
Abstract
In text classification field, many classifiers cannot deal with the features with large dimensions, thus it is very important to filter the redundant information from the original feature space efficiently and achieve the features with best qualities. On this basis, a new two-step based feature selection method is proposed in this paper. Firstly, some definitions (word semantic correlation, set semantic correlation, semantic correlative and semantic correlative set) are introduced, and the algorithm of generating the semantic correlative sets is given. Secondly, the process of the two-step based feature selection method is described: in the first step, a feature subset is obtained by using an optimal feature selection method, and a set of semantic correlative sets is generated by using the selected feature subset; in the second step, the redundant information of the selected features is filtered by using the generated semantic correlative sets. Finally, in order to avoid local optimum when searching the best threshold, the conception of memory recall position is introduced and an improved memory recall mechanism based fruit fly optimization algorithm is proposed. In the experiments, two typical classifiers: support vector machine and naïve bayes are used on four datasets: Reuters50, SMSSPAS, WebKB and 20-Newsgroups, and the 10-cross validation is carried out when the measurements of F1 and receiver operating curve are used. Experimental results show that the proposed method achieves higher accuracy than several representative traditional feature selection methods and runs faster than typical mutual information based feature selection methods, illustrating its effectiveness on achieving the best features in text classification filed.
Keywords
Introduction
In text classification field, documents are usually represented in vector space, in which each term is considered as a separate dimension (feature). However, as a text dataset usually contains thousands of features, it is very important to deal with the high dimensionality of the original feature space. Immoderate number of features not only increases the computational complexity but also deteriorates the performance of text classification [1]. Therefore, it is desirable to find suitable methods to reduce the dimensionality of the feature space and improve the quality of selected features.
Feature selection and feature extraction are two mainly types of dimensionality reduction methods. Feature selection methods select subsets from the original feature sets according to some criteria of feature importance. Existing feature selection methods in text categorization are either based on document frequency or term frequency [2]. Typical document frequency based feature selection methods include: Chi-squre (CHI) [3], improved Gini index (IMGI) [4], document frequency (DF) [3], odds ratio (OR) [5], etc. Typical term frequency based feature selection methods include: ambiguity measure (AM) [6], normal term frequency based discriminative power measure (DPMNTF) [7], t-test based feature selection (TTFS) [8], TFSM [9], etc. Feature extraction methods extract sets of new features by transforming the original features into distinct feature spaces. Typical feature extraction methods include: principal component analysis (PCA) [10], latent semantic indexing (LSI) [11], partial least square (PLS) [12], multidimensional scaling (MS) [13], latent Dirichlet allocation (LDA) [14], etc. Compared to feature extraction, feature selection maintains the physical properties of the original features, and has been widely used in time series analysis and pattern classification [15].
The filters and wrappers are two mainly types of feature selection methods [16]. Filters select features based on some classifier agnostic criterions, and are not dedicated to any classification algorithms. The methods like DF [3], darmstadt indexing approach (DIA) [17], information gain (IG) [18], CHI [3], mutual information (MI) [19], IMGI [4], TTFS [8] are all typical feature selections of filers. Wrappers rely on the performances estimated by one type of classifiers to select features and to evaluate the quality of those features [20]. Typical feature selection methods of wrappers include: forward search (FS), backward search (BS), sequential floating search (SFS), best-first search (BFS) [21], cluster based search (CBS) [22], etc. Compared to wrappers, filters are sampler and have lower computational complexities, thus have been widely used in text classification field.
Traditional feature selection methods of filters (such as DF, IG, CHI, TTFS, etc) calculate the discriminative abilities of a term with respect to different categories separately. Thus, these methods cannot deal with the redundant information of the selected feature subset, deducing the classification accuracy be decreased if the selected feature subset is used directly for text classification. For solving this problem, many MI based feature selection methods, like MIFS [23], NMIFS [24], MIFS-CR [25] and MDMR [26] have been proposed. MIFS introduced the balance parameter and gave attention to both relevance and redundancy. NMIFS improved the MIFS measurement and solved the problem that the entropy of a feature varied greatly. MIFS-CR defined a new feature redundancy measurement capable of accurately estimating mutual information between features with respect to the target class. MDMR considered the conditional redundancy between the candidate feature and the selected features, and presented a max-dependency and min-redundancy criterion for multi-label classification learning tasks.
However, the above MI based methods adopt greedy searching strategies to select features incrementally, thus face the problems of high computation complexity and parameter dependency. On this basis, we take advantage of traditional methods of filers in execution speed and propose a new two-step based feature selection method to solve the problems of MI based methods in this paper. The remainder of this paper is organized as follows. Section 2 reviews the related work on feature selection methods. Section 3 gives the motivation of the proposed method. Section 4 descripts the proposed method. Section 5 shows the experimental results. Section 6 concludes the whole paper.
Related work
Traditional feature selection methods of filters
The IG method
IG defines the expected reduction in entropy caused by partitioning the texts according to a word [18]. IG is defined as follows:
The orthogonal centroid feature selection (OCFS)
OCFS method considers the centroids of each class and all training samples, and calculates the score of a word according to the obtained centroids [6]. Given a word t
i
, the OCFS score of t
i
is calculated as follows:
The MI method
The task of feature selection is to find the features that contain as much information about the categories as possible [27]. MI measures the mutual dependence of a feature t i and a category c k . The formula for MI is given as:
Comprehensively measure feature selection (CMFS)
For solving the problem DF [3] and DIA [17] only focus on the rows or the columns of feature vector space model, Yang proposed the CMFS method, which calculates the significance of a term from both inter-category and intra-category. The CMFS score of word t i is defined as follows [28]:
In information theory, the MI methods calculate the uncertainty in a variable due to the knowledge of another variable [29], thus is widely used in feature selection as it is a good indicator of the correlation between features. The MI based methods use greedy search strategies to select the best feature subset [25]. Given a candidate feature set F, the main idea of the MI based feature selection methods is to find a subset S (S ⊂ F) which maximizes ∑
c
k
MI (S, c
k
) and minimizes ∑t
i
∈S, t
j
∈SMI (t
i
, t
j
), where c
k
is a category, t
i
and t
j
are two features in S. Obviously, as the MI based methods consider the relationship among the selected features, they become the most widely used methods for filtering the redundant information of selected feature subset. In this section, some typical MI based feature selection methods are given as follows: Improved mutual information feature selection (MIFS-ND)
As decreasing in the number of irrelevant features can lead to reduction in computation time, Hoque introduced a greedy feature selection method using mutual information. This method uses the mutual information of feature-feature and feature-class to determine an optimal set of features [30]. The objective function of MIFS-ND is defined as follows:
Multi-label feature selection based on max-dependency and min-redundancy (MDMR)
For multi-label classification learning tasks, Lin presented a max-dependency and min-redundancy criterion [26]. The objective function is described as follows:
Cumulate conditional mutual information minimization criterion feature selection (CCM)
Zhang proposed a two-step based feature subset selection algorithm with conditional mutual information [20]. Firstly, formula (7) is used to find a subset S. Secondly, formula (8) is used to find and filter the redundant features in S.
