We present a formal model of Checked C, a dialect of C that aims to enforce spatial memory safety. Our model pays particular attention to the semantics of dynamically sized, potentially null-terminated arrays. We formalize this model in Coq, and prove that any spatial memory safety errors can be blamed on portions of the program labeled unchecked; this is a Checked C feature that supports incremental porting and backward compatibility. While our model’s operational semantics uses annotated (“fat”) pointers to enforce spatial safety, we show that such annotations can be safely erased. Using PLT Redex we formalize an executable version of our model and a compilation procedure to an untyped C-like language, as well as use randomized testing to validate that generated code faithfully simulates the original. Finally, we develop a custom random generator for well-typed and almost-well-typed terms in our Redex model, and use it to search for inconsistencies between our model and the Clang Checked C implementation. We find these steps to be a useful way to co-develop a language (Checked C is still in development) and a core model of it.
The C programming language remains extremely popular despite the emergence of new, modern languages. Unfortunately, C programs lack spatial memory safety, which makes them susceptible to a host of devastating vulnerabilities, including buffer overflows and out-of-bounds reads/writes. Despite their long history, buffer overflows and other spatial safety violations are among the most prevalent and dangerous vulnerabilities on the Internet today [26].
Several industrial and research efforts – including CCured [19], Softbound [18], and ASAN [23] – have explored means to compile C programs to automatically enforce spatial safety. These approaches all impose performance overheads deemed too high for deployment use. Recently, Elliott et al. [4] introduced Checked C, an open-source extension to C with new types and annotations whose use can ensure a program’s spatial safety. Importantly, Checked C supports development that is incremental and compositional. Code regions (e.g., functions or whole files) designated as checked enforce spatial safety in a manner preserved by composition with other checked regions. But not all regions must be checked: Checked C’s annotated checked pointers are binary-compatible with legacy pointers, and may coexist in the same code, which permits a deliberate (and semi-automated) refactoring process. Parts of the FreeBSD kernel have been successfully ported to Checked C [3], and overall, performance overhead seems low enough for practical deployment.
While Checked C promises to enforce spatial safety, we might wonder whether its design and implementation deliver on this promise, or even what “spatial safety” means when a program contains both checked and unchecked code. In prior work, Ruef et al. [22] developed a core formalization of Checked C and with it proved a soundness theorem for checked code: any stuck (i.e., ill-defined) state reached by a well-typed program amounts to a spatial safety violation; such a state can always be attributed to, i.e., blamed on, the execution of code that is not in a checked region. While their work is a good start, it fails to model important aspects of Checked C’s functionality, particularly those involving pointers to arrays. In this paper, we cover this gap, making three main contributions.
Dynamically bounded and null-terminated arrays. Our first contribution is a core formalism called CoreChkC, which extends Ruef et al. [22] with several new features, most notably dynamically bounded arrays (Section 3). Dynamically bounded arrays are those whose size is known only at run time, as designated by in-scope variables using dependent types. A pointer’s accessible memory is bounded both above and below, to admit arbitrary pointer arithmetic.
CoreChkC also models null-terminated arrays, a kind of dynamically bounded array whose upper bound defines the array’s minimum length – additional space is available up to a null terminator. For example, the Checked C type nt_array_ptr<char> p:count(n) says that p has length at leastn (excluding the null terminator), but further capacity is present if p[n] is not null. Checked C (and CoreChkC) supports flow-sensitive bounds widening: statements of the form if(*p)s, where p’s type is nt_array_ptr<T> count(0), typecheck statement s under the assumption that p has type nt_array_ptr<T> count(1), i.e., one more than it was, since the character at the current-known length is non-null. Similarly, the call n = strlen(p) will widen p’s bounds to n. Subtyping permits treating null-terminated arrays as normal arrays of the same size (which does not include, and thereby protects, the null terminator).2
See Section 6 for a careful comparison of Ruef et al. [22] and CoreChkC.
We prove, in Coq, a blame theorem for CoreChkC. As far as we are aware, ours is the first formalized type system and proof of soundness for pointers to null-terminated arrays with expandable bounds.
Sound compilation of checked pointers. Our second contribution is a formalization of bounds-check insertion for array accesses (Section 4). Our operational semantics annotates each pointer with metadata that describes its bounds, and the assignment and dereference rules have premises to confirm the access is in bounds. An obvious compilation scheme (taken by Cyclone [7,10], CCured [19], and earlier works) would be to translate annotated pointers to multi-word objects: one word for the pointer, and 1–2 words to describe its lower and upper bounds. Inserted checks reference these bounds. While convenient, such “fat” pointers are expensive, and break backward binary compatibility with legacy pointers.
To show that pointer annotations can be safely erased, and thus fat pointers are not needed, we formalize a translation of CoreChkC to CoreC, which is an untyped version of CoreChkC that drops metadata annotations, and lacks bounds/null checks in the semantics rules. Instead, the compilation process inserts null/bounds checks explicitly, leveraging compile-time type information. While we do not definitively prove it, we provide strong evidence that compilation is correct. We use PLT Redex [6] to mechanize (a generalization of) CoreChkC, CoreC, and compilation between the two, and we use randomized testing to validate that the compiled program simulates the original. In addition to demonstrating the technical point that metadata annotations in the CoreChkC formalism do not necessitate fat pointers, compilation also sheds light on the actual Checked C compilation process.
As far as we are aware, CoreChkC is the first formalism to cleanly separate bounds-checking compilation from the core semantics; prior work [2,28] merged the two, conflating meaning with mechanism. In carrying out the formalization, we discovered that our compilation approach for null-terminated array pointers is more expressive than that proposed in the Checked C specification [24] (Section 4.2); we would not have discovered this improvement had we not separated checks from semantics.
Model-based randomized testing. Our third and final contribution is a strategy and implementation of model-based randomized testing (Section 5). To check the correctness of our formal model, we compare the behavior between the existing Clang Checked C implementation and our own model. This is done by a conversion tool that converts expressions from CoreChkC into actual Checked C code that can be compiled by the Clang Checked C compiler. We build a random generator of programs largely based on the typing rules of CoreChkC and make sure that, both statically and dynamically, CoreChkC and Clang Checked C are consistent after conversion. This helped rapidly prototype the model and uncovered several issues in the Checked C compiler.
CoreChkC models’ relationship to Checked C.
Summary visualization. The relationship among our contributions is visualized in Fig. 1. With the Coq model of CoreChkC we prove soundness (and with it, blame) of the Checked C type system and semantics. With the Redex model, we use randomized testing to validate both type soundness and compilation correctness, where the latter shows how compilation need not output fat pointers despite the use of pointer annotations in the CoreChkC model. The Redex CoreChkC model is also the basis of randomized testing of the correctness of the Checked C compiler implementation, both its type checker and the semantics of its emitted code, at least for the subset of the language in the Redex model. The Redex model’s syntax is slightly richer than the Coq version: conditional guards and function arguments may be arbitrary expressions, where the Coq version limits them to constants and variables, making handling of dependent types a bit simpler. We find a useful synergy between the Coq and Redex models for carrying out a language development. The richer, executable Redex model is useful for quickly modeling and testing new features, both formally and against a real implementation. Once solidified, new features can be added to the Coq model (perhaps somewhat simplified) for final proofs of correctness.
We begin with a review of Checked C (Section 2), present our main contributions (Sections 3–5), and conclude with a discussion of related and future work (Sections 6, 7). All code and proof artifacts (both for Coq and Redex) can be found at https://github.com/plum-umd/checkedc.
Checked C overview
This section describes Checked C, which extends C with new pointer types and annotations that ensure spatial safety. Development of Checked C was initiated by Microsoft Research in 2015 but starting in late 2021 was forked and is now actively managed by the Secure Software Development Project (SSDP). Details can be found in a prior overview [4] or the full specification [24]. Checked C is implemented as an extension of Clang/LLVM and the SSDP fork is freely available at https://github.com/secure-sw-dev.
Checked pointer types
Checked C introduces four varieties of checked pointer:
types a pointer that is either null or points to a single object of type ω.
structT* types a pointer that is either null or pointers to a Tstruct.
types a pointer that is either null or points to an array of ω objects. The array width is defined by a bounds expression, discussed below.
is like except that the bounds expression defines the minimum array width – additional objects may be available past the upper bound, up to a null terminator.
A bounds expression used with the latter two pointer types has three forms:
where e defines the array’s length. Thus, if pointer p has bounds count(n) then the accessible memory is in the range . Bounds expression e must be side-effect free and may only refer to variables whose addresses are not taken, or adjacent struct fields.
is like count, but expresses arithmetic using bytes, no objects; i.e., count(e) used for is equivalent to
where and are pointers that bound the accessible region (the expressions are similarly restricted). Bounds is shorthand for . This most general form of bounds expression is useful for supporting pointer arithmetic.
Dropping the bounds expression on an nt_array_ptr is equivalent to the bounds being count(0).
The Checked C compiler will instrument loads and stores of checked pointers to confirm the pointer is non-null, and the access is within the specified bounds. For pointers p of type nt_array_ptr<T>, such a check could spuriously fail if the index is past p’s specified upper bound, but before the null terminator. To address this problem, Checked C supports bounds widening. If p’s bounds expression is a program may read from (but not write to) ; when the compiler notices that a non-null character is read at the upper bound, it will extend that bound to .
Parsing a string of UTF16 hex characters in Checked C.
Ported from the Parson JSON parser, https://github.com/kgabis/parson.
The function parse_utf16_hex on lines 1–14 takes a null-terminated pointer s as its argument, from which it attempts to read four characters. These are interpreted as hex digits and converted to an uint returned via parameter result. At first, s has no specific bounds annotation, which we can interpret as count(0); this means that s[0] may be read on line 4. The true branch of the conditional (which extends all the way to the brace on line 11) is thus type-checked with s given a widened bound of count(1). Likewise, the conditionals on lines 5–7 each widen it one further; the widened pointer (s+4) is returned on success.
