
Abstract
Nonlinear identification of a distillation column process is a challenging problem in the process industry. Controller performance of nonlinear and dynamic column can be viewed or analyzed using this type of identification. In this work, a novel identification method is proposed for distillation column simulated in realistic conditions using HYSYS using hybrid artificial bee colony (ABC) and artificial neural network (ANN). Since real distillation columns are dynamic in nature, this hybrid system is used as a nonlinear function in nonlinear autoregressive with exogenous input (NARX) structure. This hybrid NARX model is called NARX ANN ABC. In NARX ANN ABC, NARX ANN is trained using ABC algorithm. ABC training process benefit of training neural network without trapping at local optimal points. Reflux rate and reboiler temperature used as variable inputs while top and bottom compositions have been used as variable outputs. HYSYS software used for generating data. 1000 samples of data was collected from HYSYS. 800 samples of data was used for training, and remaining 200 samples of that was used for validation of the proposed model. The performance of proposed model has been compared with ANN, NARX ANN, and ANN ABC. The result showed NARX ANN ABC outperformed others.
Introduction
The distillation process is the most widely used separation technique in petrochemical industries. 95% of liquids are separated in petrochemical industries employing this method [1]. Products with satisfactory purity in a distillation process can be accomplished by preserving the compositions of the products. Hence, accurate prediction of compositions is essential and realistic modeling is needed [2]. Modeling can be achieved either using first principle based modeling or employing non-parametric method derived from process input-output data [3]. Several researchers practiced first principle based modeling of the distillation column in literature [4–8]. Numerous assumptions are used to build nonlinear model using first principle and models are represented by complex equations [9]. Distillation column shows strong nonlinear dynamic characteristic during high purity operation [10, 11] and complexity of modeling rises as total number of trays increases [10].
As a solution to problem of modeling using first principles, identification of the system can be achieved using nonparametric method which employs input-output data from the system. One of the popularly used nonparametric method is neural network. The neural network has robust capability for approximating any function [12], ability for parallel processing, ability to learn from the data sets [3], capability to learn the system from input-output data [13]. Due to the advantages mentioned above, many system are identified in literature using neural network. ANN has also ability for modeling of multivariate systems [14].
ANN has been used for identifying distillation column. Macmurray & Himmelblau developed a neural network model for packed bed distillation column [3]. Ramchandran & Rhinehartt proposed neural network model for distillation column using data generated from the HYSYS process simulation software [11]. Dutta & Rhinehart practiced ANN model using commercial CAD software simulator data [15]. Fernandez de Canete et al. developed an adaptive neural network model for distillation column using Levenberg-Marquardt algorithm and softwre used for model development and control was LabView [13]. Ochoa-Estopier et al. proposed an ANN model for crude oil distillation column for optimization purpose [16]. HYSYS software used for producing simulated input output data for training of the neural network in the work [16]. Mohamed Ramli introduced an equation base neural network for prediction of composition in debutanizer column [2].
Different types of artificial neural networks are used for identification purpose. They are feed forward neural networks, radial basis function and recurrent neural networks etc. Most popularly used neural network structure is feed forward neural network or multilayer perceptron [14] due to advantages postulated in [17]. For an identification model, the error between predicted output of the model and actual value of the corresponding sample should be minimum. To achieve this purpose, several algorithms are used during training of a feed forward neural network. The simplest and mostly used one is gradient descent algorithm [18, 19]. Application of this algorithm does not provide satisfactory accuracy to achieve the minimum error between predicted neural network model output value and desired value of the output sample [18]. Because, this type of network get trapped in local optimal value of the objective function [19, 20]. Therefore, objective function value (Error, and Root Mean Square Error (RMSE), etc. in neural network) does not reach global optimization value i.e global minimal error or RMSE etc. [21].
As a solution to trapping at local optimal point of gradient descent algorithm, global optimization algorithm can be used for training of neural networks [19–21]. The chance of getting trapping in local optimial point of objective function value is comparatively less in these algorithm comparing with gradient descent algorithm [20]. Genetic algorithm (GA), particle swarm optimization (PSO), ant colony optimization, and artificial bee colony optimization algorithms are some of them. Neural network training has been accomplished using GA [22–24], PSO [25–29] and ACO [20, 30] in literature. Neural network architecture often suffers problem of permutation when GA is used for training network [25]. PSO acheives desired accuracy within less time compared to GA [25]. PSO is extensively used for optimization because it has propery of intuitive functioning and it is easy to implement [28].
Bee colony based swarm intelligence also used for optimization of neural network weights. In bee colony type intelligence, different algorithm are used based on intelligent characteristics of bees [31, 32]. Among them, artificial bee colony algorithm (ABC) is mostly used and popular one [32]. ABC has been compared with other optimization method such as GA, PSO, particle swarm inspired evolutionary algorithm (PS-EA), evolutionary algorithm (EA), differential evolution(DE) for numerical function optimization in literature [33–35]. ABC performance showed better while comparing with other algorithms. ABC algorithm can be tuned with fewer control parameters also. This is another advantage of ABC over other optimization technique such as GA, and PSO etc. ABC algorithm was used for neural network training in [19, 36]. Different application of neural network trained with ABC are reported in the literature. In [37], ANN trained with ABC was used for prediction of sediment concentration in river. An electric load forcasting model was developed using ANN trained with ABC in [38]. A neural network model trained with ABC algorithm was build up for prediction of hydroelectric energy in [39]. ANN model trained with ABC was used for detection of abnormal brain in [40]. Sludge volume index was determined using ANN model trained ABC in [41].
The objective of this paper is to introduce a novel identification method for distillation column using nonlinear autoregressive with exogenous input (NARX) artificial neural network (ANN) trained with ABC. This research article is organized as follows. Section 2 describes materials and methods. In this section, distillation column, ANN, ABC algorithm, NARX structure, and proposed model are explained. Section 3 explains simulation results. This section describes how nonlinearity is explained in distillation column and it also explains about identification data. It also describes about proposed model and briefly illustrates validation analysis, regression analysis and performance analysis of the proposed model. Section 4 concludes the article.
Materials and methods
Distillation column
Liquid or gas mixtures of two or more mixtures are separated in distillation column based on their boiling points. Low boiling point component is separated in top, where as high boiling component is separated at the bottom. Schematic diagram of a distillation column used in this study is illustrated in Fig. 1. Main equipments of distillation column are a column tower with trays, a condenser and a reboiler. Feed is a mixture consiting of tetrahydrofuran (light component, boiling point =66°C) and toluene (heavy component, boiling point =110 . 6°C). Vapor are going up while liquids are coming down inside the column. vapors are condensed at the condenser and some part of the condensed liquids are again returned to distillation column as reflux. Other parts are collected as distillate as shown in Fig. 1. Vaporization of the liquid coming down column is happening in re-boiler section. Some part of the coming down liquids are collected at the bottom as residue. Distillate and residue compositions are controlled to satisfy the required purity of the products.
