
Abstract
A massive amount of data is transmitted in the Internet of Things (IoT). Nowadays, the concerning of security issues are the major factor while transferring data through wireless networks. Since, data privacy becomes complicated. In this research work, a newly proposed model for multimedia steganography is developed. Initially, the required video is obtained from the publically available datasets, and then the acquired input is subjected to the Adaptive Discrete Cosine Transformation (DCT) based block process. The optimal blocks are chosen by the Adaptive Multi-cascaded ResNet (AMC-ResNet) model for applying stego data. Here, the parameter optimization takes place in the DCT and ResNet model to enhance the steganography performance via the Mouth Brooding Fish Emperor Penguin Optimization (MBFEPO) derived from the Mouth Brooding Fish Algorithm (MBFA) and Emperor Penguin Optimization Algorithm (EPOA). Finally, the inverse DCT is employed at the blocks to get the final stego video. In the audio steganography phase, the wanted audio is gathered from external websites. The collected data are given to the Short-time Fourier Transform (STFT) to convert into the spectrogram image, and then the spectrogram image is given to the Adaptive DCT block, selecting the block to apply stego data. Thus, the blocks are selected with the utilization of the Adaptive Multi-cascaded ResNet (AMC-ResNet), where the parameters within the DCT and the ResNet are optimized via the same MBFEPO to improve the performance. After, the Inverse ADCT is applied to reconstruct the spectrogram image. Then, the resultant stego audio is obtained by using the Inverse STFT. Finally, several experiments are conducted to estimate the working ability of the proposed steganography model. The outcome of the recommended model shows 12.3%, 52.6%, 12.3%, and 84.3% better performance SFO, HBA, MBFA, and EPOA in terms of median. The recommended model performs superior performance rather than the existing approaches.
Keywords
Introduction
With the frequent growth multimedia era, digital multimedia data has been converted into public channels [12]. Consequently, more focus has also been given to the security of public channel transmission [35]. In the initial phase, the cryptography process was utilized in order to protect the multimedia data. But, the protection has been disabled after the decryption [1]. In this case, Steganography has provided effective secrecy of images or text to protect them from attackers. Steganography is embedding the message at the time of cover images and then changed their properties. It has the ability to provide secret communication to hide the presence of a message from the attacker or hacker [33]. Securing the secret messages from detection is a crucial role in Steganography [26]. Hence, it involves various array of secret communication phases, which has concealed the message terribly existences. This scheme involves spread spectrum, covert channels, digital signatures, character arrangement, microdots, and invisible inks [6]. It has also worked on concealing video, audio, and images to integrating audio steganography and cryptography over personal computers for improving security [32]. Various multimedia steganography techniques are implemented. Most of them are based on the spatial domain that has a simple and popular scheme in extraction and embedding. Some others are based on the transform domain which is highly robust [17].
Information security is generally secured by the users in personal computers for transit across the network, and then it is restored in the cloud space [16]. It has been categorized into two types that are information hiding and encryption [2]. The process of encryption has verified the confidentiality property of the data. By utilizing the encryption, the attained ciphertext is considered an unintelligent or meaningless form that invites suspicion [25]. Hence information hiding has been generally preferred for encryption. The information hiding process has embedded the data into digital media for converting the communication into a secured form [19]. The cover of information hiding is regarded as multimedia data, in which the images are the most crucial medium in the application [22].
In recent times, deep learning depended techniques have attained better outcomes in several research fields [13]. Classical image steganography has been categorized into two classifications such as spatial domain-based and transform domain-based methods. In the spatial domain depending on techniques, the secret information has been embedded into image pixel values [30]. Typical techniques involve histogram-based approaches, prediction error, Least Significant Bit (LSB), and other techniques. The spatial domain-based algorithm has small effects on the quality of the cover images as well as embedding capacity is huge [5]. Moreover, it generally has decreased robustness. For enhancing the robustness, researchers have suggested integrating secret information in the transform domain [29]. A typical technique involves steganography depending on the “Discrete Fourier Transform (DFT), Discrete Wavelet transform (DWT), and DCT”. Classical image steganography has guaranteed information security to a certain extent. Therefore, most of the classical steganography algorithm has been identified through the classical steganalysis algorithm in terms of certain payload. Along with the enhancement of the steganalysis algorithms, classical steganography algorithms is also constantly enhance the distortion function to assist detection. The most commonly used deep learning model is ResNet. The residual functions of the weight layers are learned based on the reference to the input layers. However, the ResNet can be effectively performed to extract the features in order to enhance the performance of the model. In steganography, the ResNet has the ability to extract the steganalysis features to provide exact and accurate outcomes. Additionally, the ResNet solves the gradient vanishing and also the over fitting problems it suggested the Residual Blocks. Moreover, it helps to maintain a low error rate in the network. Here, the newly proposed multimedia steganography has been implemented.
The major attributions in the newly proposed model are given as follows.
To design a new multimedia steganography images by considering the deep learning models. Here, the multimedia steganography is quite applicable in the mobile environments.
To implement the Adaptive DCT techniques for dividing the images from both the video and audio into 8 × 8 image blocks, and the type of DCT is optimized using the MBFEPO algorithm for enhancing the performance.
To develop the AMC-ResNet for selecting the block images and to apply the stego data, where the parameters like epochs and hidden neuron count in the AMC-ResNet have been optimized by using the MBFEPO algorithm.
To recommend the new MBFEPO algorithm for optimizing the parameter in both the DCT and AMC-ResNet for increasing the performance in terms of maximized Peak Signal Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM) rate.
The upcoming section in the given steganography model is given below. Phase II describes the literature survey related to traditional steganography images. The dataset description and proposed architecture for multimedia steganography are given in Phase III. In Phase IV, image or frame decomposition by adaptive DCT is detailed. Deep learning-based block selection for multimedia steganography is explained in Phase V. The result and discussion for the multimedia steganography images are given in phase VI, and the conclusion is in phase VII.
Literature survey
Related works
In 2018, Zhang et al. [35] have recommended the coverless image steganography algorithm depending on the Latent Dirichlet Allocation (LDA) and DCT categorization. In the initial phase, LDA has been used to categorize the image database. In the second stage, the images have come under one of the topics that were chosen as 8 ∗ 8 block DCT that was performed on these images. Further, the sequence of the robust features has been produced by the relation among direct current co-efficient in the adjacent blocks. In the end, an inverted index that includes the image path, location coordinates, and feature sequence has been designed. In the whole process, there was no modification has been carried out to the original images. It has shown a better ability to resist steganalysis assimilated with the classical algorithms.
In 2019, Lu et al. [18] have explored the steganalysis techniques depending on the pre-classification as well as feature selection. In the initial phase, it utilized the features retrieved images depending on image adjacent data; the images, along with various texture and content complexity were pre-classified as multiple clusters by using the standard algorithms. Further, the performance of the various traditional steganalysis features was validated for different clusters of images and the optimal features for every cluster for final classification. The investigational outcomes have shown that the identification accuracy has enhanced the suggested model. In addition to that, availability and rationality have also been verified.
In 2018, Qian et al. [24] have implemented a novel methodology for providing multimedia security, such as multimedia tampering detection, privacy preservation on the cloud, and novel steganography. The main intention of the implemented model was to assure the security of multimedia data and for further processing of such data has provides given constant advances in big data and computational capability analytics. Thus, the implemented techniques have shown better performance over other models.
In 2021, Hao et al. [9] have recommended the semi-construction coverless steganography algorithm. In the initial phase, web crawler techniques have been employed to crawla wide range of small icons and images from the Internet. It has been utilized as the subset, and then images have been implemented in terms of construction rules. In the second phase, the Alex-Net network has been designed for training the algorithm as well as adverbial samples were added to the training set. In the third phase, images were split into a privacy carrier image in terms of the construction principle. The investigational outcomes and the evaluation have shown that the recommended algorithm has to resist steganalysis tools in an efficient manner and also has good robustness against several image attacks. These promising outcomes have proved that the recommended algorithm has been employed to build covert communications.