The parse function on lines 15–22 repeatedly invokes parse_utf16_hex with its parameter s, and fills out array p whose declared length is the parameter n. Writes happen via pointer q, which is updated using pointer arithmetic. We specify its bounds as bounds(p,p+n) to support this: even as q changes, variables p and n (and therefore also q’s bounds) do not. Converting from an array_ptr<uint> to a ptr<uint>, done for the call on line 19, requires proving the array has size at least 1. While this is true because of the loop condition q < p+n, which is q’s upper bound, the compiler is not smart enough to figure this out. To convince it, we manually insert a dynamic cast via dyn_bounds_cast, which is trusted at compile-time but confirmed with a dynamic check at run-time.
While bounds checks are conceptually inserted on every array load and store, many of these are eliminated by LLVM. For example, all of the pointer accesses to s on lines 4–7 are proved safe at compile-time, so no bounds checks are inserted for them. Elliott et al. [4] reported average run-time overheads of 8.6% on a pointer-intensive benchmark suite (49.3% in one case); Duan et al. [3] measured no overhead at all on a port of FreeBSD’s UDP and IP stacks to Checked C.
Other features
Checked C has other features not modeled in this paper. Two in regular use are interop types, which ascribe checked pointer types to unported legacy code, notably in libraries; and generic types on both functions and structs, for type-safe polymorphism. More details about these can be found in the language specification.
Spatial safety and backward compatibility
Checked C is backward compatible with legacy C in the sense that all legacy code will type-check and compile. However, only code that appears in checked regions, which we call checked code, is spatially safe. Checked regions can be designated at the level of files, functions, or individual code blocks, the first with a #pragma and the latter two using the checked keyword.4
You can also designate unchecked regions within checked ones.
Within checked regions, both legacy pointers and certain unsafe idioms (e.g., variadic function calls) are disallowed. The code in Fig. 2 satisfies these conditions, and will type-check in a checked region.
How should we think about code that contains both checked and legacy components? Ruef et al. [22] proved, for a simple formalization of Checked C, that checked code cannot be blamed: Any spatial safety violation is caused by the execution of unchecked code. In this paper we extend that result to a richer formalization of Checked C.
Formalization
This section describes our formal model of Checked C, called CoreChkC, making precise its syntax, semantics, and type system. It also develops CoreChkC’s meta-theory, including type soundness and the blame theorem.
Syntax
The syntax of CoreChkC is given by the expression-based language presented in Fig. 3.
There are two notions of type in CoreChkC. Types τ classify word-sized values including integers and pointers, while types ω classify multi-word values such as arrays, null-terminated arrays, structs, and single-word-size values. Pointer types () include a mode annotation (m) which is either checked (c) or unchecked (u) and a type (ω) denoting valid values that can be pointed to. Array types include both the type of elements (τ) and a bound (β) comprised of an upper and lower bound on the size of the array (). Bounds b are limited to integer literals n and expressions . Whether an array pointer is null terminated or not is determined by annotation κ, which is for null-terminated arrays, and · otherwise (we elide the · when writing the type). A struct type contains a struct definition name T. In Checked C, there is a global function D mapping T to a struct field list , each of which is a pair of a type τ and a field name f. Here is the corresponding Checked C syntax for these types:
As a convention we write to mean , so the above examples could be rewritten and , respectively.
CoreChkC syntax.
CoreChkC expressions include literals (), variables (x), addition (), pointer dereference and assignment () and (), resp.), struct pointer address-of (), strlen operation (), static casts (), dynamic casts () (assumed at compile-time and verified at run-time, see Section 2.2), function calls (), memory allocation (), conditionals (), unchecked blocks (), and let binding ().
Integer literals n are annotated with a type τ which can be either , or in the case n is being used as a heap address (this is useful for the semantics); (for any m and ω) represents the pointer, as usual. struct pointer address-of operations () indexes the f-th position structT item, if the expression e is evaluated to a struct pointer . The expression operates on variables x rather than arbitrary expressions to simplify managing bounds information in the type system; the more general case can be encoded with a let. We use a less verbose syntax for dynamic bounds casts; e.g., the following becomes .
CoreChkC aims to be simple enough to work with, but powerful enough to encode realistic Checked C idioms. For example, mutable local variables can be encoded as immutable locals that point to the heap; the use of & can be simulated with malloc; and loops can be encoded as recursive function calls. C-style unions have no safe typing in Checked C, so we omit them. By default, functions are assumed to be within checked regions; placing the body in an unchecked expression relaxes this, and within that, checked regions can be nested via function calls. Bounds are restricted slightly: rather than allowing arbitrary sub-expressions, bounds must be either integer literals or variables plus an integer offset, which accounts for most uses of bounds in Checked C programs. CoreChkC bounds are defined as relative offsets, not absolute ones, as in the second part of Fig. 2. We see no technical problem to modeling absolute bounds, but it would be a pervasive change so we have not done so.
We have mechanized two models of CoreChkC, one in Coq and one in PLT Redex [6], which is a semantic engineering framework implemented in Racket. Redex provides direct support for specifying the operational semantics and typing with logical rules, but then automatically makes them executable and subject to randomized testing, which is very useful during development. The model we present in the paper faithfully represents both mechanizations, but there are some differences for presentation purposes. For example, the paper and the Coq model use an explicit stack, whereas the Redex model uses let bindings to simulate one (simplifying term generation for randomized testing). Section 3.5 outlines the differences between the two models and the paper formalism.
CoreChkC semantics: evaluation.
Semantics
The operational semantics for CoreChkC is defined as a small-step transition relation with the judgment . Here, φ is a stack mapping from variables to values and H is a heap mapping addresses (integer literals) to values ; for both we ensure . While heap bindings can change, stack bindings are immutable – once variable x is bound to in φ, that binding will not be updated; we can model mutable stack variables as pointers into the mutable heap. As mentioned, value represents a pointer when τ is a pointer type; correspondingly, should always be undefined. The relation steps to a result r, which is either an expression or a or failure, representing a null-pointer dereference or out-of-bounds access, respectively. Such failures are a good outcome; stuck states (non-value expressions that cannot transition to a result r) characterize undefined behavior. The mode m indicates whether the stepped redex within e was in a checked () or unchecked () region.
The rules for the main operational semantics judgment – evaluation – are given at the bottom of Fig. 4. The first rule takes an expression e, decomposes it into an evaluation context E and a sub-expression (such that replacing the hole □ in E with would yield e), and then evaluates according to the computation relation , whose rules are given in Figs 5 and 7, discussed shortly. The second rule handles conditionals in redex position specially, delegating directly to the S-IfNTT computation rule, which supports bounds widening; we discuss this rule shortly. When the second and first rules could both apply, we always prefer the second.5
This approach is that of the PLT Redex model of CoreChkC; the Coq development uses a slightly simpler syntax to achieve the same effect.
The function determines the mode when evaluating based on the context E: if the □ occurs within inside E, then the mode is ; otherwise, it is . Evaluation contexts E define a standard left-to-right evaluation order. (We explain the syntax shortly.)
CoreChkC semantics: computation (selected rules).
Implementation of safe strcat.
Figure 5 shows selected rules for the computation relation and Fig. 7 contains the remaining rules; we explain rules in Fig. 5 with the help of the example in Fig. 6, which defines a safe version of strcat (using actual Checked C syntax). The function takes a target pointer dst of capacity n, where the first null character (determined by strlen) is at index x where x. It concatenates the src buffer to the end of dst as long as dst has sufficient space. We then explain rules in Fig. 7 briefly.
Remaining CoreChkC semantics rules (extends Fig. 5). replaces bound variables in ω with their values.
Pointer accesses. The rules for dereference and assignment operations – S-Def, S-DefNull, S-DefNTArray, and S-AssignArr – illustrate how the semantics checks bounds. Rule S-DefNull transitions attempted null-pointer dereferences to , whereas S-Def dereferences a non-null (single) pointer. When is returned by the computation relation, the evaluation relation halts the entire evaluation with (using a rule not shown in Fig. 4); it does likewise when is returned (see below).
S-AssignArr assigns to an array as long as 0 (the point of dereference) is within the bounds designated by the pointer’s annotation and strictly less than the upper bound. For the assignment rule, arrays are treated uniformly whether they are null-terminated or not (κ can be · or ) – the semantics does not search past the current position for a null terminator. The program can widen the bounds as needed, if they currently precede the null terminator: S-DefNTArray, which dereferences an NT array pointer, allows an upper bound of 0, since the program may read, but not write, the null terminator. A separate rule (not shown) handles normal arrays.
Casts. Static casts of a literal to a type τ are handled by S-Cast. In a type-correct program, such casts are confirmed safe by the type system. To evaluate a cast, the rule updates the type annotation on n. Before doing so, it must “evaluate” any variables that occur in τ according to their bindings in φ. For example, if τ was , then would produce if .
Dynamic casts are accounted for by S-DynCast and S-DynCastBound. In a type-correct program, such casts are assumed correct by the type system, and later confirmed by the semantics. As such, a dynamic cast will cause a failure if the cast-to type is incompatible with the type of the target pointer, as per the condition in S-DynCastBound. An example use of dynamic casts is given on line 5 in Fig. 6. The values of x and n might not be known statically, so the type system cannot confirm that x ⩽ n; the dynamic cast assumes this inequality holds, but then checks it at run-time.
Binding and function calls. The semantics handles variable scopes using the special form. S-Let evaluates to a configuration whose stack is φ extended with a binding for x, and whose expression is which remembers x was previously bound to ; if it had no previous binding, . Evaluation proceeds on e until it becomes a literal , in which case S-Ret restores the saved binding (or ⊥) in the new stack, and evaluates to .
Function calls are handled by S-Fun. Recall that array bounds in types may refer to in-scope variables; e.g., parameter dst’s bound count(n) refers to parameter n on lines 1 and 2 in Fig. 6. A call to function f causes f’s definition to be retrieved from Ξ, which maps function names to forms , where τ is the return type, is the parameter list of variables and their types, and e is the function body. The call is expanded into a let which binds parameter variables to the actual arguments , but annotated with the parameter types (this will be safe for type-correct programs). The function body e is wrapped in a static cast which is the function’s return type but with any parameter variables appearing in that type substituted with the call’s actual arguments . To see why this is needed, suppose that safe_strcat in Fig. 6 is defined to return a nt_array_ptr<int>:count(n) typed term, and assume that we perform a safe_strcat function call as x=safe_strcat(a,b,10). After the evaluation of safe_strcat, the function returns a value with type nt_array_ptr<int>:count(10) because we substitute bound variable n in the defined return type with 10 from the function call’s argument list. Note that the S-Fun rule replaces the annotations with (after instantiation) from the function’s signature. Using when executing the body of the function has no impact on the soundness of CoreChkC, but will violate Theorem 5, which we introduce in Section 4.
