
Abstract
Replay attacks are among the most well-known attacks against vote privacy. Many e-voting systems have been proven vulnerable to replay attacks, including systems like Helios that are used in real practical elections.
Despite their popularity, it is commonly believed that replay attacks are inefficient but the actual threat that they pose to vote privacy has never been studied formally. Therefore, in this paper, we precisely analyze for the first time how efficient replay attacks really are.
We study this question from commonly used and complementary perspectives on vote privacy, showing as an independent contribution that a simple extension of a popular game-based privacy definition corresponds to a strong entropy-based notion.
Our results demonstrate that replay attacks can be devastating for a voter’s privacy even when an adversary’s resources are very limited. We illustrate our formal findings by applying them to a number of real-world elections, showing that a modest number of replays can result in significant privacy loss. Overall, our work reveals that, contrary to a common belief, replay attacks can be very efficient and must therefore be considered a serious threat.
Introduction
Electronic voting, or e-voting, is a reality. Systems for e-voting are nowadays used for political elections all over the world, for example, in Australia, Brazil, Estonia, India, Switzerland, or the US. Furthermore, in line with the general shift toward remote technologies, numerous institutions (e.g., academic organizations such as ACM, IACR, or SIAM) employ e-voting systems to mitigate physical barriers and increase voter turnout.
The two most fundamental properties for secure e-voting are (end-to-end) verifiability and (vote) privacy. Verifiability [17] enables external and internal observers to detect and reject falsely computed election results, even when the underlying cause is an unknown programming error or malicious behavior of some of the participants. Privacy [5] guarantees that all data published during an election (including data for proving the integrity of the final result) does not leak more information on the single voters’ choices than what can be derived from the public (unbiased) election result.
Designing secure e-voting systems is very challenging, with a long and rich history going back to the 1980’s [4]. Since then, numerous e-voting systems have been proposed which aim to provide both verifiability and privacy (see, e.g., [1,13–16,34,39,40]), sometimes with additional security properties such as receipt-freeness [13] or coercion-resistance [16]. Some of these e-voting systems have been and are used in practice, for example for political elections in Australia [11], Estonia [41], Switzerland [43], and the US [12], or for non-political ones, such as IACR elections [25], to name just a few.
It is crucial to protect the voters’ privacy not only against passive observers but also against adversaries who control some of the protocol participants (e.g., voters or tallying authorities) and who let these corrupted participants actively deviate from their specified roles in order to undermine privacy of some or all (uncorrupted) voters. Guaranteeing privacy in the face of such active adversaries is a common standard which (most) modern e-voting systems aim to provide. However, it turned out that numerous e-voting systems fall short of this goal in their respective threat scenarios, including seminal systems like Helios (see [7,10,18]), Civitas (see [24,27]), or Prêt à Voter (see [10]).
One of the most prominent classes of attacks against privacy – if not the most prominent one – are replay attacks (see, e.g., [7,13,18,19,24]) to which many e-voting systems have been proven vulnerable (e.g., [1,8,16,34,39,40]). Roughly speaking, a replay attack works as follows. The adversary, who controls some corrupted voters, targets an uncorrupted voter whose privacy he wants to undermine. The adversary waits until the targeted voter has submitted her ballot and reads it from the public bulletin board. Then the adversary instructs (some of) the corrupted voters to submit (possibly a re-randomization of) the same ballot the targeted voter had submitted before. If, in a particular e-voting system, these replayed ballots are not discarded prior to tallying, then the targeted voter’s choice is amplified in the public election result. Because the adversary now obtains more information about the targeted voter’s choice than what he could derive from an unbiased election result, vote privacy is undermined.
Despite their popularity, the risk of replay attacks is often regarded as a “largely theoretical” [42] issue, even in the scientific community. In publications which unveil replay attacks against vote privacy of an e-voting system, the effect of replay attacks is typically illustrated for extreme cases only, e.g., elections with just two honest voters [10] or with many corrupted ones who all replay a single voter’s ballot [19]. While such completely artificial toy examples can be useful to explain why privacy is formally broken, they seemingly suggest that replay attacks do not pose a serious threat. It is therefore not surprising that, for instance, in response to the replay attack against Helios [1] discovered in [18], Helios Voting replied that “the risk of this attack being successfully carried out is low, as it requires “wasting” a number of votes to compromise the privacy of one voter”, concluding that, most likely, replay attacks would not matter [23]. This – as we shall see, fallacious – perspective may also explain why the latest version of Helios [1] (used, e.g., for IACR elections [25]) has not yet been patched to defend against the replay attacks discovered in [7].
Indeed, at first glance, it seems necessary to replay a targeted voter’s ballot many times in order to significantly amplify this voter’s choice in the final result. However, somewhat surprisingly, this common conjecture has never come under close scrutiny. The study by Cortier and Smyth [18] is the only previous work which attempted (in Section III.C) to analyze how replay attacks scale, but the authors considered a “definitive mathematical analysis” as future work because their underlying model was “rather naïve” [18].
In this work, we challenge the abovementioned conjecture for the first time, both rigorously and extensively, from two established and complementary perspectives on vote privacy. We precisely measure how efficient replay attacks really are, i.e., how much the affected voter’s privacy loss increases depending on the number of replays. In particular, we show that replay attacks can be devastating for a voter’s privacy even when an adversary’s resources are highly limited so that he can (or is willing to) replay a targeted voter’s ballot only very few times. This observation disproves a common conjecture that vote privacy would only be at risk if the number of replays was high. Our novel insights are immediately relevant for the security of real elections because e-voting systems vulnerable to replay attacks have been, are, and most likely will be used in practice (e.g., the latest version of Helios for IACR elections).
