
Abstract
Human-chosen passwords are the dominant form of authentication systems. Passwords strength estimators are used to help users avoid picking weak passwords by predicting how many attempts a password cracker would need until it finds a given password.
In this paper we propose a novel password strength estimator, called PESrank, which accurately models the behavior of a powerful password cracker. PESrank calculates the rank of a given password in an optimal descending order of likelihood. PESrank estimates a given password’s rank in fractions of a second – without actually enumerating the passwords – so it is practical for online use. It also has a training time that is drastically shorter than previous methods. Moreover, PESrank is efficiently tweakable to allow model personalization in fractions of a second, without the need to retrain the model; and it is explainable: it is able to provide information on why the password has its calculated rank, and gives the user insight on how to pick a better password.
We implemented PESrank in Python and conducted an extensive evaluation study of it. We also integrated it into the registration page of a course at our university. Even with a model based on 905 million passwords, the response time was well under 1 second, with up to a 1-bit accuracy margin between the upper bound and the lower bound on the rank.
Introduction
Text passwords are still the most popular authentication and are still in widespread use specially for online authentication on the Internet. Unfortunately, users often choose predictable and easy passwords, enabling password guessing attacks. Password strength estimators are used to help users avoid picking weak passwords. Usually they appear as password meters that provide visual feedback on password strength [43]. The most precise definition of password’s strength is the number of attempts that an attacker would need in order to guess it [12].
A common way to evaluate the strength of a password is by heuristic methods, e.g., based on counts of lower- and uppercase characters, digits, and symbols (LUDS). Theses password-composition policies have grown increasingly complex [15]. Despite it being well-known that these do not accurately capture password strength [49], they are still used in practice.
Subsequently, more sophisticated, cracker-based, password strength estimators have been proposed. In a cracker-based estimator, either an actual password cracker is utilized to evaluate the password strength – or the estimator uses an accurate model of the number of attempts a particular cracker would use until reaching the given password. The main approaches have been based on, e.g., Markov models [14,32,36], probabilistic context-free grammars (PCFGs) [27,50], neural networks [35,42] and others [20,52]. Based on the well known phenomenon that people often use attributes of their personal information in their passwords (their names, email addresses, birthdays etc.), [23,28,48] have proposed to tweak the prior models, based on personal information known about a given user’s password.
In this work we propose a novel addition to this line of research, called PESrank. Our goal is to provide a password strength estimator that enjoys the following properties:
It is a cracker-based estimator, that accurately models the behavior of a powerful password cracker. The modeled cracker calculates the rank of a given password in an optimal descending order of likelihood. It is practical for online use, and is able to estimate a given password’s rank in fractions of a second – i.e., without actually enumerating the passwords. Has reasonable training time, drastically shorter than previous methods (some of which require days of training). It is efficiently tweakable to allow model personalization, without the need to retrain the model. It is explainable, and provides feedback on why the password has its calculated rank, giving the user insight on how to pick a better password.
Contributions
Our idea in the design of PESrank is to cast the question of password rank estimation in a probabilistic framework used in side-channel cryptanalysis. We view each password as a point in a d-dimensional search space, and learn the probability distribution of each dimension separately. This learning process is based on empirical password frequencies extracted from leaked password corpora, that are projected onto the d dimensions. Once the d probability distributions are learned, the a-priori probability of a given password is the product of the d probabilities of its sub-passwords.
Using this model, optimal-order password cracking is done by searching the space in decreasing order of a-priori password probability, which is analogous to side-channel key enumeration; likewise, password strength estimation is analogous to side-channel rank estimation. There is extensive research and well known algorithms for both problems in the side-channel cryptanalysis literature. Using a rank estimation algorithm, our password strength estimator does not need to enumerate all the passwords in decreasing order, but can rather estimate the password’s rank in fractions of a second. We adopt a leading side-channel rank estimation called ESrank [9,30] to create our password strength estimator PESrank. The ESrank algorithm has accuracy guarantees providing both upper- and lower-bounds on the true rank.
PESrank’s training time is very reasonable, taking minutes-to-hours. It is also efficiently tweakable to allow model personalization, without the need to retrain the model. In addition, PESrank is able to help explain the password strength value: For example, PESrank can indicate that the password newyork123 is based on a leaked word that was used by 129,023 people, and uses a very popular suffix that was used by over 17 million people. Such explainability is very important since it helps guide the user on how to pick better passwords. This is in contrast to prior methods, especially those based on neural networks, which offer little-to-no explainability.
In order to demonstrate PESrank’s capabilities as an online password strength estimator we implemented PESrank in Python and integrated it into the registration page of a course at our university. Even with a model based on 905 million passwords, the end-to-end response time in the browser was well under 1 second, with up to a 1-bit accuracy margin between the upper bound and the lower bound on the rank. This allowed us to run a proof-of-concept study on how students reacted to their passwords’ strength estimates.
We also demonstrate how PESrank can be personalized if a previous password is known for the user at hand. We tweaked the model for each user according to the parts of the leaked previous password, and showed that the number of tries a cracker needs to do (i.e., the password’s rank) decreases significantly. PESrank requires no per-user re-training: the model can be tweaked once in advance in the training step so that the online response time in the browser for each user, including the personalization, remains well under 1 second.
We conducted an extensive evaluation study comparing PESrank’s accuracy to prior approaches. In our study we used Ur et al.’s Password Guessability Service [4] (PGS), which provides access to the Hashcat [21] and John the Ripper [37] crackers, the Markov [36] and PCFGs [50] methods, and to the neural-network method [35] (Monte-Carlo variant). We compared the ranks calculated by PESrank to the ranks obtained by these five password strength estimators. We show that PESrank (and, in fact, the optimal password cracker it models) is more powerful than previous methods: the model-based cracker can crack more passwords, with fewer attempts, than the password crackers we compared it to.
Organization. In the next section the background on side-channel key enumeration and rank estimation is introduced. In Section 3 the multi-dimensional password model is described. In Section 4 the usage of the model is described. In Section 5 the performance of PESrank and the implementation details are described. In Section 6 tweaking the model with personal context and previous passwords is discussed. In Section 7 the explainability of PESrank and the proof of concept usability study is discussed. In Section 8 PESrank is compared with existing methods. In Section 9 the related work is discussed and Section 10 concludes.
Rank estimation and key enumeration in cryptographic side-channel attacks
Side-channel attacks (SCA) represent a serious threat to the security of cryptographic hardware products. As such, they reveal the secret key of a cryptosystem based on leakage information gained from physical implementation of the cryptosystem on different devices. Information provided by sources such as timing [26], power consumption [25], electromagnetic radiation [1,16,40] and other sources, can be exploited by SCA to break cryptosystems. A security evaluation of a cryptographic device should determine whether an implementation is secure against such an attack. To do so, the evaluator needs to determine how much time, what kind of computing power and how much storage a malicious attacker would need to recover the key given the side-channel leakages. The leakage of cryptographic implementations is highly device-specific, therefore the usual strategy for an evaluation laboratory is to launch a set of popular attacks, and to determine whether the adversary can break the implementation (i.e., recover the key) using “reasonable” efforts.