In 2020, Gutub and Ghamdi [8] have enhanced the counting depending on secret sharing methodology for simple and fast computation as well as higher share security. The major aim of this method was to resolve the defects in the reconstruction phase through implementing new distribution techniques. Then, this technique was optimized in an effective manner. In addition, the shares reconstruction techniques have reflected the enhancement of the security in the system via steganography. Further, the multi-media images depended on steganography techniques for restoring the optimized shares. The outcomes have shown an optimized counting dependent on a secret sharing scheme regarding a promising solution.
In 2020, Sukumar et al. [31] have recommended the classier for transforming the multimedia content and then embedded into a selected cover image. Here, the produced stego images were restored in the cloud. If the multimedia content is acquired, stego images were downloaded from the cloud as well as given to the inverse form of Integer Wavelet Transform (IWT). An Investigational value has illustrated better values for the available scheme, and the robustness and security evaluation of the recommended model was also better.
In 2020, Wu et al. [33] have developed a new steganography technique for digital audio in the time domain. Unlike related techniques for image steganography that were highly based on various traditional embedding costs, the recommended techniques began from the even embedding cost and then updated the initial cost until the promising security performance has been attained. The extensive experimental outcomes have shown, in which the developed model has crucially outperformed adaptive and non-adaptive steganography techniques and then attained state-of-art outcomes. In addition to that, the investigational outcomes have investigated the utilization of embedded modification over steganography techniques.
In 2020, Mstafa et al. [19] have designed novel techniques for video steganography depending upon the LSB algorithm as well as the corner point principle. The designed model initially utilized the standard algorithm for detecting the region within the cover video frames. Further, it has utilized another heuristic algorithm for hiding confidential data inside it. Investigational outcomes have revealed that the designed model has maximized invisible and secure values more than other models.
In 2023, Sonali et al. [27] have developed the secured stego key-based video steganographic method which has been embedded with the Framelet Transform. Here, it has been performed to minimize the computational cost by utilizing the stego key. Further, the encryption was considered using the ECC. Also, this scheme was enhanced to provide better robustness of the model. The diverse performance measures have been validated with the state-of-the-art methods in terms of Bit Error Rate (BER), Peak Signal-to-Noise Ratio (PSNR), and Structural Similarity Index (SSIM).
In 2023, Massoud et al. [3] have developed a novel steganography approach which was termed as One secret Picture is sent using only Two cover Pictures (OPTP). For each secret image, the stego images were generated to provide better security and quality aspects. In order to provide better capacity, a lossy compression algorithm was determined, and also the verification takes place with the help of the bloom filter. Consequently, the developed model has achieved better performance while the validation takes place among the existing approaches.
In 2023, Aimin et al. [34] have implemented a new steganography algorithm based on the machine learning models. Initially, the images have been splitted based on the regions of foreground and background using the adaptive threshold segmentation. Next, for each pixel, the high-capacity steganography was utilized for enhancing the embedding capacity. Also, hybrid machine learning has been utilized to encrypt the data to improve security. The empirical analysis has been performed to validate the performance of the developed model along the baseline approaches.
Problem specifications
The performance of the multimedia steganography process with its advantages and disadvantages are tabulated in Table 1. LDA [35] technique has effectively detected the classical steganalysis algorithms. It has the ability to improve the ability to resist identification which has been useful for enhancing the robustness of the model. The capacity with less side information is lacking in this model. K-means algorithms [18] method has the ability to resolve the issues in the feature selection process and enhanced the steganalysis process. It has various complex texture issues while validations. Ensemble [24] technique has been used to conceal the messages within the model for security measures. This model has faced computational complexity issues. The transfer learning [9] method has the potential to enhance the effectiveness of the training model. It also has the ability to speed up the entire process. But, this model faced the issues of negative transfer. Counting-based secret sharing technique [8] computational cost of this scheme is low when assimilated over other models. It has shown its effectiveness in terms of capacity, robustness, and security. Counting-based secret sharing for enhancing the integrity and availability of the data is limited. DRT [31] technique has been developed for increasing the strength of the proposed scheme. It has also provided promising outcomes while validation and simulation analysis. The Colour image steganographic technique for cloud storage is restricted in this model. CNN [33] model has the ability to attain a very effective embedding cost. It has also resolved the issues in the gradient issues and provides better outcomes over other models. The gradient amplitudes and the adaptive parameters are limited in this work. LSBs algorithm [19] technique has been used for secretly sharing the data bits of the hidden messages. It is regarded as the simple and easiest model for implementation. But, it has faced capacity and storage issues.
Motivation. A few challenges of the existing model are depicted here. In existing approaches, handling of large amount of data becomes the complicated issue which does not provide the effective outcomes. Moreover, it consumes more computational time. Also, the accurate and reliable performance is not sufficient in the designed model.
Advantages and disadvantages of the traditional multimedia steganography process
Advantages and disadvantages of the traditional multimedia steganography process
Dataset details
In this process, the data required to perform the multimedia steganography has been gathered from two datasets that are below.
Hence, the data from both video and audio has been attained, and it is termed as
Architecture of multimedia steganography
In this modern technological era, everyone wants safety and secrecy in communicating data. There were two mechanisms for securing the data that are steganography and cryptography. Considering the cryptography text or data has been transferred into cipher text, and so no one can identify the original data without a cipher key. But, the cipher or encryption key is easily accessed by non-users and has low security. Here, steganography is developed. Steganography is defined as the procedure of switching the information inside a data source. The most widely recognized usage of this steganography has been defined as concealing a record inside another document. It is usually based on hiding the uncovered messages over the unsuspected mixed media information as well as used as a part of secret correspondence among recognized gatherings. It is regarded as the system for encryption, which has the ability to hide the information among the bits of cover objects. It has four kinds of steganography that are: video, audio, image, and text for securing the information in the required format. Image steganography has been utilized to secure data transfer over the Internet by using images. Statistical techniques have been used to modify the statistical property of an image in accordance with preserving them in the embedding process. To encode message bits in the transform domain coefficient of the data is used. The process of data embedding over the transform domain has been utilized for robust weakness. Even though traditional steganography has various advantages, there are also some limitations over the model on securing the data in the steganography. Thus, the new concept of multimedia steganography has been implemented, and its architectural depiction is given in Fig. 1.

Architectural model for the newly designed multimedia steganography.
Thus, the recommended multimedia steganography has been performed in two phases (a) Image or Video steganography phase and (b) Audio steganography phase. Initially, the wanted image and video have been attained from the publically available datasets, and then the acquired input has been fed into the Adaptive (DCT) based block process. After, the optimal blocks are selected using the AMC-ResNet model and the stego data is applied. Here, the parameter optimization takes place in the DCT and also the ResNet model to enhance the steganography performance via the MBFEPO. Finally, the inverse DCT is applied at the blocks to get the final stego image and video. In the audio steganography phase, the wanted audio has been gathered from external websites. The collected data are given to the STFT to convert into the spectrogram image, and then the spectrogram images are given to the Adaptive DCT block for selecting the number of blocks to apply stego content. Thus, the blocks are selected with the utilization of the AMC-ResNet, where the parameter within the DCT and the ResNet are optimized via the same MBFEPO to improve the performance. After, the Inverse DCT is applied for reconstructing the spectrogram image. Then the resultant stego audio is obtained by using the Inverse STFT. In the end, several investigations are done to shows the performance of the recommended steganography model.
Image formation of raw video and audio
In this phase, the data is aggregated from both the audio and video
Here, the complex unit is indicated as s, the window function which has a smaller duration related to the input signal, is given as
Hence, the time domain signals are transformed into the spectrogram images through plotting each of the data recordings as individual 256 × 256 pixel images.