Our contributions
We provide the following contributions.2
We presented the first four contributions in the conference paper [37], whereas our fifth contribution (efficiency analysis of replay attacks under the assumption of approximate prior knowledge) is novel.
Categorization of replay attacks (Section 2 ). We begin by reviewing the scientific literature to extract all replay attacks against vote privacy that have been published to date. We categorize these attacks into different classes, depending on their specific forms. Our extensive presentation highlights that replay attacks play a central role in modern secure e-voting, which demonstrates the importance of our subsequent analysis.
Efficiency analysis based on the KTV vote privacy definition (Section 4 ). We first formally analyse the efficiency of replay attacks using the vote privacy definition by Küsters, Truderung, and Vogt [30], hereafter called the KTV privacy definition (Section 3). The KTV privacy definition is not only established and widely used (see, e.g., [3,9,28,29,32]) but it proves particularly useful for our purposes because it allows us to measure the loss of vote privacy and thus the efficiency of replay attacks.
We first define an ideal functionality for an e-voting protocol which allows the adversary to replay a targeted voter’s ballot
This allows us to analyze how the ideal privacy loss is affected by the number of replays
A new entropy-based vote privacy definition (Section 5 ). A limitation of the KTV privacy definition [30] (observed for instance in [5]) is that it only measures privacy with respect to a specific security game, namely the adversary’s ability to guess between two possible votes. In particular this means that for the ideal functionality (including replays) the privacy loss is (as we will see in Section 4) entirely determined by the two least popular candidates, with the other candidates having no effect whatsoever.
Entropy-based measures of vote privacy (e.g., [6,36]) provide a complementary view because they consider privacy with respect to a variety of goals for the adversary. Unfortunately, as we will explain in Section 5, they are limited in various ways which make them difficult to apply in practice to analyse concrete elections.
In Section 5, we propose a simple extension of the KTV vote privacy definition, which we show is equivalent to a computational version of a strong entropy-based notion. This is independent of the replay attack setting, and serves to somewhat unify the KTV and strong entropy-based approaches.
We show that our novel definition can be efficiently and accurately estimated for the ideal functionality using Monte Carlo methods, and so we are able to use it to study the efficiency of replay attacks from an entropy-based perspective complementary to the game-based perspective of the KTV definition.
Analysis of real-world elections (Section 6 ). In order to complement our formal analysis, we study how replay attacks would scale in practical elections. We therefore apply our formal results to publicly available data of political elections in Estonia, Germany, the UK, and the USA. In this way, we can realistically simulate to which degree vote privacy would decrease if in such elections replay attacks had been executed. Our “field test” confirms the gist of our abstract results: even if the number of replays is very low, vote privacy can be undermined significantly.
Approximate prior knowledge (Section 7 ). Throughout all of our analyses mentioned above, we assume that the adversary knows the exact voting probabilities of the honest part of the electorate. On the one hand, this assumption is not far-fetched since in reality an adversary can access multiple sources to infer what the election result would have been if he had not polluted it with a replay attack. However, even with the help of such side information, it is realistic that an adversary only gains approximate knowledge of the honest voters’ overall preferences.
In order to account for this restriction, we additionally analyse the efficiency of replay attacks under the assumption that the adversary has only approximate knowledge of the unbiased election result. We do this with a Bayesian approach, assuming that the adversary’s prior is given by the distribution that he would obtain via sampling, namely the Dirichlet distribution. We find that while, as one would expect, the efficiency of replay decreases when the adversary’s uncertainty increases, this decrease is relatively modest and the adversary can still significantly undermine vote privacy of the targeted voter, even with relatively few replays.
The structure of our paper essentially follows our contributions as presented above. In Section 2, we categorize all replay attacks described in the literature. In Section 3, we recall the KTV privacy definition as well as the ideal privacy loss a voting protocol can achieve w.r.t. the KTV definition. In Section 4, we study the efficiency of replay attacks based on the KTV privacy definition. In Section 5, we propose our new entropy-based vote privacy definition, describe its relationship to the KTV definition, and show that it can be efficiently estimated for the ideal functionality of Section 4. In Section 6, we illustrate our theoretical results using concrete election data from political elections and discuss the consequences of our insights. In Section 7, we analyse the efficiency of replay attacks under the assumption that the adversary has only approximate prior knowledge of the honest voters’ preferences.
Categorization of replay attacks
We provide the first comprehensive categorization of all replay attacks against vote privacy described in the literature. We identified three different variants of replay attacks: basic replay attacks, homomorphic replay attacks, and re-voting replay attacks. We summarize our insights at the end of the section.
Basic replay attacks
In its most basic form, a replay attack works as follows. Assume that we have
Numerous e-voting schemes have been proven vulnerable against this basic version of replay attacks. Cortier and Smyth [18] demonstrated that basic replay attacks are possible in Helios [1], in the voting scheme by Sako and Kilian [39], and in the one by Schoenmakers [40]. The basic replay attacks against these voting schemes can be prevented by rejecting (partially) duplicated ballots.
Homomorphic replay attacks
Even if duplicated ballots are rejected in order to protect against basic replay attacks (see above), it may be possible to exploit malleability of the underlying cryptographic primitives in order to execute (more subtle) replay attacks. In what follows, we explain the general idea of such homomorphic replay attacks.3
We restrict our attention to the ballots’ ciphertexts and put further primitives (signatures etc.) aside for simplicity.
