
Abstract
The data collected by the distributed high-speed network has multiple sources. Therefore, in order to realize the rapid integration of multi-source data, this paper designs a rapid data integration method based on the characteristics of the distributed high-speed network. First, we use linear regression analysis to build a distributed perceptual data model, so that network nodes can only transmit the parameter information of the regression model, so as to simplify the data collection. Then, a dead band amplitude limiting nonlinear link is added at the high frequency channel side to filter and assimilate the data. Finally, the data feature vectors are extracted as the training samples of the neural network to obtain the mapping relationship between different feature vectors, and then the decision level data integration is achieved by training the neural network. The experimental results show that this method can accurately collect high-speed network data, and the data collection deviation is always less than 5 μrad; This method has good filtering effect on data and can eliminate the interference of burr signal; The convergence speed of this method is fast, and the data assimilation can be completed within 0.4 s, which is conducive to improving the speed of data integration; With the increase of network size, the average traffic load of this method increases less.
Keywords
Introduction
With the rapid development of cutting-edge technologies such as information technology and artificial intelligence, the amount of data is increasing day by day. With the advent of the era of big data, various Internet applications have produced different types of data documents with complex relationships [12]. Among them, multi-source heterogeneous data is an important and common data type. A large part of the multi-source data is heterogeneous data [20], which has the characteristics of high dimension, low quality, and no annotation, and it is difficult to extract its features. At the same time, due to the large number of data sources, the data analysis process becomes more complicated [3].
Data integration is an important branch of multi-source data processing. Initially, multi-source data integration technology was applied in the military field. The U.S. Department of Defense first proposed the concept of multi-source data integration in the C3I strategic system, and then the United Kingdom developed an artillery intelligent integration system. After the 1990s, my country began to widely use multi-source data integration technology in various fields.
In order to meet the increasing performance demands of current and future networks, it is necessary to effectively extract and analyze the features of multi-source data [22]. In this application background, various processing methods of high-speed network multi-source data emerge as the times require. The operation of high-speed network relies on a series of operations such as the collection, processing and uploading of monitoring environmental data information to the base station by a large number of nodes deployed in its space area. When performing monitoring tasks, the high-speed network performs long-term data collection and query tasks, and requires the monitoring results to be transmitted to the base station for further analysis and decision-making. However, high-speed network data presents the characteristics of multi-source heterogeneity and non-uniform distribution [18]. This makes the collection nodes limited in terms of energy, storage space, computing power, and the load capacity of the network itself. Data collection and transmission have brought huge network traffic pressure, resulting in large energy consumption of nodes, redundancy in collected data, and increased inconvenience with unnecessary time and space complexity. In this case, data integration processing is a necessary measure.
At present, relevant scholars have carried out research on multi-source data integration technology. Cai et al. [2] proposed a feedback convolution network intelligent data fusion method. This method mainly optimizes the convolution filter of each segment through error feedback iteration, and then fuses multiple segments of features to train the calibration model, and finally realizes the data Integration of near-infrared spectrum. However, this method has strong pertinence and poor ability to integrate network multi-source data. Yun et al. [19] designed a multi-source data integration method based on ontology and causal model, and realizes the integrated processing of multi-source data by means of integration. The method first analyzes the ACLED dataset and constructs event ontology. Then, the Karma model is built to integrate the ACLED dataset, publish the RDF data, and check the correctness of the data through SPARQL queries. Ma et al.’s [11] method uses deep belief network to integrate data and has practical application. This method mainly deals with the phenomenon of missing data. Compared with BP neural network used for data fusion, this method is closer to the actual value. Li’s study [10] mainly analyzes complex network data fusion based on the perspective of super network. This method builds a quality evaluation function for the information compression problem of seeking effective network structure, and reduces the quality evaluation function by heuristically mixing labels. Finally, data fusion analysis is realized and experimental verification is carried out.
Based on the analysis of the existing important research results, this paper designs a multi-source data rapid integration method based on distributed data acquisition for the problems existing in the process of high-speed network data acquisition. In the design of this paper, before the application of neural network to complete the final integration processing, the process of simplifying data, filtering processing and heterogeneous assimilation processing is designed to provide the integration effect by improving the quality of data itself. In the stage of neural network integration processing, the data feature vectors are used as the training samples of the neural network, and the neural network is trained by analyzing the mapping relationship between different feature vectors, which can achieve decision level data integration.
High speed network data reduction processing
The high-speed network consists of a series of nodes with wireless radio frequency transmitter modules and data sensing modules. The nodes can realize short-distance wireless communication and application environment information storage, which is conducive to the accurate and rapid recovery of data in the later stage [16]. In the high-speed network, since the data processing of high-dimensional tensors involves a lot of computation. Therefore, a linear regression model for distributed data collection is designed, which can be used to simplify data processing, thus reducing the amount of calculation in the process of data processing and fundamentally realizing rapid integration.
