
Abstract
In this paper, a novel descriptor called Weber Discrete Wavelet Transform (WDWT) is proposed. It effectively recognizes facial expressions. WDWT uses unique combination of Weber Local Descriptor (WLD) and Discrete Wavelet Transform (DWT) for efficient extraction of illumination invariant features from multi scale images. The proposed descriptor’s effectiveness is evaluated under different challenges on facial expression recognition problem. Experiments are performed on the standard face databases and results show that the proposed technique performs better than traditional LBP and WLD over a range of low resolution images. A significant decrease in the feature dimensions and substantial increase in recognition accuracy rate has been observed.
Keywords
Introduction
Face recognition has attracted significant attention in the fields of computer vision and pattern recognition due to its applications in wide range of domains including human entertainment, surveillance system and human computer interaction (HCI). In this paper, we have focused our attention on facial expression recognition from face images. A facial expression recognition algorithm can be divided into two steps namely Extraction of face features, and expression classification. In first step, geometry or appearance features [1–3] are extracted for compact representation of face image. Then, the expression classifier [4, 5] is applied on the extracted features to classify it into seven different expression classes (i.e. neutral, sad, happy, surprise, disgust, fear and angry). To filter out some irrelevant features and to avoid over-fitting problems, some researchers [6, 7] have added an intermediate step of dimensionality reduction process [8, 9].
Although this field has garnered considerable attention from Image Processing community but, there are still some underlying areas that need further attention from researchers.
Variability in illumination, pose, noise and images at different resolutions significantly affect the recognition accuracy rate. Real world applications like visual surveillance, smart meeting, and video conferencing require systems that can work adequately on images having noise, illumination and different resolutions. Figure 1 illustrates different image resolutions that have been used for experiments.
Images with different sizes.
It is the need of the hour to build good feature extraction descriptor which is robust against illumination, noise and different resolutions images. In recent years, many local descriptors have been proposed which are robust to variation in pose changes, illumination and resolutions. Ojala et al. [10] proposed a computationally efficient descriptor for texture classification known as Local Binary Pattern (LBP). Although LBP is highly discriminative, still it discards some important texture information and is also sensitive to noise [11]. Weber Local Descriptor (WLD) is another noteworthy descriptor proposed by Chen et al. [12] for face detection. WLD considers ratio of change in the pixels to characterize the texture information. WLD consists of two major components namely differential excitation and orientation. WLD first uses differential excitation to compute the local micro pattern from an image and then employs orientation component to build statistics on these patterns. It is intuitive to use Weber Local Descriptor however; the discriminative power of WLD drastically reduces in case of multi scale images. In addition to WLD and LBP, some other local descriptors such as Haar feature [13], Histogram of Oriented Gradients (HOG) [14] and SIFT [15] are also worth mentioning for facial representation. Most of these descriptors produce large data dimensions and thus are not suitable for use in real time recognition systems.
Frequency domain methods such as Discrete Cosine Transform (DCT), Discrete Fourier Transform (DFT) and Discrete Wavelet Transform (DWT) have been widely adopted for face recognition. In this domain, the signals are converted from spatial to frequency domain for further analysis. In these techniques, only a small set of discriminative features are for representing a face image. DWT locates both frequency and time signals and performs multi-resolution analysis and thus is more efficient than DCT and DFT [16, 17]. In this paper, we have proposed a novel descriptor known as Weber Discrete Wavelet Transform (WDWT) to deal with the aforementioned problems and improve the recognition performance. WDWT offers different perspective for facial expression recognition analysis task. Furthermore, we have also investigated the features with high variance.
The major contributions of our proposed work have been outlined as follows: We formulate a novel descriptor (i.e. WDWT) for multi-scale analysis of faces. We have demonstrated with different experimental settings that the proposed descriptor is more robust as compared to traditional LBP and WLD descriptors. Comprehensive experiments have been performed and the results highlights the effectiveness of our proposed descriptor in the presence of illumination effects. Proposed framework preserves both frequency and spatial characteristics resulting in an impressive increase in recognition accuracy rate. The proposed descriptor significantly reduces the length of feature vector which makes the proposed framework more suitable for real time applications.
