
Abstract
The data networks are basically designed with the aim of maximum throughput and fair resource allocation by managing available resources. A transport layer plays an important role in throughput and fairness with the help of congestion control algorithms (variants). This survey targets mainly congestion issues in high-speed data networks to improve efficiency at connection or flow level. Transmission Control Protocol (TCP) is a dominating transport layer protocol in the existing network because of its reliable service and deployment in most of the routers. A cause of congestion may be different in wired and wireless network and needs to be handled separately. Packet delay, packet loss and time out (RTO) are not caused by congestion in case of wireless network. This has been taken into account in our consideration. To overcome the dominance of TCP, Google proposed UDP based solution to handle congestion control and reliable service with minimum latency and control overhead. In the literature several methods are proposed to classify transport layer Protocols. In this survey congestion control proposals are classified based on situation handled by the algorithm such as pure congestion, link loss, packet reordering, path optimization etc. and at the end congestion control at flow level has been addressed.
Keywords
Introduction
The growth of data networks depends on Quality of Service (QoS) provided to the network users. The queuing dynamics and congestion in the data networks are playing a very important role in QoS. When nodes in the network carrying more data than link can handle QoS deteriorates due to congestion in network and packets are dropping. A network congestion generally results in delay and packet drop which block new connections. As offered load increases in the presence of congestion in network, results into a decrease in network throughput. When the amount of traffic approaches towards the maximum carrying capacity of the network that it can handle then the throughput starts to decrease. If this continues further results in network throughput collapse very rapidly and nothing is delivered. This state of transition referred or called as congestion collapse, shown in Fig. 1.
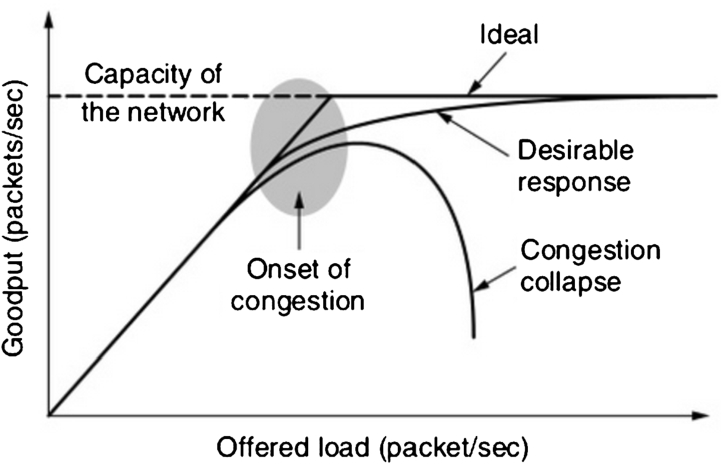
Congestion collapse event [61].

Congestion control algorithm: AIMD.
In recent days almost all computing, communication and control carried out through TCP/IP services. Many of us access some form of TCP/IP networks several times a day, either from fixed locations or while moving and either using wired or wireless medium. Today’s network services ranging from traditional information gathering to critical business transactions. As an example in online business even if Page Load Time (PLT) is more users are irritated and this results into profit loss. To maximize the benefits of online services, it is absolutely important to enhance the performance of TCP/IP network.
The emergence of high-speed network is uncovered by deployed popular TCP variants like Reno, NewReno, SACK etc. Network speed normally depends on increase in congestion window size with respect to Round Trip Time (RTT). Also with care of number of data packets network can accept without get exhausted or likely to be called as congested. The growing demand for wireless network technologies highlighted the need of transport layer protocol modification. As most of the TCP variants are designed and developed for wired networks. These variants blindly decide that congestion is the only cause of packet loss. If packet loss is due to non-congestion related issues like short term radio frequency interference or bit errors or random losses. This means there is no congestion as buffer overflow is not a cause of packet loss. So to recover from this situation there is a demand to develop loss recovery mechanism rather than simply halving congestion window size.
To resolve congestion collapse problem, lots of proposals were submitted by different researchers throughout the world. Most of them suggested similar kind of solutions like network aware rate control with, receiver driven flow control. This is the reason why congestion window concept related to network comes into existence. A congestion window size is the estimation of number of the data packets network can accept without any congestion. To calculate bound on the number of data packets present in the network for a particular situation e.g. receiver window (flow control limit), is less than congestion window (congestion control limit), is bound for outstanding packets in the network. This is the real definition for TCP rate bound, but in most of the proposals, the only congestion window is considered as a rate controlling parameter. Normally it is assumed that data processing capacity of the end nodes are much higher than the data transfer rate of the network.
The number of bytes transmitted by sender are depends on congestion and receiver window size. A minimum of these two windows decides the number of bytes sent by the sender. When the connection gets established between the sender and receiver, sender initializes congestion window. The size of congestion window equal to the maximum segment in use on that connection (maximum one segment). As shown in Fig. 2, on arrival of each acknowledgment for burst (on arrival of every acknowledgment congestion window incremented by one) double the congestion window size. The congestion window size keeps growing exponentially until either a timeout occurs or it reaches up to the receiver’s window size. This behavior of window size called Slow Start. The threshold is the third parameter used to control window size up to certain level (initially it was 64KB) to avoid packet dropping. In case a packet is not received within RTO, that is time-out occurs then the threshold is set to half of previous and the congestion window is reset to one maximum segment size.