With the field programmable gate array chip as the core, a distributed data processing structure is built [13]. According to the specific application environment of the high-speed network and the performance indicators such as the storage space and processing capacity of the communication nodes, the nearest node within a certain time interval is selected to perceive The data is assumed to be
Among them, the number of items nnn and a specific basis function
Where,
In high-speed network applications, it is assumed that 50 monitoring values recently collected by the node are selected, a third-order polynomial function model is constructed:
Let the coefficient n dimensional vector to be sought be
Then the approximation error vector δ can be expressed as equation (4), namely:
In order to minimize the approximation error δ of the estimated value, the minimum norm of δ is selected as the optimization objective, that is, it can be obtained:
The minimum value of
According to equation (4), the following matrix equation equivalent to equation (7) can be derived, namely:
The defined basis function is
Let:
Then according to equation (12), equation (11) can be written as
Where: A is the quantity product matrix of basis functions; z is the basis function projection of the measured value vector. So far, with the measurement values and basis functions, the optimized regression coefficient can be obtained by solving the typical linear system of equation (14). and complete the efficient data collection. The high-speed network distributed data acquisition process is shown in Fig. 1.
In the process of high-speed network distributed data acquisition, according to the reasonable sleep scheduling mechanism, the nodes in the cluster collect the sensing information in the monitoring environment and transmit the sampled data to the cluster head node. The cluster head node constructs the distributed linear regression model and uploads the data to the base station according to the query statistical demand. In this process, the segmented re-selection of cluster heads is completed according to the remaining energy of network multi-source nodes, the distance between nodes and base stations and the degree of trust [17]. The cluster head node compares the error between the data calculated by the distributed data acquisition linear regression model and the actual collected data. If the threshold is not exceeded, the regression model is not updated; if the threshold is exceeded, a fault-tolerant strategy is used to determine whether to update the regression model and recalculate the parameters.
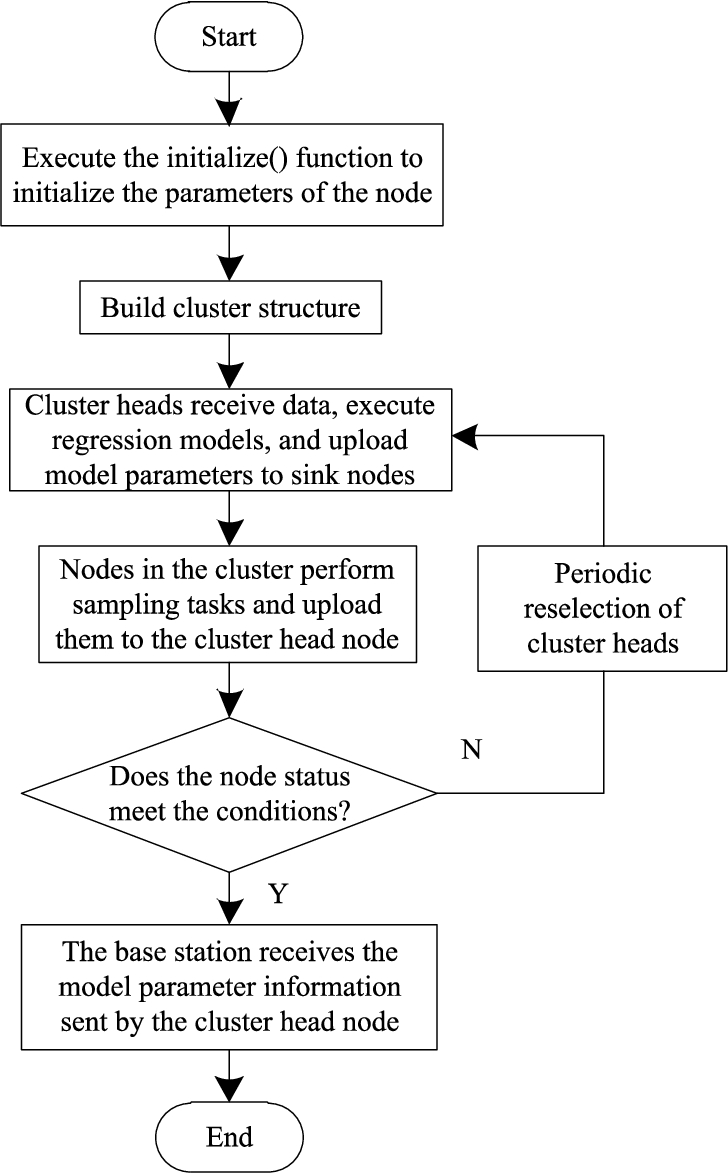
Distributed data acquisition process of high-speed wireless sensor network.
