
Abstract
Thread based programs are very much efficient in terms of increasing application response, improving structure of the program, combining with the remote procedure call(RPC) and complete utilization of the computation available. A shared-memory system along with the multithreading, can result in developing a parallel system on which different threads can run in parallel on different processor cores. Even when there are more number of threads than the processor cores, scheduling along with context switching can be done to ensure start of execution of all the threads. Keeping these benefits in mind, present research formulates that in certain cases, the results of multithreading based programming on a single system can be more convincing than making use of the cluster based distributed programming. Proposed work tests all these claims, by decomposing an image having salt and pepper noise into number of small images and then applying median filtering parallely on all these subimages using multithreading approach. Various performance measurement metrics like % Idle Time, % Processor Time, % Maximum Frequency, % Processor Utility, total execution time are used to validate the results generated by the proposed approach. Remote method invocation (RMI) based cluster for distributed programming has also been deployed to perform the same operation on a cluster based architecture with number of nodes working together, to compare the results of both the architectures.
Introduction
This research explores the idea of benefits of multithreading which is a specific implementation of the parallelism. Single program multiple data (SPMD) [1] is a technique, which is used for achieving parallelism by splitting the given task and run them simultaneously in parallel on different CPU cores. A single sequence of execution within a program is known as a thread. In a multithreading approach, it is possible to control a single program’s execution by the multiple threads. Programming languages like java help in providing the integrated view of multithreading. Not only an operating system can run multiple programs but it is now even possible to have multiple threads to be called by a program itself. By using the virtual memory and address space of the parent process, threads become the lightweight process, which helps in faster execution by efficiently using all the available resources. The idea explored in the present proposed work is that before writing distributed applications all the available resources available with the system itself must be used to their full capacity. Multithreading based parallel algorithm(MTPA) proposed in the present work is time sharing in nature. As the number of threads deployed will be more than the number of cores, so the processing [13] power is being shared between the threads using context switching. Example results generated using the computational power of the two machines using a distributed technique can be less efficient than the results generated by a single machine if proper multithreading has been done. There are number of excessive overheads in the distributed programming like communication between systems, non-shareable local memory, efforts wastage on task decomposition and merging, keeping track of the working of whole cluster etc. [8]. All these overheads can be acceptable only when the resources available on a single system itself are being used to a full capacity and there is no another alternative. Also, there are restrictions in terms of serialization, all of the data available in the given datatype cannot be serialized. So another overhead of data type conversion is being added by using distributed programming. Example while doing image processing the BufferedImage object cannot be serialized on the architecture used by Remote Method Invocation technique [2]. Such image related objects must be converted into either byte or integer type array for the purpose of serialization. MTPA is an idea related to prevention of such excessive overheads, the approach is proposed using the concept of multithreading on a single system.
Using the concepts of multithreading simultaneously number of independent threads can be deployed to perform a number of tasks in parallel in a single cycle to boost up the system performance. For this purpose, programming language Java is used for the creation of user defined threads. These threads operate on different parts of the subimage simultaneously using all the computational power available.
Median filter
Certain random bits of error which arises due to atmospheric disturbance, interference in channels, sensor temperature etc. can result in impulse noise in the image A nonlinear process known as Median filtering [12], helps in reducing salt and pepper or other impulsive noises from the image. While reducing the random noise this technique also preserves the edges of a given image.
Equation (1) represents the formula for applying median filtering.
It is possible to do parallel processing with the help of an intermediate layer framework which is being provided by the Remote Method Invocation (RMI) [3]. RMI makes it feasible, to call an object which is residing on some remote machine. Multithreading along with the RMI can be used to deploy a cluster and execute distributed programming with all the nodes in the cluster [4]. RMI registry plays an important role in such an approach, corresponding to each node in the cluster there is one corresponding registry which helps in getting the reference to the remote object [5]. Before the actual communication between the whole cluster starts, all the nodes create a stub which is being shared with a master node in the whole cluster. In the present proposed work comparison between the results generated using the RMI based cluster and proposed multithreading approach on a single system is done.
Rest of the paper is organized as follows, First, the related work is being discussed in Section 2. Then, in Section 3 proposed approach, pseudo code for the algorithm and complete workflow is discussed in detail. Section 4 covers the detailed analysis of result and discussion. Comparison between the proposed approach MTPA and RMI based cluster is done in Section 5. Finally, the conclusion and future scope are discussed in Section 6.
Literature survey
Murong et al. [4] in their paper uses the fork-join model of the OpenMP based parallel programming model to develop a parallel application in visual studio 2005 for registration of the large size images. The researchers concluded that multithreads using OpenMP and MPI can result in reducing the computation complexity, the number of iterations and large amount of computation time can be saved.
Pasricha et al. [8] in their paper uses the SIMD based model along with divide and conquer approach to implementing Strassen’s method for matrix multiplication. A number of systems were clubbed together by creating the interconnection via Microsoft Winsock control, to create a cluster and comparative study was done to find out the effectiveness of the proposed cluster. Various gaps like response delay due to shared memory of a master system, congestion due to a simultaneous transmission by different systems etc.
Arora et al. [9] in their paper deployed the cluster created using the VB 6.0 TCP/IP socket programming using Mswinsock.ocx. Different systems in the cluster work on subimage to implement the interlaced run-length compression scheme. The subimage is generated as per the number of systems in the cluster. The author concluded that efficient result generation can be done using cluster based programming.
Kika and Greca [10] in their paper proposes the use of java based multithreading approach on single and multiple-core platforms to change brightness and contrast of the chosen image. Also, the authors have implemented steganography algorithm to hide a message in an image in such a way that the modification of the image is imperceptible. Based on the experimental setup authors have concluded that the performance increases using the multithreading approach for single or multicore CPU platform.
Garg et al. [11] in their research paper discussed various variants of median filter algorithmin order to filter a digital image from various median filtering techniques like standard median filter (SMF), weighted median filter (WMF), recursive median filter (RMF), iterative median filter (IMF), directional median filter (DMF), switching median filter (SMF), adaptive median filter (AMF), median filter incorporating fuzzy logic (MIFL). Depending upon the scenario appropriate filter technique can be used for getting efficient results.
Shen et al. [13] in their paper makes use of the median filtering algorithm and proves that their system gains favorable performance and resistance to noise attack especially when the image sizes are having low resolution, images are compressed.
Kaur et al. [15] in their paper implemented proves that RMI can help in achieving better results. Researcher have tested the RMI approach by implementing the Winograd’s variant of Strassen’s method for matrix multiplication on the number of clusters. They have used various performance measurement metrics like speed up, execution time, efficiency, excessive parallel overhead to validate theirresults.
Sharma et al. [21] in their research paper perform the comparative analysis for different scheduling algorithms on the grid computing. Researchers have used various metrics and implementation environment to find out the effectiveness of various algorithms, which uses the grid computing for its scheduling. It has been concluded that there is always a requirement of the efficient scheduler which can distribute the workload in the cluster in a dynamic manner.
Bagga et al. [22] in their paper discussed virtualization technique that can help in the creation of virtual machines within a single system. The results generated are convincing in nature as all the available resources are very efficiently virtually distributed among various operating systems and multiplication is done in a simultaneous manner to implement Winograd’s variant method. Very high level of data parallelism is not achieved as a large amount of computation is being wasted in managing the virtual cluster.
From all these research papers, a new idea came to develop a proposed algorithm which is capable of handling the image processing related operations on a single system in an efficient manner. The system must have a capability that it can use all of the available resources to their full capacity. For this purpose, the uses of multithreading based parallel come into the picture. In some cases, can a multithreading based single systems can be more capable than the results produced by thenumber of systems in total? Whole research moves around to find the answer to this question.