Most of the attacks that have been published in the literature are based on a “divide-and-conquer” strategy. In the first “divide” part, the cryptanalyst recovers multi-dimensional information about different parts of the key, usually called subkeys (e.g., each of the
The key enumeration problem. The cryptanalyst obtains d independent subkey spaces
A naive solution for key enumeration is to take the Cartesian product of the d dimensions, and sort the
Unlike a cryptanalyst trying to extract the secret key, a security evaluator knows the secret key and aims to estimate the number of decryption attempts the attacker needs to do before it reaches the correct key, assuming the attacker uses the SCA’s multi-dimensional probability distributions. Formally:
The rank estimation problem. Given d independent subkey spaces of sizes
While enumerating the keys in the optimal SCA-predicted order is a correct strategy for the evaluator, it is limited by the computational power of the evaluator. Hence using algorithms to estimate the rank of a given key, without enumeration, is of great interest. Multiple rank estimation algorithms appear in the literature, the best of which are currently [9,17,30,34]. They all work in fractions of a second and generally offer sub 1-bit accuracy (so up to a multiplicative factor of 2).
Intuitively, key enumeration seems analogous to password cracking: in both cases there is a need to enumerate and test candidates in decreasing order of likelihood, based on an a-priori probability model. And similarly, rank estimation seems analogous to password strength estimation. Therefore we hypothesize that techniques used succefully in the SCA domain may be applicable in the password domain.
Multi-dimensional models for passwords
Overview
The starting point in producing a password strength estimator is a leaked password corpus: The frequency of appearance of each leaked password provides an a-priori probability distribution over the leaked passwords. Given a hash of an unknown password, trying the leaked passwords in decreasing frequency order, is the optimal strategy for a password cracker – if the password at hand is in the corpus. To crack passwords that are not in the leaked corpus as-is, password crackers rely on the observation that people often take a word, which we shall call the base word, and mutate it using various transformations such as adding digits and symbols before or after the base word, capitalizing some of the base word’s letters, or replacing letters by digits or symbols that are visually similar using “l33t” translations.
Our main idea is that if we can represent the list of base words as a dimension, and represent each possible class of transformations as another independent dimension, we can pose the password cracking problem as a key enumeration problem, and similarly, pose the password strength estimation as a rank estimation problem. Each dimension should have its own probability distribution: e.g., as we shall see, for the “suffix” dimension, the most probable in our training set is the “empty” suffix, with
Thus, we arrive at the following framework: First, identify meaningful classes of transformations, and find a suitable representation for each as a dimension. Next, build a probability distribution for each dimension using the training corpus, to create a model. Finally, use a good rank estimation algorithm with the model and evaluate its performance. For the rank estimation algorithm we use the ESrank algorithm [30]. Therefore we call our password strength estimator PESrank.
Selecting the dimensions
Our main goal in selecting the dimensions is generalization. For instance, if we recognize that a suffix of ‘1’ has probability
We chose the dimensions according to the patterns humans tend to choose in their passwords: Following [44] in order to make their password more secure, people tend to add some combination of digits and symbols either to the end of their base password (which we call the suffix) or at the beginning (which we call the prefix) as in, e.g., iloveyou!! or 123iloveyou. In addition, as also described in [52] people tend to use mixed letter case, e.g., iLoVeyOu, and l33t speak, e.g., il0v3you. We then verified the observations of [44,52] in Jason’s corpus: Table 1 shows that significant fractions of the leaked passwords fit our choice of dimensions.
Next, we show several ways to select dimensions, and then in Section 4 we compare between them and choose the best among them.
Leaked password patterns in Jason’s corpus
Leaked password patterns in Jason’s corpus
In our simplest model we divide each password into three sub-passwords: prefix, base word and suffix. We define “prefix” as the string consisting of all the digits and symbols that appear to the left of the leftmost letter of the password, and define “suffix” as the string consisting of the digits and symbols that appear to the right of the rightmost letter in the password. We define “base word” as the string starting with the leftmost letter and ending with the rightmost letter of the password. For example, if password is ‘123Pa$$w0rd!!’, the prefix is ‘123’, the suffix is ‘!!’ and the base word is ‘Pa$$w0rd’. The base word can consist of mixed-case letters, digits and/or symbols. In case there are no letters in the password, (e.g., ‘1234567890’), the password itself is considered to be the base word, and the prefix and suffix are the empty strings. In case the password starts with a letter (e.g., ‘abc123’), the prefix is the empty string, and similarly, if the password ends with a letter (‘123abc’), the suffix is the empty string. Note that the division into these three parts is purely syntactical and is not a semantic division as in [46]. Computing a good semantic division is time and space consuming, so we elected to rely on the simpler syntax-based division.
4D model: Adding the capitalization pattern
The next level of sophistication is to add another dimension, to represent the “capitalization pattern”: the pattern of upper-case and lower-case letters in the passwords.
To begin with we split a password into its 3D sub-passwords as in Section 3.2.1. We only consider the capitalization pattern within the base word: recall that for the password ‘123Pa$$w0rD!!’ the base word is ‘Pa$$w0rD’. Given a base word, it is clear which of its letters are capitalized (upper case) and which are not. However, we have a choice how to represent the pattern. The obvious option is to represent the pattern as a binary string, with a ‘1’ bit in position j indicating that the j’th letter is capitalized. However, this representation is closely tied to the word’s length: e.g., position 5 could indicate the last letter in a 5-letter word, or the before-last letter in a 6-letter word, etc. Our intuition, and a preliminary inspection of the Jason [24] corpus, show that people tend to associate significance to the distance from the word’s end: e.g., capitalizing the last letter is fairly common (
Therefore we elected to represent the capitalization pattern as a list of positive and negative indices at which capital letters appear: The negative indices count from the word end, with −1 representing the rightmost letter. The positive indices count from the word start, with 0 representing the leftmost letter. To avoid ambiguity, both the negative and the positive indices do not exceed the middle index. If there is no letter in the base word, the capitalization pattern is empty. We also added a capitalization pattern ‘all-cap’ for the special case in which all the letters are capitals (regardless of password length). So for ‘123Pa$$w0rD!!’ the capitalization pattern of the base word ‘Pa$$w0rD’ is the first letter and the last letter, denoted by ‘[0,-1]’, and for the base word ‘PASSWORD’ the capitalization pattern is ‘all-cap’.
Note that the capitalization-pattern dimension is not strictly independent of the base-word dimension: e.g., a capitalization pattern t may refer to indices that are outside a short base word b, or b’s characters at the indexed positions may be symbols or digits (which do not have a capitalized form). In such cases the transformation t degenerates into the null transformation. For a model-based password cracker, this dependence implies some inefficiency, since the cracker will test the same password multiple times, once for each capitalization-pattern that is equivalent to the null transformation for the current base word. The rank estimation accurately accounts for such a cracker’s inefficiency. This means that a more sophisticated cracker can be developed: it could skip null transformations and save itself time. Thus this dependency only increases the password strength estimation value, which is still, as we see in Section 8, better and lower than existing methods’ estimation.
