
Abstract
In recent years, there has been a noticeable surge in electric power load due to economic development and improved living standards. The growing need for smart power solutions, such as leveraging user electricity data to forecast power peaks and utilizing power data statistics to enhance end-user services, has been on the rise. However, the misuse and unauthorized access of data have prompted stringent regulations to safeguard data integrity. This paper presents a novel decentralized collaborative machine learning framework aimed at predicting peak power loads while protecting the privacy of users’ power data. In this scheme, multiple users engage in collaborative machine learning training within a peer-to-peer network free from a centralized server, with the objective of predicting peak power loads without compromising users’ local data privacy. The proposed approach leverages blockchain technology and advanced cryptographic techniques, including multi-key homomorphic encryption and consistent hashing. Key contributions of this framework include the development of a secure dual-aggregate node aggregation algorithm and the establishment of a verifiable process within a decentralized architecture. Experimental validation has been conducted to assess the feasibility and effectiveness of the proposed scheme, demonstrating its potential to address the challenges associated with predicting peak power loads securely and preserving user data privacy.
Introduction
As the economy flourishes and the income levels of residents rise, there is a discernible increase in the share of electric energy within the realm of final energy consumption. Concurrently, the demand for electric power load is experiencing swift growth. The fundamental mission of a power system is to ensure a reliable supply of uninterrupted, superior-quality, and stable electric power to a diverse range of users. Within this framework, the precision of power load supply decisions is paramount, with power load forecasting being the cornerstone of these decisions [12].
Power load forecasting technology is a critical component within the power industry, playing an essential role in its development and day-to-day operations. Precise forecasting of power loads enables efficient predictions of future load levels, offering vital insights for the development of power system scheduling plans. This, in turn, contributes to the economic operation of the power system [17].
At present, forecasting technologies are predominantly implemented through machine learning algorithms. These algorithms analyze the relationship between historical power data features and load values to predict forthcoming loads [18]. However, data security emerges as a significant concern during this process. With the advent of big data and Internet technologies, an increasing number of consumers are employing smart devices, such as smart meters, to monitor their electricity usage. Regulators also use these devices to manage power loads. Nevertheless, this practice can lead to the risk of data leakage and privacy infringement. Malicious actors can potentially deduce sensitive information, such as the number of occupants in a household, their commuting patterns, and daily routines, by analyzing peak power usage data. This poses a substantial threat to individual privacy and societal stability [2]. Moreover, the enactment of national and international legislation aimed at safeguarding data security and personal privacy, such as the Data Security Law of the People’s Republic of China and the European General Data Protection Regulation (GDPR), imposes stringent policy and legal constraints on the collection and utilization of data [6].
Therefore, determining how to protect user electricity data while enabling power companies to forecast electricity loads is one of the current problems to be solved in the power industry.
Specifically, the use of user electricity data to predict electricity load faces the following problems:
With the awakening of privacy awareness and legal and regulatory constraints, users who generate electricity data are reluctant to transmit their data directly and do not allow their data to be inferred.
Smart electrical devices such as smart meters generate a large amount of data during their operation, but they do not possess the capability for data processing and storage. The common approach is to transmit this data to a central server for further processing or storage. However, as these data are generated in real-time and in large volumes, direct transmission can exert significant pressure on network bandwidth and the computational resources of the central server.
The server processing the data may be hacked or hijacked, posing a threat to the security of the data. In addition, a single server is prone to a single point of failure. Once the server fails, the entire system will come to a standstill, causing serious losses [13].
Researchers have conducted studies related to privacy and security issues in machine learning processes. For example, secure multi-party computation has been used to process data in an encrypted state where intermediate process data is not visible except to specific participants who have access to certain results [20]. This approach ensures privacy and security during data processing, but incurs a large communication overhead. Moreover, in practical applications, such as the utilization of power data, the data is generated in real time and in large quantities, while the computational power of the devices is limited, so this approach has obvious limitations. Another representative scheme is federated learning [11]. That is, the data do not leave the local area, but rather each client trains locally using limited local data, obtains a local model, and uploads the parameter gradient or model parameters to a centralized server. Then, the centralized server generates a global model by aggregating all the uploaded local models or gradients. This approach prevents data from leaving the local area and intuitively protects individual privacy. The architecture of federated learning is shown in Fig. 1.

Federated learning architecture.
