
Abstract
Inter-vehicular communication is a very hot topic in the most recent research environment, since the management of traffic information is an important issue in order either to minimize the number of accidents, or to optimize the road safety. The most known traffic control systems are the VANETs (Vehicular Ad Hoc Network), a decentralized structure by which vehicles are able to communicate to each other, by exploiting some OBUs (On Board Units), which actually realize signals transmission.
The main idea of this work is to transform the decentralized structure, typical of the VANETs, into a centralized one. In this way, we can obtain many advantages, such as a simpler clustering process: this last is a very important operation concerning the organization of some objects in more groups, according to some criteria which can improve the performances of a system, in general. In this case, we would exploit this notion, in order to reduce a phenomenon, known as “broadcast storm”, which is very frequent when we speak about VANETs and causes most of the collisions occurring during the communication between vehicles. According to this goal, we provide, in this work, a non-exclusive clustering algorithm, by exploiting the simplicity and the expressive power of Prolog programming language.
Moreover, in this work we also underline the utility of equipping this communication framework with a central unit which, on one hand, has a full knowledge of the network topology, on the other hand, it is able to collect, manage, store, and process the most important recovered data and, consequentially, to make some significant statistics.
Finally, we evaluate some improvement possibilities of the described model, by integrating it with some of the most common electronic devices, which can rise its performances.
Introduction
The researchers play a lot of attention on the topic represented by the VANETs, due to the increasing amount of road accidents [27]. Exploiting the inter-vehicular communication appears as the best way in order to increase the road safety level.
Intuitively, the aim is to get each driver informed about the traffic conditions or the presence of exceptional road events during their travel, so that they are able to choice the best solution according to the situation. Concerning this kind of communication, we have to underline a very frequent phenomenon in VANETs, the “broadcast storm”, which is generated by redundancy in transmission, and causes some discomforts to the communication, as collisions or interruptions [4].
In this work, we provide a first approach to afford the “broadcast storm” problem and the accidents prevention, by using some spatial and temporal limitations, which allows us to find a set of significant events that represent the phenomena which most frequently determine road disservices or accidents. The idea follows by the important concept of “Internet of Things” [11], which suggests that each “thing” can be seen as a computer in a connected network: in this way, anything opportunely equipped with communication devices can be used a source of information, as well as destination of such information.
In order to improve the approach described above, we explain how a good choice of a clustering algorithm can mitigate this phenomenon and, thus, can increase the communication quality. In particular, it is possible to elect a special node, known as cluster-head, which has to manage the signals transmission, in order to avoid useless operations, such as the transmission of the same alarm message from two or more vehicles to all of their neighbours. For this reason, we propose a centralized approach, in which a central unit has the full knowledge of the network topology, and it can easily elect a cluster-head which can maximize the system performances. Moreover, it could be very helpful the storage of data, retrieved from vehicles, for the purpose of creating some statistics.
Due to the large spread of the electronic devices, it is easy to imagine that the described system, could be enriched by integrating it with smartphones, tablets and so on. The rest of this paper is organized as follows: in Section 2, we present the state of the art; in Section 3, we introduce the temporal and spatial limitations to the propagation of information; in Section 4, we summarize the most common exceptional events, by finding a relationship between them; in Section 5, we explain the centralized model, highlighting all its benefits; in Section 6, we describe a non-exclusive clustering algorithm, starting from the known DBSCAN algorithm; in Section 7, we propose the integration of electronic devices in the model, by exploiting their features; In Section 8, we evaluate our model, calculating the time complexity; finally, in Section 9, there are some conclusions and ideas for future works.
Related works
VANETs are a significant part of the Intelligent Transportation Systems (ITS) [20] and nowadays they represent an important topic of research in scientific contexts, due to the high number of roads deaths recorded every year in the world [27]. A significant feature in the most common systems for inter-vehicular communication [13] is the interaction between the nodes of the network without any central unit for data management.
In this work, we suggest a centralized model: a central server receives, manages, and stores data collected from all the detected events. In this way, we can observe many benefits, in particular the mitigation of redundancy in transmission using clustering processes. As explained in [21], the clustering can reduce some of the discomforts in communication between vehicles and for this reason they create clusters according to the vehicular mobility. Similarly, in [12] the clusters creation is based on information about the average velocity and acceleration of each vehicle and in [7] they use some metrics, based on the location or direction of travel, in order to organize vehicles into different clusters. We assume that the creation of the cluster is a task of a central unit, which stores a full knowledge of the network topology and could optimally choose a cluster-head, without using any directional antenna to address a message, as proposed in [28], or without waiting a “defertime”, as shown in [17] and [6].
