
Abstract
Due to the limited capabilities of user devices, such as smart phones, and the Internet of Things (IoT), edge intelligence is being recognized as a promising paradigm to enable effective analysis of the data generated by these devices with complex artificial intelligence (AI) models, and it often entails either fully or partially offloading the computation of neural networks from user devices to edge computing servers. To protect users’ data privacy in the process, most existing researches assume that the private (sensitive) attributes of user data are known in advance when designing privacy-protection measures. This assumption is restrictive in real life, and thus limits the application of these methods. Inspired by the research in image steganography and cyber deception, in this paper, we propose StegEdge, a conceptually novel approach to this challenge. StegEdge takes as input the user-generated image and a randomly selected “cover” image that does not pose any privacy concern (e.g., downloaded from the Internet), and extracts the features such that the utility tasks can still be conducted by the edge computing servers, while potential adversaries seeking to reconstruct/recover the original user data or analyze sensitive attributes from the extracted features sent from users to the server, will largely acquire information of the cover image. Thus, users’ data privacy is protected via a form of deception. Empirical results conducted on the CelebA and ImageNet datasets show that, at the same level of accuracy for utility tasks, StegEdge reduces the adversaries’ accuracy of predicting sensitive attributes by up to 38% compared with other methods, while also defending against adversaries seeking to reconstruct user data from the extracted features.
Introduction
As user devices, such as the Internet of Things (IoT), smart phones, and autonomous vehicles, generate an ever-growing amount of data, the demand for greater computational power for data analysis has correspondingly increased over the years. To effectively analyze the data generated by these devices, artificial intelligence (AI) models have been widely deployed and utilized, with typical applications including traffic monitoring, intelligent surveillance [48], and autonomous driving [6]. Due to the great resource requirements of neural network inference, as well as the limited capabilities of user devices in terms of computational power and battery capacity, it is generally impractical to conduct neural network inference locally on such devices [26,33]. Consequently, the paradigm of edge intelligence has been recognized by researchers as a viable means of empowering user devices with the capabilities of AI [26,49]. This paradigm typically involves either fully or partially offloading the execution of neural networks from user devices to edge computing servers, in order to achieve a suitable balance of factors such as cost, latency of transmission, and accuracy of AI models. Specifically, it is estimated by IDC that European corporate spending on edge computing would double from 2020 to 2024, and the AI component of the spending would rise to 20% in 2024 [18]. Currently, there are already multiple commercial machine learning (ML) inference services available on the market, such as Azure Stack Edge1
Despite the benefits brought by offloading the expensive AI inference to the edge, there arises the problem of protecting the data privacy of users [8], as the original or preprocessed user data are sent to edge computing servers in the paradigm of edge intelligence. To illustrate the severity of potential privacy issues, it is demonstrated that adversaries can reconstruct the raw image from the intermediate features produced by the feature extractor of neural networks [24]. Additionally, private attributes, such as gender and age, can be inferred from such intermediate features derived from images [24,44]. These features are transmitted from user devices to edge computing servers in edge intelligence systems like JointDNN [12], and the transmission therefore poses a great threat to user privacy.
To deal with the privacy issue, researchers have proposed a variety of methods to process the user data. For instance, adversarial learning techniques can be applied such that the sensitive attributes of facial images would not be inferred by adversaries [29]. In addition, attributes of the user images can be manipulated and therefore the data privacy is protected through obfuscation [5].
However, most of the existing approaches explicitly or implicitly assume the symmetric knowledge of sensitive attributes, i.e., such sensitive attributes are known to the privacy-seeking users as well as the adversaries. In reality, it might be impractical to anticipate all the sensitive attributes in advance, and it is infeasible to re-distribute the updated retrained models on user devices when new sensitive attributes are discovered [35]. Additionally, edge computing service providers may lack the incentive to search for or disclose new sensitive attributes due to factors such as cost.
As a generally applicable scenario, we assume that the users have full access to both the architecture and the model weights of the feature extractor offered by the edge computing service provider (ESP), which we call the
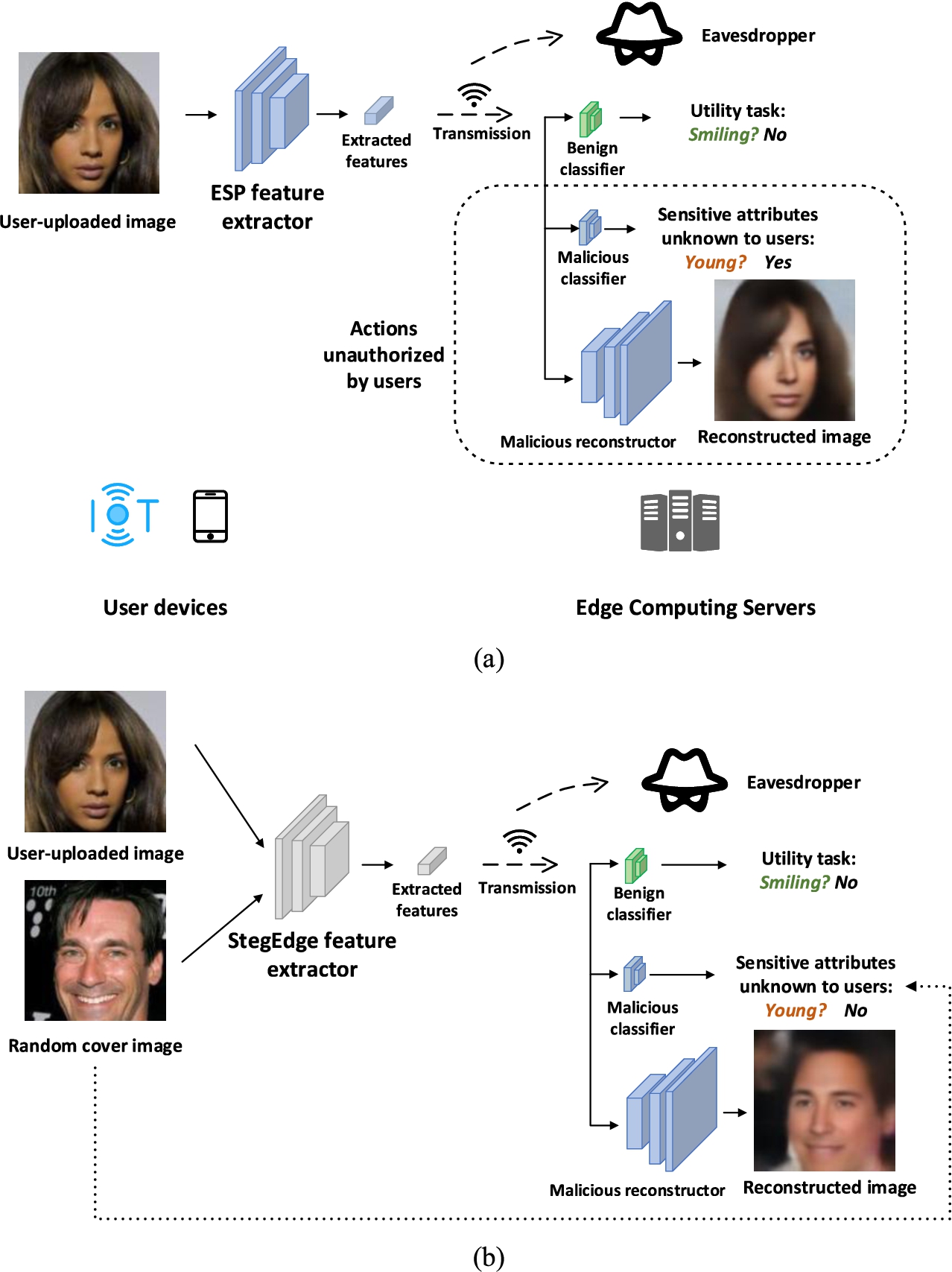
(a) An overview of the threat model for edge intelligence scenarios. (b) An illustration of StegEdge, the proposed scheme for privacy protection inspired by steganography and cyber deception.