Proposed approach
The multithreading approach is being used in the present proposed work for exploring the concept of parallelism. Threads whose count are thousands in number are being created on a given system and each thread is attached to a subimage which is being created from a single image. On each subimage the median filtering is applied to remove the salt and pepper noise from the image. So-called light weight process, threads share the same address space, use same code section, data section and OS resources, as a result overhead created during communication between the threads, can be decreased to a much greater extent. This helps in faster execution and efficient result generation.
Workflow of the proposed system
In order to achieve high performance using multithreading approach number of tasks has to be performed like: Designing an algorithm for parallel programming Partitioning the given problem as per the threads deployed, algorithm requirement Thread creation corresponding to each sub problem Scheduling of these tasks Continuously checking the liveliness of all the threads Synchronization Merging all the results to get a complete solution.
All these requirements are being mapped in a proposed work MTPA. The pseudo code for proposed is as shown in Fig. 1.

Representing pseudocode for MTPA.
Creation of 4 subimages from single image each handled by 4 threads.
Step by step workflow of proposed algorithm is shown in Fig. 3 and are also explained below:
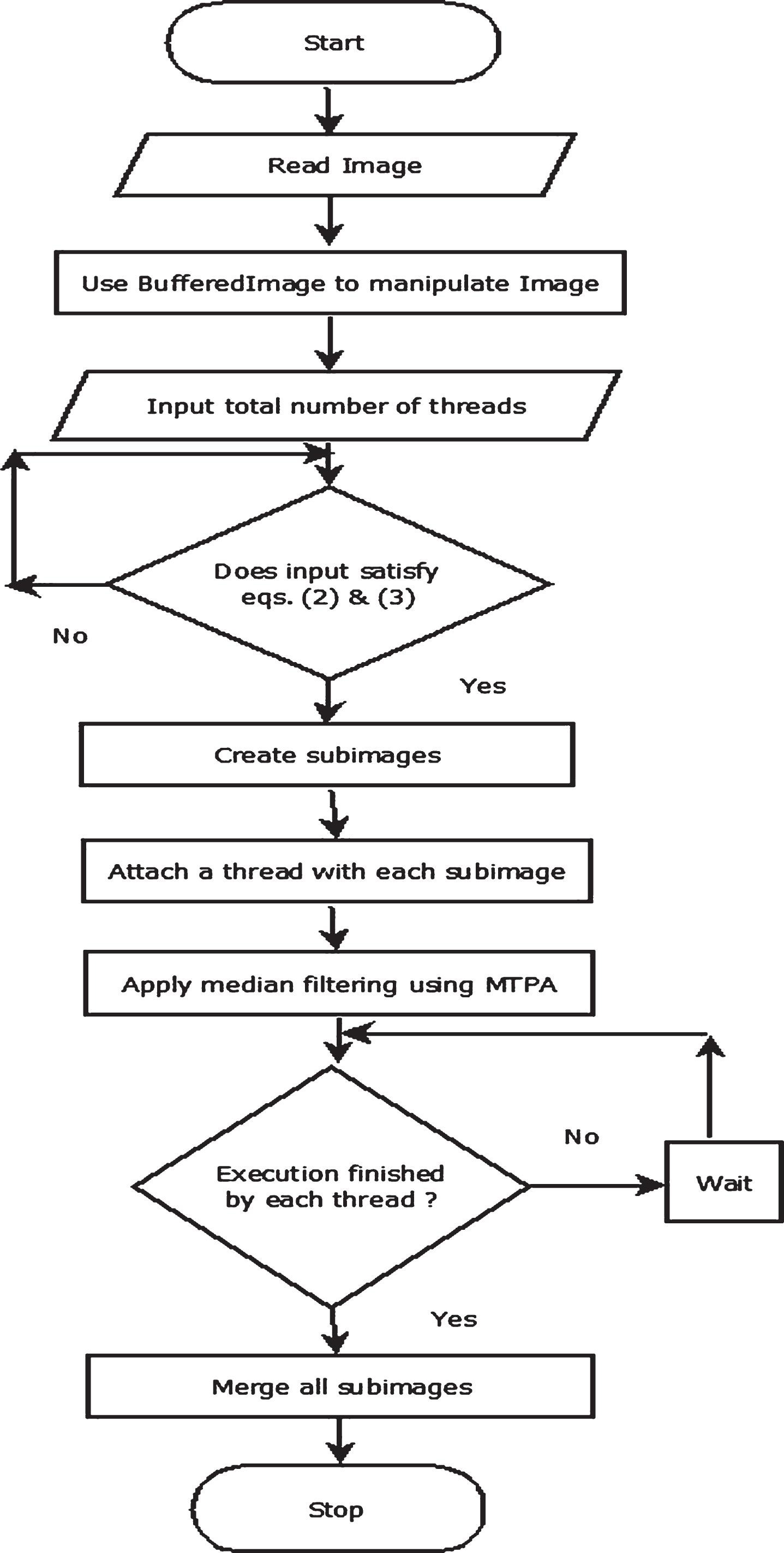
Workflow for proposed approach MTPA.
Use of File class is done for obtaining the abstract representation of a given image having salt and paper noise [18].
The BufferedImage, which is a subclass of Image class is used to manipulate the image data, which is stored in the File class object of Step 1.
In the proposed approach number of subimages created are equal to the number of threads, to be deployed for parallel execution. For each subimage, created from original image having height h, there is a dedicated thread for denoising of an image in parallel as shown in the Fig. 2.
The subimage of a given image is obtained using the method getSubimage (int x, int y, int w, int h), which returns subimage of size equal to a rectangular region specified in the given function. where
x - the x coordinate of the upper-left corner
y - the y coordinate of the upper-left corner of the specified rectangular region
w - the width of the specified rectangular region
h - the height of the specified rectangular region
The height of the subimage will be dependent upon the number of threads deployed as shown in the equations below. There will be always a constraint with respect to height of subimage, that the subimages height must be multiple of the height of the size of a mask used in the median filtering. Equations (2) and (3) represents the formulas which each height of subimage(HOESI) must satisfy.
where N is any integer value
All these threads work in parallel on each subimage for denoising of the image [17].
The number of threads that can be executed in parallel depends on the available system’s resources in terms of processors/cores [8], type of operating system and version of Java used.
Although it may appear that there are number of threads in execution simultaneously than the number of cores in a system, but in actual all of them might not be executing simultaneously [16]. The operating system uses pre-emptive scheduling for performing such multitasking [19].
There is not as much simultaneous execution of threads as expected, but the performance of the multithreading based program is always better than the sequential execution of the thread.
The join () is used to put the main thread to wait until all of the threads corresponding to each subimage complete their execution.
As there are number of BufferedImage objects corresponding to each subimage, after the completion of all of the threads, all these objects are merged to create a single object using createGraphics (). drawImage ().
At last a final denoised image is created from the single object obtained in Step 11.
The configuration of platform used for MTPA along with information about dataset used is shown in the Table 1.
Image details and the system configuration
Image details and the system configuration
Interface used in the proposed approach, is developed with the help of programming language Java, as it supports the creation of user defined threads.Further command line interface(CLI) is being used for interaction with the user. CLI is closer to the internal functioning of computer than are graphical user interface (GUI), thus it consumes lesser amount of computer’s system resources than the GUI. Further GUI requires additional system resources for handling icons, fonts, drivers etc. Thus use of integrated development environment (IDE) which uses the GUI,can result in wastage of resources for handling various GUI related tasks, present approachuses the CLI for its functioning.
Number of processor performance object counters are used to measure various aspects of processor activity. The processor object represents each processor as an instance of the object. Some of them are defined as: Formula for calculating processor time:
Even when no other thread is ready to run, there is an idle thread corresponding to each processor which consumes CPU cycles. This parameter is the indicator of the average percentage of busy time observed during the sample interval and processor activity. Sampling interval used for checking the idleness if the processor is10 ms.
