
Abstract
For a thorough understanding of procedures in various network applications, and to automatically classify, recognize, trace, and control them, it is necessary that the state machine representing application sessions is obtained in advance. This article presents a novel approach to reversely infer a protocol state machine from collected data of the application layer. Protocol state machines are derived using a method of error-correcting grammatical inference, which is based on symbol sequences that appear in the application sessions. The techniques are implemented into a tool called PREUGI, which is conducted in a real network, containing a number of real applications with several application layer protocols, to validate the proposed method.
Keywords
Introduction
Protocol reverse engineering aims to accomplish application-level protocol analysis and reconstruct communication process through analyzing sessions without learning the protocol specification, such that it grasps the format, structure, and function of the network protocol. A thorough understanding of protocol is increasingly important for the security of computer networks, such as in vulnerability discovering [1], protocols and tunneling identification, intrusion detection systems [2, 3], fuzzing testing [4], deep packet inspection, and the analysis and prevention of malware for quickly spreading of worm, botnet, and trojans [5].
Unfortunately, protocol specifications for the afore-mentioned tasks are illustrated as documentation, or, if the documentation is not available, it then depends on manual reversed engineering. However, manual efforts are painstakingly time-consuming and error-prone. To address the limitation of manual protocol analysis, automatic protocol reverse engineering was proposed. Automatic protocol involves two methods: (1) packet sequence analysis based on network trace and (2) the program’s execution sequence analysis based on dynamic behavior.
In packet sequence analysis based on network trace, the goal is to collect data pertaining to the interchanging side in the network, and then to carry out offline analysis of packet sequence for network flow. In principle, this scheme is simple and easy to implement, and it can manage the task with quick analysis speeds. For instance, the extraction of protocol fields and delimiter with heuristics is reported in [6]; the protocol message format is derived from packet sequence of network traffic in [7, 8]; Justin and colleagues analyzed network traffic to achieve a discriminating goal for inhomogeneous traffic [9] by applying statistical modeling tools. These systems have been evolved by examining the packet sequence of traffic communications, but they can only extract limited field information of protocol and attain an approximate description of the protocol format; therefore, accuracy becomes restricted.
The program’s execution sequence analysis, which is based on dynamic behavior, has to carry out an online analysis of the executing instrument during the resolving of network data. It basically acquires the instrument sequence through a taint analysis of these tasks. For example, both Polyglot [10] and AutoFormat [11] acquire field information from observation of program execution during the processing execution traces. Other analyses [12, 13] have derived various types of format specifications and semantic information. These systems can more accurately infer message structure by monitoring the resolution process of protocol entity at instrument-level during program execution. They can more profoundly obtain field semantic information, which is not reachable in the packet sequence analysis situation. However, these systems would partition field format excessively causing granularity, which tends to make system analysis complicated as well as decreases speed and performance levels.
Recent researches works have attempted to derive the protocol state machine together with the development of protocol reverse engineering, e.g., PEXT [14], Prospex [15, 16], ReverX [17] and Veritas [18, 19]. These works adopted the state machine as a structural description for network protocol specification; however, they could not entirely eliminate the state redundancy, or they needed a controlled environment.
Reports in the literature [20] indicate that grammatical inference (GI) is feasible in the field of reverse engineering of the state machine, which applied two algorithms on GI to reverse engineering the state machine for POP3 and SMTP.
In summary, the contributions of this work can be described as follows: We propose a more general approach to automatically derive the protocol state machine. We introduce a GI methodology to model protocol state, and present a novel technique based on the thinking of the error-correcting and cumulative increasing to deduce the state machine regulating the message-exchanging order. In addition, we propose several measures to advance the performance of error-correcting so as to more accurately infer the state machine of protocol. At first, we present a benchmark to locate the position that implements the error-correcting action. Moreover, we use a negative example to improve the accuracy during the process of error-correcting. Further, we propose a measure of abnormal indegree discrimination based on statistical probability to conduct the abnormal indegree pruning. We obtain a more generalized state machine with concise style in our system. We present a simplifying solution to exclude the redundant state during the reconstruction of the state machine. The proposed scheme, PREUGI, can be implemented for a number of real-world application traces that are deployed with a series of protocols. In addition, the performance characteristics for the inferred state machines are experimentally evaluated in PREUGI. The result shows that the derived state machines are considerably generalized and accurate to model the protocol structure.
Object problem statement
Grammar and the state machine are essentially equivalent. In this section, the goal and methodology for inferring the protocol state machine are depicted by using GI as the origin.