Global MI based feature selection (GMFS)
Han used the binary particle swarm optimization (BPSO) algorithm to select the best features and provided a new idea for solving feature selection problems. The objective function is described as follows [31]:
The selected feature subsets of traditional feature selection methods always contain redundant information, which is helpless to improve the text classification accuracy. On this basis, the MI based selection methods are proposed to avoid selecting the redundant features. However, the traditional MI based methods still have the following problems: (1) the correlations between the candidate feature and all categories, and the correlations between the candidate feature and the selected features should both be calculated, deducing that the time complexities of these methods are high when the numbers of all words and the selected features are both very high. (2) these methods adopt greedy searching strategies to incrementally select features, which may generate local optimal solutions. (3) these methods use parameters to control the tradeoff between relevance and redundancy, however, the best values of these parameters are hard to choose. These have motivated us to design a new feature selection method to identify an optimal subset of features which gives the best classification accuracy. In this paper, a new two-step based feature selection method which filters the redundant information is proposed.
The proposed method
Implementation of the proposed method
Mutual information can reflect the statistical relationship between two variables, thus is widely used in measuring the relevance of two words [26, 30]. However, the output values of MI method are difficult to be quantized to interval [0, 1]. On this basis, we define simple measurements to measure the relationship between any two words or two word sets. Assume that DS = {d1, d2, …, d i , …, d N d } is a sample set which contains N d documents, TS = {t1, t2, …, t i , …, t N t } is the set of the words in DS. Some definitions and propositions are given before introducing the proposed method.
Where, |s1| and |s2| are the numbers of words in s1 and s1, respectively.
If |S|=1, then S is a semantic correlative set; If there exists two subsets s1 ⊂ S, s2 ⊂ S (s1 ≠ s2), which satisfy:
(s1 ∪ s2 = S) ∧ (s1 ≡ s2) = true, then S is a semantic correlative set.
Based on the above definitions and propositions, the process of generating a set of semantic correlative sets from the word set TS is given as follows:
For example, as is shown in Fig. 1, t1 - t9 are the words in TS, and the word semantic correlations between each pair of these words are given in Fig. 1(a). When the threshold th = 0.8, as is shown in Fig. 1(b), because the word subset {t9} and the word subset {t1, t2} are semantic correlative, the word set s1 = {t1, t2, t9} is a semantic correlative set. Further, two more semantic correlative sets are obtained and denoted as e2 and e3, which are shown in Fig. 1(c-d), respectively.
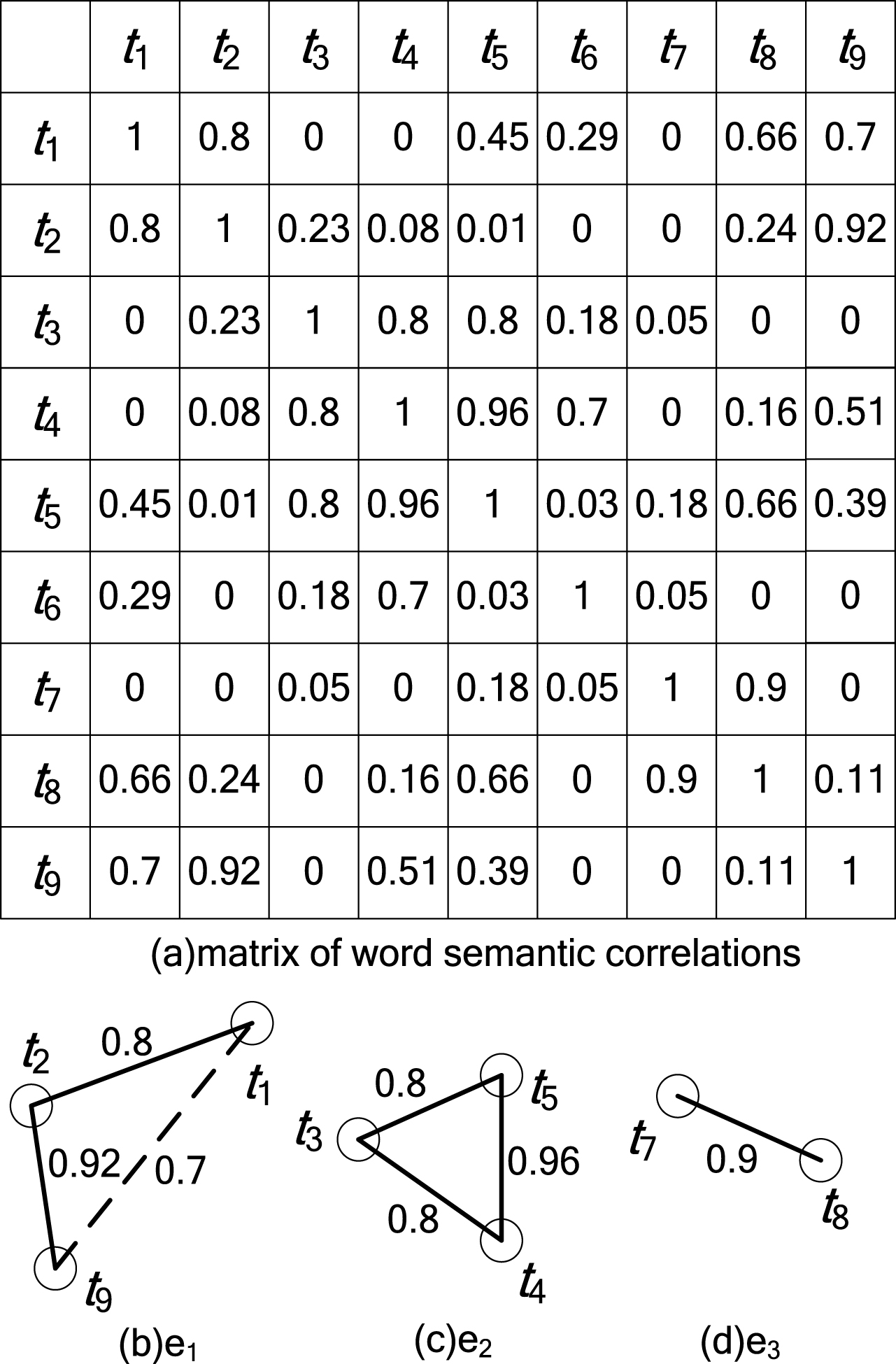
Example of semantic correlative sets (th = 0.8, the solid lines denote that the corresponding two words are semantic correlative).