Moreover, we start from the model presented in our previous work [4]: this is a logical multilayer model, whose aim is to represent the most common exceptional road events using a Petri Net, which creates a cause/effect relationship between these events, so that one event can generate another in a predictive manner. We want to improve and enrich this model in this work, by integrating it with electronic devices. In particular, we exploit the use of smartphones belonging to drivers or pedestrians.
The literature contains numerous works related to the topic covered by this paper. For example in [10] a set of applications in Android platform is proposed, in order to avoid crashes, manage and monitor the traffic, obtain weather information, and optimize the public transport. In the same way, in [9] a VANET formed by Android smartphones is presented and showed that an “information dissemination service can entirely rely on smartphone-based communications”. Instead, in [25], it is highlighted a low performance using a VANET exclusively composed by phones and for this reason we propose an integration of these devices rather than a replace of the existing technologies.
Temporal and spatial limitations
Supposing that each vehicle is equipped with Global Positioning System (GPS) in order to know its own location, there is a couple of intuitive observations we can perform, about the road exceptional events we will deal with [4].
The first fact we can observe is that any event has an average duration, which can be different from an event to the other: for example, we can trivially say that the consequences of an accident persist for a time which is longer with respect to the one needed for a puncture. An immediate consequence of this is that the transmission of data related to a certain event should only take place when this event is still potentially in place.
The second observation we can do is that a vehicle, that cannot reach the place where the event occurs before its termination, is not interested in receive information about it. It follows that the propagation of alarm messages should only take place where there are vehicles that, proceeding at a certain speed, could be affected by the event damages, since they could reach the event before it expires.
Event identification
As we explained in our previous work [6], in order to perform the event detection, and thus the improvement of road security and driver safety, we can find some typologies of events, which characterize the most frequent situations that can occur, and we can also find a relationship which links these events to each other.
The most common events are “punctures”, “collisions” and “accidents”. These three events can in turn be generated by other events that we can identify by imaging a typical road situation:
We can observe that “collisions” may happen when one travels close to the next vehicle and at low speed. Thus, we can identify this scenario as the “queue” event.
Moreover, we can say that “punctures” occur when one travels along a road which is in bad conditions. So we can introduce the “bad-roads” event.
Finally, we can guess that “accidents” may be caused either by the high speed driving, or by the driver misconduct. It follows that we can identify other two events, i.e. “high-speed road” and “reckless driving”.
The idea is to find a reason for each event, until we reach an event which can be easily detected by some devices. For this purpose, we can find many possible causes to the “queue” event, that is the presence of more consecutive traffic lights, or the travelling during rush hours, or bad weather conditions, such as rain, snow and so on.
In the same way, the presence of “bad-roads” can be generated, as before, by incessant rain, and thus in general by bad weather conditions.
All the remaining events, of whose we are not able to find a reason, have to be detected in some way, in order to trigger the events propagation, and thus their forecast. For this purpose, we can imagine to enrich our model with some electronic devices able to, for example, detect the rain, or to detect whenever the driver gives some fatigue [15], or bad-driving signals, for example by taking track of the driving trajectory along the path. Moreover, we can suppose to associate a feature vector with each road, in order to have the most significant information about the corresponding road, such as the permitted speed or the number of traffic lights that one can meet during the travel.
By this approach, we obtain an events chain, whose behaviour is predictable according to a cause/effect relationship between the most common exceptional events, and whose propagation is driven by the temporal and spatial limitations we introduced in the previous section.
Moreover, this model can be seen as a system which learns by itself, so that, by the analysis made during the time, it can create new rules and associations between the events, and the system can grow during its use.
Centralized model
It is known that a VANET represents an ad hoc network, in which a vehicle is a node and it can broadcast alarm messages to any other vehicle in the network using on-board units (OBU), wireless devices placed within each vehicle. In order to improve the model described above, we propose an innovative approach to these networks, using them in a way which is unusual for this kind of system: a centralized model.
The idea is to customize the existing model in a way that allows to have a central server, deals with data management and storage. This kind of structure could provide numerous advantages analysed below:
clustering process; full knowledge of the network topology; stronger Experience layer [4]; data storage and statistics.