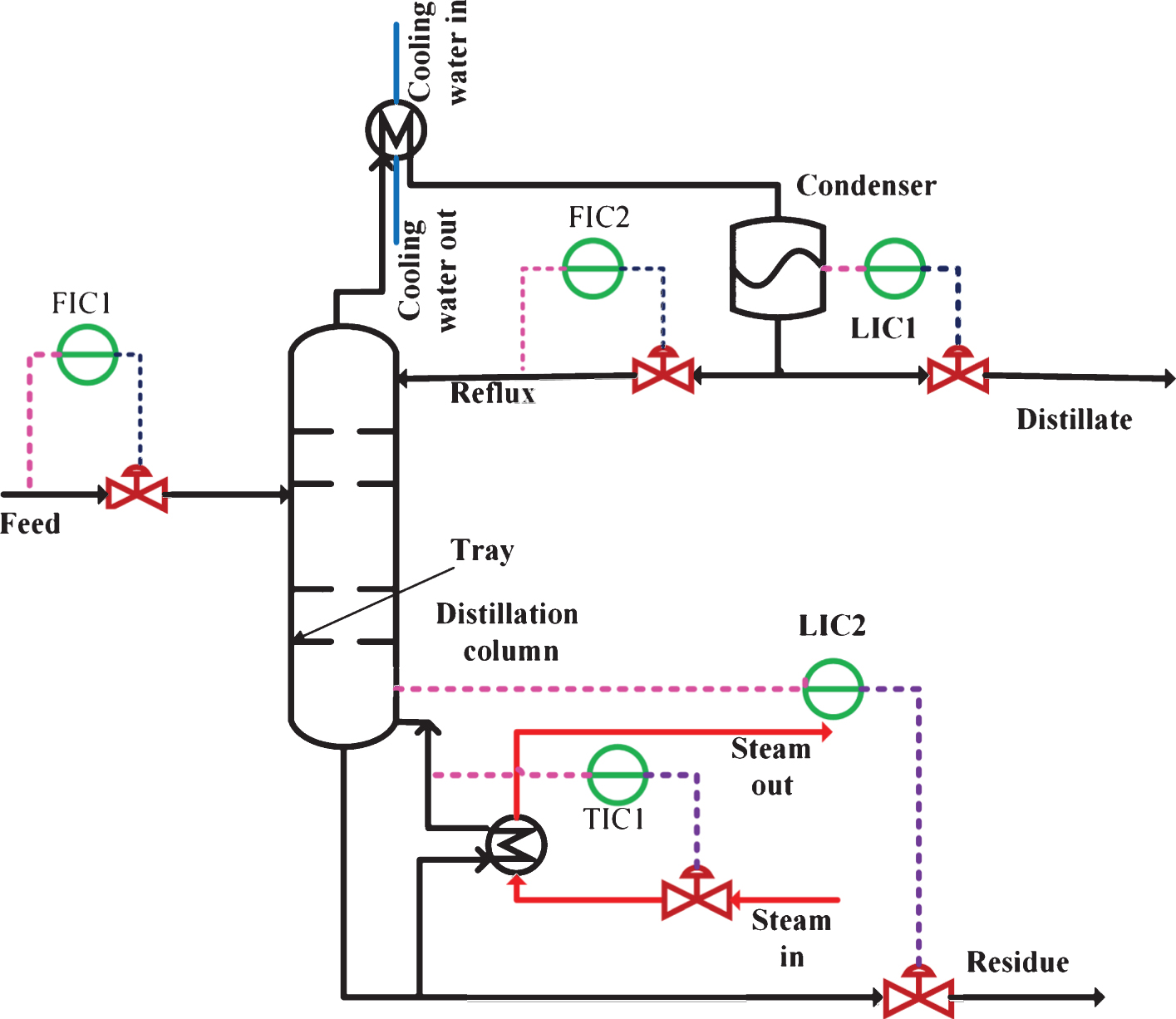
Distillation Column.
FIC1 and FIC2, LIC1, LIC2 and TIC in Fig. 1 are feed flow and reflux flow, condenser level and column bottom level controllers used for proper dynamic control. Parameters (proportional gain k c & integral time T i ) of these controllers and controller actions or modes are listed in the Table 1. By proper sizing of trays, column, reboiler and condenser, the distillation column simulated in HYSYS can be operated in realistic plant wide control mode [42].
Controller parameters and modes
Neural network is an artificial intelligence technique inspired by human brain system. Neural network consists of three parts. They are input layer, hidden layer, and output layer. ANN can be build up based on the experimental or simulation data. In such cases, such case of neural network are used to find a relation between the input and output data. Two type of neural network structure is used. Popular structure of neural network is multilayer feed forward neural network. Diagram of a multilyered feed forward network is shown in Fig. 2. Steepest descent algorithm is simplest algorithm used in back propagation training of neural network. For a multilayer neural networks, output of one network is fed as the input to the next layer.
A three layer neural network structure is used in this work. The output equation for a neural network for a three layer system is given by Equation 6.
In Equation 1, m = 0,1, …, M
m= Current hidden layer number
M= Total number of hidden layer
p= Current input number
P= Total number of inputs
r= Current number of output.
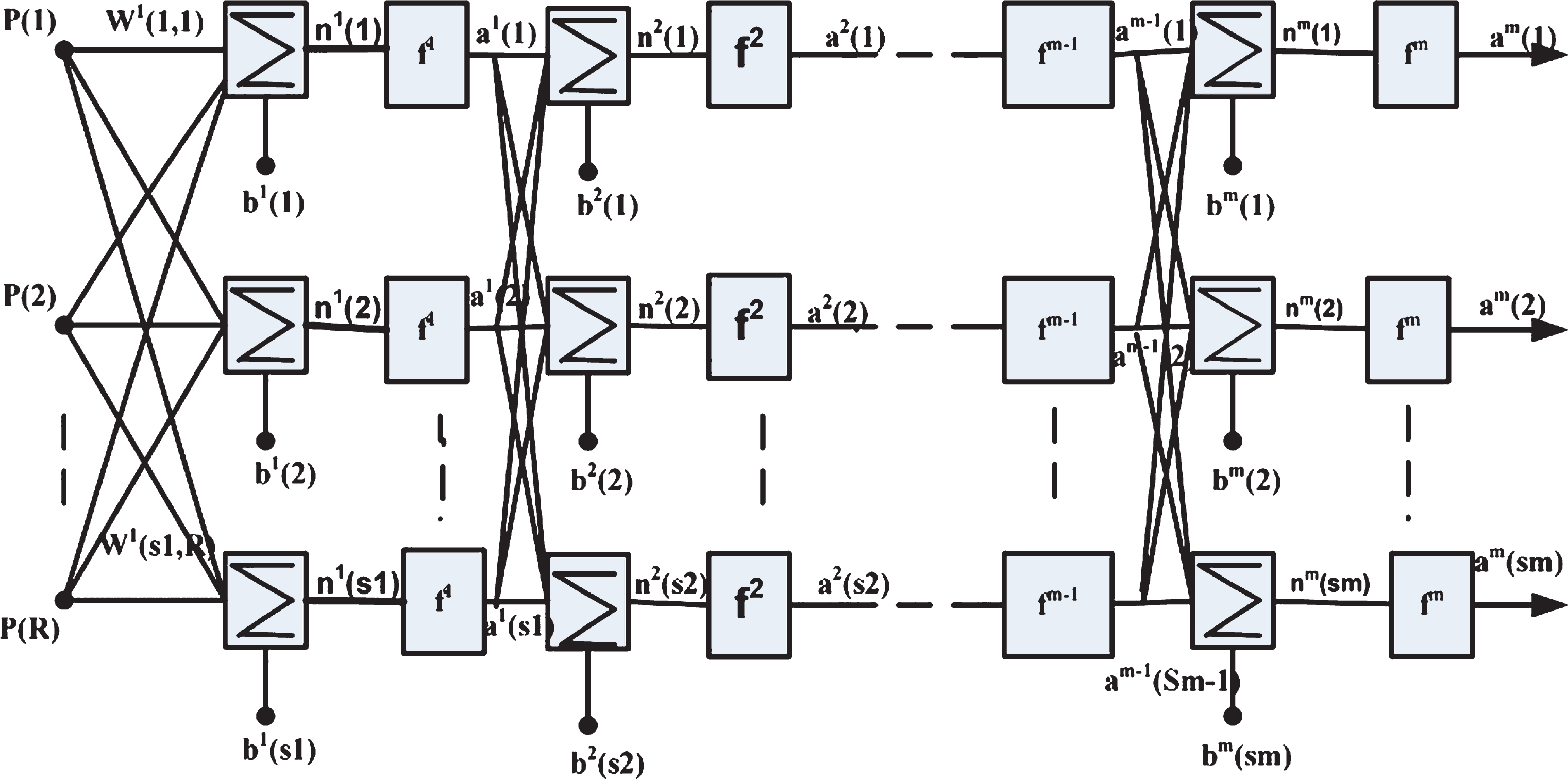
Multi-layer neural network.
