
Abstract
Alert correlation is an approach to analyze a huge number of security alerts received from network sensors. An alert correlation engine normalizes, fuses and clusters incoming alerts; then identifies relationships among them. Limitation of computing resources, like CPUs, makes such systems not satisfactory. In recent years, GPUs have been used in various fields, however, due to the dynamic nature of processes and data structures in alert correlation, correlation algorithms have not been implemented on the GPU. This paper presents a novel approach to implement alert correlation on the GPU. It focuses on alert aggregation, which is classified as a similarity-based alert correlation. This approach presents an online cooperative model which utilizes the processing power of CPUs and GPUs to aggregate security alert. This paper also presents the development of a toolkit named GTA2, which works as an assistant tool with Snort and provides online alert aggregation on alerts received. GTA2 takes advantage of unused processing power of existing GPU to aggregate security alerts generated by Snort. Evaluations illustrate the proposed method will improve the processing speed by 15 times.
Keywords
Introduction
Alert correlation analysis is one of the core functions of security operations center, which can avoid false and duplicate reports, contribute to find some potential threats and improve the efficiency and security of the network [27]. Similarity-based algorithms are the subcategory of correlation algorithms which are widely used and utilize similarity metrics to correlate alerts. Techniques used in this subcategory are classified as filtering and aggregation. Filtering technique performs a fixed task on each alert and makes a decision according to the acquired result. Alert verification and prioritization are in this class. The goal of aggregation technique is fusing or clustering incoming alerts in order to facilitate decision making. This technique utilizes similarity metrics and puts similar alerts into one category.
The performance of correlation system should be such that it can do real-time processing on incoming alerts. The algorithms that use aggregation techniques require a lot of computing resources and this restriction is as a bottleneck in correlation systems [1]. The time complexity of aggregation algorithms in the worse-case is
Graphics processors have been developed very rapidly in recent years. With each new generation, additional features are introduced that move the GPUs one step closer to wider use in general purpose computations [25]. The use of a GPU beside a CPU to perform general-purpose computations is known as General Purpose computing on Graphics Processing Units (GPGPU). To facilitate GPGPUs, an extension to C language called Compute Unified Device Architecture (CUDA) was introduced in 2007 [8]. Since then, programming with GPUs for general applications becomes much broader as it is easier than before.
Much research has been done on GPU to improve the performance of variant algorithms in other fields, such as image processing, cryptography, pattern matching and etc. There are contributions to implement filter-based algorithms like traffic classification and pattern matching on the GPU. However, due to the dynamic nature of process and data in aggregation, there are not any efforts to implement aggregation-based algorithms on the GPU.
This paper presents an architecture and a model for online CPU–GPU cooperative aggregation that can integrate the computing power of CPU and GPU to perform aggregation on alerts more efficiently and presents a real-time engine. In this model, we have used methods that reduce the negative impact of restrictions caused by irregularities of correlation algorithms.
The rest of this paper is organized as follows: First, a brief discussion of related work about correlation and the GPU is given in Section 2. Section 3 describes the serial aggregation algorithm and time complexity of aggregation algorithms in the serial manner. In Section 4, GPU-based parallel aggregation algorithm is presented and Section 5 describes proposed model. In Section 6, a GPU-based toolkit for alert aggregation is presented. Section 7 discusses experimental results and finally, Section 8 draws conclusions and outlines future works.
Related work
Over the past few years, much research has been done in the field of alert correlation. Most of these studies, especially those that were initially proposed, have focused on improving the effectiveness of correlation. In these studies, researchers have attempted to provide ways to correlate more alerts in order to improve reduction rate, to recognize more false positive alerts and to detect scenario of attacks accurately.
Most of solutions which have been proposed in correlation, are offline approaches run periodically on alerts. In addition, online solutions are only able to process alerts slowly [20]. Studies presented in [3,9,16,22,24,26] concern a number of offline cases that are seeking solutions to reduce both false positive alerts and final alerts reported. However, there are studies that have made efforts to improve the performance and speed of correlation algorithms.
In 2006, Valeur [23] improved performance of his correlation architecture, which was presented initially in 2004. In addition, in 2010, the researchers [19] proposed an agent-based approach to Valeur correlation system. In [15], in addition to present a method for fast access to required data, researchers provided a platform for clustering correlation processes. In this research, by using storage techniques and an extensible platform, researchers improved alert processing performance. In [1], researcher implies to limitations of correlation systems in terms of performance and proposes to pre-filter the generated alerts at the source (i.e. intrusion detection systems). It can reduce the amount of the alerts that received by correlation system.
