
Abstract
The automation of data analysis in the form of scientific workflows has become a widely adopted practice in many fields of research. Data-intensive experiments using workflows enabled automation and provenance support, which contribute to alleviating the reproducibility crisis. This paper investigates the existing provenance models as well as scientific workflow applications. Furthermore, here we not only summarize the models at different levels, but also compare the applications, particularly the blockchain applied to the provenance in scientific workflows. After that, a new design of secure provenance system is proposed. Provenance that would be enabled by the emerging technology is also discussed at the end.
Introduction
With the development of the new paradigm of data-intensive scientific research, research has increasingly become a data-driven knowledge discovery activity.
As a result, researchers in different fields have encountered a serious reproducible crisis [1] in front of a large amount of research data, including raw data, code, description of scientific workflow, etc., which means that many scientific experiments are difficult to reproduce.
Undoubtedly, continuous and repetitive work will consume valuable time of scientific researchers [29]. And it is not conducive to the development and the progress of science. Moreover, the public would lose trust in scientific research if scientific experiments cannot be reproduced and the results of scientific research cannot be verified, which could result in economic losses.
As a common means of managing modern scientific experiments, scientific workflow can provide efficient management for data-intensive scientific research [59], including data provenance, data layout, data management, etc. The application of scientific workflow can help to cope with the reproducibility crisis of research. Scientific workflow systems have played an important role in scientific collaboration in the fields of medicine [51], physics [6], biology [74] and so on.
Figure 1 shows an example of a scientific workflow diagram for the construction of a knowledge graph in the field of forestry. Each task (

Example of scientific workflow diagram for the construction of knowledge graph in forestry field.
Data provenance is a critical aspect of reproducibility [30]. It can improve the replicability and verifiability of scientific experiments by capturing the conversion of information from the source to the final result.
Meanwhile, the caught information offers significant documentation, which is a vital aspect for keeping up with information, evaluating the exactness and origin of the information, and repeating and approving the discoveries [32].
Over the past decade, with the rapid development of computer technology, a variety of scientific workflow systems have also been produced. Such application updates go along with the equipment of the latest computer technologies, from local computer systems [89] to cloud platforms [52] and now to big data clusters [58]. As a result, the concept and implementation of data provenance techniques have been changed.
The following is an example of the Panda provenance system to show the provenance construction case. Panda [49] is a provenance system of data oriented workflows, which inherits data based and process based sources. It also supports a full range of sources from fine to coarse granularity.
We use a detailed fictitious example to illustrate the construction process of provenance. In order to complete an experiment, Alice, a scientific researcher, crawled some data from Internet and output a report after data cleaning and analysis. Later, scientific researcher Tom wants to quote Alice’s data when doing research in Alice related fields, so it is important to understand Alice’s data origin. Tom analyzed the data and found an error in Alice’s data analysis report. Therefore, he captured the data provenance and found the steps to handle Alice’s error. The workflow is shown in the Fig. 2.
The initial input of the workflow is the data crawled on the network and stored in the local database. The workflow includes the following two steps:
Data cleaning: process null values in data, delete duplicate values, and unify date format and naming format
Data analysis: call common data analysis methods for data analysis, and output visual charts. Scientific researcher Alice organizes the results to form a data analysis report
Now, when reading Alice’s data analysis report, researcher Tom finds that a chart does not conform to mathematical rules. Tom wants to find out the cause of this error.

Workflow provenance description case, researcher Tom can trace Alice’s errors in the Panda system.
The Panda provenance system can trace back the above fictitious examples well. The architecture of the Panda system is shown in the Fig. 3. In order to track the step of the workflow, the SQLite server in the Panda system provides the following four modules:
Data Tables: used to store all data, including node metadata table, user information table, database metadata table, activity table, etc
SQL Transformation: the SQL transformation engine is used to automatically create provenance predicates for SQL transformation, and to create provenance predicate tables. However, it is not necessary for a most basic provenance system
Workflow Table: used to store information for a workflow
Provenance Predicate tables: Panda uses bipartite graph model induced by provenance predicates as the provenance model. It serializes in the form of triples to be a customer-item-probability triplet.