Artificial bee colony (ABC) is a new optimization technique proposed by Karboga [43]. It is also one of the population based algorithm. This algorithm is based on the foraging behavior of bees. There are three types of bees in ABC named as employed bees, onlooker bees, and scout bees. Each of these three bees ha different functions also.
Employed bees: Employed bees are one employed for searching for food sources or solutions in the neighborhood of food sources in their memory.
Onlooker bees: These are bees who are waiting for the information from the employed bees to chose better food source.
Scout bees: These bees carry out random search for new food sources.
Initially, ABC generates initial positions of food source or solution. These initial positions are created using the following Equation 2.
In Equation 2, i ∈ {1, 2, ⋯ , N} and j ∈ {1, 2, ⋯ , D}. N is the number of employed bees, D is the dimension of the variables to be optimized, and x
minj
and x
maxj
are minimum and maximum limit or bound vale of the variable in dimension j. Employed bees modifies the positions using Equation 3.
In Equation 3, x
ij
is the current food position, v
ij
is the updated food position, and φ
i,j is random value between -1 and 1. In Equation 3, k is not equal to i. It compares the quality (fitness value) associated with x
i
and v
i
. If the fitness value of v
i
is better than x
i
, x
i
is replaced with v
i
, and hence current position of individual bees is updated. If the fitness value of x
i
is better than v
i
, x
i
is retained. In a global minimization problem, fitness values are determined by the Equation 4.
In Equation 4, f i is the cost function value.
An onlooker bee finds better food source or solutions based on the probability of fitness value of their food source or solution. The equation for the probability is given by Equation 5.
In Equation 5, fitn i is the fitness value of individual bee. N is the total number of employed bees. Onlooker bees also produce modifications in the positions as per Equation 3. After producing new positions or solutions, these bees compares the quality of the food source or fitness value of modified solutions as per Equation 4 in the same as the employed bees.
If a particular positions of food source or solutions of bees are not achieving better one through number of predetermined trails, such type of food sources or solutions are abandoned. These predetermined number of trails are called limit. These bees are called scout bees. These scout bees search to find new solutions as per following Equation 4.
In Equation 4,
In NARX structure, a nonlinear function is used to map the input and output data. Inputs chosen are usually previous value of input and output samples. NARX structure input-output mapping can be represented by the following equation
In Equation 2.4.1, u (t - n u ) , u (t - n u-1) , ⋯ , u (t - 1) are delayed input samples and y (t - n y ) , y (t - n y-1) , ⋯ , yt - 1) are delayed ouput samples of the system. NARX based identification for distillation column has been employed in [46, 47]. NARX is also used as a soft sensor estimator for distillation column in [2, 48].
Data needed for identification of distillation column are generated using a familiar software HYSYS. Selective excitation input signal has to be used for identification [44]. As the system is nonlinear, random excitation signals are adopted instead of pseudo random signals which are used for linear system identification [45]. Here output considered are top and bottom composition of distillation column. Reflux rate and reboiler temperature are used as manipulating or input variable to change the compositions. The inputs applied to the NARX ANN is given in Table 2 and the neural network model is shown in Fig. 3. Initially training data are saled into the range of (-1, 1) and are applied to the neural network model. ABC initialize the solution or weights and biases of the neural network. These weights and biases are used as weights and biases in the neural network. The dimension of each solution in the ABC will be equal to total number of weights and biases used in the network. Total number of these weights and biases depend on number of neurons used in the hidden layer. Fitness function used is sum of root mean square (RMSE) value of top and bottom composition in the trainig data. ABC control parameters used for proposed system is also listed in Table 3. Flow chart of ABC training of neural network is illustrated in Fig. 4.
Inputs used for NARX ANN
Inputs used for NARX ANN
ABC control parametrs
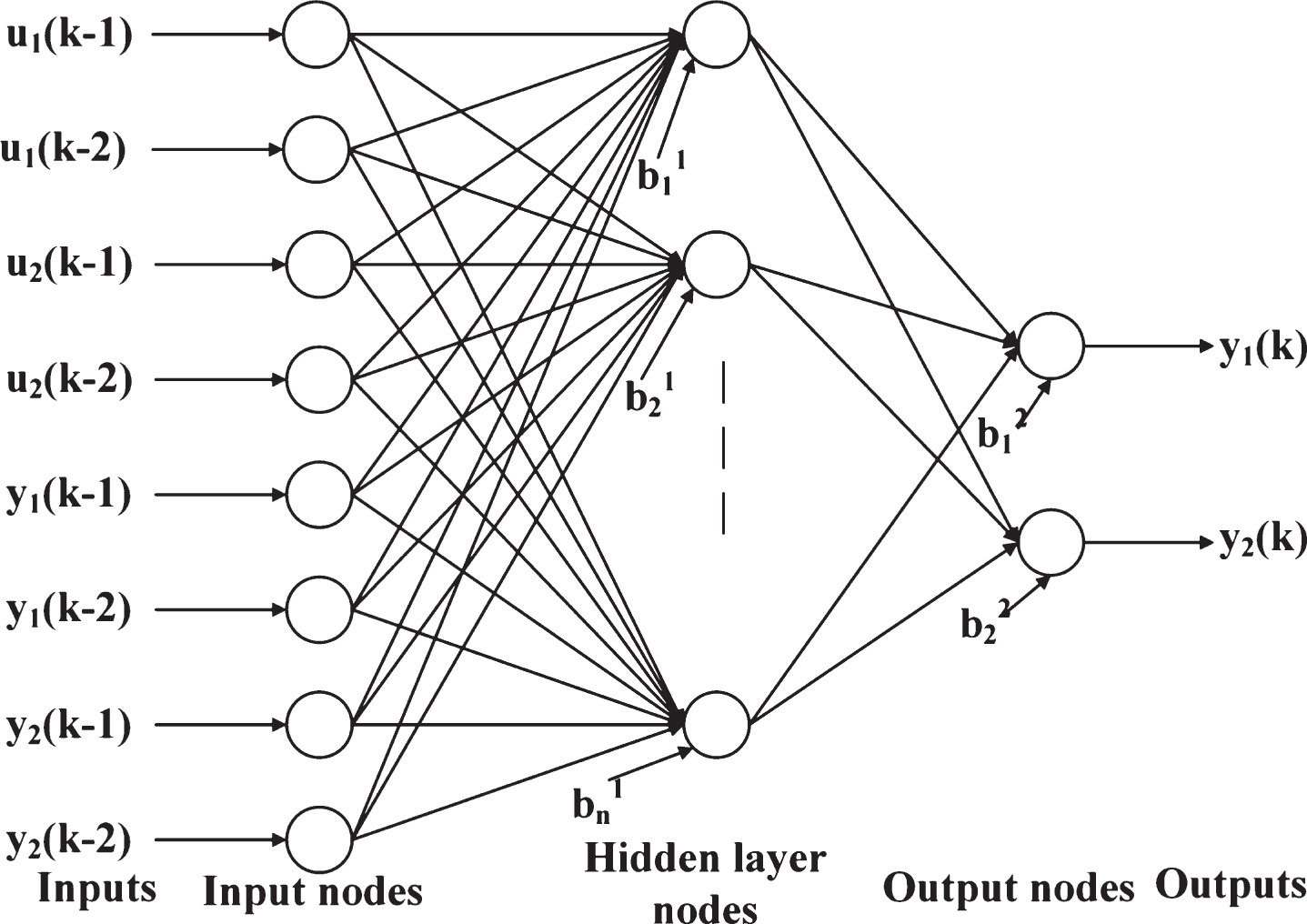
NARX Neural network modelm.