After the relevant data is collected, the data is distributed among multiple Level-One Edge Devices (LOEDs), which improves network service quality by reducing packet loss and end-to-end latency. Mobile receivers can also be used to distribute data uploads in LOEDs framework for anonymous data collection [15].
Because data in high-speed network has nonlinear characteristics, these characteristics come from its hardware structure and signal noise, especially noise information, which will reduce the accuracy of data transmission and processing. Therefore, it is necessary to implement nonlinear filtering on data.
For the distributed data in a piece of original high-speed network, according to the idea of filter [6], the original distributed data is split into first-order inertial links and actual differential links. According to the definition of the actual differential element, it can be converted to 1 minus a first-order inertia element. It was preceded by adding a deadband clipping nonlinear link. Then, the high-frequency interference signal is limited, and the low-frequency signal is processed in the dead zone to prevent the actuator from making frequent large or small adjustments due to sudden changes or frequent changes in the input data, so as to achieve the purpose of protecting the execution data. On this basis, the rate-limiting link is selected to replace the first-order inertial link in the differential link, making it a nonlinear differential link, forming a nonlinear filter with variable filtering time function with dead-band limiting. The function is:
Where,
The actual differential link in equation (15) can be changed to:
A non-linear filter can be constructed by adding a dead-band limiting link before the actual differential link, and replacing the first-order inertia link in the split actual differential link with a rate-limiting link.
Based on the characteristics of the nonlinear differential link, the response time and differential action increase with the amplitude of the input signal. The output
In formulas (17) and (18):
Fast integration of multi source data based on neural network
At present, some relevant scholars use Bayesian theory to perform low-level integration of multi-source data to obtain the posterior distribution of reliability [7]. Then it is passed to the higher level through the deterministic function related to reliability, and then the data transmitted by the lower level is transformed into the prior distribution of the life distribution parameters and fused with the higher level data. However, this process takes a long time and it is difficult to achieve rapid data integration.
Due to the heterogeneous characteristics of network multi-source data, it is necessary to use a reasonable method to integrate multi-source data with heterogeneous characteristics [4]. Therefore, on the basis of existing research, this paper realizes the rapid integration and processing of multi-source data based on neural network.
Heterogeneous data assimilation
High-speed network multi-source data integration mainly distributed data after filtering, the heterogeneous assimilation and homogenous integration process. The heterogeneous assimilation process can handle errors and incomplete information, and the homogeneous integration process handles the seamless merging of high-speed network distributed data.
The heterogeneous assimilation process is the process of expressing the distributed data of the heterogeneous high-speed network in a unified form, as shown in Fig. 2. High-speed network distributed data goes through the process of heterogeneous assimilation, and is managed uniformly in the form of homogeneous logic, and the integrated management of distributed data is realized through the remote access capability of middleware. Middleware technology establishes the mapping relationship between heterogeneous data and unifies multi-source data, thereby reducing the loss of data information caused by multi-source heterogeneous attributes [21].
The isomorphic fusion process uses a seamless integration framework to handle the whole process from seamless query initiation to seamless result set generation, which requires close cooperation of multiple parts. After receiving the seamless query result, the upper-layer module performs seamless visual analysis on the result. The seamless integration framework mainly includes the distributed environment of high-speed network distributed data, global directory service of distributed heterogeneous real-time data, global spatial index, seamless integration middleware and seamless integration service and multi-layer intelligent middleware system.

Heterogeneous distributed data assimilation process.
This research uses neural network to integrate the collected high-speed network distributed data. In the integration process, the data collected from the N nodes must be processed first, such as data filtering, denoising, normalization, etc. The deep convolutional network model is then used as a single sub-classifier to determine the class of the data samples using majority voting [14]. On this basis, the available data are associated, feature vectors are extracted as samples for neural network training, which are converted into random mapping features by a specific random mapping algorithm and stored in the hidden layer nodes, and then the activation function is transferred to the random mapping features. The transformation generates new hidden nodes, which are then wired to the output layer by output weights. Then, the mapping relationship between different feature vectors is obtained from the output information, and the neural network [9] is trained to carry out feature-level information integration, so as to realize the decision-making level information integration. The integration process is shown in Fig. 3.