Clustering process
In a VANET, and in information transmissions in general, the most frequent problem is known as “broadcast storm”: it occurs when more vehicles are trying to transmit at the same time. It generates many discomforts in communication, due to interruptions or wireless channel saturation [26]. It is necessary to reduce the redundancy in information transmission, in order to mitigate this phenomenon [23]. By using a centralized model, we can achieve this goal through a clustering process.
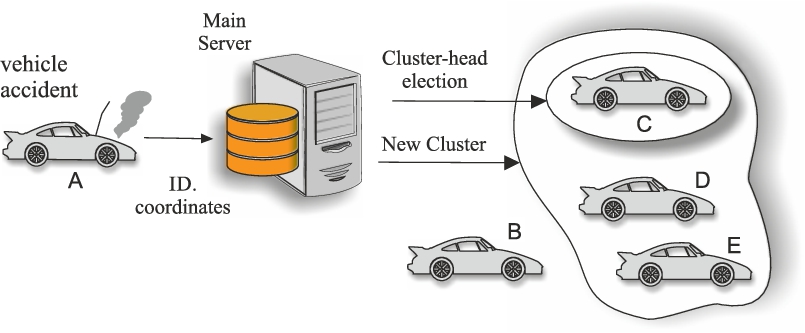
When a vehicle detects a road event, it generates a cluster with all the nodes belonging to its communication range and sends an alarm message to each member of this cluster.
According to the VANET operation, the receivers vehicles, in turn, broadcast this message to their adjacent nodes: it is possible, especially in a busy traffic condition, that two or more vehicles are really near to each other and, thus, the set of neighbours of the first vehicle contains some nodes belonging to the set of neighbours of the second vehicle. Let’s suppose that a situation as the one shown in Fig. 1 occurs. As we can see, the vehicles A and B have three and two nodes in their respective lists of neighbours, but one of them belongs both to the first and the second list. In particular, if we indicate with
This determines that the vehicle resulting from this intersection receives the same alarm message two times (from both A and B vehicles) and this is an example of redundancy in transmission.

Clustering to mitigate redundancy in transmission.
In order to avoid these repetitions in broadcasting, the central server could choose a cluster-head, interested in transmitting the received information externally. In order to explain how the cluster-head works, we have to distinguish two different kinds of road:
one-way road;
two-way road.
In a one-way road, the alarm messages propagation can occur only in the opposite to the movement direction, since (i) the vehicles, following the crashed vehicle, could detect the event and thus they may be informed about it, while (ii) the vehicles, preceding the crashed vehicle, have already passed the event location and thus they are not interested about it. For this reason, the central server has to choose only a single cluster-head between the nodes belonging to the same cluster of the crashed vehicle. In order to cover the greatest possible zone, the cluster-head must be the farthest node with respect to the crashed vehicle. For the same reason, in an iterative way, the next custer-head is chosen as the farthest vehicle with respect to the previous cluster-head. In this way, the structure allows to cover the greatest distance possible in each communication step:
The step 3 has to be repeated until one of the conditions for communication interruption holds [6].
Instead, in a two-way road, the information broadcast must occur both in the direction of travel and in its opposite one. Indeed, in this kind of road both vehicles that preceded and followed the crashed vehicle could detect the event and thus must be informed about it. For this purpose, the central server has to choose not only a single cluster-head, but two different cluster-heads: (i) the first one is the farthest node with respect to the crashed vehicle in the direction of travel (tail cluster-head), while (ii) the second one is the farthest node in the opposite direction (head cluster-head). In this way, a vehicle that receives an alarm message can in turn broadcast this last only if it is elected as a cluster-head from the central server.
In order to know if a certain road is one-way or two-way, let us suppose to associate a feature vector to it to keep track of the most important aspects of the road itself. The cluster-head election criteria are the same as the ones described above, according to which the first cluster-head depends on the crashed vehicle, and the following cluster-heads depend on the previous one.
Let’s suppose to be in the one-way road situation: since the clustering process, each time a cluster-head is elected a corresponding cluster is created. In this scenario, because of the cluster-head choice criteria explained above, the cluster-head is the last vehicle in the movement direction within the previous cluster, but we can also say that it is the first vehicle in the movement direction within the new created cluster. We can identify a problem, because of the continuous movement of each vehicle. In order to improve the described model, would be very interesting to assume not only the presence of On Board Units within each vehicle, but also the existence of Road Side Units, placed in a smart way along the road. In this way, we can consider all the elements of the road infrastructures in the same way as a generic vehicle. We can imagine, for example, that each traffic light has its own “intelligence”, and it is able to receive, and in turn transmit, useful information concerning the traffic conditions.