Obviously, given a suitable threshold th, if two words both appear in a semantic correlative set, they are relatively redundant to a great extent. On this basis, we combine the advantage of traditional feature selection methods of filters (such as IG, CMFS, CHI, etc.) in execution speed, and propose a new feature selection method which can efficiently improve the speed of filtering the redundant information while keeping the accuracy. This method mainly contains two steps: (1) obtain a feature subset FS1 by using an optimal feature selection (OFS) method and generate a set of semantic correlative sets; (2) filter the redundant information from FS1 to form the final feature subset FS by combining the generated semantic correlative sets. Because the number of features in FS1 is much lower than that of the words in the entire dataset, the time complexity of the proposed method is controllable. As is shown in Fig. 2, the skeleton frame of the proposed method is shown as Algorithm 2:
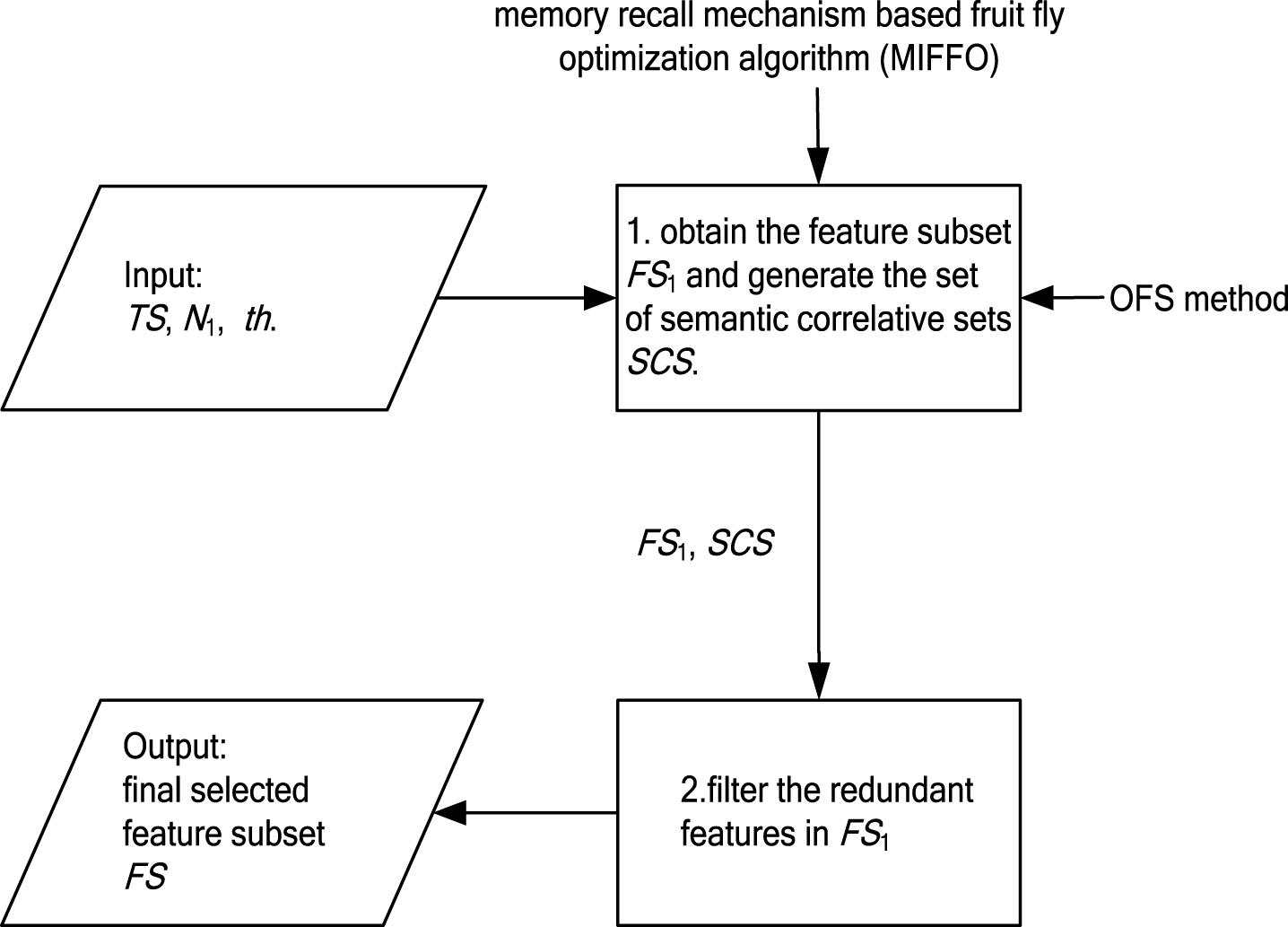
Execution process of the proposed method.
Further, we will replace the words those occur in a document but do not occur in FS by the features which are semantic correlative with the word before document representation process. Given a document d = (t1, t2, …, t
i
, …, t
n
) (t
i
is a word of d, n is the number of words in d), the word replacement process can be described as:
We use metaheuristic algorithms to search the optimal value of threshold th, which is a key parameter that effects the qualities of generated semantic correlative sets. Fruit fly optimization algorithm (FOA) is a new global optimization algorithm inspired by the foraging behavior of fruit flies [32]. Comparing with other metaheuristic algorithms, FOA has many advantages such as less control parameters, simple computational process, ease of understand and implementation, etc [33]. To improve the performance of the FOA and eliminate the drawbacks which lie with fixed values of the searching radius in FOA, Pan presented an improved FOA (IFFO) by introducing a new parameter and solution generating method [34]. The details of IFFO are given in Algorithm 3:
However, IFFO does not memorize the history best positions, and lacks the mechanism of jumping out of the local extreme value. Moreover, this method ignores the possibilities that the best global position always occurs near the history best positions. On this basis, this paper introduces the conception of memory recall position, and proposes an improved memory recall mechanism based FOA method (MIFFO) to solve the problem that the global best position cannot be improved when IFFO falls into local optimum.
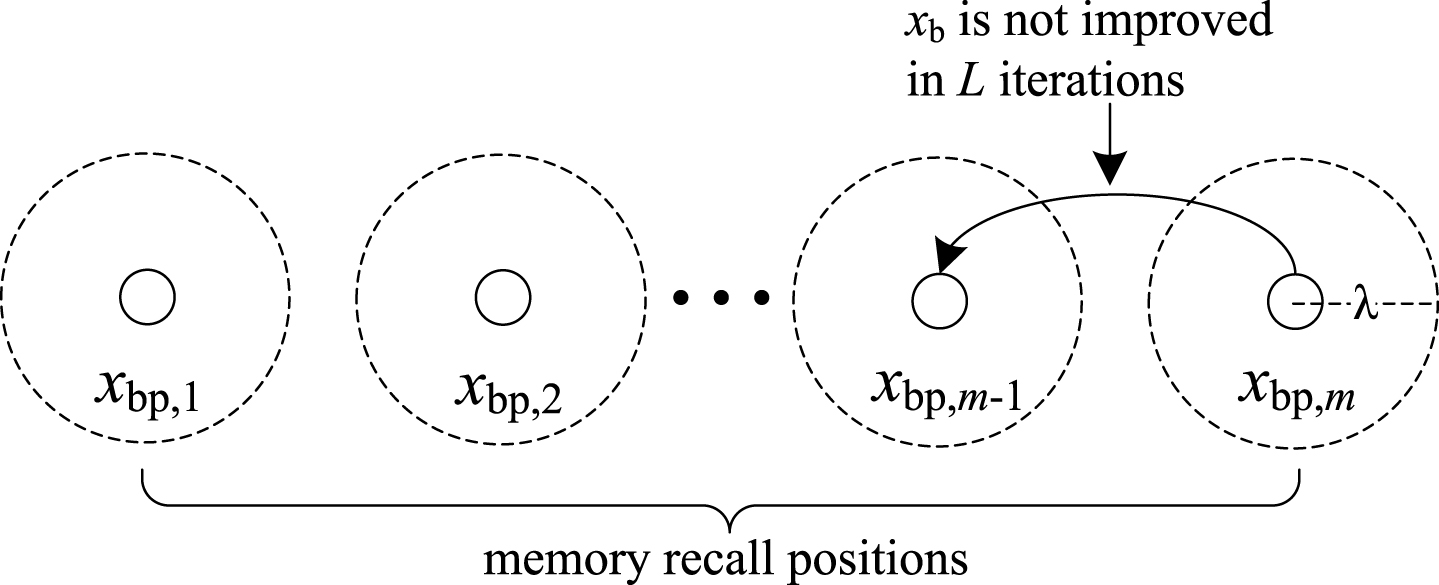
Improved memory recall mechanism based FOA method.
