016, pp. 1–6.
16.
S.Eskandarian and M.Zaharia, An oblivious general-purpose SQL database for the cloud, 2017, CoRR, arXiv:1710.00458.
17.
Z.Fu, K.Ren, J.Shu, X.Sun and F.Huang, Enabling personalized search over encrypted outsourced data with efficiency improvement, IEEE transactions on parallel and distributed systems27(9) (2015), 2546–2559. doi:10.1109/TPDS.2015.2506573.
18.
Z.Fu, X.Wu, C.Guan, X.Sun and K.Ren, Toward efficient multi-keyword fuzzy search over encrypted outsourced data with accuracy improvement, IEEE Transactions on Information Forensics and Security11(12) (2016), 2706–2716. doi:10.1109/TIFS.2016.2596138.
19.
C.Gentry, A fully homomorphic encryption scheme, Stanford University, 2009.
20.
O.Goldreich, Towards a theory of software protection and simulation by oblivious RAMs, in: Proceedings of the Nineteenth Annual ACM Symposium on Theory of Computing, ACM, 1987, pp. 182–194.
21.
O.Goldreich, S.Micali and A.Wigderson, Proofs that yield nothing but their validity or all languages in NP have zero-knowledge proof systems, Journal of the ACM (JACM)38(3) (1991), 690–728. doi:10.1145/116825.116852.
22.
Z.Han, H.Hu and Q.Ye, ReFlat: A robust access pattern hiding solution for general cloud query processing based on K-isomorphism and hardware enclave, IEEE Transactions on Cloud Computing, 2021.
23.
Y.He, R.Prabhavalkar, K.Rao, W.Li, A.Bakhtin and I.McGraw, Streaming small-footprint keyword spotting using sequence-to-sequence models, in: 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), IEEE, 2017, pp. 474–481. doi:10.1109/ASRU.2017.8268974.
24.
V.Hristidis, Y.Papakonstantinou and L.Gravano, Efficient IR-style keyword search over relational databases, in: Proceedings 2003 VLDB Conference, Elsevier, 2003, pp. 850–861. doi:10.1016/B978-012722442-8/50080-X.
25.
H.Hu, Q.Chen and J.Xu, VERDICT: Privacy-preserving authentication of range queries in location-based services, in: Proc. of the 29th IEEE International Conference on Data Engineering (ICDE ’13), IEEE, 2013, pp. 1312–1315.
26.
H.Hu, J.Xu, X.Xu, K.Pei, B.Choi and S.Zhou, Private search on key-value stores with hierarchical indexes, in: Proc. of the 30th IEEE International Conference on Data Engineering (ICDE ’14), IEEE, 2014, pp. 628–639.
27.
T.Huo, X.Meng, W.Wang, C.Hao, P.Zhao, J.Zhai and M.Li, Bluethunder: A 2-level Directional Predictor Based Side-Channel Attack against SGX, IACR Transactions on Cryptographic Hardware and Embedded Systems (2020), 321–347.
28.
IBM, IBM 4758 PCI Cryptographic Coprocessor General Information Manual, 2016. ftp://www6.software.ibm.com/software/cryptocards/4758gi.pdf.
29.
A.Ibrahim, H.Jin, A.A.Yassin and D.Zou, Secure rank-ordered search of multi-keyword trapdoor over encrypted cloud data, in: 2012 IEEE Asia-Pacific Services Computing Conference, IEEE, 2012, pp. 263–270. doi:10.1109/APSCC.2012.59.
30.
P.Indyk and R.Motwani, Approximate nearest neighbors: Towards removing the curse of dimensionality, in: Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, 1998, pp. 604–613.
D.Kim, D.Jang, M.Park, Y.Jeong, J.Kim, S.Choi and B.B.Kang, SGX-LEGO: Fine-grained SGX controlled-channel attack and its countermeasure, computers & security82 (2019), 118–139. doi:10.1016/j.cose.2018.12.001.
36.
V.Kulkarni, B.Chapuis and B.Garbinato, Privacy-preserving location-based services by using intel sgx, in: Proceedings of the First International Workshop on Human-Centered Sensing, Networking, and Systems, 2017, pp. 13–18. doi:10.1145/3144730.3144739.
37.
J.Li, Q.Wang, C.Wang, N.Cao, K.Ren and W.Lou, Fuzzy keyword search over encrypted data in cloud computing, in: 2010 Proceedings IEEE INFOCOM, IEEE, 2010, pp. 1–5.
38.
M.Li, S.Yu, N.Cao and W.Lou, Authorized private keyword search over encrypted data in cloud computing, in: 2011 31st International Conference on Distributed Computing Systems, IEEE, 2011, pp. 383–392. doi:10.1109/ICDCS.2011.55.
39.
Y.Luo, X.Jia, H.Duan, C.Wang, M.Xu and S.Fu, pRide: Private ride request for online ride hailing service with secure hardware enclave, in: Proceedings of the International Symposium on Quality of Service, 2019, pp. 1–10.
40.
