
Abstract
In this study, a hybrid time series approach has been proposed in which the fuzzy transform (F-transform) is employed for its ability of handling uncertainty due to noise and multilayer perceptron with back propagation learning for its good adapting capability. F-transform is used to decompose the time series data and then those decomposed data are used as inputs and original data are used as targets in the neural networks with back propagation (BPNN) learning to capture the pattern of original time series. Proposed approach is used in Composite Index of Shanghai Stock Exchange data collected for the period January, 1993 to December, 2009. The result is compared with the result obtained by using de-noising capability of wavelet transform along with back propagation neural network. This study also includes an empirical analysis for the forecasting of Bombay Stock Exchange SENSEX data collected for the period January, 2002 to August, 2014 and Australian electricity market – Price.
Keywords
Introduction
Recent trends of time series forecasting are based on the methods of data analysis as neural networks, fuzzy sets, rough sets etc. There are some time series observations like university enrollments, financial and medical time series which are short, imprecise and non-regular in nature. Such type of time series observations can not be analyzed by commonly used statistical methods. A considerable part of the real time series with imprecise observations can be handled by fuzzy techniques. F-transform is one of the important tools which is used for data decomposition specially for short time series.
Perfilieva [1] introduced fuzzy transform (F-transform) to bridge among other kinds of transform from classical methods, namely, Fourier transform, Laplace transform, wavelet transform and fuzzy approximation techniques. Hossein et al. [2] proposed a hybrid model based on local linear neuro fuzzy and fuzzy transform for prediction of energy consumption. It is shown that their model integrated with F-transform has been improved the forecasting accuracy. Novák et al. [3] proposed a new methodology for the analysis and forecasting of time series by hybridizing two techniques: F-transform and the perception-based logical deduction. They concluded that the F-transform and the fuzzy/linguistic rules are useful to compute long term forecasts without the influence of any kind of error correction and learning from the experience type model of forecasting. Perfilieva et al. [4] developed the two-term additive decomposition time series model, where first term is used for capturing the low-frequency trend by F-transform and second term is used for residual vector, which is treated as a stationary time series based on fuzzy tendency modeling.
Preprocessing of the time series by extracting important features or sometimes de-noising are useful to analyze the nature of it. Chaplot et al. [5] developed a time series model where features were extracted based on discrete wavelet transform and used as inputs in neural network self-organizing maps and support vector machine for classification of magnetic resonance (MR) images of the human brain. Huang et al. [6] proposed Empirical Mode Decomposition (EMD), a data analysis method for nonlinear and non-stationary time series by decomposing a time series into a small number of independent and implicational intrinsic modes based on scale separation. Zhang et al. [7] proposed Ensemble EMD (EEMD), an improvement of EMD which can better separate the scales naturally by adding white noise series to the original time series and then treating the ensemble averages as the true intrinsic modes. Muhammad et al. [8] proposed a hybrid wavelet based artificial neural network and concluded that the pre-processing of input rainfall data by wavelet transform increased the performance of the neural network models. They have shown a comparative study on Haar wavelet, Daubechies Wavelet (db), Coiflets (Coif), Symlets (Sym) and Meyer wavelet (mey). Matsumoto and Watada [9] proposed a method to model the chaotic portion from the data of small-dimensional space and increased the forecasting precision. Some economic data are not sufficiently chaotic to apply chaos theory, so it is difficult to analyze those time series data and capture the future trend. Time series data are first decomposed in small parts by wavelet transform and chaotic nature of every part has been analyzed. They observed that highly chaotic part helped in forecasting near future with 70% accuracy on the up-and-down movement of the TOPICS value.
Wang et al. [10] developed an algorithm of wavelet de-noising-based back propagation neural network for stock price time series prediction. They used Daubechies wavelet(db3) and compared their work with the simple neural network with back propagation learning. Wang and Gupta [11] also used wavelet analysis to de-noise the data and predicted future stock prices using neural network.
Zhang and Qi [12] studied the effectiveness of data preprocessing, including deseasonalization and detrending, on neural network modeling and forecasting performance. They concluded that neural networks were not able to capture seasonality or trend variations effectively with the unpreprocessed raw data and either detrending or deseasonalization can dramatically reduce forecasting errors. Moreover, a combined detrending and deseasonalization was found to be the most effective data preprocessing approach.
In this paper, F-transform and neural network with back propagation learning have been used for stock exchange time series prediction as well as Australian electricity market – Price.