5D model: l33t
As observed by [52], people sometimes mutate passwords using “l33t” transformations: replacing letters by digits and symbols that are visually similar. We elected to add the l33t transformation as a fifth dimension in this model. The l33t transformations we considered are shown in Table 2.
For simplicity, we only consider the l33t pattern within the base word, so for ‘123Pa$$w0rD!!’ the l33t transformation is only relevant in the base word ‘Pa$$w0rD’. As in the 4D case (Section 3.2.2) we need to devise a representation for the l33t pattern. In principle the l33t pattern depends on the position of the letter being mutated, and on the choice of replacement (Table 2 shows that some letters have more than one l33t replacement). In this case we elected to ignore the positionality aspect. We numbered the possible l33t replacements from 1 to 14 – e.g., transforming ‘a’ into ‘4’ is transformation number 3 – and represent the whole l33t transformation of a base word by a tuple of l33t replacement numbers. So for ‘123Pa$$w0rD!!’ the l33t transformation is $↔ s and 0 ↔ o. We assume that if a l33t replacement is applied then it is applied to all the relevant letters in the base word. So following Table 2, the l33t pattern of ‘123Pa$$w0rD!!’ is ‘[1,4]’ which means “replace all occurrences of o by 0 and all occurrences of $ by s”.
Note that our representation is unable to represent transformations in which the position matters: e.g., for a base word ‘aaaaaab’ we cannot represent a l33t pattern that produces the password ‘aa44@@b’. If we receive the password ‘aa44@@b’, PESrank divides it to the base word ‘aaaa@@b’ with the l33t transformation ‘[3]’ since 4 comes before @ and only one of them can be transformed into a. Then it returns the estimation of the combined password of this base word and this l33t transformation which is ‘4444@@b’, which is different from the original password on which we wanted to get the estimation. Note also that since the division into parts is not semantic, there might be base words containing l33t-transformation digits which may not represent a l33t transformation to the user: e.g., in the keyboard-pattern password ‘nhy67ujm’ the digits 6 and 7 are more likely to be part of the keyboard pattern than l33t transformations. This fine distinction is mostly immaterial to us since the learned password ‘nhy67ujm’ is stored in the model: it appears in the base word dimension (un-l33ted) as ‘nhygtujm’ with l33t transformation ‘[7,10]’. Note that the l33t-pattern dimension is not independent of the base-word dimension, and as before, this dependency introduces some inefficiency to a model-based password cracker.
L33t transformations
L33t transformations
Data corpus
To study the statistical properties of passwords, and then to train our method, we used Jason’s corpus of leaked passwords [24]. This corpus contains 1.4 billion pairs of username and password, compiled from multiple leaked corpora: Yahoo, Target, Facebook, Hotmail, Twitter, MySpace, hacked PHPBB instances, and many other sources. We believe that Jason’s corpus is a superset of the corpora used to train previous methods.
The “username” field in Jason’s corpus is generally an email address, e.g.,
From this corpus we sampled 300,000 username-password pairs to serve as a test set, in the following way: we picked every password whose length is at least eight and its position in the corpus passwords list is divisible by 101. We split the test set into ten separate samples, of 30,000 passwords each, and submitted all the sample sets to PGS for evaluation. To compare the ranks we received from PGS to those of PESrank, we trained PESrank on the same training corpora used by the PGS implementations of the various methods, as follows:
Learning phase
We explain the learning phase for each model separately:
We learn the distributions of the prefix, the base word and the suffix, using the training set at hand – recall Section 4.1 – as follows. Let these distributions be denoted by As in the 3D case, we divide each password into three sub-passwords, i.e., prefix, base word and suffix. Then, we find the indices at which there are upper case letters in base word, and represent their pattern using our positive/negative index representation. We increment the frequency of the pattern in the fourth dimension by 1. Before incrementing the base word’s frequency, we “uncapitalize” it, i.e., we ensure that all the base word letters are in lower case, so for the raw base word ‘Pa$$w0rD’ we increment the frequency of ‘pa$$w0rd’ in the base word (second) dimension. Examples of the 4D decomposition appear in Table 3. The two most popular capitalization patterns we found in our training set are the empty transformation ( 4D decomposition examples
As in the 4D case, we divide each password into four sub-passwords, i.e., prefix, base word, suffix and capitalization pattern. Then, we check which l33t replacements apply to the base word using the options in Table 2. To prevent a collision between two different l33t symbols that represent the same letter, we track only the leftmost replacement (in the base word) per row in Table 2. For each password we keep a tuple of all the l33t replacements that were done to the base word. As in the 4D model, before incrementing the base word’s frequency, we “un-l33t” it using the detected pattern. If there are no l33t transformations in the base word, the base word remains as-is and the l33t pattern is empty. For example: if the password is ‘g00dPa$$w0rD’, the prefix is empty, the base word is ‘goodpassword’, the suffix is empty, the capitalization pattern is ‘
As we shall see, using a 5D model gives us good generalization capabilities beyond the training data. However, following [13,29,41], we know that people have a tendency to choose passwords that contain dates and meaningful numbers. To take this observation into account, we enriched the probability distributions of the prefix, base word, and suffix dimensions, by adding strings that are not present in the training corpus. Every string that is added to a given dimension is added with a frequency
All the digit sequences of up to six digits were added to the prefix and suffix distributions.
All the digit sequences of length exactly six were added to the base word distribution.
Note that this enrichment gives good coverage of many date patterns: adding all the 6-digit strings to the base words covers all the dates that have patterns of ddmmyy or yymmdd or mmddyy, and most of the dates with a 4-digit year, such as 111998 (which could be either 1/Jan/1998 or Nov/1998). With the prefix and the suffix enrichments we cover all the 2-digit and 4-digit years such as 98 or 2003. An 8-digit date, e.g., with a ddmmyyyy format, as a stand-alone password, is also included in the model as both a 2-digit prefix plus a 6-digit base word, and as a 6-digit base word plus a 2-digit suffix.
Estimation phase
A model-based cracker based on, e.g., [50] goes over the password candidates using an optimal-order enumeration. We suggest to use a matching rank estimation algorithm using ESrank [30], to estimate the password strength. For simplicity we explain estimation phase for the 3D model, but it is the same for all the models. Given a password P, we split it into its sub-passwords
For a given password which is composed only of digits, the enriched model may include several options to reach this password by the model-based password cracker. As we saw with an 8-digit date example, a numeric password can be divided into prefix, base word, and suffix, in different ways, and the enriched model may include all the sub-passwords in the respective distributions. To account for this condition in the rank estimation, we added special handling of numeric passwords. For such a password, the PESrank algorithm iterates over all its possible divisions into three sub-passwords (of any length): for an ℓ-digit password there are exactly

Comparing the four models’ performance on a 30,000 password test set, as a CDF: each curve shows the fraction of passwords that can be cracked in up to r attempts as a function of the rank r (log scale).
