
Abstract
The Network-on-Chip (NoC) has become a promising communication infrastructure for Multiprocessors-System-on-Chip (MPSoC). Reliability is a main concern in NoC and performance is degraded when NoC is susceptible to faults. A fault can be determined as a cause of deviation from the desired operation of the system (error). To deal with these reliability challenges, this work propose OFDIM (Online Fault Detection and Isolation Mechanism),a novel combined methodology to tolerate multiple permanent and transient faults. The new router architecture uses two modules to assure highly reliable and low-cost fault-tolerant strategy. In contrast to existing works, our architecture presents less area, more fault tolerance, and high reliability. The reliability comparison using Silicon Protection Factor (SPF), shows 22-time improvement and that additional circuitry incurs an area overhead of 27%, which is better than state-of-the-art reliable router architectures. Also, the results show that the throughput decreases only by 5.19% and minor increase in average latency 2.40% while providing high reliability.
Introduction
The Network-on-Chip (NoC) has become a promising communication infrastructure for Multiprocessors-System-on-Chip (MPSoC). The NoC architectures have been proposed to replace traditional global interconnects. However, a complex system such as NoC based System-on-Chip (SoC) consists of billions of transistors which makes it vulnerable to faults; one single transistor failure in one router or link can even break down the entire system or degrade the system performance.. The performance of a NoC is expressed in terms of bandwidth, latency, power dissipation and reliability. The latter has become one of the most important metrics. Therfore, it is vital to develop reliable and efficient Fault-tolerant NoC designs.
Typically, faults refer to circuit malfunctioning or data errors, which can occur due to transistor aging, crosstalk noise, fluxes of neutron and alpha particles, power noise, energetic particle strikes, signal glitch, and skin effect [23,43]. To increase the yield and maintain performance, fault tolerance and reliability are becoming more important concerns in the future SoC design.
During manufacture and utilization, NoC cannot always be ideal. If the faults happen in the NoCs, router cannot get necessary data, or the received data is not correct. Therefore, it is necessary to ensure the reliability of NoCs through effective fault-tolerant designs. Fault-tolerance is an important issue in the field of NoCs [13,31,35]. Fault-tolerant NoCs should enhance the reliability of NoCs as far as possible. On the other hand, fault-tolerant NoCs should reduce the area overhead, power consumption, and preserve performance.
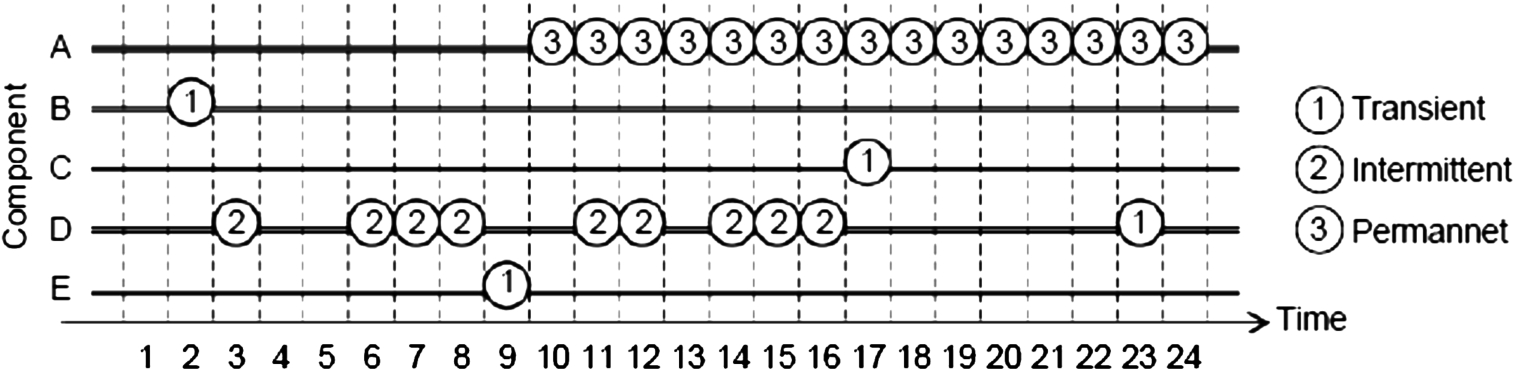
Transient fault, intermittent fault, and permanent fault.
A fault in the circuit may produce a general failure of the system. According to [43], faults can be classified into transient errors, intermittent errors, and permanent errors as shown in Fig. 1.
Permanent faults or hard faults, apparent in the NoC chip for a lifetime after their occurrence. They affect the functionality of the chip on all occasions. They are traditionally caused by several facors like: open/short circuits in links, time-dependent-dielectric-breakdown (TDDB), electro-migration (EM), stress migration, negative-bias-temperature-instability (NBTI), hot carrier injection and thermal cycling. On the other hand, transient faults, also known as soft errors, occur only for one or two clock cycles (see Fig. 1). Also, they are traditionally caused by internal or external factors such as:electrical noise, electrostatic discharge, electrical power drops, overheating, mechanical shocks, process variation, and external radiations like alpha particles and cosmic rays.
The majority of failures (80%) are produced by transient faults, while the rest of them originates mainly from permanent and intermittent faults [50]. Faults in the router architecture conduct to misrouting, deadlock, traffic hot spots, packet loss, and increased latency. Thus, reliable router architecture is necessary to avoid these undesirable fault scenarios [50]. Making the chip capable of autonomously detecting and tolerating its faults is a problem of extreme difficulty,
Fault diagnosis methods can detect and determine the reason and location of faults in NoC. The design of fault diagnosis methods involves methods and test strategies. The test methods operate and capture the faults by test vectors. Only a few works have been published on test strategies. Many works proposed test methods for NoCs especially or proposed methodologies to design test vectors for integrated circuits. Test strategies goal is reducing the impact on system performance from the test by scheduling and managing test procedures. Fault diagnosis methods can be classified into active detection methods if test vectors are injected into circuits under test, otherwise, they are called passive detection methods.