In the aforementioned studies, in order to increase the speed and quality of the correlation algorithms, researchers have focused on the algorithm itself as well as on software issues. Software approaches can improve performance of correlation; however, they are limited in improvement. None of the studies that have been mentioned above tries to use other processing platform’s capabilities.
The GPU has had significant success in the field of graphics processing, and over the past five years, researchers have made many efforts to use it in the other areas.
There are some efforts in which use the GPU to improve the performance of security algorithms, such as [4,6,10,14,17]. In [4,6] and [14], researchers are seeking to implement the matching algorithm on the GPU. In the matching engine, which is used in intrusion detection system, incoming data are compared with predefined and fixed patterns, and then, according to the result of matching, it decides about incoming data. In [2,5,12,18], researchers are seeking to implement classification algorithms on the GPU. For example, in [5], researchers implemented BitMap-RFC and BPF algorithms in parallel manner on GPU and could achieve up to 13 times improvement in performance. Pattern matching and traffic classification are filter-based algorithms that can match incoming alerts with fixed parameters.
For the first time, in [11] we implemented a prototype of aggregation engine and showed GPUs can improve the speed of correlation algorithms. This study is the base for us in this paper. In previous contribution, we implemented a light engine of aggregation which processes on incoming alerts one after another.
Aggregation algorithm
As mentioned above, alert aggregation is a class of alert correlation that uses similarity metrics and includes fusion, session reconstruction, thread reconstruction, focus recognition and multi-step correlation algorithms [23]. Keeping a sliding time window is the main feature of these algorithms. A sliding time window keeps incoming alerts in an alert queue, in order to process them later. An aggregation-based algorithm has three different phases: reconstruction, matching and merging/adding.
In the reconstruction phase, the alerts that have exceeded the time window will be removed from the alert queue and will be sent to next correlation component. The matching phase compares the incoming alert with those in time window and sends results to the merging/adding phase. In the merging/adding phase, if the incoming alert belongs to the queue – i.e. similarity criteria are satisfied –, the selected alert from the queue and incoming alert will be aggregated as an hyper-alert; otherwise, the incoming alert will be added to the end of the alert queue.
The matching operation in aggregation-based algorithms, such as filter-based algorithms, consists of two elements: incoming data and matching parameters. Incoming data is a dynamic element in both aggregation and filtering techniques, i.e. in each time the incoming data is different from previous data. In filtering technique, matching parameters are constant values, including the rules in classification algorithms and the patterns in pattern matching algorithms; but as of aggregation technique, these parameters are dynamic values, including the alerts in the time window. To sum up, due to this difference, unlike filter-based algorithms, aggregation-based algorithms have not been implemented on GPUs.
Time complexity
When a new alert arrives, the serial algorithm compares it with all alerts in the queue, starting with the first one and moves towards the end of the queue. Since alerts in queue are not sorted by time stamp and it is possible to match more than one alert, the operation must continue to the end of the queue. If no match is found, the alert will be inserted into the queue, to be considered for matching with future alerts.
If the rate of incoming alerts was r and the size of time window was
Processing time per component (ms/alert)
Processing time per component (ms/alert)
The programming model of GPU is characterized as simultaneous multithreading (SIMT) and presents some relevance with the SIMD category of parallel programming models on vector processors [7]. This feature helps us to remove comparing loop in the serial algorithm.
The operations in correlation engine that have the potential of parallel processing are:
Identifying alerts that have exceeded the time window and sending them to the next step.
Matching incoming alert with alerts in the queue.
Each thread in the GPU is responsible for processing one alert in the alert queue. Once the host (CPU) receives a new alert, after the pre-processing, correlation system transfers control to the device (GPU) and then, the GPU threads simultaneously compare new incoming alert with the alerts that they are responsible for. As a result, time complexity will decrease to
The dynamic nature of correlation algorithm causes challenges for parallelism, such as data process dependency and overhead of parallel operation calls. In the former case, the results of processing alert are not totally independent of each other. Thus, while alerts are processed simultaneously, at some stages they have to wait for other results to be processed. In the proposed model, to deal with this problem, the correlation operation was divided into several steps, which transform data dependency into step dependency. At each step, threads perform their operation independently, but the start of each step depends on the previous step.
