
Abstract
System knowledge and reasoning mechanisms are essential means for intellectualization of cyber-physical systems (CPSs). As enablers of system intelligence, they make such systems able to solve application problems and to maintain their efficient operation. Normally, system intelligence has a human-created initial part and a system-produced (extending) part, called synthetic system intelligence (SSI). This position paper claims that SSI can be converted to a new industrial asset and utilized as such. Unfortunately, no overall theory of SSI exists and its conceptual framework, management strategy, and computational methodologies are still in a premature stage. This is the main reason why no significant progress has been achieved in this field, contrary to the latent potentials. This paper intends to contribute to: (i) understanding the nature and fundamentals of SSI, (ii) systematizing the elicitation and transfer of SSI, (iii) exploration of analogical approaches to utilization of SSI, and (iv) road-mapping and scenario development for the exploitation of SSI as an industrial asset. First, the state of the art is surveyed and the major findings are presented. Then, four families of analogical approaches to SSI transfer are analyzed. These are: (i) knowledge transfer based on repositories, (ii) transfer among agents, (iii) transfer of learning resources, and (iv) transfer by emerging approaches. A procedural framework is proposed that identifies the generic functionalities needed for a quasi-autonomous handling of SSI as an industrial asset. The last section casts light on some important open issues and necessary follow-up research and development activities.
Keywords
Introduction
Intellectualization of engineered systems
Up until the emergence of the fourth industrial revolution, tool and system development happened with the goal of extending the physical capabilities of humans. In this current time of transiting from the fourth industrial revolution to the emerging fifth industrial revolution, the goal has been to extend human mental (cognitive) capabilities with artificial intelligence-based tools and systems (George & George, 2020). Representative examples of applying intellectualized tools and systems to solving structurally decomposable application problems are such as autonomous parking of vehicles, execution of surgical operations, or providing homecare assistance. In spite of the fact that artificial intelligence already surpasses human capabilities in numerous fields, the latter is still seen in this position paper as a computationally reproduced problem-solving intellect applicable in specific contexts, rather than anything comparable with natural intelligence performed by human individuals, groups, or communities. Genuine human intelligence is differentiated from the various forms of (narrow, generic or super) artificial intelligence by many physiognomic and cognitive indicators (Braga & Logan, 2017). Notwithstanding, intellectualization of engineered systems has become a strong trend and has been exemplified by second-generation cyber-physical systems (CPSs) (Pathak et al., 2019). These intellectualized systems can produce new knowledge through solving the problem or learning from the characteristics of their operation, well beyond what a chess playing software does.
Considering the current state of progression, human-comparable artificial system intelligence can only be regarded as a future objective of technology and application development (Warner, 2019). This proposition is underpinned by the fact that computationally reproduced intelligence suffers from the lack of natural will, consciousness, intuition, abstraction, creativity, sociality, and emotions. Therefore, instead of using the term ‘intelligence’ to describe the problem-solving capabilities of this family of intellectualized engineered systems, the use of the term ‘smart’ is deemed more appropriate. In this position paper, the process of embedding, gaining, and operationalization of both constituents of system intelligence is referred to as intellectualization. The use of the term ‘intellectualized engineering systems’ allows us to differentiate systems that are developed for solving application problems from those systems that are developed to mimic various manifestations of human intelligence, such as artificial vision, speech recognition, machine learning, etc. Furthermore, this interpretation is also helpful to emphasize the assumed primacy of humans in terms of (i) determining the demands, (ii) defining the objectives, (iii) providing the first input, and (iv) exercising supervisory roles (Sternberg, 2012).
Two related issues must be mentioned. The first one is that the term ‘synthetic intelligence’ has already been used differently in the literature. Namely, Lindley (2012) has used this term to describe the synthetic intelligence provided by the integration of engineered biological and mechatronic (bio-mechatronic) systems. In the work reported here, the term ‘synthetic system intelligence’ (SSI) is used to refer to the self-synthesized knowledge and mechanisms of intellectualized systems. Regrettably, no commonly accepted overall theory of SSI exists yet and this applies to intellectualized CPSs too. The fact of the matter is that the issue of transferring elements of intelligence has emerged only in the last decade and inter-systems management of system-acquired, -generated or -synthesized knowledge is still in a premature stage (Horváth, 2022). Thus, we also miss generic methodologies for generation and reuse of synthetic system knowledge and computational mechanisms. Though rapidly growing and its latent potentials are recognized, the amount of system-independent synthetic knowledge is still limited. These are the main reasons why no significant progress has been achieved in terms of utilization of SSI as a new industrial asset. However, changes can be expected due to the intensification of research (Sitti, 2021).
The second issue concerns the role of artificial intelligence research, and the position of the author. The transdisciplinary science of artificial intelligence (AI) seeks to understand and reproduce the cognitive capabilities of intelligent beings by constructing functionally and socially intelligent systems. Molina (2020) proposed that instead of a rigid characterization of whether a system is intelligent or not, a proper definition should outline the usual characteristics that might be present in an intelligent system. For example, a system might be considered intelligent if it has perception and can control action, even if it does not possess deliberative reasoning or a capacity to learn. In this paper, AI is seen and treated as not more and not less than a branch of computer science that intends to reproduce and extend human cognitive capabilities. AI can go as far as explicitly or implicitly preprogramming cognitive functions, reasoning mechanisms, and agent behaviors, including the individual or collective fundamental mechanisms of self-learning, self-adaptation, and self-evolution, but almost nothing happens beyond that.
The addressed phenomenon and the goals of this study
In the context of systems, intelligence is a complex problem solving and state management power that is based on representation of facts (knowledge) and goal/context-dependent computational reasoning. The initial (human created and inputted) part of system intelligence includes structured and coded human knowledge and human-developed reasoning mechanisms. These are needed to make intellectualized systems active, but they can acquire and develop synthetic knowledge and reasoning mechanisms on their own, during their learning, planning or problem solving operations. For this purpose, they need dedicated process monitoring, knowledge elicitation, and mechanism generation capabilities. Under normal conditions, the initial intelligence of systems can be changed or supplemented incrementally by human knowledge engineers. Under changing circumstances or due to new goals, the elements of the initial intelligence may become insignificant or even outdated.
More importantly, this initial part of system intelligence can be augmented, or partially or even completely replaced by an evolving part that is self-acquired or self-generated by an intellectualized system over its lifetime. Figure 1 illustrates the nature of the typical changes in the human embedded part and the self-produced part of the system’s knowledge over time. On the one hand, the amount of human embedded knowledge is changed at the times of system up-dates or up-grades (i.e., in a discrete manner). On the other hand, the system-produced part usually grows perpetually. Though a linear growth is shown in Fig. 1, it may change progressively. The white vertical arrows represent the total amount of system knowledge, and show the proportions of the human embedded part and the parts self-produced by the system using the original reasoning mechanisms and the additional reasoning mechanisms, respectively.

Overall changes in the proportion of the human embedded and the self-produced knowledge of intellectualized systems.
The main claim of this position paper is that the intensively growing synthetic part of system intelligence can be converted to a new industrial asset and utilized as such in an across-systems manner. These two phenomena have been addressed in the exploratory research, the outcomes of which are presented in this paper. Similar attempts were made some 50 years ago to exchange human knowledge at enterprise level (O’Leary, 1998), and, in the last three decades, in the field of data and information management (Collins & Smith, 2006). This position paper emphasizes that time has come for the needed systematic studies and technology development in the context of aggregation, compilation, fusion, transfer, and reuse (ACFTR) of the constituents of SSI. At the same time, the general opportunities and challenges of ACFTR of SSI among intellectualized engineered systems, such as next-generation cyber-physical systems, are hardly investigated in the literature, apart from some specific cases. There are two major issues related to: (i) understanding the essence and affordances of the current and near future manifestations of SSI, and (ii) providing a strategic roadmap, a practical methodology, and adaptable technologies for ACFTR beyond the boundaries of intellectualized systems.
As Pennock and Wade (2015) discussed, we engineer systems because we need some useful functionalities and services. Typically, it happens in a systematic, rather than a trial and error manner, and is facilitated by many significant advancements in hardware, software, cyberware, and brainware technologies. As a consequence, we are moving into the age of massively intellectualized systems which are deemed to be interconnected not only for data transfer, but also from the perspective of integral use of SSI. Contrary to the technology development efforts, researchers face challenges due to paradigmatic uncertainties (lack of distinguishing characterization of the multiple forms of system intelligence) and unsettled notional specifications (lack of transdisciplinary perspectives on sophisticated, smart, cognizant, or intelligent systems). This position paper also reflects the influence of these discrepancies.
