
Abstract
The differential evolution, one of the most powerful nature inspired algorithm is used to solve the real world problems. This algorithm takes minimum number of function evaluations to reach near to global optimum solution. Although its performance is very good, yet it suffers from the problem of stagnation. In this paper, some new mutation strategies are proposed to improve the performance of differential evolution (DE). The proposed method adds one more vector named as Homeostasis mutation vector in the existing mutation vectors to provide more bandwidth for selecting effective mutant solutions. The proposed approach provides more promising solutions to guide the evolution and helps DE escaping the situation of stagnation. Performance of proposed algorithm is compared with other state-of-the-art algorithms on COCO (Comparing Continuous Optimizers) framework. The result verifies that our proposed Homeostasis mutation strategy outperform most of the state-of-the-art DE variants and other state-of-the-art population based optimization algorithms.
Introduction
DE was proposed by Rainer Storn and Kenneth Price [1] in 1995. The theory of DE is inspired from the biological phenomenon of natural selection and evolution. DE updates randomly generated initial population using three operators mutation, crossover and selection. During mutation, each solution generate new solution by adding the difference of two randomly selected parameter vectors from the population into third parameter vector and during crossover each solution updates its value by randomly mixing its initial value with mutant value. The best part of DE is that if there is an improvement in new position then selection is used to accept new solutions to form part of the population otherwise new position is discarded. This process is repeated again and again until best solution is obtained, but it does not provide any guarantee that the discovered best solution will be global optimum solution.
In many situations the solutions of DE may get stuck in local optima which occurs due to lack of diversity in newly generated solutions. Since in evolutionary algorithm, mutation operator is responsible for maintaining diversity among solutions, this shows that diversity provided by classical mutation operator is not sufficient, it should be modified so that diverse solutions may be generated and stagnation problem can be removed. Moreover this removal of stagnation problem will also improve the convergence rate of DE algorithm. Therefore to prevent solutions on converging local optimal solutions, new mutation strategies are proposed in this paper and many variants of DE are designed. These variants are named as Homeostasis variants because theory of these variants are inspired from the process of Homeostasis whose whole sole purpose is to maintain the internal environment of the body. The purpose of these variants is to maintain the same diversity which was created during initial generations by adding additional vectors in mutation operator. In proposed algorithms, diversity is considered as internal environment. To check the performance of proposed Homeostasis variants, these algorithms are compared with other state-of-the-art algorithms. Performance analysis shows that these variants outperform other variants of DE.
The rest of this paper is organized as follows, in Section 2, theory of DE is discussed. In Section 3, related works are elaborated, in Section 4, proposed Homeostasis variants are discussed and in Section 5, experimental result and analysis is shown and finally in Section 6, conclusions are drawn.
Background details and related work
DE algorithm
Differential Evolution [23] is a stochastic population-based algorithm for continuous optimization problems. It performs extremely well on a wide variety of test suites. In DE, mutation and crossover operators are used to generate trail vectors and then selection operator is applied to identify the best solution between parent and trail vectors. These selected solutions will be the part of new generation. If population consists of NP parameter vectors
DE/best/1:
DE/rand - to - best/l :
DE/best/2:
DE/rand/2:
Where αbest denotes best vector, α r 1 , α r 2 , α r 3 , α r 4 and α r 5 are random vectors, γi,G denotes mutant vector, i denotes number of population (NP), G denotes generation and δ1 and δ2 are mutation factors.
Where j = 1,2,.... D, r(j) ε [0,1], jth evaluation of a uniform random generator number, Cr is the crossover constant ε [0,1], rn(i) ε (1,2,...D) is a randomly chosen index which ensures that βj,i,G+1 gets at least one element from γj,i,G+1, otherwise, no new parent vector would be produced and then the generated population would not be altered.
For j = 1, 2, . . , D. iff the trail vector βi,G+1 gives better fitness value than αi,G then βi,G+1 is set to αi,G+1; otherwise, the old value αi,G is continued.
1: Initialize initial population by generating N random solutions of D dimension within the given bounds
2:
3: itr = 1
4: while FEs < MaxFEs
5: Apply Mutation Operator and generate donor vector using Equation (2)
6: Apply crossover operator and generate trail vector using Equation (6)
7: Apply Selection operator using Equation (7)
8: itr = itr + 1
9: end while
Differential Evolution (DE) was proposed by Storn and Price in 1995 [1]. It is a well-known optimization technique which works on very simple logic and takes reasonable amount of time in capturing nearly global optimum solution. Many researchers proposed enhanced version of basic DE either by redesigning its operators or by proper tuning its control parameters. Till now many variants of DE have been developed some of them are listed below.