Bounds widening. Bounds widening occurs when branching on a dereference of a NT array pointer, or when performing . The latter is most useful when assigned to a local variable so that subsequent code can use the result, e.g., e in . Lines 3 and 4 in Fig. 6 are examples. The widened upper bound precipitated by is extended beyond the lifetime of x, as long as y is live. For example, x’s scope in line 3 at runtime is the whole function body in safe_strcat because the lifetime of the pointer dst is in the function body. This is different from the Checked C specification, which only allows bound widening to happen within the scope of x, and restoring old bound values once x dies. We allow widening to persist outside the scope at run-time as long as we are within the stack frame, and we show this does not necessarily require the use of fat pointers in Section 4.
Rule S-StrWiden implements widening. The predicate aims to find a position in the NT array that stores a null character, where no character as indexes between n and contains one. This rule handles the case when , the case is handled by a normal rule in Fig. 7.
Rule S-IfNTT performs bounds widening on x when the dereference is not at the null terminator, but the pointer’s upper bound is 0 (i.e., it’s at the end of its known range). x’s upper bound is incremented to 1, and this count persists as long as x is live. For example, s’s increment (lines 4–7) is live until the return of the function in Fig. 2; thus, line 10 is valid because s’s upper bound is properly extended.
Struct address-of and remaining rules. Rules S-StructChecked and S-StructUnChecked in Fig. 5 describe the semantic behaviors of on a given structchecked/unchecked pointers, while rule S-StructNull describes a checkedstruct null-pointer case. The difference between and mode struct pointer address-of operations is that we have an additional check for a mode pointer to test if a pointer is , while mode struct pointer has no such checks. Function computes the index position offset of the field f in struct through a traditional C implementation.
Figure 7 shows the remaining semantic rules for . We explain a selected few rules here. Rule S-Var loads the value for x in stack φ. Rule S-DefArray dereferences an array pointer, which is similar to the Rule S-DefNTArray in Fig. 5 (dealing with null-terminated array pointers). The only difference is that the range of 0 is at not , meaning that one cannot dereference the upper-bound position in an array. Rules DefArrayBound and DefNTArrayBound describe an error case for a dereference operation. If we are dereferencing an array/NT-array pointer and the mode is , 0 must be in the range from to (meaning that the dereference is in-bound); if not, the system results in a error. Obviously, the dereference of an array/NT-array pointer also experiences a state transition if .
Rules S-Malloc and S-MallocBound describe the semantics. Given a valid type that contains no free variables ( evaluates bound variables in ω to integer values), the function returns an address pointing at the first position of an allocated space whose size is equal to the size of , and a new heap snapshot that marks the allocated space for the new allocation. The is transitioned to the address n with the type and new updated heap. It is possible for to transition to a error if the is an array/NT-array type , and either or . This can happen when the bound variable is evaluated to a bound constant that is not desired.
Typing
We now turn to the CoreChkC type system. The typing judgment has the form , which states that in a type environment Γ (mapping variables to their types) and a predicate environment Θ (mapping integer-typed variables to Boolean predicates), expression e will have type τ if evaluated in mode m. All rules for this judgment are given in Figs 8 and 9. In the rules, uses the two-point lattice with .
Type rules for constants/variables.
Type rules. Ξ is a global store mapping from function variables to code. : is of the Bound syntax.
Typing rules for literal pointers. The typing of integer literals, which can also be pointed to the heap, was presented in Section 3.4 in Fig. 8.
The variable type rule () simply checks if a given variable has the defined type in Γ; the constant rule () is slightly more involved. First, it ensures that the type annotation τ does not contain any free variables. More importantly, it ensures that the literal itself is well typed using an auxiliary typing relation .
If the literal’s type is an integer, an unchecked pointer, or a null pointer, it is well typed, as shown by the top three rules in Fig. 8. However, if it is a checked pointer , we need to ensure that what it points to in the heap is of the appropriate pointed-to type (ω), and also recursively ensure that any literal pointers reachable this way are also well-typed. This is captured by the bottom rule in the figure, which states that for every location in the pointers’ range , where yields the size of its argument, then the value at the location is also well-typed. However, as heap snapshots can contain cyclic structures (which would lead to infinite typing derivations), we use a scope σ to assume that the original pointer is well-typed when checking the types of what it points to. The middle rule then accesses the scope to tie the knot and keep the derivation finite, just like in Ruef et al. [22].
Pointer access. Rules T-DefArr and T-AssignArr in Fig. 9 type-check array dereference and assignment operations resp., returning the type of pointed-to objects; rules for pointing to single objects are similar. The condition ensures that unchecked pointers can only be dereferenced in unchecked blocks; the type rule for sets when checking e. The rules do not attempt to reason whether the access is in bounds; this check is deferred to the semantics.
Casting and subtyping. Rule T-Cast rule forbids casting to checked pointers when in checked regions (when ), but τ is unrestricted when . The T-CastCheckedPtr rule permits casting from an expression of type to a checked pointer when . This subtyping relation ⊑ is given in Fig. 10; the many rules ensure the relation is transitive. Most of the rules handle casting between array pointer types. The second rule permits treating a singleton pointer as an array pointer with and .
Since bounds expressions may contain variables, determining assumptions like requires reasoning about those variables’ possible values. The type system uses Θ to make such reasoning more precise.6
Technically, the subtyping relation ⊑ and the bounds ordering relation ⩽ are parameterized by Θ; this fact is implicit to avoid clutter.
Θ is a map from variables x to predicates P, which have the form . If Θ maps x to ⊤, that means that the variable can possibly be any value; means that . We will see how Θ gets populated and give a detailed example of subtyping below. As it turns out, the subtyping relation is also parameterized by φ, which is needed when type checking intermediate results to prove type preservation; source programs would always have , which will be explained shortly below.
Rule T-DynCast typechecks dynamic casting operations, which apply to array pointer types only. The cast is accepted by the type system, as its legality will be checked by the semantics.
The subtyping relation given in Fig. 10 involves dependent bounds, i.e., bounds that may refer to variables. To decide premises , we need a decision procedure that accounts for the possible values of these variables. This process considers Θ, tracked by the typing judgment, and φ, the current stack snapshot (when performing subtyping as part of the type preservation proof).
(Inequality ⩽).
We define ⩽ as:
if n is less than or equal to m.
if n is less than or equal to m.
All other cases result in .
To capture bound variables in dependent types, the Checked C subtyping relation (⊑) is parameterized by Θ, which provides the range of allowed values for a bound variable; thus, more relation can be connected so can be statically cast to . For example, in Fig. 6, the strlen operation in line 3 turns the type of dst to be and extends the upper bound to x. In the strlen type rule T-LetStr, it also inserts a predicate x in Θ; thus, the cast operation in line 12 is valid because is provable when we know x.
The Θ set appearing in ⊑ essentially represents a decision procedure happening in compilation step, as the judgments in Θ, such as x above, describe the properties of stack variables in φ at the program point that these judgments are generated. For example, at the time of the judgment x is generated in rule T-LetStr, we know that the strlen operation produces a variable x that is greater than 0, without looking at the stack. As we can see, the main component of the decision procedure is through the inequality operation in Definition 1, where we specify the first two rules as the cases when two bounds are statically comparable, while the other situations are classified as not statically analyzable. In the Checked C implementations, the decision procedure is more comprehensive.
Bounds widening. The bounds of NT array pointers may be widened at conditionals, and calls to . Rule T-If handles normal branching operations; rule T-IfNT is specialized to the case of branching on when x is a NT array pointer whose upper bound is 0. In this case, true branch is checked with x’s type updated so that its upper bound is incremented by 1; the else branch is type-checked under the existing assumptions. For both rules, the resulting type is the join of the types of the two branches (according to subtyping). This is important for the situation when x itself is part of the result, since x will have different types in the two branches.
Rule T-Str handles the case for when does not appear in a let binding. Rule T-LetStr handles the case when it does, and performs bounds widening, where is restricted to the Bound syntax in Fig. 3. The result of the call is stored in variable x, and the type of y is updated in Γ when checking the let body e to indicate that x is y’s upper bound. Notice that the lower bound is unaffected by the call to ; this is sound because we know that will always return a result n such that , the current view of x’s upper bound. The type rule tracks ’s widened bounds within the scope of x, while the bound-widening effect in the semantics applies to the lifetime of y. Our type preservation theorem in Section 3.4 shows that our type system is a sound model of the CoreChkC semantics, and we discuss how we guarantee that the behavior of our compiler formalization and the semantics matches in Section 4.
This rule also extends Θ when checking e, adding a predicate indicating that . To see how this information is used, consider this example. The return on line 12 of Fig. 6 has an implicit static cast from the returned expression to the declared function type (see rule T-Fun, described below). In type checking the on line 3, we insert a predicate in Θ showing x. The static cast on line 12 is valid according to the last line in Fig. 10:
because and , where the latter holds since Θ proves . Without Θ, we would need a dynamic cast.
In our formal presentation, Θ is quite simple and is just meant to illustrate how static information can be used to avoid dynamic checks; it is easy to imagine richer environments of facts that can be leveraged by, say, an SMT solver as part of the subtyping check [21,25].
Dependent functions and let bindings. Rule T-Fun is the standard dependent function call rule. It looks up the definition of the function in the function environment Ξ, type-checks the actual arguments which have types , and then confirms that each of these types is a subtype of the declared type of f’s corresponding parameter. The list substitution function applies a standard substitution of variable with in , one by one in a standard left-to-right order. Because functions have dependent types, we substitute each parameter for its corresponding parameter in both the parameter types and the return type. Consider the safe_strcat function in Fig. 6; its parameter type for dst depends on n. The T-Fun rule will substitute n with the argument at a call-site.