Faced with the above practical obstacles to privacy protection, we propose StegEdge (see Fig. 1), a conceptually novel approach to reducing the private information leakage in an edge intelligence setting, which is inspired by the concepts of steganography and deception-based cyber defense. Steganography, by definition, is the practice of concealing secret messages in superficially normal messages or physical objects. For instance, researchers show that a secret image can be hidden in another “cover image” (or “container image”) by using neural networks, without visually raising any suspicion [22]. As for cyber defense achieved by deception [13], it is a widely adopted idea of presenting fabricated false information to potential cyber intruders to divert adversaries and to protect the real systems and information. For instance, false information about the operating system and network topology can be presented to adversaries [19].
To better describe StegEdge, we first make several key assumptions. (a) It is assumed that apart from the ESP FE provided to users, as a gesture of goodwill, the ESP also disclose to users the server model, which we call the
With the above assumptions, StegEdge can be summarized as “hiding” the information related to the utility task in the latent representations of a random cover/container image (see Fig. 1). The cover image can be selected by users such that it does not raise any privacy concerns (e.g., randomly downloaded from the Internet). The StegEdge feature extractor is trained by minimizing the difference between the features to be transmitted to the server and the features extracted from the cover image by the ESP FE in the latent space, while maximizing the accuracy of the utility task. Therefore, the reconstructed image and extracted sensitive attributes by adversaries would be close to the cover image, instead of the real user image, while the utility task is affected as minimally as possible.
Similar to cyber defense achieved by deception, one of the key intuitions behind our design of StegEdge is that, considering the fact that it is generally impossible to completely disentangle [5] the information contained in the transmitted features according to the utility task, deliberately presenting false information is a more feasible approach to privacy protection. In other words, since it is impractical for users to reduce the amount of non-utility information to zero, StegEdge tries to present a “negative” amount of information (false information) to the adversaries.
The main contributions of this paper are summarized as follows,
For ML inference service in the edge computing setting, a new and more realistic threat model is proposed, in which we make less restrictive assumptions than prior work.
Inspired by steganography and cyber deception, we propose StegEdge, an approach to privacy protection of unknown sensitive attributes by leveraging misinformation, which is fundamentally distinct from existing research.
As a proof of concept, StegEdge is implemented with lightweight neural networks, which protects users’ privacy while preserving the accuracy of utility tasks, and is suitable for resource-limited user devices.
Evaluation on the CelebA and ImageNet datasets shows that StegEdge reduces the adversaries’ accuracy of predicting sensitive attributes by up to 38% compared with other methods, while also defending against adversaries seeking to reconstruct user data from the extracted features.
In this section, we present several key related concepts, and clarify the distinction between them and our work.
Edge computing for DNN inference
Researchers have previously established that compared with full-offloading, improved latency, bandwidth consumption, and energy efficiency can be achieved by splitting the execution of DNN models between user devices and edge servers [45,49]. In this process, users have the opportunity to remove certain sensitive information for better privacy [15].
Cryptographic methods
Rathee et al. propose CrypTFlow2 [34], a cryptographic framework based on homomorphic encryption (HE) for two-party secure inference of neural networks, such that the server has no access to user data, but is able to compute the correct result of the neural network on behalf of users. The major drawbacks of such HE-based methods are slow computing speed and high communication overhead [30].
In contrast, methods based on trusted execution environments (TEEs) generally provide more efficiency. For instance, with the Intel SGX, Slalom [41] enables users to securely upload data to the server’s enclaves for DNN inference. The efficiency of TEE-based methods comes at the cost of requiring trust in hardware vendors [30]. Furthermore, several severe vulnerabilities have been discovered over the past years, which lead to side-channel attacks against TEEs including Intel SGX and ARM TrustZone [30].
Information bottleneck
The general idea of using information bottleneck [1] to protect user privacy is to limit the amount of information present in the latent representations transmitted to servers, such that the information related to the utility attributes is retained while other information is removed. Formally, it aims to optimize the following problem
While approaches based on the information bottleneck attempt to minimize the amount of information contained in the latent representation that is irrelevant to the utility task, it is generally impossible to reduce the amount of irrelevant information to zero (thus the information plane). In contrast, StegEdge circumvents this inherent limitation by incorporating misinformation, as further explained in Section 4.3.
Targeted protection of sensitive attributes
In [31], Morales et al. propose to apply adversarial learning to suppress the user-aware sensitive attributes in the latent space, such that such attributes are impossible to be exploited by adversaries.
In this paper, we do not introduce any major obstacle to implementing the above protection of selected attributes on top of StegEdge. These two paradigms are orthogonal to a certain extent. Therefore, they can both be utilized by users to simultaneously protect unknown and known sensitive attributes.
Adversarial attacks against neural networks
The goal of adversarial attacks against neural networks is typically to modify the input to a model, such that the model incorrectly classifies the input, either as a random label or a label specified by the attacker (called “targeted attack”). For instance, a physical stop sign can be modified such that a neural network used in autonomous driving is not able to correctly recognize it [25].
This paper is similar to adversarial attacks in the sense that they both attempt to make the target neural network make certain “wrong” predictions (i.e., StegEdge tries to make the ESP acquire the sensitive attributes of an irrelevant image instead of the real user image). StegEdge is different from adversarial attacks in the sense that the target neural network’s ability to correctly classify the utility attributes is maintained.
Image steganography
With methods such as modifying the least significant bits (LSBs) of pixels, as well transforming an image with neural networks [23], secret information (e.g., images, encrypted messages) can be hidden in cover (container) images, such that the modified image is visually indistinguishable from the cover image. While the goal of steganography is typically secret communication, StegEdge is conceptually similar to steganography in the following sense. The useful information of utility tasks contained in the extracted features is akin to the secret message in steganography, and the latent space information associated with a random cover image in StegEdge is similar to the cover (container) image in steganography. In both cases, only the intended receiver can correctly extract useful information, while others would acquire superficially correct misinformation.