Parameter tuning in DE has been implemented in many algorithms. Some papers related to parameter tuning are discussed here. Omran et al. [2] introduced SDE in 2005 in which he updated the value of F and Cr by keeping the value of normal (N) in between 0 and 1 and setting the mean of standard deviation as 0.5. This approach was tested on four benchmark functions and performed better than other versions of DE. Qin et al. [5], proposed SADE in which the scheme of generating trail vectors ‘F’ as well as the control parameter ‘Cr” are self adapted in the cause of learning from previous outcomes. A fitness based adaption for DE (FADE) has been proposed by Ali and Torn [6], in which ‘F’ is updated while ‘Cr’ is kept fixed at 0.5. A self-adaptive control parameters scheme was developed by Brest et al. [7]. The algorithm is known as jDE. Huang in 2006 [8], proposed self adaptive nature of NP. Mallipeddi et al. in 2008 [9], realized the importance of population in DE. Change in population improves the quality of solution and had less computational overhead. Das et al. [10], used a term defined by Price known as dither means to select a new value of ‘F’ for each vector and oscillatein range [0.5, 1.0]. Other DE variants which were developed by updating various operators are listed below. In 2006, a DE variant, DE/target - to - best/1 was proposed by E. Mezura-Montesat et al. [3], with a new Neighborhood-Based Mutation strategy. It favors exploitation by moving each member of the population to a local donor vector which is created by employing the best (fittest) vector in the neighborhood of that member and any two other vectors chosen from the same neighborhood. Fan et al. [4], proposed a variant of DE (i . eDE/rand/1) in which Trigonometric Mutation operator is used with a probability of γ. Tasoulis et al. [11], proposed a ParallelDE scheme that maps an entire subpopulation to a processor, allowing different subpopulations to evolve independently toward a solution. Nasimul Noman et al. [12], have proposed “a crossover based adaptive local search operation for enhancing the performance of DE”. For the basic DE algorithm, Thangaraj et al. [13], proposed five new mutation schemes. These schemes are named as MDE1, MDE2, MDE3, MDE4 and MDE5. These schemes used absolute difference between the two points with weights attached to them and a variable scaling which is governed by the Laplace distribution. In 2011, Fajfar et al. [14], proposed some new selection strategies. Yong Wang et al. 2011 [15], proposed a composite DE i.e. CoDE, which used three trail vector generations strategies proposed earlier for various DE variants i.e. rand/1/bin, rand/2/bin and current - to - rand/1 and the three control parameter settings i.e. [F = 1.0, Cr = 0.1], [F = 1.0, Cr = 0.9] and [F = 0.8, Cr = 0.2]. The proposed scheme has been shown to perform better than JADE, jDE, SADE, EPSDE, CLPSO, CMA-ES and GL-25. In 2012, Islam, Das et al. [16], proposed technique in which a variation is added in classic and greedy DE/current - to - best/1 mutation scheme changing the current target vector with the best member of a group which is formed by randomly selected population members. These groups are regenerated for each vector in a generation. Sarker et al. [17], focused on selection of appropriate control parameters in DE and shown that it is a hard problem. Wenyin Gong et al. 2014 [18], observed that in DE, “the trial vector is directly related to its binary string, but not directly related to the crossover rate” and proposed a crossover rate repair technique for the adaptive DE algorithms. “The average value of binary string is used to replace the original crossover rate”. The proposed technique improved the convergence rate and quality of generated solutions. In 2014, Zhou et al. [19], proposed RA(Role Assignment) scheme to dynamically select mutation strategies and parameter settings for different individuals of the population. The RA scheme utilizes both the fitness information and positional information of individuals to dynamically divide the population into three groups. Each group is considered as a role to exhibit different search behavior. There are three roles in total, i.e. exploiter, follower and explorer. Each role has its own mutation strategy and parameter setting during the evolution. Yi et al. [20], proposed a new framework in which new mutation operator is combined with a new self-adapting control parameters. In 2015, Fan et al. [21], DMPSADE algorithm where the control parameters and mutation strategies are dynamically adjusted by competition and each optimized variable has its own self-adaptive mutation control parameter. In 2015, Brown et al. [36], proposed a new mutation operator ‘current-by-rand-to-best’ which is applied on less than ten population size for unconstrained continuous optimization problems. In 2016, Hu et al. [37], suggested that DE cannot guarantee global convergence of multi-model functions because, the optimum solution of the multi-model functions lies near the boundary of the search space as well as they have larger deceptive optima in the search space. In 2016, Wang et al. in the work [38], empirically reviewed the selection solution for mutation in DE. In 2016, Wang et al. [39], introduced a cumulative population distribution information based DE framework called CPI-DE. In 2016, Wang et al. [40], proposed a bimodal distribution parameter as the control parameter of the mutation and crossover operators, with the goal of balancing the exploration and exploitation abilities of DE.