Rule T-Let types a expression, which also admits type dependency. The substitution function applies a standard substitution of variable x with expression (if ) in . In particular, the result of evaluating a may have a type that refers to one of its bound variables (e.g., if the result is a checked pointer with a variable-defined bound); if so, we must substitute away this variable once it goes out of scope. Note that we restrict the expression to syntactically match the structure of a Bounds expression b (see Fig. 3).
Rule T-Ret types a expression, which does not appear in source programs but is introduced by the semantics when evaluating a let binding (rule S-Let in Fig. 5); this rule is needed for the preservation proof. After the evaluation of a let binding a variable x concludes, we need to restore any prior binding of x, which is either ⊥ (meaning that there is no x originally) or some value .
Other type rules including structs. Here we discuss the type rules for other Checked C operations that have not been mentioned above. Rule T-Def is for dereferencing a non-array pointer. The statement ensures that no unchecked pointers are used in checked regions. Rule T-Struct describes the typing behavior for a struct address-of operation. In typing a struct pointer, we make sure that the field name f is a valid field name of the struct definition, and the return type of the address-of operation is the type of the field name.
Rule T-Mac deals with operations. There is a well-formedness check to require that the possible bound variables in ω must be in the domain of Γ. This is similar to the well-formedness assumption of the type environment (Definition 2) Rule T-Add deals with binary operations whose sub-terms are integer expressions, while rule T-Ind serves the case for pointer arithmetic. For simplicity, in the Checked C formalization, we do not allow arbitrary pointer arithmetic. The only pointer arithmetic operations allowed are the forms shown in rules T-Ind and T-IndAssign in Fig. 9. Rule T-Assign assigns a value to a non-array pointer location. The predicate requires that the value being assigned is a subtype of the pointer type. The T-IndAssign rule is an extended assignment operation for handling assignments for array/NT-array pointers with pointer arithmetic. Rule T-Unchecked type checks unchecked blocks.
Well-formedness for types and bounds.
Type soundness and blame
In this subsection, we focus on our main meta-theoretic results about CoreChkC: type soundness (progress and preservation) and blame. These proofs have been carried out in our Coq model, found at https://github.com/plum-umd/checkedc.
The type soundness theorems rely on several notions of well-formedness below and the well-formedness for types and bounds in Fig. 11.
(Type Environment Well-formedness).
A type environment Γ is well-formed iff every variable mentioned as type bounds in Γ are bounded by typed variables in Γ.
(Heap Well-formedness).
A heap H is well-formed iff (i) is undefined, and (ii) for all in the range of H, type τ contains no free variables.
(Stack Well-formedness).
A stack snapshot φ is well-formed iff for all in the range of φ, type τ contains no free variables.
We also need to introduce a notion of consistency, relating heap environments before and after a reduction step, and type environments, predicate sets, and stack snapshots together. In dealing with the stack consistency, an important step is to ensure that the type bounds of stack variables do not break the subtyping consistency, i.e., if a variable x having an array type that is a subtype of , we need to ensure that if is updated, the subtyping relation is not lost. The property unveils the relationship between stack snapshots and predicate set Θ, i.e., Θ represents relations for a subset of variables in the current stack snapshot φ, so the variables appearing in Θ must be consistent with their values in φ.
Here, we introduce a restricted stack snapshot for the predicate map Θ, where φ is a stack and ρ is a set of variables that are exactly as the domain of Θ. means to restrict the domain of φ to the variable set ρ. Clearly, we have the relation: . ⊑ being parameterized by refers to that when we compare two bounds , we actually do by interpreting the variables in b and with possible values in . Let’s define a subset relation ⪯ for two restricted stack snapshot and :
(Subset of Stack Snapshots).
Given two and , , iff for and y, .
For every two restricted stack snapshots and , such that , we have the following theorem in Checked C (proved in Coq):
(Stack Snapshot Theorem).
Given two types τ and, two restricted stack snapshotsand, if, andunder the parameterization of, thenunder the parameterization of.
Clearly, for every , we have . In the type checking stage, we take a stack snapshot as an input premise for proving the type preservation. In this case, we need to establish the relation between ρ and Θ to ensure that variables in them are consistent along with the preservation proof, so that Theorem 1 is used to every inductive step of the type preservation to enforce the invariant.
(Stack Consistency).
A type environment Γ, variable predicate set Θ, and stack snapshot φ are consistent – written – iff for every variable x, is defined implies for some τ and for some n, where .
(Stack–Heap Consistency).
A stack snapshot φ is consistent with heap H – written – iff for every variable x, implies .
(Heap–Heap Consistency).
A heap is consistent with H – written – iff for every constant n, implies .
Moreover, as a program evaluates, its expression may contain literals where τ is a pointer type, i.e., n is an index in H (perhaps because n was chosen by ). The normal type-checking judgment for e is implicitly parameterized by H, and the rules for type-checking literals confirm that pointed-to heap cells are compatible with (subtypes of) the pointer’s type annotation; in turn this check may precipitate checking the type consistency of the heap itself. We follow the same approach as Ruef et al. [22], and show the rules in Fig. 8; the judgment is used to confirm literal well-typing, where σ is a set of pointer literals already checked in H (to allow pointer cycles). The details are discussed in Section 3.3.
Progress now states that terms that don’t reduce are either values or their mode is unchecked:
(Progress).
For any Checked C program e, heap H, stack φ, type environment Γ, and variable predicate set Θ that are all are well-formed, consistent (and) and well typed (for some τ), one of the following holds:
e is a value ().
there existsr, such that.
, or there exists E and, such thatand.
By induction on the typing derivation. □
Preservation states that a reduction step preserves both the type and consistency of the program being reduced.
(Preservation).
For any Checked C program e, heap H, stack φ, type environment Γ, and variable predicate set Θ that are all are well-formed, consistent (and) and well typed (for some τ), if there exists,and, such that, thenis consistent with H () and there exists,andthat are well formed, consistent (and) and well typed (), where.
By induction on the typing derivation. □
Using these two theorems we can prove our main result, blame, which states that if a well-typed program is stuck – expression e is a non-value that cannot take a step7
Note that and are not stuck expressions – they represent a program terminated by a failed run-time check. A program that tries to access but H is undefined at n will be stuck, and violates spatial safety.
– the cause must be the (past or imminent) execution of code in an unchecked region.
(The Blame Theorem).
For any Checked C program e, heap H, stack φ, type environment Γ, and variable predicate set Θ that are well-formed and consistent (and), if e is well-typed (for some τ) and there exists,,, andfor, such thatand r is stuck, then there exists, such that, or there exists E and, such thatand.
By induction on the number of steps of the Checked C evaluation (), using progress and preservation to maintain the invariance of the assumptions. □
Compared to Ruef et al. [22], proofs for CoreChkC were made challenging by the addition of dependently typed functions and dynamic arrays, and the need to handle bounds widening for NT array pointers. These features required changes in the runtime semantics (adding a stack, and dynamically changing bounds) and in compile-time knowledge of them (to soundly typing widened bounds).
Differences with the Coq and Redex models
The Coq and Redex models of CoreChkC may be found at https://github.com/plum-umd/checkedc. The Coq model’s syntax is slightly different from that in Fig. 3. In particular, the arguments in a function call are restricted to variables and constants, according to a separate well-formedness condition. A function call f(e) can always be written in letx = e in f(x) to cope. In addition, conditionals have two syntactic forms: EIf is a normal conditional, and EIfDef is one whose boolean guard is of the form . By syntactically distinguishing these two cases, the Coq model does not need the [prefer] rule for if(*x)… forms as in Fig. 4. The Redex model does prioritize such forms but not the same way as in the figure. It uses a variation of the S-Var rule: The modified rule is equipped with a precondition that is false whenever S-IfNTT is applicable.
The Coq model uses a runtime stack φ as described at the start of Section 3.2. The Redex model introduces let bindings during evaluation to simulate a runtime stack. For example, consider the expression . Expression e first steps to , which in turns steps to . Since the rhs of x is a value, the let binding in e effectively functions as a stack that maps from x to . The let form remains in the expression and lazily replaces the variables in its body. The let form can be removed from the expression only if its body is evaluated to a value, e.g., steps to . The rule for popping let bindings in this manner corresponds to the S-Ret rule in Fig. 5. Leveraging let bindings adds complexity to the semantics but simplifies typing/consistency and term generation during randomized testing.
Compilation
The semantics of CoreChkC uses annotations on pointer literals in order to keep track of array bounds information, which is used in premises of rules like S-DefArray and S-AssignArr to prevent spatial safety violations. However, in the real implementation of Checked C, which extends Clang/LLVM, these annotations are not present – pointers are represented as a single machine word with no extra metadata, and bounds checks are not handled by the machine, but inserted by the compiler.
CoreC syntax.
This section shows how CoreChkC annotations can be safely erased: using static information a compiler can insert code to manage and check bounds metadata, with no loss of expressiveness. We present a compilation algorithm that converts from CoreChkC to CoreC, an untyped language without metadata annotations. The syntax and semantics CoreC in Figs 12 and 13 closely mirrors that of CoreChkC; it differs only in that literals lack type annotations and its operational rules perform no bounds, null checks, or flow sensitive mode checks, which are instead inserted during compilation, as shown in the bottom rule in Fig. 13. The closure syntax in Fig. 12 is used solely for compilation procedures, see Section 4.3. Our compilation algorithm is evidence that CoreChkC’s semantics, despite its apparent use of fat pointers, faithfully represents Checked C’s intended behavior. The algorithm also sheds light on how compilation can be implemented in the real Checked C compiler, while eschewing many important details (CoreC has many differences with LLVM IR).
CoreC semantic definitions.
Compilation is defined by extending CoreChkC’s typing judgment thusly:
There is now a CoreC output and an input ρ, which maps each nt_array_ptr value p, either a pointer constant or a variable, to a pair of shadow variables that keep p’s up-to-date upper and lower bounds; these may differ from the bounds in p’s type due to bounds widening.8
Since lower bounds are never widened, the lower-bound shadow variable is unnecessary; we include it for uniformity.