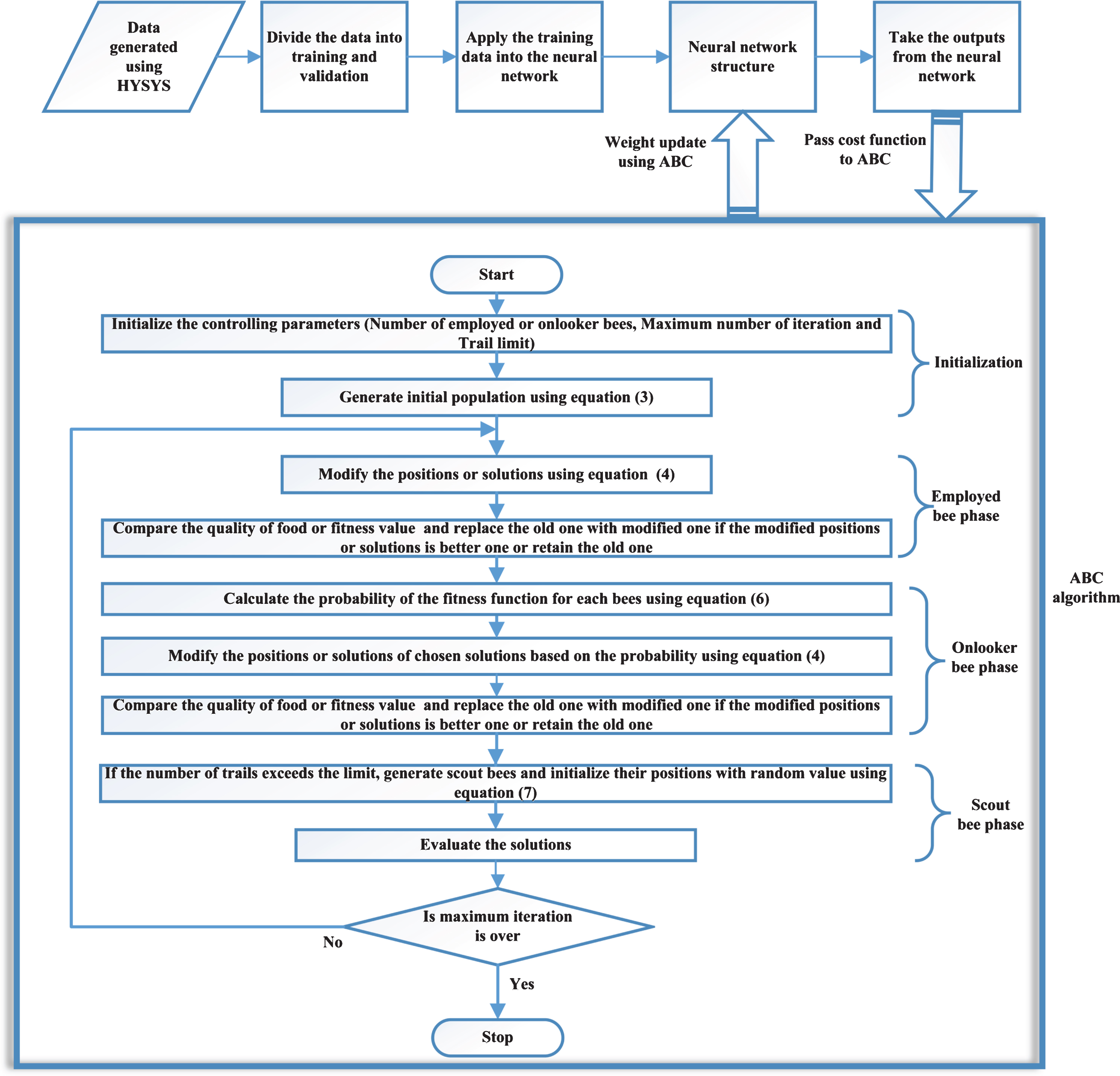
Training of neural network using ABC algorithm flow chart.
Non-linearity of distillation column
Neural network is used for identification of nonlinear systems. Non-linearity of distillation column is proved by applying step change of manipulated variable with different magnitude. Reflux rate and reboiler temperature is used as manipulated variable. Steady state gain for step change in positive and negative direction are different as shown in Fig. 5. Moreover, gain in steady state value for equal percentage change do not express equal change as in Fig. 5. Steady state gain for +10% and -10% change in reflux rate are not equal for both top and bottom compositions as illustrated in Table 4. Gain is also differers in value for +20% and -20% change for both compositions. Hence, this dynamic study indicates high nonlinearity of tetrahydrofuran-toluene distillation column.
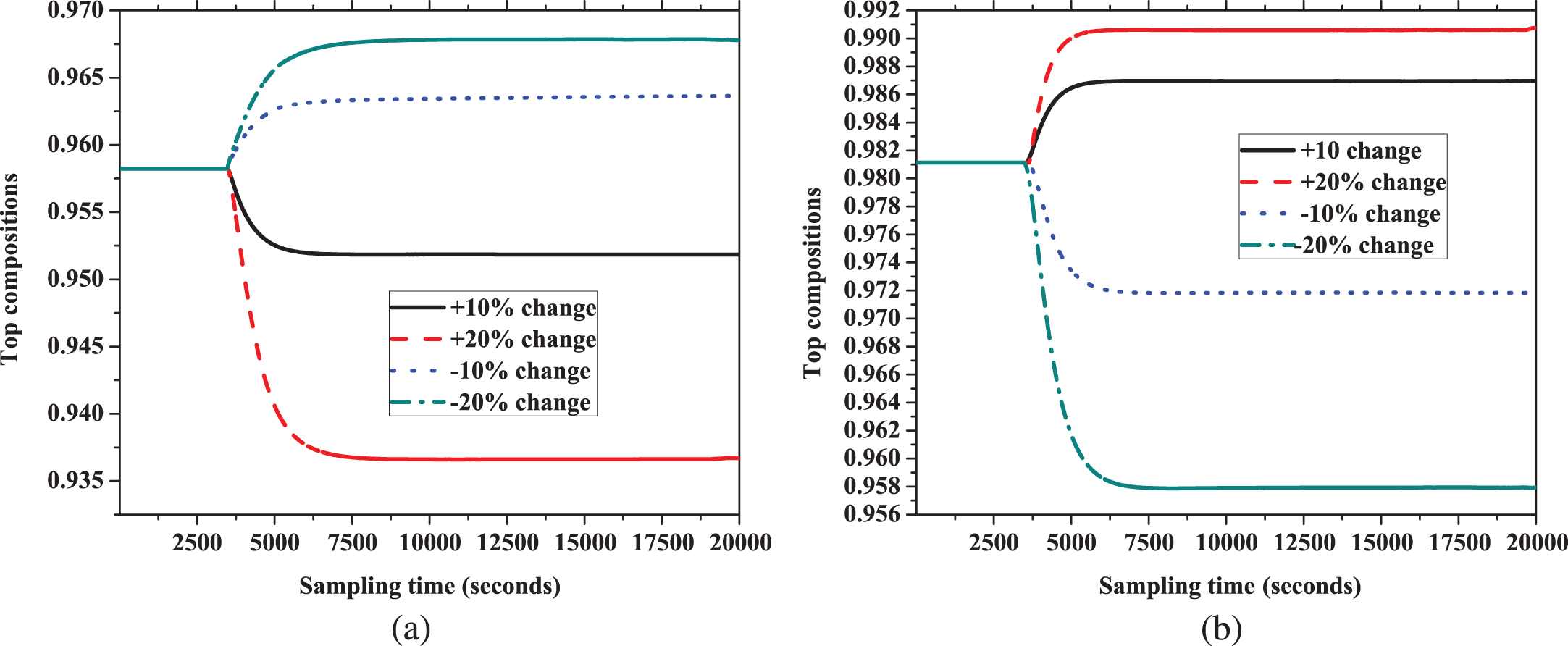
Response of top compositions for step change in manipulated variable (a) Reboiler temperature (b) Reflux rate.