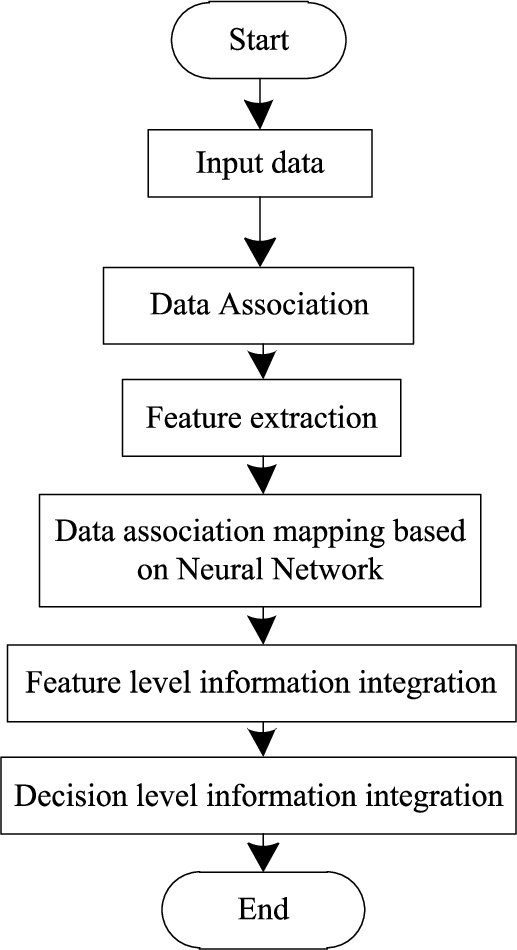
Multi source data integration process based on neural network.
The structure adopts a three-layer perceptron neural network model, which corresponds to a cluster in a high-speed network. Among them, the input layer and the first hidden layer are located in the cluster member nodes, and the output layer and the second hidden layer are located in the cluster head node.
Assuming that there is a cluster member node in a cluster in a high-speed network, and each cluster member node collects m different types of data, then the neural network model has a total of n × m input layer nodes and n × m first hidden layer neurons. The number s of neurons in the second hidden layer and the number k of neurons in the output layer can be adjusted according to the needs of practical applications, and are not necessarily related to the number of cluster member nodes. For different types of data, the number of second hidden layers can be different. There is no full connection between the input layer and the first hidden layer, and between the first hidden layer and the second hidden layer, but different types of data are processed separately; while the second hidden layer and the output layer are fully connected, which can comprehensively process different types of data.
After one round of weight adjustment of the three-layer neural network, it is obvious that the calculation of the local gradient needs to use the result of the previous calculation, and the local gradient of the previous layer is the weighted sum of the local gradients of the latter layer. Therefore, when the neural network updates the weights, it can only be calculated layer by layer from the back to the front. This back-propagation algorithm enables the neural network to learn the mapping relationship between input and output [8]. According to this three-layer perceptron neural network model, all the collected data are initially processed at each node according to the neuron function of the first hidden layer, and then the processing results are sent to the cluster head node to which the cluster belongs. The cluster head node performs further processing according to the neuron function of the second hidden layer and the neuron function of the output layer. Finally, the cluster head node sends the processing result to the sink node.
Massive raw data implies the shortcomings of manual and semi-automatic annotation, leading to the increasing research on automatic semantic annotation [1]. Therefore, in different high-speed network applications, according to the specific requirements of the application, the neural network model can be adjusted in the process of integrating multi-source data based on the neural network. For example, in the application of relatively simple data processing, the second hidden layer in the cluster head node can be combined with the output layer. In some applications where data processing is particularly complex, one or more hidden layers can be added to form more complex neural networks. In the new neural network, in order to realize the interoperability of data in different high-speed network applications, data integration is required [5].
To sum up, the design of a fast integration method for high-speed network multi-source data has been completed. The specific implementation process of the method is as follows:
Step 1: Using linear regression analysis method to build a distributed perceptual data model;
Step 2: In the constructed model, make the network nodes only transmit the parameter information of the regression model, so as to make the collected data more concise;
Step 3: In the high frequency channel of the network, add a dead band amplitude limiting nonlinear link to filter the noise signal in the data;
Step 4: Process the error and incomplete information in the data through heterogeneous assimilation to further improve the quality of the data;
Step 5: In the three-layer perceptron neural network model, extract data feature vectors as training samples, obtain the mapping relationship between different feature vectors, and then achieve decision level data integration through training neural networks.
In order to verify the practical application performance of the high-speed network distributed data integration method designed above, the following experiment is designed.
The experimental data comes from the GitHub data set, with a simulated high-speed network as the research object. In the experiment, the sampling time is 60 s, and the data samples are 800 Mb in total. The experimental indicators are: data acquisition deviation, data signal amplitude, assimilation processing time, convergence accuracy and average communication load. The experimental process and results are as follows.
Distributed data collection bias
In the case of different data acquisition information frequencies, the method in this paper is used to test the distributed data acquisition of the research object, and the deviation between the obtained results and the actual situation is shown in Fig. 4.
As can be seen from the analysis in Fig. 4, when the distributed data acquisition frequency of this method is 100 Hz, the data acquisition deviation is less than 3 μ rad, and the two peaks of information deviation appear at the 14th and 48th seconds of information collection respectively. When the frequency of distributed data collection is 300 Hz, the data collection deviation is less than 5 μ rad, and the peak value of information deviation is about 14 s, 37 s, and 50 s after information collection. The experimental results show that under the condition of the method in this paper and the distributed data collection frequency is different, the data collection deviation has a certain change. The method in this paper greatly reduces the useless data collection, so it meets the data collection and application needs of the research object.
