
Abstract
While network attacks play a critical role in many advanced persistent threat (APT) campaigns, an arms race exists between the network defenders and the adversary: to make APT campaigns stealthy, the adversary is strongly motivated to evade the detection system. However, new studies have shown that neural network is likely a game-changer in the arms race: neural network could be applied to achieve accurate, signature-free, and low-false-alarm-rate detection. In this work, we investigate whether the adversary could fight back during the next phase of the arms race. In particular, noticing that none of the existing adversarial example generation methods could generate malicious packets (and sessions) that can simultaneously compromise the target machine and evade the neural network detection model, we propose a novel attack method to achieve this goal. We have designed and implemented the new attack. We have also used Address Resolution Protocol (ARP) Poisoning and Domain Name System (DNS) Cache Poisoning as the case study to demonstrate the effectiveness of the proposed attack.
Introduction
Network intrusion detection systems (NIDS), such as Snort [50] and Zeek [53], play an essential role in enterprise network security operations. With the rapid rise of deep learning technology, neural network(NN)-based detectors (e.g., [20,31,61,62]) have been deployed in the real world to complement the existing NIDS. For example, IBM [5] and Microsoft [24] have offered artificial intelligence-based security products. IBM QRadar [5] is an AI-powered solution that “consolidates log events and network flow data from thousands of devices, endpoints, and applications”. Microsoft Security Copilot [24] “surfaces prioritized threats in real time and anticipates a threat actor’s next move with continuous reasoning based on Microsoft’s global threat intelligence”. Acting as an “ally”, NN-based detectors enable accurate detection of attacks even those not seen earlier, before the corresponding intrusion detection rule is created. NN-based detectors are usually deployed in the real world as follows: the existing network traffic monitoring tools (e.g., routers, Wireshark packet sniffers) are reused to capture the captured packets, which are usually held in PCAP files, to a node where the NN-based detectors are running with machine learning libraries (e.g, PyTorch, TensorFlow).
Because adversarial examples [16,59] are recognized as potentially a very serious threat to systems that use machine learning models, NN-based NIDS have been triggering an increasing amount of interests in the research community. In particular, several works [17,49] have recently investigated the adversarial examples specific to NN-based NIDS, and they assume the following threat model:
Although this threat model is coherent with the adversarial example studies [16,37] in other domains such as computer vision, it is
Regarding why the data manipulation threat model is not assumed by real-world NIDS, we have the following observations. First, most real-world network attacks only compromise non-admin user accounts, and such accounts have limited influence in network communications. For example, the attacker may have compromised a user account on one host, but he/she cannot directly manipulate the packets sent by another host which the compromised account has no access to. Second, packet capture repositories are usually guarded by strict access control and integrity protection. Countering such access control and integrity protection assumes additional capabilities of the attackers.
Based on the above observations, it is important to check whether the adversarial examples successfully generated under the data manipulation threat model are also successful under the de facto standard threat model. Specifically, the checking process consists of the following checkboxes: (a) whether the adversary can treat the generated adversarial examples as an adversarial attack packet; (b) whether the adversarial examples can be somehow converted to adversarial attack packets; (c) whether the target machine can be compromised by the back-converted packets; (d) whether the network communications with back-converted packets, after being collected and processed in the same way as what is required of the NN-based NIDS, is classified as benign.
Using the above attack procedure, we have checked 17 general-purpose adversarial-example generation methods. We will summarize the experiment results in Section 2. In short, we found that none of the adversarial examples generated in our experiments is still successful under the standard threat model.
In this work, we seek to develop a new approach which can generate successful adversarial examples under the de facto standard threat model. These successful adversarial examples are denoted as stealthy network attacks in this paper, since the proposed attack and the real-world network attacks follow the same threat model. Though there exist other works that present similar ideas [2,4], these works focus on aligning the feature space with the problem space. In another word, they try to generate adversarial examples in the feature space that satisfy constraints in the problem space. However, they adopt extensive feature engineering [4,17] or use network flow data [3,48,58], which makes it very difficult, if not impossible, to be verified with real network packets and replayed in real network attacks. To the best of our knowledge, this work is the
Our approach firstly uses masks to capture protocol constraints. Then, our approach adapts the existing adversarial example generation methods by applying masks to them. In particular, we make the following two main modifications: 1) we apply masks when generating perturbations; 2) when generating perturbed data samples, we confine and round all values to the valid range specified for each field. With these two modifications, our approach can generate
The main contributions of this work are as follows: 1) We developed the first approach which can generate successful adversarial examples under the de facto standard threat model. The adversary can use these adversarial examples to launch stealthy network attacks and evade NN-based NIDS. 2) We used ARP poisoning and DNS cache poisoning attacks as the case studies to demonstrate the effectiveness of the proposed approach.
The rest of the paper is organized as follows. Section 2 provides the background and highlights the motivation. Section 3 describes the NN-based detectors. Section 4 formally defines constraint-satisfying adversarial examples, and then presents our problem statement. Section 5 described our proposed approach. Section 6 presents the evaluation results of the proposed approach. Section 7 discusses several relevant issues. Section 8 summarizes the related work. Section 9 concludes the entire paper.
Background and motivation
Network attacks and NIDS
Network attacks are frequently used in Advanced Persistent Threats (APTs). Some common network attack types include probing, denial of service (DoS), Remote-to-local (R2L), etc. These attacks can often cause serious impacts. For example, ARP poisoning and DNS cache poisoning are two commonly seen network attacks belonging to R2L attack type. With ARP poisoning attack, attackers can intercept or redirect network traffics within the LAN to any desired MAC addresses. In DNS cache poisoning attack, a falsified DNS record with the fake domain-to-IP mapping will be added and persist in the local DNS server until it expires. Whenever a machine inquires the poisoned DNS server for the affected domain’s IP, it will get the fake IP address.
Signature-based, rule-based, and anomaly-based detection are commonly used to detect these network attacks. However, signature-based methods [19] can be easily fooled by slightly changing the attack payload; rule-based methods [50] need experts to formulate and regularly update rules; and anomaly based detection [22,40] tends to raise lots of false positives. Especially in attacks where attackers can intentionally craft their packets to make them seem legitimate, such as in ARP poisoning and DNS cache poisoning attacks, the aforementioned methods usually fall short. Therefore, new detection methods need to be explored.
ML-based network attack detectors
Recently, researchers have been applying traditional machine learning and deep learning techniques for network attack detection. Support vector machine (SVM) [26,27], K nearest neighbors (kNN) [42,47], and decision tree (DT) [23,30], etc. have all been applied on public cybersecurity datasets like KDD CUP 99 [52] and NSL-KDD [45]. Though many of these works present satisfying detection results, traditional “shallow” machine learning approaches share the common drawback of requiring extensive feature engineering. If data samples are represented with minimal feature engineering, traditional machine learning algorithms may not be able to achieve comparable performance with deep learning [62]. For compensation, dimension reduction (like principal component analysis) has been proposed, but this can cause loss of information.