Due to the complexity, novelty, and challenging nature of the addressed phenomenon, the background research could, and this paper can, focus only on the first mentioned issue, including a comprehensive study of (i) the notional aspects of SSI (Horváth, 2020a), (ii) the historical development of computational intelligence, and (iii) the current and near-future system engineering developments. The reported research was done with the intent of contributing to: (i) understanding the nature and fundamentals of SSI, (ii) systematizing the elicitation of SSI, (iii) exploration of current and future approaches to SSI transfer, and (iv) road-mapping and scenario development for exploitation of SSI as an industrial asset. In this context, several theoretical, methodological, computational, and practical tasks have been addressed which, nevertheless, need further research and development efforts in order to be able to make SSI a powerful industrial asset (Horváth, 2020b).
The paper is structured as follows. Section 2 summarizes the major findings of the completed investigation of the state of the art in the related domains of scholarly interest, with special attention to understanding the nature and fundamentals of SSI and the roots of the system intelligence transfer problem. Section 3 discusses various current approaches to transferring intellectual resources from and to systems. Four specific approaches and technologies of transfer are included in the analysis: (i) transfer based on repositories, (ii) transfer among agents, (iii) transfer of learning resources, and (iv) transfer by emerging approaches. They are seen as starting points of the development of dedicated computational technologies and management approaches. Section 4 elaborates on two issues of converting SSI into a new industrial asset, namely (i) the manifestation of SSI as a commercial asset, and (ii) a procedural framework for utilization of SSI as an asset. Section 5 recapitulates the open issues and the propositions for future studies.
The state of the art in the related interest domains
Understanding the nature and fundamentals of synthetic system intelligence
Like human intelligence, system intelligence is a complex, multi-faceted, and yet not completely understood phenomenon and concept. From outside, it stretches into two dimensions, as shown in Fig. 2. The vertical dimension includes the two enablers of SSI (reasoning mechanisms and application knowledge). The horizontal dimension includes the two sources of SSI (human-provided part and self-acquired part). Synthetic intelligence primarily comprises the self-acquired application-specific knowledge and reasoning mechanisms, but it is not absolutely independent from the human-provided part. Knowledge and mechanisms are functionally interconnected and make iCPSs capable of solving application problems and maintaining the efficiency of their operation. The relative amount and significance of the human created initial (inputted) part usually decreases during the operation of systems. On the other hand, the relative volume and significance of the system-produced part - the actual SSI - grows throughout the useful life-cycle of systems. From a computational point of view, the reasoning mechanisms and the problem-solving knowledge are interconnected and thus inseparable. Thannhuber (2005) proposed to consider system knowledge both from a microscopic and a macroscopic perspective, which can be extended to the associated reasoning mechanisms too. Microscopically, knowledge is given by implementation level procedures or actable coordination processes (microscopic actions of a system). Macroscopically, knowledge is given by the constraints and control of the declarative assembly mechanism that provides a meaningful system response to a given stimulus.
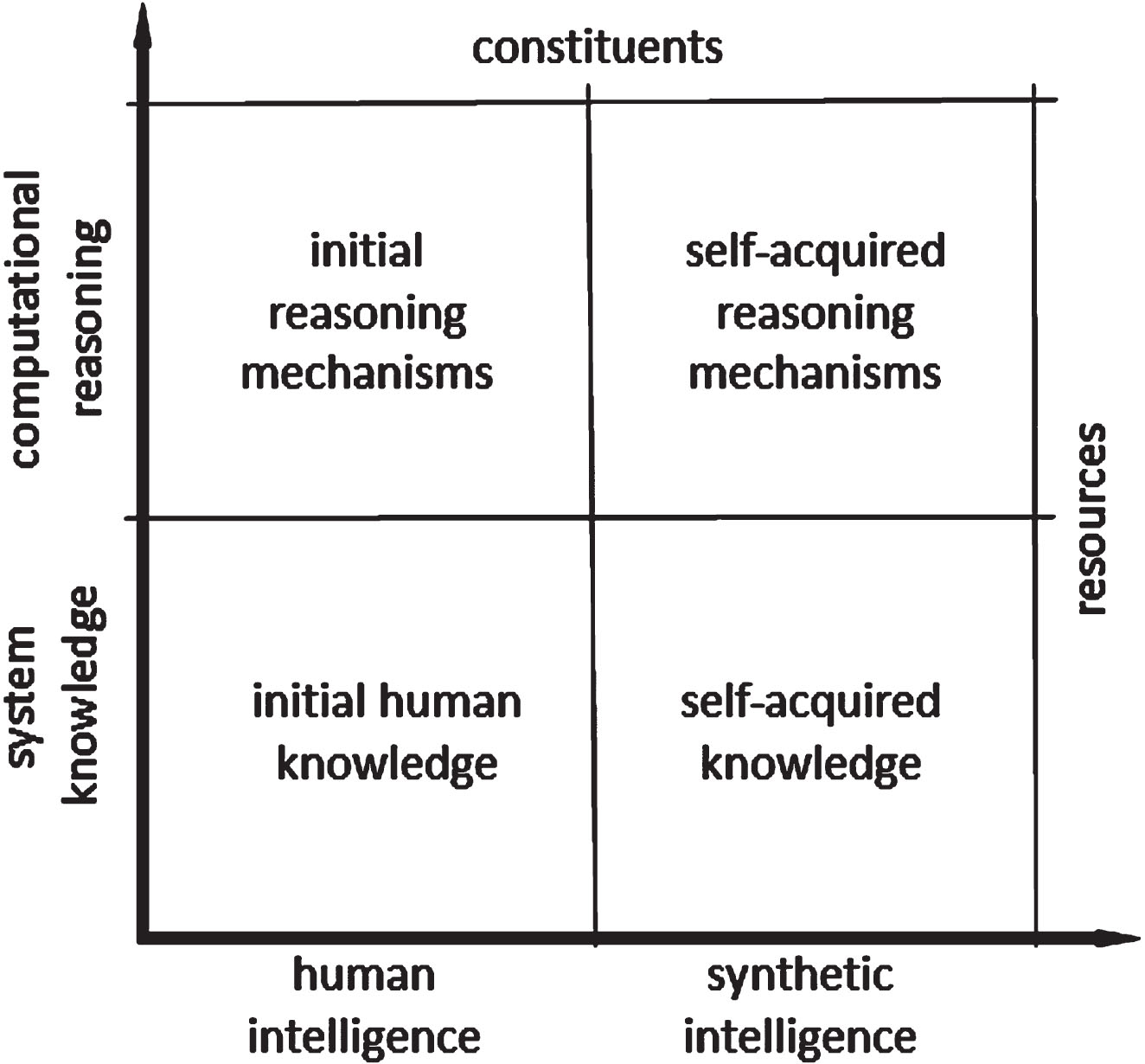
Dimensions of system intelligence.
The work of artificial intelligence researchers includes (i) experimentation with manifestations of human intelligence phenomena, (ii) embedding their foundational hypotheses on perceptive, cognitive and/or motor operations in working artificial systems, and (iii) examining the reality and qualities of the intelligent behaviors they produce (Damiano et al., 2011). For researchers who are engaged with the development of intellectualized systems, the fore-running experimentation with human problem-solving is not always or not at all possible. Therefore, they are forced to apply a ‘programmatic inversion’ of the usual order between analysis of human behavior and construction of computational models. Kugel (2002) disclosed his belief that today’s AI is like riding the right horse (the digital computer), but taking it down to a wrong road (of numerical computation).