As described so far, if even one of a given password’s five parts is not present in the relevant dimension, PESrank is unable to estimate its rank. Under analogous conditions, the algorithms in PGS [4] return −5 when they cannot estimate. As we shall see when we discuss explainability (Section 7), having a sub-password that is outside the model is often an advantage, since PESrank can indicate to the user that she made a good choice in that part of the password. However, when considering the CDF, this behavior manifests itself by reaching an upper bound well below 100%: e.g., in Fig. 1 the CDF of the enriched 5D+ model only reaches 62%. Furthermore, we would like to augment the qualitative indication with a quantitative measure of the strength of the remaining password parts, that are in the model.
Therefore, following Komanduri [27], we also introduce an optional “unleaked” smoothing mode to PESrank: when it’s active, the model is also able to provide an estimate of the strength of passwords with unleaked parts, for which we have no empirical a-priori probability. We do this as follows: if the password part s is missing from distribution
Basic model evaluation
In order to evaluate our four models (3D,4D,5D,5D+) we computed three evaluation metrics for each model. These metrics are computed without the use of the “unleaked” smoothing mode.
Following [12,35,45,50], the percentage of passwords that would be cracked after a particular number of guesses: in other words, the Cumulative Distribution Function (CDF) of each model. More powerful guessing methods guess a higher percentage of passwords in our test set, and do so with fewer guesses: hence a better model has a CDF that rises more sharply and ultimately reaches a higher percentage.
The model size: we calculated the Total Dimension Length – the sum of all the dimensions lengths, i.e.,
Volume: this is the total number of passwords that can be reached using our model, without smoothing. When the model has d dimensions, whose sizes are
We trained the four models using the PGS training set, and evaluated them using ten different test sets (recall Section 4.1). The CDF results are shown in Fig. 1. The ten graphs of the different test sets look similar, therefore we show only one of them.
In Fig. 1 the x-axis represents the number of guesses (log scale) and the y-axis shows the corresponding percentage of passwords in the test set that can be guessed in that number of guesses. As we can see, the method becomes more powerful with each added dimension, successfully cracking a greater fraction of the passwords, with fewer attempts.We also see that adding the enrichment by numeric strings as described in Section 4.3 is very effective.
Model size using the PGS training set
Model size using the PGS training set
In Table 4 we can see the model sizes of the different models. The table shows that the model size decreases with the Capitalization (4D) and L33t (5D) dimensions: despite the fact that additional probability distributions are incorporated, the base word dimension shrinks due to different passwords collapsing into the same base word. On the PGS training set the enrichment step (5D+) grows the prefix, suffix and the base word lists by approximately one million combinations of six digits. Table 4 shows that the volume grows dramatically, from a raw corpus of about
We conclude that the enriched 5D+ model is superior to the simpler alternatives, and it’s size is well within the capabilities of modern computers. In the remainder of this work we use this enriched 5D+ model.
We tested our Python implementation of PESrank’s training on a 3.40GHz core 7 PC running Windows 8.1 64-bit with 32GB RAM.The PESrank code is publicity available at GitHub [10]. We found that the PESrank training phase is quite fast – much faster than reported for previous methods. It takes only 12 minutes to train PESrank on the PGS set, in comparison to the days of training reported for the Markov [32] or PCFG [50] methods using the same set. To train our method on the PGS
Performance and implementation details
In the offline training step, PESrank goes over the training set passwords and creates five probability distribution lists stored in five files. Each file contains a list of
In the online lookup step, given a password, PESrank divides the password into its five dimension parts, then for each sub-password, it finds its probability using binary search in the corresponding probability distribution file. PESrank then multiplies the five probabilities to get the a-priori password probability. Finally, PESrank applies the rank estimation algorithm, ESrank [9,30], that receives the password probability and outputs upper and lower bounds for the rank.
The ESrank algorithm uses exponential sampling, which depends on a tunable parameter γ that affects the accuracy of the rank estimation and the time-and-memory trade-off. The ratio between the ESrank’s upper bound and lower bound of a given password is bounded by
Reducing the online lookup time
The PESrank online lookup time, given a password, includes calculating the bounds of the password probability rank using the ESrank algorithm. The ESrank algorithm receives as input d probability distributions lists and a password probability, uses exponential sampling to merge the d lists into two, and then calculates upper and lower bounds of the rank of the given probability using only the last two merged lists. Since calculating these two merged lists only depends on the d probability distribution lists, the merging step can be done in the offline training step. The online lookup step reads the last two lists and use them in calculating the rank of a given password. Thanks to the exponential sampling, the lengths of these two merged lists are small (see Table 5), therefore we placed them inline in the estimator code.
Performance
We implemented PESrank in Python. This code is publicity available at GitHub [10]. We tested its performance using a test set of 30,000 passwords as described in Section 4.1. The results are summarized in Table 5. The table shows that on average an estimation takes 33 msec, and under 1 sec in all cases, giving a good user experience. The lookup time includes: (1) dividing the password to its 5 dimensions’ values,
PESrank performance metrics
PESrank performance metrics
It is well known that it is advantageous to tweak a general-purpose password model with a user’s personal information, if such information is available – e.g., email address, name, birthday, previous seen passwords, etc. [5,23,28,36,48].
Conveniently, since PESrank uses a very simple model representation – essentially a sorted probability list of password elements per dimension – it is efficient to tweak, without the need to retrain. All that is required to tweak one of its dimensions (e.g., adding a base word w with a-priori probability p) is:
Insert w into its correct place in the sorted order, with probability p.
Normalize the probabilities of all the other values in that dimension by multiplying each with
The only change in the online lookup step is in the mapping between a password and its tweaked probability when personal information is known: Given a sub-password
Modeling password reuse
A special kind of personal information is knowledge of a previous password. It is well documented that people tend to reuse their passwords, either exactly, or with some variations.
The Jason corpus [24] does not provide us with personal information about the password owners – but it does provide a glimpse into password reuse. We found a total of 80,064,647 users in the corpus for which more than one record exists. Among them only 0.81% reuse their password exactly as is. However, as Table 6 shows, as many as 22% reuse their base word, and much higher fractions reuse their prefix, suffix, capitalization pattern and l33t transformation. Note that the percentages in Table 6 include the trivial cases: e.g., of the 90% of users reusing a previous prefix, nearly all of them reuse an empty prefix. Superficially this may seem somewhat uninteresting, however it is still very valuable information for an attacker: e.g., if Alice used a prefix-less password in the past, Table 6 implies that there is a 90% probability that her password at hand is also prefix-less. Therefore, when cracking, or evaluating the strength of a user’s password, if we know previous passwords belonging to a user with the same username, it is reasonable to assume that one of the known passwords or their variants is being reused.