In recent years, deep learning-based NIDS is attracting more attentions, where feature engineering is performed by the neural network internally. DeepDefense [60], applying recurrent neural networks (RNN) for DoS detection, achieves higher than 97% accuracy; PCCN [61] which uses convolutional neural networks (CNN) to detect abnormal network traffic flows, can achieve higher than 99% accuracy; Long-Short Term Memory (LSTM) neural network has also demonstrated an accuracy of higher than 99% for detecting network attacks [20]. Many industries, including Splunk [51], FireEye [55], and Fortinet [14], etc., are incorporating deep learning into their network security products. One recent work [62] also studies applying deep learning techniques to the detection of two network attacks: ARP poisoning and DNS cache poisoning. The best trained deep learning models are quite accurate: for ARP poisoning, the detection rate is about 99.8%; for DNS cache poisoning, the detection rate is 100%. In another word, evasion rates are about
Adversarial examples for DNNs
Adversarial examples are specialized data examples created with the purpose of confusing a DNN, resulting in the misclassification of a given data example. In the domain of computer vision, these adversarial data examples are indistinguishable to the human eye, but cause the DNN to fail to classify the corresponding images. In the domain of network security, these adversarial data examples cause the DNN to fail to classify the corresponding network data. A variety of automatic adversarial example generation methods have been proposed in the literature, and 17 of these methods will be shortly summarized in the next section.
Why the adversarial examples generated by existing methods fail under the standard threat model
The results are summarized in Table 1. The third column shows that 9 out of the 17 methods generated one or more adversarial examples, and in total more than 500 adversarial examples were generated. Unfortunately, the last column shows that none of the adversarial examples successfully compromised the target machine.
General purpose adversarial example generation methods fail when launching the ARP poisoning attack
General purpose adversarial example generation methods fail when launching the ARP poisoning attack
Before presenting our attack scheme, we will first introduce the detection neural network and the dataset on which the models are trained. In this work, we focus on the logic-flaw-exploiting (LFE) network attacks [62], which exploit the logic (security) flaws of a few widely-deployed authentication protocols. Such attacks are very different from other attacks such as memory corruption for code reusing, command and control (C&C) over HTTP/HTTPS, and (distributed) denial of service with/without botnet, etc. Memory corruption is more about the server program rather than the network protocol; C&C over HTTP/HTTPS assume the HTTP/HTTPS protocol itself is running normally; and (distributed) denial of service is usually accomplished by exhausting the server’s resources instead of exploiting a logic flaw within a protocol.
Two representative LFE network attacks are address resolution protocol (ARP) poisoning attacks and domain name system (DNS) cache poisoning attacks. ARP poisoning works by spoofing ARP responses, with which the attacker can trick the victim into falsified mappings between IP addresses and MAC addresses, and thus intervening the network communication. DNS poisoning works by spoofing DNS responses, with which the attacker can trick the victim into falsified mappings between domain names and IP address, and thus redirecting the network communication. Both of these two attacks exploit the lack of response verification in the corresponding protocol. As a result, the victims cannot verify whether the packets come from a genuine host or attacker. Also, these two attacks are difficult to be detected with traditional detection methods (e.g. signatures, rules, anomaly detections, etc.) because spoofing is applied (i.e. attacker packets are intentionally crafted to be indistinguishable from normal packets).
Dataset statistics
Dataset statistics
The detection neural networks and datasets are from another work [62], in which self-generated network datasets are generated due to lack of public datasets on the two attacks. This dataset is generated by adapting protocol fuzzing techniques, which can potentially generate new kinds of data not seen in publicly available datasets. The collected data is randomly split into a training dataset and a test dataset by ratio 4:1. Dataset statistics are shown in Table 2. The benign to malicious data sample ratio is kept at about 1:1 intentionally. Though this is different from the real-world network traffic, where the majority is benign traffic, the datasets for neural network training is balanced to avoid bias. That is, if the provided training datasets majorly contain benign data samples, then the trained neural network tends to predict data samples as benign. Balancing the benign to malicious ratio can mitigate such bias in neural network training. The dataset size is not very large, but, because we train separate neural networks for different network attacks, and that the neural network and data samples are not that complicated (details of which are presented in prior work [62]), we believe that the dataset size is sufficient for neural network training.
For ARP poisoning detection, a multi-layer perceptron (MLP) neural network is used, as shown in Fig. 1. Every data sample represents one network packet. 42 bytes are selected from each ARP packet. Every byte is then treated as a number when constructing data samples. Hence, each data sample for ARP poisoning is a 1D vector containing 42 integers.
For DNS cache poisoning detection, a convolutional neural network (CNN) is used, as shown in Fig. 2. The CNN’s input is 3D matrices. Firstly, starting from a whole network log, we filter out the DNS packets and chop them by sessions, resulting in multiple variate-length DNS sessions. Secondly, variate-length DNS sessions are chopped into fixed-length slices by applying a sliding window of size 6. Thirdly, in every DNS packet, 32 bytes from

MLP neural network for ARP poisoning detection. Visualization by Netron1.

CNN for DNS cache poisoning detection. Visualization by Netron1.
When the models are used for detection, they take in different network packets. Specifically, ARP poisoning detection takes in ARP packets, and DNS cache poisoning detection takes in DNS packets. A packet sniffing process can be configured to sniff for ARP packets only, which will be processed and fed into the ARP poisoning detection model. The similar goes for DNS cache poisoning detection. The two models’ performances when detecting real attacks are summarized in Table 3. (Please refer to the original work for more details.) It can be inferred that, if the attacker takes no counter-measurements about the neural network detection, the attack is very likely to get detected.
Test set evaluation results
Protocol-constraint-AWare adversarial examples
In this work, we first present a simple scenario, in which ARP poisoning is used as a running example for demonstration throughout the paper. The attack is completed with a single ARP packet, and the detection is also based on individual ARP packets.
As defined in Section 1, the attacker’s goal is to launch stealthy network attacks, which are accomplished by
A stealthy network attack contains at least two phases: 1) generating PCAW adversarial examples; 2) launching the stealthy network attack with the data from generated PCAW adversarial examples. The network packets that can lead to successful stealthy network attacks are called
Constructing PCAW adversarial examples for attacks in phase 1 is much more challenging than constructing adversarial examples in computer vision: 1) Network communications must follow certain protocols; 2) The attack packets must have certain bytes so that these packets are valid and can exploit the vulnerability in the target machine/service.
Therefore, the following two challenges should be addressed:
How should the PCAW adversarial examples be generated for given neural network models?
How to launch stealthy network attacks with the help of generated PCAW adversarial examples?