We have demonstrated the effectiveness of the proposed idea by performing experiments on widely used Cohn-Kanade (CK+) and MMI databases.
This paper is organized as follows, the related work is briefly described in Section 2. In Section 3, an overview of the proposed method is provided. Simulation results with discussion are presented in Section 4. We conclude our work with Section 5.
Local features’ extraction techniques are more stable in the cases of global changes such as pose and illumination variations. In the last decade, large number of local descriptors have been developed. Computationally efficient texture descriptor known as Local Binary Pattern (LBP) was proposed by Ojala et al. [10].
Shan et al. [18] investigated the effect of LBP on low resolution images. Experiments were performed on real world compressed images and they also formulated the booted-LBP technique. Zhang et al. [19] demonstrated that LBP is more efficient as compared to Gabor wavelet features. The extended version of LBP known as Local Gabor Phase Pattern was developed to handle the multiple orientation and resolution images. To exploit the Gabor phase information, Local Gabor XOP pattern was proposed in [20]. Although, the performance of Gabor-wavelet is better, it is extensive in terms of time and memory. An extended version of LBP was presented by Liao et al. [21] in which they extract features in both gradient maps and intensity for expression recognition. The technique was tested on low resolution face images. WLD was originally proposed by Chen et al. [12] for face detection. The basic idea behind the WLD is to use the ratio of change in the pixel intensity. Khan et al. [22] proposed a novel descriptor known as Pyramid of local binary pattern (PLBP) to handle low resolution images. PLBP represents the texture spatial layout and stimuli by local texture. The spatial layout information is maintained by tiling the image at different image resolution. Experiments with different datasets delineate the effectiveness of their proposed technique. Similarly, Shan et al. [23] introduced LBP to extract discriminative features from low resolution images. Support vector machine (SVM) classifier was trained and tested on the extracted features. It has been observed after comparing the performance with Gabor wavelets that the LBP features not only contain adequate information but are also simpler to compute. Yu et al. [24] used basic WLD and proposed an efficient facial expression recognition technique for multi scale facial images known as Multiscale-WLD. Multi-scale analysis was achieved by decomposing the original image into different levels and then WLD was computed from each level of image.
Further Literature has revealed that techniques used for automatic classification of facial expressions are computationally expensive. It has also been observed through detailed survey that most of the existing techniques suffer from so called curse-of-dimensionality problem. These techniques either use full face images or complex geometric or mathematical transformations which is computationally expensive. Due to these limitations, such techniques cannot be effectively utilized for solving real time applications. Some of these techniques are unable to provide efficient classification in case of variable resolution sizes and the performance is considerably worse when dealing with low resolution images. We argue that the expression recognition task can be performed in a more conducive manner if the image is transformed from spatial to frequencydomain.
Overview of the proposed technique
We first describe the basic idea and motivation of our proposed system in this section and then outline the steps used for facial expression recognition. All face images contain highly redundant information which affects the recognition accuracy rate. Only a small subset of features is necessary for preserving the most important information. Moreover, the recognition accuracy rate degrades when the low resolution images are used for experiments.
To reduce the information redundancy, the input image is transformed from spatial to frequency domain where the high frequency component mainly represents the finer details and low frequency component contributes to the global description [25]. The steps of our proposed technique are illustrated below: First the viola and Jones algorithm [26] is used to detect the face portion from the face images followed by performing histogram equalization to normalize the illumination effects. Next, WLD excitation operator is used to compute the salient micro pattern images. DWT is employed to decompose all the excitation images into four sub-bands. The two sub-bands [cA] and [cV] are passed to the next level. The high variance features are extracted from [cA] and [cV] using DCT in zigzag manner. Different machine learning classifiers are trained and tested on the extracted features.
In this section, first a brief overview of Weber Local Descriptor and Discrete Wavelet Transform is provided and then we present the proposed Weber discrete wavelet transform (WDWT).
Figure 2 shows the architecture of our proposed framework.