We formalize rules for this judgment in PLT Redex [6], following and extending our Coq development for CoreChkC. To give confidence that compilation is correct, we use Redex’s property-based random testing support to show that compiled-to simulates e, for all e.
Approach
We first explain the rules for compilation by examples, using a C-like syntax; then, the rule explanation is given in Section 4.3. Each rule performs up to three tasks: (a) conversion of e to A-normal form; (b) insertion of dynamic checks; and (c) insertion of bounds widening expressions. A-normal form conversion is straightforward: compound expressions are handled by storing results of subexpressions into temporary variables, as in the following example.
This simplifies the management of effects from subexpressions. The next two steps of compilation are more interesting.
Compilation example for check insertions.
Compilation example for dependent functions.
During compilation, Γ tracks the lower and upper bound associated with every pointer variable according to its type. At each declaration of a nt_array_ptr variable p, the compiler allocates two shadow variables, stored in ; these are initialized to p’s declared bounds and will be updated during bounds widening.9
Shadow variables are not used for array_ptr types (the bounds expressions are) since they are not subject to bounds widening.
Fig. 14 shows how an invocation of strlen on a null-terminated string is compiled into C code. Each dereference of a checked pointer requires a null check (See S-DefNull in Fig. 5), which the compiler makes explicit: Line 3 of the generated code has the null check on pointer p due to the strlen, and a similar check happens at line 8 due to the pointer arithmetic on p. Dereferences also require bounds checks: line 2 checks p is in bounds before computing strlen(p), while line 10 does likewise before computing *(p+1).
For strlen(p) and conditionals if(*p), the CoreChkC semantics allows the upper bound of p to be extended. The compiler explicitly inserts statements to do so on p’s shadow bound variables. For example, Fig. 14 line 6 widens p’s upper bound if strlen’s result is larger than the existing bound. Lines 7–12 of the generated code in Fig. 15 show how bounds are widened when compiling expression if(*p). If we find that the current p’s relative upper bound is equal to 0 (line 10), and p’s content is not null (line 8), we then increase the upper bound by 1 (line 11).
Figure 15 also shows a dependent function call. Notice that the bounds for the array pointer p are not passed as arguments. Instead, they are initialized according to p’s type – see line 2 of the original CoreChkC program at the top of the figure. Line 2 of the generated code sets the lower bound to 0 and line 3 sets the upper bound to n.
Safe strcat in Checked C that avoids a run-time error exhibited by safe_strcat (Fig. 6) when compiled with the current Checked C compiler.
Comparison with Checked C specification
The use of shadow variables for bounds widening is a key novelty of our compilation approach, and adds more precision to bounds checking at runtime compared to the official specification and current implementation of Checked C [24, 5.1.2, pg 85]. For example, the safe_strcat example of Fig. 6 compiles with the current Clang Checked C compiler but will fail with a runtime error. The statement int x = strlen(dst) at line 3 changes the statically determined upper bound of dst to x, which can be smaller than n, the full capacity of dst. The attempt to recover the full capacity of dst through a dynamic cast at line 6 will always fail if the capacity n is checked against the statically determined new upper bound x. This problem can be worked around by invoking strlen on a temporary variable tmp instead of dst as in safe_strcat_c in Fig. 16 (lines 3 and 4). Likewise, if we were to add line putchar(*(p+1)); after line 5 in the original code at the top of Fig. 14, the code will always fail: the Clang Checked C compiler (with the transliterated C code as its input) would check p against its original bounds (0,0) since the updated upper bound x is now out of the scope. Shadow variables address these problems because they retain widened bounds beyond the scope of variables that store them (i.e., x in both examples).
To make it match the specification, our compilation definition could easily eschew shadow variables and rely only on the type-based bounds expressions available in Γ for checking. However, doing so would force us to weaken the simulation theorem, reduce expressiveness, and/or force the semantics to be more awkward. We plan to work with the Checked C team to implement our approach in a future revision.
The compilation rules
This section describes the target compilation language and some compilation rules in detail. Figure 12 and Fig. 13 shows the syntax for , the target language for compilation. We syntactically restrict the expressions to be in A-normal form to simplify the presentation of the compilation rules. In the Redex model, we occasionally break this constraint to speed up the performance of random testing by removing unnecessary let bindings. To allow explicit runtime checks, we include and as part of expressions which, once evaluated, result in an corresponding error state. is a new syntactic form that modifies the stack variable x with the result of . It is essential for bounds widening. ⩽ and − are introduced to operate on bounds and decide whether we need to halt with a bounds error or widen a null-terminated string.
Compilation. as a shorthand for . , , , , and are in Figs 18 and 19.
does not include any annotations. We remove struct operations from because we can always statically convert expressions of the form into , where is the statically determined offset of f within the struct. We elide the semantics of because it is self-evident and mirrors the semantics . The difference is that in , only and can step into an error state. All failed dereferences and assignments would result in a stuck state and therefore we rely on the compiler to explicitly insert checks for checked pointers.
Figure 17 shows some rules for the compilation with the judgment for expressions as:
The judgment is slightly different from the one in the beginning of the section. For a compiled expression , we split it to become a closure context and a redex , such that . For simplicity, we also remove Θ and m because these parameters are only used for type-checking and have no impact on compilation. can be intuitively understood as a partially constructed program or context. Whereas is used for evaluation, is used purely as a device for compilation. As an example, when compiling , we would first create a fresh variable x, and then produce two outputs:
To obtain the compiled expression , we plug into using the usual notation . Through the generation of closure context during compilation, we insert additional runtime checks, which take the form , where contains the check whose evaluation must not trigger or for the program to continue (see Fig. 18 for the metafunctions that create those checks).
Metafunctions for dynamic checks. : null checks; : bounds check; : bounds checks for DynCast.
Metafunctions for widening. : ρ extension; : bound widening.
This unconventional output format enables us to separate the evaluation of the term and the computation that relies on the term’s evaluated result. Since effects and reduction (except for variables) happen only within closures, we can precisely control the order in which effects and evaluation happen by composing the contexts in a specific order. Given two closures and , we write to denote the meta operation of plugging into . We also use as a shorthand for .
Rules C-Const and C-Var are similar to the constant and variable type rules in Fig. 8, while rule C-Cast compiles a static casting operation by erasing it because such an operation is enforced in the type-checking stage. Rule C-DynCast compiles a dynamic casting operation. The procedure , β, , described in Fig. 18, generates a new closure as a dynamic check insertion, given the input pointer value as well two bounds β and . There are two rules, C-BoundDyn and C-BoundDynFV, describing the two situations of generating bounds checks for dynamic casting operations. We first query the ρ map to find out the two shadow variables of the pointer . If such shadow variables exist, which is the situation in C-BoundDyn, we generate two extra fresh shadow variables and and compose three closures to together; while if we cannot find the shadow variables, which is the situation in C-BoundDynFV, we generate four extra fresh shadow variables (, , , and ) and compose four closures to together.
Rule C-Str compiles an operation, with several check insertions. In recursively finding out the subterm closure () and the target pointer , we first generate a check , in Fig. 18, that verifies if pointer is a pointer under the mode m. A mode check generates nothing as rule C-NullU, while a mode check generates an expression to verifies if is 0 in rule C-NullC. Another generated check is a bounds check , 0, that depends on the mode m, given in Fig. 18. Rule C-BoundU shows the mode case that generates no checks, while C-BoundC looks for the shadow variables and in ρ for free variables in expression , and generates two fresh variables and for verifying the index 0 is within the bound of and . After that, we also apply a procedure , , to materialize the bound widening mechanism, given in Fig. 19. If is not in ρ, we do not need to widen the upper bound (C-WidenNo). If we find two shadow variables in ρ as and C-Widen, we create a closure as a sequence operation (), where if , we do nothing, otherwise, we assign n to the upper bound . An example compilation of a strlen operation is given in Fig. 14, where line 2 and 3 appearing on the code after the compilation describe the inserted null and bounds dynamic checks and line 7–13 inserts an additional bound widening mechanism that probably extends p’s upper bound p_hi.
Rule C-Let describes the compilation for operations. As in Section 3.3, the premise () happens when x acts as a variable in type , which means that x is a bound variable, so the expression e that is assigned to x must follow the syntax of Bound. We have a dynamic check insertion , , to extend ρ to include the new shadow variables for x ( and ) as rule C-Extend in Fig. 19. As an instance in Fig. 15, after the compilation, we create two variables p_lo and p_hi for variable p in line 2 and 3.
In the C-Ind rule, we generate the compiled code for the expressions e and as and , generates a null check as and bounds check as . Finally, the contains a closure for the addition storing in , while the closure stores the result of ’s dereference.
Rule C-Struct shows the compilation procedure of a struct address-of operation. As we mentioned above, such operation compilation does not require a struct address-of operation appearing in the target language. The key idea is to produce statically the correct pointer offset value for the corresponding struct field f; thus, the result pointer value of the pointer address-of is , the base address of the struct plus the offset value. Obviously, we still need to generate a null check for the pointer .
Metatheory
We formalize both the compilation procedure and the simulation theorem in the PLT Redex model we developed for CoreChkC (see Section 3.1), and then attempt to falsify it via Redex’s support for random testing. Redex allows us to specify compilation as logical rules (essentially, an extension of typing), but then execute it algorithmically to automatically test whether simulation holds. This process revealed several bugs in compilation and the theorem statement. We ultimately plan to prove simulation in the Coq model.
We use the notation ≫ to indicate the erasure of stack and heap – the rhs is the same as the lhs but with type annotations removed:
In addition, when and φ is well-formed, we write to denote , and for some τ respectively. Γ is omitted from the notation since the well-formedness of φ and its consistency with respect to Γ imply that e must be closed under φ, allowing us to recover Γ from φ. Finally, we use to denote the transitive closure of the reduction relation of . Unlike the , the semantics of does not distinguish checked and unchecked regions.
Simulation between CoreChkC and CoreC.
Figure 20 gives an overview of the simulation theorem.10
We ellide the possibility of evaluating to or in the diagram for readability.