For demonstration, we first use ARP poisoning attack [62]. The ARP poisoning attack is selected because: 1) The attacks can be detected largely, if not solely, based on network logs. Thus, neural network detection based on network logs is made possible. 2) The data samples of those detection neural networks present bytes from network packets, so the mapping between features in data samples and bytes in packets is straightforward. 3) There are no distinctive signatures for detecting these attacks. Thus, traditional detecting methods often fall short and deep learning can be applied. 4) The ARP poisoning attack represents single-packet network attacks, which is simpler than DNS cache poisoning, the multi-packet network attacks. It should be noted that, as long as the criteria 1 and 2 above are satisfied, our approach can also be applied to other network attacks, like Border Gateway Protocol (BGP) prefix hijacking.
Unique challenges in multi-packet stealthy network attacks
Extending the proposed stealthy attack packet generation method to the multi-packet network attack scenario has some unique challenges.
Assuming that one multi-packet attack session consists of eight packets
Without compromising other machines, attackers have no control over packets sent by other machines. In another word, attackers can only modify their own attack packets, which usually results in a small portion of the data sample(s). As a result, generating PCAW adversarial examples will be difficult for such data sample(s) because only a small portion can be perturbed. In the example above,
Apart from the difficulty of generating PCAW adversarial examples, stealthy multi-packet attacks also have challenges that stem from the nature of sessions. In multi-packet attacks and detections, one session usually corresponds to one or more data samples. In a malicious session, an attacker’s packet may appear in one or more data samples from this session, depending on how the session is processed into data samples. For example, in the aforementioned example, the attacker’s packet
When generating adversarial examples from different data samples (e.g.
Some data samples, which belong to the same session, might fail to produce adversarial examples. For example,
Even if an attack packet
All these uncertainties should be mitigated after PCAW adversarial examples are generated, but before attacks are launched in real world.
Proposed stealthy adversarial attacks
Work flow of stealthy network attacks

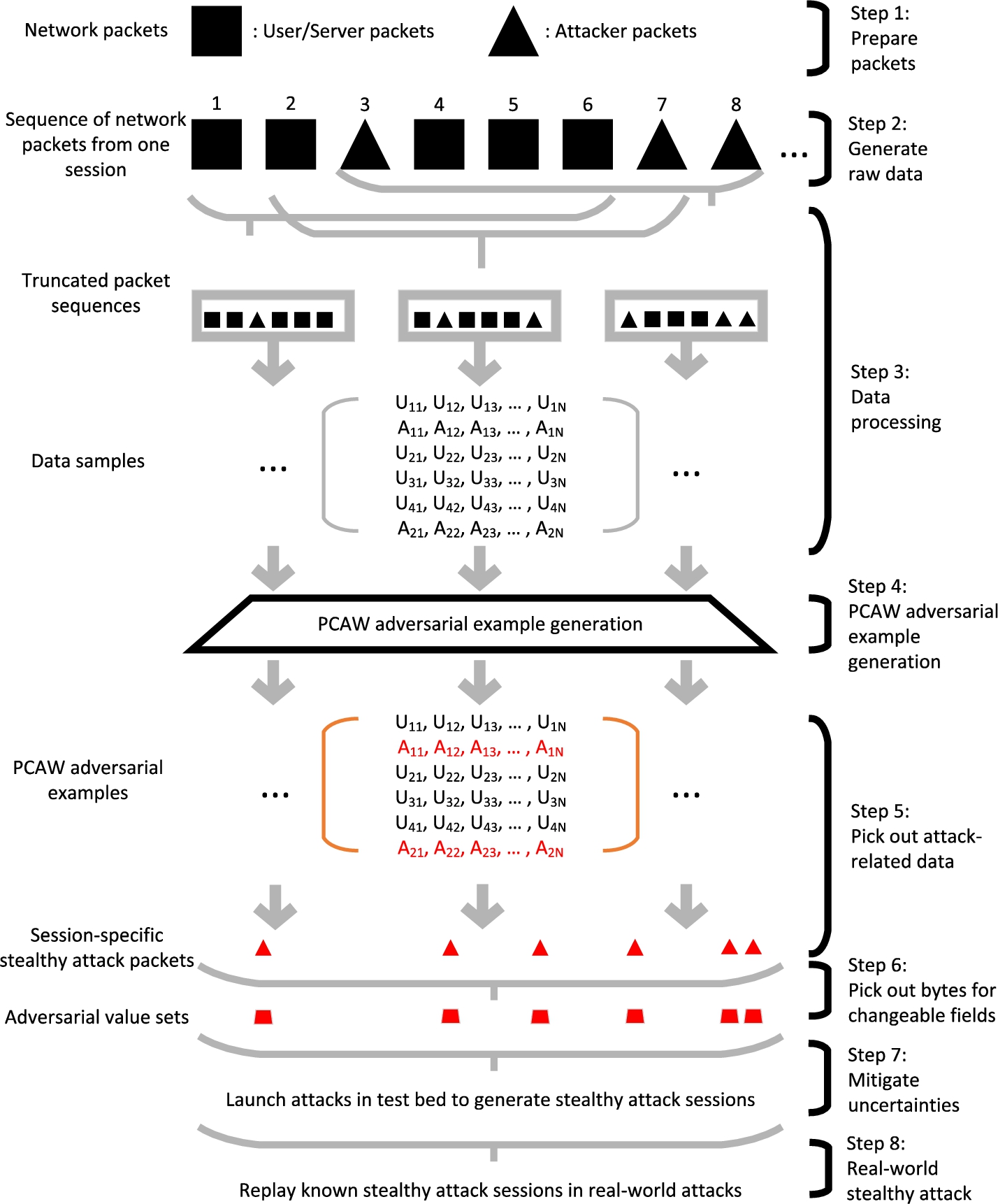
The work flow of launching stealthy network attacks.
The work flow (see Fig. 3) of the proposed stealthy network attacks is as follows:
Attackers prepare original packets.
In private test bed, attackers use the prepared attack packets to launch network attacks and gather network logs. Network logs contain packets from both normal users/servers and attackers, and are sorted in the time order.
Attackers process collected raw data into data samples.
Attackers feed data samples to the PCAW adversarial example generation tool to generate PCAW adversarial examples by only modifying changeable information in the attack packets.
From PCAW adversarial examples, attackers create candidate stealthy attack packets.
Attackers launch real-world network attacks by replaying known stealthy attack packets.
For the sake of simplification, we assume the white-box threat model, in which attackers can have full access to the target detection neural network. Attackers have different ways to accomplish this, like accessing the model with traditional cyber-attacks without compromising machines [54], or surrogate the target model [35,36].