Steady state gain in top and bottom compositions for step change in reflux rate
Process simulation software HYSYS is used for creating data for identification. Operating condition of the distillation column considered in the in the steady state simulation is shown in Table 5. Wilson fluid package was used in simulation. 95% purity is considered for tetrahydrofuran in the top stage and for toluene in the bottom stage. After developing the model in the steady state, the model is transformed into the dynamic mode. Samples for input data corresponding to reflux rate and reboiler temperature are generated randomly in matlab using system identification toolbox. These inputs are applied in HYSYS in dynamic mode in 20 minutes of time intervals to obtain corresponding outputs (top and bottom composition). A sampling time of 20 seconds used in simulation. A total of 20000 seconds (333.33 minutes/5.55 hours) are taken for data generation. 1000 samples of input-output data are collected from the HYSYS. Input and output data used for identification is shown in Figs. 6 and 7. First 800 samples of these data are used for training and remaining last 200 samples are employed for validation of the model.
Operating conditions of distillation column
Operating conditions of distillation column
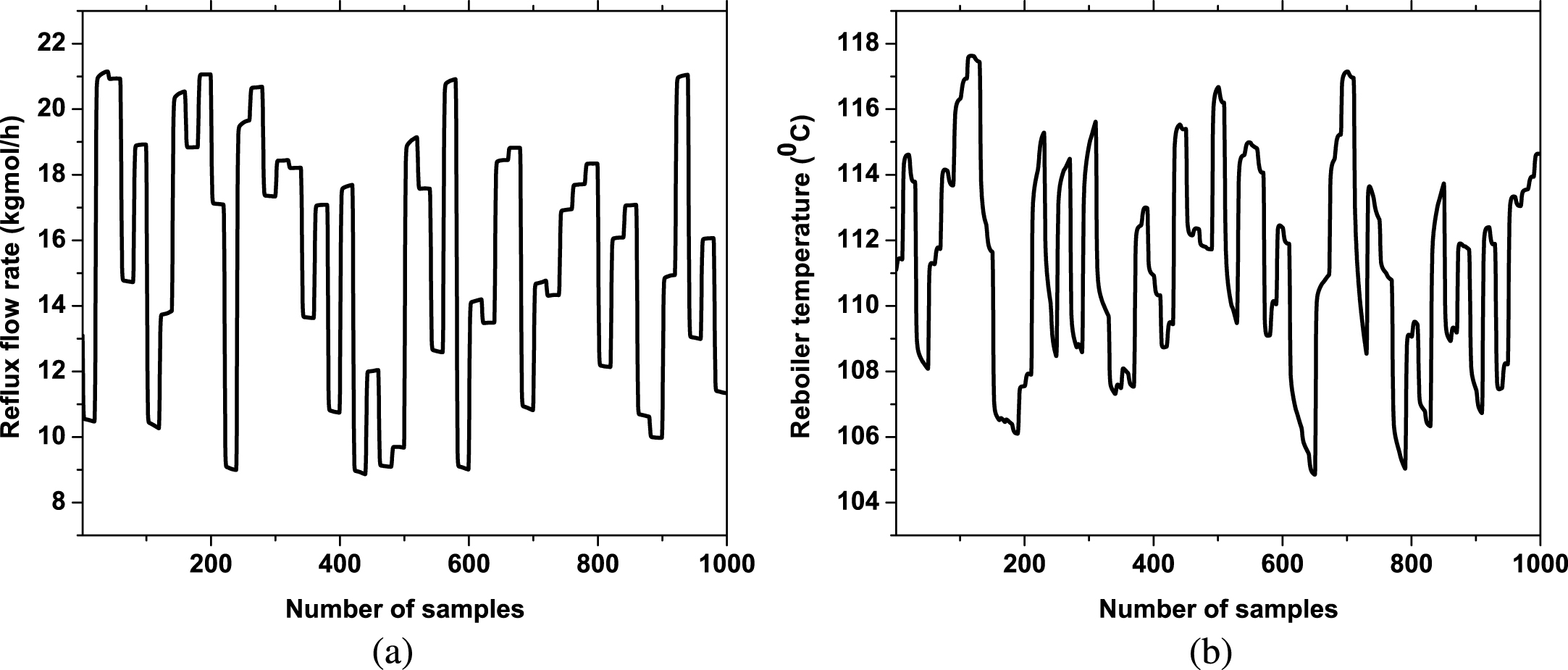
Input data used for identification (a) Reflux rate (b) Reboiler temperature.
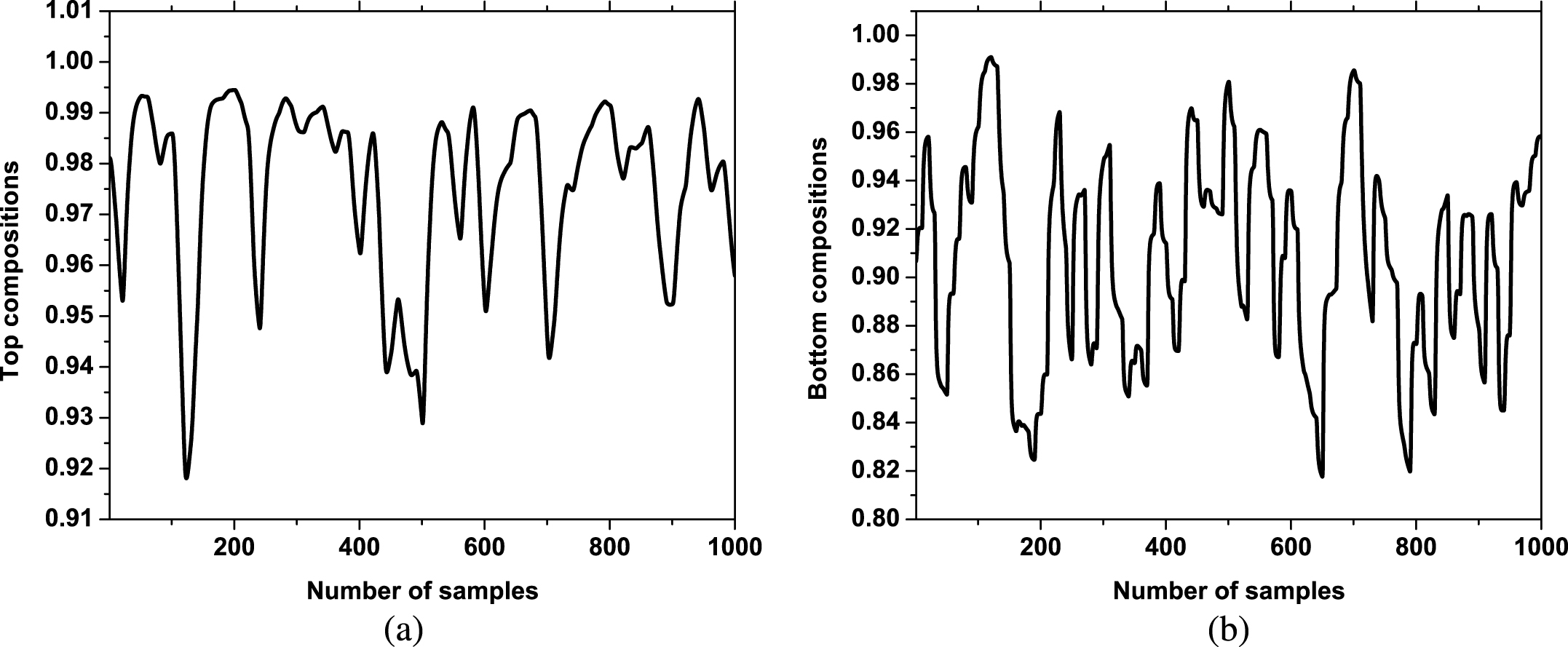
Output data used for identification (a) top compositions (b) bottom compositions.
ANN, NARX ANN, ANN ABC and NARX ANN ABC are considered for the training purpose using different number of hidden layer sizes. NARX ANN ABC shows better result for every number of hidden layer sizes as represented in Fig. 8. Root mean square error (RMSE) is less for proposed NARX ANN ABC comparing with others for various number of hidden layer size.