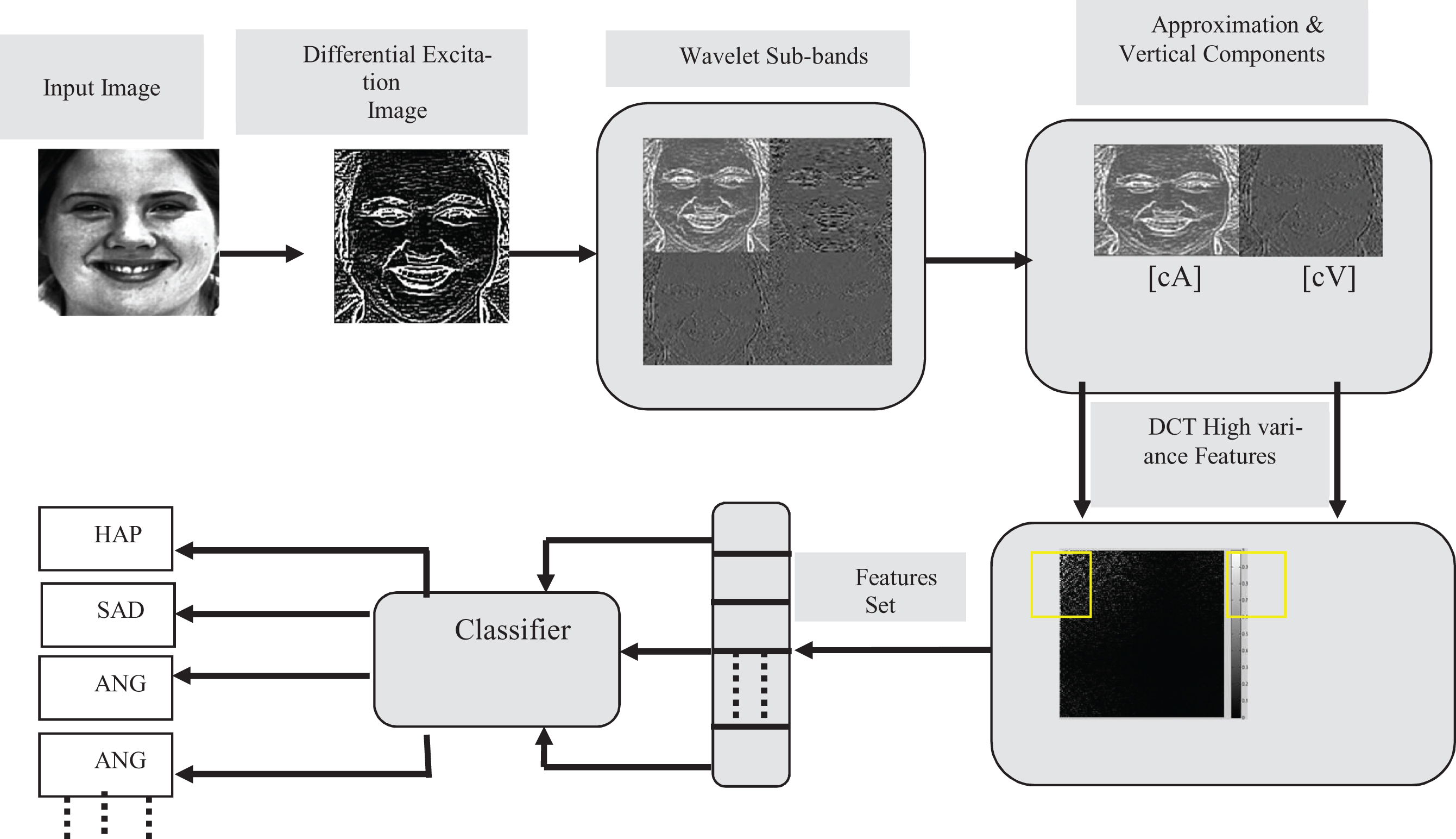
Proposed technique flow diagram.
WLD is a robust power descriptor [12] which consists of two components: gradient orientation and differential excitation. The inspiration for WLD came from “Weber’s Law”. This law states that “The change of a stimulus that will be just noticeable is a constant ratio of the original stimulus”. WLD has an advantage that it extracts the local texture information even in the presence of illumination changes and heavy noise.