MIFFO defines the latest m global best positions as the memory recall positions, which are denoted as M = {xbp,1, xbp,2, …, xbp,m} (m is the number of memory recall positions). As is shown in Fig. 3, if the current best position xb is not improved in L iterations, the new positions of the fruit flies will be generated by utilizing the memory recall positions in M, and xb will be memorized. Given the fruit fly i and a variable k, i’s position is updated using formula (18) in normal cases. However, when xb is not improved in L iterations, the formula (18) in IFFO can be rewritten as follows:
The time complexity of the proposed feature selection method can be analyzed from the following aspects: In the step of obtaining the feature subset FS1 in Algorithm 2: from reference [28] we know, the time complexity of this step is O (|C| × N
a
+ N
a
× log N
a
), where |C| is the number of categories, N
a
is the number of all words in the dataset. In the step of generating the set of semantic correlative sets (SCS) in Algorithm 2: we know that there are In the step of filtering the redundant information of FS1 in Algorithm 2: this step also takes
By combining the above results, we can obtain the time complexity of the proposed method as follows:
Further, the time complexities of three typical MI based feature selection method (CCM method, MDMR method and GMFS method) are given as follows:
Where, Nd is the number of documents, T is the max iteration number of PSO. Generally, there exists N1 << Na, and T is always set to be large enough to grantee the convergence. Therefore, we deduce that the time complexity of our method is lower than those of other methods, illustrating that the proposed method is feasible on reducing the consuming time.
The experiments are conducted on an Intel core(TM)-i5 processor with a CPU clock rate of 3.10 GHz and 4 GB main memory. The vector space model of the selected features is built on the platform of visual studio 2008, using C++ standard template library (STL). According to [28], CMFS can achieve high accuracy while keeping the execution efficiency, thus it is chosen as the OFS method. In this section, we compare the proposed method with three typical traditional feature selection methods (IG, CMFS and MI) and three typical MI based feature selection methods (MDMR, CCM and GMFS).
Datasets
In order to validate the performance of the proposed method, four widely used textual datasets: Reuters50 (RE), SMSSPAS (SM), WebKB (WE) [28] and 20-Newsgroups(NE) [35] are adopted in the following experiments. The WE dataset contains the web pages collected by the World Wide Knowledge Base project of the CMU text learning group. The RE, SM and NE datasets are all from the UCI machine learning repository, which has been widely used by the researchers all over the world as a primary source of machine learning datasets. Table 1 summarizes general information about these datasets. For ease of computation, we only consider the top 4, 6 and 8 categories with respect to WE, NE and RE, respectively. For the documents of each dataset, stop-words are removed, and the stemming process is executed by using Porter stemming algorithm [36]. Moreover, the 10-fold cross validation is executed to measure the performances of different methods.
Details of four datasets used in this paper
Details of four datasets used in this paper
Precision (PR), recall (RC), true positive rate (TPR) and false positive rate (FTR) are widely used measurements to evaluate the performances of feature selection methods. The definitions of PR, RC, TPR and FTR are given as follows:
In formulas (24) and (25), |C| denotes the number of categories; Nt is the number of testing documents; TP
i
is the number of documents which are correctly classified to category c
i
; FP
i
is the number of documents which are misclassified to category c
i
; FN
i
is the number of documents which belong to category c
i
and are misclassified. Further, the F1 measurement, which combines the measurements of PR and RC is defined as follows [17]:
As the receiver operating curve (ROC) and the area under ROC (AUC) measurements provide important information about the classifier performance [37], they are also applied to compare different feature selection methods in the following experiments.
Support vector machine (SVM) [28, 37] and Naïve bayes (NB) [28] are used to validate the performances of different feature selections. In this paper, these classifiers are implemented by matlab 2013, which is popular on machine learning and data mining. The parameters of SVM are given as follows: cost parameter c = 1.0, the tolerance of the termination criterion: e = 0.001, Kernel = RBFKernel, gamma = 0.5. Because the multinomial event model can generate higher accuracy than the multivariate Bernoulli event model in NB [38], we use the former model to classify a document when NB classifier is used.
Performance comparisons of IFFO and MIFFO
The parameters are given as follows: number of fruit flies FN = 20; maximum number of iterations T = 2000; dimension of food position D = 1; threshold L = 30; maximum value of the searching radius λmax= 0.5; minimum value of the searching radius λmin= 0.001; maximum value of food position xmax= 1; minimum value of food position xmin= 0.001. On this basis, the fitness function of different metaheuristic optimization algorithms is defined as follows:
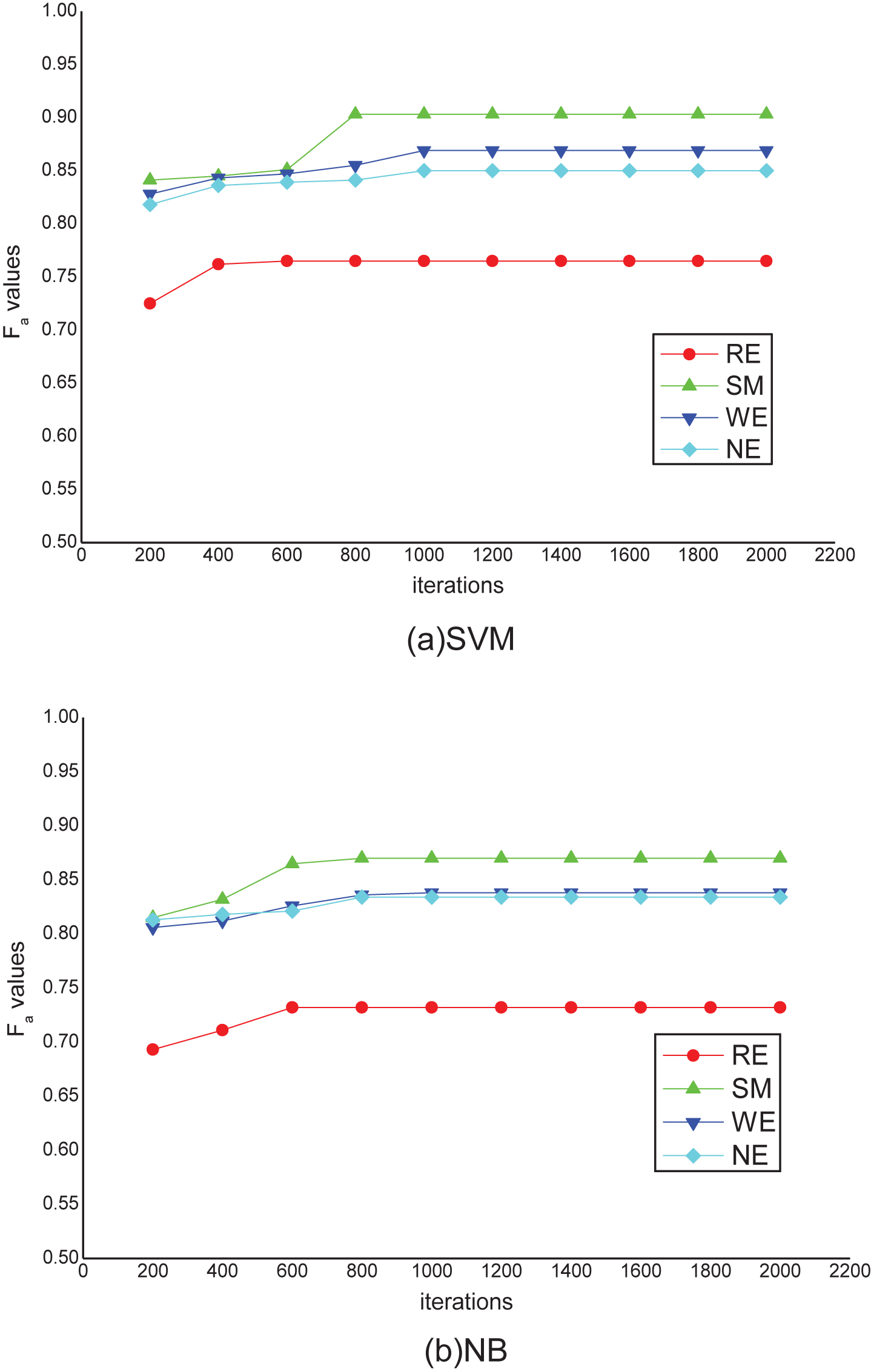
convergence histories of Fa values when IFFO is used.