The re-use probability of an entire password and of each dimension separately
The re-use probability of an entire password and of each dimension separately
Note that a properly configured site would not retain a user’s old passwords but only their hashes. However, if the username exists in a leaked password corpus like Jason, then historical passwords become available. Note also that given a previous password w, the probabilities listed in Table 6 for all 5 dimensions are so large as to effectively ensure that the tweaked probability, in every dimension i, is the maximal probability in that distribution, and is placed in
To train a tweaked PESrank model to allow for using a known password, while also taking into account the unleaked smoothing mode (Recall Section 4.5), we proceed as follows. First, we train an un-tweaked model as before. We retain the d un-tweaked probability distributions
To do so, we insert
Note that the training does not require knowledge of an actual reused password: it only needs to know the per-dimension probabilities of reuse from Table 6, which are independent of the specific user or her choice of previous password. So we can use the method of Section 5.1 to reduce the online lookup time: We run the tweaking procedure only once, in the training step.
The online lookup of the rank of the current password, given a previous password belonging to the current user, is done as follows:
Divide the previous password into its d dimensions Divide the current password into its d dimensions For each Otherwise, set Set Run ESrank on
The online lookup running time of PESrank with personalization is the same as without the personalization.

The CDFs of PESrank with and without personalization.
To evaluate the power of using personalization in PESrank, we simulate the situation of evaluating a new password, assuming the existence of a corpus of leaked passwords that contains only a single password for every user.
For the evaluation we filtered the Jason corpus for only passwords of length between 8 and 20. We split the filtered corpus into two sets: (1) The “Last” set, which contains the last password of any user in Jason corpus. Namely, if a user has only one password in the corpus then we take this password into the “Last” set, and if she has k passwords, we take the k’th password. The “Last” corpus includes 777,035,187 records, one per user; (2) The “Rest” set, which contains user+password pairs only for the users who appear more than once in the original Jason corpus, and for each such user we take all her passwords except the last one. The “Rest” set includes 116,558,449 records.
Thus in terms of records, the “Rest” set is disjoint from the “Last” set. But in terms of users, every user appearing in the “Rest” set is guaranteed to have a password in the “Last” set. We use the larger “Last” set as a training set (with and without personalization). We take the position that passwords in the “Rest” set represent new passwords that users prone to password reuse choose. Thus we randomly sample 30,000 pairs of (user, password) from the “Rest” set to be our test set. Then for each (user, password) pair in the test set we first find the password w that this user has in the “Last” file to create a test triplet (user, password, previous password) on which we activate the online rank lookup.
Figure 2 compares the PESrank CDF with and without personalization with a smoothing factor
We draw several conclusions from this experiment. First, we re-affirm that knowing the user’s previous passwords provides the password cracker with very valuable information. Second, that a good password strength estimator should use such history as context, to accurately model the cracker’s capability – and that resources such as Jason’s corpus [24] already provide a wealth of historical data on millions of users. And third, that the PESrank algorithm is well suited to use such context since it is easily tweakable for online use, without time consuming per-user retraining.
Usability of PESrank
A proof of concept study
We integrated PESrank into the registration page of the Infosec course at our university. The system provides users with a gentle “nudge”: it accepts weak passwords, yet tells the owners they are weak, and makes it easy for them to try again. The system outputs three different messages, see Fig. 3: passwords with strength below 30 bits are considered ‘weak’ (red), strengths between 30–50 bits are considered ‘sub-optimal’ (yellow) and strengths above 50 bits are considered ‘strong’ (green). Once the strength estimation message was displayed, the registration page offered a simple “Change your password” link to allow students to pick a new password. Changing the password was discretionary: the students were free to keep their password, even if it was ranked ‘weak’.
During the registration we only saved the password strength and not the password itself for statistical analysis, as approved by university’s ethics review board. The total time from clicking on the Register button until the browser shows the feedback message (including password registration, strength estimation, network delays, and browser rendering) is well under 1 second. The increase in registration time due to the strength estimation was negligible and qualitatively unnoticeable.
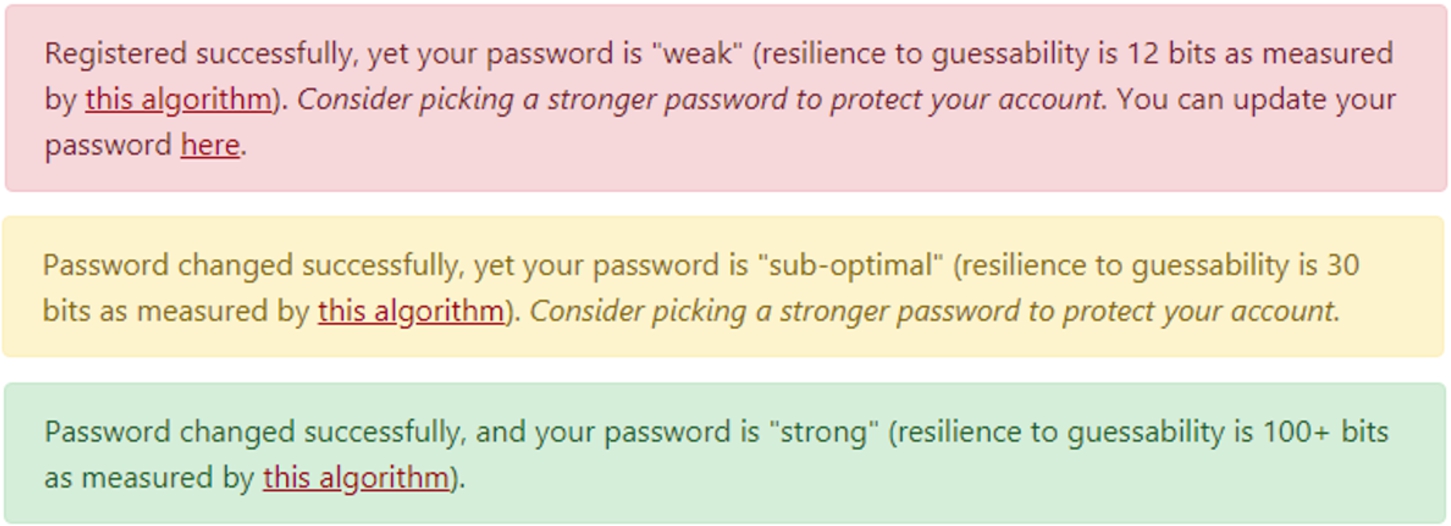
The possible messages shown by the registration page.