Active detection methods inject well-designed test vectors into the circuit under test to operate and capture faults. Built-in self-test (BIST) is one of the typical active detection methods. Due to the high fault coverage and fine-gain fault diagnosis, BIST is more suitable to detect and diagnose intermittent and permanent faults. Most proposed BIST methods for NoCs do not specify the test strategy [28]. The normal operation of NoCs has to be stopped definitely, which leads to a significant impact on the system performance.
Two typical passive detection methods are reported in the litterature: the error detection code (EDC) and the checker. The first method is used in the data path. Differently, the second method is used in the control paths. The parity check code (PCC), Hamming code, and cyclic redundancy check (CRC) are the most commonly used coding methods in NoCs [14].
Therefore, the test strategies purpose should be minimizing the impacts introduced by the test and increasing the test frequency as well. In reference [29] the authors reduced the impact on system performance by combining the off-line test and online test.
Both passive and active fault detection methods can detect the faults in one router and the entire network. Also, both passive and active fault detection methods can cover the faults in the data path and the control path. But, it costs much longer test procedure and introduces significant area overhead and power consumption. This method must isolate the circuit under test from the network which damages the integrity of the system resources and decreases the performance of the network [19].
So, in this work we proposed a reliable NoC router architecture called “OFDIM” which can detect and tolerate multiple permanent, transient faults and ensure continuous network operation. In contrast to existing reliable NoC architectures, the proposed solution can tolerate faults in all components of the router and maintain a gracefully degraded performance under heavy network traffic.
The main contributions of this paper can be summarized as follows:
Firstly, we propose a reliable architecture router that provide fault tolerance in all components of router (Buffer, Cross bar, etc) and a novelty that includes transient and permanent faults compared to existing works which treat one type errors only. Secondly, the reliability aware design-time can be performed in order to produce solutions that can be used to cure faults at runtime and reduce the chances of system failure. So the advantages of our solution are: to achieve low latency and reliability analysis using SPF metric. In addition to that, the results show that the proposed architecture achieves higher reliability by incurring smaller overhead as compared to an existing architecture. The proposed solution allows to a NoC to achieve its work even if an error is encountered. Thus, the performance and the reliability of the NoC can be improved.
The rest of this paper is organized as follows. In Section 2, related work is presented. In Section 3, the proposed router architecture is discussed. In Section 4, the components of the OFDIM are introduced. The analytical and experimental results are reported in Section 5 while the summary and conclusion are given in the last section.
One of the biggest concerns raised by the VLSI community regarding recent and future Networks-on-Chip (NoCs) designs is the continuous decrease in feature size and its impact on reliability. Also, most recent proposals in the area of NoCs favor the use of adaptive routing for fault-tolerance, requiring more sophisticated routing decisions [7]. It is therefore mandatory to provide some level of protection against errors. The problem of error detection is thoroughly studied in the context of NoC, in this section we present some works.
In reference [39], the authors propose improving the reliability by adding minimum extra circuitry and exploiting temporal parallelism. They protect all pipeline stages and are capable of coping with two faults at the RC, SA, and XB stages, and four faults at the VA stage. However, with random faults this design can tolerate up to 27 faults, in the best case. Their design has an area overhead of 31%, which they claim to lead to a SPF of 11 – they use the mean of these two numbers,
In reference [46], the authors have proposed a scheme based on a dynamic resource sharing approach that can tolerate soft errors in multiplexers, demultiplexers, and VCs of the input port unit. Poluri et al. [40] proposed the solution of tackling both transient and permanent faults in the pipeline of the router. The fault-tolerant techniques employed in the pipeline stages of the router are spatial redundancy, exploitation of idle cycles, bypassing faulty resources, and selective hardening. This solution results in better performance but results in larger area overhead. As the area increases, the fault probability. of the circuit also increases. If two faults occur in the RC stage, then the router fails its operation.
The work in reference [11] propose a comprehensive online and real-time fault detection and localization mechanism. This solution focuses on the detection and localization of faults in any components of the NoC’s control logic. Based on the notion of invariance checking. An illegal output (invariance) is specified here as an operational decision that violates the structured correctness rule(s) of a particular component. The checkers operate concurrently with normal NoC operation, thus eliminating the need for periodic, or triggered-based, self-testing. NoCAlert can detect (a) single permanent and transient faults.
The HPR [48] has designed permanent fault protection techniques for an NoC router. Error-correcting codes are utilized for the protection of single-bit faults in the flits. They presented a concept of a double routing technique for the protection of RC faults. The VA in case of faults uses the default winning technique. The SA used the runtime arbiter selection approach for tolerating the faults. The XB design used a bypass path technique for tolerating the faults in this stage. The overall design achieved higher reliability but still, the design was not able to tolerate the multiple faults occurring in the multiplexers and demultiplexers of the input ports. The router fails if permanent faults occur in these components.
In reference [34], authors consider faults in the state field of the VC. It splits the state field into two groups and gives spare registers for every group for fault tolerance. For fault detection in the state fields It uses built-in-self-test (BIST). The status register indicates the VC as faulty on the occurrence of most than one fault in a group. Afterward the VC closing strategy informs the upstream router to avoid sending flits to that downstream VC. It only take care of fault in the input port VC, leaving other router components vulnerable.
In reference [42], author proposes three different fault-tolerant architectures namely single spare, turn priority and stay alive. An additional unit is available to replace faulty units at each level in the single spare architecture. Priority-based selection is used in the case if two units at the same level get a fault. Exploiting regularity of the router, turn priority architecture uses the available resources by assembling as much input and output channels as possible. Different priorities are assigned to input and output channels to ensure router operation even in the worst case. Stay alive architecture combines these two previous architectures to enhance tolerance. These architectures incur high area overhead, i.e., single spare incurs 42%, turn priority incurs 77% and stay alive incurs 115% area overhead.
In reference [51], author uses channel slicing along with on-demand triple modular redundancy (TMR) for fault tolerance. Each node in the network contains three identical router slices that split internal paths. It supports three modes of operation. First is the parallel mode, in which divers router slices shares their control logic with each other in case of a fault in the control logic of a slice. Secondly, the separate mode, in which different router slices shares internal resources like buffers and XB’s in the case of fault in the buffer or XB of a slice. Finally the TMR mode, in which all three slices working in parallel on the same data and control signals. It uses majority voting to select the correct result at the output.