M.Mayzner, English Letter Frequency Counts: Mayzner Revisited or ETAOIN SRHLDCU, http://norvig.com/mayzner.html.
41.
P.Mishra, R.Poddar, J.Chen, A.Chiesa and R.A.Popa, Oblix: An efficient oblivious search index, in: 2018 IEEE Symposium on Security and Privacy (SP), IEEE, 2018, pp. 279–296. doi:10.1109/SP.2018.00045.
42.
M.H.Mofrad, A.Lee and S.L.Gray, Leveraging Intel SGX to Create a Nondisclosure Cryptographic library, 2017, arXiv preprint arXiv:1705.04706.
43.
S.Raghavendra, C.Geeta, K.Shaila, R.Buyya, K.Venugopal, S.Iyengar and L.Patnaik, MSSS: Most significant single-keyword search over encrypted cloud data, in: Proceedings of the 6th Annual Intrernational Conference on ICT: BigData, Cloud and Security, 2015.
44.
Z.Shen, J.Shu and W.Xue, Preferred keyword search over encrypted data in cloud computing, in: 2013 IEEE/ACM 21st International Symposium on Quality of Service (IWQoS), IEEE, 2013, pp. 1–6.
45.
Z.Shen, J.Shu and W.Xue, Keyword search with access control over encrypted data in cloud computing, in: 2014 IEEE 22nd International Symposium of Quality of Service (IWQoS), IEEE, 2014, pp. 87–92. doi:10.1109/IWQoS.2014.6914304.
46.
X.Song, G.Li, J.Feng and L.Zhou, Effective fuzzy keyword search over uncertain data, in: International Conference on Database Systems for Advanced Applications, Springer, 2009, pp. 66–70. doi:10.1007/978-3-642-00887-0_6.
47.
E.Stefanov, M.Van Dijk, E.Shi, C.Fletcher, L.Ren, X.Yu and S.Devadas, Path ORAM: An extremely simple oblivious RAM protocol, in: Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, ACM, 2013, pp. 299–310.
48.
W.Sun, R.Zhang, W.Lou and Y.T.Hou, Rearguard: Secure keyword search using trusted hardware, in: IEEE INFOCOM 2018-IEEE Conference on Computer Communications, IEEE, 2018, pp. 801–809. doi:10.1109/INFOCOM.2018.8485838.
49.
J.Van Bulck, M.Minkin, O.Weisse, D.Genkin, B.Kasikci, F.Piessens, M.Silberstein, T.F.Wenisch, Y.Yarom and R.Strackx, Foreshadow: Extracting the keys to the intel SGX kingdom with transient out-of-order execution, in: 27th USENIX Security Symposium (USENIX Security, Vol. 18, 2018, pp. 991–1008.
50.
P.Van Liesdonk, S.Sedghi, J.Doumen, P.Hartel and W.Jonker, Computationally efficient searchable symmetric encryption, in: Workshop on Secure Data Management, Springer, 2010, pp. 87–100.
51.
B.Wang, S.Yu, W.Lou and Y.T.Hou, Privacy-preserving multi-keyword fuzzy search over encrypted data in the cloud, in: IEEE INFOCOM 2014-IEEE Conference on Computer Communications, IEEE, 2014, pp. 2112–2120. doi:10.1109/INFOCOM.2014.6848153.
52.
J.Wang, H.Ma, Q.Tang, J.Li, H.Zhu, S.Ma and X.Chen, Efficient verifiable fuzzy keyword search over encrypted data in cloud computing, Computer science and information systems10(2) (2013), 667–684. doi:10.2298/CSIS121104028W.
53.
J.Wang, X.Yu and M.Zhao, Privacy-preserving ranked multi-keyword fuzzy search on cloud encrypted data supporting range query, Arabian Journal for Science and Engineering40(8) (2015), 2375–2388. doi:10.1007/s13369-015-1737-3.
54.
Y.Wang, L.Liu, C.Su, J.Ma, L.Wang, Y.Yang, Y.Shen, G.Li, T.Zhang and X.Dong, CryptSQLite: Protecting Data Confidentiality of SQLite with Intel SGX, in: Networking and Network Applications (NaNA), 2017 International Conference on, IEEE, 2017, pp. 303–308.
C.Xu, J.Xu, H.Hu and M.-H.Au, When query authentication meets fine-grained access control: A zero-knowledge approach, in: Proc. of the 2018 ACM SIGMOD International Conference on Management of Data, ACM, 2018, pp. 147–162.
57.
Z.Zhang, M.Hadjieleftheriou, B.C.Ooi and D.Srivastava, Bed-tree: An all-purpose index structure for string similarity search based on edit distance, in: Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, 2010, pp. 915–926. doi:10.1145/1807167.1807266.
58.
K.Zheng, X.-M.Shu and H.-Y.Yuan, Hot spot information auto-detection method of network public opinion, Computer Engineering36(3) (2010), 4–6.
59.
M.Zheng and H.Zhou, An efficient attack on a fuzzy keyword search scheme over encrypted data, in: 2013 IEEE 10th International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing, IEEE, 2013, pp. 1647–1651.