Homeostasis mutation based differential evolution algorithm (HMBDE)
DE suffers from the problem of stagnation as its solutions start stagnating as number of generation increases. Since in evolutionary algorithms mutation operator is used to provide diversity among solutions, this shows mutation operator of DE is not very effective in handling stagnation problem. Therefore some modifications are required in the Mutation operator of DE algorithm so that the problem of stagnation can be solved and convergence rate of algorithm can be improved. The basic mutation strategy of DE simply adds the difference of two random vectors into third parameter vector which are selected from current population. This mutation operator is designed to provide diversity among solutions so that whole search area can be explored and good solutions from all areas can be identified during selection. In Initial generation this mutation operator provides required diversity but as number of generation increases this operator becomes ineffective and looses its diversity. The reason of loss in diversity lies in selection of vectors which always select good solutions from the pool of selected solutions. After some generations, these solutions start converging to a particular region and lost their diversity. This shows that some additional vectors are required to provide diversity when generation increases.
In this approach, an additional pair of vectors is generated from the whole search space to maintain the diversity among solutions. This process is very similar to Homeostasis as it keeps the internal environment of DE algorithm constant by adding an additional mutation function ψ for adding diversity as and when required.
This is the common procedure for creating new Homeostasis variant of DE. To generate Homeostasis mutation operator of DE/best/1, difference of Homeostasis vectors are added to an existing strategy. First random difference vector is created and then the difference of Homeostasis random vectors is added to basic mutation strategy in mutation operators. We Define the general difference vector and add the Homeostasis ψ (means difference of Homeostasis vectors).
Where
Generate the new mutant vector:
Where α HRV 1 and α HRV 2 are the Homeostasis random vectors which are selected randomly from the best of entire search space. Pseudo code for HMBDE as shown in Algorithm 2.
1: Set initial values of parameters as δ1 = rand/2 + 0.6, where rand value (0 to 1) δ2 = 0.8;
2: PopSize = 40*D
3: Initialize POPi (all individual (solution) of population randomly)
4: itr = 1
5: while FEs < MaxFEs
6: Apply Homeostasis Mutation Operator and generate donor vector using Equation (9)
7: Apply crossover operator and generate trail vector using Equation (6)
8: Apply Selection operator using Equation (7)
9: itr = itr + 1
10: end while
1: Set initial values of parameters as δ1 = rand/2 + 0.6, where rand value (0 to 1) δ2 = 0.8;
2: PopSize = 40*D
3: Initialize POPi (all individual (solution) of population randomly)
4: itr = 1
5: while FEs < MaxFEs
6: Apply Homeostasis Mutation Operator and generate donor vector γi,G:
7: Apply crossover operator and generate trail vector using Equation (6)
8: Apply Selection operator using Equation (7)
9: itr = itr + 1
10: end while
1: Set initial values of parameters as δ1 = rand/2 + 0.6, where rand value (0 to 1) δ2 = 0.8;
2: PopSize = 40*D
3: Initialize POPi (all individual (solution) of population randomly)
4: itr = 1
5: while FEs < MaxFEs
6: Apply Homeostasis Mutation Operator and generate donor vector γi,G:
7: Apply crossover operator and generate trail vector using Equation (6)
8: Apply Selection operator using Equation (7)
9: itr = itr + 1
10: end while
Test functions and experimental setup
The performance of proposed HMBDE algorithm is tested on 24 Black-Box Optimization Benchmarking (BBOB) which are provided as testing functions [25, 26] on Comparing Continuous Optimizers (COCO) software for year 2015 [27, 42]. These test functions include both uni-modal and multi modal functions. Results generated by proposed algorithm are compared with state-of-the-art version of DE algorithms. BBOB standard Benchmark Functions are stated in Table 2.
Parameter of Pseudo code
Parameter of Pseudo code
Benchmark functions
BBOB-framework is composed of 24 benchmark functions which are all noise-free and works on real-parameter having a single-objective [25, 42]. These functions have been further divided into 5 groups according to their similarity as mentioned in Table 2.