In MTPA, the clock of the processor is being shared among various threads for generating efficient results corresponding to various performance metrics.Such sharing of processor’s clock, among threads,is done using context switching. During context switching interrupts are frequently generated by the clock, this helps the operating system to schedule the execution of all the threads. In general, there are to main steps followed during context switching: Saving of the values of the CPU registers in the table just before the occurrence of the clock interrupt. Loading of the registers with the values corresponding to the new thread to be executed.
Threads being a lightweightprocess shares the address space and resources with other resources, as a result the time taken for context switching decreases.
Results
Experimental results corresponding to various performance metrics of threads are shown in the Tables 2 and 3. The graphical representation of execution time corresponding to these threads are shown in Figs. 4–6.
Execution Time of various threads for MTPA
Execution Time of various threads for MTPA
Showing values of various performance matrices on different data sets for MTPA
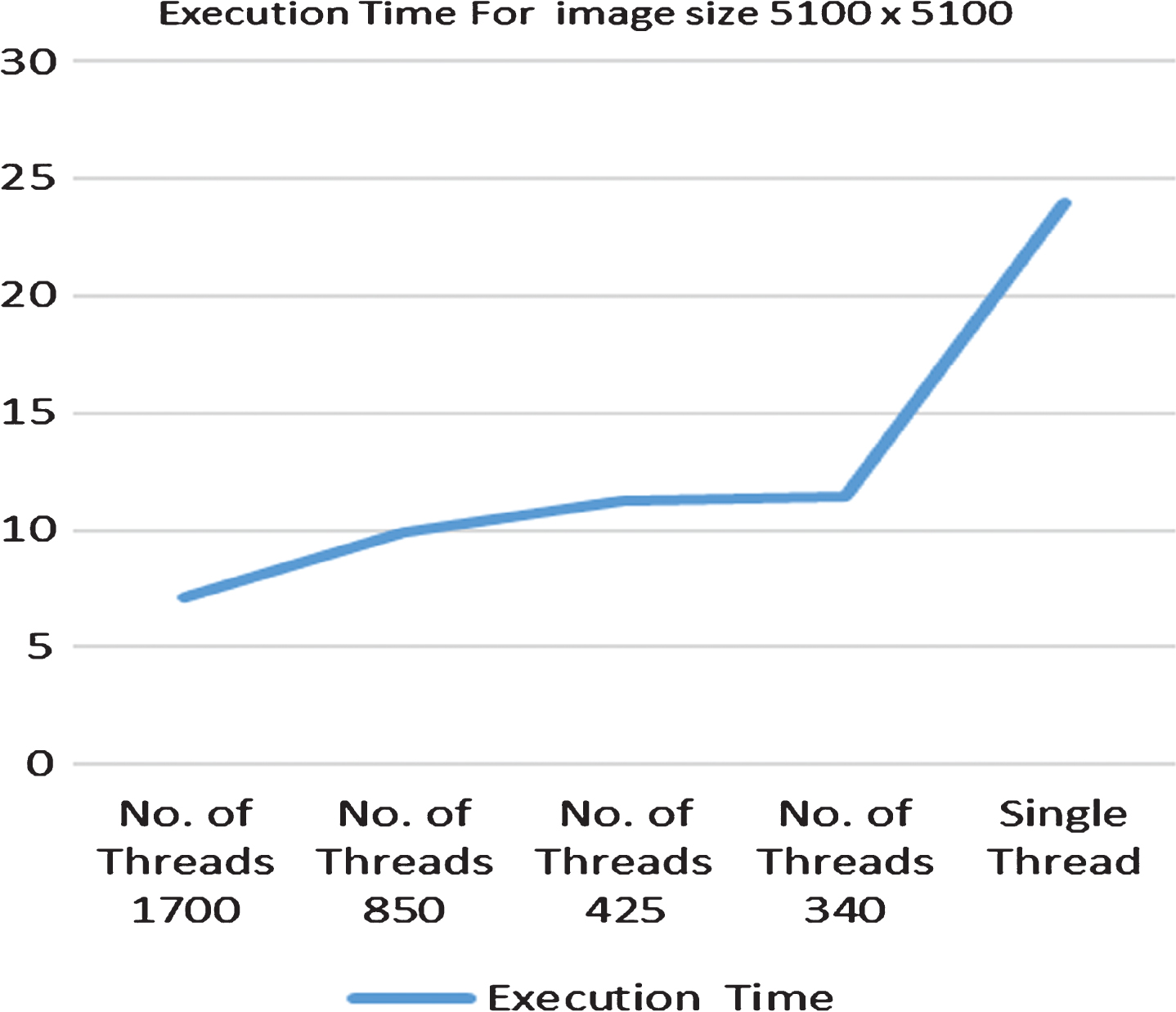
Showing execution time for MTPA.
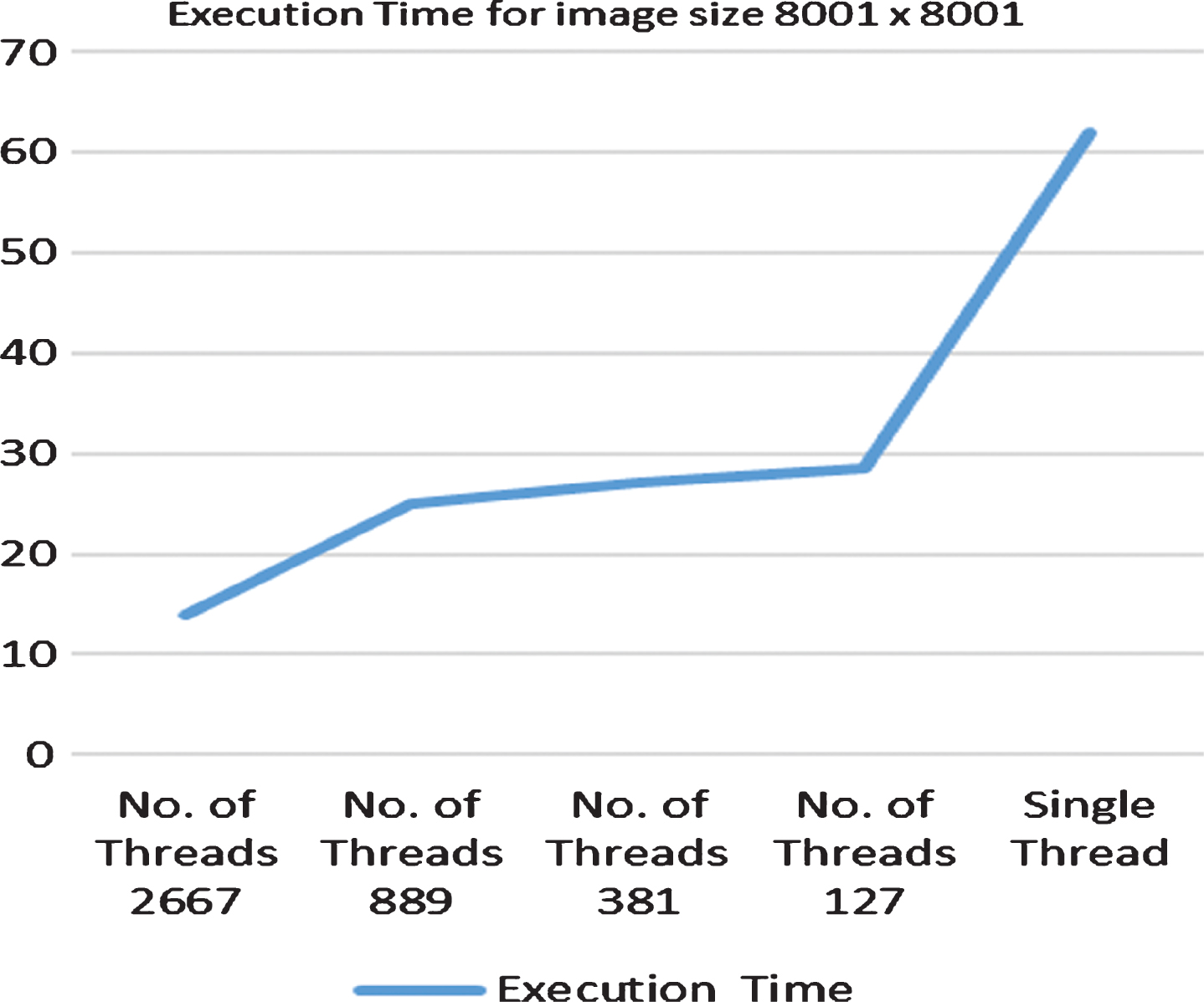
Showing execution time for image size 8001×8001 MTPA.