The remainder of this paper is organized as follows. Section 2 presents the basic concepts of F-transform and neural network with back propagation learning. The model which combines the F-transform and neural network with back propagation (BPNN) learning is described in Section 3. In Section 4, there is numerical illustration. In Section 5, the computational results have been analyzed. Finally, the conclusions and future research directions are presented in Section 6.
Basic concepts
F-transform and multilayer perceptron with back propagation learning are discussed in this section.
Fuzzy transform
For any transformation the basic idea is to transform an original space into a special space of functions for analyzing and mining information. Then transform back to the original space either to reveal the original data or some near estimation of original data [1]. Similar ideas are followed in case of F-transform also. It can be applied to a continuous function defined on a fixed interval, say [a, b] ⊂ R (set of real numbers). The F-transform maps the original space into a space consists of a finite vector of numbers on the basis of basic functions of fuzzy partitions of the given domain or universe. Inverse transform maps the transformed values into a function which is near approximation of the original function.
In case of discrete F-transform, f be given at nodes p1, p2, . . . , p
l
and A1, A2, . . . , A
n
, n < l are basic functions which form a fuzzy partition on [a, b], then [F1, F2, . . . , F
n
] are given by
Components from continuous as well as discreteF-transform of a function are the weighted mean values of that function where the weights are obtained by the basic functions [1].
Let A1, A2, . . . , A
n
be basic functions forming a fuzzy partition on [a, b], f be a function from set of continuous functions C ([a, b]) and
This theorem states that after applying inverse F-transform on some function which is transformed by F-transform, we get near approximation of the original function.
Values of basic functions in matrix form
Using Equation (3), we get F1 = f (p1) +1/6 * f (p2), F2 = 5/6 * f (p2) +1/3 * f (p3), F3 = 2/3 * f (p3) +1/2 * f (p4), F4 = 1/2 * f (p4) +2/3 * f (p5), F5 = 1/3 * f (p5) +5/6 * f (p6) and F6 = 1/6 * f (p6) + f (p7).
Using equation Equation (4), we get the inverse F-transform values which are fF,6 (p1) = F1, fF,6 (p2) =1/6 * F1 + 5/6 * F2, fF,6 (p3) =1/3 * F2 + 2/3 * F3, fF,6 (p4) =1/2 * F3 + 1/2 * F4, fF,6 (p5) =2/3 * F4 + 1/3 * F5, fF,6 (p6) =5/6 * F5 + 1/6 * F6 and fF,6 (p7) = F6.
In this paper, neural network with three layers naming input, hidden and output have been used with back propagation learning. Basic steps of the algorithm are given below.
Calculate change of weight Δw
jk
using error correction term δ
k
and learning rate α as below
Also, send δ k to the hidden layer backwards.
The term δ
inj
gets multiplied with the derivative of f (z