In power data scenarios, the use of federated learning is a preferred option due to the more decentralized data generation sources. However, the following problems still exist:
Some researchers have stated that during the federated learning process, a malicious attacker can compute part of the raw data by observing the parameters of the local model, i.e.,
The trustworthiness of the federated learning server cannot be ensured, and a risk of a single point of failure exists.
In power scenarios, the terminals are devices with limited computing and storage capabilities, which are unable to perform local training tasks, such as smart meters [19].
To address these issues, researchers have tried to combine blockchain, secure multi-party computation, and edge computing. Kumar et al. [10] first used blockchain to validate the data and then utilized federated learning to train a deep learning model globally to improve recognition accuracy against CT images of COVID-19 patients. Qi et al. [16] used a blockchain-based federated learning framework to predict traffic and added noise to the model to strengthen privacy guarantees, where the model was verified by miners. This scheme can effectively prevent poisoning attacks, but the model validity is somewhat affected. Edge computing is also commonly used in cutting-edge research in machine learning, in which the utilization of edge nodes to offload computational and storage tasks from a central server can effectively improve training efficiency. Khelifi et al. [9] explored the applicability of deep learning models (i.e., convolutional neural networks, recurrent neural networks, and reinforcement learning) to IoT devices. The study sought to assess the future trends of deep learning and edge computing. The finding indicated that convolutional neural models can be used in the IoT domain and that reliable machine learning models can be trained even with data from complex environments.
The aim of this study is to design a privacy-preserving decentralized and efficient training scheme for power load forecasting. The architecture of this scheme is shown in Fig. 2.

Scheme overview.
In Fig. 2, 1◯ refers to the appliances inside the home, such as refrigerators, televisions, water heaters, etc.; 2◯ refers to the smart meter, which is used to collect power data generated by the appliances; 3◯ refers to the edge computing device connected to the meter [4], and in this scenario, the home PC is assumed to act as an edge computing device, which is used to perform local training; and 4◯ refers to the blockchain [22], where edge computing devices act as nodes in a peer-to-peer network collaborating to execute the aggregation of models through smart contracts [21]. Synchronization and maintenance are performed using the blockchain through a consensus algorithm.
On the basis of the data flow, the flow of the scheme is described as follows:
User
The smart meter collects electricity usage data
Edge computing node
All edge computing nodes elect two aggregation nodes
The hashing algorithm means that given an input, a string of fixed length (also called message digest) can be obtained, the same input can generate the same output, and different inputs can yield different outputs with high probability. However, the output cannot be calculated to determine the value of the input. The consistent hashing algorithm is to map all possible hash values to an abstract circle, where each point above the circle represents a hash value [8].
In this scheme, the nodes in the blockchain are uniformly mapped to the ring, assuming that the position of
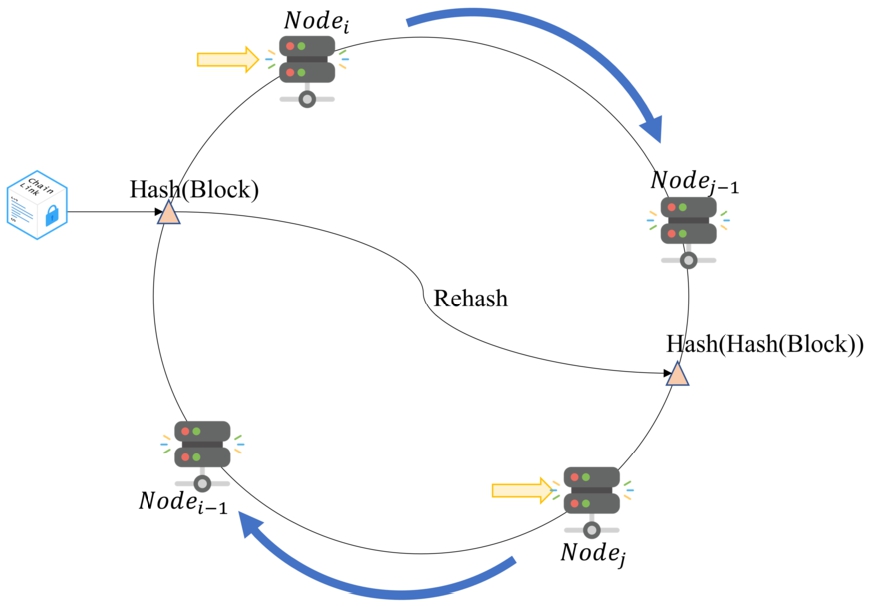
Aggregation node election.