In the latter case, the revocation of parallel operation has an overhead on the system, thus when many alerts arrive, the overhead of the system increases. In order to solve this problem, three solutions have been presented:
Using a cooperative model in which the efficient platform processes alerts instantaneously. When the size of the alert queue is smaller than a threshold (
Sending a block of alerts to the correlation engine instead of one alert. If the incoming alerts are sent to correlation engine as a block, the overhead of revoking parallel operations will be divided among alerts that are within the block and as a result, the overall overhead decreases. The correlation engine in GPU receives the block of alerts and performs correlation process on each alert of the block. In addition, alerts in the block can be processed in parallel by some steps. The following section will explain about detection of best value for the block size.
Executing some parallel operations periodically. The revocation of some parallel operations has overhead and can be executed in certain periods. This idea reduces overall overhead of the system.
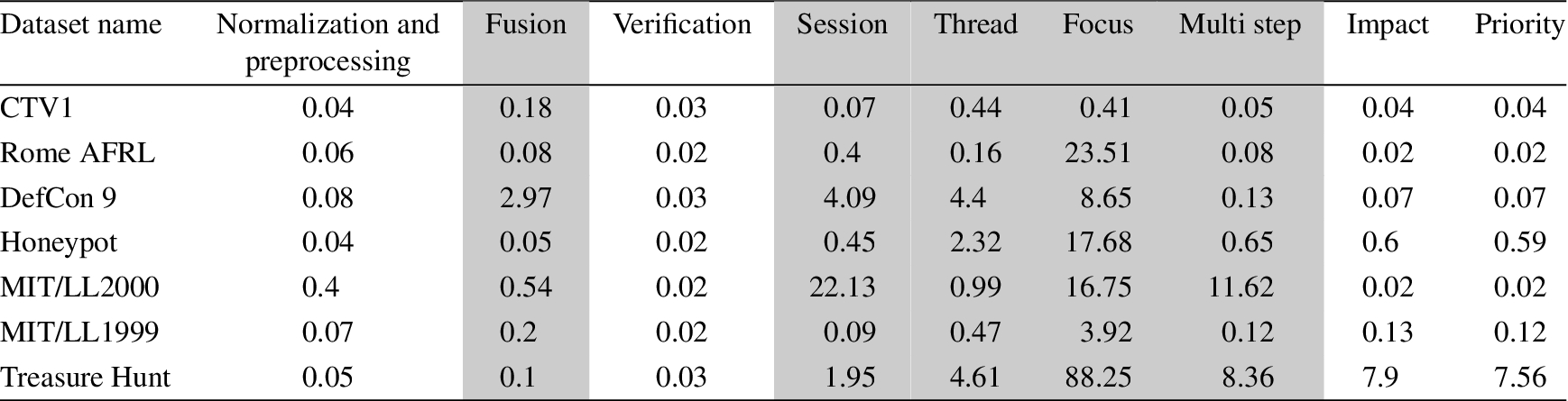
Figure 1 shows the architecture of presented model. This figure illustrates the cooperation between a GPU and a CPU. In each component, the module R denotes Reconstruction phase, the module M denotes matching phase and the module M/A denotes merging/adding phase. Each arrow denotes a processing thread that is responsible for a certain task. The numbers next to the arrows indicate the time complexity of each module in an algorithm revoking. For the modules M and R in Parallel Aggregation Component, n threads will be run on the alert queue. It means each thread is responsible for one element of the alert queue; as a result, the number of running threads is n (alert queue size). For the module M/A, m threads will be run on the alert block and each thread is responsible for one element of the alert block array. As a result, time order of the modules R and M decline to m from

The architecture of presented model.
With the arrival of a new alert, the host will pre-process it and puts it on an alert block. In pre-processing operation, the host aggregates incoming alert; indeed, in this step, the alert block is considered as a small instance of the alert queue and the operation performed on the alert block is considered as a primary correlation operation. When the alert block is full, it will sent to main correlation engine and according to predefined thresholds, the host or the device processes the alerts that are in the alert block. When the device is responsible for the alert block, the host creates a kernel code – a code executed on device – and transfers control to the device. When the code is completely executed, control returns to the host.