inj
) to calculate the error term:
Calculate change of weight Δv
ij
using error correction term δj and learning rate α as below
Each hidden unit z
j
, j = 1, . . . , p updates the weights:
In this section, we present a learning scheme for proposed model. Figure 1 illustrates the flowchart of the learning algorithm for F-transform based BPNN model. In the proposed model, data is decomposed first using fuzzy transformation [1]. Total data set is broken into blocks of four data points. Each data points of the time series are equally time spaced points. To utilize fuzzy transformation, we interpolate one new point within first and second time series data point and another within second and third time series data point of each block, in this way we get seven fixed points of each block. We are using Equation (3) to get F-transform of each block, where f (x
i
) , i = 1, 2, 3, . . .s are time series data points, A
k
(x)s are basic functions at k = 1, 2, . . . , n. Those
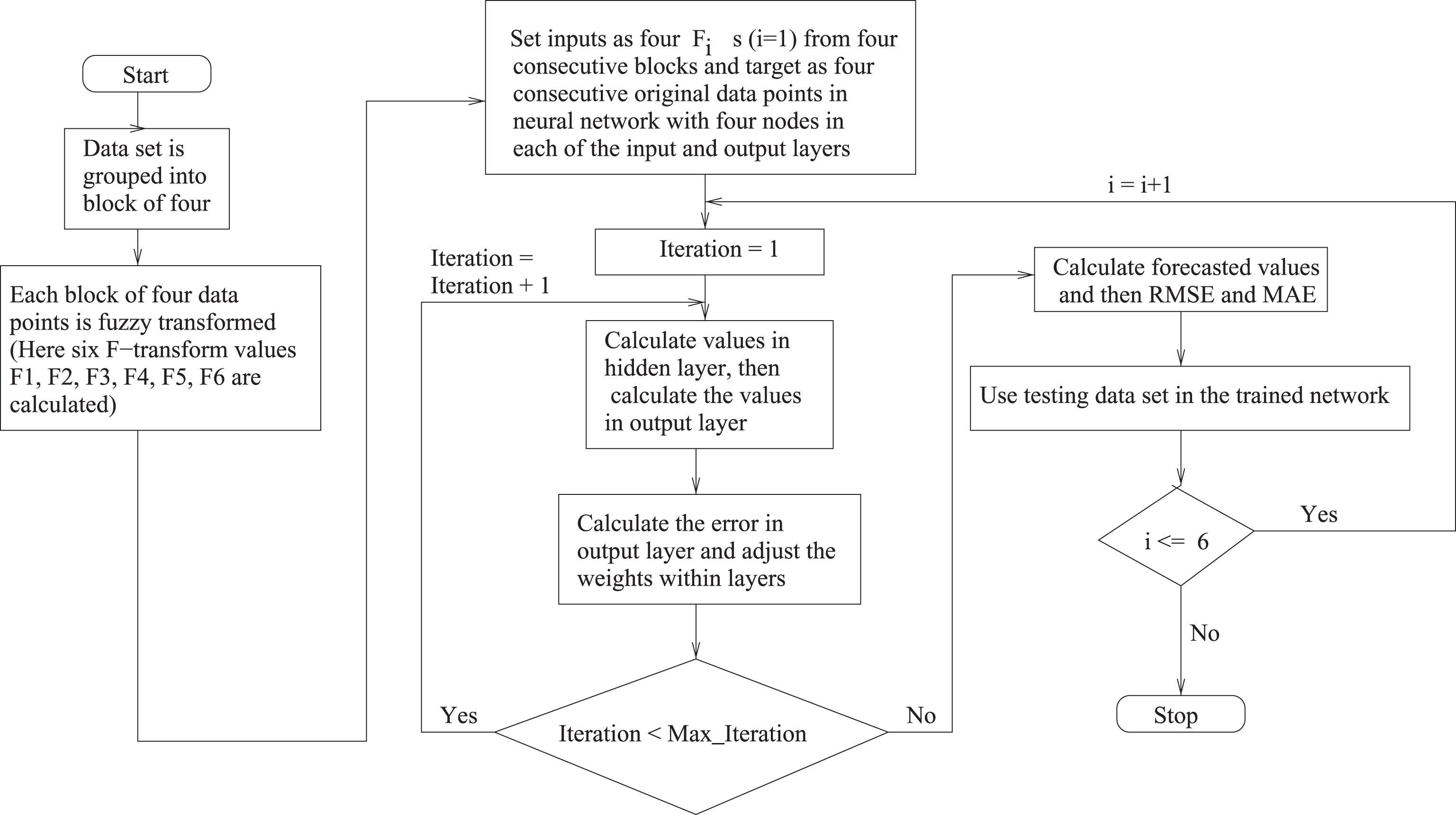
Flowchart of the learning algorithm for F-transform based BPNN.
From the error measurement and the test data set, we have tried to find which F
k
s are able to approximate the original time series mostly. We concluded from that the set of those
Steps of the proposed algorithm are as follows.
After completion of training, testing data sets are used to test the proposed model.
Proposed model is applied on some data sets namely Shanghai Stock Exchange, Bombay Stock Exchange data and Australian electricity market – Price.
We have compared our work with the work by Wang et al. [10]. They have developed the wavelet de-noising-based back propagation neural network and used discrete wavelet transform with Daubechies wavelet on 204 trading months of SCI closing price collected on the Shanghai Stock Exchange from January 1993 to December, 2009. They have trained their model with 80% training data set and the remaining worked as testing data set. We have been able to collect the same data from January, 1993 to December, 2009, total 204 trading months. In our case, 70% of the collected data are used as training data set and remaining is used for testing purpose.
Also we have considered the data set on Bombay Stock Exchange SENSEX closing price collected from January, 2002 to August, 2014 [13] for further analysis. We have used 152 data points in the proposed model, of which 70% is used for training purpose and the remaining is used for testing purpose.
Another time series on Australian electricity price [14, 15] from September, 2013 to September, 2014 is collected as real life time series to observe the performance of the proposed model. Here, the results from the work by Gromov and Borisenko [14] is compared with our proposed idea using this time series. Also, data of four weeks in the year 2004 are collected to compare with other models mentioned in [14].