Description and analysis of object problem
The examples needed for GI are arbitrarily synthesized with basic elements or signs, and the usual method for generating these examples is concatenation. When GI is applied to protocol inferring, it must initially analyze interchanging data examples of network protocol, that is, the network flows have to be divided into sessions. The packets for a majority of protocols are analyzed in hierarchical order. There are format fields signifying the manner for analysis of protocol structure in the hierarchical analyzing process. The tokens and symbols, which act as fields with the most behavioral meaning of protocol and sign the current state logic, are state tokens that describe the interchanging behavior of the protocol. Thus, the token sequence most representing the protocol logic is extracted from the data example in a session. The results extracted from multiple sessions comprise a set of token sequences representing the protocol feature, which is represented as
Where T = {(Ω1, l1) , …, (Ω
m
, l
m
)} denotes the string set comprising the element pair of tokens and each element pair, (Ω
i
, l
i
) ∈ Σ* × N, denotes an input token Ω
It can be found that the inferring state machine of protocol with GI needs a series of tokens, which are characterized elements that express the interactive behavior of the network protocol with the most behavioral meaning. However, the process described above is achieved on the basis of the condition that the token set is known, which would be unreachable for a closed protocol or an unknown application. Therefore, some researchers have carried out research to obtain the token set by data mining and clustering.
In this article, an automatic scheme of GI based on the principle of error-correcting GI, called PREUGI, is presented. Figure 1 presents an overview of system framework. At first, token sequences are extracted from data samples of the application layer session by using the known ‘tokens set’. The token sequences are abstracted as state-transiting sequences from the session of protocol entity. The state-transiting sequence of a session corresponds to a path of state machine. Then, the path constructed by the state-transiting sequence is compared individually with the paths in the state machine to identify the best-matching path, and the path is revised to be consistent to the sample. The state-transiting sequence of a session for protocol entity makes up a subset of state machine, and the state-transiting sequences set is extracted from the sessions of a similar protocol. The APTA consistent with the sample set is constructed by recursively carrying out the process described above. Finally, the compact state machine is derived to describe the interchanging process of protocol entity with DFA by combining the repeated tokens on the basis of same tokens and reducing tokens again with regard to a similar sense of behavior.
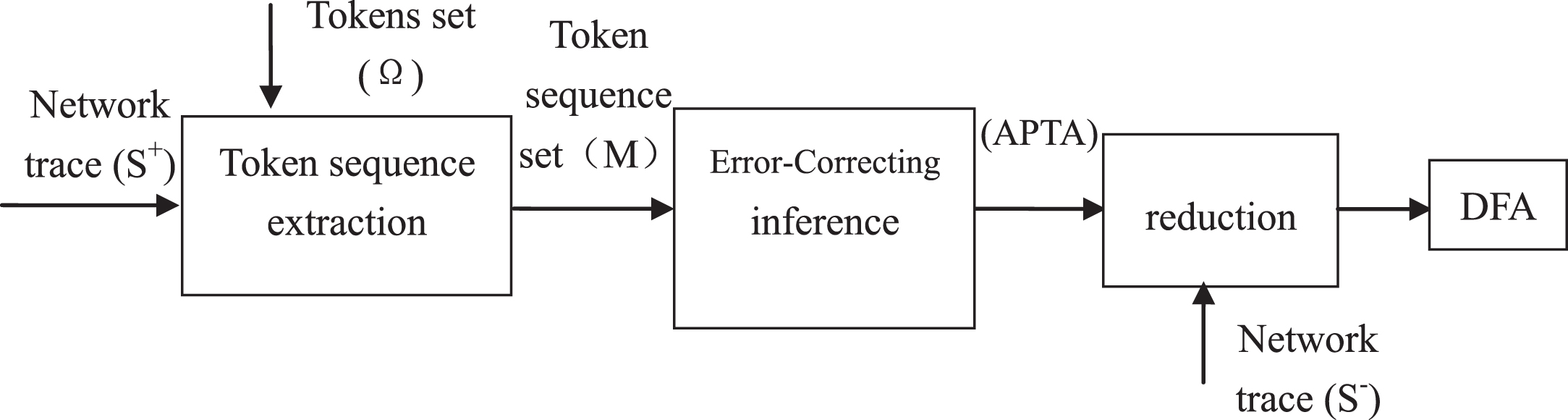
System framework overview.
Extracting token sequences
It is obviously improper to directly use all data for inferring the protocol state machine during training data examples. According to GI, initial extraction from examples has to be carried out based on the tokens set. For the open protocol with the document of protocol specification, its token set comprises tokens. We can derive the sample set of the token sequence as
These token sequences are extracted through the process described above against the data set of the session examples belonging to the same protocol.