Human reasoning is the progenitor model of computationally implemented inferring and reasoning processes. It is an intricate mental process of making logical conclusions and predictions from available knowledge in various application contexts (Stenning & Van Lambalgen, 2012). It can be both intuitive (heuristic) and formal (systematic), but both forms are influenced by the actor, purpose, problem-specific knowledge, and context information. The overall formal mechanisms of reasoning are underpinned by computational thinking. It is characterized by a logical procedure that involves the following steps: (i) specification (choosing and formulating a problem), (ii) decomposition (breaking a complex problem down to smaller and manageable sub-problems), (iii) patterning (identifying and representing a structure or a trend within the problem), (iv) abstraction (identifying specific similarities and differences among resembling problems), (v) algorithmizing (developing step-by-step instructions for solving the problem at hand), and (vi) analysis (reflecting on the characteristics of finding a solution for the problem). With regard to computational reasoning, three core features are to be considered, namely, (i) moving from multiple inputs to a single output, which can be a conclusion or an action, (ii) making multiple steps through a state space to achieve a final outcome (in numerous ways), and (iii) processing the objectives, a mixture of previous knowledge, novel information, and the dynamic contexts (Mohaghegh & McCauley, 2016). Usually, search space-based (retrieval) and additional content deriving (ampliative) computational reasoning mechanisms (CRM) are differentiated. Ampliative CRMs are mechanisms that produce additional knowledge based on the knowledge externally embedded in or internally acquired by the system. Systems engineering also distinguishes system-level and constituent-level reasoning mechanisms.
Knowledge is never a fully baked bread. The classical concepts of human knowledge have been revised and reinterpreted many times over the centuries, and various theoretical/conceptual frameworks have been proposed for unproved and proved human knowledge. Scientifically-based human knowledge revolves around the idea of truth, which is an unconsolidated concept with regard to system knowledge. The term ‘truth’ is used to characterize correctly tested appropriate beliefs of humans. It is hard even for the current most sophisticated machine learning mechanisms to discover true facts in a partly simulated and partly real environment in which they exist. In the context of intellectualized systems, the term ‘proper’ has been used as a proxy of the “truth” of system knowledge. Properness is interpreted from the perspective of relevance and potential of problem solving. Though useful for differentiation, the act of naming does not provide answers to two principal questions associated with iCPSs, namely: (i) How can a system know what is meant by proper in general and/or in given application contexts? and (ii) How can a system figure out or learn if a given body of synthetic knowledge is proper or not? These questions extend well beyond the cause-effect relationships that machine learning can synthesize for self-derived causal models. Actually, it belongs to the field of metaphysics. Contrary to this fact, De Luca (2021) concluded that, “as a consequence of the on-going developments in the sector of AI, there is no sector of formalized knowledge and reasoning of humans about the environment which is not replicable by machine systems”.
The origins of transferring various forms and resources of system intelligence can be traced back to the 1970 s. This was the time when it was recognized that system intelligence can be a problem-solving power. While the transfer of symbolic knowledge of knowledge-based systems was in the center in the 1970 s, nowadays the transfer of learning resources and models of machine/deep learning systems is of distinguished importance. Among the first efforts in the fields of knowledge-intensive systems and artificial intelligence development was the paper of Chandrasekaran (1986) that addressed the use of high-level structured knowledge blocks for expert systems. Attempting to move beyond the capabilities of contemporary KBSs mandates knowledge bases that are substantially larger than those we have today. McDermott (1990) described how artificial intelligence research could make software development easier by writing programs “to act as frameworks for handling instances of problem classes in software engineering”.
The need for and the possibility of knowledge exchange between engineered systems was also addressed in the seminal work of Neches et al. (1991). They identified three possible forms of knowledge sharing: (i) communication of the principles of knowledge bases to facilitate their reimplementation, (ii) facilitation through the inclusion of source specifications into new knowledge components, and (iii) run-time invocation of external modules or services. On the other hand, they also identified four impediments: (i) heterogeneous representations, (ii) dialects within language families, (iii) lack of communication conventions, and (iv) model mismatches at the knowledge level. Smith and Poulter (1993) recognized the need for open knowledge-based systems and proposed an open infrastructure that permitted the integration and interoperability of different knowledge-based systems (KBS) and ensured that each system could utilize whichever representation for knowledge is appropriate to its tasks. As elements of an open KBS infrastructure, they defined: (i) standard knowledge representations, (ii) knowledge interchange format, (iii) knowledge manipulation and query language, (iv) common shared ontology, and (v) agent-based software engineering framework. The open KBS infrastructure supported run-time sharing of complexly structured knowledge between knowledge bases and their associated inference engines even if they used different knowledge representation formalisms and different inference mechanisms.
There were parallel efforts that yielded the Initial Graphics Exchange Specification (IGES) and the now international standard (ISO 10303) Standard for Exchange Product Data a decade later. The latter has been under development since 1984 and in use since 1994 (Pratt, 2005). The initial parts of the standard were orientated towards transferring voluminous artifact and process model data (CAD CADE, CAPP, and CAXX data) between multiple design and engineering systems using neutral representation formats. The latter parts, such as the ISO 10303-239 (application protocol for product life cycle support - STEP PLCS), have covered the entire product development and use process from conceptual design to recycling.
Like other productive resources, system intelligence resources can be (i) shared among similar systems, (ii) adapted and combined on purpose, (iii) warehoused and archived, and (iv) retailed as a cognitive product. Over the years, many technologies have emerged that can support the real-life implementation of all of these general options. At the same time, exchange and reuse of system intelligence of iCPSs has not obtained due attention in the literature yet, nor has it been addressed in large-scale projects. In principle, it can happen: (i) in a human-assisted manner, (ii) in a systems-planned autonomous manner, and (iii) in a hybrid manner. Since there is a high probability of autonomous extension of the functional profile of iCPSs, SSI transfer may become a practical technological solution for obtaining the needed intellectual resources. However, it should be seen as a partial solution because the whole spectrum of resources (interoperating analogue and digital hardware, system-level and application-oriented software, and signals, data and information) are to be availed (acquired in run-time) too. Runtime resource management is the major issue for adaptive and, in particular, for evolving iCPSs.
Reflections on the findings
The exchange and reuse of knowledge among intellectualized systems has become both a functional necessity and a technological opportunity. This emerging trend is already raising many questions, but the studied literature has almost failed to give satisfying answers to the related questions. Contrary to its growing volume and importance, the general theoretical underpinning and the practical utilization of synthetic systems intelligence are still underdeveloped. Actually, the whole field of interests has not received sufficient attention. The fact of the matter is that the SSI self-acquired or self-generated by intellectualized engineered systems is becoming an important complement of human knowledge and problem-solving intellect. In addition, if externalized and transferred, synthetic system knowledge can be shared and can become an imported knowledge resource for other systems. Knowledge becomes more if shared. This inter-systems knowledge sharing may open up a new direction for utilization of SSI and may amplify the problem-solving potential of iCPSs as has happened with human knowledge and companies. Some pioneering researchers believe that such cooperative systems, or systems of systems, have the potential to be a game changer in multiple creative and productive domains.
According to the traditional interpretation of the knowledge transfer problem, there is a need to identify the highest common denominator among the knowledge representation and interchange mechanisms of the systems to be integrated. In contrast with this, the completed research pointed at the opportunity of applying a different approach to utilizing system intelligence, which may be based on the principle of ‘share it if you need it’. Recommender systems may collect information about the exchangeable SSI as well as meta-information about the demands and supplies. Nevertheless, as the first step towards using SSI as a system-independent asset, disconnecting it from the original producer system warrants attention. It should be made transferable in the simplest way, without losing its problem-solving power. Intelligence-oriented dynamic networking of systems, beyond their physical and communicative networking, is a new phenomenon. Re-operationalization or adaptation of the knowledge and mechanism constituents of SSI in the recipient iCPSs also warrants research attention. These together call for conceptual and procedural frameworks. Since there is a strong association between the problem-solving knowledge and the processing mechanisms (e.g., production rules < —>inference engine, analogy-based cases < —>case comparator, fuzzy rules < —>fuzzy reasoning engine, chromosome constructs < —>genetic algorithms, training data sets < —>artificial neural network), they have to be considered as duals of SSI transfer. Such a duals-oriented intelligence transfer needs different packaging mechanisms than the neutral interchange format-based mechanisms, typically applied in the case of traditional knowledge-based systems.
Exemplifying specific approaches to system intelligence transfer
For the purpose of this work, intelligence transfer is understood as all of the structured activities related to separating application-specific knowledge and processing mechanisms from one system and embedding them into several interoperating systems. Due to the obvious space limitations, the main features of the particular approaches can be presented only from a birds-eye-view. However, this is deemed sufficient to understand the logic of reasoning and the conceptual relationships.