In the end, by using the STFT techniques, the spectrogram image is attained and termed as
Consequently, in terms of video data, it usually contains various frames in it, and then the frames are usually considered as images. It is used to enhance the quality of the given images. Thus, the images attained from the video data have been termed as the
DCT-based decomposition
In this research work, the DCT based decomposition is performed which shows the effective performance rather than the existing techniques. Here, the decomposition takes place in the image into the spatial frequency spectrum. However, the DCT is widely applicable in videos, images, media, audio, etc. Thus, the DCT has the ability to produce the real transform coefficients. The images attained from both the audio and video are depicted as
The 1D-DWT for the sequence
When the value of
The first transform coefficient is regarded as the average of all the samples in the sequence that are called as DC coefficients as well as the other transform coefficients are called as AC coefficients.
By, using the DCT techniques, the decomposed images from video and audio have been attained and it is termed as
Adaptive DCT-based decomposition
DCT has been used to separate the images into various parts. It also has high computational power. But, it does not reveal any information about the spatial domain. To tackle the disadvantages in the DCT model, the newly designed adaptive DCT is used. In this phase adaptive DCT model has been used for splitting up the decomposed images into 8 × 8 blocks for all channels (RGB). Commonly, RGB images have three channels red, green, and blue. The maximized dimensional-rich features through the residuals of channel differences over the images have been extracted for effective steganography. Here, the recommended MBFEPO algorithm has been used for optimizing the DCT model for enhancing the performance of the steganography process, in which the type of DCT from [1,12,33,35] is optimized in this phase. Then, the process of adaptive DCT-based image decomposition and block split is given in Fig. 2.
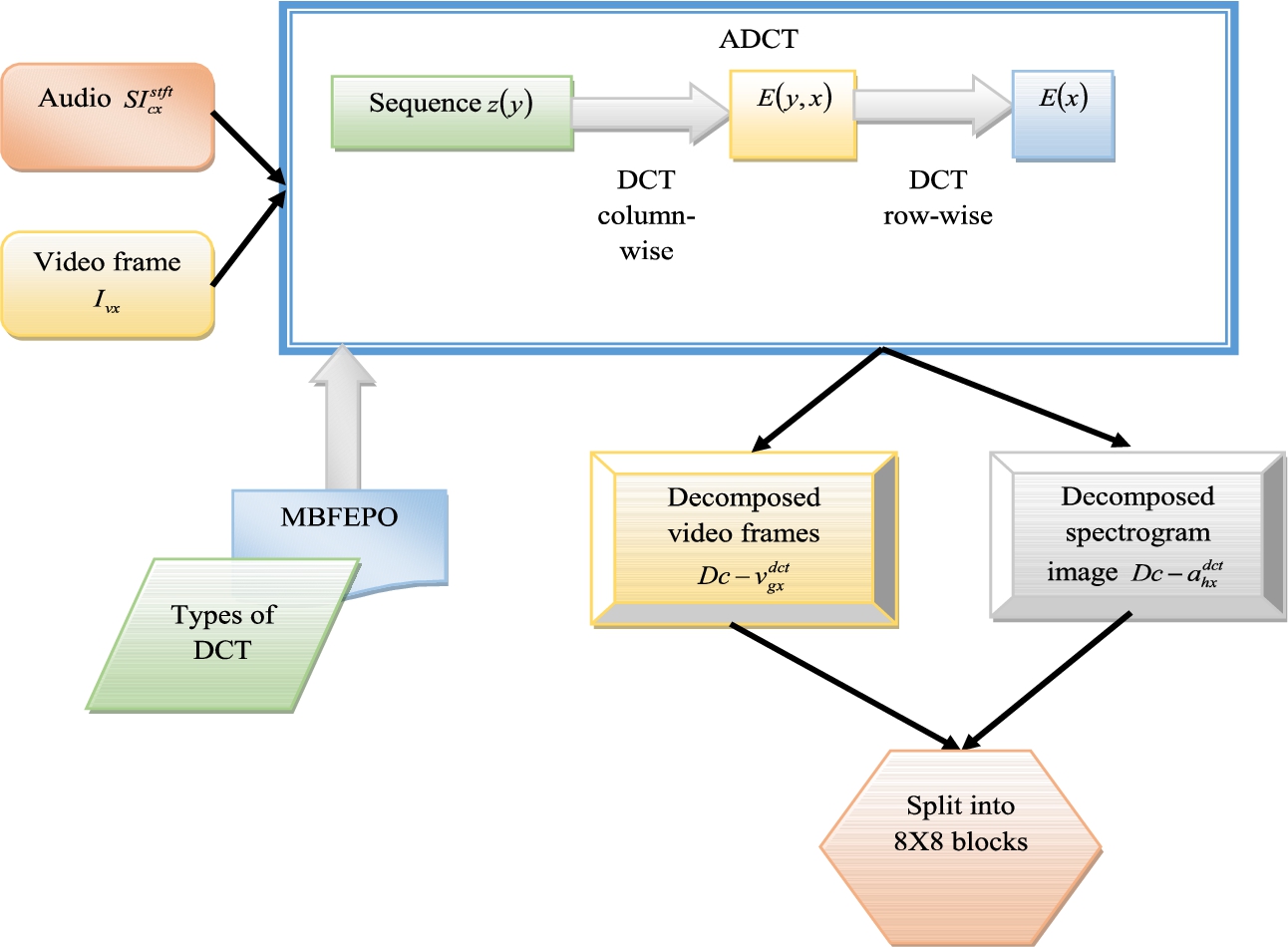
Adaptive DCT-based image decomposition and block split process.
The related studies for multimedia steganography are investigated and also the numerous technologies are developed to achieve the significant performance. In existing works, we have analyzed the diverse algorithms in this research area but, the techniques fail to provide effective performance. Moreover, the existing techniques falls into the local minima problems. Also, the training process requires more time to validate the model. Thus, the convergence speed gets affected. In order to solve the issues, we have considered the MBFA and EPOA algorithms due to its effective performance. The binary version of the EPOA for resolving the multi-objective issues is restricted in this model. Consequently, the MBFA has yielded powerful as well as efficient results for determining the optimum solution for structural optimization issues. It has also been used to minimize the construction cost of the model. But, it has faced storage issues that degrade the performance of the model.
The newly designed MBFEPO algorithm is implemented by using Eq. (5).
Here, the term
The vector ϕ is then combined with the gradient α for producing the complex potential expressed in Eq. (7).
Here, the location of the emperor penguins has been updated randomly towards the location of the emperor penguin. The analytical function on the polygon plane is depicted as A, and the imaginary constant is given as a.
Here, time for detecting the best optimal solution is represented as
Here, the current iteration is given as b, The position vector of the emperor penguin is indicated as
Here, the random function over
Here, exploration and exploitation parameters are indicated as d and e, and the expression function is given as f.
Here, the next updated position of the emperor penguin is denoted as
Here, the mother’s source point for the next iteration is indicated as
Here, the mother’s source point damp is denoted as
Here, the amount of dispersion that control parameters and could increase or decrease the effect of this movement is denoted as
Here, the current position for each cichlid is depicted as
Here, the best position of the last and current generation is termed as
Here, the best position of cichlids at last iteration is represented as
In terms of main movements, every child has the ability to propagate no more than the “Additional Surrounding Dispersion Negative or Additional Surroundings Dispersion Positive (ASDN or ASDP)”. Then, the two parameters mentioned have been expressed as in Eq. (22).
Here, the maximum and minimum limits of the problem variation are depicted as
When the current location is out of the search space area, then the new movement has been added by utilizing the mirror effects, and it is equated as in Eq. (23).
Here, the movements of cichlids before and after of mirror effects are given as
Here, the mother’s source point is indicated as
Here, the number of the cells that are to be changed is represented as
Here, the dispersion positive and negative limits for the left-out cichlid’s propagation are represented as
Here, the new position of left-out cichlids after the second part of the movements is
Here, the number of cichlids for the shark attack effect is given as
Here, the randomly selected cichlids are depicted as

Developed MBFEPO
Then, the overall process included in the MBFEPO algorithm is given in flowchart form, and it is given in Fig. 3.