Aggregation nodes election
The technique used in the fifth step is homomorphic encryption with double trapdoors. The traditional homomorphic encryption scheme allows the user to perform operations on the encrypted data directly, so that the result of the computation can be decrypted to obtain the same result as the plaintext computation [3]. That is,
In our scheme, first,

Interaction between user and
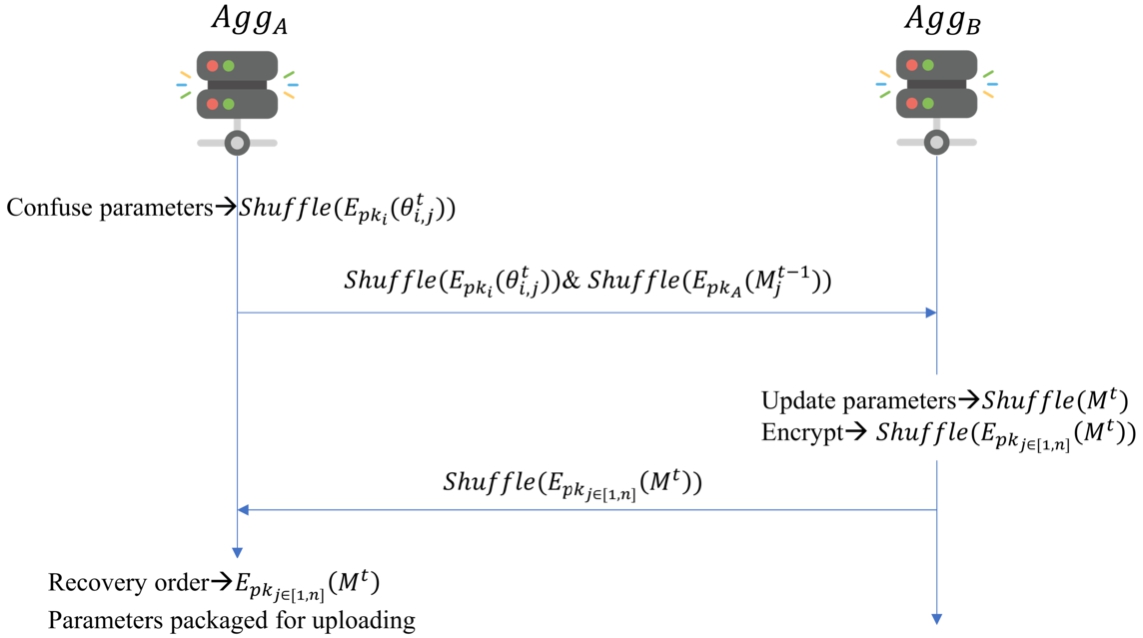
Interaction between
The update of each parameter in the model is essentially independent. The process of updating the model parameters is
Our scheme uses Pedersen commitments in cryptography, in which the commitment party chooses sensitive data m, computes the corresponding commitment c, and sends the commitment c to the verifier. Through the commitment c, the verifier can determine if c is computed from m, while the commitment party cannot replace m. Pedersen commitments also have their own unique additive homomorphism property, i.e.,
Utilizing this property, our scheme designs a verifiable model aggregation method, in which

Aggregation verification
Previous Federated Learning with Homomorphic Encryption solutions primarily utilized established generic Homomorphic Encryption techniques without adequate optimization for computation overhead. This approach led to scalability issues in encrypted computation and communication during federated training, effectively limiting its applicability in real-world scenarios. However, in our approach, as described in Section 2.2, we require participants to divide their local gradients into N blocks, encrypting only a portion of them homomorphically. The aggregation node then decrypts these encrypted gradients to complete global parameter updates. This method effectively reduces computational costs while protecting the privacy of participants’ gradients. Related studies [5,15] have analyzed privacy leaks and proposed “partial transparency”, such as hiding parts of the model to limit adversaries’ ability to successfully execute attacks like gradient inversion attacks. Jin et al. [7] have also reduced computational overhead by encrypting the most sensitive parameters while ensuring the privacy of gradients.
To verify the effectiveness of the proposed scheme, we design experiments and obtain the experimental results.