Showing execution time for MTPA.
In Table 2 the execution time for various data sets is discussed. Starting from a single thread, the number of threads deployed for parallel execution are increased step by step. During each increment in the number of threads,the corresponding effect on the execution time is verified. There is a remarkable effect of an increase in deployment of the number of parallel threads, on processing of image under consideration. As with each increase in the number of threads the corresponding value of time decreases.
Figure 4 shows that for image size 5100×5100, in comparison to single thread based execution time, there is 70% decrease in execution time when number of threads deployed are 1700, 59% decrease in execution time when number of threads deployed are 850, 53% decrease in execution time when number of threads deployed are 425, 53% decrease in execution time when number of threads deployed are 340.
Figure 5 shows that for image size 8001×8001, in comparison to single thread based execution time, there is 77% decrease in execution time when number of threads deployed are 2667, 60% decrease in execution time when number of threads deployed are 889, 56% decrease in execution time when number of threads deployed are 381, 54% decrease in execution time when number of threads deployed are 127.
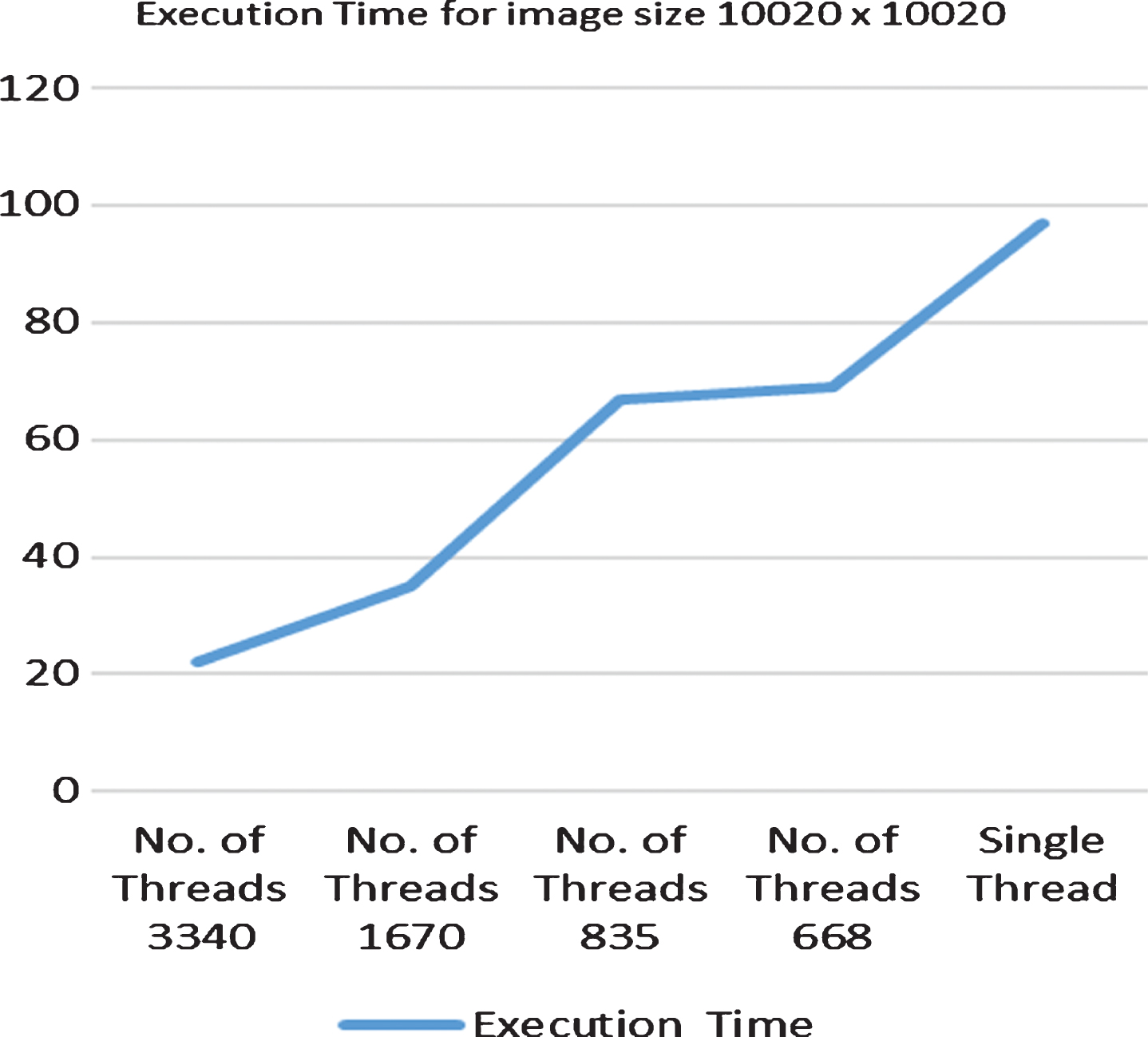
Figure 6 shows that for image size 10020×10020, in comparison to single thread based execution time, there is 77% decrease in execution time when number of threads deployed are 3340, 64% decrease in execution time when number of threads deployed are 1670, 31% decrease in execution time when number of threads deployed are 835, 29% decrease inexecution time when number of threads deployed are 668.
Figure 7 shows that for image size 9000×9000, in comparison to single thread based execution time, there is 77% decrease in execution time when number of threads deployed are 3000, 68% decrease in execution time when number of threads deployed are 1500, 62% decrease in execution time when number of threads deployed are 1000, 59% decrease in execution time when number of threads deployed are 750.