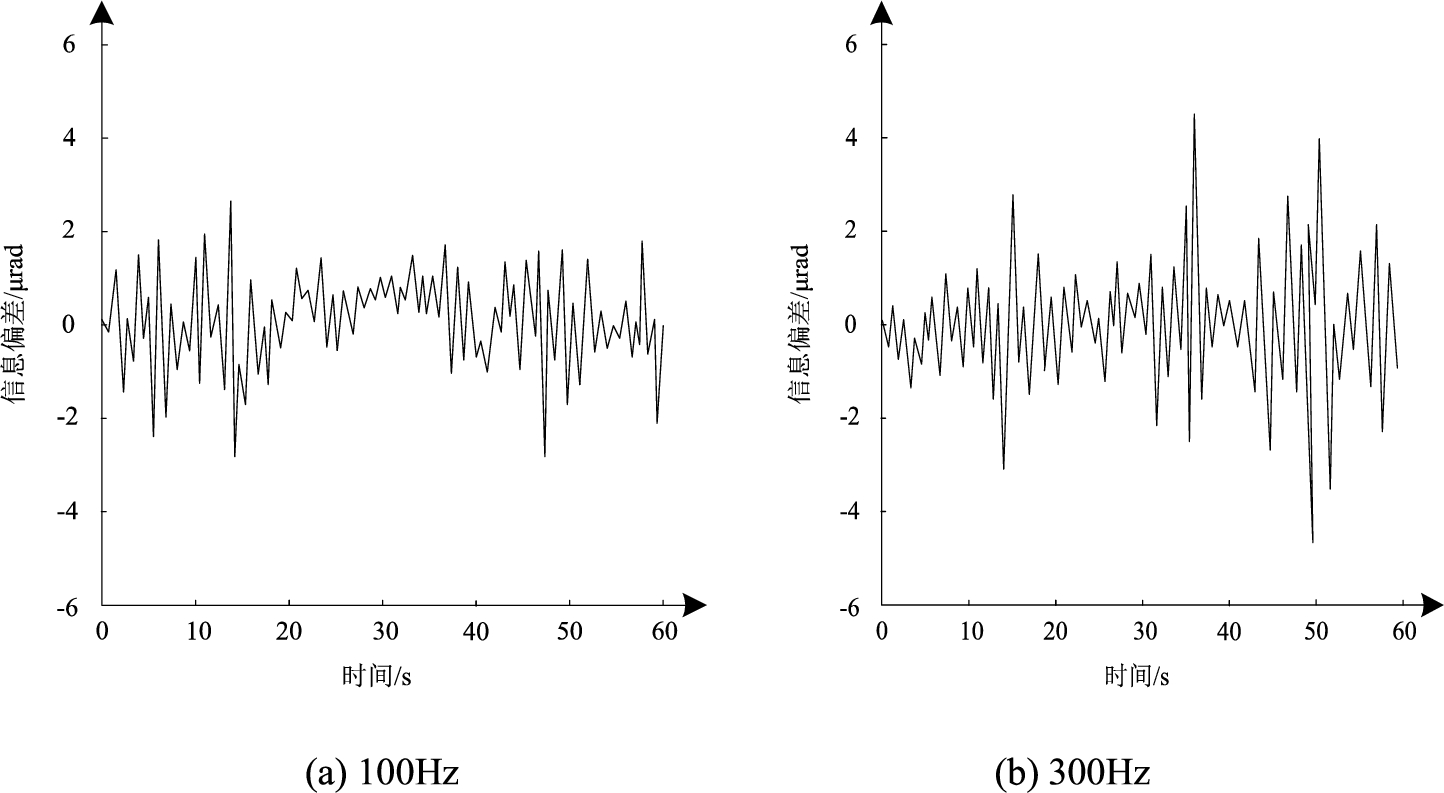
Distributed data acquisition deviation analysis.
Figure 5 shows the nonlinear filtering performance of the proposed method on the data collected by the study object in different application environments.