The protocol state machine comprises a series of state; the arc and arrow denote the relation of transition between states, and the tokens provide the conditions of transition. Each token sequence
The path is the best-matching one if it matches optimally with the current token sequence in comparison to all paths in the hypothesis state machine, which uses the best-match rate as the criterion. Suppose there are n tokens in a token sequence sample, the first token is individually compared with each of the tokens in the current path. If they match each other, then the process adds 1 to count; otherwise, it transfers to the next token in the current path and implements the same process described above for every token up to the last in the example. Therefore, the matching rate to the current token sequence against the current path is , namely,
This denotes the conditional matching rate for the examples of token sequence. The path with the most matching rate is the best-matching path for the current token sequence after comparison with all other paths in the hypothetical state machine, and it has the best-matching rate, which is expressed as
It needs to revise the best-matching path after identification if the best-matching rate is not 1. There are two operations for updating: one is the addition of one state if it is new; another involves addition of a directional arc to set up the relation between the two states if the state is in existence. For example, if the best-matching path selected is 220→ USER → 331 → PASS → 230 → TYPE → 227 → CWD, which is demonstrated as token sequence. Then, each string inside the sequence denotes the condition needed for transition of state. If the current token sequence example is
We can find that the identifiers 220, USER, 331, PASS lie in the best-matching path.
When the pointer moves to ‘200’, the corresponding state would not be found in the best-matching path, and therefore, a new path would need to be created, with an assigned property value of ‘200’. In addition, it needs to add a transition arc from the preceding state (PASS) to the new one (200). The corresponding path alters as

after the same process as for ‘PASV’.
When the motion is to be ‘227’, it lies in the best-matching path; therefore, it need not add a new path. However, because of the absence of the transition to ‘227’, it needs to add a directional arc from the preceding state ‘PASV’ to ‘227’, then, the new path becomes:

‘CWD’ lies in the best-matching path similarly, but it is different in that the directional arc between that state and the preceding one (i.e., ‘227’) is existent; therefore, it does not need to do anything for the update.
All sequences in the sample set of the token sequence are dealt with consequently using the preceding best-matching criterion for the best-matching path and state updating; then, the APTA for the protocol state machine is reconstructed by the cumulative update process. It is a no-loop multi-branch tree according to the data structure.
In the above sections, the state machine was derived on the basis of the error-correcting parsing of the paths, and the selection criterion of the path depends on the least overhead. However, the states of the state machine would increase endlessly with augmentation of examples. The resulting state machine would have to make some reduction according to the features of network protocol for its efficient use.
State combination relying on the identical token of state
The size of the state machine derived in Section 3.2 is too large, which arose from the same repeating operation contained in the examples, and the examples were gathered from a real network application. Thus, the identical state has been used repeatedly. The state tree can be updated as
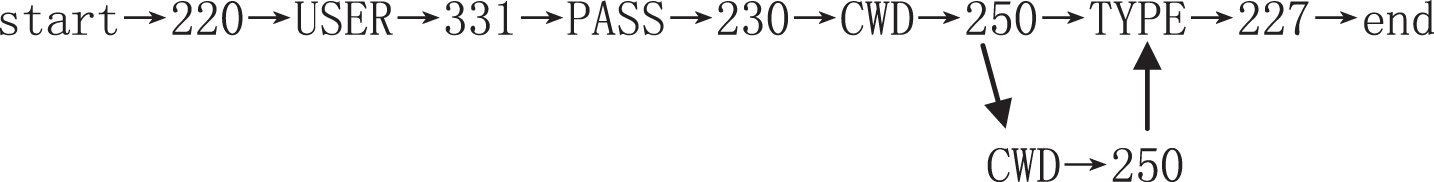
according to the scheme in Section 3.2.
Because of unused existing identical states, two states were inserted instead. If there are such n cases, that means an increase to 2n states! This would result in the state expanding considerably, which must lead to unpredictable calculating costs and cause the state machine to become unavailable for practical application. Each identifier denotes an operation or response for each part during intercommunication. Thus, it should be viewed as the same operation to the identical token, which replaces the repeated updating with inserting operation.