One of the most important steps in the above flow is Step 4 – creating adversarial examples. To create adversarial examples from the original data samples, feature-based perturbations are usually used. Perturbation values are calculated based on the minimum component (feature) within the data sample, indicating the direction of how changes should be made to alter the model output. For example, if the perturbation for a feature is positive, increasing the value of this feature tends to change this data sample into an adversarial example. A problem that needs to be considered in this process is the existence of invariants, which are the packet features that should not be changed. To address this issue, we propose to use
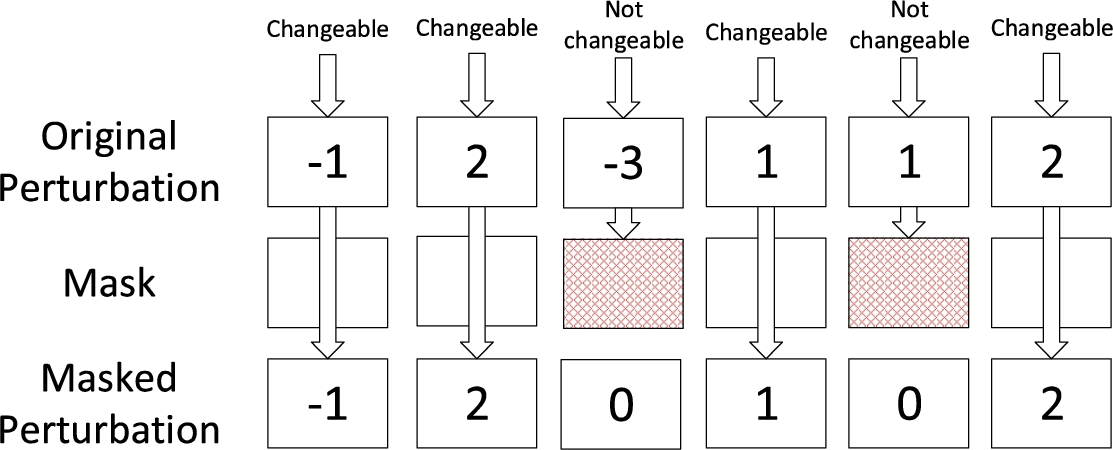
Mask illustration.
To find out which fields in the packets are changeable, we refer to the protocol specifications to rule out fields related to the packet integrity, such as checksum and length fields. In addition, though some values (such as certain reserved bits) are marked as unchangeable in the protocol specifications, the servers may just ignore them in practice, so it is still safe to change them during perturbation. We launched network attacks in our test bed to find out such fields. For example, one changeable field is the time-to-live (TTL) in the IP layer. Though commonly set to 64, programs usually do not check the TTL value and simply let packets pass regardless. Therefore, this field is changeable for attackers: no matter how this value is changed, this packet will still be accepted rather than abandoned. As for fields related to the packet’s validity, such as checksum, they are decided after changes are made. In another word, we first generate the original attack packet, then change values in changeable fields, and finally re-calculate validity fields. Admittedly, after the checksum is re-calculated, the packet may not be adversarial. However, we do not run PCAW adversarial generation again because checksum is not controllable in real attacks. For example, the checksum field in the IP layer takes the identification field into calculation, and the value of the identification field changes very frequently. In our evaluations presented in Section 6.2, results also show that a secondary PCAW adversarial example generation is not necessary.
After we have generated the mask, we apply it in two well-known adversarial example generation methods, namely FGSM and ZOO.
We modify the original FGSM for application in network attacks, as illustrated in Fig. 5b. Main changes include two parts: 1) masks are applied when generating perturbations; 2) during generating perturbed data samples, we confine and round all values to the valid range. Perturbations and the magnitude parameter may introduce decimal fraction or make values out of the valid range. For example, in ARP poisoning detection, every value should be integers within [0, 255]. In DNS cache poisoning, every value is either 0 or 1. Hence, these values should be confined and rounded.
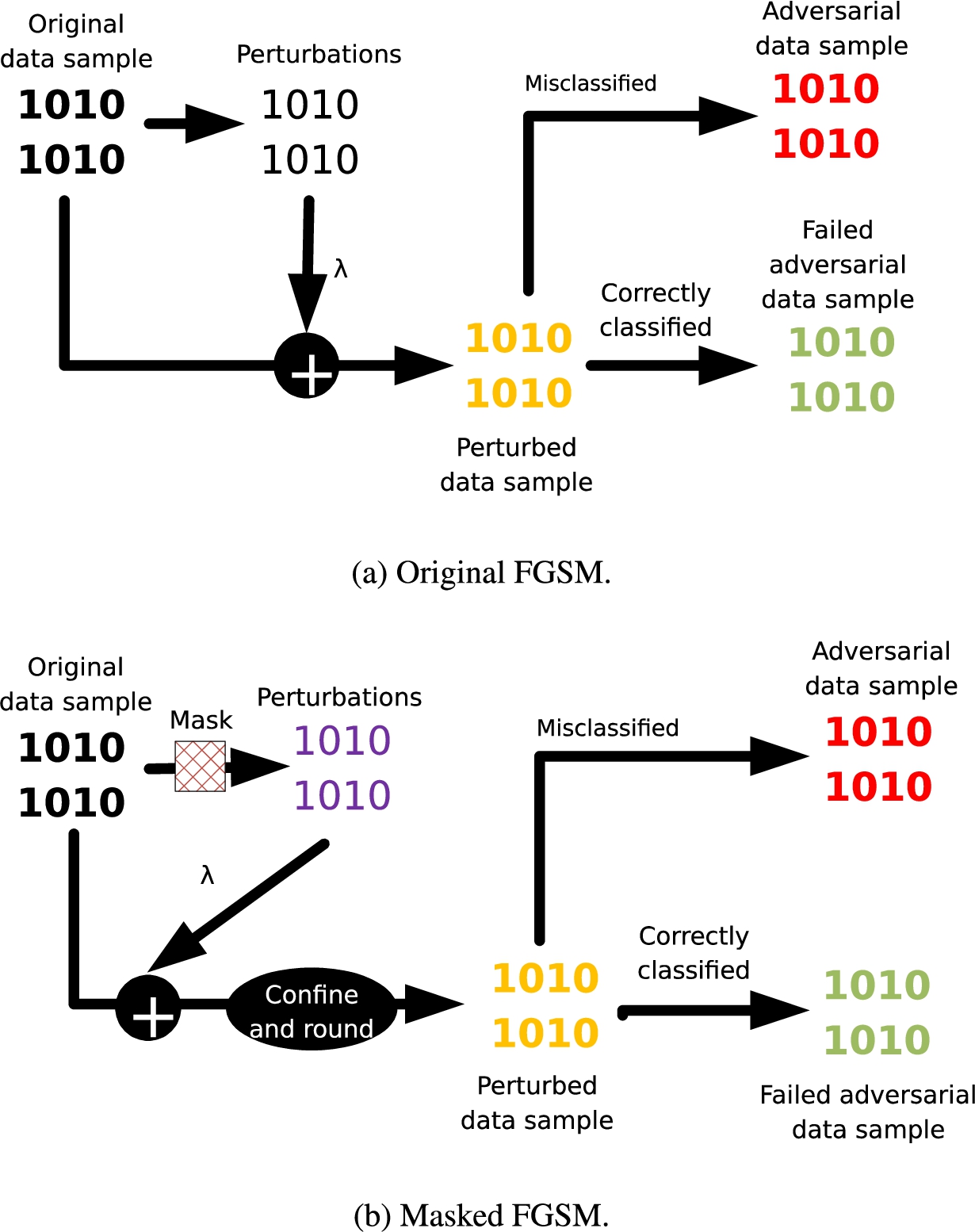
Illustration for FGSM.