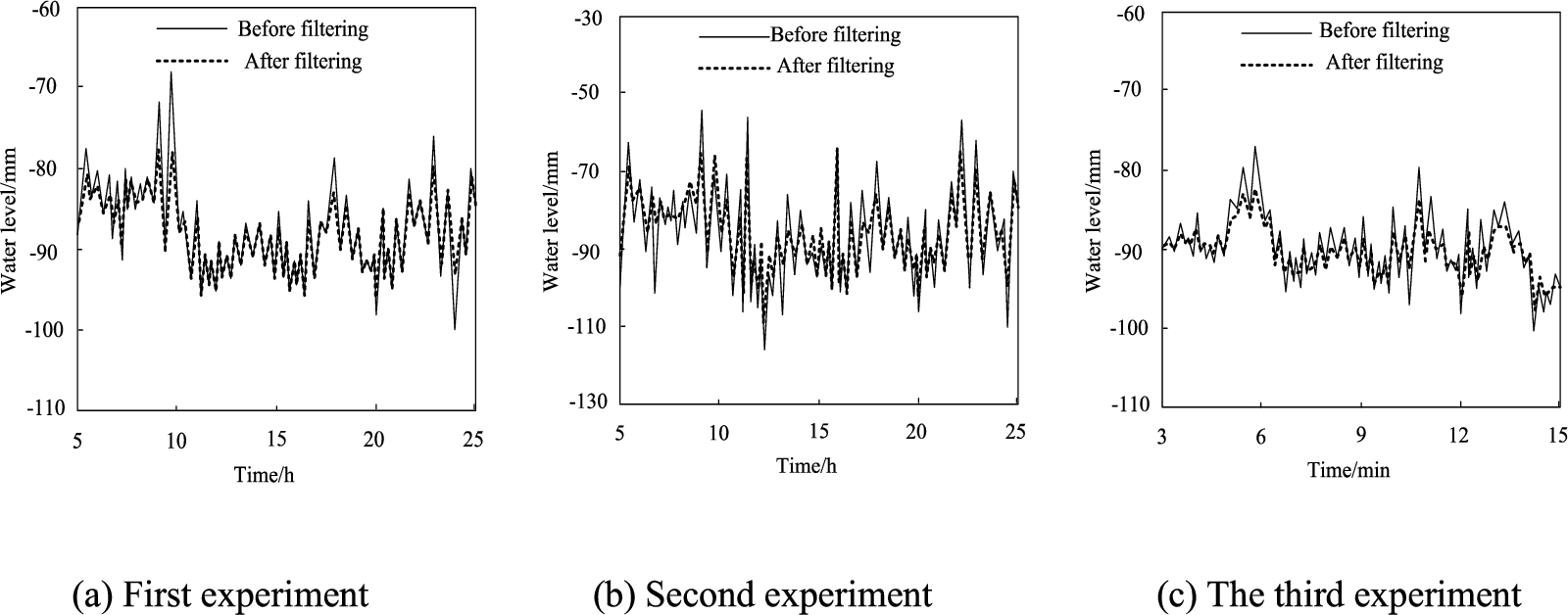
Nonlinear filtering performance of data acquisition results.
Figure 5(a) is the output comparison before and after nonlinear filtering using the method in this paper. Although the data fluctuates frequently, there is no signal whose instantaneous signal changes greatly. Therefore, the deadband limit in the filter is finite. The amplitude link has no effect. It mainly relies on the nonlinear rate-limiting link for filtering, and the filtered waveform is better than the original signal.
Figure 5(b) is the second filtering experiment. This paper uses this method to compare the output before and after nonlinear filtering. It shows that the collected signals fluctuate very frequently due to the frequent changes of data. In this paper, the method is adopted to carry out the filter. The filter plays a very good role in limiting the high frequency parts which vary greatly from front to back. Because there is a nonlinear rate limiting link in the filter, the frequency that fluctuates frequently in the limiting The rate of change of the signal is reduced and the waveform is smoother.
Figure 5(c) The uncertain disturbance caused by the unstable working condition causes the actual collected signal to contain a large amount of burr interference. Most of these burr interferences are low-frequency interference signals. For these low-frequency interference signals, the filtering method in this paper has a good effect and can eliminate the interference of burr signals.
For the collected distributed data samples, the distributed heterogeneous data assimilation processing is carried out by the method in this paper, and the convergence efficiency of the assimilation processing process of the method in this paper is analyzed. The results are shown in Fig. 6.