Several e-voting schemes are vulnerable to such homomorphic replay attacks, for example the one by Lee et al. [34] (pointed out by Dreier, Lafourcade and Lakhnech [19]), or the one by Blazy, Fuchsbauer, Pointcheval, and Vergnaud [8] (pointed out by Chaidos, Cortier, Fuchsbauer, and Galindo [13]) which is the predecessor of BeleniosRF [13].
In order to protect against homomorphic replay attacks, many e-voting schemes employ zero-knowledge proofs (ZKPs) of knowledge which each voter uses to prove that she knows the plaintexts (and randomness) in the ciphertexts of her ballot. By this, a corrupted voter can no longer re-randomize the observed voter’s ballot because he is not able to come up with a (valid) proof of plaintext knowledge.
Typically, e-voting schemes employ ZKPs of knowledge which are non-interactive, i.e., where the voter does not communicate with the verifier while proving knowledge (and correctness) of her encrypted choice. To construct such non-interactive ZKPs, most (modern) e-voting schemes use the Fiat–Shamir transformation [20]. However, as we will recall in what follows, applying the Fiat–Shamir transformation correctly is non-trivial.
Bernhard, Pereira, and Warinschi [7] demonstrated that great care has to be taken when the Fiat–Shamir transformation is used. Bernhard et al. showed that the Fiat–Shamir transformation in the implementation of Helios [1] is too weak because the hash function does not take the statement to be proven as input. Therefore, a voter’s ZKP in Helios [1] is in fact not a proof of knowledge, enabling an adversary to still execute homomorphic replay attacks.
Bursuc, Dragan, and Kremer [10] explained that, even if (partial) ballot duplicates are strictly removed and a (correct) ZKP of knowledge is used (see above), replay attacks against Helios [1] are still feasible if the ballot box is corrupted. We note that, in principle, this replay attack is not restricted to the case of Helios. In what follows, we describe the idea of this replay attack, which is due to P. B. Rønne originally (according to [10]).
If the adversary controls the ballot box (i.e., the server to which voters send their ballots), it can claim that the ballot casting of the voter under observation
Summary
Our comprehensive presentation demonstrates that replay attacks are a recurrent and often subtle issue in the construction and employment of secure e-voting systems, even when deliberately designed to protect against them. While some pitfalls making replay attacks possible are straightforward to solve (e.g., removing duplicates), others are more subtle and require very close attention (e.g., using strong Fiat–Shamir transformations). Based on our systematic literature review, we conjecture that, despite its popularity, the threat of replay attacks is a recurrent issue of e-voting. It is therefore important to precisely understand the risk that replay attacks pose to the crucial property of vote privacy. In the remainder of this paper, we provide the first formal analysis of this fundamental threat.
KTV vote privacy definition
The first part of our formal analysis of replay attacks (Section 4) is based on the vote privacy definition proposed by Küsters, Truderung, and Vogt [30], hereafter called the KTV (privacy) definition. We explain the motivation for this privacy definition and the formal definition itself in Section 3.2, after first recalling the underlying computational model in Section 3.1. In Section 3.3, we recall the best possible privacy loss an arbitrary voting protocol can achieve according to the KTV privacy definition; this ideal privacy loss is expressed as a parameterized formula that we will use to precisely measure the efficiency of replay attacks in Section 4.4
What we call privacy loss in this work was in the original paper [30] called privacy level. Because the privacy bound δ is higher when more private information is leaked, we prefer to use the term privacy loss for δ.
We briefly recall the computational model of the KTV privacy definition, in particular the notions of processes, protocols, instances, and properties. We refer to [30] for full technical details.
Process. A process is a set of probabilistic polynomial-time interactive Turing machines (ITMs, also called programs), which are connected via named tapes (also called channels). We write a process π as
Protocol. A protocol
Instance. Let
Property. A property γ of
Negligible, overwhelming, δ-bounded. As usual, a function f from the natural numbers to the interval
Privacy definition
The KTV privacy definition [30] formalizes privacy of an e-voting protocol as the inability of an adversary
To be more precise, according to [30], a voting protocol provides δ-privacy if any adversary
Now, the intuition described above is formally defined as follows.
(Vote Privacy [30]).
Let
In other words, the privacy loss δ is an upper bound of an arbitrary adversary’s advantage to distinguish whether
Ideal privacy
Since we have seen that the privacy loss δ is typically not perfect, the following questions are obvious: What is the best possible privacy loss that can be achieved in a given election? How does this ideal privacy loss depend on basic parameters, such as the number of voters or the voters’ preferences? These questions have been answered precisely in [30] and we will recall the results in what follows. These results will be the foundation of our formal analysis of replay attacks in Section 4.
Ideal voting protocol. In order to have a lower bound on the privacy loss for all voting protocols, Küsters et al. [30] derived a formula for the privacy loss an ideal voting protocol provides.5
The ideal privacy loss derived in [30] is formulated for result functions that reveal the complete tally, i.e., number of votes for each choice. Subsequently, a more general ideal privacy loss was derived in [28] which is formulated for arbitrary result functions, including tally-hiding result functions that may, for instance, only reveal the winner but nothing else. Because all e-voting systems mentioned in Section 2 employ a result function which returns the complete tally, we restrict our attention to the ideal privacy loss derived in [30].
Number of choices
Number of honest voters
The number of dishonest voters is not relevant for result functions that reveal the full tally because an adversary can derive the “honest” election result by subtracting the dishonest voters’ choices from the final election result.
Voting distribution
In slight abuse of notation we identify
The ideal voting protocol

Protocol of ideal voting functionality.