Based on the discussion presented above, we now present a reducing scheme for the state machine; it merges two states expressing the same operation continuously until only one is left for these states. Moreover, the merging process extends to the other operation appearing in the state machine; therefore, we can obtain a concise state machine. However, some accidental cases would need to be avoided. The following description presents the primary idea. The search begins with the second state (because the 0th and first states are assigned to ‘start’ and ‘end’ as signing symbols, respectively). The second state is referred to as the ‘targetstate’. If the same state as the second one is found during the forward search, the resulting state is indicated as ‘mergestate’. After merging ‘mergestate’ with ‘targetstate’, the outgoing state adjacent to ‘mergestate’ (referred to as the ‘outdegree’) and the incoming state adjacent to ‘mergestate’ (referred to as ‘indegree’) have to be combined to ‘targetstate’ in order to avoiding losing; that is, the outdegree of ‘mergestate’ will add to the outdegree of ‘targetstate’, and the indegree of ‘mergestate’ merges with the indegree of ‘targetstate’. A more detailed description is shown in the following example.
In Table 1, the first column presents the sequence number for states (only considers the 8th–15th state), the second column indicates the token providing the condition for transferring to the corresponding state, and the third column demonstrates the outdegree belonging to the corresponding state. The example begins with the 8th state, and the search moves forward against the 8th state as the targetstate. The first match state is the10th state, which is the same as the targetstate with the token ‘+OK’; therefore, the 10th state is merged with the 8th state, and the outdegree of the 10th state is combined with that of the 8th state and the indegree of the 10th state is added to that of the 8th state; finally, the 10th state is deleted. The 13rd state is merged with the 8th state by using the same method. The result is shown in Table 2.
The state machine before removing the repeating states
The state machine before removing the repeating states
The state machine after removing the repeating states
In order to gain a more accurate state machine, the error in the partial state machine derived above has to be revised. The training examples used above belong to the same specific selected protocol, and these examples are referred to as positive examples. The training examples used to exclude the error are those belonging to the other protocol; these examples have tokens similar to that of the positive example, and are referred to as negative examples. For example, there are similar responders for POP3 and FTP protocol; therefore, data examples belonging to the FTP may be selected as the negative examples to infer the state machine for POP3. A detailed revision is similar to the process producing a partial state machine depicted in Sections 3.1 and 3.2. After extracting the token sequence for each negative example, each token sequence is compared with the path in the state machine by calculating the best-matching rate recursively. If the matching rate is equal to 1, the current path in the state machine is considered identical to the agreement denoted by the negative example, that is, the current path is not a part of the protocol structure of the positive example. Therefore, it needs to start the updating process to delete the redundant part. It is obvious that deleting the whole path would affect the other correct path. We aim to delete the portion of the path that is not shared with other paths, that is, the states that only contain one state in outdegree and indegree.
Model reduction relying on similar semantic
As described previously, the construction of the protocol state machine is based on a set of token sequence. Each token expresses an action or a response. From the view of intercommunication of protocol, some operation is in series, that is, the action only occurs once during the entire session. Later, the following action is in parallel, that is, it does not exhibit a dependent relation of time between actions, it could carry out different actions, and the amount of repeating action is not limited. For the state of ‘DELETE’, ‘LIST’, ‘UIDL’, and ‘RETR’ shown in Table 2, they have the same prefixed and suffixed state sets, and it would be possible to consider combination of the four actions into a state to gain a concise state machine. The reducing process not only maintains the original interacting structure but also combines the state with a similar semantic. The removal of the repeating token depicted previously can be regarded as reducing formally, and the reduction in this case can be considered to be reducing semantically.
All states with a similar semantic should implement reducing ideally. Finally, we can obtain the considerably compact models of the protocol state machine.
Evaluation of the inferred state machine
In this section, we evaluate the feasibility of reversely inferring the determinate finite state machine reflecting the complicated protocol structure from appropriate training data examples.
The inferred state machine for the protocol specification
For the purpose of eliminating the limitation of only using positive examples, we added the negative examples to the set of training examples. These negative examples, using the other protocol, are similar to the examples using the protocol under consideration. The example sets of network trace used in learning are listed in Table 3. The network traces containing HTTP, SMTP, POP, and FTP originate from MIT DARPA 1998 [21].
Set of training examples for inferring protocol state machine
Set of training examples for inferring protocol state machine
The definite finite state machine derived with our approaches is shown in Figs. 2–5. Figure 2 depicts the state machine derived for HTTP. The client sends a request to the server together with a method in the set of Λ and the version value of protocol (in Δ), and the server responds to the request with the version value of protocol in θ and the responding code.

Setting for document template.