Experimental setup and parameter settings
The search space for all functions is taken as [-5, 5]
D
, proposed algorithm is tested on all dimensions provided in COCO framework these are D = 2, 3, 5, 10, 20 and 40. Fifteen instances of each function were taken to remove any randomness in testing. The terminal conditions are either maximum function evaluations has reached or a solution with a precision of more than 10-8 fitness is obtained. If fopt is optimal function value, defined for each benchmark function individually and Δf is required precision i.e. tolerable difference to optimal function value then ftarget = fopt + Δf is target value of function to reach. COCO framework uses the value of Δf as 10-8 in computations. Maximum number of function evaluations (FEs) are measured with the help of following equations:
Where,
Convergence rate and accuracy of solutions metrics are used to compare HMBDE with state-of-the-art algorithms. The expected running time (ERT), used in the figures and table, depends on a given target function value, ftarget = fopt + Δf. It is computed over all relevant trials as the number of function evaluations executed during each trial while the best function value did not reach ftarget, summed over all trials and divided by the number of trials that actually reached ftarget [25, 41].
Empirical cumulative distribution functions (ECDF)
Empirical cumulative distribution functions (ECDF), plotting the fraction of trials with an outcome not larger than the respective value on the x-axis for 5-D and 20-D respectively. Figure 1 include ECDF of the number of function evaluations (FEvals) divided by search space dimension D, to fall below fopt + Δf with Δf = 10 k , where k is the first value in the legend. The thick red line represents the most difficult target value fopt + 10-8.
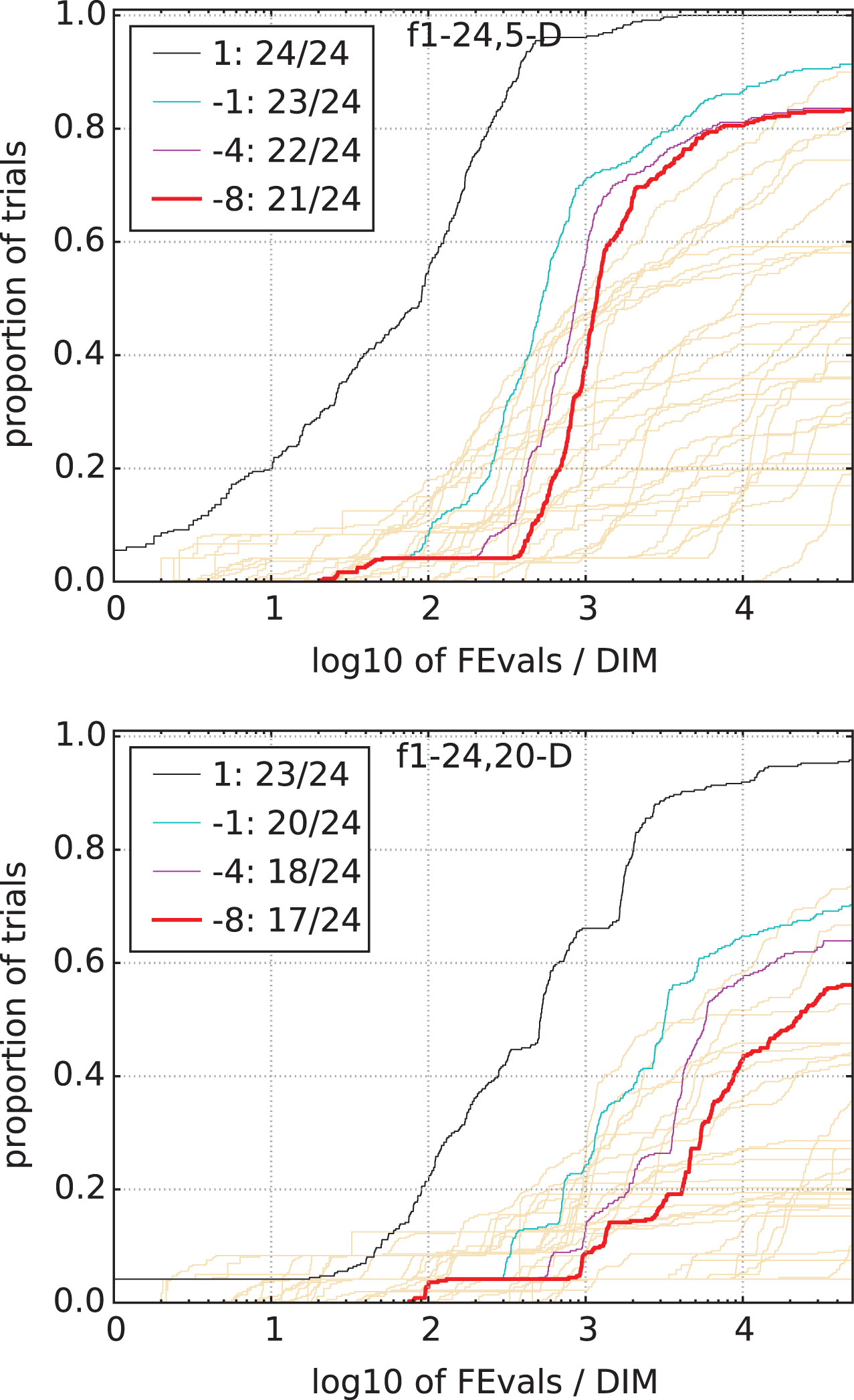
Run length distribution of HMBDE variant for target value all function (f1 -f24) on 5-D and 20-D.