In this paper, we give a perspective on current data provenance in scientific workflow. At the beginning of this paper, we rearrange the current provenance technique based on the previous literature and focus on the provenance constructed on blockchain in recent years. Subsequently, we compare the provenance techniques applied in scientific workflow to help scientific data management or developers design provenance systems. Then, we propose a provenance system architecture design based on blockchain and proVOC model. Finally, the application of graph databases and knowledge graph technology in the field of provenance in scientific workflow is envisaged.
The remainder of the paper is organized as follows. Section 2 describes the provenance model, which is an indispensable part of building a provenance system in a scientific workflow. Section 3 introduces and contrasts common provenance applications in scientific workflows in both conventional and blockchain technologies. Section 4, the new security provenance system architecture is proposed. Challenges and opportunities in provenance research are given in Section 5. At last, we conclude in Section 6.

Architecture of the Panda system, including client, Graphical interface, Panda layer, SQLite server and file system.
The provenance model forms the basis for the data provenance system. Generally speaking, the construction of a provenance model is divided into three steps as follows.
Firstly, as a kind of metadata [83], the provenance elements should be predefined [14]. Secondly, the provenance should be transformed into a form that can be processed by computer based on standard definition or self-defined provenance representation model. Last, if the security needs are guaranteed, a provenance security model should also be introduced or constructed specifically.
Currently, numerous provenance models have been developed in different fields and organizations. Such models are built based on different tasks. Some of them have good universality, while others are used for specific data objects or application scenarios.
This section summarizes the provenance structure from three layers: record, representation, and security. To be noted, the record is the annotation which should be captured.
Record of provenance
The record of provenance is what should be recorded of the data provenance, containing the derived history of the data product, and is gathered as annotations along with descriptions of the source data and procedures. This is an eager form of representation in that readily usable as metadata [7]. However, excessive metadata records often cause a greater burden on the storage, so a reasonable record design of provenance can contribute to improving the efficiency of data provenance.
Early studies only capture the historical origin of a small amount of data and can not achieve the purpose of the whole data provenance. With the increase of data volume and the deepening of research, Buneman et al. [12] put forward Why and Where provenance.
It is used to answer the two questions of which existing data affects the provenance and where the provenance data is located. The Why provenance of an output tuple provides a set of witnesses for that output tuple. Nevertheless, it does not provide additional information on how the output tuple is actually derived. Green uses semirings of polynomials to represent a comprehensive provenance. So, the query results can be expressed as polynomials on provenance semirings, which can infer more detailed data derivative processes. Green named this approach How provenance [43].
However, such taxonomy is not suitable in other fields, such as scientific workflow. Sudha et al. [75] proposed a W7 model and pointed out that the record of provenance should include Who, When, Where, How, Which, What and Why.
The records can be richer and, in addition to the derivation history, often include the parameters passed to the derivation process and the version of the workflow, which will enable reproduction of the data and even related publication references [71].
Farah et al. [90] propose a provenance framework to achieve consistency of provenance across different granularities in a hierarchical manner and support comprehensive and fully re-executable workflows equipped with domain-specific data. The proposed framework takes common workflow language (CWL) as the carrier of workflow, represents provenance based on the PROV representation model, and finally encapsulates the recorded data into research objects for information exchange. They also sorted out the records that should be considered in the construction of the provenance system, and summarized 19 recommendations, which are divided into five categories: Data Sharing, Retrospective Provenance, Prospective Provenance, Execution Environment, Findability & Understandability. The details mentioned in the recommendations are shown in the Fig. 4.

19 recommendations summarized in the article [90] published by Farah et al., such recommendation is intended to provide reference for the recording of provenance.
There are a wide range of representation model to represent provenance data. Representation models are utilized to represent specific types and aspects of data provenance information in the format of various vocabularies and ontologies, such as attributes, references, versions, and so on. The first typical general representation model is the OPM [67] which promulgated by the first International Provenance and Annotation Workshop (IPAW). It extends OPMV by defining more constraints using complex OWL2 constructors and defines a core set of rules that describe inter-transaction relationships, including three entities Artifact, Process and Agent that are linked using causal relationships, representing their dependency used, was generated by, was controlled by, was triggered by, and was derived from. In general, the relationship between nodes is described by constructing a graph of data provenance [66].