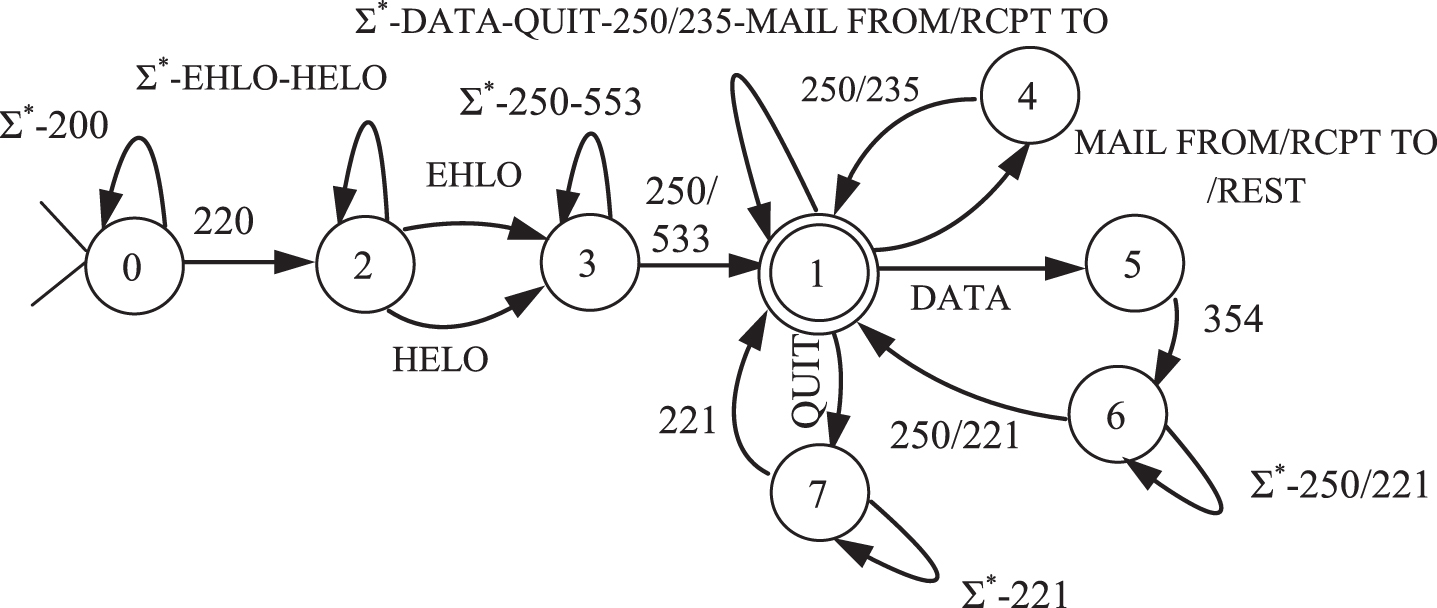
The state machine derived for SMTP.
The state machine derived for SMTP.
The state machine derived for SMTP.
Figure 3 depicts the state machine extracted for SMTP. The path 0 → 2 →3 → 1 represents the login process, which consists of two methods, that is, EHLO and HELO. The path 0 → 2 →3 → 1 indicates the case of login failure; the path 1 → 4 →1 shows the mail-exchanging process; path 1 → 5 →6 → 1 renders the data exchange; and the 1 → 7 →1 indicates the quitting of protocol.