Differential excitation (DE) and Gradient orientation
WLD computes the differential excitation ξ
c
components from the ratio between sum of differences of center pixels against its neighbor pixels and the intensity of the current pixel. Mathematically it can be calculated as follow:
In Equation 1, x c represents the center of the current pixel and x i is the current pixel’s ith neighbor pixel. The arctan function is used to bound the output for quick increase and decrease in the output [12]. The value of DE can be either negative or positive. The negative value indicates that the current pixel is lighter as compared to its surroundings and the positive value indicates that the current pixel is darker as compared to its neighbors.
Formula for computing the gradient orientation is given in Equation 2.
We can see that orientation component utilizes only four pixels as compared to excitation which makes use of all neighboring pixels resulting in overwhelming structure information. This is one of the main reasons for avoiding the gradient orientation operator.
Researchers have been using wavelets for image processing and signal analysis for many years now. These have been effectively utilized by image processing community since 1985 [27, 28] mainly due to their ability to simultaneously represent an input image into spatial and frequency domains. Wavelets decompose the input data into multiple layers of spatial and frequency domain and help in extraction of important features using various feature extraction techniques. The division of frequency components into different sub-bands easily separates the inherent changes in image such as changes in expressions known as intrinsic deformations. Furthermore, they also separate the external factors involved in image acquisition such as change in illumination. This capability of wavelet transforms helps the research community to focus their attention on application and use of sub-bands which are more relevant to the application areas. Some of these sub-bands can also be combined depending on the application type. Once the mother wavelet has been selected, it can be further divided into numerous wavelet families. Haar wavelet transform is a simple and effective technique for multi-resolution analysis that has been extensively used for feature extraction in automated facial recognition [27]. It has been observed that the low frequency component contains significantly more information and can be efficiently used for recognition and classification tasks. The study conducted by [29] shows that low frequency component is different than high frequency band. Low frequency bands contribute towards global description while high frequency components contain detailed information and thus have a different role for classification task. They have concluded that same objects can have local variations while expressing different expressions and emotions. By separating low frequency and high frequency components, robust and reliable system can be developed. The process of decomposing the input images with different resolutions into different frequency sub-bands brings them into common resolutions of low frequency sub-band and high frequency sub-bands. In this way, both global and local information can be preserved. The DWT of an image f(x,y) of size M X N is calculated using the Equations 3 and 4. Two 2-D wavelet transform scaling functions φx,y and three 2-D wavelets,
The scaled and translated basis functions are computed using the following formula given in Equations 6 and 7.
Then the discrete wavelet transform is calculated using the following Equations 8 and 9 respectively.
Here, W φ is the scaling function and W ψ is the wavelet function. As depicted in Fig. 3, input image of size N by N is divided into four new sub-band images and size of each of these new images is one fourth of the original image. These new images are generated as a result of application of low frequency sub-band filter and high frequency sub-band filter. Image called LL is the approximation component and contains low frequency sub-band with high variation details and can be further used for decomposition. LH image is generated by applying the low-pass filter in horizontal direction containing horizontal edge features and applying high-pass filter in vertical direction. HL image contains vertical features.

A 2 level DWT decomposition of the original image.
The high frequency information detail is present in HH image. It contains detailed information but lesser variations and thus is not useful for recognition or identification tasks. The LH image is a result of applying the low-pass filter in horizontal direction and high-pass filter in vertical direction. It also contains the noisy data.
DCT has been used in many areas of digital image processing and signal processing. It has the capability of capturing the most important information and has been successfully utilized as a feature extraction and compression technique for solving various problems. DCT transforms the input image into frequency domain and the most significant information with large variation gets concentrated in low-frequency components. Many researchers have utilized DCT for solving facial recognition problems [27]. It can be concluded that DCT yields high accuracy with reduced complexity. DCT also has high discriminative power. High variation components having low frequency lie in upper left corner. It separates the high frequency detailed components from low frequency components having high variations. Both DCT and DFT have similarities of transforming input image from spatial domain to frequency domain and have proven to have excellent de-correlation and information packing abilities. There are dissimilarities as well like DCT has better information packing capability than DFT and uses simpler cosine-based basis functions. DFT is a more complex transform and specifies encoding of phase information and magnitude of the image.
DCT of an input image f (x, y) of size N × M can be calculated using the Equations 10 and 11.