Ideal privacy loss. We now recall from [30] how the privacy loss
Let
The intuition of the ideal privacy loss described above is formally captured by the following definition:
The following theorem (Theorem 3 of [30], proved in Appendix C of the eprint version [31]) states that the loss
The ideal protocol
Efficiency analysis based on the KTV vote privacy definition
In this section, we formally study the efficiency of replay attacks using the KTV privacy definition. First, in Section 4.1 we focus on capturing the effect of replay attacks. We define a suitable ideal functionality for a voting protocol whose only flaw is that it allows the adversary to execute a replay attack. We characterise its KTV privacy loss analogously to the characterisation for the truly ideal protocol (without replays) in [30] (Theorem 2). Because this characterisation is not computationally tractable, we then show a reduction to an election with only three candidates (Theorem 3), and obtain a tractable formula which we use to demonstrate the devastating effect of even a small number of replays on realistically-sized example elections.
Based on these insights, in Section 4.2 we then study the efficiency of replay attacks in general: we analyse (Theorem 7) how the ideal privacy loss behaves asymptotically in the number of replayed ballots
Ideal privacy loss
We analyse the ideal privacy loss if the adversary can replay the observed voter’s choice

Protocol of ideal voting functionality which allows for replaying the observed voter’s choice
In what follows, we first derive a representation of the ideal privacy loss
First representation. Analogously to
Now, analogously to
We thus obtain our first representation of the ideal privacy loss with
The following theorem states that the loss
The ideal protocol
The proof of Theorem 2 is exactly the same as the proof of Theorem 1, with
Note that the formula in (4) for
Second representation. We now show that for the ideal functionality of Fig. 2, the definition of the KTV privacy loss can be greatly simplified. Recall that in Definition 1, we measure privacy as the adversary’s maximum advantage over all possible choices
Let j,
In order to prove Theorem 3 we will first show the technical Lemma 1. Lemma 1 states that for each choice of j and
The formula (5) of Lemma 1, combined with Theorem 3, gives an explicit expression for the ideal privacy loss as a sum of at most
We will introduce a new variable
Let
We give only a short sketch, with many details relegated to the Appendix in Lemma 3. To simplify notation we write
Now
By definition
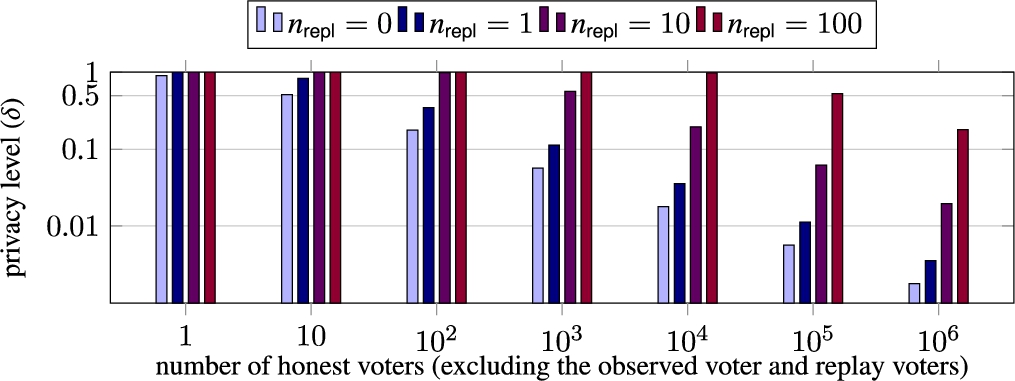
KTV privacy loss δ for the ideal protocol with 10 candidates and the uniform vote distribution. Note that the y-axis is on a log scale.
In Fig. 3, we give some concrete values of the ideal privacy loss with replays
In the first part of our analysis, we focused on the effect of replay attacks: our results in Section 4.1 state which privacy loss can be achieved ideally if an adversary replays the observed voter’s choice
Our main result on the efficiency of replay attacks is Theorem 7. Its proof is based on the explicit representation of the ideal privacy loss from Theorem 1. In what follows, we will first deduce Theorem 7 and eventually illustrate it for specific settings.
We use the terminology introduced in Section 4.1. We remark first, that one can choose
We can isolate the terms for r and t to get
Our series approximation becomes weak for
From what we have shown above, we obtain the following central result.
Let C,
Observe that
Intuitively, Theorem 7 essentially states that the KTV privacy loss of an election with
To give some concrete examples, again with 10 candidates and a uniform distribution: in an election with 10 honest and no corrupted voters (and hence no replays possible) the adversary wins the privacy game with probability
An important limitation of the KTV privacy definition is that it only considers vulnerability with respect to a very specific goal, namely for the adversary to guess between two possible votes (which earns it a rating of ‘too limited’ in the survey article [5]), and a similar limitation applies to most game-based definitions. Various works have sought to address this by considering entropy-based privacy definitions, most notably [6] and [36] (we note that the game-based vote privacy definitions in the line of [5], which are often used to formally analyse vote privacy – see, e.g., [5,10,13,26] – reduce to the entropy-based approach, as proven in [5]). In this section we will show that a simple extension of the KTV definition, which we term ‘strong vote privacy’, is equivalent to a computational version of a strong entropy-based definition.
Related work
In [6] at CCS 2012, the authors propose a family of entropy-based privacy definitions, parametrised by a number of modeling choices that must be made: firstly, we fix a distribution on the votes, both of the observed voter and the innocent third parties; secondly, we fix a ‘target function’ that the adversary is interested in learning, for example the observed voter’s vote; thirdly, we must choose an ‘entropy notion’ to measure the adversary’s success in learning the target information, for example the ‘average min-entropy’, which measures the adversary’s ability to guess the value of the target function with a single guess. The privacy measure is then the posterior vulnerability of the target function with respect to the chosen entropy notion (for the examples just mentioned, that is the probability that the adversary will correctly guess the observed voter’s vote after seeing the election). The setting of a computationally bounded adversary is dealt with indirectly, by saying that the vulnerability of an output distribution is the minimum vulnerability among distributions computationally indistinguishable from the true distribution.