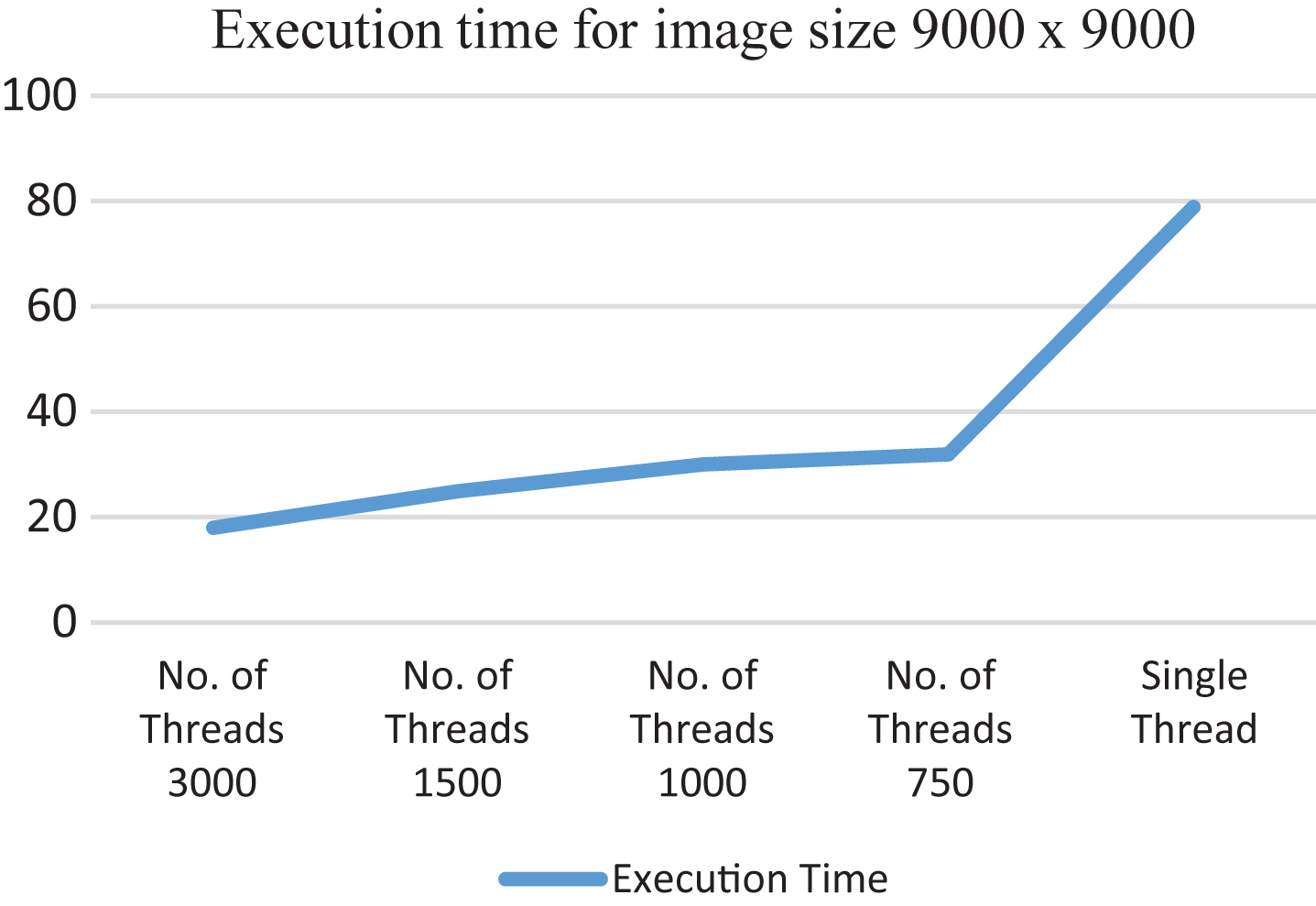
Showing execution time for image size 9000×9000 MTPA.
The main objective to create Table 3 is to the validate the proposed MTPA using various performance metrics. It shows the values for various performance metrics like Idle time, Processor Time, Maximum Frequency, Processor Utility corresponding to the different set of images, depending on the number of threads deployed. The effect of increase in the number of threads deployed is being verified using these performance metrics.
Figure 8 shows that for image size 5100×5100, in comparison to single thread based approach, the MTPA has 52% decrease in idle time, 150% increase in processor time, 134% increase in processor utility, 11% decrease in processor’s maximum frequency, when the number of threads deployed are increased to 1700.

Comparison of metrics for image size 5100×5100 on MTPA.
Figure 9 shows that for image size 6000×6000, in comparison to single thread based approach, the MTPA has 63% decrease in idle time, 181% increase in processor time, 165% increase in processor utility, 8.8% decrease in processor’s maximum frequency, when the number of threads deployed are increased to 2000.
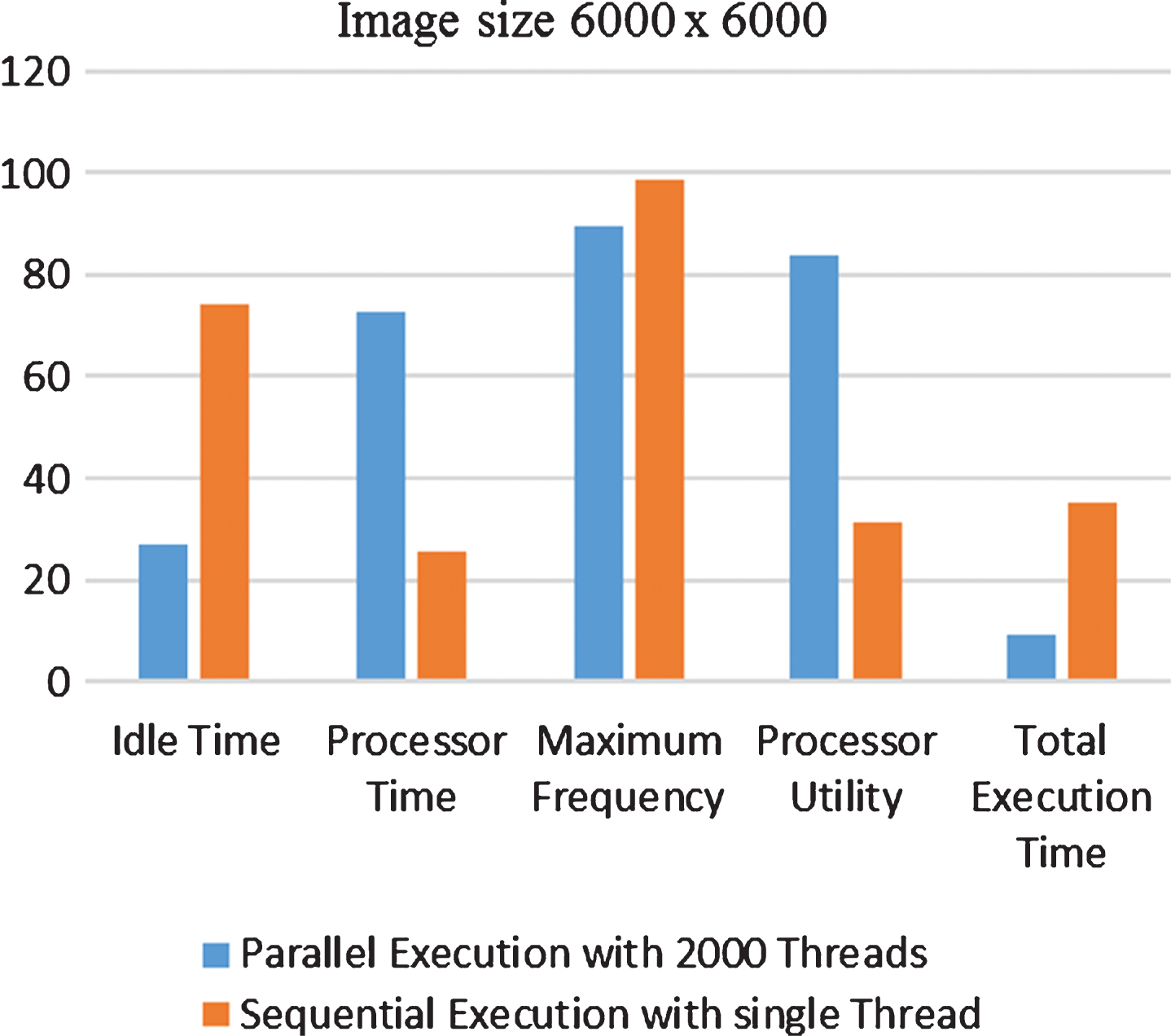
Comparison of metrics for image size 6000×6000 on MTPA.
Figure 10 shows that for image size 8001×8001, in comparison to single thread based approach, the MTPA has 62% decrease in idle time, 179% increase in processor time, 163% increase in processor utility, 9% decrease in processor’s maximum frequency, when number of the threads deployed are increased to 2667.

Comparison of metrics for image size 8001×8001 on MTPA.
Figure 11 shows that for image size 8250×8250, in comparison to single thread based approach single thread based approach, the MTPA has 60% decrease in idle time, 171% increase in processor time, 155% increase in processor utility, 12% decrease in processor’s maximum frequency, when number of the threads deployed are increasedto 2750.