Proposed score-based attack
The proposed score-based attack is illustrated in Algorithm 1. First, changeable fields are randomly selected from the mask and a standard basis vector
As stated in Section 4, one of the reasons to choose ARP poisoning for demonstration is that, the conversion between data samples and network packets is straightforward. Basically, the back-conversion is a reverse process of data processing. In the case of ARP poisoning detection, each ARP packet is processed into one data sample with no information loss. Every byte in the original packet is preserved (except padding bytes) in the resulting data sample as a converted integer. Therefore, the back-conversion is to convert integers back to bytes in the original order to form a packet, and add padding bytes if needed. For more details, please refer to the data processing part in the work [62].
Mitigate uncertainties for multi-packet attacks
The threat model for stealthy multi-packet network attacks.
In Section 5.2, we ensure the packet’s validity by using mechanisms such as masks, value confine and round, but these mechanisms do not ensure the session’s validity. This subsection demonstrates how to use PCAW adversarial examples to launch stealthy multi-packet network attacks.
In Fig. 6, we present the threat model for stealthy multi-packet network attacks using DNS cache poisoning as an example:
Attackers prepare original attack packets.
In their own test bed, attackers use the prepared attack packets to launch network attacks, and gather network logs at the same time. Network logs contain packets from both normal users/servers and attackers, and are sorted in the time order.
Attackers truncate network logs into truncated packet sequences, which are in turn processed into data samples. Meanwhile, attack packets’ orders in data samples are recorded, to be used later.
Attackers feed data samples to the PCAW adversarial example generation tool to generate PCAW adversarial examples by only modifying changeable information in the attack packets, as the attack packets are the only ones that can be controlled by attackers.
From PCAW adversarial examples, attackers pick out the bytes related to attack packets (using the order information from before) if needed.
From session-specific attack packets, attackers select bytes for changeable fields to form adversarial value sets.
To mitigate the uncertainties discussed earlier, attackers use adversarial value sets to simulate the network attacks in his/her own test bed. Any successful stealthy attack sessions will be recorded in the adversarial value set database.
Attackers launch real-world network attacks by replaying known stealthy attack sessions from his/her simulations.
In a DNS cache poisoning attack, packet 1 corresponds to DNS query sent by the user, packet 2 corresponds to DNS query sent by the local DNS server, packet 3 corresponds to attacker’s spoofed DNS response, and packet 4 corresponds to global DNS server’s DNS response. Packets 5 and 6 correspond to the remaining steps or other DNS packets, and packets 7 and 8 stand for dummy attack packets, the impact of which will be discussed in Section 6.2. In the data samples, we use U to stand for bytes from user/server packets, and A to stand for bytes from attacker packets. The subscripts stand for position of bytes in the packets. For example,
For step 5 and step 6, we extract values of the changeable fields from generated PCA adversarial examples to create multiple “adversarial value sets”, each set corresponds to one original attack packet in one data sample. Step 6 and 7 are only needed for multi-packet attacks. Step 6 is necessary for DNS because the attack packets have to be crafted based on the user/server packets, and session-specific attack packets cannot be directly used in future attacks. That is why adversarial value sets are extracted: they are expected to carry the adversarial effects to evade neural networks. Step 7 is to mitigate the uncertainties by generating stealthy attack sessions in attackers’ own test bed. Those stealthy attack sessions can be used to build an adversarial value set database, to which attackers can refer in later real-world attacks. With this database, a patient and cautious attacker can persist in the LAN while sniffing packets. Only when a perfect attack chance appears will the attacker take action, trying to replay the stealthy attack session the attacker already knows. In this way, the three problems raised earlier are bypassed.
To generate stealthy attack sessions, the following factors can be used to reduce detection rates (DR) and possibly generate more stealthy attack sessions.
After attackers have got stealthy attack sessions in their own test bed, they can build a database structured as in Fig. 7. The database consists of entry keys and sub-tables of key-value pairs. Each key is a hash value, each sub-table, marked by one specific entry key, represents a known stealthy attack session, and the values are the adversarial value sets. Each hash value is calculated based on the selected bytes from previous (up to 5, because the windows size is 6) packets in the session. Hash values are used as keys instead of directly comparing raw data for the sake of performance, because DNS cache poisoning attack requires quick response at the attackers’ side. If the entry key is matched, the corresponding stealthy attack session is selected to be replayed.
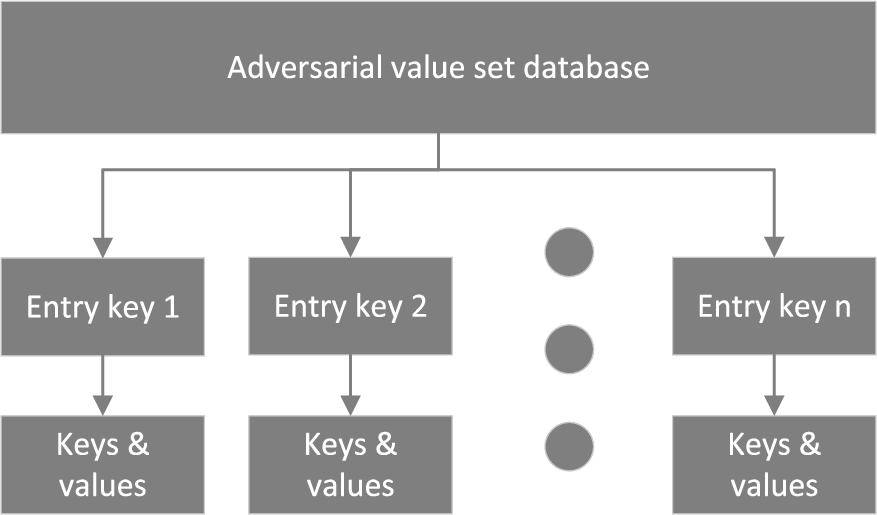
Adversarial value set database structure.