Figure 2 shows the ERT loss ratio for 5-D and 20-D respectively. These figures display plotted log10 of ERT loss ratio versus given budget FEvals = FEs in log10. Box-Whisker plot shows 25-75% -ile (box) with median, 10-90% -ile (caps), and minimum and maximum ERT loss ratio (points). The black line is the geometric mean. The vertical line gives the maximal number of function evaluations. maxFE/D gives the maximum number of function evaluations divided by the dimension. RLUS/D gives the median number of function evaluations for unsuccessful trials [41].
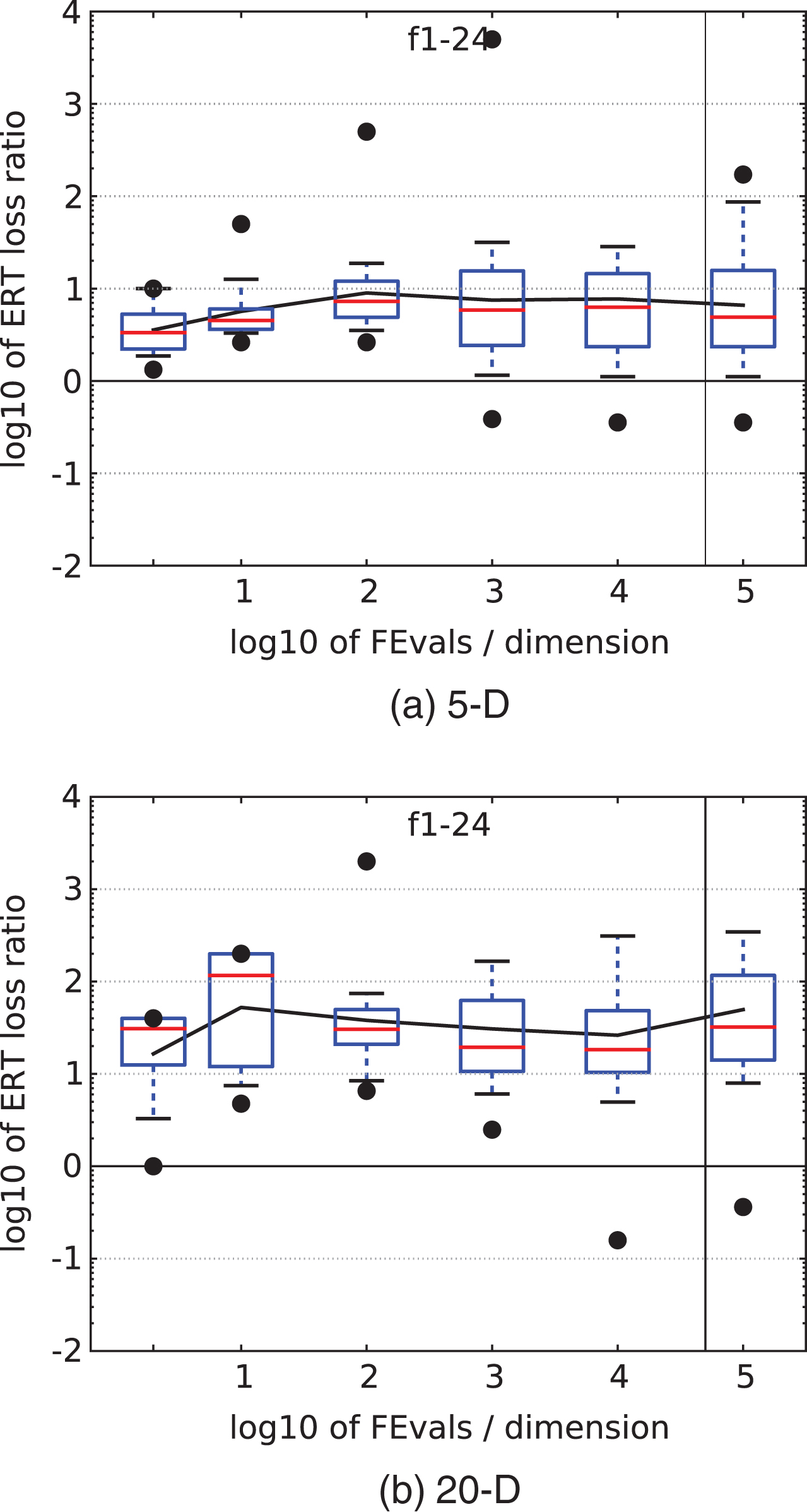
HMBDE: Box-whisker plots of the loss ratios of the expected run time compared to best line 2009 on 5-D and 20-D.