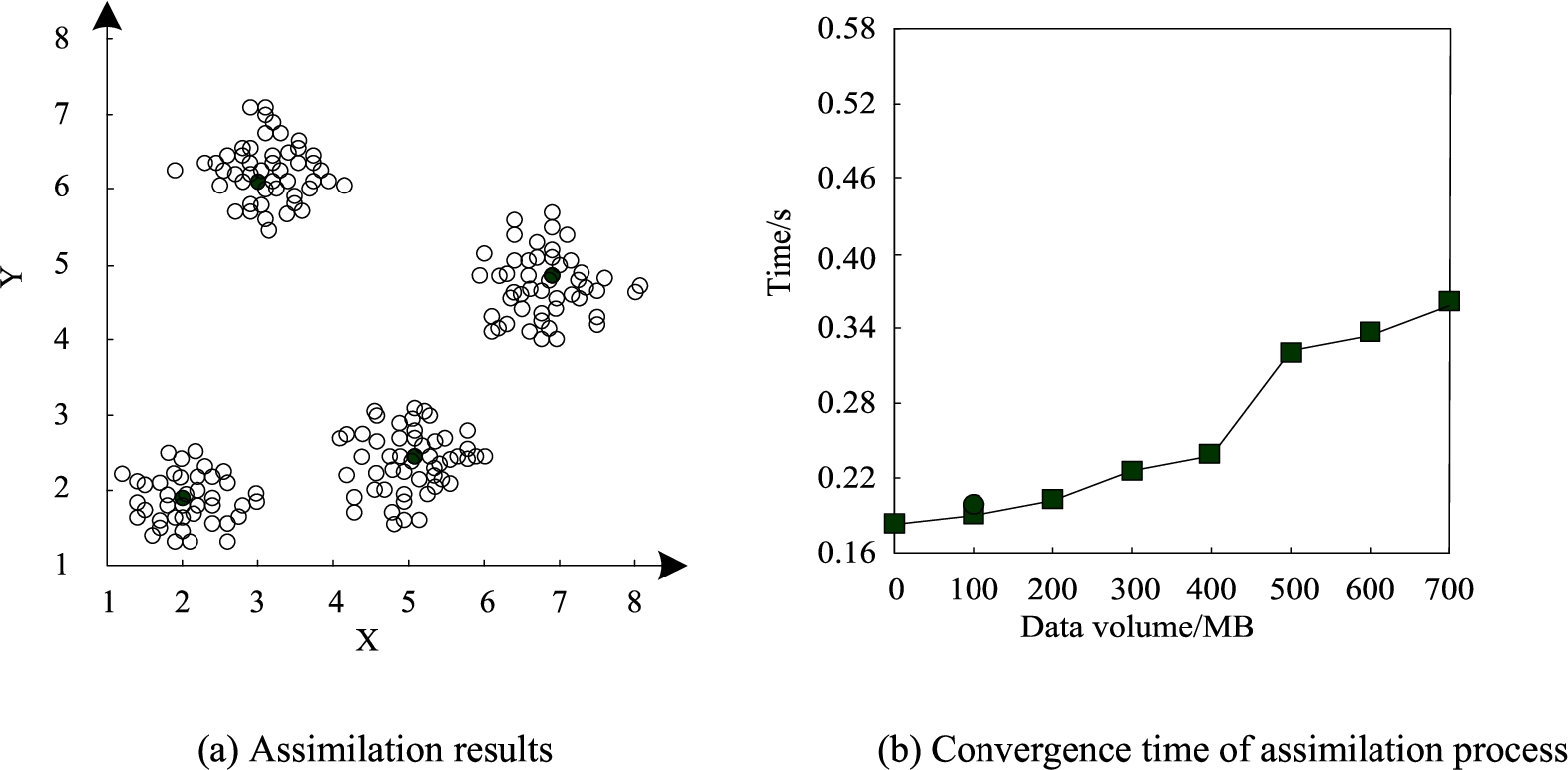
Performance analysis of distributed heterogeneous data assimilation processing.
The analysis of Fig. 6(a) shows that this method can effectively realize the function of distributed heterogeneous data assimilation. The analysis of Fig. 6(b) shows that the convergence speed of the proposed method is relatively fast, and the assimilation process can be basically completed within 0.4 s, indicating that the convergence speed of the proposed method is relatively fast, which is more conducive to improving the accuracy of distributed data integration processing in the research object.
In the process of neural network data integration in this paper, the number of hidden layer nodes has a direct impact on the accuracy of the data integration process. The changes in the convergence accuracy of the neural network model under different number of nodes are analyzed, and the results are shown in Fig. 7.
The analysis of Fig. 7 shows that with the increase of the number of nodes in the hidden layer, the convergence accuracy of the neural network of the method in this paper shows a trend of gradual improvement. However, at the same time, the increase in the number of nodes in the hidden layer also significantly increases the complexity and time consumption of the neural network model calculation process. Combined with the analysis results of relevant scholars on the convergence speed of the neural network, it is obtained under the comprehensive analysis that the hidden layer of the neural network is calculated. Under the condition that the number of nodes is 7, the convergence accuracy and convergence speed of the neural network are comprehensively optimal. Therefore, in the data integration process of the method in this paper, it is most appropriate to set the number of hidden layer nodes in the neural network model to 7.