Example of cluster-head election.
It is possible to imagine that on a certain instant the central server identifies a situation as the one shown in Fig. 2. According to the explained criteria, the next cluster-head will be the A vehicle, since it is the farthest vehicle (or road infrastructure element) with respect to the previous cluster-head. Actually, it could be a better choice identify as cluster-head the road infrastructure element which is very close to the A vehicle. Since the few distances between the A vehicle and the B traffic light, it’s preferable choosing as cluster-head something which is fixed on the road rather than a vehicle which is in continuous movement, in order to guarantee the coverage of the greatest area possible, in any case. Because of the continuous movement, a vehicle chosen as cluster-head could travel with a speed such that some vehicles could be excluded from the transmission, and thus the maximum coverage is not satisfied. For this reason we can fix a very little distance d such that, during the cluster-head selection, if the farthest vehicle is at a distance d from a road infrastructure element (in the same cluster), than this last will be chosen as cluster-head.
The presence of a central server in a system for inter-vehicular communication allows to have an entity with a full knowledge of the network topology. This fact cannot happen in a decentralized structure and brings some benefits. For example, in this kind of structure it is possible to choose the optimal routing protocol, according to the topology features.
In [18] the authors distinguish among three kinds of routing approaches (broadcast, multicast, and unicast), which are based only on the number of senders and receivers. Conversely, in [24] the authors identify two groups of routing protocols (proactive and reactive) according to the network topology. In addition, in [19] the authors add a third group, represented by hybrid routing, and they say that, in the topology-based routing, some routing choices are made according to the information of the communication links.
In this kind of routing approach, the Link State and Distance Vector algorithms are the most used, due to their suitability to vehicular contexts.
Experience layer & storage and statistics
An important layer of the multi-layer structure described in our previous work [4] is the Experience layer, which stores all the data of the events observed by a specific vehicle: it can be useful when some events usually occur in a certain area, without understanding their causes, according to a predictive model.
In our previous work, we tried to find a technique in order to understand in a deterministic way when an event can occur, according to the circumstances. For this purpose, we built a multi-layer model, based on a logical approach, in which we identified the most frequent and dangerous road exceptional events, and we found a strategy in order to understand how these events can interact to each other. The final goal was a structure which allows us to handle the events occurrence in a predicting manner. But, we considered the possibility that our model cannot cover all the possible situations concerning road exceptional events, and for this reason we introduced an additional layer, the Experience layer, which manages the stored information, obtained from the vehicles during the time. Thanks to this layer, we have some additional information and we can consider the cases not covered by the Petri Net model. If this layer had an important meaning in a decentralized structure, it actually has a more important role in a centralized one, since the surveys don’t affect a single vehicle, but all the vehicles going across a certain road.
This layer is really useful, on the one hand, for the purpose of a correct forecast of exceptional road events and, on the other hand, for the purpose of creating some statistics data concerning a certain road; for example, if on a street it is frequently detected the event “punctures”, it probably means that those street is in bad conditions and this suggests contacting some public entities for the road maintenance. Thus, we can say that the Experience layer supports the data storage, by collecting all the observations made by each vehicle concerning a certain road. In this way, it is possible to have a more complete knowledge of traffic conditions and also to increase the road safety.
It would be very useful create a link between this layer and some public entities, in order to create an automatic information flow whenever an event becomes very frequent on a certain road. The information stored in the Experience layer are very meaningful, since the data are actually retrieved by vehicles, thus they represent events actually occurred, and not just supposed.
Clustering algorithm
The clustering algorithm we present is a non-exclusive clustering, since each vehicle could belong to more than one cluster. We were inspired by a known density-based algorithm, the DBSCAN [16], in order to create a customized algorithm for cluster creation in a centralized model. For simplicity, let us assume the case of a one-way road, expandable also to a two-way road.
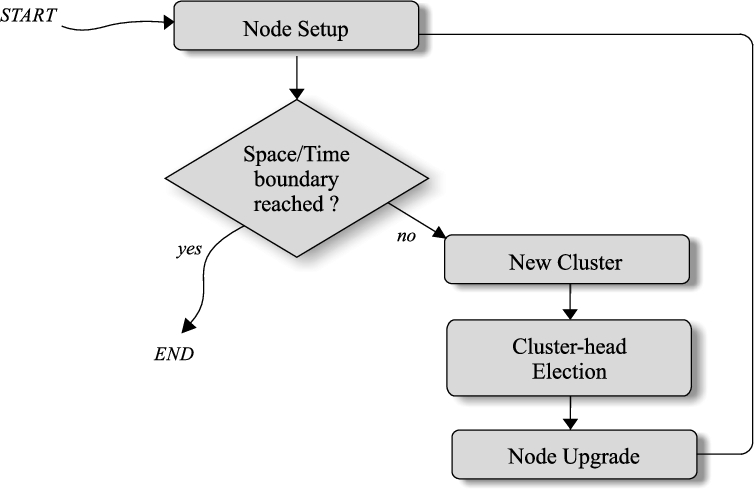
Control flow for clusters creation.