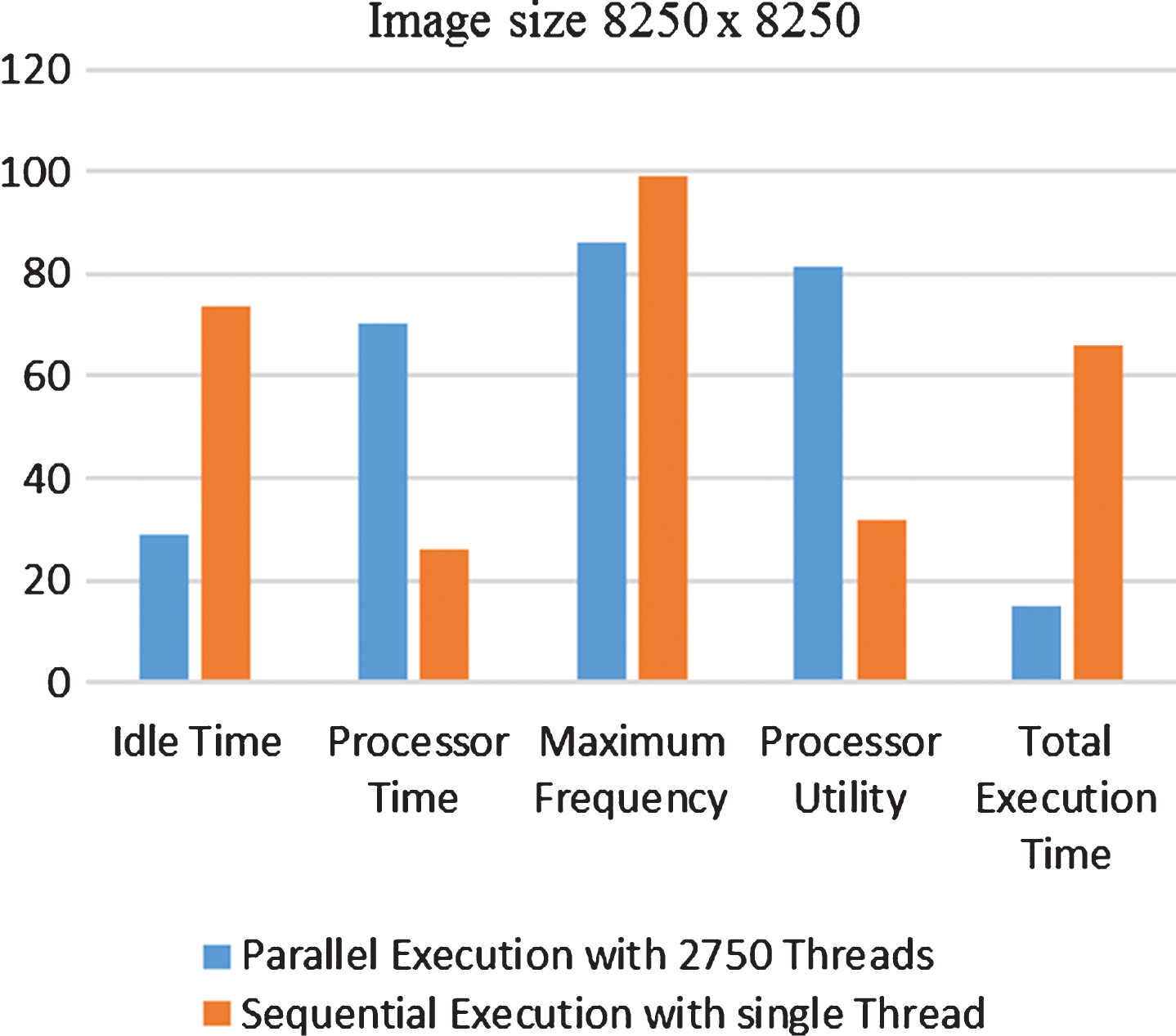
Comparison of metrics for image size 8250×8250 on MTPA.
Figure 12 shows that for image size 9000×9000, in comparison to single thread based approach, the MTPA has 68% decrease in idle time, 193% increase in processor time, 175% increase in processor utility, 0.45% decrease in processor’s maximum frequency, when number of the threads deployed are increased to 3000.
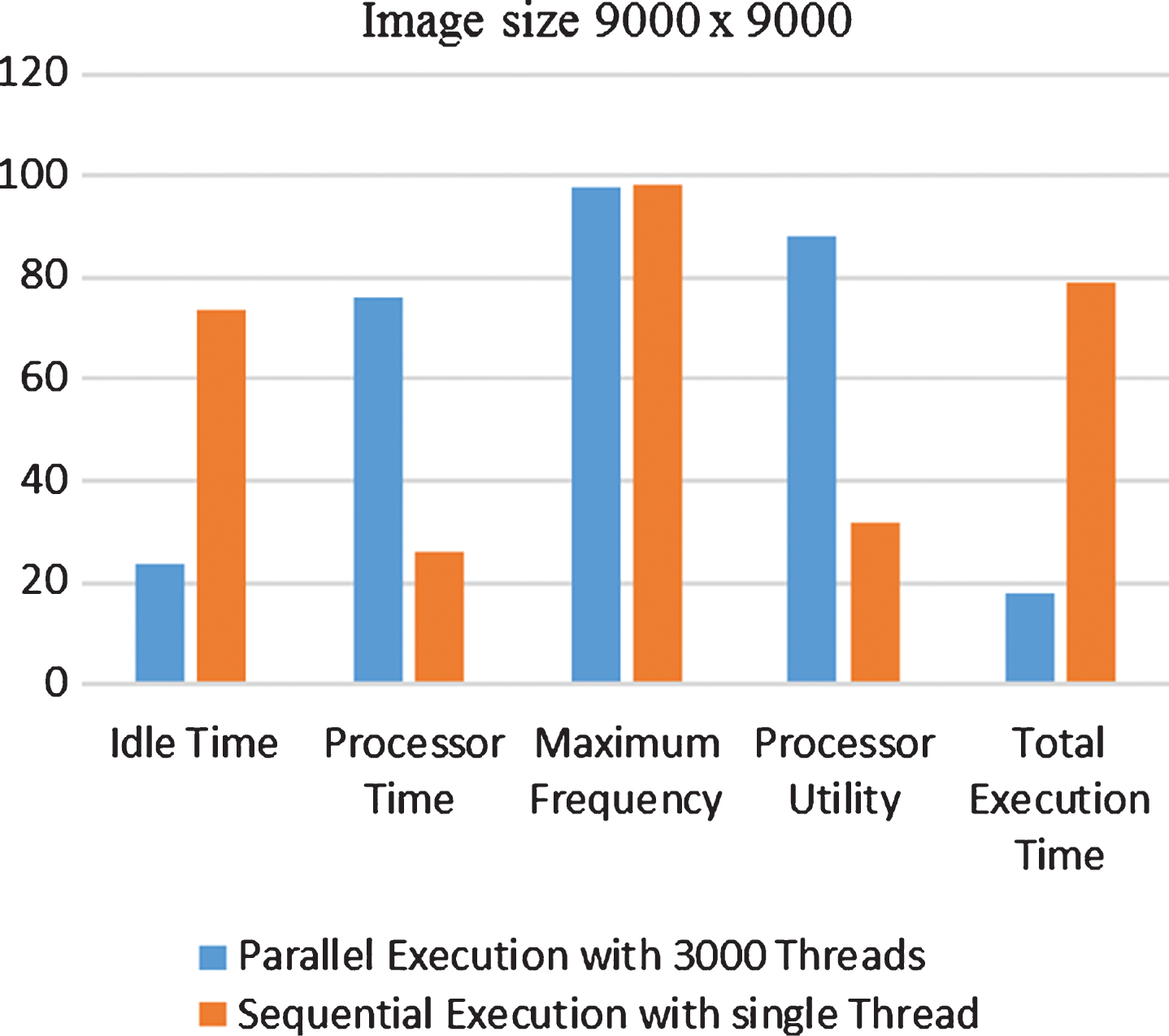
Comparison of metrics for image size 9000×9000 on MTPA.