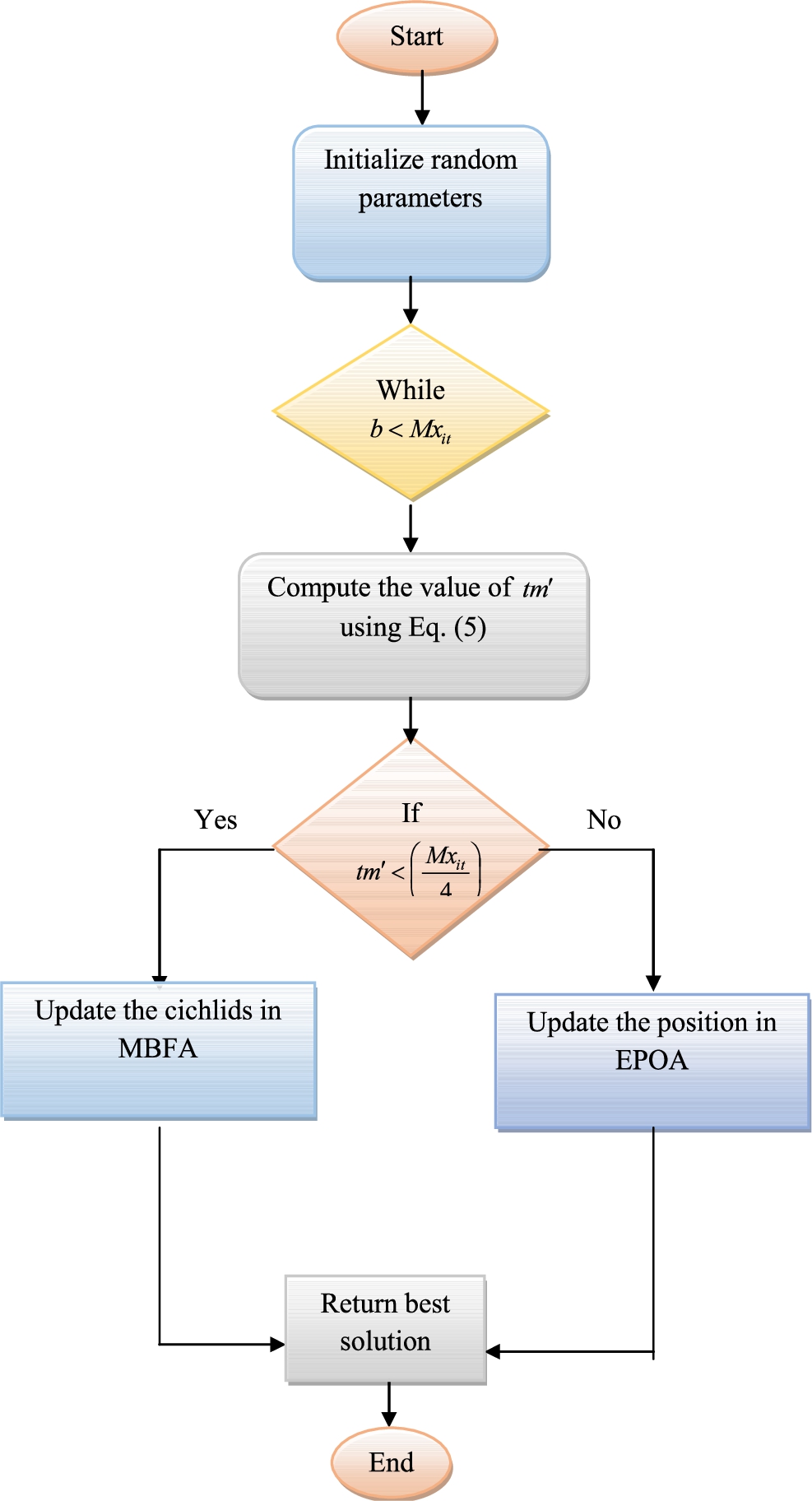
The flowchart for the given MBFEPO algorithm.
Adaptive multi-cascaded ResNet-based block selection
In this phase, the 8 × 8 image blocks obtained by using the adaptive DCT model have been fed to the AMC-ResNet model for selecting the blocks from the images for applying stego data into it.
In this phase, two ResNet models are parallel cascaded to form the AMC-ResNet model. Here, two separate ResNet models are considered for the process and attain two different scores from both ResNet. Further, it is taken averaging and concatenated to obtain the final single outcome.
Here, it has included training and testing phases in the AMC-ResNet model. In both the training and testing phases, the 8 × 8 image blocks are given as the input for attaining the target as selected blocks. The targets are considered as 0 and 1. The smooth region is considered as 1, and the sharp region is considered as 0 in the image. It is calculated by using the standard deviation of the image pixel. In the case of the smooth region, the intensity of the images is the same, and therefore there is no loss of information. On the other hand, the sharp region has different intensities, and there is a loss of information. In regard to this, the testing and training phase in the AMC-ResNet model has been carried out to effectively select the block for embedding.
The ResNet model has been used to tackle vanishing issues by utilizing identity mapping. The network model with the maximized amount of layers is trained easily without increasing the percentage of training error. But, it is infeasible in terms of real-time application. On the other hand, the DCT has more efficient for validating the illumination variation as well as it has been used for the contrast enhancement process. But, it has failed to localize the frequency component over the space. In order to tackle the difficulties in both the ResNet and DCT model, the newly designed MBFEPO algorithm has been used for optimization, and the process is detailed in the objective function, and it is equated in Eq. (30).
Here, the objective function is represented as
Here, the term
Here, the term
Here, the variable
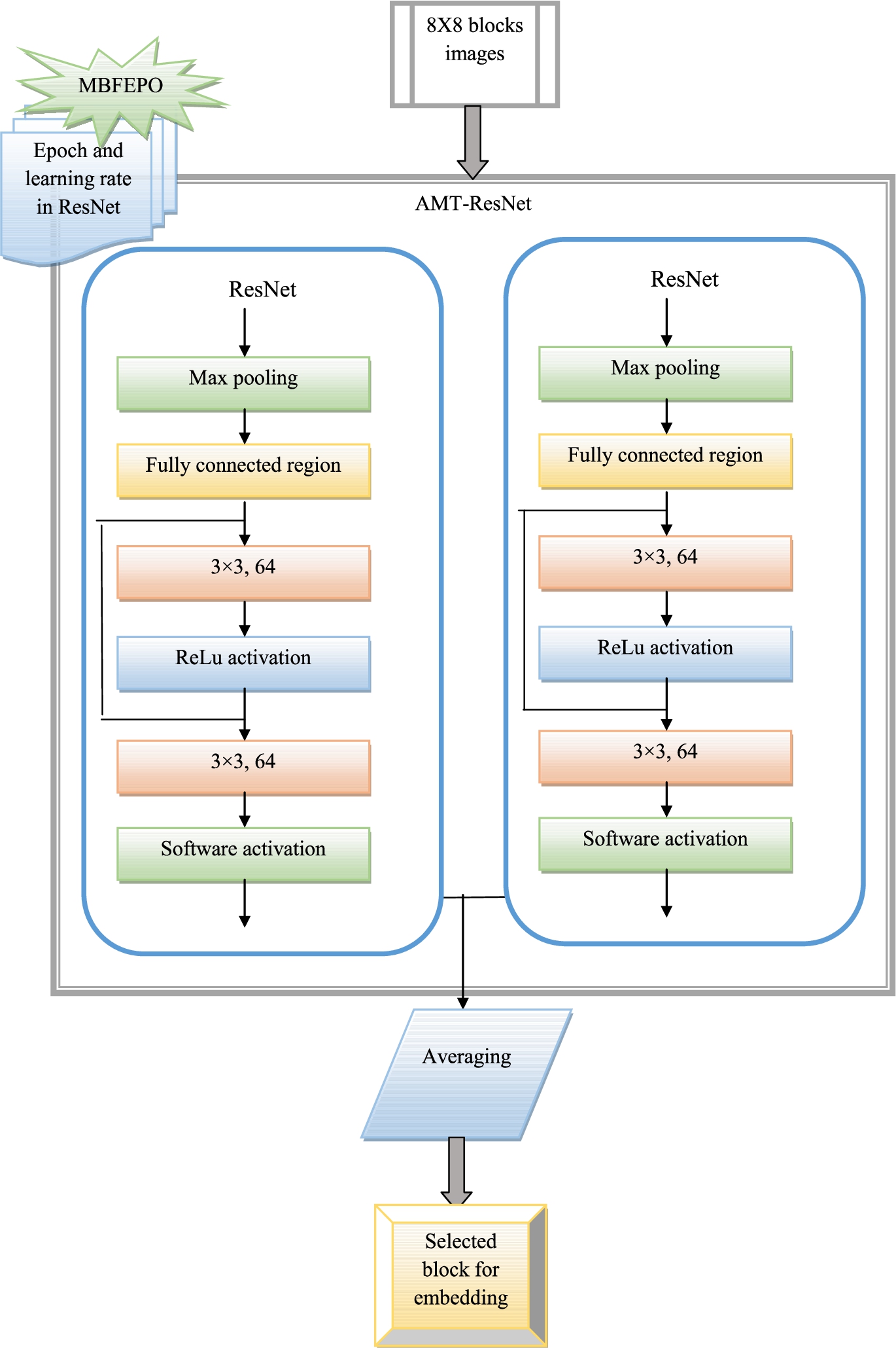
Diagrammatic depiction of AMC-ResNetmodel for block selection.