Experimental environment
Our experiment uses the Household Electric Power Consumption dataset, which measures the electricity consumption of one household for almost 4 years at a sampling rate of 1 min. Different electrical metric quantities and some submetric values are included. The data comprise the values of reactive and active power in that user’s home in time, as well as specific values in certain scenarios, such as kitchens, laundries, water heaters, and so on. A total of 2,075,259 data were obtained from measurements during the period 2006–2010. This experiment assumes that these 2,075,259 pieces of data are held by 100 different organizations, with no duplication of data held by each organization. These 100 different organizations aim to jointly predict the electricity consumption of the customer at the next moment without disclosing part of the data they hold. Given that the data are time series, modeling is done using the LSTM algorithm. The CPU used is an 11th generation Core i7 with 16 GB of RAM. The experiment adopts the PyTorch deep learning framework to build the LSTM model, the SecretFlow framework to implement the model encryption and transmission, and the FISCO BCOS framework to execute the decentralized smart contract construction.
Experimental results
This experiment demonstrates the effectiveness of the program in terms of accuracy, communication volume, and time used for training.
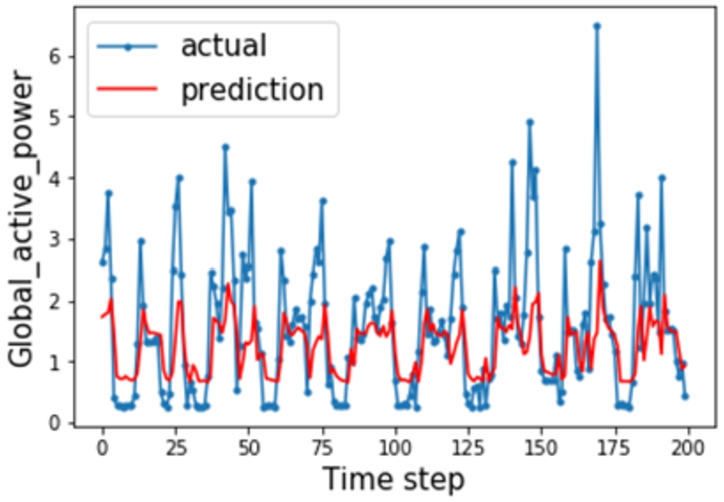
Accuracy of our scheme.
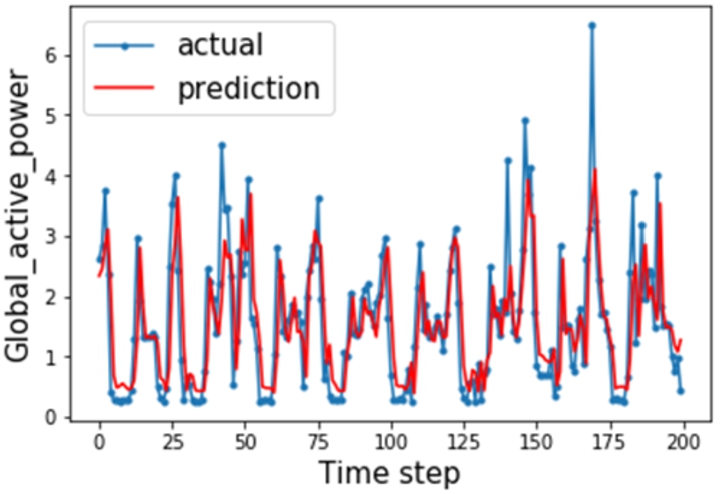
Accuracy of centralized learning.
Figure 6 and 7 illustrate the gap between predicted and actual values of active voltage over time, with the red line being the predicted value and the blue line being the actual value. Figure 6 shows the experimental results of our scheme, and Fig. 7 depicts the results of centralized training, i.e., all the data are pooled together for traditional machine learning training. Compared with the centralized training, our scheme is slightly lacking in accuracy, but it is basically able to accurately predict the peaks and valleys, which in turn can be very helpful for electricity companies.