Task-agnostic privacy protection
In [35], Samragh et al. apply singular value decomposition to protect the privacy of user data against the extraction of unknown sensitive attributes. The authors make the assumption of an honest edge computing service provider, and require the ESP to train the whole model with a privacy-friendly method. In this case, users need to unilaterally believe that the providers are behaving in a bona fide manner and offering the genuine privacy-protecting model, while such potentially restrictive assumptions are not made in this paper.
To similarly protect privacy against the extraction of unknown sensitive attributes, Wu et al. propose to use the ensemble of several known sensitive attributes to defend against the exploitation of unknown sensitive attributes [43]. As the knowledge and training data of such known sensitive attributes may be difficult for users to obtain in practice, we adopt a less restrictive threat model and do not require knowledge of such attributes.
Threat model
In this section we discuss the key assumptions made by StegEdge, and the rationale behind them.
Limited trust in ESPs. Certain researches assume that the ESPs take privacy protection into consideration during the initial process of model training (e.g., [35]). In other words, the ESP is considered bona fide and cooperative in the protection of users’ data privacy. However, due to factors such as lack of incentive, potential new discoveries of new sensitive attributes, monetary cost, difficulties in re-distribution of updated models [35], the assumption of bona fide ESPs can be limiting, considering that there also exists the threat of data breach of ESP servers, as well as potential malicious eavesdroppers with access to the transmitted features.
Asymmetric knowledge of sensitive attributes. While most existing work related to privacy protection in ML inference service makes the assumption that the users are aware of the exact sensitive attributes in advance, this assumption may lead to certain limitations in practice. In this paper, we assume that the knowledge of sensitive attributes is asymmetric for ESPs and users. Specifically, the adversaries try to extract, from the received latent features, sensitive attributes of user data, or attempt to classify user data into new classes that are beyond the knowledge of users. For instance, the ESP may provide users with the service of classifying images into 50 classes, while secretly classifying them into 100 classes to gain more detailed information on user data.
Asymmetric access to training data. As the performance of neural networks significantly relies on the amount of training data, the unequal amount of training data available to users and ESPs is a realistic yet seldom considered factor in the literature. It is highly impractical to make the assumption that users have access to the same amount of training data as ESPs when developing their measures of privacy protection. On top of that, the training data available to ESPs are valuable commercial intellectual properties and are subject to various regulations like GDPR, leaving privacy-seeking users in a disadvantageous position.
Disclosure of the benign classifier. It is not impractical for us to make the assumption that ESPs disclose the benign classifier to users as a gesture of good faith, while the provider may secretly switch to a privacy-intruding classifier in practice. Alternatively, eavesdroppers or data leaks/breaches on the ESP side would similarly result in the compromise of users’ data privacy. By contrast, in two-party secure inference systems like CtypTFlow2 [34], it is necessary for users to have knowledge of the detailed neural network architecture of the server’s model. However, it is our belief that the assumption of ESP’s disclosure of the benign classifier can be relaxed, and a “black-box” model can be adopted instead, since black-box attacks against neural networks have been quite successful over the past years [2]. For instance, researchers have shown that users can make few queries to the server’s model, and design a “surrogate” model to substitute the original server’s model [40]. The black-box scenario will be investigated in future work.
Inconspicuous privacy protection. The act of trying to protect privacy per se, could lead to privacy concerns in some cases. For instance, such users could be labeled as “privacy-sensitive” (“have something to hide”), and in turn receive targeted advertisement [38]. As an effective measure against these concerns, a study shows 40% of Internet users report presenting false information about themselves to commercial websites, in order to protect their privacy [36]. In our case, protecting the act of privacy protection is further complicated by the fact that the ESP (as well as eavesdroppers) could easily detect such an act by evaluating the quality of the reconstructed image, when users apply techniques such as replacing non-utility information with noise [14]. To solve this problem, StegEdge adopts deception and makes it less likely for users’ privacy protection measures to raise suspicion.
Details of StegEdge
The following two primary factors are considered in the general process of model design for StegEdge (see Fig. 2). First, the StegEdge FE should be as
For simplicity, we assume that the cover images are a large fixed set of images that do not cause any privacy concerns to users. Consequently, the probability is low for a potential adversary to find the cover image used by the StegEdge user and subsequently extract more sensitive information. After training, the user would randomly select a cover image, and it is very unlikely that an attacker would make a correct guess about which cover image was used by the user, provided that the attacker knows that StegEdge is being applied. It is possible for users to select a cover image not within the training set, but could lead to inferior performance.
As a proof of concept, we base our model on ResNet-50 and MobileNet v3 respectively for two scenarios, namely facial attribute classification and image classification. As detailed in Section 5.2, we double the number of CNN filters in the first several layers of the feature extractor, such that the information of both the cover image and the user image can be retained for merging in the subsequent layers. This design is similar to some models in image steganography, e.g., [10].
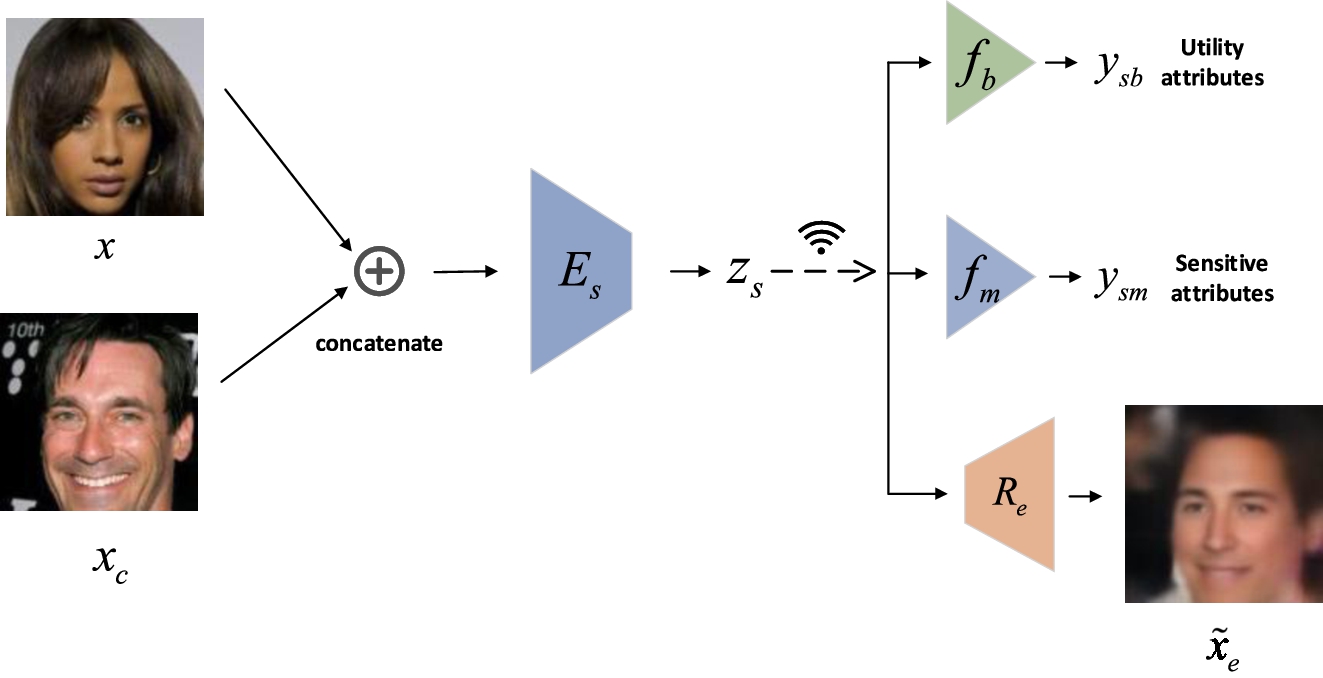
A detailed illustration of StegEdge.