To improve up on performance in terms of utilization of resources and network congestion, congestion control algorithms are developed. But the effectiveness of these algorithms is based on effective handling of congestion, resource utilization, fairness (everyone gets a fair share of resource used) and efficiency (network resources are used well) of congestion control algorithm. To achieve above said objectives, Chiu and Jain [10] formulated fairness measure (F) shown in equation-1 called Jain’s fairness index. This single dimensionless fraction is the network resource consumption function by each user sharing the same path.
n = number of flows sharing the resource and
Jain’s fairness index is a predominant fairness measure for TCP flows. This fairness index ranges from
A congestion window size is one of the important parameter and decide time required for sender to transfer available data to receiver. The Equation (2) is used to calculate time (T) in second, which is required for sender to send data.
Phase plot in Fig. 3 shows fairness and efficiency of the network. In this each axis represents a particular user or sender allocation. In this case, there are two users and their allocations are represented by x1 and x2. If the capacity of the network is C, then an optimal operating line is at x1 + x2 = C.
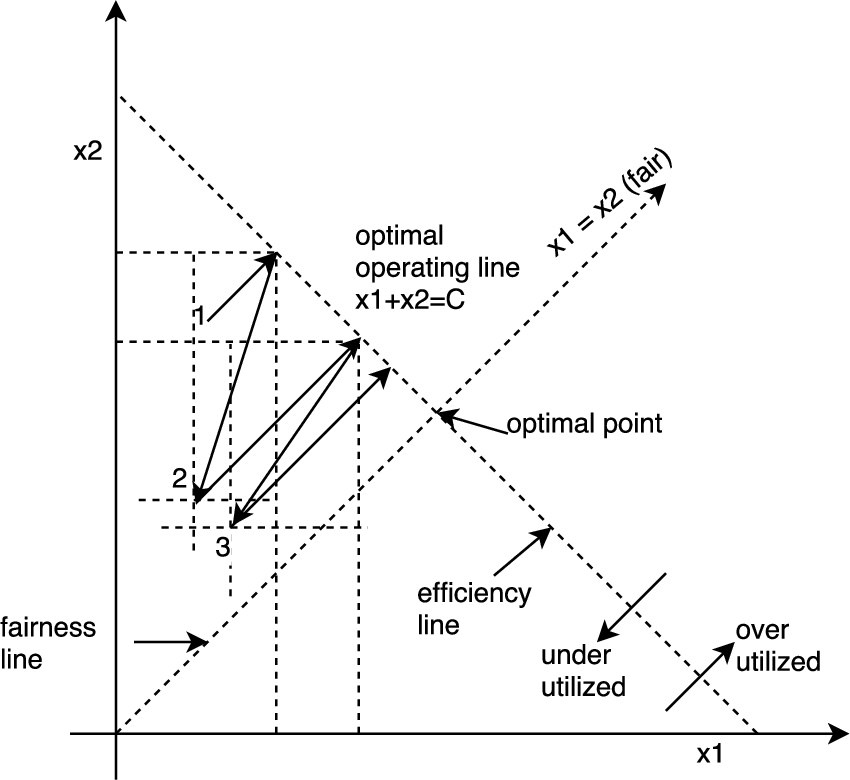
Phase plot for fairness and efficiency.
In general, Additive Increase Multiplicative Decrease (AIMD) converges to fairness and efficiency. Suppose if at any point 1, TCP window size of both senders Additively Increase (AI) their sending rates, additive increase results moving line parallel to x1 and x2 towards efficiency line since both senders increase their rates by same amount. Additive increase continued until network becomes overloaded that is touching to efficiency line. At this point of time, both senders decrease their sending rate by a Multiplicative Decrease (MD) fashion with a specific factor, in this case, half of previous. If the line is drawn parallel to x1 and x2 then new operating point 2 comes, again senders increase their sending rates in additive increase fashion and once again hits efficiency line towards optimal point. In this way, sender’s rate converges towards optimal operating point [55]. This means, if additive increase applied that increases efficiency where as when multiplicative decrease applied, improves fairness.
In transport layer till today, TCP contributed a lot for networking industry by delivering remarkable results, also it has some issues to deal with. Since about 30% to 35% of all Internet traffic route through Google server, Google has detail analysis of TCP performance in recent networks. In addition to this Google’s Chrome browser most popular browser in the web world with approximate 40% of market share. Based on above experience in 2013, Hamilton et al. [28] from Google started implementation new protocol based on UDP named as Quick UDP Internet Connections (QUIC). Protocol stack is shown in Fig. 4, shows the deployment option of QUIC. QUIC is a simple protocol suitable for supports application protocols for booting which is on top of UDP. As per the discussion on replacing existing TCP transport layer protocol to get out of its complex structure by designing new. Google designed protocol based on UDP is really challenging and very complex task. As an example, UDP interactions with many layers of deployed middle boxes like Network Address Translation (NAT) traversal is a very complex task. Initially, developed TCP variants are designed to avoid overflow at input buffers at the receiver end. The mechanism developed is based on the receiver’s window size. In this technique, a sender transmits a prepared data packet. This must not increase receiver’s capacity (receiver window size) and in case receiver unable to process data as fast as sender sends the buffer overflow event occurs. And to avoid this receiver reports reducing sliding window size. That is the whole transmission will eventually synchronize with receiver’s processing rate.