Transfer based on repositories
The first examples of transferring intellect between systems are related to the symbolic and analogical methods of artificial intelligence research and system development. During the 1980’s, it was recognized that building new knowledge-based systems usually entailed constructing new knowledge bases from scratch (Gonzalez & Dankel, 1993). Therefore, the scope of the built systems remained restricted, their development needed a lot of time, and the costs and efforts ran high. As a solution, proposals were made to assemble reusable knowledge components by system developers and to make succeeding systems able to interoperate with existing systems and use them to perform some of their reasoning tasks (Gruber, 1991). In this way, as it was argued, declarative knowledge, problem-solving techniques, and reasoning services could all be shared among systems. However, both specific technologies and sophisticated infrastructures are needed to realize the repository concept on a large scale (Yacci, 1999).
The idea of repository-based knowledge exchange has gone through a number of developmental stages, such as (i) database sharing, (ii) semantic networks, (iii) symbolic rule-fact bases, (iv) analogical example libraries, (v) relational knowledge-bases, (vi) resource description frameworks, (vii) web ontology languages, and (viii) knowledge fusion frameworks. Common characteristics of these milestone concepts are that they (i) formalize and structure human knowledge chunks, (ii) assume various description or specification languages, (iii) provide opportunity for external queries, and (iv) are not, or not directly, related to application cases (Kankanhalli et al., 2005). These approaches allow transferring knowledge content from the repository to one system, but do not support direct knowledge sharing among application-oriented systems. Not only the knowledge engineering process, but also the knowledge acquisition (retrieval or extraction) process is human dependent.
The pioneering knowledge transfer approaches rested on agreements concerning (i) a standard syntax and semantics, (ii) a knowledge interchange format, (iii) a set of protocols to query a virtual knowledge base, (iv) a common shared ontology content, (v) a vocabulary and constraints on the well-formed use of contents, and (vi) an agent-based software engineering framework (Okabe et al., 2010). Typical implementations concern (i) computational routine libraries, (ii) chunks of procedural knowledge, (iii) rule interchange format, (iv) labelled case libraries, (v) annotated object repositories, and (vi) product and service catalogues. The examples indicate that repository-based transfer may include both content knowledge and processing mechanisms (Parnafes & Disessa, 2004). In practice, repository-based SSI transfer may concern three purposes (i) transferring synthetic system knowledge only, (ii) transferring reasoning mechanisms only, and (iii) transferring synthetic systems intelligence. Artificial intelligence research comprehensively studies the various application-independent, but task-driven forms of computational reasoning approaches (Griffiths et al., 2019).
Transfer among agents and of agents
The second example is taken from the field of multi-agent collaborative systems. Multi-agent systems are decentralized structures formed by autonomous computational entities that communicate and share data, information, and state-maintaining and problem-solving knowledge with each other (Leitão et al., 2016). Agents represent real-world or virtual entities with varying levels of fidelity, intellectualization, commitment, and socialization. They are implemented as intellectualized entities, which have sufficient intellect and capacity for (i) building situational awareness, (ii) making logical decisions, and (iii) performing functional agency. Therefore, many works consider them ‘intelligent’ entities (Rudowsky, 2004). Informally, their rational intelligence is seen as the ability to achieve goals in a complex environment, whereas their social intelligence is the ability to successfully interact in an environment full of other agents (Insa-Cabrera & Hernández-Orallo, 2013). Agents act, learn, negotiate, and adapt autonomously and try to understand their environment in order to pursue their goal. With regard to the autonomy of the agents, important issues are goal delegation and goal adoption, which are seen as ingredients of organization, social commitment, and contract of the agents, and then of the knowledge exchange process.
In multi-agent systems or system-of-systems, the issue of transferring intelligence, resources, and/or knowledge from one actor agent to others has been known for a long time (Sycara et al., 1996). To communicate, the agents are supposed to comply with output guaranties and input assumptions, otherwise their interoperability is not provided. While there are papers discussing in-process communication and information exchange among agents, much less is published on transferring aggregated knowledge from one agent to others (Allen et al., 2002). The inter-agent transfer of intelligence among hardware and software agents concerns not only signals, data, and pieces of information, but also chunks of knowledge and experiences that they have individually learnt according to their operation strategy (Da Silva et al., 2020). Transfer can be initiated both by a receiver agent and by a sender agent when the knowledge and logic required to perform an activity is unavailable, incomplete, or out of date. The knowledge shared by the agents constitutes beliefs proven individually or collectively by the collaborating agents. As a result of this, multiple collaborating agents build distributed intelligence.
The transfer of the necessary knowledge and processing logic may enable an agent to execute a new task or to execute a given task better (Iglesias et al., 1998). The process includes three main steps: (i) packing and decoupling the knowledge and algorithms from the sender agent, (ii) routing and transferring, and (iii) unpacking and embedding in the receiving agents. Alternatively, when the knowledge is processed by local algorithms of the receiver systems, (iv) activation of the various local algorithms should also be considered. As a whole, the multi-agent system may harmonize the package sending and processing over all sender and receiver agents, or may leave it on their own decision which depends on their programmed objectives, social character, and local context (Cardoso & Ferrando, 2021). As explained by O’Neill and Soh (2022), the subsequent steps of the process are: (i) triggering the messaging actions either by a pre-programmed timer poll or by an event-driven framework, (ii) building local situational awareness according to data obtained from own sensors or memory, or received by communicating with other agents, (iii) understanding the meaning of between-agent communications (Williams, 2004), (iv) making a decision based on the logical image and the built situational awareness, (v) execution of the decision locally or in cooperation with other concerned agents, (vi) consulting as an action carried out locally or potentially by some other agent through a cooperative or delegated process. The level of situation awareness depends on whether the agent only aggregates data, or actuates its functional model by time-wise obtained data.
Smart agents can migrate from one system to another, taking their knowledge with them and, after hospitalization in the target system, they can continue their operation from where they left off. The principle of agent hopping as a transfer mechanism may contribute to finding a solution to the system intelligence utilization problem where the system’s actors can be agentized. The pioneers, such as Bharat and Cardelli (1995) developed the principles of how application migration could be implemented at the programming language/environment level. They proposed to include two complementing elements, namely suitcases and briefings. A suitcase is the long-term memory of the agent that contains all pieces of knowledge that the agent can take with it. It may include own-knowledge to share and own-tasks to execute. The briefings are chunks of knowledge that the migrating/migrated agent receives from the target system. The contents of these containers are updated before every migration. Thus, suitcases and briefings are the enablers of the interoperation of an agent with other hosting agents (Xu & Qi, 2008). Smart software agents of iCPSs can diagnose the opportunities of migrating and can make decisions on the execution and timing of a migration autonomously, based on the possessed data and obtained communications (hop instruction). Agents may duplicate themselves and send their copies to multiple target systems. A recognized issue is that agents with diverse ontologies may assign different meanings to the same concept, or consider different concepts and messages with the same meaning (Athanasiadis, 2005). Coordination of nearly concurrent migrations of agents is an additional computational issue, as well as the negotiation protocol development for autonomous multi-agent systems.
Transfer of learning resources
A third evolving example of technological opportunities for knowledge transfer between intellectualized systems is the transfer of learning resources (data, models, algorithms, mechanisms, rules) (Zhuang et al., 2020). Actually, two complementary forms of computational learning deserve attention. One approach, referred to as transfer learning, is associated with the recently developed sophisticated computational mechanisms of machine and deep learning (Neyshabur et al., 2020). The most basic form of transfer learning is fine tuning a pre-trained model. In addition to the mentioned transfer learning, federated learning deserves attention. It also aims at transferring learning resources, but differently (AbdulRahman et al., 2020).
Transfer learning has been proposed to enable modification of the architecture of deep learning networks by pre-trained layers and to solve the problem of insufficient training data (Pan & Yang, 2010). The architecture modification is typically a focused action, i.e., involves editing only the last few layers of the target network, as opposed to modifying the layers in the command line. This way, the output functionality of a network can be changed, for instance, from classification to clustering, as happens in the case of MatLab (Fig. 3). The overall process of reusing pre-trained layer components of deep neural networks includes six phases: (i) loading a pre-trained network, (ii) replacing the final layers of the network by layers able to learn new features, (iii) retraining the modified network by adjusting training options, (iv) prediction of the accuracy of the network by repeated test cases, (v) prediction of the accuracy of the network by statistical analysis, and (vi) further algorithmic improvements of the performance of the network.