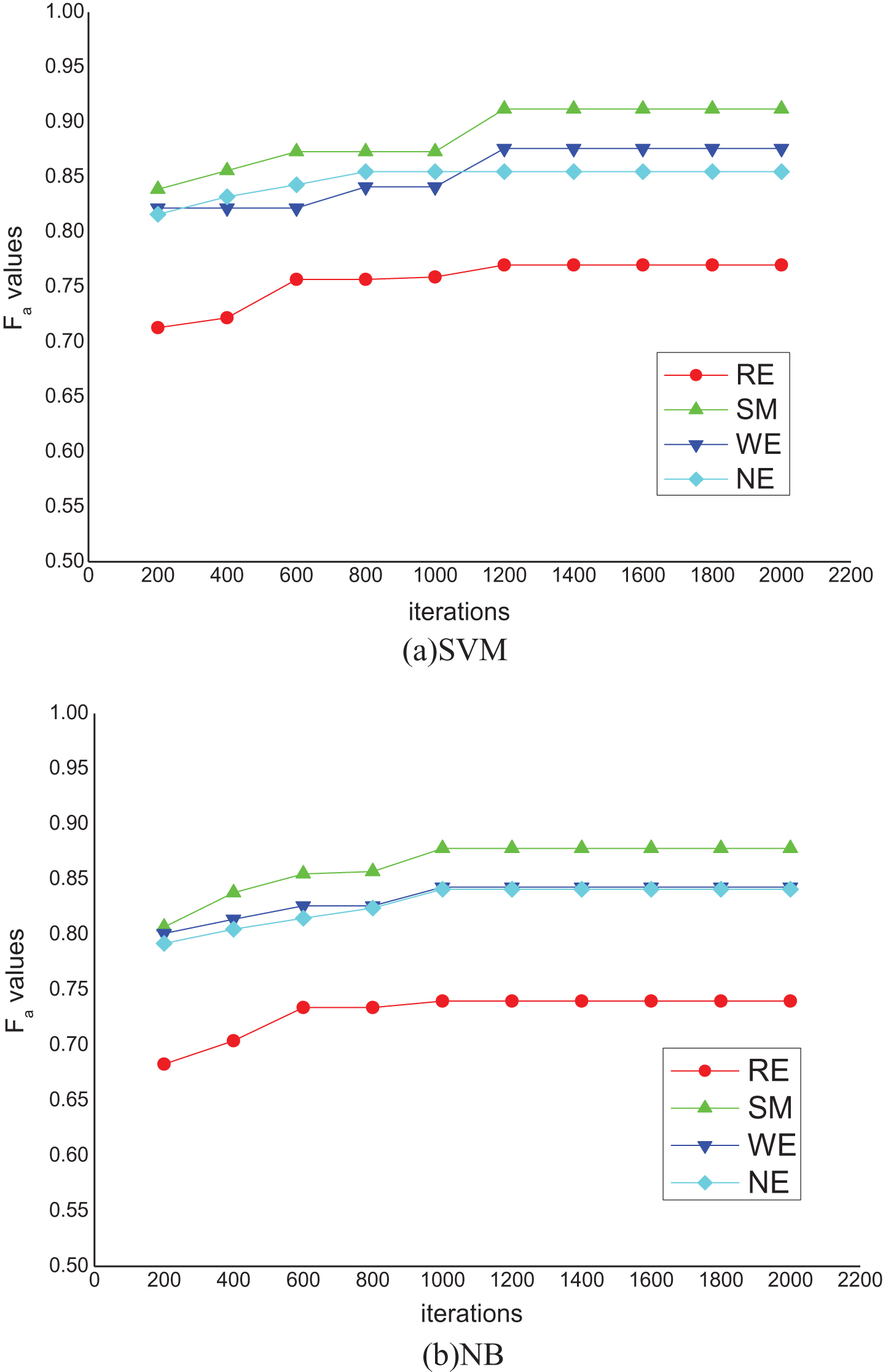
convergence histories of Fa values when MIFFO is used.
Obviously, the converged iteration numbers are about 1000 and 800 with respect to SVM and NB when IFFO is used, while the corresponding converged iteration numbers of MIFFO are 1200 and 1000, respectively. When IFFO is used, the average converged Fa values are 0.847 and 0.819 when SVM and NB are applied. However, when MIFFO is used, the corresponding average converged Fa values are 0.853 and 0.826, respectively. Though the convergence rate of MIFFO is lower than IFFO, the former obtains significant improvements on Fa values, denoting the efficiency of MIFFO in utilizing the experience of the fruit flies and improving the global searching accuracy when comparing with IFFO method.
We compare the average execution time (denoted as eta) of each method when the ratio of selected features ranges from 1% to 10% with a step of 1%, and the results are shown in Table 2. It can be seen from this table that the results of MI based feature selection methods (CCM, MDMR and GMFS) are much higher than those of traditional feature selection methods like IG, CMFS and MI. The reason is that the MI based methods are much more time-consuming as they consider both the correlations between the candidate feature and all categories, and the correlations between the candidate feature and the selected features. GMFS obtains the maximum eta value (21.642) on NE dataset, and MI obtains the minimum eta value (0.436) on SM dataset. Further, we notice that the eta values of GMFS is significantly higher than those of other methods, illustrating that GMFS is very time-consuming as it uses PSO algorithm to optimize the best features. It is noteworthy that the etta values of the proposed method are slightly higher than those of IG, CMFS and MI, with the average increment of about 0.8 s over those of CMFS. Moreover, the proposed method performs obviously better than CCM, MDMR and GMFS, with the largest improvement about 19.2 s over GMFS on NE dataset, illustrating the effectiveness of the proposed method on reducing the execution time of redundant information filtering process.
eta values of seven feature selection algorithms (eta is expressed as seconds)
eta values of seven feature selection algorithms (eta is expressed as seconds)
In this section, we compare the proposed method with six typical feature selection methods when the ratio of the final selected features ranges from 2% to 10% with a step of 2%.