For example, in the DNS cache poisoning example, one session contains eight packets
After the adversarial value set database is built, we use it to simulate a patient and cautious attacker. Such attacker will always wait for a perfect chance to take action. That is, this attacker will only send out attacker packets when the observed packets’ hash has a perfect match in the database. Even if the entry key is matched, as long as the observed packets at a later time does not match hashes in the sub-table, the attacker stops at once and let go of the current session. Taking the earlier example, the attacker will first wait for
Therefore, we propose to build a dictionary that can be used to effectively search for the proper adversarial value sets. The dictionary consists of multiple entries; and each entry contains a key and one or more values. The keys in the dictionary are the DNS query packets sent out by the local DNS server. The values are the adversarial value sets. This dictionary can be created in the following way:
Map local DNS server’s query packet to the attack packet. This map is one-to-one.
Map the attack packet to the adversarial value set. This map is one-to-one or one-to-none, because not all data samples can be used to generate PCAW adversarial examples.
With the two steps above, establish the mapping between local DNS server’s query packet (as key) and the adversarial value set (as value).
Merge key-value pairs that have the same key.
When use the dictionary, we need to choose the adversarial value sets based on the keys. However, in actual attacks, we cannot guarantee that there is always an exactly matching key for the local DNS server’s query packet. Therefore, the distances between the query packet and the keys can be measured to find out the closest key. Depending on how the distance is defined, one observed local DNS query packet may refer to different entries. If the chosen entry holds multiple adversarial value sets (because of merging key-value pairs), one of them is randomly chosen. Assuming
With the distance measuring method, the closest key is selected for each observed local DNS server query packet, and the corresponding entry is also determined. Please note that such distance measuring introduces additional processing time at the attacker’s side. However, for DNS cache poisoning to succeed, attacker’s packet has to arrive earlier than the global DNS server’s packet. To rule out the impact of the additional distance measuring time on the attack success, in our experiments, we manually insert time lags between the local DNS server and the global DNS server’s communications, so that attack packets always arrive earlier.
In this section, we will evaluate the effectiveness and efficiency of our proposed methods. Specifically, we want to answer the following evaluation questions:
Q1: How effective are our proposed stealthy network attack against ARP poisoning detection?
Q2: How effective are our proposed stealthy network attack against DNS cache poisoning detection?
Q3: How costly are our proposed methods?
All experiments are performed using a Windows machine equipped with an Intel Core i9-9900KS CPU and Nvidia RTX 3090 for accelerating computations. For software, we use Python 3.8.5, TensorFlow 2.4.1 with GPU support, ART 1.6.1 [34], and FoolBox 3.3.1 [43,44]. All data samples and trained detection models are retrieved from another work [62].
Q1: Stealthy ARP poisoning
Proposed PCAW adversarial example generation methods’ performances towards ARP poisoning detection
Proposed PCAW adversarial example generation methods’ performances towards ARP poisoning detection
1 PCAWAE: Number of PCAW adversarial examples generated. 2 Masked random: Randomly changes the changeable portions regardless of gradients. This serves as a baseline. 3 Suc. ARP Atk: Number of successful stealthy ARP poisoning attacks.
We inspect the remaining 13 failed candidate stealthy attack packets that lead to failed ARP poisoning attacks, and find out that the IP addresses in those packets are modified to an invalid address, such as 192.168.100.0. This is because when the mask for ARP poisoning is created, the whole last byte (corresponds to the “0” in the IP) in the IP address field is marked as changeable. The masked ZOO algorithm can thus change it to any integer in [0, 255]. However, addresses like 192.168.100.0 are usually reserved for broadcasting, and are not mapped to any particular machine in this LAN. That is why ARP poisoning attack attempts using such IP addresses fail.
Since 23 of the candidate stealthy attack packets are actual stealthy attack packets, the overall stealthy attack success rate of the masked ZOO approach is
As discussed earlier, more attack packets in the data sample give attackers more chances to modify the data sample, and thus more PCAW adversarial examples can likely be generated. Therefore, we inspect all data samples to find out how many attack packets each data sample contains. The majority of all data samples contains only one attack packets, so we randomly choose 100 of them to generate the PCAW adversarial examples. For the other 89 data samples (less than 1% of all data samples) that contain two attack packets, we use all of them. The PCAW adversarial example generation results are presented in Table 5. It is generally more difficult to generate PCAW adversarial examples for DNS cache poisoning than for ARP poisoning. This is not surprising because: 1) The DNS cache poisoning detection neural network is more accurate than that of ARP poisoning, as shown in Section 2; 2) The ratio of changeable portions in data samples is smaller than that of ARP poisoning. The attack packets are only 1/6 or 1/3 of a data sample, and only part of the attack packet are changeable. Despite the difficulties, our proposed methods still succeed in generating PCAW adversarial examples, as shown in Table 5. The table also shows that, if there are two attack packets in the data sample, PCAW adversarial example generation is easier than if there is only one.
Proposed PCAW adversarial example generation methods’ performances towards DNS cache poisoning detection
Proposed PCAW adversarial example generation methods’ performances towards DNS cache poisoning detection
1 There are no data samples representing three or more attack packets. 2 Seed: Number of original data samples fed to the generation methods. 3 PCAWAE: PCAW adversarial examples. 4 Masked random: Randomly changes the changeable portions regardless of gradients. This serves as a baseline. 5 Memory: The memory taken in MB.
After PCAW adversarial examples are generated, attackers extract adversarial value sets and use them to launch DNS cache poisoning attacks in the test bed in order to generate stealthy attack sessions which the attackers can replay in real-world attacks. There are several factors that can help attackers to decrease DR on the data sample level and lead to more stealthy attack sessions: dummy attack packets, adversarial value set selection, and attacker packet index.
Impact of Dummy Attack Packets. To evaluate the impact of dummy attack packets, the attacker machine not only sends out attack packets as usual when an attack chance appears, but also sends out dummy attack packets periodically, regardless of whether there is an attack chance or not.
DNS cache poisoning with/without dummy attacker packets
1 Dummy interval: The time interval to send out dummy attacker packets. “None” means no dummy attacker packets are sent out. 2 Total number of data samples. 3 Number of misclassified data samples. 4 DR: Detection rate. 5 Average number of attack packets represented in the data samples.
The results are shown in Table 6. Our observation is that the DRs of neural networks decrease as the numbers of dummy packets in a data sample increase. In another word, more dummy packets lead to lower DRs. When there is no dummy attack packets, or dummy attack packets are sent less frequently than every 0.3 second, the average DRs on the data sample level are above 90%. (There are less than 2 attack packets in every data sample, on average. The less frequently dummy attack packets are sent, the less attack packets get into data samples.) When the time interval drops to 0.2 second, DR drops to about 78%. (There are more than 2 attack packets in every data sample, on average.) When the time interval further drops to 0.1 second, DR drastically drops to about 55%. (There are more than 3 attack packets in every data sample, on average.) However, a careful examination of all the DNS cache poisoning attack sessions reveals that out of the 33177 attack sessions in total, only 2 of them are stealthy attack sessions, as shown in Table 7. This means, though dummy attack packets help lower DRs, using it alone may not be efficient enough for attackers to generate stealthy attack sessions.