Where f (x, y) represents the pixel intensities at point (x, y) and u = {0, 1 … N - 1} and v = {0, 1 … M - 1}. The function α (u) and α (v) are defined as;
In most cases, high variation features lie at frequencies. In order to extract these high variation features, the low frequency components are relocated to the top left corner. The high frequency feature values with lesser variations lie in lower right corner. This realizes the effectiveness of the DCT for featureextraction.
As discussed already in Section 2, Most of the feature extraction technique are either computationally expensive or are incapable of handling multi-scale images in the presence of illumination effects. The computational complexity increases in case the extracted features of face images vary in illumination and size. The computational complexity increases further if multiple feature extraction techniques are used to handle these variations.
An alternative transform-based technique is investigated and suggested in this paper that first Pre-processes the face images to suppress the illumination effects. Next, Weber local descriptor is used to compute the differential excitation image. We have only used the excitation operator of WLD because it retains more local texture information than the orientation component with no evident performance degradation. The orientation operator is segmented into different directions which is not an efficient way to extract local features.
It is intuitive to use WLD for face representation as a face image is composed of micro texture patterns [7, 51]. However, computing WLD over global face image does not preserve the spatial information and the discriminative power of WLD significantly decreases in case the of image size variations. In order to overcome this issue, we keep the image pixels spatial correlation intact by represent the image with frequency component using DWT. DWT decomposes the image into four sub-bands: Diagonal component (cD), vertical component (cV), horizontal component (cH) and approximation component (cA). The cA is the most stable sub-band and cV contains most of the facial expression information. Figure 4 illustrates the four sub-bands of DWT.

1 level DWT decomposition.
The sub-band [cA] only holds the global information of face image and does not possess the local information of face components. To overcome this deficiency, two sub-bands [cA] and [cV] are combined to generate more robust representation of a face image.
DWT has these advantages that it localizes both frequency and time information and is able to perform multi-resolution analysis. Although DWT has the power of extracting most relevant data but still its data dimensions are too high to handle multi resolution images. DCT is another well-known transformation technique which is used for compression. DCT is utilized to transform the features from spatial domain to frequency domain which improves the efficiency by selecting the high variance features. The WDWT procedure is described in the algorithm below.
Here I f represents face portion of the input image. WI Ex is differential excitation calculated from face portion and then two level daubechies wavelet is used and the approximation and vertical components are then combined and the high variance features extracted using DCT. DWLD fs contains the significant features and have been used for classification purpose.
Four different classifiers are used to evaluate the performance of the proposed system.
Sequential minimal optimization (SMO)
SMO is fast learning algorithm and provides solutions for optimization problems [4]. It divides a larger problem into a series of smaller problems. These small sub problems are then solved systematically. Another property of SMO is its lesser memory consumption which allows it to handle problems of large sizes. It is computationally efficient than other algorithms used.
K-nearest neighbors (KNN)
KNN is an instance based learning algorithm which makes no prior assumptions about the data. It uses distance measure and assigns class label to the input sample with least distance from K- number of samples. Input sample is assigned a class label with majority from the K- Nearest Neighbors. In case value of K is 1, test sample is assigned to the class of its closest neighbor and in case K > 1, the majority class of its K closest neighbors is assigned to the test sample. We have used Euclidean distance to find closest neighbors.
Random forest
Random Forest is a well-known classification technique that uses ensemble method for classification. It builds many decision trees consisting of branches and nodes. Sample data is fragmented into set of decision rules. A single test is produced to get the partition in each node. We have used C4.5 paradigm [29] for classification. All the trees are independent from each other. It combines all the trees in such a way that every tree depends on the random vector values. All the values are distributed equally and are independent [5].
Multilayer perceptron (MLP)
An Artificial Neural network (ANN) is a biologically inspired model of neurons in which each artificial neuron receives input from outside world. Each neuron processes that input and transmits it to the other neurons. Each ANN has input layer and output layer. It also has an intermediate layer known as hidden layer.
MLP is a type of ANN and is also known as logistic regression classifier. In MLP, the input is transformed using a non-linear transformation. This transformation projects the input data into a space where it becomes linearly separable. MLP can become universal approximation algorithm by using only a single hidden layer. However, significant benefits can be achieved using more hidden layers. In our experiments we have made use of 10 hidden layers.