When the queue size is close to
If the queue size is smaller than
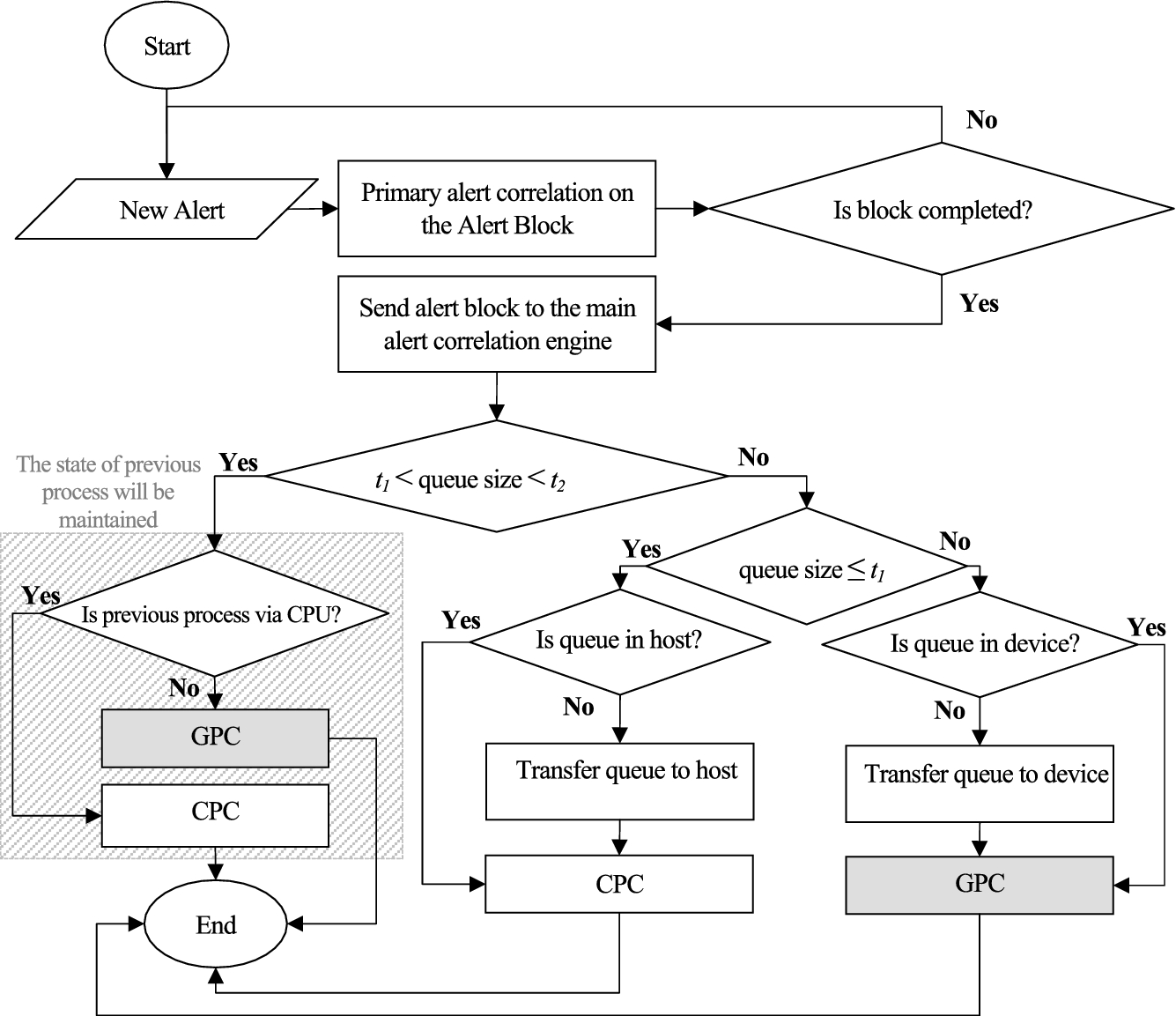
The model of cooperative alert aggregation.
The flowchart presented in Fig. 2 has two main components: CPU Processing Component (CPC) and GPU Processing Component (GPC). The CPC is a component with serial processing algorithm and the GPC is a component with parallel processing algorithm. Figure 3 shows the flowchart of CPC, which has been described in Section 3.