The overall process included in the image steganography is given below.
The inverse form of the ADCT techniques is equated in Eq. (34).
This equation is generally defined as the inverse transform or synthetic formula. The basic sequence is given as
Finally, the multimedia steganography images are obtained with the maximization of PSNR and SSIM values.
Process of audio steganography
The overall process included in the audio steganography is given as follows.
The inverse of STFT is given in Eq. (35).
Finally, the multimedia steganography images are obtained with the maximization of PSNR and SSIM values.
Results and discussion
Experimental setup
The performance estimation over the recommended multi-media steganography model was validated in Python. Here, the performance validation was carried out by utilizing various measures such as “NCC, Mean Squared Error (MSE), Bit Rate (BR), and SSIM, PSNR, and Embedding Capacity (EC)”. The “Sunflower Optimization (SFO) [7], Honey Badger Algorithm (HBA) [10], EPOA [28], MBFA [4] Lifting Wavelet Transform (LWT) [21], Dual Tree Complex Wavelet Transform (DTCWT [23]” were some of the algorithm and classifiers used for validation. The number of population was 1, the Chromosome length was 3 and the maximum iteration was 25 was utilized.
Performance metrics
The various performance metrics included in the process are represented below.
Here, the term
Here, the maximum size of embedded data is represented as
Here, the term
Proposed steganography results
The experimental results for the proposed multimedia steganography are given in Fig. 5.

Experimental results for the proposed multimedia steganography.
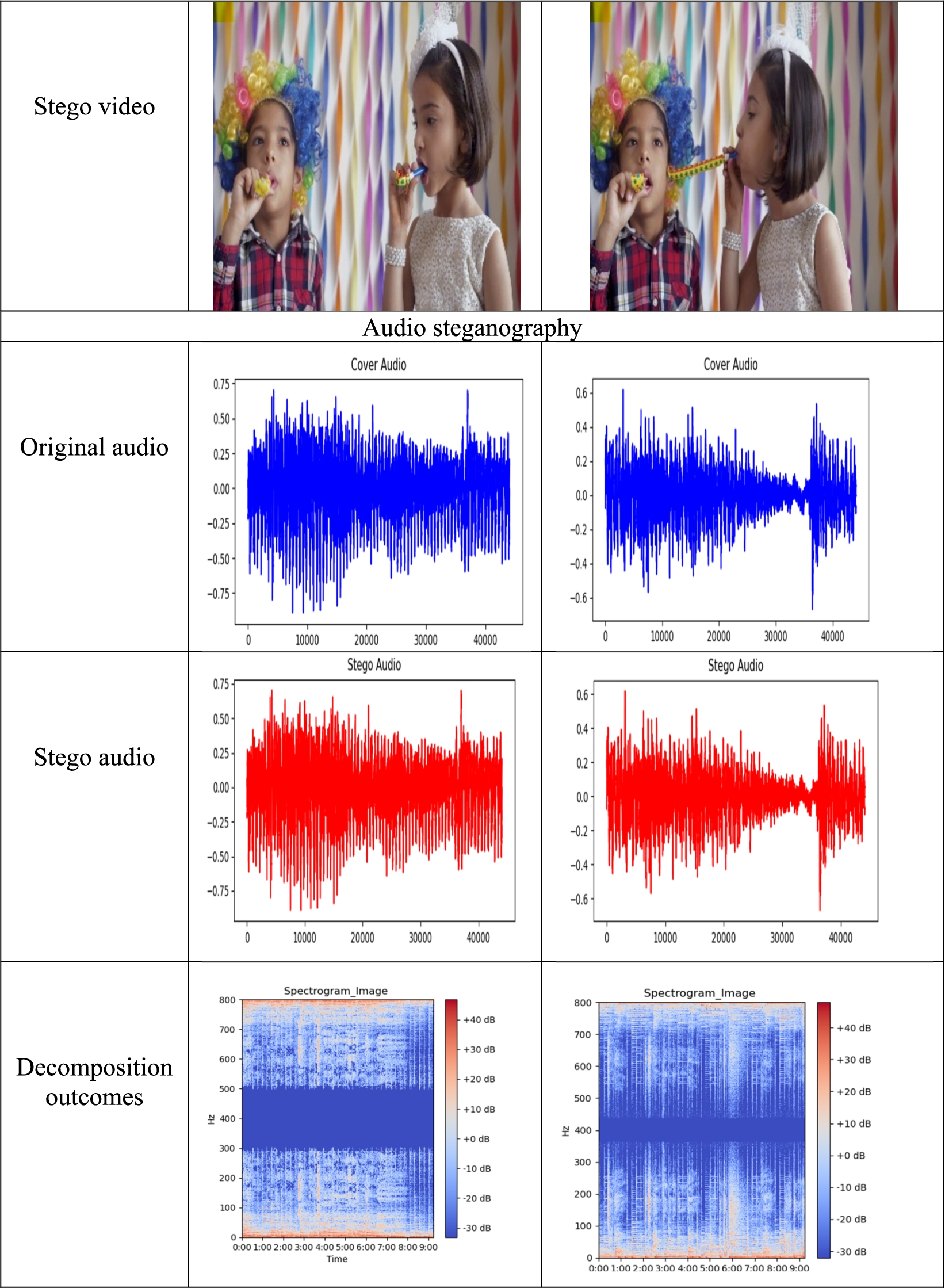
(Continued.)
Figures 6 and 7 represent the performance analysis for the given multimedia steganography by varying the classical algorithms for datasets 1 and 2. The value of MSE for the newly designed MBFEPO-AMC-ResNet has 47%, 19%, 15%, and 26% smaller values when assimilated over SFO-AMC-ResNet, HBA-AMC-ResNet, MBFA-AMC-ResNet, and EPOA-AMC-ResNet for dataset 1. It is similar for dataset 2 also. Therefore, the statistical analysis of the given multimedia steganography shows better outcomes.