The control flow is summarizable in the following steps:
Repeat:
Until time and space limitations are satisfied.
Initially, the
Creation of a cluster in a one-way road.
Assume that each alarm message has four different fields:
the identifier (
the time (T), when the event occurred;
the location (L), where the event occurred;
a message (M), which really explains the event.
When an event is observed, only the vehicle which detects its presence has to broadcast an alarm message without additional checks. Any other receiving vehicle does not transmit the received message automatically, but only if it is chosen as a cluster-head from the central server.
Thus, the vehicle which detects the event transmits its
Let’s analyse the algorithm, which explains how the cluster-head could be selected (see Algorithm 1).

Cluster-head selection
When the first vehicle transmits the coordinates of the event location, the central server calculates a maximum longitude (
Thanks to the coordinates procedure, we can select the group of vehicles V that satisfy the described properties. As shown in Fig. 5, we create a clustering tree [8], by separating a group of vehicle from another one according to their geographic coordinates and their distance from the event location.

Example of a clustering tree.
After the cluster creation, the central server can elect one or two cluster-head, according to the retrieved information concerning the way of the road (6–10 lines).
If the road where the event occurred is a one-way road, the central server chooses a single cluster-head, by choosing it as the farthest from the transmitter vehicle between the nodes of the cluster represented by List. Otherwise, if the road is a two-way road, the central server selects two different cluster-heads: the first one is the farthest node in the List cluster in the same lane of the crashed vehicle, while the second one is the farthest node in the opposite lane.
Now, we can apply the cluster-head selection method also to a two-ways road:
Repeat:
Until time and space limitations are satisfied.
In this case, we need two different starting nodes, which are initially both equal to the crashed vehicle. We also need two different directions (
The logical model presented in [4] could be improved by integrating in it the use of commercial smartphones belonging to drivers or pedestrians. Thanks to the low costs of these devices and their large spread, it is possible to say that, by now, each vehicle probably is equipped with at least one smartphone, the one belonging to the driver. To see the usefulness of considering smartphones, assume that an accident occurs in a certain road and the driver loses consciousness. It would be very dangerous to wait that someone realizes that there was an accident and calls an ambulance: the smartphones connected to the Wi-Fi of the vehicles could automatically warn an ambulance, so that relief efforts arrive as soon as possible. This could considerably increase the road safety level.
In general, the idea is to integrate our model with smartphones (or any other electronic device) whenever the occurred event could be dangerous for the safety of the driver (or anyone involved in the event). Of course, the event which should determine an automatic warning about its occurrence, in order to alarm some public entity, is the “accident” event, which, as we explained in [4], is supposed to be verified on high speed roads (on low speed roads we speak about “collision” event).
Moreover, pedestrian collisions are also a hot issue of research [5]. For example, in [1] they try to calculate the location of a pedestrian through his geographic longitude and latitude, his class-speed and other metrics; similarly, in [14] the authors exploit some parameters such as speed and position in order to predict possible collisions.
Smartphones and any other electronic device belonging to pedestrians can be used in order to predict and avoid pedestrian collisions, permitting the communication between these devices and the on-board units placed within each vehicle for the exchange of alarm messages.
In particular, in order to avoid collision between pedestrians and vehicles, we can use the information about both the trajectories of movement of the vehicle and the pedestrian.
Let’s assume that there is the risk of a vehicle-pedestrian collision only if they are at a risk distance
As shown in Fig. 6, it is possible to prolong the trajectory of V and the one of P, in order to check if there is an intersection between these extensions. We can say that the presence of this intersection is the necessary condition in order to have a collision, but it is not sufficient. If the necessary condition holds, then it’s time to do some computations concerning the speed of both vehicle and pedestrian: let’s call I the intersection point between the two extensions of the trajectories, we can compute how many times the vehicle V needs in order to reach I, and similarly for the pedestrian P.