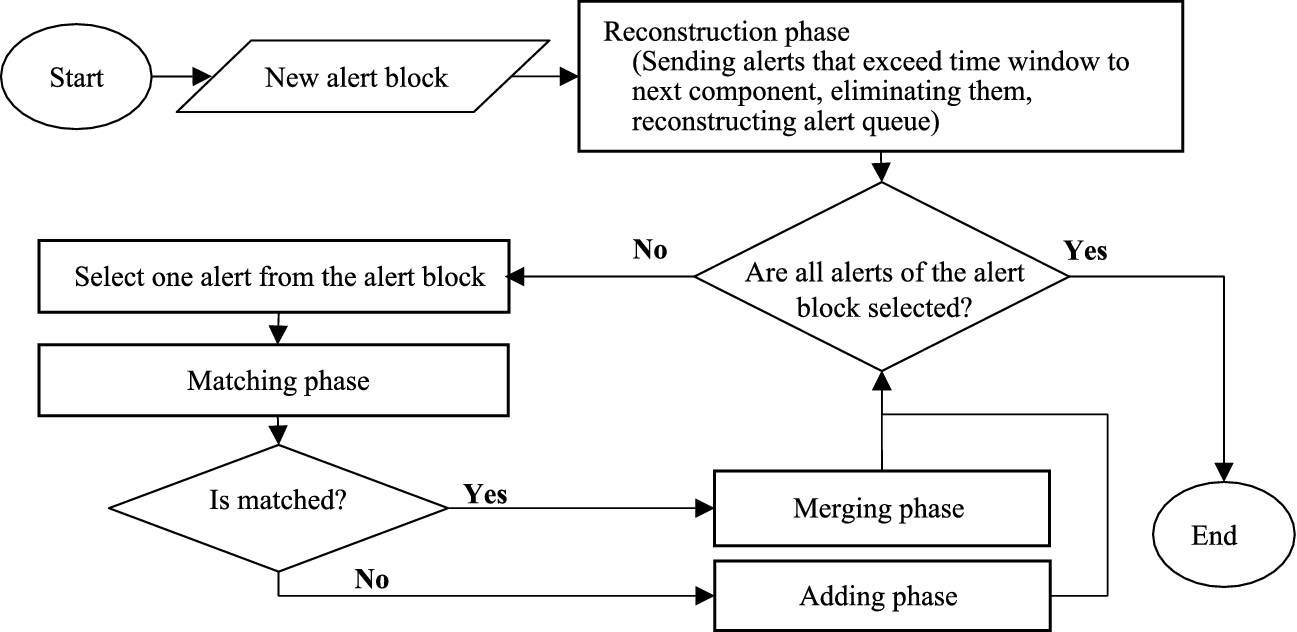
CPU Processing Component flowchart.
Figure 4 shows the GPC in details. As discussed in Section 4, the kernel code must be divided into three parts. But there are no peer-to-peer mapping between three phases of the aggregation algorithm and three parts of the kernel code.
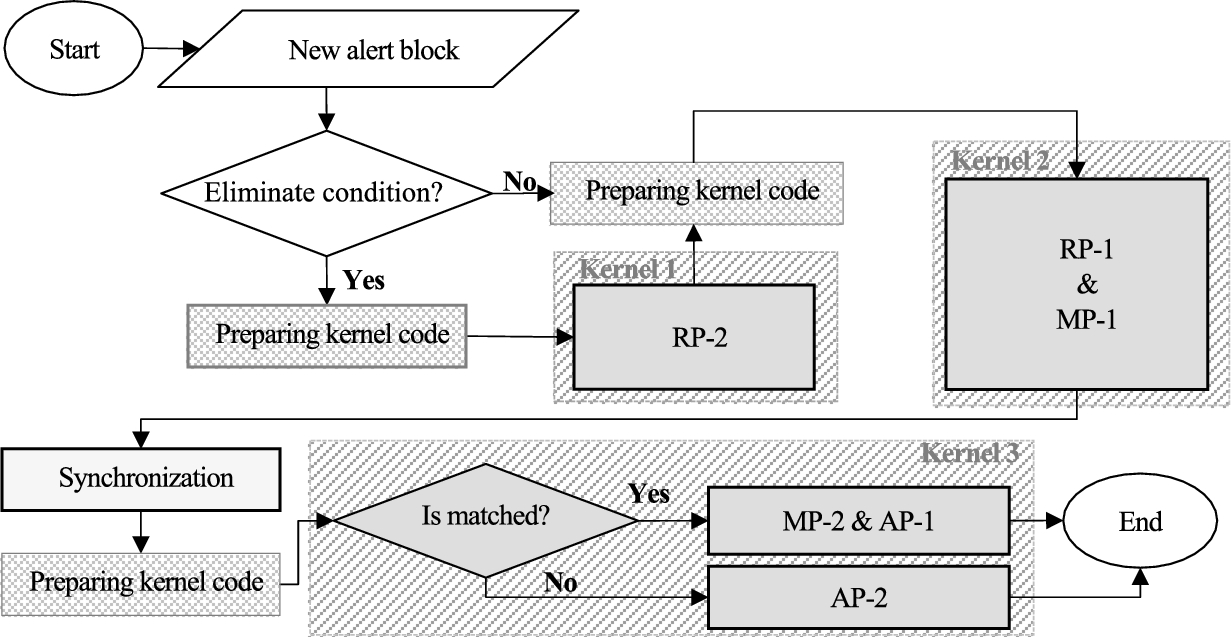
GPU Processing Component flowchart.