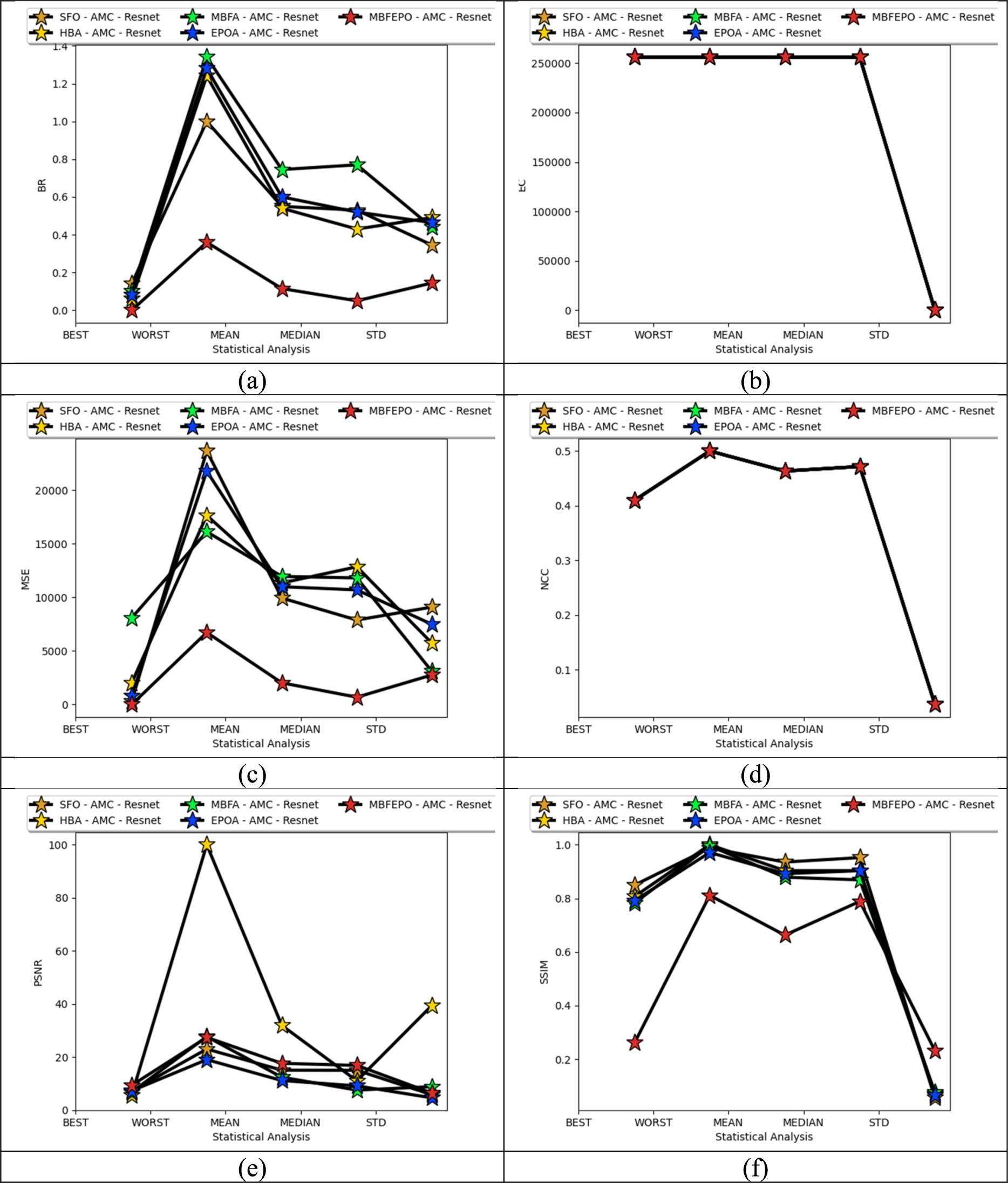
Validation over various algorithms for proposed multimedia steganography images for dataset 1 regarding “(a) BR, (b) EC, (c) MSE, (d) NCC, (e) PSNR, and (f) SSIM”.
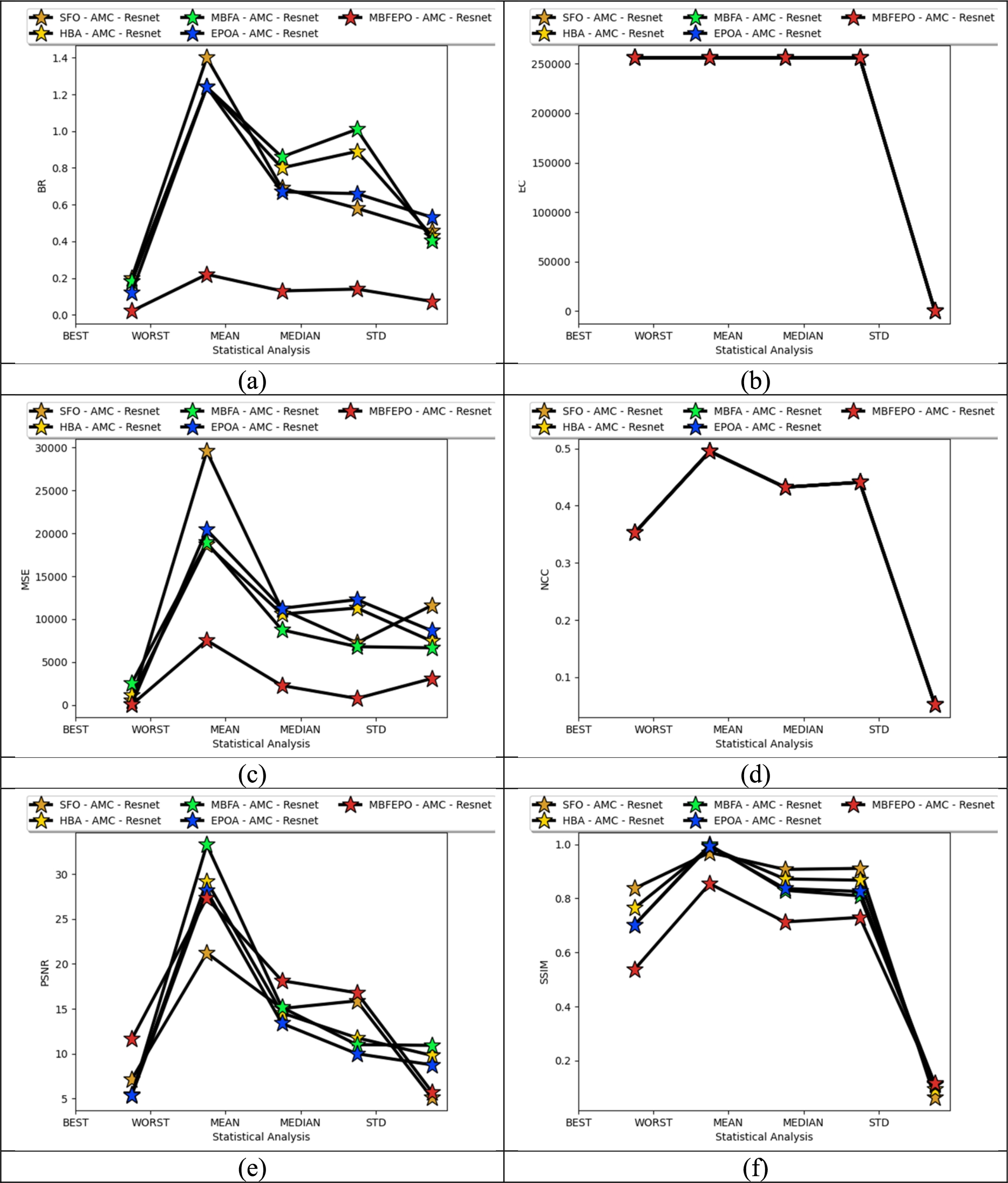
Validation over various algorithms for proposed multimedia steganography images for dataset 1 regarding “(a) BR, (b) EC, (c) MSE, (d) NCC, (e) PSNR, and (f) SSIM”.