At this point, we just need to compare these values in order to understand in the sufficient condition holds:
Compute the extensions of the trajectories of both V and P.
Compute the intersection I between the extensions.
If I exists, compute the time
Compute the time
Compare
If it is so, generate a preventive alarm message in order to warn both V (through On Board Units) and P (by smartphone) about the risk.
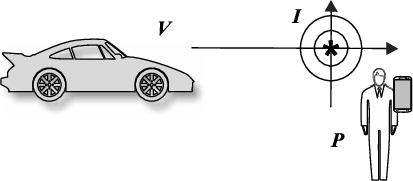
Pedestrian-vehicle collision.
It’s important to underline that a collision could happen only in some circumstances:
Urban roads;
Intersections without traffic lights: in order to understand if this circumstance is verified, it is enough to check if along the trajectory of V or P there is a traffic light.
Thus, it’s meaningful compute the analysis described above just under the hypothesis that both the previous circumstances are satisfied. This technique could improve significantly the road safety.
In this section, we evaluate the performance of our model, analysing the Prolog code more precisely. We want to calculate the time complexity of our algorithm with respect to the cardinality of the set of neighbours of the crashed vehicle, or the first vehicle detecting the event.
The first step for the operation of the cluster-head election is the cluster creation. The idea is that the central server receives the main information about the vehicle V which observed the road exceptional event. In this way, it could create a cluster containing some adjacent nodes to V, according to the distance covered by the transmission protocol. Thus, called A the cardinality of the list of adjacent vehicle to the vehicle V, we can say that the operation of the creation of the cluster (lines 2–4) has a time complexity
Then, the next operation consists in electing one or two cluster-head for the new created cluster, represented by List. The cluster-head choice happens by selecting the node in List which is the farthest with respect to the vehicle V, according to the coordinates of each node in the cluster:
in the case of a one-way road, it is necessary to elect a single cluster-head;
in a two-way road, instead, it needs two different cluster-heads in the two opposite lane.
In both cases, a comparison between the coordinates of the nodes in the cluster is made, so the time complexity required is
Thus, we can say that a generic execution of the presented code requires a time complexity
So, the time complexity is linear with respect to the cardinality of List, and thus the cardinality of the cluster.
Conclusions and future works
This work is a part of an interesting context of research, represented by the VANETs. This is a very hot topic in the scientific area, thanks to the possibilities, offered by these structures, of improving traffic conditions and increasing road safety. VANETs are often used in decentralized structures, based on ad hoc networks where each vehicle has the role of a node and is able to receive some information and in turn to broadcast them to other vehicles. The main innovative aspect of this work is the idea to use the VANETs in a centralized model, by introducing a central server.
This clearly brings some benefits, such as (i) the possibility of using a clustering algorithm in an optimal way, since the central server can properly choose a cluster-head, according to the vehicles’ location within the network, (ii) the full knowledge of the network topology and, thus, the opportunity of using the best routing protocol possible, (iii) the creation of an Experience Layer which is more robust than the one described in our previous model [6], (iv) the chance of collecting, analysing, and storing information about road exceptional event, which could be very useful in constructing some statistics concerning the frequency of certain events in a specific road.
We also explain, in this work, how the central server could select the cluster-head correctly, exploiting the knowledge of the topology, and choosing as cluster-head the node which is the farthest from the source of information transmission. This is a valid technique in order to minimize the redundancy in information exchange and, thus, to reduce the “broadcast storm” phenomenon. We also explain the difference in choosing the cluster-head in one-way roads and two-ways roads, by underlining the necessity of choosing two different cluster-heads in the second case (one per movement direction).
Thanks to a centralized model, this is possible without using any directional antennas or waiting time, as proposed in other works [17,28], and [9].
Moreover, we highlight the usefulness of the smartphones integration in a system for inter-vehicular communication. Indeed, smartphones could improve the safety conditions, calling the adequate road authorities, according to the road exceptional event occurred. They could also contribute to reduce the pedestrian collisions, locating pedestrians on the road, and predicting possible collisions before they happen. We explained the hypothesis under which a pedestrian-vehicle collision may be possible, by proposing some computations in order to warn drivers and pedestrians in advance.
This work could be the starting point for the creation of a centralized structure, more flexible than the decentralized one. Moreover, this could constitute a hint for future works, with the integration of smartphones or any electronic devices which can compensate the limitations of an information transmission based only on OBU placed within each vehicle, and RSU used in order to improve the network connectivity [2,3,22].