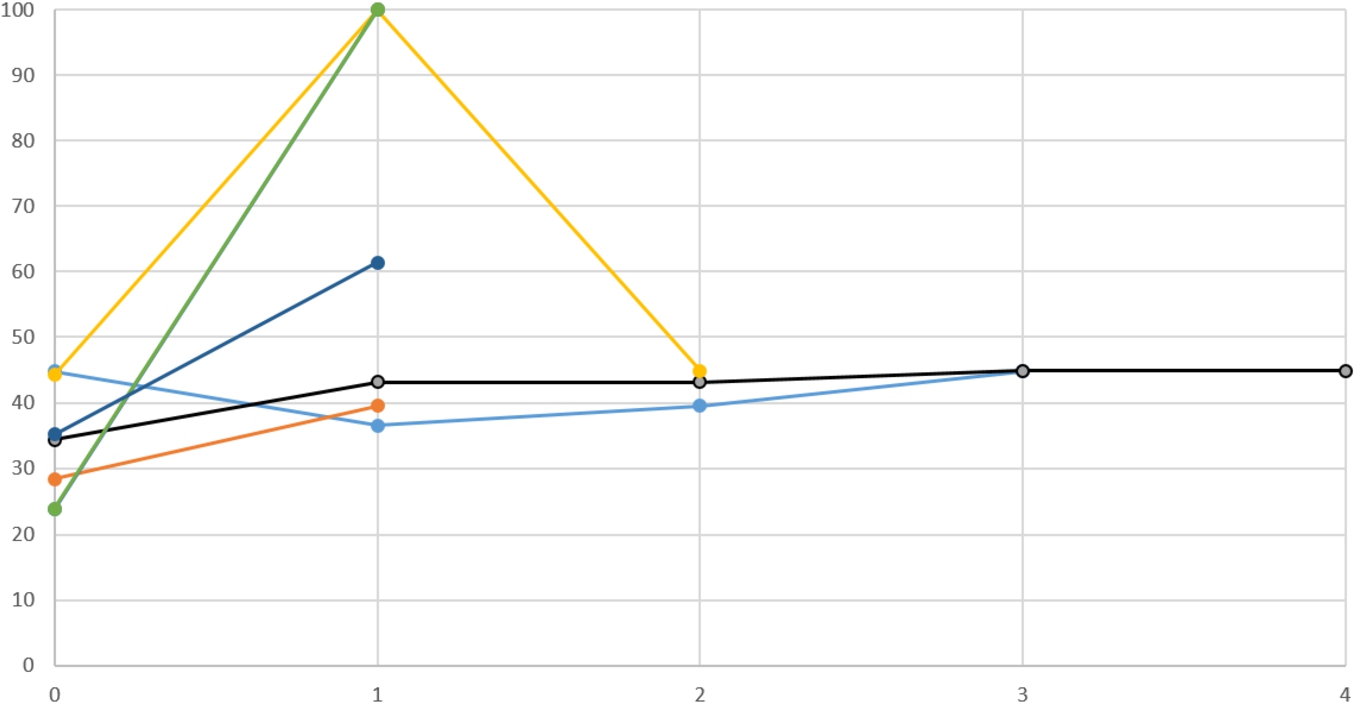
The password strength versus password-change number for the seven students who changed their password: index 0 indicates the strength of the initial password chosen by each student.
There were 98 students who registered to this course, between the ages of 18–30 years. They were all students of Electrical Engineering or Computer Science, at their third or forth year. Their participation in the password-strength proof of concept was mandatory: creating an account and registering a password was required in order to gain access to the course materials.
The median password strength of the first password chosen by the students was 41.51 bits, with the weakest having strength of 14.14 bits. Out of the 98 students, seven students changed their passwords to stronger passwords. The median strength of these students’ first passwords was 34.32 bits, and the median strength of their final passwords was 44.88 bits: a significant improvement.
In Fig. 4, we can see the evolution of passwords strengths of the seven students who changed their password (there are two students whose lines overlap due to similar strength choices). The figure shows that five students indeed picked a stronger password in their first change – one of whom later changed the password a second time in favor of a weaker password. Interestingly, two students changed their passwords three and four times, respectively, without significantly improving their strength.
The anecdotal evidence from the proof of concept leads us to realize that while providing the password strength encourages some to pick a better password, a good strength estimator should give the user guidance on how to pick a better password.
One of the advantages of PESrank is that it is inherently potentially “explainable.” As part of its calculation it discovers the a-priority probability (and frequency) of each sub-password – and this information can be shown to the user. E.g., in the latest version of the code, for the password NewY0rk123 we provide the following feedback: “Your password is sub-optimal, its guessability strength is 32 bits, based on 905 million leaked passwords. Your password is based on the leaked word: ‘newyork’ that was used by 129,023 people. It uses a suffix that was used by 17,631,940 people. It uses a capitalization pattern that was used by 592,568 people. It uses a l33t pattern that was used by 4,395,598 people.”
This tells the user that (a) the transformations do not hide the leaked base word, that (b) they use a very common suffix and that (c) a simple l33t transformation is only marginally effective. And most importantly – it teaches that the split into the five dimensions is something password crackers know about and take advantage of.
Furthermore, if the password has parts that are unleaked (recall Section 4.5), this means the user actually selected a strong password part in that dimension – and PESrank is able to explain this. E.g. on a password “Dmmihhvk123”, it would explain “Your password is strong, its guessability strength is 53 bits, based on 905 million leaked passwords. Your password is based on a good (unleaked) base word. It uses a suffix that was used by 17,631,940 people and a capitalization pattern used by 34,102,338 people”.

The PESrank implementation as a Google Cloud Function.
We also created an alternative implementation, as a serverless Google Cloud Function: in this implementation the probability distributions are placed in a MySQL database. The Google Cloud Function is meant to work as an API that can be embedded into any web site’s password registration page. Figure 5 shows a screenshot of the Google Cloud Function implementation. We are planning to conduct a wider scale experiment in the future using the improved code.
Overview
In order to test the power and accuracy of PESrank, we compared it to multiple prior approaches. We first compared its guessing power and its storage requirements, to those of four cracker-based methods offered in PGS [4]: (1) the Markov model [32]; (2) the PCFGs model [50] with Komanduri’s improvements [27]; (3) Hashcat [21]; (4) John the Ripper [37] mangled dictionary models. Then we compared it to the neural network-based model of Melicher et al. (with Monte-Carlo estimation) [35]. In all cases we used the algorithms’ default settings and training data. To have a fair comparison, we trained PESrank on the PGS set for comparison with the PCFG, Markov, hashcat and JtR algorithms, and on the PGS
In order to evaluate PESrank and compare its performance to existing methods we computed for each model the percentage of passwords that would be cracked after a particular number of guesses: in other words, the Cumulative Distribution Function (CDF) of each model. More powerful guessing methods guess a higher percentage of passwords in our test set, and do so with fewer guesses: hence a better model has a CDF that rises more sharply and ultimately reaches a higher percentage.