The simulation theorem is specified in a way that is similar to the one by Merigoux et al. [17]. An ordinary simulation property would replace the middle and bottom parts of the figure with the following:
Instead, we relate two erased configurations using the relation ∼, which only requires that the two configurations will eventually reduce to the same state. We formulate our simulation theorem differently because the standard simulation theorem imposes a very strong syntactic restriction to the compilation strategy. Very often, reduces to a term that is semantically equivalent to , but we are unable to syntactically equate the two configurations due to the extra binders generated for dynamic checks and ANF transformation. In earlier versions of the Redex model, we attempted to change the compilation rules so the configurations could match syntactically. However, the approach scaled poorly as we added additional rules. This slight relaxation on the equivalence relation between target configurations allows us to specify compilation more naturally without having to worry about syntactic constraints.
(Simulation (∼)).
ForCoreChkCexpressions, stacks,, and heap snapshots,, if,, and if there exists somesuch that, then the following facts hold:
if there existssuch thatand, then there exists some,,, such thatand.
ifor, then we havewhere,.
Our random generator (discussed in the next section) never produces expressions (whose behavior could be undefined), so we can only test a the simulation theorem as it applies to checked code. This limitation makes it unnecessary to state the other direction of the simulation theorem where is stuck, because Theorem 2 guarantees that will never enter a stuck state if it is well-typed in checked mode.
The current version of the Redex model has been tested against 20000 expressions with depth less than 10. Each expression can reduce multiple steps, and we test simulation between every two adjacent steps to cover a wider range of programs, particularly the ones that have a non-empty heap.
Random testing via the implementation
In addition to using the CoreChkC Redex model to establish simulation of compilation (Section 4.4), we also used it to gain confidence that our model matches the Clang Checked C implementation. Disagreement on outcomes signals a bug in either the model or the compiler itself. Doing so allowed us to quickly iterate on the design of the model while adding new features, and revealed several bugs in the Clang Checked C implementation.
Generating well typed terms. For this random generation, we follow the approach of Pałka et al. [20] to generate well-typed Checked C terms by viewing the typing rules as generation rules. Suppose we have a context Γ, a mode m and a type τ, and we are trying to generate a well-typed expression. We can do that by reversing the process of type checking, selecting a typing rule and building up an expression in a way that satisfies the rule’s premises.
Recall the typing rule for dereferencing an array pointer, which we depict below as G-DefArr,11
Generator rules G-* correspond one to one with the type rules T-* in Section 3.3.
color-coded to represent and of the generation process:12
This input-output marking is commonly called a mode in the literature, but we eschew this term to avoid confusion with our pointer mode annotation.
If we selected G-DefArr for generating an expression, the generated expression has to have the form , for some , to be generated according to the rule’s premises. To satisfy the premise : , we essentially need to make a recursive call to the generator, with appropriately adjusted inputs. However, the type in this judgment is not fixed yet – it contains three unknown variables: , , and – that need to be generated before making the call. Looking at the second premise informs that generation: if the input mode is , then needs to be as well; if not, it is unconstrained, just like and , and therefore all three are free to be generated at random. Thus, the recursive call to generate can now be made, and the G-DefArr rule returns as its output.
Using such generator rules, we can create a generator for random well-typed terms of a given type in a straightforward manner: find all rules whose conclusion matches the given type and then randomly choose a candidate rule to perform the generation. To ensure that this process terminates, we follow the standard practice of using “fuel” to bound the depth of the generated terms; once the fuel is exhausted, only rules without recursive premises are selected [12]. Similar methods were used for generating top level functions and definitions.
While using just the typing-turned-generation rules is in theory enough to generate all well-typed terms, it’s more effective in practice to try and exercise interesting patterns. As in Pałka et al. [20] this can be viewed as a way of adding admissible but redundant typing rules, with the sole purpose of using them for generation. For example, below is one such rule, G-ASTR, which creates an initialized null-terminated string that is statically cast into an array with bounds .
Given some positive number , numbers , and a fresh variable (which are arbitrarily generated), we can recursively generate a pointer with bounds , and initialize it with the generated using to temporarily store the pointer.
This rule is particularly useful when combined with G-IfNT since there is a much higher chance of obtaining a non-zero value when evaluating in the guard of , skewing the distribution towards programs that enter the branch. Relying solely on the type-based rules, entering the branch requires that G-AssignArr was chosen before G-IfNT, and that assignment would have to appear before , which means additional G-Let rules would need to be chosen: this combination would therefore be essentially impossible to generate in isolation.
Adding admissible generation rules like G-Astr in this manner, as described in Pałka et al. [20], is a manual process. It is guided by gathering statistics on the generated data and focusing on language constructs that appear underrepresented in the posterior distribution. For example, we arrived at the G-Astr rule by recognizing that the pure type-based generation was not generating non-trivial null-terminated strings, and then analyzing the sequence of random choices that could lead to their generation.
Generating ill-typed terms. We can use generated well-typed terms to test our simulation theorem (Section 4) and test that CoreChkC and Checked C Clang agree on what is type-correct. But it is also useful to generate ill-typed terms to test that CoreChkC and Checked C Clang also agree on what is not. However, while it is easy to generate arbitrary ill-typed terms, they would be very unlikely to trigger any inconsistencies; those are far more likely to exist on the boundary between well- and ill-typedness. Therefore, we also manually added variations of existing generation rules modified to be slightly more permissive, e.g., by relaxing a single premise, thus allowing terms that are “a little” ill-typed to be generated. Unlike coming up with admissible generation rules like G-Astr (which is quite challenging to automate), systematically and automatically relaxing premises of existing rules seems feasible, and worthwhile future work.
Random testing for language design. We used our Redex model and random generator to successfully guide the design of our formal model, and indeed the Clang Checked C implementation itself, which is being actively developed. To that end, we implemented a conversion tool that converts CoreChkC into a subset of the Checked C language and ensured that model and implementation exhibit the same behavior (accept and reject the same programs and yield the same return value).
This approach constitutes an interesting twist to traditional model-based checking approaches. Usually, one checks that the implementation and model agree on all inputs of the implementation, with the goal of covering as many behaviors as possible. This is the case, for example, in Guha et al. [8], where they use real test suites to demonstrate the faithfulness of their core calculus to Javascript. Our approach and goal in this work is essentially the opposite: as the Clang Checked C implementation does not fully implement the Checked C spec, there is little hope of covering all terms that are generated by Clang Checked C. Instead, we’re looking for inconsistencies, which could be caused by bugs either in the Clang Checked C compiler or our own model.
One inconsistency we found comes from the following: In this code, the function fun is supposed to return a checked array pointer of size 3. Internally, it allocates such an array, but instead of returning the pointer x to that array, it increments that pointer by 3. Then, the main function just calls fun, and tries to assign 0 to its result. Our model correctly rules out this program, while the Clang Checked C implementation happily accepted this out-of-bounds assignment. Interestingly, it correctly rejected programs where the array had size 1 or 2. This inconsistency has been fixed in the latest version of the compiler.
We also found the opposite kind of inconsistency – programs that the Clang Checked C implementation rejects contrary to the spec. For instance:13
After minimization, this turned out to be a known issue: https://github.com/microsoft/checkedc-clang/issues/1008.
In this piece of code both f and g functions compute a pointer to the same index in an array of size 5 (as f calls g). The main function then creates a ternary expression whose branches call f and g, but the Clang Checked C implementation rejects this program, as its static analysis is not sophisticated enough to detect that both branches have the same type.
Related work
Our work is most closely related to prior formalizations of C(-like) languages that aim to enforce memory safety, but it also touches on C-language formalization in general.
Formalizing C and low-level code. A number of prior works have looked at formalizing the semantics of C, including CompCert [1,14], Ellison and Rosu [5], Kang et al. [11], and Memarian et al. [15,16]. These works also model pointers as logically coupled with either the bounds of the blocks they point to, or provenance information from which bounds can be derived. None of these is directly concerned with enforcing spatial safety, and that is reflected in the design. For example, memory itself is not be represented as a flat address space, as in our model or real machines, so memory corruption due to spatial safety violations, which Checked C’s type system aims to prevent, may not be expressible. That said, these formalizations consider much more of the C language than does CoreChkC, since they are interested in the entire language’s behavior.
Spatially safe C formalizations. Several prior works formalize C-language transformations or C-language dialects aiming to ensure spatial safety. Hathhorn et al. [9] extends the formalization of Ellison and Rosu [5] to produce a semantics that detects violations of spatial safety (and other forms of undefinedness). It uses a CompCert-style memory model, but “fattens” logical pointer representations to facilitate adding side conditions similar to CoreChkC’s. Its concern is bug finding, not compiling programs to use this semantics.
CCured [19] and Softbound [18] implement spatially safe semantics for normal C via program transformation. Like CoreChkC, both systems’ operational semantics annotate pointers with their bounds. CCured’s equivalent of array pointers are compiled to be “fat,” while SoftBound compiles bounds metadata to a separate hashtable, thus retaining binary compatibility at higher checking cost. Checked C uses static type information to enable bounds checks without need of pointer-attached metadata, as we show in Section 4. Neither CCured nor Softbound models null-terminated array pointers, whereas our semantics ensures that such pointers respect the zero-termination invariant, leveraging bounds widening to enhance expressiveness.
Cyclone [7,10] is a C dialect that aims to ensure memory safety; its pointer types are similar to CCured. Cyclone’s formalization [7] focuses on the use of regions to ensure temporal safety; it does not formalize arrays or threats to spatial safety. Deputy [2,28] is another safe-C dialect that aims to avoid fat pointers; it was an initial inspiration for Checked C’s design [4], though it provides no specific modeling for null-terminated array pointers. Deputy’s formalization [2] defines its semantics directly in terms of compilation, similar in style to what we present in Section 4. Doing so tightly couples typing, compilation, and semantics, which are treated independently in CoreChkC. Separating semantics from compilation isolates meaning from mechanism, easing understandability. Indeed, it was this separation that led us to notice the limitation with Checked C’s handling of bounds widening.