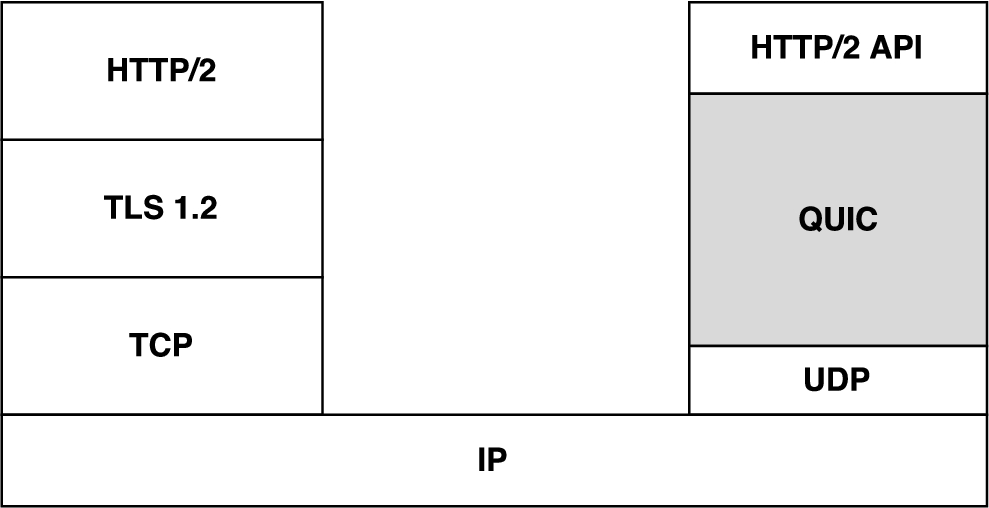
QUIC placement in protocol stack.
To avoid unnecessary packet drops precaution need to take by the end nodes. A Sally Floyd suggested solution by sending congestion notification to the sender [15]. When bulk of data is considered in that case data arriving time of last packet is only important and no need to take care of individual packets. For delay sensitive traffic such as mice traffic which exist for very little time in the network for example like button in Facebook or telnet traffic. If unnecessary packet drop or packet retransmission takes place then that result into very high throughput degradation for such low bandwidth network. So to avoid this Sally Floyd designed Explicit Congestion Notification (ECN) and this has been investigated by Kwon et al. [42] and further extended by Ramani and Karandikar for wireless and lossy links [3].
Mainly congestion control approaches are divided into two groups Reactive (Loss-based) and Proactive (Delay-based) to estimate congestion state in the network. But still after that due to popularity of TCP many more approaches comes into existence based on fine tune congestion state impairments. However, now days due to digitization more digital documents generated by numerous applications. This is an elastic traffic and network performance is depends on number of connections currently sharing links of the network, which varies based on begin and end of the flows. To analyze flow level performance of the network a flow based network state traffic model shown in Fig. 5 has been suggested by Sukhov et al. [70].
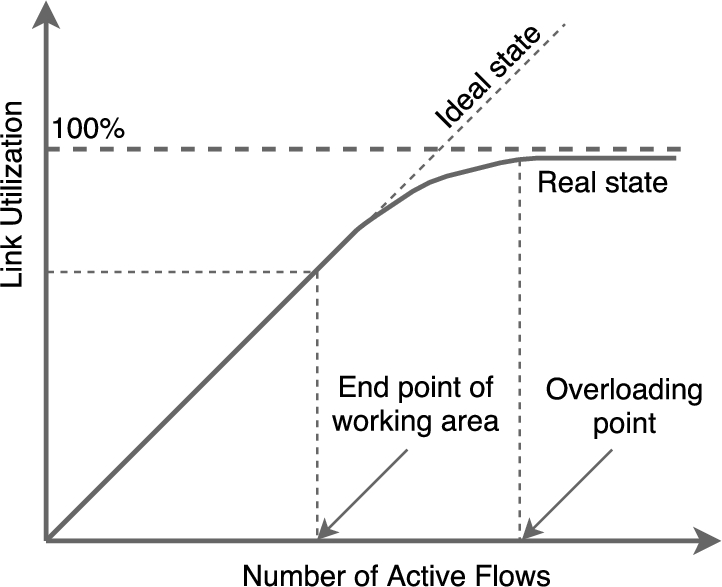
A flow based traffic model for uncongested backbone links [70].
The flow level congestion control protocol standards sometimes remain unaware of network resources available, which creates unexpected effects on the Internet. The congestion control means intelligent network resource aware and makes effective use of resources available in packet-switched networks. Congestion control is one of the largely studied areas in the Internet research conducted over the last more than 25 years, and a number of proposals submitted and targeted to improve various aspects of the congestion-responsive data flows. Several surveys were prepared by researchers targeting specific requirement of interest like congestion control in ad hoc networks by Hanbali et al. [29], congestion control for mobile ad-hoc networks for single and multiple flow by Lochert et al. [49], and Ikeda et al. [32], congestion control for non-TCP protocols by Widmer et al. [77], congestion control for networks with high levels of packet reordering by Leung et al. [47], fairness issues in congestion control by Hasegawa and Murata [30], Host-to-host congestion control for TCP by Afanasyev et al. [2], congestion control for wireless networks by Balakrishnan et al. [3]. In this survey, we tried to collect, classify and analyze major congestion control schemes for wireless high-speed data networks. Table 1 gives summery information of standard TCP variants with their services and limitations.