Denote by
Operations including the (optional) quantization and compression of
Denote by
Given the cover image
Suppose the ESP secretly uses a reconstructor neural network
Denote the loss function of the utility task (e.g., cross-entropy) as
Loss functions
Therefore, from the perspective of ESPs, the goal is to train the ESP FE, the benign classifier, the malicious classifier, and the ESP reconstructor, such that the reconstructed image is close to the user image, and that the classification of both utility and sensitive attributes is as accurate as possible. The optimization problem is as follows,
For StegEdge, to measure the similarity between
An information-theoretic perspective
From a general point of view, consider a universal framework of privacy protection (StegEdge can be regarded as a special case) which transforms the user input X into the latent representation Z. The ESP then classifies Z as the utility attributes
Consequently, the typical problem (the Information Bottleneck) of privacy protection is formulated as follows,
As directly computing
An alternative approach to privacy protection proposed by Xiao et al. [44] is to optimize
As the entropy
The inherent limitation of this approach, as mentioned by Xiao et al. [44], is that the conditional entropy
Therefore, minimizing
From the perspective of information theory, the above methods intend to reduce the amount of information in Z that is irrelevant to the utility attributes, and inevitably leaves a certain amount of sensitive information remaining. In contrast, StegEdge accepts the fact that it is impractical to completely remove the sensitive information contained in Z, and attempts to apply misinformation (i.e., the cover image) to the users’ advantage. Denote by
As
Evaluation
In this section, we evaluate StegEdge to answer the following questions:
Is StegEdge able to protect sensitive attributes which are unknown to users, while preserving the ability to classify the utility attributes? (Section 5.4.1, Section 5.4.3) Is it easy for the ESP to detect the users’ act of privacy protection? (Section 5.4.2, Section 5.4.6) How are the attributes entangled in the latent space? (Section 5.4.4) How does StegEdge visually affect the reconstructed images? (Section 5.4.6) How much additional computation is introduced, and is StegEdge lightweight for user devices? (Section 5.4.7) What are the impacts of a different amount of training data available to users? (Section 5.4.8)
Evaluation settings
Datasets. The first dataset used is CelebA [27], which includes facial images of celebrities annotated with 40 attributes. It has 163k, 20k, and 20k images in the training set, validation set, and test set respectively. The images are normalized, cropped, and resized to 128 × 128 according to the practice of TensorFlow.3
The second dataset is ImageNet [7], in which 10% of the original train set is used as our validation set from the perspective of users, while the original validation set is used as our test set. After the standard procedure of center cropping to 224 × 224 pixels, the images are then normalized. Of all the 1000 classes in ImageNet, we choose the first 800 classes for the utility task, and the remaining 200 for evaluating the privacy leakage. Thus, the pretrained MobileNet-v3-large model can be used without major modifications.
The training at the users’ side only involves 80% of the training set for CelebA. Similarly, for ImageNet, only the images with labels in any of the first 800 classes are used at the users’ side, while all training images are available at the ESP’s side.
The cover images required by the training of StegEdge are randomly chosen from the users’ portion of the respective training set, with a fixed seed. During testing, all the images in the training set are randomly chosen as the cover.
Metrics. The metrics for the evaluation of the objective quality of reconstructed images are the Peak Signal-to-Noise Ratio (PSNR), and the Structural Similarity Index Measure (SSIM).
For CelebA, the metrics for classification are the F1 score and Matthews correlation coefficient (MCC) [4], which is defined as follows,
For ImageNet, the metric for classification is simply the accuracy (percentage of samples correctly classified).
Hardware. All experiments are conducted on a server with two Intel Xeon E5-2678 v3 @2.50GHz CPUs, and four Nvidia RTX 3080 graphics cards. The file reading and writing operations required by benchmarking of performance are conducted in a ramdisk instead of the hard drive.
Methods for comparison. Similar to other relevant work such as Deep Poisoning [14], methods for comparison include,
Gaussian Filter (GF), using the Python library scikit-image4
Gaussian Noise (GN). For images that are normalized to 0.0 to 1.0, Gaussian noise is added using Numpy,5
Deep Poisoning (DP) [14]. The details are described below.
While the original paper of Deep Poisoning [14] attempts to make the reconstructed image as noisy as possible, we make a slight modification in our paper and try to make the extracted features as noisy as possible, for better suitability for our threat model and more meaningful comparison with StegEdge. Similar to StegEdge, we define the features extracted by the encoder of DP
The objective of the (modified) Deep Poisoning model is to minimize the error of classifying the utility attributes, while maximizing the distance between the features extracted by the DP FE and the features extracted by the ESP FE in the latent space. The loss function to be minimized is as follows,
From the perspective of information theory, the DP can be equivalently considered as a method based on the information bottleneck, as explained as follows,
Training settings. The StegEdge model is trained with each value of weight
For StegEdge and Deep Poisoning which are based on neural networks, the models are all trained for 30 epochs. The effective batch size of for the two datasets and the two methods are set to 800 since a total of 4 GPUs are used. The Adam optimizer is adopted with default parameters. The initial learning rates are all set to 4e-3 as a relatively conservative choice. Only a few learning rates were tried, with the aim of selecting one that stabilizes training while achieving a tolerable convergence speed. For CelebA, the learning rates for the two methods are reduced by 20% for every two epochs. The widely used cosine annealing scheduler is adopted for training on the ImageNet. No fine-tuning of the hyper-parameters is conducted for the following two reasons. First, investigating the trade-off of accuracy for the utility and sensitive attributes requires training many models, and will thus make the resource demand of hyper-parameter tuning prohibitively high. Second, this paper primarily serves as a proof of concept, and we demonstrate in our experiments that even without such tuning, StegEdge achieves promising results.
All models in our experiments are implemented with PyTorch v1.8.2.
The whole models. For CelebA, the final layers (the ones after the average pooling layer) of the ResNet-50 model are replaced with a shared module, which is followed by twelve separate modules (one for each attribute). The shared module consists of a linear layer (2048 × 512), a batchnorm layer, a dropout layer with dropout rate 0.15, and the ReLU activation function. Each module used for a single attribute consists of two linear layers (512 × 256, and 256 × 1), and outputs the classification result for that attribute. Thus, the benign and malicious classifiers (
For ImageNet, the pretrained MobileNet-v3-large model [16] downloaded from torchvision is used as the whole ESP model. Since the model outputs a total of 1000 classes at the final linear layer, the benign classifier is chosen as the first 800 output classes while ignoring the rest 200 classes, and the malicious classifier
Selection of the splitting layer. In edge AI inference systems like JointDNN [12], the splitting point of the AI model inference between the user device and the edge computing server is generally chosen such that a balance between the amount of computation of user devices and the size of transmitted latent features is achieved.