In the process of using OPM, gradually, many problems with OPM are exposed, such as vague concept terms and usage or improper concept design (e.g., Time, Properties, and Relations) [5]. Therefore, W3C proposed a standard model for PROV based on OPM. Its core is the conceptual data model PROV-DM [60], the structure of which includes Entity, Activity, Agent and seven types of relation sets. In addition to strengthening the description of semantic relationships among data, it also makes the data model constructed too complex. Every relationship between entities is associated with all the relationship types defined in the model. Thus, in the specific application process, the data model needs to be optimized to save the provenance information completely and reduce the number of data tables.
Although PROV is so refined and detailed that most domain expert applications cover only part of the complete recommendation, there are exceptions. Moreau and Missier extend the W3C PROV Data Model (PROV-DM) [68], which is used by most of the provenance community. A provenance graph represents entities, activities, and agents. ProvStore [48] and PROV-WF [26] provide, respectively, a web service to manipulate provenance documents and a runtime provenance that can be queried even during the workflow execution.
ProVOC [19], a provenance representation model published in the form of a Chinese national standard. It consists of three basic categories: Data, Activity and Agent, Data includes two subclasses: parameter and dataset. Among them, parameter includes three subclasses: Temporal parameter, Spatial parameter and Condition parameter. The structure of the ProVOC model is shown in the following Fig. 5.

Structure of ProVOC model.
In some special scenarios, the standardized representation model cannot meet the specific application scenarios. To solve this, many specific models have been developed.
In the field of scientific workflow, Roger S et al. propose Provenir [80], and take the Neptune Project as an example of scientific workflow to explain the construction of the provenance model in detail. Similarly, Provenir contains three basic categories, that is, Data, Agent and Process. Since Provenir is built on OWL-DL [64], Data and Agent are defined as specializations of the continuant class of OWL-DL, whereasProcess is a synonym of occurrent.
The concepts proposed by provenir are equivalent to the three top-level concepts of the OPM ontology [65]. Paolo et al. further extended the Provenir model to better represent the domain semantics of workflow. Garijo and Gil propose an Open Provenance Model for Workflows (OPMW) [39]. It gives a structure to distribute computational workflows, which includes the specification of an OPMW ontology for the depiction of workflow provenance and their layouts. Based on OPMW, an approach for the automatic detection of the most common workflow fragments among scientific workflow datasets is created and subsequently [38]. ProvONE [27] is another data model for scientific workflow provenance representation. It was built to be compatible with PROV-DM and provides constructs to model workflow specification and workflow execution provenance. Such models like ProvONE, PROV-DM, and OPMW can catch, store, and search the provenance of a workflow, as well as trace it in a typical, machine-readable format. However, it lacks the ability to correctly and totally determine control-flow driven workflows, leading to incomplete workflow structure and unspecified workflow issues. In this vein, ProvONE+ [13] catch the provenance of workflows by extending the ProvONE.
In majority of instances, provenance data is sensitive and a small variation or adjustment leads to a change in the entire chain of the data connected [53]. It is imperative for provenance data to be secured against unauthorized access and to not leak any information about the data against which it is collected, since metadata of provenance is transmitted and stored as data [11].
To date, most studies of provenance security has basically re-applied existing mechanisms, for example, access control, advanced marks, data stream control, or data protection, without answering the semantic questions above. A significant special case is Chong’s proposal to define provenance security guidelines [21], drawing on the provenance model presented by Acar, Ahmed, and Cheney [20]. Uri and Avi [9] use two non-interfering models which protect the workflow and restrict users’ access to nodes to protect data in the process of provenance. As an improvement on the previous model, they (Uri and Avraham) view the provenance as a causality graph with annotations in which each node represents an object and each edge represents a relationship between two objects. Based on this concept, a provenance model has been developed that can interact with other access control models [10]. Hasan et al. [46] created an analytic data provenance threat model based on the encryption and incremental chained signature mechanism, to ensure the integrity and confidentiality of file system provenance information. However, as an attacker is able to strip away the provenance information of a file, the problem of data leakage in malicious environments is not tackled by their approach. Zhang et al. [96] improved the threat model and proposed a method based on checksum to verify the integrity of provenance information in the database. Davidson et al. [31] proposed improvements from the perspective of database privacy and anonymity. In Taha et al. [2], a trusted framework is organized using a Trusted Platform Module(TPM) to guarantee data provenance collected to be admissible, complete, and confidential at the level of the operating system.