The work presented in [47] is a built-in-self-test (BIST) strategy for the data path and control path of NoC architecture. It uses free time slots of data path components for testing. It uses idle cycles of inter-router links for data path testing. But for control path testing, it isolates the components with the help of test wrappers. In the test mode, to ensure the secure connection of core with the network it connects the local port with the east or west port. To favor this setting, it uses the adaptive routing algorithm. This testing approach needs complex control and routing mechanism. The area overhead is 9.88% and power overhead is 4.63% for this fault detection strategy.
Besides the permanent faults that could occur within the router, the links between them are also a source of faults [9,52], Faulty links could cause wrongly transmitted bits between routers, possibly breaking the connection between them and cannot guarantee anymore service.
In reference [45], the authors propose an online diagnosis mechanism that reads error symptoms to locate faulty links, while ECC is used to correct the data errors. The diagnosis resolution of this method is limited to the links between routers and does not directly consider faults inside the routers.
Under the realistic traffic, the exploitation rate of links is not high so that there are many slots without flits to deliver. In reference [33], the author’s proposed to use these free slots for tests. This method does not require to isolate links away from the network and avoid blocking the normal communication. Consequently, the impacts on the network are reduced.
DiTomaso et al. [18] provided 4 links between routers. The direction of all links can be modified to address different traffic and fault distributions. This work also provided a backup ring path to preserve the communications under massive faults. In another work [1], a test method is presented to try to detect and locate faults in links. The work take on four routers in the test process. This test method needs four test rounds to complete the fault diagnosis, which imposes a large overhead.
Table 1 summarizes some previous works. All these works aim to provide higher reliability with lower hardware consumption, but they neglect the performance degradation during the process of tolerating faults. Consequently, we propose a simple and effective method that allows detection of precise location of the fault in router/link.
Some previous works
Some previous works
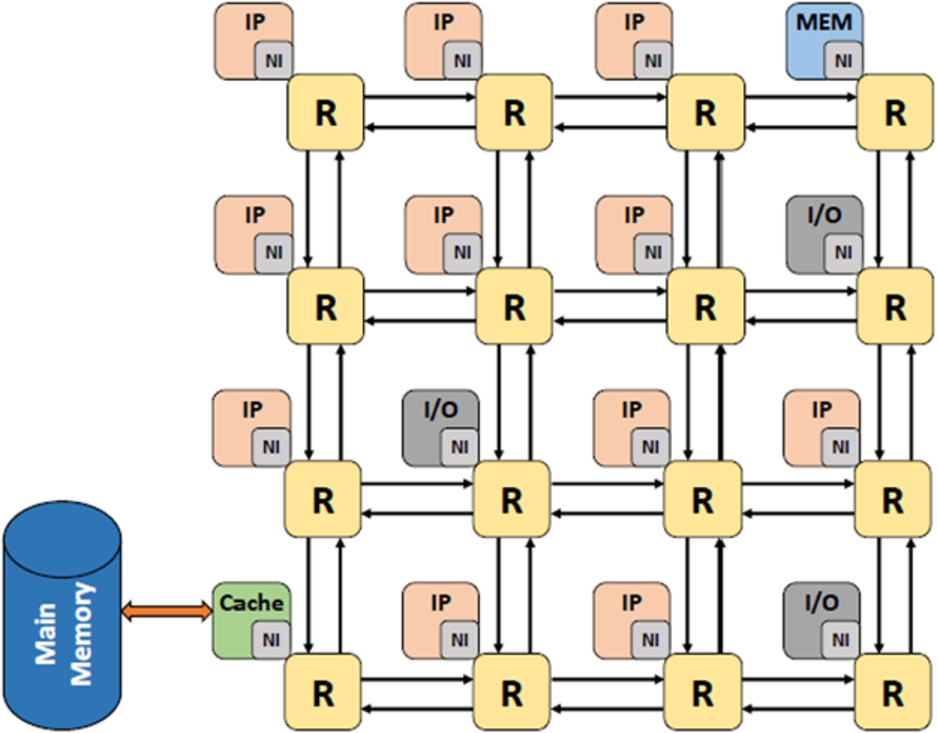
The Multi/Many-Processor Systems-on-Chip (MPSoCs) scheme interconnected using network on chip (NoC).
A Multiprocessors System-on-Chip (MPSoC) is widely used in embedded systems to increase their performance. It is composed of many processing elements (PEs), a memory hierarchy, and I/O devices. All these various components are connected to each other through a NoC. Figure 2 shows a graphical depiction of a MPSoC composed of several PEs, memories, and I/O devices.