Statistics and detection results with respect to dummy interval on session level
* The number of data samples in sessions.
Detection Rates with respect to Attacker Packet Indices. We have conducted statistics and find that detection rates corresponding to different attacker packet indices are very polarized. Full results are shown in Fig. 8. Indices are shown with numbers. For example,
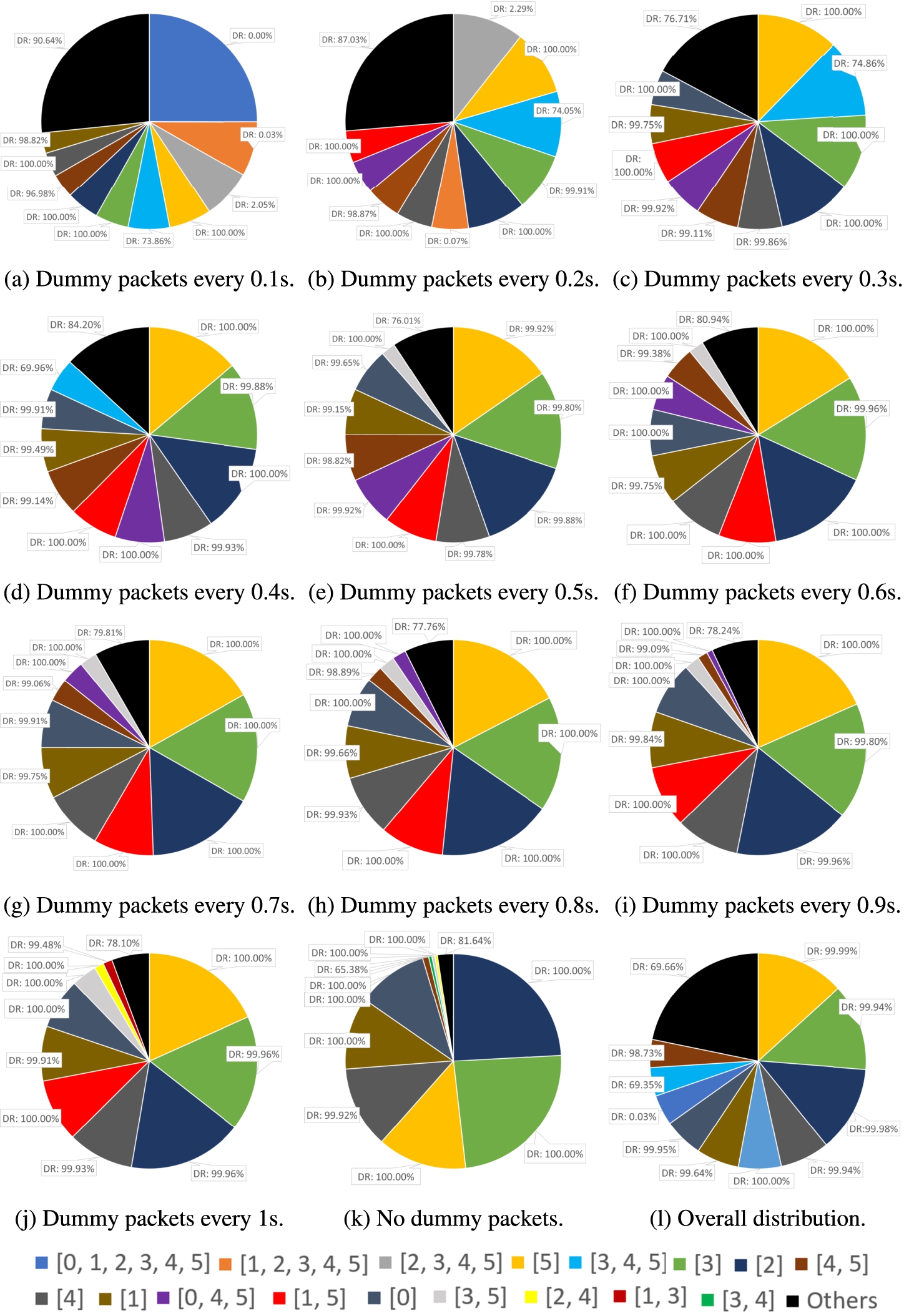
Attacker packet index distributions and corresponding detection rates.
Generally speaking, less frequent dummy attack packets result in the high detection rates. For example, when dummy packets are sent out every 0.1 s, one-third (of 3 attacker packet indices or pies) of the data samples have DRs close to 0%; when the time interval is 0.2 s, the rate drops to about 10% (of just 1 attacker packet index or pie); when the time interval becomes greater than 0.2 s, the most common ten attacker packet indices all have high detection rate. In a word, the distribution of attacker packet indices is not a uniform distribution, different attacker packet indices have different DRs, and how frequently dummy attack packets are sent have a big influence on attacker packet index distribution.
Impact of Adversarial Value Set Selection. To build the dictionary that helps to select the suitable adversarial value set, we have conducted additional DNS cache poisoning attacks to collect data and generate PCAW adversarial examples with masked FGSM (Masked ZOO is too time-consuming, so it is not used here.) After launching the DNS cache poisoning attack for 60000 times with dummy attack packets, a total of 244340 data samples are generated, which result in a dictionary with 148 keys holding 202 adversarial value sets.
We tried all the distance measuring methods mentioned in Section 5.4, and experiment results are summarized in Table 8. Each row shows results for one method (with 5000 attack sessions conducted for each method respectively), and each column shows the detection rates with respect to the number of attack packets represented in one data sample. The last column shows the average numbers of represented attack packets and the average detection rates. Similar to Table 6, the more attack packets represented in one data sample, the less likely the attack can be detected. When no dummy attack packets are sent out, DRs are almost 100%. When dummy attack packets are used, 1)
Detection rates with respect to the number of different distance measuring methods
1 “Random” means the dictionary is not used and adversarial value sets are selected totally randomly. The two “random” cases serve as the baselines. 2 Dummy attack packets, if used, are sent out every 0.1 s.
In addition to the data sample level, we have also inspected the collected data on the session level. To our surprise, the results show that none of the sessions in the ten cases shown in Table 8 are stealthy attack sessions, which probably means they can all be detected. This indicates that though adversarial value set selection can effectively lower the DRs at data sample level on general, it is not effective at the session level. A closer look at the sessions and the data samples also shows that, it is usually the first several data samples in the session that cannot get misclassified. Such data samples have only 1 or 2 attack packets inside. The reason is that the local DNS server, on receiving the user machine’s query packet, will send out several packets successively: query the IP address of the desired domain name, query the authoritative DNS server, query the IP addresses of root DNS servers, etc. As a result, every session is certain to have data samples that have very few attack packets, and the DR on the session level cannot be effectively lowered.