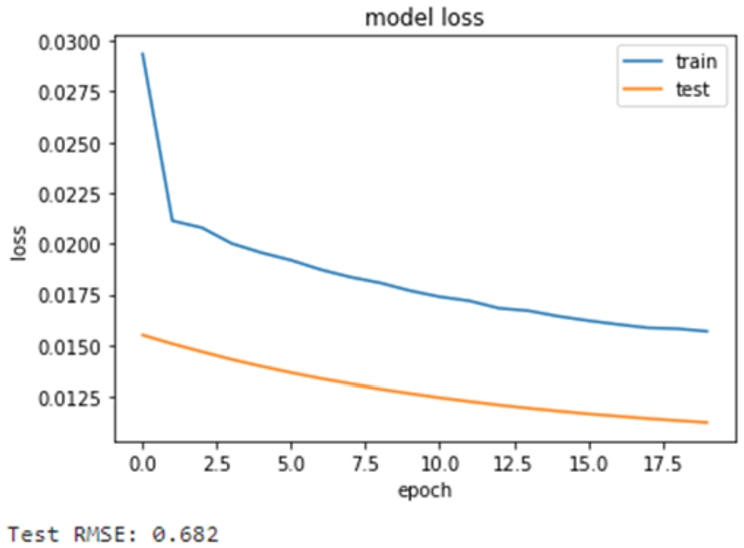
Loss of our scheme.

Loss of centralized learning.
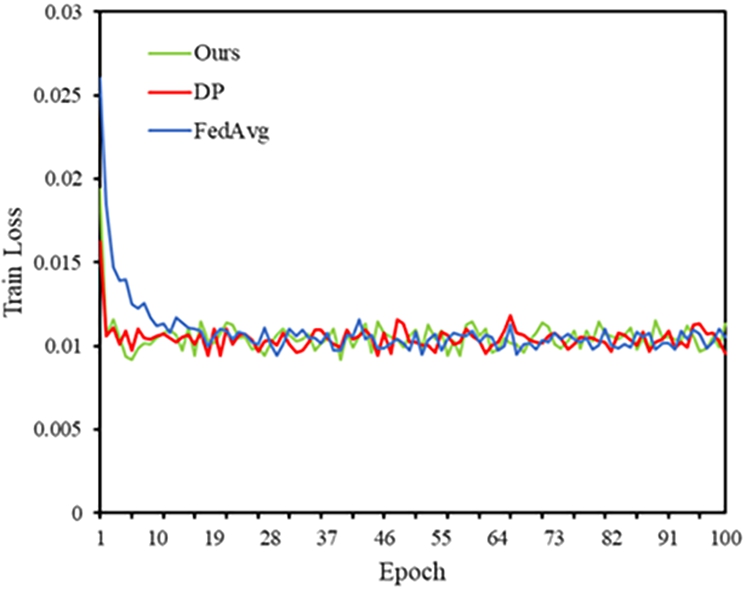
Train loss achieved by the different methods.

Validation loss achieved by the different methods.
Figure 8 and 9 show the convergence of the training process. Specifically, Fig. 8 demonstrates the convergence of our scheme, and Fig. 8 shows the convergence of the centralized learning. Given that the training samples are dispersed across different devices, a certain loss of performance occurs in the aggregation process. Moreover, a slow rate of convergence is expected, but this slowing down is considered acceptable.
Furthermore, to investigate the effects of various privacy-enhancing techniques on model performance, we contrast federated learning without privacy measures (such as FedAvg) with federated learning incorporating differential privacy (DP) [1] alongside our proposed method. The experimental outcomes are illustrated in Figs 10 and 11. We present the training and validation loss achieved by different approaches when training LSTM models in a federated learning setting with 100 clients and a 20% participation rate. For the DP method, the clipping threshold C is set at 4.0, and the noise level
We further calculate the communication overhead. The communication overhead for 1 round with 100 data holders participating in the training is 2.158 MB, which is 16.6 MB in traditional federated learning. The selective gradient uploading approach mentioned in Section 2.2 helps considerably by greatly reducing the number of parameters uploaded by each client.
We introduce a novel decentralized machine learning framework designed to protect the privacy of electric power user data. It employs a suite of technologies, such as smart contracts, consistent hashing, and homomorphic encryption, to achieve a secure and controllable training process without compromising privacy. We utilize this framework for electric power time series forecasting of power loads and validate the model training effectiveness on a dataset. The results demonstrate that, compared to other existing distributed machine learning solutions, our approach fully achieves the desired performance, particularly in terms of communication.
Footnotes
Acknowledgements
This work is supported by the Key Technologies for Sharing Value of Power Data Based on ‘Blockchain + Privacy Computing’ – Project 2: Research on Computing Technology for Sharing Power Data Based on Hybrid Privacy Computing (NO.52062623000C).
Conflict of interest
The authors have no conflict of interest to report.