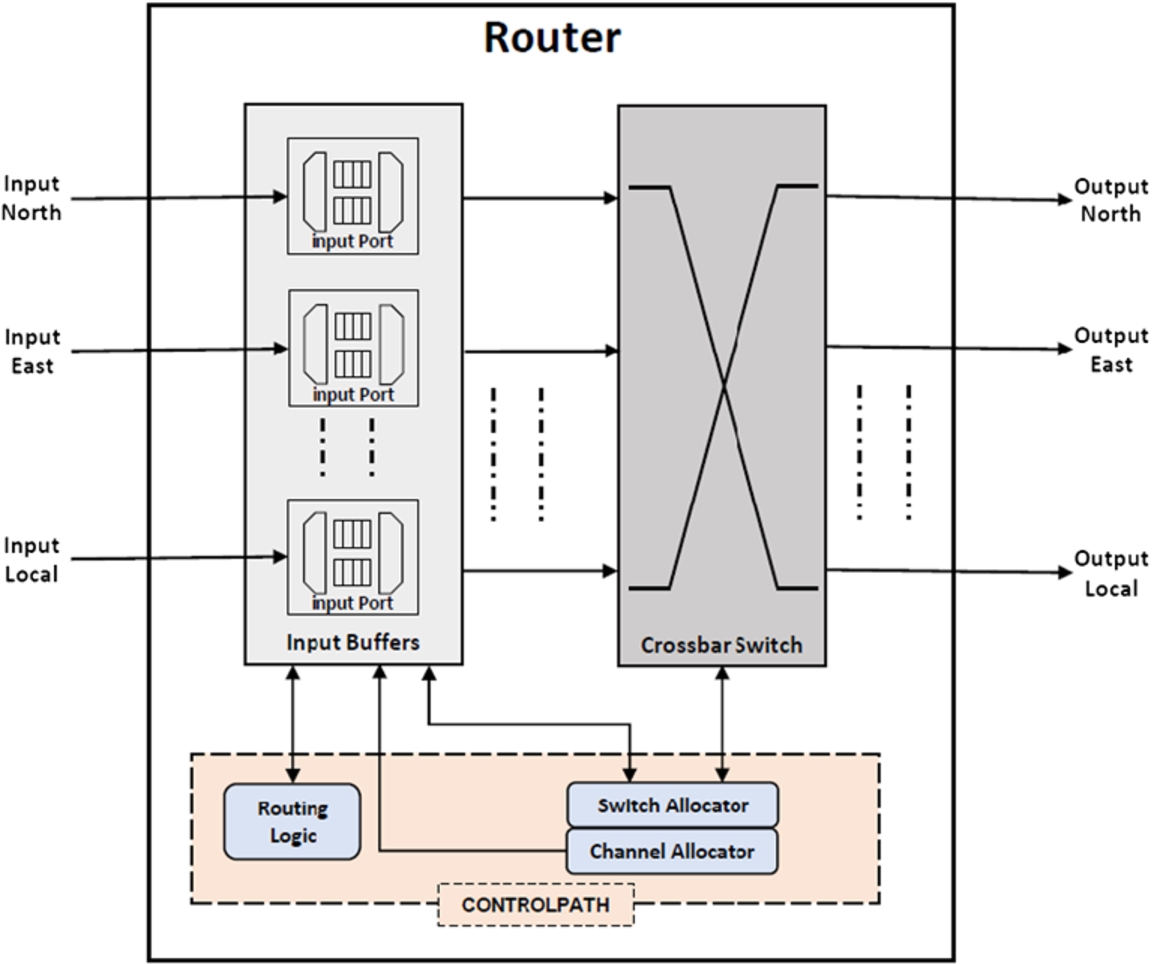
The architecture of baseeline 4-stage NoC router.
The Router is the main component in the NoC [25]. It is the communication backbone in the NoC-based interconnect architecture. It receives incoming data packets and analyzes their routing information to select the best path, based on the routing function. A typical router is composed of two main components, the Datapath, where the packets go through from an input port to an output port, and the Controlpath to lead the flow of the data packets in the router depicted in Fig. 3. The control path includes the buffer control logic, pipeline control logic, arbiters, and so on.
A traditional NoC consists of a set of elements, called IPs, which can be processor cores, built-in memory, separate specialized hardware modules, I/O interfaces. In general, each IP has one router to provide packet routing. Intermediate layer, which is a NI (Network Interface), connects routers with IP nodes. All these components are interconnected by connecting lines [5]. For the communication infrastructure to dynamically pinpoint components with permanent or transient faults and to autonomously self-reconfigure, the router needs to exhibit some inner intelligence.
Fault diagnosis includes three tasks, that is, fault localization or detection, fault isolation, and fault identification.
The technique to locate the faults is the most basic task of fault diagnostic. Fault locating is also essential in fault tolerance in order to pinpoint faults on router or link [20,50]. So, to check whether there is malfunction or faulty component in the system, it is preferrable to know and localize the fault on NoC and his type to allow the implementation of the suitable approach.

The proposed router.
The schematic of fault-tolerant control is depicted in Fig. 4, which shows that fault diagnosis is integrated with fault-tolerant control. Real-time fault diagnosis cannot whether the system is faulty and inform where the fault occurs. From this valuable information, the control system can thus take appropriate fault tolerant actions. The fault information known by routers has a direct relation with the fault-tolerant capacity and network performance.
A Router is an entity that facilate communication between PEs cores in Networks on chip. We introduce in the section below the proposed router architecture and its main components. The router is the back-bone component of the NoC design. The two necessary components which are added to the basic router architecture are Fault Register (FR) and Test Module (TM) are shown in Fig. 4. Each end node has a maximum number of 4 input and 4 output ports. One input/output port is used to connect the switch to the NI, in the perspective to eliminate the extra area overhead and the power consumption. Each router can be connected to a maximum of four adjacent routers as well as the local intellectual property (IP) across NI.
The router architecture of OFDIM is shown in Fig. 4, sharing a similar structure as the traditional NoC router [25] as shown in Fig. 3. This method need special control circuitry and elements to be built for the system, which are usually very complicated because of their design, but offers a good reliability in terms of detecting permanent and soft errors in parallel with small area overhead as compared to static fault tolerance approach. It is considered as a promising method for networks-on-chip. Each step of the sequence is explained below.
During the first step, we will focus on the design and implementation of a robust router resistant to a given number and type of faults. We will identify the router’s most sensitive parts that have to be protected. This information will be used to customize the fault tolerance techniques for each block of the router (input and output buffer, switch, controller, etc), as shown in Fig. 5. This approach having as a goal the minimization of the hardware overhead and the overall energy consumption of the router and the NoC. However, some router components may be very expensive to protect or they can tolerate a given number of errors (e.g. buffers using a correction code limited to two errors).
Detection mechanism
In this subsection, we have utilized the concept of online fault detection. It is introduced as an additional circuitry to detect single stuck-at faults (stuck-at 0 and stuck-at 1) during the operation of the system [2,15,16,22].
The basic detection mechanisms are either the end-to-end (E2E) [36] or switch-to-switch (S2S) [35]. E2E checks packets for error at destinations only, whereas (S2S) performs error detection at intermediate routers [44].