We build an adversarial value set database with the two stealthy attack sessions we found, and use it to simulate a patient and cautious attacker. If the attacker takes no action in a DNS session, it is referred as a “no-attack session”; if the attacker takes some action(s), but aborts before the attack is finished and does not fully replay the template session, it is referred as an “aborted session”; if the attacker fully replays the template session, it is referred as a “replayed session”. In our experiment, it takes about four days with 46545 DNS sessions, to get a perfect attack chance. The 46545 DNS sessions contains 46541 no-attack sessions, 3 aborted sessions, and the last one replayed session. We have also verified that none of the no-attack sessions are reported as false positive; all aborted sessions are correctly detected as malicious (stealthy attack session is not fully replayed, so aborted sessions cannot guarantee to be stealthy); for the one replayed session, it is not detected, and the attack succeeds.
Though it seems that a perfect chance is hard to wait, considering that attackers can even wait for months to take actions in APT campaigns, we believe several days is realistic and acceptable for attackers. To provide an estimation of the waiting time, we have the following observation: 1) in a large-scale enterprise network, a typical local DNS server’s network throughput is about 6 Mbps, namely
PCAW adversarial examples’ average losses
PCAW adversarial examples’ average losses
* Some results cannot be presented because there are no PCAW adversarial examples in those cases, and losses cannot be calculated.
Limitations
Attack success rates and stealthiness are usually the top concerns of attackers, especially for the ones conducting Advanced Persistent Threats (APTs).
We have proposed new evasion methods to generate malicious adversarial examples, so that attack success rate and stealthiness are both preserved. However, as shown in Section 6, they are not very efficient. For network attacks that need multiple network packets to launch and detect, such as DNS cache poisoning, sending dummy attacker packets is an effective way to substantially decrease the chances of being detected by neural networks. Nevertheless, dummy packets can also increase the attackers’ risks of being noticed due to the abnormal packet contents and the increased interaction with the target machines or servers.
Therefore, it is very challenging for attackers to find a perfect solution that can preserve network attack success rate, stealthiness, and efficiency all at once. Attackers will need to make trade-offs among these aspects. PCAW adversarial examples can be pre-generated, so that the attacker can quickly refer to them and send out attack packets when launching real attacks. Nevertheless, the attacker still needs to invest lots of time and effort to gather data and generate PCAW adversarial examples (and to mitigate uncertainties for multi-packet network attacks). We identify those as necessary costs to the attacker. As for defenders, it is recommended to combine multiple detection approaches rather than just using one, such as outlier detectors.
Counter measures
The previous sections presented a novel attack type with PCAWAEs. This attack is stealthier than traditional network attacks and can still result in the malicious impact. What is more, because attackers modify the contents of the packets, network flow-based IDS may not be effective detecting this attack. However, because the PCAWAE generation is still based on observed adversarial example generation methods, PCAWAE may be rejected if adversarial learning techniques are applied.
This paper focuses on the attacking aspect, so we will only briefly discuss the counter measures. Generally speaking, adversarial learning techniques can be categorized based on the time point of deployment [57]: before or after the original model is produced. Some common adversarial learning techniques include adversarial training [16], where adversarial examples are augmented into the training data to train a robust model, defensive distillation [38], where a separate model is learned based on the output of a previous model, and data compression [13], where the original data samples are compressed to mitigate the effect of attacker perturbations. However, adversarial training needs a lot of adversarial examples. In our case, they should be PCAWAEs, which are not easy to generate. Defensive distillation does not need adversarial examples as input, but it is not effective against some advanced attacks [8,9]. Unlike images, data compression may break some intrinsic patterns within network packet data. Therefore, instead of the above-mentioned common techniques, we select DeepCloak [15], which adds a mask layer just before the output layer of the detection model, so that extracted features that are affected by adversarial examples most will be filtered out.
We applied DeepCloak to the ARP poisoning detection neural network. As shown in Fig. 1, the output layer contains 2 units for binary classification, and there are 35 extracted features from the previous layer. Our experiment results show that, when 1 extracted feature is filtered out, out of the 36 PCAWAEs generated by masked ZOO, 33 of them are now correctly predicted as malicious, and changes to the evaluation metrics (accuracy, recall, precision, and F1 score) on the original dataset is about 0.0001. We continue to increase the number of filtered out extracted features, and find out that the maximum number of reverted PCAWAEs is 34. When the number of filtered out extracted features is nearing half of all extracted features, the model’s evaluation metrics will decrease drastically. In conclusion, though DeepCloak may not be able to revert all PCAWAEs’ predicted labels to the correct labels, it is still an effective defense approach because it can revert about 90% of the PCAWAEs’ predicted labels.
Related work
In the domain of network security, all the existing work on generating adversarial examples are under the data manipulation threat model. In particular, we break them down into two groups.
In [49], the authors conducted systematic experiments to evaluate whether the generated adversarial examples can evade the NN-based detectors. However, since the data manipulation threat model is assumed in this study, the authors did not propose any method for using the generated adversarial examples to generate the adversarial attack packets. Without these adversarial attack packets, the authors did not launch any real network attacks in their experiments. Another main difference between [49] and our work is as follows: the network constraints considered in [17,49] focus on transport layer protocols (e.g., TCP and UDP); in contrast, because we aim to launch real network attacks under the standard threat model, the protocol constraints considered in our work are specific to individual attacks. For example, for the DNS cache poisoning attack, we focus on the constraints specific to the DNS protocol.
Another work [41] proposes to modify packets themselves, but it only pads the packets with redundant bits, making the packets in question easy to be filtered out and noticed by security operators.
Conclusion
With deep-learning-based detection systems being increasingly deployed in enterprise networks, if the adversary continues to launch network attacks (as usual) without any adjustment, their APT campaigns would become significantly less stealthy. Noticing that none of the existing adversarial example generation methods could generate malicious packets that can simultaneously compromise the target machine and evade the neural network detection model, we introduced a practical way for launching stealthy network attacks, and proposed the approach of implementing this type of attack. We used ARP poisoning and DNS cache poisoning attacks as the case study to demonstrate the effectiveness of the proposed method.
Disclaimer
Dr. Liu and The Pennsylvania State University own equity in DayZero Systems. These financial interests have been reviewed by the University’s Conflict of Interest Committees and are currently being managed by the University.
This paper is not subject to copyright in the United States. Commercial products are identified in order to adequately specify certain procedures. In no case does such identification imply recommendation or endorsement by the National Institute of Standards and Technology, nor does it imply that the identified products are necessarily the best available for the purpose.
Footnotes
Acknowledgment
This work was supported by NIST 60NANB22D144, NSF CNS-2019340, and NSF ECCS-2140175. Xiaoyan Sun was supported by NSF DGE-2105801.