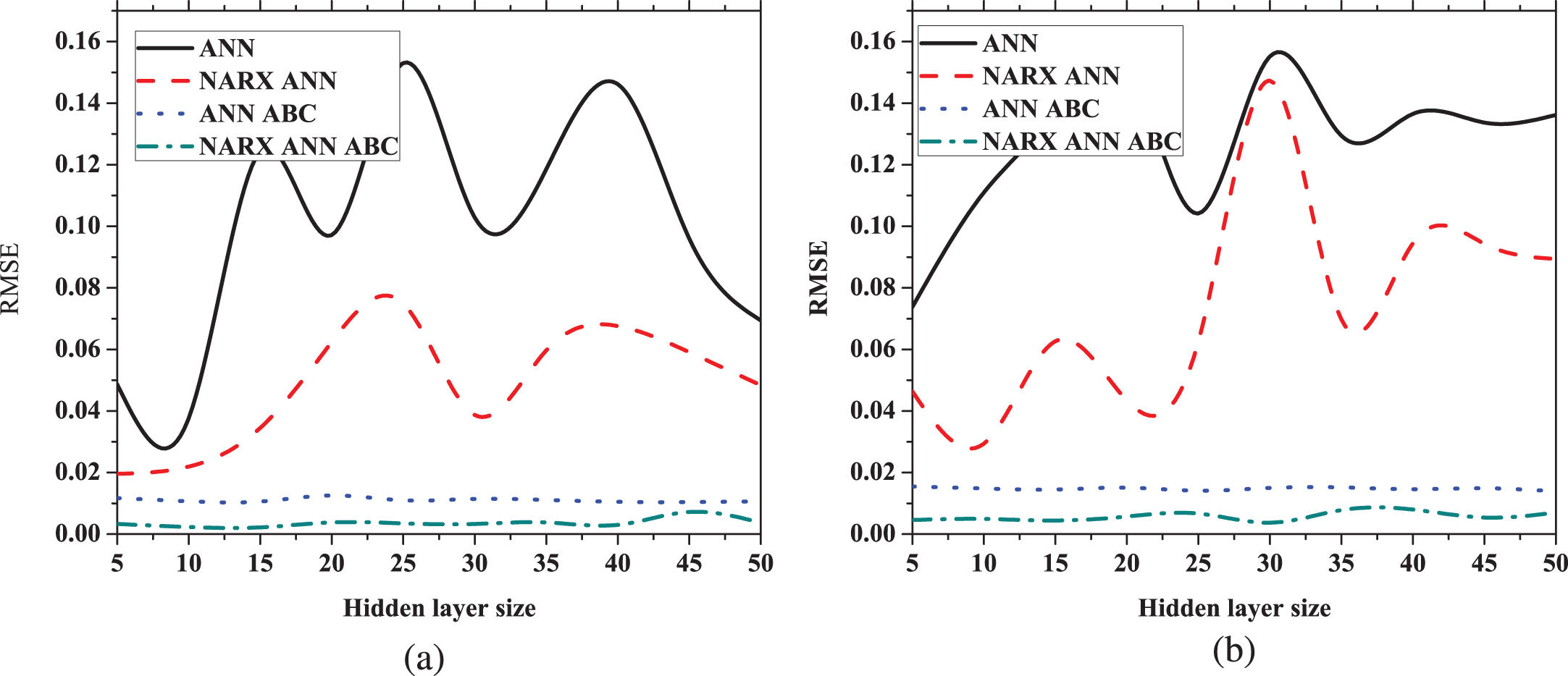
RMS value plot for hidden layer sizes (a) top compositions (b) bottom compositions.
RMSE is calulated as per the following Equation 34
In Equation 34, N, y
t
(k) and
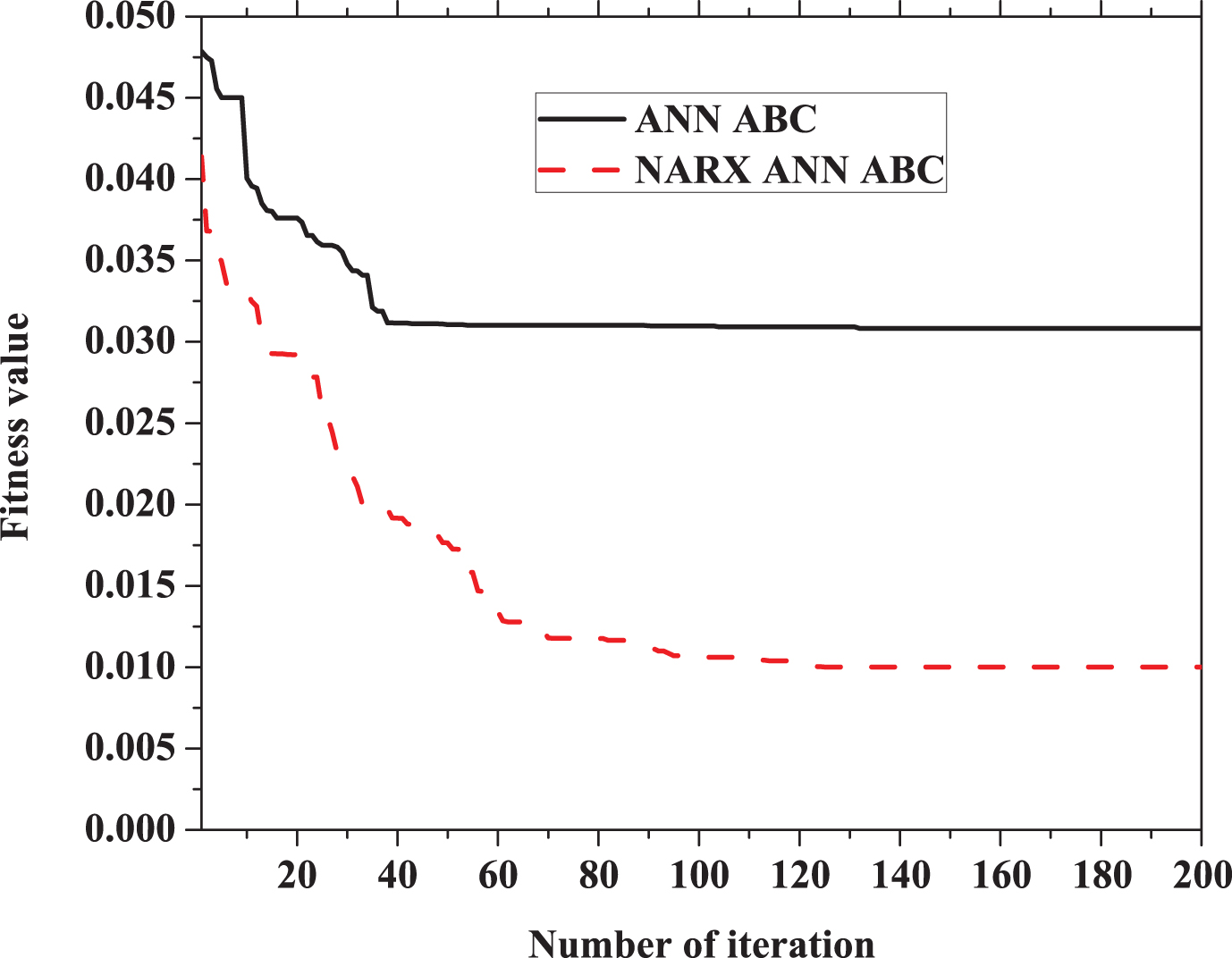
Fitness value plot for ANN ABC and NARX ANN ABC.
Validation of proposed model is carried out in two way. (1) 200 input samples of validation data are applied to the model and real values or output samples of validation data and predicted output values are compared. (2) Outputs of the step inputs of real dynamic simulation model in HYSYS is compared with model outputs with same inputs.