The most closely related work is the formalization of Checked C done by Ruef et al. [22]. They present the type system and semantics of a core model of Checked C, mechanized in Coq, and were the first to prove a blame theorem. CoreChkC’s Coq-based development (Section 3) substantially extends theirs to include conditionals, dynamically bounded array pointers with dependent types, null-terminated array pointers, dependently typed functions, and subtyping. They postulate that pointer metadata can be erased in a real implementation, but do not show it. Our CoreChkC compiler, formalized and validated in PLT Redex via randomized testing, demonstrates that such metadata can be erased; we found that erasure was non-obvious once null-terminated pointers and bounds widening were considered.
Conclusion and future work
This paper presented CoreChkC, a formalization of an extended core of the Checked C language which aims to provide spatial memory safety. CoreChkC models dynamically sized and null-terminated arrays with dependently typed bounds that can additionally be widened at runtime. We prove, in Coq, the key safety property of Checked C for our formalization, blame: if a mix of checked and unchecked code gives rise to a spatial memory safety violation, then this violation originated in an unchecked part of the code. We also show how programs written in CoreChkC (whose semantics leverage fat pointers) can be compiled to CoreC (which does not) while preserving their behavior. We developed a version of CoreChkC written in PLT Redex, and used a custom term generator in conjunction with Redex’s randomized testing framework to give confidence that compilation is correct. We also used this framework to cross-check CoreChkC against the Checked C compiler, finding multiple inconsistencies in the process.
As future work, we wish to extend CoreChkC to model more of Checked C, with our Redex-based testing framework guiding the process. The most interesting Checked C feature not yet modeled is interop types (itypes), which are used to simplify interactions with unchecked code via function calls. A function whose parameters are itypes can be passed checked or unchecked pointers depending on whether the caller is in a checked region. This feature allows for a more modular C-to-Checked C porting process, but complicates reasoning about blame. A more ambitious next step would be to extend an existing formally verified framework for C, such as CompCert [13] or VeLLVM [27], with Checked C features, towards producing a verified-correct Checked C compiler. We believe that CoreChkC’s Coq and Redex models lay the foundation for such a step, but substantial engineering work remains.
Footnotes
Acknowledgments
We thank the anonymous reviewers for their helpful, constructive comments. This work was supported in part by a gift from Microsoft.
References
1.
S.Blazy and X.Leroy, Mechanized semantics for the Clight subset of the C language, Journal of Automated Reasoning43(3) (2009), 263–288. doi:10.1007/s10817-009-9148-3.
2.
J.Condit, M.Harren, Z.Anderson, D.Gay and G.C.Necula, Dependent types for low-level programming, in: Proceedings of European Symposium on Programming (ESOP’07), 2007.
3.
J.Duan, Y.Yang, J.Zhou and J.Criswell, Refactoring the FreeBSD kernel with Checked C, in: IEEE Cybersecurity Development Conference (SecDev), 2020.
4.
A.S.Elliott, A.Ruef, M.Hicks and D.Tarditi, Checked C: Making C safe by extension, in: 2018 IEEE Cybersecurity Development (SecDev), 2018, pp. 53–60. doi:10.1109/SecDev.2018.00015.
5.
C.Ellison and G.Rosu, An executable formal semantics of C with applications, in: Proceedings of the 39th Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, POPL’12, ACM, New York, NY, USA, 2012, pp. 533–544. ISBN 978-1-4503-1083-3. doi:10.1145/2103656.2103719.
6.
M.Felleisen, R.B.Findler and M.Flatt, Semantics Engineering with PLT Redex, 1st edn, The MIT Press, 2009. ISBN 0262062755.
7.
D.Grossman, G.Morrisett, T.Jim, M.Hicks, Y.Wang and J.Cheney, Region-based memory management in cyclone, in: PLDI, 2002.
8.
A.Guha, C.Saftoiu and S.Krishnamurthi, The essence of Javascript, in: Proceedings of the 24th European Conference on Object-Oriented Programming, ECOOP’10, Springer-Verlag, Berlin, Heidelberg, 2010, pp. 126–150. ISBN 3642141064.
9.
C.Hathhorn, C.Ellison and G.Roşu, Defining the undefinedness of C, SIGPLAN Not.50(6) (2015), 336–345. doi:10.1145/2813885.2737979.
10.
T.Jim, G.Morrisett, D.Grossman, M.Hicks, J.Cheney and Y.Wang, Cyclone: A safe dialect of C, in: USENIX Annual Technical Conference, USENIX, Monterey, CA, 2002, pp. 275–288.
11.
J.Kang, C.-K.Hur, W.Mansky, D.Garbuzov, S.Zdancewic and V.Vafeiadis, A formal C memory model supporting integer-pointer casts, SIGPLAN Not.50(6) (2015), 326–335. doi:10.1145/2813885.2738005.
12.
L.Lampropoulos and B.C.Pierce, QuickChick: Property-Based Testing in Coq, Software Foundations Series, Vol. 4, Electronic textbook, 2018, Version 1.0, http://www.cis.upenn.edu/~bcpierce/sf.
13.
X.Leroy, Formal verification of a realistic compiler, Communications of the ACM52(7) (2009), 107–115, http://doi.acm.org/10.1145/1538788.1538814. doi:10.1145/1538788.1538814.
14.
X.Leroy, A.W.Appel, S.Blazy and G.Stewart, The CompCert memory model, version 2, Research Report, RR-7987, INRIA, 2012. https://hal.inria.fr/hal-00703441.
15.
K.Memarian, V.B.F.Gomes, B.Davis, S.Kell, A.Richardson, R.N.M.Watson and P.Sewell, Exploring C semantics and pointer provenance, Proc. ACM Program. Lang.3(POPL) (2019), 67:1–67:32. doi:10.1145/3290380.
16.
K.Memarian, J.Matthiesen, J.Lingard, K.Nienhuis, D.Chisnall, R.N.M.Watson and P.Sewell, Into the depths of C: Elaborating the de facto standards, SIGPLAN Not.51(6) (2016), 1–15. doi:10.1145/2980983.2908081.
17.
D.Merigoux, N.Chataing and J.Protzenko, Catala: A programming language for the law, 2021, arXiv preprint arXiv:2103.03198.
18.
S.Nagarakatte, J.Zhao, M.M.K.Martin and S.Zdancewic, SoftBound: Highly compatible and complete spatial memory safety for C, in: Proceedings of the 30th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI’09, Association for Computing Machinery, New York, NY, USA, 2009, pp. 245–258. ISBN 9781605583921. doi:10.1145/1542476.1542504.
19.
G.C.Necula, J.Condit, M.Harren, S.McPeak and W.Weimer, CCured: Type-safe retrofitting of legacy software, ACM Transactions on Programming Languages and Systems (TOPLAS)27(3) (2005). doi:10.1145/1065887.1065892.
20.
M.H.Pałka, K.Claessen, A.Russo and J.Hughes, Testing an optimising compiler by generating random lambda terms, in: Proceedings of the 6th International Workshop on Automation of Software Test, AST’11, ACM, New York, NY, USA, 2011, pp. 91–97. ISBN 978-1-4503-0592-1. doi:10.1145/1982595.1982615.
21.
R.Peña, An introduction to liquid Haskell, in: Electronic Proceedings in Theoretical Computer Science, Vol. 237, 2017, pp. 68–80. doi:10.4204/eptcs.237.5.
22.
A.Ruef, L.Lampropoulos, I.Sweet, D.Tarditi and M.Hicks, Achieving safety incrementally with Checked C, in: Principles of Security and Trust, F.Nielson and D.Sands, eds, Springer International Publishing, Cham, 2019, pp. 76–98. ISBN 978-3-030-17138-4. doi:10.1007/978-3-030-17138-4_4.
23.
K.Serebryany, D.Bruening, A.Potapenko and D.Vyukov, AddressSanitizer: A fast address sanity checker, in: Proceedings of the 2012 USENIX Conference on Annual Technical Conference, 2012.
24.
D.Tarditi, Extending C with Bounds Safety and Improved Type Safety, 2021, https://github.com/secure-sw-dev/checkedc/.
25.
N.Vazou, E.L.Seidel, R.Jhala, D.Vytiniotis and S.Peyton-Jones, Refinement types for Haskell, SIGPLAN Not.49(9) (2014), 269–282. doi:10.1145/2692915.2628161.
26.
B.Zeng, G.Tan and U.Erlingsson, Strato: A retargetable framework for low-level inlined-reference monitors, in: Proceedings of the 22Nd USENIX Conference on Security, 2013.
27.
J.Zhao, S.Nagarakatte, M.M.K.Martin and S.Zdancewic, Formalizing the LLVM intermediate representation for verified program transformations, SIGPLAN Not.47(1) (2012), 427–440. doi:10.1145/2103621.2103709.
28.
F.Zhou, J.Condit, Z.Anderson, I.Bagrak, R.Ennals, M.Harren, G.Necula and E.Brewer, SafeDrive: Safe and recoverable extensions using language-based techniques, in: 7th Symposium on Operating System Design and Implementation (OSDI’06), USENIX Association, Seattle, Washington, 2006.