Result of the proposed algorithm
Forecasting is an important field of learning or adopting as it helps human being to take right decision at right moment. In case of stock market data, the movement of itself is uncertain due to several factors and hence it is noisy. So, it is really hard to decide for stock investors about their buying and selling of stocks. Predictions will be accurate when the historical data are de-noised as sudden ups and downs are removed. Wavelet transform is utilized to de-noise data and then fit those in neural network models. In our work, we have used fuzzy transform to serve the same purpose and then fit those de-noised data in neural network with back propagation learning to predict the movement of stocks from those data.
Number of basic functions is user defined, hence the number of FkNN will be same as number of basic functions. Proposed models are always compared with existing models to show the improvement and a comparison is perfect only when the methods are formed by considering same environment. We have compared our work with work in [10], where six models are developed. So, we have modeled our concepts in such a way that it is also developing six models i.e., k = 6 is considered here.
In the proposed model, we have calculated sixF-transform, say, F1, F2, . . . , F6 for each block of four data points with six basic functions and seven fixed nodes of equal length. We have formed six neural network models with back propagation learning where inputs are F1s for F1NN, F2s for F2NN,..., F6s for F6NN respectively.
Each model has four nodes in input layer, four nodes in hidden layer and four nodes in output layer in case of Shanghai Stock Exchange data. Similar architecture for BPNN is used in case of Bombay Stock Exchange data. Figure 2 depicts the diagram of the six models FkNN, k = 1, 2, . . . , 6 for Shanghai Stock Exchange Data.

Diagram of the six models FkNN, k = 1, 2, . . . , 6 for Shanghai Stock Exchange Data.
The RMSE and MAE values of both SSE CI and BSE closing price data for each six models are shown in Tables 2 and 3 respectively.
Calculated prediction error for SSE CI closing price data
Calculated prediction error for BSE closing price data
Figures 5 and 6 depict the respective original data for SSE CI and BSE and their inverse F-transform data. Figure 3 depicts the original data and all the test results for F1, F2, F3, F4, F5 and F6 for SSE CI data. Training and test results for individual F1, F2, F3, F4, F5 and F6 of SSE CI data are shown in Fig. 7(a), 7(b), 7(c), 7(d), 7(e) and 7(f) respectively. Figure 4 depicts the original data and all the test results for F1, F2, F3, F4, F5 and F6 for BSE data. Training and test results for individual F1, F2, F3, F4, F5 and F6 of BSE data are shown in Fig. 8(a), 8(b), 8(c), 8(d), 8(e) and 8(f) respectively.