Figure 13 shows that for image size 10020×10020, in comparison to single thread based approach, the MTPA has 68% decrease in idle time, 192% increase in processor time, 176% increase in processor utility, 2.61% decrease in processor’s maximum frequency, when number of the threads deployed are increased to 3340.
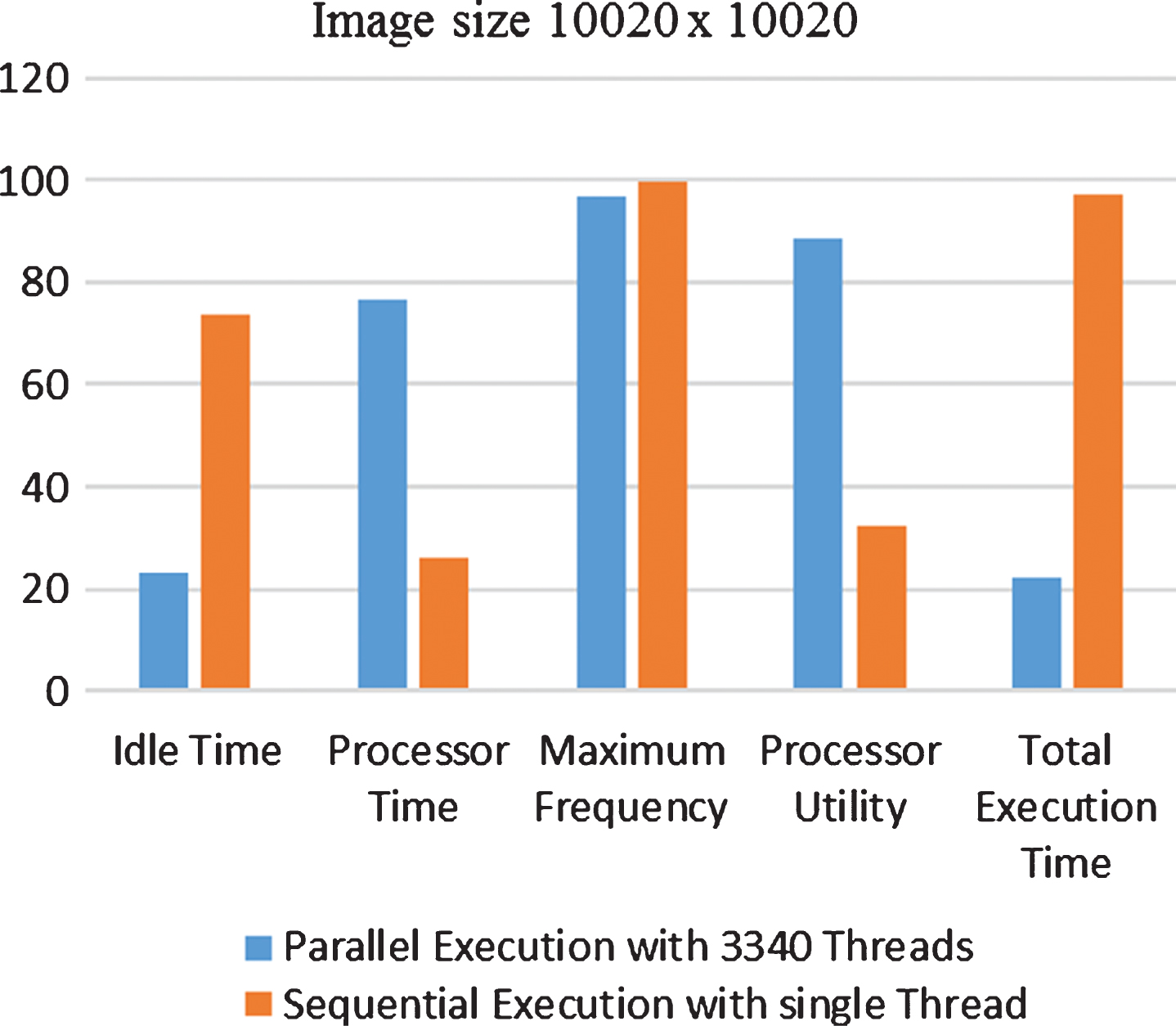
Comparison of metrics for image size 9000×9000 on MTPA.
In a nut shell: Idle time for the given time interval its decreases, as the number of threads deployed keep the processor busy for performing given task. Processor time is dependent upon the idle time. In the given proposed work for solving a problem, there is an increase in the value correspondent to the processor time, it is as a result of a decrease in the idle time. There is a decrease in the values corresponding to the maximum frequency for the given proposed work. this indicates that single threading approach is wasting the resources in terms of processor cycles, the same task can be done in lesser time without any computation wastage. There is a drastic increase in the value corresponding to processor utility, which indicates that more quantity of work is finished in a given time interval. The values corresponding to the most common parameter overall execution time decreases using the proposed work due to efficient resource utilization.
Comparison between the Parallelism implemented using
Comparison between MTPA and RMI based distributed application
Comparison between MTPA and RMI based distributed application
Experimental setup for implementing RMI based cluster
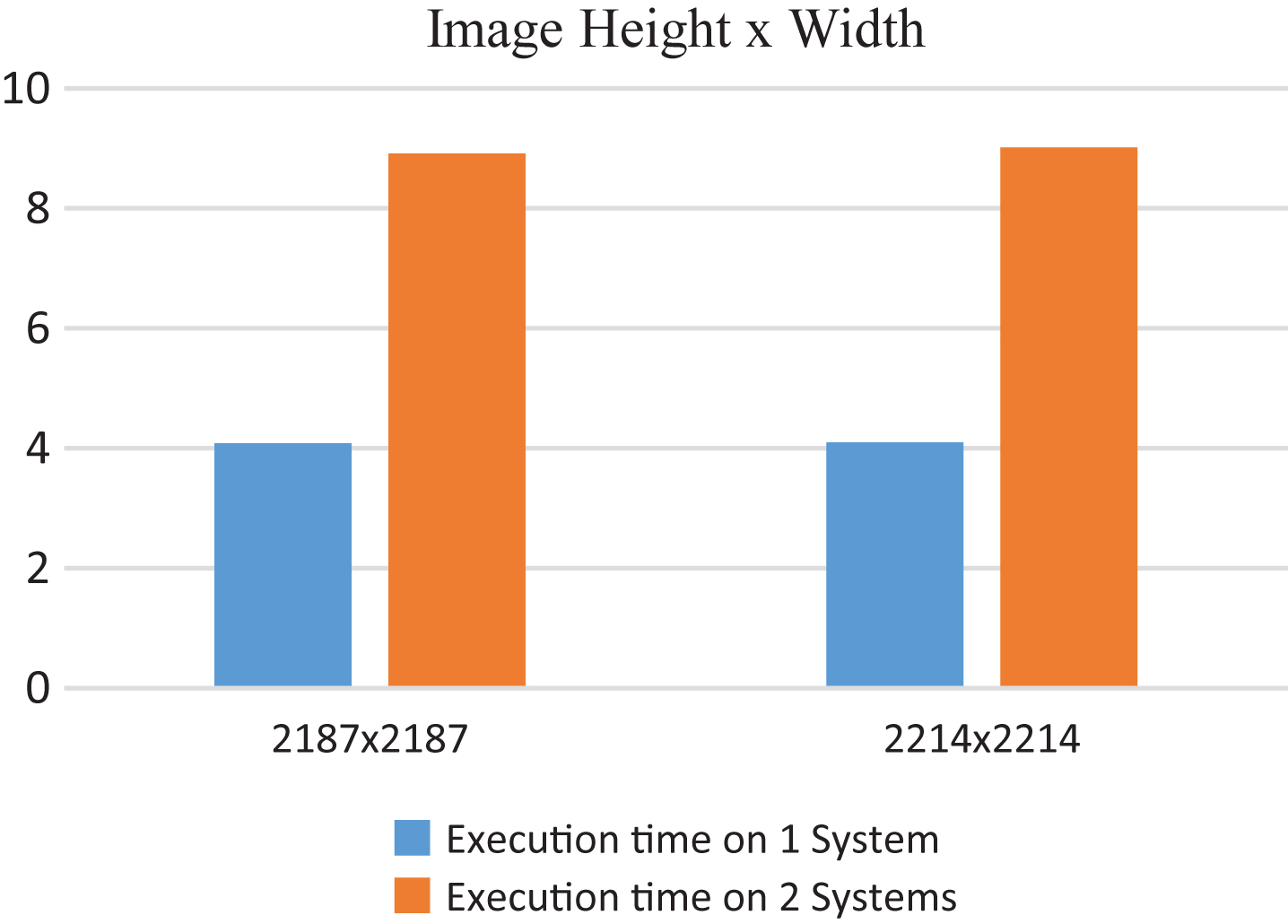
Shows execution time corresponding to the RMI.