Newly created Homeostasis mutation based differential evolution algorithm (HMBDE) i.e. HMBDE-R1 and HMBDE-CB are compared with existing DE algorithms like JADEcr [18], JADE [24], DE [1], DEb [30], DE-PAL [31] and MVDE [32] and other state-of-the-art population based optimization algorithms like GA [33], PSO [34] and CMAES [35]. Figures 3–9 shows the comparison for 2-D, 3-D, 5-D, 10-D,20-D and 40-D. Table 3 shows the position of HMBDE variants among nine state-of-the-art algorithms after comparison over BBOB benchmark functions. It also shows the numbers preceding the various algorithms is the position of that optimization algorithm with respect to other optimization algorithms.
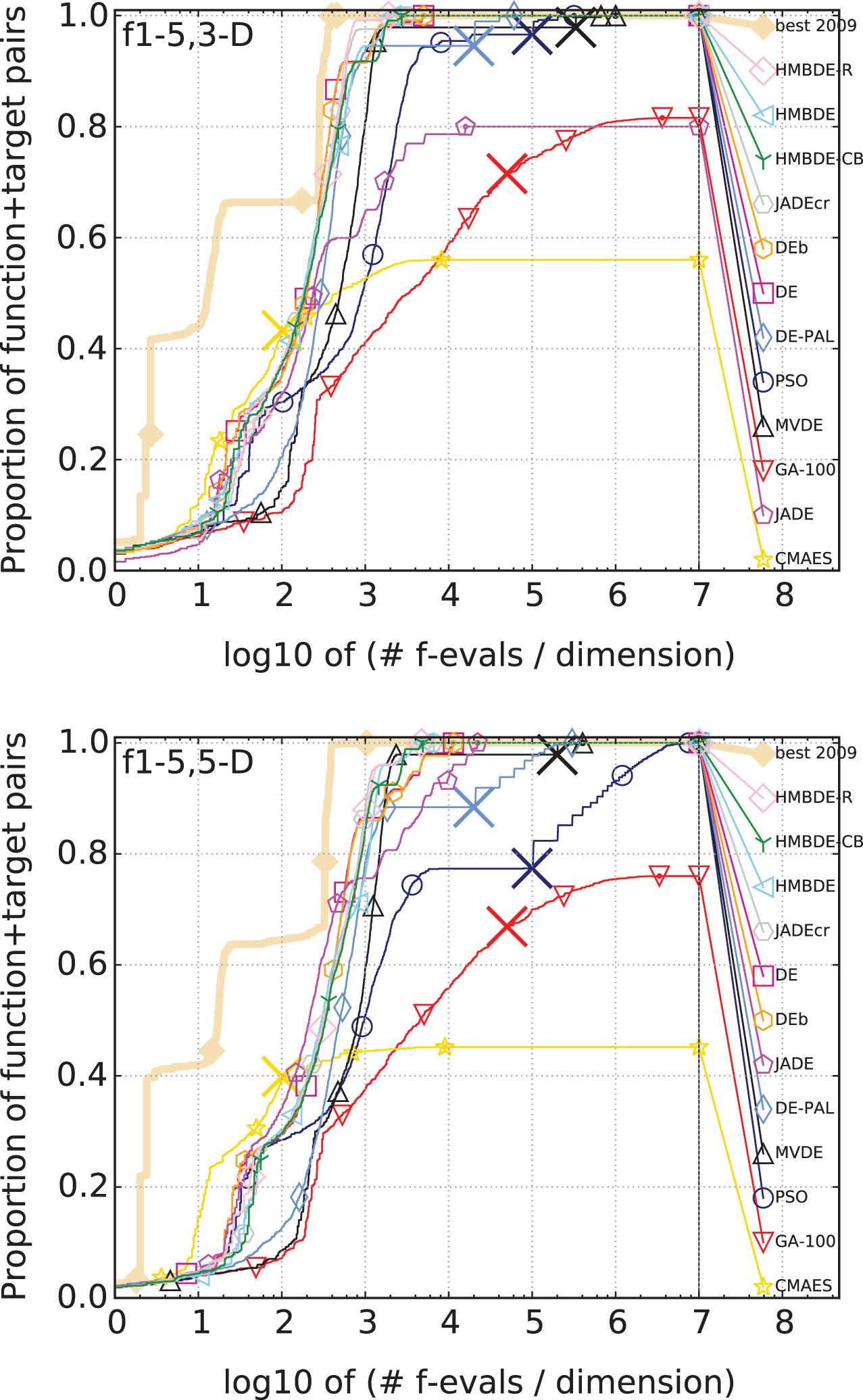
Comparison of HMBDE variants with other state-of-the-art algorithms in 3-D and 5-D on separable function.