In our evaluation, we select the splitting point of ResNet-50 (for CelebA) such that the aforementioned shared module and the twelve classifiers are used as the ESP’s classifier, while all the preceding layers are used as the ESP feature extractor
For the MobileNet model used for ImageNet, the first 14 layers are chosen as the users’ feature extractor, yielding extracted features of size 160 × 7 × 7 given an input size of 224 × 224, i.e., 5.21% of the original size. We believe such selections are consistent with the practice in the relevant literature like [12,17].
DP and StegEdge models. For Deep Poisoning, the architectures of the feature extractors for both datasets are the same as the ESP feature extractor. The modified models used by StegEdge FEs based on the original models are presented in Table 1, in which conv(A,B) represents a convolutional layer with A input channels and B output channels, BN is BatchNorm, IN is InstanceNorm, and IR is the inverted residual module used by the MobileNet model. No modification is made to the rest of the layers.
Model architectures of the ESP FE (without any modification to the respective original models) and StegEdge FE
Model architectures of the ESP FE (without any modification to the respective original models) and StegEdge FE
Reconstructors. The model architectures of the reconstructor used by the users and the ESP are listed in Table 2, where “conv” represents deconvolution (transposed convolution), and
Model architectures of the reconstructor used by the users and the ESP
From the users’ perspective, all the relevant models are trained on 80% of the training set for both datasets, while the ESP’s models are trained on 100% of the training set.
Without loss of generality, the procedures for training the relevant models are summarized as follows,
Train the “whole” model of the modified ResNet mentioned in Section 5.2 (including the ESP FE and the classifiers for 12 attributes). The pretrained MobileNet-v3-large model is downloaded.
The trained ESP classifiers are split into the “benign” part for utility attributes, and the “malicious” part for sensitive attributes.
The ESP reconstructors are trained based on the FEs. The user reconstructors can also be optionally trained.
The StegEdge FE and DP FE are trained, given the benign ESP classifiers.
As users do not have access to the sensitive attributes, training a user reconstructor to simulate the real ESP reconstructor does not provide significant practical benefits. Consequently, from the users’ perspective, we train the StegEdge FE and DP FE, and select the result of the epoch that yields the highest accuracy of the utility task in validation.
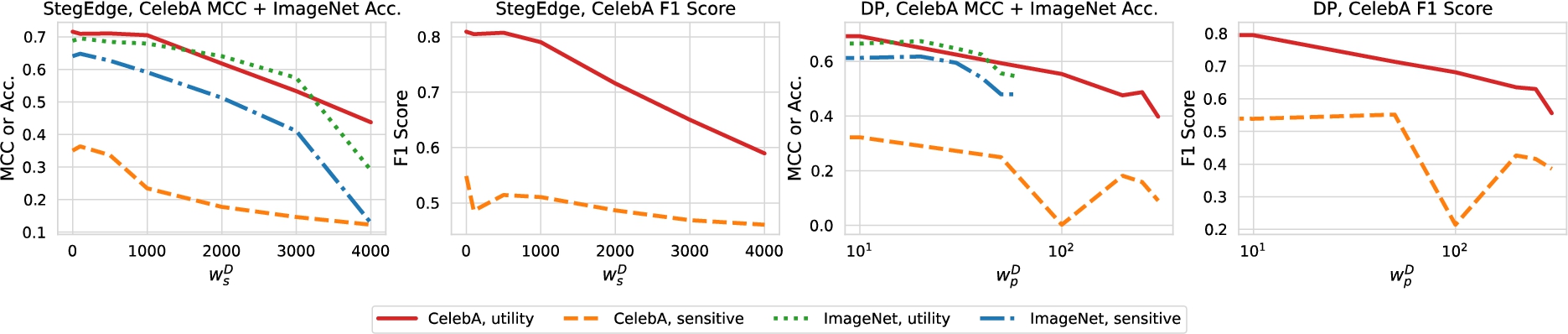
The weight
Impacts of
and
Figure 3 presents the accuracy metrics for both the utility and sensitive attributes under varying weights for in the loss function (i.e.
For Deep Poisoning, a larger
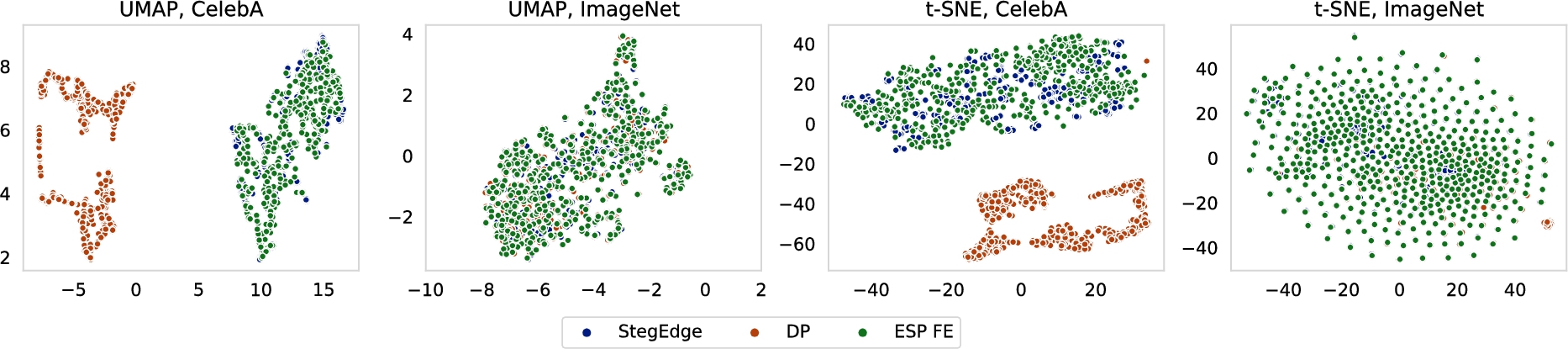
Visualization of the extracted features for CelebA and ImageNet. A total of 500 images in the test set are used as user images.
To analyze the characteristics of the extracted features of StegEdge, Deep Poisoning, as well as the ESP FE, and investigate whether inconspicuous privacy protection can be achieved, we resort to the widely adopted methods of t-SNE [42] and the Uniform Manifold Approximation and Projection (UMAP) [28]. The default parameters for both t-SNE and UMAP are adopted. The weight
Figure 4 shows the visualization of extracted features for the two datasets. For CelebA, it is evident from the results of both t-SNE and UMAP that the features extracted by Deep Poisoning (orange) are straightforwardly distinguishable from the features extracted by the ESP FE (green), making the act of privacy protection likely to be detected and draw attention if the ESP implements even rudimentary measures to validate the features they receive. In contrast, the extracted features of StegEdge (blue) successfully blend in with the features extracted by the ESP FE. The two distributions largely overlap, rendering the privacy protection process of StegEdge inconspicuous from the perspective of adversaries.