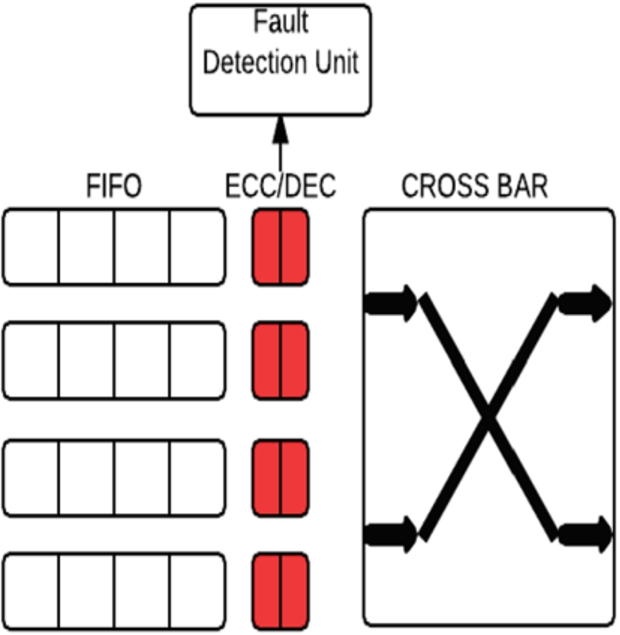
ECC achieved fault detection.
In terms of fault detection in on-chip network, built-in-sift-test (BIST) [14] is a traditional solution in integrated circuits which can be appropriated as a fault-detection scheme to handle the faults in routers, links and network interfaces. This method is a fault detection scheme. But this technique needs external circuits to perform error detection, and time to test which can reduce the performance of the NoC in term of latency. Another drawback the disconnection of the system for test that is required in BIST and the original traffic flow is affected which make dependability and performance hardly balanced. So, for minimizing the impact during fault detection, more online fault detection schemes are under investigation [3,4].
The fault detection can be implemented in any one of the following forms [24].
periodic tests: Tests are performed occasionally and output is verified.
self-checking circuits: Duplication in terms of circuit or time with comparison for output verification.
watchdog timers: It checks the timer value and resets when its value has exceeded. It is commonly used in multiple processor systems.
However, most fault detection methods focus only on permanent faults [3,6,8,32], ignoring the transient and intermittent faults. Transient faults have a various characteristic that they occur frequently in fixed positions while having a certain randomness on the time of occurrence. One solution to detect transient faults is increasing the test frequency.
The main goal is to keep the logic of our circuit as simple as possible, thus, it would be desirable that the total area of a checker would not exceed the area of the router it is checking.
To develop our approach, we have opted for the Cyclic Redundancy Cycle (CRC), a solution that can be used to perform error detection by comparing an input and output of each router to detect wrong packets and faulty components in a NoC. This approach is inspired by [19], with some modifications. Each router is equipped with a Test Module (TM). The goal of this mechanism is to enable online fault detection. The CRC polynomial used is
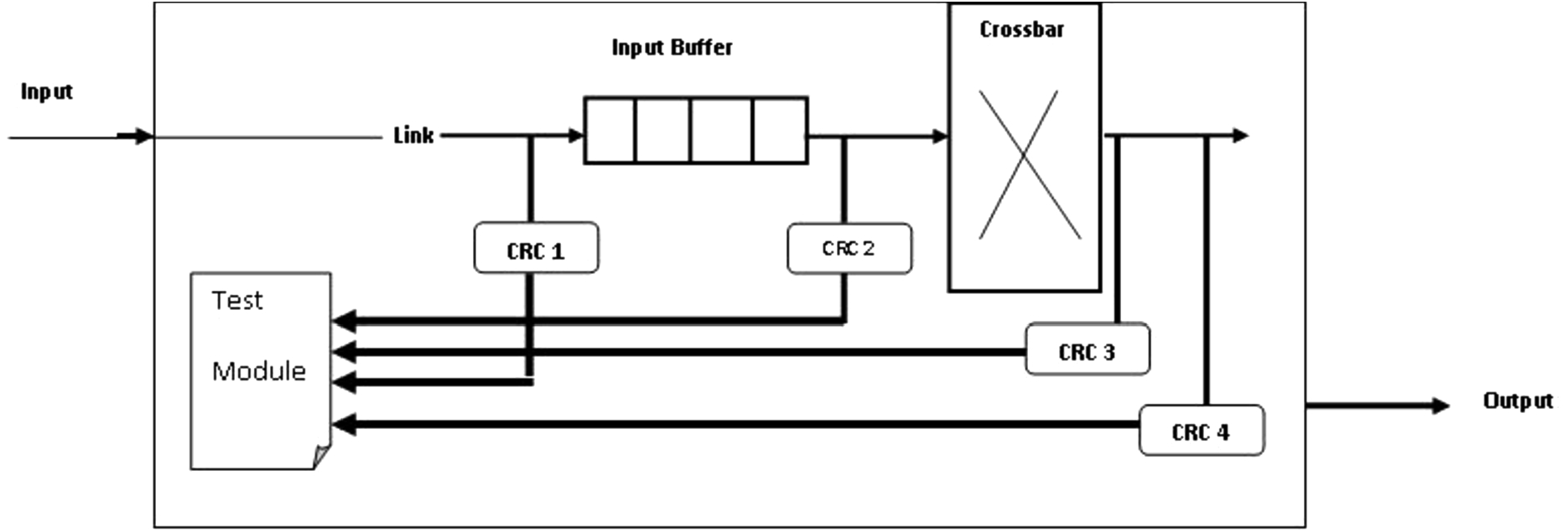
Internal architecture of the router.
To test and diagnose the communication infrastructure in the NoC. First of all, it is necessary to detect the fault, secondly how to identify the faulty components: routers, links or cores. Finally, we analyze how to use efficiently the remaining components that are fault free. In the router, the fault can occur in all the components of the router (crossbar, buffers and others). At this high core density in networks on chip, considering faults only in the routers or links do not provide the optimal safety. Other components such as input-buffers and crossbar should be given prominent attention to ensure the fault tolerance and improve the system reliability.