Mapping aggregation phases to kernel parts
The kernel 1 uses Thrust library [13], which executes serial function by GPU’s threads. Thrust is a CUDA library of parallel algorithms which provides many fundamental programming logic like sorting, prefix-sums, reductions, transformations. Since the revoking of a function of Thrust library causes overhead to the system, the kernel 1 is periodically executed under predefined conditions. These conditions are:
The pseudo code (see Fig. 5) shows the kernel functions of the proposed model.

Pseudo code.
In order to test the presented approach, a toolkit were developed, called GTA2 (GPU-based Toolkit for Alert Aggregation). GTA2 works together with Snort and processes the alerts generated by such software. Figure 6 gives a graphical representation of GTA2 operations along with Snort. As shown in this figure, when Snort sends an alert out, GTA2 receives that alert and after the aggregation process, sends result to Syslog.

The architecture of GTA2.
In this evaluation, the performance of alert processing is calculated with respect to serial, parallel and mixed modes. The experiments were executed locally on an Intel CPU with a 2.93 GHz clock speed and on the NVIDIA GTX 580 GPU with 512 cores. The operating system used is Ubuntu 11.10 and the programming toolkit is CUDA 5.0. In all scenarios of this experiment, the argument of “block_size”, which shows the number of threads per block, for kernel 2 and kernel 3 is 512. Also the number of blocks per kernel for kernel 2 is calculated as follows:
And the number of blocks per kernel for kernel 3 is calculated as follows:
Since the goal of this study is to improve the performance of correlation system, it is important to have a great number of alerts that cover all possible states for processing. So, we used three different datasets, including similar alerts, dissimilar alerts and real alerts. The first two datasets consist of 600,000 alerts and the other one consists of 200,000 alerts. In the first case, the incoming alerts always merge with an alert or hyper-alert in the queue. In the second case, the incoming alerts do not merge with any alerts in the alert queue; instead, they are added at the end of the queue. The real alert dataset is collected by DefCon 9 [21] which simulates a real condition.
For each alert type, two scenarios are considered:
Scenario with the block size of one.
Scenario with the best value for block size.
As a result, six evaluation scenario were developed (Table 3).
Experimental scenarios
Experimental scenarios
In order to acquire best value for the alert block size, an experiment was implemented. In this experiment, six timers were utilized to measure processing time of every component of parallel operation. The experiment was repeated for the real alert dataset with the block size of 1 to 23,750. The best alert queue size is achieved when the total time of processing is minimum. Results shown in Fig. 7 represent the time of one execution of parallel correlation.
The dotted curve represents the GPU processing time, the dashed curve represents the pre-processing time required by the CPU and the solid one is the sum of both. The pre-processing function, which is required for creating the alert block and performing primary correlation on it, causes a distance between tow continuous GPU processes. As shown in Fig. 7, the longer the alert block, the pre-processing time of CPU is greater. When the size of alert blocks is in the range of 50 to 1,000, the processing time of parallel operation – solid curve – will be minimum. Accurate tests show that the number of 250 is the best value for the incoming alert block.

Processing time of parallel operation with respect to different block size. (Colors are visible in the online version of the article; https://dx-doi-org.web.bisu.edu.cn/10.3233/JHS-150509.)
Figure 8 shows the result of case 1 as similar alert scenarios. Part (a) is the speed of aggregation operation of the serial algorithm with alert block size of one (CPU), the serial algorithm with alert block size of 250 (CPU250), the parallel algorithm with alert block size of one (GPU) and the parallel algorithm with alert block size of 250 (GPU250). Part (b) is improvement of CPU250, GPU and GPU250 algorithms in comparing to CPU algorithm.