The performance analysis for the given multimedia steganography by varying the classical classifiers for datasets 1 and 2 is given in Fig. 8 and 9. On considering dataset 2, the recommended MBFEPO-AMC-ResNet model has 14%, 11%, 30% and 10% lesser values than DWT, LWT, DTCWT, and ResNet for the value of BR in STD. Hence, the performance validation for the recommended MBFEPO-AMC-ResNet model provides promising outcomes, thus enhancing the performance of the model.
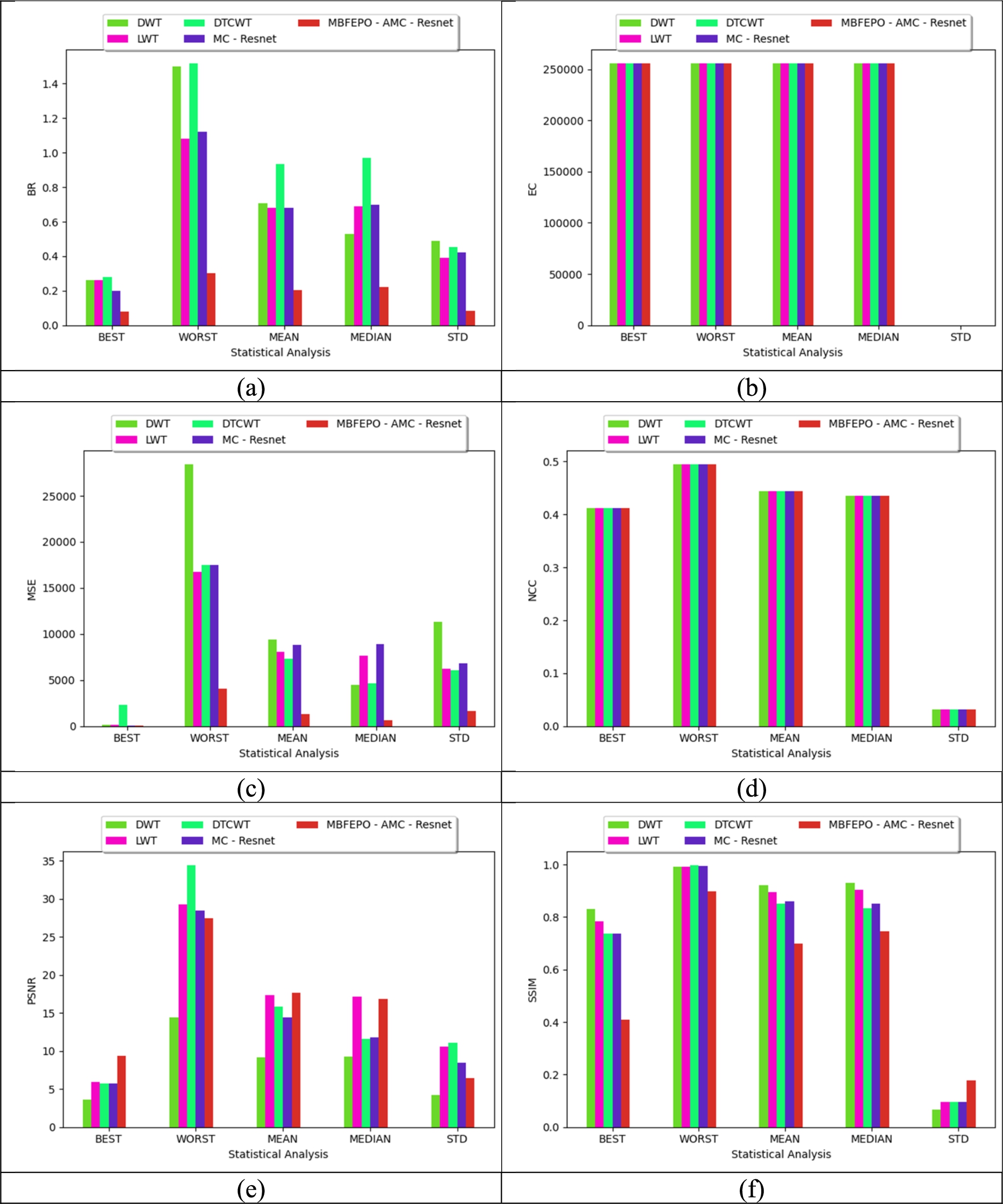
Validation over various classifiers for proposed multimedia steganography images for dataset 1 regarding “(a) BR, (b) EC, (c) MSE, (d) NCC, (e) PSNR, and (f) SSIM”.
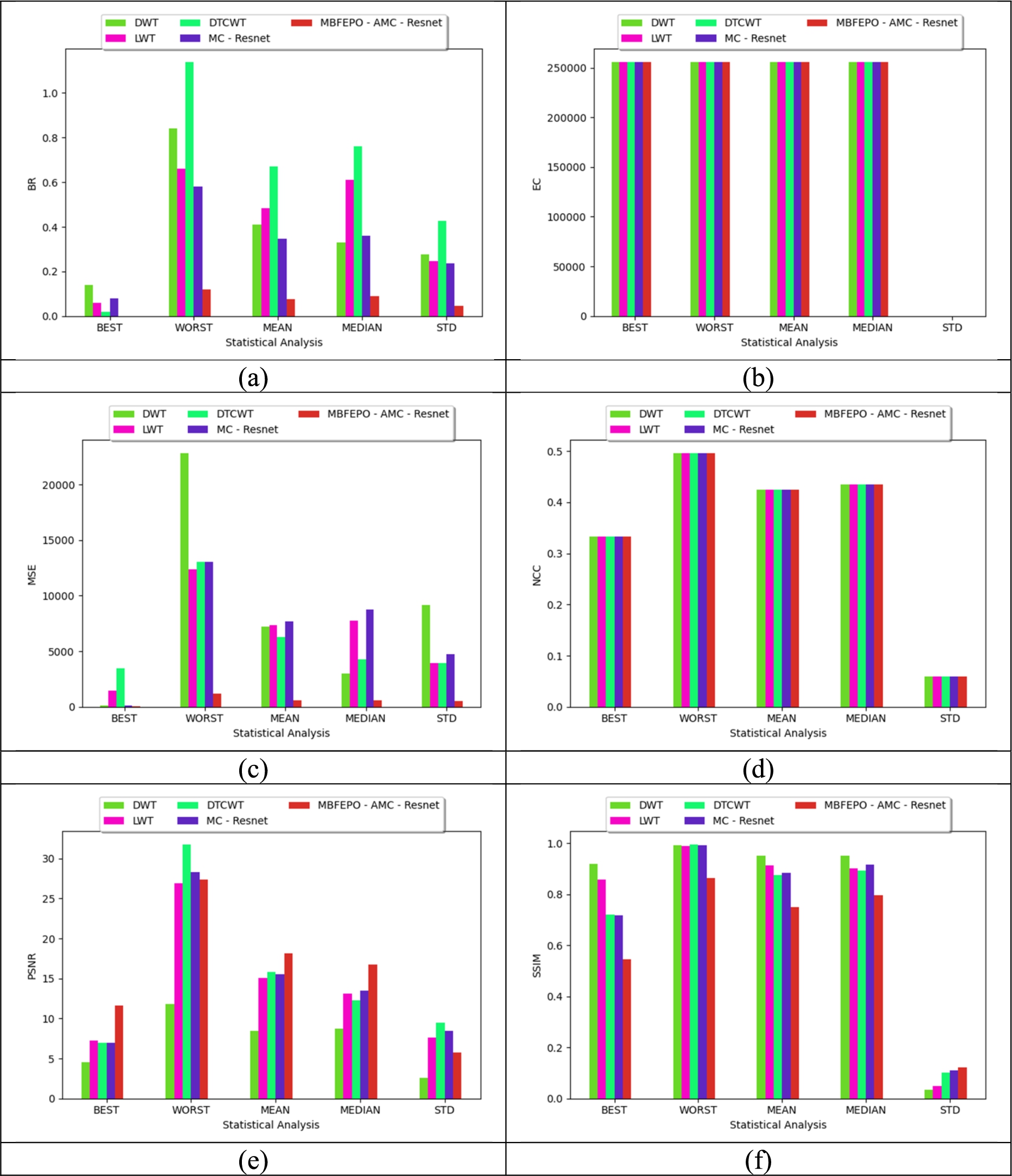
Validation over various classifiers for proposed multimedia steganography images for dataset 2 regarding “(a) BR, (b) EC, (c) MSE, (d) NCC, (e) PSNR, and (f) SSIM”.