Next part of the paper divided as, Section 2 is devoted to congestion controlling challenges that gives current scope of work in terms of challenges with their brief idea. In Section 3 congestion controlling strategies for random and link losses present due to a wireless medium are reviewed. In Section 4 congestion controlling algorithms which improve efficiency in high speed and long delay networks are reviewed. Section 5 deals with congestion control at flow level (see Fig. 6). Finally, paper end-up with conclusion and future research directions in the Section 6.
Features and limitations of standard TCP varients
Features and limitations of standard TCP varients
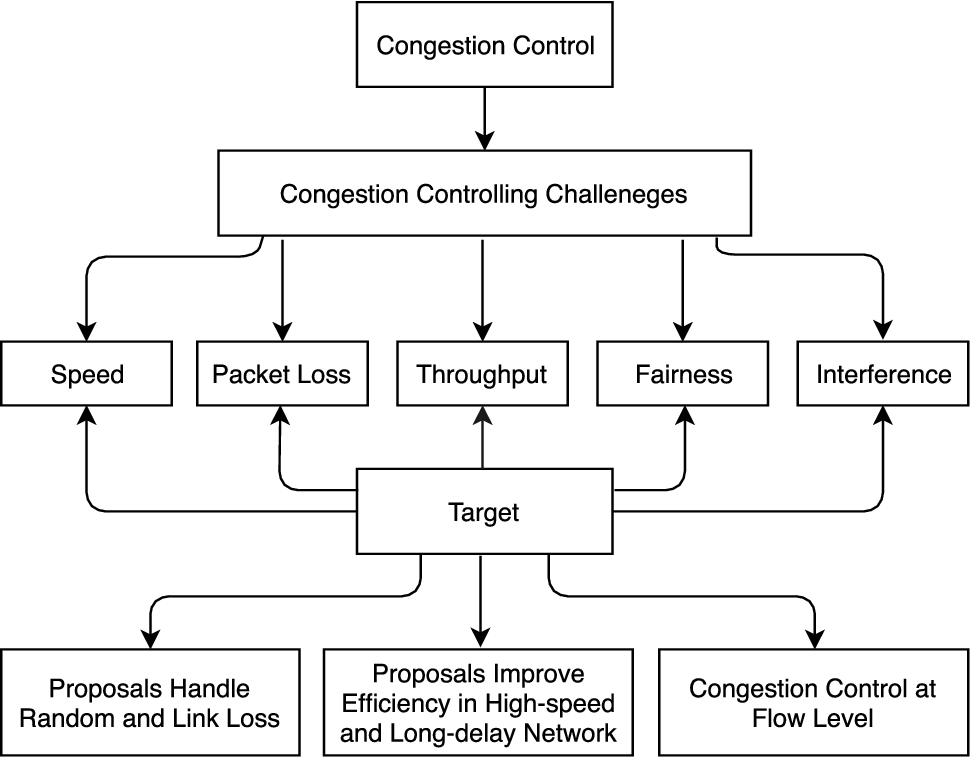
Paper organization.
In today’s world, congestion control mechanisms are presented as an artificial feedback system and deployed in all routers. The Internet features are continuously growing in size, diversity, and applicability. These features are playing very important role to integrate other networks like treading, banking etc. With a firm understanding of how this fundamental resource is controlled becomes even more decisive. Following are the key challenges in front of researchers working for congestion detection and controlling schemes [31,58].
High speed
Within past few years, the growth rate of Web technology and Performance Optimization industry indicates growing importance and demand for speed of operation. Results show that speed is not a psychological need in accelerating and connecting world. In online business, in which within one click items are get available to our door step. But the performance of this business decided by how fast we compare with a competitor.
More the speed leads to faster sites and better user satisfaction.
More the satisfaction better will be the user retention.
More the retention lead to higher conversions.
Future demands more and more speed and to satisfy or fulfill demand we need to understand many factors and analysis of fundamental limitations. Latency and Bandwidth are the critical components plays very important role to analyze performance of the network in terms of speed.
High packet delivery ratio
This is the ratio of number of correctly received packets at the receiver and the total number of packets transmitted by the sender. Major sources of packet loss are (i) buffer overflow at the intermediate routers, and (ii) packet corruption caused by transmission errors. A high packet loss rate can severely degrade the performance of data and multimedia applications.
Effective throughput
This is defined by the number of application bytes transferred in seconds. For large file transfers, the effective throughput of the application is a key performance measure. An inefficient transport layer algorithm or implementation can significantly reduce the effective throughput even if the underlying network provides a very high-speed communication channel.
Less throughput variation
Throughput variation is a metric to measure the variability in the received bandwidth over a given time scale. In general, the larger the time scale, the lower the throughput variability. For a given context, it is important to define a time scale over which throughput variability should be measured.