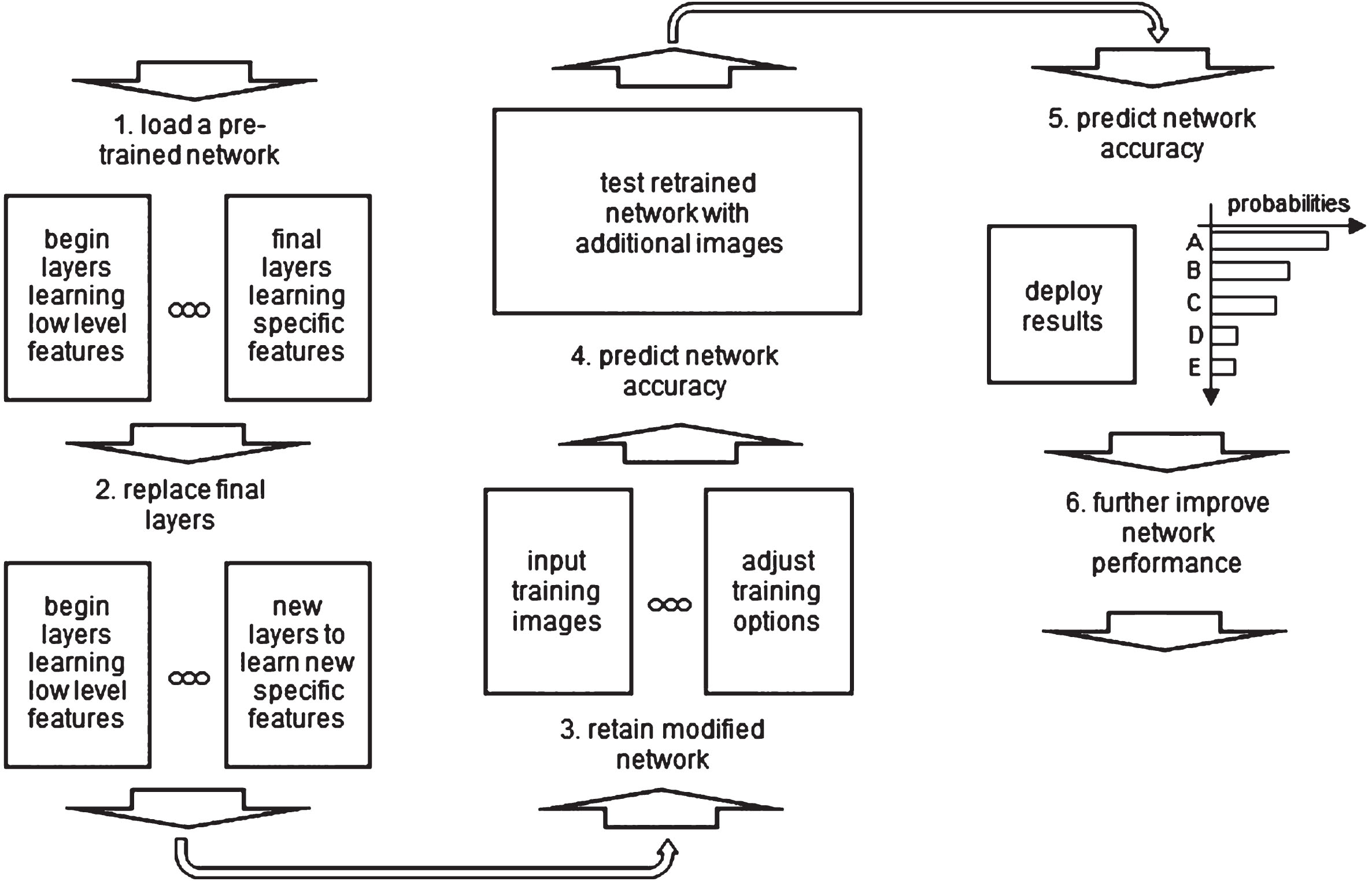
The overall process of reusing pre-trained layer components of deep neural networks.
This form of computational learning also supports cases where training data are expensive or difficult to collect, and makes it possible to provide labelled deep learning data or to change the algorithmic elements of the learning mechanism (Torrey & Shavlik, 2010). In this way, data and algorithms can be used more efficiently and aptly in other application cases, having a number of characteristics in common and being not prone to negative transfer. As an example of the latter, Zhang et al. (2018) posited that recommender systems often suffer from the data sparsity problem that is prevalent in newly-launched systems having had not enough time yet to amass sufficient data. To solve this knowledge insufficiency problem, these systems apply cross-domain knowledge transfer (i.e., transfer relevant data and relationships from a rich source domain to assist recommendations in the target domain).
Like multi-task learning, transfer learning also exploits relations between different learning tasks (Zamir et al., 2018). In contrast to multi-task learning, which simultaneously (jointly) solves many related individual learning tasks, the methods of transfer learning operate in a sequential fashion and solve the learning tasks consecutively. Transfer learning is enabled by constructing regularization terms for a learning task by (re)using the results of a previous learning task (Weiss et al., 2016). A popular implementation is deep transfer learning. Deep learning mechanisms attempt to learn high-level features from mass data by automatically extracting data features by unsupervised or semi-supervised feature learning and hierarchical feature extraction, and to use the learnt features to classify objects. Deep transfer learning is often categorized based on the computational approaches used. Based on these, the following categories are identified: (i) instances-based (utilizing instances in source domain by appropriate weight), (ii) mapping-based (mapping instances from two domains into a new data space with better similarity), (iii) network-based (reuse the partial of network pre-trained in the source domain), and (iv) adversarial-based (use adversarial technology to find transferable features that both suitable for two domains). Deep learning has a very strong dependence on massive training data compared to traditional machine learning methods.
The term ‘federated learning’ (FL) was first introduced in McMahan (2016) to name the approach of collaboratively training a machine learning model based on distributed resources. Strictly speaking, FL is an umbrella term for ML/DL methods that train models in a collaborative fashion. Opposing the other centralized approaches, FL is a distributed machine learning approach, which keeps the raw data decentralized without being moved to a single server or data center (Khan et al., 2021). That is, the mechanism of FL brings the code to the data, instead of bringing the data to the code. On the other hand, it coordinates the distributed trainers to efficiently carry out the training process of machine learning (Sattler et al., 2020). There are three aspects in which FL differs from other centralized learning approaches: (i) it allows transferring the learnt (intermediate) data among the distributed computing resources, while avoiding the transfer of training (direct raw) data, (ii) it exploits the distributed computing resources in multiple regions or organizations, (while the centralized approach generally utilizes only a single server or a cluster in a single region, which belongs to a single organization), and (iii) FL generally takes advantage of encryption or other defense techniques to ensure the data privacy or security, while the centralized approach pays little attention to these security issues (Smith et al., 2017).
FL is formally defined as a machine learning approach where multiple clients collaborate in solving a machine learning problem, while the raw data is stored locally and is neither exchanged nor transferred (Shaheen et al., 2018). Federated learning does not allow communication (while the centralized approaches have no restrictions), whereby it addresses the fundamental problems of privacy, ownership, and locality of data. The concept of FL was extended to three data scenarios, i.e., horizontal, vertical, and transfer (Zhang et al., 2021). The distributed machine learning implemented according to the horizontal data scenario of FL addresses decentralized data of the same features, while the identifications are different. Features are those properties (predictors) of a data construct that can be measured or computed in an automated fashion. For example, colors are features of a pixel in a bitmap image. The vertical data scenario handles decentralized data of the same identifiers with different features. The hybrid data scenario deals with data of different identifiers and different features. Network coding techniques have been applied to the design and analysis of FL methods (Sarcheshmehpour et al, 2021). The various approaches of transfer and federated learning offer mechanisms that can be used as analogical in the case of system intelligence and knowledge transfer.
As a fourth example of the current approaches of knowledge transfer between intellectualized systems, computational approaches of knowledge graphs (KGs) reuse (Hogan et al., 2021) and collective intelligence have been taken into consideration. The term ’knowledge graph’ (like the term ‘semantic network’) was introduced in the literature at the beginning of 1970’s (Schneider, 1973). It has been revitalized by commercial companies at the beginning of 2010’s (Noy et al., 2019). The reason for this revival is that graphs provide an intuitive and concise abstraction for a variety of knowledge domains, where nodes, edges, and paths capture different, potentially complex relations between the chunks of knowledge. Knowledge bases and knowledge graphs show some similarities. The relational records of a knowledge base are replaced by single- or double-orientated entity-relation/predicate-entity constructs of knowledge graphs. Though versatile, KGs are also not always sufficient for problem-solving by iCPSs (Abu-Salih, 2021). That is why they have many different forms of extension mechanisms.