Simulation results and discussions
In this section we present the empirical results of our experiments.
For testing different scenario settings, we have performed our experiments on two different but well known image databases i.e. MMI and CK+. In the first part, experiments were performed on MMI expression dataset which contains mostly spontaneous face images. In Second settings, the experiments were performed on extended Cohn-Kanade (CK+) database which contains 593 video sequences of universal expressions.
Voila and Jones object detection algorithm [26] has been used to obtain the region of interest and is further processed to normalize the illumination variation. Cross validation of 10 fold is performed in all experiments. For all the input images, we first computed the differential excitation image using WLD. In next step, DWT coefficients are extracted from all the differential excitation images. The original image size is reduced to 1/4 of its original size using 2-dimensional daubechies wavelet. After performing 1 level wavelet decomposition, the sub-bands of cA and cV are used for further processing. High variance coefficients are selected in zigzag manner using DCT from cA and cV images. These coefficients are then passed to classifiers for classification.
First experiments on MMI dataset
MMI [30] comprises of sequences of videos including both posed and spontaneous expressions. A Total of 273 frames are extracted from different videos. Some sample images of MMI database are shown in Fig. 5.

The Sample images of MMI database.
Table 1 shows the images classification per expression for MMI dataset.
Number of images from each expression of MMI dataset
The proposed framework achieved an average recognition rate of 91% and 94.1% for Random forest and 2-nearest neighbor classifier respectively. Algorithm of Khan et al. [22] achieved the recognition accuracy rate of 90.3% and 91.4% for Random forest and 2-nearest neighbor classifier using the same facial expression dataset. Thus, our technique yielded better results in similar experimental settings.
CK+ face database [31] is extensively used by researchers for facial expression recognition and we have also used it to highlight the efficacy of our proposed technique. Figure 6 provides some sample images of CK+ database.

The Sample images of CK+ database.
From each video, five frames are captured showing a particular expression. A total number of 540 images are used for experiments. Table 2 provides the detail of the number of images per expressions.
Number of images from each expression of CK+ dataset
Proposed framework is tested on four different image resolution sizes of 24×18, 48×36, 96×72 and 192×144. The original image sequences were down sampled in order to obtain the low resolution images. Table 3 provides the average recognition accuracy rate using Sequential Minimal Optimization (SMO), K-nearest Neighbors (KNN), Multilayer Perceptron (MLP) and Random forest (RF) classifier
Average recognition rate of proposed framework
The bold values are the maximum accuracy rate achieved for specific image resolution.
The Image of size 24×18 contains a total of 40 features. We extracted total number of 110 and 100 features from images of size 96×72 and 192×144 respectively. We decided not to increase the number of features after that as we observed that there was no significant increase in accuracy rate after this threshold but addition of more features resulted in an increase in feature extraction time. It can be noticed that the proposed framework works equally well for low resolution images as well as high resolution images. As mentioned already, we transform the features from spatial domain to frequency domain which significantly decreases the feature dimension and thus can be used for real time applications with added advantage of lower memory consumption. Proposed technique provides excellent results for simple non-parametric method such as KNN and it does not need computationally expensive methods like decision tree, multi-layer perceptron or Random forest.
We compared the average recognition performance of our proposed descriptor in terms of memory and features extraction, and computational cost with the works of Khan et al. [22], Shan et al. [18] and Bartlett et al. [32]. It is evident that the proposed descriptor can be a better choice for real time applications as not only it is memory efficient but also less computationally expensive as compared to other descriptor as shown in Table 4.
Proposed descriptor with other descriptors in terms of time and feature dimensions
Average recognition accuracy rate is compared with some state-of-the-art techniques mentioned in Table 4 using the same database (i.e. CK+). It can be observed that the expression recognition accuracy rate of the proposed descriptor is at-par with other descriptors reported in literature but with added advantages of being memory efficient and computationally less expensive.
Figure 7 illustrates the recognition accuracy for six expressions on different image sizes. It is pertinent to mention that the results on low resolution images (24×18) are still comparable with other image sizes. All the six expressions are efficiently recognized in different sizes of images with varying number of features. Experimental results indicate that the proposed framework performance is not affected by low resolution images and reports impressive results on classical datasets.