Fairness
Fairness becomes important when two or more applications compete for resources in a congested router. Fairness can be defined over the long term or short term. Long term fairness refers to the fair allocation of resources in the long run. Short-term fairness is defined in much smaller time scales. A given network algorithm may allocate bandwidth fairly in the long run yet exhibit unfairness in the short-term.
Short-term radio frequency interference
Day by day demand for a wireless network is growing and surely it will grow further. So as our traditional protocols are basically designed and developed to serve wired network demands, needs modifications as per the today’s demand for wireless networking. If we think of transport layer design in wired network, congestion is the primary cause of packet loss. So that traditional TCP is unable to react to packet loss which is not related to congestion. For example, if packet loss is due to interference caused by short term radio frequencies in which there is no router overflow event but still TCP reaction is to reduces transmission rate by reducing congestion window size. Instead of that reducing congestion recovery from loss is the solution to this problem and continue transmission with same rate this results into unnecessary throughput reduction.
Proposals handle random and link loss
The growing demand for mobile communication and wireless network technologies such as Cellular Communication or Wireless Local Area Network (WLAN) shown in Fig. 7, highlighted the need of transport layer protocol modification. As we know through different surveys most of the TCP variants are designed and developed for wired networks. These variants blindly decide that congestion is the only cause of packet loss [1]. If packet loss is due to non-congestion related issues like short term radio frequency interference or bit errors or random losses this means there is no congestion as buffer overflow is not a cause of packet loss. So to recover from this situation we need to develop loss recovery mechanism rather than simply halving congestion window size. Figure 7 shows typical hybrid network with lossy links in which link losses are mainly due to interference and random bit errors. Table 2 shows summery of proposals which contribute towards random and link loss.

Typical network scenario with lossy links [65].
Proposals handling random and link losses
First time in 1999, congestion control policies for wireless multimedia CDMA network is applied by Lu et al. [48] in which they have applied burst level congestion control is applied. In this they have studied reverse link and issues related to multimedia traffic in wireless network. Balakrishnan et al. [3] compared different mechanisms for improving TCP performance over wireless links and tested in LAN and WAN environments using throughput and goodput as the metrics. It has been shown that in traditional wired networks congestion is the primary cause of packet loss. Networks with wireless and other lossy links also suffer from significant losses due to bit errors and handoffs. The selective acknowledgments and explicit loss notification techniques are quite effective and show significant performance improvement in lossy link especially when losses occur in bursts. Ratnam and Matta [64] in their Wireless-TCP (WTCP) handle loss due to wireless link and mobility by using local retransmission strategy. Samaraweera [66] in his Non-congestion Packet Loss Detection (NCPLD) algorithm differentiates loss due to congestion from loss due to link noise. If there is packet loss due to any reason recovery is the reaction for that may be a retransmission of the packet is one of the solutions. But as soon as packet drop takes place reduction in the rate of transmission is also the reaction assuming that there is congestion. To identify loss is due to non-congestion type that is may be due to link noise. A RTT base calculations are used to identify network utilization and if it shows underutilized fast retransmission takes place assuming that loss is due to non-congestion. As we come to know that loss is due to non-congestion it continues transmission with the same rate that is it avoid window reduction.
Parsa and Garcia-Luna-Aceves proposed TCP Santa Cruz to improve TCP congestion control for mix networks maybe we can say heterogeneous network or wired cum wireless network. This protocol address problem created due to asymmetrical paths, out of order delivery, lossy links, less bandwidth and delay variation. Here only forward path delay is measured instead of round trip time. So that to avoid congestion specific threshold is assigned to a number of packets present in the bottleneck link. So here there is no need to count acknowledgments to set next limit for congestion window. The experimentation results through simulation show that TCP Santa Cruz achieves significantly higher throughput, smaller delays, and smaller delay variances than Reno and Vegas [57]. Ma et al. developed Fast-TCP for IP network with a wireless link. The basic idea of the Fast-TCP method is to delay the ACKs being transferred from the TCP destination towards the TCP source. Fast-TCP can speed up TCP flow control time, reduce buffer oscillation, increase bandwidth utilization, increase throughput, and reduce packet losses in the IP networks [52].
Ramani and Karandikar suggested modified ECN mechanism for wireless and lossy links in this they developed sender aware mechanism which reports some of the packet losses are not because of congestion. This is done through explicit feedbacks from the network in the form of ECN (notification) about the link congestion status in the network [62]. Saverio et al. in TCP Westwood rely on end-to-end bandwidth estimation to differentiate the cause of packet loss (congestion or wireless channel effect) which is a major problem in TCP Reno. Unlike TCP Reno, Westwood using slow start threshold and congestion window parameters related to effective bandwidth at the time of congestion rather than three duplicate ACKs concept to control congestion window [67]. In Westwood random losses over radio link are differentiated from congestion and cause of random loss is radio interference and avoids unnecessary congestion window reduction. TCP Westwood is extremely effective in mixed wired and wireless networks where they claimed throughput improvements up to 550% by their observations [73,74].