Table 3 shows F1 values of different methods on RE dataset. For each ratio, the highest F1 values are all denoted in bold. When SVM is used, the F1 values of the proposed method are generally higher than those of the other methods when the ratio of the selected features equals to 4% or 6%. When NB is used, the proposed method outputs better results than those of the other methods when the ratio of the selected feature is 4%, 8% or 10%, and it obtains the highest F1 value (0.749) when 8% of the features are selected. Figure 6 shows the ROC curves of different methods on RE dataset, and the TPR and FPR values are averaged when SVM and NB are used. In Fig. 6, the numbers in the brackets are the AUC values of different methods. It can be seen that the performances of MDMR and CCM are similar. Obviously, MI obtains the lowest AUC value 0.925, and the proposed method achieves the highest AUC value 0.966, with the improvement of 0.009 over that of CMFS, illustrating the effectiveness of the proposed method in selecting the best features.
F1 values of different feature selection methods on RE dataset when SVM and NB are used, respectively
F1 values of different feature selection methods on RE dataset when SVM and NB are used, respectively
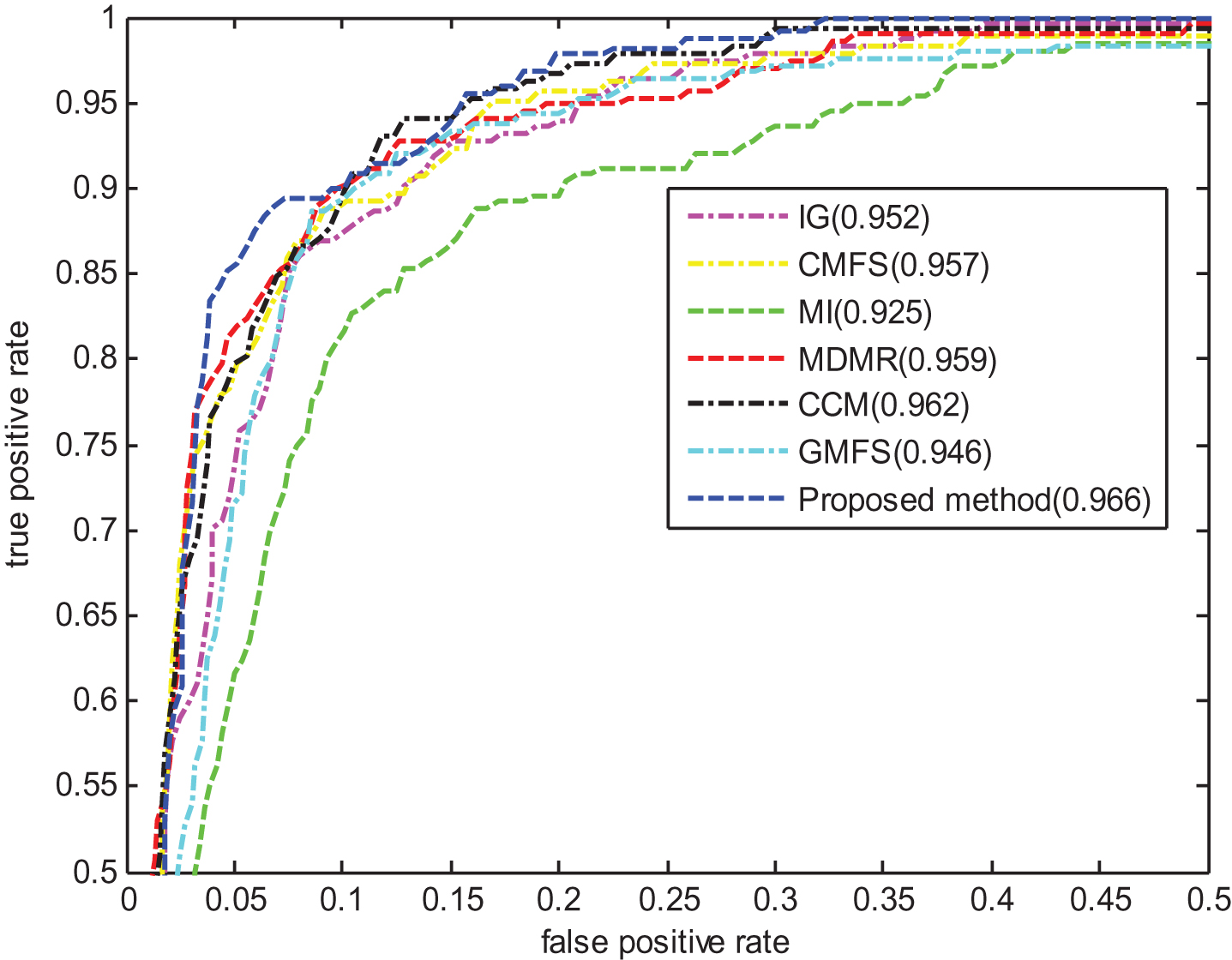
ROC curves of seven methods on RE dataset.
Table 4 shows F1 values of different methods on SM dataset. According to Table 4 we know, when the performances of different classifiers are compared, the SVM classifier shows a higher performance than NB classifier, denoting the high accuracy of SVM in dealing with text classification problems. When SVM is used, MDMR and CCM perform generally better than other methods as they considered the conditional redundancy between the candidate feature and the selected features. The proposed method obtains the highest F1 value 0.924 when 8% features are selected. Moreover, when NB is used, the proposed method obtains the highest F1 values 0.898 and 0.893 when 4% and 8% features are selected, respectively. Figure 7 shows the ROC curves of different methods on SM dataset, and the TPR and FPR values are averaged when SVM and NB are used. From Fig. 7 we know, CMFS performs generally better than IG as its AUC value is slightly higher than that of IG. Moreover, the AUC value of MDMR, CCM and the proposed method are similar, showing the high ability of the methods which filter redundant information on searching the most discriminative features.
F1 values of different feature selection methods on SM dataset when SVM and NB are used, respectively
ROC curves of seven methods on SM dataset.