To achieve this goal, we present in this section the Test Module (TM) added in our router (depicted in Fig. 6). The TM is one of the main components of our system, because it manages the diagnosis from all kinds of faults in four main components: inter-router links, input-buffers, crossbar, and header flit. We start in this subsection to describe the main functionalities of the Test-Module (TM) and its important role in orchestrating the different processes inside the router. Test Module detects and locates the faulty routers or links. Therefore, only the adjacent routers can communicate this information. In order to keep the fault occurrence in the input-buffers and the crossbar and header flits, this information is always sent to the FR (Fault Register). The aim is to be used during the selection of the next port. We used a simple fault detection mechanism based on a Cyclic- Redundancy-Check (CRC) in each output component of the router that reads the incoming flit to detect any error. Depending on this verification, the Test-Module (TM) sends a single-bit signal to the TM of upstream node that can be either 0 or 1, for valid or faulty, respectively, as shown in Fig. 5. Each router sends the collected information corresponding to its own fault status to all the neighboring nodes. This information is represented in a 3-bit (see Table 2) signal representing the router/link status in each direction (North, East, South, and West). Depending on these states, our router (OFDIM) reads the fault status of the next nodes/links received from the TM and checks the number of possible safety directions. For example, when a fault is detected in the buffer, a signal is sent to inform the TM module about the fault presence. The same case is applied for the other components. When receiving this signal, the TM disables the entire output-port and the faulty router to save the dynamic power. At the same time, TM updates the FR-status array by flagging the link connected to the faulty router.
Codification of different states of links and routers
The permanent errors cannot be eliminated by a simple reset of the circuit. The routers adjacent to a router with a permanent fault are informed about its state. This is to prevent any traffic to this defective router (for example, they can disable the output ports leading to this router). The same case is applied for defective links.
Transient fault detection
The transient errors occur typically during a very short time and are not destructive. So, after k attempts, the test module can consider the (temporary) dynamic faults as permanent. So we want to tolerate several on-line faults without resetting the circuit.
Fault location
After fault detection, we also need to keep the fault ocurence. Upon the detection of errors, fault diagnosis can only be performed with the information collected from fault detection. This information is constantly sent to all the TMs for all neighboring nodes, as shown in Fig. 7.
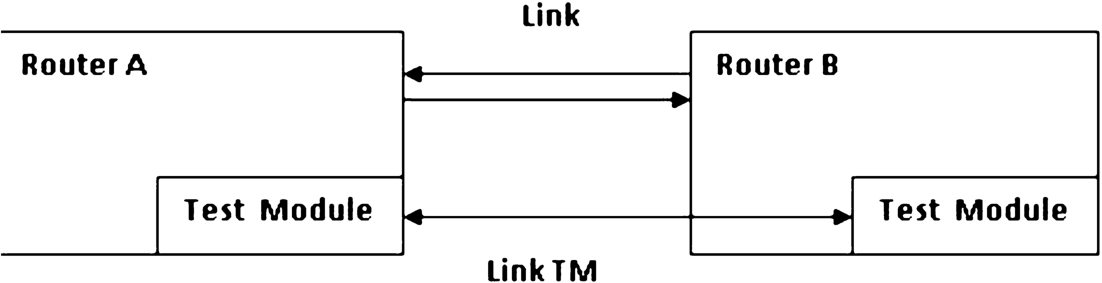
Communication between two neighboring routers.
When receiving this signal, the TM disables the entire output-port and the faulty router to save the dynamic power. At the same time, the TM updates the FR-status array by flagging the link connected to the faulty router. Finally, to keep the faults information in routers or links, the TM interacts with the FR unit to exchange fault information and control signals, as shown in Fig. 8.
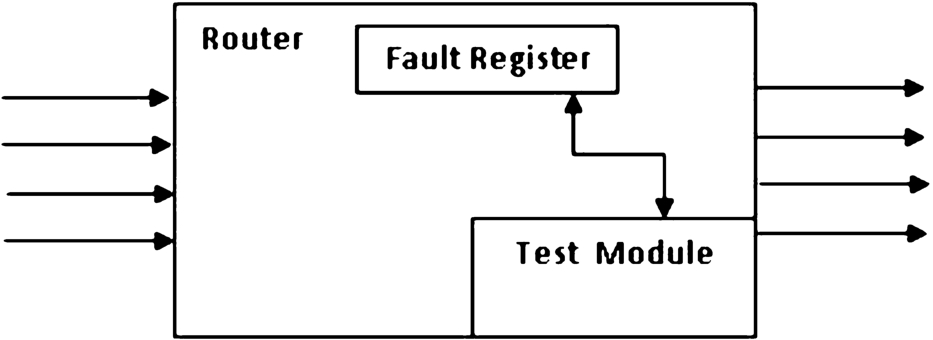
Communication between TM and FR.
We devote this section to assess and analyze the performance of the proposed solution and discuss the performance variation. We have selected Random traffic pattern to evaluate the performance of the OFDIM router. In order to compare the performance of our reliable router design, we modify the booksim simulator [26] to support these two kinds of fault tolerant routers. We compare the latency caused by the add module for achieving fault tolerance. All the simulations are conducted on a
Reliability analysis
The reliability of a NoC router Rr(t) [49] is the probability that a router performs its functionalities correctly from time 0 to time t. It is decided by the failure rate, λ, which is measured by the number of failures per time unit.
The reliability model for the traditional
The reliability curve of traditional

Reliability analysis of various size of mesh from 1-10 years.
To estimate the reliability improvement of our router as compared to the existing reliable routers, we use the MDTF metric. MDTF of a system is given by:
To calculate the MDTF of our solution, we first calculate the maximum and the minimum number of faults tolerates. If all four primary links become faulty, the output ports become unreachable. Therefore, a minimum of 4 faults causes failure.
Thus, the OFDIM can tolerate a maximum 53 faults. To calculate MDTF, we need a maximum number of faults to cause failure. Thus, for the proposed architectre, the maximum number of faults to cause failure are
Thus, an average of 29 faults cause the failure. We compare MDTF of our solution with the existing reliable routers such as SHIELD [40]and HPR [48].