Fu and Liew in TCP-Veno [23], monitors the network congestion level and uses that information to decide whether packet losses are likely to be due to congestion or random bit errors. TCP-Veno modifies multiplicative decrease to improve its applicability by using slow start threshold adjustment based on the level of congestion rather than fix factor. Veno trying to mention connections in the operating point region for longer or full time so that networks whole bandwidth gets utilized. One of the salient features of Veno is it’s only sender side modification. Xu et al. developed TCP-Jersey [78] which is capable of distinguishing the packet loss due to wireless effects like radio interface, bit error, random errors from the congestion effect and decisions are made. TCP-Jersey divides into two parts Available Bandwidth Estimation (ABE) algorithm and routers with Congestion Warning (CW) mechanism. ABE is a sender side modification which contentiously monitors and estimates bandwidth available to the application. And based on ABE’s estimation sender will adjust the rate of transmission. CW is a router configuration for a network through which routers generates and send an alert message to end nodes by marking all packets as soon as incipient (beginning to develop) congestion is detected. Based on packet marking sender comes to know whether packet loss is due to congestion or due to wireless link errors [38].
Biaz et al. [5] proposed de-randomization to distinguish congestion losses and random losses. As described in the introduction part most of the variants designed basically by assuming packet loss is due to congestion. To mitigate this misconception de-randomization is one of the solution in which bias is used to differentiate congestion and wireless link loss. Mainly this concept is used in heterogeneous wireless error prone links. Through simulation results, accurate boundaries are found out to differentiate congestion loss and wireless link loss. Due to this technique, they got 95% accuracy in congestion loss detection where as 75% accuracy in case of wireless link loss detection.
Lachlan et al. proposed Curtailing the Large TCP Advertised windows to Maximize Performance (CLAMP) protocol [44] to allocate resources fairly in Wireless Networks. On wireless link through interaction between the scheduling of MAC layer and flow control, they try to manage a share of each flow in such a way that each gets same bandwidth allocation. They have used the infrastructure based wireless network in which multiple users get serve by one common access point. Each user suffers from fading effect and scheduler allocates a channel to each user based on channel quality with consideration of fairness and latency. As per results, TCP NewReno compromises in fair channel allocation as far as MAC schedule is a concern. CLAMP is a receiver side modification which controls TCP sender rate by setting receiver window size (
Rath et al., proposed a cross layer based congestion control technique called Reno-2 for wireless networks. In this, both transport layer and physical layers are working hand in hand to control congestion. In Reno-2, as per channel conditions and interference level, physical layer controls the power of transmission signal and transport layer controls congestion by controlling flow [63]. Matlab simulation results show that the cross layer congestion control technique provides performance improvement in terms of throughput and congestion window variations. The data transmission using wireless network suffers from insufficient bandwidth, transmit latency and high interference. The standard TCP congestion control mechanisms are fail to identify available bandwidth or buffer size and blindly halves congestion window after receiving three duplicate ACKs. Chang and Li proposed cross layer messages to identify bottleneck link status as a access or shared. The congestion window size has been adjusted as per the link location and packet loss reason is differentiated as network congestion or random loss. The cross-layer messages based on Adaptive Modulation and Coding are used to adjust congestion window size. In this the numerical results proved that the proposed approach significantly improve the Goodput with precise packet loss identification at various loss rates. As an example for wireless link with 4% packet loss rate the proposed approach increases Goodput up to 77.25%, compared with NewReno [9]. Figure 8 shows cross-layer design approaches (a) for small amount of information exchange direct communication between each other is possible, normally defined as a non-manager method, (b) in this indirect communication takes place between layers through vertical plane (shared information), normally defined as a manager method [22].
Berg et al. proposed a complete distributed algorithm, which creates prioritized TCP flows to allocate network resources (bandwidth) within flows. This enables autonomous conversions to loss of network resources due to cyber attack or failures by ensuring that users receive prioritized utility from available network resources. This approach is fully-distributed, self-adaptive to prioritization of mission-critical TCP with a weighted Nash Bargaining solution to distribute network bandwidth among the flows [71].

Cross-layer-based approach [59].
To illustrate the problem of improving efficiency in high speed and long delay networks sometimes referred as a bandwidth delay product problem. To discover network resources minimum time required is [
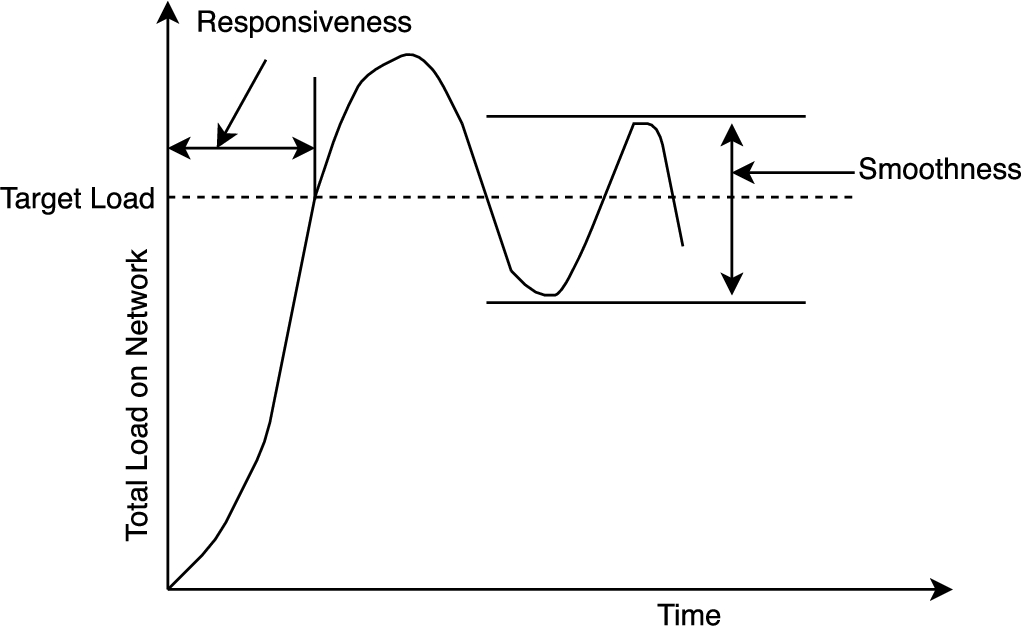
Network convergence response [10].