As for ImageNet, the three methods do not show any significant difference in Fig. 4. This can be explained by the fact that the extracted features of CelebA only have 2048 elements and a total of merely 12 attributes are involved, while the extracted features of ImageNet have
Utility-privacy trade-off
Instead of a fixed single trade-off between privacy protection and the accuracy of utility tasks, StegEdge aims to provide users with the opportunity to balance privacy protection and the accuracy of utility tasks based on their own preferences. The utility-privacy trade-off for the four methods are illustrated in Fig. 5. As shown in the two subfigures, the traditional methods of adding noise and mean filtering do not offer adequate protection of users’ data privacy, which is also verified by the visual inspection in Fig. 8 and Fig. 9 of Section 5.4.6.
For the two datasets, StegEdge generally yields the lowest leakage of sensitive information, i.e., the best Pareto front. In Fig. 5(a), at the same level of utility accuracy, especially in the range of 0.6 to 0.7 which might be considered the most useful in practice, StegEdge achieves the best performance. Note that in each subfigure of Fig. 5, the rightmost part of the lines for GN and GF corresponds to zero modification to the original images. Consequently, it is obvious that, in the extreme case of ignoring privacy protection to gain the highest utility accuracy, the utility accuracy achieved by StegEdge is very close to that of conducting classification directly on unmodified images.
As users do not have access to the “unknown” sensitive attributes, the validation step for the StegEdge and Deep Poisoning models does not gain many practical benefits, and therefore the curves of them in Fig. 5 are not smooth. Additionally for Deep Poisoning, its curves are rougher, since it tries to push the features extracted by Deep Poisoning FE and those by the ESP FE apart in the latent space without a specific direction, leading to certain randomness as mentioned above.
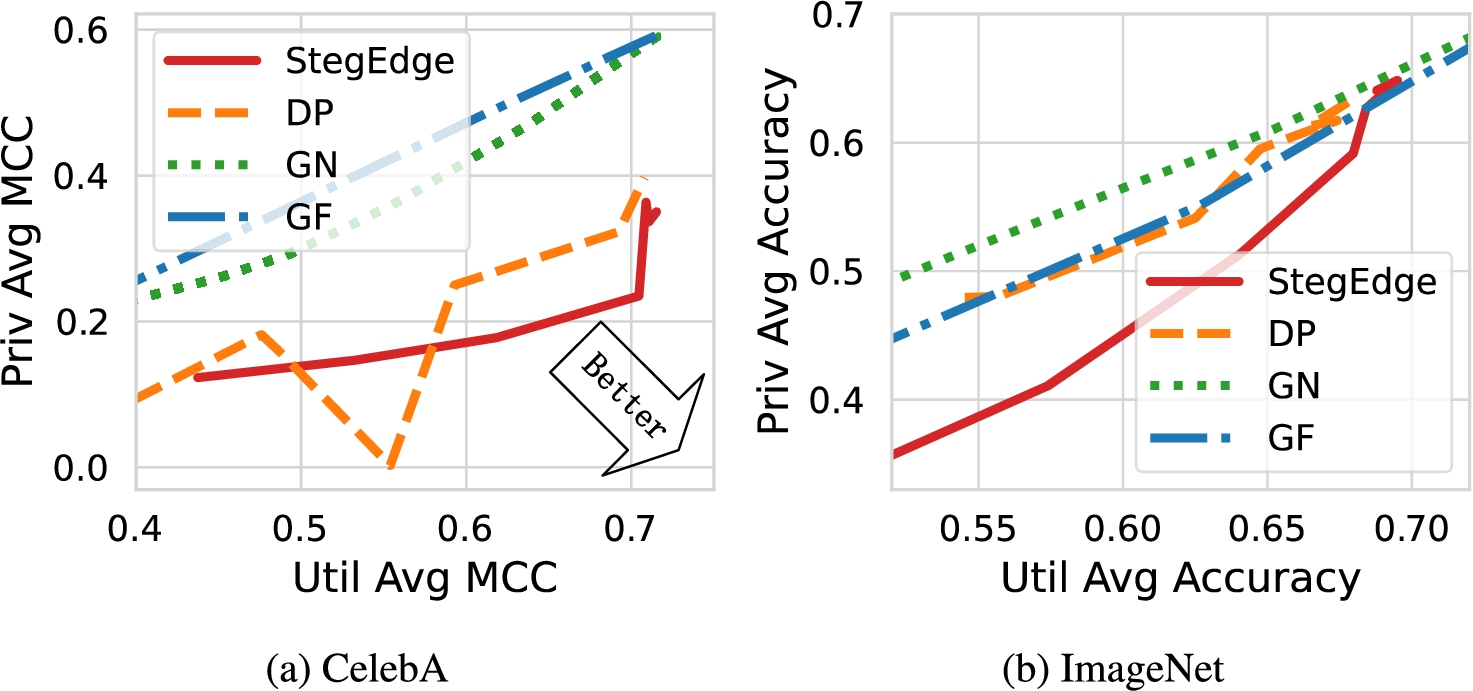
The utility-privacy tradeoff for different methods.
To investigate the inherent overlap of information related to each attribute (i.e., entanglement [5]) in the latent space, we conduct an experiment on the selected twelve attributes of the CelebA dataset. To that end, we train the ResNet model (with the aforementioned classifiers) for 12 times. Each time, the model is trained for 10 epochs and only a single attribute is used in the calculation of loss function (cross-entropy). After that, the model parameters of the feature extractor and the classifier for the single attribute are frozen, and the classifier modules for the remaining 11 attributes are trained for 3 epochs. Finally, the test set is used to obtain the resultant accuracy for all of the 12 attributes.
In Fig. 6, we illustrate how much the training of one attribute leads to the accuracy improvement of other attributes, as an indirect way of showing how the information of these attributes overlap in the latent space. For instance, the final box of the top row represents how the training of the attribute Attractive increases the accuracy of Young compared with a random guess (i.e., 50% accuracy). By comparing any two rows, we can acquire a qualitative understanding of the correlation between attributes. For example, by comparing the 8th and 9th boxes in the first column, it can be seen that the attribute Straight Hair is more correlated with the attribute Attractive than Smiling.