In practice, many factors need to be considered in the construction of a traditional security provenance model, such as confidentiality and privacy, as described in [94]. This will make the provenance framework builder have to spend a lot of time thinking about the design of security mechanisms. Fortunately, the application of blockchain technology alleviates the current dilemma.
Blockchain is a growing list of records, securely linked together by blocks distributed across servers (nodes). Because each node of a chain stores all the information in the chain, it is extremely difficult to tamper with the information in the chain. Compared with traditional networks, the blockchain has two core features: tamper-proofing and decentralization. Based on these two characteristics, the information recorded by blockchain is more authentic and reliable, which can help solve the problem of data security in scientific workflow.
Ramachandran et al. [77] developed a secure and immutable scientific data provenance management model framework, smartProvenance, on top of the blockchain. In this case, the framework uses smart contracts and OPM to record provenance information. The blockchain serves as a platform to promote the collection, verification, and management of trusted data sources, so as to prevent any malicious tampering.
Liang et al. [56] proposed ProvChain, an architecture collects and verifies cloud data provenance by embedding the provenance data into blockchain transactions. It provides the following four abilities to audit data operations for cloud storage: Real-time Cloud Data Provenance, Tamper-proof Environment, Enhanced Privacy Preservation, and Provenance Data Validation. Wanghu et al. [17] created ProChain to share scientific workflow provenance in light of blockchain in a community of scientific research in which data provenance is managed on-chain and delivered off-chain. Working on ProChain, scientists can share workflow segments in a trustworthy and reliable way, including location as well as related description metadata.
A scientific data authentication model based on blockchain and distributed ledger, bloxberg, was introduced by Kevin et al. [91], to improve the reusability and integrity of data in scientific workflow.
To help information responsibility and provenance tracking for European Union residents’ data, a private blockchain-based network is being utilized by Ricardo et al. [70].
Provenance techniques
Provenance has been applied in many fields. For scientific data provenance, different solutions and technologies have been born from varied disciplines over the last decade. such as Karma [84,85], Vistrails [4], Taverna [47], SPADE [40], Kepler [8] and other special data provenance application systems. This section mainly explores provenance applications in scientific workflow.
Before the advent of blockchain technology, researchers established data provenance applications or systems by building description model and representation models, respectively. For applications that clearly need to ensure data security, means of access control [61], digital signatures, information flow control, privacy or even semantic definitions [22] will be introduced.
At present, with the continuous development of blockchain technology, the construction of security models becomes more convenient, so some data provenance techniques or applications based on blockchain have also been created.
The following subsections respectively introduce and compare the traditional provenance application and blockchain-based provenance application in scientific workflow.
Traditional provenance application
In the field of scientific workflow, there are many applications for scientists, for instance myExperiment [78], CrowdLabs [62], and KNIME [89], can be used by scientists to publish workflow definitions and share them over the web. In addition, Michaelides et al. [63] introduced a domain-specific PROV-based provenance for help the portability and reproducibility of programming suites. They caught basic elements from the logs of workflow implementations and addressed them utilizing an intermediate notation. Yang et al. [93] introduced the design and implementation of DEEP, an executable document environment that generates scientific results dynamically and interactively and also keeps the provenance of these outcomes in the record. They integrate provenance with the system’s internal data structure by utilizing a specialization of the PROV-DM to depict the behavior and asset association of the system. Provenance is exposed to DEEP users by an interface, which provides the users with varying levels of understanding of the structure of the resource and ways to navigate the document.
Another project, PASS [69,81], was described by Seltzer et al. to track provenance automatically. By recording provenance metadata for each object, it helps scientists get their job done better at a less significant cost. The Lineage File System(LPM) [3] is an instance of a PASS. It focuses on executables, command lines, and input files as the source of provenance like PASS, but it ignores the hardware and software environment in which such processes run. Subsequently, Camflow [72], a continuation of PASS and LPM [3], has a cleaner architecture and is easier to maintain. It is a system-based provenance system that was proposed by Pasquier et al., demonstrating retrospective provenance catch at different levels in the system. Other eminent domain-specific efforts utilizing established standards to document provenance and contextual information are PROV-man [5], PoeM [37], and micropublications [23].
Many systems also have built-in retrospective provenance support, such as VisTrails [36], Taverna [47], Confucius [97], WINGS [42] and PLIER [41]. They all build provenance ontologies based on a representation model such as OPM or PROV-DM to provide data or workflow in a visual interactive way. It even improves the scalability of applications by providing APIs.