Shows execution time corresponding to the RMI approach the RMI approach.

Shows execution time corresponding to the MTPA.
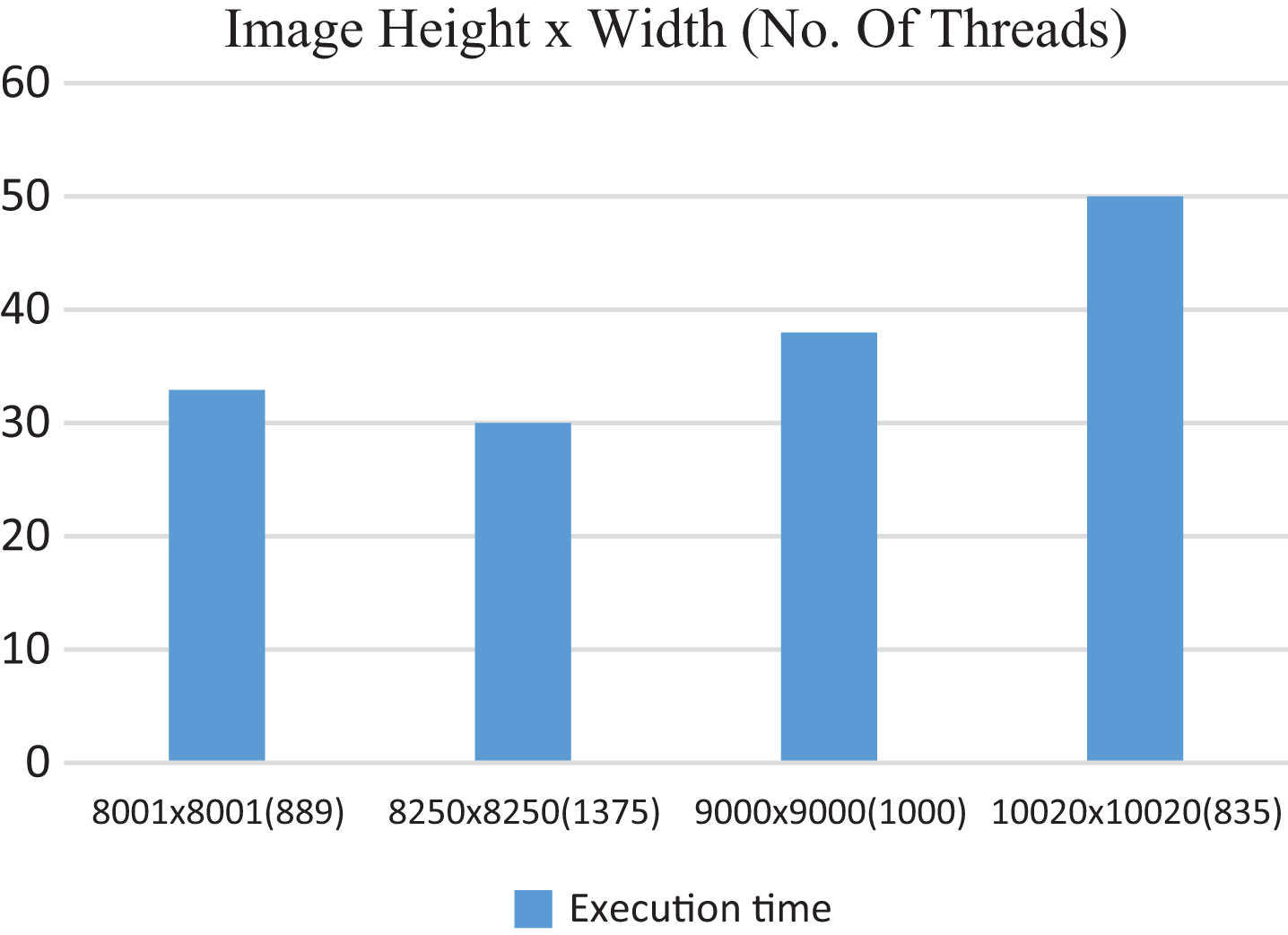
Shows execution time corresponding to the MTPA the RMI approach.
Table 4 represents various factors like execution time on the single system, the size of a cluster, execution time on give cluster, data set of images included, the number of threads created and total execution time corresponding to these threads.
Figure 14 shows that for the image size 2214×2214 there is 54% decrease in the execution time, for the image size 2187×2187 there is 54% decrease in the execution time.
Figure 15 shows for the image size 5049×5049 there is 27% decrease in the execution time, for the image size 5040×5040 there is 25% decrease in the execution time, for the image size 4509×4509 there is 33% decrease in the execution time, for the image size 4500×4500 there is 46% decrease in the execution time, for the image size 2268×2268 there is 55% decrease in the execution time.
Figure 16 represents results corresponding to MTPA. It shows that 59% of the decrease in the execution time for the image size 5100×5100, when the number of threads deployed are 850. 63% of decrease in the execution time for the image size 6000×6000, when the number of threads deployed are 1000. 61% of decrease in the execution time for the image size 7002×7002, when number of threads deployed are 1167.
Figure 17 also represents results corresponding to MTPA. It shows that 60% of decrease in the execution time for the image size 8001×8001, when the number of threads deployed are 889, 64% of decrease in the execution time for the image size 8250×8250, when number of threads deployed are 1375,62% of decrease in the execution time for the image size 9000×9000, when the number of threads deployed are 1000, 31% of the decrease in the execution time for the image size 10020×10020, when the number of threads deployed are 835.
Results generated using the proposed architecture are very much convincing in comparison to distributed object application using RMI [23]. Reason for more efficient results using Multithreading approach are [24]: All the data on which filtering has to be done is available locally. Concurrent execution of threads for data processing. No overhead related to data transfer between systems in a cluster. More efficient use of system resources. No bottleneck caused by the slowest system in the cluster, as result generation of the whole cluster is dependent upon the system with least computational level.
Conclusion and future enhancements
From the above experimental facts overall, it can beconcluded that: Given system works intelligently for parallel execution of the tasks on the decomposed data. Before using a distributed programming technique more and more amount of multithreading [26] must be deployed to fully utilize the available resources. When all the computation power of a given system is used to the full capacity only then distributed programming must be used as lots of excessive overhead are their while using the same. Some of these overheads included are problem of serialization, conversion of data from one form to another to form it serializable, communication overhead between systems in a cluster, non-shareable local memory, efforts wastage. In terms of cost no extra requirements of hardware like Switch, CAT cables etc. is there.
Future enhancements
From the experimental facts, it has been concluded that large amount of time is utilized during the merging the number of small buffered objects to form a single object so that final image can be created from that. In the present proposed work createGraphics(). drawImage() is used for the given purpose. Better merging technique and more intelligent multithreading approach can be enhancement of the results.