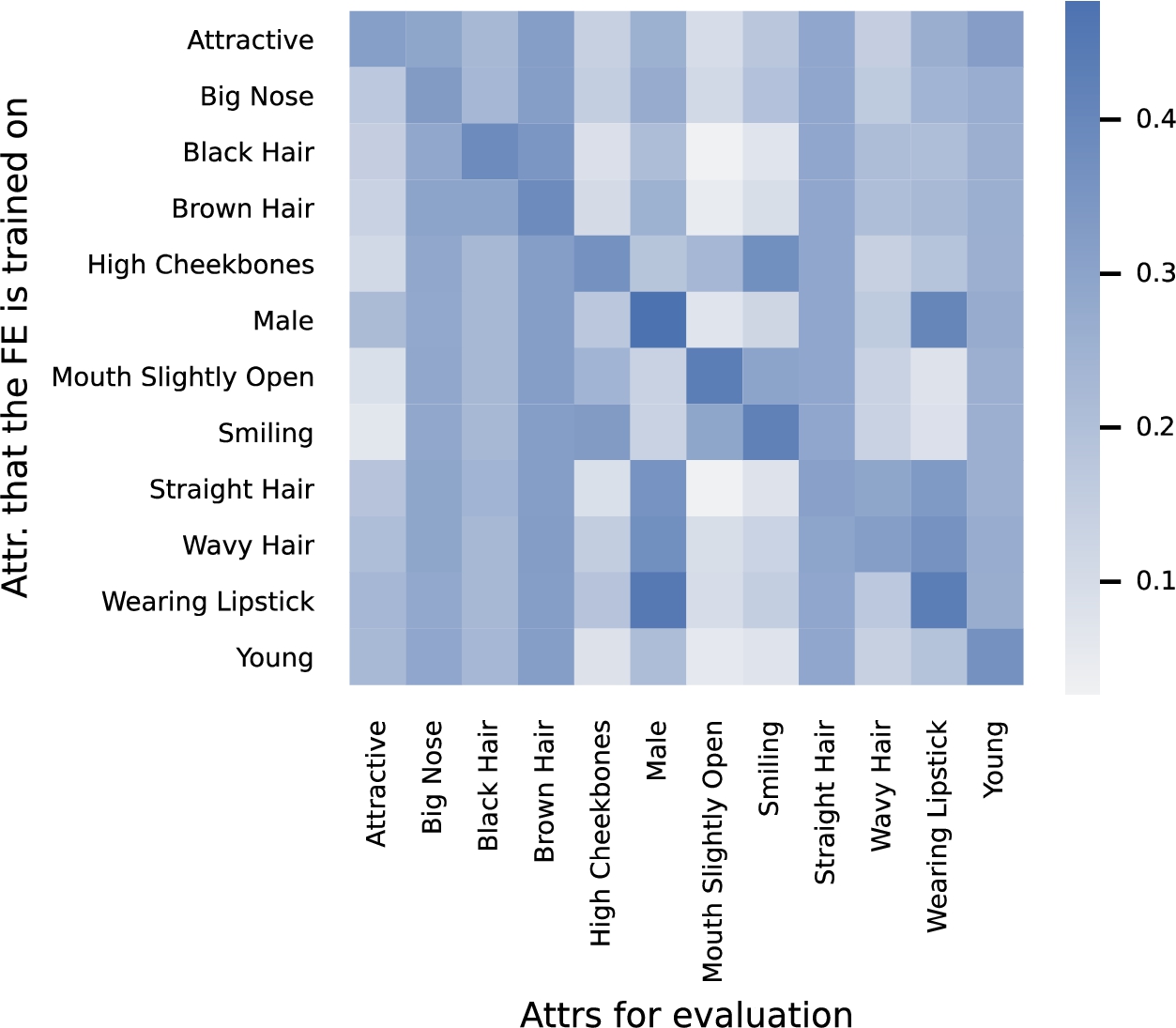
An empirical illustration of how well the classifiers for the 12 attributes behave compared with random guess (i.e., 50% accuracy), when the feature extractor is trained for only a single attribute (each row).
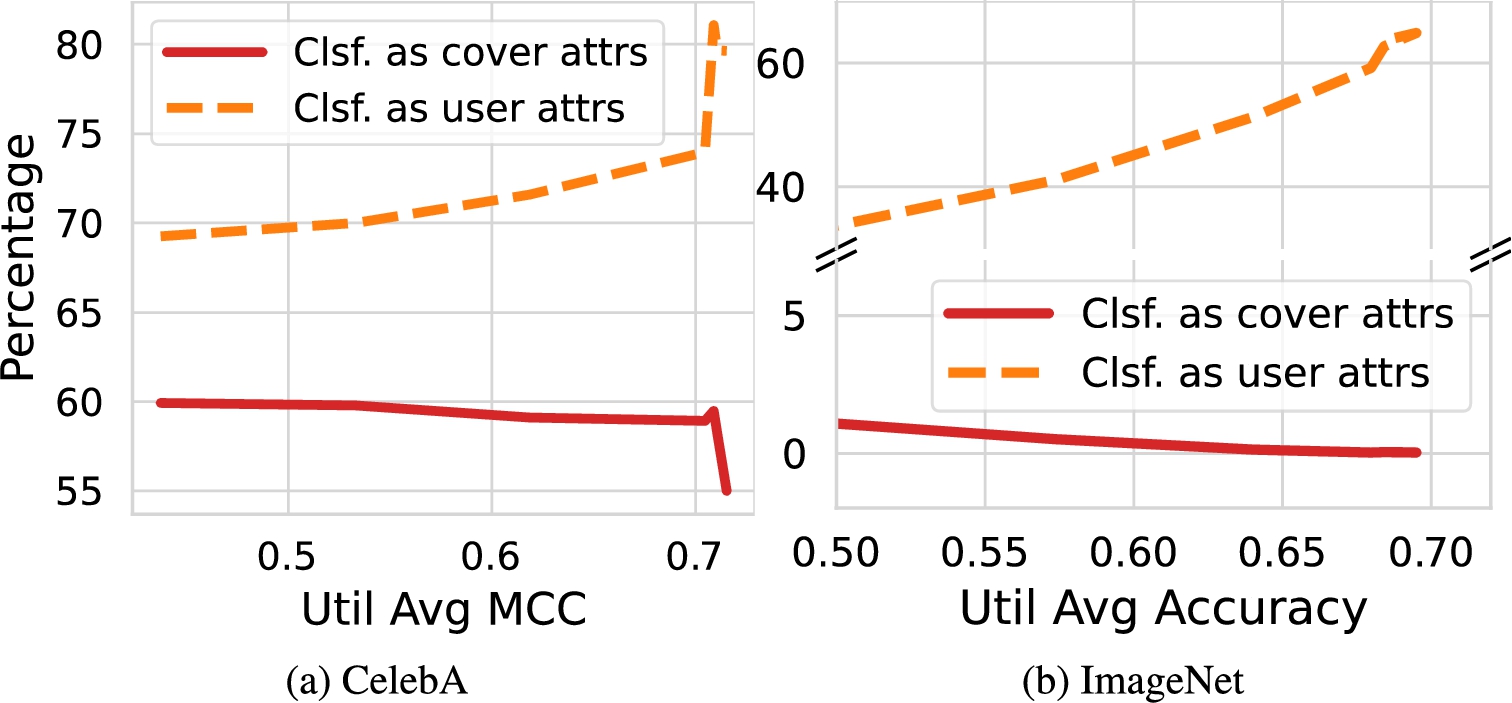
For StegEdge, the percentages of sensitive attributes classified as those of the cover images and those of the user images by the ESP’s malicious classifiers.