All of these efforts use standardized methods for documenting provenance and are therefore related to our work on traditional documenting of retrospective provenance.
Provenance application base on blockchain
This section gives a brief introduction to blockchain technology and lists some current data provenance applications based on blockchain in scientific workflow systems.
The emergence of blockchain technology provides a convenient interface to establish a security mechanism for data provenance, which enables the developers and researchers of scientific workflow management systems to achieve secure provenance based on the relevant interface of blockchain [57]. Compared with traditional system construction, the blockchain-based system builder can concentrate on the construction of the provenance business without spending too much spirit on solving the security problems, such as whether captured data is tampered with or the database is attacked [44].
The blockchain uses P2P communication protocol, PoW, PoS, PBFT and other consensus algorithms, asymmetric encryption, and database technology to ensure data availability. The blockchain architecture [82] is shown in the Fig. 6, which is generally divided into five layers: network layer, consensus layer, data layer, smart contract layer and application layer. In order to achieve the data tamper resistance, the blockchain has introduced a chain structure with blocks as units. Although the specific details of the data structure of different blockchain platforms are different, the overall architecture is basically the same. The block structure is shown in the Fig. 7. Taking Bitcoin as an example, the elements stored in the block header include header hash, random number, Merkle root, etc. Profit by the unique design of the blockchain, developers can use smart contracts to write blockchain programs, deploy them to the blockchain, and ensure the automatic, transparent and reliable execution of contracts with the help of the trust mechanism jointly maintained by the whole network.
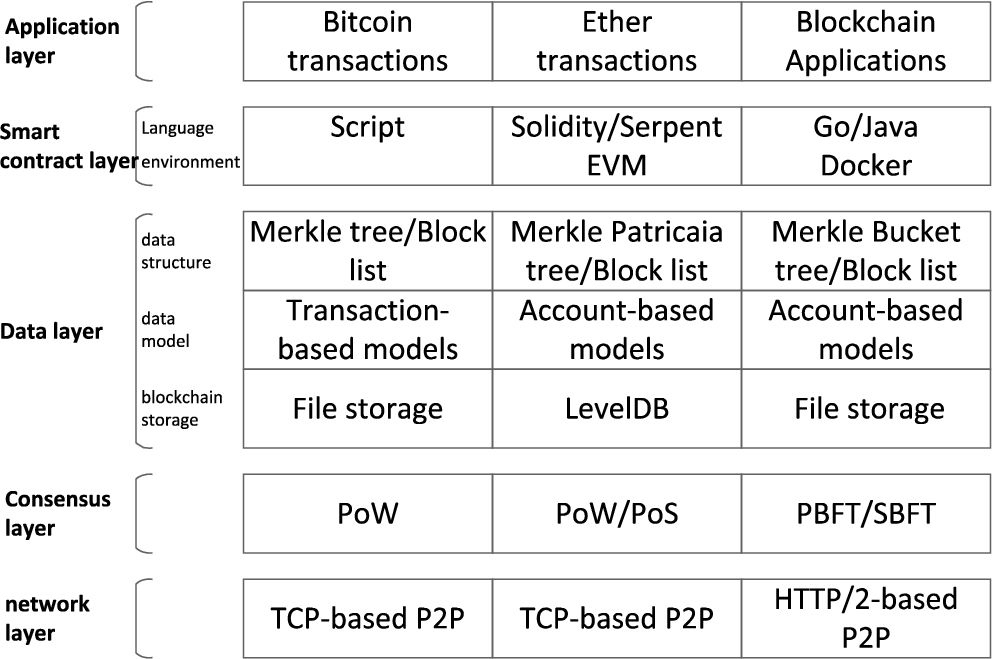
Blockchain architecture, including network layer, consensus layer, data layer, smart contract layer and application layer.