Silicon protection factor (SPF) analysis
To estimate the reliability improvement of our architecture as compared to the basic router, we use SPF [50]. It considers the fault-tolerant capability of the architecture with respect to the hardware cost. It is given as:
The router achieves the highest mean number of faults, resulting in a higher SPF value, as shown in Table 2. According to the definition of SPF, a higher SPF value means better reliability. The router achieves the highest means number of faults and SPF as compared to existing architectures.
The results are shown in Table 3.
Comparison of area overhead for Shield, Wang and our proposed router
Comparison of area overhead for Shield, Wang and our proposed router
Table 3 shows the SPF comparison of our solution with state-of-the-art reliable router architectures. It is evident that the proposed architecture is more economical than the existing reliable router architectures.
The area overhead [27] plays an important role to determine the fault tolerance capacity of router architecture design. A comparison of area overhead with state-of-the-art fault-tolerant router architecture is shown in Fig. 10. It is shown by comparing the baseline router and proposed solution that the area overhead of the proposed design is 27%. For fault detection, we utilized checkers design mehanism. The results show (see Fig. 10) that the proposed architecture achieves higher reliability by incurring smaller overhead as compared to HPR and SHIELD architecture.
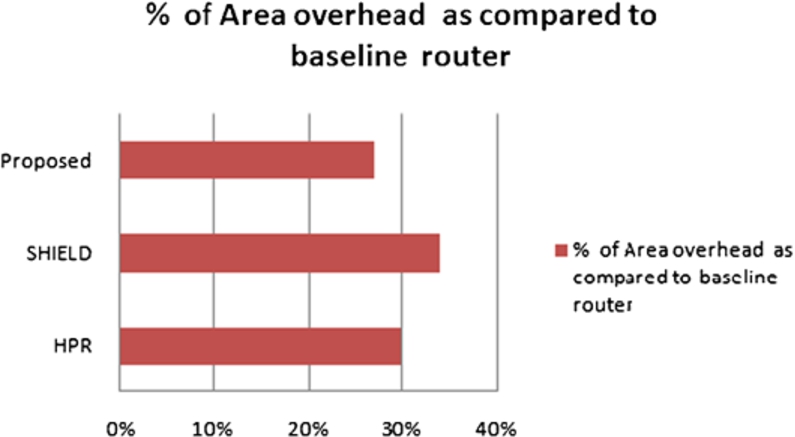
Comparison of area overhead.
A comparison of the area overhead with some related works for fault-tolerant router architecture is shown in Fig. 10. It is shown by comparing the baseline and the proposed OFDIM (which performs 27% of the area overhead). For fault detection, we used checkers with a fault detection mechanism. The results show that the proposed solution achieves higher reliability by incurring smaller overhead as compared to an existing architecture.
In the simulation of throughput, 100 different fault patterns are randomly generated. In this evaluation, all PEs are assumed to be healthy. As revealed, an error-free network has the highest throughput. The throughput decreases as the number of faulty routers increases. However, in an
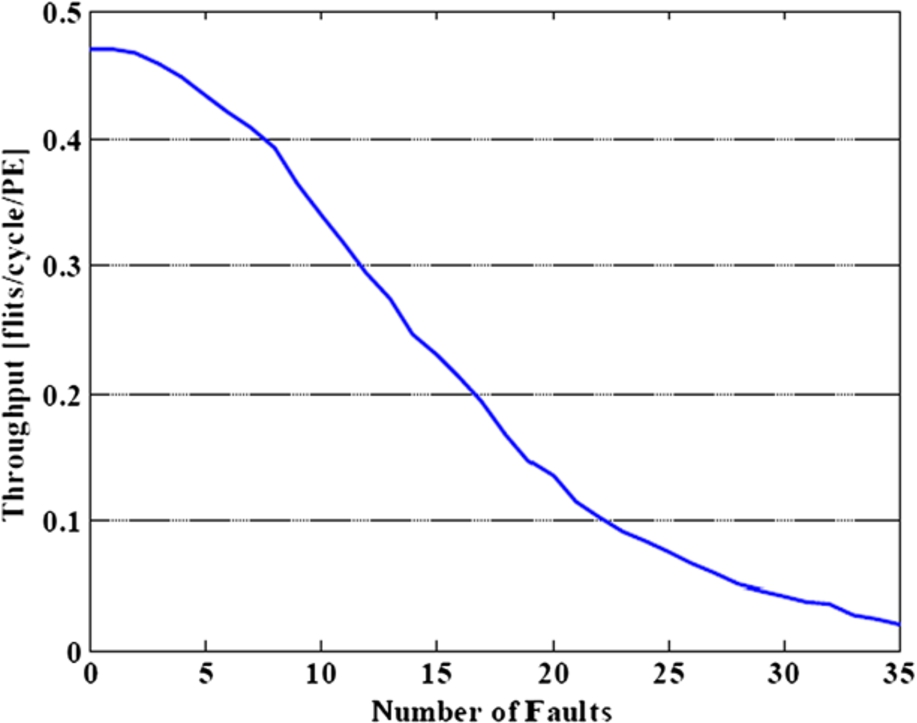
Average throughput for a network of 64 PEs.