The assumption that we know in advance the voting behaviour of the innocent third-party voters may well be reasonable – we can estimate this based on opinion polls and the results of previous elections – and the same assumption is made both in the KTV definition and in our definition below. The same assumption for the observed voter is more problematic, since the adversary may well choose to attack a highly atypical voter about whom they possess side-information (for example, someone who is known or suspected to belong to an opposition group). Note, however, that some such assumption seems inevitable in any measure focusing exclusively on posterior vulnerability, since in the case that the observed voter follows a point distribution (i.e. the adversary has total knowledge of her vote) any target function will be totally compromised.
The choice of target function may also be far from straightforward: while the observed voter’s vote is certainly very reasonable, it may not be the only thing the adversary could care about. For example, if candidates are grouped into parties the adversary may only care about which party a voter voted for, or in the case of ranked choice voting the adversary may care about who the voter ranked first. Again some assumption of this kind seems necessary in any posterior vulnerability measure, since for instance a target which is a constant function will trivially be compromised.
Finally, the choice of entropy notion may not be entirely clear, but we agree with the use of average min-entropy because of its clear operational interpretation as the adversary’s best single guess for the target.
The idea of the adversary’s target function is further developed in [36], which considers the voting system as a communication channel from the voters to the result, and applies ideas from the theory of Quantified information flow, in particular the notion of g-leakage. The idea is to define a set
However, the framework of [36] also has a number of important limitations. It does not attempt at all to consider either adversaries who may interact during the protocol, or computationally bounded adversaries. It is still parametrised by choices of both gain function and vote distribution. Indeed, this is some sense inevitable in that we cannot hope to quantify loss of privacy by the overall capacity of the channel (which would be the supremum over possible gain functions and vote distributions), because the tally does reveal substantial information about the joint distribution of the voters’ votes – this is the whole point of running an election!
Strong vote privacy
The key idea for our definition is to think of the voting system not as a channel from the votes of all the voters, but rather as a noisy channel from the vote of the observed voter, with noise coming from the random votes of the innocent third-party voters. This means that we can measure the loss of vote privacy as the min-entropy capacity of this channel, and so we can consider the maximum over all possible gain functions and all possible priors on the observed voter.
In order to allow for interactive and computationally bounded adversaries, we will phrase our definition not in the language of channels and information flow, but directly using the operational interpretation of min-entropy, in terms of the maximum advantage that can be gained by a computationally bounded interactive adversary – essentially an interactive and computational version of g-leakage as discussed above.
We consider all possible gain functions g and all possible priors π the adversary may have for the voter’s actions. We then define the privacy loss to be the maximum possible (multiplicative) increase in expected payoff for an adversary who is permitted to mount an attack on the system, compared to one who is not and just makes a guess based on his prior.
(Strong vote privacy).
Let
Remarkably, it turns out that this is equivalent to a simple strengthening of the KTV privacy definition, which may therefore (depending on the reader’s tastes) alternatively be seen as the primary definition:
(Strong vote privacy, II).
Let
The proof of this equivalence, which will be the main theorem of this section, is essentially a computational and interactive version of the ‘miracle’ theorem of QIF, Theorem 5.1 of [2]. We first note that Definition 3 is indeed an extension of the KTV definition:
KTV vote privacy (Definition
1
) is equivalent to Definition
3
with the adversary
Let
It trivially follows that the KTV privacy loss is a lower bound for the strong privacy loss, and that for two-candidate elections the definitions are equivalent.
We now establish the main theorem: Trivially Definition 2 implies Definition 3 (take To prove the converse implication, let Our task is now to construct an adversary Note, however, that the values of Define the adversary By the definition of Writing
Precise analysis of strong vote privacy for the ideal functionality discussed above is rather less straightforward than for the KTV definition (partly since unlike the latter it depends on the entire distribution of the honest voters, rather than only with respect to the two least popular candidates). However, for the ideal replay attack functionality in which the adversary’s only action is to make a guess based on the output tally it is possible to obtain fairly accurate estimates by Monte Carlo methods, as we now show. The first observation is that the optimal output is one which can be easily simulated.
For a protocol for which the adversary’s output is a function on some finite set of tallies T, the sum in Definition
3
is maximised by the ‘maximum likelihood adversary’, which on tally t outputs the vote
We have
Note that the maximum likelihood adversary can be easily implemented for the ideal protocol of the previous section: for an election with k candidates,
Now observe that if
Then to estimate δ we repeatedly sample
Figure 4 shows the privacy loss of the ideal functionality for an election with 10 candidates and various numbers of honest and replay voters (with the honest voters voting according to the uniform distribution). Figure 5 shows a direct comparison of our definition with the KTV definition, for elections with between 2 and 10 candidates. All estimates in this section and in Section 6 are with 10,000,000 trials, so standard error
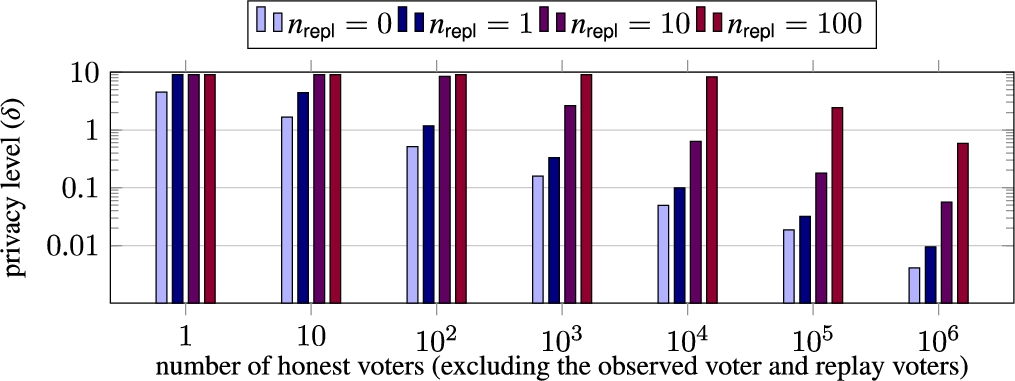
Strong privacy loss δ for the ideal protocol with 10 candidates and the uniform vote distribution.