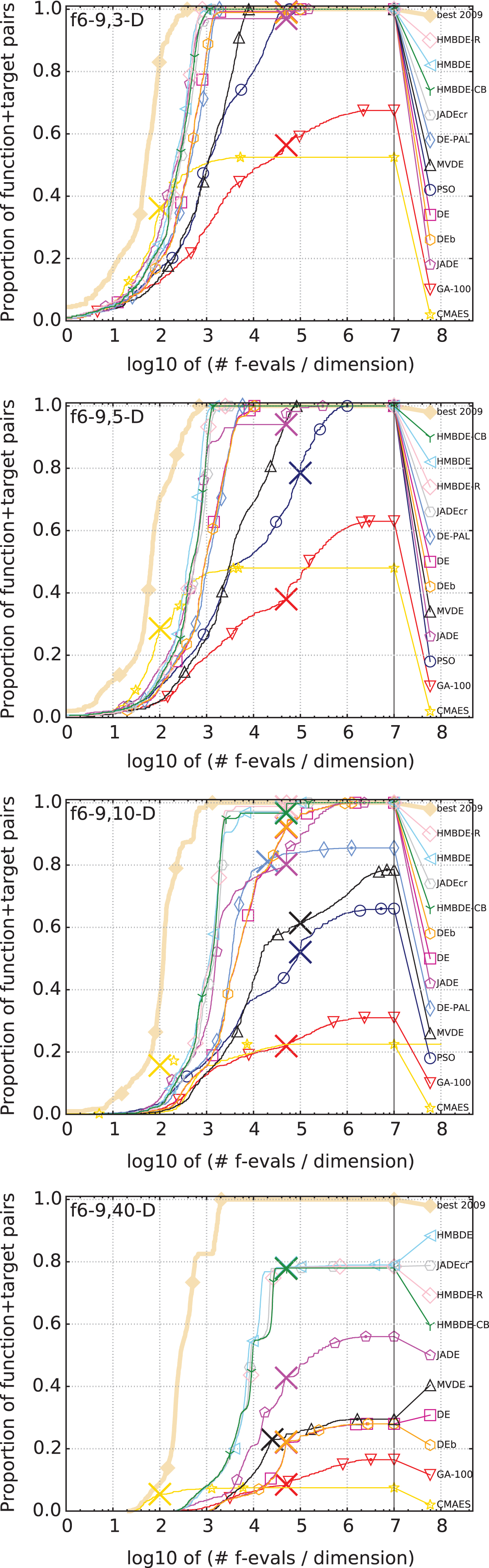
Comparison of HMBDE variants with other state-of-the-art algorithms in 3-D, 5-D, 10-D and 40-D on low or moderate conditioning function.

Comparison of HMBDE variants with other state-of-the-art algorithms in 3-D, 5-D, 10-D and 40-D on unimodel with high conditioning function.