Tables 2 and 3 have represented the overall performance analysis for the given video and audio steganography for both the algorithms and classifiers. For dataset 1, the value of BEST for the MBFEPO-AMC-ResNet model has 39%, 53%, 54% and 54 % higher values over SFO-AMC-ResNet, HBA-AMC-ResNet, MBFA-AMC-ResNet, and EPOA-AMC-ResNet. On the other hand, the recommended MBFEPO-AMC-ResNet model has 23%, 40%, 27% and 22% higher values than DWT, LWT, DTCWT, and ResNet for the value of BEST for dataset 1. Hence, the given recommended MBFEPO-AMC-ResNet model in the multimedia steganography images gives maximized PSNR values and thus increased the performance of the model.
Overall performance validation on dataset 1 over various algorithms and classifiers
Overall performance validation on dataset 1 over various algorithms and classifiers
Overall performance validation on dataset 2 over various algorithms and classifiers
The time and space analysis of the designed method is provided in Tables 4 and 5. The analysis shows that the designed method attains better performance rather than the existing methods.
Time analysis of the developed model for multimedia steganography
Time analysis of the developed model for multimedia steganography
Space analysis of the offered model for multimedia steganography
The convergence analysis of the recommended MBFEPO-AMC-ResNet model is evaluated using the existing approaches and it is shown in Fig. 10. If the iteration increases then, the cost function of the recommended model gets decreased. Thus, the convergence analysis provides the effective outcomes while the validation takes place among the existing approaches.
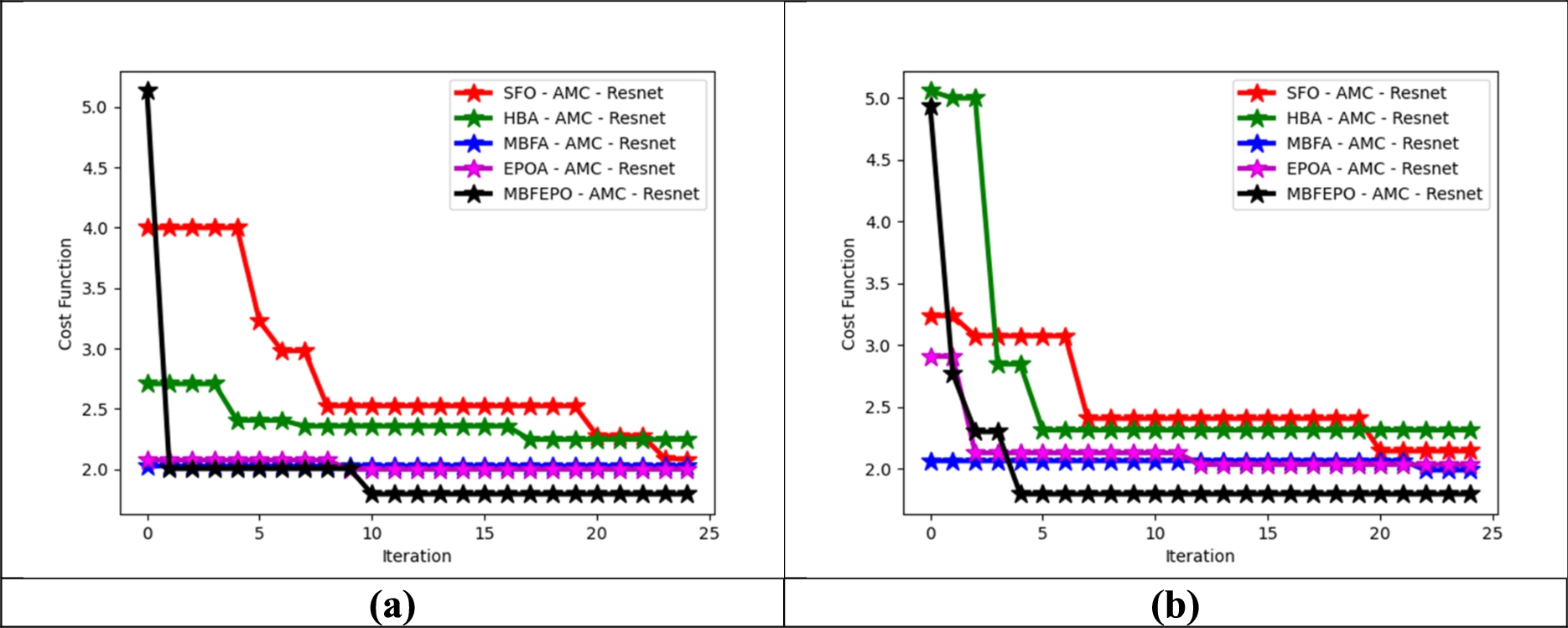
Convergence analysis of the developed model in terms of (a) dataset 1 and (b) dataset 2.
Screenshot for the Python codes.
The implementation screenshot for the designed approach using the Python platform is shown in Fig. 11
Conclusion
Steganography is performed to hide a message signal in the host signal without providing perceptual distortion in the host signal. The steganography was performed to provide better security for the data. Thus, this technique helps to secure files, audio, video, and messages on other media covers. However, the existing approaches are not sufficient to provide the effective performance. Here, the inserting of many characters causes vulnerable, and also security issues are emerged. Owing to these issues, this paper has implemented the multimedia steganography model with the aid of AMT-ResNet and the MBFEPO algorithm. Initially, the required video was obtained from the datasets, and then the acquired input was subjected to the Adaptive DCT-based block process. After, the optimal blocks were selected by utilizing the AMC-ResNet model. Here, the parameter optimization in the DCT and ResNet model was carried out to enhance the steganography performance using the MBFEPO algorithm. Finally, the inverse DCT was applied at the blocks to get the final stego image and video. In the audio steganography phase, the required audio was gathered from external websites. The collected data were given to the STFT to convert into the spectrogram image, and then the spectrogram image was given to the Adaptive DCT block for processing to get a number of blocks. Thus, the blocks were selected with the utilization of the AMC-ResNet, where the parameter within the DCT and the ResNet was optimized using the same MBFEPO to improve the performance. After, the Inverse DCT was applied for reconstructing the spectrogram image. Then the resultant stego audio was obtained by using the Inverse STFT. The value of the recommended MBFEPO-AMC-ResNet model has 48%, 1%, 10%, and 18% higher values than DWT, LWT, DTCWT, and ResNet for dataset 2 in MEAN. In the end, various investigations were conducted for evaluating the performance of the proposed steganography model, and it has shown promising outcomes along with the maximized PSNR and SSIM values. The limitations of the developed model are depicted below. The standard performance metrics like accuracy, FNR, and precision cannot be validated to show the accurate performance of the developed model. However, the accuracy of the model could not be predicted. Moreover, the real time data cannot be utilized in the designed model. In the future we will try to implement and evaluate the real time data using the developed model. Also, the combined evaluation of the steganography and cryptography will be investigated in the upcoming works.
Practical applications. In various fields, the IoT is widely utilized and also applicable in diverse applications like smart home, smart city, health care, mobility etc. Due to the emerging of technology, a huge amount of data is transmitted through wireless networks. Thus, the steganography are utilized to secure the data over the Internet. In a practical scenario, information-hiding techniques like steganography are widely applicable in smart homes to protect communications in critical IoT environment. Thus, it provides significant economic growth and safety prospects.