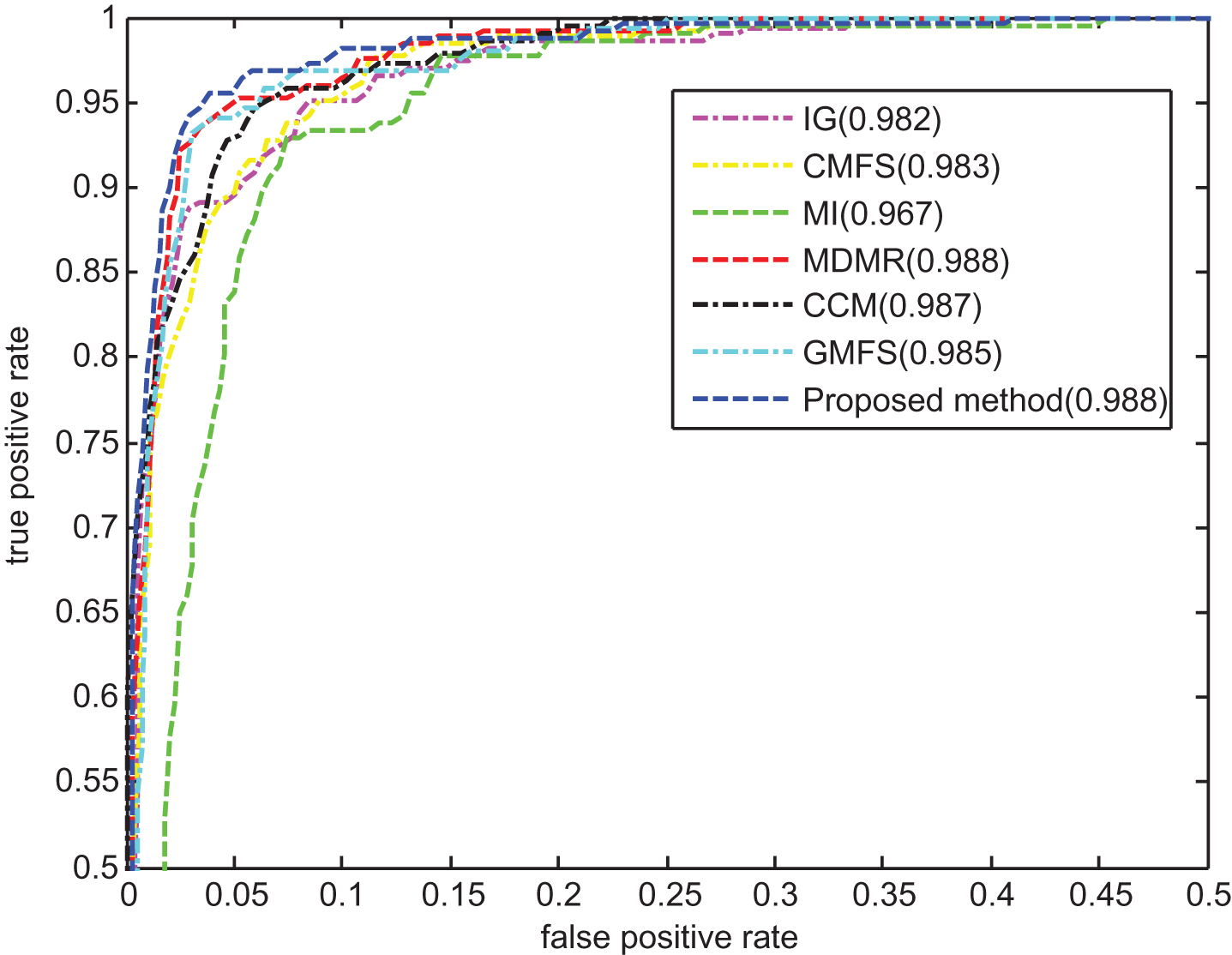
Table 5 shows F1 values of different methods on WE dataset. According to Table 5, the highest F1 value 0.868 with SVM is obtained by CCM when 10% of the features are selected, and the second highest F1 value 0.864 is obtained by the proposed method when 8% of the features are selected. In addition, when NB is used, the proposed method outperforms other methods when 4% or 10% of the features are selected, illustrating the efficiency of the proposed method in classifying the web pages of WE dataset. Figure 8 shows the ROC curves of different methods on WE dataset, and the TPR and FPR values are averaged when SVM and NB are used. We can see that the performances of IG and CMFS are similar as their AUC values are 0.978 and 0.977, respectively. Moreover, MI and GMFS perform worst, and their AUC values are 0.965 and 0.973, respectively. Further, the proposed method obtains the second highest AUC value 0.987, which is significantly higher than those of other methods except for CCM.
F1 values of different feature selection methods on WE dataset when SVM and NB are used, respectively
ROC curves of seven methods on WE dataset.
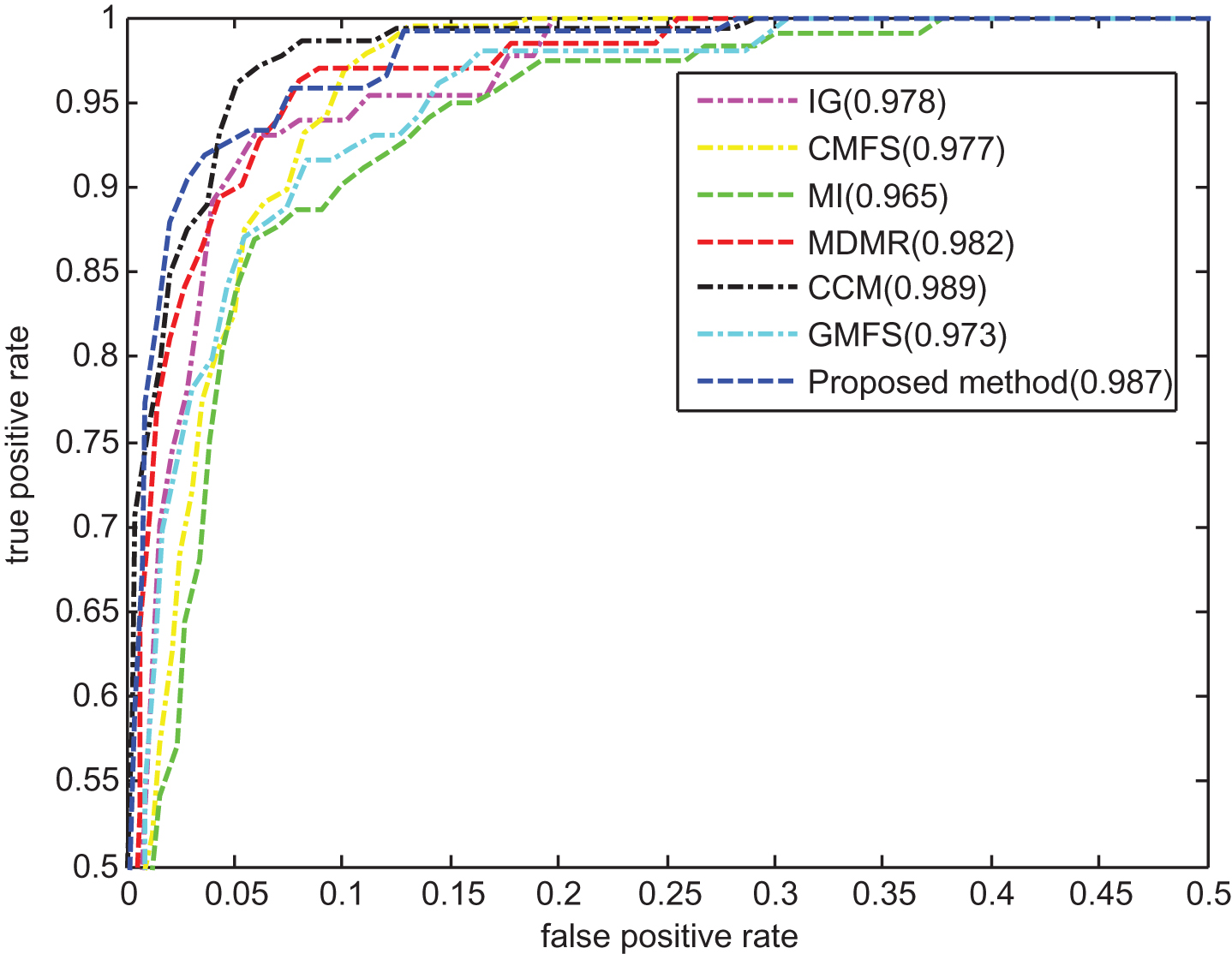
Table 6 shows F1 values of different methods on NE dataset, respectively. When SVM is used, the proposed method obtains the highest F1 values for 2 times, which are generally higher than those of the other methods. When NB is used, the F1 values of the proposed method are significantly better than those of other methods when 6% or 8% features are selected, with the highest improvement 0.029 over that of CMFS when 10% features are selected. Figure 9 shows the ROC curves of different feature selection methods on NE dataset, and the TPR and FPR values are averaged when SVM and NB are used. It can be seen that the proposed method and MDMR are the top two best methods of which the AUC values are 0.981 and 0.979, respectively. Generally, the MI based feature selection methods perform better than other methods, the reason is that the features selected by the former methods contain less redundant information, achieving high category discriminating ability when facing with multi-label classification tasks.