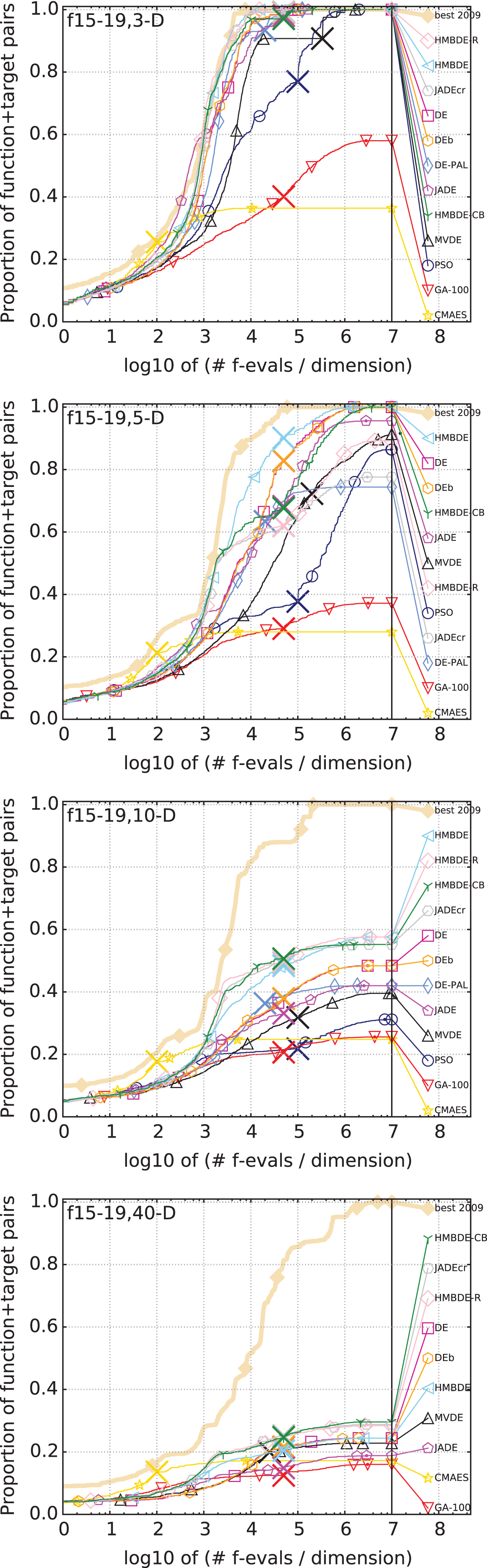
Comparison of HMBDE variants with other state-of-the-art algorithms in 3-D, 5-D, 10-D and 40-D on multi-model with adequate global structure function.

Comparison of HMBDE variants with other state-of-the-art algorithms in 3-D, 5D, 10-D, 20-D and 40-D on multi-model with weak global structure function.
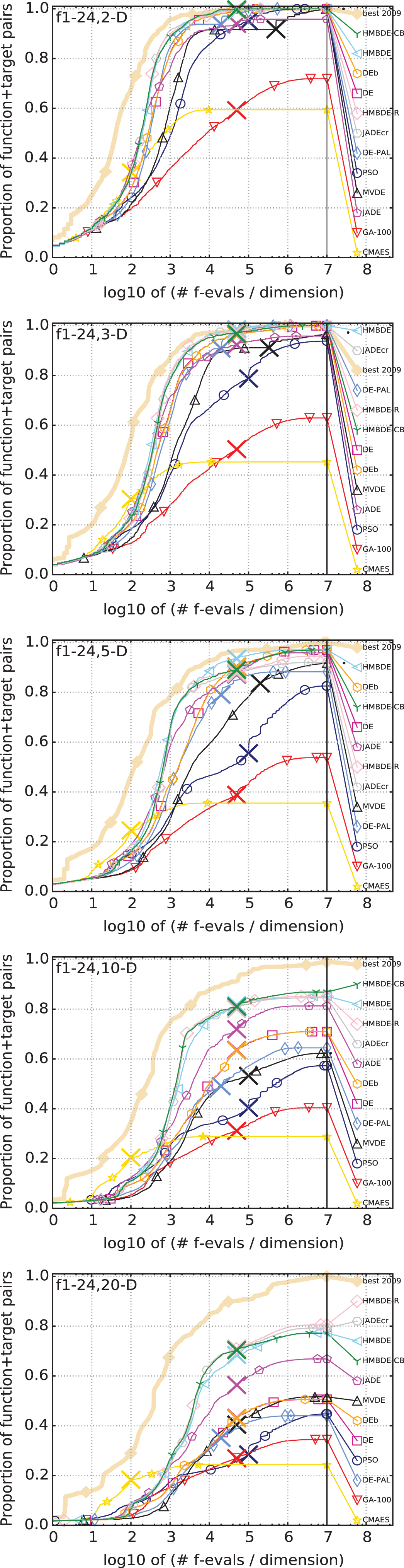
Comparison of HMBDE variants with other state-of-the-art algorithms in 2-D, 3-D, 5-D, 10-D and 20-D on all function.

Comparison of HMBDE variants with other state-of-the-art algorithms in 40-D on all function.
Position of HMBDE variants on nine state-of-art algorithms over BBOB benchmark functions
Conclusion
In this paper, some new mutation strategies are proposed to overcome the problem with existing optimization algorithms. Searching capability of HMBDE has been improved by introducing a new Homeostasis mutation operator that is capable to do more exploration and exploitation. From the Table 3 it is clear that on all dimensions the proposed HMBDE variants has dominated all latest state-of-the-art DE variants and other state-of-the-art population based optimization algorithms. The performance of these variants were almost very good in all kinds of functions and a very little downfall have been seen in very high dimensions.