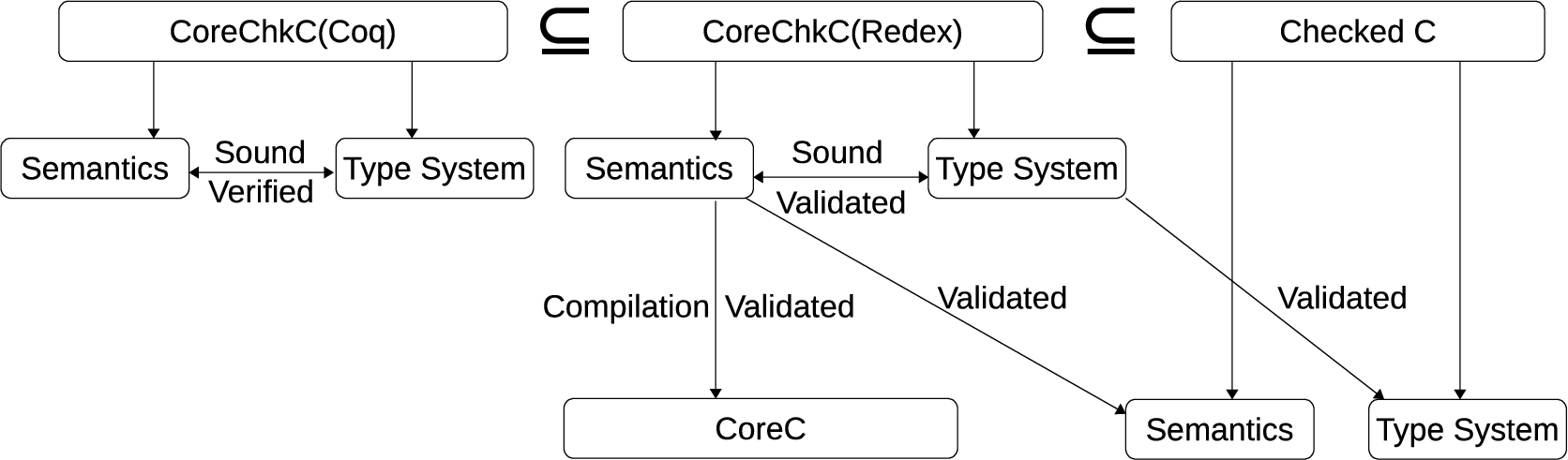






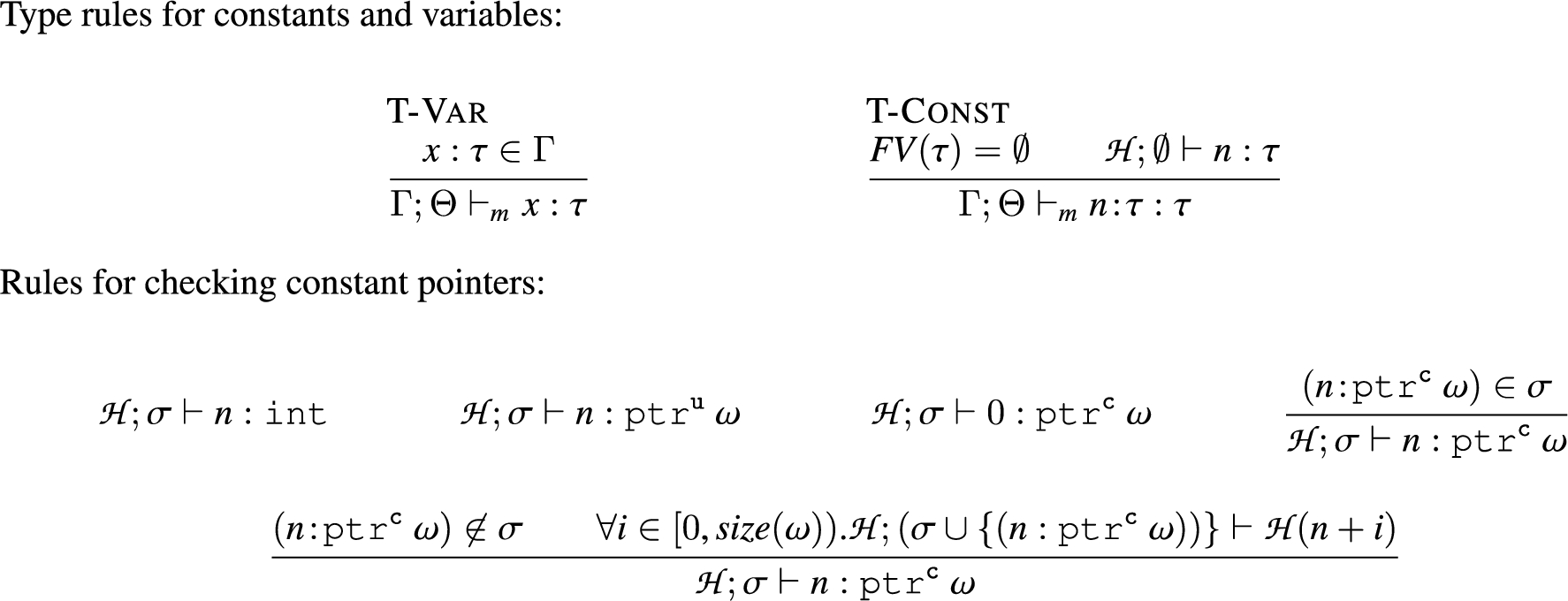

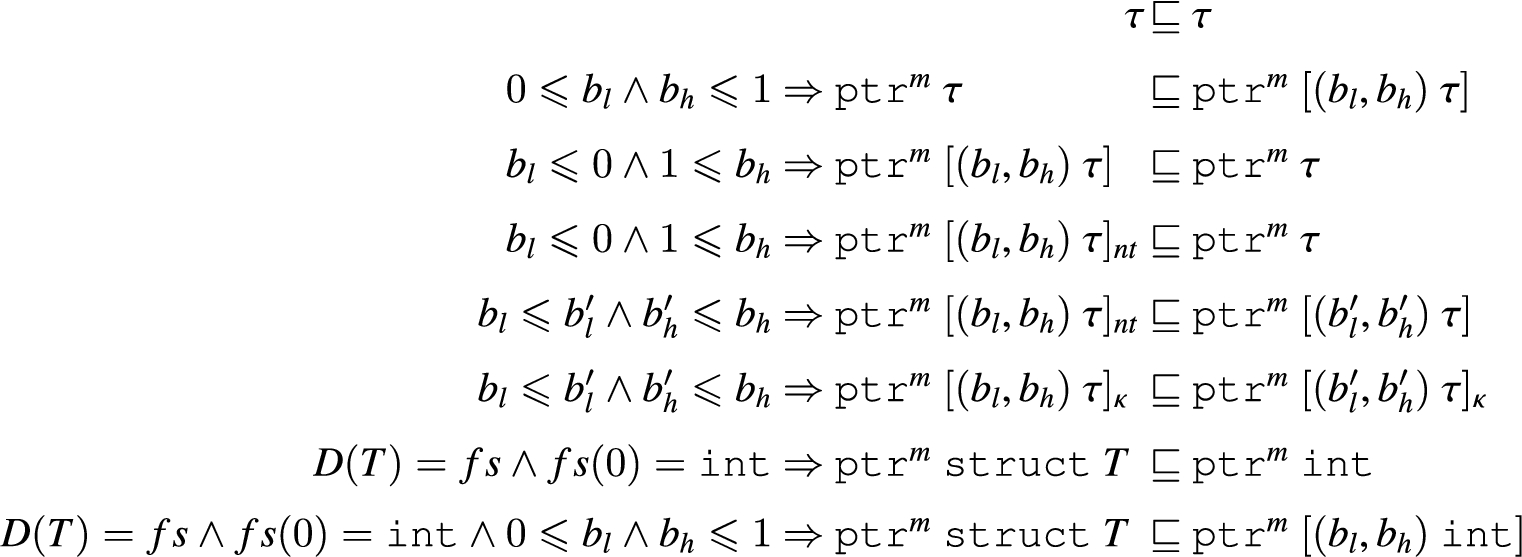



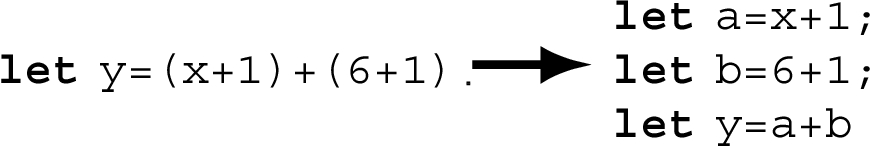






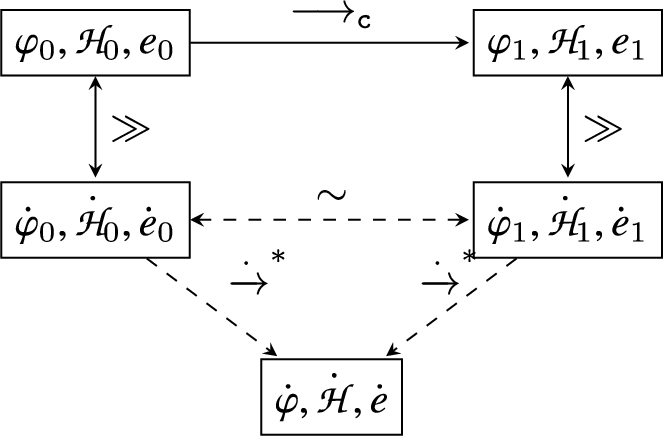
 and
and  of the generation process:12
of the generation process:12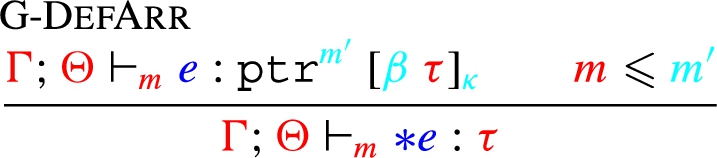
 , for some
, for some  , to be generated according to the rule’s premises. To satisfy the premise
, to be generated according to the rule’s premises. To satisfy the premise  :
:  , we essentially need to make a recursive call to the generator, with appropriately adjusted inputs. However, the type in this judgment is not fixed yet – it contains three unknown variables:
, we essentially need to make a recursive call to the generator, with appropriately adjusted inputs. However, the type in this judgment is not fixed yet – it contains three unknown variables:  ,
,  , and
, and  – that need to be generated before making the call. Looking at the second premise informs that generation: if the input mode
– that need to be generated before making the call. Looking at the second premise informs that generation: if the input mode  is
is  needs to be
needs to be  and
and  , and therefore all three are free to be generated at random. Thus, the recursive call to generate
, and therefore all three are free to be generated at random. Thus, the recursive call to generate  can now be made, and the
can now be made, and the  as its output.
as its output.
 , numbers
, numbers  , and a fresh variable
, and a fresh variable  (which are arbitrarily generated), we can recursively generate a pointer
(which are arbitrarily generated), we can recursively generate a pointer  with bounds
with bounds  , and initialize it with the generated
, and initialize it with the generated  to temporarily store the pointer.
to temporarily store the pointer. In this code, the function
In this code, the function  In this piece of code both
In this piece of code both