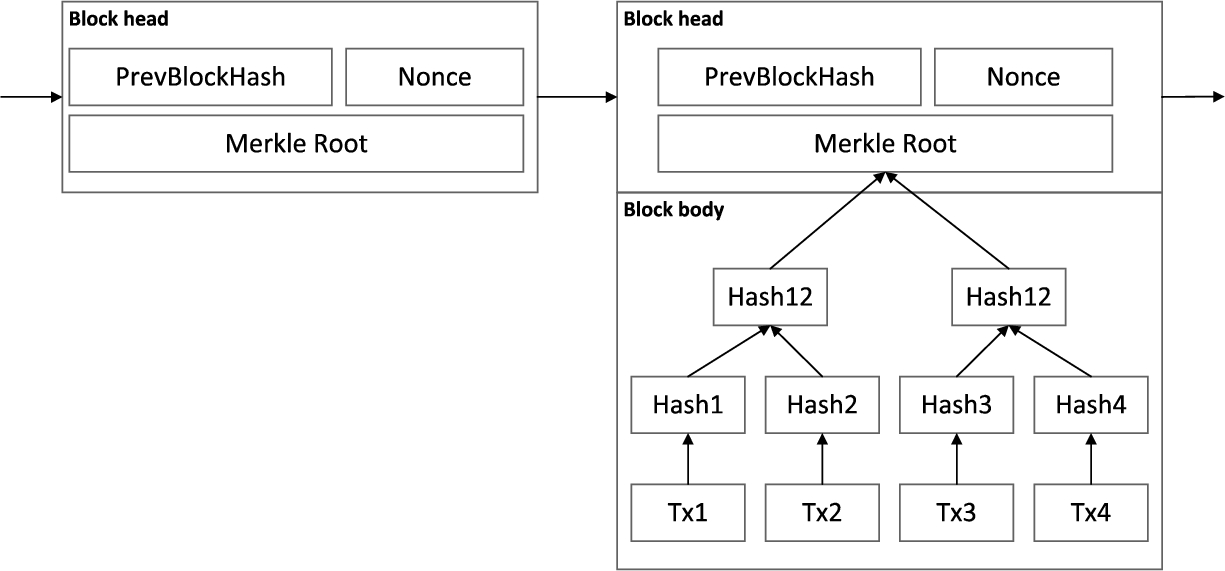
The two block structures of the Bitcoin blockchain, light nodes need to store less information than full nodes, reducing the burden of it.
Considering the big advantages of blockchain in decentralization, trustworthiness, and high reliability, many provenance applications based on blockchain have been proposed in the field of scientific workflow [18,34].
In view of the problem of data provenance in the scientific data sharing management platform, Hao et al. [45] constructed the layered blockchain architecture of scientific data sharing, and explored the realization mechanisms of interactive information, data blocks, consensus mechanisms, intelligent contracts, etc. Based on Hyperledger Fabric, Gu et al. constructed the alliance chain model [50] for humanities and social science data sharing, which solved the problems of weak provenance ability and untraceable data used in traditional data sharing.
To address the problem of integrity and authenticity of data in scientific workflow, Dinuni et al. [35] developed the SciBlock system based on blockchain to provide data storage for the provenance of scientific workflow, which allows users to query provenance and gives the capacity to nullify some unacceptable or obsolete provenance data without deleting it. Besides, Wittek et al. [70] use a private blockchain-based mechanism to help information responsibility and provenance tracking for European Union occupants’ information. By combining blockchain technology, smart contracts, and metadata-driven data management, Demichev et al. [33] proposed a distributed data provenance management method, ProvHL (Provenance Hyperledger), which supports the storage and exchange of data generated by scientific experiments in a distributed environment. It realizes fault-tolerant and secure provenance management of metadata.
Furthermore, Ramachandran and Kantarcioglu construct a SmartProvenance system on top of smart contracts that further augments the trustworthiness and integrity of data provenance by implementing randomized voting and encryption mechanisms, respectively. It utilizes open provenance model (OPM) to record immutable data provenance [77].
The use of blockchain is often accompanied by cloud environments for scientific workflows.
Zawoad et al. [95] analyzed the threat of trusted provenance in cloud environment under a blockchain application and proposed secure application provenance SECAP (secure application provenance) scheme, which can effectively ensure the integrity and confidentiality required for provenance. Blockcloud [87], a cloud computing provenance framework based on blockchain, improving the POS (proof of stake) [34] consensus mechanism, was built by Tosh. ProvChain [56], a data provenance system based on blockchain, which can provide tamper-proof records, enable the transparency of data accountability in the cloud, and help to enhance the privacy and availability of the provenance data. Different from other provenance systems, Provchain does not build a data presentation layer based on a representation model, but instead customizes a set of metadata to record user actions on data files stored in the cloud. Similarly, Wanghu et al. [17] proposed a blockchain-based system called Prochain for sharing provenance data during the execution of scientific workflows. Moreover, Coelho et al. [24] proposed a BlockFlow architecture with the ProvONE [27] model to provide trust support for scientists on the Science Ecosystem Platform (E-SECO) to perform their collaborative experiments on the cloud platform.