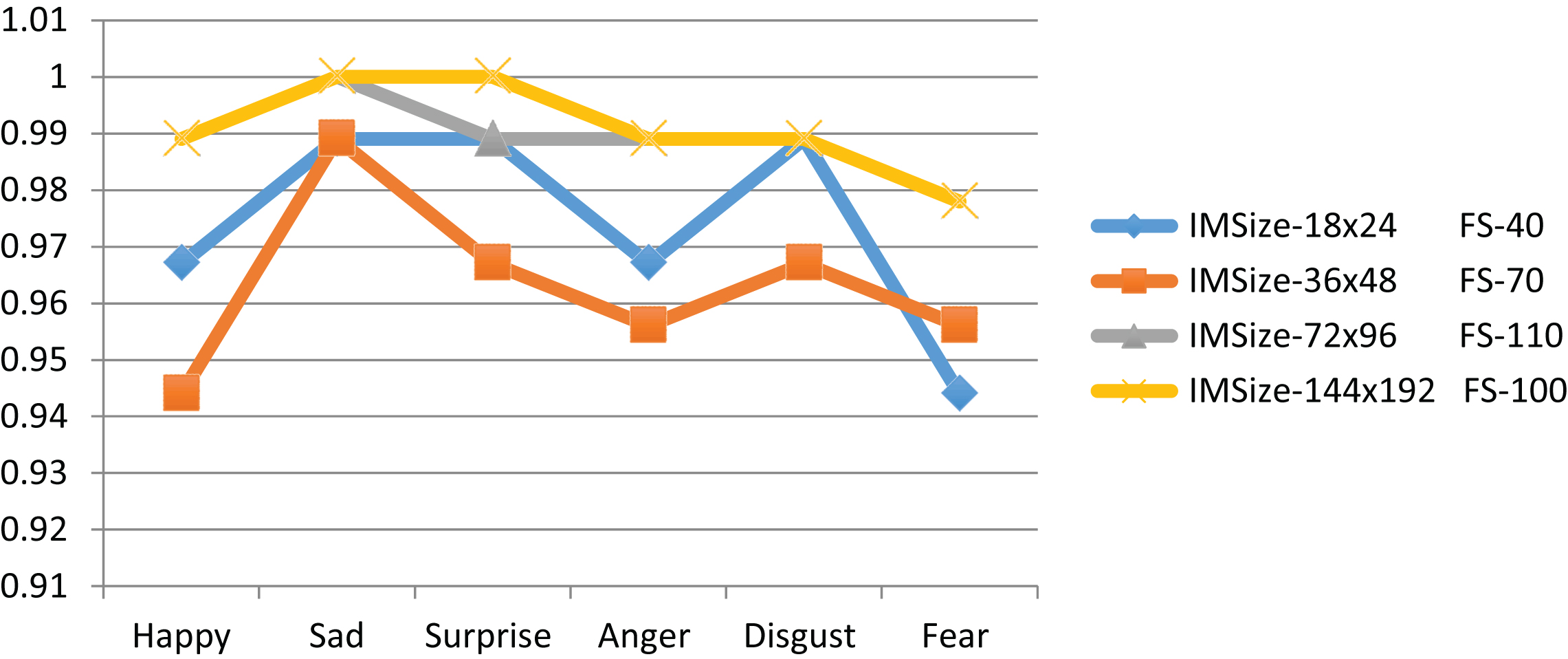
Recognition accuracy rate of different image size for six facial expressions.
In this paper, we propose a descriptor known as WDWT for efficient facial expressions recognition. WDWT consist of two main components: Differential excitation and DWT. We extract the local micro pattern for face image through differential excitation. DWT performs multi resolution analysis and localizes both frequency and time information. The feature subset selection process is done through DCT which provides most relevant features. Proposed framework handles images with high and low resolution with equal capability. Experimental results have shown that proposed framework improves the classification performance both in terms of complexity (i.e., number of features) and recognition accuracy. Proposed framework outperforms other similar techniques in terms of computational complexity and is also capable of handling low resolution images with no significant degradation in classification accuracy rate.