Comparison of privacy losses for strong privacy and KTV privacy, for an election with 10000 honest voters, 10 replays and 2–10 candidates, uniform distribution.
In order to complement our formal analysis, we study how replay attacks would scale in practical elections. We therefore apply our formal results to publicly available data of political elections in Estonia, Germany, the UK, and the USA. In this way, we can realistically simulate to which degree vote privacy would decrease if in such elections replay attacks had been executed. Our “field test” confirms the gist of our abstract results: even if the number of replays is very low, vote privacy can be undermined significantly.
In the remainder of this section, we first discuss the modeling assumptions used for our analysis (Section 6.1), then describe our real-world examples and the results of our simulations (Section 6.2). Finally we discuss these results, explain why they confirm our theoretical analysis, and elaborate on the consequences of our new insights (Section 6.3).
Modeling assumptions
Throughout all of our analysis we, like Küsters, Truderung and Vogt in [30], assume that the adversary’s knowledge about the actions of the honest voters is represented by a vector of vote probabilities
An important feature of all the elections we consider is that they are national elections for which results are published at the constituency or even per-polling station level. This means that if voters were nationally homogeneous then the adversary could easily discover the vote distribution
Of course, in reality electorates are almost never nationally homogeneous, and there will be systematic variation between North and South, East and West, rich and poor regions, and so on. The adversary’s goal, therefore, is to estimate the distribution
The second task, for us as analysts to estimate the vote probabilities in order to perform the analysis, is considerably simpler. Unlike the adversary we have access to the actual results in the relevant area (unpolluted by replay attacks), and so we can use the proportion of votes cast for each candidate as an unbiased estimator of the underlying vote probabilities.
Examples
We use public data from political elections in Estonia, Germany, the UK, and the USA, to simulate the potential privacy loss if these elections had been conducted using an e-voting scheme vulnerable to replay attacks.10
We published our implementation at
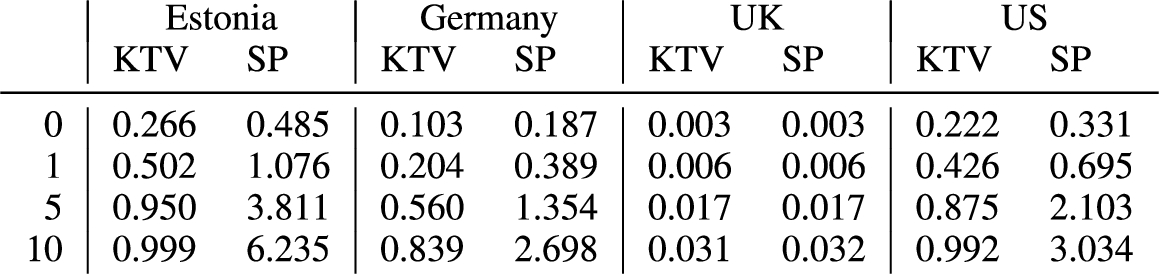
In each of these elections, the partial election result of each polling station/area was published. We use these partial results to analyse the efficiency of replay attacks because it is reasonable to assume that an adversary knows in which partial result a targeted voter’s choice is included. For each election, we chose a polling station/area where the number of votes was close to the overall average of votes per polling station/area. Our results are summarized in Fig. 6.
In the Riigikogu (parliamentary) elections in 2019, 561,141 votes were cast in total. The number of polling stations was 451, which results in 1,244 votes per polling stations on average. In this example, we choose polling station S53P in Mustamäe linnaosa where 1,404 valid votes were cast.11
See
The public election result is even more fine-grained because the number of votes per candidate on each party list is revealed. We aggregated the number of votes for each party list and consider adversaries who merely know the aggregated result; this makes our overall argument only stronger.
In the Landtag (parliamentary) election in the state of Rhineland-Palatinate in 2021, 1,922,579 votes were cast in total. The number of polling stations was (roughly) 2,300, which results in
See
In the EU referendum in the UK 2016, 33,551,983 votes were cast in total. The number of areas was 382, which results in 87,832 votes per area on average. In this example, we choose the area of Kingston-upon-Thames (London) where 85,270 votes were cast.14
See
For the US presidential election in 2020, we were not able to determine the number of polling stations nationwide, so we focused on the results of one state, namely Massachusetts. Here, the average number of votes per polling station was (roughly) 1,500. In this example, we choose the polling station for Precinct 13 of Ward 1 in Boston, where 1,430 votes were cast.15
See
Observe that for the Estonian, German and US elections, which have many candidates, even a very small number of replays would have a devastating impact on vote privacy. For example, in the Estonian election even a single replay already has a substantial effect, and with only 5 replays privacy is almost completely lost (similarly for Germany and the US 1–5 replays compromise privacy, and 5–10 destroy it completely).