The Fig. 10 shows real value and predicted output value for top and bottom compositions. Real value and predicted values are very close to each other for both cases. The Fig. 11 illustrates the comparison of response of the model and real value for a step change in reflux rate. Similarly, the Fig. 12 shows the behavior of response for a step change in reboiler temperature. Both Figs. 11 and 12 reveals capability of the model to predict the actual response for step change.
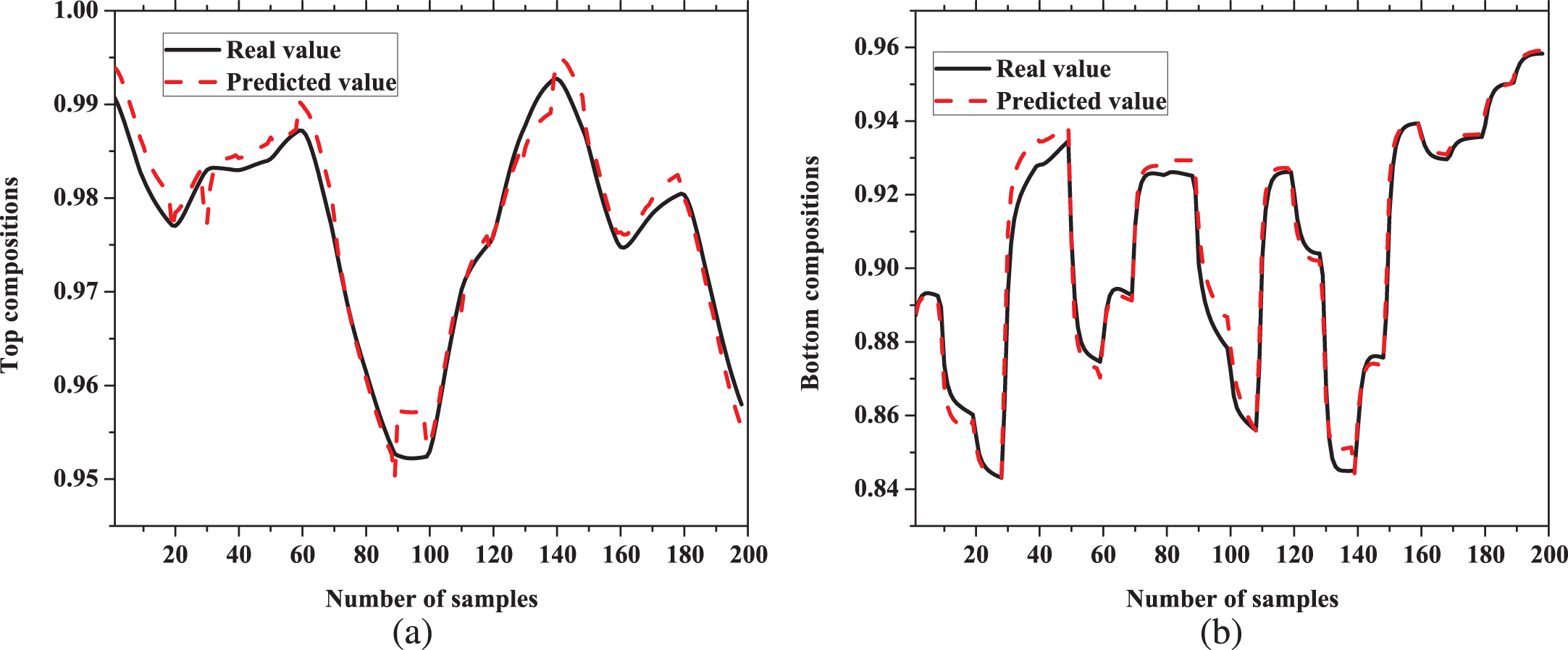
Response of top and bottom compositions for validation data (a) top compositions (b) bottom compositions.
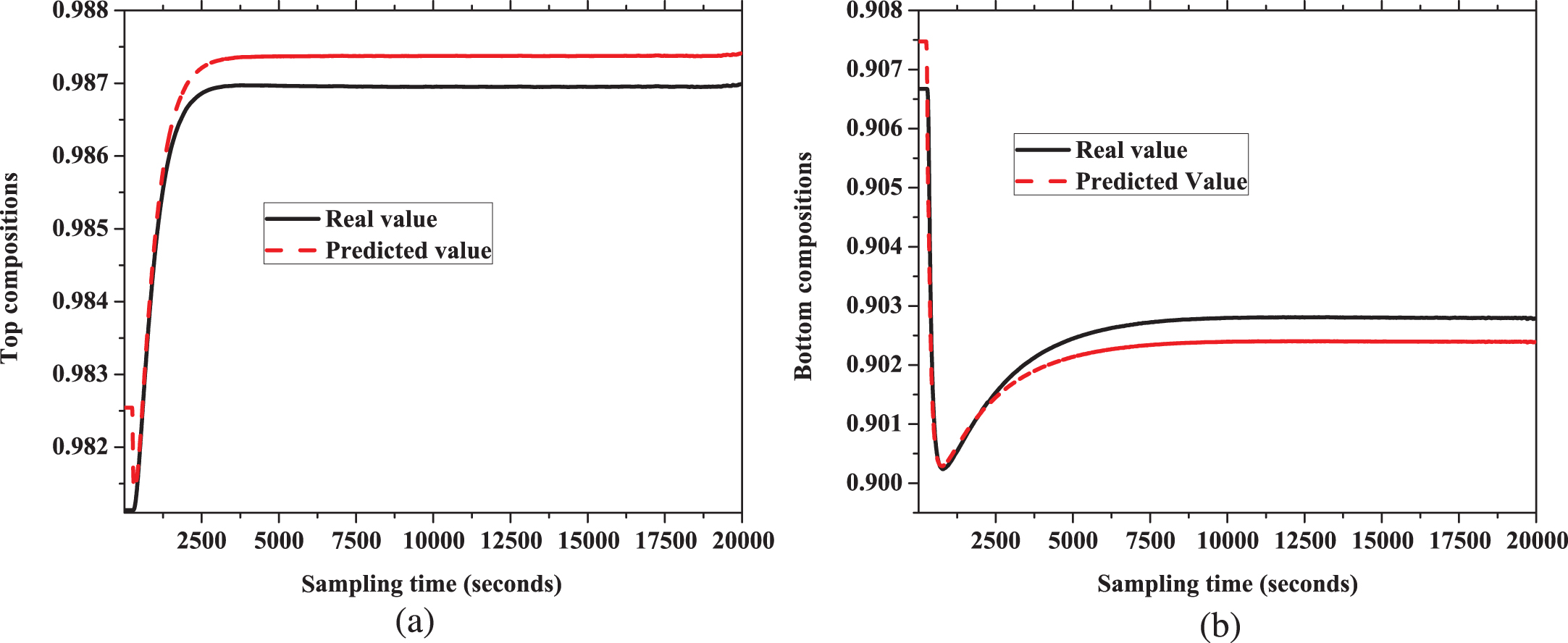
Response for step change in reflux rate for validation (a) top compositions (b) bottom compositions.