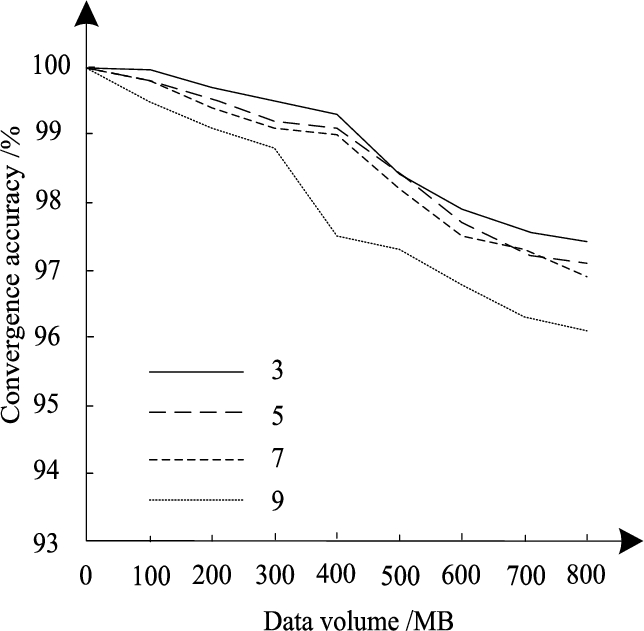
Convergence analysis accuracy of data integration process.
Figure 8 shows the comparison results of the average communication load of the research subjects with and without using the method in this paper for the data integration algorithm under different network scales.
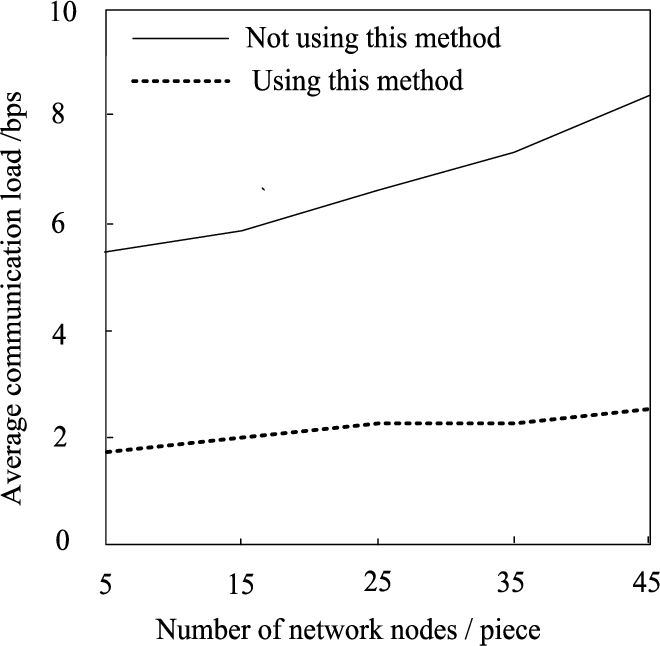
Effect of neural network data integration on average communication load.
By analyzing Fig. 8, the following conclusions can be drawn:
In the case of data integration using the method in this paper, the average communication load of the research object is always significantly lower than the average communication load when the method in this paper is not used;
Without using the method in this paper for data integration, with the increase of the network size of the research object (increase in the number of nodes), the average communication load increases significantly, with a minimum value of 3.74 and a maximum value of 5.27;
In the case of data integration using the method in this paper, with the increase of the network size of the research object, the average communication load does not increase significantly, with a minimum value of 0.72 and a maximum value of 0.94.
From the test results, after data integration using the method in this paper, the communication load in the research object is effectively reduced, and the energy consumption is saved.
It can be seen from the above experiments that the method in this paper can not only accurately collect high-speed network data, but also filter the data well and eliminate the interference of burr signals. This method requires less average traffic load growth while maintaining a fast convergence rate. The reason for this result is that this method simplifies the data in the distributed perceptual data model at the early stage of design, and improves the convergence speed of the method by reducing unnecessary computation. On this basis, the data quality is improved through data filtering and heterogeneous assimilation, thus reducing the average communication load and effectively eliminating the interference of burr signals.
Conclusion
Aiming at the redundancy of data collected by nodes in high-speed networks, this paper studies a fast integration method of multi-source data in high-speed networks. According to the fact that the data measurement values collected by the nodes near the same monitoring area have great correlation, the distributed data collection linear regression model is constructed to represent the distributed sensing data of the network, so that the original data information can not only be obtained effectively and completely. The ground structure representation also reduces the energy consumption of the node. For the collected data, the neural network-based data integration is used to make the data fusion point infinitely close to the data source node, and to extract the important features of the data, which can well meet the needs of different applications.
The experimental results show that this method can accurately collect high-speed network data, and the data collection deviation is always less than 5 μ rad; This method can eliminate the interference of burr signal by filtering; The convergence speed of this method is fast, and the data assimilation can be completed in 0.4 s; And with the increase of network size, the average traffic load growth of this method is less. The above results show that the method in this paper has good application performance and achieves the expected research purpose.
In the next stage of work, we will consider expanding the application scope of this method to make it suitable for rapid data integration of more types of networks.
Conflict of interest
None to report.