When “unleaked” smoothing mode is active, the CDF exhibits two features: first, the CDF has a sharp upward “jump” at a rank that is influenced by the choice of α, and second, the CDF by definition always reaches 100%: even a password that has unleaked parts in all five dimensions will receive a minimal probability of
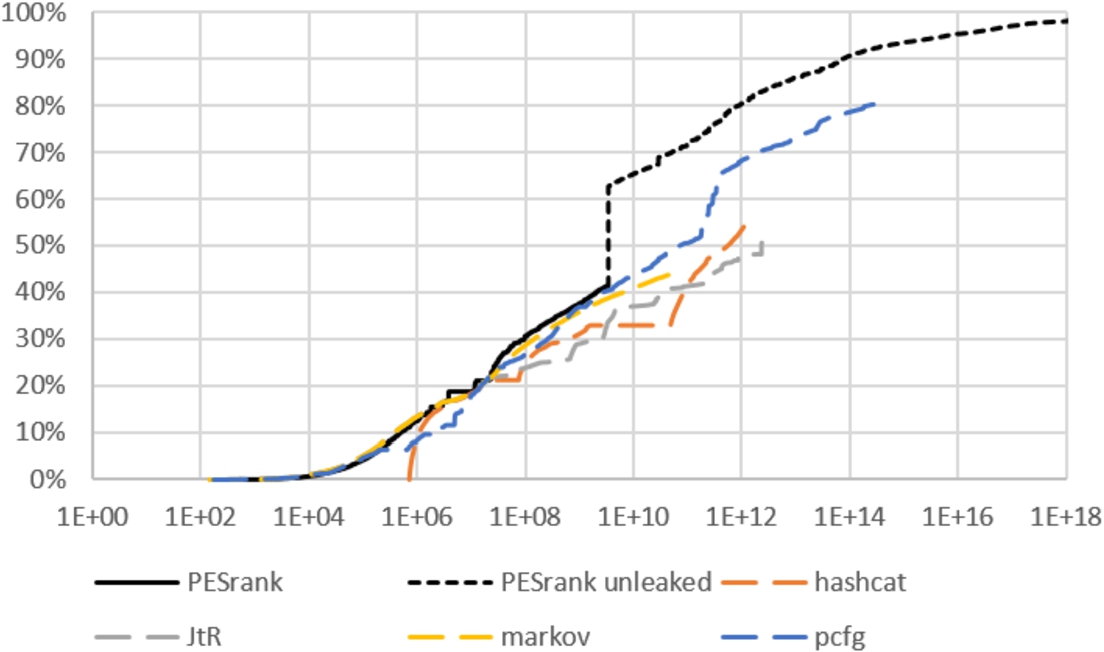
The CDFs of PESrank in unleaked mode versus PCFG, Markov, Hashcat and JtR.

The CDFs of PESrank in unleaked mode versus Neural.
Figure 6 shows the comparing PESrank, trained on the PGS set, with PCFG, Markov, hashcat and JtR algorithms with PESrank in “unleaked” mode, with
Figure 7 shows the results comparing PESrank, in “unleaked” mode, trained on the PGS
Figure 8 shows the CDFs of all the methods we compared, each trained on the maximal training set available to it (PESrank in “unleaked” mode). When PESrank is trained on a 905 million password training set, its advantage over the other methods, as provided by the PGS service [4], grows. While this figure mostly demonstrates the advantage of using a larger training set, it also shows that PESrank is actually able to digest such a large training set, due to its fast training time, whereas the other methods’ ability to do so in reasonable time is currently unknown.
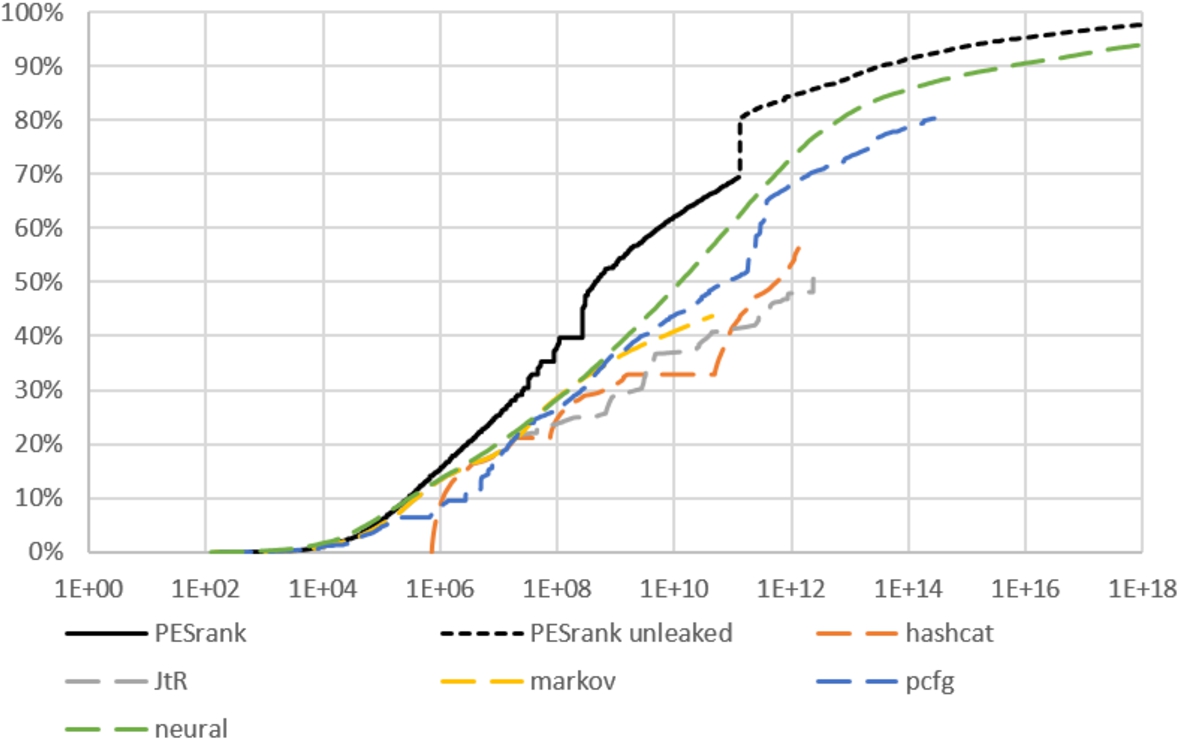
The CDF of each method trained on all the passwords available to it: PESrank in unleaked mode – on Jason, Neural – on PGS
Table 7 summarizes the storage space of the different methods, as reported by [35] – where, unlike in the PGS service [4], the authors trained the earlier methods on the PGS
Storage requirements for the various methods as reported by [35] when all methods are trained on the PGS
corpus
Storage requirements for the various methods as reported by [35] when all methods are trained on the PGS
Overall performance comparison to existing methods
In Table 8 we summarize the overall differences between the leading methods according to several criteria: training time, lookup time, tweaking time, storage, explainabilty and accuracy. The information about PCFGs in this comparison is taken from [27,50] plus [23,28,48] regarding its tweakability.
The table shows that the PESrank method outperforms all of the leading alternatives, in different ways. Versus PCFGs, PESrank is online and its training time is significantly shorter. Versus the Neural method in its pure variant again PESrank is superior since it is online, has shorter training time, plus it is tweakable and explainable. Finally, versus the Neural method’s Monte-Carlo variant (which is practical as an online estimator), PESrank retains all its other advantages in training and tweak time, explainability, and provable accuracy.