The following compares and analyzes some provenance applications mentioned in this paper from four aspects [73] (see Table 1): Provenance model, Data access, Storage, and Security mechanism. Among them, Provenance model refers to the data model adopted by the corresponding application, Data access refers to where it is provided a way through which prevention data can be accessed and explored [28], Storage indicates the location of the provenance data storage (eg. on-chain or off-chain), and whether to provide a security mechanism is marked by the Security mechanism.
As shown in Table 1, of the 24 proposals we investigated, 10 were based on blockchain to build data provenance applications, and the remaining 14 were traditional. Among them, all applications based on blockchain provide corresponding security mechanisms to ensure the security of provenance data, while only 6 of the 14 traditional provide security mechanisms. This is because the blockchain technology has a data security mechanism, so developers do not need to redesign the security mechanism. Due to the current block transaction information capacity limitation of the blockchain (for example, 1MB in Ethereum [92]), the amount of data that transactions on the public chain can sink in is far lower than that in the local database. Therefore, blockchain based applications have to simplify the records of provenance, or store the provenance data in a combination of on-chain and off-chain. For the same reason, it is very difficult to combine the provenance model in the blockchain. Only 4 of the 10 blockchain based applications are built based on the provenance model, while 11 of the 14 traditional applications are built based on the provenance model. Although the current based blockchain applications are tamper proof and some also try to combine the provenance model to better support data interchange on the web, intuitive data access means have not been provided, which needs to be improved for blockchain based applications.
In general, according to the collation and comparison of 24 data provenance applications in this paper, the following conclusions are drawn. Building a provenance system based on blockchain can provide sufficient data security mechanism, but the current proposal has less application of provenance model, and the way of data access needs to be further improved. In the future, it is necessary to carry out more research on the capacity limitation of blocks, and expand the block capacity as much as possible to store more provenance data without affecting the data consistency and under the acceptable consensus duration.
Comparison of some provenance applications sorted out in this paper
Comparison of some provenance applications sorted out in this paper
1
2Provenance Manager System.
3Provenance-Based Data Loss Prevention.
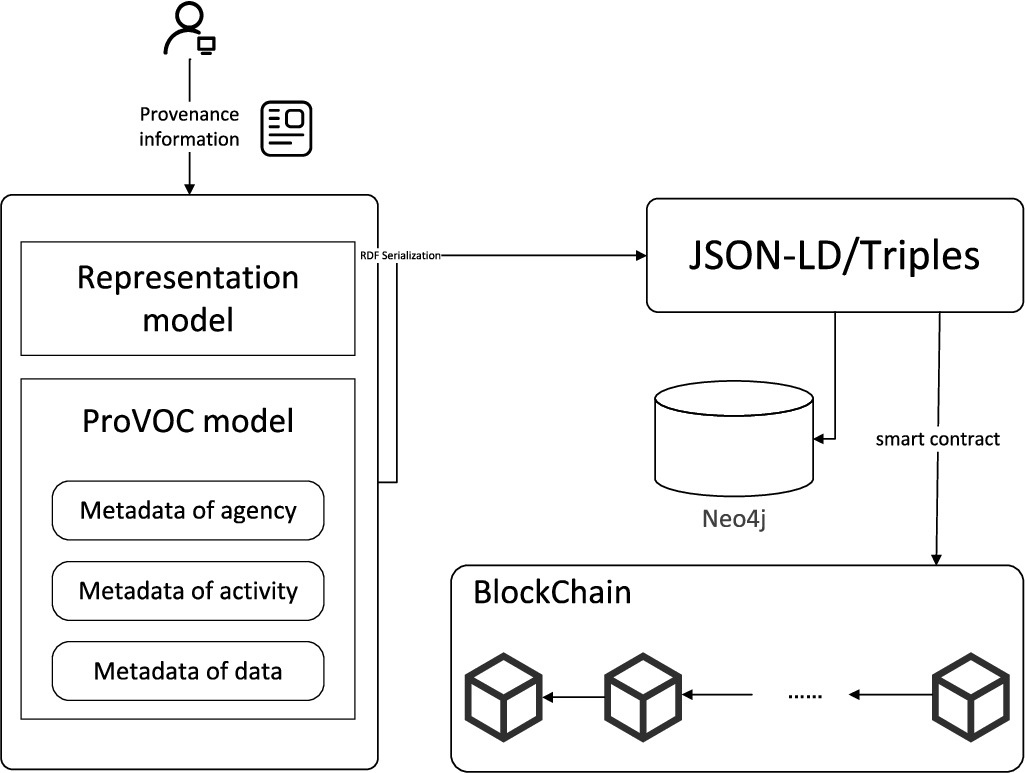
Based on the provenance model ProVOC and blockchain, this paper proposes a secure scientific workflow data provenance framework, Fig. 8. The model consists of the following parts:
The input data model specifies the data source information monitored by the provenance system, including metadata of agency, metadata of activity, metadata of dataset
Data serialization, taking RDF as the data model, serializes the data source information into JSON-LD or Triples format for data transmission and exchange
Neo4j database is used to improve the efficiency of data query, data tracking and process reproduction. Using graph database to store data, in this scenario of data provenance, graph database has more advantages than relational database [88]
Blockchain, based on the smart contract, we can link the provenance information to verify whether the information is reliable and has not been tampered with