Conceptually analogous to a non-hierarchical concept map, KGs are seen as more complex than image or text data types, which are characterized by (i) lack of reference points, (ii) arbitrary size, and (iii) diverse network topology. In principle, knowledge graphs can be constructed without any underpinning predefined ontology schema. Nevertheless, the literature does not report on computational methods for automated graph construction, only on graph processing (e.g., on transformation of entities and relations into a continuous vector space). In this arrangement, the knowledge graph is the knowledge container and the machine learning mechanisms may avail its content for use by different systems. Typical models of KGs are (i) directed edge-labelled graphs, (ii) heterogeneous information networks, (iii) entity-property-value graphs, (iv) graph meta datasets, and (v) stratified hyper-graphs. Reasoning can be (i) inductive symbolic (e.g., self-supervised rule-mining and axiom-mining) and (ii) inductive numeric (e.g., unsupervised graph analytics, self-supervised embeddings, and supervised graph neural networks).
Since the real-world knowledge graphs are large and highly incomplete, inferring new facts based on them is challenging. Being a network of entities and their relations in their simplest form, KGs embed discrete but linkable elements of knowledge and can be extended with various reasoning and learning mechanisms (Tiwari et al., 2021). Direct processing of knowledge graphs includes (i) knowledge graph embedding in vector spaces, (ii) knowledge representation learning, (iii) knowledge graph completion, (iv) extraction of relation paths, and (v) knowledge graph completion (Ji et al., 2021). The knowledge graphs stored on a cloud, a fog, or an edge are actually not shared, but directly accessed by multiple systems even concurrently. Machine learning mechanisms can learn the interrelated knowledge hiding in the relational structures within domain-specific or domain-independent heterogeneous KGs (Tian et al., 2022). By embedding a graph in a vector space, its logical representation can be transferred to (a dense) numerical representation. For instance, Liu et al. (2022) extended a given knowledge graph representation with machine learning. The encoding of KGs can be executed by deep learning through relational graph convolutional network (GCN). The entity and relationships constructs are embedded by using translational models such as TransE, ConvE, ComplEx, RotatE, QuatE, and AutoSF. Many researchers share the opinion that knowledge graphs can become a confluence of technologies from different areas with the common objective of maximizing the knowledge that can be distilled from diverse sources at large scale using a graph-based data abstraction (Hur et al., 2021).
As discussed by (Lykourentzou et al., 2011), the idea of collective intelligence (CI) and collective intelligence systems (CISs) has emerged in the context of producing higher-order intelligence, solutions, and innovation by large groups of cooperating individuals. However, the attention has twisted to the implementation of synthetic collective intelligence in the last decade. In the formulation of Sulis (1997), a CIS consists of a large number of quasi-independent, stochastic agents, interacting locally both among themselves, as well as with an active environment, in the absence of hierarchical organization but in the presence of adaptive behavior. The three principles (stochastic determinism, interactive determinism, and nonrepresentational contextual determinism) and the two major behavioral control processes (non-directed communication and stigmergy) he identified in a different context, have logical links to swarms of systems and their swarm intelligence. Gunasekaran et al. (2015) proposed a theory of collective intelligence that mimics the communication process typically occurring in the collaboration of human entities in self-managing multi-actor systems. It attempts to explain the emergence of intelligent collective behaviors, among others, in social systems. Musil et al., (2015) proposed a multi-layer model that includes three constituents: (i) human actors as proactive components, (ii) a single, homogeneous CI artifact network as a passive component, and (iii) reactive/adaptive component for computational analysis, management and dissemination.
Passive and active CISs have been distinguished. Zhang and Mei (2020) presented a constructive model for collective intelligence, which continuously executes exploration, integration, and feedback in computational loops. The idea of CISs can be extrapolated to the transfer of synthetic system intelligence based on adaptation of the previously proposed approaches and introducing new ones. Artificial collective intelligence is seen as a new perspective of AI, which is enriching computational intelligence techniques (Williams, 2021). The latest implementations of this technology seek to merge human and machine intelligence with the aim of achieving results unattainable by either one of these entities alone (Smirnov et al., 2019). From a practical point of view, it facilitates achieving the goals of a multi-actor system at a collective (group or crowd) level. The elements of the overall knowledge transfer process are (i) discussion, (ii) argumentation, (iii) negotiation, and (iv) decision making.
Leitão et al. (2022) completed an extensive literature study concerning the concept and features of collective intelligence in an agent-based CPS. According to them, the concept of collective intelligence provides an alternative way to design complex systems with several benefits, such as modularity, flexibility, robustness, and re-configurability to condition changes, but it also presents several challenges to be managed (e.g., non-linearity, self-organization, and myopia). What differentiates CISs from multi-agent systems is that the shared knowledge is transformed, cross-fertilized, moderated, and consolidated through a series of discursive interactions among the actors. Notwithstanding, each included entity has its own personal intelligence. Chunks of crowdsourced information and collective intelligence can be used as input to learning mechanisms. Zheng et al., (2018) proposed a computational platform to support the development of a multi-agent-based reinforcement learning for artificial collective intelligence.
Synthetic system intelligence as a new industrial asset
Utilizing SSI has two important facets: (i) providing a comprehensive and robust solution, or solutions, to cover the wide-range of technological implementations of iCPSs, and (ii) providing effective approaches to utilization and business processes. As the findings of the above studies show, the research and development efforts are in an early stage in both domains and there is no real catalyst to bring together the divided efforts. Nevertheless, this position paper assumes not only the importance and high potential of this overall phenomenon, but also the solvability of the related theoretical, methodological, organizational, etc. problems if they are clearly defined. This latter is exactly what is hindered by the lack of what-is and how-to knowledge. The bottom line is: If intellectualized systems, such as iCPSs, will be able to make decisions on the necessity, possibility, goal, and realization of the transfer processes of SSI on their own, then many doors will open up towards even an autonomous utilization as an ampliative industrial asset.
Technological framework for managing SSI as an asset
Section 3 presented seven already consolidated or currently developing computational technologies that show affinity to a comprehensive and robust SSI transfer process as well as to each other. Shown in the outer rim in Fig. 4, these are: (i) distributed (intelligence) repository management, (ii) collaborative multi-agent-based transfer, (iii) migrating multi-agent-based transfer, (iv) transfer of learning resources, (v) decentralized federated learning, (vi) knowledge graphs-based transfer, and (vii) collective intelligence-based transfer. It is fair to mention that this set of probable technologies reflects the subjective opinion of the author.