We evaluate whether StegEdge makes the ESP’s malicious classifiers wrongly classify their inputs as the sensitive attributes of the cover images, and present the classification results of sensitive attributes in Fig. 7. As can be seen in Fig. 7(a), for CelebA, at a lower level of utility accuracy, a higher percentage of the sensitive attributes are classified as those of the cover images. Such a phenomenon is less significant for ImageNet in Fig. 7(b), since the latent space of MobileNet at the splitting layer is more complex as mentioned before. Compared with the case of CelebA shown in Fig. 8, the complexity of the latent space for MobileNet (corresponding to ImageNet) can also be understood in Fig. 9, in which the reconstructor is able to render images of relatively rich details given the extracted features.
Image reconstruction

Visual comparison of the relevant images of all methods for CelebA.

Visual comparison of the relevant images of all methods for ImageNet.
Visualization of the images related to all the methods is illustrated in Fig. 8 and Fig. 9. It is noticeable that given a higher weight
In Fig. 8, it is obvious that the reconstructed images of Deep Poisoning are distinct from those of other methods, and could potentially raise the ESP’s suspicion. For StegEdge, the reconstructed images appear relatively natural, and achieves the objective of inconspicuous privacy protection. As can be seen in Fig. 8, Deep Poisoning leads to reconstructed images that are quite similar, except for the utility attributes (e.g., the eyebrows in the figure). While both StegEdge and Deep Poisoning lead to drastic changes of the images, the reconstructed images for the traditional methods of GN and GF are visually closer to the user images in Fig. 8. Such an effect is less obvious for ImageNet in Fig. 9, as the latent space of the selected splitting layer of MobileNet is more complex than the one of ResNet.
To quantitatively measure the quality of reconstructed images for each method, we adopt the PSNR and SSIM, and a higher value means the target image is more similar to the reference image. As can be seen in Fig. 10, among all the methods, StegEdge consistently achieves low PSNR and SSIM of the reconstructed images measured against the user images, and thus reduces the leakage of sensitive information. With regard to the PSNR and SSIM measured against the cover images of StegEdge, it is intuitive that at a higher level of accuracy for utility attributes (i.e., lower emphasis on reducing the distance in the latent space), the reconstructed image would be less similar to the cover image.

The quality of the ESP’s reconstructed images measured by PSNR and SSIM against the user images (
Comparison of the model complexity and computing speed at the user side
The model complexity of the StegEdge FEs and ESP FEs, as well as the computing speed of the methods are illustrated in Table 3, where MAC is “Multiply–accumulate operation”. The results for DP FEs are not listed, since they have exactly the same architecture as the ESP FEs. While modifications of the relevant neural networks (e.g., weight quantization [20]) are generally required in practice for them to be more efficiently run on resource-constrained devices, they are out of the scope of this paper. Note that the neural networks are run on a single GPU, while the methods of Gaussian filter and Gaussian noise are run on the CPU.
Compared with the ESP FE, the StegEdge FE increases the number of parameters by 81.8% and 0.82% respectively for CelebA and ImageNet, while increasing the time required for computation by 90.5% and 5.1%. The computing speed of StegEdge is competitive against traditional methods of GN and GF. The computing speed and model complexity should be considered in the design of model architectures of StegEdge FE in reality, and is out of the scope of this paper.

The MCC scores of utility vs sensitive attributes on CelebA, when the user trains StegEdge and Deep Poisoning models with 60%, 80%, and 100% of the training data available to the ESP.
In the setting of the previous experiments, only 80% of the training data are available to the users, while 100% of the data are available to the ESP. We now investigate how a different percentage contributes to the accuracy levels of utility and sensitive attributes in CelebA. Specifically, the percentage is set to 60% and 100% with all other things being equal. In addition to the StegEdge and DP feature extractors, the ESP reconstructors are also trained with the respective settings of percentage.
In Fig. 11(a), it is evident that with a higher percentage of training data available, StegEdge consistently achieves lower leakage of sensitive information at the same level of utility accuracy. Shown in Fig. 11(b), a higher percentage generally leads to lower leakage of sensitive information, and the roughness of the curves can be explained by the inherent randomness of DP as mentioned before.
Discussion
Potential countermeasures against StegEdge
Offense and defense are an ever-escalating game. For either side, gaining knowledge about the other side leads to remarkable advantages. A great defense would largely benefit from attackers’ unawareness of the specific defensive techniques being applied. In our case, attackers are even deceived into believing that no measures of privacy protection is put in place by users, i.e., inconspicuous privacy protection. Considering the advantages ESPs have over users, including computational resources and data availability, we believe that such deception would help users alleviate the imbalance of positions.
Regarding the potential countermeasures/attacks that could compromise the privacy protection of StegEdge, the following cases are considered to the best of our effort.
Advanced anomaly detection. Although in Fig. 4 we show that it is hard to distinguish between no privacy protection and StegEdge at the level of latent space with UMAP and t-SNE, it is possible for ESPs to deploy sophisticated anomaly detection systems [32], confirm users’ maniputation of the latent codes, and subsequently devise targeted countermeasures. Model watermarking [47]. The ESP could present to users a feature extractor with hidden watermarks. Consequently, when users make modifications to the feature extractor for privacy protection, it can be easily detected by the ESP. Compromised utility classifiers. The ESP could present users with a compromised utility classifier, such that the utility and sensitive attributes are highly entangled [39] in the latent space of the classifier. As a result, it would be difficult for users to protect their privacy without causinig significant reduction in accuracy of utility attributes.
Obfuscated images vs obfuscated features
In this paper, the focus is on manipulating the latent space such that privacy is protected while utility is maintained, since we assume the setting splitting the execution of neural networks between user devices and the edge computing server, due to its superior latency and energy efficiency [49].
Alternatively, users could make directly send obfuscated images instead of obfuscated features to servers. For instance, as in [46], they could apply GANs to modify the utility attributes of a randomly selected image from the Internet to match those of the user image, such that ESP’s accuracy of classifying the utility attributes is maintained while adversaries could not extract the true sensitive unknown attributes. However, this approach requires heavy computation on the user’s side by involving extracting features, manipulating attributes, and generating obfuscated images, while obviously contradicting the fundamental goal of edge computing, i.e., offoading computation from user devices to servers.
Conclusion
In the paradigm of edge intelligence where user devices upload extracted features to edge computing servers for neural network inference, users’ data privacy needs to be protected against unauthorized data reconstruction, as well as extraction of sensitive private attributes unknown to the users. In a more realistic setting considering factors that hinder privacy protection, such as limited trust in edge computing service providers, and users’ disadvantageous access to training data, we propose StegEdge, a conceptually novel approach to data privacy protection, inspired by the concepts of steganography and deception-based cyber defense. StegEdge maximizes the amount of information related to the utility task in the extracted features, while replacing the rest of the information with features extracted from a random cover image, such that the accuracy of the utility task is not severely impaired. Evaluation on the CelebA and ImageNet datasets shows that StegEdge is able to defend against data reconstruction attacks, and can reduce adversaries’ accuracy of predicting the sensitive attributes by up to 38%, at the same level of utility task accuracy.
Footnotes
Acknowledgments
This work is partially supported by the Natural Science Foundation of Tianjin (No. 20JCZDJC00610), the National Natural Science Foundation of China (No. 62172241), the Technology Research and Development Program of Tianjin (No. 18ZXZNGX00200).