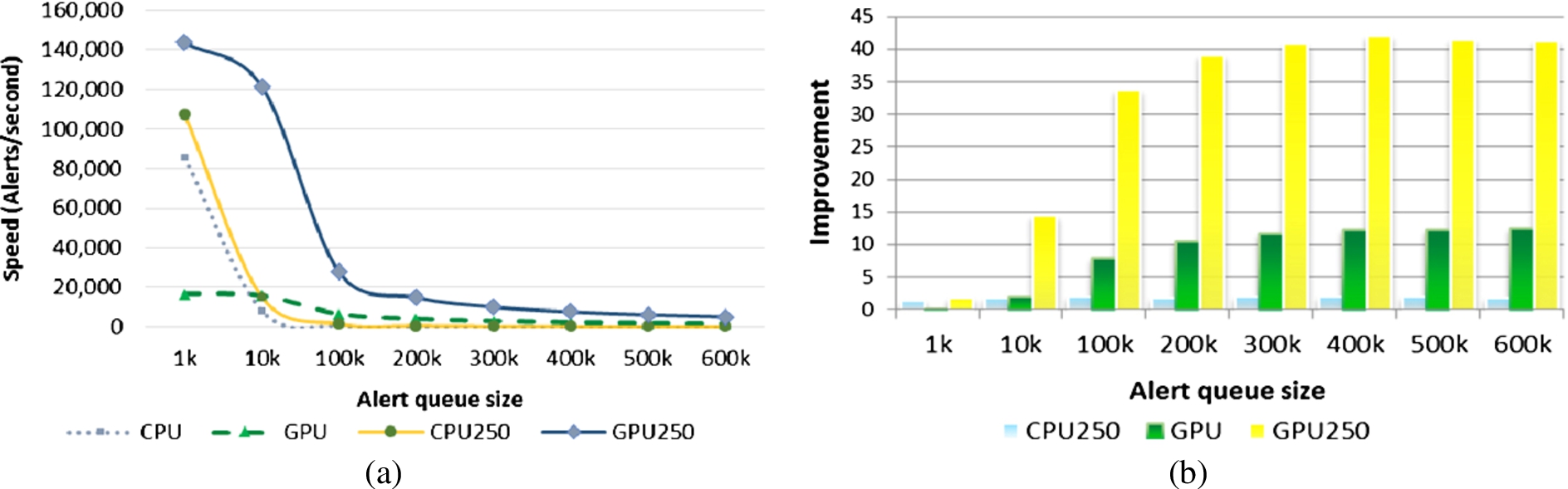
Experimental results of similar alert. (a) Speed of the aggregation operation; (b) Improvement of proposed algorithms. (Colors are visible in the online version of the article;
Figure 9 shows the result of case 2 as dissimilar alert scenarios and Fig. 10 shows the result of case 3 as real alert scenarios.
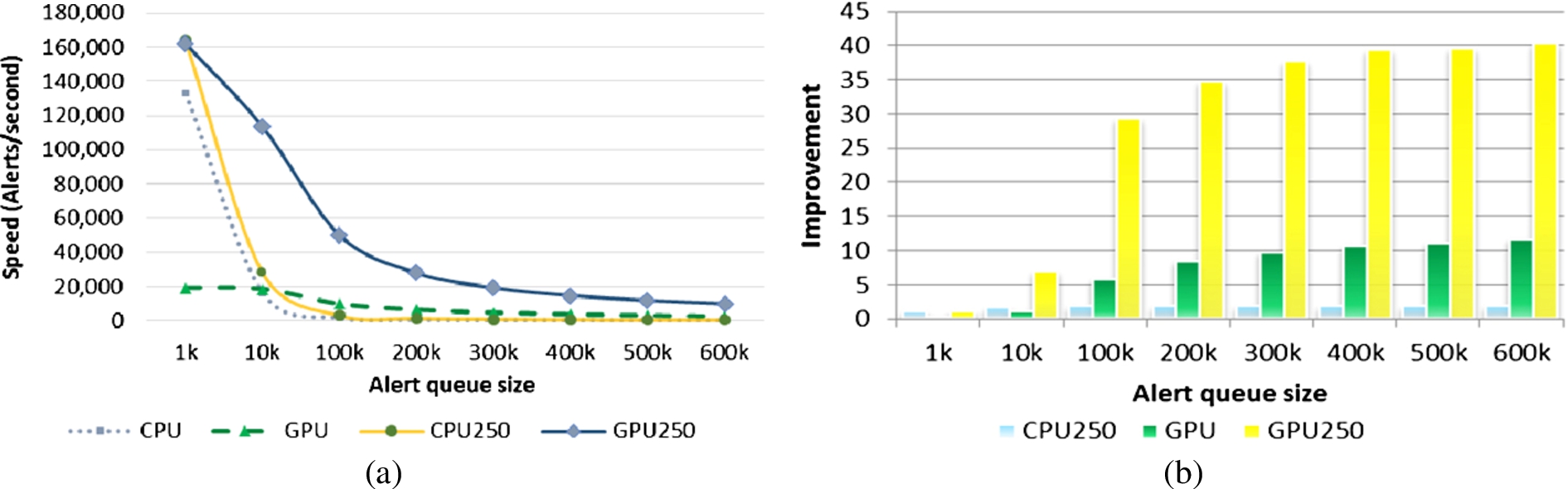
Experimental results of dissimilar alert. (a) Speed of the aggregation operation; (b) Improvement of proposed algorithms. (Colors are visible in the online version of the article;
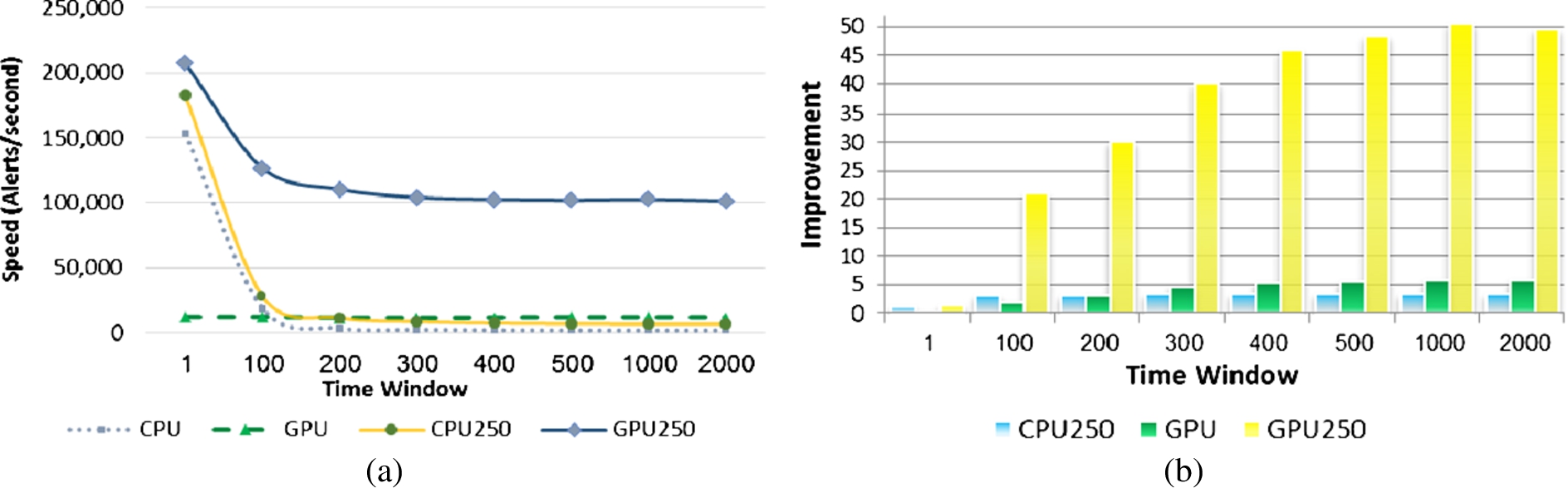
Experimental results of real alert. (a) Speed of the aggregation operation; (b) Improvement of proposed algorithms. (Colors are visible in the online version of the article;
In evaluation cases 1 and 2, the horizontal axis are alert queue size and in evaluation case 3, the horizontal axis is the time window.
Experiments illustrate that proposed model improves the speed of aggregation algorithms. Improvement is variable with respect to the time window and the alert queue size. In real condition, if the time window is 100 s, improvement will be achieved up to 20 times and for time window 2,000 s, up to 50 times. We can illustrate the improved GPU-based approach (GPU-250) aggregate security alerts 6.5× faster than improved CPU-based approach (CPU-250) when the time window is 100 s, and 15× faster when the time window is 1,000 s. Reduced rate for time window 100 s and 2,000 s is 64.50% and 75.50%, respectively. The processing speed of mixed approach is calculated as follows:
This paper presented a real-time cooperative model to aggregate alerts, which increase the performance of correlation system. As a result, we developed GTA2 that use the processing power of GPUs beside CPUs for aggregating security alerts that generate by Snort. By experimentations, we can find that the model proposed is effective and is able to correlate alerts rapidly. However, there are some issues worthy of future research. In the future, we expect to improve the above model and algorithm to reach better performance and extend it to all aspects of correlation system. Also, issues such as memory bandwidth and allocation of the resource must be considered with more details in future work.