When users create workflows in the provenance system, the system will automatically capture the provenance information. When the workflow is created and executed, the relevant provenance information will be serialized in the form of RDF and synchronized to the Neo4j and the blockchain respectively. When user needs to analyze the workflow, he can query it through the Cypher interface provided by Neo4j and obtain the entire data of workflow. Finally, if the current workflow information needs to be verified for tampering, the user can call the verification interface provided by the blockchain for verification.
The advantage of this framework is that it combines ProVOC provenance model and blockchain, has practical feasibility, and stores data in the form of RDF, which can improve the interoperability between the current system and other provenance systems. The graph database Neo4j is used to store the information. Compared with the traditional relational database, it has more advantages in data analysis and visualization.
Example of scientific workflow diagram for the construction of knowledge graph in forestry field.
Contrasting the initial use cases and what can actually be achieved with current provenance systems makes it clear that research is needed in a number of areas.
Querying and inference. The research on semantic-based provenance has made great progress. Although a variety of semantic models have been used in the provenance of workflow, the inference potential of semantic models has not fully burst out. These are still challenging problems. In recent years, benefit of the rapid development of Machine Learning and Deep Learning, the Knowledge Graph technique based on Natural Language Processing technology has also begun to be studied and applied in various fields. The Knowledge Graph based on various graph databases also provides serve such as data lineage analysis and data provenance, and can achieve satisfactory query speed compared with the provenance system based on traditional relational database.
Delicacy provenance. Big data technologies, such as Spark and Flink, have been widely used in e-commerce, short-video platforms, and other fields. How to build a finer provenance to provide fine-grained data collection and information, allowing researcher behavior and system error prediction, limiting error propagation, or self-diagnosing changes in output quality will be the direction of future research.
Security and privacy. Although blockchain technology has brought us dawn, security is still a major challenge at present. For every important scientific research, it is necessary to build a comprehensive security scientific workflow system from the hardware layer to the application layer. For example, there are studies that use differential privacy to protect personal privacy data [55], and use searchable symmetric encryption(SSE) to prevent database information disclosure [54]. The construction of a complete security system can ensure that key scientific research achievements would not be stolen by hackers.
Conclusion
In this paper, we provide a systematic literature review of published studies that focus on provenance in scientific workflow. First, we introduced the scientific workflow and provenance. In particular, we illustrate the representation of scientific workflows with real-examples, namely the construction of forestry knowledge graphs. Then, the provenance model was introduced in three levels: the record model, representation model, and the security model. This is immediately followed by the multiple provenance applications shown in the scientific workflows and demonstrated by the usage of blockchain. Finally, we propose a provenance system architecture design based on blockchain and proVOC model and discuss future research directions that could include hotspots such as big data, machine learning, and knowledge graphs.
Footnotes
Acknowledgement
This study is funded by the Guangdong Science and Technology Plan Project (2021B1212100004, 2019B010139001), Guangzhou Science and Technology Plan Project (201902020016) and Guangdong Natural Science Fund Project (2021A1515011243).
Conflict of interest
None to report.