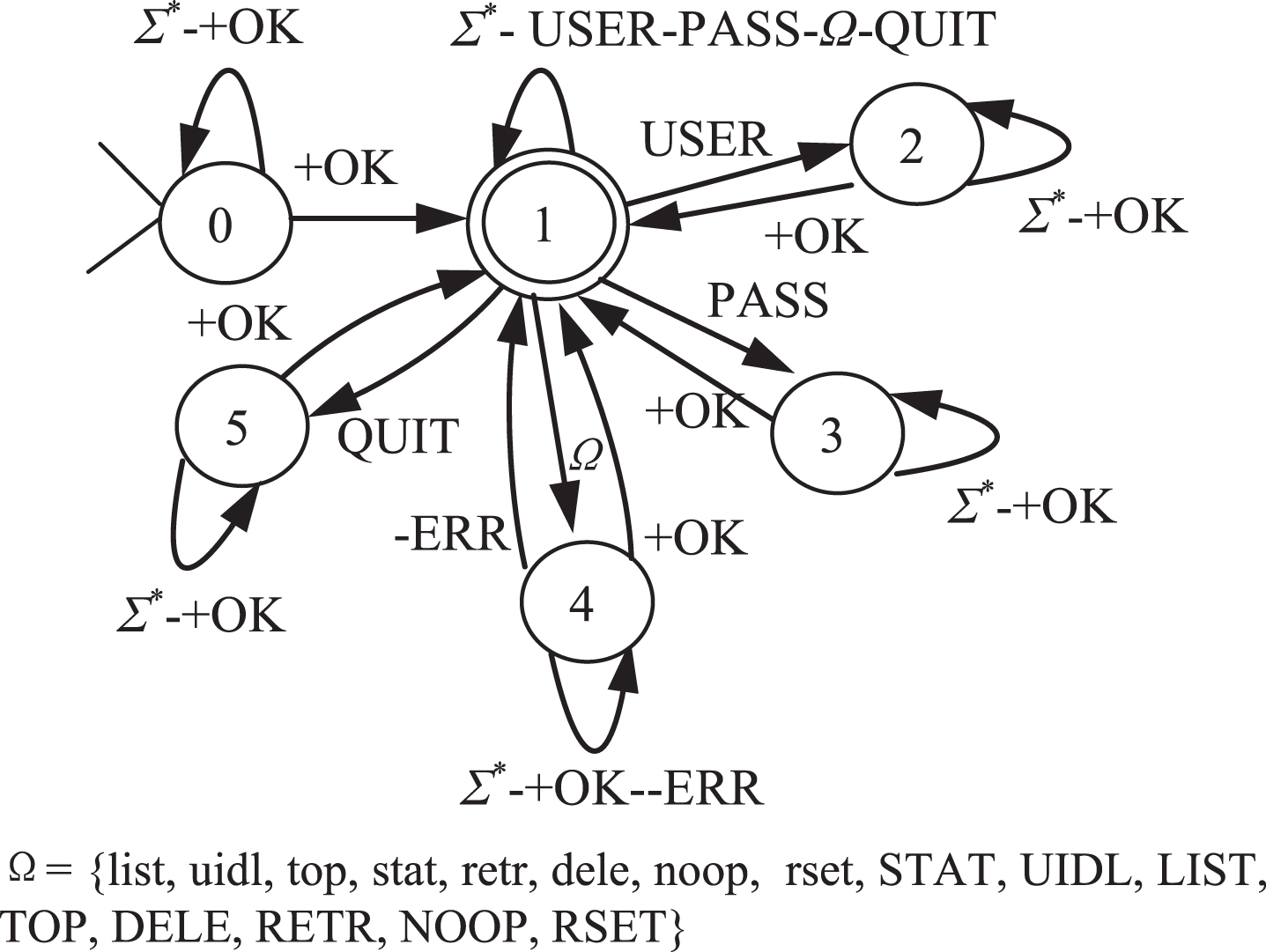
Figure 4 shows the state machine derived for POP3. The path 0 → 1 →2 → 1 →3 → 1 reflects the initializing process of protocol; 0 → 1 contains the cases for the initializing failure; 1 → 4 →1 represents the client communication with the server using one method in Ω; and the 1 → 5 →1 provides a path for quitting the protocol.
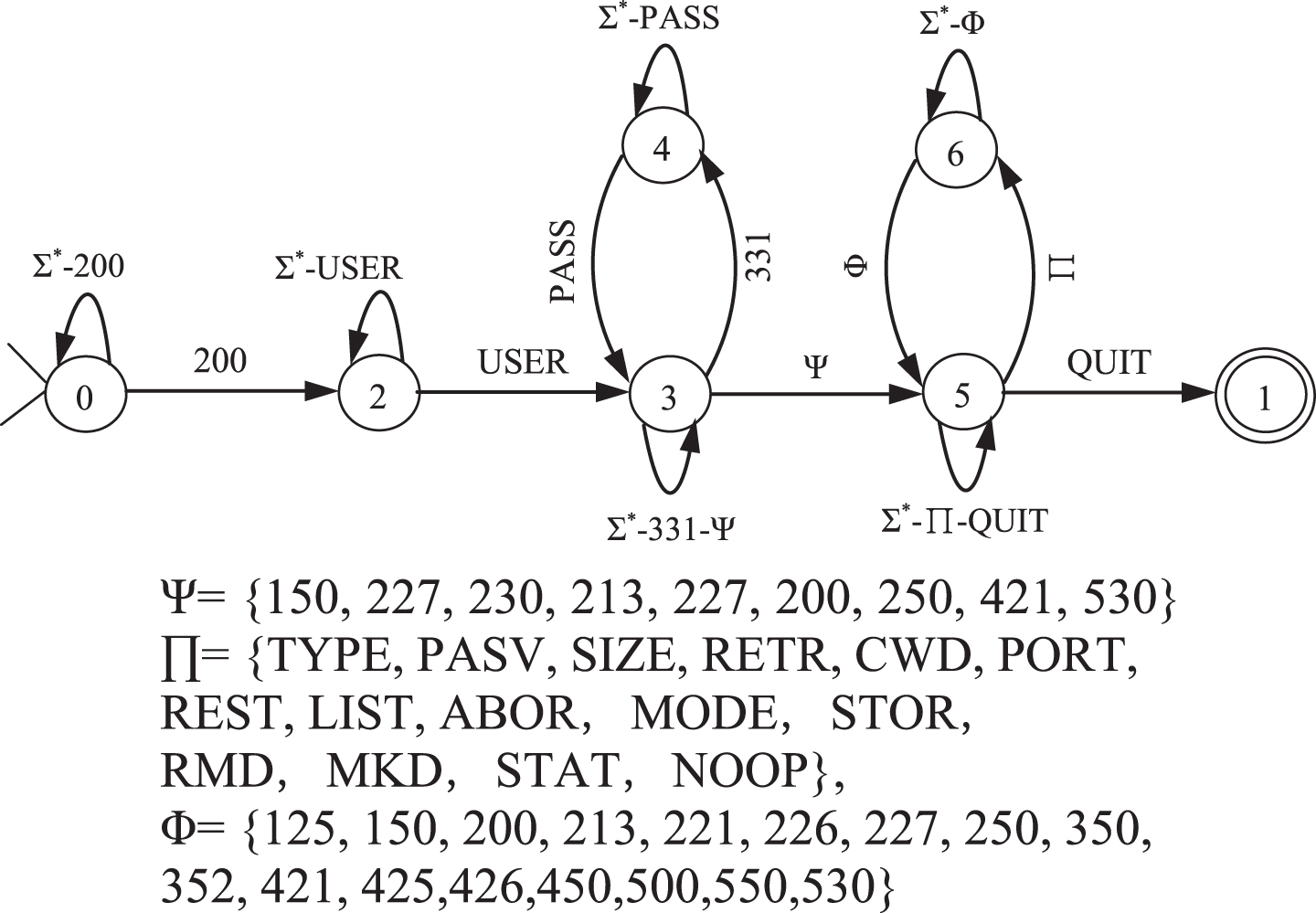
Figure 5 represents the state machine derived for FTP; the paths 0 → 2 →3 → 4 →3 → 5 and 0 → 2 →3 → 5 indicate the method of logging into the ftp server; 5 → 6 →5 reflects the various interaction processes between the client and server; and 5 → 1 represents the exiting of ftp protocol.
The derived state machine, when compared with the target state machine may be over-restrictive or over-generalized. From the perspective of state machine structure, if the derived state machine does not contain the states and transitions used to express itself accurately, the derived state machine is over-restrictive. If the derived state machine contains more redundant states and transitions than the minimal target state machine, the derived state machine is over-generalized. In order to scale the property of over-restriction or over-generalization, it needs to introduce an appropriate metric.
To measure the performance of the derived state machine for protocol specification, we refer to a metric defined in the literature [22]. For the sake of convenience of statement, the target model is denoted as U, the inferred model is denoted as V. There are two metrics to measure the similarity between U and V against the traces generated by U and V, respectively. First, the present rate accepted by V against the examples generated by U denotes the accurate information collected by V, and the metric is referred to as recall. Second, the percent rate accepted by U against the examples generated by V denotes the portion of correct information produced by the inferred model, and the metric is called precision [23]. According to reports in the literature [24], the recall is related with completeness, and it is a metric to measure completeness; however, precision is associated with soundness, and it becomes the metric for measuring soundness.
If the protocol is not over-restrictive, the protocol is complete, that is, the protocol would accept a valid session of protocol; if the protocol specification is not over-generalized, it is sound, that is, it rejects the invalid session of protocol.
Completeness for the inferred state machine
For the purpose of testing for the completeness of the inferred protocol specification, the derived protocol state machine is used to analyze the network trace of real application. The protocol implemented in these network traces comprises HTTP, SMTP, POP3, FTP, BT, MSN, and FECTION. The datasets extracted from these trace are listed in Table 4, and it is different from that listed in Table 3. After the analysis described above, the successful rate to be the end state of the derived state machine is shown inTable 4.