Related work
Password strength measurement often takes one of two conceptual forms: heuristic pure-estimator approaches, and cracker-based approaches. In the latter, either an actual password cracker is utilized to evaluate the password strength – or the meter uses an accurate model of the number of attempts a particular cracker would use until reaching the given password. All existing cracker-based methods are generative: they enumerate the passwords in their model either in their training phase or in their lookup phase. In heuristic pure-estimator approaches, the model provides a strength estimate directly from attributes of the password, without an accompanying passwords cracker that can achieve the predicted number of attempts.
PESrank belongs to the cracker-based approaches. However, unlike previous methods, it is not generative. Its underlying rank estimation algorithm works directly on the multi-dimensional probability distribution. This non-generative estimation is the reason why PESrank’s training time and tweaking time are dramatically faster than those of [35,36,50].
Heuristic pure-estimator approaches
The earliest and probably the most popular methods of password strength estimation are based on LUDS: counts of lower- and uppercase letters, digits and symbols. The de-facto standard for this type of method is the NIST 800-63 standard [3,19]. It proposes to measure password strength in entropy bits, on the basis of some simple rules such as the length of the password and the type of characters used (e.g., lower-case, upper-case, or digits). These methods are known to be quite inaccurate [11].
Wheeler proposed an advanced password strength estimator [51], that extends the LUDS approach by including dictionaries, considering l33t speak transformations, keyboard walks, and more. Due to its easy-to-integrate design, it is deployed on many websites. The meter’s accuracy was later backed up by scientific analysis [52]. Guo et al. [20] proposed a lightweight client-side meter. It is based on cosine-length and password-edit distance similarity. It transforms a password into a LUDS vector and compares it to a standardized strong-password vector using the aforementioned similarity measures.
Such pure-estimator approaches have the advantage of very fast estimation – typically in fractions of a second – which makes them suitable for online client-side implementation. However, they do not directly model adversarial guessing so their accuracy requires evaluation.
Cracker-based approaches
Software tools are commonly used to generate password guesses [18]. The most popular tools transform a wordlist using mangling rules, or transformations intended to model common behaviors in how humans craft passwords. Two popular tools of this type are Hashcat [21] and John the Ripper [37].
These tools typically run until a timeout is triggered. If they crack the given password before the timeout then their accuracy is perfect: they can report exactly how many attempts they used. However, if they fail to crack the password by the timeout, they do not estimate how many more attempts would have been necessary. Since they generally take a long time to run (minutes to hours, depending on the timeout setting) their usefulness as online strength estimators is limited.
A probabilistic cracker method, based on a Markov model, was first proposed in 2005 [36], and studied more comprehensively subsequently [6,14,32]. Markov models predict the probability of the next character in a password based on the previous characters, or context characters. This method is generative: it calculates the rank of a given password by enumerating over all possible passwords in descending order of likelihood, which is computationally intensive. and makes it impractical as an online strength estimator. In addition, in order to tweak this method for each user (based the user’s personal information), the model method should be retrained for each user separately [5]. Since the training takes days, it is unrealistic to tweak.
Weir et al. [50] proposed a very influential method which uses probabilistic context-free grammars (PCFG). The intuition behind PCFG is that passwords are built with template structures (e.g., six letters followed by two digits) and terminals that fit into those structures. A password’s probability is the probability of its structure multiplied by those of its terminals. In 2015 the PCFG method was integrated with the techniques reported by Komanduri in his PhD thesis [27]. Conceptually, this method is similar to ours since it also assumes probability independence between model components: Our method divides a given password into d dimensions, and the password’s probability is the product of the d probabilities of its corresponding sub-passwords. Like the Markov method, the PCFG method is generative: it calculates the rank of a given password by enumerating over all possible passwords in descending order of likelihood, so it is also impractical as an online strength estimator. In contrast, PESrank calculates the rank of a given password in the descending order of likelihood without enumerating over the passwords themselves. Due to its 2-level model (template + terminals), which is fairly intuitive, we believe PCFG may be explainable – although its authors did not develop or discuss this capability.
Melicher et al. [35] proposed to use a recurrent neural network for probabilistic password modeling. Like Markov models, neural networks are trained to generate the next character of a password given the preceding characters of a password. In its pure form this method is also generative and therefore it is computationally intensive.
However, the authors also describe a Monte-Carlo method to estimate the rank of a given password. To do so they split the algorithm into two phases: the training and sampling phase (which is generative), and a lookup phase, which uses the sampled model to provide an estimate. Therefore, like PESrank, in Monte-Carlo mode the Neural method’s lookup is non-generative, making it suitable for online strength estimation. The authors do not provide bounds on the estimation error introduced by the Monte Carlo method. However, the Neural method’s training phase remains generative: it enumerates the passwords to train the neural network. Thus, in order to personalize the neural network method for each user, it should be retrained for each user separately. Since the training takes days, this method cannot be personalized for different users in real-time. Moreover, like most neural-network-based systems, the algorithm is inherently “un-explainable,” only providing a numeric rank without any hints about “why” or what to do to improve.
Tweakable extensions and variations
Several authors (cf. [23,28,48]) extended the PCFG approach to develop systems that also use personal information. The nature of the extensions was to add a new grammar variable for each type of personal information, (e.g., B for birthday, N for name and E for email) which makes the approach tweakable. However these extended methods are impractical for online use for the same reasons PCFG is impractical: they are all generative.
Personalized password strength meters (PPSMs) which rely on previous password knowledge have also been proposed [7,38]: PPSMs warns users when they pick passwords that are vulnerable based on previously compromised passwords. Similarly, PESrank can be personalized based on previous passwords, but also can be personalized based on any kind of user personal information (name, email, etc.).
Recently [22] introduced PassGAN, an approach that replaces human-generated password rules by machine learning algorithms. The PassGAN uses a Generative Adversarial Network (GAN) to learn the distribution of real passwords from actual password leaks, and to generate password guesses. The authors did not compare their results with previous rank estimators and did not report on the required training time.
Conclusions
In this paper we proposed a novel password strength estimator, called PESrank, which accurately models the behavior of a powerful password cracker. PESrank calculates the rank of a given password in an optimal descending sorted order of likelihood. It is practical for online use, and is able to estimate a given password’s rank in fractions of a second. Its training time is drastically shorter than previous methods. Moreover, PESrank is efficiently tweakable to allow model personalization, without the need to retrain the model; and it is explainable: it is able to provide information on why the password has its calculated rank, and gives the user insight on how to pick a better password.
PESrank casts the question of password rank estimation in a multi-dimensional probabilistic framework used in side-channel cryptanalysis, and relies on the ESrank algorithm for side-channel rank estimation. We found that an effective choice uses
We conclude that PESrank is a practical strength estimator that can easily be deployed in any web site’s online password registration page to assist users in picking better passwords. It provides accurate strength estimates, negligible response-time overhead, good explainability, and reasonable training time.