On the other hand, in the UK Brexit referendum, which has only two ‘candidates’ and far more votes at the most granular reporting level, we see that the effect of up to 10 replays is far less. This example also illustrates most clearly the result of Theorem 7 that the KTV privacy loss scales approximately proportionately to
The referendum results should not make us too complacent, however, because in fact the number of replays required to obtain a KTV privacy loss
It is interesting to compare the results for the US election with the UK results, because these are both elections for which the vast majority of votes went to just two candidates, but the privacy loss for the US is much greater than for the UK (by a factor of approximately 70). The number of votes in the UK example exceeds that in the US by a factor of approximately 60; Theorem 7 tells us that the KTV privacy loss δ scales as
It may seem odd or even undesirable that the measured loss of privacy should be so heavily influenced by the small number of voters who support minority parties. However, we would argue that ballot privacy must mean privacy for all voters. Indeed, it may well be supporters of unpopular candidates who are at most risk of stigmatisation or reprisals; note that the adversary does not have to choose the targeted voter at random, but can choose to target someone they already suspect of supporting a minority position.
Approximate prior knowledge
In the foregoing, we have assumed that the behaviour of the honest voters is modelled by the voters independently selecting their votes according to a probability distribution which is known to the adversary; this means that the total of the honest voter’s votes is a multinomially-distributed random variable with parameters known to the adversary. In reality, however, the adversary is unlikely to have precise knowledge of the ‘true’ underlying vote distribution, but instead will have to estimate it in some way, such as via opinion polls or extrapolating from the known results from other voting districts (as discussed above in Section 6.1).
In this section, we will model the effect of the adversary having only partial information about the honest voters’ preferences. In Section 7.1 we introduce the model in more detail. We then in Sections 7.2 and 7.3 adapt our results from Section 4 above on KTV privacy to this setting, and finally in Section 7.4 we give some data to show the effect of this additional uncertainty on the efficiency of replay attacks, as measured by both KTV and strong privacy.
The Dirichlet prior
We will take a Bayesian approach and assume that the adversary’s uncertainty is represented by a prior distribution on the honest vote probabilities. In particular, we will assume that the adversary’s prior is given by a Dirichlet distribution, because this is the conjugate prior to the multinomial distribution and so is the class of prior that the adversary would obtain via sampling (such as opinion polling) [38].
The model is thus that the honest vote probabilities are drawn according to the Dirichlet distribution, and then the votes themselves are drawn as a multinomial distribution with these probabilities; this means that the vote totals are given by a Dirichlet-multinomial distribution (note that the reader may be more familiar with the two-outcome case of these distributions, which are known as the Beta and Beta-binomial distributions respectively). The adversary has access to the parameters of the Dirichlet prior (which he can use to compute likelihoods of various honest vote totals), but not the actual sampled probabilities.
This requires a slight adjustment to the ideal functionality as presented in Fig. 2 above, which is now parameterised not by a probability distribution for each individual voter (since they are no longer assumed to be i.i.d.), but rather by a joint probability distribution on the overall tally of the honest voters. This modified ideal functionality is shown in Fig. 7. As discussed above, we will take the joint distribution

Protocol of ideal replay voting functionality with the honest voters not assumed to be i.i.d.. The differences between the protocol in Fig. 2) and the one presented here are highlighted in red.
The Dirichlet distribution is parameterised by ‘concentration parameters’
So what should
Note that none of the work of Section 5 on strong privacy depended on the actual distribution of the honest vote tally and so everything carries over immediately to this setting, except that in the Monte Carlo algorithm described in Section 5.3 the likelihood of obtaining tally
On the other hand, the proofs of the main theorems in Section 4 did depend on the vote distribution being multinomial, and so some further work is required to show that they still hold in the Dirichlet-multinomial setting, which we undertake in the next section.
In this section we discuss how privacy is affected by an adversary who has access to the parameters
The definition of δ-privacy directly transfers to the new setups, namely we define
In order to find the reduction in the case of the Dirichlet-multinomial distribution, we have to simplify the condition in Equation (11). Unfortunately, this is technically much more involved than in the multinomial case. The techniques used are however typical when working with Γ- and beta functions. We therefore present this part in more detail.
We start with the integral representation of the Dirichlet-multinomial distribution. Recall that
Similar to Section 4, we set
In order to isolate the variables j,
For
We then have to check, when the inequality is satisfied, i.e. we have to determine the sign of the previous term. The sign of the whole term is in fact determined by
We can further simplify by substituting
Since the case
We hence only have to check
To simplify the notation, we will assume that products with 0 are 0, even if the second factor is not well-defined, i.e. we extend
Now we return to the computation of the privacy
Let
After the reduction, we also want to remove the remaining absolute value from Formula (14). Again this works similarly to our construction in Section 4 although it is technically more challenging.
We first define
Let
The proof of this lemma is included in Appendix A.2.
Finally, the absolute KTV-privacy Let j,
Similar to our discussion in Theorem 7, we want to take a closer look at the asymptotic behaviour of the privacy level. We will therefore analyse the explicit formula in Equation (15).
For large
(Asymptotics).