Original SSE CI data and corresponding forecasted results.

Original BSE Sensex data and corresponding forecasted results.

Original SSE CI data and corresponding inverseF-transform data.
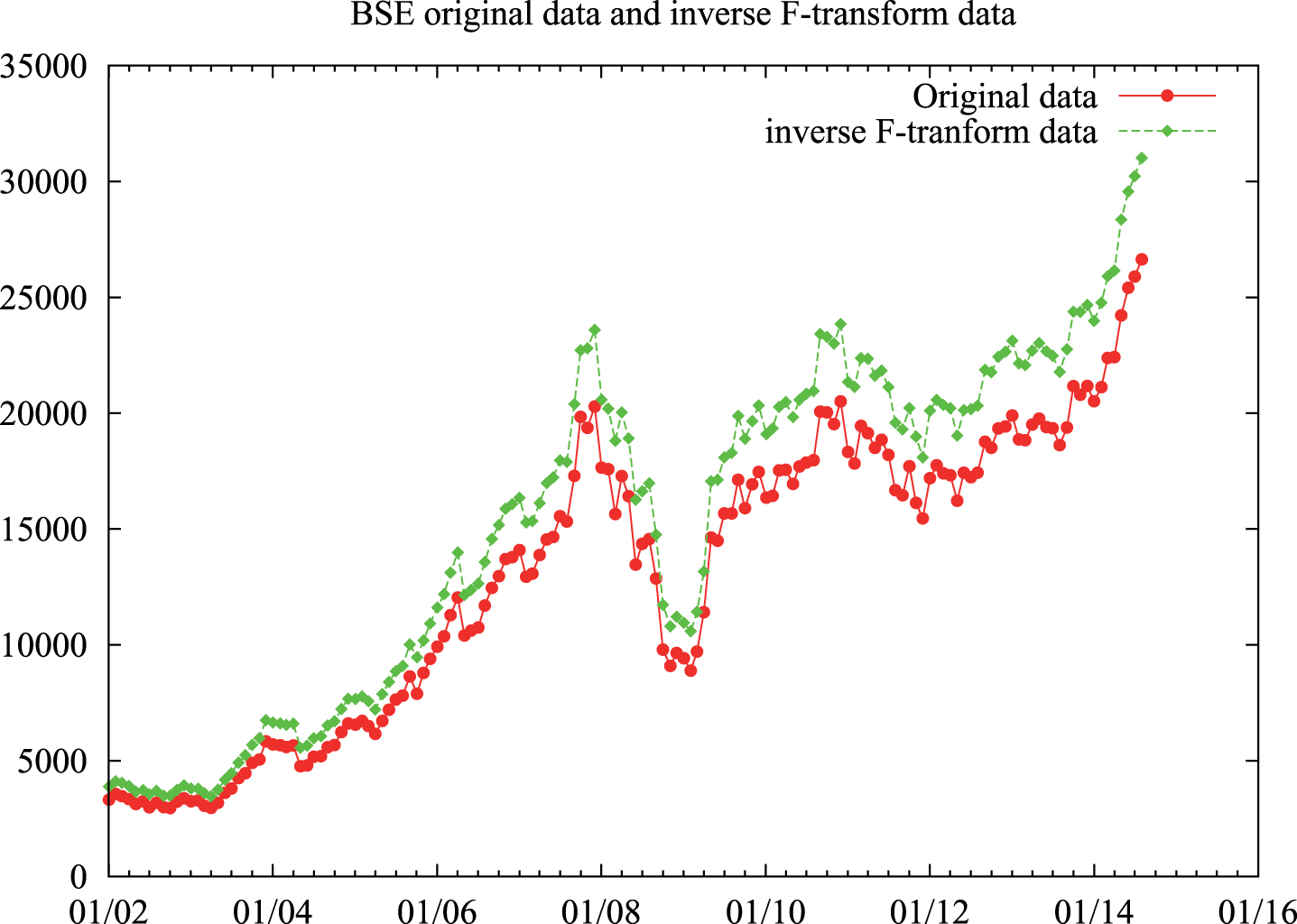
Original BSE data and corresponding inverse F-transform data.

Original Shanghai data and corresponding forecasted results.

Original BSE data and corresponding forecasted results.
In Table 2, calculated RMSE and MAE for the proposed model and model by Wang et al. [10] are compared. It is observed that our models are capable for forecasting with less prediction error. Results of testing data set by our model are shown in Figs. 3 and 4 for the two time series. The models which have bold face values are best model for our case and for the work by Wang et al. [10] respectively in Table 2.
In Table 3, model which have bold face value is best for BSE data set in our work.
Tables 4 and 5 show the results on Australian electricity market – Price. Table 4 shows the RMSE, MAE and MER with respect to different number of nodes in input and output layer of our approach. It shows that MER are lesser in comparison to the work in [14] than RMSE and MAE. Table 5 shows the better performance of proposed approach comparison to DWT, MLP, SVM, PSF and PCW where the time series on Australian electricity market – Price has been considered of four weeks from different months of the year 2004.
RMSE, MAE and MER of the time series Australian electricity market – Price with different numbers of nodes in input and output layer
MER for some weeks of the year 2004 (Australian electricity market – Price) [14]
DWT: Discrete wavelet transform, MLP: Multilayer perceptron, SVM: Support vector machine, PSF: Pattern sequence-based forecasting, PCW: predictive clustering with Wishart clustering algorithm.
In this paper, we proposed a hybrid algorithm to predict the time series of the Shanghai (composite index), Bombay (SENSEX) stock exchange and Australian electricity market – Price, where good results are obtained and shows that this algorithm is efficient in respect to forecasting errors compare to others.
Simulation results show that proposed algorithm with F-transform based preprocessing of data outperforms the algorithms where wavelet transform based preprocessing of data has been used along with BPNN in both data processing transformation.
In addition, the proposed hybrid learning algorithm has been used to get more than six F-transform value as it will approximate the curve with more accuracy. We have used triangular membership functions to compute basic functions of F-transform, so other membership functions can be tested to get the basic functions, also higher order fuzzy logic can be implemented.
Footnotes
Acknowledgments
The first author would like to thank DST INSPIRE, India for their help and supports to sustain the work.