For speed, convergence time is a most important parameter; it is the speed (time) with which system reaches to its stable state (target load). However, because of binary nature of feedback used in the network to control congestion, the system generally does not converge to a single steady state. As shown in Fig. 9, time to reach target load value, determines responsiveness and size of oscillation, determine smoothness. Ideally, time and oscillations to be small [16,17]. Normal TCP variants are suitable to solve pure congestion problem but can’t work for high-speed networks such as optical or satellite network in which reaction time is very less. That is normal variants are not efficient to handle congestion in high-speed network, so to improve efficiency, Floyd proposed High Speed (HS) TCP [16,17]. In this experimental approach mainly efficiency improvement in high BDP networks and fairness in the lossy environment are the set objectives. To achieve set objectives in HS-TCP standard NewReno protocol is modified by replacing increase factor α as a function of congestion window size (w),
Proposals improve efficiency in high-speed and/or long-delay network
(Continued)
As many of the researchers claim that traditional AIMD congestion control approach is not suitable for high-speed and long-delay networks. Kelly says that, AIMD is not effective and proposed Scalable TCP (STCP) as an alternative to HS-TCP [40]. In AIMD complicated task is to calculate increase/decrease rate coefficients and in STCP this is simplified by introducing Multiplicative Increase Multiplicative Decrease (MIMD) approach. As increase/decrease approaches used in STCP are very aggressive it sharpens the characteristic graph. But because of this aggressiveness, it creates intra-fairness congestion and it leads further to the congestion collapse. Particularly for higher RTT values due to MIMD policy STCP flows are very unfair to both STCP (intra-fairness) and other TCP flows (inter-fairness) [60].
Leith and Shorten suggested different solution H-TCP to cope up with fairness (inter, intra and RTT) for different RTT value flows are competing and to improve the efficiency of TCP [45,46]. From previous studies, it’s proved that flow having greater RTT value always loses to flows with shorter RTT value. In H-TCP, congestion window size increase function, α of CA phase is a non-decreasing function with respect to time elapsed, Δ since congestion event. Whereas H-TCP increase congestion window size by
Caini and Firrincieli, claim that standard TCP-NewReno gives lower throughput for long-delay networks [7]. Normally networks like satellite (long-delay) RTTs are differing largely causes terrible unfair resource distribution. To resolve this TCP-Hybla algorithm is proposed, which suggested modification in Slow-Start and Congestion Avoidance phases by making them semi-independent on RTT value. In TCP-Hybla scaling factor, ρ is calculated as,
In BIC (Binary Increase Congestion-control) TCP proposal, Xu et al. suggested a solution for RTT unfairness when the loss is detected simultaneously by two competing flows [79]. In such a situation in HS-TCP flow having RTT, x times smaller will get network share
Ha et al., proposed an enhanced version of BIC as a CUBIC, in which they have introduced RTT independent congestion window growth function [27]. To achieve this CUBIC picked up H-TCP approach of congestion window size calculation as a cubic function of elapsed time Δ since last congestion event.
Jin et al. proposed TCP-FAST, which is similar to Vegas with some modifications in congestion window estimation. In FAST congestion window, w is updated with fixed-rate.
NewVegas is an extended version of Vegas suggested by Sing and Soh. NewVegas scheme defines a new phase called Rapid Window Convergence by retaining original benefits of Vegas and standard NewReno [69]. Particularly delay based congestion control approach is more beneficial for high-BDP networks due to sufficient time to converge network for a different conditions. In Rapid Window Convergence phase slow-start state of the network is extended when buffering is more or it exceeds the certain threshold value. But as a precaution resource probing must be under control means it is exponential like Vegas but with reduced intensity. In this phase for every RTT, congestion window is increased by number of packets x as follows.
To improve TCP performance and preserve friendliness to standard TCP in high-speed networks, Shimonishi and Murase suggested a solution in terms of Adaptive Reno (AR) [68]. In this proposal combination of constant increase and scalable increase based on congestion state kind of technique is used. When the network is congestion free (
A Modified Linear Quadratic Guass (MLQG) [26] is proposed to control over long range dependence network and compared with standard LQG algorithm. In this congestion issue is solved with a stochastic optimal control problem. Kaneko et al. combine some good characteristics of Westwood, DUAL and Vegas called Fusion [39]. Normally in fusion technique, to achieve expected objectives properties of different variants were collected and used. In Fusion, algorithm author suggested three different levels (in terms of the threshold value) of queuing delay in second.