F1 values of different feature selection methods on NE dataset when SVM and NB are used, respectively
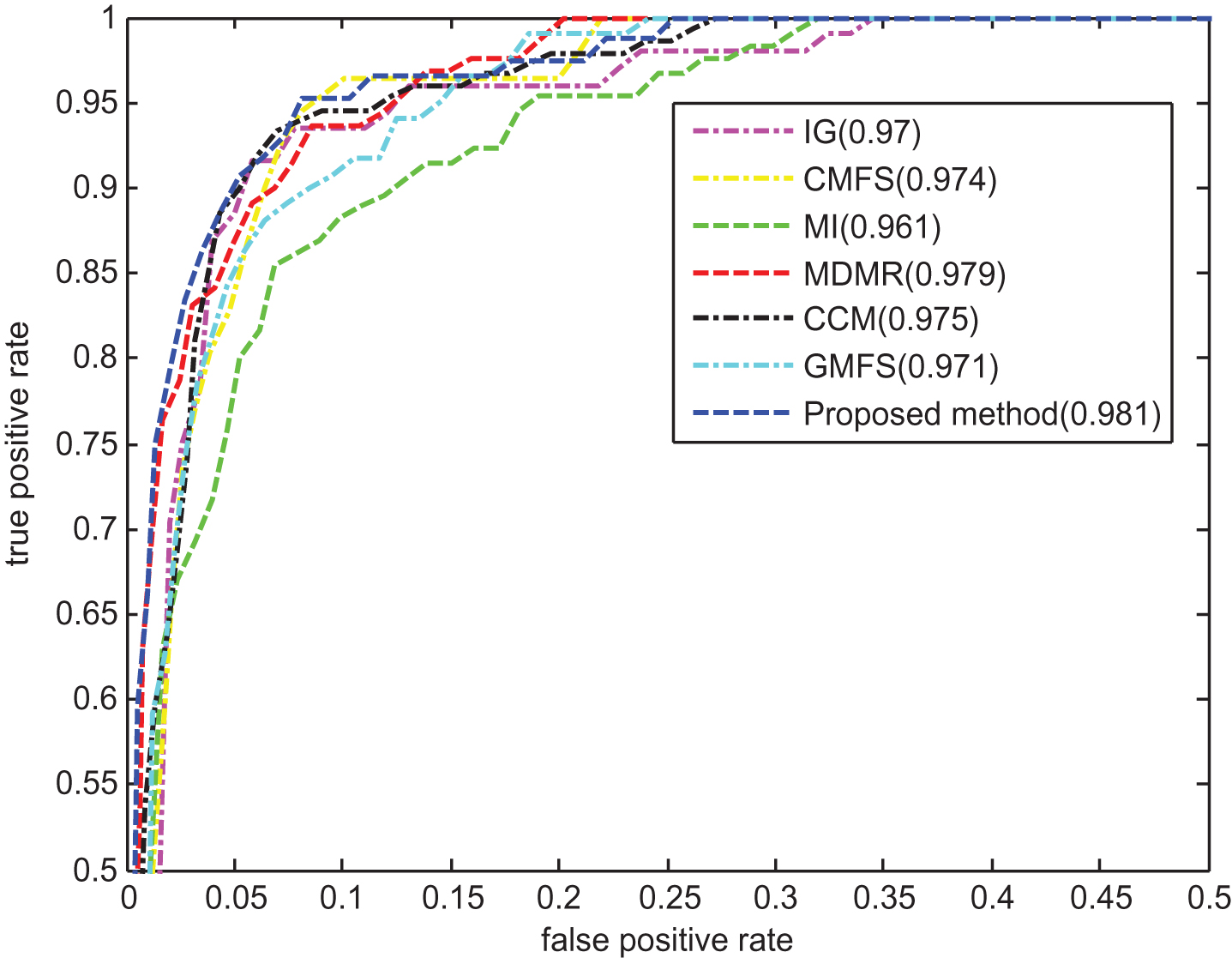
ROC curves of seven methods on NE dataset.
We use the widely used nonparametric two-tail Wilcoxon signed ranks test [39] to evaluate the performance of our method in terms of F1 value using SVM and NB classifiers. The Wilcoxon signed ranks test computes a value called test statistic z value, which measures how statistically significant the results are.
The null hypothesis of Wilcoxon signed ranks test is that the mean values of the two paired values are equal. If |z| is less than the critical z value (Z α ), then the null hypothesis is accepted, otherwise, the null hypothesis is rejected. When the significance level (α) equals to 0.05, Z α equals to 1.96 [40]. On this basis, 10 times experiments are carried out and the average z values between the proposed method and each method are computed when the ratio of selected features ranges from 1% to 10% with the step of 1%, and the results are shown in Table 7.We know from Table 7 that, the z values are greater than Z α in 30 of 48 cases, showing that the proposed method outperforms other methods significantly in 62.5% of the cases. As the traditional feature selection methods (IG, CMFS and MI) do not deal with the redundant information, they perform worse than the proposed method in all cases. When compared to the OFS method (CMFS), we notice that the corresponding z values are all greater than Z α , showing the improvement of the proposed method over the OFS method. In addition, the proposed method performs similarly with MDMR and CCM in most cases and outperforms GMFS in 5 of 8 cases, illustrating the effectiveness of the proposed method in filtering the redundant information.
Results of statistical analysis when SVM and NB are used, respectively
Results of statistical analysis when SVM and NB are used, respectively
It is very important to reduce the dimensionality of the feature space and improve the quality of selected features in text classification field. Traditional feature selection methods of filters cannot deal with the redundant information which deteriorates the classification accuracy. Moreover, the MI based feature selection methods have the problems of high computational complexity and parameter dependency. On this basis, we propose a new two-step based feature selection for filtering redundant features. In order to improve the execution speed of the MI based feature selection method, firstly, we introduced the definitions of word semantic correlation, set semantic correlation, semantic correlative and semantic correlative set; then, based on the above definitions, we give the details of generating a set of semantic correlative sets and propose a two-step based feature selection method for filtering the redundant information of selected features. In order to search the best parameter, we introduce the conception of memory recall position and propose an improved memory recall mechanism recall based FOA algorithm (called IMFFO) which avoids the problem of local optimum. The efficiency of the proposed method is examined through the experiments of text classification with SVM and NB classifiers on four textual datasets: Reuters50, SMSSPAS, WebKB and 20-Newsgroups. By comparing the proposed method with six typical feature selection methods on the aspects of execution speed and classification accuracy, we find that: (1) the proposed method has obviously improvement over traditional methods of filers on classification accuracy; (2) the proposed method can highly improve the execution speed while guaranteeing the classification accuracy when compared to MI based feature selection methods.
In the future, we will study deeply in the following two aspects: (1) generating a new set of semantic correlative sets which contains more semantic information; (2) investigating new OFS methods to improve the performance of the proposed method and extend it to online applications.
Footnotes
Acknowledgments
This research is supported by the Beijing Natural Science Foundation, under grant no. 4174105 and the Discipline Generation Foundation of the Central University of Finance and Economics, under grant no. 2016XX02.
The Young Teachers Development Fund of Central University of Finance and Economics (No. QJJ1635).