Completeness test for the state machine
Completeness test for the state machine
The result demonstrates the completeness of message format and the derived state machine. As many as 11,172 sessions, from a total of 11,551 sessions, were successfully analyzed; this rate is considerably high and indicates the correction of the selected message format and perfect understanding of the order of structure. After checking those sessions analyzed unsuccessfully, the reasons of failure can be summarized as follows: 1) these sessions cover some encrypted sessions; 2) the examples in the training set did not contain all the error conditions. Therefore, there are some limitations to the proposed approach, that is, it cannot dispose of encrypted content, and it is somewhat less than complete.
To evaluate the performance of the derived state machine, a reference state machine needs to be set up for every protocol. A direct approach is to manually construct a reference state machine A’ according to the online specification documentation of open protocol. The construction process for A’ is similar to that of the aforementioned state machine A: it first extracts the interaction path by using permutation and combination method based on the protocol tokens provided from the protocol specification documentation and the process of the protocol interaction. Then, the A’ PTA is constructed according to the interaction path using the aforementioned error-correcting cumulative parsing. For simplicity and convenient, the above processes have not included all the error conditions, and exceedingly rare conditions have been excluded. Last, the reference state machine A’ is produced by using the aforementioned merging reduction algorithm. Thus, the reference state machine A’ is an approximate state machine related to the target one. Because it lacks the open specification document for the private protocol, we selected the network application implementing the open protocol specification as the testing object, including HTTP, POP3, SMPT, and FTP.
Because the RECALL is associated with completeness, the recall measures of the number of examples produced by reference A’ versus the number of examples accepted by the derived state machine A, which is a metric for measuring completeness. In order to test the completeness of the derived state machine, such as AHTTP, some random walks on the reference state machine (e.g., A’HTTP) were carried out, and some valid session traces were produced for the protocol specification. These sessions as input were analyzed by the derived state machine (e.g., AHTTP), and the results of the test are shown in Table 5. It is obvious that the derived state machine cannot completely analyze all the session examples produced by the reference state machine; this is because the proposed method cannot learn the portion of protocol structure that does not appear in the training data. In this regard, the derived state machine is somewhat short of completeness, and the result is the same as that indicated in sub-section 4.2.1.
Structural completeness test for protocol state machine
Structural completeness test for protocol state machine
In this section, we undertake a performance comparison between our approach and that reported in [20] in an attempt to demonstrate that the grammatical inference approach in current article has more applicability for protocol reverse engineering.
For the purpose of convenience during comparison, the same experimental conditions of the evaluation in [20] were used, that is, the used network trace is from MIT DARPA 1998 [21] and the checked object is limited in application data using POP3 and SMTP protocol. In order to measure the difference of the performance feature between algorithms, metrics such as recall and precision described in Section 4.2 were adopted for testing, and the reference state machine A’ described in Section 4.2 were also used to measure the precision. As shown in Table 6, AK - RI and Ak - TSSI are optimizing derived state machines that use the two algorithms reported in the literature [20], APREUGI is deduced on the basis of the approach presented in this article.
Comparison of performance characteristics
Comparison of performance characteristics
The results of a comparison of performance characteristics shown in Table 6 are basically identical with those derived using k-RI and k-TSSI algorithms, reported in [20]; that is, the derived state machine using k-RI has better recall capability than that derived using k-TSSI, and the result generated by k-TSSI is more inclined to produce over-restrictive protocol specifications. Moreover, from the results presented in Table 6, it is apparent that the method proposed in the present work is superior to that presented in [20] because it can achieve a protocol specification model that is closer to the reference protocol.
Further, according to the experimental results reported in [14], a comparison of the size of the state machine is carried out between the most optimizing result in [20] and that in the current work and the result is presented in Table 7.
Comparison of performance characteristics
From Table 7, it is apparent that the more compact state machine is obtained on the basis of the approach introduced in this work, and it simultaneously maintains excellent performance, which validates the claim that it improves efficiency and throughput.
In the present work, the interacting model is derived with a scheme of error-correcting GI. The protocol state machine is reversely inferred on the basis of the state sequences. Based on the complexity of network protocol, we presented a criterion of best-matching path to solve the difficulty of path selection during the error-correcting process. Moreover, negative example sets with similar tokens were adopted to reinforce the error-collecting performance. We present a simplifying measure to obtain a compact protocol state machine that expresses the internal operating mechanism of the protocol accurately. Through experiments using real network data containing various protocols, a series of tests targeting the performance characteristic were conducted for the derived protocol specification state machine. The results indicate that the approach presented in this article can effectively infer network protocol specification.
Footnotes
Acknowledgments
This work was supported by the plan project of science and technology of Guangzhou/Guangdong of China under grants 201604020015 and 2015B010101012, for which we are grateful.