If the current queuing delay is less than the threshold then congestion window size increased very fast per RTT with Westwood’s scalable increase factor.
If queuing delay is greater than three times of threshold value then congestion window decreased by a number of packets in the buffer at that time (similar to Vegas estimation).
If queuing delay lies in between one to three times of threshold value congestion window size remain unchanged.
To take a precaution for optimum performance Fusion must be equal to standard Reno, if Fusion congestion window size (
In similar fashion based on a reduced handshake, Iyengar and Swett from Google suggested QUIC protocol in their Internet draft [8,33,54]. QUIC protocol is a new multiplexed and secure transport atop UDP. In both TFO and QUIC once connection gets establish between sender and receiver for next every transmission direct data transmission takes place within a time out. To improve bandwidth utilization and fast data delivery UDP protocol is the option, whereas for reliable service TCP through connection establishment services like handshake makes network slow and adds extra overhead. To overcome TCP disadvantage by preserving reliability property QUIC is a new multiplexed and secure transport layer protocol (there is difference of opinions about QUIC location in the protocol stack in some of the literature it appears as an application layer protocol) designed by Google group. QUIC is on top of UDP based protocol designed from the ground up and optimized for HTTP/2 semantics [11,24,28,76].
A flow level congestion can be defined as when number of flows of mean size σ arrive at a link of capacity, C at mean rate λ and the link load

Network throughput performance for shared bandwidth during transient overload in terms of number of flows.
There is relatively limited literature related to flow level congestion control work is available. However, it’s worth to do survey on flow level congestion control as this is an important aspect in network performance and QoS. Barkat et al. [4] designed traffic model for uncongested IP backbone links. In this they have modeled traffic at flow level by using Poisson shot-noise process. This model shows very good approximation with respect real backbone traffic. The applicability of this model is investigated with network dimensioning and provisioning, prediction of the total rate and generation of backbone traffic. Oueslati and Roberts [56] proposed Flow Aware Networking (FAN) in this admission control [41] and scheduling is applied on user defined flows. They claimed QoS and performance guarantee with cost effective solution as FAN. The FAN supports only for the cross-protect enabled routers. The cross-protect routers improve performance very slowly for network with flooded links.
A study of congestion at flow level using statical bandwidth sharing has been carried out by Fredj et al. [21]. In this packet level simulations are used to extract the properties of TCP, whereas theory of stochastic network has been proposed to trace the observations. They observed that if the sessions are appearing as per Poisson process then the throughput is insensitive to both the flow size distribution and the flow arrival process. In this author has demonstrated that fluid flow statistical bandwidth sharing models can accurately predict the results of ns packet-level simulations and also claimed that in fair network distribution of number flows in progress and the expected flow have very simple relation which is valid for wide range real traffic. Sukhov et al. [70] used Gaussian approximation to locate the working area of a link based on its utilization and vigilant operators indicating overload points. These indicators they have used to upgrade capacity to avoid congestion at flow level. To validate hypothesis they have prepared testbed using boarder gateway routers and tested for wide range of link utilization.
The data networks are scalable and used to accommodate more and more users in wide spread. These users are generating huge amount of data traffic and responsibility of network administrator is to manage this traffic. One of the important task among all responsibilities of network administrator is to mange data traffic without network congestion. Congestion controlling proposals discussed in this survey are limited to standard, lossy network and high-speed-long-delay data network. The congestion control at flow level is an another focused area of research which is helpful to improve overall network performance and QoS. There is no universal solution available to address all problems. Internet of Things is a technological development in which all devices/things will come into the network so surely there is a scope to handle further more congestion issues. In this survey, we have not addressed large (elephant), medium (cat) and small (mice) size live traffic handling situations. In above discussed proposals, all three are treated same but this is not the fact and need to handle separately otherwise Head of Line (HoL) blocking like situations will arise.
Fairness is most of the time decided with Jain’s fairness index. Really, is this sufficient to check fair share of resources?, we need to check. Jain’s fairness index calculation is very simple control system model of n flows sharing the same link and receiving the same feedback signal. It can well describe the static properties of competing flows. However, the characteristics of the new network architectures and environments where dynamic. The heterogeneity is more if new or different traffic characteristic cannot be well captured in all aspects by that model.
Still, a bufferbloat problem is unsolved in which processing delay is more than TCP connection time. In bufferbloat problem queuing delay is more than RTT in TCP, due to this TCP connection shows congestion in the network, so to avoid this need to use appropriate size RAM at a different level of networks. To solve this active and passive queue management techniques are suggested. Standard buffer size suggested is equal to BDP but if long-delay networks this is not the feasible solution. The cost of the buffer depends on buffer size more the size more need to pay. Industry is demanding solution to optimize the buffer size in such a way that they can pay less. Congestion control in Data Center Networks (DCN) is new opportunity to contribute, in this different congestion controlling approaches were need to consider. In DCN we can contribute to solve problems like TCP incast, queue buildup, buffer pressure, TCP outcast etc.