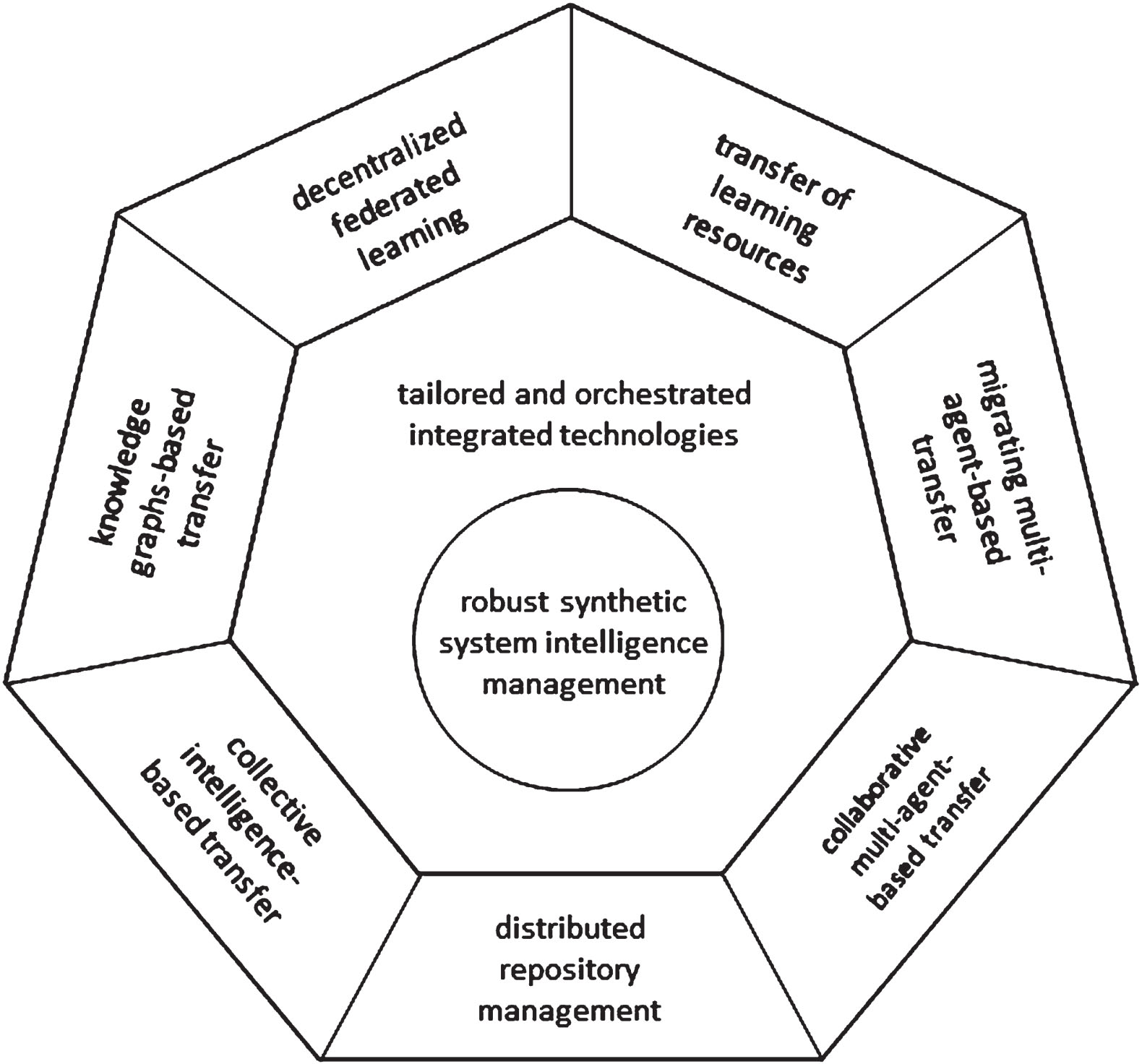
From discrete potential transfer technologies to a robust SSI management.
It is very probable that none of them alone will be sufficient for all SSI transfer problems of iCPSs. Notwithstanding, these technologies warrant consideration for further development. They will probably reach that level of maturity, which is required in the context of transferring SSI. As an intermittent stage in research and development, a subset, the whole set, or an extended set of the above-discussed technologies can be integrated into procedurally and computationally tailored and orchestrated transfer technologies It should also be taken into account that there are several - yet in sprouting - technologies, such as knowledge transfusion and knowledge distillation, but it is not clear how they can contribute to solving the problem of transferring synthetic system intelligence.
The main concepts underpinning the utilization of SSI as an industrial asset are shown in Fig. 5. From a technological point of view, the overall asset management process of SSI can be divided into local processes and a global interoperation process. There are two types of local processes named neutralization sub-process and naturalization sub-process. The neutralization sub-process is about separation of transferable SSI from the generating system, while the naturalization sub-process is about the integration of transferred SSI with the native SSI of a system. The outcome of the local neutralization sub-process is the packets of SSI self-generated by a particular system (called export SSI), whereas the outcome of the local naturalization sub-process is the SSI packets integrated with the native SSI of a system (called import SSI). Both the export and import SSIs include task-oriented problem solving knowledge and processing mechanism combinations.
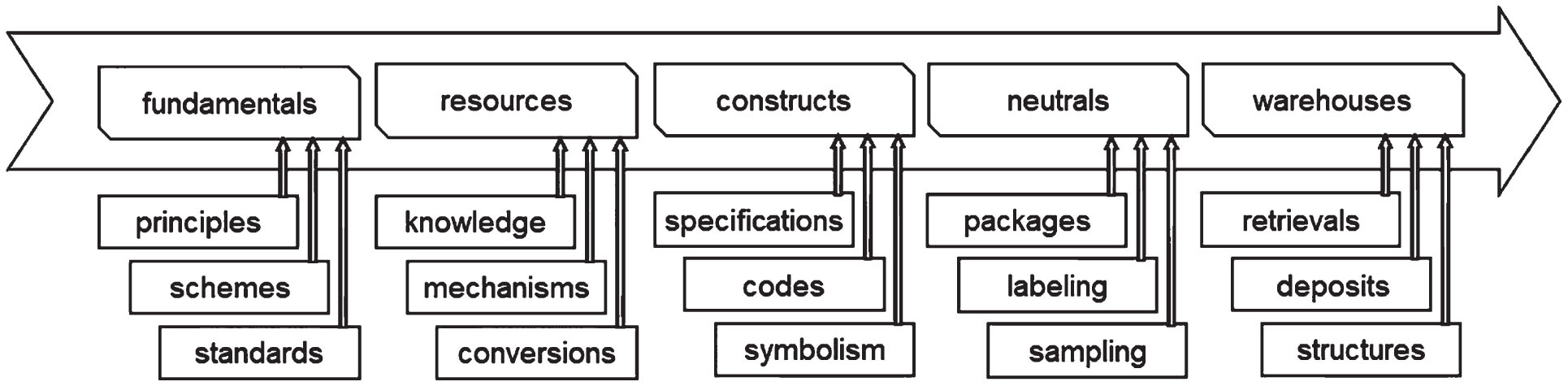
Concepts underpinning the utilization of SSI as an industrial asset.
Figure 6 is a birds-eye-view on the relationship of these processes and their activity elements. The lower blocks include the local, system-specific activities of self-acquiring and self-construction of problem-solving knowledge and ampliative processing mechanisms, respectively. The flows of activities on the outmost left side and on the outmost right side, respectively, represent the sub-process(es) of local utilization of synthetic system intelligence. The left side flow, represented by the upward pointed arrow in the middle of the figure, includes the five major activities of neutralization of synthetic system intelligence in the system that has produced it. On top of the figure, the dual pointed arrow of the global interaction process includes the six activities that enable the exchange of the neutralized SSI among multiple interoperating systems. The right side flow, represented by the downward pointed arrow in the middle of the figure, includes the seven major activities of naturalization of synthetic system intelligence for the system that is going to utilize it. The outcome of the global process is the generic SSI distributed over all interoperating systems.

The technological processes of utilizing SSI as an industrial asset.
The neutralization sub-process is a (tail) extension of the local intelligence management process. Thus, this extends: (i) self-acquiring problem solving knowledge, (ii) self-acquiring processing mechanisms, (iii) self-construction of problem solving knowledge, (iv) self-construction processing mechanisms, and (v) operationalizing SSI in application context with (vi) creating intelligence exchange packets (IEPs), (vii) assigning applicability meta-information to IEPs, (viii) warehousing exportable IEPs, (ix) brokering with exportable IEPs, and (x) dispatching exportable IEPs for external use. The naturalization sub-process is a (front) extension of local intelligence management processes. It appends (i) recognizing the need for importable IEPs, (ii) searching for importable IEPs in warehouses, (iii) qualifying IEPs for use in tasks, (iv) importing qualified IEPs, (v) pre-testing and adaptation of imported IEPs, (vi) integrating the contents of imported IEPs with native SSI used for problem solving activities and self-management activities by the host system. The activities of the global interoperation process are: (i) registration of interoperating systems and their resources, (ii) monitoring the transfer traffic of IEPs, (iii) offering small scale sampling opportunity, (iv) managing protocols and standards, (v) extracting meta-information for improvements, and (vi) managing overall security.
Implementation of SSI transfer means extra overheads for intellectualized systems from four aspects: (i) operationalization, including (a) pretesting, (b) integration, and (c) refinement, (ii) long-term wrangling, including (a) evaluation, (b) filtering, (c) chunking, (d) extension, and (e) structuring, (iii) enrichment, including (a) annotating, (b) contextualization, and (c) tailoring, and (iv) packaging, including (a) assembling, (b) labelling, and (c) standardization.