We have simulated the NoCs with various sizes and various numbers of faulty routers and links. Only the latency for the
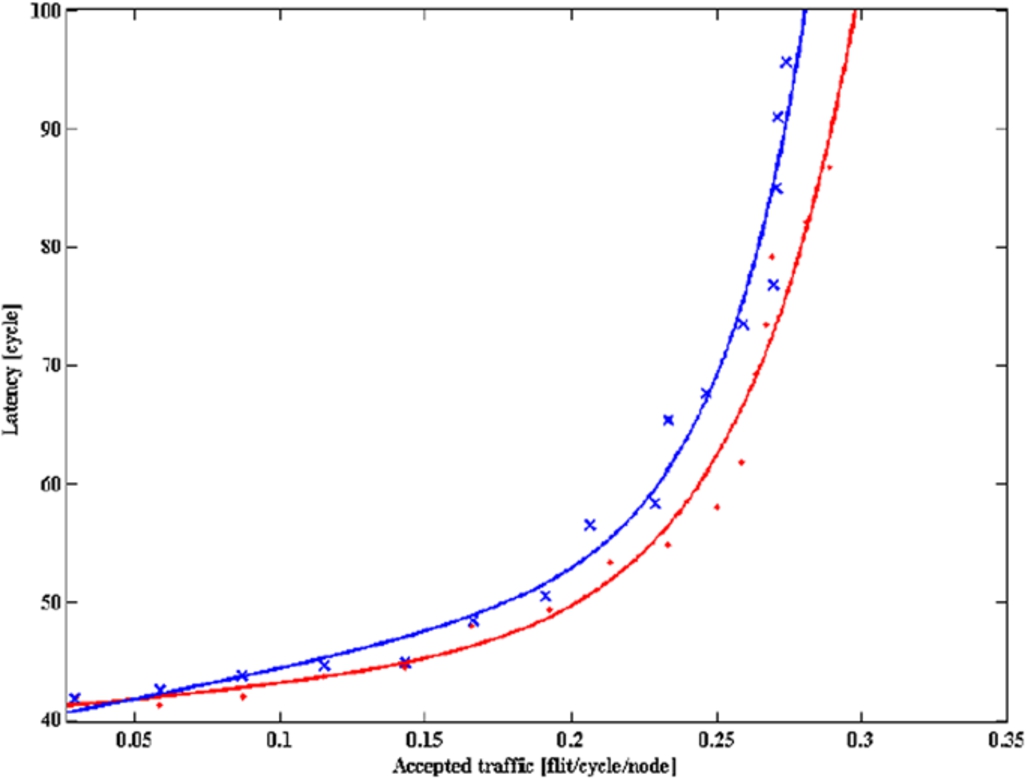
Latency for
To evaluate the performance of the proposed router architecture, we modify the baseline router architecture. All simulation is evaluated on simulating 64 nodes in a 2D mesh network. The mesh network is evaluated on synthetic traffic patterns. The uniform random traffic patterns is injected in the networks on a varying injection rate of 0.1 to 0.5. The proposed router architecture can tolerate the faulty links and all components of the router. The fault is inserted during the runtime simulation and added randomly in the network. Initially, one fault is injected, and the total number of faults is injected until the router reaches a stage where it can tolerate the maximum number of faults. It is observed that, as the number of faults increases, the latency of the router also increases, but it continues working.
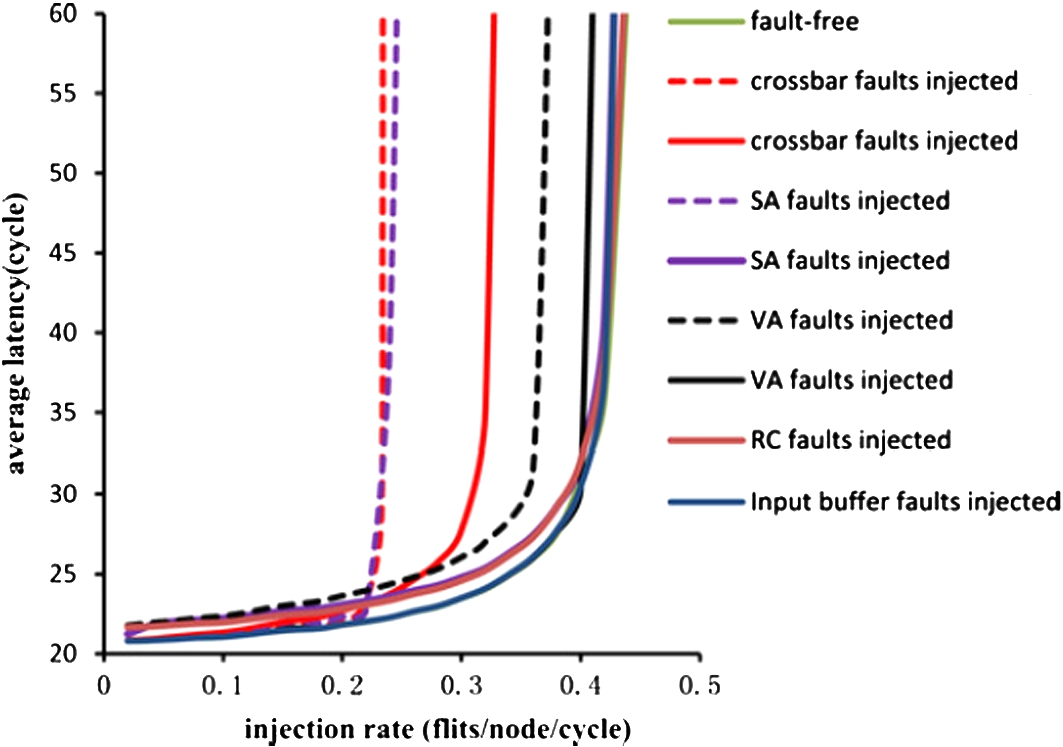
Comparison of average latency with the faults injected in our design and HPR. Dashed lines show the result of HPR design. Real lines show the result of our design.
We analyze the impact of average latency under the uniform random traffic pattern with the faults injected. Figure 13 compares the average latency of HPR reliable NoC router with our design when faults are injected to different components. The result of our proposed router is shown in real lines. Fault-tolerant strategies for the input buffer, the RC, the VA and the SA bring minor performance decrease.
From the evaluation results, we could observe how the proposed router architecture was able to satisfy these three important requirements: 1) 100% functionality regardless of the location of faults 2) graceful performance degradation 3) low area overhead.
In this paper, we proposed a reliable fault tolerant router architecture, called OFDIM, endorsed with two mechanisms; detection and isolation. The proposed architecture manages to avoid the system failure at the presence of a large number of faults while ensuring graceful high reliability and performance degradation while minimizing the additional hardware complexity. Despite the good results obtained with the proposed architecture, some points should be fixed to enhance its performance and reliability. The first one is Local congestion and second global congestion caused by faults in router. Completing the fault-detection mechanism and implementing thermal-power-aware techniques [21] aim to improve the reliability of our solution and maintain the obtained good performance.