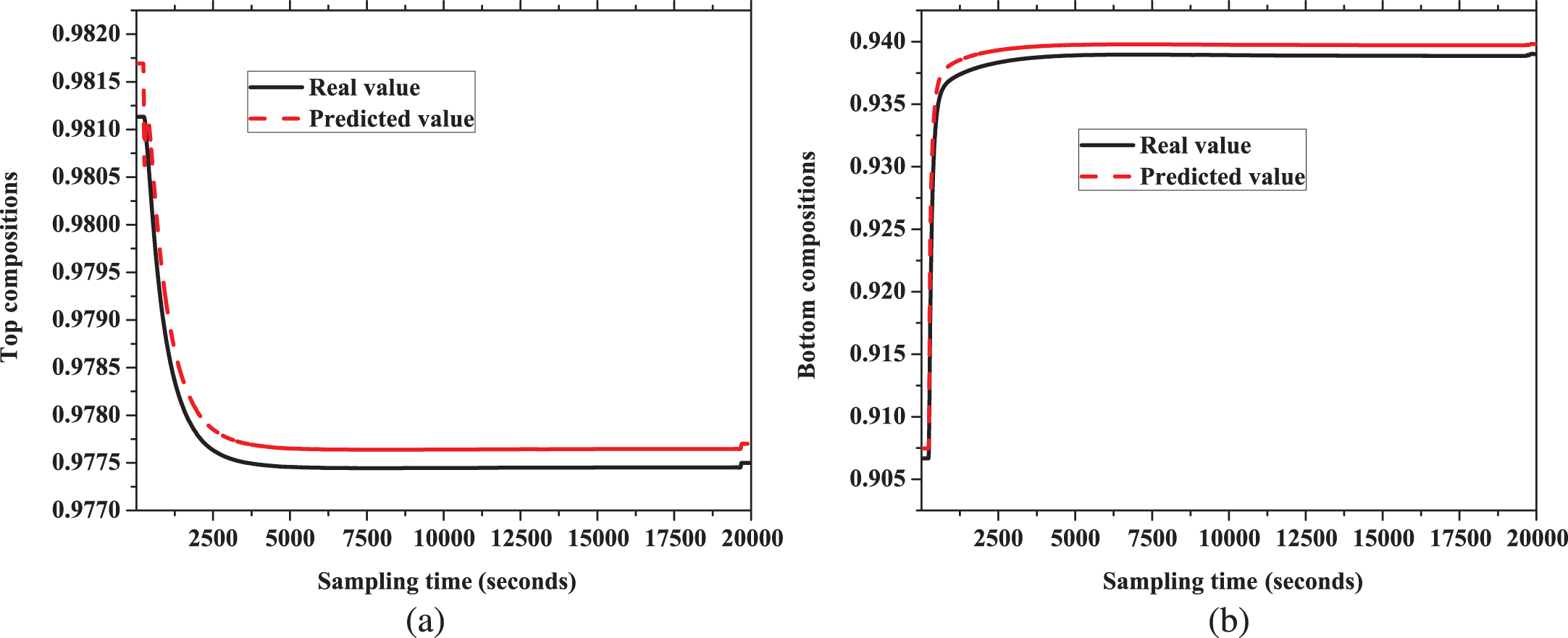
Response for step change in reboiler temperature for validation (a) top compositions (b) bottom compositions.
If the predicted output values are more close to the Actual = Predicted line, and regression line is more close to Actual = Predicted line, model will be more accurate. Regression plots are shown from Fig. 13. NARX ANN ABC model output values are more close to the Actual = Predicted line in both figures. Moreover, NARX ANN ABC regression line is very close to the Actual = Predicted line. Therefore, proposed model is very close to the actual system.
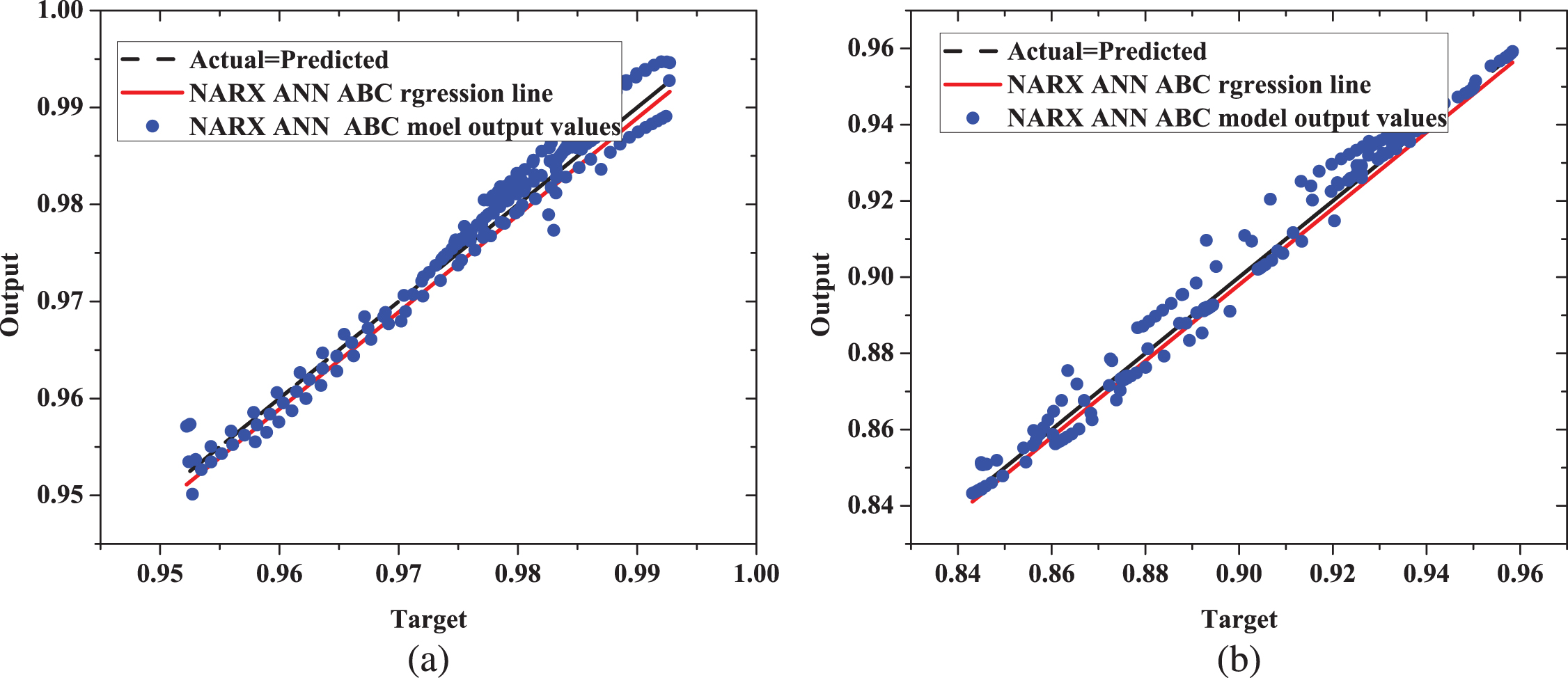
Regression plot (a) top and compositions (b) bottom compositions.
Two measures are used for performance analysis. (1) RMSE (2) Correlation coefficient. RMSE calculation is given by Equation 35
In Equation 35, M, y
v
(k) and
In Equation 36,
RMSE value is in between zero and one. RMSE value of zero indicate perfect matching of the predicted model and actual model of the system. RMSE value of one represent greater mismatching between the predicted model and actual one. R-value lies between 0 and 1. R 2-value of one represents the perfect matching of predicted model and and actual model. R 2-value of zero represents that there is no relation between predicted model and actual model of the system. Hence, as R-value becomes more close to one, the predicted model will be more close to actual model of the system.
In the performance results in Table 6, least value of RMSE for top composition (0.0022) observes for NARX ANN ABC. Similarly, low value of RMSE for bottom composition (0.0044) is also for the same model. Hence based on the RMSE, NARX ANN ABC is more close to real system comparing with other models (ANN, NARX ANN and ANN ABC) in the Table 6. High value of R 2 value in the Table 6 has been shown for the case of NARX ANN ABC for both compositions (0.9836 & 0.9927). Hence, bsed on the consideration of R 2 value also, the proposed model is accurate than other models.
Table for comparison of statistical criteria RMSE, & R 2 for top and bottom composition
In this article, a novel identification using hybrid artificial neural network and artificial bee colony is used for tetrahydrofuran-toluene distillation column. High non-linearity and dynamic nature of this distillation column is captured by the proposed model. Since the system is dynamic in nature, NARX structured model outperforms models without NARX structure. Proposed model is validated using both validation data and step inputs of manipulated variale. Better results was provided for these validations. This work can be extended to provide more improved results using enhanced ABC or combining ABC algorithm with other meta-heuristic optimization methods.