The increase of industrial revenues and social benefits poses a continual need for novel innovations and new assets. Traditionally, an asset is a resource owned and controlled by an individual, a production or servicing company, or a government. It is a result of past or current activities, and the enabler of economic benefits. In the past, multiple forms of human knowledge (scientific, technological, enterprise, educational, etc.) have been used as industrial assets. What constitutes human knowledge assets are (i) the outputs of the knowledge transformation processes, and (ii) the accumulated depository of skills, knowledge and experience of human professionals. Knowledge produced by artificial intelligence has also reached this status.
In comparison with the conventional assets, SSI has unique characteristics since it is: (i) intangible, (ii) sharable, (iii) reproductive, (iv) evolutionary, and (v) context-valued. It can be possessed as a property, and/or accessed as a service. Thus, SSI contrasts the traditional (narrow sense) interpretation of industrial assets as means (equipment, tools, chemicals, vehicles, infrastructure, computers, materials, etc.) deployed to convert inputs to industry outputs, which can then be marketed as products, services, and experiences, with the expectation that they will generate future cash flows. Handling SSI may become a part of the practice of asset management, because it has the potential to grow in volume and value, and to increase total wealth over time. The reasoning regarding the logic of provisioning SSI as an industrial asset may start out from the key properties of an asset. Typically, three properties are identified: (i) ownership/access, (ii) economics, and (iii) supply. In addition to the technological and business issues, these important issues also need further attention.
For instance, ownership seems to be a simple matter in view to the current status quo of engineered systems and the concerned legal regulations, but in fact it is not. According to the latter, the responsible owner of the SSI is the original developer and/or the actual owner of the system producing the asset, as contracted. However, this is not so straightforward in the case of autonomous systems of the near future, which produce their synthetic resources/assets largely independent of humans, or at least not under the direct control of human stakeholders. The other side of the coin of the ownership of SSI is that (i) proprietary, (ii) shared, and (iii) open forms of possession may take place. Proprietary SSI means that the body of knowledge and the processing mechanisms belong inseparably to a system (or to the owner of similar systems). This knowledge is primarily stored in the repositories of the system or on those of the owner company (e.g., on edge computing devices or on a private cloud of the company or a third party, with no or limited access to other enterprise and partner networks, and retaining a high degree of control, privacy, and security). Shared SSI means that the body of knowledge is jointly aggregated by cooperating systems and/or their owner companies over multiple systems. It is managed either on shared edge networks or on a community cloud whose infrastructural elements and processing rights are shared by several organizations or third parties which share concerns, common objectives, and optimization of benefits. Open synthetic system knowledge (SSK) means that a body of knowledge is made openly accessible, processable, and usable for the systems, developers, and researchers of a large industry group, academic organization, and eventually, the broad public. In other words, the historically aggregated and maintained intelligence may reside on publicly accessible clouds or may be availed by a cloud service provider, enabling standardized data and application portability.
As well, the economic value of the exchanged, sold, or obtained SSI assets is a complicated matter (Amin et al., 2018). Assets are associated with ownership and can eventually be turned into cash and cash equivalents for the owners. Ultimately, it means that the total amount of investments should be less than the total amount of financial return (profit). The investments include all (primary) costs of (i) the implementation of the system shell, (ii) the knowledge engineering in the set-up stage, including the preparation of the reasoning and control mechanisms, (iii) the processing (extraction) of system intelligence during operation of a source system, (iv) transferring system intelligence to a target system or to a warehouse, and (v) reactivation of the transferred system intelligence in a target system. The returns include the (primary) income based on (i) selling and maintaining the system shell, (ii) vending knowledge engineering means and services, (iii) selling system intelligence, (iv) sharing the benefits of reusing transferred system intelligence by the target system(s). Here, only the direct and indirect costs and benefits are thought of, and the secondary costs and benefits are ignored. Both the investment side and the return side involve complex activity flows, whose financial consequences are difficult to capture in detail and, therefore, comprehensively forecast and quantify. The evaluation is even more complicated if multiple (large number of) systems (or a dynamic system of systems) are considered which have different commitments and involvement in asset generation and utilization, and may show different levels of successful and unsuccessful operations.
The supply aspect of converting SSI into an industrial asset involves not only opportunities, but also challenges. Traditionally, the concept of asset convertibility is used to classify assets according to how easy or difficult they are to be supplied and to get converted into cash. The primary issue would be the motivation of the owners of autonomous systems to make positive decisions on collaboration and to equip their systems up-front, or augment them in use time, with facilities for SSI management. However, utilization of SSI as a novel industrial asset is supposed to happen not only over the boundaries of systems, but also over the borders of companies and enterprises. This novel form of asset exploitation is deemed to be part of their information technological (IT) asset management. It must complement the combined practices of technological, financial, inventory, and contractual functions within the IT environment, and help strategic decision-making, optimization of spending, and support lifecycle management.
Conclusive remarks
In a sense, history repeats itself: In the 1970’s–1980’s, the need for technological solutions for transferring product data and inference knowledge among dissimilar systems was a stimulant of information systems research. In the 2010’s and 2020’s, the need for (and the opportunity of) technological solutions to transfer synthetic knowledge among intellectualized systems gives orientation to the research of CPS research. The overall assumption of the background research was that shared synthetic system knowledge and reasoning/learning mechanisms can eventually become a valuable industrial asset. As an intellectual capital, SSI can contribute to the net working capital of a company or even to the problem-solving potential of the whole society. This position paper was intended to present the thoughts of the author concerning a number of recognized issues and technological affordances –with an obvious incompleteness.
It is well-known to scientist that the process of learning and knowing a yet unknown research phenomenon goes through such stages as discovery, description, explanation, prediction, and regulation. Since the emerging phenomenon of managing synthetic system intelligence is novel even on a conceptual level, the research could focus only on the identification and the characterization of this complex, multi-faceted phenomenon. Therefore, a larger part of the contents presented in this position paper belongs to the stage of discovery and description, and only a smaller part to the stage of explanation and prediction. Due to the newness of the phenomenon, the literature is rather scarce and unspecific. Thus, the intention of the structured literature study was to get deeper insights in the state of science and practice. The completed survey informed us about the lack of generic theories, conceptual frameworks, and methodological approaches. Many of my own concepts and ideas are only work-in-progress and they still must be addressed extensively from the perspective of an industry-wide implementation. Thus, a supplementary goal of the paper has been to stimulate and encourage research and development efforts in this direction. As good research questions imply new questions, a novel prognostic research should encourage many strands of follow-up research.
Like patents and copyrights, SSI is to be treated as a (i) partially-physical, (ii) intangible, (iii) liquid, (iv) functional, and (v) net identifiable potential asset that needs a socio-technical process to get converted into cash. The road to an industrial solution for utilization of SSI will most probably be long, curvy, and bumpy. Nevertheless, it is wise to deal with it in the framework of digital transformation, which has rapidly turned itself to a digital disruption in terms of intellectualization of engineered systems (Vial, 2021). This position paper has made an attempt to provide procedural framing of the process of transforming synthetic systems knowledge into a common industrial asset and capital. Obviously, there are many fundamental unanswered questions concerning the vision of SSI and utilizing it as a new industrial asset. For instance: What is the true future of system intelligence? Where does SSK go? Where do the computational reasoning mechanisms go? But nothing can be an obstacle to imagination, design, and planning.
Not surprisingly, this position paper also closes with a question, rather than with an answer. The question is: Can the investigated transfer mechanisms and the proposed procedural framework be the starting points of system intelligence transfer between iCPSs, or should they be reduced, integrated, extended, or substituted by something else that serves better for the purpose? Is there any affinity or complementarity among them? Research in this direction needs holistic (multi-, trans-, and supra-disciplinary), rather than reductionist approaches. The fact that the specific principles of doing this type of research are only partially known makes studying this complex problem difficult. And, then the practical question is: Can the above be triggering research questions and the sources of hypotheses for follow-up research? This position paper would not have been submitted to the journal if the author believed the opposite.
As the analysis showed, there are at least seven ‘carriages’ needed to move ahead on the road: (i) obtaining deep scientific insights into the overall phenomenon, (ii) elaboration of the fundamentals (underpinning knowledge and specifications), (iii) creation of conceptual, procedural, and methodological frameworks and models, (iv) working out the across-systems intellectual and computational mechanisms and resources of SSI transfer, (v) implementation of the technological, engineering, and organizational enablers, (vi) realization of demonstrative prototypes with the involvement of autonomous iCPSs, and (vii) identification and propagation of the best practices among iCPSs developers.