Let C,
This asymptotic behaviour heavily relies on the validity of the approximation
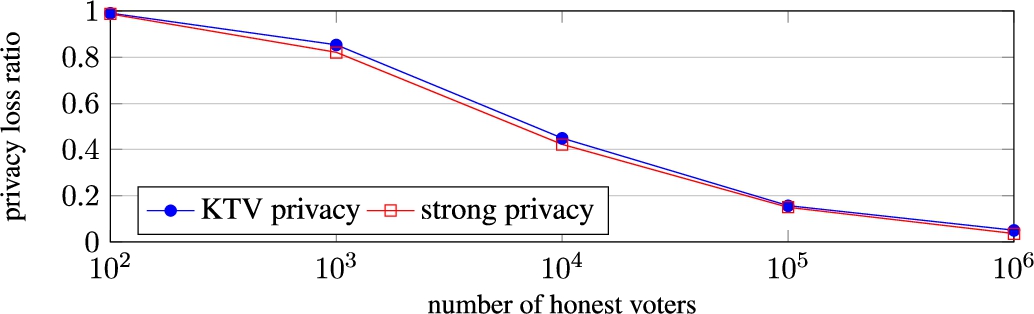
Privacy loss ratios (i.e. privacy loss with
This behaviour is also illustrated in Fig. 8 where we consider
This confirms our theoretical prediction in Equation (28) that the ratio between approximate level and multinomial level varies as
In the discussion above we concluded that the adversary can expect to achieve a value of
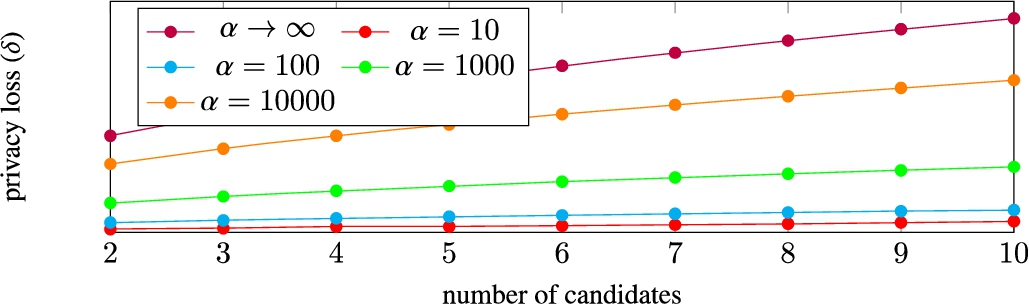
Comparison of privacy losses depending on the uncertainty in α for KTV privacy, for an election with 10000 honest voters, 10 replays and 2–10 candidates, uniform distribution.
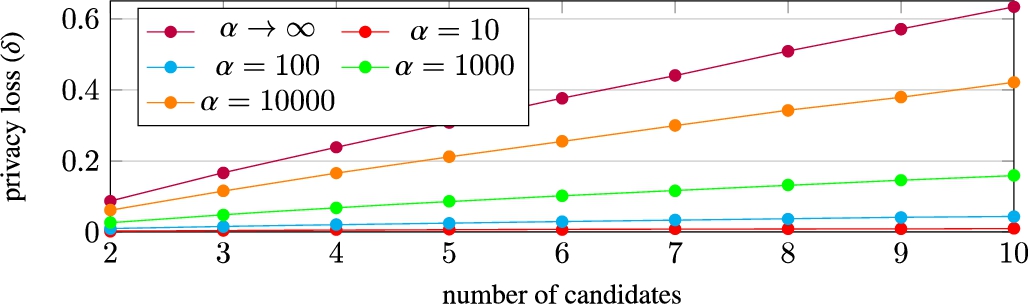
Comparison of privacy losses depending on the uncertainty in α for strong privacy, for an election with 10000 honest voters, 10 replays and 2–10 candidates, uniform distribution.
As expected, we observe that lower values
We now turn to the real-world elections previously considered above in Section 6. There we saw that an adversary with access to the actual vote probabilities can break privacy with a fairly low number of replays. We now repeat this analysis for an adversary with the Dirichlet prior and our estimated value of
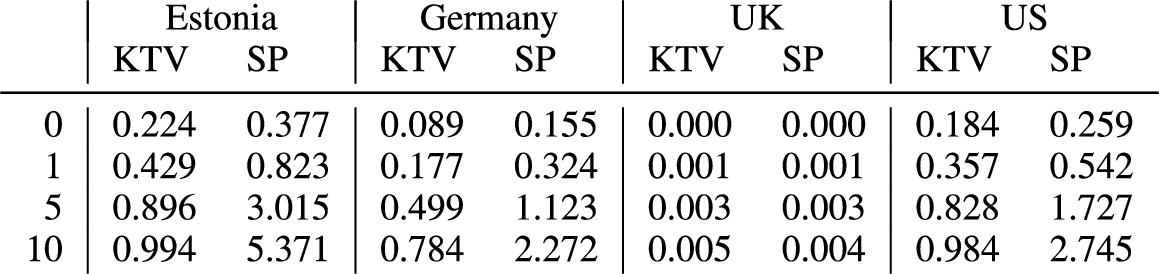
By comparison with Fig. 6, which describes the case
In summary, we see that the privacy loss in the approximate model is smaller than in the exact model. This behaviour is completely natural and expected: A replay attack by an adversary who has less information is less successful. However, we also see that an adversary who only gets access to polls can still perform very successful replay attacks, especially for typical smaller constituency sizes.
Footnotes
Acknowledgments
David Mestel was supported by the Luxembourg National Research Fund (FNR) under grant number INTER FNRS/15/11106658/SeVoTe. Johannes Müller was supported by FNR under the CORE Junior project FP2 (C20/IS/14698166/FP2/Mueller). Pascal Reisert was supported by the DFG through grant KU 1434/11-1 and by the CRYPTECS project founded by the German Federal Ministry of Education and Research under Grant Agreement No. 16KIS1441 and from the French National Research Agency under Grant Agreement No. ANR-20-CYAL-0006.